

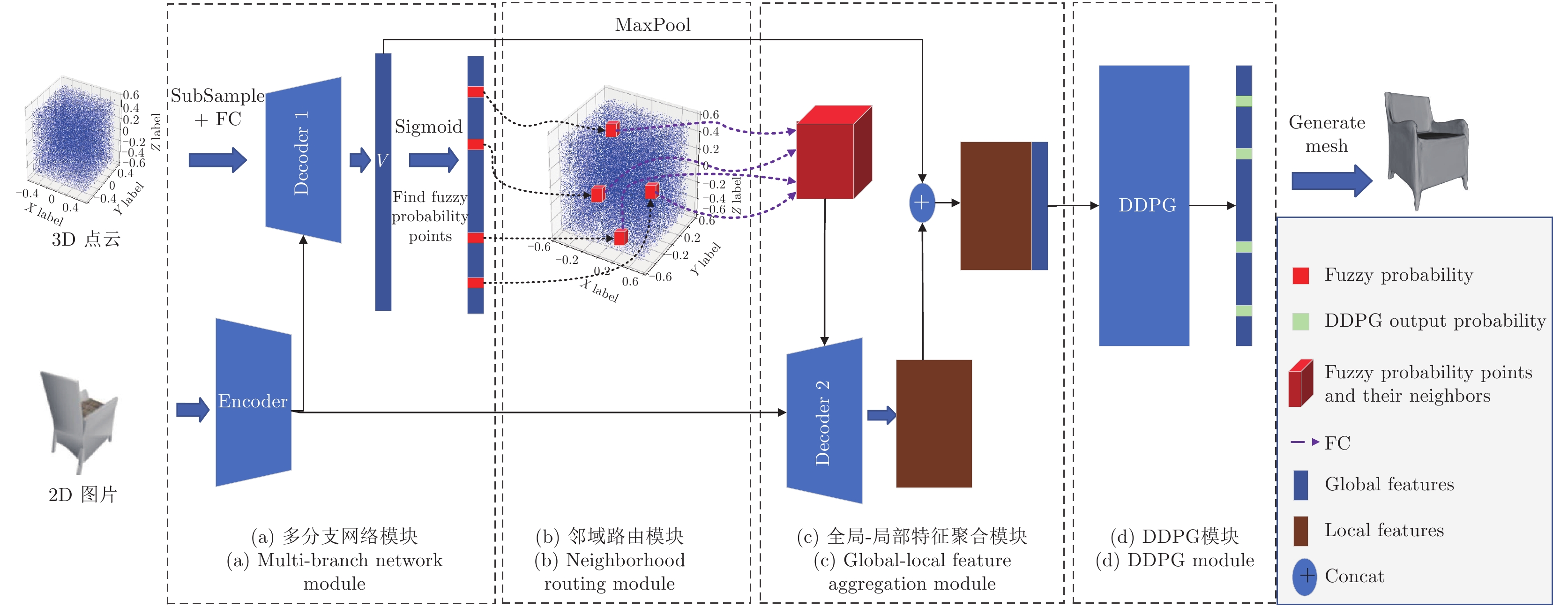
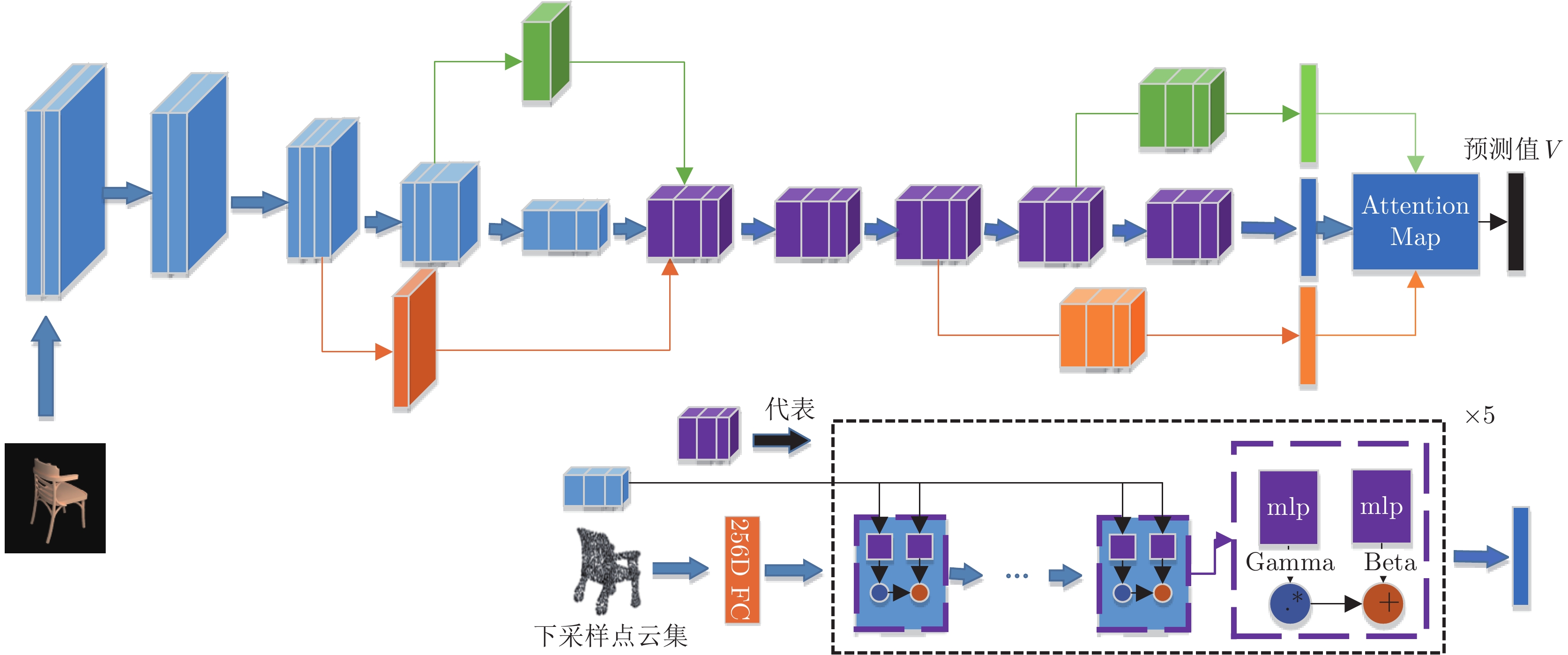
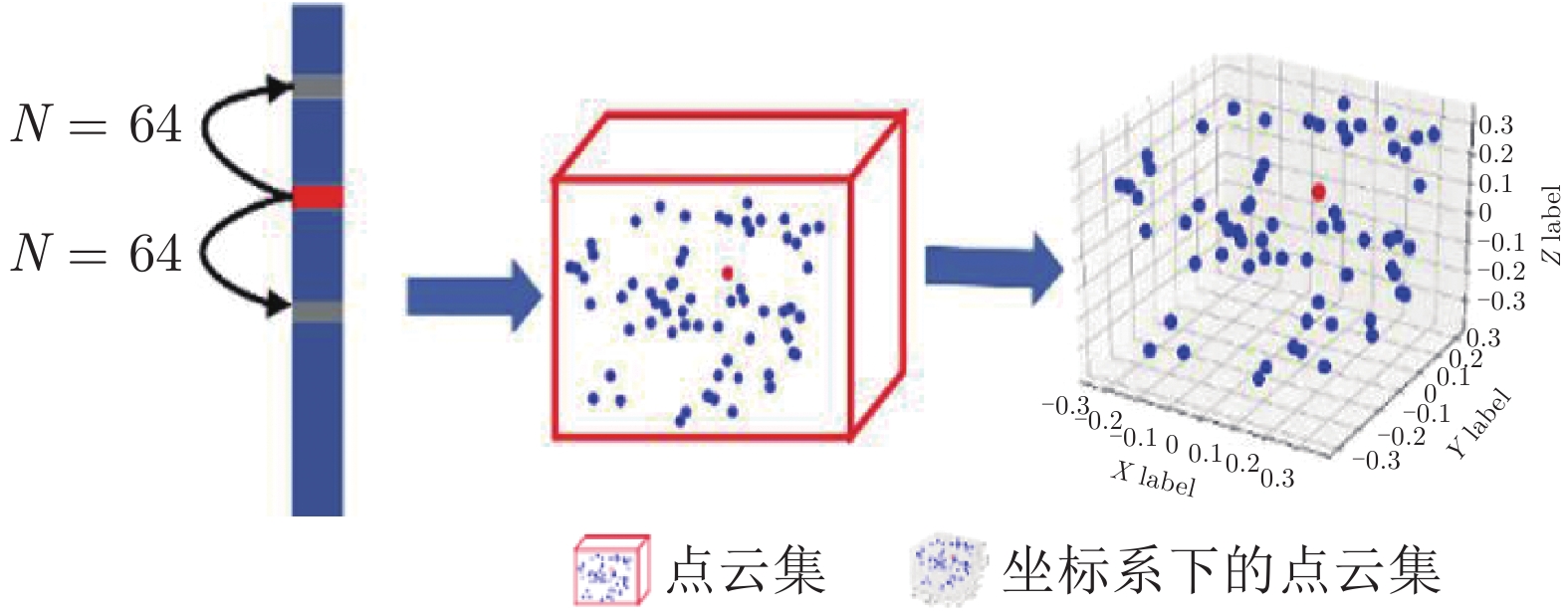
Fuzzy Probability Points Reasoning for 3D Reconstruction Via Deep Deterministic Policy Gradient
-
摘要: 单视图物体三维重建是一个长期存在的具有挑战性的问题. 为了解决具有复杂拓扑结构的物体以及一些高保真度的表面细节信息仍然难以准确进行恢复的问题, 本文提出了一种基于深度强化学习算法深度确定性策略梯度 (Deep deterministic policy gradient, DDPG)的方法对三维重建中模糊概率点进行再推理, 实现了具有高保真和丰富细节的单视图三维重建. 本文的方法是端到端的, 包括以下四个部分: 拟合物体三维形状的动态分支代偿网络的学习过程, 聚合模糊概率点周围点的邻域路由机制, 注意力机制引导的信息聚合和基于深度强化学习算法的模糊概率调整. 本文在公开的大规模三维形状数据集上进行了大量的实验证明了本文方法的正确性和有效性. 本文提出的方法结合了强化学习和深度学习, 聚合了模糊概率点周围的局部信息和图像全局信息, 从而有效地提升了模型对复杂拓扑结构和高保真度的细节信息的重建能力.Abstract: 3D object reconstruction from a single-view image is a long-standing challenging problem. In order to address the difficulty of accurately predicting the objects of complex topologies and some high-fidelity surface details, we propose a new method based on DDPG (Deep deterministic policy gradient) to reason the fuzzy probability points in 3D reconstruction and achieve high-quality detail-rich reconstruction result of single-view image. Our method is end-to-end and includes four parts: the dynamic branch compensation network learning process to fit the 3D shape of objects, the neighborhood routing mechanism to aggregate the points around the fuzzy probability points, the attention guidance mechanism to aggregate the information, and the deep reinforcement learning algorithm to perform probabilistic reasoning. Extensive experiments on a large-scale public 3D shape dataset demonstrate the validity and efficiency of our method. Our method combines reinforcement learning and deep learning, aggregates local information around the fuzzy probability points and global information of the image, and effectively improves the model's ability to reconstruct complex topologies and high-fidelity details.
-
近年来, 随着计算机技术、网络通信、控制工程等新兴产业的相互融合与促进, 信息物理系统(Cyber-physical system, CPS)随之出现, 并朝着大规模、复杂化、智能化的方向发展.多智能体系统分布式协调控制问题作为CPS系统的典型问题, 引起了众多研究者的广泛关注.分布式协同控制因效率高、鲁棒性强等优点, 被广泛应用于无人机编队控制[1]、多机器人协同控制[2]、多飞行器系统群集控制[3-4]等领域.
一致性问题是多智能体协同控制领域的基本问题, 也是协调控制中的研究热点之一[5-13].多智能体系统通过各智能体之间互相协调合作进行信息传递, 按照控制协议改变自身的状态, 从而使各个智能体达到状态一致.近年来诸多学者已经分别针对一阶、二阶、混合阶以及高阶多智能体系统展开了深入的研究[5-7].考虑到许多自然现象的动力学特性不能用整数阶方程描述, 分数阶(非整数阶)动力学的智能个体合作行为也引起了许多研究者的关注[8-9].此外, 在解决多智能体系统一致性问题时, 常常会遇到存在领导者的情况, 这被称为Leader-follower (领导跟随型)问题[10].在多个领导者情况下, 多智能体系统的跟踪问题就变成包容控制问题[11-14].这是领导跟随型一致性问题在多个领导者情况下的扩展, 跟随者在通信协议的作用下最终收敛到由多个领导者围成的某一目标区域内.文献[13]分别研究了通信拓扑为动态联合联通且存在通信时延情况下二阶网络化系统的包容控制问题.文献[14]研究了具有时延的分数阶多智能体系统的包容控制问题, 利用Laplace变换和频域定理, 提出了无向网络分数阶多智能体系统包容控制协议.
上述研究成果均是假设多智能体系统中各个智能体的状态渐近达到稳定, 即当时间趋于无穷大时, 各个智能体的状态可以达到某一共同值.然而在实际应用中, 特别是某些控制精度比较高的系统, 往往要求系统在很短的时间内能够达成一致.与渐近收敛相比, 有限时间一致性控制法不仅可以保证系统的收敛速度更快, 在系统存在外部干扰时也表现出更好的鲁棒性[15].因此研究多智能体系统的有限时间一致性是很有实际意义的.目前关于多智能体系统的有限时间一致性问题已取得比较丰富的研究成果[16-18], 文献[16]研究了二阶多智能体系统有限时间快速收敛问题.文献[17]研究了带有外部干扰的二阶多智能体系统分布式有限时间包容控制, 提出了分布式有限时间包容控制算法使得跟随者的状态在有限时间内收敛到由领导者组成的动态区域内.文献[18]针对联合连通拓扑下具有多领导者的二阶多智能体系统群集运动问题, 提出了一种有限时间收敛的包容控制算法.
由于复杂多变的工作环境, 多智能体系统通常会受到各种干扰的影响.为了处理系统干扰, 研究者提出了许多先进的控制方法, 包括自适应控制[19]、鲁棒控制[20], 滑模控制[21-22]等.然而大多数方法仅考虑匹配干扰, 即干扰与控制输入在同一通道中.在多智能体系统中, 常常存在异于控制输入通道进入系统的干扰, 即不匹配干扰.不匹配干扰广泛存在于实际工程系统中, 例如多导弹系统[23]和工业磁悬浮列车控制系统[24].由于不匹配干扰无法直接利用反馈控制器消除, 因此对带有不匹配干扰系统的协同控制的研究意义重大.文献[24]以工业磁悬浮列车控制系统为例, 详细介绍了不匹配干扰的成因和影响, 基于干扰观测器方法, 介绍了状态通道和输出通道不匹配不确定系统干扰主动控制方法.文献[25]提出基于控制的干扰观测器(Disturbance observer based control, DOBC)方法, 利用干扰前馈补偿和输出反馈复合控制来消除干扰.文献[26]研究了带有不匹配干扰的高阶多智能体系统分布式主动抗干扰控制方法, 结合滑模控制理论和DOBC方法, 实现系统的输出一致性.但文中各智能体的状态最终渐近收敛, 没有考虑有限时间收敛的情况.文献[27]研究了不匹配二阶多智能体受扰系统的输出一致性问题, 文献[28]研究了带有不匹配干扰的多智能体系统有限时间包容控制问题.这两篇文献对系统模型作了处理, 将不匹配干扰转变成匹配干扰, 从而可以利用常规的处理方式消除干扰.然而在实际应用中存在很多情况不能如此处理, 因此该方法有一定的局限性.文献[29]研究了基于扰动观测器的复合积分滑模制导律设计, 给出一种基于积分滑模控制理论和非线性扰动观测理论的复合制导律方法, 但是该方法没有考虑到系统中存在不匹配干扰的情况.
本文以文献[24]介绍的不匹配干扰为研究对象, 研究带有不匹配干扰的二阶多智能体系统的有限时间包容控制问题.相对于文献[27-28], 本文的创新点在于设计了主动有限时间干扰观测器直接估算智能体的不匹配干扰, 并在控制协议中做出干扰补偿, 提出了较为新颖的复合分布式积分滑模控制律.应用滑模控制和现代控制等相关理论, 研究了具有不匹配干扰二阶多智能体系统的有限时间包容控制问题.
1. 预备知识
1.1 代数图论
假设$n$个节点的权重连接图用$G=(V, E, A)$来表示, 其中为$n$个节点的集合, 节点的下标集合$N=\{1, 2, \cdots , n\}$, $E\subseteq V\times V$为边的集合, 为图$G$的权重邻接矩阵, 其中矩阵元素${{a}_{ij}}$表示节点${{v}_{i}}$与节点${{v}_{j}}$的连接权重.定义为节点${{v}_{i}}$的邻居集合.当${{v}_{j}}\in {{N}_{i}}$时, ${{a}_{ij}}>0$, 否则${{a}_{ij}}=0$.若对$\forall i \in N$, ${{a}_{ij}}={{a}_{ji}}$, , 则图$G$为无向拓扑图, 且邻接矩阵$A$为对称矩阵.若对, ${{a}_{ij}}\ne$ ${{a}_{ji}}$, , 则图$G$为有向拓扑图, 且邻接矩阵$A$为非对称矩阵.假设图$G$中任一节点无自环, 即对于$\forall i\in N$, ${{a}_{ii}}=0$.定义$D$为图$G$的度对角矩阵$D$ , 其中节点${{v}_{i}}$的度${{d}_{i}}=$ $\sum\nolimits_{j=1}^{n}{{{a}_{ij}}}$.图$G$的Laplacian矩阵定义为$L=D$ $-$ $A$.无向联通拓扑图的Laplacian矩阵为对称矩阵.
1.2 相关引理和定义
引理1 (Input-to-state stability theorem, ISS)[30].考虑非线性系统$\dot{x}=f(x, u, t)$, 如果系统$\dot{x}=f(x, 0, t)$是全局均一化指数型稳定, 当 $=$ $0$时, 系统的$\dot{x}=f(x, u, t)$状态渐近收敛到0, 即${\lim_{t\to \infty } }x(t)=0$.
引理2[15].考虑系统$\dot{x}=f(x)$, $f(0)=0$, $x$ $\in$ ${{\bf R}^{n}}$, 假设存在一个正定连续函数$V(x):U\to {\bf R}$, 且实数$c>0$, $\alpha \in (0, 1)$, 在${{U}_{0}}\subset U$的邻域上满足, , 则$V(x)$在有限时间内收敛到0.此外有限时间$T$满足$T$ $\le$ $\frac{{{V}^{1-\alpha }}(x(0))}{c(1-\alpha )}$.
定义1[12-13].假设集合$X$是向量空间的子集, 集合$X$的凸包定义为 ${{a}_{i}}$ $\ge 0$, $\sum\nolimits_{i=1}^{k}{{{a}_{i}}=1} \}$.
定义2[15, 18].考虑连续非线性系统: $\dot{\pmb x}=f({\pmb x})$, , 其中连续向量流$f({\pmb x})=[ {{f}_{1}}({\pmb x})$, 与带有扩张, ${ {r}_{i}}>0$的度$\kappa \in \bf R$是齐次的, 如果对于任意的$\varepsilon$ $>$ $0$, ${\pmb x}\in {{\bf R}^{n}}$都有 , $i=1, 2, \cdots , n$.
引理3[15, 18].若系统与带有扩张, ${{ r}_{i}}>0$的度$\kappa$ $\in$ $\bf R$是齐次的, 函数$f({\pmb x})$是连续的, 且${\pmb x}=0$是其一个渐近稳定平衡点.如果齐次度$\kappa <0$, 则该系统是有限时间稳定的.
定义3.如果网络化系统中的一个自主体至少存在一个邻接成员, 则称之为跟随者, 否则称为领导者.
2. 二阶多智能体系统的有限时间包容控制
假设一个具有$n$个跟随者和$m$个领导者的多智能体系统, 其中每个智能体可理解为加权无向图$G$中的一个顶点, 各智能体之间的信息传递可理解为图$G$的边.考虑二阶多智能体系统未受到干扰时的动力学模型为
$ \begin{align}\label{1} \begin{cases} {{{\dot{x}}}_{i}}(t)={{v}_{i}}(t) \\ {{{\dot{v}}}_{i}}(t)={{u}_{i}}(t) \end{cases} \end{align} $
(1) 其中, $i= \{ 1, 2, \cdots , n, n+1, \cdots , n+m \}$, $n$表示跟随者的个数, $m$表示领导者的个数, 跟随者和领导者集合分别表示为$F= \{ 1, 2, \cdots , n \}$和$L=\{ n+1$, $n+2$, $\cdots , n+m \}$. ${{x}_{i}}(t)$和${{v}_{i}}(t)$分别表示系统第$i$个智能体在$t$时刻的位置和速度, ${{u}_{i}}(t)$是控制输入.假设领导者为作匀速运动的动态领导者, 对于$\forall i$ $\in$ $L$, 其动力学模型为
$ \begin{align}\label{2} \begin{cases} {{{\dot{x}}}_{i}}(t)={{v}_{i}}(t) \\ {{{\dot{v}}}_{i}}(t)=0 \end{cases} \end{align} $
(2) 多Leader-follower型多智能体系统(1)和(2)的通信拓扑图可描述成${{G}_{n+m}}=( {{V}_{n+m}}, {{E}_{n+m}}$, , 其中$m$表示领导者的个数, $n$表示跟随者的个数.图${{G}_{n+m}}$的邻接矩阵为 $\in$ ${{\bf R}^{ ( n+m )\times ( n+m )}}$, Laplacian矩阵为${{L}_{n+m}}=[ {{l}_{ij}} ]\in$ , 可描述成, ${{L}_{f}}$ $\in {{\bf R}^{n\times n}}$, ${{L}_{d}}\in {{\bf R}^{n\times m}}$.
假设1.领导者相互间不通信, 领导者与跟随者之间单向通信, 跟随者之间为双向通信, 且每个智能体都可接收到它邻居发送的状态信息和干扰估计信息.
假设2.多Leader-follower型多智能体系统的通信拓扑${{G}_{n+m}}$包含至少一条有向生成树.
引理4[12].如果假设2成立, 多Leader-follower型多智能体系统的${{L}_{f}}$是正定的, 此外$-L_{f}^{-1}{{L}_{d}}$为非负的且行和为1.
引理5[12].令, ${{\pmb x}_{L}}=$ , 若有, 则网络化系统可以实现包容控制.
为了简化, 令, ${{\pmb v}_{F}}=[{{v}_{1}}$, , , ${{\pmb v}_{L}}=$ , . , , ${{v}_{c2}}$, .由定义1、引理3和引理5可知, ${{\pmb x}_{F}}\to {{\pmb x}_{c}}$ $({{x}_{i}}\to {{x}_{ci}}$, $i\in F)$意味着${{x}_{i}}$, 收敛到凸包$Co \{ {{x}_{j}}, j\in L \}$内, 即实现包容控制.
基于上述描述, 本节首先考虑不存在干扰的情况, 设计分布式控制协议, 使得各个跟随者的状态在有限时间内实现包容控制, 即.
首先令跟踪误差为
$ \begin{align}\label{3} \begin{cases} \omega _{i}^{x}= & \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)}} \\[2mm] \omega _{i}^{v}= & \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( {{v}_{i}}-{{v}_{j}} \right)+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{v}_{i}}-{{v}_{j}} \right)}} \end{cases} \end{align} $
(3) 基于跟踪误差(3), 设计控制器如下:
$ \begin{align}\label{4} {{u}_{i}}= -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( \omega _{i}^{x} \right)- {{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\left( \omega _{i}^{v} \right) \end{align} $
(4) 其中, 控制增益${{k}_{1}}$, ${{k}_{2}}>0$, $0<{{\alpha }_{1}} <1$, ${{\alpha }_{2}}=$ ${2{{\alpha }_{1}}}/({{\alpha }_{1}}+1)$. , 表示符号函数.假设 , .
定理1. 考虑由$n$个跟随者和$m$个领导者组成的二阶动态多智能体系统(1)和(2), 其通信拓扑图可描述成, 如果假设1和假设2成立, 则多智能体系统基于分布式控制协议(4)可实现全局有限时间包容控制.
证明.由引理4可知, 多智能体系统(1)和(2)的${{L}_{f}}$是正定的.令, ${{\bar{\pmb v}}_{F}}={{\pmb v}_{F}}$ $+$ $L_{f}^{-1}{{L}_{d}}{{\pmb v}_{L}}$, 则跟踪误差(3)转变成矩阵形式为
$ \begin{align}\label{5} \begin{cases} {{\pmb {\omega }}_{x}}={{L}_{f}}{{\pmb x}_{F}}+{{L}_{d}}{{\pmb x}_{L}}={{L}_{f}}{{{\bar{\pmb x}}}_{F}} \\ {{\pmb {\omega }}_{v}}={{L}_{f}}{{\pmb v}_{F}}+{{L}_{d}}{{\pmb v}_{L}}={{L}_{f}}{{{\bar{\pmb v}}}_{F}} \end{cases} \end{align} $
(5) 其中, , $\omega _{n}^{v}]^{\rm T}$, 且${{\dot{\pmb \omega }}_{x}}={{\pmb \omega }_{v}}$.因此速度跟踪误差${{\bar{\pmb v}}_{F}}$的微分方程为
$ \begin{align}\label{6} {{\dot{\bar{\pmb v}}}_{F}}=-{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( {{\pmb \omega }_{x}} \right)-{{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\left( {{\pmb \omega }_{v}} \right) \end{align} $
(6) 构造Lyapunov函数
$ \begin{align}\label{7} {{V}_{1}}=\frac{1}{2}\bar{\pmb v}_{F}^{\texttt{T}}{{L}_{f}}{{\bar{\pmb v}}_{F}}+\frac{{{k}_{1}}{{\left| {{\pmb \omega }_{x}} \right|}^{{{\alpha }_{1}}+1}}}{{{\alpha }_{1}}+1} \end{align} $
(7) 对${{V}_{1}}$函数沿着式(6)求一次导, 得
$ \begin{align} {{{\dot{V}}}_{1}}= &\ \bar{\pmb v}_{F}^{\rm{T}}{{L}_{f}}{{{\dot{\bar{\pmb v}}}}_{F}} +{{k}_{1}}{{\left| {{\pmb \omega }_{x}} \right|}^{{{\alpha }_{1}}}} {\pmb \omega _{v}}^{\rm{T}}{\rm sgn}\left( {{\pmb \omega }_{x}} \right) = \nonumber\\ &\ {\pmb \omega _{v}}^{\rm{T}}\left( -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( {{\pmb \omega }_{x}} \right)-{{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\left( {{\pmb \omega }_{v}} \right) \right)+ \nonumber\\ &\ {{k}_{1}}{\pmb \omega _{v}}^{\rm{T}}{{\rm sig} ^{{{\alpha }_{1}}}}\left( {{\pmb \omega }_{x}} \right) = -{{k}_{2}}{{\left| {{\pmb \omega }_{v}} \right|}^{{{\alpha }_{2}}+1}} \le 0 \nonumber \end{align} $
注意到, 当${{\dot{V}}_{1}}=0$时, ${{\pmb \omega }_{v}}=0$, 由于${{\pmb \omega }_{v}}={{L}_{f}}{{\bar{\pmb v}}_{F}}$, 且${{L}_{f}}$是正定的, 所以${{\bar{\pmb v}}_{F}}=0$.由式(6)可知 $0$.因此只有在平衡点${{\pmb \omega }_{x}}=0$, 处才有${{\dot{V}}_{1}}$ $=$ $0$.根据Lyapunov第二稳定性定理可知, 该系统在平衡点处渐近稳定.进一步由式(5)可得${{\pmb x}_{F}}$ $\to$ , ${{\pmb v}_{F}}\to -L_{f}^{-1}{{L}_{d}}{{\pmb v}_{L}}$, 由引理5可知系统可以实现渐近包容控制.
下面分析系统的齐次性.假设原动力学系统为
$ \begin{align}\label{8} \begin{cases} {{f}_{1}}\left( {{x}_{i}}, {{v}_{i}} \right)= & {{v}_{i}}\left( t \right) \\ {{f}_{2}}\left( {{x}_{i}}, {{v}_{i}} \right)= & {{u}_{i}}\left( t \right) \end{cases} \end{align} $
(8) 取${{r}_{1}}=2$, ${{r}_{2}}=1+{{\alpha }_{1}}$, , 则有
$ \begin{align} &{{f}_{1}}\left( {{\varepsilon }^{{{r}_{1}}}}{{x}_{i}}, {{\varepsilon }^{{{r}_{2}}}}{{v}_{i}} \right)={{\varepsilon }^{{{r}_{2}}}} {{v}_{i}}\left( t \right)={{\varepsilon }^{{{r}_{1}}+\kappa }} {{f}_{1}}\left( {{x}_{i}}, {{v}_{i}} \right)\notag\\ &{{f}_{2}}\left( {{\varepsilon }^{{{r}_{1}}}}{{x}_{i}}, {{\varepsilon }^{{{r}_{2}}}}{{v}_{i}} \right) =\notag\\ &\qquad -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\bigg( \sum\limits_{j=1}^{n+m}{{{a}_{ij}}\left( {{\varepsilon }^{{{r}_{1}}}}{{x}_{i}}-{{\varepsilon }^{{{r}_{1}}}}{{x}_{j}} \right)} \bigg)- \notag\\ &\qquad {{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\bigg( \sum\limits_{j=1}^{n+m}{{{a}_{ij}}\left( {{\varepsilon }^{{{r}_{2}}}}{{v}_{i}}-{{\varepsilon }^{{{r}_{2}}}}{{v}_{j}} \right)} \bigg) = \notag\\ &\qquad -{{k}_{1}}{{\varepsilon }^{{{r}_{1}}{{\alpha }_{1}}}}{{\rm sig}^{{{\alpha }_{1}}}}\bigg( \sum\limits_{j=1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)} \bigg)- \notag\\ &\qquad {{k}_{2}}{{\varepsilon }^{{{r}_{2}}{{\alpha }_{2}}}}{{\rm sig}^{{{\alpha }_{2}}}}\bigg( \sum\limits_{j=1}^{n+m}{{{a}_{ij}}\left( {{v}_{i}}-{{v}_{j}} \right)} \bigg) = \notag\\ &\qquad {{\varepsilon }^{2{{\alpha }_{1}}}}\bigg( -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\bigg( \sum\limits_{j=1}^{n+m} {{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)} \bigg)- \notag\\ &\qquad {{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\bigg( \sum\limits_{j=1}^{n+m} {{{a}_{ij}}\left( {{v}_{i}}-{{v}_{j}} \right)} \bigg) \bigg) =\notag \\ &\qquad {{\varepsilon }^{{{r}_{2}}+\kappa }}{{f}_{2}}\left( {{x}_{i}}, {{v}_{i}} \right) \nonumber \end{align} $
由定义2可知, 多智能体系统(1)和(2)与带有扩张的度是齐次的, 且由引理3可知, 系统(8)可在有限时间内收敛.
综上可知, 多智能体系统(1)和(2)可实现有限时间包容控制.
3. 带有不匹配干扰的多智能体系统的有限时间包容控制
本节考虑二阶多智能体系统中存在的不匹配干扰和匹配干扰等多源干扰的情况, 假设二阶受扰多智能体系统的动力学模型为
$ \begin{align}\label{9} \begin{cases} {{{\dot{x}}}_{i}}(t)= {{v}_{i}}(t)+{{d}_{i1}}(t) \\ {{{\dot{v}}}_{i}}(t)= {{u}_{i}}(t)+{{d}_{i2}}(t) \end{cases} \end{align} $
(9) 其中, $i\in F= \{ 1, 2, \cdots , n \}$, $n$表示跟随者的个数, ${{x}_{i}}(t)$和${{v}_{i}}(t)$分别是智能体的位置和速度, ${{u}_{i}}(t)$是控制输入, ${{d}_{i1}}(t)$和${{d}_{i2}}(t)$分别表示不匹配干扰和匹配干扰.
领导者的动力学模型为
$ \begin{align}\label{10} \begin{cases} {{{\dot{x}}}_{j}}(t)={{v}_{j}}(t) \\ {{{\dot{v}}}_{j}}(t)=0 \end{cases} \end{align} $
(10) 其中, $j\in L= \{ n+1, n+2, \cdots , n+m \}$, $m$表示领导者的个数, ${{x}_{j}}(t)$和${{v}_{j}}(t)$分别是领导者位置和速度.
为了解决系统(9)中的不匹配干扰并保持系统的标称性能, 本节将结合积分滑模控制和非线性干扰观测器给出复合分布式控制协议.首先, 通过设计非线性干扰观测器, 在有限时间内估算出系统的状态和干扰信息.然后, 基于干扰估计值, 设计出带有前馈补偿项的复合分布式积分滑模控制协议.
3.1 非线性干扰观测器设计
假设3.干扰${{d}_{ik}}(t)$和, $k$ $= 1, 2$, 都是有界的.
注1. 假设3在DOBC领域是很常见的假设.一方面, 如果干扰具有很快时变, 那么干扰观测器很难进行估算; 另一方面, 在实际应用上, 有很多种干扰满足这种假设, 例如:常值干扰, 谐波干扰等[27-29].
引理6[31].对于一般系统
$ \begin{align}\label{11} \dot{x}=f+gu+d \end{align} $
(11) 其中, $x$为状态量, $u$为控制量, $d$为系统干扰, $f, g$已知.设计的非线性干扰观测器如下:
$ \begin{align}\label{12} \begin{cases} \dot{\hat{x}}= f+gu+z \\ z= -{{\lambda }_{1}}{{\rm sig}^{\frac{2}{3}}}(\hat{x}-x)+\hat{d} \\ \dot{\hat{d}}= -{{\lambda }_{2}}{{\rm sig}^{\frac{1}{2}}}(\hat{d}-z) \end{cases} \end{align} $
(12) 其中, 增益${{\lambda }_{1}}$, ${{\lambda }_{2}}>0$, $\hat{x}$和$\hat{d}$分别是状态$x$和干扰$d$的估计值, 则该观测器是有限时间收敛的.
根据引理6, 设计干扰观测器如下:
$ \begin{align}\label{13} \begin{cases} {{{\dot{\hat{x}}}}_{i}}= {{v}_{i}}+{{z}_{i1}} \\ {{z}_{i1}}= -{{\lambda }_{i1}}{{\rm sig}^{\frac{2}{3}}}({{{\hat{x}}}_{i}}-{{x}_{i}})+{{{\hat{d}}}_{i1}} \\ {{{\dot{\hat{d}}}}_{i1}}= -{{\lambda }_{i2}}{{\rm sig}^{\frac{1}{2}}}({{{\hat{d}}}_{i1}}-{{z}_{i1}}) \\ {{{\dot{\hat{v}}}}_{i}}= {{u}_{i}}+{{z}_{i2}} \\ {{z}_{i2}}= -{{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}}({{{\hat{v}}}_{i}}-{{v}_{i}})+{{{\hat{d}}}_{i2}} \\ {{{\dot{\hat{d}}}}_{i2}}= -{{\lambda }_{i4}}{{\rm sig}^{\frac{1}{2}}}({{{\hat{d}}}_{i2}}-{{z}_{i2}}) \end{cases} \end{align} $
(13) 其中, $i\in F$, ${{\hat{x}}_{i}}$和${{\hat{v}}_{i}}$分别是系统中跟随者的位置状态和速度的估计值, ${{\hat{d}}_{i1}}$和${{\hat{d}}_{i2}}$分别是干扰的估计量, ${{z}_{i1}}$和${{z}_{i2}}$为中间量, 为观测增益.
设${{e}_{{{x}_{i}}}}={{x}_{i}}-{{\hat{x}}_{i}}$, ${{e}_{{{d}_{i1}}}}={{d}_{i1}}-{{\hat{d}}_{i1}}$, ${{e}_{{{v}_{i}}}}={{v}_{i}}-{{\hat{v}}_{i}}$, ${{e}_{{{d}_{i2}}}}$ $={{d}_{i2}}-{{\hat{d}}_{i2}}$, 则
$ \begin{align}\label{14} \begin{cases} {{{\dot{e}}}_{{{x}_{i}}}}= -{{\lambda }_{i1}}{{\rm sig}^{\frac{2}{3}}}({{e}_{{{x}_{i}}}})+{{e}_{{{d}_{i1}}}} \\ {{{\dot{e}}}_{{{d}_{i1}}}}= -{{\lambda }_{i2}}{{\rm sig}^{\frac{1}{2}}}({{e}_{{{d}_{i1}}}}-{{{\dot{e}}}_{{{x}_{i}}}})+{{{\dot{d}}}_{i1}} \\ {{{\dot{e}}}_{{{v}_{i}}}}= -{{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}}({{e}_{{{v}_{i}}}})+{{e}_{{{d}_{i2}}}} \\ {{{\dot{e}}}_{{{d}_{i2}}}}= -{{\lambda }_{i4}}{{\rm sig}^{\frac{1}{2}}}({{e}_{{{d}_{i2}}}}-{{{\dot{e}}}_{{{v}_{i}}}})+{{{\dot{d}}}_{i2}} \end{cases} \end{align} $
(14) 其中, .由引理6可知, 存在大于零的增益, 使得观测器是有限时间收敛, 即存在一个时刻${{ T}^{*}}$, 当$t\in [0, {{ T}^{*}}]$时, ${{e}_{{{x}_{i}}}}$, ${{e}_{{{d}_{i1}}}}$, ${{e}_{{{v}_{i}}}}$, ${{e}_{{{d}_{i2}}}}$均有界; 当$t>{{ T}^{*}}$时, ${{e}_{{{x}_{i}}}}=0$, ${{e}_{{{d}_{i1}}}}$ $=$ $0$, ${{e}_{{{v}_{i}}}}=0$, ${{e}_{{{d}_{i2}}}}=0$.
3.2 复合式分布式控制律设计
下面基于上述设计的有限时间干扰观测器, 结合滑模控制理论, 设计复合分布式控制协议消除干扰, 并使得系统(9)和系统(10)实现有限时间包容控制.
首先令跟踪误差为
$ \begin{align}\label{15} \begin{cases} \omega _{i}^{x}= \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)}} \\[2mm] \omega _{i}^{v}= \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( ( {{{\hat{v}}}_{i}}+{{{\hat{d}}}_{i1}} )-( {{{\hat{v}}}_{j}}+{{{\hat{d}}}_{j1}} ) \right)}\, +\\ \qquad \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( ( {{{\hat{v}}}_{i}}+{{{\hat{d}}}_{i1}} )-{{v}_{j}} \right)} \end{cases} \end{align} $
(15) 基于跟踪误差(15), 设计复合分布式控制协议如下:
$ \begin{align}\label{16} {{u}_{i}}= & -{{k}_{0}}{\rm sgn}\left( \sum\limits_{j=1}^{n}{{{a}_{ij}} \left( {{s}_{i}}-{{s}_{j}} \right)}+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}} {{s}_{i}}} \right)- \nonumber\\ &\ {{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( \omega _{i}^{x} \right)- {{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\left( \omega _{i}^{v} \right)-{{{\hat{d}}}_{i2}} \end{align} $
(16) 其中, ${{k}_{0}}, {{k}_{1}}, {{k}_{2}}>0$, 分别是干扰观测器(13)对系统速度和干扰的估计值, $i\in F$, 非线性动态积分滑模面为
$ \begin{align}\label{17} {{s}_{i}}= &\ {{{\hat{v}}}_{i}}+{{{\hat{d}}}_{i1}}-\left( {{{\hat{v}}}_{i}} (0)+{{{\hat{d}}}_{i1}}(0) \right)+ \nonumber\\ &\ \int_{0}^{t}\left({ {{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}( \omega _{i}^{x} ) +{{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}( \omega _{i}^{v} ) }\right){\rm d}\tau \end{align} $
(17) 其中, $0<{{\alpha }_{1}}<1$, .当$t=0$时, ${{s}_{i}}(0)$ $=0$, 表示各智能体的状态从初始时刻就位于非线性滑模面(17)上.
定理2.考虑由$n$个跟随者和$m$个领导者组成的二阶受扰多智能体系统(9)和(10), 其通信拓扑图可描述成, 如果假设1~3成立, 当切换增益满足${{k}_{0}}>\delta $时, 基于有限时间干扰观测器(13)和非线性积分滑模面(17)的复合分布式非线性积分滑模控制协议(16)可使得系统实现全局有限时间包容控制.其中, , $e_{{{v}_{i}}}^{*}$ $=$ , , $k=1, 2, 3$, .
证明.首先对滑模面(17)求一次导, 得
$ \begin{align*} {{{\dot{s}}}_{i}} =&\ {{{\dot{\hat{v}}}}_{i}}+{{{\dot{\hat{d}}}}_{i1}}+{{k}_{1}} {{\rm sig}^{{{\alpha }_{1}}}}\left( \omega _{i}^{x} \right)+{{k}_{2}}{{\rm sig}^ {{{\alpha }_{2}}}}\left( \omega _{i}^{v} \right)= \\ & \ {{u}_{i}}-{{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}}({{{\hat{v}}}_{i}}-{{v}_{i}})+ {{{\hat{d}}}_{i2}}+{{{\dot{\hat{d}}}}_{i1}}\, + \\ & \ {{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( \omega _{i}^{x} \right)+{{k}_{2}}{{\rm sig}^ {{{\alpha }_{2}}}}\left( \omega _{i}^{v} \right)=\\ & -{{k}_{0}}{\rm sgn}\left( \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( {{s}_{i}}-{{s}_{j}} \right)}+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}{{s}_{i}}} \right)- \\ &\ {{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}}\left( {{{\hat{v}}}_{i}}-{{v}_{i}} \right)+{{{\dot{\hat{d}}}}_{i1}}= \\ & -{{k}_{0}}{\rm sgn}\left( \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( {{s}_{i}}-{{s}_{j}} \right)}+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}{{s}_{i}}} \right)+ \\ &\ {{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}}\left( {{e}_{{{v}_{i}}}} \right)+{{\lambda }_{i2}}{{\rm sig}^{\frac{1}{2}}}\left( {{\lambda }_{i1}}{{\rm sig}^{\frac{2}{3}}}\left( {{e}_{{{x}_{i}}}} \right) \right) \nonumber \end{align*} $
令${\pmb S}={[{{s}_{1}}, {{s}_{2}}, \cdots , {{s}_{n}}]}^{{\rm T}}$, 将上式转换成矩阵形式
$ \begin{align}\label{18} \dot{\pmb S}= & -{{k}_{0}}{\rm sgn}\left( {{L}_{f}}{\pmb S} \right)+{{\lambda }_{3}} {{\rm sig}^{\frac{2}{3}}}\left( {{\pmb e}_{v}} \right)+ \notag\\ &\ {{\lambda }_{2}} {{\rm sig}^{\frac{1}{2}}}\left( {{\lambda }_{1}}{{\rm sig}^{\frac{2}{3}}}\left( {{\pmb e}_{x}} \right) \right) \end{align} $
(18) 其中, ${{L}_{f}}$为系统的Laplacian矩阵, , ${{\lambda }_{21}}$, , , ${\rm diag} \{ {{\lambda }_{13}}$, , , , ${{\pmb e}_{v}}$ .
构造函数, 对$V_2$求一次导, 得
$ \begin{align*} {{{\dot{V}}}_{2}} =&\ {{\pmb S}^{\rm{T}}}{{L}_{f}}\dot{\pmb S} = {{\pmb S}^{\rm{T}}}{{L}_{f}}\left( -{{k}_{0}}{\rm sgn}\left( {{L}_{f}}{\pmb S} \right) \right)+ \\ &\ {{\pmb S}^{\rm{T}}}{{L}_{f}}\left( {{\lambda }_{3}}{{\rm sig}^{\frac{2}{3}}} \left( {{\pmb e}_{v}} \right)+{{\lambda }_{2}}{{\rm sig}^{\frac{1}{2}}}\left( {{\lambda }_{1}}{{\rm sig}^{\frac{2}{3}}} \left( {{\pmb e}_{x}} \right) \right) \right) = \\ & -{{k}_{0}}\sum\limits_{i=1}^{n}{\left| {{\left[ {{L}_{f}}{\pmb S} \right]}_{i}} \right|}+ \sum\limits_{i=1}^{n}\bigg( {{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}} \left( {{e}_{{{v}_{i}}}} \right)+\\ &\ {{\lambda }_{i2}}{{\rm sig}^{\frac{1}{2}}}\left( {{\lambda }_{i1}} {{\rm sig}^{\frac{2}{3}}} \left( {{e}_{{{x}_{i}}}} \right) \right) \bigg)\left| {{\left[ {{L}_{f}}{\pmb S} \right]}_{i}} \right| \le \\ & -\left( {{k}_{0}}-\delta \right){{\left\| {{L}_{f}}{\pmb S} \right\|}_{1}} \le -\left( {{k}_{0}}-\delta \right){{\left\| {{L}_{f}}{\pmb S} \right\|}_{2}} \nonumber \end{align*} $
其中, , , , , $k=1, 2, 3$, .由有限时间观测器(13)可知, 在$[0, {{ T}^{*}}]$内, ${{e}_{{{x}_{i}}}}$, ${{e}_{{{v}_{i}}}}$是有界的, 因此$\delta $一定存在.由于${{L}_{f}}$是正定的, .因此
$ \begin{align}\label{19} \dot{V}\le -\sqrt{2}\left( {{k}_{0}}-\delta \right)\lambda _{\min }^{\frac{1}{2}}\left( {{L}_{f}} \right)V_{2}^{\frac{1}{2}} \end{align} $
(19) 因此, 当${{k}_{0}}>\delta $时, 由引理2可知各智能体状态可在有限时间内到达非线性滑模面(17)上.假设各智能体状态可在${{t}_{1}}$时刻到达滑模面上, 由引理2可得
$ \begin{align}\label{20} {{t}_{1}}\le &\ \frac{\sqrt{2}V_{2}^{\frac{1}{2}}(0)}{\left( {{k}_{0}} -\delta \right)\lambda _{\min }^{\frac{1}{2}}\left( {{L}_{f}} \right)} \le\notag\\[2mm] &\ \frac{{{\left( {{\pmb S}^{\rm{T}}}(0)L_{f}^{2}{\pmb S}(0) \right)}^{\frac{1}{2}}}} {\left( {{k}_{0}}-\delta \right){{\lambda }_{\min }}\left( {{L}_{f}} \right)}=0 \end{align} $
(20) 式(20)表明各智能体状态从初始时刻开始就一直发生在非线性滑模面上.
下面证明系统有限时间包容控制.首先假设跟随者的状态跟踪误差为, , , ${{\bar{v}}_{n}}]^{\rm{T}}$.
由有限时间观测器(13)可知, 存在一个时刻${{T}^{*}}$, 当$t>{{ T}^{*}}$时, ${{e}_{{{x}_{i}}}}={{e}_{{{d}_{i1}}}}={{e}_{{{v}_{i}}}}={{e}_{{{d}_{i2}}}}=0$.因此, 闭合系统(9), (10), (16)的有限时间稳定性可分两步证明, 即上状态跟踪误差${{\bar{x}}_{i}}$, ${{\bar{v}}_{i}}$有界, 及$t$ $>$ ${{T}^{*}}$时, 全局有限时间收敛.
1) 注意到系统的状态一直发生在非线性积分滑模面上, 因此
$ \begin{align}\label{21} {{\dot{s}}_{i}}=\, &{\dot{\hat{v}}_{i}}+{\dot{\hat{d}}}_{i1}+ {{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( \omega _{i}^{x} \right)+ {{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\left( \omega _{i}^{v} \right)=0 \end{align} $
(21) 令${{\tilde{v}}_{i}}={{\hat{v}}_{i}}+{{\hat{d}}_{i1}}$, 则, 因此
$ \begin{align}\label{22} \begin{cases} {{{\dot{x}}}_{i}}= {{{\tilde{v}}}_{i}}+{{e}_{{{v}_{i}}}}+{{e}_{{{d}_{i1}}}} \\ {{{\dot{\tilde{v}}}}_{i}}= -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}} \Big( \sum\limits_{j=1}^{n}{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)+\\ \qquad\, \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)} \Big)- {{k}_{2}}\, \times\\ \qquad\, {{\rm sig}^{{{\alpha }_{2}}}}\Big( \sum\limits_{j=1}^{n}{{{a}_{ij}} \left( {{{\tilde{v}}}_{i}}-{{{\tilde{v}}}_{j}} \right)+ \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{{\tilde{v}}}_{i}}-{{v}_{j}} \right)}} \Big) \end{cases} \end{align} $
(22) 应用ISS稳定性引理, 假设${{e}_{{{v}_{i}}}}$, ${{e}_{{{d}_{i1}}}}=0$, 则系统(22)转变为
$ \begin{align}\label{23} \begin{cases} {{{\dot{x}}}_{i}}= {{{\tilde{v}}}_{i}} \\ {{{\dot{\tilde{v}}}}_{i}}= -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}} \Big( \sum\limits_{j=1}^{n}{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)+\\ \qquad\, \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)} \Big)-{{k}_{2}}\, \times \\ \qquad\, {{\rm sig}^{{{\alpha }_{2}}}}\Big( \sum\limits_{j=1}^{n}{{{a}_{ij}} \left( {{{\tilde{v}}}_{i}}-{{{\tilde{v}}}_{j}} \right)+ \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{{\tilde{v}}}_{i}}-{{v}_{j}} \right)}} \Big) \end{cases} \end{align} $
(23) 由定理1可知, 系统(23)是有限时间包容控制的, 结合引理1, 系统(22)是ISS稳定的.由观测器可知, 在$[0, {{ T}^{*}}]$内${{e}_{{{v}_{i}}}}$和${{e}_{{{d}_{i1}}}}$有界, 因此系统(22)状态跟踪误差${{\bar{x}}_{i}}$和${{\bar{\tilde{v}}}_{i}}$有界.而假设1中说明${{d}_{i1}}$是有界的, 因此${{\hat{d}}_{i1}}$也是有界的, 所以速度跟踪误差${{\bar{v}}_{i}}$是有界的.
2) (全局有限时间包容控制)当$t>{{ T}^{*}}$时, ${{e}_{{{x}_{i}}}}$ $=$ ${{e}_{{{d}_{i1}}}}={{e}_{{{v}_{i}}}}= {{e}_{{{d}_{i2}}}}=0$.令${{\tilde{v}}_{i}}={{\hat{v}}_{i}}+{{\hat{d}}_{i1}}= {{v}_{i}}+$ ${{d}_{i1}}$, 则
$ \begin{align}\label{24} \begin{cases} {{{\dot{x}}}_{i}}= {{{\tilde{v}}}_{i}} \\ {{{\dot{\tilde{v}}}}_{i}}= -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}} \Big( \sum\limits_{j=1}^{n}{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)+\\ \qquad\, \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)} \Big)- {{k}_{2}}\, \times\\ \qquad\, {{\rm sig}^{{{\alpha }_{2}}}}\Big( \sum\limits_{j=1}^{n}{{{a}_{ij}} \left( {{{\tilde{v}}}_{i}}-{{{\tilde{v}}}_{j}} \right)+ \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{{\tilde{v}}}_{i}}-{{v}_{j}} \right)}} \Big) \end{cases} \end{align} $
(24) 由定理1可知, 系统可实现全局有限时间包容控制, 即在有限时间内, $\to$ $-L_{f}^{-1}{{L}_{d}}{{\pmb v}_{L}}$.
注2.文献[26]研究了带有不匹配干扰的高阶多智能体系统分布式主动抗干扰控制方法, 同时采用了滑模控制理论和DOBC方法, 然而文献[26]设计的是常规的线性滑模面, 会出现抖振现象, 而本文设计的非线性积分滑模面不仅能有效消除抖振, 而且能增强系统的鲁棒性能.文献[27-28]在研究带有不匹配干扰的多智能体系统时对系统模型进行了处理, 假设不匹配干扰二阶可微, 则可将不匹配干扰转变成匹配干扰, 然后利用常规的处理方式消除干扰.但在实际应用中存在很多情况不能如此处理, 因此这种方法有一定的局限性.本文则直接对干扰进行观测, 并在控制器中添加干扰补偿项, 可有效抵消干扰的影响, 而不影响系统的性能.
4. 数值仿真
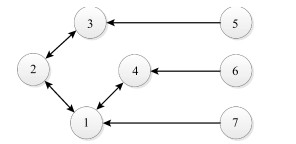
考虑4个跟随者和3个领导者组成的网络, 如图 1所示.
图 1中节点1~ 4是无向连通的跟随者, 节点5~7是单向发送信息的领导者.假设拓扑图所有边的权重都是1, 则系统的Laplacian矩阵为
$ \begin{align*}L=\begin{bmatrix} 3 & -1 & 0 & -1 & 0 & 0 & -1 \\ -1 & 2 & -1 & 0 & 0 & 0 & 0 \\ 0 & -1 & 2 & 0 & -1 & 0 & 0 \\ -1 & 0 & 0 & 2 & 0 & -1 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ \end{bmatrix}\end{align*} $
其中,
$ $${{L}_{f}}=\!\begin{bmatrix} 3 & -1 & 0 & -1 \\ -1 & 2 & -1 & 0 \\ 0 & -1 & 2 & 0 \\ -1 & 0 & 0 & 2 \\ \end{bmatrix}, ~~ {{L}_{d}}=\!\begin{bmatrix} 0 & 0 & -1 \\ 0 & 0 & 0 \\ -1 & 0 & 0 \\ 0 & -1 & 0 \\ \end{bmatrix}$$ $
假设4个智能体都受到干扰影响:智能体1: ${{d}_{1, 1}}$ $=2\tanh (2t)$, ${{d}_{1, 2}}=2$; 智能体2: ${{d}_{2, 1}}=4\tanh (t)$, ${{d}_{2, 2}}=1$; 智能体3: ${{d}_{3, 1}}={\rm sigmoid}(t)$, ${{d}_{3, 2}}$ ; 智能体4: ${{d}_{4, 1}}=3{\rm sigmoid}(t)$, ${{d}_{4, 2}}$ $=-\tanh (t)$, $t>0$.其中${{d}_{i1}}$, ${{d}_{i2}}$ ($i=1, 2, 3, 4$)分别表示不匹配干扰和匹配干扰.
控制器的参数设置为${{k}_{0}}=10$, ${{k}_{1}}=20$, ${{k}_{2}}=$ $30$, ${{\alpha }_{1}}=0.8$.干扰观测器的参数设置为${{\lambda }_{i, 1}}=10$, ${{\lambda}_{i, 2}}$ $=20$, ${{\lambda}_{i, 3}}=15$, ${{\lambda}_{i, 4}}=32$, $i=1, 2, 3, 4$; 假设4个跟随者的初始位置分别为${{x}_{1}}=(2, 0)$, ${{x}_{2}}=$ $(4, 0)$, ${{x}_{3}}=(0, 2)$, ${{x}_{4}}=(0, 4)$, 领导者的初始坐标分别为${{x}_{5}}=(6, 8)$, ${{x}_{6}}=(8, 8)$, ${{x}_{7}}= (8, 6)$.领导者为动态领导者, 其初始速度为${{v}_{5}}=(1, 1)$, ${{v}_{6}}=(1.2, 1.2)$, ${{v}_{7}}$ $=(1, 1)$.仿真结果如图 2~4所示.
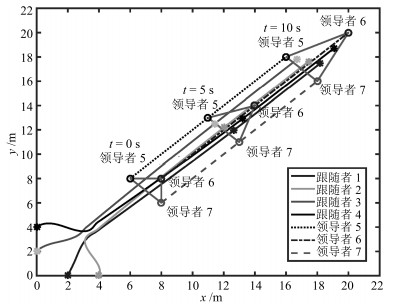 图 4 跟随者与动态领导者的位置关系Fig. 4 The trajectories of position for the followers and dynamic leaders
图 4 跟随者与动态领导者的位置关系Fig. 4 The trajectories of position for the followers and dynamic leaders图 2是干扰观测器(13)对受扰系统(9)中各智能体的不匹配干扰和匹配干扰的观测量和估计误差, 从图 2(a) 和图 2(c)可以看出观测器可以快速估计出智能体所受的干扰, 在图 2(b)和图 2(d)中各智能体所受干扰的观测误差很快的趋于0, 说明观测器可准确地估算出系统中的干扰, 表现出较好的观测性能.图 3是智能体的位置和速度状态观测误差.从图 3可知, 在不到1 s的时间误差曲线趋于0, 直观地说明观测器可快速准确地估算出跟随者的状态信息, 从而确保控制器的有效作用.
图 4是多智能体系统的位置状态轨迹图, 其中星号表示跟随者, 圆圈表示动态领导者, 可以看出3个动态领导者以一定的速度沿着某一方向移动, 而4个跟随者通过相互作用最终收敛到有领导者组成的几何体中.特别地, 当时, 跟随者还没有完全进入凸包内, 而当$t=10 \, \rm s$时, 各跟随者均进入凸包内, 且跟随着领导者同步运动.因此, 在控制律(16)下各智能体能够快速地跟踪到领导者, 并进入由领导者组成的几何体中, 实现了包容控制.
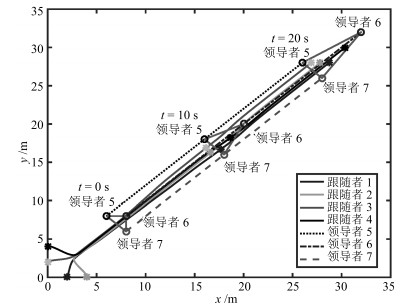
文献[26]研究的是带有不匹配干扰的多智能体系统滑模控制.为了进一步说明本文方法的优越性, 本文将文献[26]所提方法拓展到多领导者情况.利用上述数值参数, 得到图 5所示的仿真图.由图 5可知, 当$t=10\, \rm s$时跟随者没有完全进入凸包内, 当$t$ $=$ $20\, \rm s$时, 系统才实现包容控制.与文献[26]的实验结果比较, 说明本文方法可以更加快速地达到一致, 取得较好的结果.
综上, 带干扰的多智能体系统(9)和(10)通过有限时间干扰观测器(13)快速地估算干扰, 在复合分布式控制协议(16)下快速消除干扰, 使得各跟随者的状态收敛到由动态领导者组成的动态凸包内, 即, 实现了包容控制.
5. 结论
本文研究带有不匹配干扰的二阶多智能体系统协同控制问题.设计了非线性有限时间干扰观测器, 使得智能体的干扰可被观测和补偿.利用滑模控制理论和基于控制的干扰观测器方法, 提出了复合分布式非线性积分滑模控制协议.通过使用Lyapunov稳定性理论、代数图论、齐次性理论等方法, 研究了带有不匹配干扰的多智能体系统有限时间包容控制.最后数值仿真表明了所提控制算法的有效性.
由于复杂多变的工作环境, 多智能体系统通常会受到各种干扰的影响.在实际工程应用中, 不匹配干扰是十分常见的干扰, 因此本文所提方法具有一定的发展前景, 而且更具有普适性.未来的研究方向将针对更为复杂的环境, 设计新型的干扰观测器, 研究多智能体系统的协同控制问题.
-
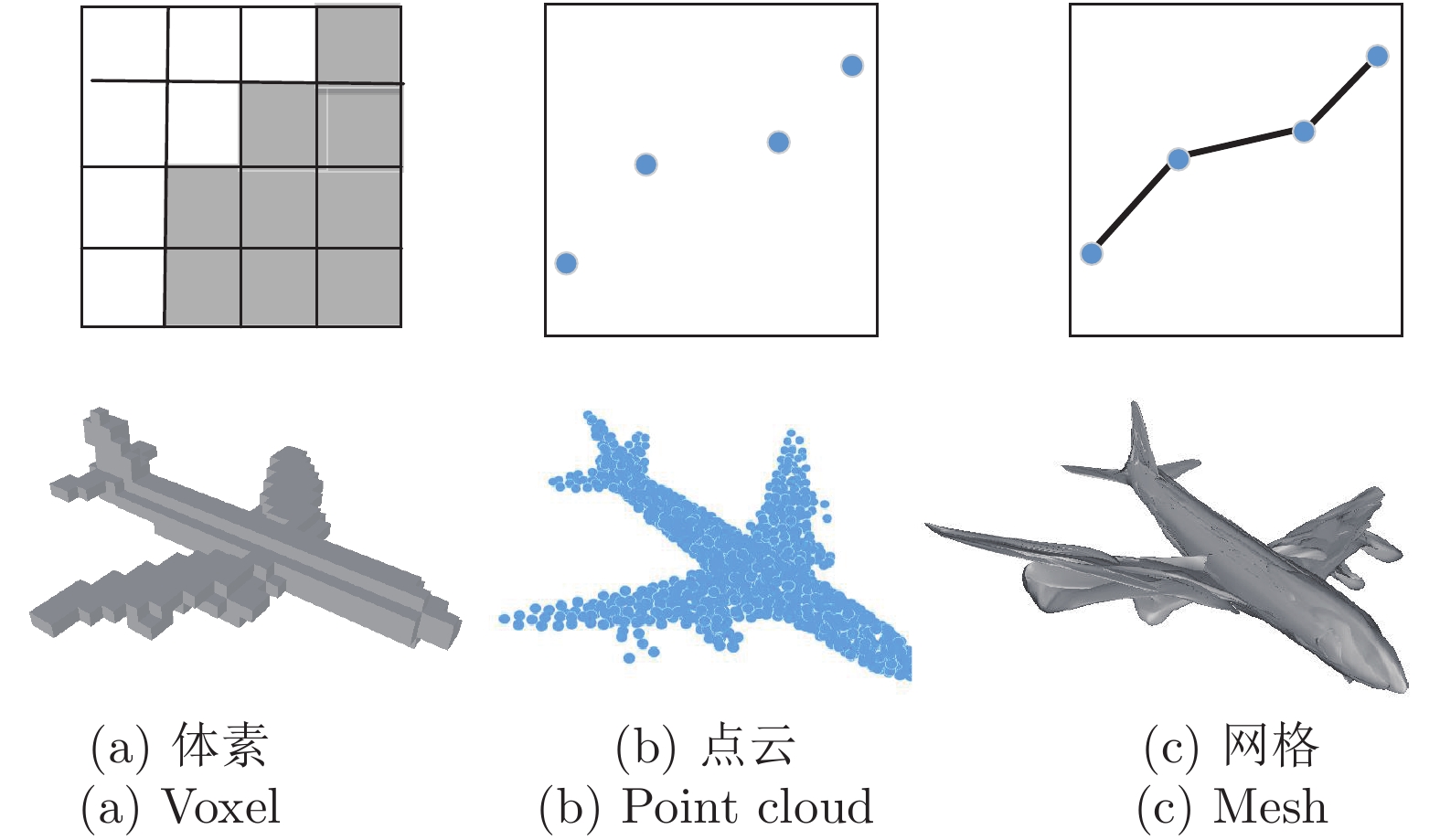
图 1 基于深度学习的单视图三维重建中三种表示形状
Fig. 1 Three representation shapes for single-view 3D reconstruction based on deep learning

图 2 本文方法和DISN方法在真实图像上的单视图重建结果
Fig. 2 Single image reconstruction using a DISN, and our method on real images

图 9 Online Products dataset的定性结果
Fig. 9 Qualitative results on Online Products dataset
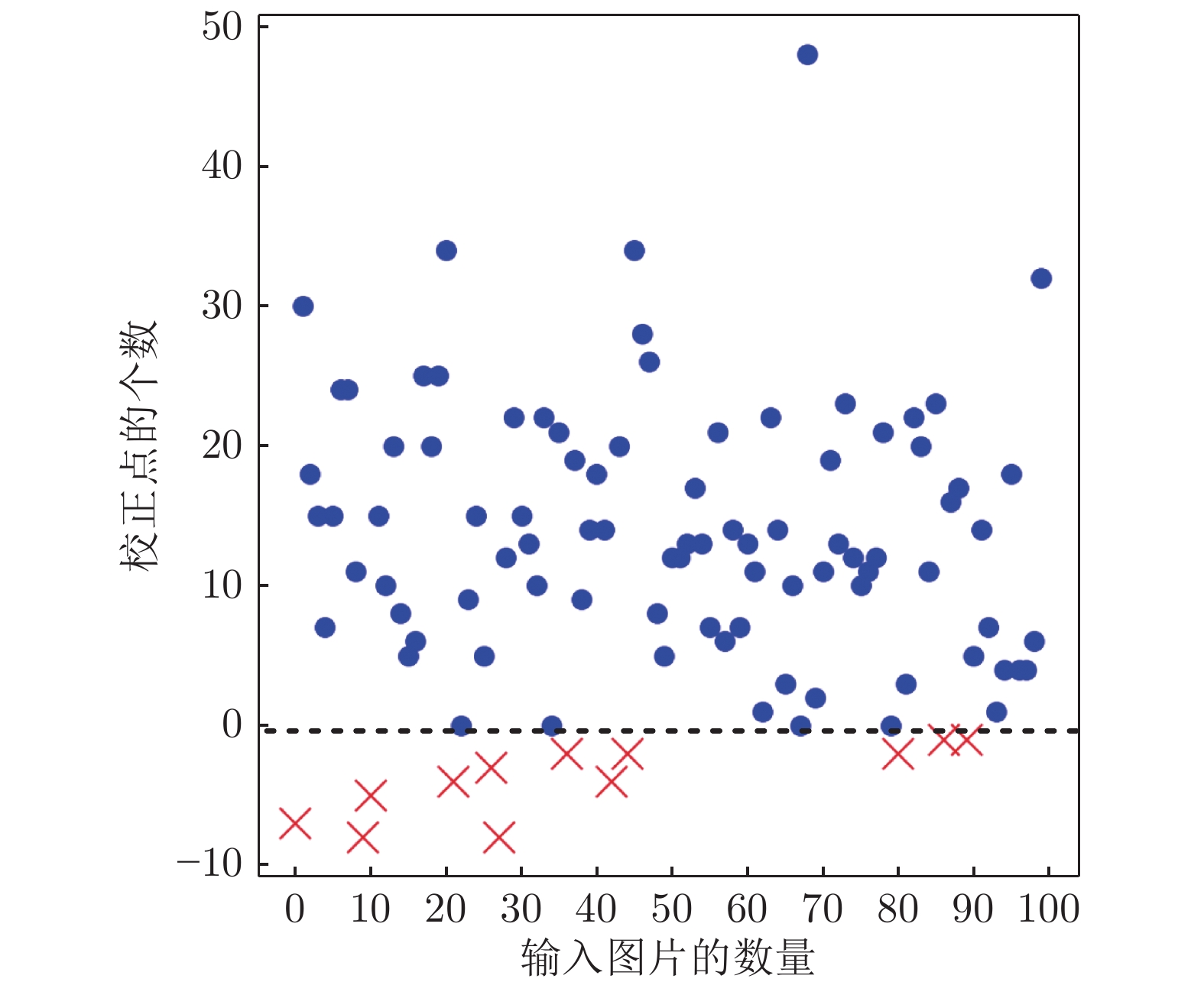
图 11 MNGD随机调整100张图片中模糊概率点的结果
Fig. 11 The result of MNGD adjusting the fuzzy probability points in 100 random images
表 1 本文的方法在ShapeNet数据集上与最先进方法的交并比(IoU)的定量比较
Table 1 The quantitative comparison of our method with the state-of-the-art methods for IoU on ShapeNet dataset
类别\方法 3D-R2N2 Pix2Mesh AtlasNet ONet Our Airplane 0.426 0.420 — 0.571 0.592 Bench 0.373 0.323 — 0.485 0.503 cabinet 0.667 0.664 — 0.733 0.757 Car 0.661 0.552 — 0.737 0.755 Chair 0.439 0.396 — 0.501 0.542 Display 0.440 0.490 — 0.471 0.548 Lamp 0.281 0.323 — 0.371 0.409 Loudspeaker 0.611 0.599 — 0.647 0.672 Rifle 0.375 0.402 — 0.474 0.500 Sofa 0.626 0.613 — 0.680 0.701 Table 0.420 0.395 — 0.506 0.547 Telephone 0.611 0.661 — 0.720 0.763 Vessel 0.482 0.397 — 0.530 0.569 Mean 0.493 0.480 — 0.571 0.605  下载: 导出CSV
下载: 导出CSV
表 2 本文的方法在ShapeNet数据集上与最先进方法法线一致性(NC)的定量比较
Table 2 The quantitative comparison of our method with the state-of-the-art methods for NC on ShapeNet dataset
类别\方法 3D-R2N2 Pix2Mesh AtlasNet ONet Our Airplane 0.629 0.759 0.836 0.840 0.847 Bench 0.678 0.732 0.779 0.813 0.818 Cabinet 0.782 0.834 0.850 0.879 0.887 Car 0.714 0.756 0.836 0.852 0.855 Chair 0.663 0.746 0.791 0.823 0.835 Display 0.720 0.830 0.858 0.854 0.871 Lamp 0.560 0.666 0.694 0.731 0.751 Loudspeaker 0.711 0.782 0.825 0.832 0.845 Rifle 0.670 0.718 0.725 0.766 0.781 Sofa 0.731 0.820 0.840 0.863 0.872 Table 0.732 0.784 0.832 0.858 0.864 Telephone 0.817 0.907 0.923 0.935 0.938 Vessel 0.629 0.699 0.756 0.794 0.801 Mean 0.695 0.772 0.811 0.834 0.844
下载: 导出CSV
表 3 本文的方法在ShapeNet数据集上与最先进方法倒角距离 (CD)的定量比较
Table 3 The quantitative comparison of our method with the state-of-the-art methods for CD on ShapeNet dataset
类别\方法 3D-R2N2 Pix2Mesh AtlasNet ONet Our Airplane 0.227 0.187 0.104 0.147 0.130 Bench 0.194 0.201 0.138 0.155 0.149 Cabinet 0.217 0.196 0.175 0.167 0.146 Car 0.213 0.180 0.141 0.159 0.144 Chair 0.270 0.265 0.209 0.228 0.200 Display 0.314 0.239 0.198 0.278 0.220 Lamp 0.778 0.308 0.305 0.479 0.364 Loudspeaker 0.318 0.285 0.245 0.300 0.263 Rifle 0.183 0.164 0.115 0.141 0.130 Sofa 0.229 0.212 0.177 0.194 0.179 Table 0.239 0.218 0.190 0.189 0.170 Telephone 0.195 0.149 0.128 0.140 0.121 Vessel 0.238 0.212 0.151 0.218 0.189 Mean 0.278 0.216 0.175 0.215 0.185
下载: 导出CSV
表 4 消融实验
Table 4 Ablation study
模型\指标 IoU NC CD FM w/o DR, MB 0.593 0.840 0.194 FM w/o MB 0.599 0.839 0.194 FM 0.605 0.844 0.185
下载: 导出CSV
-
[1] 陈加, 张玉麒, 宋鹏, 魏艳涛, 王煜. 深度学习在基于单幅图像的物体三维重建中的应用. 自动化学报, 2019, 45(4): 657-668Chen Jia, Zhang Yu-Qi, Song Peng, Wei Yan-Tao, Wang Yu. Application of deep learning to 3D object reconstruction from a single image. Acta Automatica Sinica, 2019, 45(4): 657-668 [2] 郑太雄, 黄帅, 李永福, 冯明驰. 基于视觉的三维重建关键技术研究综述. 自动化学报, 2020, 46(4): 631-652Zheng Tai-Xiong, Huang Shuai, Li Yong-Fu, Feng Ming-Chi. Key techniques for vision based 3D reconstruction: A review. Acta Automatica Sinica, 2020, 46(4): 631-652 [3] 薛俊诗, 易辉, 吴止锾, 陈向宁. 一种基于场景图分割的混合式多视图三维重建方法. 自动化学报, 2020, 46(4): 782-795Xue Jun-Shi, Yi Hui, Wu Zhi-Huan, Chen Xiang-Ning. A hybrid multi-view 3D reconstruction method based on scene graph partition. Acta Automatica Sinica, 2020, 46(4): 782-795 [4] Wu J J, Zhang C K, Xue T F, Freeman W T, Tenenbaum J B. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates, Inc., 2016. 82−90 [5] Choy C B, Xu D F, Gwak J Y, Chen K, Savarese S. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 628−644 [6] Yao Y, Luo Z X, Li S W, Fang T, Quan L. MVSNet: Depth inference for unstructured multi-view stereo. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 785−801 [7] Wu J J, Wang Y F, Xue T F, Sun X Y, Freeman W T, Tenenbaum J B. MarrNet: 3D shape reconstruction via 2.5D sketches. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates, Inc., 2017. 540−550 [8] Fan H Q, Su H, Guibas L. A point set generation network for 3D object reconstruction from a single image. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 2463−2471 [9] Wang N Y, Zhang Y D, Li Z W, Fu Y W, Liu W, Jiang Y G. Pixel2Mesh: Generating 3D mesh models from single RGB images. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 55−71 [10] Scarselli F, Gori M, Tsoi A C, Hagenbuchner M, Monfardini G. The graph neural network model. IEEE Transactions on Neural Networks, 2009, 20(1): 61-80 doi: 10.1109/TNN.2008.2005605 [11] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors. Nature, 1986, 323(6088): 533-536 doi: 10.1038/323533a0 [12] Roth S, Richter S R. Matryoshka networks: Predicting 3D geometry via nested shape layers. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1936−1944 [13] Wu J J, Zhang C K, Zhang X M, Zhang Z T, Freeman W T, Tenenbaum J B. Learning shape priors for single-view 3D completion and reconstruction. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 673−691 [14] Groueix T, Fisher M, Kim V G, Russell B C, Aubry M. A Papier-Mache approach to learning 3D surface generation. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 216−224 [15] Kanazawa A, Black M J, Jacobs D W, Malik J. End-to-end recovery of human shape and pose. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7122−7131 [16] Kong C, Lin C H, Lucey S. Using locally corresponding CAD models for dense 3D reconstructions from a single image. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 5603−5611 [17] Mescheder L, Oechsle M, Niemeyer M, Nowozin S, Geiger A. Occupancy networks: Learning 3D reconstruction in function space. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 4455−4465 [18] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning [Online], available: https: //arxiv.org/abs/1509. 02971, July 5, 2019 [19] Li D, Chen Q F. Dynamic hierarchical mimicking towards consistent optimization objectives. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 7639−7648 [20] Chang A X, Funkhouser T, Guibas L, et al.Shapenet:An information-rich 3d model repository [Online], available: https: //arxiv.org/abs/1512. 03012, December 9, 2015 [21] Durou J D, Falcone M, Sagona M. Numerical methods for shape-from-shading: A new survey with benchmarks. Computer Vision and Image Understanding, 2008, 109(1): 22-43 doi: 10.1016/j.cviu.2007.09.003 [22] Zhang R, Tsai P S, Cryer J E, Shah M. Shape-from-shading: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1999, 21(8): 690-706 doi: 10.1109/34.784284 [23] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672−2680 [24] Kingma D P, Welling M. Auto-encoding variational bayes [Online], available: https: //arxiv. org/abs/1312. 6114, May 1, 2014 [25] Kar A, Hane C, Malik J. Learning a multi-view stereo machine. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates, Inc., 2017. 364−375 [26] Tatarchenko M, Dosovitskiy A, Brox T. Octree generating networks: Efficient convolutional architectures for high-resolution 3D outputs. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2107−2115 [27] Wang W Y, Ceylan D, Mech R, Neumann U. 3DN: 3D deformation network. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 1038−1046 [28] Bernardini F, Mittleman J, Rushmeier H, Silva C, Taubin G. The ball-pivoting algorithm for surface reconstruction. IEEE Transactions on Visualization and Computer Graphics, 1999, 5(4): 349-359 doi: 10.1109/2945.817351 [29] Kazhdan M, Hoppe H. Screened poisson surface reconstruction. ACM Transactions on Graphics, 2013, 32(3): Article No. 29 [30] Calakli F, Taubin G. SSD: Smooth signed distance surface reconstruction. Computer Graphics Forum, 2011, 30(7): 1993-2002 doi: 10.1111/j.1467-8659.2011.02058.x [31] Chen Z Q, Zhang H. Learning implicit fields for generative shape modeling. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 5932−5941 [32] Wang W Y, Xu Q G, Ceylan D, Mech R, Neumann U. DISN: Deep implicit surface network for high-quality single-view 3D reconstruction. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates, Inc., 2019. Article No. 45 [33] Wang Q L, Wu B G, Zhu P F, Li P H, Zuo W M, Hu Q H. ECA-Net: Efficient channel attention for deep convolutional neural networks. In: Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 11531−11539 [34] Selvaraju R R, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 618−626 [35] Garland M, Heckbert P S. Simplifying surfaces with color and texture using quadric error metrics. In: Proceedings of the 1998 Visualization′ 98 (Cat. No.98CB362-76). Research Triangle Park, USA: IEEE, 1998. 263−269 [36] Lorensen W E, Cline H E. Marching cubes: A high resolution 3D surface construction algorithm. ACM SIGGRAPH Computer Graphics, 1987, 21(4): 163-169 doi: 10.1145/37402.37422 [37] Drucker H, Le Cun Y. Improving generalization performance using double backpropagation. IEEE Transactions on Neural Networks, 1992, 3(6): 991-997 doi: 10.1109/72.165600 [38] Oh Song H, Xiang Y, Jegelka S, Savarese S. Deep metric learning via lifted structured feature embedding. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 4004−4012 [39] Stutz D, Geiger A. Learning 3D shape completion from laser scan data with weak supervision. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1955−1964 [40] de Vries H, Strub F, Mary J, Larochelle H, Pietquin O, Courville A C. Modulating early visual processing by language. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates, Inc., 2017. 6597−6607 [41] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [42] Kingma D P, Ba J. Adam: A method for stochastic optimization [Online], available: https: //arxiv. org/abs/1412. 6980, January 30, 2017 [43] Zhu C C, Liu H, Yu Z H, Sun, X H. Towards Omni-supervised face alignment for large scale unlabeled videos. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 13090−13097 [44] Zhu C C, Li X Q, Li J D, Ding G T, Tong W Q. Spatial-temporal knowledge integration: Robust self-supervised facial landmark tracking. In: Proceedings of the 28th ACM International Conference on Multimedia. Lisboa, Portugal: ACM, 2020. 4135−4143 期刊类型引用(31)
1. Zhiguang Feng,Sibo Yao. Dynamic Event-Triggered Active Disturbance Rejection Formation Control for Constrained Underactuated AUVs. IEEE/CAA Journal of Automatica Sinica. 2025(02): 460-462 .  必应学术
必应学术2. 吴锦娃,刘勇华,苏春翌,鲁仁全. 具有不确定控制增益严格反馈系统的自适应命令滤波控制. 自动化学报. 2024(05): 1015-1023 . 本站查看3. 游星星,杨道文,郭斌,刘凯,佃松宜,朱雨琪. 基于观测器和指定性能的非线性系统事件触发跟踪控制. 自动化学报. 2024(09): 1747-1760 . 本站查看4. 邱俊豪,程志键,林国怀,任鸿儒,鲁仁全. 具有执行器故障的非线性系统指定性能控制. 广东工业大学学报. 2023(02): 55-63 . 百度学术5. 周淑燕,程玉虎,王雪松. 具有新型状态约束的非线性系统神经网络自适应控制. 系统科学与数学. 2023(08): 1952-1968 . 百度学术6. 郭徽,王健安. 基于事件触发的多机器人固定时间编队控制. 太原科技大学学报. 2023(06): 515-521 . 百度学术7. 罗傲,肖文彬,周琪,鲁仁全. 基于强化学习的一类具有输入约束非线性系统最优控制. 控制理论与应用. 2022(01): 154-164 . 百度学术8. 范利蓉,王芳,周超,王坤. 状态时延和全状态约束下的多智能体系统自适应事件触发控制. 控制与决策. 2022(04): 892-902 . 百度学术9. 张瑀航,姜玉莲,崔立朝,王海伟. 间歇通信的非线性多智能体系统协调跟踪控制. 计算机技术与发展. 2022(03): 180-185 . 百度学术10. 蒲志强,易建强,刘振,丘腾海,孙金林,李非墨. 知识和数据协同驱动的群体智能决策方法研究综述. 自动化学报. 2022(03): 627-643 . 本站查看11. YANG Bin,CAO Liang,XIAO Wenbin,YAO Deyin,LU Renquan. Event-Triggered Adaptive Neural Control for Multiagent Systems with Deferred State Constraints. Journal of Systems Science & Complexity. 2022(03): 973-992 . 必应学术12. 王敏,黄龙旺,杨辰光. 基于事件触发的离散MIMO系统自适应评判容错控制. 自动化学报. 2022(05): 1234-1245 . 本站查看13. 韩松,李晓孟,陈广登,孟伟. 重放攻击下不确定CPS的安全滤波. 控制工程. 2022(06): 1004-1010 . 百度学术14. 吴宜,梅珂琪,丁世宏,葛群辉,王巍植. 基于扩张状态观测器的永磁同步电机转速环连续螺旋控制. 广东工业大学学报. 2022(05): 112-119 . 百度学术15. 杨翊卓,代伟. 事件触发机制下的工业过程多速率模型预测控制方法. 广东工业大学学报. 2022(05): 68-74 . 百度学术16. 李争,刘磊,刘艳军. 具有时变全状态约束的非线性随机切换系统的自适应神经网络控制. 广东工业大学学报. 2022(05): 127-136 . 百度学术17. 周林娜,金南南,王海,杨春雨. 双永磁同步电机滑模协调控制及实验研究. 广东工业大学学报. 2022(05): 83-92 . 百度学术18. 范利蓉,王芳,周超,王坤. 执行器故障和非对称误差约束下的时延多智能体系统自适应事件触发控制. 中国科学:信息科学. 2022(07): 1287-1301 . 百度学术19. 王洪斌,高静,苏博,王跃灵. 基于事件触发的AUVs固定时间编队控制. 自动化学报. 2022(09): 2277-2287 . 本站查看20. 杨盼,毕文豪,张安. 基于事件驱动的多智能体有限时间分群一致控制. 控制与决策. 2022(11): 2925-2933 . 百度学术21. 贾新春,吕腾,王悦,白文杰. 基于多率采样的MASs在FDI攻击下的安全一致性. 山西大学学报(自然科学版). 2022(05): 1186-1194 . 百度学术22. 李文杰,张正强. 非线性时滞系统基于降阶观测器的反步镇定控制. 控制理论与应用. 2022(08): 1433-1441 . 百度学术23. 李枝强,刘洋,周琪,鲁仁全. 精确估计下的多智能体系统漏斗复合控制. 控制理论与应用. 2022(08): 1417-1425 . 百度学术24. 杨祎桀,刘冬,曲袁超. 基于指定性能的非线性系统数据驱动滑模控制. 沈阳师范大学学报(自然科学版). 2022(06): 502-508 . 百度学术25. 范睿超,孔宪仁,胡文坤,钟智雄. 基于扩张观测器的航天器无速度旋量信息姿轨一体化控制. 南京信息工程大学学报(自然科学版). 2021(01): 1-9 . 百度学术26. Liang CAO,Hongru REN,Wei MENG,Hongyi LI,Renquan LU. Distributed event triggering control for six-rotor UAV systems with asymmetric time-varying output constraints. Science China(Information Sciences). 2021(07): 193-208 . 必应学术27. 韩俊先,乔静兵,任宁,袁瑞,赵思. 基于事件触发的时滞网络系统稳定性研究. 信息与电脑(理论版). 2021(06): 192-195 . 百度学术28. 时侠圣,杨涛,林志赟,王雪松. 基于连续时间的二阶多智能体分布式资源分配算法. 自动化学报. 2021(08): 2050-2060 . 本站查看29. 赵光同,曹亮,周琪,李鸿一. 具有未建模动态的互联大系统事件触发自适应模糊控制. 自动化学报. 2021(08): 1932-1942 . 本站查看30. 张毅,方国伟,杨秀霞,严瑄. 基于事件触发的多机编队目标跟踪控制. 北京航空航天大学学报. 2021(11): 2215-2225 . 百度学术31. 徐光辉,余蒙,付波,赵熙临,陈洁. 事件触发机制下二阶多智能体系统量化追踪控制. 华侨大学学报(自然科学版). 2020(05): 667-673 . 百度学术其他类型引用(50)
-

 下载:
下载:





计量
- 文章访问数: 1753
- HTML全文浏览量: 614
- PDF下载量: 225
- 被引次数: 81
