

Error-Tracking Iterative Learning Control for Robot Manipulators With Iteration Varying Lengths
-
摘要: 针对任意初始状态下机械臂轨迹跟踪问题, 提出一种变长度误差跟踪迭代学习控制(Iterative learning control, ILC)方法. 首先, 构造不依赖于期望轨迹的双曲余弦型期望误差轨迹, 放宽经典迭代学习控制初始状态要求严格一致的条件. 由于该误差轨迹只需设置一个常数项, 因而能够有效减少计算量, 使得期望误差轨迹的设计更为简单. 其次, 考虑机械臂运行区间随迭代次数变化的问题, 构建虚拟误差变量补偿机制, 通过定义虚拟误差变量对未运行区间进行信息补偿, 放宽经典迭代学习控制的迭代长度不变条件. 在此基础上, 基于Lyapunov-like理论设计迭代学习控制器和全限幅学习律, 实现机械臂关节位置在指定区间上跟踪给定的期望轨迹和保证未知参数估计值的有界性. 最后, 仿真结果验证了所提方法的有效性.Abstract: In this paper, an error-tracking iterative learning control (ILC) scheme with iteration varying length is proposed for the trajectory tracking of robot manipulators with arbitrary initial shifts. Firstly, a hyperbolic cosine-shaped desired error trajectory independent of the desired trajectory is constructed to relax the identical initial condition requirement in traditional iterative learning control. In the presented desired error trajectory, only one constant parameter needs to be set in prior, such that the computation can be reduced, and the design of the desired error trajectory becomes simpler. Then, the problem that the operating range of the robot manipulator varies with the number of iterations is investigated, and an error compensation mechanism is established to compensate for the error information of the non-operation intervals by defining virtual error variables. Consequently, the identical iterative length condition in traditional iterative learning control can be relaxed. Based on the Lyapunov-like theory, an iterative learning controller and a fully saturated learning law are designed to guarantee that the joint position of the robot manipulator could track the given desired trajectory in the specified interval and the boundedness of the estimation of the unknown parameters, respectively. Numerical simulation results are provided to demonstrate the effectiveness of the proposed scheme.
-

图 3 关节位置$q_{11,k}$和期望位置信号$q_{d1}$
Fig. 3 Joint position $q_{11,k}$ and desired position signal $q_{d1}$
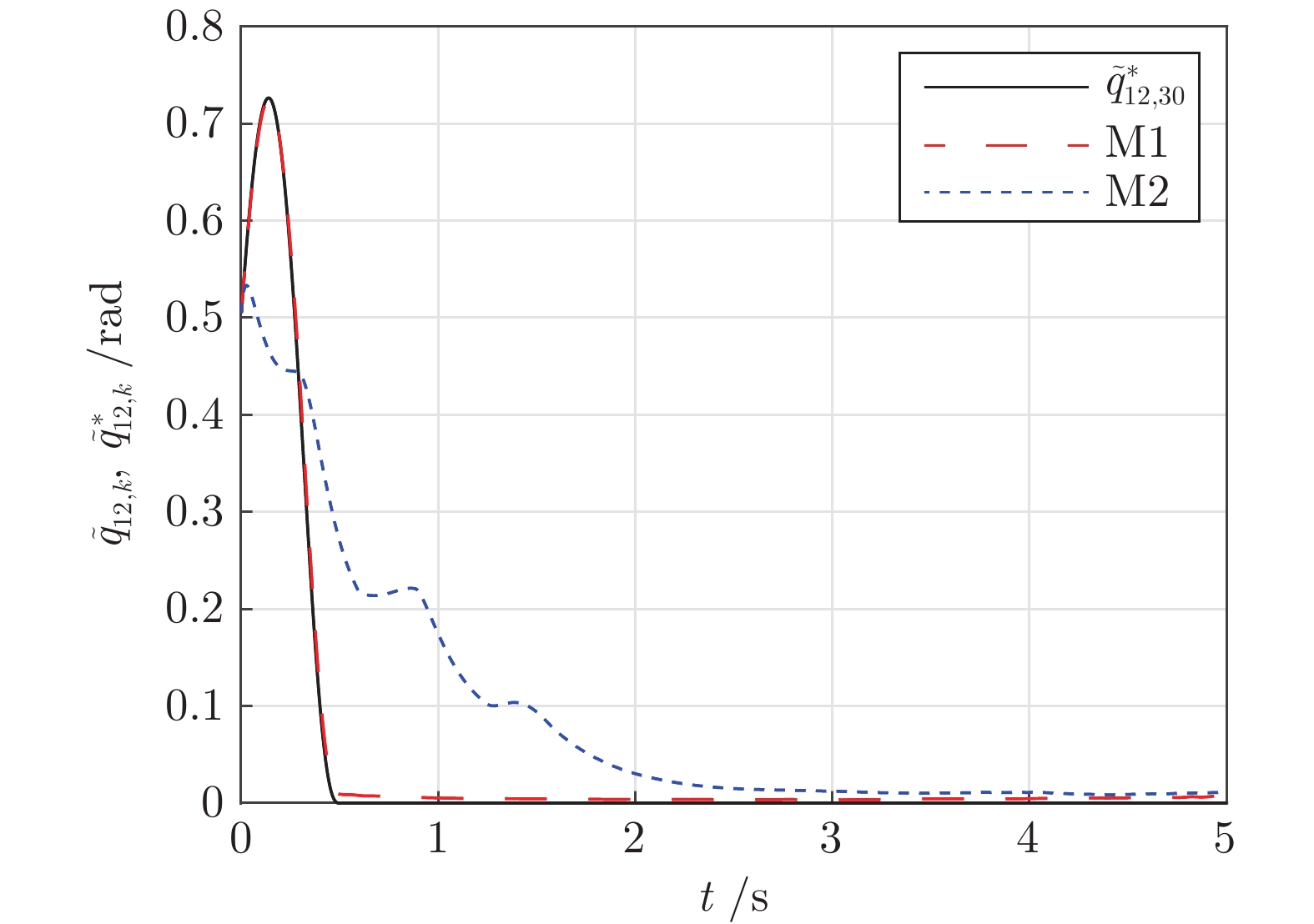
图 11 关节位置误差$\tilde q_{12,30}$收敛过程对比
Fig. 11 The comparison of the error $\tilde q_{12,30}$ convergence processes
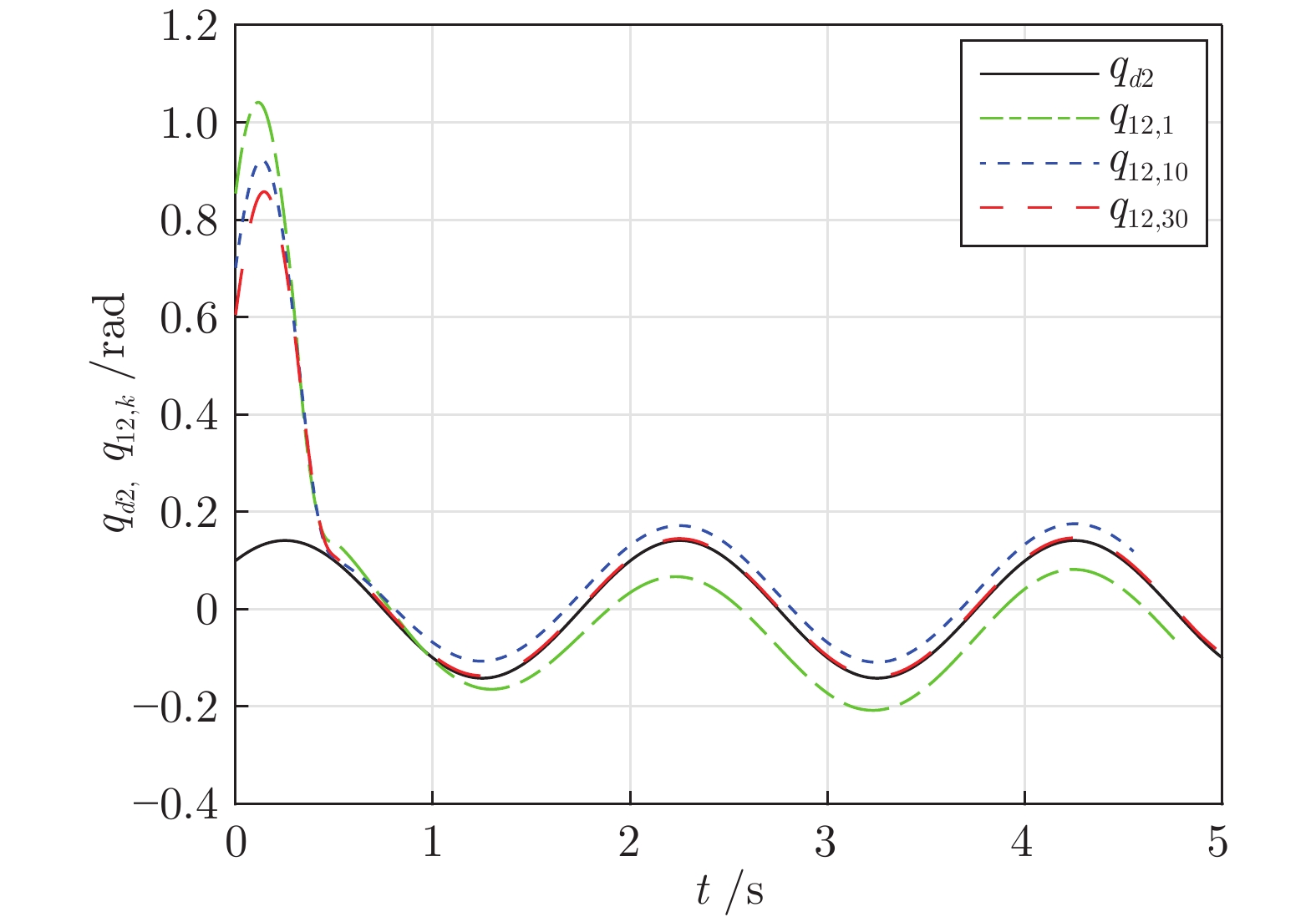
图 4 关节位置$q_{12,k}$和期望位置信号$q_{d2}$
Fig. 4 Joint position $q_{12,k}$ and desired position signal $q_{d2}$
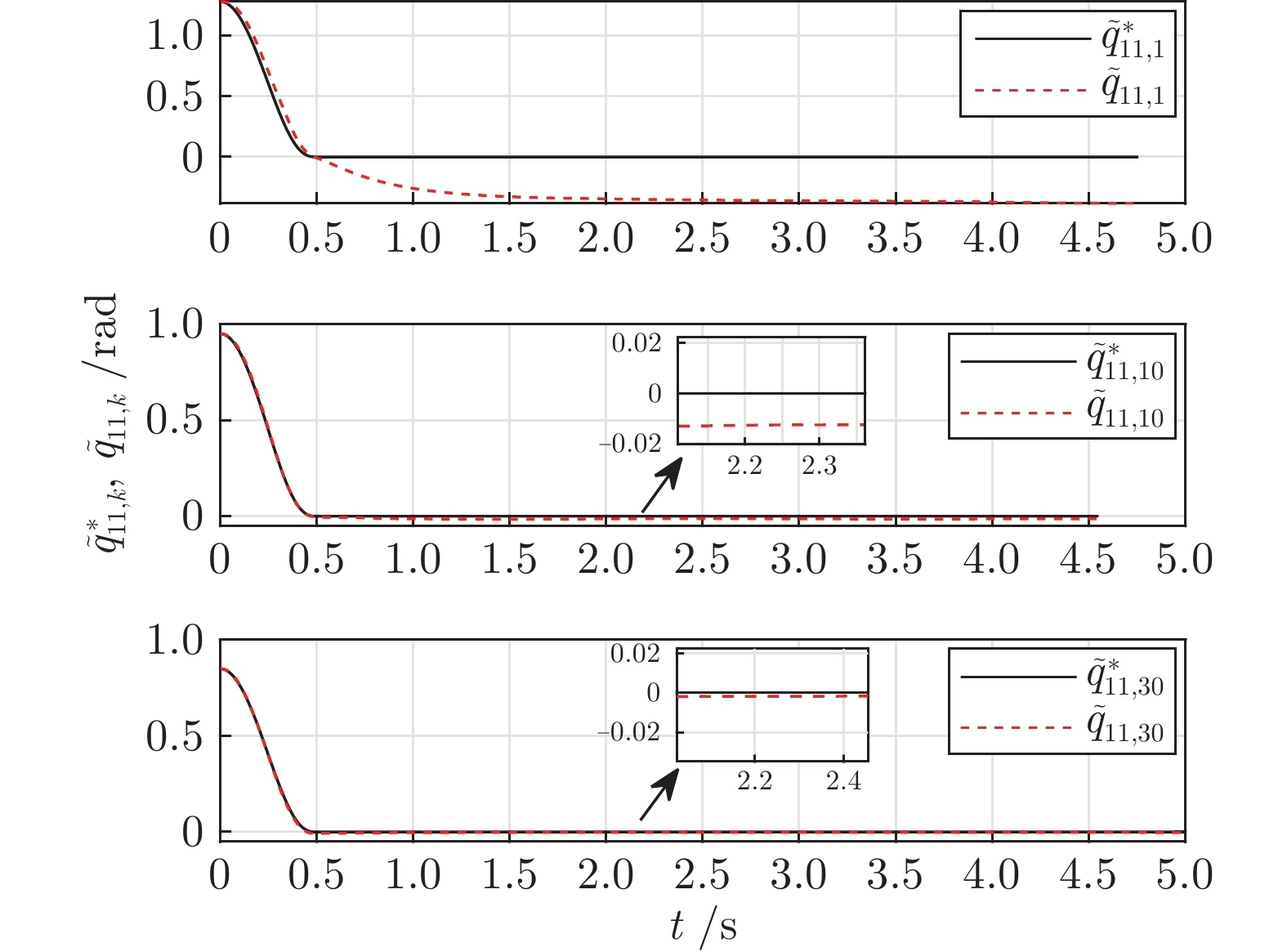
图 5 误差轨迹$\tilde q_{11,k}$ 和期望误差轨迹$\tilde q_{11,k}^*$
Fig. 5 Error trajectory $\tilde q_{11,k}$ and desired error trajectory $\tilde q_{11,k}^*$
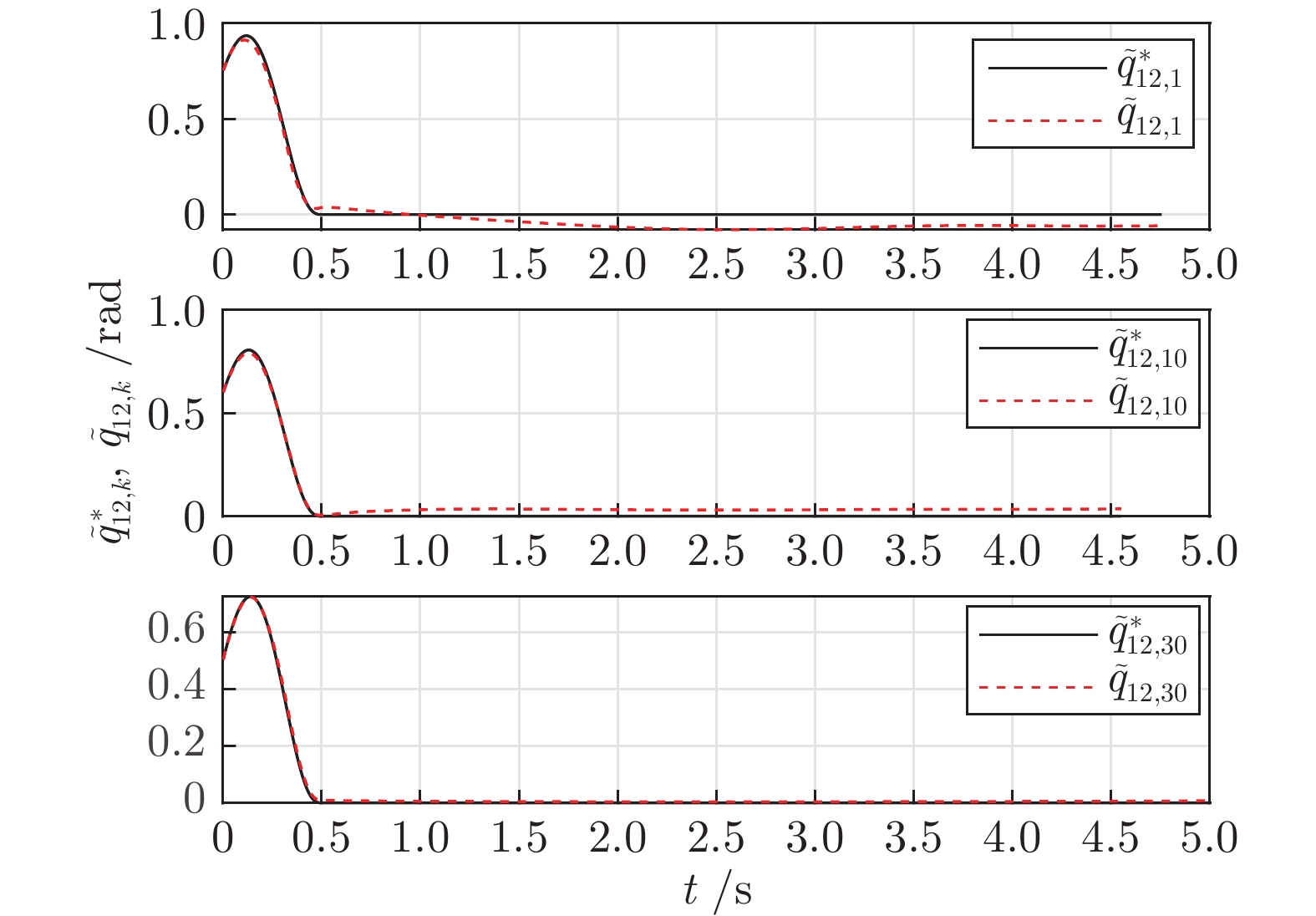
图 6 误差轨迹$\tilde q_{12,k}$和期望误差轨迹$\tilde q_{12,k}^*$
Fig. 6 Error trajectory $\tilde q_{12,k}$ and desired error trajectory $\tilde q_{12,k}^*$
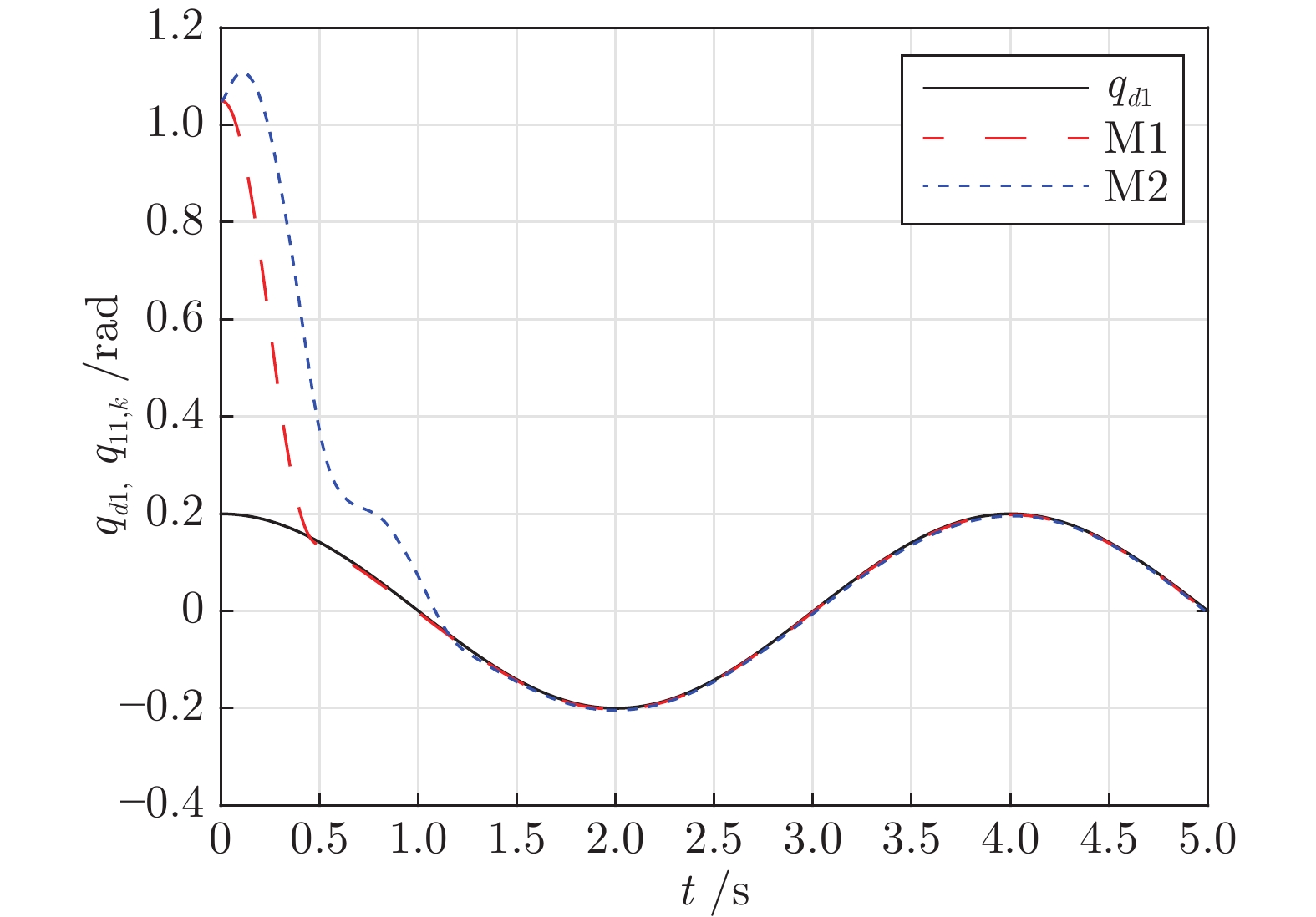
图 8 关节位置$q_{11,k}$跟踪性能对比
Fig. 8 The comparison of joint position $q_{11,k}$ tracking performance
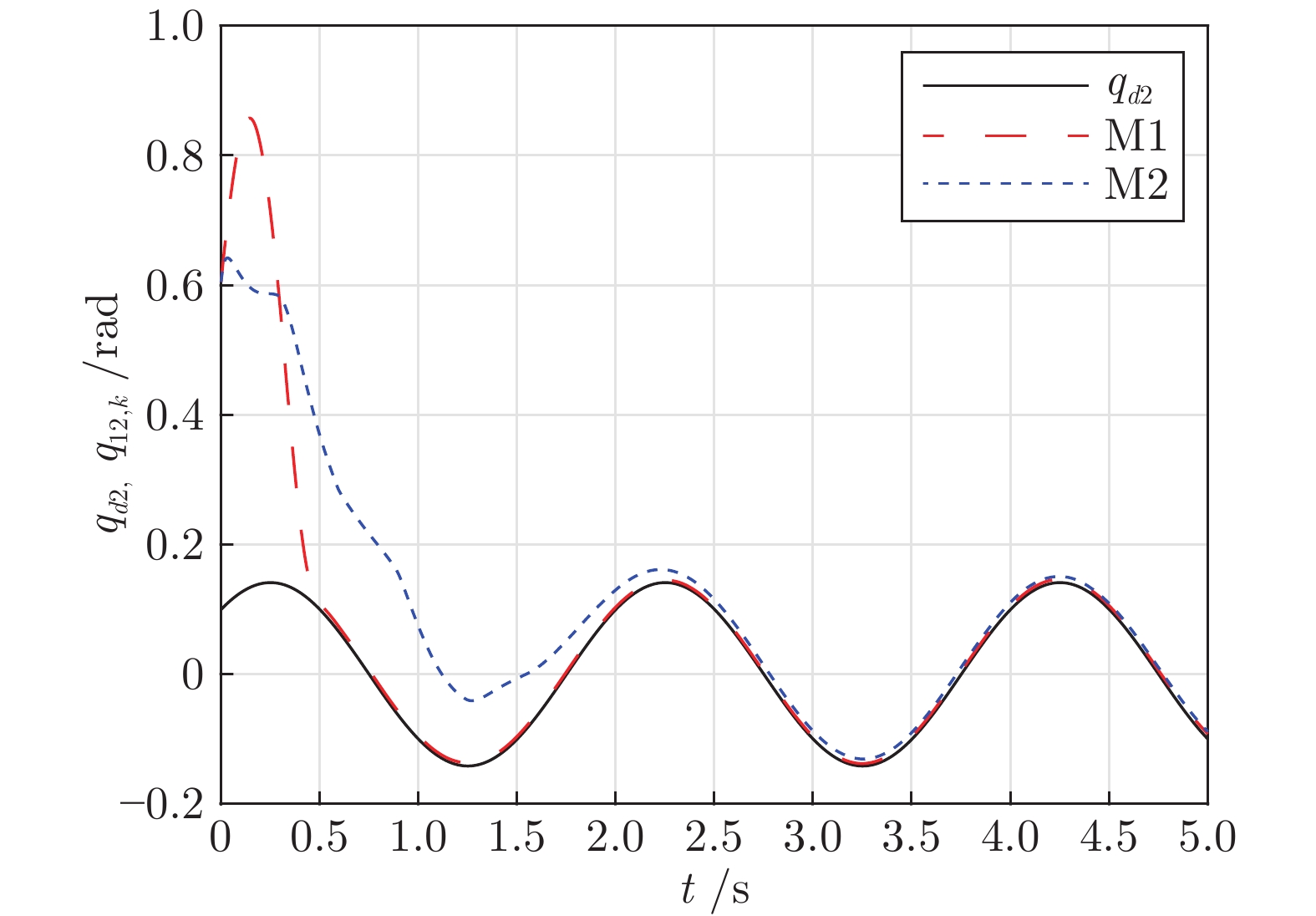
图 9 关节位置$q_{12,k}$跟踪性能对比
Fig. 9 The comparison of joint position $q_{12,k}$ tracking performance
-
[1] Bondi P, Casalino G, Gambardella L. On the iterative learning control theory for robotic manipulators. IEEE Journal on Robotics and Automation, 1988, 4(1): 14-22. doi: 10.1109/56.767 [2] Tayebi A. Adaptive iterative learning control for robot manipulators. Automatic, 2004, 40(7): 1195-1203. doi: 10.1016/j.automatica.2004.01.026 [3] Wu B, Wang D, Poh E K. High precision satellite attitude tracking control via iterative learning control. Journal of guidance, control, and dynamics, 2015, 38(3): 528-534. doi: 10.2514/1.G000497 [4] Hu Y N, Wei J M, Sun M M. Adaptive repetitive learning control for trajectory-keeping of satellite formation flying. Journal of Control & Decision, 2014, 1(4): 317-331. [5] 徐建明, 王耀东, 孙明轩. 基于初次控制信号提取 的迭代学习控制方法. 自动化学报, 2020, 46(2): 294-306.Xu Jian-Ming, Wang Yao-Dong, Sun MingXuan. Iterative learning control based on extracting initial iterative control signals. Acta Automatica Sinica, 2020, 46(2): 294-306. [6] Arimoto S, Kawamura S, Miyazaki F. Better operation of robots by learning. Journal of Robotic Systems, 1984, 1(2): 123-140. doi: 10.1002/rob.4620010203 [7] 孙明轩, 黄宝健. 迭代学习控制. 北京: 国防工业出版社, 1999.Sun Ming-Xuan, Huang Bao-Jian. Iterative Learning Control. Beijing: National Defense Industry Press, 1999. [8] 谢胜利, 田森平, 谢振东. 迭代学习控制的理论与应用. 北京: 科学出版社, 2005.Xie Sheng-Li, Tian Sen-Ping, Xie Zhen-Dong. Theory and Application of Iterative Learning Control. Beijing: Science Press, 2005. [9] Yu Q X, Hou Z S, Xu J X. D-type ilc based dynamic modeling and norm optimal ILC for highspeed trains. IEEE Transactions on Control Systems Technology, 2018, 26(2): 652-663. doi: 10.1109/TCST.2017.2692730 [10] Xu J X, Xu J. On iterative learning from different tracking tasks in the presence of timevarying uncertainties. IEEE Transactions on Systems Man & Cybernetics Part B Cybernetics, 2004, 34(1): 589-597. [11] Tayebi A, Chien C. A unified adaptive iterative learning control framework for uncertain nonlinear systems. IEEE Transactions on Automatic Control, 2007, 52(10): 1907-1913. doi: 10.1109/TAC.2007.906215 [12] 朱胜, 孙明轩, 何熊熊. 严格反馈非线性时变系 统的迭代学习控制. 自动化学报, 2010, 36(3): 454-458. doi: 10.3724/SP.J.1004.2010.00454Zhu Sheng, Sun Ming-Xuan, He Xiong-Xiong. Iterative learning control of strict-feedback nonlinear time-varying systems. Acta Automatica Sinica, 2010, 36(3): 454-458. doi: 10.3724/SP.J.1004.2010.00454 [13] Sun M X. A barbalat-like lemma with its application to learning control. IEEE Transactions on Automatic Control, 2009, 54(9): 2222-2225. doi: 10.1109/TAC.2009.2026849 [14] 吕庆. 抑制初态误差影响的自适应迭代学习控制. 自动化学报, 2015, 41(7): 1365-1372.Lv Qing. Adaptive iterative learning control for inhibition effect of initial state random error. Acta Automatica Sinica, 2015, 41(7): 1365-1372. [15] Xu J X, Tan Y. A composite energy functionbased learning control approach for nonlinear systems with time-varying parametric uncertainties. IEEE Transactions on Automatic Control, 2002, 47(11): 1940-1945. doi: 10.1109/TAC.2002.804460 [16] Ji H H, Hou Z S, Zhang R K. Adaptive iterative learning control for high-speed rrains with unknown speed delays and input saturations. IEEE Transactions on Automation Science and Engineering, 2016, 13(1): 260-273. doi: 10.1109/TASE.2014.2371816 [17] Sugie T, Ono T. An iterative learning control law for dynamical systems. Automatica, 1991, 27(4): 729-732. doi: 10.1016/0005-1098(91)90066-B [18] Chien C J, Hsu C T, Yao C Y. Fuzzy systembased adaptive iterative learning control for nonlinear plants with initial state errors. IEEE Transactions on Fuzzy Systems, 2004, 12(5): 724-732. doi: 10.1109/TFUZZ.2004.834806 [19] Xu J X, Yan R. On initial conditions in iterative learning control. IEEE Transactions on Automatic Control, 2005, 50(9): 1349-1354. doi: 10.1109/TAC.2005.854613 [20] Jin X. Nonrepetitive leader-follower formation tracking for multiagent systems with LOS range and angle constraints using iterative learning control. IEEE Transactions on Cybernetics, 2019, 49(5): 1748-1758. doi: 10.1109/TCYB.2018.2817610 [21] 孙明轩, 严求真. 迭代学习控制系统的误差跟踪设计方法. 自动化学报, 2013, 39(3): 251-262. doi: 10.1016/S1874-1029(13)60027-0Sun Ming-Xuan, Yan Qiu-Zhen. Error tracking of iterative learning control systems. Acta Automatica Sinica, 2013, 39(3): 251-262. doi: 10.1016/S1874-1029(13)60027-0 [22] Sun M X, Wu T, Chen L J, Zhang G F. Neural AILC for error tracking against arbitrary initial shifts. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(7): 2705-2716. doi: 10.1109/TNNLS.2017.2698507 [23] Chen Q, Shi H H, Sun M X. Echo state network-based backstepping adaptive iterative learning control for strict-feedback systems: an error-tracking approach. IEEE Transactions on Cybernetics, 2020, 50(7): 3009-3022. doi: 10.1109/TCYB.2019.2931877 [24] Li X F, Xu J X, Huang D Q. An iterative learning control approach for linear systems with randomly varying trial lengths. IEEE Transactions on Automatic Control, 2014, 59(7): 1954-1960. doi: 10.1109/TAC.2013.2294827 [25] Li X F, Xu J X. Lifted system framework for learning control with different trial lengths. International Journal of Automation & Computing, 2015, 12(3): 273-280. [26] Shen D, Zhang W, Wang Y Q, Chien C J. On almost sure and mean square convergence of p-type ILC under randomly varying iteration lengths. Automatica, 2016, 63(1): 359-365. [27] Shi J T, Xu J X, Sun J, Yang Y H. Iterative learning control for time-varying systems subject to variable pass lengths: application to robot manipulators. IEEE Transactions on Industrial Electronics, 2020, 67(10):8629-8637. doi: 10.1109/TIE.2019.2947838 [28] Shen D, Xu J X. Adaptive learning control for nonlinear systems with randomly varying iteration lengths. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(4): 1119-1132. doi: 10.1109/TNNLS.2018.2861216 [29] Jin X. Iterative learning control for MIMO nonlinear systems with iteration-varying trial lengths using modified composite energy function analysis. IEEE Transactions on Cybernetics, 2021, 51(12): 6080−6090 [30] Zeng C, Shen D, Wang J R. Adaptive learning tracking for robot manipulators with varying trial lengths. Journal of the Franklin Institute, 2019, 356(12): 5993-6014. doi: 10.1016/j.jfranklin.2019.04.034 -

 下载:
下载:


计量
- 文章访问数: 2105
- HTML全文浏览量: 666
- PDF下载量: 309
- 被引次数: 0
