

-
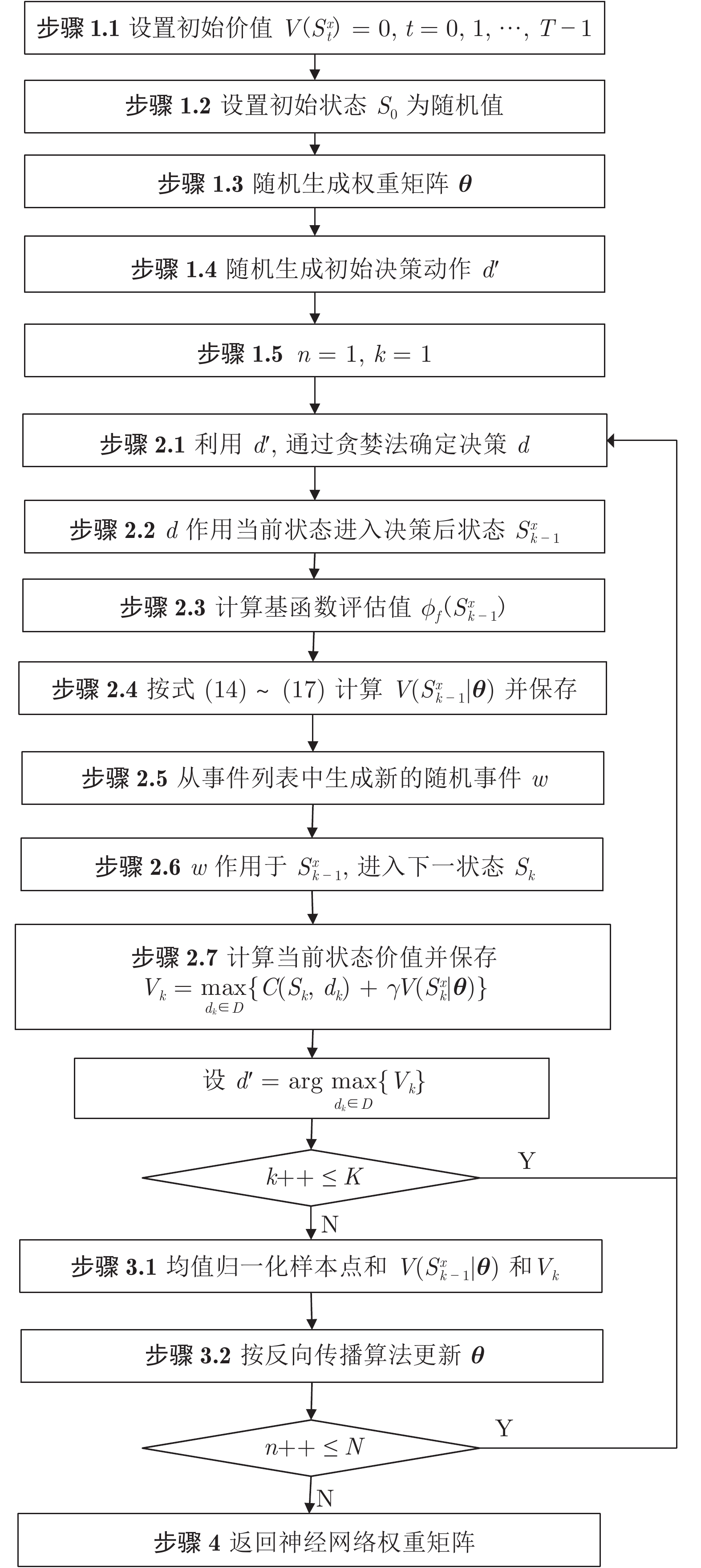
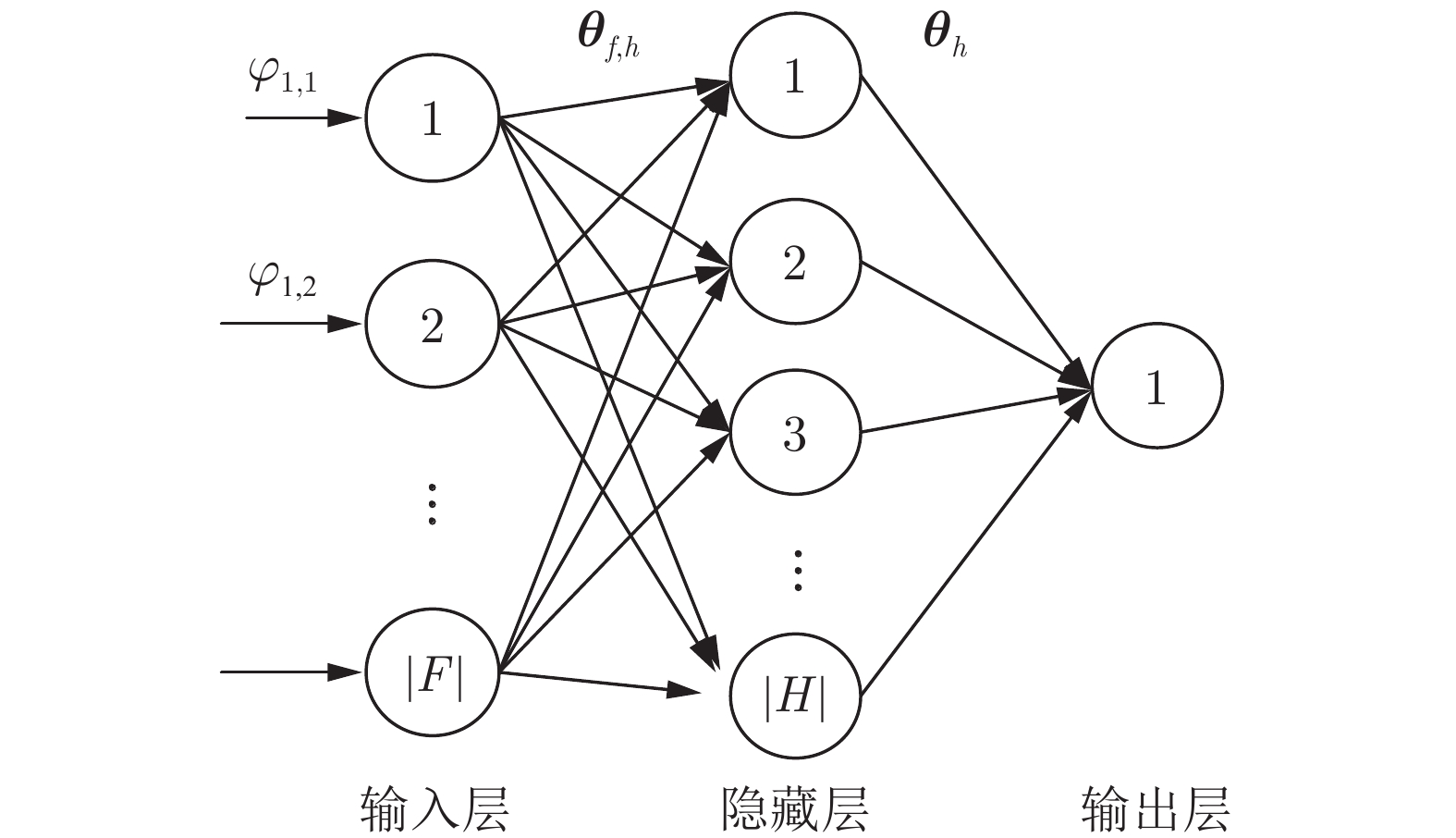
摘要: 复杂多变的战场环境要求后装保障能够根据战场环境变化, 预见性地做出决策. 为此, 提出基于强化学习的动态调度方法. 为准确描述保障调度问题, 提出支持抢占调度、重分配及重部署决策的马尔科夫决策过程(Markov decision process, MDP)模型, 模型中综合考量了任务排队、保障优先级以及油料约束等诸多问题的影响; 随后设计改进策略迭代算法, 训练基于神经网络的保障调度模型; 训练后的神经网络模型能够近似计算状态价值函数, 从而求解出产生最大期望价值的优化调度策略. 最后设计一个分布式战场保障仿真实验, 通过与常规调度策略的对比, 验证了动态调度算法具有良好的自适应性和自主学习能力, 能够根据历史数据和当前态势预判后续变化, 并重新规划和配置保障资源的调度方案.Abstract: It is necessary for the logistics and equipment support to make decision according to battlefield environment changes in the complicated and changeable battlefield. A dynamic scheduling method is proposed to overcome the problem. Firstly, a Markov decision process (MDP) model is proposed to formulate the preemptive scheduling, reassignment and redeployment of wartime logistics support force, which considers the impact of task queuing, maintenance priorities and oil limits, etc. Secondly, an improved policy iterative algorithm is designed to train the scheduling model based on neural network. The trained neural network model can approximate the state value function and solve the optimal scheduling decision resulting in the best expected value. Finally, a distributed logistics support experiment is designed to verify the applicability of dynamic scheduling algorithm compared to the traditional scheduling scheme, the results show that the algorithm has the capabilities of adjusting and re-planning the scheduling scheme according to historical data and prediction based on current situation.
-
表 1 仿真实验结果
Table 1 Simulation results
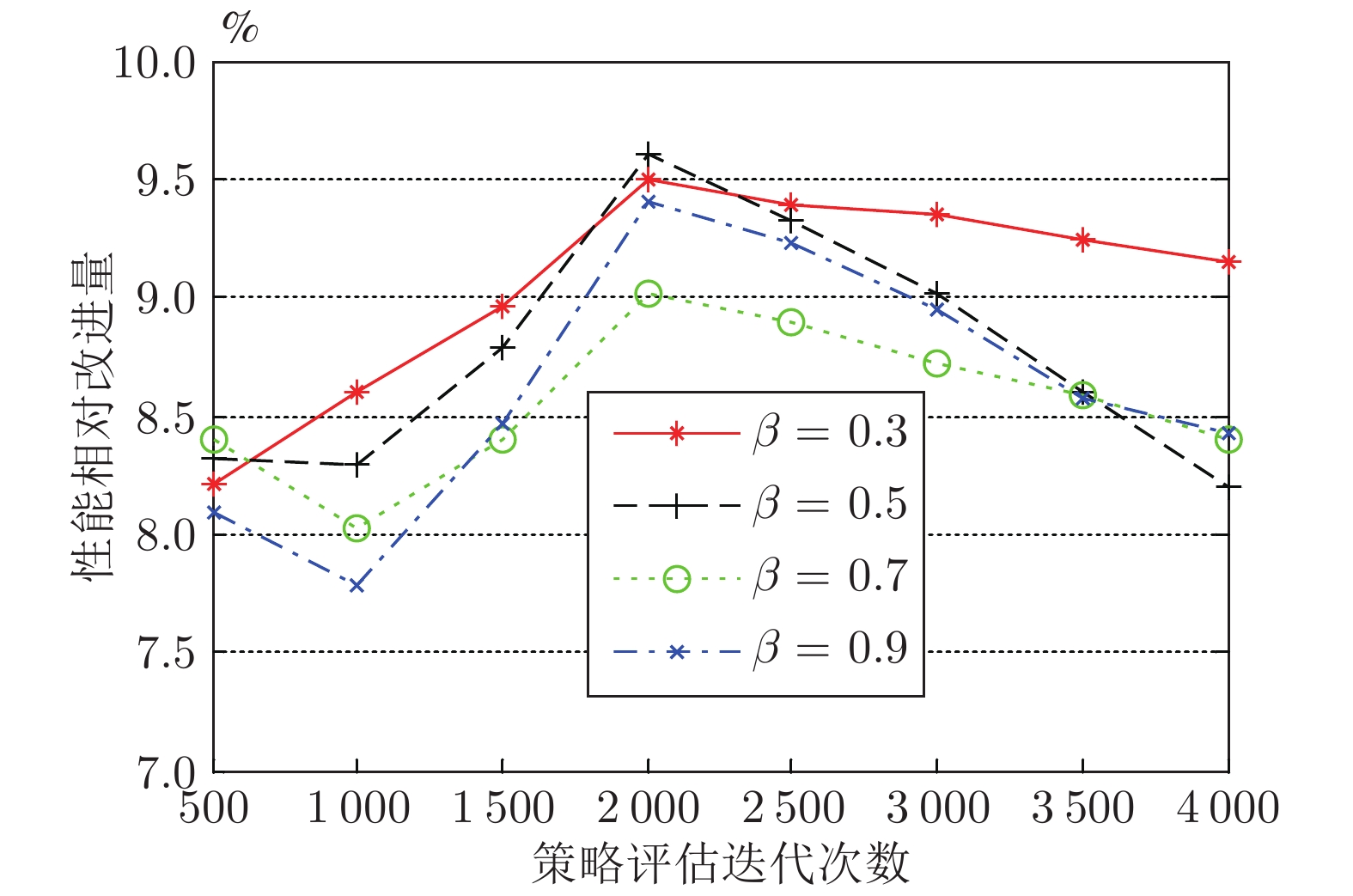
N K β Impr1,A Impr1,B Impr2,A Impr2,B 30 500 0.3 8.2±0.2 5.3±0.2 6.9±0.2 3.1±0.1 35 1000 0.3 8.6±0.2 5.6±0.1 7.8±0.1 3.2±0.2 25 2000 0.3 9.5±0.2 6.5±0.2 7.2±0.2 4.2±0.1 18 4000 0.3 9.3±0.2 6.4±0.2 5.1±0.1 2.9±0.1 10 500 0.5 8.3±0.2 5.3±0.1 6.9±0.2 2.7±0.2 9 1000 0.5 8.3±0.2 5.3±0.1 7.4±0.2 2.3±0.2 28 2000 0.5 9.6±0.2 6.6±0.2 6.8±0.1 2.7±0.1 12 4000 0.5 8.2±0.2 5.2±0.1 7.1±0.1 4.2±0.1 10 500 0.7 8.4±0.2 5.4±0.1 5.9±0.2 4.1±0.2 6 1000 0.7 8.0±0.1 5.1±0.1 7.8±0.1 4.5±0.1 25 2000 0.7 9.0±0.2 6.0±0.2 8.1±0.2 4.4±0.2 4 4000 0.7 8.4±0.2 5.4±0.1 6.4±0.2 4.3±0.2 30 500 0.9 8.1±0.2 5.2±0.1 5.9±0.1 2.1±0.1 7 1000 0.9 7.8±0.1 4.9±0.1 7.2±0.1 4.9±0.2 33 2000 0.9 9.4±0.2 6.4±0.2 5.7±0.2 3.4±0.1 25 4000 0.9 8.4±0.1 5.4±0.1 5.3±0.2 2.9±0.2  下载: 导出CSV
下载: 导出CSV
表 2 动态算法和比对策略的性能比较
Table 2 Comparison of the algorithms and policies
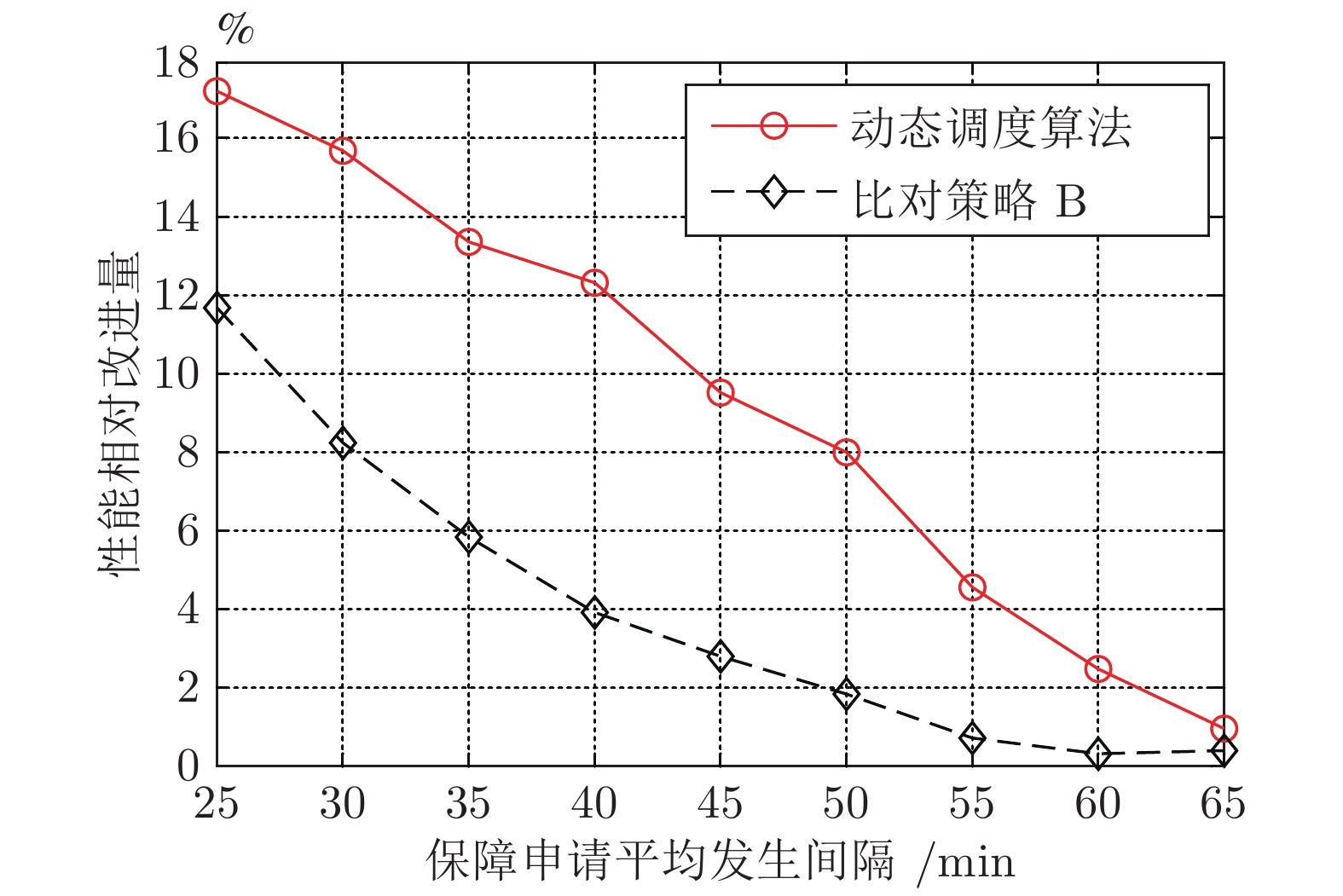
调度策略 响应时间(min) 性能相对改进量(%) 紧急申请 一般申请 比对策略A 56.3±0.2 56.8±0.2 — 比对策略B 53.4±0.1 57.7±0.2 2.9±0.1 动态调度 48.1±0.1 57.9±0.1 9.6±0.2
下载: 导出CSV
-
[1] 昝翔, 陈春良, 张仕新, 王铮, 刘彦. 多约束条件下战时装备维修任务分配方法. 兵工学报, 2017, 38(8): 1603-1609 doi: 10.3969/j.issn.1000-1093.2017.08.019Zan X, Chen C L, Zhang S X, Wang Z, Liu Y. Task Allocation Method for Wartime Equipment Maintenance under Multiple Constraint Conditions. Acta Armamentarii, 2017, 38(8): 1603-1609 doi: 10.3969/j.issn.1000-1093.2017.08.019 [2] 何岩, 赵劲松, 王少聪, 刘亚东, 周玄. 基于维修优先级的战时装备维修保障力量优化调度. 军事交通学院学报, 2019, 21(5): 42-46He Y, Zhao J S, Wang S C, Liu Y D, Zhou X. Maintenance Priority-Based Optimization and Scheduling of Equipment Maintenance Support Strength in Wartime. Journal of Military Transportation University, 2019, 21(5): 42-46 [3] 曹继平, 宋建社, 王正元, 黄超. 战时装备维修保障资源优化调度方法研究. 系统工程与电子技术, 2007, 29(6): 915-919 doi: 10.3321/j.issn:1001-506X.2007.06.019Chao J P, Song J S, Wang Z Y, Huang C. Study on optimization dispatching method of the equipment maintenance support resources in wartime. Systems Engineering and Electronics, 2007, 29(6): 915-919 doi: 10.3321/j.issn:1001-506X.2007.06.019 [4] 曾斌, 姚路, 胡炜. 考虑不确定因素影响的保障任务调度算法. 系统工程与电子技术, 2016, 38(3): 595-601Zeng B, Yao L, Hu W. Scheduling Algorithm for Maintenance Tasks under uncertainty. Systems Engineering and Electronics, 2016, 38(3): 595-601 [5] 任帆, 吕学志, 王宪文, 曲长征. 巡回修理中的维修任务调度策略. 火力与指挥控制, 2013, 38(12): 171-175 doi: 10.3969/j.issn.1002-0640.2013.12.045Ren F, Lv X Z, Wang X W, Qu C Z. Research on Maintenance Task Scheduling Strategies in Contact Repairing. Fire Control & Command Control, 2013, 38(12): 171-175 doi: 10.3969/j.issn.1002-0640.2013.12.045 [6] 陈春良, 刘彦, 王生凤, 陈伟龙, 等. 装备维修任务调度研究综述. 装甲兵工程学院学报. 2018, 32(1): 2-11Chen C L, Liu Y, Wang S F, Chen W L. Summary of Research on Equipment Maintenance Task Scheduling. Journal of Academy of Armored Force Engineering, 2018, 32(1): 2-11 [7] 师娇, 刘宸宁, 冷德新, 郑鑫, 李宝玉. 面向未来作战的装备智能化保障模式研究. 兵器装备工程学报, 2019, 29(10): 226-229Shi J, Liu C N, Leng D X, Li B Y. Weapon Intelligent Support Mode of Future War. Journal of Ordnance Equipment Engineering, 2019, 29(10): 226-229 [8] 梁星星, 冯旸赫, 马扬, 程光权, 黄金才, 王琦, 等. 多Agent深度强化学习综述. 自动化学报, 2020, 46(12): 2537−2557Liang X X, Feng Y H, Ma Y, Cheng G Q, Huang J C, Wang Q, et al. Deep multi-agent reinforcement learning: a survey. Acta Automatica Sinica, 2020, 46(12): 2537−2557 [9] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301−1312Sun C Y, Mu C X. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301−1312 [10] Ji S, Zheng Y, Wang Z, Li T. A deep reinforcement learning-enabled dynamic redeployment system for mobile ambulances. In: Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies. Washington, USA: IEEE Press, 2019. 1−20 [11] Hamasha M M, Rumbe G. Determining optimal policy for emergency department using Markov decision process, World Journal of Engineering, 2017, 14(5): 467-472 doi: 10.1108/WJE-12-2016-0148 [12] Ni Y, Wang K, Zhao L. A Markov decision process model of allocating emergency medical resource among multi-priority injuries. International Journal of Mathematics in Operational Research, 2017, 10(1): 1-17 doi: 10.1504/IJMOR.2017.080738 [13] Lee E K, Viswanathan H, Pompili D. RescueNet: Reinforcement-learning-based communication framework for emergency networking. Computer Networks, 2016, 98(5), 14-28 [14] Nadi A, Edrisi A. Adaptive multi-agent relief assessment and emergency response. International journal of disaster risk reduction, 2017, 24(6): 12-23 [15] Keneally S K, Robbin M J, Lunday B J. A markov decision process model for the optimal dispatch of military medical evacuation assets. Health care management science, 2016, 19(2): 111-129 doi: 10.1007/s10729-014-9297-8 [16] Huang Q, Huang R, Hao W, et al. Adaptive Power System Emergency Control Using Deep Reinforcement Learning. IEEE Transactions on Smart Grid, 2020, 11(2): 1171-1182 doi: 10.1109/TSG.2019.2933191 [17] 王云鹏, 郭戈. 基于深度强化学习的有轨电车信号优先控制. 自动化学报, 2019, 45(12): 2366−2377Wang Y P, Guo G. Signal priority control for trams using deep reinforcement learning. Acta Automatica Sinica, 2019, 45(12): 2366−2377 [18] Wang C, Ju P, Lei S, et al. Markov Decision Process-based Resilience Enhancement for Distribution Systems: An Approximate Dynamic Programming Approach. IEEE Transactions on Smart Grid, 2020, 11(3): 2498 – 2510 doi: 10.1109/TSG.2019.2956740 [19] Senn M, Link N, Pollak J, et al. Reducing the computational effort of optimal process controllers for continuous state spaces by using incremental learning and post-decision state formulations. Journal of Process Control, 2014, 24(3): 133-143 doi: 10.1016/j.jprocont.2014.01.002 [20] Berthier E, Bach F. Max-plus linear approximations for deterministic continuous-state markov decision processes. IEEE Control Systems Letters, 2020, 4(3): 767-772 doi: 10.1109/LCSYS.2020.2973199 [21] Li J, Zhou Y, Chen H, Shi Y M. Age of aggregated information: Timely status update with over-the-air computation. In: Proceedings of GLOBECOM IEEE Global Communications Conference. Washington, USA: IEEE Press, 2020. 1−6 [22] Wang C, Lei S, Ju P, et al. MDP-based distribution network reconfiguration with renewable distributed generation: Approximate dynamic programming approach. IEEE Transactions on Smart Grid, 2020, 11(4): 3620-3631 doi: 10.1109/TSG.2019.2963696 [23] Sharma H, Jain R, Gupta A. An empirical relative value learning algorithm for non-parametric mdps with continuous state space. In: Proceedings of the 18th European Control Conference (ECC). Washington, USA: IEEE Press, 2019. 1368−1373 [24] Madjiheurem S, Toni L. Representation learning on graphs: A reinforcement learning application. In: Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics. Okinawa, Japan: PMLR, 2019. 3391−3399 [25] Bai W, Zhou Q, Li T, et al. Adaptive reinforcement learning neural network control for uncertain nonlinear system with input saturation. IEEE transactions on cybernetics, 2019, 50(8): 3433-3443 [26] Bertsekas D. Multiagent reinforcement learning: Rollout and policy iteration. IEEE/CAA Journal of Automatica Sinica, 2021, 8(2): 249-272 doi: 10.1109/JAS.2021.1003814 -

 下载:
下载:



图(6) / 表(2)
计量
- 文章访问数: 1238
- HTML全文浏览量: 311
- PDF下载量: 163
- 被引次数: 0
