

Utterance-level Feature Extraction in Text-independent Speaker Recognition: A Review
-
摘要: 句级 (Utterance-level) 特征提取是文本无关说话人识别领域中的重要研究方向之一. 与只能刻画短时语音特性的帧级 (Frame-level) 特征相比, 句级特征中包含了更丰富的说话人个性信息; 且不同时长语音的句级特征均具有固定维度, 更便于与大多数常用的模式识别方法相结合. 近年来, 句级特征提取的研究取得了很大的进展, 鉴于其在说话人识别中的重要地位, 本文对近期具有代表性的句级特征提取方法与技术进行整理与综述, 并分别从前端处理、基于任务分段式与驱动式策略的特征提取方法, 以及后端处理等方面进行论述, 最后对未来的研究趋势展开探讨与分析.Abstract: Utterance-level feature extraction is one of the most important researches in text-independent speaker recognition. Compared with the frame-level features which only contain the short-term speech characteristics, the utterance-level features can effectively capture more speaker discriminative information. Meanwhile, it also has another advantage that any utterance with a variable duration can be represented as a fixed-dimension feature. Thus, the utterance-level features are easy to integrate with most commonly-used pattern recognition methods. In recent years, the researches on utterance-level feature extraction have made great progress. Considering the importance of utterance-level feature extraction in speaker recognition, this paper will organize and summarize the typical methods. Specifically, the front-end processing, the feature extraction based on the task-segmented strategy and task-driven strategy, and the back-end processing are introduced respectively. Finally, the future trends in speaker recognition are discussed and analyzed.
-

图 3 帧级特征序列经特征规整后的直方图对比
Fig. 3 Histogram comparison of frame-level feature sequences after feature normalization
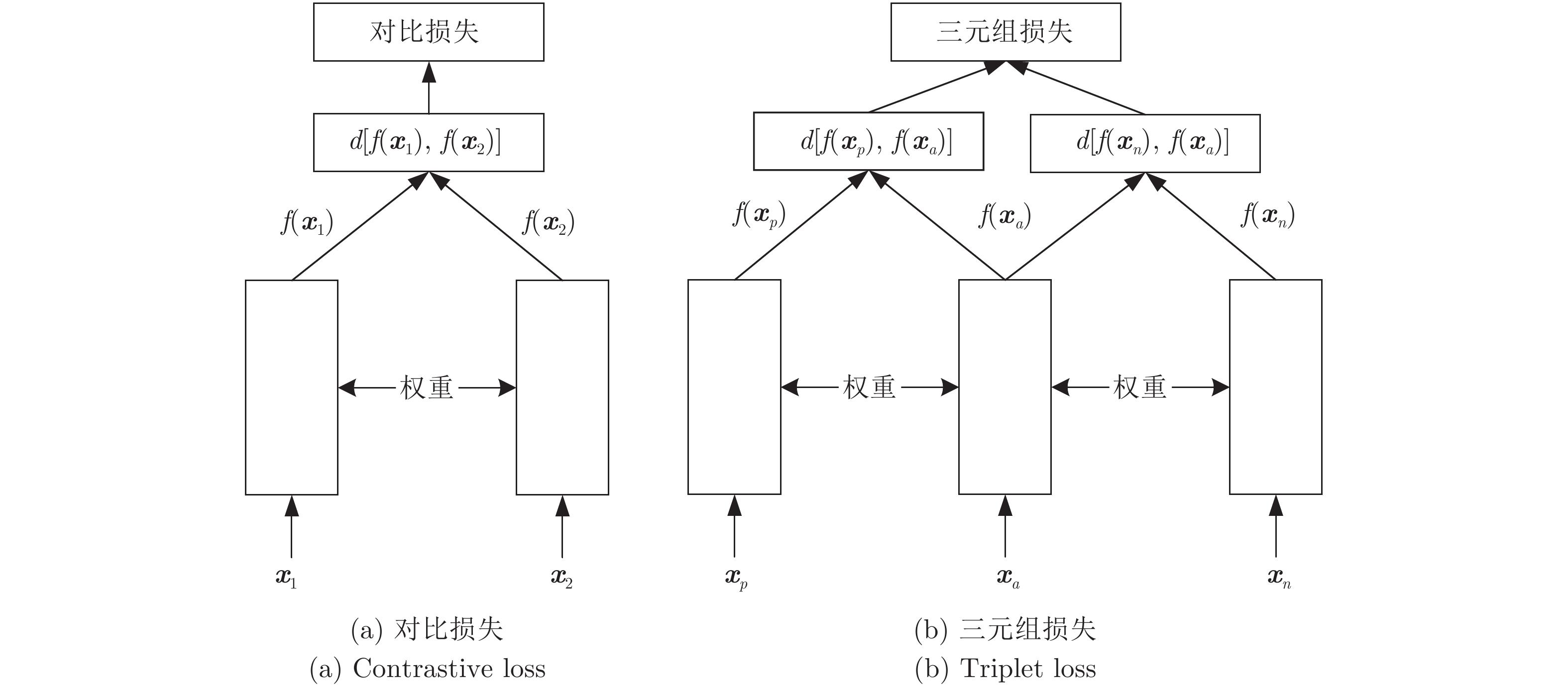
图 6 两种目标函数对应网络的结构示意图对比
Fig. 6 Comparison of the structure of the networks corresponding to the two different objective functions
表 1 不同特征空间学习方法汇总信息
Table 1 Information of different feature space learning methods
方法 描述 特点 经典MAP方法[29] $ {\boldsymbol{M}}_{s,h}={\boldsymbol{m}}+{\boldsymbol{D}}{\boldsymbol{z}}_{s,h} $ MAP 自适应方法 $ {\boldsymbol{D}} $为对角矩阵, $ {\boldsymbol{z}}_{s,h} \sim {\rm{N}}\left({\bf{0}},{\boldsymbol{I}}\right) $ 无法进行信道补偿 本征音模型[36-37] $ {\boldsymbol{M}}_{s,h}={\boldsymbol{m}}+{\boldsymbol{V}}{\boldsymbol{y}}_{s,h} $ 能够获得低维句级特征表示 $ {\boldsymbol{V}} $为低秩矩阵, $ {\boldsymbol{y}}_{s,h} \sim {\rm{N}}\left({\bf{0}},{\boldsymbol{I}}\right) $ 无法进行信道补偿 本征信道模型[37] $ {\boldsymbol{M}}_{s,h}={\boldsymbol{m}}+{\boldsymbol{D}}{\boldsymbol{z}}_{s}+{\boldsymbol{U}}{\boldsymbol{x}}_{h} $ 能够进行信道补偿 $ {\boldsymbol{D}} $为对角矩阵, $ {\boldsymbol{z}}_{s} \sim {\rm{N}}\left({\bf{0}},{\boldsymbol{I}}\right) $ 需要提供同一说话人的多信道语音数据 $ {\boldsymbol{U}} $为低秩矩阵, $ {\boldsymbol{y}}_{s,h} \sim {\rm{N}}\left({\bf{0}},{\boldsymbol{I}}\right) $ 说话人子空间中包含残差信息 联合因子分析模型[38] ${\boldsymbol{M} }_{s,h}={\boldsymbol{m} }+V{\boldsymbol{y} }_{s}+{\boldsymbol{U} }{\boldsymbol{x} }_{h}+{\boldsymbol{D} }{\boldsymbol{z} }_{s,h}$ 独立学习说话人信息与信道信息
需要提供同一说话人的多信道语音数据, 计算复杂度高$ {\boldsymbol{V}} $为低秩矩阵, $ {\boldsymbol{y}}_{s} \sim {\rm{N}}\left({\bf{0}},{\boldsymbol{I}}\right) $ $ {\boldsymbol{U}} $为低秩矩阵, $ {\boldsymbol{x}}_{h} \sim {\rm{N}}\left({\bf{0}},{\boldsymbol{I}}\right) $ $ {\boldsymbol{D}} $为对角矩阵, $ {\boldsymbol{z}}_{s} \sim {\rm{N}}\left({\bf{0}},{\boldsymbol{I}}\right) $ 总变化空间模型[39-40] $ {\boldsymbol{M}}_{s,h}={\boldsymbol{m}}+{\boldsymbol{T}}{\boldsymbol{w}}_{s,h}+{\boldsymbol{\varepsilon}}_{s,h} $ 学习均值超矢量中的全部变化信息 $ {\boldsymbol{T}} $为低秩矩阵, $ {\boldsymbol{w}}_{s,h} \sim {\rm{N}}\left({\bf{0}},{\boldsymbol{I}}\right) $ 获取 I-vector 特征后再进行会话补偿 $ {\boldsymbol{\varepsilon}}_{s,h} $为残差矢量 $ {\boldsymbol{\varepsilon}}_{s,h} $在不同方法中的形式不同  下载: 导出CSV
下载: 导出CSV
表 2 基于不同残差假设的无监督总变化空间模型
Table 2 Unsupervised TVS model based on different residual assumptions
方法 描述 E 步 M 步 计算复杂度 FEFA[40] $ {{\boldsymbol{M} }_{s,h}={\boldsymbol{m} }+{\boldsymbol{T} }{\boldsymbol{w} }_{s,h}}$
输入为统计量无残差假设${\begin{align}&{\boldsymbol{L} }={\left({\boldsymbol{I} }+\displaystyle\sum\limits_{c=1}^{C}{N}_{s,h}^{c}{ {\boldsymbol{T} } }_{c}^{\rm{T} }{\boldsymbol{\Sigma }}_{c}^{-1}{ {\boldsymbol{T} } }_{c}\right)}^{-1}\\ &{\boldsymbol{E} }={\boldsymbol{L} }\displaystyle\sum\limits_{c=1}^{C}{ {\boldsymbol{T} } }_{c}^{\rm{T} }{\boldsymbol{\Sigma } }_{c}^{-1}\left({\boldsymbol{F} }_{s,h}^{c}-{N}_{s,h}^{c}{\boldsymbol{\mu } }_{c}\right)\\ &\Upsilon ={\boldsymbol{L}}+{\boldsymbol{E}}{{\boldsymbol{E}}}^{\rm{T}}\end{align}} $ $ {{ {\boldsymbol{T} } }_{c}=\left[\displaystyle\sum\limits_{s,h}\left({\boldsymbol{F} }_{s,h}^{c}-{N}_{s,h}^{c}{\boldsymbol{\mu } }_{c}\right){\boldsymbol{E} }\right]{\left(\displaystyle\sum\limits_{s,h}{N}_{s,h}^{c}\Upsilon \right)}^{-1}}$ $ { {\rm{O}}\left(CFR+C{R}^{2}+{R}^{3}\right)} $ PPCA[43-44] $ { {\boldsymbol{M}}_{s,h}={\boldsymbol{m}}+{\boldsymbol{T}}{\boldsymbol{w}}_{s,h}+{\boldsymbol{\varepsilon}}_{s,h}} $
残差协方差矩阵各向同性$ {\begin{align}&{\boldsymbol{L} }={\left({\boldsymbol{I} }+\dfrac{1}{ {\sigma }^{2} }{ {\boldsymbol{T} } }^{\rm{T} }{\boldsymbol{T} }\right)}^{-1}\\ &{\boldsymbol{E} }=\dfrac{1}{ {\sigma }^{2} }{\boldsymbol{L} }{ {\boldsymbol{T} } }^{\rm{T} }\left({\boldsymbol{M} }_{s,h}-{\boldsymbol{m} }\right)\\ &\Upsilon ={\boldsymbol{L}}+{\boldsymbol{E}}{{\boldsymbol{E}}}^{\rm{T}} \end{align}}$ $ {\begin{aligned}{\boldsymbol{T} }=&\left[\displaystyle\sum\limits_{s,h}\left({\boldsymbol{M} }_{s,h}-{\boldsymbol{m} }\right){\boldsymbol{E} }\right]{\left(\displaystyle\sum\limits_{s,h}\Upsilon \right)}^{-1}\\{\sigma }^{2}=&\;\dfrac{1}{CF\displaystyle\sum\limits _{s,h}1}\{ {\left({\boldsymbol{M} }_{s,h}-{\boldsymbol{m} }\right)}^{\rm{T} }\left({\boldsymbol{M} }_{s,h}-{\boldsymbol{m} }\right)-\\ &{\rm{t} }{\rm{r} }\left(\Upsilon { {\boldsymbol{T} } }^{\rm{T} }{\boldsymbol{T} })\right\} \end{aligned} }$ $ {{\rm{O}}\left(CFR\right) }$ FA[44-45] $ { {\boldsymbol{M}}_{s,h}={\boldsymbol{m}}+{\boldsymbol{T}}{\boldsymbol{w}}_{s,h}+{\boldsymbol{\varepsilon}}_{s,h} }$
残差协方差矩阵各向异性$ {\begin{align} &{\boldsymbol{L}}={\left({\boldsymbol{I}}+{{\boldsymbol{T}}}^{\rm{T}}{\boldsymbol{\varPhi }}^{-1}{\boldsymbol{T}}\right)}^{-1}\\ &{\boldsymbol{E}}={\boldsymbol{L}}{{\boldsymbol{T}}}^{\rm{T}}{\boldsymbol{\varPhi }}^{-1}\left({\boldsymbol{M}}_{s,h}-{\boldsymbol{m}}\right) \\ &\Upsilon ={\boldsymbol{L}}+{\boldsymbol{E}}{{\boldsymbol{E}}}^{\rm{T}}\end{align}} $ $ {\begin{aligned}{\boldsymbol{T} }=&\left[\displaystyle\sum\limits_{ {\boldsymbol{s} },{\boldsymbol{h} } }\left({\boldsymbol{M} }_{ {\boldsymbol{s} },{\boldsymbol{h} } }-{\boldsymbol{m} }\right){\boldsymbol{E} }\right]{\left(\displaystyle\sum\limits_{s,h}\Upsilon \right)}^{-1}\\ {\sigma }^{2}=\;&\dfrac{1}{CF\displaystyle\sum\limits _{s,h}1}\{\left({\boldsymbol{M} }_{s,h}-{\boldsymbol{m} }\right){\left({\boldsymbol{M} }_{s,h}-{\boldsymbol{m} }\right)}^{\rm{T} }-\\ &{ {\boldsymbol{T} } }^{\rm{T} }\Upsilon {\boldsymbol{T} }\}\odot {\boldsymbol{I} } \end{aligned} }$ $ { {\rm{O}}\left(CFR\right)} $
下载: 导出CSV
表 3 基于不同映射关系假设的无监督总变化空间模型
Table 3 Unsupervised TVS model based on different mapping relations
下载: 导出CSV
表 6 不同目标函数汇总信息
Table 6 Information of different objective functions
目标 方法 目标函数 多分类 交叉熵 ${L_{{\rm{cro}}} } = - [y\log \hat y + (1 - y)\log (1 - \hat y)]$ Softmax ${L_s} = - \dfrac{1}{N}\displaystyle \sum\limits_{n = 1}^N {\log } \frac{ { { {\rm{e} } ^{ {\boldsymbol{\theta } }_{ {y_n} }^{\rm{T} }f({ {\boldsymbol{x} }_n})} } } }{ {\displaystyle \sum\limits_{k = 1}^K { { {\rm{e} } ^{ {\boldsymbol{\theta } }_k^{\rm{T} }f({ {\boldsymbol{x} }_n})} } } } }$ Center[98] ${L}_{c}=\dfrac{1}{2N}{\displaystyle \sum\limits_{n=1}^{N}\Vert f(}{\boldsymbol{x} }_{n})-{\boldsymbol{c} }_{ {y}_{n} }{\Vert }^{2}$ L-softmax[99] ${L}_{{\rm{l}}\text{-}{\rm{s}}}=-\dfrac{1}{N}{\displaystyle \sum\limits_{n=1}^{N}{\rm{log} } }\displaystyle\frac{ {\rm{e} }^{\Vert { {\boldsymbol{\theta } } }_{ {y}_{n} }\Vert \Vert f({\boldsymbol{x} }_{n})\Vert {\rm{cos} }(m{\alpha }_{ {y}_{n},n})} }{ {\rm{e} }^{\Vert { {\boldsymbol{\theta } } }_{ {y}_{n} }\Vert \Vert f({\boldsymbol{x} }_{n})\Vert {\rm{cos} }(m{\alpha }_{ {y}_{n},n})}+{\displaystyle \sum\limits_{k\ne {y}_{n} }{\rm{e} }^{\Vert { {\boldsymbol{\theta } } }_{k}\Vert \Vert f({\boldsymbol{x} }_{n})\Vert {\rm{cos} }({\alpha }_{k,n})} } }$ A-softmax[100] ${L}_{{\rm{a}}\text{-}{\rm{s}}}=-\dfrac{1}{N}{\displaystyle \sum\limits_{n=1}^{N}{\rm{log} } }\displaystyle\frac{ {\rm{e} }^{\Vert f({\boldsymbol{x} }_{n})\Vert {\rm{cos} }(m{\alpha }_{ {y}_{n},n})} }{ {\rm{e} }^{\Vert f({\boldsymbol{x} }_{n})\Vert {\rm{cos} }(m{\alpha }_{ {y}_{n},n})}+{\displaystyle \sum\limits_{k\ne {y}_{n} }{\rm{e} }^{\Vert { {\boldsymbol{\theta } } }_{k}\Vert \Vert f({\boldsymbol{x} }_{n})\Vert {\rm{cos} }({\alpha }_{k,n})} } }$ AM-softmax[101] ${L_{{\rm{am}}\text{-}{\rm{s}}} } = - \dfrac{1}{N}\displaystyle \sum\limits_{n = 1}^N {\log } \frac{ { { {\rm{e} } ^{s \cdot [\cos ({\alpha _{ {y_n},n} }) - m]} } } }{ { { {\rm{e} } ^{s \cdot [\cos ({\alpha _{ {y_n},n} }) - m]} } + \displaystyle \sum\limits_{k \ne {y_n} } { { {\rm{e} } ^{\cos ({\alpha _{k,n} })} } } } }$ 度量学习 Contrastive[102] ${L_{{\rm{con}}} } = yd\left[ {f({ {\boldsymbol{\boldsymbol{x} } }_1}),f({ {\boldsymbol{\boldsymbol{x} } }_2})} \right] + (1 - y)\max \{ 0,m - d\left[ {f({ {\boldsymbol{\boldsymbol{x} } }_1}),f({ {\boldsymbol{\boldsymbol{x} } }_2})} \right]\}$ Triplet[103] ${L_{{\rm{trip}}} } = \max \{ 0,d\left[ {f({ {\boldsymbol{\boldsymbol{x} } }_p}),f({ {\boldsymbol{\boldsymbol{x} } }_a})} \right] - d\left[ {f({ {\boldsymbol{\boldsymbol{x} } }_n}),f({ {\boldsymbol{\boldsymbol{x} } }_a})} \right] + m\}$
下载: 导出CSV
表 8 常用数据库信息
Table 8 Information of common databases
数据库 年份 声学环境 类别数 语音段数/总时长 开源 CN-CELEB[126] 2019 多媒体 1000 300 h √ VoxCeleb[89]: VoxCeleb1[73] 2017 多媒体 1251 153516 √ VoxCeleb2[75] 2018 多媒体 6112 1128246 √ SITW[127] 2016 多媒体 299 2800 √ Forensic Comparison[128] 2015 电话 552 1264 √ NIST SRE12[129] 2012 电话/麦克风 2000+ — — ELSDSR[130] 2005 纯净语音 22 198 √ SWITCHBOARD[131] 1992 电话 3114 33039 — TIMIT[132] 1990 纯净语音 630 6300 —
下载: 导出CSV
-
[1] Reynolds D A. An overview of automatic speaker recognition technology. In: Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing. Orlando, USA: IEEE, 2002. IV-4072−IV-4075 [2] Aghajan H, Delgado R L C, Augusto J C. Human-Centric Interfaces for Ambient Intelligence. Burlington: Academic Press, 2010. [3] Poddar A, Sahidullah M, Saha G. Speaker verification with short utterances: A review of challenges, trends and opportunities. IET Biometrics, 2018, 7(2): 91-101 doi: 10.1049/iet-bmt.2017.0065 [4] 韩纪庆, 张磊, 郑铁然. 语音信号处理. 第3版. 北京: 清华大学出版社, 2019.Han Ji-Qing, Zhang Lei, Zheng Tie-Ran. Speech Signal Processing (3rd edition). Beijing: Tsinghua University Press, 2019. [5] Nematollahi M A, Al-Haddad S A R. Distant speaker recognition: An overview. International Journal of Humanoid Robotics, 2016, 13(2): Article No. 1550032 doi: 10.1142/S0219843615500322 [6] Hansen J H L, Hasan T. Speaker recognition by machines and humans: A tutorial review. IEEE Signal Processing Magazine, 2015, 32(6): 74-99 doi: 10.1109/MSP.2015.2462851 [7] Kinnunen T, Li H Z. An overview of text-independent speaker recognition: From features to supervectors. Speech Communication, 2010, 52(1): 12-40 doi: 10.1016/j.specom.2009.08.009 [8] Markel J, Oshika B, Gray A. Long-term feature averaging for speaker recognition. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1977, 25(4): 330-337 doi: 10.1109/TASSP.1977.1162961 [9] Li K, Wrench E. An approach to text-independent speaker recognition with short utterances. In: Proceedings of the 1983 IEEE International Conference on Acoustics, Speech, and Signal Processing. Boston, USA: IEEE, 1983. 555−558 [10] Chen S H, Wu H T, Chang Y, Truong T K. Robust voice activity detection using perceptual wavelet-packet transform and Teager energy operator. Pattern Recognition Letters, 2007, 28(11): 1327-1332 doi: 10.1016/j.patrec.2006.11.023 [11] Fujimoto M, Ishizuka K, Nakatani T. A voice activity detection based on the adaptive integration of multiple speech features and a signal decision scheme. In: Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing. Las Vegas, USA: IEEE, 2008. 4441−4444 [12] Li K, Swamy M N S, Ahmad M O. An improved voice activity detection using higher order statistics. IEEE Transactions on Speech and Audio Processing, 2005, 13(5): 965-974 doi: 10.1109/TSA.2005.851955 [13] Soleimani S A, Ahadi S M. Voice activity detection based on combination of multiple features using linear/kernel discriminant analyses. In: Proceedings of the 3rd International Conference on Information and Communication Technologies: From Theory to Applications. Damascus, Syria: IEEE, 2008. 1−5 [14] Sohn J, Kim N S, Sung W. A statistical model-based voice activity detection. IEEE Signal Processing Letters, 1999, 6(1): 1-3 doi: 10.1109/97.736233 [15] Chang J H, Kim N S. Voice activity detection based on complex Laplacian model. Electronics Letters, 2003, 39(7): 632-634 doi: 10.1049/el:20030392 [16] Ramirez J, Segura J C, Benitez C, Garcia L, Rubio A. Statistical voice activity detection using a multiple observation likelihood ratio test. IEEE Signal Processing Letters, 2005, 12(10): 689-692 doi: 10.1109/LSP.2005.855551 [17] Tong S B, Gu H, Yu K. A comparative study of robustness of deep learning approaches for VAD. In: Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Shanghai, China: IEEE, 2016. 5695−5699 [18] Atal B S. Automatic recognition of speakers from their voices. Proceedings of the IEEE, 1976, 64(4): 460-475 doi: 10.1109/PROC.1976.10155 [19] Davis S, Mermelstein P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1980, 28(4): 357-366 doi: 10.1109/TASSP.1980.1163420 [20] Hermansky H. Perceptual linear predictive (PLP) analysis of speech. Journal of the Acoustical Society of America, 1990, 87(4): 1738-1752 doi: 10.1121/1.399423 [21] Koenig W, Dunn H K, Lacy L Y. The sound spectrograph. The Journal of the Acoustical Society of America, 1946, 18(1): 19-49 doi: 10.1121/1.1916342 [22] LeCun Y, Boser B, Denker J S, Henderson D, Howard R E, Hubbard W, et al. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989, 1(4): 541−551 [23] 林景栋, 吴欣怡, 柴毅, 尹宏鹏. 卷积神经网络结构优化综述. 自动化学报, 2020, 46(1): 24-37Lin Jing-Dong, Wu Xin-Yi, Chai Yi, Yin Hong-Peng. Structure optimization of convolutional neural networks: A survey. Acta Automatica Sinica, 2020, 46(1): 24-37 [24] Furui S. Cepstral analysis technique for automatic speaker verification. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1981, 29(2): 254-272 doi: 10.1109/TASSP.1981.1163530 [25] Pelecanos J W, Sridharan S. Feature warping for robust speaker verification. In: Proceedings of the 2001 A Speaker Odyssey: The Speaker Recognition Workshop. Crete, Greece: ISCA, 2001. 1−5 [26] Sadjadi S O, Slaney M, Heck A L. MSR Identity Toolbox v1.0: A MATLAB Toolbox for Speaker Recognition Research, Microsoft Research Technical Report MSR-TR-2013-133, 2013. [27] Campbell W M, Sturim D E, Reynolds D A. Support vector machines using GMM supervectors for speaker verification. IEEE Signal Processing Letters, 2006, 13(5): 308-311 doi: 10.1109/LSP.2006.870086 [28] Reynolds D A. Speaker identification and verification using Gaussian mixture speaker models. Speech Communication, 1995, 17(1−2): 91-108 doi: 10.1016/0167-6393(95)00009-D [29] Reynolds D A, Quatieri T F, Dunn R B. Speaker verification using adapted Gaussian mixture models. Digital Signal Processing, 2000, 10(1−3): 19-41 doi: 10.1006/dspr.1999.0361 [30] Wang W, Han J, Zheng T, Zheng G, Liu H. A robust sparse auditory feature for speaker verification. Journal of Computational Information Systems, 2013, 9(22): 8987-8993 [31] Wang W, Han J Q, Zheng T R, Zheng G B. Robust speaker verification based on max pooling of sparse representation. Journal of Computers, 2014, 24(4): 56-65 [32] He Y J, Chen C, Han J Q. Noise-robust speaker recognition based on morphological component analysis. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association. Dresden, Germany: ISCA, 2015. 3001−3005 [33] Wang W, Han J Q, Zheng T R, Zheng G B, Zhou X Y. Speaker verification via modeling kurtosis using sparse coding. International Journal of Pattern Recognition and Artificial Intelligence, 2016, 30(3): Article No. 1659008 doi: 10.1142/S0218001416590084 [34] Dempster A P, Laird N M, Rubin D B. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 1977, 39(1): 1-22 [35] Gauvain J L, Lee C H. Maximum a posteriori estimation for multivariate Gaussian mixture observations of Markov chains. IEEE Transactions on Speech and Audio Processing, 1994, 2(2): 291-298 doi: 10.1109/89.279278 [36] Kuhn R, Junqua J C, Nguyen P, Niedzielski N. Rapid speaker adaptation in eigenvoice space. IEEE Transactions on Speech and Audio Processing, 2000, 8(6): 695-707 doi: 10.1109/89.876308 [37] Kenny P, Mihoubi M, Dumouchel P. New MAP estimators for speaker recognition. In: Proceedings of the 8th European Conference on Speech Communication and Technology (EUROSPEECH). Geneva, Switzerland: ISCA, 2003. 2961−2964 [38] Kenny P, Boulianne G, Ouellet P, Dumouchel P. Joint factor analysis versus eigenchannels in speaker recognition. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(4): 1435-1447 doi: 10.1109/TASL.2006.881693 [39] Dehak N, Dehak R, Kenny P, Brümmer N, Dumouchel P. Support vector machines versus fast scoring in the low-dimensional total variability space for speaker verification. In: Proceedings of the 10th Annual Conference of the International Speech Communication Association (INTERSPEECH). Brighton, UK: ISCA, 2009. 1559−1562 [40] Dehak N, Kenny P J, Dehak R, Dumouchel P, Ouellet P. Front-end factor analysis for speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4): 788-798 doi: 10.1109/TASL.2010.2064307 [41] Wold S, Esbensen K, Geladi P. Principal component analysis. Chemometrics and Intelligent Laboratory Systems, 1987, 2(1−3): 37-52 doi: 10.1016/0169-7439(87)80084-9 [42] Lei Z C, Yang Y C. Maximum likelihood I-vector space using PCA for speaker verification. In: Proceedings of the 12th Annual Conference of the International Speech Communication Association (INTERSPEECH). Florence, Italy: ISCA, 2011. 2725−2728 [43] Tipping M E, Bishop C M. Probabilistic principal component analysis. Journal of the Royal Statistical Society: Series B Statistical Methodology), 1999, 61(3): 611-622 doi: 10.1111/1467-9868.00196 [44] Vestman V, Kinnunen T. Supervector compression strategies to speed up I-vector system development. In: Proceedings of the 2018 Odyssey: The Speaker and Language Recognition Workshop. Les Sables d' Olonne, France: ISCA, 2018. 357−364 [45] Gorsuch R L. Factor Analysis (2nd edition). Hillsdale: Lawrence Erlbaum Associates, 1983. [46] Roweis S T. EM algorithms for PCA and SPCA. In: Proceedings of the 10th International Conference on Neural Information Processing Systems. Denver, USA: MIT Press, 1997. 626−632 [47] Chen L P, Lee K A, Ma B, Guo W, Li H Z, Dai L R. Local variability vector for text-independent speaker verification. In: Proceedings of the 9th International Symposium on Chinese Spoken Language Processing. Singapore, Singapore: IEEE, 2014. 54−58 [48] Xu L T, Lee K A, Li H Z, Yang Z. Sparse coding of total variability matrix. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association (INTERSPEECH). Dresden, Germany: ISCA, 2015. 1022−1026 [49] Ma J B, Sethu V, Ambikairajah E, Lee K A. Generalized variability model for speaker verification. IEEE Signal Processing Letters, 2018, 25(12): 1775-1779 doi: 10.1109/LSP.2018.2874814 [50] Shepstone S E, Lee K A, Li H Z, Tan Z H, Jensen S H. Total variability modeling using source-specific priors. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(3): 504-517 doi: 10.1109/TASLP.2016.2515506 [51] Ribas D, Vincent E. An improved uncertainty propagation method for robust I-vector based speaker recognition. In: Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Brighton, UK: IEEE, 2019. 6331−6335 [52] Xu L T, Lee K A, Li H Z, Yang Z. Generalizing I-vector estimation for rapid speaker recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(4): 749-759 doi: 10.1109/TASLP.2018.2793670 [53] Travadi R, Narayanan S. Efficient estimation and model generalization for the totalvariability model. Computer Speech and Language, 2019, 53: 43-64 [54] Chen C, Han J Q. Partial least squares based total variability space modeling for I-vector speaker verification. Chinese Journal of Electronics. 2018, 27(6): 1229-1233 doi: 10.1049/cje.2018.06.001 [55] Chen C, Han J Q, Pan Y L. Speaker verification via estimating total variability space using probabilistic partial least squares. In: Proceedings of the 18th Annual Conference of the International Speech Communication Association. Stockholm, Swedish: ISCA, 2017. 1537−1541 [56] Lei Y, Hansen J H L. Speaker recognition using supervised probabilistic principal component analysis. In: Proceedings of the 11th Annual Conference of the International Speech Communication Association (INTERSPEECH). Makuhari, Japan: ISCA, 2010. 382−385 [57] Huber J. A robust version of the probability ratio test. Annals of Mathematical Statistics, 1965, 36(6): 1753-1758 doi: 10.1214/aoms/1177699803 [58] Hautamäki V, Cheng Y C, Rajan P, Lee C H. Minimax i-vector extractor for short duration speaker verification. In: Proceedings of the 14th Annual Conference of the International Speech Communication Association (INTERSPEECH). Lyon, France: ISCA, 2013. 3708−3712 [59] Vogt R, Baker B, Sridharan S. Modelling session variability in text-independent speaker verification. In: Proceedings of the 9th European Conference on Speech Communication and Technology (INTERSPEECH). Lisbon, Portugal: ISCA, 2005. 3117−3120 [60] Fisher R A. The use of multiple measurements in taxonomic problems. Annals of Eugenics, 1936, 7(2): 179-188 doi: 10.1111/j.1469-1809.1936.tb02137.x [61] Hatch A O, Kajarekar S S, Stolcke A. Within-class covariance normalization for SVM-based speaker recognition. In: Proceedings of the 9th International Conference on Spoken Language Processing (INTERSPEECH). Pittsburgh, USA: ISCA, 2006. 1471−1474 [62] Campbell W M, Sturim D E, Reynolds D A, Solomonoff A. SVM based speaker verification using a GMM supervector kernel and NAP variability compensation. In: Proceedings of the 2006 IEEE International Conference on Acoustics Speech and Signal Processing. Toulouse, France: IEEE, 2006. [63] Sadjadi S O, Pelecanos J W, Zhu W Z. Nearest neighbor discriminant analysis for robust speaker recognition. In: Proceedings of the 15th Annual Conference of the International Speech Communication Association (INTERSPEECH). Singapore, Singapore: ISCA, 2014. 1860−1864 [64] Misra A, Ranjan S, Hansen J H L. Locally weighted linear discriminant analysis for robust speaker verification. In: Proceedings of the 18th Annual Conference of the International Speech Communication Association. Stockholm, Sweden: ISCA, 2017. 2864−2868 [65] Misra A, Hansen J H L. Modelling and compensation for language mismatch in speaker verification. Speech Communication, 2018, 96: 58-66 doi: 10.1016/j.specom.2017.09.004 [66] Li M, Zhang X, Yan Y H, Narayanan S S. Speaker verification using sparse representations on total variability I-vectors. In: Proceedings of the 12th Annual Conference of the International Speech Communication Association (INTERSPEECH). Florence, Italy: ISCA, 2011. 2729−2732 [67] Wang W, Han J Q, Zheng T R, Zheng G B, Shao M G. Speaker recognition via block sparse Bayesian learning. International Journal of Multimedia and Ubiquitous Engineering, 2015, 10(7): 247-254 doi: 10.14257/ijmue.2015.10.7.26 [68] 王伟, 韩纪庆, 郑铁然, 郑贵滨, 陶耀. 基于Fisher判别字典学习的说话人识别. 电子与信息学报, 2016, 38(2): 367-372Wang Wei, Han Ji-Qing, Zheng Tie-Ran, Zheng Gui-Bin, Tao Yao. Speaker recognition based on Fisher discrimination dictionary learning. Journal of Electronics and Information Technology, 2016, 38(2): 367-372 [69] Variani E, Lei X, McDermott E, Moreno I L, Gonzalez-Dominguez J. Deep neural networks for small footprint text-dependent speaker verification. In: Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Florence, Italy: IEEE, 2014. 4052−4056 [70] Snyder D, Garcia-Romero D, Povey D, Khudanpur S. Deep neural network embeddings for text-independent speaker verification. In: Proceedings of the 18th Annual Conference of the International Speech Communication Association. Stockholm, Sweden: ISCA, 2017. 999−1003 [71] Snyder D, Garcia-Romero D, Sell G, Povey D, Khudanpur S. X-Vectors: Robust DNN embeddings for speaker recognition. In: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Calgary, Canada: IEEE, 2018. 5329−5333 [72] Chatfield K, Simonyan K, Vedaldi A, Zisserman A. Return of the devil in the details: Delving deep into convolutional nets. In: Proceedings of the 2014 British Machine Vision Conference (BMVC). Nottingham, UK: BMVA Press, 2014: 1−5 [73] Nagrani A, Chung J S, Zisserman A. VoxCeleb: A large-scale speaker identification dataset. In: Proceedings of the 18the Annual Conference of the International Speech Communication Association. Stockholm, Sweden: ISCA, 2017. 2616−2620 [74] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [75] Chung J S, Nagrani A, Zisserman A. VoxCeleb2: Deep speaker recognition. In: Proceedings of the 19th Annual Conference of the International Speech Communication Association. Hyderabad, India: ISCA, 2018. 1086−1090 [76] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672−2680 [77] Zhang Z F, Wang L B, Kai A, Yamada T, Li W F, Iwahashi M. Deep neural network-based bottleneck feature and denoising autoencoder-based dereverberation for distant-talking speaker identification. Eurasip Journal on Audio, Speech, and Music Processing, 2015, 2015(1): Article No. 12 doi: 10.1186/s13636-015-0056-7 [78] Richardson F, Reynolds D, Dehak N. Deep neural network approaches to speaker and language recognition. IEEE Signal Processing Letters, 2015, 22(10): 1671-1675 doi: 10.1109/LSP.2015.2420092 [79] Chen Y H, Lopez-Moreno I, Sainath T N, Visontai M, Alvarez R, Parada C. Locally-connected and convolutional neural networks for small footprint speaker recognition. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association (INTERSPEECH). Dresden, Germany: ISCA, 2015. 1136−1140 [80] Li L T, Chen Y X, Shi Y, Tang Z Y, Wang D. Deep speaker feature learning for text-independent speaker verification. In: Proceedings of the 18th Annual Conference of the International Speech Communication Association. Stockholm, Sweden: ISCA, 2017. 1542−1546 [81] Prince S J D, Elder J H. Probabilistic linear discriminant analysis for inferences about identity. In: Proceedings of the 11th IEEE International Conference on Computer Vision. Rio de Janeiro, Brazil: IEEE, 2007. 1−8 [82] Peddinti V, Povey D, Khudanpur S. A time delay neural network architecture for efficient modeling of long temporal contexts. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association (INTERSPEECH). Dresden, Germany: ISCA, 2015. 3214−3218 [83] Villalba J, Chen N X, Snyder D, Garcia-Romero D, McCree A, Sell G, et al. State-of-the-art speaker recognition for telephone and video speech: The JHU-MIT submission for NIST SRE18. In: Proceedings of the 20th Annual Conference of the International Speech Communication Association. Graz, Austria: ISCA, 2019. 1488−1492 [84] Povey D, Cheng G F, Wang Y M, Li K, Xu H N, Yarmohammadi M, et al. Semi-orthogonal low-rank matrix factorization for deep neural networks. In: Proceedings of the 19th Annual Conference of the International Speech Communication Association. Hyderabad, India: ISCA, 2018. 3743−3747 [85] Snyder D, Garcia-Romero D, Sell G, McCree A, Povey D, Khudanpur S. Speaker recognition for multi-speaker conversations using X-vectors. In: Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Brighton, UK: IEEE, 2019. 5796−5800 [86] Kanagasundaram A, Sridharan S, Ganapathy S, Singh P, Fookes C. A study of X-vector based speaker recognition on short utterances. In: Proceedings of the 20th Annual Conference of the International Speech Communication Association. Graz, Austria: ISCA, 2019. 2943−2947 [87] Garcia-Romero D, Snyder D, Sell G, McCree A, Povey D, Khudanpur S. X-vector DNN refinement with full-length recordings for speaker recognition. In: Proceedings of the 20th Annual Conference of the International Speech Communication Association. Graz, Austria: ISCA, 2019. 1493−1496 [88] Hong Q B, Wu C H, Wang H M, Huang C L. Statistics pooling time delay neural network based on X-vector for speaker verification. In: Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Barcelona, Spain: IEEE, 2020. 6849−6853 [89] Nagrani A, Chung J S, Xie W D, Zisserman A. Voxceleb: Large-scale speaker verification in the wild. Computer Science and Language, 2020, 60: Article No. 101027 [90] Hajibabaei M, Dai D X. Unified hypersphere embedding for speaker recognition. arXiv preprint arXiv: 1807.08312, 2018. [91] Xie W D, Nagrani A, Chung J S, Zisserman A. Utterance-level aggregation for speaker recognition in the wild. In: Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Brighton, UK: IEEE, 2019. 5791−5795 [92] Zhang C L, Koishida K. End-to-end text-independent speaker verification with triplet loss on short utterances. In: Proceedings of the 18th Annual Conference of the International Speech Communication Association. Stockholm, Sweden: ISCA, 2017. 1487−1491 [93] Cai W C, Chen J K, Li M. Exploring the encoding layer and loss function in end-to-end speaker and language recognition system. In: Proceedings of the 2018 Odyssey: The Speaker and Language Recognition Workshop. Les Sables d'Olonne, France: ISCA, 2018. 74−81 [94] Li C, Ma X K, Jiang B, Li X G, Zhang X W, Liu X, Cao Y, Kannan A, Zhu Z Y. Deep speaker: An end-to-end neural speaker embedding system. arXiv preprint arXiv:1705.02304, 2017. [95] Ding W H, He L. MTGAN: Speaker verification through multitasking triplet generative adversarial networks. In: Proceedings of the 19th Annual Conference of the International Speech Communication Association. Hyderabad, India: ISCA, 2018. 3633−3637 [96] Zhou J F, Jiang T, Li L, Hong Q Y, Wang Z, Xia B Y. Training multi-task adversarial network for extracting noise-robust speaker embeddings. In: Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Brighton, UK: IEEE, 2019. 6196−6200 [97] Yang Y X, Wang S, Sun M, Qian Y M, Yu K. Generative adversarial networks based X-vector augmentation for robust probabilistic linear discriminant analysis in speaker verification. In: Proceedings of the 11th International Symposium on Chinese Spoken Language Processing (ISCSLP). Taipei, China: IEEE, 2018. 205−209 [98] Li N, Tuo D Y, Su D, Li Z F, Yu D. Deep discriminative embeddings for duration robust speaker verification. In: Proceedings of the 19th Annual Conference of the International Speech Communication Association. Hyderabad, India: ISCA, 2018. 2262−2266 [99] Liu Y, He L, Liu J. Large margin softmax loss for speaker verification. In: Proceedings of the 20th Annual Conference of the International Speech Communication Association. Graz, Austria: ISCA, 2019. 2873−2877 [100] Huang Z L, Wang S, Yu K. Angular softmax for short-duration text-independent speaker verification. In: Proceedings of the 19th Annual Conference of the International Speech Communication Association. Hyderabad, India: ISCA, 2018. 3623−3627 [101] Yu Y Q, Fan L, Li W J. Ensemble additive margin softmax for speaker verification. In: Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Brighton, UK: IEEE, 2019. 6046−6050 [102] Bhattacharya G, Alam J, Gupta V, Kenny P. Deeply fused speaker embeddings for text-independent speaker verification. In: Proceedings of the 19th Annual Conference of the International Speech Communication Association. Hyderabad, India: ISCA, 2018. 3588−3592 [103] Zhang C L, Koishida K, Hansen J H L. Text-independent speaker verification based on triplet convolutional neural network embeddings. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(9): 1633-1644 doi: 10.1109/TASLP.2018.2831456 [104] Zheng T R, Han J Q, Zheng G B. Deep neural network based discriminative training for I-vector/PLDA speaker verification. In: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Calgary, Canada: IEEE, 2018. 5354−5358 [105] Chen C, Wang W, He Y J, Han J Q. A bilevel framework for joint optimization of session compensation and classification for speaker identification. Digital Signal Processing, 2019, 89: 104-115 doi: 10.1016/j.dsp.2019.03.008 [106] Chen C, Han J Q. Task-driven variability model for speaker verification. Circuits, Systems, and Signal Processing, 2020, 39(6): 3125-3144 doi: 10.1007/s00034-019-01315-7 [107] Rohdin J, Silnova A, Diez M, Plchot O, Matějka P, Burget L. End-to-end DNN based speaker recognition inspired by I-vector and PLDA. In: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Calgary, Canada: IEEE, 2018. 4874−4878 [108] Chen C, Han J Q. TDMF: Task-driven multilevel framework for end-to-end speaker verification. In: Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Barcelona, Spain: IEEE, 2020. 6809−6813 [109] Migdalas A, Pardalos P M, Varbränd P. Multilevel Optimization: Algorithms and Applications. Boston: Springer Science and Business Media, 2013. [110] Kenny P. Bayesian speaker verification with heavy-tailed priors. In: Proceedings of the 2010 Odyssey: The Speaker and Language Recognition Workshop. Brno, Czech Republic: ISCA, 2010. 1−4 [111] Garcia-Romero D, Espy-Wilson C Y. Analysis of I-vector length normalization in speaker recognition systems. In: Proceedings of the 12th Annual Conference of the International Speech Communication Association (INTERSPEECH). Florence, Italy: ISCA, 2011. 249−252 [112] Pan Y L, Zheng T R, Chen C. I-vector Kullback-Leibler divisive normalization for PLDA speaker verification. In: Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP). Montreal, Canada: IEEE, 2017. 56−60 [113] Burget L, Plchot O, Cumani S, Glembek O, Matějka P, Brümmer N. Discriminatively trained probabilistic linear discriminant analysis for speaker verification. In: Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Prague, Czech Republic: IEEE, 2011. 4832−4835 [114] Cumani S, Laface P. Joint estimation of PLDA and nonlinear transformations of speaker vectors. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(10): 1890-1900 doi: 10.1109/TASLP.2017.2724198 [115] Cumani S, Laface P. Scoring heterogeneous speaker vectors using nonlinear transformations and tied PLDA models. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(5): 995-1009 doi: 10.1109/TASLP.2018.2806305 [116] Kenny P, Stafylakis T, Ouellet P, Alam J, Dumouchel P. PLDA for speaker verification with utterances of arbitrary duration. In: Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, Canada: IEEE, 2013. 7649−7653 [117] Ma J B, Sethu V, Ambikairajah E, Lee K A. Twin model G-PLDA for duration mismatch compensation in text-independent speaker verification. In: Proceedings of the 17th Annual Conference of the International Speech Communication Association. San Francisco, USA: ISCA, 2016. 1853−1857 [118] Ma J B, Sethu V, Ambikairajah E, Lee K A. Duration compensation of I-vectors for short duration speaker verification. Electronics Letters, 2017, 53(6): 405-407 doi: 10.1049/el.2016.4629 [119] Villalba J, Lleida E. Handling I-vectors from different recording conditions using multi-channel simplified PLDA in speaker recognition. In: Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, Canada: IEEE, 2013. 6763−6767 [120] Garcia-Romero D, McCree A. Supervised domain adaptation for I-vector based speaker recognition. In: Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Florence, Italy: IEEE, 2014. 4047−4051 [121] Richardson F, Nemsick B, Reynolds D. Channel compensation for speaker recognition using MAP adapted PLDA and denoising DNNs. In: Proceedings of the 2016 Odyssey: The Speaker and Language Recognition Workshop. Bilbao, Spain: ISCA, 2016. 225−230 [122] Hong Q Y, Li L, Zhang J, Wan L H, Guo H Y. Transfer learning for PLDA-based speaker verification. Speech Communication, 2017, 92: 90-99 doi: 10.1016/j.specom.2017.05.004 [123] Li N, Mak M W. SNR-invariant PLDA modeling in nonparametric subspace for robust speaker verification. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(10): 1648-1659 doi: 10.1109/TASLP.2015.2442757 [124] Mak M W, Pang X M, Chien J T. Mixture of PLDA for noise robust I-vector speaker verification. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(1): 130-142 doi: 10.1109/TASLP.2015.2499038 [125] Villalba J, Miguel A, Ortega A, Lleida E. Bayesian networks to model the variability of speaker verification scores in adverse environments. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(12): 2327-2340 doi: 10.1109/TASLP.2016.2607343 [126] Fan Y, Kang J W, Li L T, Li K C, Chen H L, Cheng S T, et al. CN-Celeb: A challenging Chinese speaker recognition dataset. In: Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Barcelona, Spain: IEEE, 2020. 7604−7608 [127] McLaren M, Ferrer L, Castán D, Lawson A. The speakers in the wild (SITW) speaker recognition database. In: Proceedings of the 17th Annual Conference of the International Speech Communication Association. San Francisco, USA: ISCA, 2016. 818−822 [128] Morrison G S, Zhang C, Enzinger E, Ochoa F, Bleach D, Johnson M, et al. Forensic database of voice recordings of 500+ Australian English speakers [Online], available: http://databases.forensic-voice-comparison.net/, November 10, 2020 [129] Greenberg C S. The NIST Year 2012 Speaker Recognition Evaluation plan, Technical Report NIST_SRE12_evalplan.v17, 2012. [130] Feng L, Hansen L K. A New Database for Speaker Recognition, IMM-Technical Report, 2005. [131] Godfrey J J, Holliman E C, McDaniel J. SWITCHBOARD: Telephone speech corpus for research and development. In: Proceedings of the 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing. San Francisco, USA: IEEE, 1992. 517−520 [132] Jankowski C, Kalyanswamy A, Basson S, Spitz J. TIMIT: A phonetically balanced, continuous speech, telephone bandwidth speech database. In: Proceedings of the 1990 IEEE International Conference on Acoustics, Speech, and Signal Processing. Albuquerque, USA: IEEE, 1990. 109−122 [133] 王金甲, 纪绍男, 崔琳, 夏静, 杨倩. 基于注意力胶囊网络的家庭活动识别. 自动化学报, 2019, 45(11): 2199-2204Wang Jin-Jia, Ji Shao-Nan, Cui Lin, Xia Jing, Yang Qian. Domestic activity recognition based on attention capsule network. Acta Automatica Sinica, 2019, 45(11): 2199-2204 [134] Wang H J, Dinkel H, Wang S, Qian Y M, Yu K. Dual-adversarial domain adaptation for generalized replay attack detection. In: Proceedings of the 21st Annual Conference of the International Speech Communication Association. Shanghai, China: ISCA, 2020. 1086−1090 [135] 黄雅婷, 石晶, 许家铭, 徐波. 鸡尾酒会问题与相关听觉模型的研究现状与展望. 自动化学报, 2019, 45(2): 234-251Huang Ya-Ting, Shi Jing, Xu Jia-Ming, Xu Bo. Research advances and perspectives on the cocktail party problem and related auditory models. Acta Automatica Sinica, 2019, 45(2): 234-251 [136] Lin Q J, Hou Y, Li M. Self-attentive similarity measurement strategies in speaker diarization. In: Proceedings of the 21st Annual Conference of the International Speech Communication Association. Shanghai, China: ISCA, 2020. 284−288 -

 下载:
下载:


计量
- 文章访问数: 1974
- HTML全文浏览量: 1437
- PDF下载量: 370
- 被引次数: 0
