

-
摘要: 现有基于深度学习的立体匹配算法在学习推理过程中缺乏有效信息交互, 而特征提取和代价聚合两个子模块的特征维度存在差异, 导致注意力方法在立体匹配网络中应用较少、方式单一. 针对上述问题, 本文提出了一种多维注意力特征聚合立体匹配算法. 设计2D注意力残差模块, 通过在原始残差网络中引入无降维自适应2D注意力残差单元, 局部跨通道交互并提取显著信息, 为匹配代价计算提供丰富有效的特征. 构建3D注意力沙漏聚合模块, 以堆叠沙漏结构为骨干设计3D注意力沙漏单元, 捕获多尺度几何上下文信息, 进一步扩展多维注意力机制, 自适应聚合和重新校准来自不同网络深度的代价体. 在三大标准数据集上进行评估, 并与相关算法对比, 实验结果表明所提算法具有更高的预测视差精度, 且在无遮挡的显著对象上效果更佳.Abstract: Existing deep learning-based stereo matching algorithms lack effective information interaction in the learning and reasoning process, and there is difference in feature dimension between feature extraction and cost aggregation, resulting in less and single application of attention methods in stereo matching networks. In order to solve these problems, a multi-dimensional attention feature aggregation stereo matching algorithm was proposed. The two-dimensional (2D) attention residual module is designed by introducing the adaptive 2D attention residual unit without dimensionality reduction into the original residual network. Local cross-channel interaction and extraction of salient information provide abundant and effective features for matching cost calculation. The three-dimensional (3D) attention hourglass aggregation module is constructed by designing a 3D attention hourglass unit with a stacked hourglass structure as the backbone. It captures multi-scale geometric context information and expand the multi-dimensional attention mechanism, adaptively aggregating and recalibrating cost volumes from different network depths. The proposed algorithm is evaluated on three standard datasets and compared with related algorithms. The experimental results show that the proposed algorithm has higher accuracy in predicting disparity and has better effect on unobstructed salient objects.
-
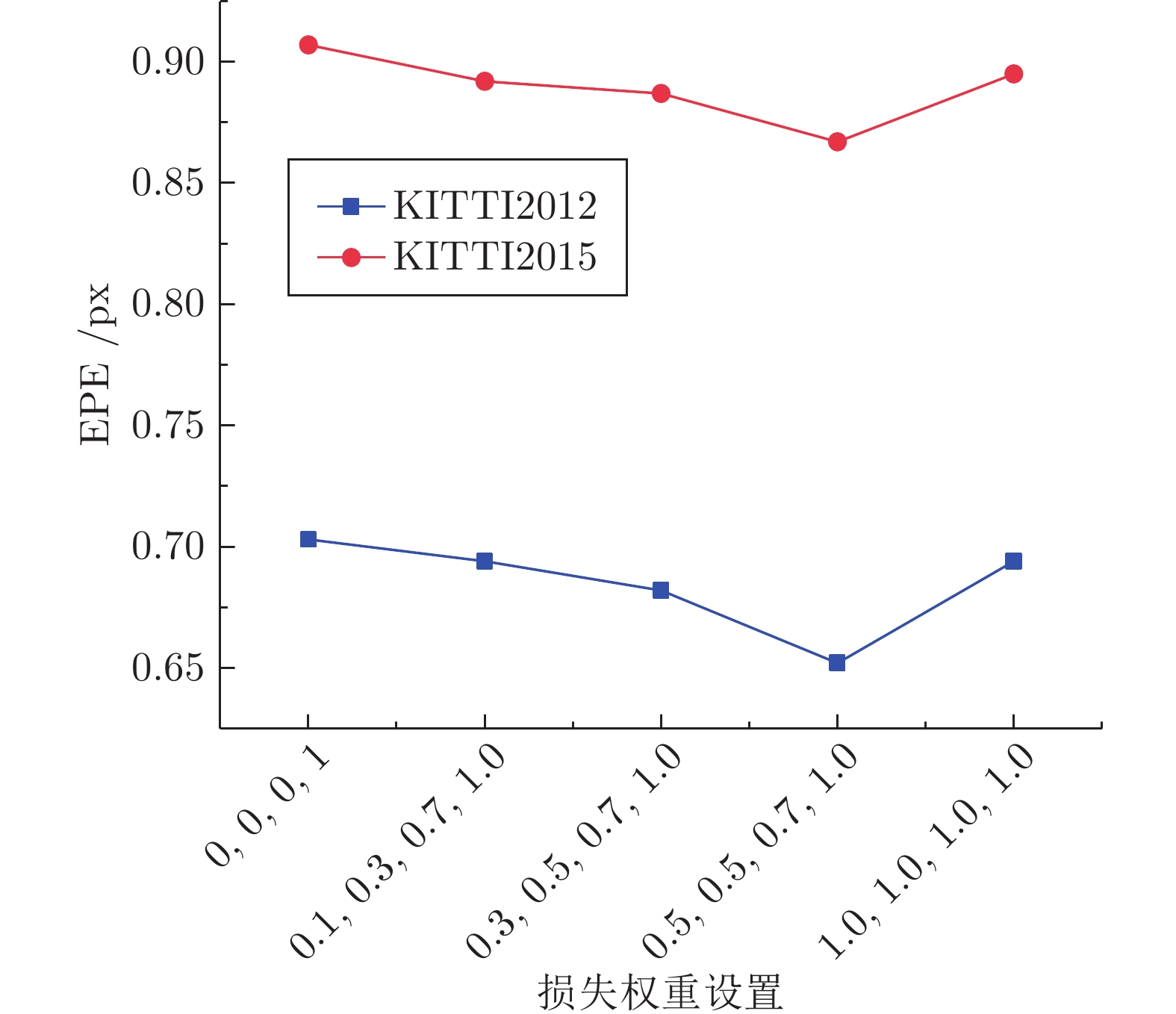
图 6 损失函数权重对网络的影响
Fig. 6 The influence of the weight of loss function on network performance
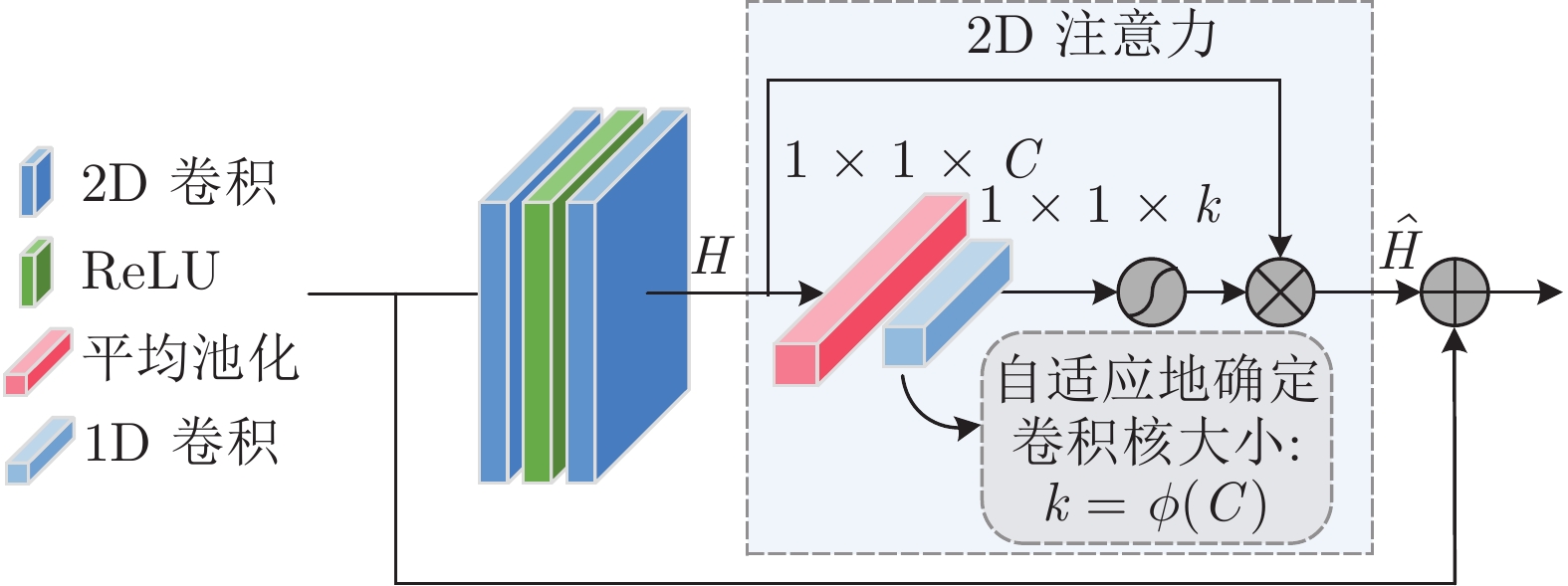
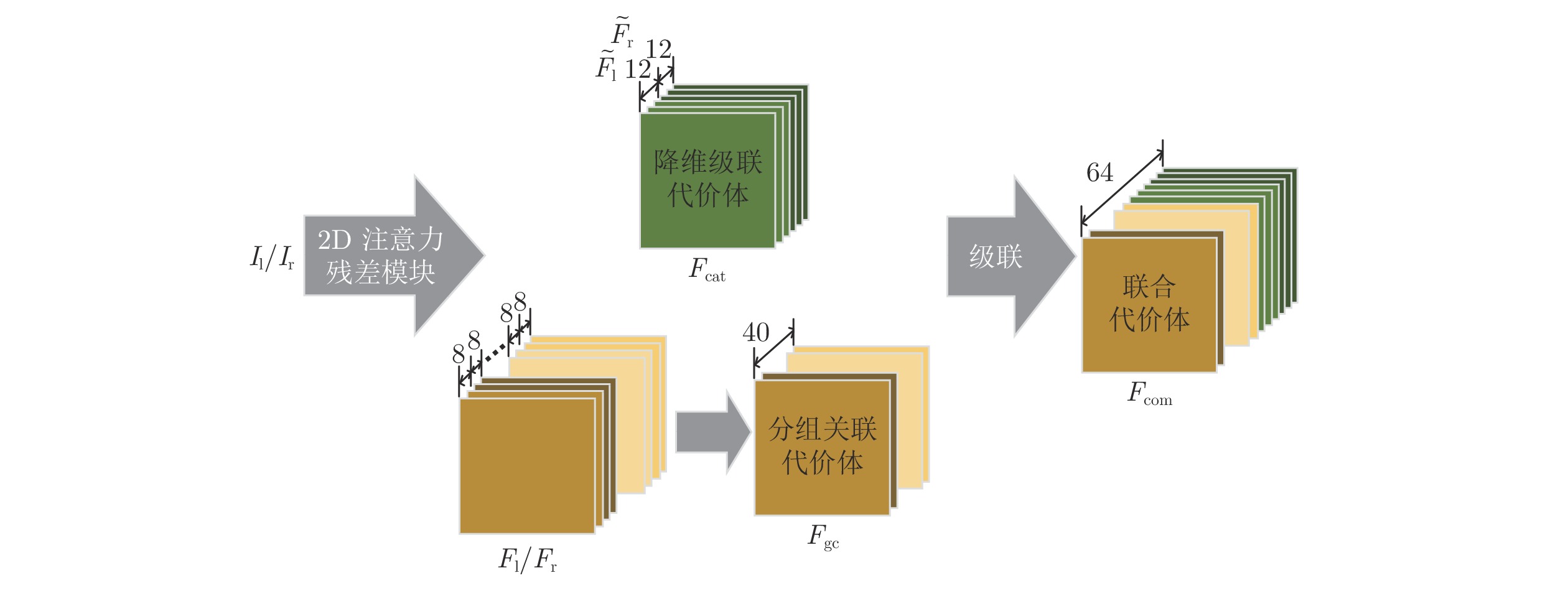
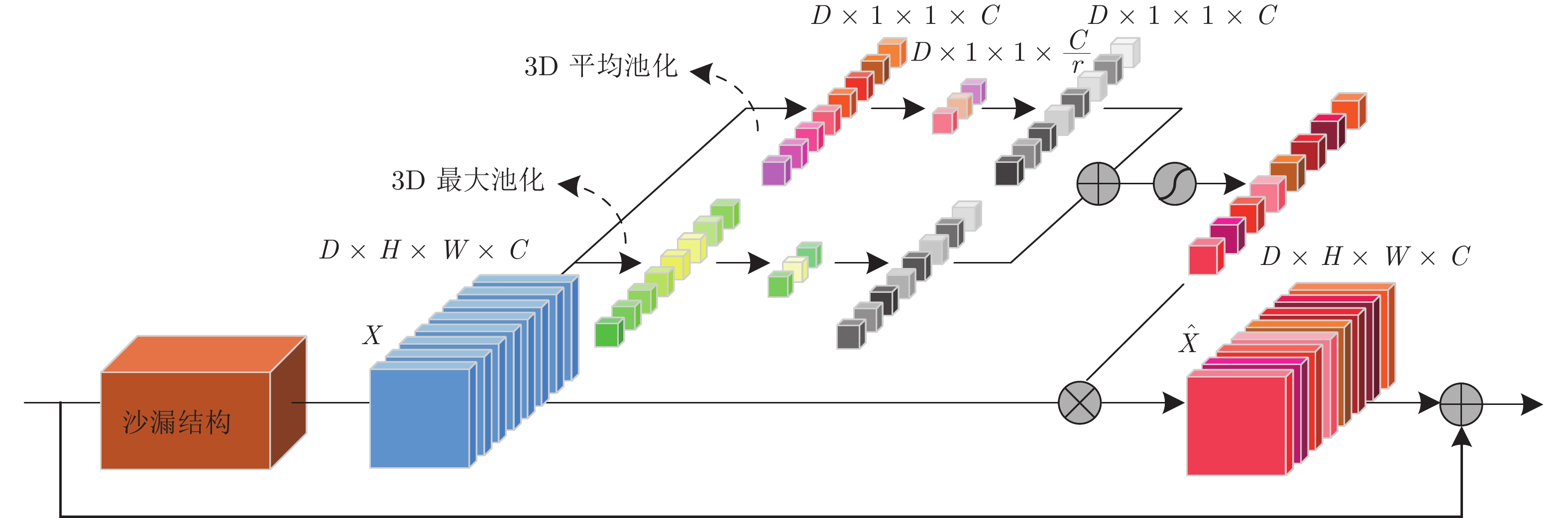
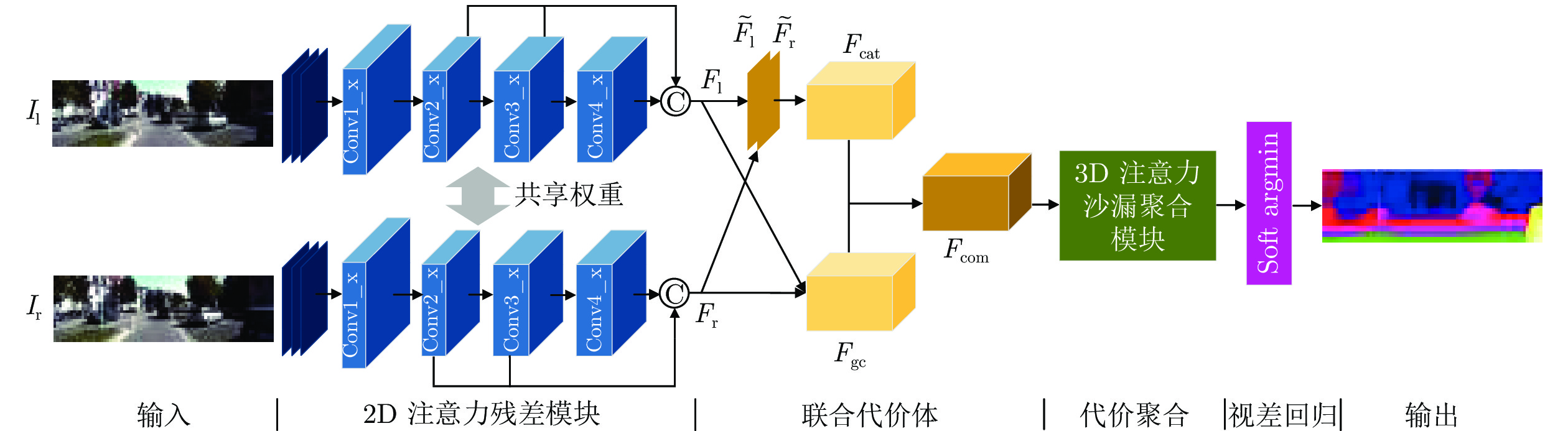
表 1 2D注意力残差单元和联合代价体的参数设置(D表示最大视差, 默认步长为1)
Table 1 Parameter setting of the 2D attention residual unit and combined cost volume (D represents the maximum disparity. The default stride is 1)
层级名称 层级设置 输出维度 ${ { { {{F} }_{\rm{l}}} } / { { {{F} }_{\rm{r}}} } }$ 卷积核尺寸, 通道数, 步长 H×W×3 2D 注意力残差模块 Conv0_1 $3 \times 3,32,$ 步长 = 2 ${1 / 2}H \times {1 / 2}W \times 32$ Conv0_2 $3 \times 3,32,$ ${1 / 2}H \times {1 / 2}W \times 32$ Conv0_3 $3 \times 3,32,$ ${1 / 2}H \times {1 / 2}W \times 32$ Conv1_x $\left[ \begin{aligned} 3 \times 3,32 \\ 3 \times 3,32 \end{aligned} \right] \times 3$ ${1 / 2}H \times {1 / 2}W \times 32$ Conv2_x $\left[ \begin{aligned} 3 \times 3,32 \\ 3 \times 3,32 \end{aligned} \right] \times 16$, 步长 = 2 ${1 / 4}H \times {1 / 4}W \times 64$ Conv3_x $\left[ \begin{aligned} 3 \times 3,32 \\ 3 \times 3,32 \end{aligned} \right] \times 3$ ${1 / 4}H \times {1 / 4}W \times 128$ Conv4_x $\left[ \begin{aligned} 3 \times 3,32 \\ 3 \times 3,32 \end{aligned} \right] \times 3$ ${1 / 4}H \times {1 / 4}W \times 128$ ${ {{F} }_{\rm{l}}}$/${ {{F} }_{\rm{r}}}$ 级联: Conv2_x, Conv3_x, Conv4_x ${1 / 4}H \times {1 / 4}W \times 320$ 联合代价体 ${ {{F} }_{{\rm{gc}}} }$ — ${1 / 4}D \times {1 / 4}H \times {1 / 4}W \times 40$ ${\tilde {{F} }_{\rm{l}}}$/${\tilde {{F} }_{\rm{r}}}$ $\left[ \begin{aligned} 3 \times 3,128 \\ 1 \times 1,{\rm{ } }12 \end{aligned} \right]$ ${1 / 4}H \times {1 / 4}W \times 12$ ${ {{F} }_{{\rm{cat}}} }$ — ${1 / 4}D \times {1 / 4}H \times {1 / 4}W \times 24$ ${ {{F} }_{{\rm{com}}} }$ 级联: ${ {{F} }_{{\rm{gc}}} }$, ${ {{F} }_{{\rm{cat}}} }$ ${1 / 4}D \times {1 / 4}H \times {1 / 4}W \times 64$  下载: 导出CSV
下载: 导出CSV
表 2 2D注意力残差模块在不同设置下的性能评估
Table 2 Performance evaluation of 2D attention residual module with different settings
网络设置 KITTI2015 2D 注意力单元 > 1 px (%) > 2 px (%) > 3 px (%) EPE (px) — 13.6 3.49 1.79 0.631 最大池化 + 降维 12.9 3.20 1.69 0.623 平均池化 + 降维 12.7 3.26 1.64 0.620 $ \checkmark$ 12.4 3.12 1.61 0.615
下载: 导出CSV
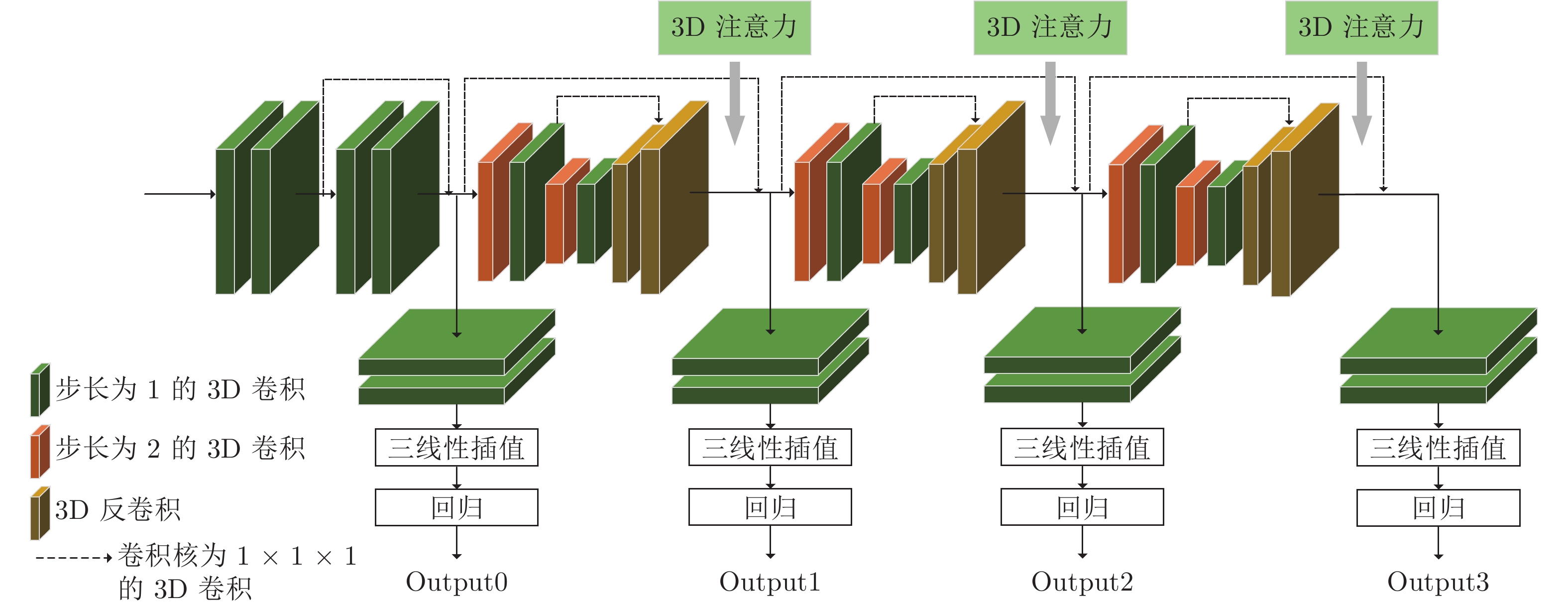
表 3 联合代价体和3D注意力沙漏聚合模块在不同设置下的性能评估
Table 3 Evaluation of 3D attention hourglass aggregation module and combined cost volume with different settings
网络设置 KITTI2012 KITTI2015 联合代价体 3D 注意力单元 EPE (px) D1-all (%) EPE (px) D1-all (%) 3D 最大池化 3D 平均池化 $ \checkmark$ — — 0.804 2.57 0.615 1.94 $ \checkmark$ $ \checkmark$ — 0.722 2.36 0.610 1.70 $ \checkmark$ — $ \checkmark$ 0.703 2.33 0.607 1.68 PSMNet[17] $ \checkmark$ $ \checkmark$ 0.867 2.65 0.652 2.03 $ \checkmark$ $ \checkmark$ $ \checkmark$ 0.654 2.13 0.589 1.43
下载: 导出CSV
表 4 不同算法在SceneFlow数据集上的性能评估
Table 4 Performance evaluation of different methods on the SceneFlow dataset
下载: 导出CSV
表 5 不同算法在KITTI2015上的性能评估 (%)
Table 5 Performance evaluation of different methods on the KITTI2015 dataset (%)
下载: 导出CSV
表 6 不同算法在KITTI2012上的性能评估 (%)
Table 6 Performance evaluation of different methods on the KITTI2012 dataset (%)
下载: 导出CSV
-
[1] Feng D, Rosenbaum L, Dietmayer K. Towards safe autonomous driving: capture uncertainty in the deep neural network for lidar 3D vehicle detection. In: Proceedings of the 21st International Conference on Intelligent Transportation Systems. Maui, HI, USA: IEEE, 2018. 3266−3273 [2] Schmid K, Tomic T, Ruess F, Hirschmüller H, Suppa M. Stereo vision based indoor/outdoor navigation for flying robots. In: Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems. Tokyo, Japan: IEEE, 2013. 3955−3962 [3] 李培玄, 刘鹏飞, 曹飞道, 赵怀慈. 自适应权值的跨尺度立体匹配算法. 光学学报, 2018, 38(12): 248-253.Li Pei-Xuan, Liu Peng-Fei, Cao Fei-Dao, Zhao Huai-Ci. Weight-adaptive cross-scale algorithm for stereo matching. Acta Optica Sinica, 2018, 38(12): 248-253. [4] 韩先君, 刘艳丽, 杨红雨. 多元线性回归引导的立体匹配算法. 计算机辅助设计与图形学学报, 2019, 31(1): 84-93.Han Xian-Jun, Liu Yan-Li, Yang Hong-Yu. A stereo matching algorithm guided by multiple linear regression. Journal of Computer-Aided Design & Computer Graphics, 2019, 31(1): 84-93. [5] Zagoruyko S, Komodakis N. Learning to compare image patches via convolutional neural networks. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 4353−4361 [6] Luo W, Schwing A G, Urtasun R. Efficient deep learning for stereo matching. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 5695−5703 [7] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651. [8] Mayer N, Ilg E, Hausser P, Fischer P, Cremers D, Dosovitskiy A, Brox T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 4040−4048 [9] Song X, Zhao X, Fang L, Hu H. Edgestereo: An effective multi-task learning network for stereo matching and edge detection. International Journal of Computer Vision, 2020, 128(4): 910-930. [10] Song X, Zhao X, Hu H W, Fang L J. Edgestereo: A context integrated residual pyramid network for stereo matching. In: Proceedings of the 14th Asian Conference on Computer Vision. Springer, Cham, 2018. 11365: 20−35 [11] Yang G R, Zhao H S, Shi J P, Deng Z D, Jia J Y. Segstereo: Exploiting semantic information for disparity estimation. In: Proceedings of the 15th European Conference on Computer Vision. Springer Verlag: 2018. 11211: 660−676 [12] Zhang J, Skinner K A, Vasudevan R, Johnson-Roberson M. Dispsegnet: leveraging semantics for end-to-end learning of disparity estimation from stereo imagery. IEEE Robotics and Automation Letters, 2019, 4(2): 1162-1169. [13] Jie Z Q, Wang P F, Ling Y G, Zhao B, Wei Y C, Feng J S, Liu W. Left-right comparative recurrent model for stereo matching. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018.3838−3846 [14] Liang Z F, Feng Y L, Guo Y L, Liu H Z, Chen W, Qiao L B, Zhou L, Zhang J F. Learning for disparity estimation through feature constancy. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 2811−2820 [15] 程鸣洋, 盖绍彦, 达飞鹏. 基于注意力机制的立体匹配网络研究. 光学学报, 2020, 40(14): 144-152.Cheng Ming-Yang, Gai Shao-Yan, Da Fei-Peng. A stereo-matching neural network based on attention mechanism. Acta Optica Sinica, 2020, 40(14): 144-152. [16] 王玉锋, 王宏伟, 于光, 杨明权, 袁昱纬, 全吉成. 基于三维卷积神经网络的立体匹配算法. 光学学报, 2019, 39(11): 227-234.Wang Yu-Feng, Wang Hong-Wei, Yu Guang, Yang Ming-Quan, Yuan Yu-Wei, Quan Ji-Cheng. Stereo matching based on 3D convolutional neural network. Acta Optica Sinica, 2019, 39(11): 227-234. [17] Chang J R, Chen Y S. Pyramid stereo matching network. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 5410−5418 [18] Zhu Z D, He M Y, Dai Y C, Rao Z B, Li B. Multi-scale cross-form pyramid network for stereo matching. In: Proceedings of the 14th IEEE Conference on Industrial Electronics and Applications. Xi'an, China: IEEE, 2019. 1789−1794 [19] Zhang L, Wang Q H, Lu H H, Zhao Y. End-to-end learning of multi-scale convolutional neural network for stereo matching. In: Proceedings of Asian Conference on Machine Learning. 2018. 81−96 [20] Mayer N, Ilg E, Hausser P, Fischer P. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 4040−4048 [21] Kendall A, Martirosyan H, Dasgupta S, Henry P, Kennedy R, Bachrach A, Bry A. End-to-end learning of geometry and context for deep stereo regression. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 66−75 [22] Lu H H, Xu H, Zhang L, Ma Y B, Zhao Y. Cascaded multi-scale and multi-dimension convolutional neural network for stereo matching. In: Proceedings of the 2018 IEEE Visual Communications and Image Processing. Taichung, China: IEEE, 2018. 1−4 [23] Rao Z B, He M Y, Dai Y C, Zhu Z D, Li B, He R J. MSDC-Net: Multi-scale dense and contextual networks for automated disparity map for stereo matching. arXiv PreprintarXiv: 1904.12658, 2019. [24] Guo X Y, Yang K, Yang W K, Wang X G, Li H S. Group-wise correlation stereo network. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 3273−3282 [25] Liu M Y, Yin H J. Cross attention network for semantic segmentation. In: Proceedings of the 2019 IEEE International Conference on Image Processing. Taipei, China: IEEE, 2019. 2434−2438 [26] 王亚珅, 黄河燕, 冯冲, 周强. 基于注意力机制的概念化句嵌入研究. 自动化学报, 2020, 46(7): 1390-1400.Wang Ya-Shen, Huang He-Yan, Feng Chong, Zhou Qiang. Conceptual sentence embeddings based on attention mechanism. Acta Automatica Sinica, 2020, 46(7): 1390- 1400. [27] Kim J H, Choi J H, Cheon M, Lee J S. RAM: Residual attention module for single image super-resolution. arXiv PreprintarXiv: 1811.12043, 2018. [28] Jeon S, Kim S, Sohn K. Convolutional feature pyramid fusion via attention network. In: Proceedings of the 2017 IEEE International Conference on Image Processing. Beijing, China: IEEE, 2017. 1007−1011 [29] Sang H, Wang Q, Zhao Y. Multi-scale context attention network for stereo matching. IEEE Access, 2019, 7: 15152-15161. [30] Zhang G, Zhu D, Shi W, et al. Multi-dimensional residual dense attention network for stereo matching. IEEE Access, 2019, 7: 51681-51690. [31] Hu J, Shen L, Albanie S, Sun G, Wu E. Squeeze-and-excitation networks. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2019, 42(8). 2011-2023. [32] Wang Q L, Wu B G, Zhu P F, Li P H, Zuo W M, Hu Q H. ECA-Net: Efficient channel attention for deep convolutional neural networks. In: Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2020. 11531−11539 [33] Menze M, Geiger A. Object scene flow for autonomous vehicles. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 3061−3070 [34] Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 3354−3361 [35] Pang J H, Sun W X, Ren J S, Yang C X, Yan Q. Cascade residual learning: A two-stage convolutional neural network for stereo matching. In: Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops. Venice, Italy: IEEE, 2017. 878−886 [36] Žbontar J, Lecun Y. Stereo matching by training a convolutional neural network to compare image patches. Journal of Machine Learning Research, 2016, 17. [37] Tulyakov S, Ivanov A, Fleuret F. Practical deep stereo (PDS): Toward applications-friendly deep stereo matching. In: Proceedings of the 32nd Conference on Neural Information Processing Systems. Montreal, Canada: 2018. -

 下载:
下载:




计量
- 文章访问数: 2054
- HTML全文浏览量: 1070
- PDF下载量: 235
- 被引次数: 0
