

-
摘要: 针对杂波环境下的目标跟踪问题, 提出了一种基于变分贝叶斯的概率数据关联算法(Variational Bayesian based probabilistic data association algorithm, VB-PDA). 该算法首先将关联事件视为一个随机变量并利用多项分布对其进行建模, 随后基于数据集、目标状态、关联事件的联合概率密度函数求取关联事件的后验概率密度函数, 最后将关联事件的后验概率密度函数引入变分贝叶斯框架中以获取状态近似后验概率密度函数. 相比于概率数据关联算法, VB-PDA算法在提高算法实时性的同时在权重Kullback-Leibler (KL)平均准则下获取了近似程度更高的状态后验概率密度函数. 相关仿真实验对提出算法的有效性进行了验证.Abstract: Aiming at the problem of target tracking in clutter, this paper proposes a variational Bayesian based probabilistic data association algorithm (VB-PDA). Firstly, associated events are regarded as a random variable and modelled by the multi-nomial distribution. Then, the joint probability density function of data set, target state and associated events is constructed and the posterior probability density function of associated events is obtained by using this joint probability density function. Finally, the posterior probability density function of associated events is introduced into the framework of variational Bayesian to obtain the approximate posterior probability density function of state. Compared with the probabilistic data association algorithm, the VB-PDA algorithm obtains a state posterior probability density function with higher approximation degree based on the weight Kullback-Leibler (KL) average criterion while improving real-time performance. The simulation experiments verify the effectiveness of proposed algorithm.
-
随着互联网技术的快速发展, 数字图像、视频等多媒体数据呈现爆发式增长, 基于数字图像及视频的图像处理技术也在迅猛发展.显著性检测通过模拟人类视觉系统选择图像中具有重要信息的区域[1], 可将其作为其他图像处理步骤的一种预处理工作, 并已成功应用于目标识别、目标跟踪和图像分割[2-4]等多种计算机视觉任务之中.
近年来国内外计算机视觉领域在图像显著性检测的研究方面提出许多行之有效的方法.Borji等[5]将这些方法分为两类, 一类方法基于模拟生物视觉系统构建注意力预测模型(Visual saliency prediction)[6-9]. Itti等[6]提出的IT算法, 根据人眼视觉特性, 针对多尺度图像通过底层特征的中心–周围对比度得到相应的显著图, 并通过显著图融合获取最终显著图.由于人类视觉系统生物结构复杂导致此算法计算复杂度极高.近年来基于频域的显著性检测模型成为此类方法中关注热点, Hou等[7]提出一种普残差方法, 认为图像包含显著信息和冗余信息, 通过在图像幅度谱上做对数运算并利用平均滤波器进行卷积运算得到冗余信息, 以幅度谱与卷积结果的差值表示显著信息再反变换到空间域上获得显著区域.在谱残差方法基础上Guo等[8]提出相位谱四元傅里叶变换法, 通过相位谱提取图像多特征分量得到显著区域, 利用四元傅里叶变换将亮度、颜色和运动信息一起并行处理来计算时空显著性. Li等[9]提出超傅里叶变换方法, 通过对谱滤波进行扩展, 利用超复数表示图像多为特征并使用傅里叶变化得到时空显著性.
另一类方法基于计算机视觉任务驱动构建显著目标检测模型(Salient object detection).这类方法通常包括两个步骤.首先检测图像中突出显著区域, 在此基础上分割出完整目标.虽然这类方法本质上本质是解决前景与背景分割问题, 但与图像分割相比显著性目标检测根据内容将图像分割为一致区域.一些经典算法使用底层特征对图像内容进行表示[10-14], 比如Cheng等[10]使用图割方法对图像进行分割, 通过稀疏直方图简化图像颜色, 利用空间位置距离加权的颜色对比度之和来衡量图像区域的显著性. Shen等[11]提取图像的颜色特征、方向特征以及纹理特征得到特征矩阵, 利用主成分分析(Principal component analysis, PCA)对矩阵进行降维表示再计算对比度得到显著图. Yang等[12]通过将图像划分为多尺度图层, 针对每个图层计算其颜色特征与空间特征的对比度, 融合多个图层生成的显著图获取最终显著图.该方法能够保证显著性目标的一致性与完整性, 但当显著性目标较小时, 会将显著性目标当作背景融入到背景区域. Cheng等[13]采用高斯混合模型将颜色特征相似的像素聚为图像区域, 综合考虑各区域的颜色对比度和空间分布, 以概率模型生成显著图. Li等[14]以稀疏表示分类(Sparse representation-based classification, SRC)原理为基础, 对分割图超像素块进行稠密和稀疏重构, 通过多尺度重构残差建立显著图.
使用不同底层特征的显著性检测方法往往只针对某一类特定图像效果显著, 无法适用于复杂场景下多目标图像, 如图 1所示.基于视觉刺激的底层特征缺乏对显著目标本质的理解, 不能更深层次的表示显著性目标的特征.对于图像中存在的噪声物体, 如与底层特征相似但不属于同一类目标, 往往会被错误的检测为显著目标.杨赛等[15]提出一种基于词袋模型的显著性检测方法, 首先利用目标性计算先验概率显著图, 建立一种表示中层语意特征的词袋模型计算条件概率显著图, 最后通过贝叶斯推断对两幅显著图进行合成.中层语意特征能够比底层特征更准确的表示图像内容, 因此检测效果更加准确. Jiang等[16]将显著性检测作为一个回归问题, 集成多分割尺度下区域对比度, 区域属性以及区域背景知识特征向量, 通过有监督学习得到主显著图.由于背景知识特征的引入使算法对背景对象有更好的识别能力, 进而得到更准确的前景检测结果.
近几年来, 基于深度学习的自动学习获取深度特征(或高层特征)的方法已经开始在图像显著性检测中得到应用.李岳云等[17]通过提取超像素块区域和边缘特征, 送入卷积神经网络学习得到显著置信图.采用条件随机场求能量最小化的区域进行显著性检测.对单显著目标检测效果较好, 但由于特征选择问题不适用于多目标图像. Li等[18]通过深度卷积神经网络来学习得到获取图像超像素区域的局部和全局深度特征来进行显著性检测MDF (Multiscale deep features), 检测效果相比于一般方法有明显著的提升, 但运行速度较慢. Hu等[19]通过结合卷积神经网络和区域验证的先验知识获取局部和全局特征.算法检测效果较好, 但高度复杂的模型影响了算法运行效率.本文着重研究图像背景信息相对复杂的多目标情况, 提出一种基于先验知识与深度特征的显著性检测方法.首先对图像进行多尺度分割, 对第一个分割图通过卷积神经网路提取所有超像素块的深度特征并计算显著值, 并生成预显著区域.将其余分割图的预显著区域超像素块输入卷积神经网络, 通过提取的深度特征计算显著值并更新预显著区域.不断迭代此过程得到各尺度下的显著图, 最终通过加权元胞自动机方法对多尺度显著图进行融合.目标先验可过滤大部分背景信息, 减少不必要的深度特征提取, 显著提升算法检测速率.
本文结构安排如下:第1节详细阐述基于多尺度目标先验与深度特征的多目标显著性检测方法; 第2节通过与已有算法在公开数据集上进行定性定量比较, 评价本文所提方法; 第3节总结本文所做工作并提出下一步研究方向.
1. 显著性检测方法
本节提出了一种基于深度特征显著性检测算法, 总体框架如图 2所示.对于输入图像$ l $, 首先采用超像素分割算法将图像分割为数目较少的超像素块.对所有超像素块提取深度特征, 通过主成分分析提取包含图像关键信息的多维特征.基于关键特征计算得到粗分割显著图, 从中提取初始显著区域组成超像素集$ Supselect $.利用$ Supselect $集中超像素与背景区域超像素相似性, 对其进行优化.对输入图像不同尺度超像素分割, 选择包含$ Supselect $集中超像素块的区域进行深度特征提取, 基于相同方法得到这一尺度下显著图$ Map^{s} $和$ Supselect $集.最终采用加权元胞自动机融合得到最终显著图$ M_{\rm final} $.
1.1 基于多尺度分割的显著区域提取
超像素分割是根据颜色、纹理和亮度等底层特征, 将相邻相似的像素点聚成大小不同图像区域[20], 降低了显著性计算的复杂度.常用的超像素生成算法有分水岭[21]和简单线性迭代聚类(Simple linear iterative clustering, SLIC) [22]两种分割算法.本文结合二者各自特点, 在粗分割时采用SLIC方法, 获取形状规则, 大小均匀的分割结果.在细分割时采用分水岭算法获得良好的对象轮廓.
对于$ {N} $个分割尺度$ s_{1}, \cdots, s_{n} $, 在某一分割尺度下得到的超像素集用$ Sup_j = \{Sp^j_i\}^{N_j}_{i = 1} $. $ N_{j} $表示分割尺度$ s_{j} $下的超像素个数, $ {20\leq N_{j}\leq250} $. $ Sp^{j}_{i} $为$ s_{j} $分割尺度下第$ {i} $个超像素. $ Sp^{j}_{i}(v) = \{R, G, B $, $ L, a, b\} $为该超像素中像素点两种颜色特征的特征向量.
1.1.1 预选区域提取
将粗分割尺度$ s_{j} $的分割图作为输入, 通过深度特征提取和显著值计算(在第1.2节和第1.3节中详细介绍)得到的显著图$ Map_{j} $. $ Map_{j} $作为下一个分割尺度检测时的目标先验知识, 用以指导预选目标区域提取.对显著图$ Map_{j} $进行二值化处理, 采用自适应的阈值策略, 将$ Map_{j} $的值分为$ K $个通道.用$ p(i) $表示属于通道$ i $的像素数量, 并确定所有通道中像素数量最多的通道$ k $, 通过式(1)计算阈值$ T. $
$ \begin{align} T = \frac{k+1}{K} \end{align} $
(1) 为防止$ T $取值过大, 确保在显著目标占据图像大部分空间时, 较为显著的像素不被二值化为0.每个通道像素数目必须满足$ {p(i)/area(I)<\varepsilon} $, 其中area(I)为图像$ l $的像素个数. $ {\varepsilon} $是落在[0.65, 0.95]范围内的经验值.所得二值化目标先验图为MapB$ _{j} $.
使用MapB$ _{j} $作为目标先验知识, 选取下一个尺度s$ _{j+1} $下$ {Sup_{j+1} = \{Sp^{j+1}_i\}^{N_{j+1}}_{i = 1}} $相应位置的超像素区域构成预选显著性超像素集$ Supselect_{j+1} = $ $ \{Sp^{j+1}_i\}^{M_{j+1}}_{i = 1} $. $ M_{j+1} $是在分割尺度$ s_{j+1} $上提取的预选显著目标超像素个数, $ M_{j+1}<N_{j+1} $.假设Num$ _{i} $为超像素$ {Sp^{j+1}_i} $中像素总数, num是二值图MapB$ _{j} $对应位置上值为1的像素个数, 若满足条件$ num/Num_j $ $ > $ $ 0.5 $则认为相应位置处的超像素属于$ {Supselect_{j+1}} $.
1.1.2 区域优化
预选目标超像素集$ Supselect_{j+1} $可能包含一些背景区域或缺失部分显著区域.需对预选目标区域进行优化, 将$ Supselect_{j+1} $中可能的背景区域去除掉, 并将背景区域中可能的显著性区域加入进来.
根据两种颜色空间特征的欧氏距离来构造超像素之间的相异矩阵$ Difmat $, 表示超像素之间的相异性. $ Difmat $是一个$ N_{j+1} $阶对称矩阵.
$ \begin{align} &Difmat(i, j) = Difmat(Sp_i, Sp_j) = \\ &\qquad\sqrt{\sum\limits_{k = 1}^6(F_{i, k}-F_{j, k})^2} \end{align} $
(2) 其中, $ {F_{i, k}} $为超像区域$ Sp_i $的第$ k $个特征, $ k $从1到6分别对应$ R, G, B, L, a $和$ b $特征.对于$ {Sp_k} $ $ \in $ $ Supselect_{j+1} $, 通过式(3)计算局部的平均相异度
$ \begin{align} MavDif(Sp_k) = \frac{\sqrt{\sum\limits^{{M}_{j+1}}_{l = 1, l\neq k}Difmat(Sp_k, Sp_l)^2}}{M_{j+1}} \end{align} $
(3) 其中, $ {Sp_k} $, $ {Sp_l\in Supselect_{j+1}} $, $ {M_{j+1}} $是预选显著区域集$ {Supselect_{j+1}} $中超像素个数.计算$ {Supselect_{j+1}} $中每个超像素$ {Sp_k} $与其相邻的背景区域的平均相异度
$ \begin{align} MavDif(Sp_k)' = \frac{\sqrt{\sum\limits^{{M'}_{j+1}}_{l = 1, l\neq k}Difmat(Sp_k, Sp_l)^2}}{M_{j+1}'} \end{align} $
(4) 其中, $ {Sp_k\in Supselect_{j+1}} $, $ {Sp_l\nsubseteq Supselect_{j+1}} $, 且$ {Sp_k} $与$ {Sp_l} $相邻, $ {M_{j+1}'} $表示背景区域中与$ {Sp_k} $相邻的超像素个数.如果$ MavDif(Sp_k)' $ $ > $ $ DavDif(Sp_k) $, 表明$ {Sp_k} $与相邻的背景区域的相似度更高, 则将$ {Sp_k} $从$ {Supselect_{j+1}} $删除.
同样, 对于任意$ {Sp_h\nsubseteq Supselect_{j+1}} $, 可计算$ {Sp_h} $与相邻背景区域中的平均相异度$ {MavDif(Sp_h)'} $, 及$ {Sp_h} $与相邻预选显著区域的平均相异度$ {MavDif(Sp_h)} $.如果满足条件$ MavDif(Sp_h)' $ $ > $ $ MavDif(Sp_h) $, 则说明与其他背景区域相比, $ {Sp_h} $与相邻显著区域的相似度更高, 则将$ {Sp_h} $加入到$ {Supselect_{j+1}} $中.
通过比较$ {Supselect_{j+1}} $中超像素与其他显著区域及背景区域的相异度, 从而不断更新$ {Supselect_{j+1}} $, 直到$ {Supselect_{j+1}} $中超像素不再变化.
1.2 预显著区域深度特征提取
本节基于卷积神经网络的深度特征提取方法如图 3所示.在首次超像素分割时提取所有超像素的深度特征, 在之后的深度特征提取过程中, 只对$ {Supselect} $集中超像素进行提取.在一定的分割策略下, 大大降低计算量, 提高计算速度.
 图 3 基于卷积神经网络的深度特征提取架构图Fig. 3 Deep features extraction based on convolutional neural network
图 3 基于卷积神经网络的深度特征提取架构图Fig. 3 Deep features extraction based on convolutional neural network假设不是首次分割, 对于每一个超像素$ Sp_i $ $ (Sp_i $ $ \in $ $ Supselect) $分别提取局部区域深度特征和全局区域深度特征.
超像素的局部特征包括两部分: 1)包含自身区域的深度特征$ {F_{\rm self}} $; 2)包含自身及相邻超像素区域的深度特征$ {F_{\rm local}} $.
首先, 根据预选目标超像素集$ {Supselect} $, 提取每个超像素$ Sp_i $ $ (Sp_i\in Supselect) $所在的最小矩形区域$ {Rect_{\rm self}} $ (如图 3区域内的荷花).由于多数超像素不是规则的矩形, 提取到的矩形一定包含其他像素点, 这些像素点用所在超像素的平均值表示.通过深度卷积网络就可以得到只包含自身区域的深度特征$ {F_{\rm self}} $.
仅有特征$ {F_{\rm self}} $经过显著性计算得到的显著值是没有任何意义的, 在不与其他相邻超像素显著性的对比情况下, 无法确定它是否是显著的.因此还需提取包含$ {Sp_i} $自身及其相邻超像素的最小矩形区域$ {Rect_{\rm local}} $, 从而获得局部区域的深度特征$ {F_{\rm local}} $.
区域在图像中的位置是一个判断其是否显著的重要因素.通常认为位于图像中心的区域比位于边缘的区域成为显著区域的可能性更高.因此, 以整幅图像作为矩形输入区域$ {Rect_{\rm local}} $, 提取全局区域的深度特征$ {F_{\rm global}} $.
深度卷积神经网络模型是由一个数据输入层、多个卷积层和下采样层、全连接层和输出层共同构成的深度神经网络[23].卷积层和下采样层构成神经网络中间结构, 前者负责特征提取, 后者则负责特征计算.在一个或者多个下采样层之后会连接一个或多个全连层, 每个全连层都可将特征进行输出.卷积层输出结果为
$ \begin{align} d^l_n = f\left(\sum\limits_{\forall m}(d^{i-1}_m*k^l_{m, n})+b^l_n\right) \end{align} $
(5) 其中, $ {d^l_n} $和$ {d^{i-1}_m} $是当前层和上一层特征图, $ {k^l_{m, n}} $是模型的卷积核, $ {f(x) = 1/[1+\exp(-x)]}$为神经元激活函数, $ {b^l_n} $为神经元偏置.下采样层特征提取结果为
$ \begin{align} d^l_n = f\left(k^l_n\times \frac{1}{s^2}\sum\limits_{s\times s} d^{l-1}_n+b^l_n\right) \end{align} $
(6) 其中, $ {s\times s} $是下采样模板尺度, $ {k^l_n} $为模板权值.本文利用训练好的AlexNet深度卷积神经网络模型来提取预选目标区域的深度特征, 并在此模型基础上去除标签输出层以获取深度特征.将预处理后图像输入模型, 卷积层$ C1 $利用96个大小为$ 11\times11 \times $ $ 3 $的图像滤波器来对大小为$ 224\times224\times3 $的输入图像进行滤波.
卷积层$ C2 $, $ C3 $, $ C4 $, $ C5 $分别将上一层下采样层的输出作为自己的输入, 利用自身滤波器进行卷积处理, 得到多个输出特征图并传给下一层.全连接层$ F6 $和$ F7 $每层都有4 096个特征输出, 每个全连接层的输出结果可为
$ \begin{align} d^{\rm out}_n = f\left(\sum (d^{{\rm out}-1}_m\times k^{\rm out}_{m, n})+b^{\rm out}_n\right) \end{align} $
(7) 1.3 基于深度特征的显著值计算
主成分分析(Principle component analysis, PCA) [24]是最常见的高维数据降维方法, 可以把$ p $个高维特征用数目更少的$ m $个特征取代.对于$ n $个超像素, 卷积神经网络输出特征可以构成一个$ n $ $ \times $ $ p $维的样本矩阵$ W $, $ {p = 12\, 288} $.通过式(8)计算样本的相关系数矩阵$ {R = (r_{ij})_{p\times p}} $
$ \begin{align} r_{ij} = \frac{\sum\limits_{k = 1}^n(x_{ki}-\bar{x}_i)(x_{kj}-\bar{x}_j)}{\sqrt{\sum\limits_{k = 1}^n(x_{ki}-\bar{x}_i)^2\sum\limits_{k = 1}^n(x_{kj}-\bar{x}_j)^2}}, \\ i, j = 1, 2, \cdots, p \end{align} $
(8) 其中, $ {\bar{x}_i = \frac{1}{n}\sum^n_{i = 1}x_{ij}} $, $ j = 1, 2, \cdots, p $.通过解方程$ |\lambda I-R| = 0 $, 求出特征值并按从大到小的顺序排列.计算每个特征值$ {\lambda_i} $的贡献率和累积贡献率
$ \begin{align} \frac{\lambda_i}{\sum\limits_{k = 1}^p\lambda_k}, \qquad \frac{\sum\limits_{k = 1}^i\lambda_k}{\sum\limits_{k = 1}^P\lambda_k} \end{align} $
(9) 计算每个特征值$ {\lambda_i} $对应的正交单位向量$ {\pmb z}_i = $ $ [z_{i1} $, $ z_{i2}, \cdots, z_{ip}]^{\rm T} $, 选取累计贡献率达到95 %的前$ m $个特征对应的单位向量, 构成转换矩阵$ Z = [{\pmb z}_1, $ $ {\pmb z}_2 $, $ \cdots, {\pmb z}_m]_{p\times m} $.通过式(10)对高维矩阵$ M $进行降维, $ {Sp_i(df) = (f_{i, 1}, f_{i, 2}, \cdots, f_{i, m})} $表示降维后的$ m $维主成分特征.图像不同尺度的分割图使用同一转换矩阵提取主成分特征.
$ \begin{align} Sp_i(df) = W_{n\times p}Z_{p\times m} \end{align} $
(10) 1.3.1 对比特征
对比度特征反映了某一区域与相邻区域的差异程度.超像素$ {Sp_i} $的对比特征值$ {w^c(Sp_i)} $, 是用它与其他超像素所有特征的距离来定义的, 如式(11)所示
$ \begin{align} w^c(Sp_i) = \frac{1}{n-1}\sum^n_{i = 1, i\neq k}\|Sp(df)_i-Sp(df)_k\|_2 \end{align} $
(11) 其中, $ n $表示超像数的个数, $ {\|\cdot\|_2} $是2-范数.
1.3.2 空间特征
在人类视觉系统中对不同空间位置的关注度不同, 越靠近中心越能引起注意.图像中不同位置的像素到图像中心的距离满足高斯分布, 对任一超像素$ {Sp_i} $, 其空间特征值$ {w^s(Sp_i)} $用式(12)计算
$ \begin{align} w^s(Sp_i) = \exp\left(\frac{-d(Sp_{i, x}, c)}{\sigma^2}\right) \end{align} $
(12) 其中, $ {Sp_{i, x}} $为超像素$ {Sp_i} $的中心坐标, c为图像中心区域.与图像中心的平均距离越小的超像素块空间特征值越大.超像素$ {Sp_i} $的显著值用式(13)表示
$ \begin{align} Map(Sp_i) = w^c(Sp_i)\times w^s(Sp_i) \end{align} $
(13) 计算得到第一个分割图的显著图$ {Map^1} $, 作为后序分割尺度的目标先验知识来指导预选目标区域的提取和优化.
1.3.3 目标先验显著性计算
通过目标先验知识提取预选目标区域$ Supselect $后, 超像素集中显著性区域占绝大部分, 即显著性区域不在是稀疏的.因此, 再按照式(11)计算对比特征值是不准确的.
提取预显著区域的平均超像素特征用$ Sp'(d) $ $ = $ $ (f_1', f_2', \cdots, f_m') $来表示, 超像素$ Sp_i $ $ (Sp_i\in $ $ Supselect) $的对比特征值$ {w^c(Sp_i)} $使用式(14)计算
$ \begin{align} w^c(Sp_i)' = \|Sp_i-Sp'\|_2 \end{align} $
(14) 在已知目标的大致空间分布的情况下, 特别是分散的多目标情况, 根据图像中心来计算空间特征不够准确.可以根据已知的显著目标空间分布来以目标先验图中的显著性区域的中心来代替图像中心进行计算, 如式(15)所示.
$ \begin{align} w^s(Sp_i)' = \exp\left(\frac{-d(Sp_{i, x}, c')}{\sigma^2}\right) \end{align} $
(15) 其中, $ {Sp_{i, x}} $为超像素$ {Sp_i} $的中心坐标, $ {c'} $为目标先验图中的显著性区域的中心.如果存在多个独立的显著性区域, 那么$ {c'} $表示与超像素$ {Sp_i} $最近的显著性区域的中心.由式(13)计算最终显著值得到目标先验下的显著性图$ {Map^i} $, $ i $代表不同的尺度.
1.4 基于加权元胞自动机的显著图融合
Qin等[25]提出了多层元胞自动机(Multi-layer cellular automata, MCA)融合方法.显著图中每一个像素点表示一个元胞, 在$ M $层元胞自动机中, 显著图中的元胞有$ M-1 $个邻居, 分别位于其他显著图上相同的位置.
如果元胞$ i $被标记为前景, 则它在其他显著图上相同位置的邻居$ j $被标记为前景的概率$ \lambda = P(\eta_i $ $ = +1|i\in F) $.同样, 可以用$ \mu = P(\eta_i = +1|i\in B) $来表示元胞$ i $标记背景时, 其邻居$ j $成为背景的概率.
对于不同方法得到的显著图, 可以认为是相互独立的.在同步更新时认为所有显著图的权重是一样的.不同分割尺度下的显著图之间有指导和细化关系, 在融合的过程中权重不能认为是相等的.在不同的分割尺度中, 假设首次分割尺度得到的显著图的权重为$ {\lambda_1} $, 用$ {w_i = \lambda_1} $来表示.不分割尺度下的显著图权重用式(16)表示为
$ \begin{align} w_i = \lambda_{i-1}+\left(1-\frac{o_i}{O_i}\right), \; \; \; i = 2, \cdots, 6 \end{align} $
(16) 其中, $ {O_i} $表示预选目标集中所有超像素包含的像素总数, $ {o_i} $表示第$ i $幅显著性区所包含的像素数量.将$ {\lambda_1} $的初始值设置为1, 同步更新机制$ f:Map^{M-1} $ $ \rightarrow $ $ Map $, 定义为
$ \begin{align} l(Map^{t+1}_m) = &\ w_m\sum^M_{k = 1, k\neq m}{\rm sign}(Map^t_k-\gamma_k\cdot I)\, \times\\&\ \ln(\frac{\lambda}{1-\lambda}) +l(Map^t_m) \end{align} $
(17) 其中, $ {Map^t_m = [Map^t_{m, 1}, \cdots, Map^t_{m, H}]^{\rm T}} $表示$ t $时刻, 第$ m $幅显著图上的所有元胞的显著性值, 矩阵$ {I} $是有$ H $个元素的矩阵$ {[1, \cdots, 1]^{\rm T}} $.如果一个元胞的邻居被判定为前景, 则相应的增加自身的显著性值, 即应有$ {\ln(\lambda/1-\lambda)} $, 则有$ {\lambda>0.5} $.并根据经验设置$ \ln(\lambda/1-\lambda) $ $ = 0.15 $, 在$ {T_2} $个时间步后, 可以通过下式得到最终的显著图$ {Map_{\rm final}} $
$ \begin{align} Map_{\rm final} = \frac{1}{N}\sum^M_{m = 1}Map_m^{T_2} \end{align} $
(18) 将多尺度分割显著图经过加权MCA融合后得到最终的显著图, 从而完成单幅图像的显著性检测.根据前面内容对本文的基于深度特征的多目标显著性检测算法的整个流程进行了总结, 如算法1所示.
算法1.基于深度特征的多目标显著性检测算法
输入.原始输入图像$ I $和多尺度分割个数$ N $和每个尺度下的分割参数.
输出.显著图for $ i = 1:N $
{
if $ i = 1 $ then
1) 根据确定好的参数, 用SLIC对图像$ l $进行超像素分割;
2) 确定每个超像素的输入区域$ Rect_{\rm self} $, $ Rect_{\rm local} $, $ Rect' $;
3) 将输入区域送入Alexnet网络, 提取深度特征$ {[F_{\rm self}, F_{\rm local}, F_{\rm global}]}$;
4) 将所有超像素的深度特征构成矩阵$ W $, 利用PCA算法计算$ W $的转换矩阵$ A $, 获取主成分特征;
5) 根据主成分特征计算无目标先验的显著值, 得到首次分割显著图$ {Map_1} $;
else
6) 根据确定好的参数, 用分水岭算法对图像$ l $进行超像素分割;
7) 将显图$ {Map^{i-1}} $当作目标先验图, 提取并优化预选目标区域集$ Supselect $;
8) 确定$ Supselect $中每个超像素的输入区域$ {Rect_{\rm self}, Rect_{\rm local}, Rect_{\rm global}} $;
9) 将输入区域送入Alexnet网络, 提取深度特征$ {[F_{\rm self}, F_{\rm local}, F_{\rm global}]}$;
10) 将所有超像素的深度特征构成矩阵$ W, $用转换矩阵$ A $得到主成分特征;
11) 根据主成分特征计算有目标先验的显著值, 得到显著图$ {Map_i} $;
end if
}
12) 计算每个尺度下的显著图的权重$ {w_i} $;
13) 用加权MCA对得到的$ N $幅显著图进行融合, 得到最终的显著图$ {Map_{\rm final}} $.
2. 实验结果与分析
2.1 数据集介绍
数据集SED2 [26]是目前比较常用的多目标数据集, 它包含了100幅图像和相应的人工标注图, 每幅图像中都包含了两个显著目标. HKU-IS [18]包含近4 500幅由作者整理挑选的图像, 每幅图像中至少包含2个显著目标, 并且目标与背景的颜色信息相对复杂, 同时提供人工标注的真实图.本文是针对多目标的检测算法, 因此只选择HKU-IS中具有两类或两个以上目标的2 500幅图像进行实验.另外为分析本文算法各部分性能, 从HKU-IS中随机选择500幅图像建立测试数据集, 在进行参数选择和评价PCA以及自适应元胞自动机性能时均使用此测试集.
2.2 评价标准与参数设置
在本节的实验中, 通过对比显著图的准确率(Precision)–查全率(Recall)曲线(PR曲线)、准确率–查全率–F-measure柱状图(F-measure柱状图)与平均绝对误差(Mean absolute error, MAE)柱状图三个标准来评价显著性检测的效果, 从而选出相对较好的分割尺度.
查准率与查全率是图像显著性检测领域最常用的两个评价标准, PR曲线越高表示显著性检测的效果越好, 相反PR曲线越低, 相应的检测效果就越差.对于给定人工标注的二值图$ G $和显著性检测的显著图$ S, $查准率Precision与查全率Recall的定义如式(19)所示
$ \begin{align} P = \frac{sumA(S, G)}{sumB(S)}, \; \; \; R = \frac{sumA(S, G)}{sumB(S)} \end{align} $
(19) 其中, $ {sumA(S, G)} $表示显著性检测的视觉特征图$ S $和人工标注的真实二值图$ G $对应像素点的值相乘后的和, $ {sumB(S)} $、$ {sumB(G)} $分别表示的是视觉特征图S和人工标注的真实二值图$ G $上所有像素点的值之和.
不同于准确率–召回率曲线, 在绘制准确率–召回率–F-measure值柱状图时, 利用每幅图像的自适应阈值$ T $对图像进行分割
$ \begin{align} T = \frac{2}{W\times H}\sum^W_{x = 1}\sum^H_{y = 1}S(x, y) \end{align} $
(20) 其中, 参数$ W $与$ H $分别指代图像的宽度与高度.对每个数据集中的显著图, 计算它们的平均准确率与召回率.根据式(21)计算平均的F-measure值, F-measure的值超高超好. F-measure值用于综合评价准确率与查全率, 在显著性检测中查准率要比查全率更加重要, 所以$ {\beta^2} $的值常设置成0.3[19].
$ \begin{align} {\rm F\text{-}measure} = \frac{(\beta^2+1)PR}{\beta^2P+R} \end{align} $
(21) 平均绝对误差通过对比显著图与人工标注图的差异来评价显著性模型[20].根据式(22)可以计算每个输入图像的MAE值, 并利用计算出的MAE值绘制柱状图, MAE值越低表明算法越好[21].
$ \begin{align} {\rm MAE} = \frac{1}{W\times H}\sum^W_{x = 1}\sum^H_{y = 1}|S(x, y)-G(x, y)| \end{align} $
(22) 2.2.1 确定分割尺度
本文算法参数主要为分割尺度.分割尺度太多会增加计算复杂度, 太少则会影响显著性检测效果的准确性.因此, 根据经验设置15个分割尺度并将其限定在[20, 25]范围内.
在随机选取的数据上进行实验, 根据经验设置15个分割尺度, 提取分割图中所有超像素的深度特征计算显著图.不同分割尺度显著性检测结果的Precision-Recall曲线图如图 4所示.从中选择6个效果较好的分割尺度.通过对比分析发现分割尺度1, 3, 4, 6, 8, 13这6个分割尺度下的显著性检测效果相对较好.选择这6个分割尺度作为本文算法的最终分割尺度.
 图 4 不同分割尺度下显著性检测的PR曲线图Fig. 4 Precision-Recall curves of saliency detection in different segmentation scales
图 4 不同分割尺度下显著性检测的PR曲线图Fig. 4 Precision-Recall curves of saliency detection in different segmentation scales2.2.2 预显著区域提取策略选择
在结合目标先验知识后, 不同的分割策略组合得到的结果并不一致, 且运行速度也存在较大差异.按照分割所得超像素个数进行组合, 可分为由少到多、由多到少、多少多交叉和少多少交叉共4种组合策略.在这4种分割组合策略和不加目标先验情况下显著性检测结果的PR曲线图以及MAE柱状图如图 5所示.运行时间如表 1所示.由图可以看出, 4种策略的PR曲线大致相当, 但策略4的要稍高于其他3种分割策略, 与无标先验的的显著性检测相差不大.从表中可以看出策略4运行速度最快, 与无目标先验的检测相比, 在检测效果相差无几的情况下, 平均每幅图像的检测时间提高了50 %左右.
 图 5 不同分割策略下显著性检测的PR曲线图以及MAE柱状图Fig. 5 Precision-recall curves and MAE histogram in different segmentation strategies表 1 不同分割策略下平均每幅图像检测时间Table 1 The average detection time for each image in different segmentation strategies
图 5 不同分割策略下显著性检测的PR曲线图以及MAE柱状图Fig. 5 Precision-recall curves and MAE histogram in different segmentation strategies表 1 不同分割策略下平均每幅图像检测时间Table 1 The average detection time for each image in different segmentation strategies方法 时间(s) 分割策略1 2.70017 分割策略2 2.33585 分割策略3 2.52179 分割策略4 2.31023 无目标先验 4.52449 2.2.3 PCA参数确定
为验证PCA算法从深度特征中选取主成分的有效性, 本节通过测试集的500幅图像中各超像素块中所提取的深度特征作为数据集, 通过可解释方差(Percentage of explained variance, PEV) [27]来衡量主成分在整体数据中的重要性, 该指标是描述数据失真率的一个主要指标, 累计率越大, 数据保持率越高.计算方式为
$ \begin{align} PEV = \frac{\sum\limits_{i = 1}^mR_{ii}^2}{{\rm tr}(\Sigma)} \end{align} $
(23) 其中, $ {R_{ii}^2} $为主成分矩阵$ {M'} $奇异值分解后的右矩阵, $ {\Sigma} $为协方差矩阵. 图 6给出前50个主成分与累计可解释方差.从图中可以看出随着主成分个数的增加累计可解释方差呈上升趋势, 但这种上升趋势会随着主成分个数的增加而逐渐放缓.当主成分个数超过10后累计可解释方差达到80 %以上, 认为其能够代表数据整体信息, 在本文设计算法中选取前10个主成分进行显著值计算.
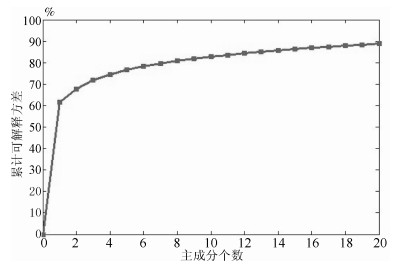 图 6 主成分个数与累计可解释方差关系图Fig. 6 The relationship between the number of principal component and percentage explained variance
图 6 主成分个数与累计可解释方差关系图Fig. 6 The relationship between the number of principal component and percentage explained variance2.2.4 元胞自动机评价
为评估自适应元胞自动机融合有效性, 对测试集使用9种不同方式得到显著图, 分别是本文所选6种分割尺度、线性融合[17]、MCA [24]以及加权元胞自动机.通过PR值与MAE值对这9种方法进行评价, 所得结果如图 7所示.
 图 7 不同融合方法的PR曲线与MAE柱状图Fig. 7 Precision-Recall curves and MAE histogram of different fusion methods
图 7 不同融合方法的PR曲线与MAE柱状图Fig. 7 Precision-Recall curves and MAE histogram of different fusion methods通过对比可以发现, 不同分割尺度下所得显著图的PR曲线十分相似, 但是查准率与查全率均不理想.通过线性融合方法得到的显著图能改善单一尺度检测结果的鲁棒性使其在检测结果更加稳定.MCA融合方法明显好于线性方法得到的显著图, 而改进后的加权MCA方法得到的多尺度分割融合图具有更好的查准率, 因此所得融合结果将更加准确.从MAE柱状图中也可看到相同结果.
2.3 实验结果对比
为验证本文提出的多目标显著性检测方法的性能, 在两个数据集上同10种显著性检测算法进行对比, 包括FT09[28], GC13[13], DSR13[29], GMR13[12], MC13[14], HS13[14], PISA13[30], HC15[10], SBG16[31], DRFI[16]和MDF15[18].除MDF算法外, 其他都是基于底层特征进行显著性计算的, 也是近几年显著性检测算法中相对较好的一些经典算法.而MDF算法是最早的应用深度卷积神经网络进行显著性检测的算法之一, 且是目前为数不多的提供了源代码的深度学习算法.
2.3.1 主观评价
从主观的视觉上, 图 8~10分别显示了在两个数据集上的视觉显著图.从左至右依次是:原始输入图像, 对比算法DSR, FTvGCvGMR, HCvHSvMCvPISA, SBG, DRFI, MDF的显著图, 以及本文算法显著图和人工标注的真实图.
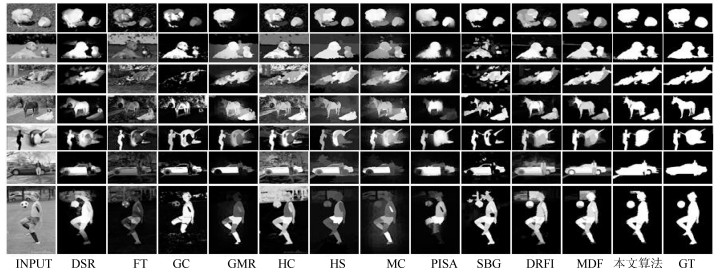 图 9 不同算法在具有不同类别目标的数据集HKU IS上的视觉显著图Fig. 9 Saliency maps of different algorithms on dataset HKU IS with different classes of objects
图 9 不同算法在具有不同类别目标的数据集HKU IS上的视觉显著图Fig. 9 Saliency maps of different algorithms on dataset HKU IS with different classes of objects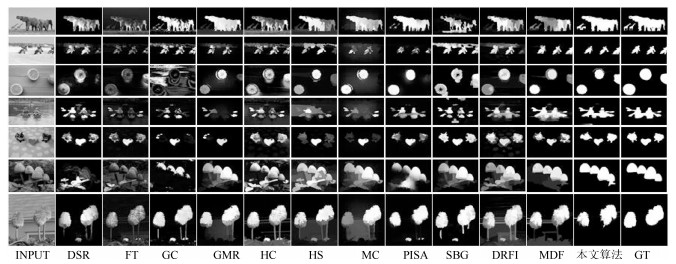 图 10 不同算法在具有多个目标的数据集HKU IS上的视觉显著图Fig. 10 Saliency maps of different algorithms on dataset HKU IS with different multiple objects
图 10 不同算法在具有多个目标的数据集HKU IS上的视觉显著图Fig. 10 Saliency maps of different algorithms on dataset HKU IS with different multiple objects图 8显示了本文算法与其他算法在数据集SED2上的显著图对比情况.通过对比可以看出, 本文算法对位于图像边缘的目标(如图 8中的第2~4行和9行)的检测效果明显优于对比算法.此外对于图像中的小目标(如图 8中第4~6行)检测效果也很优异.
图 9和图 10是不同算法在复杂多目标数据集HKU_IS上的显著图对比情况.与图 8相比, 图 9中图像的背景相对要复杂一些, 而图 10中的图像都包含了3个以上的显著目标.通过与其他算法显著图的对比可以看出, 本文算法和MDF算法相比于其他算法在多目标的复杂图像的显著性检测的效果更好, 这充分特征了深度特征在图像表达方面的优势.本文算法经过加权MCA融合后的显著图中, 显著目标区域内显著值的一致性要明显著优于其他方法.
2.3.2 定量比较
为了更加客观地评价本文算法与其他算法, 本文根据不同的评价标准, 在两个数据集上进行了对比实验分析.
图 11是根据准确率–召回率和准确率–召回率–F-measure值评价标准, 不同检测算法在数据集SED2上检测结果的PR曲线图和F-measure柱状图.通过图 11对比分析可以看出本文算法在数据集SED2上的PR曲线与F-measure柱状图上与MDF算法相当, 但明显优于其他对比算法.这与主观视觉特征的评价相致, 进一步体现了深度特征在图像表达上的优势.
 图 11 不同算法在数据集SED2上的PR曲线图和F-measure柱状图Fig. 11 PR curves and F-measure histogram of different algorithms on dataset SED2
图 11 不同算法在数据集SED2上的PR曲线图和F-measure柱状图Fig. 11 PR curves and F-measure histogram of different algorithms on dataset SED2图 12是不同检测算法在数据集HKU_IS上的PR曲线图和F-measure柱状图, 可以看出在复杂数据HKU_IS上, 本文算法与MDF算法相比, 随着查全率的变化, 查准率各有高低, 但都能保持较高的水平.但在F-measure值上, 本文算法要比MDF算法高出7.18 %.
 图 12 不同算法在数据集HKU IS上的PR曲线图和F-measure柱状图Fig. 12 PR curves and F-measure histogram of different algorithms on dataset HKU_IS
图 12 不同算法在数据集HKU IS上的PR曲线图和F-measure柱状图Fig. 12 PR curves and F-measure histogram of different algorithms on dataset HKU_IS相比于数据集SED2, 数据集HKU_IS的图像中包含更多的显著目标和相对复杂的背景信息.与除MDF算法外的其他算法相比, 无论是PR曲线值, 还是F-measure值, 本文算法都明显高于其他对比算法, 并且与在数据集SED2的结果相比, 优势更加明显.这些充分体现了本文算法在图像信息相对复杂的多目标显著性检测中的优越性, 如显著性目标位于图像边缘、多个显著性目标、显著性目标包含多个对比度明显的区域等情况.
图 12是不同算法根据平均绝对误差这一评价标准在两个数集上的MAE柱状图.同样, 本文算法的平均绝对误差远低于其他算法, 在两个数据集上降低到了10 %以内, 并且在数据集HKU_IS更是降到了7.2 %.
2.3.3 运行时间
不同算法在对图像处理的速度上也存在明显的差异, 如表 2所示.在显著性检测的速度上, 本文方法要比FT、GC等算法要慢的多, 这也是基于深度学习算法的不足之处.但与MDF算法相比, 处理效率上提高7倍左右, 这说明本文的目标先验知识的应用在提高速度上的有效性.
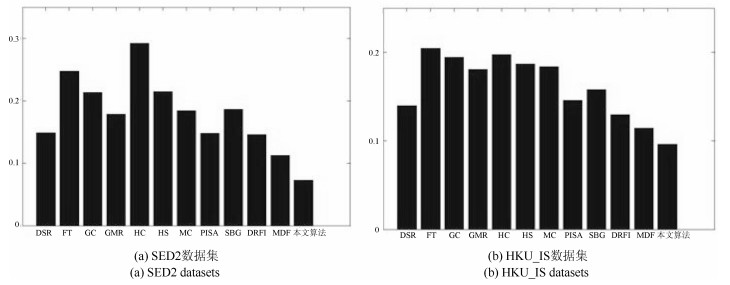 图 13 不同算法在数据集SED2和HKU_IS上的MAE柱状图Fig. 13 The MAE histogram of different algorithms on dataset of SED2 and HKU_IS表 2 平均检测时间对比表Table 2 Table of contrast result in running times
图 13 不同算法在数据集SED2和HKU_IS上的MAE柱状图Fig. 13 The MAE histogram of different algorithms on dataset of SED2 and HKU_IS表 2 平均检测时间对比表Table 2 Table of contrast result in running times方法 DSR FT GC GM HS MC SBG DRFI MDF 本文算法 代码类型 MATLAB C++ C++ MATLAB C++ MATLAB MATLAB MATLAB MATLAB MATLAB 时间(s) 3.534 0.023 0.095 0.252 0.492 0.146 3.882 12.135 15.032 2.31 综上所述可以看出, 无论从视觉特征图上进行主观评价, 还是基于三种评价标准上的客观分析, 本文算法与其他算法相比都具有十分明显的优势.而MDF算法与其他基于低层特征的算法相比优势同样也较为明显.这些都证明了本文算法的在显著性检测上的有效性, 同时也表明基于深度学习的显著性检测算法在计算机视觉领域的巨大潜力.
3. 结束语
基于深度学习的显著性检测算法能够克服传统的基于底层特征的显著性检测算法在检测效果上的不足, 但运行速率与之相比又有明显不足.本文提出一种多尺度分割和目标先验的目标预提取方法, 在此基础上通过深度特征提取进行显著值计算, 使用加权元胞自动机对尺度显著图进行融合与优化.本文方法虽然在多目标显著性检测的效果和速度上有所提升, 但仍存在许多不足, 主要工作将继续完善深度神经网络的构建和效率提升等问题.
-
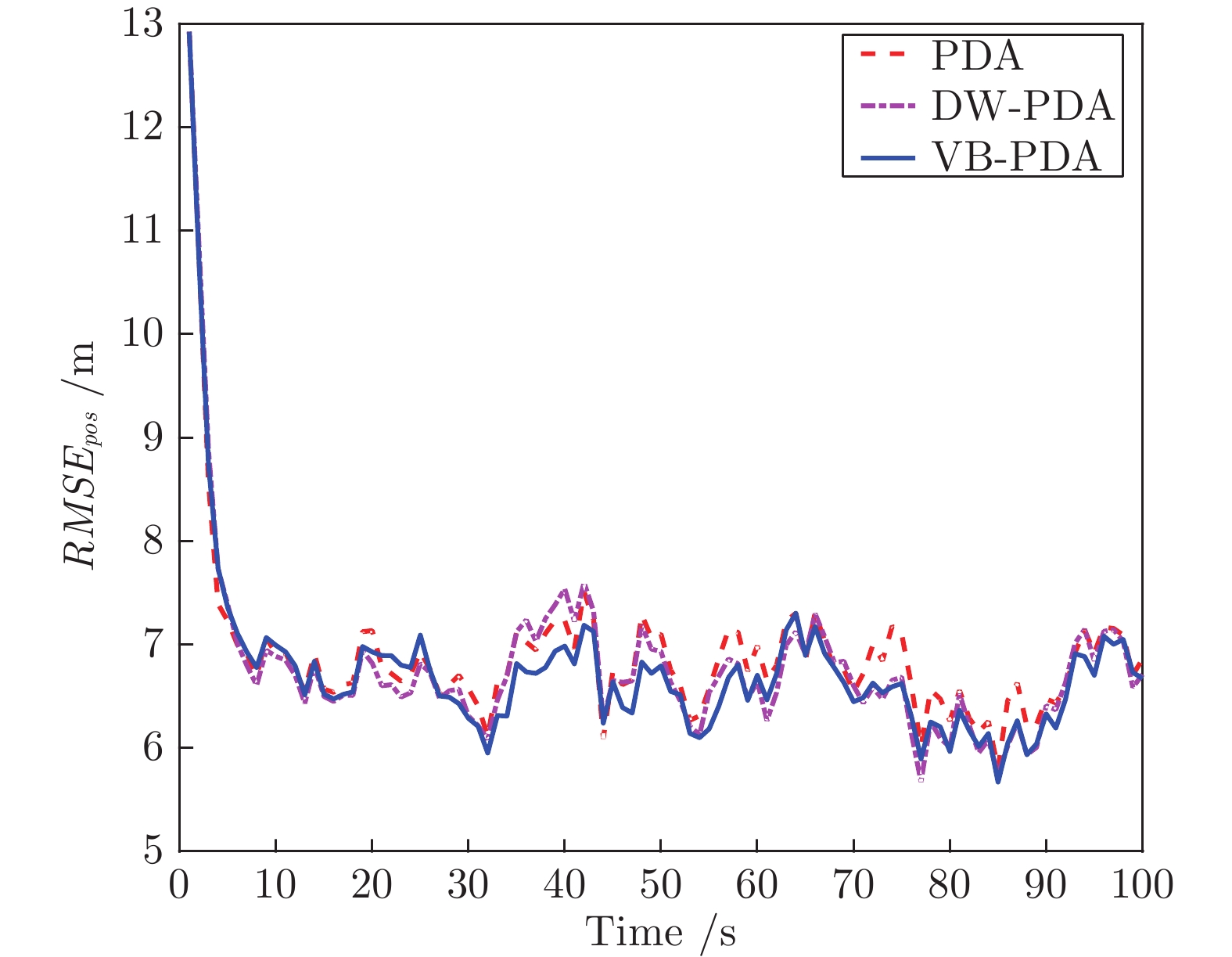
图 1 场景 1 下 3 种算法的位置 RMSE
Fig. 1 The RMSE of position from three algorithms in scenario 1
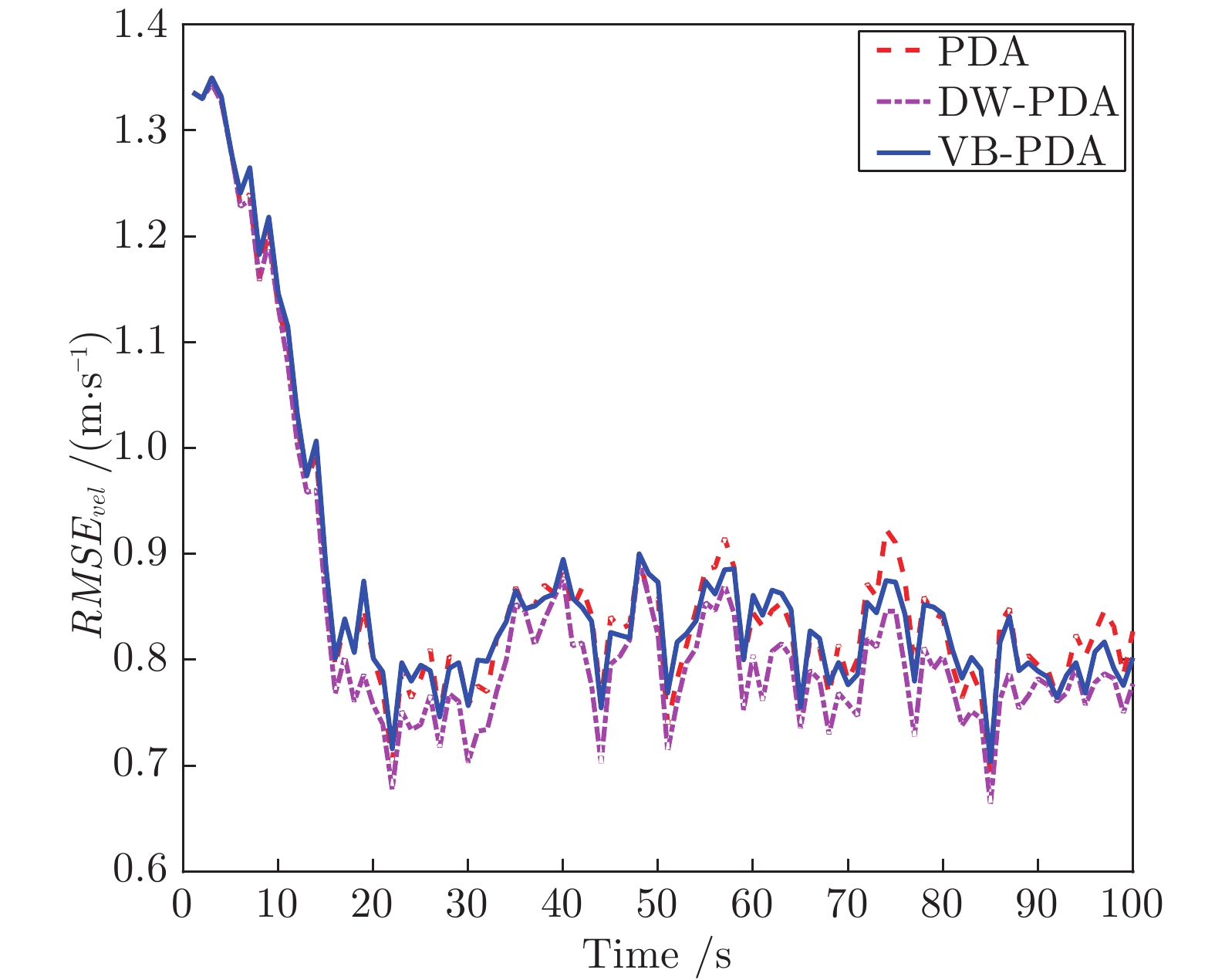
图 2 仿真场景 1 下 3 种算法的速度 RMSE
Fig. 2 The RMSE of velocity from three algorithms in scenario 1

图 3 仿真场景 2 下 3 种算法的位置 RMSE
Fig. 3 The RMSE of position from three algorithms in scenario 2

图 4 仿真场景 2 下 3 种算法的速度 RMSE
Fig. 4 The RMSE of velocity from three algorithms in scenario 2
表 1 一步状态更新过程中所需的加减运算与乘除运算次数
Table 1 The number of addition and subtraction operations and multiplication and division operations required in the process of one-step state update
算法 加减法运算次数 乘除法运算次数 PDA $\begin{aligned} &{r^3}{n_{k + 1} } + {r^2}(m{n_{k + 1} } - {n_{k + 1} } + 2) + \\ &\qquad r({n_{k + 1} } + 1 + 2m) + 2{n_{k + 1} } - 1 +\\ & \qquad m{n_{k + 1} } - m\end{aligned}$ $\begin{aligned} & {r^3} + {r^2}(2{n_{k + 1} } + m + 3) + \\ &\qquad r(2m + 1) + m{n_{k + 1} } + 1 \end{aligned}$ DW-PDA $\begin{aligned} & {r^3}{n_{k + 1} } + {r^2}(m{n_{k + 1} } - {n_{k + 1} } + 2)\; + \\ &\qquad r({n_{k + 1} } + 1 + 2m) + 4{n_{k + 1} } - 3 + \\ &\qquad m{n_{k + 1} } - m\end{aligned}$ $\begin{aligned} &{r^3} + {r^2}(2{n_{k + 1} } + m + 3)+ \\ &\qquad r(2m + 1) + m{n_{k + 1} } + 4{n_{k + 1} } + 1\end{aligned}$ VB-PDA $\begin{aligned} & {r^3}{n_{k + 1} } + {r^2}(m{n_{k + 1} } - 2{n_{k + 1} } + 1)\; + \\ & \qquad2mr + 2{n_{k + 1} } - 1 + m{n_{k + 1} } - m \end{aligned}$ $\begin{aligned} & {r^3} + {r^2}m + r(2m + 1)+\; \\ &\qquad m{n_{k + 1} } + 1 + {m^2} \end{aligned}$  下载: 导出CSV
下载: 导出CSV
表 2 场景 1 下 3 种算法的 TRMSE
Table 2 The TRMSE of three algorithms in scenario 1
算法 位置 TRMSE (m) 速度 TRMSE (m/s) PDA 6.892 0.873 DW-PDA 6.792 0.839 VB-PDA 6.742 0.872
下载: 导出CSV
表 3 场景 1 下一次蒙特卡洛仿真实验所需的计算时间
Table 3 The computational time at one Monte Carlo simulation experiment in scenario 1
算法 计算时间 (ms) PDA 56.52 DW-PDA 58.72 VB-PDA 46.70
下载: 导出CSV
表 4 仿真场景2下3种算法的TRMSE
Table 4 The TRMSE of three algorithms in scenario 2
算法 位置TRMSE (m) 速度TRMSE (m/s) IMM-PDA 8.409 1.874 IMM-DW-PDA 8.101 1.818 IMM-VB-PDA 7.967 1.784
下载: 导出CSV
-
[1] 孟琭, 杨旭. 目标跟踪算法综述. 自动化学报, 2019, 45(7): 1244-1260MENG Lu, YANG Xu. A Survey of Object Tracking Algorithms. Acta Automatica Sinica, 2019, 45(7): 1244-1260 [2] Sobhani B, Paolini E, Giorgetti A. Target Tracking for UWB Multistatic Radar Sensor Networks. IEEE Journal of Selected Topics in Signal Processing, 2017, 8(1): 125-136 [3] 甘林海, 王刚, 刘进忙, 李松. 群目标跟踪技术综述. 自动化学报, 2020, 46(3): 411-426GAN Lin-Hai, WANG Gang, LIU Jin-Mang, LI Song. An Overview of Group Target Tracking. Acta Automatica Sinica, 2020, 46(3): 411-426 [4] 何友, 黄勇, 关键, 陈小龙. 海杂波中的雷达目标检测技术综述. 现代雷达, 2014, 36(12): 1-9HE You, HUANG Yong, GUAN Jian, CHEN Xiao -Long. An overview on radar target detection in sea clutter. Modern radar, 2014, 36 (12): 1-9 [5] 陈一梅, 刘伟峰, 孔明鑫, 张桂林. 基于GLMB滤波和Gibbs采样的多扩展目标有限混合建模与跟踪算法. 自动化学报, 2020, 46(7): 1445-1456CHEN Yi-Mei, LIU Wei-Feng, KONG Ming-Xin, ZHANG Gui-Lin. A Modeling and Tracking Algorithm of Finite Mixture Models for Multiple Extended Target Based on the GLMB Filter and Gibbs Sampler. Acta Automatica Sinica, 2020, 46(7): 1445-1456 [6] Kirubarajan T, Bar-Shalom Y. Probabilistic data association techniques for target tracking in clutter. Proceedings of the IEEE, 2004, 92(3):536-557. doi: 10.1109/JPROC.2003.823149 [7] Wu P L, Zhou Y, Li X X. Space-based passive tracking of non-cooperative space target using robust filtering algorithm. Proceedings of the Institution of Mechanical Engineers, Part I: Journal of Systems and Control Engineering, 2016, 230(6): 551-561. doi: 10.1177/0959651816637770 [8] Song T L, L D G, R J. A probabilistic nearest neighbor filter algorithm for tracking in a clutter environment. Signal Processing, 2005, 85(10): 2044-2053. doi: 10.1016/j.sigpro.2005.01.016 [9] Sinha A, Ding Z, Kirubarajan T, Farooq, M. Track Quality Based Multitarget Tracking Approach for Global Nearest-Neighbor Association. IEEE Transactions on Aerospace & Electronic Systems, 2012, 48(2): 1179-1191. [10] Aziz, Ashraf M. A new nearest-neighbor association approach based on fuzzy clustering. Aerospace Science & Technology, 2013, 26(1): 87-97. [11] Bar-Shalom Y, Tse E. Tracking in a cluttered environment with probabilistic data association. Automatica, 1975, 11(5): 451-460. doi: 10.1016/0005-1098(75)90021-7 [12] Wu P L, Li X X, Kong J S, Liu J L. Heterogeneous multiple sensors joint tracking of maneuvering target in clutter. Sensors, 2015, 15(7):17350-17365. doi: 10.3390/s150717350 [13] 程婷, 何子述, 李亚星. 一种具有自适应关联门的杂波中机动目标跟踪算法. 电子与信息学报, 2012 34(4):865-870.CHENG Ting, HE Zi-Shu, LI Ya-Xing. A maneuvering target tracking algorithm in clutter with adaptive correlation gate. Journal of Electronics and Information, 2012 34 (4): 865-870. [14] Barshalom Y, Daum F, Huang J. The Probabilistic Data Association Filter. IEEE Control Systems Magazine, 2012, 29(6):82 - 100. [15] Kirubarajan T, Bar-Shalom Y, Blair W D, Watson G A. IMMPDAF for radar management and tracking benchmark with ECM. IEEE Transactions on Aerospace & Electronic Systems, 1998, 34(4): 1115-1134. [16] 潘泉, 刘刚, 戴冠中, 张洪才. 联合交互式多模型概率数据关联算法. 航空学报, 1999, 20(3): 234-238.PAN Quan, LIU Gang, DAI Guan-Zhong, ZHANG Hong-Cai. Combined interacting multiple models probabilistic data association algorithm. Acta Aeronautica ET Astronautica Sinica, 1999, 20(3): 234-238. [17] 陈晓, 李亚安, 李余兴, 蔚婧. 基于距离加权的概率数据关联机动目标跟踪算法. 上海交通大学学报, 2018, 52(4):100-105CHEN Xiao, LI Ya-An, Li Yu-Xing, WEI Jing. Maneuvering Target Tracking Algorithm Based on Weighted Distance of Probability Data Association. Journal of Shanghai Jiao Tong University, 2018, 52(4):100-105. [18] Yun P, Wu P L, He S. Pearson Type VⅡ Distribution-Based Robust Kalman Filter under Outliers Interference. IET Radar, Sonar & Navigation. 2019; 13(8): 1389-1399. [19] Battistelli G, Chisci L. Kullback–Leibler average, consensus on probability densities, and distributed state estimation with guaranteed stability. Automatica, 2014, 50(3):707-718. doi: 10.1016/j.automatica.2013.11.042 [20] Huang Y L, Zhang Y G, Li N, Wu Z M, Chambers J. A novel robust student's t-based Kalman filter. IEEE Transactions on Aerospace and Electronic Systems, 2017, 53(3): 1545-1554. doi: 10.1109/TAES.2017.2651684 [21] Panta K, Ba-Ngu V, Singh S. Novel data association schemes for the probability hypothesis density filter. IEEE Transactions on Aerospace and Electronic Systems, 2007, 43(2):556-570. doi: 10.1109/TAES.2007.4285353 [22] Blom H A P, Bar-Shalom Y. The interacting multiple model algorithm for systems with Markovian switching coefficients. IEEE Transactions on Automatic Control, 1988, 33(8), 780–783. doi: 10.1109/9.1299 期刊类型引用(12)
1. 刘志昌. 基于深度学习的电机外观缺陷智能检测系统设计. 自动化与仪器仪表. 2023(05): 314-317 .  百度学术
百度学术2. 黄建才,蒋朝辉,桂卫华,潘冬,许川,周科. 基于状态识别的高炉料面视频关键帧提取方法. 自动化学报. 2023(11): 2257-2271 . 本站查看3. 王正文,宋慧慧,樊佳庆,刘青山. 基于语义引导特征聚合的显著性目标检测网络. 自动化学报. 2023(11): 2386-2395 . 本站查看4. 陈俊霖,谭攀. 多尺度测量的可视化遥感图像覆盖特征提取研究. 测绘技术装备. 2022(02): 82-86 . 百度学术5. 王安志,任春洪,何淋艳,杨元英,欧卫华. 基于多模态多级特征聚合网络的光场显著性目标检测. 计算机工程. 2022(07): 227-233+240 . 百度学术6. 郑雯,张标标,吴俊宏,马仕强,任佳. 适于多尺度宫颈癌细胞检测的改进算法. 光电子·激光. 2022(09): 948-958 . 百度学术7. 金海燕,肖照林,蔡磊,王彬. 显著性目标检测理论与应用研究综述. 计算机技术与发展. 2022(09): 1-7 . 百度学术8. 张莉,孙克雷. 基于改进区域推荐网络的多尺度目标检测算法. 安庆师范大学学报(自然科学版). 2021(02): 26-31 . 百度学术9. 王勤学,佃松宜,马飞跃. 基于多尺度显著性的GIS腔体内部异物智能识别. 高压电器. 2021(12): 177-184 . 百度学术10. 左保川,王一旭,张晴. 基于密集连接的层次化显著性物体检测网络. 应用技术学报. 2020(03): 281-289 . 百度学术11. 赵媛媛. 基于显著性信息的数字绘画图像自主分类系统. 现代电子技术. 2020(22): 132-135+139 . 百度学术12. 李少波,杨静,王铮,朱书德,杨观赐. 缺陷检测技术的发展与应用研究综述. 自动化学报. 2020(11): 2319-2336 . 本站查看其他类型引用(18)
-


 下载:
下载:


计量
- 文章访问数: 1753
- HTML全文浏览量: 535
- PDF下载量: 275
- 被引次数: 30
