

Event-triggered Adaptive Critic Fault-tolerant Control for a Class of Discrete-time MIMO Systems
-
摘要: 本文针对具有执行器故障的一类离散非线性多输入多输出(Multi-input multi-output, MIMO)系统, 提出了一种基于事件触发的自适应评判容错控制方案. 该控制方案包括评价和执行网络. 在评价网络里, 为了缓解现有的非光滑二值效用函数可能引起的执行网络跳变问题, 利用高斯函数构建了一个光滑的效用函数, 并采用评价网络近似最优性能指标函数. 在执行网络里, 通过变量替换将系统状态的将来信息转化成关于系统当前状态的函数, 并结合事件触发机制设计了最优跟踪控制器. 该控制器引入了动态补偿项, 不仅能够抑制执行器故障对系统性能的影响, 而且能够改善系统的控制性能. 稳定性分析表明所有信号最终一致有界且跟踪误差收敛于原点的有界小邻域内. 数值系统和实际系统的仿真结果验证了该方案的有效性.Abstract: In this paper, an event-triggered adaptive critic fault-tolerant control scheme is proposed for a class of discretetime multi-input multi-output (MIMO) nonlinear systems with actuator fault. The proposed control scheme includes the critic and action neural networks (NNs). In the critic NN, a smooth utility function is constructed based on the Gaussian function, which avoids the possible chattering problem caused by the existing non-smooth utility function. Subsequently, the critic NN is used to approximate the optimal strategic utility function. In the action NN, the future system state is expressed by the functions of present system states by using the variable substitution method. By the combination of event-triggered mechanism, this paper designs the optimal tracking controller. An dynamic auxiliary signal is introduced in the developed controller, thereby eliminating the effect of the actuator fault and improving the control performance. Stability analysis indicates that all signals in the control-loop are ultimately uniformly bounded, and the tracking error converges to a small neighborhood of the origin. Finally, simulations of a numerical system and a practical system are performed to demonstrate the effectiveness of the proposed scheme.
-
表 1 仿真实验对比1
Table 1 Comparison of simulation results
触发次数 MAE ABO (bit/s) 无执行器补偿,非光滑效用函数 921 $ z_{1,1} $ 0.0201 5894.4 $ z_{2,1} $ 0.0335 有执行器补偿,非光滑效用函数 907 $ z_{1,1} $ 0.0185 5804.8 $ z_{2,1} $ 0.0229 有执行器补偿,光滑效用函数 843 $ z_{1,1} $ 0.0130 5395.2 $ z_{2,1} $ 0.0147 注: “无执行器补偿” 表示$\omega_j(k) = \hat{ {\boldsymbol{W} } }^{\rm T}_j(k){\boldsymbol{\varphi}}_j({\boldsymbol{Z} }_j(k_t))$; “有执行器补偿” 表示$\omega_j(k) = \hat{ {\boldsymbol{W} } }^{\rm T}_j(k){\boldsymbol{\varphi}}_j({\boldsymbol{Z} }_j(k_t))+\hat{\mu}_j(k)$; “非光滑效用函数” 表示若$ |z_{j,1}(k)| $大于一个给定的正常数, 则$ q_j(k) = 1 $. 否则, $ q_j(k) = 0 $; “光滑效用函数” 表示$q_j(k) = 1 - {\rm{e}}^{-z_{j, 1}^{2}(k)/\eta_j}$.  下载: 导出CSV
下载: 导出CSV
表 2 仿真实验对比2
Table 2 Comparison of simulation results
触发条件 触发次数 MAE ABO (bit/s) CPU耗时(s) SETC 843 $ z_{1,1} $ 0.0130 5395.2 0.6875 $ z_{2,1} $ 0.0147 DETC 801 $ z_{1,1} $ 0.0129 5126.4 0.8125 $ z_{2,1} $ 0.0144
下载: 导出CSV
-
[1] Zhang G C, Wu Q Q, Cui M, Zhang R. Securing UAV communications via joint trajectory and power control. IEEE Transactions on Wireless Communications, 2019, 18(2): 1376-1389 doi: 10.1109/TWC.2019.2892461 [2] Bullo F, Cort\’{e}s J, Mart\’{i}nez S. Distributed Control of Robotic Networks: A Mathematical Approach to Motion Coordination Algorithms. Princeton: Princeton University Press, 2009. 57-134 [3] Tabuada P. Event-triggered real-time scheduling of stabilizing control tasks. IEEE Transactions on Automatic Control, 2007, 52(9): 1680-1685 doi: 10.1109/TAC.2007.904277 [4] 董滔, 李小丽, 赵大端. 基于事件触发的三阶离散多智能体系统一致性分析. 自动化学报, 2019, 45(7): 1366-1372Dong Tao, Li Xiao-Li, Zhao Da-Duan. Event-triggered consensus of third-order discrete-time multi-agent systems. Acta Automatica Sinica, 2019, 45(7): 1366-1372 [5] Sahoo A, Xu H, Jagannathan S. Neural network-based event-triggered state feedback control of nonlinear continuous-time systems. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(3): 497-509 doi: 10.1109/TNNLS.2015.2416259 [6] Wu L G, Gao Y B, Liu J X, Li H Y. Event-triggered sliding mode control of stochastic systems via output feedback. Automatica, 2017, 82: 79-92 doi: 10.1016/j.automatica.2017.04.032 [7] Dai S L, He S D, Lin H, Wang C. Platoon formation control with prescribed performance guarantees for USVs. IEEE Transactions on Industrial Electronics, 2018, 65(5): 4237-4246 doi: 10.1109/TIE.2017.2758743 [8] Dai S L, He S D, Wang M, Yuan C Z. Adaptive neural control of underactuated surface vessels with prescribed performance guarantees. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(12): 3686-3698 doi: 10.1109/TNNLS.2018.2876685 [9] He W, Dong Y T. Adaptive fuzzy neural network control for a constrained robot using impedance learning. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(4): 1174-1186 doi: 10.1109/TNNLS.2017.2665581 [10] Wang M, Yang A L. Dynamic learning from adaptive neural control of robot manipulators with prescribed performance. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2017, 47(8): 2244-2255 doi: 10.1109/TSMC.2016.2645942 [11] Chen M, Ren B B, Wu Q X, Jiang C S. Anti-disturbance control of hypersonic flight vehicles with input saturation using disturbance observer. Science China Information Sciences, 2015, 58(7): 1-12 [12] Xu B, Sun F C, Yang C G, Gao D X, Ren J X. Adaptive discrete-time controller design with neural network for hypersonic flight vehicle via back-stepping. International Journal of Control, 2011, 84(9): 1543-1552 doi: 10.1080/00207179.2011.615866 [13] 李会, 刘允刚, 黄亚欣. 不确定非线性系统自适应动态事件触发输出反馈镇定. 控制理论与应用, 2019, 36(11): 1871-1878 doi: 10.7641/CTA.2019.90475Li Hui, Liu Yun-Gang, Huang Ya-Xin. Adaptive stabilization via dynamic event-triggered output feedback for uncertain nonlinear systems. Control Theory & Applications, 2019, 36(11): 1871-1878 doi: 10.7641/CTA.2019.90475 [14] Zhang Y H, Sun J, Liang H J, Li H Y. Event-triggered adaptive tracking control for multiagent systems with unknown disturbances. IEEE Transactions on Cybernetics, 2020, 50(3): 890-901 doi: 10.1109/TCYB.2018.2869084 [15] 杨彬, 周琪, 曹亮, 鲁仁全. 具有指定性能和全状态约束的多智能体系统事件触发控制. 自动化学报, 2019, 45(8): 1527-1535Yang Bin, Zhou Qi, Cao Liang, Lu Ren-Quan. Event-triggered control for multi-agent systems with prescribed performance and full state constraints. Acta Automatica Sinica, 2019, 45(8): 1527-1535 [16] Li Y X, Yang G H. Model-based adaptive event-triggered control of strict-feedback nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(4): 1033-1045 doi: 10.1109/TNNLS.2017.2650238 [17] Chen F C, Khalil H K. Adaptive control of a class of nonlinear discrete-time systems using neural networks. IEEE Transactions on Automatic Control, 1995, 40(5): 791-801 doi: 10.1109/9.384214 [18] Ge S S, Li G Y, Lee T H. Adaptive NN control for a class of strict-feedback discrete-time nonlinear systems. Automatica, 2003, 39(5): 807-819 doi: 10.1016/S0005-1098(03)00032-3 [19] Ge S S, Zhang J, Lee T H. Adaptive neural network control for a class of MIMO nonlinear systems with disturbances in discrete-time. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2004, 34(4): 1630-1645 doi: 10.1109/TSMCB.2004.826827 [20] Yang C G, Ge S Z, Xiang C, Chai T Y, Lee T H. Output feedback NN control for two classes of discrete-time systems with unknown control directions in a unified approach. IEEE Transactions on Neural Networks, 2008, 19(11): 1873-1886 doi: 10.1109/TNN.2008.2003290 [21] Liu Y J, Tong S C. Optimal control-based adaptive NN design for a class of nonlinear discrete-time block-triangular systems. IEEE Transactions on Cybernetics, 2016, 46(11): 2670-$2680 doi: 10.1109/TCYB.2015.2494007 [22] Tang L, Liu Y J, Chen C L P. Adaptive critic design for pure-feedback discrete-time MIMO systems preceded by unknown backlashlike hysteresis. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(11): 5681-5690 doi: 10.1109/TNNLS.2018.2805689 [23] Li Y X, Yang G H. Event-based adaptive NN tracking control of nonlinear discrete-time systems. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(9): 4359-4369 doi: 10.1109/TNNLS.2017.2765683 [24] Wang M, Wang Z D, Chen Y, Sheng W G. Adaptive neural event-triggered control for discrete-time strict-feedback nonlinear systems. IEEE Transactions on Cybernetics, 2020, 50(7): 2946-2958 doi: 10.1109/TCYB.2019.2921733 [25] Wang M, Wang Z D, Chen Y, Sheng W G. Event-based adaptive neural tracking control for discrete-time stochastic nonlinear systems: A triggering threshold compensation strategy. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(6): 1968-1981 doi: 10.1109/TNNLS.2019.2927595 [26] 王鼎. 基于学习的鲁棒自适应评判控制研究进展. 自动化学报, 2019, 45(6): 1031-1043Wang Ding. Research progress on learning-based robust adaptive critic control. Acta Automatica Sinica, 2019, 45(6): 1031-1043 [27] Werbos P J. Approximate dynamic programming for real-time control and neural modeling. Handbook of Intelligent Control: Neural, Fuzzy, and Adaptive Approaches. New York: Van Nostrand Reinhold, 1992. [28] He P G, Jagannathan S. Reinforcement learning neural-network-based controller for nonlinear discrete-time systems with input constraints. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2007, 37(2): 425-436 doi: 10.1109/TSMCB.2006.883869 [29] Yang R X, Yang C G, Chen M, Annamalai A S K. Discrete-time optimal adaptive RBFNN control for robot manipulators with uncertain dynamics. Neurocomputing, 2017, 234: 107-115 doi: 10.1016/j.neucom.2016.12.048 [30] Dong L, Zhong X G, Sun C Y, He H B. Adaptive event-triggered control based on heuristic dynamic programming for nonlinear discrete-time systems. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(7): 1594-1605 doi: 10.1109/TNNLS.2016.2541020 [31] Wang Z S, Liu L, Wu Y M, Zhang H G. Optimal fault-tolerant control for discrete-time nonlinear strict-feedback systems based on adaptive critic design. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(6): 2179-2191 doi: 10.1109/TNNLS.2018.2810138 [32] 杨浩, 姜斌, 周东华. 互联系统容错控制的研究回顾与展望. 自动化学报, 2017, 43(1): 9-19Yang Hao, Jiang Bin, Zhou Dong-Hua. Review and perspectives on fault tolerant control for interconnected systems. Acta Automatica Sinica, 2017, 43(1): 9-19 [33] 何潇, 郭亚琦, 张召, 贾繁林, 周东华. 动态系统的主动故障诊断技术. 自动化学报, 2020, 46(8): 1557-1570He Xiao, Guo Ya-Qi, Zhang Zhao, Jia Fan-Lin, Zhou Dong-Hua. Active fault diagnosis for dynamic systems. Acta Automatica Sinica, 2020, 46(8): 1557-1570 [34] Laghrouche S, Liu J X, Ahmed F S, Harmouche M, Wack M. Adaptive second-order sliding mode observer-based fault reconstruction for PEM fuel cell air-feed system. IEEE Transactions on Control Systems Technology, 2015, 23(3): 1098-1109 doi: 10.1109/TCST.2014.2361869 [35] Wang M, Wang Z D, Chen Y, Sheng W G. Observer-based fuzzy output-feedback control for discrete-time strict-feedback nonlinear systems with stochastic noises. IEEE Transactions on Cybernetics, 2020, 50(8): 3766-3777 doi: 10.1109/TCYB.2019.2902520 [36] Girard A. Dynamic triggering mechanisms for event-triggered control. IEEE Transactions on Automatic Control, 2015, 60(7): 1992-1997 doi: 10.1109/TAC.2014.2366855 [37] Liu D, Yang G H. Dynamic event-triggered control for linear time-invariant systems with L_2-gain performance. International Journal of Robust and Nonlinear Control, 2019, 29(2): 507-518 doi: 10.1002/rnc.4403 [38] Xiong S X, Chen M, Wu Q X. Predictive control for networked switch flight system with packet dropout. Applied Mathematics and Computation, 2019, 354: 444-459 doi: 10.1016/j.amc.2019.01.005 [39] Deng C, Wen C Y. Distributed resilient observer-based fault-tolerant control for heterogeneous multiagent systems under actuator faults and DoS attacks. IEEE Transactions on Control of Network Systems, 2020, 7(3): 1308-1318 doi: 10.1109/TCNS.2020.2972601 [40] Xing L T, Wen C Y, Liu Z T, Su H Y, Cai J P. Adaptive compensation for actuator failures with event-triggered input. Automatica, 2017, 85: 129-136 doi: 10.1016/j.automatica.2017.07.061 [41] Zhang C H, Yang G H. Event-triggered adaptive output feedback control for a class of uncertain nonlinear systems with actuator failures. IEEE Transactions on Cybernetics, 2020, 50(1): 201-210 doi: 10.1109/TCYB.2018.2868169 -

 下载:
下载:

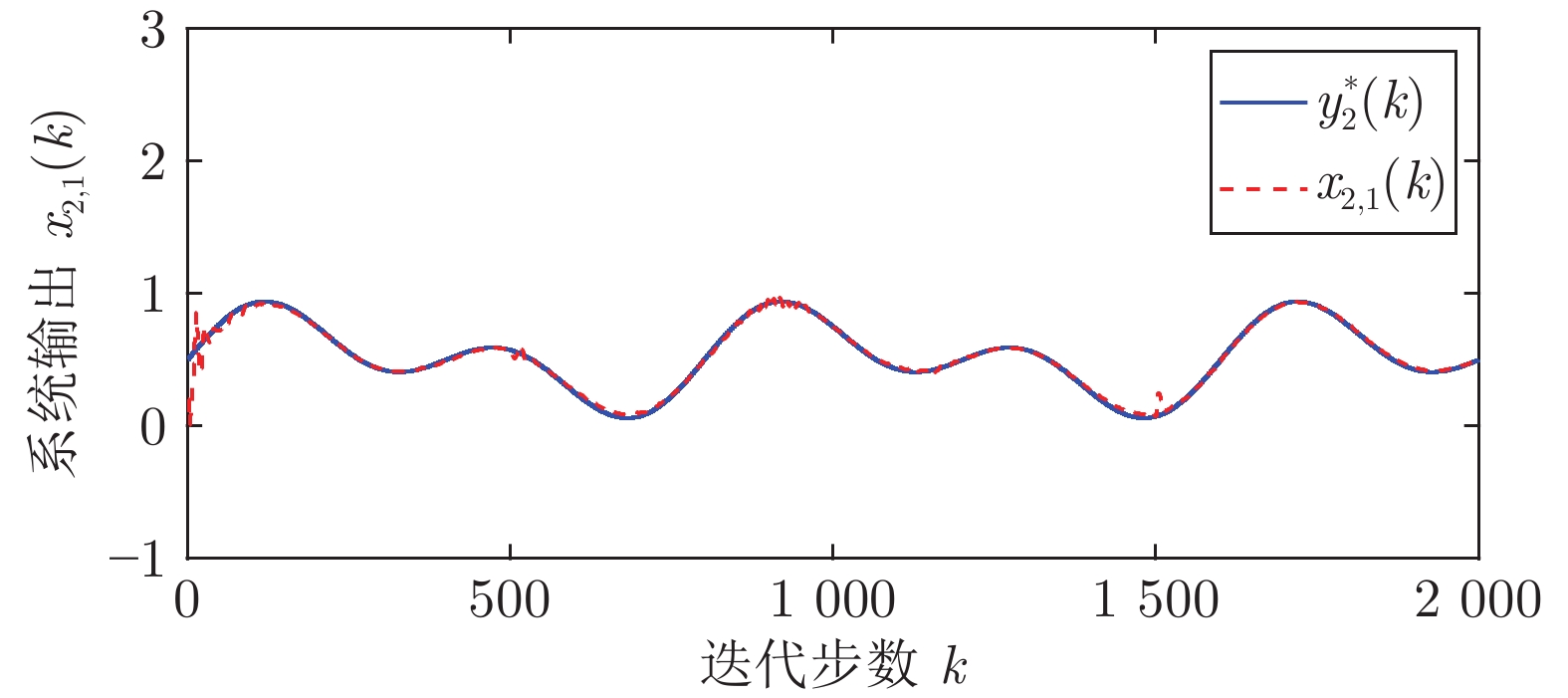
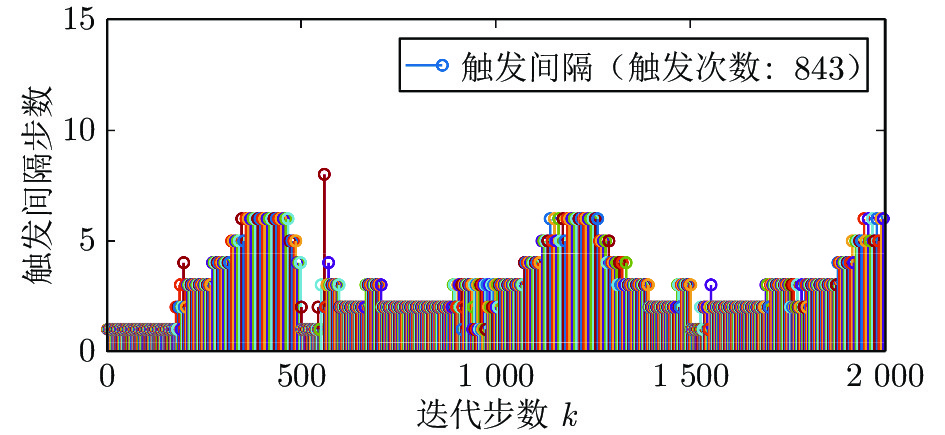
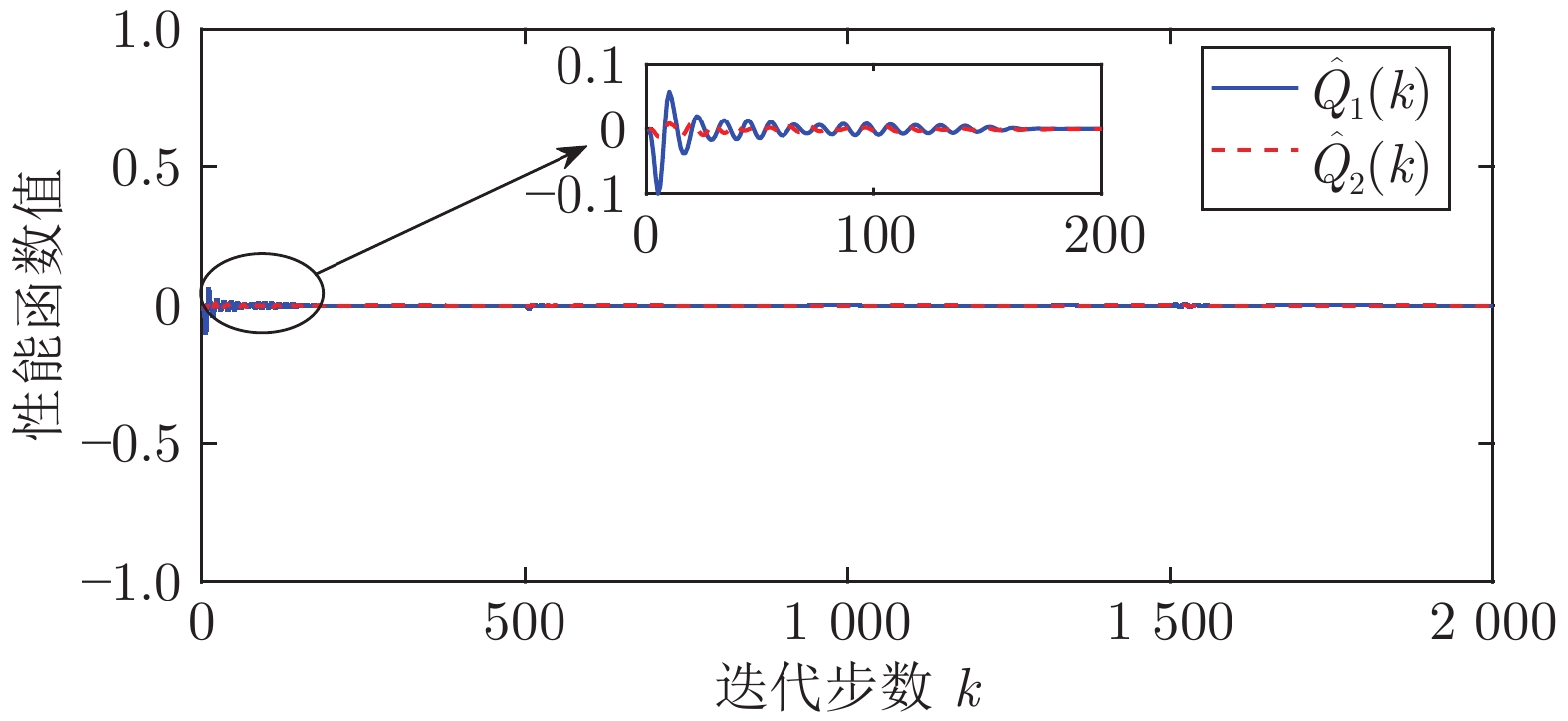
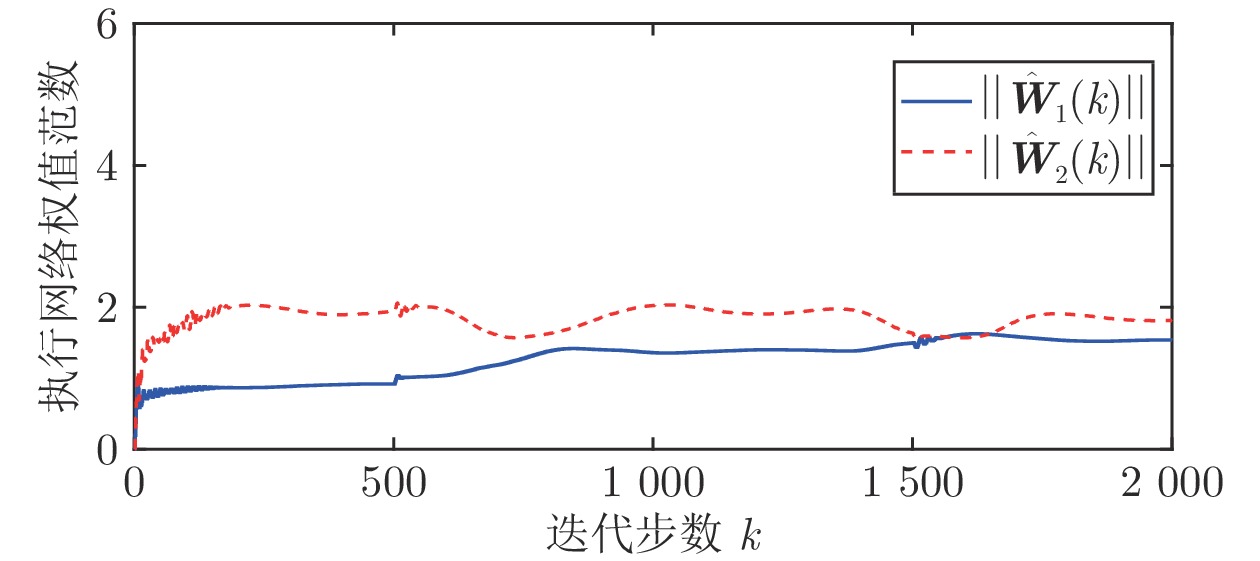



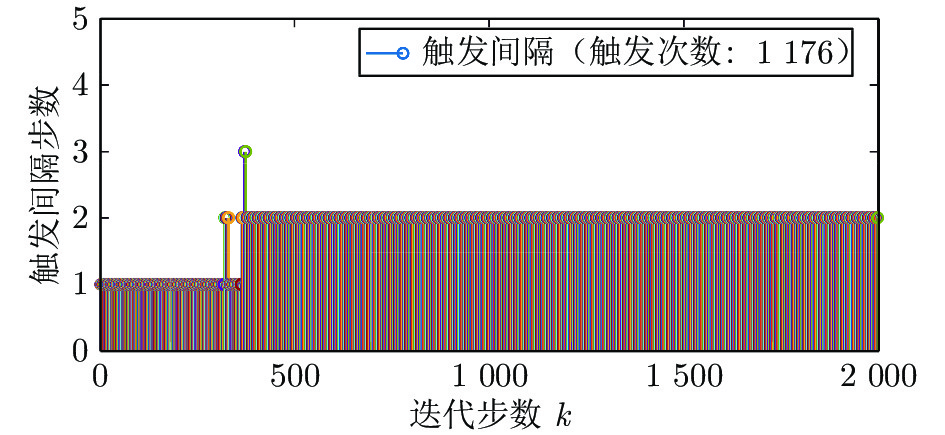
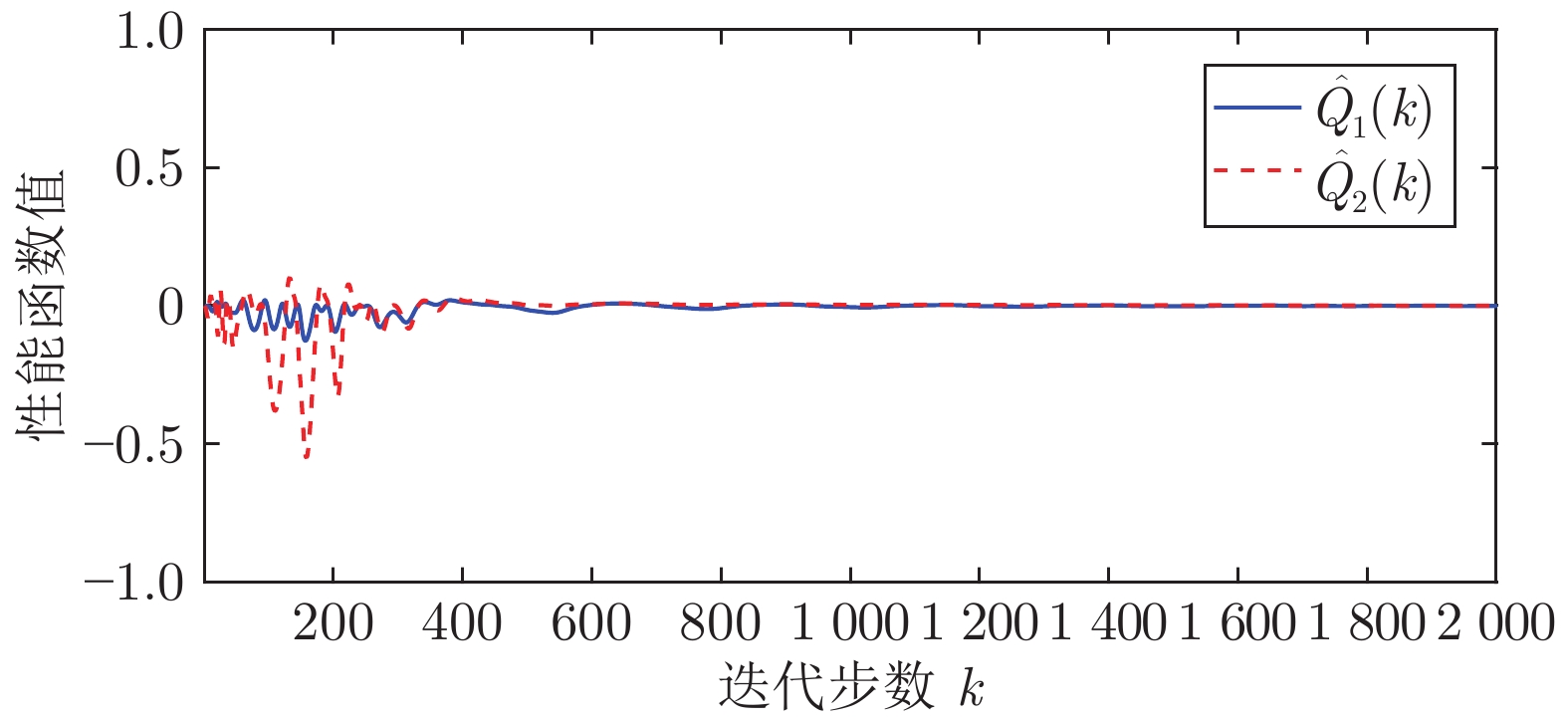
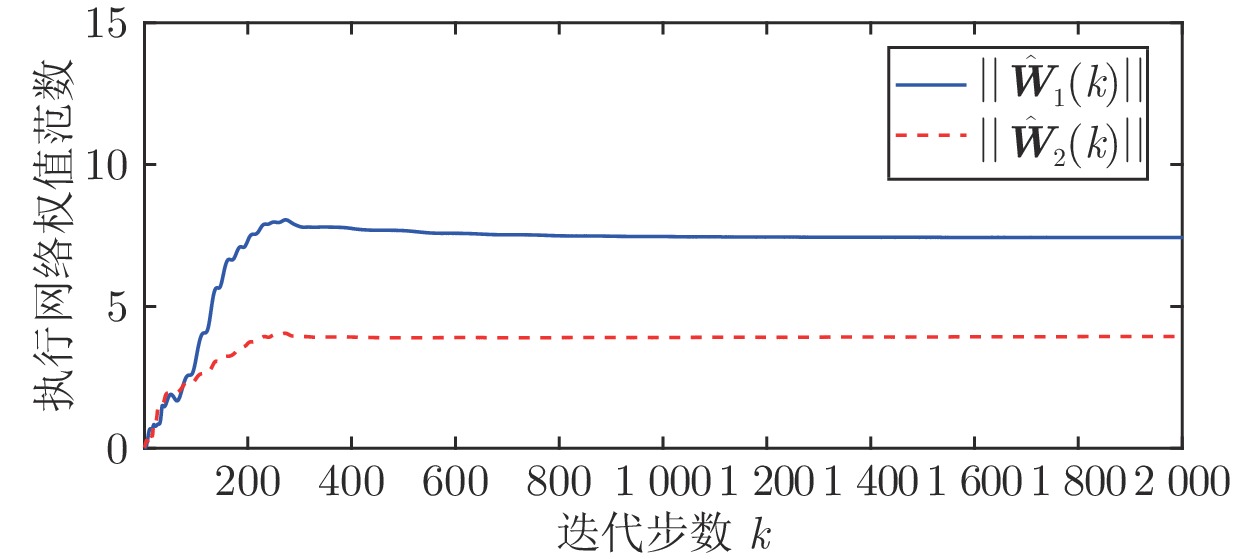



图(13) / 表(2)
计量
- 文章访问数: 1782
- HTML全文浏览量: 523
- PDF下载量: 349
- 被引次数: 0
