

Parallel Point Clouds: Point Clouds Generation and 3D Model Evolution via Virtual-real Interaction
-
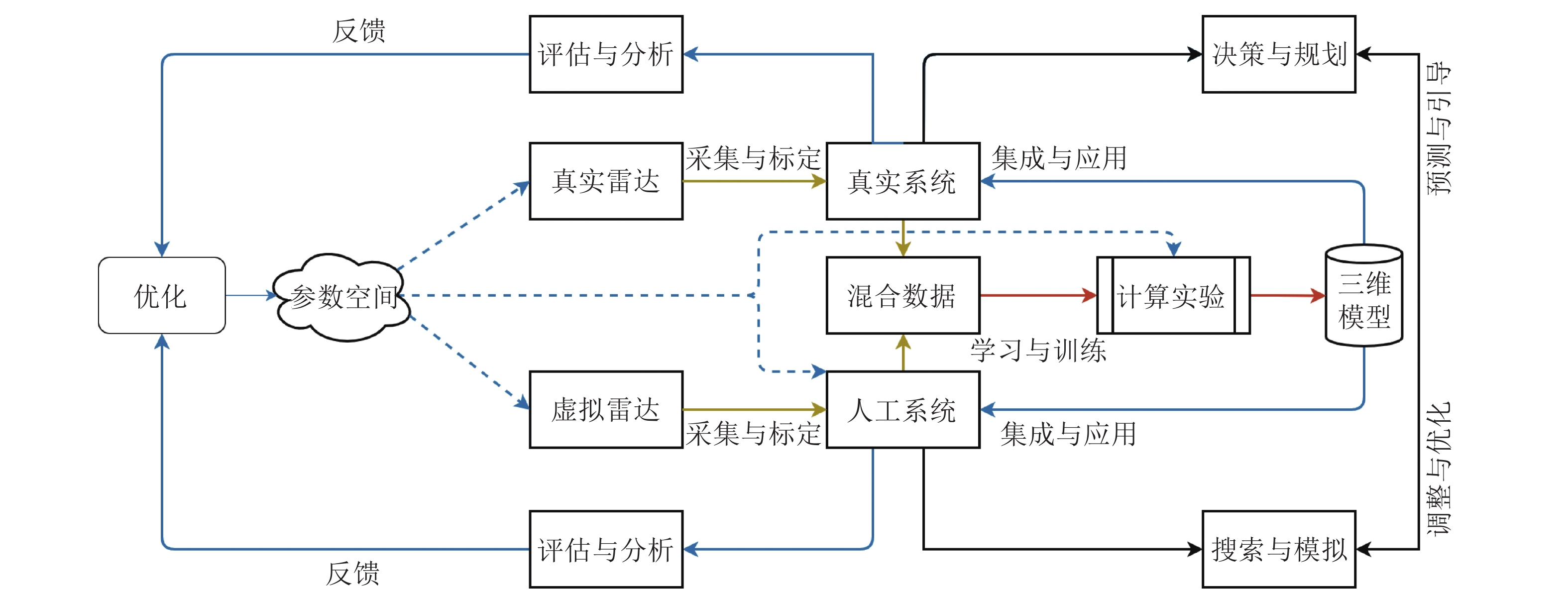
摘要: 三维信息的提取在自动驾驶等智能交通场景中正发挥着越来越重要的作用, 为了解决以激光雷达为主的深度传感器在数据采集方面面临的成本高、样本覆盖不全面等问题, 本文提出了平行点云的框架. 利用人工定义场景获取虚拟点云数据, 通过计算实验训练三维模型, 借助平行执行对模型性能进行测试, 并将结果反馈至数据生成和模型训练过程. 通过不断地迭代, 使三维模型得到充分评估并不断进化. 在平行点云的框架下, 我们以三维目标检测为例, 通过闭环迭代, 构建了虚实结合的点云数据集, 在无需人工标注的情况下, 可达到标注数据训练模型精度的72%.Abstract: The extraction of 3D information is playing an increasingly important role in intelligent traffic scenes such as autonomous driving. In order to solve the problems faced by LiDAR sensor such as the high cost and incomplete coverage of possible scenarios, this paper proposes parallel point clouds and its framework. For parallel point clouds, virtual point clouds are obtained by building artiflcial scenes. Then 3D models are trained through computational experiments and tested by parallel execution. The evaluation results are fed back to the data generation and the training process of 3D models. Through continuous iteration, 3D models can be fully evaluated and updated. Under the framework of Parallel Point Clouds, we take the 3D object detection as an example and build a point clouds dataset in a closed-loop manner. Without human annotation, it can be used to effectively train the detection model which can achieve the 72% of the performance of model trained with annotated data.
-
Key words:
- Parallel point clouds /
- virtual-real interaction /
- 3D vision models /
- 3D object detection
-

图 3 CARLA仿真环境及虚拟雷达点云
Fig. 3 CARLA simulation environment and virtual LiDAR point clouds

图 6 KITTI (左)与ShapeKITTI (右)点云数据可视化对比
Fig. 6 The visualization of point clouds from KITTI (left) and ShapeKITTI (right)
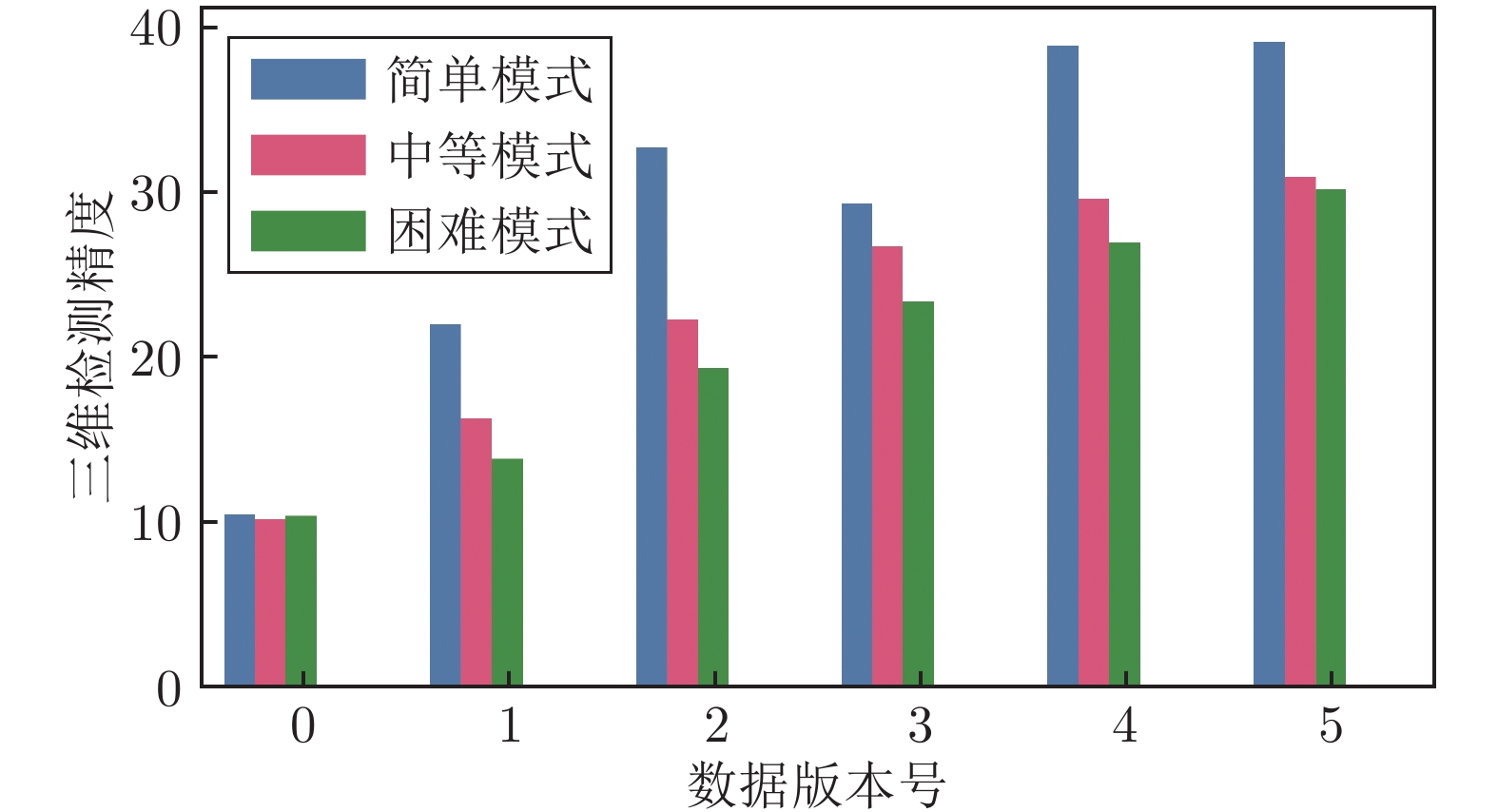
图 7 点云数据生成对三维检测模型性能的影响
Fig. 7 The influence of point clouds generation on the 3D detector performance
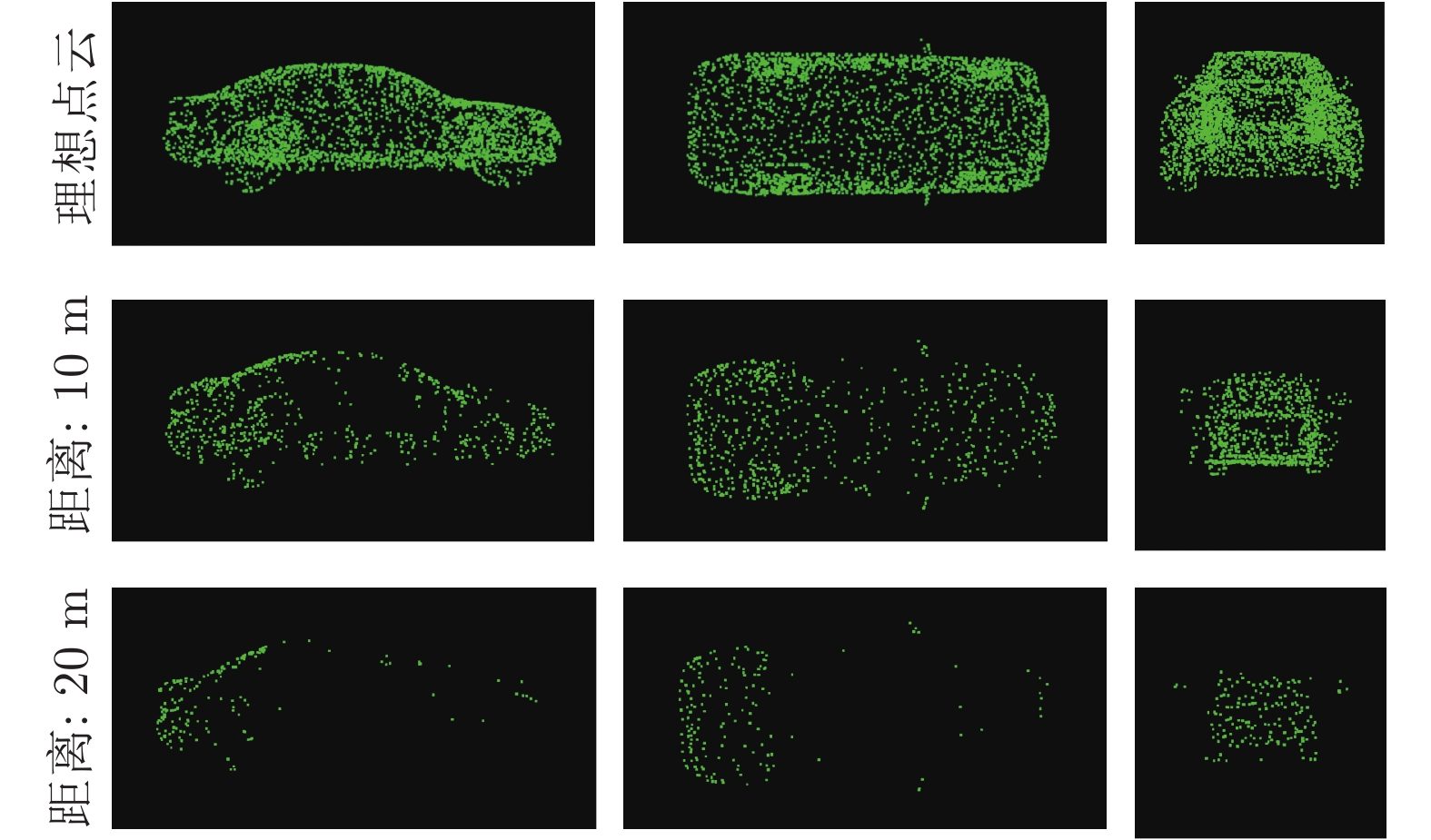
图 8 不同距离下的虚拟点云生成效果
Fig. 8 The visualization of virtual point clouds under difierent distance
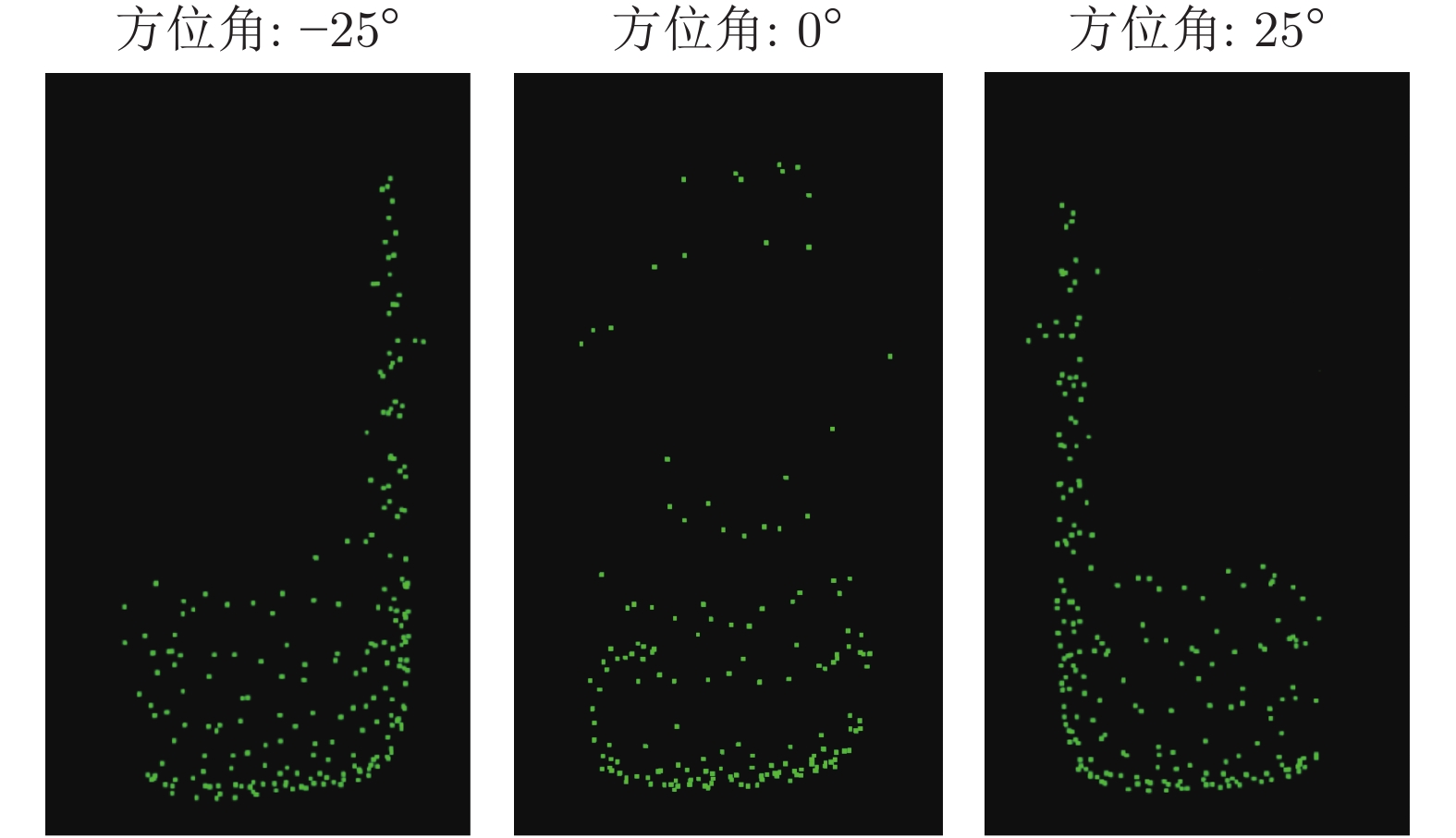
图 9 不同方位角的虚拟点云生成效果
Fig. 9 The visualization of virtual point clouds under difierent azimuths
表 1 激光雷达属性描述
Table 1 The description of LiDAR attributes
属性 描述 默认值 Channels 激光器数量 32 Range 测量/射线广播的
最大距离(米)10.0 Points per second 每秒所有激光
器产生的点56000 Rotation frequency 激光雷达旋转频率 10.0 Upper field of view 最高激光的角度(度) 10.0 Lower field of view 最低激光的角度(度) −30 Atmosphere attenuation rate 测量每米LiDAR强
度损失的系数0.004 Dropoff general rate 随机掉落的总点数比例 0.45 Dropoff intensity limit 对于基于强度的下降,阈值
强度值不超过任何点0.8  下载: 导出CSV
下载: 导出CSV
表 2 基于ShapeKITTI的三维目标检测模型(PointPillars)平均精度 (%)
Table 2 The average precision of 3D object detector (PointPillars) based on ShapeKITTI dataset (%)
评测项目 简单模式 中等模式 困难模式 3D AP (Real) 85.21 75.86 69.21 3D AP (Ours) 71.44 54.39 52.30 BEV AP (Real) 89.79 87.44 84.77 BEV AP (Ours) 82.81 70.44 65.68 AOS AP (Real) 90.63 89.34 88.36 AOS AP (Ours) 84.02 69.65 68.08
下载: 导出CSV
表 3 基于ShapeKITTI的三维目标检测模型(SECOND)平均精度 (%)
Table 3 The average precision of 3D object detector (SECOND) based on ShapeKITTI dataset (%)
评测项目 简单模式 中等模式 困难模式 3D AP (Real) 87.43 76.48 69.10 3D AP (Ours) 59.67 41.18 37.67 BEV AP (Real) 89.52 87.28 83.89 BEV AP (Ours) 73.55 53.37 52.34 AOS AP (Real) 90.49 89.45 88.41 AOS AP (Ours) 75.01 54.72 54.13
下载: 导出CSV
表 4 基于闭环反馈的三维检测模型性能进化过程 (%)
Table 4 The evolutionary process of 3D detection model based on the closed-loop feedback (%)
序号 AP (简单) AP (中等) AP (困难) 反馈 建议 AP提升 G0 10.64 10.32 10.53 仅对少数目标能有效检测 增加CAD模型种类 — G1 22.14 16.46 13.98 目标尺寸估计欠佳 改进CAD模型尺寸 6.14 (G0 to G1) G2 32.85 22.40 19.52 对稀疏目标检测效果欠佳 降低前景目标密度 5.94 (G1 to G2) G3 29.43 26.85 23.51 目标高度估计效果欠佳 调整前景目标高度 4.45 (G2 to G3) G4 38.99 29.74 27.10 对稀疏目标检测效果仍然欠佳 进一步降低前景目标密度 2.89 (G3 to G4) G5 39.22 31.04 30.30 — — 2.30 (G4 to G5)
下载: 导出CSV
-
[1] He K M, Zhang X Y, Ren S Q, Sun J. Residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [2] Huang G, Liu Z, Van Der Maaten L, Weinberger K Q. Densely connected convolutional networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 2261−2269 [3] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. In: Proceedings of the 2015 Annual Conference on Neural Information Processing Systems. Montreal, Canada: 2015. 91−99 [4] Zhu Z, Wu W, Zou W, Yan J J. End-to-end flow correlation tracking with spatial-temporal attention. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 548−557 [5] Shen T Y, Wang J G, Gou C, Wang F-Y. Hierarchical fused model with deep learning and type-2 fuzzy learning for breast cancer diagnosis. IEEE Transactions on Fuzzy Systems, 2020, DOI: 10.119/TFUZZ.2020.3013681 [6] Shen T Y, Gou C, Wang F-Y, He Z L, Chen W G. Learning from adversarial medical images for X-ray breast mass segmentation. Computer Methods and Programs in Biomedicine, 2019, 180: 105012 doi: 10.1016/j.cmpb.2019.105012 [7] Chen X Z, Ma H M, Wan J, Li B, Xia T. Multi-view 3D object detection network for autonomous driving. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 6526−6534 [8] Wang C, Xu D F, Zhu Y K, Martín-Martín R, Lu C W, Li F F, Savarese S. Densefusion: 6D object pose estimation by iterative dense fusion. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 3343−3352 [9] Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 3354−3361 [10] Sun P, Kretzschmar H, Dotiwalla X, Chouard A, Patnaik V, Tsui P, et al. Scalability in perception for autonomous driving: Waymo open dataset. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 2443−2451 [11] Huang X Y, Wang P, Cheng X J, Zhou D F, Geng Q C, Yang R G. The apolloscape open dataset for autonomous driving and its application. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2702−2719 doi: 10.1109/TPAMI.2019.2926463 [12] Wang Y, Chao W L, Garg D, Hariharan B, Campbell M, Weinberger K Q. Pseudo-LiDAR from visual depth estimation: Bridging the gap in 3D object detection for autonomous driving. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 8437−8445 [13] Qian R, Garg D, Wang Y, You Y R, Belongie S, Hariharan B, et al. End-to-end pseudo-LiDAR for image-based 3D object detection. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 5880−5889 [14] Elmadawi K, Abdelrazek M, Elsobky M, Eraqi H M, Zahran M. End-to-end sensor modeling for LiDAR Point Cloud. In: Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC). IEEE, 2019. 1619−1624 [15] Fang J, Zhou D F, Yan F L, Zhao T T, Zhang F H, Ma Y, et al. Augmented LiDAR simulator for autonomous driving. IEEE Robotics and Automation Letters, 2020, 5(2): 1931−1938 doi: 10.1109/LRA.2020.2969927 [16] 王飞跃. 平行系统方法与复杂系统的管理和控制. 控制与决策, 2004, 19(5): 485−489, 514 doi: 10.3321/j.issn:1001-0920.2004.05.002Wang Fei-Yue. Parallel system methods for management and control of complex systems. Control and Decision, 2004, 19(5): 485−489, 514 doi: 10.3321/j.issn:1001-0920.2004.05.002 [17] Wang F-Y. Parallel control and management for intelligent transportation systems: Concepts, architectures, and applications. IEEE Transactions on Intelligent Transportation Systems, 2010, 11(3): 630−638 doi: 10.1109/TITS.2010.2060218 [18] 王飞跃. 平行控制: 数据驱动的计算控制方法. 自动化学报, 2013, 39(4): 293−302Wang Fei-Yue. Parallel control: A method for data-driven and computational control. Acta Automatica Sinica, 2013, 39(4): 293−302 [19] Guo Y L, Wang H Y, Hu Q Y, Liu H, Liu L, Bennamoun M. Deep learning for 3D point clouds: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020 doi: 10.1109/TPAMI.2020.3005434 [20] Su H, Maji S, Kalogerakis E, Learned-Miller E. Multi-view convolutional neural networks for 3D shape recognition. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 945−953 [21] Riegler G, Osman Ulusoy A, Geiger A. OctNet: Learning deep 3D representations at high resolutions. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 6620−6629 [22] Qi Charles R, Su H, Kaichun M, Guibas L J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 77−85 [23] Wu B C, Wan A, Yue X Y, Keutzer K. SqueezeSeg: Convolutional neural nets with recurrent CRF for real-time road-object segmentation from 3D LiDAR point cloud. In: Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA). Brisbane, Australia: IEEE, 2018. 1887−1893 [24] Hou J, Dai A, Nießner M. 3D-SIS: 3D semantic instance segmentation of RGB-D scans. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 4416−4425 [25] Wang Z J, Lu F. VoxSegNet: Volumetric CNNs for semantic part segmentation of 3D shapes. IEEE Transactions on Visualization and Computer Graphics, 2020, 26(9): 2919−2930 doi: 10.1109/TVCG.2019.2896310 [26] Lang A H, Vora S, Caesar H, Zhou L B, Yang J, Beijbom O. Pointpillars: Fast encoders for object detection from point clouds. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 12689−12697 [27] Tian Y L, Wang K F, Wang Y, Tian Y L, Wang Z L, Wang F-Y. Adaptive and azimuth-aware fusion network of multimodal local features for 3D object detection. Neurocomputing, 2020, 411: 32−44 doi: 10.1016/j.neucom.2020.05.086 [28] Giancola S, Zarzar J, Ghanem B. Leveraging shape completion for 3D Siamese tracking. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 1359−1368 [29] Mueller M, Smith N, Ghanem B. Context-aware correlation filter tracking. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 1387−1395 [30] Caesar H, Bankiti V, Lang A H, Vora S, Liong V E, Xu Q, et al. nuScenes: A multimodal dataset for autonomous driving. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 11618−11628 [31] Manivasagam S, Wang S, Wong K, Zeng W, Sazanovvich M, Tan S, Yang B, Ma W-C, Urtasun R. LiDARsim: Realistic LiDAR simulation by leveraging the real world. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. 11167−11176 [32] Prendinger H, Gajananan K, Zaki A B, Fares A, Molenaar R, Urbano D, et al. Tokyo virtual living lab: Designing smart cities based on the 3D Internet. IEEE Internet Computing, 2013, 17(6): 30−38 doi: 10.1109/MIC.2013.87 [33] Ros G, Sellart L, Materzynska J, Vazquez D, López A M. The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 3234−3243 [34] Gaidon A, Wang Q, Cabon Y, Vig E. VirtualWorlds as proxy for multi-object tracking analysis. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 4340−4349 [35] Li X, Wang K F, Tian Y L, Yan L, Deng F, Wang F Y. The ParallelEye dataset: A large collection of virtual images for traffic vision research. IEEE Transactions on Intelligent Transportation Systems, 2019, 20(6): 2072−2084 doi: 10.1109/TITS.2018.2857566 [36] Tian Y L, Li X, Wang K F, Wang F-Y. Training and testing object detectors with virtual images. IEEE/CAA Journal of Automatica Sinica, 2018, 5(2): 539−546 doi: 10.1109/JAS.2017.7510841 [37] Johnson-Roberson M, Barto C, Mehta R, Sridhar S N, Rosaen K, Vasudevan R. Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? In: Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA). Singapore: IEEE, 2017. 746−753 [38] Yue X Y, Wu B C, Seshia S A, Keutzer K, Sangiovanni-Vincentelli A L. A LiDAR point cloud generator: From a virtual world to autonomous driving. In: Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval. Yokohama, Japan: ACM, 2018. 458−464 [39] Li W, Pan C W, Zhang R, Ren J P, Ma Y X, Fang J, et al. AADS: Augmented autonomous driving simulation using data-driven algorithms. Science Robotics, 2019, 4(28): arXiv: 1901.07849v3 doi: 10.1126/scirobotics.aaw0863 [40] 王坤峰, 苟超, 王飞跃. 平行视觉: 基于ACP的智能视觉计算方法. 自动化学报, 2016, 42(10): 1490−1500Wang Kun-Feng, Gou Chao, Wang Fei-Yue. Parallel vision: An ACP-based approach to intelligent vision computing. Acta Automatica Sinica, 2016, 42(10): 1490−1500 [41] 王坤峰, 鲁越, 王雨桐, 熊子威, 王飞跃. 平行图像: 图像生成的一个新型理论框架. 模式识别与人工智能, 2017, 30(7): 577−587Wang Kun-Feng, Lu Yue, Wang Yu-Tong, Xiong Zi-Wei, Wang Fei-Yue. Parallel imaging: A new theoretical framework for image generation. Pattern Recognition and Artificial Intelligence, 2017, 30(7): 577−587 [42] 李力, 林懿伦, 曹东璞, 郑南宁, 王飞跃. 平行学习 — 机器学习的一个新型理论框架. 自动化学报, 2017, 43(1): 1−8Li Li, Lin Yi-Lun, Cao Dong-Pu, Zheng Nan-Ning, Wang Fei-Yue. Parallel learning — A new framework for machine learning. Acta Automatica Sinica, 2017, 43(1): 1−8 [43] Wang F-Y, Zheng N N, Cao D P, Martinez C M, Li L, Liu T. Parallel driving in CPSS: A unified approach for transport automation and vehicle intelligence. IEEE/CAA Journal of Automatica Sinica, 2017, 4(4): 577−587 doi: 10.1109/JAS.2017.7510598 [44] 郭超, 鲁越, 林懿伦, 卓凡, 王飞跃. 平行艺术: 人机协作的艺术创作. 智能科学与技术学报, 2019, 1(4): 335−341Guo Chao, Lu Yue, Lin Yi-Lun, Zhuo Fan, Wang Fei-Yue. Parallel art: Artistic creation under human-machine collaboration. Chinese Journal of Intelligent Science and Technology, 2019, 1(4): 335−341 [45] 吕宜生, 陈圆圆, 金峻臣, 李镇江, 叶佩军, 朱凤华. 平行交通: 虚实互动的智能交通管理与控制. 智能科学与技术学报, 2019, 1(1): 21−33 doi: 10.11959/j.issn.2096-6652.201908Lv Yi-Sheng, Chen Yuan-Yuan, Jin Jun-Chen, Li Zhen-Jiang, Ye Pei-Jun, Zhu Feng-Hua. Parallel transportation: Virtual-real interaction for intelligent traffic management and control. Chinese Journal of Intelligent Science and Technology, 2019, 1(1): 21−33 doi: 10.11959/j.issn.2096-6652.201908 [46] 王飞跃. 平行传感与平行感知: 平行传感器的原理、框架与设计. 青岛智能产业技术研究院报告, 青岛, 中国, 2015. [47] Zhang H, Luo G Y, Tian Y L, Wang K F, He H B, Wang F-Y, et al. A virtual-real interaction approach to object instance segmentation in traffic scenes. IEEE Transactions on Intelligent Transportation Systems, 2020, DOI: 10.1109/TITS.2019.2961145. [48] Goodfellow I. NIPS 2016 tutorial: Generative adversarial networks. arXiv: 1701.00160, 2016. [49] Dosovitskiy A, Ros G, Codevilla F, López A M, Koltun V. CARLA: An open urban driving simulator. In: Proceedings of the 1st Annual Conference on Robot Learning. Mountain View, USA: PMLR, 2017. 1−16 [50] Rong G D, Shin B H, Tabatabaee H, Lu Q, Lemke S, Možeiko M, et al. LGSVL simulator: A high fidelity simulator for autonomous driving. arXiv: 2005.03778, 2020. [51] Von Neumann-Cosel K, Dupuis M, Weiss C. Virtual test drive provision of a consistent tool-set for [D, H, S, V]-in-the-loop. In: Proceedings of the Driving Simulation Conference. Monaco, 2009. [52] You Y R, Wang Y, Chao W L, Garg D, Pleiss G, Hariharan B, et al. Pseudo-LiDAR++: Accurate depth for 3D object detection in autonomous driving. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: OpenReview, 2020. [53] Chang A X, Funkhouser T, Guibas L, Hanrahan P, Huang Q X, Li Z M, et al. ShapeNet: An information-rich 3D model repository. arXiv: 1512.03012, 2015. [54] Yan Y, Mao Y X, Li B. SECOND: Sparsely embedded convolutional detection. Sensors, 2018, 18(10): 3337 doi: 10.3390/s18103337 -

 下载:
下载:




计量
- 文章访问数: 2325
- HTML全文浏览量: 1314
- PDF下载量: 629
- 被引次数: 0
