

-
摘要: 针对杂波环境下的目标跟踪问题, 提出了一种基于变分贝叶斯的概率数据关联算法(Variational Bayesian based probabilistic data association algorithm, VB-PDA). 该算法首先将关联事件视为一个随机变量并利用多项分布对其进行建模, 随后基于数据集、目标状态、关联事件的联合概率密度函数求取关联事件的后验概率密度函数, 最后将关联事件的后验概率密度函数引入变分贝叶斯框架中以获取状态近似后验概率密度函数. 相比于概率数据关联算法, VB-PDA算法在提高算法实时性的同时在权重Kullback-Leibler (KL)平均准则下获取了近似程度更高的状态后验概率密度函数. 相关仿真实验对提出算法的有效性进行了验证.Abstract: Aiming at the problem of target tracking in clutter, this paper proposes a variational Bayesian based probabilistic data association algorithm (VB-PDA). Firstly, associated events are regarded as a random variable and modelled by the multi-nomial distribution. Then, the joint probability density function of data set, target state and associated events is constructed and the posterior probability density function of associated events is obtained by using this joint probability density function. Finally, the posterior probability density function of associated events is introduced into the framework of variational Bayesian to obtain the approximate posterior probability density function of state. Compared with the probabilistic data association algorithm, the VB-PDA algorithm obtains a state posterior probability density function with higher approximation degree based on the weight Kullback-Leibler (KL) average criterion while improving real-time performance. The simulation experiments verify the effectiveness of proposed algorithm.
-
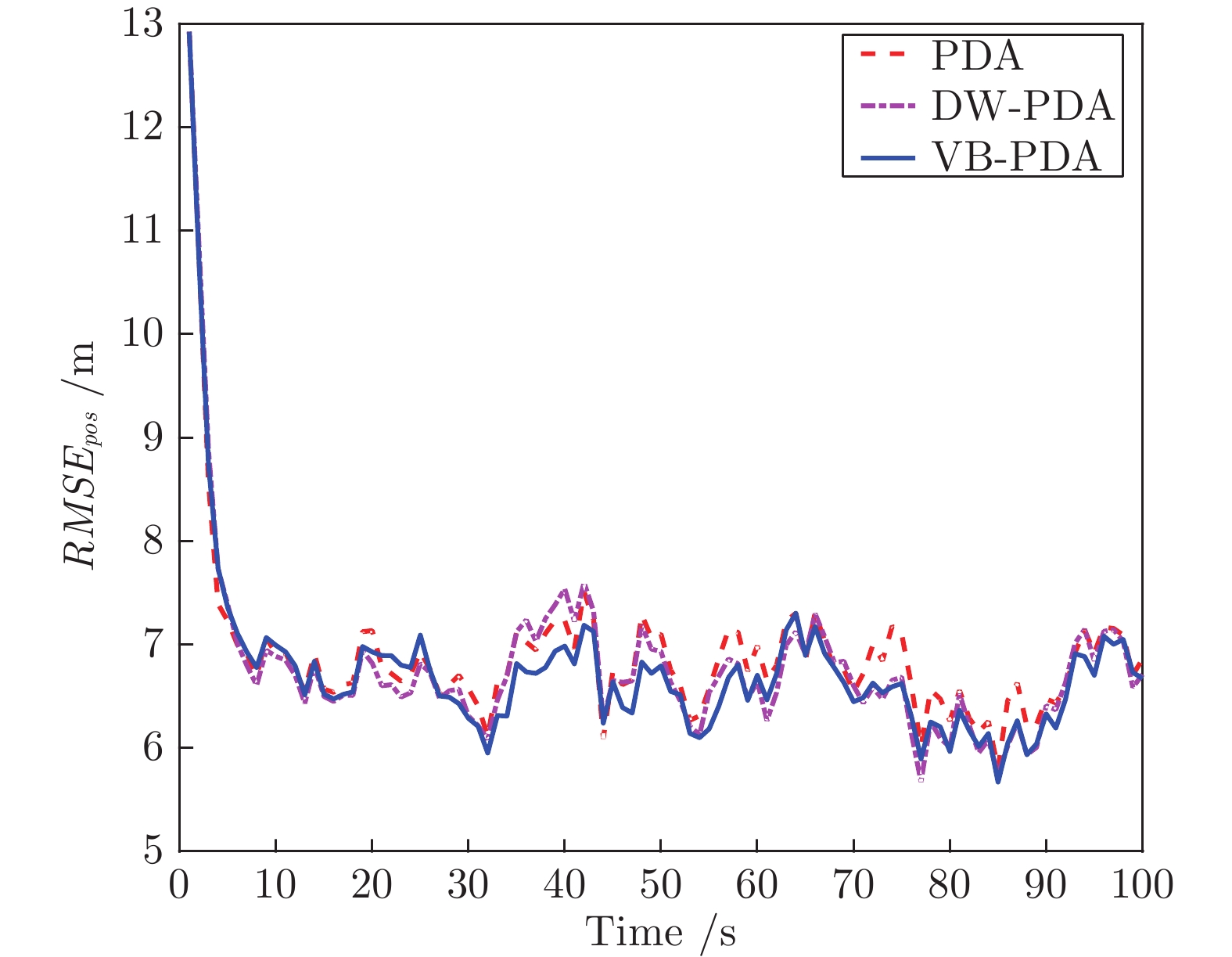
图 1 场景 1 下 3 种算法的位置 RMSE
Fig. 1 The RMSE of position from three algorithms in scenario 1
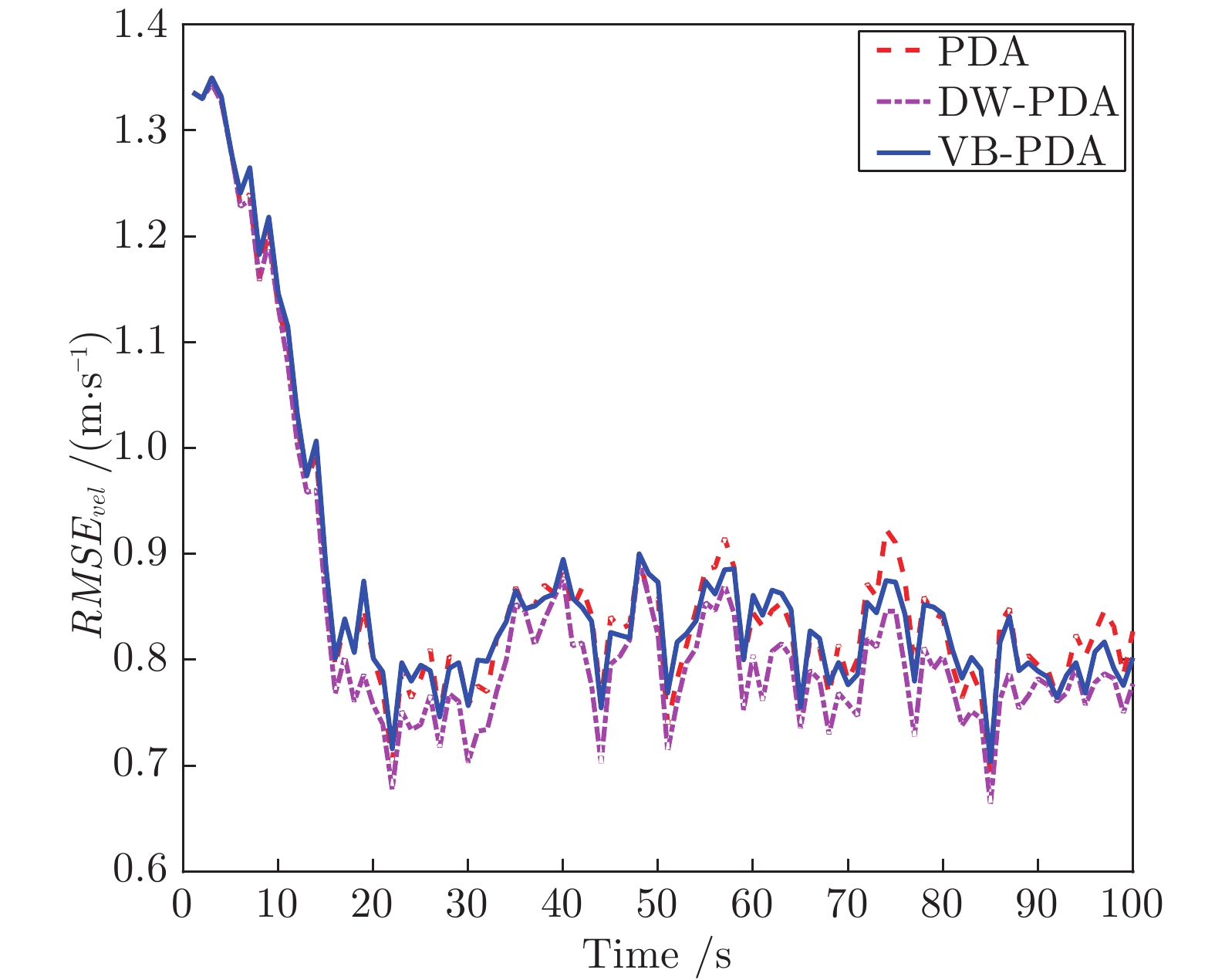
图 2 仿真场景 1 下 3 种算法的速度 RMSE
Fig. 2 The RMSE of velocity from three algorithms in scenario 1

图 3 仿真场景 2 下 3 种算法的位置 RMSE
Fig. 3 The RMSE of position from three algorithms in scenario 2

图 4 仿真场景 2 下 3 种算法的速度 RMSE
Fig. 4 The RMSE of velocity from three algorithms in scenario 2
表 1 一步状态更新过程中所需的加减运算与乘除运算次数
Table 1 The number of addition and subtraction operations and multiplication and division operations required in the process of one-step state update
算法 加减法运算次数 乘除法运算次数 PDA $\begin{aligned} &{r^3}{n_{k + 1} } + {r^2}(m{n_{k + 1} } - {n_{k + 1} } + 2) + \\ &\qquad r({n_{k + 1} } + 1 + 2m) + 2{n_{k + 1} } - 1 +\\ & \qquad m{n_{k + 1} } - m\end{aligned}$ $\begin{aligned} & {r^3} + {r^2}(2{n_{k + 1} } + m + 3) + \\ &\qquad r(2m + 1) + m{n_{k + 1} } + 1 \end{aligned}$ DW-PDA $\begin{aligned} & {r^3}{n_{k + 1} } + {r^2}(m{n_{k + 1} } - {n_{k + 1} } + 2)\; + \\ &\qquad r({n_{k + 1} } + 1 + 2m) + 4{n_{k + 1} } - 3 + \\ &\qquad m{n_{k + 1} } - m\end{aligned}$ $\begin{aligned} &{r^3} + {r^2}(2{n_{k + 1} } + m + 3)+ \\ &\qquad r(2m + 1) + m{n_{k + 1} } + 4{n_{k + 1} } + 1\end{aligned}$ VB-PDA $\begin{aligned} & {r^3}{n_{k + 1} } + {r^2}(m{n_{k + 1} } - 2{n_{k + 1} } + 1)\; + \\ & \qquad2mr + 2{n_{k + 1} } - 1 + m{n_{k + 1} } - m \end{aligned}$ $\begin{aligned} & {r^3} + {r^2}m + r(2m + 1)+\; \\ &\qquad m{n_{k + 1} } + 1 + {m^2} \end{aligned}$  下载: 导出CSV
下载: 导出CSV
表 2 场景 1 下 3 种算法的 TRMSE
Table 2 The TRMSE of three algorithms in scenario 1
算法 位置 TRMSE (m) 速度 TRMSE (m/s) PDA 6.892 0.873 DW-PDA 6.792 0.839 VB-PDA 6.742 0.872
下载: 导出CSV
表 3 场景 1 下一次蒙特卡洛仿真实验所需的计算时间
Table 3 The computational time at one Monte Carlo simulation experiment in scenario 1
算法 计算时间 (ms) PDA 56.52 DW-PDA 58.72 VB-PDA 46.70
下载: 导出CSV
表 4 仿真场景2下3种算法的TRMSE
Table 4 The TRMSE of three algorithms in scenario 2
算法 位置TRMSE (m) 速度TRMSE (m/s) IMM-PDA 8.409 1.874 IMM-DW-PDA 8.101 1.818 IMM-VB-PDA 7.967 1.784
下载: 导出CSV
-
[1] 孟琭, 杨旭. 目标跟踪算法综述. 自动化学报, 2019, 45(7): 1244-1260MENG Lu, YANG Xu. A Survey of Object Tracking Algorithms. Acta Automatica Sinica, 2019, 45(7): 1244-1260 [2] Sobhani B, Paolini E, Giorgetti A. Target Tracking for UWB Multistatic Radar Sensor Networks. IEEE Journal of Selected Topics in Signal Processing, 2017, 8(1): 125-136 [3] 甘林海, 王刚, 刘进忙, 李松. 群目标跟踪技术综述. 自动化学报, 2020, 46(3): 411-426GAN Lin-Hai, WANG Gang, LIU Jin-Mang, LI Song. An Overview of Group Target Tracking. Acta Automatica Sinica, 2020, 46(3): 411-426 [4] 何友, 黄勇, 关键, 陈小龙. 海杂波中的雷达目标检测技术综述. 现代雷达, 2014, 36(12): 1-9HE You, HUANG Yong, GUAN Jian, CHEN Xiao -Long. An overview on radar target detection in sea clutter. Modern radar, 2014, 36 (12): 1-9 [5] 陈一梅, 刘伟峰, 孔明鑫, 张桂林. 基于GLMB滤波和Gibbs采样的多扩展目标有限混合建模与跟踪算法. 自动化学报, 2020, 46(7): 1445-1456CHEN Yi-Mei, LIU Wei-Feng, KONG Ming-Xin, ZHANG Gui-Lin. A Modeling and Tracking Algorithm of Finite Mixture Models for Multiple Extended Target Based on the GLMB Filter and Gibbs Sampler. Acta Automatica Sinica, 2020, 46(7): 1445-1456 [6] Kirubarajan T, Bar-Shalom Y. Probabilistic data association techniques for target tracking in clutter. Proceedings of the IEEE, 2004, 92(3):536-557. doi: 10.1109/JPROC.2003.823149 [7] Wu P L, Zhou Y, Li X X. Space-based passive tracking of non-cooperative space target using robust filtering algorithm. Proceedings of the Institution of Mechanical Engineers, Part I: Journal of Systems and Control Engineering, 2016, 230(6): 551-561. doi: 10.1177/0959651816637770 [8] Song T L, L D G, R J. A probabilistic nearest neighbor filter algorithm for tracking in a clutter environment. Signal Processing, 2005, 85(10): 2044-2053. doi: 10.1016/j.sigpro.2005.01.016 [9] Sinha A, Ding Z, Kirubarajan T, Farooq, M. Track Quality Based Multitarget Tracking Approach for Global Nearest-Neighbor Association. IEEE Transactions on Aerospace & Electronic Systems, 2012, 48(2): 1179-1191. [10] Aziz, Ashraf M. A new nearest-neighbor association approach based on fuzzy clustering. Aerospace Science & Technology, 2013, 26(1): 87-97. [11] Bar-Shalom Y, Tse E. Tracking in a cluttered environment with probabilistic data association. Automatica, 1975, 11(5): 451-460. doi: 10.1016/0005-1098(75)90021-7 [12] Wu P L, Li X X, Kong J S, Liu J L. Heterogeneous multiple sensors joint tracking of maneuvering target in clutter. Sensors, 2015, 15(7):17350-17365. doi: 10.3390/s150717350 [13] 程婷, 何子述, 李亚星. 一种具有自适应关联门的杂波中机动目标跟踪算法. 电子与信息学报, 2012 34(4):865-870.CHENG Ting, HE Zi-Shu, LI Ya-Xing. A maneuvering target tracking algorithm in clutter with adaptive correlation gate. Journal of Electronics and Information, 2012 34 (4): 865-870. [14] Barshalom Y, Daum F, Huang J. The Probabilistic Data Association Filter. IEEE Control Systems Magazine, 2012, 29(6):82 - 100. [15] Kirubarajan T, Bar-Shalom Y, Blair W D, Watson G A. IMMPDAF for radar management and tracking benchmark with ECM. IEEE Transactions on Aerospace & Electronic Systems, 1998, 34(4): 1115-1134. [16] 潘泉, 刘刚, 戴冠中, 张洪才. 联合交互式多模型概率数据关联算法. 航空学报, 1999, 20(3): 234-238.PAN Quan, LIU Gang, DAI Guan-Zhong, ZHANG Hong-Cai. Combined interacting multiple models probabilistic data association algorithm. Acta Aeronautica ET Astronautica Sinica, 1999, 20(3): 234-238. [17] 陈晓, 李亚安, 李余兴, 蔚婧. 基于距离加权的概率数据关联机动目标跟踪算法. 上海交通大学学报, 2018, 52(4):100-105CHEN Xiao, LI Ya-An, Li Yu-Xing, WEI Jing. Maneuvering Target Tracking Algorithm Based on Weighted Distance of Probability Data Association. Journal of Shanghai Jiao Tong University, 2018, 52(4):100-105. [18] Yun P, Wu P L, He S. Pearson Type VⅡ Distribution-Based Robust Kalman Filter under Outliers Interference. IET Radar, Sonar & Navigation. 2019; 13(8): 1389-1399. [19] Battistelli G, Chisci L. Kullback–Leibler average, consensus on probability densities, and distributed state estimation with guaranteed stability. Automatica, 2014, 50(3):707-718. doi: 10.1016/j.automatica.2013.11.042 [20] Huang Y L, Zhang Y G, Li N, Wu Z M, Chambers J. A novel robust student's t-based Kalman filter. IEEE Transactions on Aerospace and Electronic Systems, 2017, 53(3): 1545-1554. doi: 10.1109/TAES.2017.2651684 [21] Panta K, Ba-Ngu V, Singh S. Novel data association schemes for the probability hypothesis density filter. IEEE Transactions on Aerospace and Electronic Systems, 2007, 43(2):556-570. doi: 10.1109/TAES.2007.4285353 [22] Blom H A P, Bar-Shalom Y. The interacting multiple model algorithm for systems with Markovian switching coefficients. IEEE Transactions on Automatic Control, 1988, 33(8), 780–783. doi: 10.1109/9.1299 -

 下载:
下载:

计量
- 文章访问数: 1949
- HTML全文浏览量: 703
- PDF下载量: 288
- 被引次数: 0
