

-
摘要: 近年来, 深度学习在图像分类、目标检测及场景识别等任务上取得了突破性进展, 这些任务多以卷积神经网络为基础搭建识别模型, 训练后的模型拥有优异的自动特征提取和预测性能, 能够为用户提供“输入–输出”形式的端到端解决方案. 然而, 由于分布式的特征编码和越来越复杂的模型结构, 人们始终无法准确理解卷积神经网络模型内部知识表示, 以及促使其做出特定决策的潜在原因. 另一方面, 卷积神经网络模型在一些高风险领域的应用, 也要求对其决策原因进行充分了解, 方能获取用户信任. 因此, 卷积神经网络的可解释性问题逐渐受到关注. 研究人员针对性地提出了一系列用于理解和解释卷积神经网络的方法, 包括事后解释方法和构建自解释的模型等, 这些方法各有侧重和优势, 从多方面对卷积神经网络进行特征分析和决策解释. 表征可视化是其中一种重要的卷积神经网络可解释性方法, 能够对卷积神经网络所学特征及输入–输出之间的相关关系以视觉的方式呈现, 从而快速获取对卷积神经网络内部特征和决策的理解, 具有过程简单和效果直观的特点. 对近年来卷积神经网络表征可视化领域的相关文献进行了综合性回顾, 按照以下几个方面组织内容: 表征可视化研究的提起、相关概念及内容、可视化方法、可视化的效果评估及可视化的应用, 重点关注了表征可视化方法的分类及算法的具体过程. 最后是总结和对该领域仍存在的难点及未来研究趋势进行了展望.Abstract: In recent years, deep learning has made breakthrough progress on image classification, object detection, and scene recognition tasks. These tasks mostly build recognition models based on the convolutional neural network (CNN). The trained models have excellent automatic feature extraction and prediction performance, which is able to provide users with “input-output” end-to-end solutions. However, due to the distributed feature coding and the increasingly complex model structure, users cannot yet accurately understand the internal knowledge representation of the model as well as the potential reasons for a specific decision. On the other hand, the application of the CNN models in some high-risk areas also requires a full understanding of the reason for their decisions, so as to get user's trust. Therefore, the interpreting ability of CNN has gradually attracted attention. Researchers have proposed a serious of methods for understanding and interpreting CNN, including post-hoc interpretation methods and building self-explainable models. These methods have their respective focuses and advantages, performing feature analysis and decision interpretation of CNN from various aspects. As one of the important CNN interpreting ability methods, representation visualization can visually present the features learned by CNN and the correlation between the input and output. In this way, a straightforward understanding of CNN internal features and decision-making can be obtained in a simple and intuitive way. This paper gives a comprehensive review of the related literatures on CNN representation visualization research in recent years, and organizes the content according to the following aspects: the introduction of representation visualization research, related concepts and contents, visualization methods, visualization effect evaluation, and the application of visualization. The classification of the representation visualization methods and the specific algorithms are our focus. Finally, the difficulties and future trends in the field are prospected, and the full text is summarized.
-
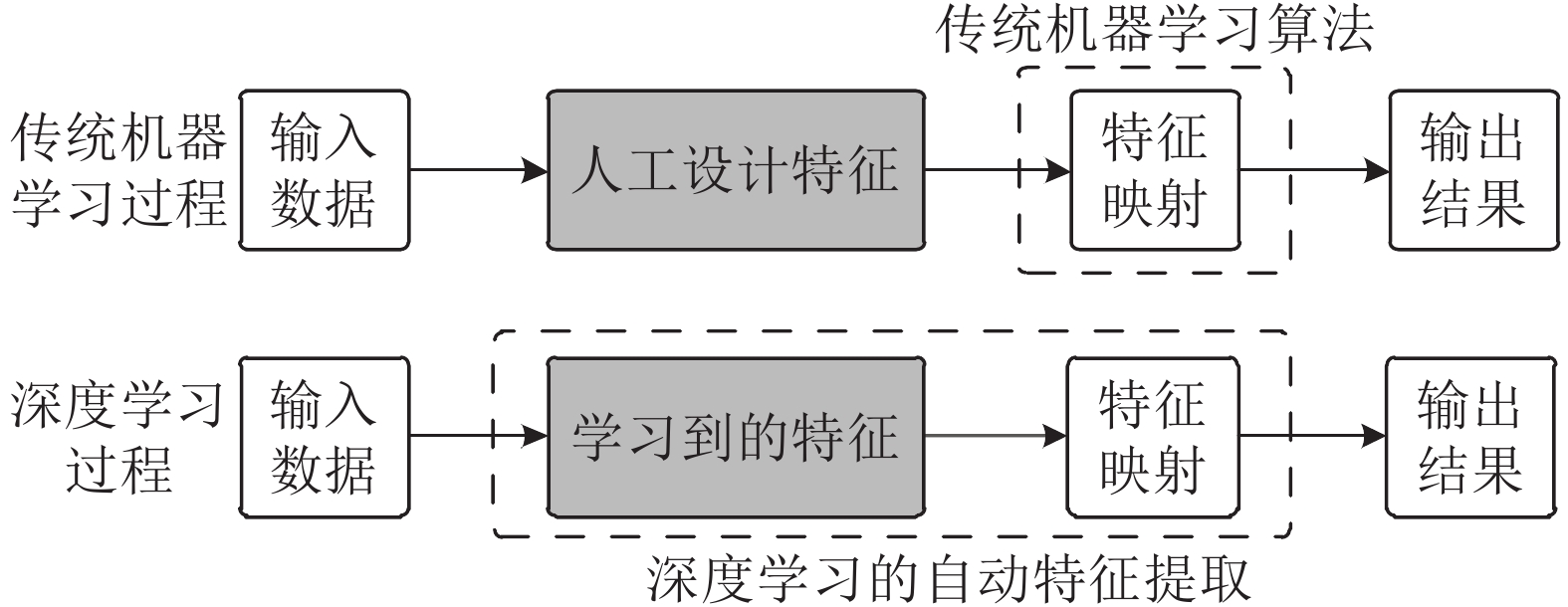

图 2 可解释性深度学习的研究内容划分
Fig. 2 The division of the research content of the interpretable deep learning







图 30 LIME在AlexNet、VGGNet16及ResNet50模型上可视化结果示例
Fig. 30 Example of LIME visualization results on AlexNet, VGGNet16 and ResNet50 models

图 32 可视化方法的效果比较. 每张输入图像分别展示了灰度和彩色两种可视化结果
Fig. 32 Comparison of the effects of visualization methods. Each input image shows two visualization results of grayscale and color image


表 1 梯度方法及其变种的特点比较
Table 1 Comparison of the characteristics of the gradient method and its variants
方法 显著图生成依据 特点 VBP 普通梯度 过程简单, 但存在梯度噪声问题 GBP 每一层使用 ReLU 过程简单, 但存在梯度噪声问题 积分梯度 梯度图的平均 过程复杂, 需多次迭代, 耗时 平滑梯度 梯度图的平均 过程复杂, 需多次迭代, 耗时 整流梯度 阈值过滤后的梯度 过程较复杂, 阈值的选取需要经验  下载: 导出CSV
下载: 导出CSV
表 2 类激活映射方法的比较
Table 2 Comparision of the class activation mapping methods
方法 通道权重 优点 缺点 CAM Softmax 层权重 类别区分性 依赖 GAP 层 Grad-CAM 各通道的梯度平均值 类别区分性, 结构通用 梯度不稳定 Grad-CAM++ 各通道的梯度平均值, 高阶梯度 类别区分性, 结构通用 梯度不稳定, 高阶梯度计算复杂 Score-CAM 对各通道的预测值 类别区分性, 结构通用, 权重稳定 权重计算过程复杂, 重复迭代耗时
下载: 导出CSV
表 3 可视化方法的特点比较
Table 3 Comparison of characteristics of visualization methods
方法分类 方法名称 发表年份 细粒度/
区域级类别相关 在线/
离线模型明晰/
模型不可知可视化视角 局部解释/
全局解释扰动 简单扰动[13, 42–43] 2014、2018 区域级 否 离线 模型不可知 输出类 局部 有意义的扰动[44] 2017 区域级 否 离线 模型明晰的 输出类 局部 生成式扰动[45–46] 2019 区域级 是 离线 模型明晰 输出类 局部 反向传播 梯度类反向传播 VBP[22–23] 2010、2013 细粒度 否 离线 模型明晰 输出类 局部 GBP[50] 2014 细粒度 否 离线 模型明晰 输出类 局部 Smooth gradient[52] 2017 细粒度 否 离线 模型明晰 输出类 局部 Integrated gradient[53] 2017 细粒度 否 离线 模型明晰 输出类 局部 Rectified gradient[54] 2019 细粒度 否 离线 模型明晰 输出类 局部 规则类反向传播 Deconvolution[13] 2013 细粒度 否 离线 模型明晰的 神经元/层 局部 LRP[58] 2015 细粒度 否 离线 模型明晰 输出类 局部 DTD[61] 2017 细粒度 否 离线 模型明晰 输出类 局部 CLRP[59]、SGLRP[60] 2018、2019 细粒度 是 离线 模型明晰 输出类 局部 类激活映射 CAM[62] 2015 区域级 是 在线 模型明晰 输出类 局部 Grad-CAM[63–64] 2016、2017 区域级 是 离线 模型明晰 输出类 局部 Grad-CAM++[65] 2018 区域级 是 离线 模型明晰 输出类 局部 Score-CAM[66] 2019 区域级 是 离线 模型明晰 输出类 局部 激活最大化 AM[81] 2009 细粒度 是 离线 模型明晰 神经元/输出类 全局 DGN-AM[82] 2016 细粒度 是 离线 模型明晰的 神经元/输出类 全局 注意为掩码 通道注意力[18] 2017 区域级 否 在线 模型明晰的 层 局部 空间–通道注意力[72] 2018 区域级 否 在线 模型明晰 层 局部 类别注意力 — 区域级 是 在线 模型明晰 层 — 其他方法 LIME[78] 2016 区域级 是 离线 模型不可知 输出类 局部 SHAP[79] 2017 细粒度 是 离线 模型不可知 输出类 局部
下载: 导出CSV
表 4 CNN表征可视化相关的综述文献统计
Table 4 Review literature statistics related to CNN representation visualization
文献 发表年份 侧重内容 [103] 2016 几种典型的特征可视化方法 (如扰动、反向传播、
激活最大化等), 以及相互之间的关系分析[104] 2017 特征可视化的必要性, 基于反向传播的可视化方法 [105] 2017 模型可视化, 不限于 CNN 可解释性领域 [19] 2018 基于反向传播的可视化方法
(AM、VBP、DTD 和 LRP 等)[106] 2018 自解释的 CNN [20] 2018 可解释性的概念, 相关文献分类 [107] 2018 人工智能的可解释性 [102] 2019 机器学习的可解释性方法与评估 [108] 2020 机器学习的可解释性 [109] 2020 深度学习的可解释性 [110] 2020 人工智能的可解释性 [111] 2020 人工智能的可解释性
下载: 导出CSV
-
[1] Krizhevsky A, Sutskever I, Hinton G. Imagenet classification with deep convolutional neural networks. In: Proceedings of the 26th Annual Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: 2012. 1106–1114 [2] Deng J, Dong W, Socher R, Li L, Li K, L F. ImageNet: A large-scale hierarchical image database. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami Beach, Florida, USA: 2009. 248–255 [3] Lin T, Maire M, Belongie S J, Hays J, Perona P, Ramanan D, Dollar P, Zitnick C L. Microsoft COCO: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: 2014. 740–755 [4] Li M, Zhang T, Chen Y, Smola A J. Efficient mini-batch training for stochastic optimization. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: 2014. 661–670 [5] Hinton G E, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov R R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint, 2012, arXiv: 1207.0580 [6] Nair V, Hinton G E. Rectified linear units improve restricted boltzmann machines. In: Proceedings of the 27th International Conference on Machine Learning. Haifa, Israel: 2010.807–814 [7] 刘颖, 雷研博, 范九伦, 王富平, 公衍超, 田奇. 基于小样本学习的图像分类技术综述. 自动化学报, 2021, 47(2): 297−315.Liu Ying, Lei Yan-Bo, Fan Jiu-Lun, Wang Fu-Ping, Gong Yan-Chao, Tian Qi. Survey on image classification technology based on small sample learning. Acta Automatica Sinica, 2021, 47(2): 297−315. [8] Goodfellow I, Bengio Y, Courville A. Deep Learning. Cambridge, The MIT Press, 2016. [9] LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278-2324. doi: 10.1109/5.726791 [10] Maas A L, Hannun A Y, Ng A Y. Rectifier nonlinearities improve neural network acoustic models. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, USA: 2013. [11] He K, Zhang X, Ren S, Sun J. Delving deep into rectifiers: Surpassing human-level performance on imageNet classification. In: Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: 2015. 1026–103 [12] 林景栋, 吴欣怡, 柴毅, 尹宏鹏. 卷积神经网络结构优化综述. 自动化学报, 2020, 46(1): 24-37.LIN Jing-Dong, WU Xin-Yi, CHAI Yi, YIN Hong-Peng. Structure Optimization of Convolutional Neural Networks: A Survey. ACTA AUTOMATICA SINICA, 2020, 46(1): 24-37. [13] Zeiler M D, Fergus R. Visualizing and Understanding Convolutional Networks. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: 2014. 818–833 [14] Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: 2015. 1–9 [15] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint, 2014, arXiv: 1409.1556v6 [16] He K, Zhang X, Ren S, and Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: 2016. 770–778 [17] Huang G, Liu Z, Maaten L, Weinberger K Q. Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: 2017. 2261–2269 [18] Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: 2018. 7132–7141 [19] Montavon G, Samek W, Müller K R. Methods for interpreting and understanding deep neural networks. Digital Signal Processing, 2018, 73: 1–15. doi: 10.1016/j.dsp.2017.10.011 [20] Gilpin L H, Bau D, Yuan B Z, Bajwa A, Specter M, Kagal L. Explaining explanations: An approach to evaluating interpretability of machine learning. arXiv preprint, 2018, arXiv: 1806.00069 [21] Mitros J, Namee B M. A Categorisation of post-hoc explanations for predictive models. arXiv preprint, 2019, arxiv: 1904.02495 [22] Baehrens D, Schroeter T, Harmeling S, Kawanabe M, Hansen K, Müller K R. How to Explain Individual Classification Decisions. Journal of Machine Learning Research, 2010, 11(61): 1803–1831. [23] Simonyan K, Vedaldi A, Zisserman A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint, 2013, arXiv: 1312.6034 [24] Li O, Liu H, Chen C, Rudin C. Deep learning for case-based reasoning through prototypes: A neural network that explains its predictions. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: 2018. 3530–3537 [25] Arik S Ö, Pfister T. ProtoAttend: Attention-Based Prototypical Learning. Journal of Machine Learning Research, 2020, 21(210): 1–3. [26] Gulshad S, Smeulders A. Explaining with counter visual attributes and examples. In: Proceedings of the 2020 International Conference on Multimedia Retrieval. Dublin, Ireland: 2020: 35–43 [27] Hendricks L A, Akata Z, Rohrbach M, Donahue J, Schiele B, Darrell T. Generating visual explanations. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, Netherlands: 2016. 3–19 [28] Vinyals O, Toshev A, Bengio S, Erhan D. Show and tell: A neural image caption generator. In: Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: 2015. 3156–3164 [29] Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, et al. Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: 2018. 6077–6086 [30] Zhang Q, Wu Y N, Zhu S C. Interpretable convolutional neural networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: 2018. 8827–8836 [31] Wan A, Dunlap L, Ho D, Yin J, Lee S, Jin H, et al. NBDT: Neural-backed decision trees. arXiv preprint, 2020, arxiv: 2004.00221 [32] Ming Y, Cao S, Zhang R, Li Z, Chen Y, Song Y, et al. Understanding hidden memories of recurrent neural networks. In: Proceedings of the 2017 IEEE Conference on Visual Analytics Science and Technology (VAST). Phoenix, Arizona, USA: 2017. 13–24 [33] Strobelt H, Gehrmann S, Pfister H, Rush A M. LSTMVis: A Tool for Visual Analysis of Hidden State Dynamics in Recurrent Neural Networks. IEEE Transactions on Visualization and Computer Graphics, 2018, 24(1): 667–676. doi: 10.1109/TVCG.2017.2744158 [34] Karpathy A, Johnson J, Li F. Visualizing and understanding recurrent networks. arXiv preprint, 2015, arXiv: 1506.02078 [35] Arras L, Montavon G, Müller K R, Samek W. Explaining recurrent neural network predictions in sentiment analysis. In: Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. Copenhagen, Denmark: 2017. 159–168 [36] Ding Y, Liu Y, Luan H, Sun M. Visualizing and understanding neural machine translation. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, BC, Canada: 2017. 1150–1159 [37] 刘建伟, 谢浩杰, 罗雄麟. 生成对抗网络在各领域应用研究进展. 自动化学报, 2020, 46(12): 2500−2536.Liu Jian-Wei, Xie Hao-Jie, Luo Xiong-Lin. Research progress on application of generative adversarial networks in various fields. Acta Automatica Sinica, 2020, 46(12): 2500−2536. [38] Chen X, Duan Y, Houthooft R, Schulman J, Sutskever I, Abbeel P. InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: 2016. 2180–2188 [39] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint, 2015, arXiv: 1511.06434 [40] Zhu J Y, Krähenbühl P, Shechtman E, Efros A A. Generative visual manipulation on the natural image manifold. In: Proceedings of the European Conference on Computer Vision. Amsterdam, Netherlands: 2016. 597–613 [41] Shen Y, Gu J, Tang X, Zhou B. Interpreting the latent space of GANs for semantic face editing. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Virtual Event: 2020. 9243–9252 [42] Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A. Object detectors emerge in deep scene CNNs. arxiv: 1412.6856, 2014. [43] Petsiuk V, Das A, Saenko K. Rise: Randomized input sampling for explanation of black-box models. arXiv preprint, 2018, arxiv: 1806.07421 [44] Fong R C, Vedaldi A. Interpretable explanations of black boxes by meaningful perturbation. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: 2017. 3449–3457 [45] Agarwal C, Schonfeld D, Nguyen A. Removing input features via a generative model to explain their attributions to classifier's decisions. arXiv: 1910.04256, 2019. [46] Chang C H, Creager E, Goldenberg A, Duvenaud D. Explaining image classifiers by counterfactual generation. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: 2019. [47] Fong R, Patrick M, Vedaldi A. Understanding deep networks via extremal perturbations and smooth masks. In: Proceedings of the IEEE International Conference on Computer Vision. Seoul, Korea: 2019. 2950–2958 [48] Wagner J, Kohler J M, Gindele T, Hetzel L, Wiedemer J T, Behnke S. Interpretable and fine-grained visual explanations for convolutional neural networks. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: 2019. 9097–9107 [49] Vedaldi A. Understanding models via visualizations and attribution [Online], available: https://interpretablevision.github.io/slide/iccv19_vedaldi_slide.pdf, 2019. [50] Springenberg J T, Dosovitskiy A, Brox T, Riedmiller M A. Striving for simplicity: The all convolutional net. arXiv preprint, 2014, arXiv: 1412.6806 [51] Sundararajan M, Taly A, Yan Q. Gradients of counterfactuals. arXiv: 1611.02639, 2016. [52] Smilkov D, Thorat N, Kim B, Viegas F B, Wattenberg M. Smoothgrad: Removing noise by adding noise. arXiv preprint, 2017, arXiv: 1706.03825 [53] Sundararajan M, Taly A, Yan Q. Axiomatic attribution for deep networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, NSW, Australia: 2017. 3319–3328 [54] Kim B, Seo J, Jeon S, Koo J, Choe J, Jeon T. Why are Saliency maps noisy? Cause of and solution to noisy saliency maps. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop. Seoul, Korea: 2019. 4149–4157 [55] Hooker S, Erhan D, Kindermans P J, Kim B. A benchmark for interpretability methods in deep neural networks. In: Proceedings of the Annual Conference on Neural Information Processing Systems. Vancouver, Canada: 2019. 9737–9748 [56] Ancona M, Ceolini E, Öztireli C, Gross M. Towards better understanding of gradient-based attribution methods for Deep Neural Networks. In: Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada: 2018. [57] Rieger L, Hansen L K. Aggregating explanation methods for stable and robust explainability. arXiv: 1903.00519, 2019. [58] Bach S, Binder A, Montavon G, Klauschen F, Müller K, Samek W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLOS ONE, 2015, 10(7): 0130140. [59] Gu J, Yang Y, Tresp V. Understanding individual decisions of cnns via contrastive backpropagation. In: Proceedings of the 14th Asian Conference on Computer Vision. Perth, Australia: 2018. 119–134 [60] Iwana B K, Kuroki R, Uchida S. Explaining convolutional neural networks using softmax gradient layer-wise relevance propagation. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop. Seoul, Korea: 2019. 4176–4185 [61] Montavon G, Lapuschkin S, Binder A, Samek W, Müller K R. Explaining nonlinear classification decisions with deep Taylor decomposition. Pattern Recognition, 2017, 65: 211–222. doi: 10.1016/j.patcog.2016.11.008 [62] Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: 2016. 2921–2929 [63] Selvaraju R R, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: 2017. 618–626 [64] Selvaraju R R, Das A, Vedantam R, Cogswell M, Parikh D, Batra D. Grad-CAM: Why did you say that? arXiv preprint, 2016, arXiv: 1611.07450 [65] Chattopadhay A, Sarkar A, Howlader P, Balasubramanian V N. Grad-CAM++: Generalized gradient-based visual explanations for deep convolutional networks. In: Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Lake Tahoe, Nevada, USA: 2018. 839–847 [66] Wang H, Du M, Yang F, Zhang Z. Score-CAM: Improved visual explanations via score-weighted class activation mapping. arXiv preprint, 2019, arXiv: 1910.01279 [67] Patro B, Lunayach M, Patel S, Namboodiri V. U-CAM: visual explanation using uncertainty based class activation maps. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea: 2019. 7444–7453 [68] Omeiza D, Speakman S, Cintas C, Weldermariam K. Smooth Grad-CAM++: An enhanced inference level visualization technique for deep convolutional neural network models. arXiv preprint, 2019, arXiv: 1908.01224 [69] Nguyen A, Yosinski J, Clune J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: 2015. 427–436 [70] Mahendran A, Vedaldi A. Visualizing Deep Convolutional Neural Networks Using Natural Pre-images. International Journal of Computer Vision, 2016, 120(3): 233–255. doi: 10.1007/s11263-016-0911-8 [71] Yosinski J, Clune J, Nguyen A M, Fuchs T J, Lipson H. Understanding neural networks through deep visualization. arXiv preprint, 2015, arXiv: 1506.06579 [72] Woo S, Park J, Lee J Y, Kweon I S. CBAM: Convolutional block attention module. In: Proceedings of the European Conference on Computer Vision. Munich, Germany: 2018. 3–19 [73] Li K, Wu Z, Peng K C, Ernst J, Fu Y. Tell me where to look: Guided attention inference network. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: 2018. 9215–9223 [74] Fukui H, Hirakawa T, Yamashita T, Fujiyoshi H. Attention branch network: Learning of attention mechanism for visual explanation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: 2019. 10705–10714 [75] Zhang J, Lin Z L, Brandt J, Shen X, Sclaroff S. Top-down neural attention by excitation backprop. In: Proceedings of the European Conference on Computer Vision. Amsterdam, Netherlands: Springer, 2016. 543–559 [76] Hua Y, Mou L, Zhu X X. Recurrently exploring class-wise attention in a hybrid convolutional and bidirectional LSTM network for multi-label aerial image classification. Isprs Journal of Photogrammetry and Remote Sensing, 2019, 149: 188–199. doi: 10.1016/j.isprsjprs.2019.01.015 [77] Li J, Lin D, Wang Y, Xu G, Ding C. Deep discriminative Representation learning with attention map for scene classification. arXiv preprint, 2019, arXiv: 1902.07967 [78] Ribeiro M T, Singh S, Guestrin C. Why should I trust you? Explaining the predictions of any classifier. In: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations. San Diego, USA: 2016. 97–101 [79] Lundberg S M, Lee S I. A unified approach to interpreting model predictions. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: 2017. 4768–4777 [80] Shapley L S. A Value for N-Person Games. Contributions to The Theory of Games (AM-28). Princeton: Princeton University Press, 1953. 2: 307–317 [81] Erhan D, Bengio Y, Courville A, Vincent P. Visualizing Higher-layer Features of a Deep Network, Technical Report 1341, Department of Computer Science and Operations Research, University of Montreal, Canada, 2009 [82] Nguyen A, Dosovitskiy A, Yosinski J, Brox T, Clune J. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. In: Proceedings of the Annual Conference on Neural Information Processing Systems. Barcelona, Spain: 2016. 3387–3395 [83] Ozbulak U. PyTorch CNN Visualizations [Online], available: https://github.com/utkuozbulak/pytorch-cnn-visualizations, 2019. [84] Zhang Q, Wang W, Zhu S C. Examining CNN representations with respect to dataset bias. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, USA: 2017. 4464–4473 [85] Adebayo J, Gilmer J, Muelly M C, Goodfellow I, Hardt M, Kim B. Sanity checks for saliency maps. In: Proceedings of the Annual Conference on Neural Information Processing Systems. Montréal, Canada: 2018. 9505–9515 [86] Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow I, et al. Intriguing properties of neural networks. In: Proceedings of the 2014 ICLR International Conference on Learning Representations. Banff, Canada: 2014. [87] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. In: Proceedings of the 2015 ICLR International Conference on Learning Representations. San Diego, USA: 2015. [88] Gu J, Tresp V. Saliency Methods for explaining adversarial attacks. arXiv preprint, 2019, arXiv: 1908.08413 [89] Ghorbani A, Abid A, Zou J. Interpretation of neural networks is fragile. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, Hawaii, USA: 2019. 3681–3688 [90] Dombrowski A K, Alber M, Anders C, Ackermann M, Müller K R, Kessel P. Explanations can be manipulated and geometry is to blame. In: Proceedings of the 33rd Conference on Neural Information Processing Systems. Vancouver, Canada: 2019. 13589–13600 [91] Heo J, Joo S, Moon T. Fooling neural network interpretations via adversarial model manipulation. In: Proceedings of the 33rd Conference on Neural Information Processing Systems. Vancouver, Canada: 2019. 2925–2936 [92] Zheng H, Fernandes E, Prakash A. Analyzing the interpretability robustness of self-explaining models. arXiv preprint, 2019, arXiv: 1905 [93] Singh M, Kumari N, Mangla P, Sinha A, Balasubramanian V N, Krishnamurthy B. On the benefits of attributional robustness. arXiv preprint, 2019, arXiv: 1911.13073 [94] Krug A, Stober S. Introspection for convolutional automatic speech recognition. In: Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. Brussels, Belgium: 2018. 187–199 [95] Kumar D, Daya I B, Vats K, Feng J, Taylor G W, Wong A. Beyond explainability: Leveraging interpretability for improved adversarial learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Long Beach, USA: 2019. 16–19 [96] Kim J, Kim M, Kang H, Lee K H. U-GAT-IT: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: 2020. [97] Tan Y, Zhang M, Liu Y, Ma S. Rating-boosted latent topics: Understanding users and items with ratings and reviews. In: Proceedings of the 25th International Joint Conference on Artificial Intelligence. New York, USA: 2016. 2640–2646 [98] Zhang Y, Chen X. Explainable Recommendation: A Survey and New Perspectives. Foundations and Trends in Information Retrieval, 2020, 14(1): 1–101. doi: 10.1561/1500000066 [99] Bojarski M, Choromanska A, Choromanski K, Firner B, Jackel L, Muller U, et al. VisualBackProp: Visualizing CNNs for autonomous driving. arXiv preprint, 2016, arxiv: 1611.05418 [100] Kim J, Canny J. Interpretable learning for self-driving cars by visualizing causal attention. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: 2017. 2961–2969 [101] Zhang Z, Xie Y, Xing F, McGough M, Yang L. MDNet: A semantically and visually interpretable medical image diagnosis network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: 2017. 3549–3557 [102] Carvalho D V, Pereira E M, Cardoso J S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics, 2019, 8(8): 832. doi: 10.3390/electronics8080832 [103] Grün F, Rupprecht C, Navab N, Tombari F. A taxonomy and library for visualizing learned features in convolutional neural networks. arXiv preprint, 2016, arXiv: 1606.07757 [104] Samek W, Wiegand T, Müller K R. Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models. arXiv preprint, 2017, arXiv: 1708.08296 [105] Seifert C, Aamir A, Balagopalan A, Jain D, Sharma A, Grottel S, Gumhold S. Visualizations of Deep Neural Networks in Computer Vision: A Survey. Studies in Big Data, 2017, 123–144. [106] Zhang Q, Zhu S. Visual interpretability for deep learning: A survey. Frontiers of Information Technology & Electronic Engineering, 2018, 19(1): 27–39. [107] Adadi A, Berrada M. Peeking Inside the Black-Box: A survey on Explainable Artificial Intelligence (XAI). IEEE Access, 2018, 6: 52138-52160. doi: 10.1109/ACCESS.2018.2870052 [108] Samek W, Montavon G, Lapuschkin S, Anders C J, Müller K. Toward interpretable machine learning: Transparent deep neural networks and beyond. arXiv preprint, 2020, arXiv: 2003.07631 [109] Xie N, Ras G, Gerven M van, Doran D. Explainable deep learning: A field guide for the uninitiated. arXiv preprint, 2020, arXiv: 2004.14545 [110] Arrieta A B, Díaz-Rodríguez N, Ser J D, Bennetot A, Tabik S, Barbado A, Garcia S, Gil-Lopez S, Molina D, Benjamins R, Chatila R, Herrera F. Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI. Information Fusion, 2020, 58: 82–115. doi: 10.1016/j.inffus.2019.12.012 [111] Das A, Rad P. Opportunities and challenges in explainable artificial intelligence (XAI): A survey. arXiv preprint, 2020, arXiv: 2006.11371 [112] Vedaldi A, Lux M, Bertini M. MatConvNet: CNNs are also for MATLAB users. ACM Sigmultimedia Records, 2018, 10(1): 9–9. doi: 10.1145/3210241.3210250 [113] Kim B. Understanding NN [Online], available: https://github.com/1202kbs/Understanding-NN, August 22, 2020. [114] Wang Z J, Turko R, Shaikh O, Park H, Das N, Hohman F, Kahng M, Chau D H. CNN Explainer: Learning Convolutional Neural Networks with Interactive Visualization. IEEE Transactions on Visualization and Computer Graphics, 2021, 27: 1396-1406. doi: 10.1109/TVCG.2020.3030418 -

 下载:
下载:










计量
- 文章访问数: 5752
- HTML全文浏览量: 3078
- PDF下载量: 1313
- 被引次数: 0
