

-
摘要: 甲骨文字图像可以分为拓片甲骨文字与临摹甲骨文字两类. 拓片甲骨文字图像是从龟甲、兽骨等载体上获取的原始拓片图像, 临摹甲骨文字图像是经过专家手工书写得到的高清图像. 拓片甲骨文字样本难以获得, 而临摹文字样本相对容易获得. 为了提高拓片甲骨文字识别的性能, 本文提出一种基于跨模态深度度量学习的甲骨文字识别方法, 通过对临摹甲骨文字和拓片甲骨文字进行共享特征空间建模和最近邻分类, 实现了拓片甲骨文字的跨模态识别. 实验结果表明, 在拓片甲骨文字识别任务上, 本文提出的跨模态学习方法比单模态方法有明显的提升, 同时对新类别拓片甲骨文字也能增量识别.Abstract: There are two types of oracle character images: handprinted ones that are clean, and ones scanned from bones and shells that are noised. The collection of handprinted samples is easier than that of scanned images. Therefore, to improve the recognition of scanned oracle characters, we propose a method based on cross-modal deep metric learning to take advantage of the handprinted samples. Via shared feature space learning using cross-modal handprinted and scanned samples, scanned characters can be recognized by nearest neighbor classification in the shared space. Experimental results demonstrate that the proposed method not only achieves better performance in oracle character recognition but also can recognize new categories incrementally.
-
甲骨文字是早在中国商朝时期就出现的文字, 是世界上最古老的文字之一, 同时也是中国及东亚已知的最早成体系的一种文字形式. 自动识别甲骨文字对考古学、古文字学以及历史年代学等多个领域都有着非常重要的应用价值. 目前甲骨文字标注基本只能依靠甲骨文专家手动处理, 计算机自动检测与识别技术刚刚起步, 性能远不能达到实用化水平. 随着人工智能技术的发展, 如何让计算机像处理现代文字一样处理甲骨文字, 成为计算机学者和文字与语言学者共同关注的课题.
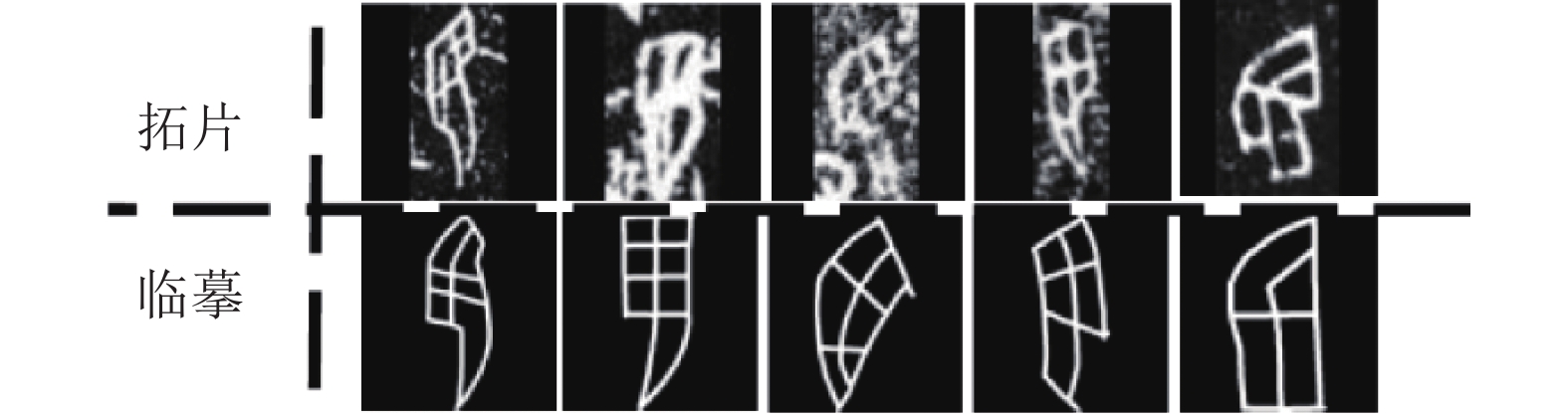
如图1所示, 甲骨文字图像可以分为临摹甲骨文字图像与拓片甲骨文字图像两类. 拓片甲骨文字图像是从龟甲、兽骨等载体上获取的原始拓片图像, 临摹甲骨文字图像是专家临摹拓片甲骨文字后得到的高清图像, 修复了拓片甲骨文字图像的残缺和噪声等问题. 临摹甲骨文字图像可以通过临摹、手绘得到大量样本, 而拓片甲骨文字因为客观条件的限制难以获取. 由于缺少训练样本, 拓片甲骨文字识别很难取得较高的识别精度[1]. 因此, 本文研究如何用临摹甲骨文字样本辅助训练分类器进行拓片甲骨文字识别. 同时, 由于一些拓扑甲骨文字类别没有训练样本, 甲骨文字的增量识别也是辅助甲骨文字专家进行语言研究的重要手段.
由于甲骨文字本身具有噪声严重、图像残缺(如图2所示)、类内样本少、类间样本不均衡等问题, 文字识别领域性能优异的深度学习方法[2-4]由于依赖大量样本训练而难以得到满意的识别性能. Guo等[5]提出了一种基于卷积神经网络(Convolutional neural network, CNN)的甲骨文字分类方法, 他们在基于Gabor算子的低层特征和基于稀疏自编码器[6]的中层特征表示基础上, 设计了一种多特征融合的层次化特征表示方法, 继而通过CNN[7]实现了更好的识别效果. 这种方法依然是基于常规分类任务的CNN框架, 并没有充分利用甲骨文字自身的特点, 所以对样本极少的类别很难取得良好的识别性能.
为了充分利用临摹甲骨文字训练样本以提高拓片甲骨文字的识别性能, 我们提出一种基于深度度量学习的跨模态甲骨文字识别方法. 基于CNN和深度度量学习分别将拓片甲骨文字与临摹甲骨文字映射到相同维度的特征空间, 并通过对抗学习算法使相同类别的拓片甲骨文字和临摹甲骨文字具有相似的特征分布, 再使用深度度量学习对拓片甲骨文字特征进行修正, 以增大拓片字符样本与异类临摹甲骨文字特征的距离, 同时减小与同类临摹甲骨文字特征的距离, 实现甲骨文字的跨模态特征空间建模. 在跨模态特征学习的基础上, 我们以临摹甲骨文字特征作为原型, 使用最近邻分类方法对拓片甲骨文进行识别, 不仅可以提高已知(已训练)类别的识别性能, 还可以对没有训练样本的拓片甲骨文字进行增量识别(使用临摹甲骨文字原型). 根据已有资料来看, 本文工作首先在甲骨文字识别中提出跨模态学习方法, 通过利用临摹甲骨文字明显提高了拓片甲骨文字的识别精度, 并且可以实现对无训练样本的新类别拓片甲骨文字增量识别.
本文接下来的组织结构如下: 第1节主要介绍与本文研究相关的甲骨文字识别和草图识别, 以及深度度量学习和跨模态特征学习; 第2节介绍本文提出的跨模态甲骨文字识别方法; 第3节介绍实验设置和实验结果及分析; 第4节给出全文总结.
1. 相关工作
1.1 基于深度学习的甲骨文字识别和草图识别
甲骨文字带有明显的图画痕迹, 因而也可以被看作是一种草图. 早期的草图识别工作, 一般都是先提取一些人工设计的特征, 例如形状上下文特征(Shape context, SC)[8]、方位形状直方图(Histogram of orientation shape context, HOOSC)[9] 等; 然后将这些特征送入支撑向量机(Support vector machine, SVM)[10] 等分类器进行识别.
随着深度学习的发展, 研究者们开始采用深度学习方法进行草图识别. Yu等[11]提出了一种多尺度、多架构的CNN 框架以及两种新颖的数据增强策略, 通过基于联合贝叶斯的方案对多个子网络进行融合后, 得到了较高识别性能. Creswell等[12]提出了一种基于生成对抗神经网络(Generative adversarial networks, GAN)[13] 的CNN 特征提取器. 其采取了一种无监督的方式来训练生成对抗神经网络, 使之能够生成可以以假乱真的数据, 然后把去掉最后一层全连接层的网络作为特征提取器. 该方法在一个商业图标数据集上进行草图检索实验, 取得了不错的效果.
相对而言, 基于深度学习的甲骨文字识别的工作目前十分稀缺. Guo等[5]提出了一种基于CNN 的甲骨文字分类方法, 他们设计了一种多层次特征融合的表示方法, 继而通过结合CNN提高了识别精度. 然而, 他们在实验中丢掉了小样本量的类别, 仅仅在一个样本量类间分布均衡且类别数较小的数据集上进行了相关实验.
1.2 深度度量学习
度量学习的目标是学习一个可以衡量样本间相似性的度量方法[14-16]. 深度度量学习是指用一个深度神经网络(如CNN)来建模上述度量函数或特征空间. 早期的深度度量学习是应用于已经人工设计好的特征上的, 而近年来的工作主要用CNN 来建模从特征提取到度量函数的整个流程. Schroff 等[17]提出了一个框架FaceNet, 基于CNN直接将人脸数据映射到一个欧氏距离度量空间. 在该度量空间内, 人脸验证或者聚类等问题便可以基于距离度量的方法较为简单地实现. 在训练过程中, FaceNet基于两个对应同一人的人脸图像与一个他人的人脸图像构建三元组来对CNN 进行训练, 并提出了一个动态的三元组选择方法.
1.3 基于领域自适应的共享特征空间学习
计算机视觉和模式识别任务中经常遇到一类跨领域问题: 有两类数据, 一类数据有标签信息, 而另一类没有标签信息或者标签信息较少. 已知这两类数据非常相关的情况下, 如何利用有标签的数据学习得到一个可以应用于无/少标签数据的模型. 这就是典型的领域自适应问题[18-20], 其中有标签的数据与无标签的数据对应的域分别称为“源域”与“目标域”. 领域自适应方法是解决跨模态共享特征空间学习、实现跨模态识别的一种有效方法.
如果直接在源域训练模型并将其应用于目标域, 效果往往不好. 这是因为尽管两个域具有较强相关性, 但两者的特征分布还是会存在一定的差别. 为了消除这个差别, 近年来的主流方法大多是基于对抗学习的方法[21-23], 即通过对抗训练的方式使得两个域上学到的特征服从相同的分布. 通过该方式, 实现了源域上训练得到的模型在目标域上应用的目的. 本文提出的跨模态甲骨文字识别方法中, 同样基于对抗训练的思路, 将拓片甲骨文字映射到与临摹甲骨文字相同的特征空间中, 并约束二者服从尽可能相似的分布. 为了令对抗训练的过程更加稳定, 我们采用了Wasserstein GAN[24]的框架与训练技巧[25].
2. 基于跨模态学习的甲骨文字识别
图3为本文方法的总体框架图. 该框架包括一个基于CNN的临摹甲骨文字特征编码器、一个拓片甲骨文字特征编码器. 通过学习共享特征空间, 实现跨模态分类. 由于临摹甲骨文字有更多样本和类别, 本方法首先基于单模态度量学习的方式对临摹甲骨文字编码器进行训练, 将临摹甲骨文字图像映射到一个特征空间. 然后, 基于领域自适应与度量学习算法训练拓片甲骨文字编码器(网络结构和临摹甲骨文字编码器相同, 而参数不同), 将拓片甲骨文字映射到同样的共享特征空间. 由于拓片甲骨文字样本的特点(类别数大、类内样本不均衡、噪声严重···), 采用Softmax输出的神经网络由于输出概率的闭集特性, 难以推广到新类别进行增类识别. 因此, 我们采用扩展性更强、更接近人类模式识别方式的原型分类器. 在上述深度神经网络(CNN)学习得到的特征空间内, 用最近邻分类得到识别结果. 最近邻分类所使用的原型来自于与待识别输入(拓片甲骨文字)不同的模态(临摹甲骨文字), 故而称为“跨模态最近邻分类”. 此外, 通过跨模态最近邻分类与Softmax分类进行结合的方式, 可以进一步提升拓片甲骨文字的识别性能. 同时, 只要提供相应的临摹甲骨文字样本, 便可以基于跨模态最近邻分类识别新增类别的拓片甲骨文字.
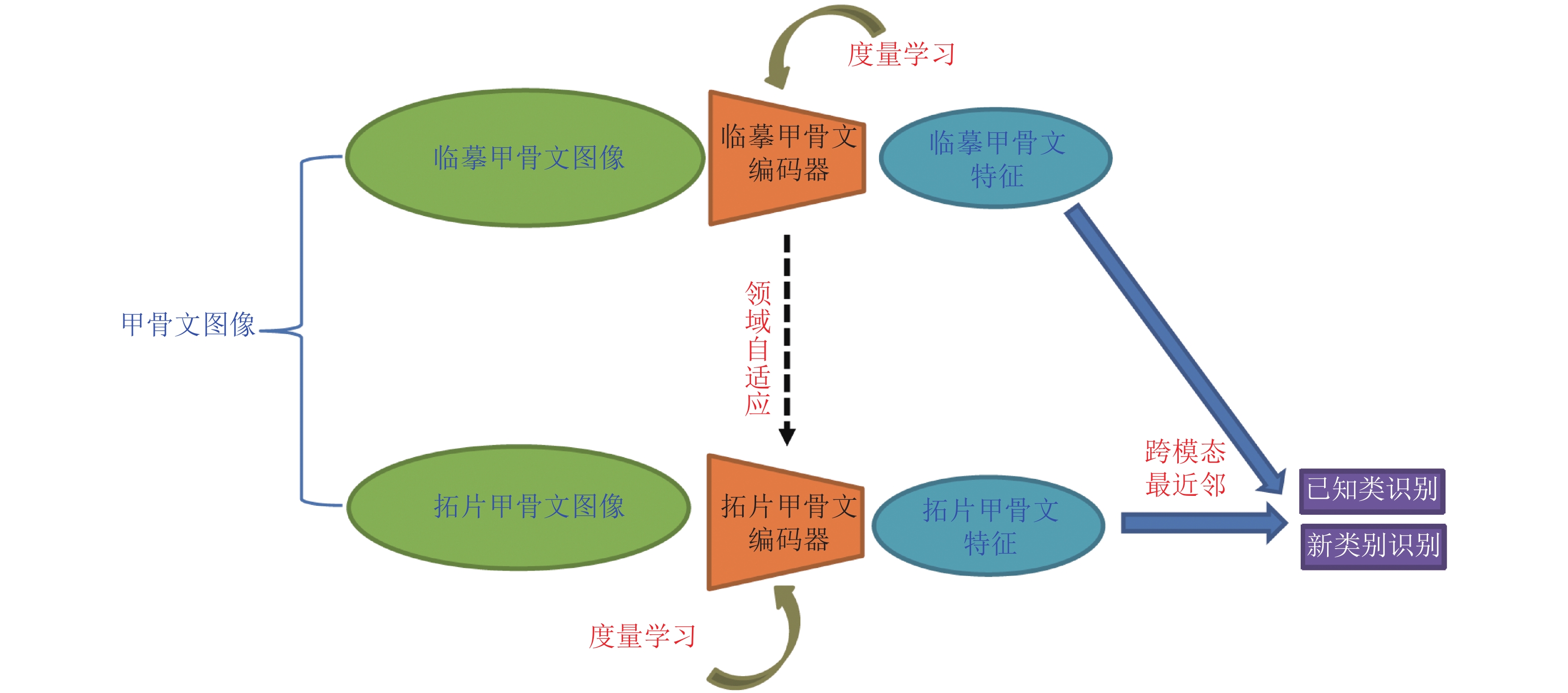 图 3 基于跨模态深度度量学习的拓片甲骨文字识别Fig. 3 Oracle character recognition based on cross-modal deep metric learning
图 3 基于跨模态深度度量学习的拓片甲骨文字识别Fig. 3 Oracle character recognition based on cross-modal deep metric learning下面对临摹甲骨文字编码器的训练算法、拓片甲骨文字编码器的训练算法和跨模态识别方法进行详细阐述.
2.1 临摹甲骨文字编码器训练
2.1.1 临摹甲骨文字编码器
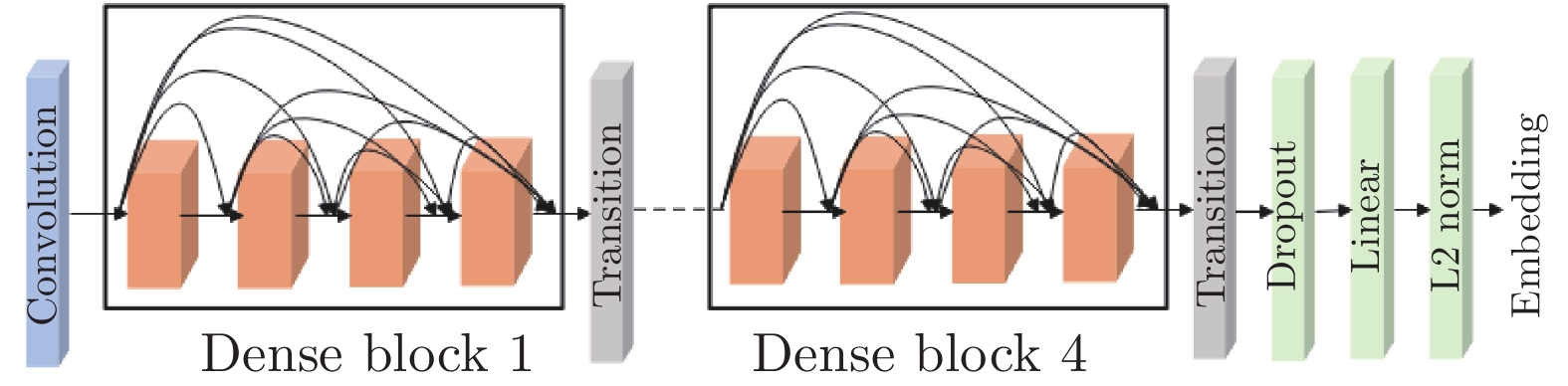
考虑识别性能, 我们采用视觉识别中常用且性能优良的DenseNet作为甲骨文字识别的编码器[26], 如图4所示. 编码器的输入是一个64×64的单通道图像, 输入图像先经过一个卷积层, 再先后经过4个Dense block, 相邻的Dense block之间会基于Transition对特征进行下采样. Transition由Batch Normalization层、输入输出通道数相等的1×1卷积层以及一个2×2的平均池化层组成. 最后一个Transition 的输出经过Dropout层[26]后作为全连接层的输入. 全连接层的输出为128维的向量, 经过L2范数归一化后便是整个网络的输出特征.
上述每一个Dense block 内, 各个层之间的特征会采用稠密连接的方式, 即第l层的输入就是前l − 1层的输出, 每个Dense block包含9个卷积层, 且每层的输出特征通道数均为6, 第l层的输出Ol可以形式化表达为:
$$ {O}_{l}={H}_{l}\left(\left[{O}_{1},{O}_{2},\cdots ,{O}_{l-1}\right]\right) $$ (1) 其中, [·] 表示特征的连接操作,
$ {H}_{l} $ 表示由Batch normalization (BN)[27]、ReLu[28]以及一个3×3 卷积层组成的复合函数.2.1.2 训练算法
给定一个临摹甲骨文字图像x, 它会由临摹甲骨文字编码器映射到特征空间f (x), 特征间的欧氏距离衡量了临摹甲骨文字图像间的差异. 由于临摹甲骨文字编码器(图4)的输出经过了L2范数归一化, 故而f(x) 满足
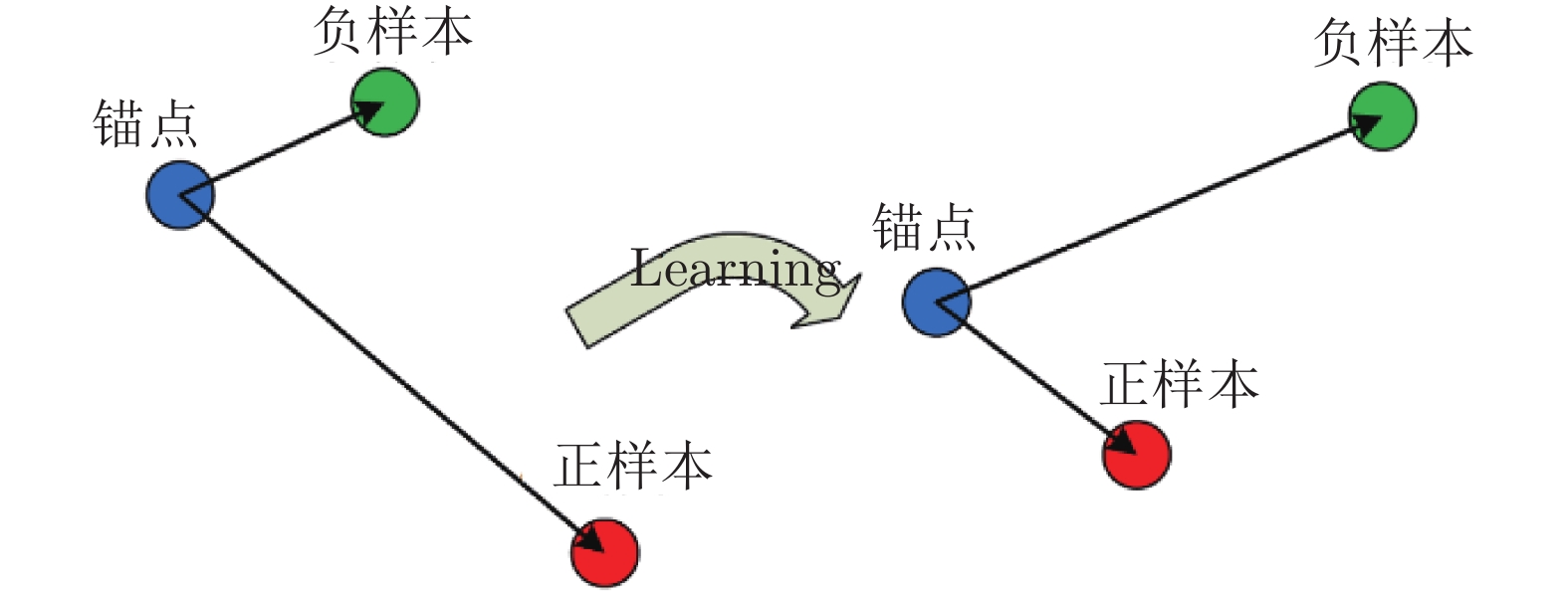
${\left|\left|{f}\left({x}\right)\right|\right|}_{2}=1$ . 在距离度量学习框架下, 本文使用三元组损失函数[17]来优化特征表示, 具体来说, 第i个三元组包括一个锚点$ {x}_{a}^{i} $ , 一个与锚点同类的正样本$ {x}_{p}^{i} $ , 一个与锚点异类的负样本$ {x}_{n}^{i} $ . 我们的编码器优化目标是同类样本更近、异类样本更远(如图5所示):$$\begin{split} &\left| |{{f}}\left( {x_a^i} \right) - {{f}}\left( {x_p^i} \right)|\right| _2^2 + {{\alpha }}<\left| | {{f}}\left( {x_a^i} \right) - {{f}}\left( {x_n^i} \right)|\right|_2^2\\ &\forall \left( {{{f}}\left( {x_a^i} \right),{{f}}\left( {x_p^i} \right),{{f}}\left( {x_n^i} \right)} \right) \in {{\tau }} \end{split}$$ (2) 其中, α为超参, 表示三元组中锚点与正样本、负样本特征距离的间隔, 本文中α设定为0.2 (与Schroff等[17]的设置保持一致), τ表示容量为N的三元组集合, 故而i = 1, 2, ···, N.
由于训练的过程中, 大部分三元组很快就会满足式(2), 不会再对编码器参数的更新产生影响, 故而为了使得训练更加高效, 在训练过程中会动态选择难以区分的三元组, 即不满足式(2)的三元组. 在整个训练过程中, 三元组的构建分为两个阶段:
阶段 1. 由于网络参数随机初始化后, 大部分三元组仍然不满足式(2), 所以在第一阶段三元组采用完全随机的策略进行构建.
阶段 2. 阶段一的训练收敛后, 已经有大量的三元组不再影响网络参数的更新, 此时开始动态地选择难以区分正负样本的三元组来训练网络. 具体来说, 由于网络基于批优化进行训练, 所以我们可以令每批(Mini-batch)都由来自不同类别的若干锚点-正样本对(
$ {x}_{a}^{i} $ ,$ {x}_{p}^{i} $ )组成, 并选择和锚点距离最近的异类样本作为负样本$ {x}_{n}^{i} $ , 继而构成三元组($ {x}_{a}^{i} $ ,$ {x}_{p}^{i} $ ,$ {x}_{n}^{i} $ ).2.2 拓片甲骨文字编码器训练
拓片甲骨文字编码器的网络结构与临摹甲骨文字编码器(见第2.1.1节)完全一致. 其训练过程分为两个步骤: 先基于跨模态对抗训练进行领域自适应, 使同类的不同模态文字具有相似的特征分布; 然后基于度量学习对特征进行修正, 使不同模态的文字特征可以更好的度量欧氏距离.
2.2.1 基于对抗训练的领域自适应
如图6所示, 对每个类别c均引入一个判别器
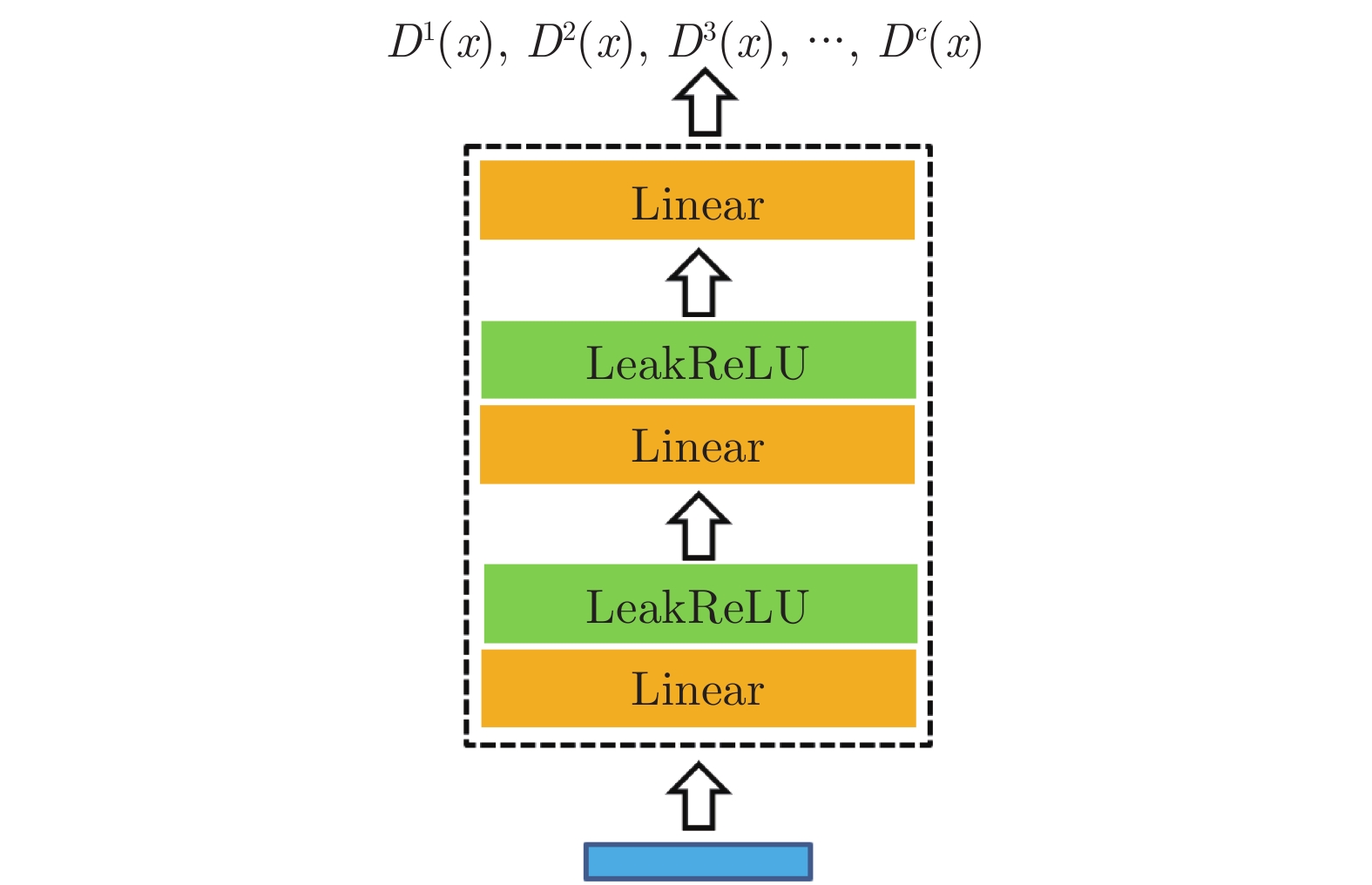
$ {D}^{c}(x)$ 与拓片甲骨文字编码器进行对抗训练, 各个类别的判别器共享最后一层之前的网络参数. 网络输入为128 维的多模态甲骨文字特征, 经过两层以LeakReLU为激活函数的全连接层后, 再基于全连接回归对应各个类别的$D^c(x)$ .对于第c个类别, 记对应该类别的拓片甲骨文字和临摹甲骨文字的后验概率分别为
$ {P}_{g}^{c} $ 和$ {P}_{r}^{c} $ . 对抗训练过程中, 判别器$D^c(x)$ 的目标是将$ {P}_{g}^{c} $ 与$ {P}_{r}^{c} $ 进行区分, 而甲骨文字编码器的目标是令判别器无法区分$ {P}_{g}^{c} $ 与$ {P}_{r}^{c} $ . 通过两者的博弈最终达到$ {P}_{g}^{c} $ 与$ {P}_{r}^{c} $ 服从相同分布的目标. 我们采用Wasserstein GAN[24-25]的训练框架可以令上述对抗训练过程更加稳定,$ {D}^{c}\left(x\right) $ 对应的损失函数为:$$\begin{split} L_{dis}^c =\;& {E_{\tilde x \sim P_g^c}}\left[ {{D^c}\left( {\tilde x} \right)} \right] - {E_{{x} \sim P_r^c}}\left[ {{D^c}\left( {{x}} \right)} \right] + \\ &{\lambda {E_{\hat x \sim P_{\hat x}^c}}\left[ {{{\left( {{{\left\| {{\nabla _{\hat x}}{D^c}\left( {\hat x} \right)} \right\|}_2} - 1} \right)}^2}} \right]} \end{split}$$ (3) 其中,
$P_{\hat x}^c$ 表示第c个类别的临摹甲骨文字与拓片甲骨文字在特征空间的插值所对应的概率分布,${\nabla _{\hat x}}{D^c}\left( {\hat x} \right)$ 表示$ {D}^{c}\left(x\right) $ 对于输入$\hat x$ 的梯度向量.基于损失函数(3), 判别器
$ {D}^{c}\left({x}\right) $ 经过训练后会使得${E_{\tilde x \sim P_g^c}}\left[ {{D^c}\left( {\tilde x} \right)} \right]$ 相比于${E}_{\mathrm{x}\sim {P}_{r}^{c}}\left[{D}^{c}\left(x\right)\right]$ 更小, 且在正则化项${E_{\hat x \sim P_{\hat x}^c}}\!\left[ {{{\left( {{{\left\| {{\nabla _{\hat x}}{D^c}\left( {\hat x} \right)} \right\|}_2} \!-\! 1} \right)}^2}} \right]$ 的约束下,$ {D}^{c}\left({x}\right) $ 在特征空间会平滑地变化. 故而, 以增大${E_{\tilde x \sim P_g^c}}\left[ {{D^c}\left( {\tilde x} \right)} \right]$ 为目标训练拓片甲骨文字编码器可以令$ {P}_{g}^{c} $ 向$ {P}_{r}^{c} $ “靠拢”. 因而在训练判别器$ {D}^{c}\left({x}\right) $ 后, 拓片甲骨文字编码器基于以下损失函数进行优化:$$L_{{\rm{gen}}}^c = - {E_{\tilde x \sim P_g^c}}\left[ {{D^c}\left( {\tilde x} \right)} \right]$$ (4) 基于损失函数(3)与(4)的迭代对抗训练, 可以令
$ {P}_{g}^{c} $ 与$ {P}_{r}^{c} $ 服从近似相同的分布.2.2.2 基于度量学习的特征修正
第2.2.1节的领域自适应可以使得拓片甲骨文字与临摹甲骨文字在每个类内都有着相似的特征分布. 然而该方法并不能保证拓片甲骨文字与异类临摹甲骨文字具有足够的特征分布差异, 直接使用上述特征进行跨模态最近邻分类不一定能得到正确分类. 举例说明如下.
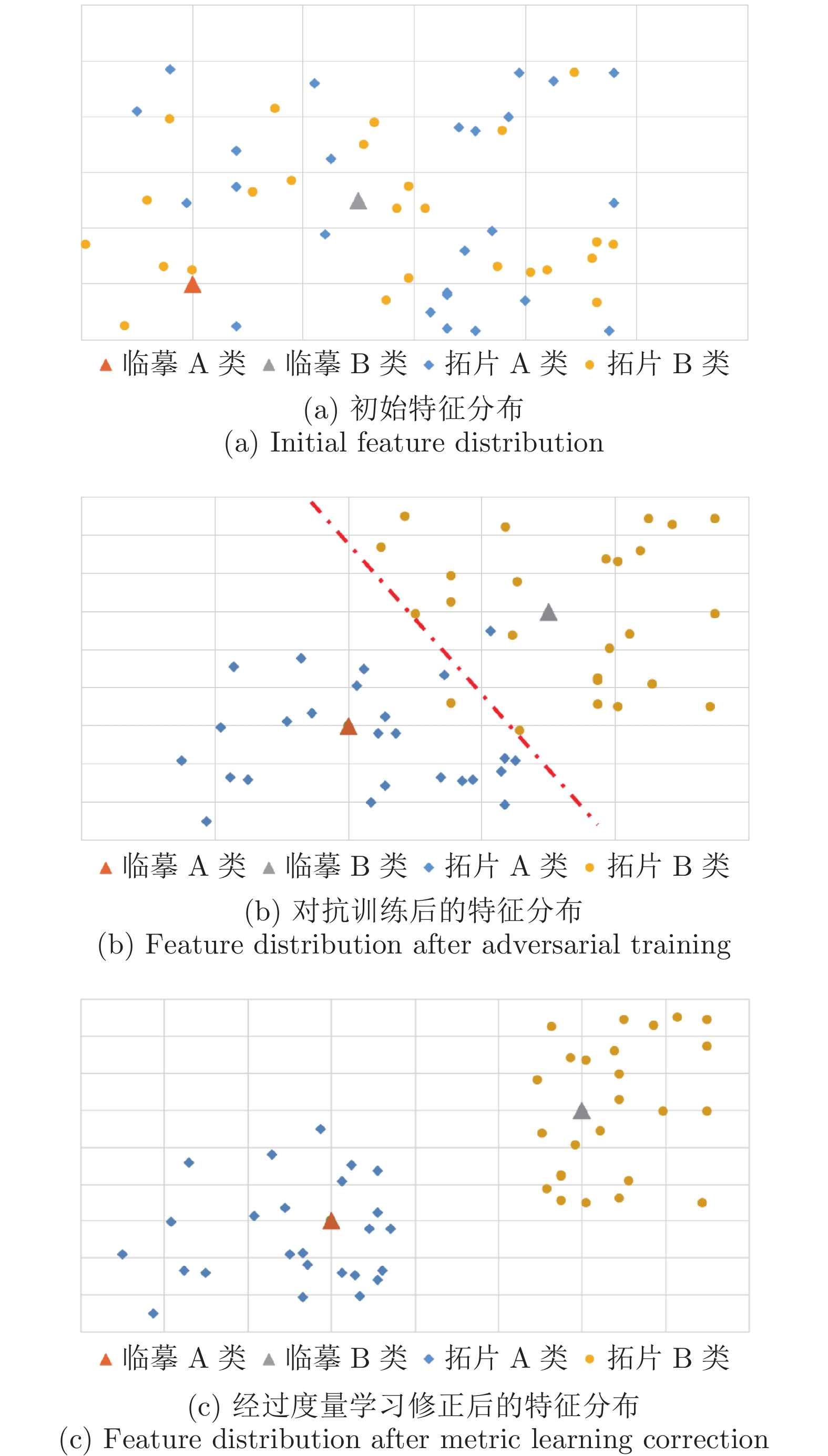
图7(a)表示未经训练的甲骨文字特征分布, 其中每个点代表一个样本, 包括属于A、B 两类的临摹甲骨文字和拓片甲骨文字. 此时拓片甲骨文字编码器尚未训练, 故而拓片甲骨文字特征近似随机分布. 图7(b)表示经过对抗训练后的特征分布, 每个类别的拓片甲骨文字样本会服从以同类临摹甲骨文字为中心的类高斯分布. 然而此时由于没有利用异类临摹甲骨文字样本进行判别学习, 部分样本会越过最近邻分类的“分类面”落入其他类别所在的区域. 我们在本文采用度量学习的方式, 可以使拓片甲骨文字的特征与同类临摹甲骨文字特征更近、与异类临摹甲骨文字特征更远, 如图7(c)所示, 此时基于跨模态最近邻分类可以达到更好的效果.
此处的度量学习方法与第2.1.2节类似, 同样是基于三元组式(2). 三元组包含一个拓片甲骨文字样本(锚点样本)、一个与锚点同类的临摹甲骨文字样本(正样本)以及一个与锚点异类的临摹甲骨文字样本(负样本). 以式(2)为目标对拓片甲骨文字编码器进行训练, 以减小正样本与锚点的距离、同时增大负样本与锚点的距离. 与第2.1.2节不同, 由于拓片甲骨文字编码器已经进行过对抗训练, 多数三元组都满足式(2), 故而度量学习的训练过程略过阶段1, 仅包括阶段2.
我们利用反卷积方法对临摹甲骨文和拓片甲骨文特征进行可视化, 如图8所示. 对于128维特征的每个维度, 我们均可获得一个与输入图像同尺寸的特征图, 为了更清晰的观察特征的分布区域, 我们将128个特征图通过在每个空间位置求和的方式融合为一个特征图. 可以看出, 无论是临摹甲骨文还是拓片甲骨文, 学到的共享特征均集中于文字区域(而不是背景区域), 反映了文字本质结构特点.
 图 8 不同模态的甲骨文特征可视化Fig. 8 Visualization of oracle character features with different modals
图 8 不同模态的甲骨文特征可视化Fig. 8 Visualization of oracle character features with different modals2.3 基于跨模态最近邻分类的拓片甲骨文字识别
以临摹甲骨文字的特征为原型, 检索待识别的拓片甲骨文字特征, 距离最近的临摹甲骨文字的类别就是拓片甲骨文字的识别结果. 只要存在对应类别的临摹甲骨文字, 就可以对拓片甲骨文字进行识别, 所以可以实现新类拓片甲骨文字的增量识别(即使拓片甲骨文字没有训练过).
针对已知类识别, 为了进一步提高识别性能, 我们可以采用单模态CNN模型和跨模态最近邻分类相结合的方法. 单模态CNN的网络结构与甲骨文字编码器基本一致(仅将图4最后的全连接层输出维度设置为与类别数相等, 并且将L2归一化层替换为Softmax层). 这里分两步分类: 当单模态CNN 的分类置信度较高时(类别置信度最大值高于一个阈值), 直接输出CNN的分类结果; 否则, 通过跨模态最近邻分类给出识别结果. 这样很好地利用了两个分类器的互补性. 为了提高最近邻分类器的计算效率, 原型检索仅仅在单模态CNN输出置信度最高的若干类别中进行.
3. 实验
3.1 数据集介绍
本文使用的甲骨文字数据集由安阳师范学院甲骨文信息处理实验室提供. 拓片甲骨文字[1]包含样本数较多的241个类别, 共295466个样本, 其中每个类别最少16个、最多25898个、平均1226个样本. 样本量的类间分布不均衡, 如图9 所示. 本实验会对图像进行缩放使得长边为64像素, 然后将其置于一个大小为64×64的黑色背景图像的中心. 临摹甲骨文字数据集[26]包含2583个类别, 共39062个样本, 其中每个类别最少2个、最多287个、平均16个样本. 我们使用了其中241个对应于拓片甲骨文字的类别进行实验. 其余类别的样本可用于拓片甲骨文字增量识别(也就是只要有临摹文字样本的类别, 就可以识别对应的拓片甲骨文字), 但由于这些类别没有拓片甲骨文字测试样本, 我们没有进行评测, 而是用241类拓片甲骨文字样本中的41类进行新类的增量识别评测(详见第3.4节), 已知类别识别的数据是全部241类拓片甲骨文字样本(详见第3.2节、第3.3节).
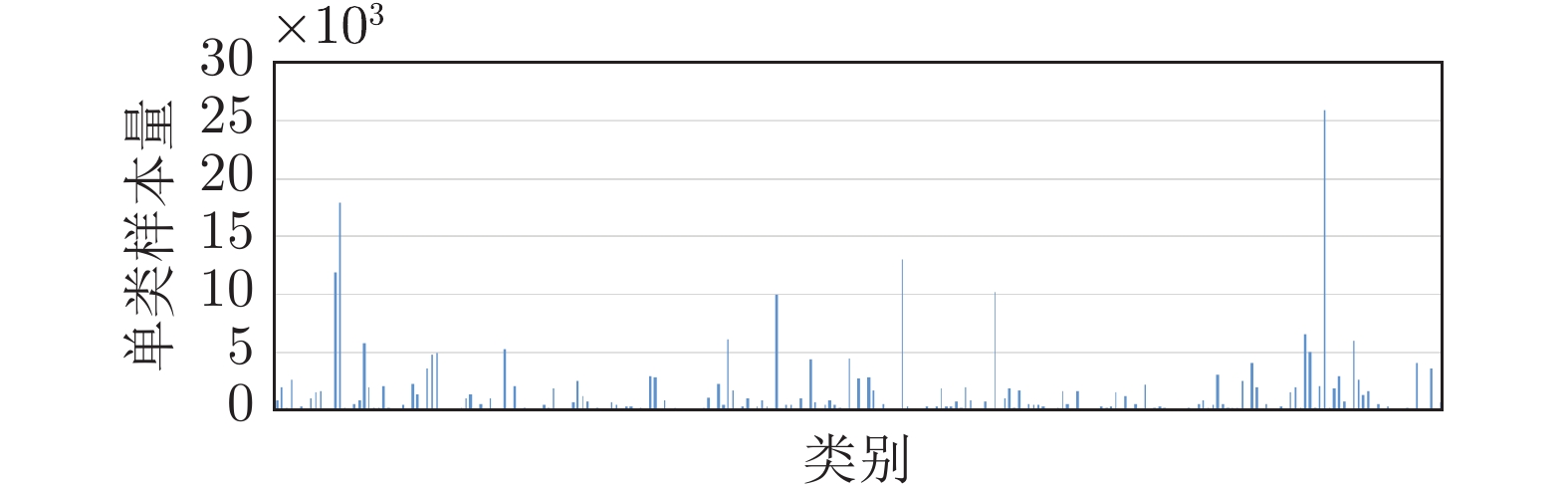 图 9 拓片甲骨文字中241个类别的样本个数分布Fig. 9 Sample distribution of oracle characters scanned from bones and shells
图 9 拓片甲骨文字中241个类别的样本个数分布Fig. 9 Sample distribution of oracle characters scanned from bones and shells3.2 基于对抗训练的领域自适应
如图10 所示, 对于拓片甲骨文字, 每一类内往往包含了多种字形. 如果在特征空间, 某拓片甲骨文字与某临摹甲骨文字的特征距离十分相近, 他们对应的图像应该不仅仅属于同一类, 更应该对应相近的字形. 由于我们只有拓片甲骨文字与临摹甲骨文字的类别信息, 而没有类别下具体的字形标签, 故而在构建三元组的时候无法选择合适的锚点与正样本. 如果锚点与正样本来自同一类下的两个不同字形, 通过优化令二者在度量空间相近是难以做到的. 基于上述分析, 在利用度量学习的方式训练拓片甲骨文字编码器前, 先对拓片甲骨文字特征进行基于对抗训练的领域自适应学习.
 图 10 拓片甲骨文字类内样本示例, 每一列属于同一类Fig. 10 Oracle images with the same characters in each array
图 10 拓片甲骨文字类内样本示例, 每一列属于同一类Fig. 10 Oracle images with the same characters in each array实验设置 训练集的构建方式为(241类):
1) 对于样本量小于900 的类别, 随机调取2/3的样本加入训练集.
2) 对于样本量大于等于900的类别, 随机调取600个样本加入训练集.
其余样本作为后续已知类识别实验的测试集. 图11展示了领域自适应后的五组最近邻对, 观察数据可以发现, 进行领域自适应之后, 同一类内不同模态的最近邻对已经在字形上非常相似. 可以看到尽管拓片甲骨文字图像被噪声污染严重, 其字形结构与最近邻的临摹甲骨文字是一致的. 故而可以基于对抗训练的结果, 以上述最近邻对作为三元组中的锚点与正样本进行深度度量学习.
3.3 拓片甲骨文字已知类别识别
这里比较4个分类方法的性能: 单模态最近邻分类器[26]、单模态CNN、跨模态最近邻分类器、融合跨模态信息的CNN. 单模态最近邻分类和单模态CNN的训练集构建与第3.2节一致, 训练样本之外的拓片甲骨文字样本为测试集. 单模态最近邻分类中, 拓片甲骨文字编码器训练方法与第2.1.2节临摹甲骨文字编码器的训练方法一致. 单模态CNN的网络结构与甲骨文字编码器基本一致(如第2.3节所述). 跨模态最近邻分类的原型来自临摹甲骨文字特征, 临摹甲骨文字特征编码器的相关设置和文献[26]相同. 融合跨模态信息的CNN是指CNN分类置信度(输出类别置信度最大值)低于给定阈值τ时采用跨模态最近邻分类, 并在CNN置信度最高的K个类别上搜索最近邻原型. 下面我们首先分别研究阈值τ和参数K对融合跨模态信息的CNN分类性能的影响. 再对4种不同的甲骨文识别方法进行比较.
图12 反映了阈值τ对融合跨模态信息的CNN分类性能的影响. 当阈值τ过小时, 主要由CNN分类模块发挥作用. 由于甲骨文字的特点, 即使本实验中数据充足(每个类平均1226个样本), 单凭该模块也难以达到较高的识别性能. 当置信度阈值过大时, 主要由跨模态最近邻分类发挥作用. 由于对应较高置信度的CNN分类结果往往比较可靠, 如果没有利用该信息, 同样会降低识别性能. 通过曲线可以看到, 本文所采用的阈值0.66 是一个相对较好的平衡点, 后续实验的τ值固定为0.66.
 图 12 置信度阈值与识别精度关系曲线图Fig. 12 Relationship between confidence threshold and recognition accuracy
图 12 置信度阈值与识别精度关系曲线图Fig. 12 Relationship between confidence threshold and recognition accuracy图13 展示了参数K对融合跨模态信息的CNN分类性能的影响. 可以看到, 当K小于4时, 由于考虑的类别数太小, 识别精度会很低. 当K大于4时, 不仅仅最近邻检索效率变低, 算法精度也会逐渐变低. 这说明考虑置信度过低的类别不仅仅会增加最近邻检索的计算量, 同时这些类别会对最近邻识别产生干扰并降低精度. 后续实验的K值设定为4.
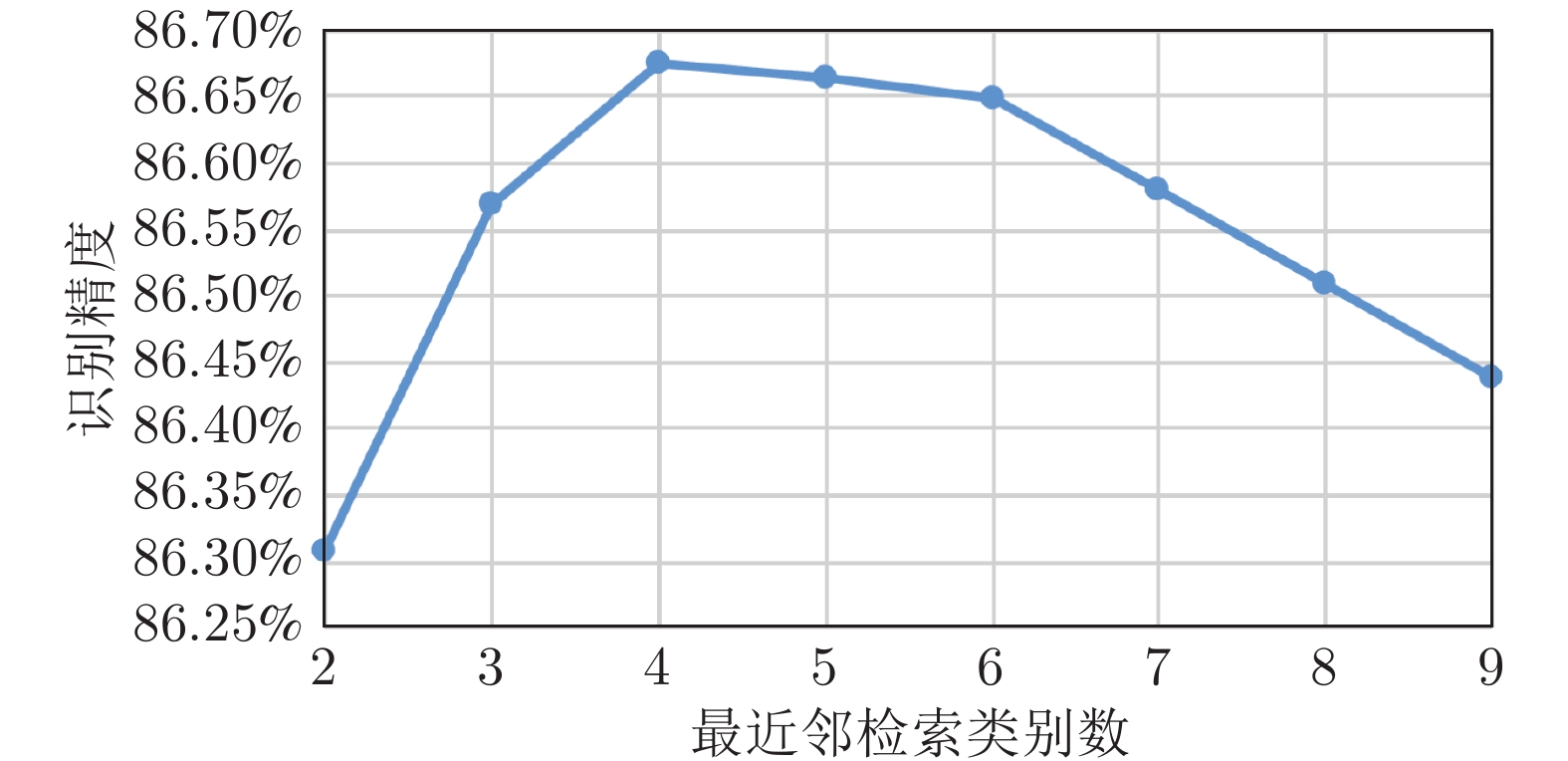 图 13 最近邻检索的类别数与识别精度关系图Fig. 13 Relationship between character number of nearest neighbor retrieval and recognition accuracy
图 13 最近邻检索的类别数与识别精度关系图Fig. 13 Relationship between character number of nearest neighbor retrieval and recognition accuracy在进行不同识别方法的对比前, 我们首先对不同尺度图像的识别性能进行比较. 如表1所示, 我们分别对32×32、64×64、128×128三个大小的甲骨文图像进行了识别. 可以看出, 图像分辨率是32×32时, 性能比64×64降低很多. 图像分辨率是128×128时, 性能仅仅提升一个百分点, 但是由于图像宽度和高度同时增加一倍, 所以计算量增大到4倍. 所以本文设置的图像分辨率64×64是一个识别率和计算效率都比较合理的选择.
表 1 不同图像尺度对性能的影响Table 1 Effects of different image scales图像大小 识别率 (%) 32×32 76.80 64×64 82.10 128×128 83.40 4种不同的拓片甲骨文识别方法如表2所示, 融合跨模态信息的CNN分类可以将拓片甲骨文字的识别精度相对于单模态CNN从84.4%提高到86.7%. 这说明了临摹甲骨文字信息对拓片甲骨字的识别是有促进的. 同时也可以看到, 单模态的最近邻分类精度非常低, 相对于跨模态最近邻分类低了7.96%, 进一步证明了跨模态识别的有效性. 这里, 仅用拓片甲骨文字样本训练CNN得到的识别精度比较高(84.40%), 这是因为训练样本数比较大而类别数比较小. 而且, 该CNN分类器不能识别训练样本类别(已知类别)以外的新类别样本.
表 2 拓片甲骨文字分类精度对比Table 2 Comparison of different oracle character recognition methods方法 识别率 (%) 单模态最近邻 74.14 单模态CNN 84.40 跨模态最近邻 82.10 融合跨模态信息的CNN 86.70 本文进一步对实验结果进行分析, 发现基于常规的CNN分类难以准确地对包含多种字形结构的类别进行识别. 如图14 所示, 该类别包含的字形结构差异很大, 单模态CNN的识别精度仅达到66.6%, 而基于跨模态最近邻分类, 可将精度提升至88.4%, 由此可见我们提出的跨模态最近邻分类方法的优势.
3.4 拓片甲骨文字的新类别识别
基于本文所提出的跨模态最近邻分类方法, 可以实现新类别拓片甲骨文字的增量识别. 将241类的拓片甲骨文字样本分为两部分, 第一部分包括200类, 作为已知类, 用于训练拓片甲骨文字编码器; 其余41类数据作为新类识别的测试样本. 以度量学习训练临摹甲骨文字编码器得到的特征作为原型, 并在已知类上使用第2.2.1节与第2.2.2节的方法训练拓片甲骨文字编码器, 然后在41个新类上进行跨模态最近邻识别(度量学习+领域自适应+特征修正). 同时本文设置了一个对比实验, 只使用第2.2.1节的领域自适应方法训练拓片甲骨文(度量学习+领域自适应), 验证第2.2.2节特征修正的有效性.
如表3 所示, 利用第2.1.2节提出的方法训练临摹甲骨文字编码器, 而后基于第2.2.1节提出的领域自适应方法训练拓片甲骨文字编码器, 新类别上的识别精度可以达到43.67%. 基于第2.2.2节提出的方法对拓片甲骨文字编码器进一步进行特征修正, 识别精度便可提升到62.1%. 由此可见, 本文提出的跨模态最近邻分类方法可以对新类别进行较好的识别, 从而辅助语言学专家进行甲骨文字鉴别.
表 3 新类别拓片甲骨文字识别Table 3 Recognition performance of new oracle characters特征学习方法 跨模态近邻分类精度 (%) 度量学习+领域自适应 43.67 度量学习+领域自适应+特征修正 62.10 4. 结论
本文提出了一种基于深度度量学习和最近邻分类的跨模态甲骨文字识别框架, 相对于传统的CNN分类框架和单模态识别方法都具有明显的优势. 首先, 基于领域自适应的方式将拓片甲骨文字和临摹甲骨文字映射到相同的特征空间, 并保证来自同类的拓片甲骨文字与临摹甲骨文字特征具有相近的分布; 接着, 通过基于深度度量学习的特征修正, 增大拓片甲骨文字特征与异类临摹甲骨文字特征的距离, 同时减小拓片甲骨文字特征与同类临摹甲骨文字特征的距离; 最后, 以临摹甲骨文字特征为原型, 使用最近邻分类方法对拓片甲骨文字进行识别, 并在已知类识别和新类增量识别中验证了算法的有效性.
本文方法基于临摹甲骨文字原型可以对没有训练样本的拓片甲骨文字类别进行增类识别, 这对实际应用场合的拓片甲骨文字解读提供帮助. 如果临摹甲骨文字和拓片甲骨文字的训练样本能提供细粒度的同类异形标记, 将有助于训练更好的模型, 进一步提高识别精度.
-
图 3 基于跨模态深度度量学习的拓片甲骨文字识别
Fig. 3 Oracle character recognition based on cross-modal deep metric learning
图 8 不同模态的甲骨文特征可视化
Fig. 8 Visualization of oracle character features with different modals
图 9 拓片甲骨文字中241个类别的样本个数分布
Fig. 9 Sample distribution of oracle characters scanned from bones and shells
图 10 拓片甲骨文字类内样本示例, 每一列属于同一类
Fig. 10 Oracle images with the same characters in each array
图 12 置信度阈值与识别精度关系曲线图
Fig. 12 Relationship between confidence threshold and recognition accuracy
图 13 最近邻检索的类别数与识别精度关系图
Fig. 13 Relationship between character number of nearest neighbor retrieval and recognition accuracy
表 1 不同图像尺度对性能的影响
Table 1 Effects of different image scales
图像大小 识别率 (%) 32×32 76.80 64×64 82.10 128×128 83.40  下载: 导出CSV
下载: 导出CSV
表 2 拓片甲骨文字分类精度对比
Table 2 Comparison of different oracle character recognition methods
方法 识别率 (%) 单模态最近邻 74.14 单模态CNN 84.40 跨模态最近邻 82.10 融合跨模态信息的CNN 86.70
下载: 导出CSV
表 3 新类别拓片甲骨文字识别
Table 3 Recognition performance of new oracle characters
特征学习方法 跨模态近邻分类精度 (%) 度量学习+领域自适应 43.67 度量学习+领域自适应+特征修正 62.10
下载: 导出CSV
-
[1] Huang S P, Wang H B, Liu Y G, Shi X S, Jin L W. OBC306: A large-scale Oracle Bone character recognition dataset. ICDAR 2019: 681−688 [2] 金连文, 钟卓耀, 杨钊, 杨维信, 谢泽澄, 孙俊. 深度学习在手写汉字识别中的应用综述. 自动化学报, 2016, 42(8): 1125−1141Jin Lian-Wen, Zhong Zhuo-Yao, Yang Zhao, Yang Wei-Xin, Xie Ze-Cheng, Sun Jun. Applications of deep learning for handwritten Chinese character recognition: A review. Acta Automatica Sinica, 2016, 42(8): 1125−1141 [3] Zhang X Y, Bengio Y, Liu C L: Online and offline handwritten Chinese character recognition: A comprehensive study and new benchmark. Pattern Recognition, 2017, 61: 348−360 [4] 李文英, 曹斌, 曹春水, 黄永祯. 一种基于深度学习的青铜器铭文识别方法. 自动化学报, 2018, 44(11): 2023−2030Li Wen-Ying, Cao Bin, Cao Chun-Shui, Huang Yong-Zhen. A deep learning based method for bronze inscription recognition. Acta Automatica Sinica, 2018, 44(11): 2023−2030 [5] Guo J, Wang C H, Roman-Rangel E, Chao H Y, Rui Y. Building hierarchical representations for oracle character and sketch recognition. IEEE Transactions on Image Processing, 2016, 25(1): 104−118 doi: 10.1109/TIP.2015.2500019 [6] Bengio Y, Lamblin P, Popovici D, Larochelle H. Greedy layer-wise training of deep networks. NIPS 2006: 153−160 [7] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S E, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. CVPR 2015: 1−9 [8] Berg A C, Berg T L, Malik J. Shape matching and object recognition using low distortion correspondences. CVPR 2005: 26−33 [9] Roman-Rangel E, Pallan C, Odobez J M, Gatica-Perez D. Analyzing ancient Maya glyph collections with contextual shape descriptors. Int. J. Computer Vision, 2011, 94(1): 101−117 doi: 10.1007/s11263-010-0387-x [10] Cortes C, Vapnik V. Support-vector networks. Machine Learning, 1995, 20(3): 273−297 [11] Yu Q, Yang Y X, Liu F, Song Y Z, Xiang T, Hospedales T M. Sketch-a-Net: A deep neural network that beats humans. Int. J. Computer Vision, 2017, 122(3): 411−425 doi: 10.1007/s11263-016-0932-3 [12] Creswell A, Bharath A A. Adversarial training for sketch retrieval. ECCV Workshops 2016: 798-809. [13] Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial networks. Advances in Neural Information Processing Systems, 2014, 3: 2672−2680 [14] Yang L, Jin R, Sukthankar R, Liu Y: An efficient algorithm for local distance metric learning. AAAI 2006: 543−548. [15] Yang L, Jin R, Sukthankar R. Bayesian active distance metric learning. UAI 2007: 442−449. [16] Hu J L, Lu J W, Tan Y P. Discriminative deep metric learning for face verification in the wild. CVPR 2014: 1875−1882 [17] Schroff F, Kalenichenko D, Philbin J: FaceNet: A unified embedding for face recognition and clustering. CVPR 2015: 815−823. [18] Gong B Q, Shi Y, Sha F, Grauman K. Geodesic flow kernel for unsupervised domain adaptation. CVPR 2012: 2066−2073. [19] Pan S J, Yang Q. A Survey on transfer learning. IEEE Trans. Knowl. Data Eng., 2010, 22(10): 1345−1359 doi: 10.1109/TKDE.2009.191 [20] Fernando B, Habrard A, Sebban M, Tuytelaars T. Unsupervised visual domain adaptation using subspace alignment. ICCV 2013: 2960−2967 [21] Solomon J, de Goes F, Peyré G, Cuturi M, Butscher A, Nguyen A, Du T, Guibas L J. Convolutional Wasserstein distances: Efficient optimal transportation on geometric domains. ACM Trans. Graph., 2015, 34(4): 1−66 [22] Sankaranarayanan S, Balaji Y, Jain A, Lim S, Chellappa R: Unsupervised domain adaptation for semantic segmentation with GANs. CoRR abs/1711.06969 (2017). [23] Kim T, Cha M, Kim H, Lee J K, Kim J. Learning to discover cross-domain relations with generative adversarial networks. ICML 2017: 1857−1865 [24] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN. CoRR abs/1701.07875 (2017). [25] Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville A C. Improved training of Wasserstein GANs. NIPS 2017: 5767−5777 [26] Zhang Y K, Zhang H, Liu Y G, Yang Q, Liu C L. Oracle character recognition by nearest neighbor classification with deep metric learning. ICDAR 2019: 309−314 [27] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. ICML 2015: 448−456 [28] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks. AISTATS 2011: 315−323 期刊类型引用(12)
1. 鄢琳. 基于增强现实的交互式产品三维虚拟展示设计. 信息技术. 2024(01): 85-90 .  百度学术
百度学术2. 史小松,代记圆. 基于DeepLabV3+的甲骨拓片图像文字分割方法. 信息技术与信息化. 2024(04): 216-220 . 百度学术3. 刘畅,杨春,殷绪成. 基于文字局部结构相似度量的开放集文字识别方法. 自动化学报. 2024(10): 1977-1987 . 本站查看4. 刘宗昊,彭文杰,代港,黄双萍,刘永革. 语义增强的零样本甲骨文字符识别. 电子学报. 2024(10): 3347-3358 . 百度学术5. 刘洋,陆逸,魏钰驰,孙智莹,朱立芳. 甲骨文识别技术研究现状与展望. 知识管理论坛. 2023(02): 115-125 . 百度学术6. 毛亚菲,毕晓君. 改进ResNeSt网络的拓片甲骨文字识别. 智能系统学报. 2023(03): 450-458 . 百度学术7. 王振东,徐振宇,李大海,王俊岭. 面向入侵检测的元图神经网络构建与分析. 自动化学报. 2023(07): 1530-1548 . 本站查看8. 刘成林,金连文,白翔,李晓辉,殷飞. 文档智能分析与识别前沿:回顾与展望. 中国图象图形学报. 2023(08): 2223-2252 . 百度学术9. 柯永红,沈小妮. 甲骨文已识字自动检测和识别研究. 民俗典籍文字研究. 2023(01): 73-88+250 . 百度学术10. 刘江,章晓庆. 面向非计算机专业的人工智能导论课程建设与探索. 中国大学教学. 2022(Z1): 46-51 . 百度学术11. 刘芳,李华飙,马晋,闫升,金沛然. 基于Mask R-CNN的甲骨文拓片的自动检测与识别研究. 数据分析与知识发现. 2021(12): 88-97 . 百度学术12. 王帅,李鹏,苏倩文. 甲骨文信息化研究之路简述. 黄河.黄土.黄种人. 2022(18): 16-21 . 百度学术其他类型引用(12)
-
 跨模态零样本文字识别PPT.pdf
跨模态零样本文字识别PPT.pdf

-

 下载:
下载:

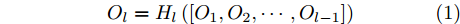
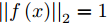
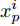
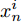
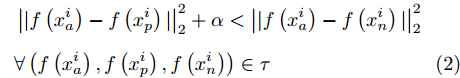
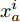
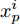
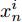
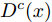
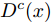
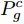
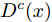
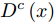
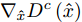
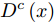
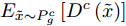
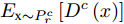
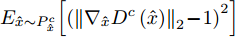
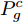
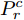
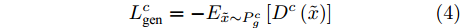
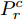


计量
- 文章访问数: 2389
- HTML全文浏览量: 922
- PDF下载量: 643
- 被引次数: 24
