

-
摘要: 虽然深度神经网络 (Deep neural networks, DNNs) 在许多任务上取得了显著的效果, 但是由于其可解释性 (Interpretability) 较差, 通常被当做“黑盒”模型. 本文针对图像分类任务, 利用对抗样本 (Adversarial examples) 从模型失败的角度检验深度神经网络内部的特征表示. 通过分析, 发现深度神经网络学习到的特征表示与人类所理解的语义概念之间存在着不一致性. 这使得理解和解释深度神经网络内部的特征变得十分困难. 为了实现可解释的深度神经网络, 使其中的神经元具有更加明确的语义内涵, 本文提出了加入特征表示一致性损失的对抗训练方式. 实验结果表明该训练方式可以使深度神经网络内部的特征表示与人类所理解的语义概念更加一致.Abstract: Deep neural networks (DNNs) have demonstrated impressive performance on many tasks, but they are usually considered opaque due to their poor interpretability. In this paper, we examine the internal representations of DNNs on image classification tasks using adversarial examples, which enable us to analyze the interpretability of DNNs in the perspective of their failures. Based on the analyses, we find that the learned features of DNNs are inconsistent with human-understandable semantic concepts, making it problematic for understanding and interpreting the representations inside DNNs. To realize interpretable deep neural networks, we further propose an adversarial training scheme with a consistent loss such that the neurons are endowed with the human-interpretable concepts to improve the interpretability of DNNs. Experiments show that the proposed method can make the features in DNNs more consistent with semantic concepts.
-
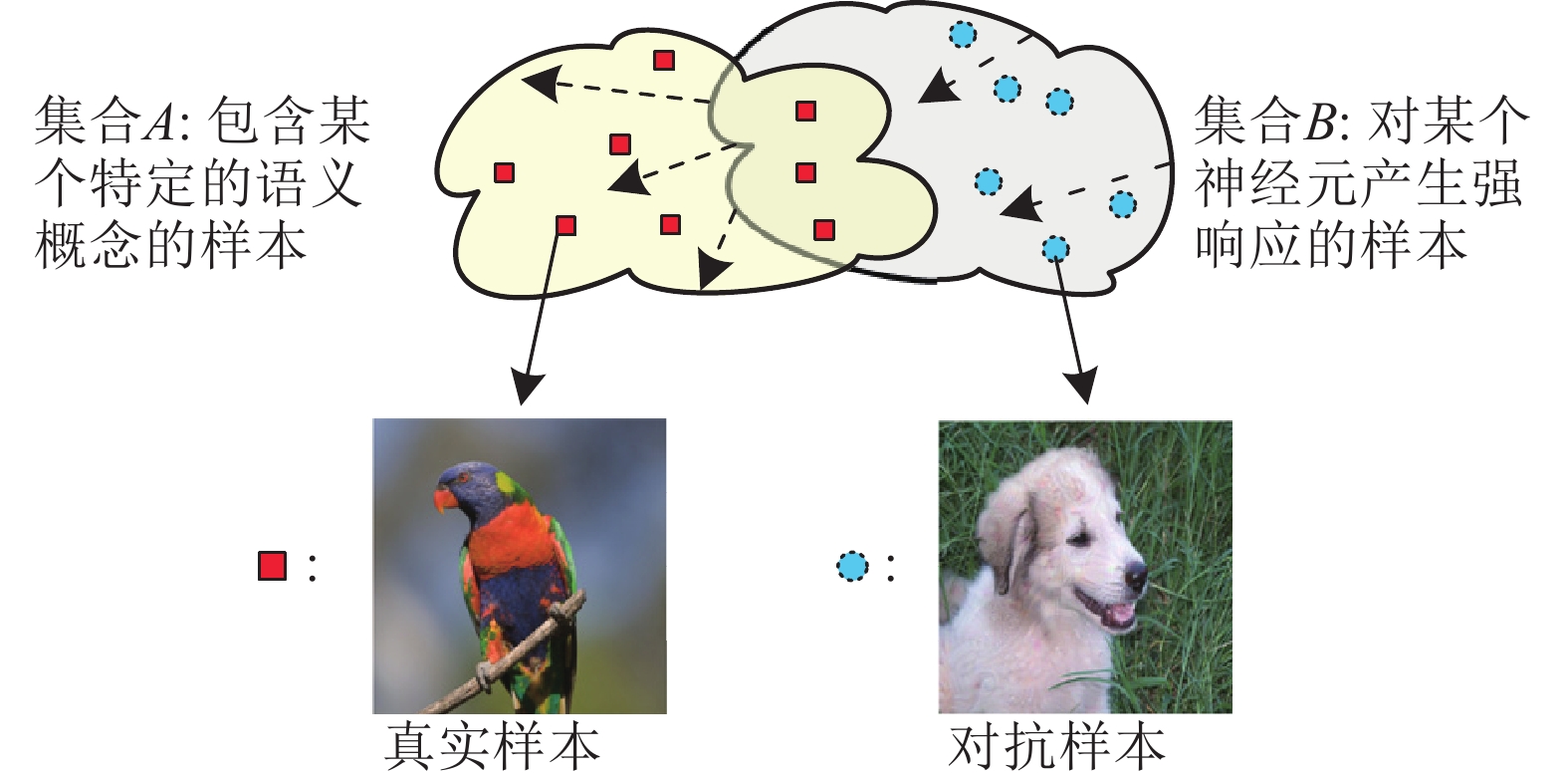
图 1 语义概念与神经元学习到的特征存在不一致性的示意图
Fig. 1 Demonstration of the inconsistency betweena semantic concept and the learned features of a neuron

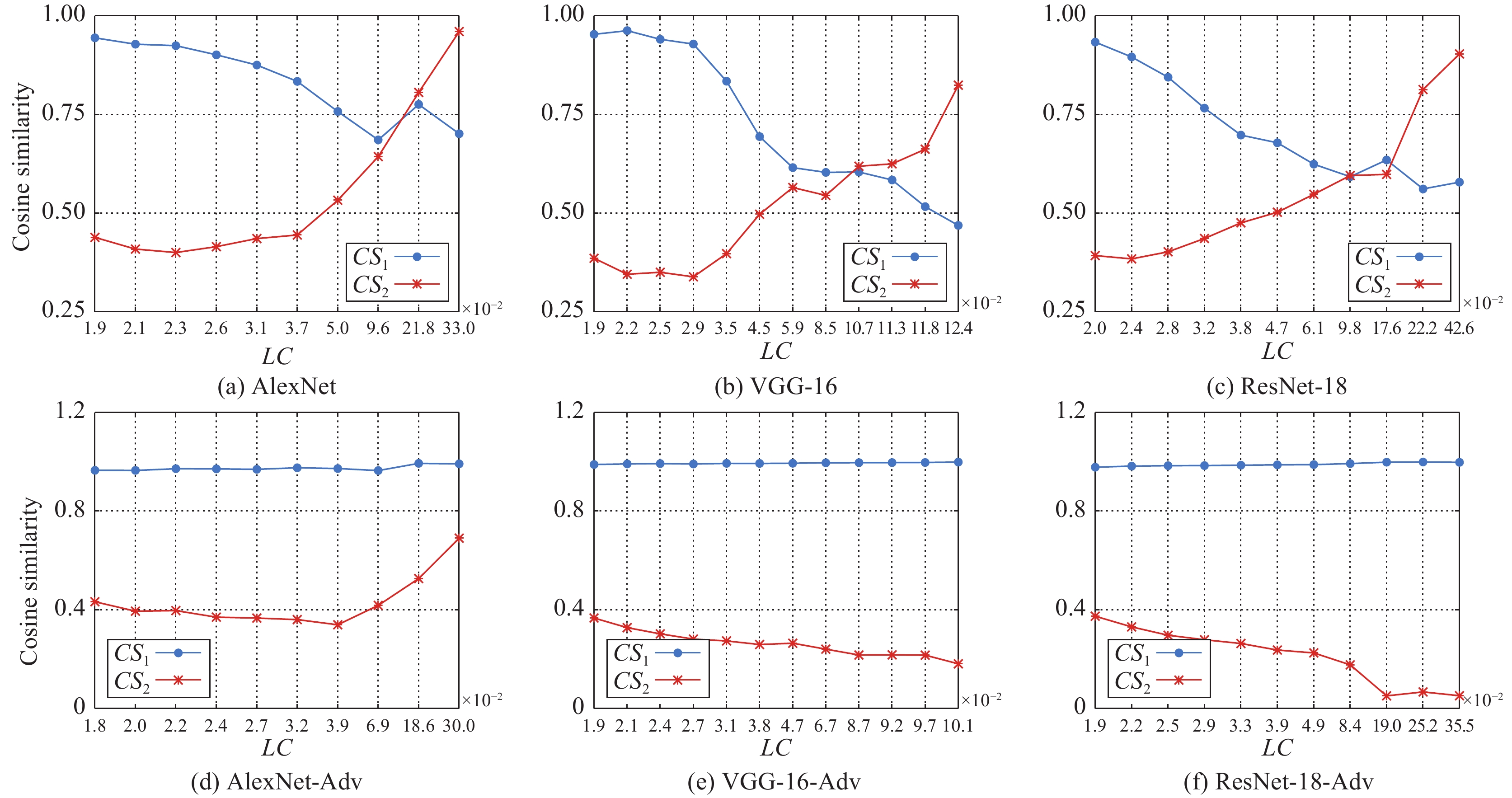
图 2 VGG-16网络中神经元(来自conv5_3层)特征可视化
Fig. 2 The visualization results of the neuron (from the conv5_3 layer) features in VGG-16


图 4 AlexNet网络中神经元(来自conv5层)特征可视化
Fig. 4 The visualization results of the neuron (from the conv5 layer) features in AlexNet

图 5 ResNet-18网络中神经元(来自conv5b层)特征可视化
Fig. 5 The visualization results of the neuron (from the conv5b layer) features in ResNet-18

图 6 AlexNet-Adv网络中神经元(来自conv5层)特征可视化
Fig. 6 The visualization results of the neuron (from the conv5 layer) features in AlexNet-Adv

图 7 VGG-16-Adv网络中神经元(来自conv5_3层)特征可视化
Fig. 7 The visualization results of the neuron (from the conv5_3 layer) features in VGG-16-Adv

图 8 ResNet-18-Adv网络中神经元(来自conv5b层)特征可视化
Fig. 8 The visualization results of the neuron (from the conv5b layer) features in ResNet-18-Adv

图 9 Adv-Inc-v3网络中神经元(来自最后一层)特征可视化
Fig. 9 The visualization results of the neuron (from the last layer) features in Adv-Inc-v3
表 1 各个模型面对真实图片和对抗图片时其中与语义概念关联的神经元的比例(%)
Table 1 The ratio (%) of neurons that align with semantic concepts for each model when showing real and adversarial images respectively
模型 真实图片 对抗图片 C T M S P O C T M S P O AlexNet 0.5 13.4 0.4 0.4 4.1 6.1 0.5 10.3 0.1 0.0 1.6 2.3 AlexNet-Adv 0.5 12.7 0.3 0.6 5.5 7.8 0.5 11.6 0.3 0.2 4.8 6.3 VGG-16 0.6 13.2 0.4 1.3 6.8 14.7 0.5 9.5 0.0 0.0 2.3 5.2 VGG-16-Adv 0.6 13.0 0.4 1.6 8.0 16.2 0.5 11.4 0.3 0.9 6.9 14.8 ResNet-18 0.3 14.2 0.3 1.9 4.1 14.1 0.3 8.2 0.1 0.6 2.1 4.8 ResNet-18-Adv 0.3 14.0 0.3 2.1 5.3 17.2 0.3 10.8 0.3 1.5 4.7 15.3 Inc-v3 0.4 11.2 0.6 4.0 8.1 23.6 0.4 7.6 0.3 0.2 2.9 6.7 Adv-Inc-v3 0.4 10.7 0.5 4.5 8.6 25.3 0.4 8.6 0.4 2.5 5.3 15.4 VGG-16-Place 0.6 12.4 0.5 7.0 5.9 16.7 0.6 9.3 0.0 1.3 2.1 6.8  下载: 导出CSV
下载: 导出CSV
表 2 各个模型在ImageNet验证集及对于FGSM攻击的准确率(%) (扰动规模为
$ {\rm{\epsilon}} =4 $ )Table 2 Accuracy (%) on the ImageNet validation set and adversarial examples generated by FGSM with
$ {\rm{\epsilon}}=4 $ 模型 真实图片 对抗图片 Top-1 Top-5 Top-1 Top-5 AlexNet 54.53 78.17 9.04 32.77 AlexNet-Adv 49.89 74.28 21.16 49.34 VGG-16 68.20 88.33 15.13 39.82 VGG-16-Adv 64.73 86.35 47.67 71.23 ResNet-18 66.38 87.13 4.38 31.66
下载: 导出CSV
-
[1] LeCun Y, Bengio Y, Hinton G. Deep Learning. Nature, 2015, 521(7553): 436-444 doi: 10.1038/nature14539 [2] Bengio Y, Courville A, Vincent P. Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 2013, 35(8): 1798-1828 doi: 10.1109/TPAMI.2013.50 [3] Zhou B L, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 2921−2929 [4] Koh P W, Liang P. Understanding black-box predictions via influence functions. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 1885−1894 [5] Simonyan K, Vedaldi A, Zisserman A. Deep inside convolutional networks: Visualising image classification models and saliency maps. In: Proceedings of the 2014 International Conference on Learning Representations. Banff, Canada: 2014. [6] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In: Proceedings of the 2014 European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 818−833 [7] Liu M, Shi J, Li Z, Li C, Zhu J, Liu S. Towards better analysis of deep convolutional neural networks. IEEE Transactions on Visualization and Computer Graphics, 2017, 23(1): 91-100 doi: 10.1109/TVCG.2016.2598831 [8] Zhou B L, Khosla A, Lapedriza A, Oliva A, Torralba A. Object detectors emerge in deep scene CNNs. In: Proceedings of the 2015 International Conference on Learning Representations. San Diego, USA: 2015. [9] Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow I, Fergus R. Intriguing properties of neural networks. In: Proceedings of the 2014 International Conference on Learning Representations. Banff, Canada: 2014. [10] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. In: Proceedings of the 2015 International Conference on Learning Representations. San Diego, USA: 2015. [11] Kurakin A, Goodfellow I, Bengio S. Adversarial examples in the physical world. arXiv preprint arXiv: 1607.02533, 2016. [12] Carlini N, Wagner D. Towards evaluating the robustness of neural networks. In: Proceedings of the 2017 IEEE Symposium on Security and Privacy. San Jose, USA: 2017. 39−57 [13] Dong Y P, Liao F Z, Pang T U, Su H, Zhu J, Hu X L, Li J G. Boosting adversarial attacks with momentum. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE 2018. 9185−9193 [14] Dong Y P, Pang T U, Su H, Zhu J. Evading defenses to transferable adversarial examples by translation-invariant attacks. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE 2019. 4312−4321 [15] Bau D, Zhou B L, Khosla A, Oliva A, Torralba A. Network dissection: Quantifying interpretability of deep visual representations. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE 2017. 3319−3327 [16] Zhang Q S, Cao R M, Shi F, Wu Y N, Zhu S C. Interpreting CNN knowledge via an explanatory graph. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 4454−4463 [17] Dong Y P, Su H, Zhu J, Zhang B. Improving interpretability of deep neural networks with semantic information. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE 2017. 975−983 [18] Al-Shedivat M, Dubey A, Xing E P. Contextual explanation networks. arXiv preprint arXiv: 1705.10301, 2017. [19] Sabour S, Frosst N, Hinton G E. Dynamic routing between capsules. In: Proceedings of the 2017 Advances in Neural Information Processing Systems. Long Beach, USA: Curran Associates, Inc., 2017. 3856−3866 [20] Kurakin A, Goodfellow I, Bengio S. Adversarial machine learning at scale. In: Proceedings of the 2017 International Conference on Learning Representations. Toulon, France: 2017. [21] Tramer F, Kurakin A, Papernot N, Boneh D, McDaniel P. Ensemble adversarial training: Attacks and defenses. In: Proceedings of the 2018 International Conference on Learning Representations. Vancouver, Canada: 2018. [22] Madry A, Makelov A, Schmidt L, Tsipras D, Vladu A. Towards deep learning models resistant to adversarial attacks. In: proceedings of the 2018 International Conference on Learning Representations. Vancouver, Canada: 2018. [23] Zhang H Y, Yu Y D, Jiao J T, Xing E P, Ghaoui L E, Jordan M I. Theoretically principled trade-off between robustness and accuracy. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 7472−7482 [24] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 2015 International Conference on Learning Representations. San Diego, USA: 2015. [25] 张芳, 王萌, 肖志涛, 吴骏, 耿磊, 童军, 王雯. 基于全卷积神经网络与低秩稀疏分解的显著性检测. 自动化学报, 2019, 45(11): 2148-2158.Zhang Fang, Wang Meng, Xiao Zhi-Tao, Wu Jun, Geng Lei, Tong Jun, Wang Wen. Saliency detection via full convolutional neural network and low rank sparse decomposition. Acta Automatica Sinica, 2019, 45(11): 2148-2158 [26] 李阳, 王璞, 刘扬, 刘国军, 王春宇, 刘晓燕, 郭茂祖. 基于显著图的弱监督实时目标检测. 自动化学报, 2020, 46(2): 242-255Li Yang, Wang Pu, Liu Yang, Liu Guo-Jun, Wang Chun-Yu, Liu Xiao-Yan, Guo Mao-Zu. Weakly supervised real-time object detection based on saliency map. Acta Automatica Sinica, 2020, 46(2): 242-255 [27] Liao F Z, Liang M, Dong Y P, Pang T Y, Zhu J, Hu X L. Defense against adversarial attacks using high-level representation guided denoiser. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE 2018. 1778−1787 [28] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3): 211-252 doi: 10.1007/s11263-015-0816-y [29] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. In: Proceedings of the 2012 Advances in Neural Information Processing Systems. Lake Tahoe, USA: Curran Associates, Inc., 2012. 1097−1105 [30] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [31] 刘建伟, 赵会丹, 罗雄麟, 许鋆. 深度学习批归一化及其相关算法研究进展. 自动化学报, 2020, 46(6): 1090-1120Liu Jian-Wei, Zhao Hui-Dan, Luo Xiong-Lin, Xu Jun. Research progress on batch normalization of deep learning and its related algorithms. Acta Automatica Sinica, 2020, 46(6): 1090-1120 [32] Miller G A, Beckwith R, Fellbaum C, Gross D, Miller K J. Introduction to wordnet: An on-line lexical database. International journal of lexicography, 1990, 3(4): 235-244 doi: 10.1093/ijl/3.4.235 [33] Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 2818−2826 [34] Tsipras D, Santurkar S, Engstrom L, Turner A, Madry A. Robustness may be a odds with accuracy. In: Proceedings of the 2019 International Conference on Learning Representations. New Orleans, USA: 2019. -

 下载:
下载:



计量
- 文章访问数: 3256
- HTML全文浏览量: 1153
- PDF下载量: 796
- 被引次数: 0
