

Robust Cross-lingual Dialogue System Based on Multi-granularity Adversarial Training
-
摘要:
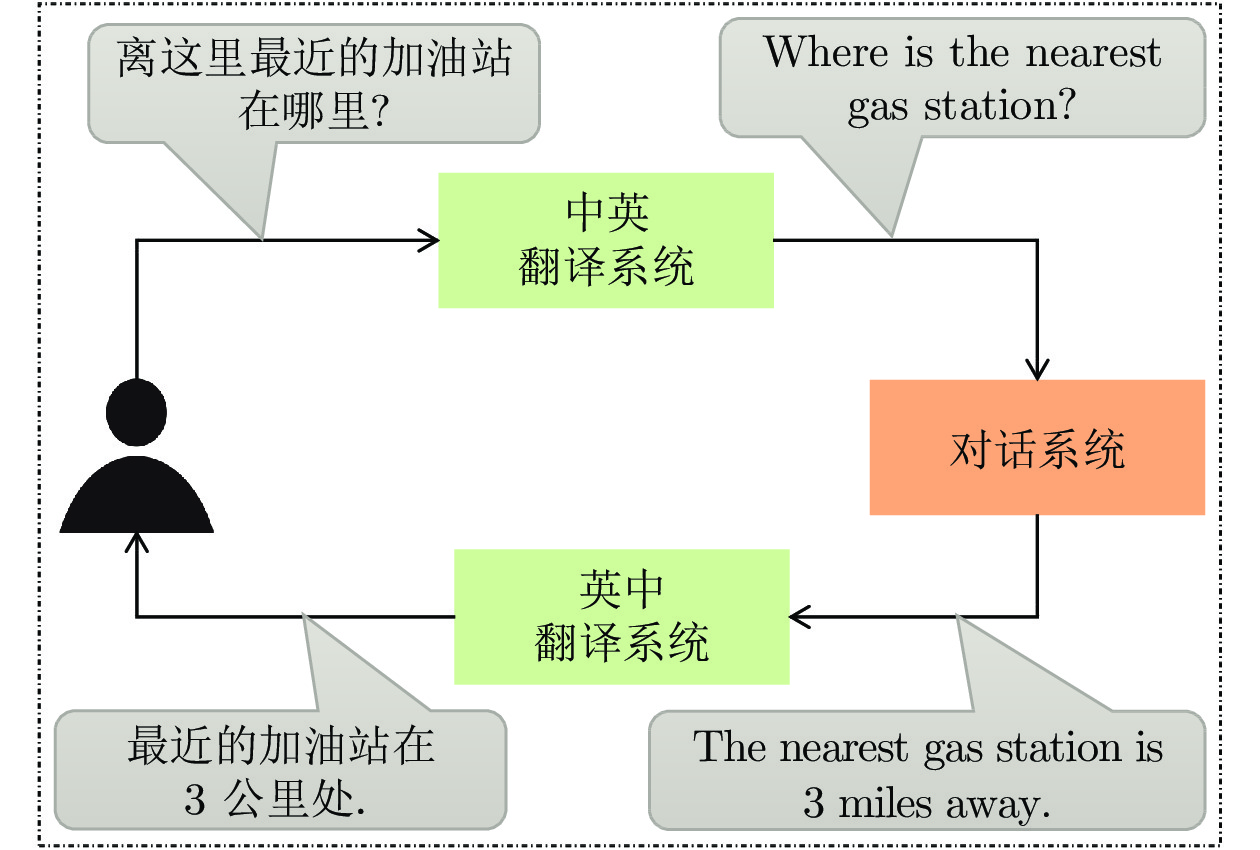
跨语言对话系统是当前国际研究的热点和难点. 在实际的应用系统搭建中, 通常需要翻译引擎作为不同语言之间对话的桥梁. 然而, 翻译引擎往往是基于不同训练样本构建的, 无论是所在领域, 还是擅长处理语言的特性, 均与对话系统的实际应用需求存在较大的差异, 从而导致整个对话系统的鲁棒性差、响应性能低. 因此, 如何增强跨语言对话系统的鲁棒性对于提升其实用性具有重要的意义. 提出了一种基于多粒度对抗训练的鲁棒跨语言对话系统构建方法. 该方法首先面向机器翻译构建多粒度噪声数据, 分别在词汇、短语和句子层面生成相应的对抗样本, 之后利用多粒度噪声数据和干净数据进行对抗训练, 从而更新对话系统的参数, 进而指导对话系统学习噪声无关的隐层向量表示, 最终达到提升跨语言对话系统性能的目的. 在公开对话数据集上对两种语言的实验表明, 所提出的方法能够显著提升跨语言对话系统的性能, 尤其提升跨语言对话系统的鲁棒性.
Abstract:Cross-lingual dialogue system is attractive and also very difficult for current international research. In real-word system implementations, machine translation engines are often needed to serve as a bridge for different languages. However, machine translation engines are often built based on different training data. No matter the field they focus on, or the characteristics of the language that they are expert at processing, there still remains huge gaps to the demands of the dialogue system, resulting in poor robustness and low response performance of the entire dialogue system. Therefore, how to improve the robustness of the cross-lingual dialogue system has very important realistic significance for boosting its practicability. This paper proposes a robust cross-lingual dialogue system building method based on multi-granularity adversarial training. This method firstly constructs multi-granularity noise data oriented to machine translation, generating corresponding adversarial samples at the word, phrase, and sentence level. Then, the adversarial training over multi-granularity noise data and clean data is adopted to update the parameters of the dialogue system, guiding the dialogue system to learn noise-independent hidden representations, so as to improve the performance of the cross-lingual dialogue system. Experimental results on publicly available dialogue datasets and two language pairs show that the proposed method can significantly improve the performance of the cross-lingual dialogue system, especially the robustness of the cross-lingual dialogue system.
-
Key words:
- Multi-granularity noise /
- adversarial training /
- robust /
- cross-lingual /
- dialogue system
-
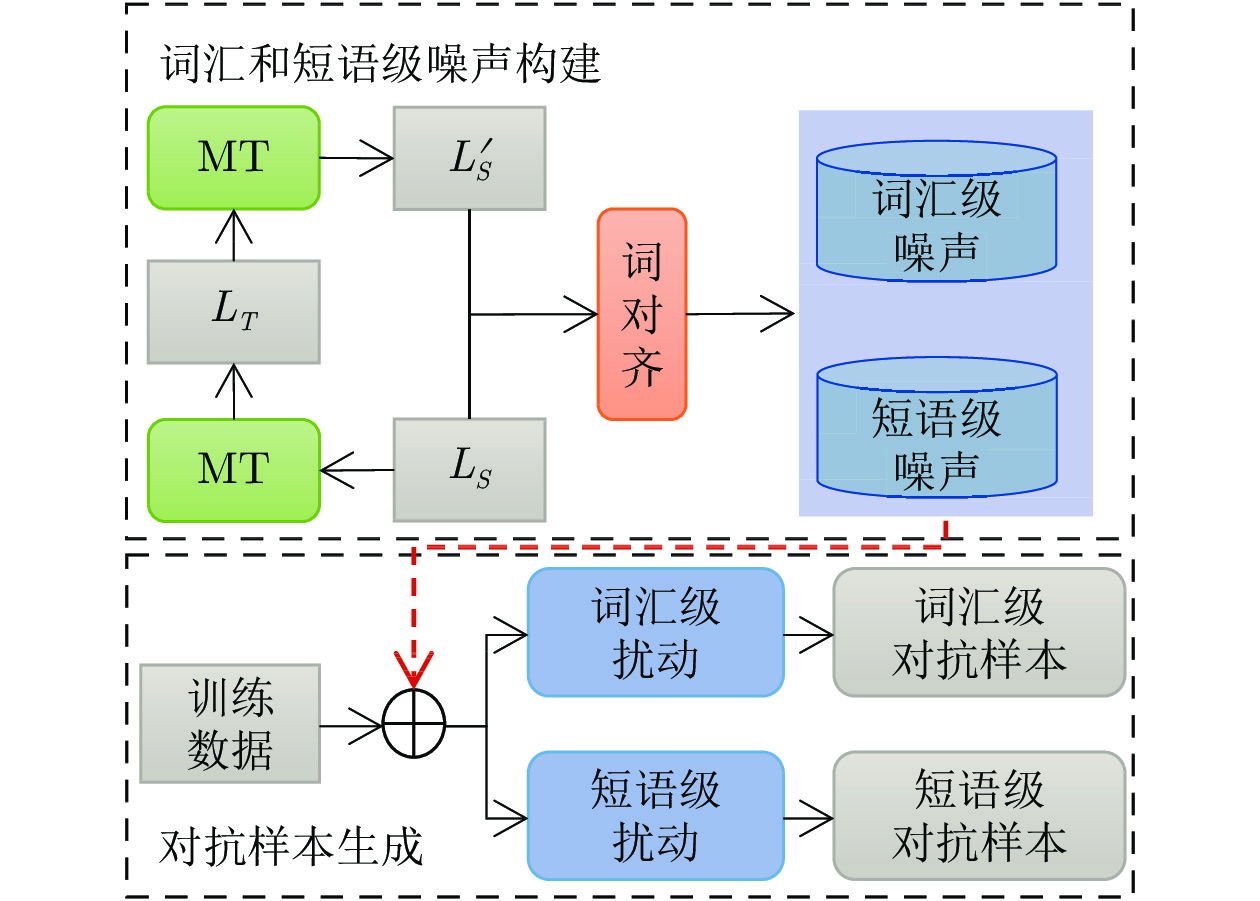
图 3 词汇级和短语级对抗样本生成框架
Fig. 3 The framework of word-level and phrase-level adversarial examples generation
表 1 数据集统计信息
Table 1 Statistics of datasets
数据集 CamRest676 规模 训练集: 405 验证集: 135 测试集: 136 领域 餐馆预定 数据集 KVRET 规模 训练集: 2425 验证集: 302 测试集: 302 领域 日程规划、天气信息查询、导航  下载: 导出CSV
下载: 导出CSV
表 2 CamRest676数据集上的实验结果
Table 2 Experimental results on CamRest676
对抗样本 Cross-test Mono-test BLEU 实体匹配率 成功率${{F} }_{1}$ 组合分数 BLEU 实体匹配率 成功率${{F} }_{1}$ 组合分数 0 基线系统 0.1731 0.4776 0.6485 0.7361 0.2001 0.9328 0.8204 1.0767 1 随机交换 0.1759 0.4851 0.6599 0.7484 0.2159 0.9104 0.7639 1.0530 2 停用词 0.1692 0.5000 0.6347 0.7365 0.2300 0.9179 0.7803 1.0791 3 同义词 0.1805 0.4403 0.7051 0.7532 0.2159 0.9030 0.7824 1.0586 4 词汇级 0.1941 0.4552 0.7503 0.7969 0.2056 0.8955 0.8227 1.0647 5 短语级 0.2017 0.4478 0.7602 0.8057 0.2215 0.8507 0.7992 1.0465 6 句子级 0.1937 0.4925 0.7662 0.8231 0.2127 0.8731 0.8121 1.0553 7 多粒度 0.2178 0.5149 0.7925 0.8715 0.2343 0.8881 0.8269 1.0918
下载: 导出CSV
表 3 KVRET数据集上的实验结果
Table 3 Experimental results on KVRET
对抗样本 Cross-test Mono-test BLEU 实体匹配率 成功率${{F} }_{1}$ 组合分数 BLEU 实体匹配率 成功率${{F} }_{1}$ 组合分数 0 基线系统 0.1737 0.4218 0.7073 0.7382 0.2096 0.7929 0.7948 1.0034 1 随机交换 0.1751 0.4436 0.7122 0.7531 0.2056 0.8400 0.8033 1.0273 2 停用词 0.1676 0.4327 0.7183 0.7431 0.1961 0.8109 0.8016 1.0023 3 同义词 0.1680 0.4145 0.7234 0.7370 0.1944 0.8109 0.7898 0.9947 4 词汇级 0.1805 0.4436 0.7696 0.7871 0.2095 0.8109 0.8202 1.0251 5 短语级 0.1933 0.4727 0.7603 0.8097 0.2219 0.8255 0.8170 1.0431 6 句子级 0.1803 0.4727 0.7843 0.8088 0.1965 0.8218 0.8136 1.0142 7 多粒度 0.1762 0.5236 0.7859 0.8309 0.1944 0.8218 0.8235 1.0171
下载: 导出CSV
表 4 KVRET数据集上德到英的跨语言实验结果
Table 4 Cross-lingual experimental results from German to English on KVRET
对抗样本 Cross-test Mono-test BLEU 实体匹配率 成功率${{F} }_{1}$ 组合分数 BLEU 实体匹配率 成功率${{F} }_{1}$ 组合分数 0 基线系统 0.1641 0.3964 0.7162 0.7203 0.2096 0.7927 0.7948 1.0034 1 词汇级 0.1661 0.4618 0.7596 0.7768 0.2011 0.8109 0.8163 1.0147 2 短语级 0.1842 0.5127 0.7922 0.8367 0.1975 0.8218 0.8248 1.0208 3 句子级 0.1844 0.5091 0.7774 0.8277 0.2067 0.8291 0.8095 1.0260 4 多粒度 0.1743 0.5309 0.8117 0.8456 0.1905 0.7964 0.8186 0.9981
下载: 导出CSV
表 5 跨语言对话实验结果实例
Table 5 Examples of cross-lingual experimental results
Cross-test Mono-test CamRest676 实验结果实例 实例1 User: 请推荐给我一些位于南方的价位适中的餐厅.
MT: please recommend me some restaurant at the
appropriate price in the south.User: please suggest me some moderately priced
restaurant in the south.Gold_bspan: moderate south Gold_response: i found two moderately priced restaurants in the south part of town. would you prefer food_SLOT or food_SLOT food? 基线系统 generated_bspan: south
generated_response: there are no restaurants in the
south part of town.generated_bspan: moderate south
generated_response: there are two restaurants in
the south part of town.多粒度 generated_bspan: moderate south
generated_response: there are two moderately priced
restaurants in the south part of town. would you like
more information?generated_bspan: moderate south
generated_response: there are two moderately priced
restaurants in the south part of town. would you like
more information?KVRET 实验结果实例 实例2 Driver: 最近的停车场怎么走?
MT: how can the latest car park go?Driver: what are the direction to the closest parking garage? Gold_bspan: parking garage
Gold_response: the closest parking garage is poi_SLOT, located distance_SLOT away at address_SLOT.基线系统 generated_bspan: ITEM_3
generated_response: there is a ITEM_0 one and poi_SLOT, distance_SLOT away with traffic_info_SLOT.generated_bspan: parking garage
generated_response: the nearest parking garage is
poi_SLOT, distance_SLOT away.多粒度 generated_bspan: parking garage
generated_response: the closest parking garage is
distance_SLOT away.generated_bspan: parking garage
generated_response: the closest parking garage is
poi_SLOT.实例3 Driver: 安排 5 日上午 11 点与副会长会面.
MT: arranged for him to meet with the vice
president at 11am on the 5th.Driver: schedule a conference with the vice president
on the 5th at 11am.Gold_bspan: 5th; vice president; conference; 11am
Gold_response: conference scheduled for the 5th at 11am with the vice president.基线系统 generated_bspan: 5th; vice president; vice president
generated_response: the 5th is set the president
to discus the president.generated_bspan: 5th; vice president; conference; 11am
generated_response: the 5th is with a vice president for
the 5th at address_SLOT with a high of the 5th of the 5th
of the 5th of the 5th of the 5th of the 5th is with the 5th.多粒度 generated_bspan: 5th; vice president; conference; 11am
generated_response: your conference with vice president
at this 5th at with the vice president at the 5th.generated_bspan: 5th; vice president; conference; 11am
generated_response: you have a conference with the
vice president on the 5th at this 5th.
下载: 导出CSV
表 6 翻译现象类别实例
Table 6 Categories of translation phenomena
类别 1 原始单语句子 I am looking for a moderately priced restaurant in the south part of town. 中文测试集 你知道镇北部有什么价格适中的餐馆吗? MT I' m looking for a cheap restaurant in the south of the town. 类别 2 原始单语句子 A restaurant in the moderately priced range, please. 中文测试集 请给我一家中等价位的餐馆. MT Please give me a mid-priced restaurant. 类别 3 原始单语句子 I would like a cheap restaurant that serves greek food. 中文测试集 我想要一家供应希腊食物的便宜餐馆. MT I' d like a cheap restaurant to supply greek food.
下载: 导出CSV
表 7 翻译系统噪声类型分析
Table 7 Noise type analysis of machine translation
翻译结果分类 轮数 类别 1 27 类别 2 72 类别 3 23 类别 4 55
下载: 导出CSV
表 8 4种翻译现象上的实验结果
Table 8 Experimental results on four translation phenomena
类别 Cross-test Mono-test BLEU/ 实体匹配率/ 成功率${{F} }_{1}$ BLEU/ 实体匹配率/ 成功率${{F} }_{1}$ 基线系统 1 0.1229/ 0.2632/ 0.3548 0.1987/ 1.0000/ 0.6571 2 0.1672/ 0.2879/ 0.4234 0.2093/ 0.9394/ 0.6239 3 0.1429/ 0.3500/ 0.5538 0.1588/ 0.8500/ 0.6757 4 0.1640/ 0.5909/ 0.5629 0.1891/ 0.8864/ 0.6595 多粒度 1 0.1706/ 0.4737/ 0.5135 0.2301/ 1.0000/ 0.6835 2 0.2327/ 0.5000/ 0.6748 0.2594/ 0.8939/ 0.6935 3 0.1607/ 0.3000/ 0.5352 0.1801/ 0.7000/ 0.5278 4 0.2066/ 0.5909/ 0.5989 0.1924/ 0.8182/ 0.6448
下载: 导出CSV
表 9 CamRest676数据集上使用其他单语基线对话系统的跨语言实验结果
Table 9 Cross-lingual experimental results using other monolingual baseline dialogue systems on CamRest676
对抗样本 Cross-test Mono-test BLEU 实体匹配率 成功率${{F} }_{1}$ 组合分数 BLEU 实体匹配率 成功率${{F} }_{1}$ 组合分数 SEDST 0 基线系统 0.1671 0.6455 0.7294 0.8545 0.2107 0.9545 0.8120 1.0940 1 多粒度 0.2093 0.8333 0.8193 1.0356 0.2292 0.9259 0.8378 1.1111 LABES-S2S 2 基线系统 0.1910 0.7450 0.7260 0.9265 0.2350 0.9640 0.7990 1.1165 3 多粒度 0.2300 0.8150 0.8290 1.0520 0.2400 0.9440 0.8580 1.1410
下载: 导出CSV
-
[1] Li X J, Chen Y N, Li L H, Gao J F, Celikyilmaz A. End-to-end task-completion neural dialogue systems. In: Proceedings of the Eighth International Joint Conference on Natural Language Processing. Taipei, China: Asian Federation of Natural Language Processing, 2017. 733−743 [2] Liu B, Lane I. End-to-end learning of task-oriented dialogs. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop. New Orleans, Louisiana, USA: Association for Computational Linguistics, 2018. 67−73 [3] Wen T H, Vandyke D, Mrkšić N, Gašić M, Rojas-Barahona L M, Su P H, et al. A network-based end-to-end trainable task-oriented dialogue system. In: Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. Valencia, Spain: Association for Computational Linguistics, 2017. 438−449 [4] Wang W K, Zhang J J, Li Q, Zong C Q, Li Z F. Are you for real? Detecting identity fraud via dialogue interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, China: Association for Computational Linguistics, 2019. 1762−1771 [5] Wang W K, Zhang J J, Li Q, Hwang M Y, Zong C Q, Li Z F. Incremental learning from scratch for task-oriented dialogue systems. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 3710−3720 [6] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, California, USA: arXiv Press, 2015. 1412.6572 [7] Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow I J, et al. Intriguing properties of neural networks. arXiv preprint arXiv: 1312. 6199, 2013. [8] 董胤蓬, 苏航, 朱军. 面向对抗样本的深度神经网络可解释性分析. 自动化学报, DOI: 10.16383/j.aas.c200317Dong Yin-Peng, Su Hang, Zhu Jun. Towards interpretable deep neural networks by leveraging adversarial examples. Acta Automatica Sinica, DOI: 10.16383/j.aas.c200317 [9] 孔锐, 蔡佳纯, 黄钢. 基于生成对抗网络的对抗攻击防御模型. 自动化学报, DOI: 10.16383/j.aas.c200033Kong Rui, Cai Jia-Chun, Huang Gang. Defense to adversarial attack with generative adversarial network. Acta Automatica Sinica, DOI: 10.16383/j.aas.c200033 [10] Young S, Gasic M, Thomson B, Williams J D. POMDP-based statistical spoken dialog systems: a review[J]. Proceedings of the IEEE, 2013, 101(5): 1160−1179. doi: 10.1109/JPROC.2012.2225812 [11] Williams J D, Young S. Partially observable markov decision processes for spoken dialog systems[J]. Computer Speech & Language, 2007, 21(2): 393−422. [12] Mesnil G, Dauphin Y, Yao K, Bengio Y, Zweig G. Using recurrent neural networks for slot filling in spoken language understanding[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2015, 23(3): 530−539. [13] Bai H, Zhou Y, Zhang J J, Zong C Q. Memory consolidation for contextual spoken language understanding with dialogue logistic inference. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 5448−5453 [14] Lee S, Stent A. Task lineages: Dialog state tracking for flexible interaction. In: Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue. Los Angeles, California, USA: Association for Computational Linguistics, 2016. 11−21 [15] Zhong V, Xiong C, Socher R. Global-locally self-attentive encoder for dialogue state tracking. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: Association for Computational Linguistics, 2018. 1458−1467 [16] Wang W K, Zhang J J, Zhang H, Hwang M Y, Zong C Q, Li Z F. A teacher-student framework for maintainable dialog manager. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 3803−3812 [17] Sharma S, He J, Suleman K, Schulz H, Bachman P. Natural language generation in dialogue using lexicalized and delexicalized data. In: Proceedings of the 5th International Conference on Learning Representations Workshop. Toulon, France: arXiv Press, 2017. 1606.03632v3 [18] Eric M, Manning C D. Key-value retrieval networks for task-oriented dialogue. In: Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue. Saarbrücken, Germany: Association for Computational Linguistics, 2017. 37−49 [19] Madotto A, Wu C S, Fung P. Mem2seq: Effectively incorporating knowledge bases into end-to-end task-oriented dialog systems. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: Association for Computational Linguistics, 2018. 1468−1478 [20] Wu C S, Socher R, Xiong C. Global-to-local memory pointer networks for task-oriented dialogue. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, Louisiana, USA: arXiv Press, 2019. 1901.04713v2 [21] Lei W Q, Jin X S, Kan M Y, Ren Z C, He X N, Yin D W. Sequicity: Simplifying task-oriented dialogue systems with single sequence-to-sequence architectures. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: Association for Computational Linguistics, 2018. 1437−1447 [22] García F, Hurtado L F, Segarra E, Sanchis E, Riccardi G. Combining multiple translation systems for spoken language understanding portability. In: Proceedings of the 2012 IEEE Spoken Language Technology Workshop (SLT). Miami, FL, USA: IEEE, 2012. 194−198 [23] Calvo M, García F, Hurtado L F, Jiménez S, Sanchis E. Exploiting multiple hypotheses for multilingual spoken language understanding. In: Proceedings of the Seventeenth Conference on Computational Natural Language Learning. Sofia, Bulgaria: Association for Computational Linguistics, 2013. 193−201 [24] Calvo M, Hurtado L F, Garcia F, Sanchis E, Segarra E. Multilingual Spoken Language Understanding using graphs and multiple translations[J]. Computer Speech & Language, 2016, 38: 86−103. [25] Bai H, Zhou Y, Zhang J J, Zhao L, Hwang M Y, Zong C Q. Source critical reinforcement learning for transferring spoken language understanding to a new language. In: Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe, New Mexico, USA: Association for Computational Linguistics, 2018. 3597−3607 [26] Chen W H, Chen J S, Su Y, Wang X, Yu D, Yan X F, et al. Xl-nbt: A cross-lingual neural belief tracking framework. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 414−424 [27] Schuster S, Gupta S, Shah R, Lewis M. Cross-lingual transfer learning for multilingual task oriented dialog. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, Minnesota: Association for Computational Linguistics, 2019. 3795−3805 [28] Ebrahimi J, Rao A, Lowd D, Dou D J. HotFlip: White-box adversarial examples for text classification. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: Association for Computational Linguistics, 2018. 31−36 [29] Miyato T, Dai A M, Goodfellow I. Adversarial training methods for semi-supervised text classification. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: arXiv Press, 2017. 1605.07725 [30] Belinkov Y, Bisk Y. Synthetic and natural noise both break neural machine translation. In: Proceedings of the 5th International Conference on Learning Representations. Vancouver, BC, Canada: arXiv Press, 2018. 1711.02173 [31] Cheng Y, Jiang L, Macherey W. Robust neural machine translation with doubly adversarial inputs. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 4324−4333 [32] Cheng Y, Tu Z P, Meng F D, Zhai J J, Liu Y. Towards robust neural machine translation. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: Association for Computational Linguistics, 2018. 1756−1766 [33] Li J W, Monroe W, Shi T L, Jean S, Ritter A, Jurafsky D. Adversarial learning for neural dialogue generation. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen, Denmark: Association for Computational Linguistics, 2017. 2157−2169 [34] Tong N, Bansal M. Adversarial over-sensitivity and over-stability strategies for dialogue models. In: Proceedings of the 22nd Conference on Computational Natural Language Learning. Brussels, Belgium: Association for Computational Linguistics, 2018. 486−496 [35] Gu J T, Lu Z D, Li H, Li V O K. Incorporating copying mechanism in sequence-to-sequence learning. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: Association for Computational Linguistics, 2016. 1631−1640 [36] Och F J, Ney H. A systematic comparison of various statistical alignment models[J]. Computational Linguistics, 2003, 29(1): 19−51. doi: 10.1162/089120103321337421 [37] Koehn P, Hoang H, Birch A, Callison-Burch C, Federico M, Bertoldi N, et al. Moses: Open source toolkit for statistical machine translation. In: Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions. Prague, Czech Republic: Association for Computational Linguistics, 2007. 177−180 [38] Kingma D, Ba J. Adam: A method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, California, USA: arXiv Press, 2015. 1412.6980 [39] Mehri S, Srinivasan T, Eskenazi M. Structured fusion networks for dialog. In: Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue. Stockholm, Sweden: Association for Computational Linguistics, 2019. 165−177 [40] Jin X S, Lei W Q, Ren Z C, Chen H S, Liang S S, Zhao Y H, et al. Explicit state tracking with semi-supervision for neural dialogue generation. In: Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York, USA: Association for Computing Machinery, 2018. 1403−1412 [41] Zhang Y C, Ou Z J, Wang H X, Feng J L. A probabilistic end-to-end task-oriented dialog model with latent belief states towards semi-supervised learning. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Online: Association for Computational Linguistics, 2020. 9207−9219 -

 下载:
下载:



计量
- 文章访问数: 1686
- HTML全文浏览量: 527
- PDF下载量: 224
- 被引次数: 0
