

-
摘要: 为解决孪生网络跟踪器鲁棒性差的问题, 重新设计了孪生网络跟踪器的分类与回归分支, 提出一种基于像素上直接预测方式的高鲁棒性跟踪算法—无锚框全卷积孪生跟踪器(Anchor-free fully convolutional siamese tracker, AFST). 目前高性能的跟踪算法, 如SiamRPN、SiamRPN++、CRPN都是基于预定义的锚框进行分类和目标框回归. 与之相反, 提出的AFST则是直接在每个像素上进行分类和预测目标框. 通过去掉锚框, 大大简化了分类任务和回归任务的复杂程度, 并消除了锚框和目标误匹配问题. 在训练中, 还进一步添加了同类不同实例的图像对, 从而引入了相似语义干扰物, 使得网络的训练更加充分. 在VOT2016、GOT-10k、OTB2015三个公开的基准数据集上的实验表明, 与现有的跟踪算法对比, AFST达到了先进的性能.Abstract: In order to solve the problem of poor robustness of siamese trackers, this paper redesigns the classification and regression branches, and proposes a high robustness siamese tracker AFST (Anchor-free fully convolutional siamese tracker) based on direct prediction on pixels. Current high-performance object tracker, such as SiamRPN, SiamRPN++, CRPN, are based on predefined anchor boxes for classification and regression. On the contrary, the proposed AFST is to directly classify and predict the target box on each pixel. By removing the anchor, this paper greatly simplifies the complexity of classification task and regression task, and eliminates the problem of mismatching between anchor and target. In the training, we have further added image pairs of different instances of the same kind, thereby introducing similar semantic interferers, making the network training more adequate. Experiments on three open benchmarks datasets, VOT2016, GOT-10k and OTB2015, show that AFST achieves advanced performance compared with existing tracking algorithms.
-
Key words:
- Siamese tracker /
- prediction on pixels /
- similar semantic interferers /
- anchor-free /
- center score
-
目标跟踪作为计算机视觉的基础工作之一, 近几十年来一直作为一个热门研究方向, 被广泛应用在视觉监控、人机交互、安防检测、自动驾驶和军事侦查等领域中. 视觉跟踪分为单目标跟踪和多目标跟踪, 目前的研究热点都集中在单目标跟踪上, 通过在第一帧图像中给定目标的信息, 不断预测更新后续帧图像中目标的状态信息, 实现对目标稳定的跟踪. 但是目标跟踪的应用场景极为复杂, 光照变化、物体遮挡、目标的剧烈形变和运动以及相似物体的干扰仍然是目前跟踪领域极大的挑战.
随着深度学习技术的快速发展, 近年来基于孪生网络的跟踪算法 (SiamRPN[1]、SiamFC[2]、DaSiamRPN[3]、SiamRPN++[4]、CRPN[5])成为了目标跟踪领域的主流方向之一. 这些孪生网络跟踪器将视觉跟踪问题表示为通过目标模板特征与搜索区域特征交叉相关后得到的向量学习目标与搜索区域的相似度.
孪生网络跟踪器通常具有分类与回归两个分支. 分类分支负责输出相似度, 提供了跟踪目标的一个粗略的位置信息. 大多数孪生网络跟踪算法对于分类分支的设计大同小异, 但是在训练样本的采样中具有很大的区别. SiamRPN和SiamFC在训练中仅仅采集同一物体的图像对作为输入, 由于搜索图像中简单的背景信息和无语义的填充像素占据了大部分的区域, 因此有效的负样本很少, 导致模型辨别能力不强. DaSiamRPN在此基础上添加了不同物体构成的图像对, 由此引入了不同语义干扰物, 提高了模型的辨别能力, 但是仍然不能有效分辨同类 (相似语义) 的干扰物, 导致网络的鲁棒性仍然较差, 容易跟丢目标.
回归分支负责预测目标准确的状态信息. 目前孪生跟踪算法对于回归分支的设计主要分为两类. SiamFC采用了多尺度的测试方法, 该方法通过将搜索图像块经过多尺度调整后的多个图像块一一送入跟踪器检测, 并选取分类得分最高的图像块对应的尺度作为目标的尺度. 由于测试的尺度有限, 因此最终的目标尺度信息是很不准确的, 而且多尺度的测试会增加计算负担, 降低跟踪器的运行速度, 所以该方法是低效、不准确的. SiamRPN系列算法 (SiamRPN、DaSiamRPN、SiamRPN++) 通过在孪生网络后添加一个区域提议网络 (之后简称为RPN[6]), 实现了极高的定位精度, 这主要得益于多个锚框能够在整体上适应物体的剧烈形变, 但是多锚框的设置增加了分类与回归任务的复杂程度, 降低了跟踪器的运行效率.
针对孪生网络跟踪器鲁棒性差、设计复杂的问题, 本文构造了基于中心点搜索的无锚框全卷积孪生跟踪器 (Anchor-free fully convolutional siamese tracker with searching center point, AFST), 使系统性能得到极大提升.
1. 传统孪生网络跟踪器与检测器
下面主要对传统孪生网络跟踪器及目标检测任务中目标的回归方式进行阐述.
1.1 跟踪框架
最近, 基于孪生网络的跟踪器因为良好的跟踪精度和效率而受到了极高关注, 成为目标跟踪领域的一个热门. SINT[7]最早将跟踪任务描述为将目标区域与搜索区域匹配的过程. SiamFC改进了GOTURN[8]剪裁输入的方法, 并提出了相关性操作, 奠定了后来孪生网络跟踪器的基础. SiamRPN在相关性操作后引入了RPN模块, 在锚框上进行联合分类和回归, 大幅度提高了跟踪精度. DaSiamRPN在训练中引入了不同语义的干扰物, 并将检测数据集DET[9]、COCO[10]添加到训练中, 进一步提高了跟踪性能. SiamRPN++首次将深度网络引入跟踪器中, 并在多层特征上进行预测, 跟踪性能得到了大幅提高.
1.2 检测框架
虽然目标检测与目标跟踪具有很多差异, 但是它们的回归任务是极其相似的, 都是类别无关的, 因此目标检测的回归方式能够应用到目标跟踪任务中. 比如Faster RCNN[6]提出的RPN结构被应用在SiamRPN系列算法 (SiamRPN、DaSiamRPN、SiamRPN++、CRPN) 中, 取得了极高的定位精度.
目前目标检测器的回归方式分为三种.
使用RPN[6]的众多目标检测器 (Faster RCNN、FPN[11]、SSD[12]、RetinaNet[13]、Cascade RCNN[14]、RefineDet[15]) 在整个特征图上铺设多种不同尺度和宽高比的锚框, 通过这种稠密的采样, 检测器获得了很高的召回率. 同时通过输出物体中心和宽高相对于锚框中心和宽高的编码, 预测物体的准确的状态信息. Cascade RCNN通过堆叠多层RPN实现了极高的定位精度.
IoU-Net[16]同样借助于修正人工设定的初始框来获得最终的目标框, 其通过梯度上升的方式多次迭代修改初始框, 使初始框越来越靠近真实的目标框. 该方法定位精度极高, 并且解决了多次迭代修正目标框的问题.
相比于以上两种回归方式, 无锚框的回归方式非常简单方便, 而且取得了媲美RPN的定位精度. YOLO[17]在目标中心点附近的点直接预测目标框的大小; CornerNet[18]检测目标框的一对角点; RepPoints[19]将目标表示为多个点, 通过预测每个点的偏移使所有点匹配到物体上; FCOS[20]预测目标内的点与目标框四个边的距离来组成预测框. 无锚框回归方式编码简单, 而且不需要对初始框超参数进行调优, 很适合应用在目标跟踪任务中.
2. 基于中心点搜索的无锚框全卷积孪生网络跟踪器
本文提出的基于中心点搜索的无锚框全卷积孪生跟踪器基本思想为: 1) 相似语义负样本采样策略: 在训练过程中引入了相似语义干扰物, 提高网络的分辨能力; 2) 多层特征融合: 提出一种新的特征融合方式msf (Multistage feature fusion module), 融合高中低三层特征 (对应ResNet50[21]的第二层、第三层、第四层特征), 保证跟踪器同时具备鲁棒能力和辨别能力, 大幅减少跟踪失败的次数, 提高跟踪器的鲁棒性; 3) 新的回归方式: 提出一种基于像素上直接预测的回归方式, 在每个位置仅仅预测一次目标状态信息, 不需要进行关于锚框的复杂编码解码过程, 大幅简化了整个跟踪任务; 4) 目标框质量得分: 为输出高质量的目标框, 本文定义了一种目标框质量得分, 负责对每个位置预测的目标框打分, 并依据目标框质量得分选取得分最高的目标框作为最后的输出.
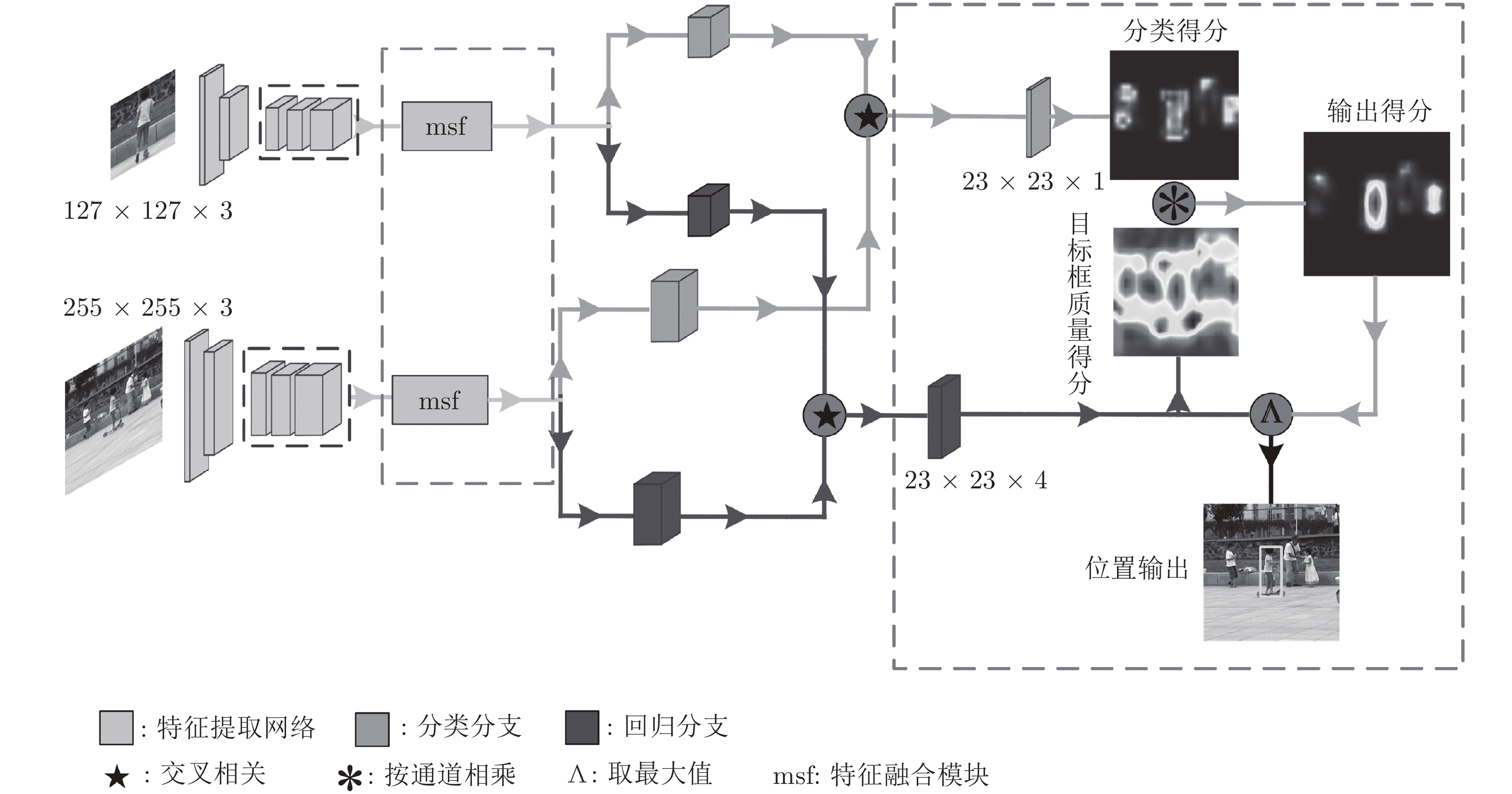
AFST跟踪器是在SiamFC[2]上改进的, 如图1所示. AFST框架由一个用于特征提取的孪生网络 和用于分类与回归的两个子网络构成, 分类分支负责对前景与背景进行分类, 回归分支负责预测目标的状态信息. 其中主干网络为ResNet50, 提取其第二层、第三层、第四层特征进行融合, 作为分类分支和回归分支的输入特征.
2.1 多级特征融合
为提高跟踪器的鲁棒性, 提出多级特征融合模块 msf, 来融合物体的细粒度表观特征和高阶的语义特征.
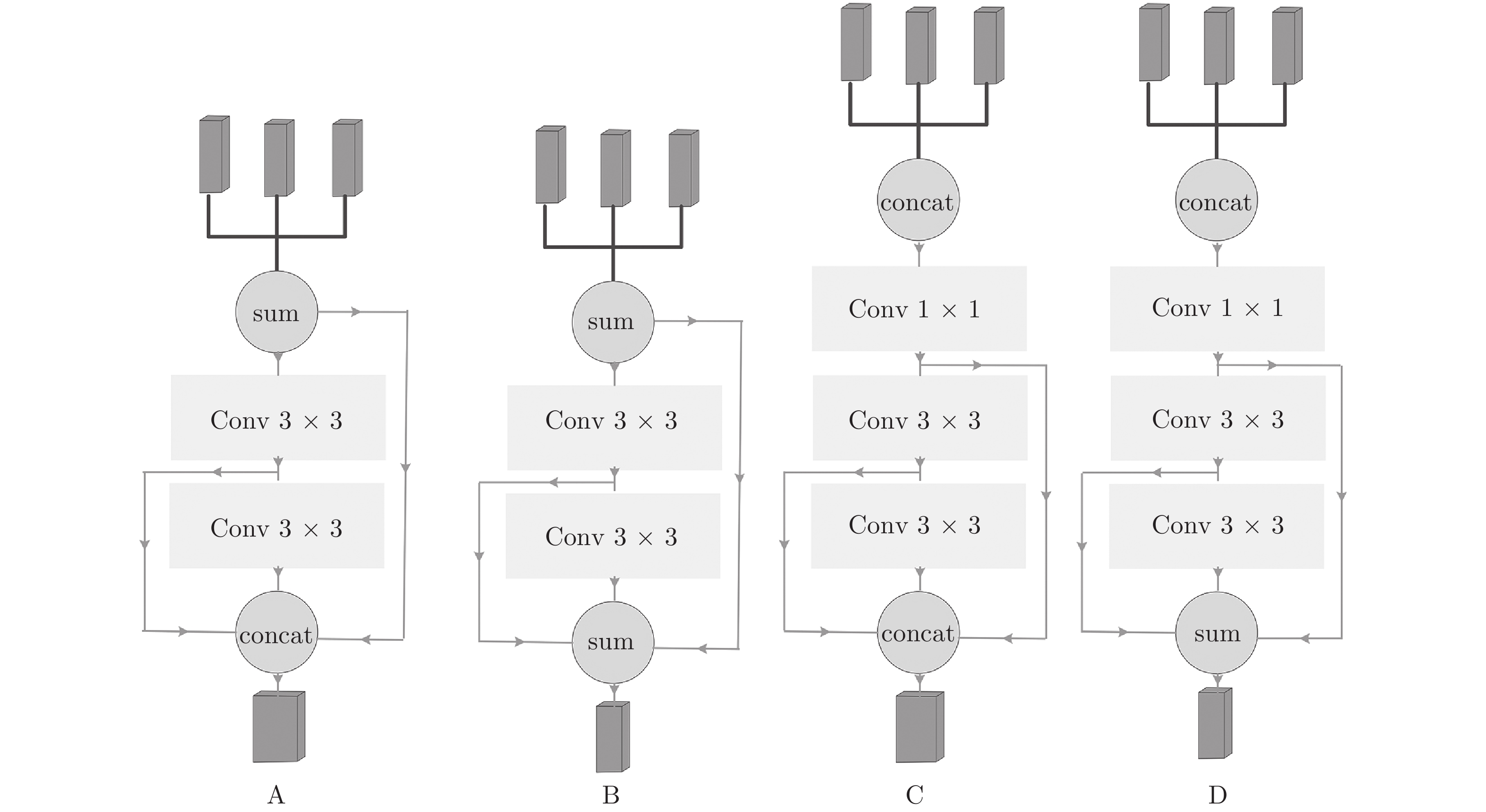
如图2, 首先采集特征, 提取网络中高中低三层特征 (对应ResNet50第四层、第三层、第二层特征), 然后使用通道上相加 (之后称为sum) 或通道上连接 (之后称为concat) 融合高中低三层特征作为模块的输入特征, 随后对输入特征进行多次3 × 3的卷积操作进一步提高特征的鲁棒能力. 为了保留细粒度特征, 在输出中通过concat或者sum融合输入特征和每个3 × 3卷积的输出特征. concat融合方式比sum融合方式能够更好地保留特征, 由于模块C在输入阶段和输出阶段均使用concat方式, 因此理论上其性能最强. 但是输入阶段使用concat会造成输入特征通道数量非常大, 只能通过1×1卷积大幅度降低维度, 导致性能降低. 因此最好在输入阶段使用sum融合方式, 避免大幅降低特征维度造成的信息丢失, 输出阶段使用concat, 尽量保留更多的信息, 所以猜想方式A性能最好. 为验证猜想, 对分别使用4种融合方式的4个跟踪器进行10个epoch的训练, 最终证明使用方式A的跟踪器在VOT2016[22]上性能最强 (Robustness最低, 为0.243). 因此方式A作为本文默认的融合方式.
2.2 相似度学习
目标跟踪任务可以描述为一个学习相似度的问题. 孪生网络具有两个分支, 模板分支负责对输入的模板图像
$ z $ 提取特征, 搜索分支负责对包含目标的搜索区域图像$ x $ 提取特征, 然后使用交叉相关操作 (Cross-correlation) 对两个特征进行处理, 输出相关性向量, 最后在相关性向量上学习相似概率. 由于两个分支的网络参数相同, 所以对$ z $ 和$ x $ 进行的映射是相同的, 因此交叉相关得到的相关特征能够反映搜索图像中的每一个区域与模板图像的相 似程度, 其定义如下$$ \begin{split} f_{i}(z,\;x) =\;& u_{i}({\rm{msf}}(\phi_{2}(z),\;\phi_{3}(z),\;\phi_{4}(z)){\text{★}} \\ &u_{i}({\rm{msf}}(\phi_{2}(x),\;\phi_{3}(x),\;\phi_{4}(x))) \end{split}$$ (1) 上式中,
$ \phi $ 代表孪生网络特征提取操作, msf 表示第2.1节中的多级特征融合操作, u表示不同任务下用来调整特征的卷积操作, i = cls、reg分别表示分类与回归任务,${\text{★}} $ 表示交叉相关操作.2.3 分类标签设计
分类任务的本质是输出当前点属于目标的概率, 因此目标框内部的点都应该作为正样本. 但是由于网络初始训练时最后的特征层对应的有效感受野比理论感受野小, 导致目标边缘区域的特征点不一定包含整个物体的信息, 其属于目标的概率相比于靠近目标中心的点属于目标的概率小. 为了对网络稳定地训练, 于是对于目标框内不同点的分类损失需要进行一定的衰减, 衰减系数定义如下
$$ damping(x,\;y) = {\rm{e}}^{\tfrac{1}{2}\left(\left(\tfrac{x-c_x}{w}\right)^{2}+\left(\tfrac{y-c_y}{h}\right)^{2}\right)\ln {\rm{\beta}}} $$ (2) 上式中,
$c_x$ 、$c_y$ 是目标中心点的坐标;$ x $ 、$ y $ 为正样本点的坐标;$ w $ 、$ h $ 为目标的宽和高; 常量${\rm{\beta}}$ 为离目标中心最远的点的衰减系数取值大小, 本文默认使用${\rm{\beta}}$ = 0.5. 加上衰减系数后, 最终的分类损失函数定义如下$$ \begin{split} L_{{\rm{pos}}} =\; &\frac{1}{N_{{\rm{pos}}}}\sum\limits_{x,\;y}1_{\{c_{x,\;y}>0\}}{ damping}(x,\;y)^{{\rm{\alpha}}} \\ & L_{{\rm{cls}}}(p_{x,\;y},\;c_{x,\;y}) \end{split} $$ (3) 上式中,
$N_{{\rm{pos}}}$ 表示正样本点的数量;$L_{{\rm{cls}}}$ 表示交叉熵误差;$ p_{x,\;y} $ 、$ c_{x,\;y} $ 分别表示输出的分类得分和分类标签; 常量${\rm{\alpha}}$ 取值默认为2, 用于控制衰减的程度.2.4 回归方式
本文的回归方式将目标框内所有的点作为正样本, 并抛弃了锚框, 不再将真实目标位置信息通过锚框进行编码, 而是直接预测目标中心
$c_x$ 、$c_y$ 相对于该特征点位置$ x $ 、$ y $ 的偏移$ off_{x}^{*} $ 与$ off_{y}^{*} $ 以及目标真实的大小$ w^{*} $ 与$h^{*}$ , 如图3所示.坐标
$ x $ 、$ y $ 的回归目标定义如下$$ off_{{x}}^{*} = \frac{x-c_x}{s}, \quad off_{{y}}^{*} = \frac{y-c_y}{s} $$ (4) $$ w^{*} = \frac{w}{s},\quad h^{*} = \frac{h}{s} $$ (5) 式(4)、式(5)中,
$ s $ = 8为网络的步长.2.5 基于质量得分搜索目标框
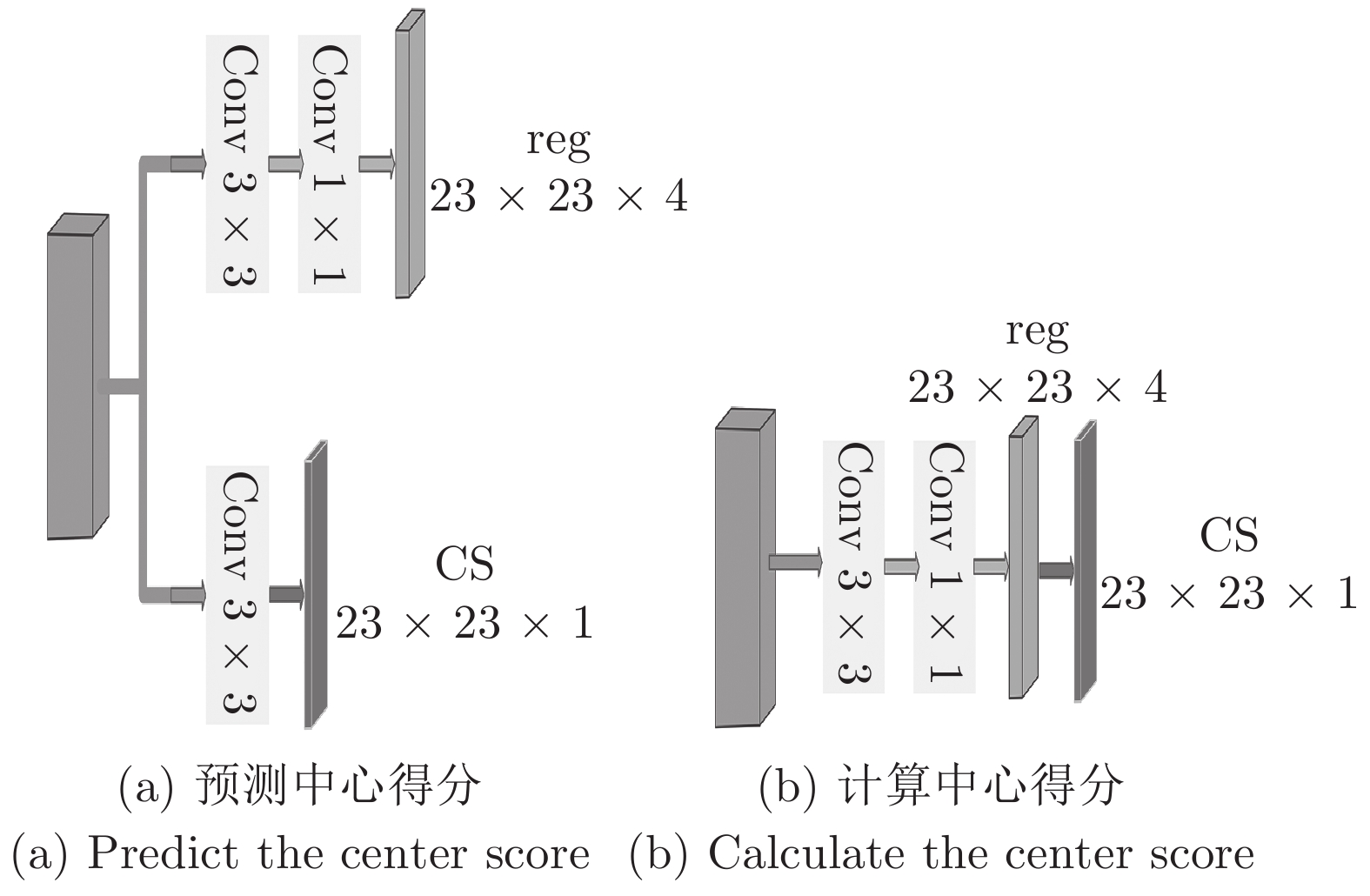
经典的检测算法是利用分类得分作为置信度来选择最终的预测框, 但是IoU-Net[16]提出分类得分与预测框的好坏是没有必然联系的. 假定越靠近目标中心的点预测的目标框越准确, 于是提出了中心得分 (Center score, CS), 用于对每个点预测的目标框进行打分, 然后依据每个点的得分搜索出最终的目标框. 中心得分有两种形式, 定义如下
$$ {{\rm{CS}}} = {\rm{e}}^{\tfrac{1}{2}\left(\left(\tfrac{off_x}{w}\right)^{2}+\left(\tfrac{off_y}{h}\right)^{2}\right)\ln {\rm{\beta}}} $$ (6) 上式中,
$off_x$ 与$off_y$ 分别为当前点相对于目标中心的偏移,$ w $ 、$ h $ 为目标框的宽和高, 通过常量${\rm{\beta}}$ 限定了目标框顶点处的目标框得分大小, 实验中取0.25. 图4展示了两种计算CS的方式.图4 (a) 为在回归分支上加上一个CS预测分支, 训练时的标签直接通过式(6)计算得到; 图4 (b) 为利用回归分支预测输出的状态信息
$ off_{x}^{*} $ 、$ off_{y}^{*} $ 、$ w^{*} $ 、$ h^{*} $ 按照式(6)直接计算CS得分. 通过回归输出直接计算CS方式虽然稳定性较差, 但是由于不需要添加额外的预测分支, 能够简化网络结构, 因此本文跟踪器默认直接计算CS得分. 为了验证直接计算出CS得分的有效性, 图5中用热力图的方式可视化了CS得分和分类得分.图5 (a) 为分类分支的得分, 由于整个目标框内所有点被作为正样本, 因此分类得分中的响应区域为一个矩形; 图5 (b) 为计算的CS得分, 中间响应高, 四周响应低, 符合CS得分的定义; 图5 (c) 为经过图5 (a)、图5 (b)相乘得到的修正后的分类得分, 由中心向四周逐渐递减; 图5 (d) 为通过图5 (c)搜索到的最后的目标框.
2.6 采样策略
为提高跟踪器的辨别能力, 提出了相似语义负样本的采样策略, 在训练中引入相似语义干扰物. 图6对比了不同的图像对采样方式.
图6中, 第1列和第2列为SiamFC训练中采样得到的图像对 (之后称作正样本图像对), 可以看出第1列的搜索图像大部分都是填充的像素, 没有任何语义信息, 第2列的搜索图像则大部分都是地面、 草地这些简单的背景信息. 这两种情况大量存在于训练集中, 导致跟踪器缺乏足够的困难负样本进行有效地训练. 第3列为DaSiamRPN训练中新增的图像对 (之后称作不同语义负样本图像对), 在搜索图像中引入不同语义的干扰物作为负样本, 使跟踪器学习到区分不同语义干扰物的能力. 第4列和第5列为新增的采样方式获取的图像对 (之后称作相似语义负样本图像对), 模板图像中的目标与搜索图像中的目标为同一类物体, 引入了相似语义干扰物, 使得跟踪器能够学习到区分相似语义干扰物的能力. 最终训练图像对由正样本图像对、不同语义负样本图像对和相似语义负样本图像对构成, 三者比例为4 : 1 : 1.
不同语义的物体和无语义的背景属于目标的概率为0, 但是相似语义干扰物与目标类别相同, 经过交叉相关操作后会有较高的响应, 所以其属于目标的概率不应该为0. 因此对相似语义负样本的误差进行一定程度地衰减, 不对其进行完全的惩罚. 为了便于编程, 将相似语义负样本的标签设为 –1, 则负样本的误差函数定义如下
$$ \begin{split} L_{{\rm{neg}}} =\;& \frac{1}{N_{{\rm{neg}}}}\sum\limits_{x,\;y}1_{\{c_{x,\;y} = \;0\}}L_{{\rm{cls}}}(p_{x,\;y},c_{x,\;y})+ \\ &0.5_{\{c_{x,\;y}<0\}}^{\rm{c}}L_{{\rm{cls}}}(p_{x,\;y},c_{x,\;y}+1) \end{split}$$ (7) 上式中,
$N_{{\rm{neg}}}$ 为负样本点的数量; 常量$ {\rm{c}} $ 默认为2, 控制着相似语义负样本误差衰减的程度.2.7 损失函数
整个网络损失由分类损失和回归损失共同构成
$$ L = \frac{1}{2}\lambda_{1}L_{{\rm{pos}}}+\frac{1}{2}\lambda_{2}L_{{\rm{neg}}}+\lambda_{3}L_{{\rm{reg}}} $$ (8) 上式中,
$L_{{\rm{pos}}}$ 、$L_{{\rm{neg}}}$ 、$L_{{\rm{reg}}}$ 分别为正负样本分类损失和回归损失,$ \lambda_{1} $ 、$ \lambda_{2} $ 、$ \lambda_{3} $ 表示正负样本分类损失和回归损失的权重. 本文为了平衡正负样本的损失, 将$ \lambda_{1} $ 、$ \lambda_{2} $ 都设为1. 由于训练中对于负样本图像对只对分类分支计算梯度, 为了平衡两个分支的梯度, 本文中将$ \lambda_{3} $ 设为1.5.3. 算法实验
3.1 实验设计
由于机能和资源的限制, 只采用了ILSVRC-VID2015[9]、GOT-10k[23]以及COCO[10]的一部分作为基础的训练数据集. 整个训练过程中, 正样本图像对、不同语义负样本图像对和相似语义负样本图像对的比例为4 : 1 : 1, 同时在搜索图像上进行均匀地移动及均匀地尺度缩放.
由于融合的特征包含有浅层特征, 而浅层特征的改动很容易破坏整个网络的性能, 所以冻结了ResNet50的参数, 并在第10个epoch时对ResNet50第三层和第四层进行训练, 第15个epoch时加入ResNet50第二层进行训练. 初始学习率为0.01, 经过20个epoch逐步衰减到0.0001, 每个epoch包含16万个图像对. 使用的GPU为单个RTX 2070, batch大小为18, 训练时长为65个小时.
3.2 消融实验
AFST是以SiamFC网络为基准进行改进的, 经过添加各种组件后, 最终的跟踪器AFST的性能得到了较大的提升. 在消融实验中, 使用ILSVRC-VID2015和一部分COCO作为训练集, 并在VOT2016[22]数据集上计算准确率 (A)、鲁棒性 (R) 和期望平均重叠率 (EAO) 三种指标的性能, 观察各种改进方案带来的性能上的提升.
如表1所示, 第1行为对比的基准SiamFC网络, 仅仅只执行分类任务 (cls), 通过多尺度测试来估计目标的状态; 第2行通过偏移输入的方式引入深度网络ResNet50作为SiamFC的主干网络; 第3行加入简单的回归分支 (reg); 第4行进一步融合高、中、低三层特征; 第5行开始在训练时添加相似语义负样本; 第6行到第8行进一步引入CS质量评估得分, 并分别使用concat、sum与msf三种特征融合方式.
表 1 消融实验Table 1 Ablation experiments序号 主干网络 子网络 质量得分 A R EAO 融合方式 新采样策略 1 Alex cls none 0.530 0.466 0.235 none none 2 ResNet50 cls none 0.579 0.386 0.280 none none 3 ResNet50 cls + reg none 0.592 0.333 0.345 none none 4 ResNet50 cls + reg none 0.602 0.302 0.355 sum none 5 ResNet50 cls + reg none 0.607 0.242 0.382 sum yes 6 ResNet50 cls + reg CS 0.610 0.224 0.415 concat yes 7 ResNet50 cls + reg CS 0.614 0.238 0.397 sum yes 8 ResNet50 cls + reg CS 0.624 0.205 0.412 msf yes 对比第1行与第2行, 可以看出更强的主干网络将大幅提高跟踪的性能, 提升幅度达到A (+0.049)、R (−0.080)、EAO (+0.045). 对比第2行与第3行, 在添加了简单的回归分支后, EAO得到进一步大幅度的提升, 达到+0.065, 同时R出现了−0.053的提升, 主要是由于加入回归分支后采用了与SiamFC不同的正样本定义策略, 增强了跟踪器的鲁棒性. 第4行在第3行的基础上使用sum融合方式在原有的高层特征上引入中层、低层特征, 最终的结果显示R出现明显的−0.031的提升, 同时A和EAO也得到了+0.010的增长, 说明中、低层特征由于特征等级低, 具有一定的分辨能力, 同时低层特征在一定程度上也能提高定位的精度. 第5行在训练中添加了相似语义样本对, R出现了−0.060的提升, 这表明新的采样策略确实有效, 能够大幅提升网络对于干扰物体的辨别能力. 对比第5行与第7行, 在引入目标框的质量得分CS以后, A和EAO能够得到进一步明显的提升, 而R的提升不明显, 说明CS确实能够辅助找到靠近目标中心的高质量目标框. 对比第6行与第7行得出, concat融合方式是优于sum的. 第8行引入最终的融合方式msf构成最终的AFST算法, 对比第7行, R得到了明显的提高, 达到−0.033, 这主要是由于msf 融合的过程中进一步提高了特征的鲁棒性, 同时又融合了低层的细粒度特征, 兼具了强分辨力特征.
3.3 多个数据集上性能对比实验
3.3.1 VOT2016测试结果对比
VOT2016包含60个视频, 具有遮挡、尺度变化、快速运动等挑战. 在VOT2016数据集上计算了准确率 (A)、鲁棒性 (R) 和期望平均重叠率 (EAO) 三个指标的性能. 表2对比了AFST与多个跟踪器在VOT2016上的性能, AFST在所有指标上均超越了DaSiamRPN、MDNet[24]、SiamRPN++等先进的跟踪器.
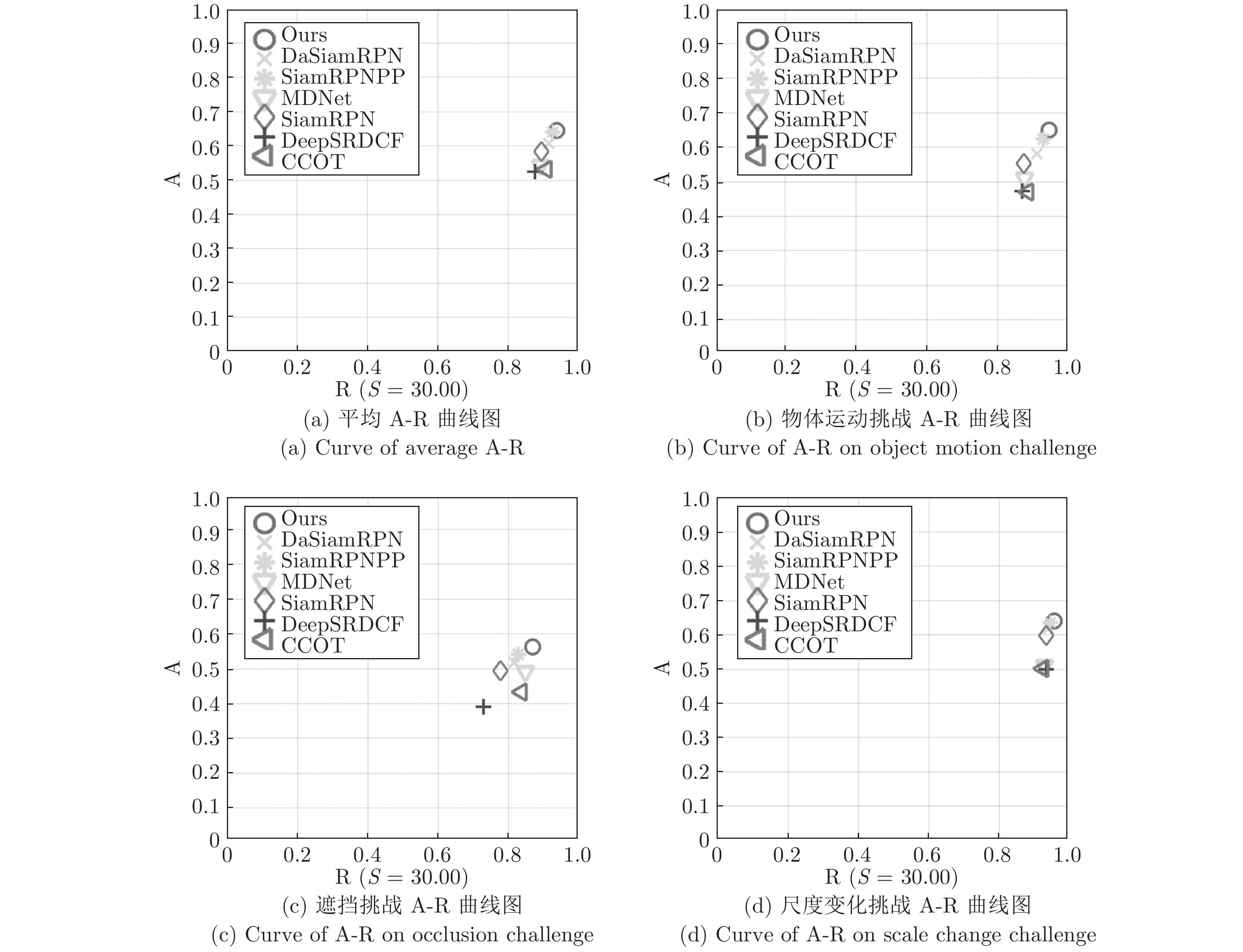
表 2 VOT2016上与多个跟踪器对比Table 2 Compare with multiple trackers on VOT2016CCOT ECO MDNet DeepSRDCF SiamRPN DaSiamRPN Ours SiamRPN++ A 0.541 0.550 0.542 0.529 0.560 0.609 0.651 0.642 R 0.238 0.200 0.337 0.326 0.260 0.224 0.149 0.196 EAO 0.331 0.375 0.257 0.276 0.344 0.411 0.485 0.464 为深入分析AFST鲁棒性的来源, 表3中记录了AFST与其他算法在遮挡、运动变化、相机运动等多种挑战因素下的跟踪失败率, 以及整体的平均失败率和加权失败率. 从表3中可以发现, AFST跟踪器在物体运动、遮挡、尺度变化挑战中失败率大幅低于其他跟踪器, 且在整体的平均失败率和加权失败率上达到了最好的性能, 超越了SiamRPN++.为直观反映AFST的高鲁棒性能, 图7 (a) ~ 图7 (d)分别记录了平均情况下以及在物体运动变化、遮挡、尺度变化挑战中的精度−鲁棒性曲线图. 图7中, SiamRPNPP代表SiamRPN++.
表 3 不同挑战因素下的失败率Table 3 Failure rates under different challenge factors相机运动 目标丢失 光照变化 物体运动 遮挡 尺度变化 平均 加权 CCOT 24 11 2 20 14 13 14.0 16.6 Ours 20 3 2 9 11 7 8.7 10.2 DaSiamRPN 26 4 2 15 16 10 12.2 14.2 SiamRPN 33 13 1 22 20 11 16.7 20.1 SiamRPN++ 20 7 1 12 15 9 10.7 12.4 MDNet 33 18 4 21 13 12 17.0 21.1 DeepSRDCF 28 17 3 23 25 11 17.9 20.3 为进一步直观地测试算法在各种情况下的鲁棒性, 在图8中, 挑选了具有背景干扰、物体运动变化、遮挡三个挑战属性的视频, 对6种算法进行实验对比. 下面对三个视频上的跟踪结果进行分析.
图8中, 从上到下的三个视频分别为handball1、birds1、nature. handball1用来测试算法对于背景中干扰物的辨别能力. handball1视频中, 当背景中的干扰物越来越多地进入搜索区域时, 大部分算法由于辨别能力不足, 导致跟踪到了错误的目标, 而AFST由于采用了低层特征, 能够很好地辨别相似的干扰物, 对目标进行准确的跟踪.
birds1视频中目标的快速运动会产生极大的形态变化. AFST由于使用了深层语义特征, 并进一步通过融合模块提高特征的鲁棒性, 能够在物体形变和模糊等情况下仍然产生较强的响应. AFST是唯一能够全程准确跟踪目标的跟踪器.
nature视频中, 目标会被相似的物体遮挡住大部分区域, 此时仅仅只有AFST和DaSiamRPN克服遮挡跟踪到了目标. 但是接下来当目标和相似干扰物分离时, DaSiamRPN由于对相似干扰物辨别能力不足, 错误跟踪到了干扰物体, 而AFST凭借出色的辨别能力, 准确跟踪到了目标.
3.3.2 OTB2015测试结果对比
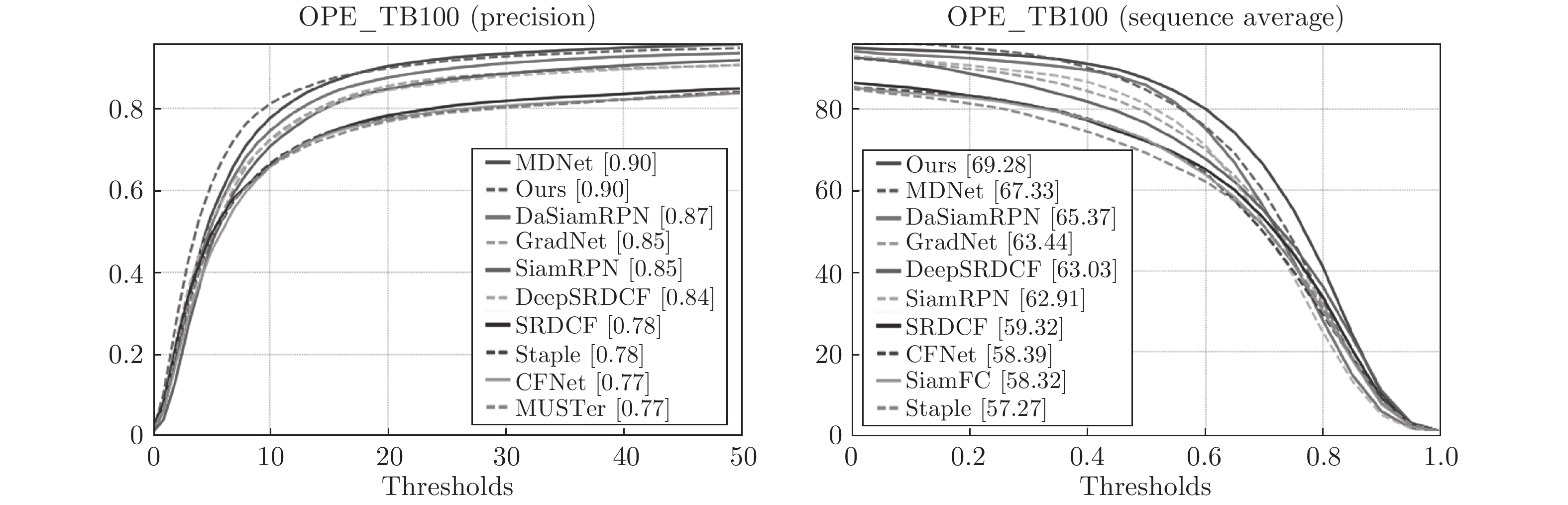
在OTB2015[25]数据集上利用常规测试对AFST算法与DaSiamRPN、GradNet[26]、DeepSRDCF[27]、CFNet[28]、SiamFC、MDNet[24]等9种算法进行比较. 在图9中绘制了准确率和成功率曲线, 其中左边是准确率曲线, 右边为成功率曲线. 从图9得出, AFST无论在准确率还是成功率指标上均达到了先进的性能. (由于SiamRPN++ 官方代码库pysot中用于测试OTB数据集的模型文件不完整, 无法用于测试, 并且SiamRPN++ 用于测试OTB、VOT的模型是分别训练的, 所以不与其比较.)
3.3.3 GOT-10k测试结果对比
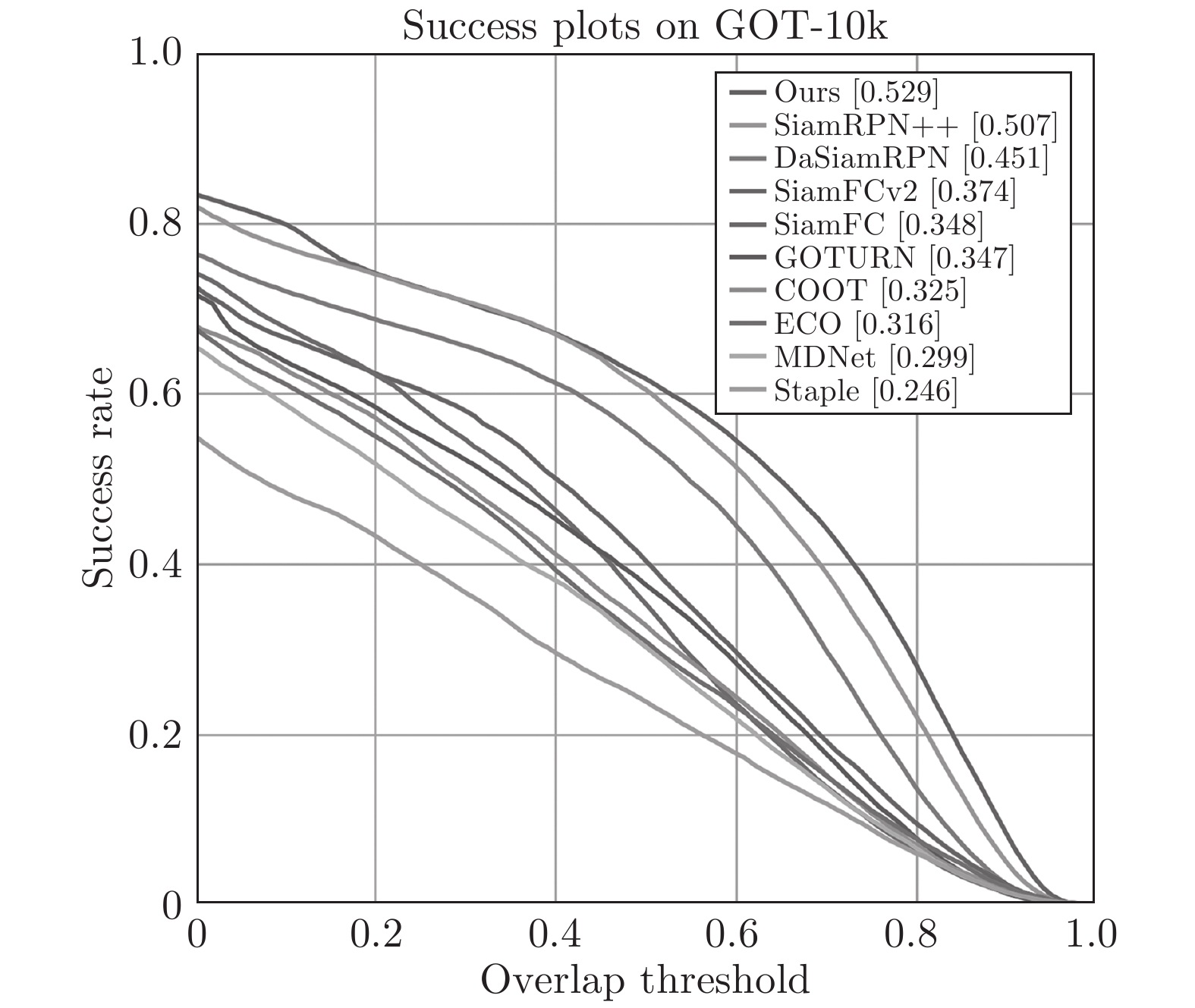
在GOT-10k[23]测试集上对AFST进行测试, 计算了AO (平均重叠率)、SR5和SR75 (不同重叠阈值下的成功率) 三个指标的性能, 并与一系列深度学习算法和相关滤波算法比较. 表4可以看出, AFST全面超过了SiamRPN++、MDNet等先进的算法. 图10将AFST与GOT-10k官方记录的多个跟踪器的结果对比, 并绘制了不同重叠率下的成功率曲线图.
表 4 GOT-10k上与多个跟踪器对比Table 4 Compare with multiple trackers on GOT-10kSiamFC ECO MDNet DeepSRDCF SiamRPN++ Ours AO 0.348 0.316 0.299 0.451 0.507 0.529 SR75 0.098 0.111 0.099 0.216 0.311 0.370 SR5 0.353 0.303 0.303 0.543 0.605 0.617 3.3.4 与SiamRPN++ 算法对比
在VOT2016的性能对比实验中, AFST在物体快速运动和尺度变化等挑战下的鲁棒性能大幅领先于SiamRPN++, 于是在包含物体运动和尺度变化挑战的视频上对AFST 和SiamRPN++ 的输出进行对比分析. 如图11两个不同序列的图像对中, 第一行为SiamRPN++ 的输出结果, 第二行为AFST 的输出结果. 当物体短时间内产生较大的形变和尺度变化后, SiamRPN++ 会对目标的周围物体或背景产生相当高的响应, 形成所谓的假阳性输出. 将假阳性的样本点对应的锚框绘制出来 (为简洁篇幅, 只讨论一种类型的锚框的错误匹配问题), 发现输出假阳性的锚框与目标框的重叠度(Intersec-tion over union, IoU)超过了0.3, 甚至逼近0.5. 在SiamRPN++训练中, 与目标框IoU大于0.3、小于0.6的锚框是不参与惩罚的, 由此猜测这些与目标框IoU大于0.3、小于0.6的锚框会随机产生高响应, 造成假阳性的输出.
为证明与目标框IoU大于0.3、小于0.6的外部锚框会产生假阳性输出, 在VOT2016部分视频序列上运行SiamRPN++ 跟踪器, 统计与目标框IoU不同的锚框和对应的得分, 图12中绘制了所有锚框的散点图.
图12中可以看出, 当锚框与目标框的IoU处于0.3到0.6之间, 输出的得分是近乎随机的. 于是得出SiamRPN++ 鲁棒性差的本质原因在于, 其利用模板与锚框进行比较会产生误匹配的情况. 即当物体发生剧烈形变和尺度变化时, 物体大小与锚框大小失衡, 物体周围的锚框会与物体的重叠率高于0.3, 甚至逼近0.5, 造成错误匹配, 而由于RPN的输出特性, 导致这些错误匹配的锚框会产生很强的响应, 于是形成假阳性的输出. AFST直接将模板与搜索区域上子窗口对应的点进行匹配, 将目标内的所有点作为正样本, 不会出现SiamRPN++ 算法中的误匹配问题, 因此AFST的鲁棒性更强. 同时观察到与目标框IoU 为0 的锚框会产生很强的响应, 主要是由于SiamRPN++ 算法无法有效辨别干扰物, 而AFST 在训练中加入了相似语义负样本, 进一步提高了鲁棒性. AFST 在设计中克服了以上两个影响鲁棒性的因素, 因此达到了更高的性能.
4. 结论
本文分析了传统孪生网络跟踪器鲁棒性不足和分类回归任务复杂的缺点, 并以SiamFC为基准设计了全新的分类与回归分支, 引入了相似语义负样本的训练策略和边界框评估分数等措施, 构成了AFST算法, 并通过消融实验证明了每个添加组件和策略对于跟踪性能的提升作用. 在多个跟踪数据集上进行测试, 证明了本文算法具有先进的性能. 值得注意的是, 本文算法目前仅仅只利用了ILSVRC-VID2015、GOT-10k和COCO的一部分进行训练, 未来将增大训练数据集以进一步提升性能.
-
表 1 消融实验
Table 1 Ablation experiments
序号 主干网络 子网络 质量得分 A R EAO 融合方式 新采样策略 1 Alex cls none 0.530 0.466 0.235 none none 2 ResNet50 cls none 0.579 0.386 0.280 none none 3 ResNet50 cls + reg none 0.592 0.333 0.345 none none 4 ResNet50 cls + reg none 0.602 0.302 0.355 sum none 5 ResNet50 cls + reg none 0.607 0.242 0.382 sum yes 6 ResNet50 cls + reg CS 0.610 0.224 0.415 concat yes 7 ResNet50 cls + reg CS 0.614 0.238 0.397 sum yes 8 ResNet50 cls + reg CS 0.624 0.205 0.412 msf yes  下载: 导出CSV
下载: 导出CSV
表 2 VOT2016上与多个跟踪器对比
Table 2 Compare with multiple trackers on VOT2016
CCOT ECO MDNet DeepSRDCF SiamRPN DaSiamRPN Ours SiamRPN++ A 0.541 0.550 0.542 0.529 0.560 0.609 0.651 0.642 R 0.238 0.200 0.337 0.326 0.260 0.224 0.149 0.196 EAO 0.331 0.375 0.257 0.276 0.344 0.411 0.485 0.464
下载: 导出CSV
表 3 不同挑战因素下的失败率
Table 3 Failure rates under different challenge factors
相机运动 目标丢失 光照变化 物体运动 遮挡 尺度变化 平均 加权 CCOT 24 11 2 20 14 13 14.0 16.6 Ours 20 3 2 9 11 7 8.7 10.2 DaSiamRPN 26 4 2 15 16 10 12.2 14.2 SiamRPN 33 13 1 22 20 11 16.7 20.1 SiamRPN++ 20 7 1 12 15 9 10.7 12.4 MDNet 33 18 4 21 13 12 17.0 21.1 DeepSRDCF 28 17 3 23 25 11 17.9 20.3
下载: 导出CSV
表 4 GOT-10k上与多个跟踪器对比
Table 4 Compare with multiple trackers on GOT-10k
SiamFC ECO MDNet DeepSRDCF SiamRPN++ Ours AO 0.348 0.316 0.299 0.451 0.507 0.529 SR75 0.098 0.111 0.099 0.216 0.311 0.370 SR5 0.353 0.303 0.303 0.543 0.605 0.617
下载: 导出CSV
-
[1] Li B, Yan J J, Wu W, Zhu Z, Hu X L. High performance visual tracking with siamese region proposal network. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 8971−8980 [2] Bertinetto L, Valmadre J, Henriques J F, Vedaldi A, Torr P H. Fully-convolutional siamese networks for object tracking. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 850−865 [3] Zhu Z, Wang Q, Li B, Wu W, Yan J J, Hu W M. Distractor-aware siamese networks for visual object tracking. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 101−117 [4] Li B, Wu W, Wang Q, Zhang F Y, Xing J L, Yan J J. SiamRPN++: Evolution of siamese visual tracking with very deep networks. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 4282−4291 [5] Fan H, Ling H B. Siamese cascaded region proposal networks for real-time visual tracking. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 7952−7961 [6] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. In: Procoeedings of the 2015 Advances in Neural Information Pro cessing Systems. Montreal, Canada: MIT Press, 2015. 91−99 [7] Tao R, Gavves E, Smeulders A W M. Siamese instance search for tracking. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1420−1429 [8] Held D, Thrun S, Savarese S. Learning to track at 100 fps with deep regression networks. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 749−765 [9] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3): 211−252 doi: 10.1007/s11263-015-0816-y [10] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 740−755 [11] Lin T Y, Dollar P, Girshick R, He K M, Hariharan B, Belongie S. Feature pyramid networks for object detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 2117−2125 [12] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y, et al. Ssd: Single shot multibox detector. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 21−37 [13] Lin T Y, Goyal P, Girshick R, He K M, Dollar P. Focal loss for dense object detection. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2980−2988 [14] Cai Z W, Vasconcelos N. Cascade R-CNN: Delving into high quality object detection. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 6154−6162 [15] Zhang S F, Wen L Y, Bian X, Lei Z, Li S Z. Single-shot refinement neural network for object detection. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 4203−4212 [16] Jiang B R, Luo R X, Mao J Y, Xiao T T, Jiang Y N. Acquisition of localization confidence for accurate object detection. In: Proceedings of the 15th European Conference on Computer Vision. Salt Lake City, USA: IEEE, 2018. 784−799 [17] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 779−788 [18] Law H, Deng J. Cornernet: Detecting objects as paired keypoints. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 734−750 [19] Yang Z, Liu S H, Hu H, Wang L W, Lin S. Reppoints: Point set representation for object detection. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, Korea: IEEE, 2019. 9657−9666 [20] Tian Z, Shen C H, Chen H, He T. Fcos: Fully convolutional one-stage object detection. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, Korea: IEEE, 2019. 9627−9636 [21] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [22] Kristan M, Leonardis A, Matas J, Felsberg M, Chi Z Z. The visual object tracking VOT2016 challenge results. In: Proceedings of the 14th European Conference on Computer Vision Workshop. Amsterdam, The Netherlands: Springer, 2016. 191−217 [23] Huang L, Zhao X, Huang K. GOT-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019: 1−1 [24] Nam H, Han B. Learning multi-domain convolutional neural networks for visual tracking. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 4293−4302 [25] Wu Y, Lim J, Yang M. Object tracking benchmark. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1834−1848 doi: 10.1109/TPAMI.2014.2388226 [26] Li P X, Chen B Y, Ouyang W L, Wang D, Yang X Y, Lu H C. Gradnet: Gradient-guided network for visual object tracking. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, Korea: IEEE, 2019. 6162−6171 [27] Danelljan M, Hager G, Shahbaz Khan F, Felsberg M. Convolutional features for correlation filter based visual tracking. In: Proceedings of the 2015 IEEE International Conference on Computer Vision Workshops. Santiago, Chile: IEEE, 2015. 58−66 [28] Valmadre J, Bertinetto L, Henriques J, Vedaldi A, Torr P H. End-to-end representation learning for correlation filter based tracking. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 2805−2813 -

 下载:
下载:


























































计量
- 文章访问数: 971
- HTML全文浏览量: 383
- PDF下载量: 229
- 被引次数: 0
