

Operating Performance Assessment Method and Application for Complex Industrial Process Based on ISDAE Model
-
摘要: 工业过程的运行状态评价对保证产品质量及提升企业综合经济效益具有重要意义. 针对工业过程中存在强非线性、信息冗余以及不确定性因素影响而难以建立稳健可靠的运行状态评价模型问题, 提出一种基于综合经济指标驱动的稀疏降噪自编码器模型(Comprehensive economic index driven sparse denoising autoencoder, ISDAE)的复杂工业过程运行状态评价方法. 首先, 在SDAE (Sparse denoising autoencoder)模型中引入综合经济指标预测误差项, 迫使SDAE学习与综合经济指标相关的数据特征, 建立ISDAE特征提取模型. 其次, 将ISDAE模型所学特征作为输入训练运行状态识别模型, 级联特征提取模型和运行状态识别模型并通过微调网络结构参数获得运行状态评价模型. 另外, 针对非优状态, 提出一种基于自编码器贡献图算法的非优因素追溯方法, 通过计算变量的贡献率识别非优因素. 最后, 将所提方法应用于重介质选煤过程, 验证所提方法的有效性和实用性.Abstract: The operating performance assessment of industrial process is of great significance to ensure the product quality and improve the comprehensive economic benefits of the enterprise. In view of the problems of strong process non-linearity, information redundancy and the influence of uncertainty factors in the complex industrial processes that are not conducive to establishing a robust and reliable operating performance assessment model, a comprehensive economic index driven sparse denoising autoencoder model (ISDAE) based operating performance assessment method is proposed for complex industrial processes. Firstly, SDAE (Sparse denoising autoencoder) is forced to learn data features related to comprehensive economic indexes by introducing comprehensive economic indexes prediction error term and a feature extraction model based on ISDAE is established. Secondly, the features learned from the ISDAE model will be used as input to train the operating performance identification model, and then the feature extraction model and performance assessment model are cascaded and the operating performance assessment model is obtained by fine-tuning the neural network. Then, for the non-optimal operating performance, a non-optimal cause identification method based on the autoencoder contribution plot algorithm is proposed, and the non-optimal cause is identified by calculating the contribution rate of the variables. Finally, the proposed method is applied to the dense medium coal preparation process to verify its effectiveness and practicability.
-
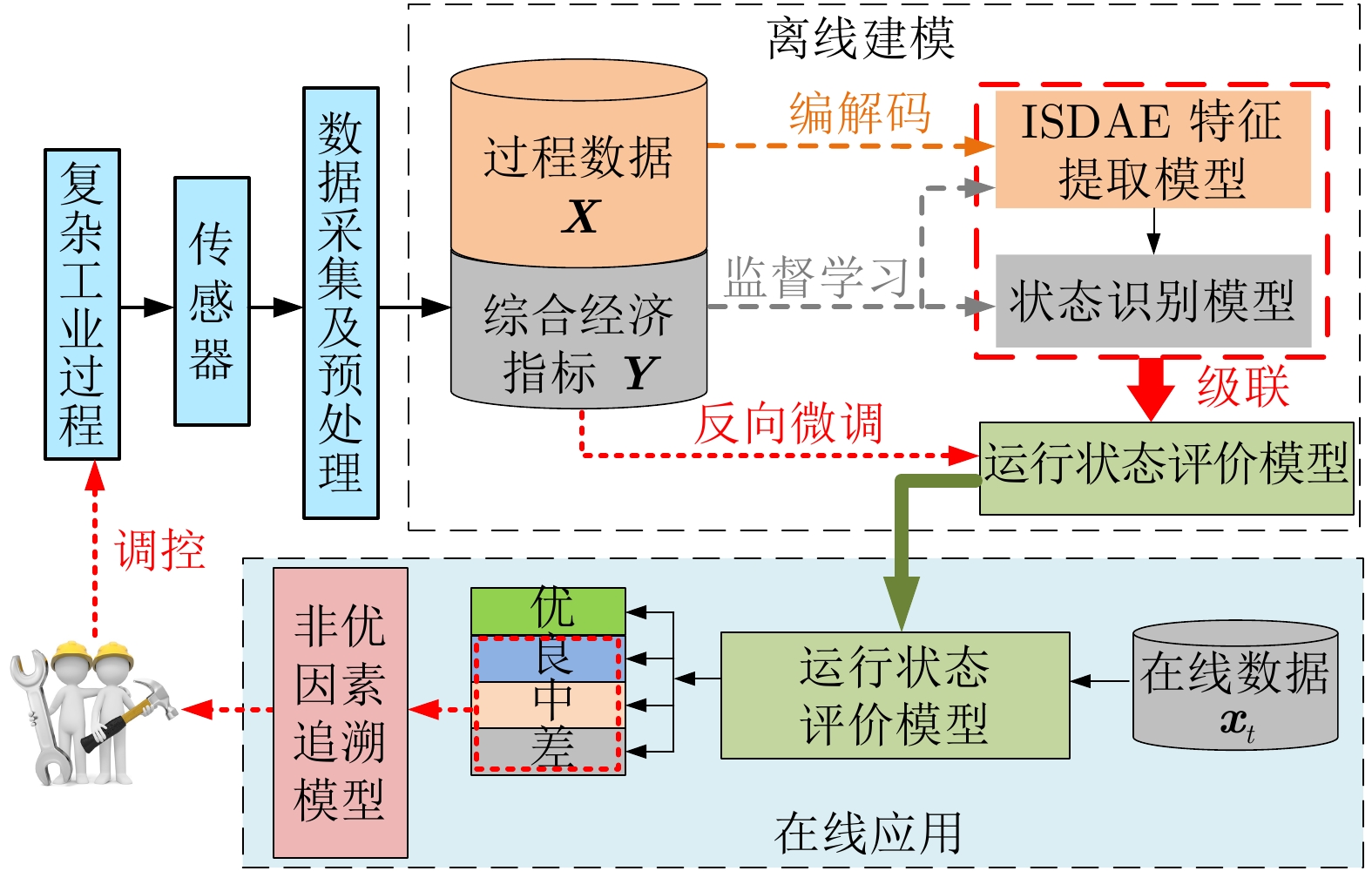
图 2 基于ISDAE模型的运行状态评价系统框图
Fig. 2 The system block diagram of ISDAE model based operating performance assessment
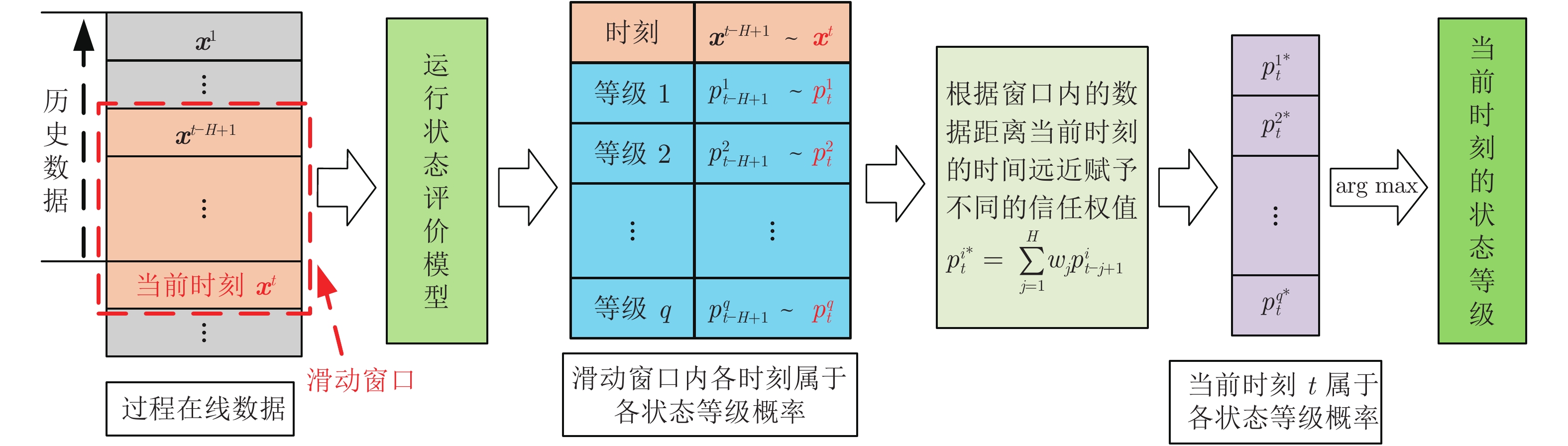
图 3 运行状态在线评价示意图
Fig. 3 The schematic diagram of online operating performance assessment

图 4 重介质选煤工艺流程图
Fig. 4 The process flow diagram of dense medium coal preparation process

图 5 模型精度与隐藏层神经元个数的关系图
Fig. 5 The relationship between the model accuracy and the number of neurons in hidden layer

图 6 未引入滑动窗口的机理模型数据运行状态在线评价结果
Fig. 6 Online operating performance assessment results of mechanism model data without sliding window
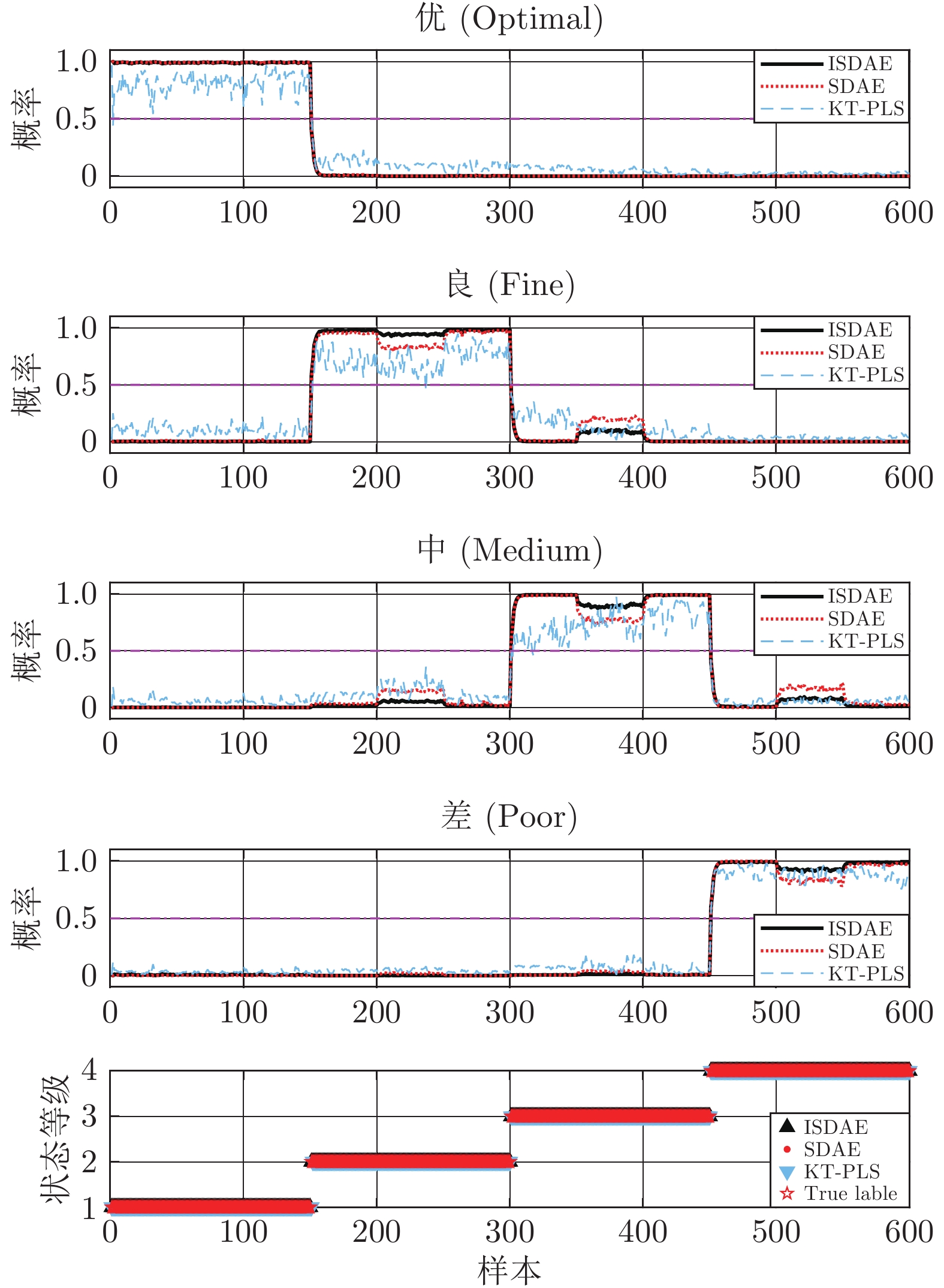
图 7 引入滑动窗口的机理模型数据运行状态在线评价结果
Fig. 7 Online operating performance assessment results of mechanism model data with sliding window

图 9 未引入滑动窗口的实际过程数据运行状态在线评价结果
Fig. 9 Online operating performance assessment results of field date without sliding window
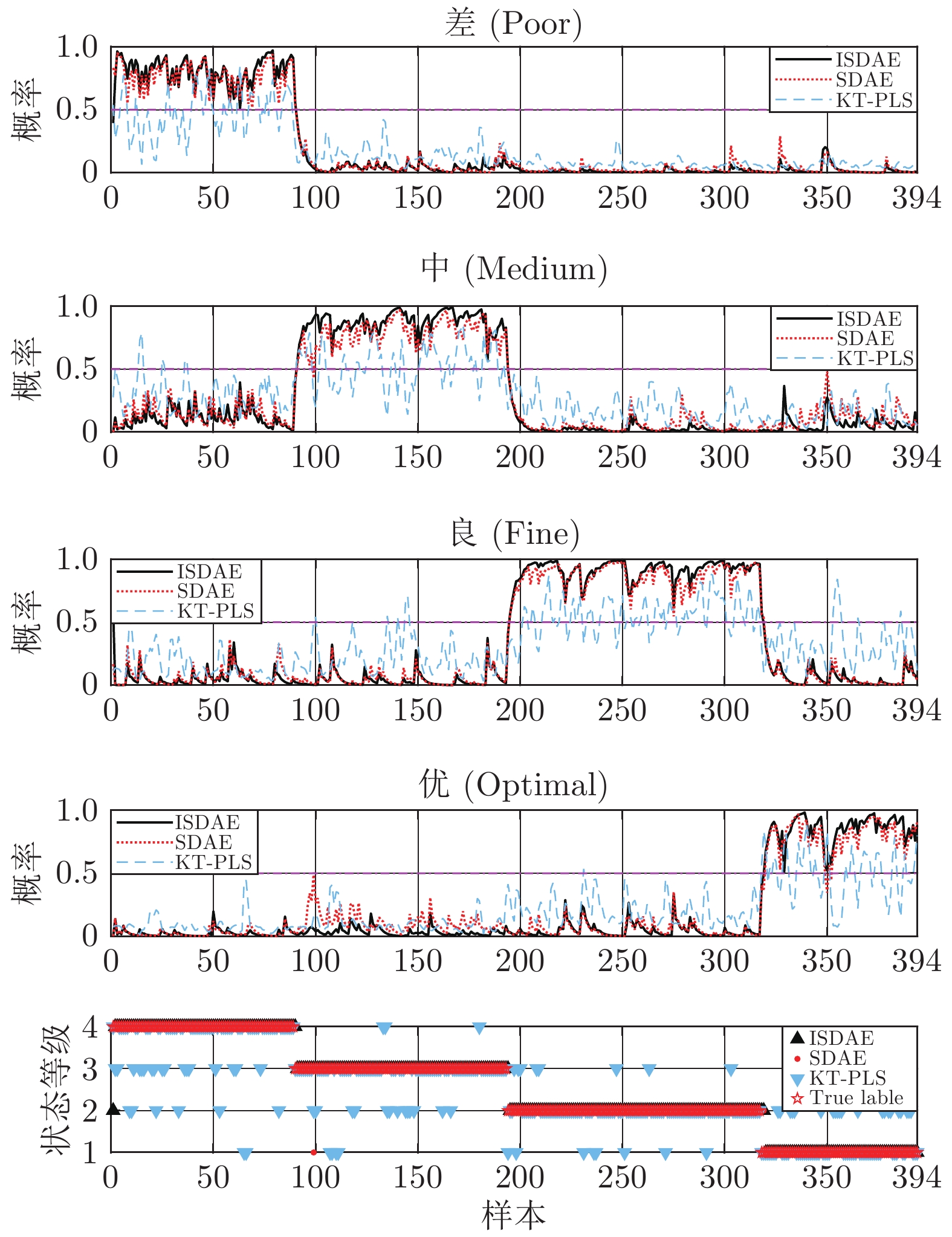
图 10 引入滑动窗口的实际过程数据运行状态在线评价结果
Fig. 10 Online operating performance assessment results of field data with sliding window
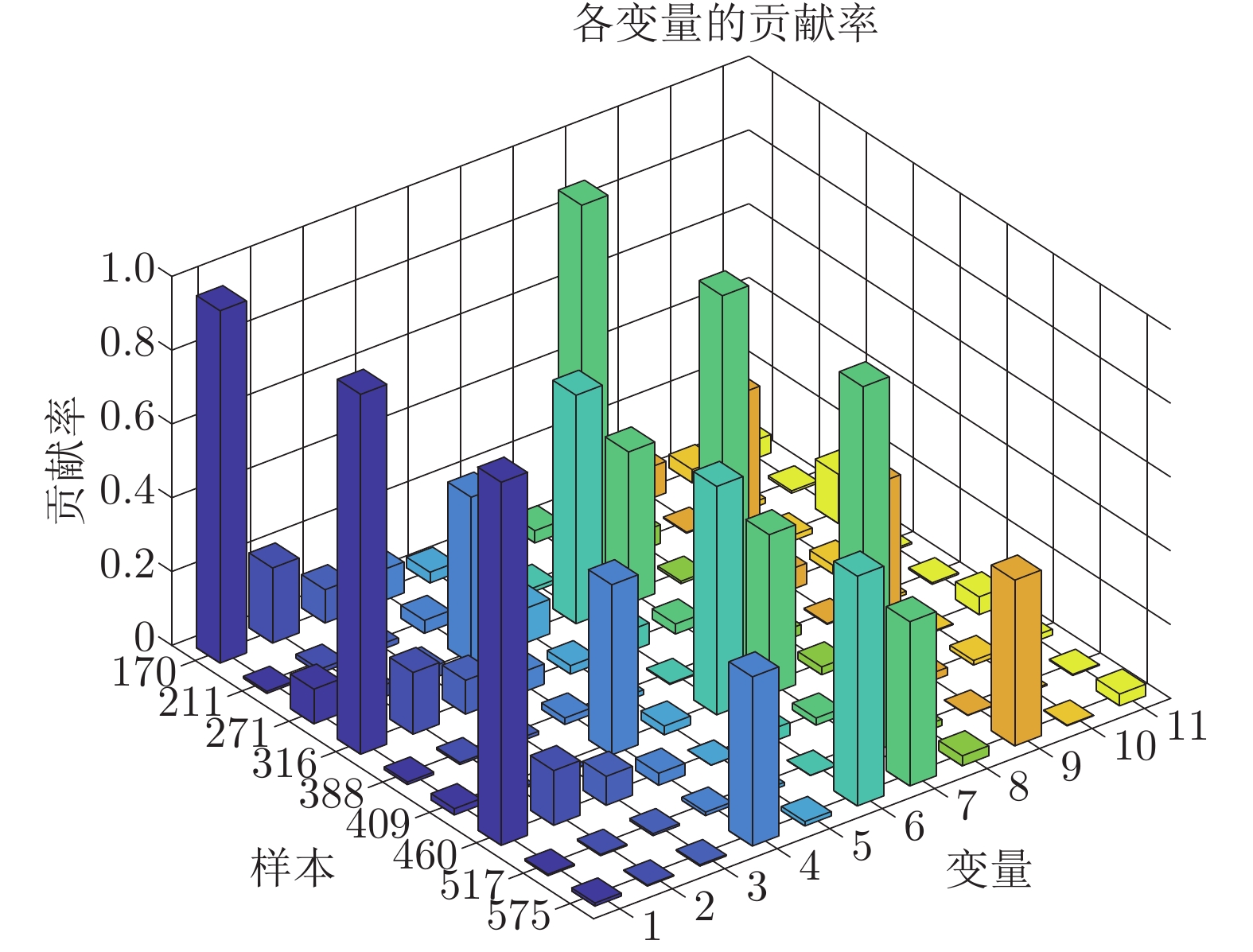
图 11 机理模型数据的非优因素追溯结果: 第170、211、271个样本为状态“良”的各变量贡献率; 第316、388、409个样本为状态“中”的各变量贡献率; 第460、517、575个样本为状态“差”的各变量贡献率
Fig. 11 Non-optimal cause identification results of mechanism model data: The contribution rate of each variable of the 170th, 211st, and 271st samples, when the state is “fine”; the contribution rate of each variable of the 316th, 388th, and 409th samples, when the state is “medium”; the contribution rate of each variable of the 460th, 517th, and 575th samples, when the state is “poor”
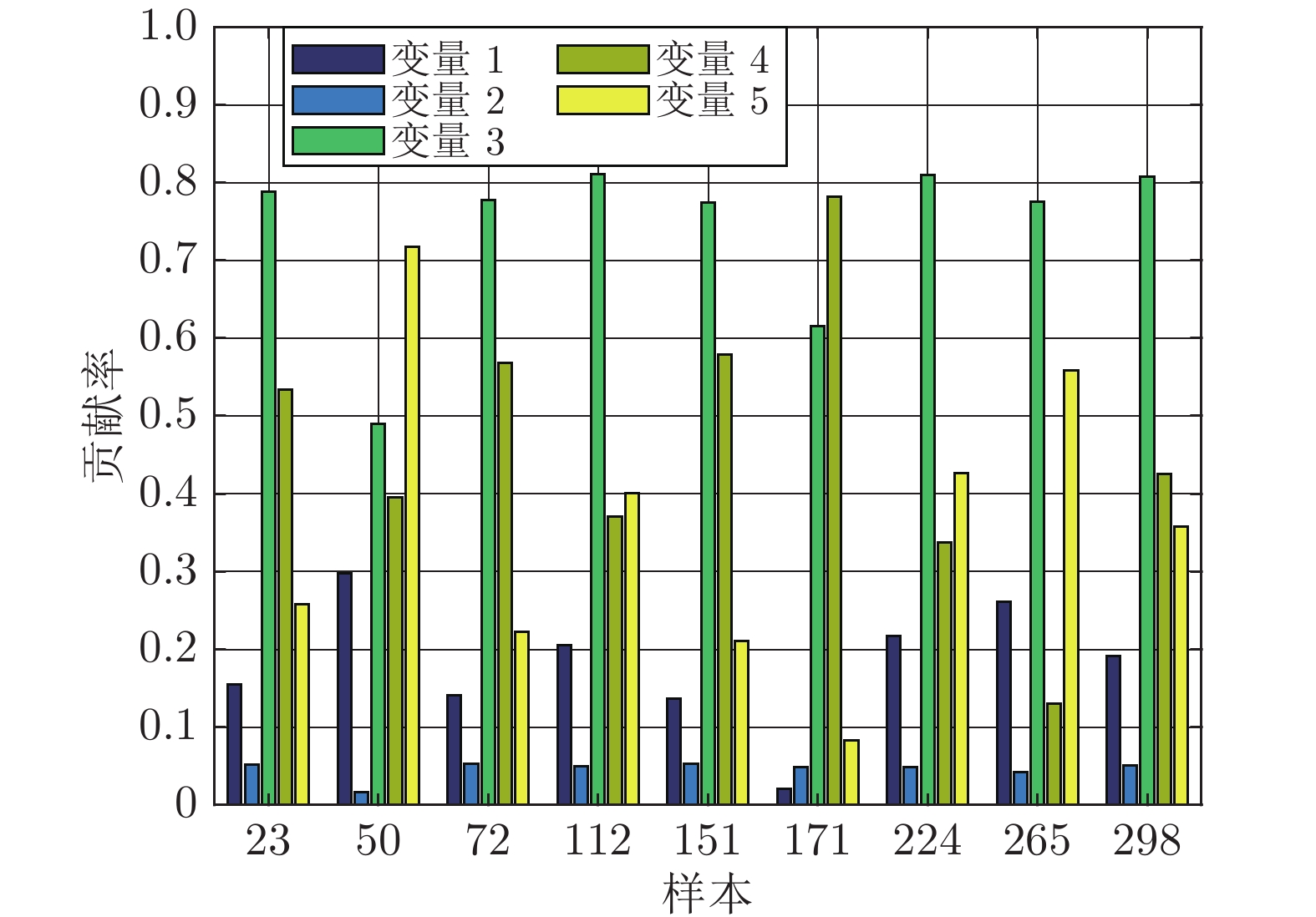
图 12 实际选煤过程数据的非优因素追溯结果
Fig. 12 The non-optimal cause identification results of coal preparation field data
表 1 过程变量选择
Table 1 The selection of process variable
编号 变量名 1 选煤厂原煤入料 (kg/s) 2 双层筛底板筛下流量 (kg/s) 3 单层筛顶板上流量 (kg/s) 4 混合箱出料密度 (kg/m3) 5 混料箱出料流量 (m3/s) 6 进入混料箱的重介质密度 (kg/m3) 7 旋流器入料压力 (Pa) 8 磁性物添加量 (kg/s) 9 合格介质桶输出的介质密度 (kg/m3) 10 合格介质桶液位 (m) 11 合格介质桶出料流量 (m3/s)  下载: 导出CSV
下载: 导出CSV
表 2 机理模型数据运行状态等级划分及等级标签设置
Table 2 Operating performance level division and level label setting of mechanism model data
溢流灰分值 状态等级 等级标签 4.5 % ~ 5.5 % 优 1 5.5 % ~ 6.7 % 良 2 6.7 % ~ 7.7 % 中 3 7.7 % ~ 8.7 % 差 4
下载: 导出CSV
表 3 离线建模数据集中的非优因素设置
Table 3 Non-optimal factors setting in offline modeling dataset
状态等级 优 良 中 差 样本 1 ~ 300 301 ~ 400 401 ~ 500 501 ~ 600 601 ~ 700 701 ~ 800 801 ~ 900 901 ~ 1000 1001 ~ 1100 1101 ~ 1200 非优因素 — 变量1 变量7 变量6 变量1 变量7 变量6 变量1 变量7 变量6
下载: 导出CSV
表 4 实际过程数据运行状态等级划分及等级标签设置
Table 4 Operating performance level division and level label setting of field data
溢流灰分值 状态等级 等级标签 6.0% ~ 6.5% 优 1 6.5% ~ 7.2% 良 2 7.2% ~ 8.0% 中 3 8.0% ~ 9.0% 差 4
下载: 导出CSV
表 5 模型参数设置
Table 5 Model parameter setting
PR $\rho $ lr $\beta $ $\alpha $ $\gamma $ 基于机理模型数据的神经网络模型 0.2 0.1 0.001 2 0.02 0.3 基于实际过程数据的神经网络模型 0.1 0.1 0.001 2 0.01 0.1
下载: 导出CSV
表 6 测试数据集中的非优因素设置
Table 6 Non-optimal cause setting in test dataset
状态等级 优 良 中 差 样本 0 ~ 150 151 ~ 200 201 ~ 250 251 ~ 300 301 ~ 350 351 ~ 400 401 ~ 450 451 ~ 500 501 ~ 550 551 ~ 600 非优因素 — 变量1 变量7 变量6 变量1 变量7 变量6 变量1 变量7 变量6
下载: 导出CSV
表 7 TP/FP/FN/TN参数含义
Table 7 Meaning of parameter TP/FP/FN/TN
真实情况 预测结果 正例 反例 正例 TP (真正例) FN (假反例) 反例 FP (假正例) TN (真反例)
下载: 导出CSV
表 8 未引入滑动窗口的运行状态评价结果报告
Table 8 Report of operating performance assessment results without sliding window
ISDAE SDAE KT-PLS 精确率 召回率 F1值 精确率 召回率 F1值 精确率 召回率 F1值 差 (Poor) 1.00 0.85 0.92 0.95 0.81 0.87 0.90 0.62 0.73 中 (Medium) 0.91 0.97 0.94 0.82 0.90 0.86 0.60 0.68 0.64 良 (Fine) 0.93 0.97 0.95 0.92 0.95 0.94 0.60 0.71 0.65 优 (Optimal) 0.94 0.95 0.94 0.89 0.88 0.89 0.70 0.61 0.65 宏平均 0.94 0.94 0.94 0.90 0.89 0.89 0.70 0.66 0.67 加权平均 0.94 0.94 0.94 0.90 0.89 0.89 0.69 0.66 0.67
下载: 导出CSV
表 9 引入滑动窗口的运行状态评价结果报告
Table 9 Report of operating performance assessment results with sliding window
ISDAE SDAE KT-PLS 精确率 召回率 F1值 精确率 召回率 F1值 精确率 召回率 F1值 差 (Poor) 0.99 0.99 0.99 0.99 1.00 0.99 0.96 0.72 0.82 中 (Medium) 0.99 0.99 0.99 0.98 0.98 0.98 0.76 0.81 0.78 良 (Fine) 0.98 0.99 0.98 0.98 0.99 0.99 0.73 0.87 0.79 优 (Optimal) 1.00 0.97 0.99 0.99 0.96 0.97 0.79 0.70 0.74 宏平均 0.99 0.99 0.99 0.99 0.98 0.98 0.81 0.78 0.78 加权平均 0.99 0.99 0.99 0.98 0.98 0.98 0.80 0.79 0.79
下载: 导出CSV
-
[1] Li W Q, Zhao C H, Gao F R. Linearity evaluation and variable subset partition based hierarchical process modeling and monitoring. IEEE Transactions on Industrial Electronics, 2017, 65(3): 2683−2692 [2] Jiang Q C, Yan S F, Yan X F, Yi H, Gao F R. Data-driven two-dimensional deep correlated representation learning for nonlinear batch process monitoring. IEEE Transactions on Industrial Informatics, 2019, 16(4): 2839−2848 [3] Xu J, Gu Y, Ma S. Data based online operational performance optimization with varying work conditions for steam-turbine system. Applied Thermal Engineering, 2019, 151: 344−353 doi: 10.1016/j.applthermaleng.2019.02.032 [4] Hu J, Wu M, Chen X, Du S, Cao W, She J. Hybrid modeling and online optimization strategy for improving carbon efficiency in iron ore sintering process. Information Sciences, 2019, 483: 232−246 doi: 10.1016/j.ins.2019.01.027 [5] Frangos M. Uncertainty quantification for cuttings transport process monitoring while drilling by ensemble Kalman filtering. Journal of Process Control, 2017, 53: 46−56 doi: 10.1016/j.jprocont.2017.02.008 [6] 刘洋, 张国山. 基于敏感稀疏主元分析的化工过程监测与故障诊断. 控制与决策, 2016, 31(7): 1213−1218Liu Yang, Zhang Guo-Shan. Chemical process monitoring and fault diagnosis based on sensitive sparse principal component analysis. Control and Decision, 2016, 31(7): 1213−1218 [7] Liu Y, Wang F L, Chang Y Q. Operating optimality assessment based on optimality related variations and nonoptimal cause identification for industrial processes. Journal of Process Control, 2016, 39: 11−20 doi: 10.1016/j.jprocont.2015.12.008 [8] Liu Y, Chang Y Q, Wang F L. Online process operating performance assessment and nonoptimal cause identification for industrial processes. Journal of Process Control, 2014, 24(10): 1548−1555 doi: 10.1016/j.jprocont.2014.08.001 [9] Liu Y, Wang F L, Chang Y Q, Ma R C. Operating optimality assessment and nonoptimal cause identification for non-Gaussian multimode processes with transitions. Chemical Engineering Science, 2015, 137: 106−118 doi: 10.1016/j.ces.2015.06.016 [10] Zou X Y, Wang F L, Chang Y Q. Assessment of operating performance using cross-domain feature transfer learning. Control Engineering Practice, 2019, 89: 143−153 doi: 10.1016/j.conengprac.2019.05.007 [11] Vo H X, Durlofsky L J. Data assimilation and uncertainty assessment for complex geological models using a new PCA-based parameterization. Computational Geosciences, 2015, 19(4): 747−767 doi: 10.1007/s10596-015-9483-x [12] Zhang Q C, Yang L T, Chen Z K, Li P. A survey on deep learning for big data. Information Fusion, 2018, 42: 146−157 doi: 10.1016/j.inffus.2017.10.006 [13] Eren L, Ince T, Kiranyaz S. A generic intelligent bearing fault diagnosis system using compact adaptive 1D CNN classifier. Journal of Signal Processing Systems, 2019, 91(2): 179−189 doi: 10.1007/s11265-018-1378-3 [14] Wang J J, Ma Y L, Zhang L B, Gao R X, Wu D Z. Deep learning for smart manufacturing: Methods and applications. Journal of Manufacturing Systems, 2018, 48: 144−156 doi: 10.1016/j.jmsy.2018.01.003 [15] Sun W J, Shao S Y, Zhao R, Yang R Q, Zhang X W. A sparse auto-encoder-based deep neural network approach for induction motor faults classification. Measurement, 2016, 89: 171−178 doi: 10.1016/j.measurement.2016.04.007 [16] Jiang L, Ge Z Q, Song Z H. Semi-supervised fault classification based on dynamic sparse stacked auto-encoders model. Chemometrics and Intelligent Laboratory Systems, 2017, 168: 72−83 doi: 10.1016/j.chemolab.2017.06.010 [17] Yu W K, Zhao C H. Robust monitoring and fault isolation of nonlinear industrial processes using denoising autoencoder and elastic net. IEEE Transactions on Control Systems Technology, 2019, 28(3): 1−9 [18] 李炜, 宋威, 王晨妮, 张雨轩. 标签约束的半监督栈式自编码器分类算法. 小型微型计算机系统, 2019, 40(3): 488−492 doi: 10.3969/j.issn.1000-1220.2019.03.005Li Wei, Song Wei, Wang Chen-Ni, Zhang Yu-Xuan. Label regularization semi-supervised stacked autoencoder classification algorithm. Journal of Chinese Computer Systems, 2019, 40(3): 488−492 doi: 10.3969/j.issn.1000-1220.2019.03.005 [19] Chai Z L, Song W, Wang H L, Liu F. A semi-supervised auto-encoder using label and sparse regularizations for classification. Applied Soft Computing, 2019, 77: 205−217 doi: 10.1016/j.asoc.2019.01.021 [20] Yuan X F, Huang B, Wang Y L, Yang C H, Gui W H. Deep learning-based feature representation and its application for soft sensor modeling with variable-wise weighted SAE. IEEE Transactions on Industrial Informatics, 2018, 14(7): 3235−3243 doi: 10.1109/TII.2018.2809730 [21] Yuan X F, Zhou J, Huang B, Wang Y L, Yang C H, Gui W H. Hierarchical quality-relevant feature representation for soft sensor modeling: A novel deep learning strategy. IEEE Transactions on Industrial Informatics, 2019, 16(6): 3721−3730 [22] Sohaib M, Kim J M. Reliable fault diagnosis of rotary machine bearings using a stacked sparse autoencoder-based deep neural network. Shock and Vibration, 2018, 2018: 1−11 [23] Bengio Y. Learning deep architectures for AI. Foundations & Trends in Machine Learning, 2009, 2(1):1−127 [24] Chen Z Y, Li W H. Multisensor feature fusion for bearing fault diagnosis using sparse autoencoder and deep belief network. IEEE Transactions on Instrumentation and Measurement, 2017, 66(7): 1693−1702 doi: 10.1109/TIM.2017.2669947 [25] Lv F Y, Wen C L, Liu M Q, Bao Z J. Weighted time series fault diagnosis based on a stacked sparse autoencoder. Journal of Chemometrics, 2017, 31(9): e2912 doi: 10.1002/cem.2912 [26] Long W, Gao L, Li X Y. A new deep transfer learning based on sparse auto-encoder for fault diagnosis. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2017, 49(1): 136−144 [27] Vincent P, Larochelle H, Lajoie I, Bengio Y, Manzagol P A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 2010, 11(12): 3371−3408 [28] 刘国梁, 余建波. 知识堆叠降噪自编码器. 自动化学报, DOI: 10.16383/j.aas.c190375Liu Guo-Liang, Yu Jian-Bo. Knowledge-based stacked denoising autoencoder. Acta Automatica Sinica, DOI: 10.16383/j.aas.c190375 [29] 邹筱瑜, 王福利, 常玉清, 郑伟. 基于两层分块GMM-PRS的流程工业过程运行状态评价. 自动化学报, 2019, 45(11): 2071−2081Zou Xiao-Yu, Wang Fu-Li, Chang Yu-Qing, Zheng Wei. Plant-wide process operating performance assessment based on two-level multi-block GMM-PRS. Acta Automatica Sinica, 2019, 45(11): 2071−2081 [30] 王慧玲, 宋威, 王晨妮. 稀疏和标签约束半监督自动编码器的分类算法. 计算机应用研究, 2019, 36(9): 2613−2617Wang Hui-Ling, Song Wei, Wang Chen-Ni. Semi-supervised auto-encoder using sparse and label regularizations for classification. Application Research of Computers, 2019, 36(9): 2613−2617 [31] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors. Cognitive Modeling, 1988, 5(3): 1 [32] Miller P, Swanson R E, Heckler C E. Contribution plots: A missing link in multivariate quality control. Applied Mathematics and Computer Science, 1998, 8(4): 775−792 [33] Yoon S, Mac Gregor J F. Fault diagnosis with multivariate statistical models part I: Using steady state fault signatures. Journal of Process Control, 2001, 11(4): 387−400 doi: 10.1016/S0959-1524(00)00008-1 [34] 蒋立. 基于自编码器模型的非线性过程监测[博士学位论文], 浙江大学, 中国, 2018Jiang Li. Nonlinear Process Monitoring Based on Auto-encoder Model [Ph. D. dissertation], Zhejiang University, China, 2018 [35] 褚菲, 赵旭, 代伟, 马小平, 王福利. 数据驱动的最优运行状态鲁棒评价方法及应用. 自动化学报, 2020, 46(3): 439−450Chu Fei, Zhao Xu, Dai Wei, Ma Xiao-Ping, Wang Fu-Li. Data-driven robust evaluation method and application for the optimal operating status. Acta Automatica Sinica, 2020, 46(3): 439−450 [36] Meyer E J, Craig I K. The development of dynamic models for a dense medium separation circuit in coal beneficiation. Minerals Engineering, 2010, 23: 791−805 doi: 10.1016/j.mineng.2010.05.020 [37] Zhang L J, Xia X H, Zhu B. A dual-loop control system for dense medium coal washing processes with sampled and delayed measurements. IEEE Transactions on Control Systems Technology, 2017, 25(6): 2211−2218 doi: 10.1109/TCST.2016.2640946 [38] Liu Y, Chang Y Q, Wang F L, Ma R C, Zhang H L. Complex process operating optimality assessment and non-optimal cause identification using modified total kernel PLS. In: Proceedings of the 26th Chinese Control and Decision Conference. Changsha, China: IEEE, 2014. 1221−1227 -

 下载:
下载:

计量
- 文章访问数: 1780
- HTML全文浏览量: 694
- PDF下载量: 254
- 被引次数: 0
