

Secure State Estimation Based on Distributed Sparse Optimization Under Malicious Attacks
-
摘要: 恶意生成的量测攻击信号是导致信息物理系统(Cyber-physical system, CPS)探测失效的主要原因, 如何有效削弱其影响是实现精准探测、跟踪与感知的关键问题. 分布式传感器网络(Distributed sensor network, DSN)依靠多传感器协作与并行处理突破单一监测节点的任务包线, 能够显著提升探测系统跟踪精度与可靠性. 首先, 依据压缩感知理论, 将单一节点的目标运动状态估计建模为一种基于l0范数最小化的稀疏优化问题, 采用正交匹配追踪法(Orthogonal matching pursuit, OMP)重构量测攻击信号, 以克服采用凸优化算法求解易陷入局部最优的缺陷. 通过卡尔曼滤波量测更新抵消攻击信号影响, 恢复目标运动的真实状态. 其次, 针对错误注入攻击等复杂量测攻击形式, 基于势博弈理论, 提出一种分布式稀疏优化安全状态估计方法, 利用多传感器节点信息交互与协作提升探测与跟踪的稳定性. 仿真结果表明, 所提方法在分布式传感器网络协作抵抗恶意攻击方面具有优越性.Abstract: Malicious attacks against the measurements is one of the primary cause accounting for the detection failure of cyber-physical systems (CPS). Reducing the impact of measurement attack is a key problem of the accurate detection, target tracking, and sensing for CPS. Distributed sensor networks (DSN) are able to break through the task envelope of single surveillance node through coordination and parallel processing and thus remarkably improve the tracking performance and reliability of detection systems. Based on the compressive sensing theory, the state estimation for single-plant target tracking is modelled as an l0-norm minimization problem, which is also equivalent to a sparse optimization problem. Under sparse malicious attacks, the orthogonal matching pursuit (OMP) is utilized to reconstruct the attack signals and to avoid the local optima induced by the convex optimization algorithms. A combined Kalman filter is presented to obtain the true target information where the attack signals are compensated in the measurement update. Then, a distributed secure state estimation method based on the potential game theory is proposed in view of the complex attacks such as the false data injection, where a potential game framework is established to enhance the stability of target tracking by the information exchange and coordination among neighboring sensors. Simulation results demonstrate the effectiveness of the proposed method against the sparse malicious attacks on DSNs.
-

图 1 分布式稀疏优化安全状态估计流程图
Fig. 1 Flowchart of secure state estimation algorithm based on distributed sparse optimizations

图 3 测试算法对目标轨迹的跟踪效果对比
Fig. 3 Comparison of trajectory tracking by the candidate algorithms
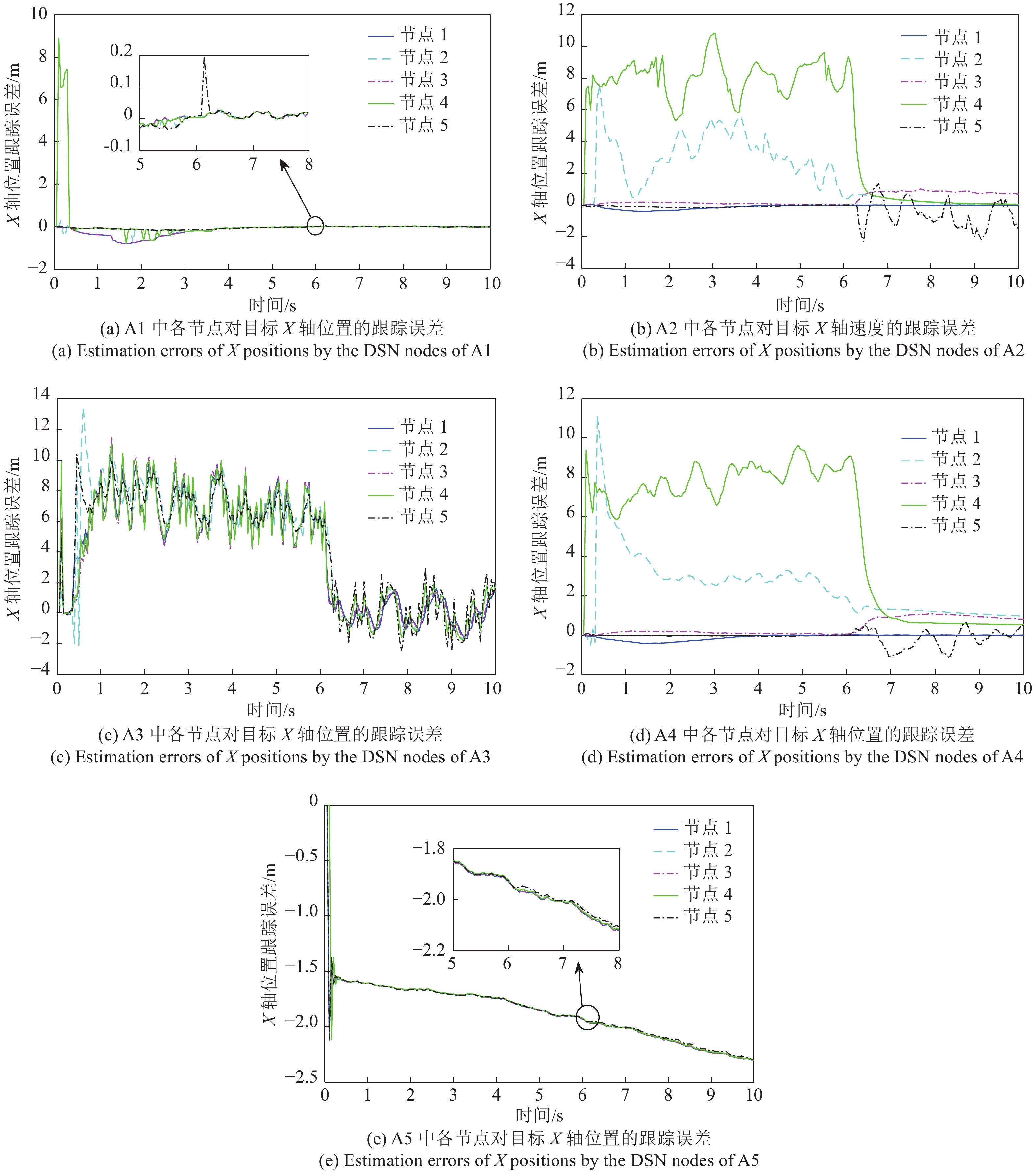
图 4 测试算法对目标X轴位置的跟踪误差对比
Fig. 4 Comparison of X-position estimation errors by the candidate algorithms

图 5 测试算法对目标X轴速度的跟踪误差对比
Fig. 5 Comparison of X-velocity estimation errors by the candidate algorithms
表 1 DSN遭受的分时段攻击列表
Table 1 Time sharing attacks of DSN detection nodes
节点 时段 0 s ~ 3 s 3 s ~ 6 s 6 s ~ 9 s 9 s ~ 10 s 1 无 无 无 I类 2 I类 I类 无 无 3 无 无 II类 II类 4 II类 II类 无 无 5 无 无 I类 I类  下载: 导出CSV
下载: 导出CSV
表 2 5种算法对X轴位置的均方估计误差比较 (m)
Table 2 Comparison of mean square errors (meters) of position estimations in X-axis by the five algorithms
A1 A2 A3 A4 A5 节点 1 0.0724 0.0238 28.6083 0.0302 3.6060 节点 2 0.0150 7.2185 33.0688 8.3714 3.5778 节点 3 0.0724 0.2550 29.0511 0.3338 3.6056 节点 4 1.3807 40.6553 29.5093 39.4624 3.5778 节点 5 0.0054 0.4213 31.6166 0.1078 3.5785
下载: 导出CSV
-
[1] Rajkumar R, Lee I, Sha L, Stankovic J. Cyber-physical systems: The next computing revolution. In: Proceedings of the 47th Design Automation Conference. Anaheim, CA, USA: IEEE, 2010. 731−736 [2] 庞岩, 王娜, 夏浩. 基于博弈论的信息物理融合系统安全控制. 自动化学报, 2019, 45(1): 185−195Pang Yan, Wang Na, Xia Hao. A game theory approach for secure control of cyber-physical systems. Acta Automatica Sinica, 2019, 45(1): 185−195 [3] Ding D, Han Q, Wang Z, Ge X. A survey on model-based distributed control and filtering for industrial cyber-physical systems. IEEE Transactions on Industrial Informatics, 2019, 15(5): 2483−2499 doi: 10.1109/TII.2019.2905295 [4] Torfs T, Sterken T, Brebels S, Santana J, Van Den Hoven R, Spiering V, et al. Low power wireless sensor network for building monitoring. IEEE Sensors Journal, 2013, 13(3): 909−915 doi: 10.1109/JSEN.2012.2218680 [5] Gupta H P, Rao S V, Venkatesh T. Critical sensor density for partial coverage under border effects in wireless sensor networks. IEEE Transactions on Wireless Communications, 2014, 13(5): 2374−2382 doi: 10.1109/TWC.2014.022714.131454 [6] Liu S, Chen B, Zourntos T, Kundur D, Butler-Purry K. A coordinated multi-switch attack for cascading failures in smart grid. IEEE Transactions on Smart Grid, 2014, 5(3): 1183−1195 doi: 10.1109/TSG.2014.2302476 [7] Guan Y, Ge X. Distributed attack detection and secure estimation of networked cyber-physical systems against false data injection attacks and jamming attacks. IEEE Transactions on Signal and Information Processing Over Networks, 2018, 4(1): 48−59 doi: 10.1109/TSIPN.2017.2749959 [8] Liu Y, Li C. Secure distributed estimation over wireless sensor networks under attacks. IEEE Transactions on Aerospace and Electronic Systems, 2018, 54(4): 1815−1831 doi: 10.1109/TAES.2018.2803578 [9] 袁天, 罗震明, 刘晨, 车伟. 基于欺骗噪声复合干扰的组网雷达对抗方法. 探测与控制学报, 2019, 41(6): 69−74Yuan Tian, Luo Zhen-Ming, Liu Chen, Che Wei. Antagonistic method of deception and noise complex jamming against netted radar. Journal of Detection and Control, 2019, 41(6): 69−74 [10] Cintuglu M H, Ishchenko D. Secure distributed state estimation for networked microgrids. IEEE Internet of Things Journal, 2019, 6(5): 8046−8055 doi: 10.1109/JIOT.2019.2902793 [11] Manandhar K, Cao X, Hu F, Liu Y. Combating false data injection attacks in smart grid using Kalman filter. In: Proceedings of the 3rd International Conference on Computing, Networking and Communications. Honolulu, HI, USA: IEEE, 2014. 16−20 [12] Li Y, Shi L, Cheng P, Chen J, Quevedo D E. Jamming attacks on remote state estimation in cyber-physical systems: A game-theoretic approach. IEEE Transactions on Automatic Control, 2015, 60(10): 2831−2836 doi: 10.1109/TAC.2015.2461851 [13] Kwon C, Hwang I. Hybrid robust controller design: Cyber attack attenuation for cyber-physical systems. In: Proceedings of the 52nd IEEE Conference on Decision and Control. Florence, Italy: IEEE, 2013. 188−193 [14] 周雪, 张皓, 王祝萍. 扩展卡尔曼滤波在受到恶意攻击系统中的状态估计. 自动化学报, 2020, 46(1): 38−46Zhou Xue, Zhang Hao, Wang Zhu-Ping. Extended Kalman filtering in state estimation systems with malicious attacks. Acta Automatica Sinica, 2020, 46(1): 38−46 [15] Fawzi H, Tabuada P, Diggavi S. Secure estimation and control for cyber-physical systems under adversarial attacks. IEEE Transactions on Automatic Control, 2014, 59(6): 1454−1467 doi: 10.1109/TAC.2014.2303233 [16] Chang Y H, Hu Q, Tomlin C J. Secure estimation based Kalman filter for cyber-physical systems against sensor attacks. Automatica, 2018, 95: 399−412 doi: 10.1016/j.automatica.2018.06.010 [17] Shoukry Y, Tabuada P. Event-triggered state observers for sparse sensor noise/attacks. IEEE Transactions on Automatic Control, 2016, 61(8): 2079−2091 doi: 10.1109/TAC.2015.2492159 [18] Wu C, Hu Z, Liu J, Wu L. Secure estimation for cyber-physical systems via sliding mode. IEEE Transactions on Cybernetics, 2018, 48(12): 3420−3431 doi: 10.1109/TCYB.2018.2825984 [19] Liang C, Wen F, Wang Z. Trust-based distributed Kalman filtering for target tracking under malicious cyber attacks. Information Fusion, 2019, 46: 44−50 doi: 10.1016/j.inffus.2018.04.002 [20] 敖伟, 宋永端, 温长云. 受攻击信息物理系统的分布式安全状态估计与控制—一种有限时间方法. 自动化学报, 2019, 45(1): 174−184Ao Wei, Song Yong-Duan, Wen Chang-Yun. Distributed secure state estimation and control for CPSs under sensor attacks—A finite time approach. Acta Automatica Sinica, 2019, 45(1): 174−184 [21] Candes E J, Tao T. Decoding by linear programming. IEEE Transactions on Information Theory, 2005, 51(12): 4203−4215 doi: 10.1109/TIT.2005.858979 [22] Hayden D, Chang Y H, Goncalves J, Tomlin C J. Sparse network identifiability via compressed sensing. Automatica, 2016, 68: 9−17 doi: 10.1016/j.automatica.2016.01.008 [23] Cai T T, Wang L. Orthogonal matching pursuit for sparse signal recovery with noise. IEEE Transactions on Information Theory, 2011, 57(7): 4680−4688 doi: 10.1109/TIT.2011.2146090 [24] Donoho D L, Tsaig Y, Drori I, Starck J L. Sparse solution of underdetermined systems of linear equations by stagewise orthogonal matching pursuit. IEEE Transactions on Information Theory, 2012, 58(2): 1094−1121 doi: 10.1109/TIT.2011.2173241 [25] Marden J R, Arslan G, Shamma J S. Cooperative control and potential games. IEEE Transactions on Systems, Man, and Cybernetics—Part B: Cybernetics, 2009, 39(6): 1393−1407 doi: 10.1109/TSMCB.2009.2017273 [26] Li P, Duan H. A potential game approach to multiple UAV cooperative search and surveillance. Aerospace Science and Technology, 2017, 68: 403−415 doi: 10.1016/j.ast.2017.05.031 [27] Yang A Y, Sastry S S, Ganesh A, Ma Y. Fast $\substack {l_1 }$-minimization algorithms and an application in robust face recognition: A review. In: Proceedings of the 17th IEEE International Conference on Image Processing. Hong Kong, China: IEEE, 2010. 1849−1852 [28] Olfati-Saber R. Distributed Kalman filtering for sensor networks. In: Proceedings of the 46th IEEE Conference on Decision and Control. New Orleans, LA, USA: IEEE, 2007. 5492−5498 -

 下载:
下载:


计量
- 文章访问数: 1387
- HTML全文浏览量: 633
- PDF下载量: 369
- 被引次数: 0
