

-
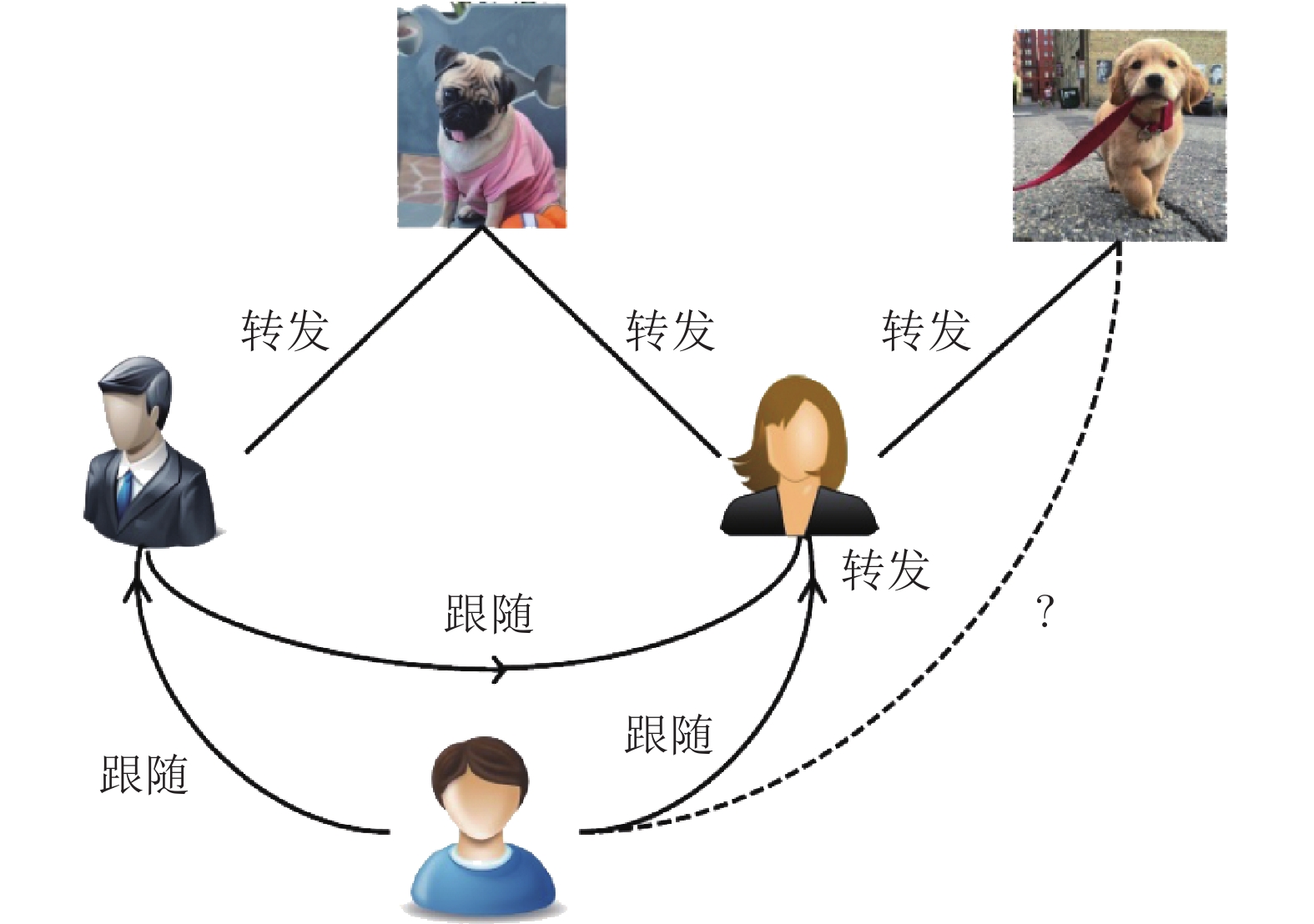
摘要: 转发预测在社交媒体网站(Social media sites, SMS)中是一个很有挑战性的问题. 本文研究了SMS中的图像转发预测问题, 预测用户再次转发图像推特的图像共享行为. 与现有的研究不同, 本文首先提出异构图像转发建模网络(Image retweet modeling, IRM), 所利用的是用户之前转发图像推特中的相关内容、之后在SMS中的联系和被转发者的偏好三方面的内容. 在此基础上, 提出文本引导的多模态神经网络, 构建新型多方面注意力排序网络学习框架, 从而学习预测任务中的联合图像推特表征和用户偏好表征. 在Twitter的大规模数据集上进行的大量实验表明, 我们的方法较之现有的解决方案而言取得了更好的效果.Abstract: Retweet prediction is a challenging problem in social media sites (SMS). In this paper, we study the problem of image retweet prediction in social media, which predicts the image sharing behavior that the user reposts the image tweets from their followees. Unlike previous studies, we learn user preference ranking model from their past retweeted image tweets in SMS. We first propose a heterogeneous image retweet modeling network (IRM) that exploits users past retweeted image tweets with associated contexts, their following relations in SMS and preference of their followees. We then develop a novel attentional multi-faceted ranking network learning framework with textually guided multi-modal neural networks for the proposed heterogenous IRM network to learn the joint image tweet representations and user preference representations for prediction task. The extensive experiments on a large-scale dataset from Twitter site show that our method achieves better performance than other state-of-the-art solutions to the problem.
-
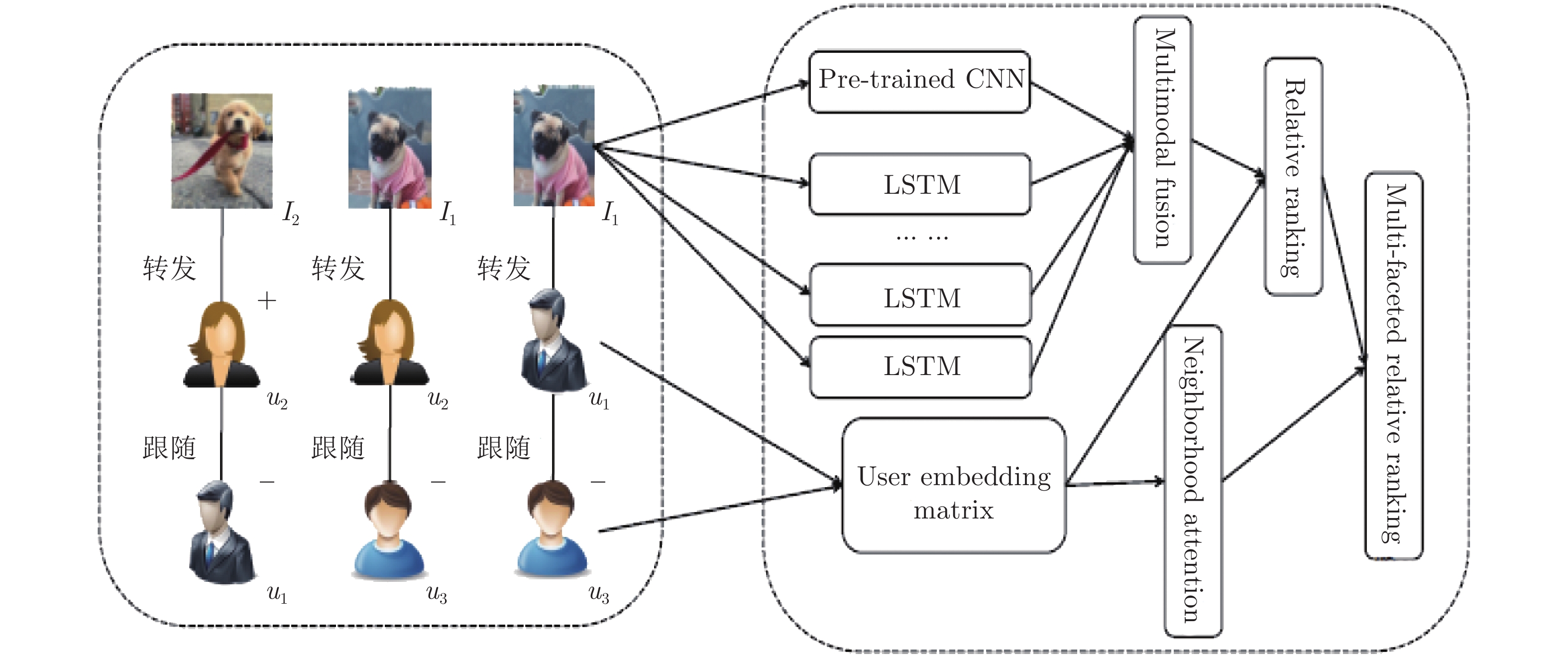
图 2 用于图像转发预测的注意多方面排序网络学习纵览
Fig. 2 The overview of textually guided ranking network for attentional image retweet modeling

图 4 AMNL+ 在图像转发预测任务中的实验结果
Fig. 4 Experimental results of AMNL+ on the image retweet prediction task
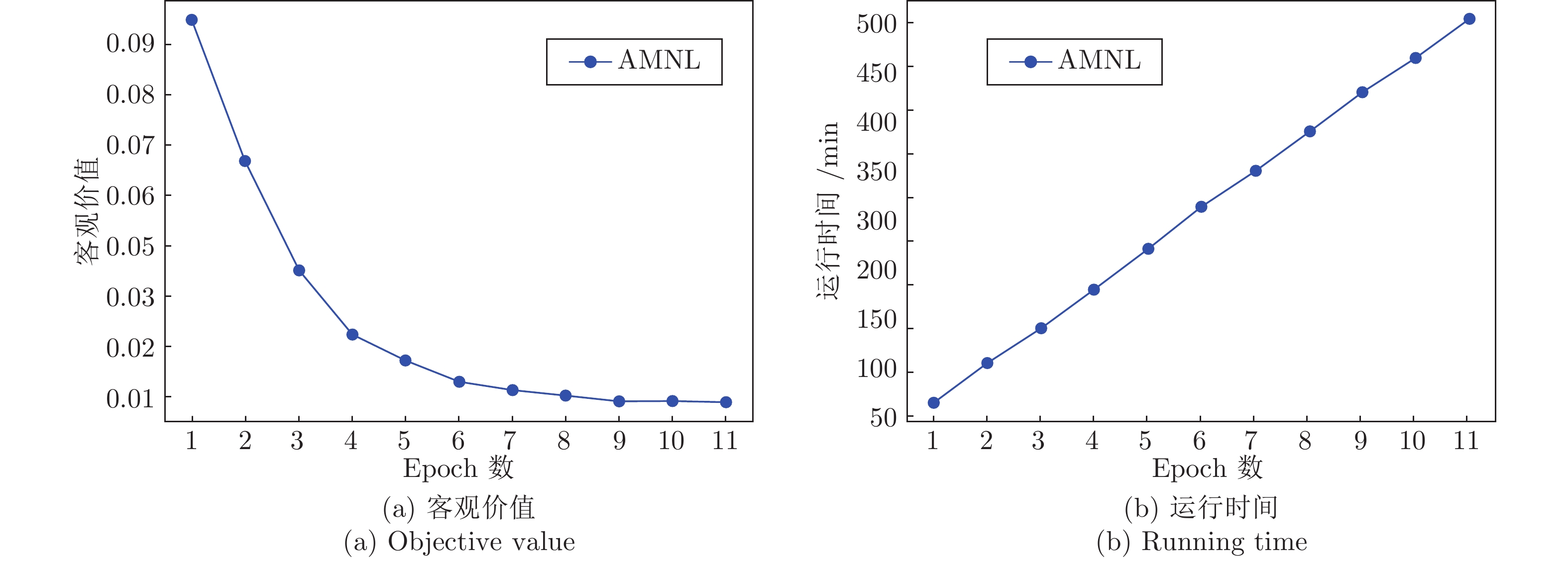
图 5 随着Epoch客观价值和运行时间的变化
Fig. 5 Objective value and running time versus the number of epochs
表 1 不同方法的Precision@1结果
Table 1 Experimental results on precision@1 of different approaches
方法 Precision@1 60 % 70 % 80 % RRFM 0.6253 0.6474 0.6583 VBPR 0.6399 0.6525 0.6793 D-RNN 0.7001 0.7191 0.7385 IRBLRUS 0.7193 0.7295 0.7516 ADABPR 0.6394 0.6488 0.6692 CITING 0.7463 0.7608 0.7773 AMNL 0.8691 0.8975 0.9008 AMNL+ 0.9341 0.9444 0.9585  下载: 导出CSV
下载: 导出CSV
表 2 不同方法的Precision@3结果
Table 2 Experimental results on precision@3 of different approaches
方法 Precision@3 60 % 70 % 80 % RRFM 0.5973 0.6284 0.6400 VBPR 0.6082 0.6304 0.6432 D-RNN 0.6468 0.6702 0.6879 IRBLRUS 0.6593 0.6684 0.6813 ADABPR 0.5980 0.6198 0.6301 CITING 0.7304 0.7467 0.7677 AMNL 0.7519 0.7791 0.7959 AMNL+ 0.8680 0.8796 0.8823
下载: 导出CSV
表 3 不同方法的AUC结果
Table 3 Experimental results on AUC of different approaches
方法 AUC 60 % 70 % 80 % RRFM 0.5032 0.5195 0.5282 VBPR 0.5491 0.5799 0.5814 D-RNN 0.6834 0.6973 0.6999 IRBLRUS 0.7145 0.7342 0.7440 ADABPR 0.5393 0.5601 0.5782 CITING 0.5802 0.5982 0.6425 AMNL 0.7703 0.7998 0.8486 AMNL+ 0.8792 0.8986 0.9126
下载: 导出CSV
表 4 用80 %的数据进行训练, 消融实验的实验结果
Table 4 Experimental results with different modalities and components using 80 % of the data for training
方法 Precision@1 Precision@3 AUC AMNL+i 0.8427 0.7673 0.8204 AMNLd 0.7892 0.7719 0.7962 AMNLhfunc 0.8598 0.7900 0.8095 AMNL 0.9008 0.7959 0.8486 AMNL+i 0.9227 0.8276 0.8724 AMNL+hfunc 0.9199 0.8195 0.8689 AMNL+ 0.9585 0.8823 0.9126
下载: 导出CSV
-
[1] Zhang Q, Gong Y Y, Guo Y, Huang X J. Retweet behavior prediction using hierarchical dirichlet process. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Austin, Texas, USA: AAAI Press, 2015. 403−409 [2] Chen T, He X N, Kan M Y. Context-aware image tweet modelling and recommendation. In: Proceedings of the 24th ACM International Conference on Multimedia. Amsterdam, The Netherlands: ACM, 2016. 1018−1027 [3] Zhang J, Tang J, Li J Z, Liu Y, Xing C X. Who influenced you? Predicting retweet via social influence locality. ACM Transactions on Knowledge Discovery from Data, 2015, 9(3): Article No.: 25 [4] Firdaus S N, Ding C, Sadeghian A. Topic specific emotion detection for retweet prediction. International Journal of Machine Learning and Cybernetics, 2019, 10(8): 2071-2083 doi: 10.1007/s13042-018-0798-5 [5] Szegedy C, Toshev A, Erhan D. Deep neural networks for object detection. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, United States: Curran Associates Inc., 2013. 2553−2561 [6] Zhao Z, Yang Q F, Lu H Q, Weninger T, Cai D, He X F, et al. Social-aware movie recommendation via multimodal network learning. IEEE Transactions on Multimedia, 2018, 20(2): 430-440 doi: 10.1109/TMM.2017.2740022 [7] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, CA, USA, 2015. [8] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [9] Hoang T A, Lim E P. Retweeting: An act of viral users, susceptible users, or viral topics? In: Proceedings of the 2013 SIAM International Conference on Data Mining (SDM). Austin, Texas, USA: SIAM, 2013. 569−577 [10] Jiang B, Lu Z G, Li N, Wu J J, Jiang Z W. Retweet prediction using social-aware probabilistic matrix factorization. In: Proceedings of the 18th International Conference on Computational Science. Wuxi, China: Springer, 2018. 316−327 [11] Atrey P K, Hossain M A, El Saddik A, Kankanhalli M S. Multimodal fusion for multimedia analysis: A survey. Multimedia Systems, 2010, 16(6): 345-379 doi: 10.1007/s00530-010-0182-0 [12] Yuan Z Q, Sang J T, Xu C S, Liu Y. A unified framework of latent feature learning in social media. IEEE Transactions on Multimedia, 2014, 16(6): 1624-1635 doi: 10.1109/TMM.2014.2322338 [13] Luong T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal: The Association for Computational Linguistics, 2015. 1412−1421 [14] Nie L Q, Yan S C, Wang M, Hong R C, Chua T S. Harvesting visual concepts for image search with complex queries. In: Proceedings of the 20th ACM International Conference on Multimedia. Nara, Japan: ACM, 2012. 59−68 [15] Yang Y, Tang J, Leung C W K, Sun Y Z, Chen Q C, Li J Z, et al. RAIN: Social role-aware information diffusion. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Texas, USA: AAAI Press, 2015. 367−373 [16] Chen J D, Li H, Wu Z J, Hossain M S. Sentiment analysis of the correlation between regular tweets and retweets. In: Proceedings of the 16th International Symposium on Network Computing and Applications (NCA). Cambridge, MA, USA: IEEE, 2017. 1−5 [17] Macskassy S A, Michelson M. Why do people retweet? Anti-homophily wins the day! In: Proceedings of the 5th International AAAI Conference on Weblogs and Social Media. Barcelona, Catalonia, Spain: AAAI Press, 2011. 209−216 [18] Xu Z H, Zhang Y, Wu Y, Yang Q. Modeling user posting behavior on social media. In: Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval. Portland, Oregon, USA: ACM, 2012. 545−554 [19] Luo Z C, Osborne M, Tang J T, Wang T. Who will retweet me? Finding retweeters in twitter. In: Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. Dublin, Ireland: ACM, 2013. 869−872 [20] Bourigault S, Lagnier C, Lamprier S, Denoyer L, Gallinari P. Learning social network embeddings for predicting information diffusion. In: Proceedings of the 7th ACM International Conference on Web Search and Data Mining. New York, USA: ACM, 2014. 393−402 [21] Bi B, Cho J. Modeling a retweet network via an adaptive Bayesian approach. In: Proceedings of the 25th International Conference on World Wide Web. Montréal, Québec, Canada: ACM, 2016. 459−469 [22] Jiang B, Liang J G, Sha Y, Wang L H. Message clustering based matrix factorization model for retweeting behavior prediction. In: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. Melbourne, Australia: ACM, 2015. 1843−1846 [23] Wang B D, Wang C, Bu J J, Chen C, Zhang W V, Cai D, et al. Whom to mention: Expand the diffusion of tweets by @ recommendation on micro-blogging systems. In: Proceedings of the 22nd International Conference on World Wide Web. Rio de Janeiro, Brazil: ACM, 2013. 1331−1340 [24] Liu Y B, Zhao J Z, Xiao Y P. C-RBFNN: A user retweet behavior prediction method for hotspot topics based on improved RBF neural network. Neurocomputing, 2018, 275: 733-746 doi: 10.1016/j.neucom.2017.09.015 [25] Firdaus S N, Ding C, Sadeghian A. Retweet prediction considering user's difference as an author and retweeter. In: Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM). San Francisco, CA, USA: IEEE, 2016. 852−859 [26] Feng W, Wang J Y. Retweet or not? Personalized tweet re-ranking. In: Proceedings of the 6th ACM International Conference on Web Search and Data Mining. Rome, Italy: ACM, 2013. 577−586 [27] Peng H K, Zhu J, Piao D Z, Yan R, Zhang Y. Retweet modeling using conditional random fields. In: Proceedings of the 11th International Conference on Data Mining Workshops. Vancouver, BC, Canada: IEEE, 2011. 336−343 [28] Chen K L, Chen T Q, Zheng G Q, Jin O, Yao E P, Yu Y. Collaborative personalized tweet recommendation. In: Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval. Portland, Oregon, USA: ACM, 2012. 661−670 [29] Nie L Q, Song X M, Chua T S. Learning from multiple social networks. Synthesis Lectures on Information Concepts, Retrieval, and Services, 2016, 8(2): 1-118 doi: 10.2200/S00714ED1V01Y201603ICR048 [30] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 1−9 [31] Zhang H W, Kyaw Z, Chang S F, Chua T S. Visual translation embedding network for visual relation detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 3107−3115 [32] Zhao W Q, Guan Z Y, Luo H Z, Peng J Y, Fan J P. Deep multiple instance hashing for object-based image retrieval. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: AAAI Press, 2017. 3504−3510 [33] Zhao Z, Lin J H, Jiang X H, Cai D, He X F, Zhuang Y T. Video question answering via hierarchical dual-level attention network learning. In: Proceedings of the 25th ACM International Conference on Multimedia. Mountain View, CA, USA: ACM, 2017. 1050−1058 [34] Nair V, Hinton G E. Rectified linear units improve restricted boltzmann machines. In: Proceedings of the 27th International Conference on International Conference on Machine Learning. Haifa, Israel: Omnipress, 2010. 807−814 [35] Zhao Z, Yang Q F, Cai D, He X F, Zhuang Y T. Video question answering via hierarchical spatio-temporal attention networks. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: AAAI Press, 2017. 3518−3524 [36] Java A, Song X D, Finin T, Tseng B. Why we twitter: Understanding microblogging usage and communities. In: Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 Workshop on Web Mining and Social Network Analysis. San Jose, CA, USA: ACM, 2007. 56−65 [37] Pennington J, Socher R, Manning C. Glove: Global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: ACL, 2014. 1532−1543 [38] He R N, McAuley J. VBPR: Visual Bayesian personalized ranking from implicit feedback. In: Proceedings of the 13th AAAI Conference on Artificial Intelligence. Phoenix, Arizona, USA: AAAI Press, 2016. 144−150 [39] Rendle S, Freudenthaler C, Gantner Z, Schmidt-Thieme L. BPR: Bayesian personalized ranking from implicit feedback. In: Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence. Montreal, QC, Canada: AUAI Press, 2009. 452−461 [40] Li H Y, Hong R C, Lian D F, Wu Z A, Wang M, Ge Y. A relaxed ranking-based factor model for recommender system from implicit feedback. In: Proceedings of the 25th International Joint Conference on Artificial Intelligence. New York, USA: AAAI Press, 2016. 1683−1689 -

 下载:
下载:

计量
- 文章访问数: 1535
- HTML全文浏览量: 389
- PDF下载量: 241
- 被引次数: 0
