

Operating Performance Assessment Based on Granular Clustering forIron Ore Sintering Process
-
摘要: 烧结过程的运行性能是生产效率和能源利用的综合表现. 运行性能评价是保持烧结过程的运行性能处于最优等级的前提. 考虑到时间序列数据的冗余, 提出一种基于粒度聚类的铁矿石烧结过程运行性能评价方法. 首先, 利用单因素方差分析方法选取影响运行性能等级的检测参数; 然后, 采用多粒度区间信息粒化实现检测参数时间序列数据的降维, 并进行粒度聚类, 得到聚类标签; 最后, 以聚类得到的聚类标签为输入, 利用随机森林算法进行运行性能等级评价. 利用实际钢铁企业的运行数据进行实验, 构建两个对比实验, 分别采用基于时间序列数据聚类(Time series data clustering, TSDC)方法和基于时间序列特征聚类(Time series feature clustering, TSFC)方法. 实验结果表明, 该方法为有效评价烧结过程的运行性能提供了一套可行方案, 为操作人员提升烧结过程运行性能提供了有力的指导.Abstract: The operating performance of the sintering process is about the comprehensive representation of production efficiency and energy utilization. The operating performance assessment is a prerequisite to maintain the operating performance of the sintering process at the optimal grade. By considering the redundancy of time series data, an operating performance assessment method based on granular clustering for the iron ore sintering process is presented in this paper. First, the one-way analysis of variance method is used to select the detection parameters that affect the operating performance grade. Then, the multi-granularity interval information granulation is used to achieve dimensionality reduction of the time series data for the detection parameters, and the granules are clustered to form the clustering labels. Finally, with labels obtained by clustering being the input, the random forest algorithm is used to assess the operating performance grade. Experiments are performed using the actual running data of iron and steel enterprises, and two comparative experiments are constructed using a method based on time series data clustering (TSDC) and a method based on time series feature clustering (TSFC), respectively. Results show that the proposed method provides a feasible scheme to assess the operating performance of the sintering process effectively, and provides powerful guidance for operators to improve the operating performance of the sintering process.
-
Key words:
- Granular clustering /
- sintering process /
- time series /
- operating performance
-
城市固废焚烧(Municipal solid waste incineration, MSWI) 具有占地面积小、处理时间短、资源回收利用率高等优势, 是我国目前处理城市固废的首选方案[1]. 从MSWI过程控制的角度来看, 将焚烧炉的一燃室烟气温度均值(以下简称为炉温) 稳定控制在工艺要求的850 ℃以上、余热锅炉出口的烟气含氧量控制在6% ~ 9%, 才有可能使得炉内固废与可燃性烟气充分燃烧, 从而保障二次污染物(如: 氮氧化物、强致癌物二噁英等) 的排放浓度达标[2-3]. 因此, 建立准确的炉温与烟气含氧量预测模型有利于操作人员或自动控制系统及时发现焚烧炉运行状况的变化, 从而采取相应的措施来避免异常情况的发生, 对实现MSWI过程的平稳、高效、环保运行具有重要的现实意义.
目前, 针对MSWI过程的炉温与烟气含氧量建模方法主要有机理建模与数据驱动建模两种. 例如: 从能量守恒与物料守恒的角度出发, 利用物理、化学方程式建立固废焚烧炉与余热锅炉的机理模型, 通过分析进料量、风量、炉排速度等参数对炉温与烟气含氧量的影响, 可为MSWI过程的优化控制提供指导[4-5]. 然而, 由于焚烧炉类型不同、固废组分复杂、模型简化等因素的影响, 基于机理的炉温与烟气含氧量建模方法难以推广应用, 且模型精度往往无法满足实际应用需求. 值得注意的是, MSWI过程中存在丰富的运行数据, 这些离线或在线数据中隐含了设备与工艺参数的变化信息, 在这种情况下, 研究基于数据驱动的炉温与烟气含氧量建模方法可有效避免机理建模的局限性.
由于神经网络具有较好的非线性学习能力, 在数据驱动参数建模领域受到研究人员的广泛关注[6-7]. 在MSWI过程参数建模方面, 文献[8]利用基于梯度下降算法的自组织T-S模糊神经网络来预测炉温的变化趋势. 文献[9]利用卷积神经网络对数据增强后的焚烧火焰图像进行智能识别, 其识别结果可为现场操作人员修正焚烧控制策略提供参考. 文献[10]则采用改进的长短时记忆神经网络建立烟气含氧量预测模型, 并在控制过程中根据实际工况在线更新模型参数. 但梯度下降算法在进行网络参数学习时易陷入局部最优, 且模型训练周期较长. 为提升神经网络的建模效率, 以随机向量函数链网络(Random vector functional link, RVFL)[11] 为代表的随机权神经网络相继被提出, 但这类网络一般在固定区间内随机生成隐含层节点参数, 其通用逼近性有时难以保证, 且网络结构需预先指定. 于是, 文献[12]提出了随机配置网络(Stochastic configuration network, SCN), SCN在可变区间内通过监督机制配置隐含层新增节点参数以增量构建学习网络, 并利用最小二乘法计算输出权值. 与基于梯度下降算法的误差反传网络、径向基神经网络等相比, SCN的建模效率与精度相对较高, 在污水处理[13]、金属热轧[14]、原油提炼[15]等工业过程中得以成功应用. 因此, 文献[16]将SCN与递推最小二乘法相结合, 构建了炉温动态预测模型, 并将其用于炉温非线性模型预测控制中. 文献[17]以正则化SCN为基模型, 提出一种异构特征与负相关学习策略的集成建模方法来提升炉温预测模型的准确性与训练效率. 然而, 上述均是针对炉温或烟气含氧量单目标进行建模, 难以为MSWI过程的多目标协同优化控制提供全面的预测信息. 文献[18]针对MSWI过程构建了基于T-S模糊神经网络的多目标被控对象模型, 但其未利用炉温与烟气含氧量等多目标间的相关性来提升建模精度. 此外, 固废焚烧环境十分复杂, 从现场采集到的数据中不可避免地包含噪声或离群点, 上述方法还未充分考虑这些异常数据对模型准确性的负面影响.
综上所述, 为实现对MSWI过程炉温与烟气含氧量的准确预测, 本文以建模效率高且具有通用逼近性的SCN为基础, 提出一种基于改进SCN的多目标鲁棒建模方法(Multi-target robust modeling method based on improved SCN, MRI-SCN) 以促进MSWI过程的平稳高效运行, 进而提升固废焚烧发电量、降低二次污染物排放浓度. 本文主要工作如下: 1) 在参数自适应的不等式监督机制下, 采用并行构造的方式配置隐含层节点, 以增强模型的非线性映射能力; 2) 利用矩阵弹性网将炉温与烟气含氧量间的相关性假设转化为对模型参数的稀疏约束, 以提高建模精度; 3) 将混合拉普拉斯(Laplace) 分布作为每个目标建模误差的先验分布, 并使用最大后验估计来优化SCN模型的输出权值, 以降低其对异常数据的敏感性. 通过实验验证了所提建模方法的有效性.
本文余下部分的组织结构安排是: 第1节是MSWI工艺流程描述与建模分析; 第2节介绍MRI-SCN建模方法的实现过程; 第3节是实验测试与结果分析; 最后总结全文并提出展望.
1. MSWI工艺流程描述与建模分析
本节主要介绍MSWI的工艺流程与SCN的参数学习过程, 并分析将SCN用于构建数据驱动的炉温与烟气含氧量多目标鲁棒预测模型时需要解决的问题.
1.1 MSWI工艺流程
以北京市某固废焚烧厂的炉排炉为例, MSWI的工艺流程如图1所示, 主要包括固废储运、固废焚烧、余热锅炉、蒸汽发电、烟气净化5个子系统. 固废焚烧过程大致如下: 固废吊车将堆放发酵后的固废投入进料斗, 并由进料器推送至炉排上; 固废经过干燥炉排时, 在高温一次风对流干燥、炉膛内侧壁辐射干燥以及炉排热传导干燥的共同作用下蒸发水分, 挥发份析出并不断升温达到着火点; 固废通过燃烧炉排时, 二次风由上而下吹入, 促进炉排上的固废与炉内可燃性烟气充分燃烧; 最后, 固废在燃烬炉排上完全燃烧, 冷却后形成稳定的固体残渣. 固废焚烧产生的高温烟气经余热锅炉系统回收热能, 产生饱和蒸汽用于推动汽轮机发电, 焚烧尾气经过脱酸反应、布袋除尘等处理后排入大气.
在MSWI过程中, 炉温与烟气含氧量是反映固废焚烧质量的关键指标[2], 具体来说: 固废焚烧工艺要求将炉温稳定控制在850 ℃以上, 否则炉温过低, 炉内固废与烟气无法充分燃烧, 从而导致固废焚烧效率下降, 二次污染物排放浓度超标. 就烟气含氧量而言, 通过优化一、二次风量及其配比, 使炉内烟气具有良好的湍流度, 在保证炉内固废充分燃烧的同时, 降低余热锅炉的排烟热损失以增加主蒸汽产量, 这有利于提高固废焚烧发电厂的经济效益. 然而, 目前已有的针对MSWI过程的炉温与烟气含氧量预测大多是单目标模型, 即分别对每个目标建立预测模型. 这种单目标模型只关注某个指标的变化情况, 并未考虑到炉温与烟气含氧量的整体变化趋势, 所能提供的预测信息相对较少. 由于炉温与烟气含氧量均为反映固废焚烧质量的指标, 二者在变化机理与趋势上具有一定的关联性. 为促进MSWI过程的平稳、高效运行, 同时兼顾模型的简洁性与鲁棒性, 本文力求在一个整体框架内实现炉温与烟气含氧量预测, 从而构建出炉温与烟气含氧量多目标鲁棒预测模型.
由固废焚烧机理可知, 下一时刻的炉温与烟气含氧量主要受固废组分、入炉固废量、固废在炉内的停留时间、风量、风温以及当前时刻的炉温与烟气含氧量等因素的影响. 在固废热值、一次风压等诸多干扰中, 固废热值的波动对炉温与烟气含氧量的影响较大, 但该参数难以直接测量. 考虑到炉排与固废直接接触, 炉排温度在一定程度上可以反映固废热值的变化, 所以可将炉排温度作为炉温与烟气含氧量预测建模的辅助变量. 因此, 本文选取进料器速度、炉排速度、风量、炉排温度等47个变量作为预测模型的输入, 变量明细表如附录中的表A1所示.
1.2 SCN参数学习过程
SCN是一种单隐含层的随机学习模型, 其隐含层参数在不等式监督机制下随机生成, 并采用最小二乘法求解隐含层输出权值, 从而保证了SCN模型的通用逼近性. 下面简介SCN的参数学习过程, 关于SCN的详细介绍可阅读文献[12].
对于目标函数$ f:{\bf{R}}^{d}\rightarrow {\bf{R}}^{m} $, 假设SCN训练集的输入为$ {\boldsymbol{X}}=\{{\boldsymbol{x}}_{1}, {\boldsymbol{x}}_{2},\cdots, {\boldsymbol{x}}_{N}\} $, 输出为${\boldsymbol{Y}}=\{{\boldsymbol{y}}_{1}, {\boldsymbol{y}}_{2},\cdots, {\boldsymbol{y}}_{N}\}$, 当SCN隐含层已配置完成$ L-1 $个节点时, 其输出表达式如下所示:
$$ \begin{align} f_{L-1}({\boldsymbol{x}})=\sum^{L-1}_{j=1} {\boldsymbol{\beta}}_{j} g_j({\boldsymbol{w}}_{j}^\text{T}{\boldsymbol{x}}+b_{j}) \end{align} $$ (1) 其中, $ {\boldsymbol{\beta}}_{j} $表示隐含层第$ j $个节点的输出权值; $ g_{j}(\cdot) $表示隐含层第$ j $个节点的激活函数; $ {\boldsymbol{w}}_{j} $与$ b_{j} $分别表示隐含层第$ j $个节点的输入权值与偏置. 当网络残差大于容忍误差$ \tau $且隐含层节点数量未超过最大预设值$ L_{\text{max}} $时, 根据式(2)所示的监督机制在可变区间$ \Upsilon=[\gamma_\text{min}: \triangle\gamma: \gamma_\text{max}] $内随机分配$ T_\text{max} $个候选节点, 每个候选节点对应一组输入权值$ {\boldsymbol{w}}_{L} $与偏置$ b_{L} $. 为提升网络收敛速度, SCN将$ \xi_{L} $最大值对应的候选节点作为最优节点添加到隐含层中, 并利用式(4)重新计算隐含层输出权值$ {\boldsymbol{\beta}} $.
$$ \begin{split} {\xi}_{L}=\;&\frac{({\boldsymbol{e}}^{\text{T}}_{L-\text{1}}({\boldsymbol{X}}){\boldsymbol{h}}_{L}({\boldsymbol{X}}))^{2}} {{\boldsymbol{h}}_{L}^{\text{T}}({\boldsymbol{X}}){\boldsymbol{h}}_{L}({\boldsymbol{X}})}- \\ & (1-r-\mu_{L}) {\boldsymbol{e}}_{L-\text{1}}^{\text{T}}({\boldsymbol{X}}) {\boldsymbol{e}}_{L-\text{1}}({\boldsymbol{X}})\geq 0 \end{split} $$ (2) $$ \begin{split} {\boldsymbol{h}}_{L}({\boldsymbol{X}})=\;& [g_L({\boldsymbol{w}}_{L}^\text{T}{\boldsymbol{x}}_{1}+b_{L}), g_L({\boldsymbol{w}}_{L}^\text{T}{\boldsymbol{x}}_{2}+b_{L}),\cdots,\\ &g_L({\boldsymbol{w}}_{L}^\text{T}{\boldsymbol{x}}_{N}+b_{L})]^{\text{T}}\\[-10pt] \end{split} $$ (3) $$ \begin{align} [{\boldsymbol{\beta}}_{1}^{*}, {\boldsymbol{\beta}}_{2}^{*},\cdot\cdot\cdot, {\boldsymbol{\beta}}_{L}^{*}]= \text{arg}\underset{\boldsymbol{\beta}}{\text{min}} \|{\boldsymbol{H}}_{L}{\boldsymbol{\beta}}-{\boldsymbol{Y}}\|_{{ \text{F}}}^{2} ={\boldsymbol{H}}_{L}^{\dagger}{\boldsymbol{Y}} \end{align} $$ (4) 其中, $ {\boldsymbol{e}}_{L-1}({\boldsymbol{X}}) $表示隐含层节点为$ L-\text{1} $时的网络残差; $ {\boldsymbol{h}}_{L}({\boldsymbol{X}}) $表示隐含层第$ L $个节点的输出; $ 0 < r < 1 $; $ \{\mu_{L} \}$表示非负实数序列, $ {\lim_{L\rightarrow +\infty}\mu_{L}}=0 $且$ \mu_{L}\leq(1-r) $; $ {\boldsymbol{H}}_{L}=[{\boldsymbol{h}}_{1}, {\boldsymbol{h}}_{2}, \cdot\cdot\cdot, {\boldsymbol{h}}_{L}] $表示隐含层输出矩阵; $ (\cdot)^{\dagger} $表示伪逆运算; $ \|\cdot\|_{ \text{F}} $表示矩阵的Frobenius范数(简称F范数), 其计算方式如下所示:
$$ \begin{split} \|{\boldsymbol{A}}\|_{ \text{F}}=\sqrt{\sum\limits_{i=1}^{m}\sum\limits_{j=1}^{n}{\boldsymbol{A}}_{ij}^{2}},\; \; {\boldsymbol{A}}\in {\bf{R}}^{m\times n} \end{split} $$ (5) 1.3 SCN多目标建模问题分析
SCN在参数学习速度与建模精度等方面具有优势[12], 其单目标建模性能已在MSWI、污水处理等工业过程中得以验证[13-17], 但多目标建模需同时对输入输出之间的非线性与多目标之间的相关性进行建模[19], 因此将SCN用于数据驱动的炉温与烟气含氧量多目标预测建模时, 以下问题仍需进一步研究:
1) SCN隐含层映射多样性存在不足. SCN隐含层在增量构建过程中通常采用单一构造方式, 使得隐含层映射多样性存在不足, 从而限制了模型的非线性映射能力. 通过增加隐含层节点数量在一定程度上可以避免映射单一化, 但会导致模型存在过拟合的风险, 同时模型复杂度也相对较高, 因而有必要从映射多样性方面考虑如何提升SCN的建模性能.
2) 多目标间的相关性建模. SCN在进行多输入多输出建模时, 并未考虑到利用多目标间的相关性来提升模型精度, 仅是对输入输出间的非线性映射关系进行建模. 若直接将其用于构建炉温与烟气含氧量多目标预测模型, 则模型性能可能无法满足实际应用需求.
3) SCN学习算法难以识别训练数据集中的异常样本. 由于固废焚烧环境十分复杂, 从现场采集到的数据中会包含噪声与离群点, 而SCN在进行参数学习时, 难以区分正常样本与异常样本, 即认为所有训练数据同等重要. 若用于训练SCN模型的数据受到污染, 则学习到的模型不具备鲁棒性, 建模质量较低.
2. MRI-SCN建模方法
本节针对SCN在隐含层映射多样性、多目标间的相关性建模以及模型鲁棒性3个方面的不足进行研究并给出相应的解决策略, 从而提出一种基于改进SCN的多目标鲁棒建模方法(MRI-SCN), 以实现对MSWI过程炉温与烟气含氧量的准确预测.
2.1 隐含层并行构造
利用神经网络进行建模时, 增强隐含层映射多样性往往可以提升模型的学习能力[20-21]. SCN属于一种单隐含层的前馈神经网络, 拓扑结构如图2(a)所示, 其隐含层采用标准前馈构造, 即隐含层节点只接受上一层节点的输出, 隐含层节点之间并无信息传递, 模型结构相对简单. 标准前馈构造的隐含层第$ L $个节点的输出可表示为:
$$ \begin{align} \tilde{{\boldsymbol{h}}}_{L}({\boldsymbol{X}})= g_L({\boldsymbol{w}}_{L}^\text{T}{\boldsymbol{X}}+{\boldsymbol{b}}_{L})^{\rm{T}},\; L\geq 1 \end{align} $$ (6) 其中, ${\boldsymbol{b}}_{L}$表示元素均为${{b}}_{L}$的向量.
 图 2 前馈神经网络隐含层构造方式Fig. 2 The hidden layer construction methods of feedforward neural network
图 2 前馈神经网络隐含层构造方式Fig. 2 The hidden layer construction methods of feedforward neural network文献[22]指出级联构造的神经网络在解决某些问题时具有更好的信息处理能力. 级联构造允许网络隐含层节点间进行信息叠加与跨越连接[23], 其拓扑结构如图2(b)所示. 但随着隐含层节点间信息叠加与跨越连接次数的增加, 模型复杂度也会逐渐上升. 级联构造的隐含层第$ L $个节点的输出可表示为:
$$ \begin{split} \bar{{\boldsymbol{h}}}_{L}({\boldsymbol{X}})= &\left\{\begin{aligned} &g_L({\boldsymbol{w}}_{L}^\text{T}{\boldsymbol{X}}+{\boldsymbol{b}}_{L})^{\rm{T}}, && L = 1 \\ &g_L({\boldsymbol{w}}_{L}^\text{T}{\boldsymbol{X}}+{\boldsymbol{b}}_{L}+\sum\limits_{j=1}^{L-1}{\boldsymbol{q}}_{j} \bar{{\boldsymbol{h}}}_{j}^{\rm{T}}({\boldsymbol{X}}))^{\rm{T}}, && L\geq 2 \end{aligned}\right.\ \end{split} $$ (7) 其中, $ {\boldsymbol{q}}_{j} $表示隐含层第$ j $个节点与其他隐含层节点之间的连接权值.
为综合考虑SCN模型的非线性映射能力与复杂度, 本节从隐含层映射多样性的角度出发, 将标准前馈构造与级联构造相融合, 采用并行构造的方式增量构建SCN隐含层. 采用并行构造时, SCN隐含层第$ L $个节点的输出可表示为:
$$ \begin{split} {\boldsymbol{h}}_{L}({\boldsymbol{X}})= &\left\{\begin{aligned} &\tilde{{\boldsymbol{h}}}_{L}({\boldsymbol{X}}),\; \xi(\tilde{{\boldsymbol{h}}}_{L}({\boldsymbol{X}})) \geq \xi(\bar{{\boldsymbol{h}}}_{L}({\boldsymbol{X}})) \\ &\bar{{\boldsymbol{h}}}_{L}({\boldsymbol{X}}),\; \xi(\tilde{{\boldsymbol{h}}}_{L}({\boldsymbol{X}})) < \xi(\bar{{\boldsymbol{h}}}_{L}({\boldsymbol{X}})) \end{aligned}\right.\ \end{split} $$ (8) 在SCN建模过程中, 式(2)中的参数$ r $用于控制监督不等式的约束强度[12]. 随着隐含层新增节点的配置难度逐渐增加, 监督不等式的约束强度应逐渐降低. 标准SCN利用线性搜索获得最佳参数$ r $, 但基于多次循环的线性搜索会降低SCN隐含层参数的配置效率, 甚至会出现新增节点配置失败的情况. 因此, 为提升SCN的参数配置效率, 本文在满足SCN模型通用逼近性的前提下, 基于监督不等式约束先紧后松的思想, 提出自适应变化的参数$ r $, 具体如下:
定理 1. 假设span$ (\Gamma) $稠密于$ L_{2} $空间, $ \forall {\boldsymbol{g}}\in \Gamma $, $ 0<\|{\boldsymbol{g}}\|_{2}<b_{g} $, $ b_{g}\in {\bf{R}}^{\text{+}} $. 对于$ L=1, 2, \cdot\cdot\cdot $, 令$ r =1- \text{ln}(1+1/(L+1)^P), P >1 $, $ 0<\mu_{L}\leq (1-r)/(L+ 1) $. 如果隐含层新增节点满足式(2)所示的监督不等式, 并根据式(4)求解隐含层输出权值, 则$ \lim_{L\to +\infty}\,\left\| {\boldsymbol{e}}_{L}^{*} \right\|_{ \text{F}}=0 $.
证明. 当SCN隐含层节点个数为$ L $时, 其残差可表示为$ {\boldsymbol{e}}_{L}^{*}={\boldsymbol{e}}_{L-\text{1}}^{*}-\boldsymbol{\beta}_{L}^{*}{\boldsymbol{h}}_{L} $. 令$ {\tilde{\boldsymbol \beta}_{L}}=\langle{\boldsymbol{e}}_{L-1}^{*},{\boldsymbol{h}}_{L}\rangle/ \|{\boldsymbol{h}}_{L}\|_{2}^{2} $, 于是:
$$ \begin{split}\|{\boldsymbol{e}}_{L}^{*} \|_{ \text{F}}^{2} \leq \; &\| \tilde{{\boldsymbol{e}}}_{L}^{*} \|_{ \text{F}}^{2}=\\ &\langle {\boldsymbol{e}}_{L-\text{1}}^{*}-\tilde{\boldsymbol{\beta}}_{L}{\boldsymbol{h}}_{L}, {\boldsymbol{e}}_{L-\text{1}}^{*}-\tilde{\boldsymbol{\beta}}_{L}{\boldsymbol{h}}_{L}\rangle= \\ &\|{{\boldsymbol{e}}}_{L-1}^{*} \|_{ \text{F}}^{2}- \frac{{\langle{\boldsymbol{e}}_{L-1}^{*},{\boldsymbol{h}}_{L}\rangle}^{2}}{\|{\boldsymbol{h}}_{L}\|_{2}^{2}} \leq \|{\boldsymbol{e}}_{L-1}^{*}\|_{ \text{F}}^{2} \end{split} $$ (9) 即残差$\|{\boldsymbol{e}}_{L}^*\|_{ \text{F}}^{2}$单调递减. 当$ x > 0 $时, 由于
$$ \begin{align} \frac{x}{x+1}<\text{ln}(1+x)<x \end{align} $$ (10) 所以:
$$ \begin{align} 1-x < 1-\text{ln}(1+x) < 1-\frac{x}{x+1} \end{align} $$ (11) 令$ \|{\boldsymbol{e}}_{0}\|_{ \text{F}}^{2}=\|f\|_{ \text{F}}^{2} $, 当$ r=1-\text{ln}(1+1/(L+1)^{P}) $时, 可得:
$$ \begin{split} & \|{\boldsymbol{e}}_{L}^{*}\|_{ \text{F}}^{2}-(r+\mu_{L})\|{\boldsymbol{e}}_{L-1}^{*}\|_{ \text{F}}^{2}< \\ &\quad\quad \|{\boldsymbol{e}}_{L}^{*}\|_{ \text{F}}^{2}-r\|{\boldsymbol{e}}_{L-1}^{*}\|_{ \text{F}}^{2} = \\ &\quad\quad\|{\boldsymbol{e}}_{L}^{*}\|_{ \text{F}}^{2}-\left(1-\text{ln}\left(1+\frac{1}{{(L+1)}^{P}}\right)\right)\|{\boldsymbol{e}}_{L-1}^{*}\|_{ \text{F}}^{2}< \\ &\quad\quad\|{\boldsymbol{e}}_{L}^{*}\|_{ \text{F}}^{2}-\left(1-\frac{1}{{L+1}}\right)\|{\boldsymbol{e}}_{L-1}^{*}\|_{ \text{F}}^{2} < \\ &\quad\quad\prod\limits_{i=1}^{L}\left(1-\frac{1}{i+1}\right)\|{\boldsymbol{e}}_{0}\|_{ \text{F}}^{2} \leq \\ &\quad\quad\text{exp}\left(-\sum\limits_{i=1}^{L}\frac{1}{i+1}\right)\|f\|_{ \text{F}}^{2}\\[-15pt] \end{split} $$ (12) 所以, 当$ {L\to +\infty} $时, $\lim_{L\to +\infty}\,\text{exp}(-\sum\nolimits_{i=\text{1}}^{L}{\frac{1}{i+1}})\text{=0}$, 于是$ \lim_{L\to +\infty}\,\|{\boldsymbol{e}}_{L}^{*}\|_{ \text{F}}^{\text{2}}\text{=0} $, 即$ \lim_{L\to +\infty}\,\|{\boldsymbol{e}}_{L}^{*}\|_{ \text{F}}=0 $.
□ 2.2 矩阵弹性网
从信息处理的角度来看, 炉温与烟气含氧量以不同的视角展现了炉内固废的焚烧状态, 利用炉温与烟气含氧量之间的相关性进行建模可以充分挖掘建模数据中的隐含信息; 从机器学习归纳偏置的角度来看, 多目标建模倾向于获得可以同时处理多个相关任务的解决方案, 这有利于降低模型过拟合的风险[24-25]. 由于炉温与烟气含氧量多目标建模共享同一组输入特征且输出之间具有关联性, 这使得预测模型的参数具有稀疏性. 因此, 将炉温与烟气含氧量间的相关性假设转化为对SCN模型输出权值的稀疏约束可进一步提升建模质量.
向目标函数中引入由$ L_{1} $范数与$ L_{2} $范数正则项组合构成的矩阵弹性网[26], 可让学习到的模型参数具有稀疏性且模型泛化性能较好, 但包含$ L_{1} $正则项的目标函数一般无法直接进行参数求导, 使得模型参数的优化求解比较困难. 相对于$ L_{1} $范数与$ L_{2} $范数而言, $ L_{2,1} $范数首先求矩阵每一行的$ L_{2} $范数, 再将得到的结果求$ L_{1} $范数[27], 将基于$ L_{2,1} $范数的正则项加入目标函数中也可保证模型参数具有良好的稀疏性[28-29]且便于参数求导, $ L_{2,1} $范数正则项已广泛用于机器学习[30]、模式识别[31]等领域中. SCN在进行多目标建模时, 输出权值$ {\boldsymbol{\beta}} $为矩阵形式, 其对应于向量空间的$ L_{2} $范数称为F范数[29]. 因此, 本节采用F范数与$ L_{2,1} $范数正则项构建矩阵弹性网对SCN模型的输出权值进行稀疏约束, 以建模炉温与烟气含氧量之间的相关性. 输出权值$ {\boldsymbol{\beta}} $的$ L_{2,1} $范数计算公式如下所示:
$$ \begin{align} {\| {\boldsymbol \beta}\|}_{2,1}=\sum\limits_{i=1}^{L}{\sqrt{\sum\limits_{j=1}^{m}{{\boldsymbol \beta} _{ij}^{2}}}} \end{align} $$ (13) 其中, $ {{\left\| \,\cdot \, \right\|}_{\text{2,1}}} $表示矩阵的$ L_{2,1} $范数. 此时, 输出权值$ {\boldsymbol \beta} $的目标函数可表示为:
$$ \begin{split} J({\boldsymbol{\beta}})=\;& \frac{1}{2}\| {{\boldsymbol{H}}_{L}}{\boldsymbol{\beta}}-{\boldsymbol{Y}} \|_{ \text{F}}^{2}\;+ \\ &\lambda \left(\alpha {{\| {\boldsymbol{\beta}} \|}_{2,1}}+ \frac{1-\alpha }{2}\| {\boldsymbol{\beta}} \|_{ \text{F}}^{2}\right) \end{split} $$ (14) 其中, $ \lambda $与$ \alpha $表示正则化系数. 令$ \frac{\partial J({\boldsymbol{\beta}})}{\partial {\boldsymbol{\beta}}}=0 $, 可得:
$$ \begin{align} {\boldsymbol{H}}_{L}^{\text{T}}{\boldsymbol{H}}_{L}{\boldsymbol{\beta}}+\lambda \alpha \frac{\partial \|{\boldsymbol{\beta}}\|_{2,1}}{\partial {\boldsymbol{\beta}}}+\lambda (1-\alpha ){\boldsymbol{\beta}}={\boldsymbol{H}}_{L}^{\text{T}}{\boldsymbol{Y}} \end{align} $$ (15) 其中, $ \frac{\partial {{\|{\boldsymbol{\beta}} \|}_{2,1}}}{\partial {\boldsymbol{\beta}}} $可表示为[28]:
$$ \begin{split} \frac{\partial {\|{\boldsymbol{\beta}}\|_{2,1}}}{\partial {\boldsymbol{\beta}}}= \text{diag } \left\{\frac{1}{{{\| {{\boldsymbol{\beta}}_{1}} \|}_{2}}}, \cdots, \frac{1}{\| {{\boldsymbol{\beta}}_{L}}\|}_{2}\right\} {\boldsymbol{\beta}}={\boldsymbol{U}}{\boldsymbol{\beta}} \end{split} $$ (16) 其中, $ {\boldsymbol{U}} $表示系数矩阵; ${\boldsymbol{\beta}}_L$表示输出权值$ {\boldsymbol{\beta}} $的第$ L $个行向量; $ \|\cdot\|_{2} $表示向量的$ L_{2} $范数. 综合式(15)、式(16), 输出权值$ {\boldsymbol{\beta}} $迭代求解的表达式如下所示:
$$ \begin{split} {\boldsymbol{\beta}}^{*(t+1)}=\;& [{\boldsymbol{H}}_{L}^{\text{T}}{{{\boldsymbol{H}}}_{L}}+\lambda \alpha {{{\boldsymbol{U}}}^{(t+1)}}\;+\\ &\lambda (1-\alpha ){\boldsymbol{I}}]^{-1}{\boldsymbol{H}}_{L}^{\text{T}}{\boldsymbol{Y}} \end{split} $$ (17) $$ \begin{split} {\boldsymbol{U}}^{(t+1)}= \text{diag } \left\{\frac{1}{{{\| {{\boldsymbol{\beta}}_{1}^{(t)}} \|}_{2}}}, \cdots, \frac{1}{\| {{\boldsymbol{\beta}}_{L}^{(t)}}\|}_{2}\right\} \end{split} $$ (18) 其中, I表示单位矩阵. 迭代终止条件如下所示:
$$ \begin{align} \|{\boldsymbol{\beta}}^{*(t+1)}-{\boldsymbol{\beta}}^{*(t)}\|_{ \text{F}} < \kappa \end{align} $$ (19) 其中, $ \kappa $表示趋于$ 0 $的正实数, 本文取$ 10^{-3} $.
2.3 鲁棒建模
当训练数据中的噪声或离群点为非高斯分布时, 基于最小二乘算法求解的模型参数并不具备鲁棒性[32]. 由于Laplace分布具有良好的尖锋、重尾特性, 因此其常被作为噪声或离群点的先验分布[33-34], 但实际生产环境中的噪声十分复杂, 采用混合概率分布作为噪声的先验分布可以提升模型的鲁棒性[35]. 为避免异常数据对SCN模型准确性的负面影响, 本节采用混合Laplace分布作为每个目标建模误差的先验分布, 并通过最大后验估计来优化SCN模型的输出权值.
根据文献[36], 通过引入潜变量$ v $, Laplace分布可以写成高斯分布与指数分布的乘积形式, 如下所示:
$$ \begin{split} &{\cal{L}}(x,v|\mu ,\sigma )={\cal{N}}(x|v,\mu ,\sigma ){\cal{G}}(v)=\\ &\quad\quad\frac{1}{{{v}^{2}}\sigma \sqrt{\pi}}\exp \left(-\frac{{{v}^{2}}{{(x-\mu )}^{\text{2}}}}{{{\sigma }^{2}}}-\frac{1}{2{{v}^{\text{2}}}}\right) \end{split} $$ (20) 其中, $ \mu $与$ \sigma $分别表示高斯分布的均值与标准差. $ {\cal{N}}(x|v,\mu ,\sigma) $与$ {\cal{G}}(v) $的表达式为:
$$ \begin{align} {\cal{N}}(x|v,\mu ,\sigma )=\frac{v}{\sigma \sqrt{\pi}}\exp \left(-\frac{{{v}^{\text{2}}}{{(x-\mu )}^{\text{2}}}}{{{\sigma }^{\text{2}}}}\right) \end{align} $$ (21) $$ \begin{align} {\cal{G}}(v)=\frac{\text{1}}{{{v}^{\text{3}}}}\exp \left(-\frac{\text{1}}{\text{2}{{v}^{\text{2}}}}\right) \end{align} $$ (22) 对于给定的训练数据集${\boldsymbol{D}}=\{{\boldsymbol{X}},{\boldsymbol{y}}\}= \{({{{\boldsymbol{x}}}_{n}}, {{y}_{n}})\}_{n=1}^{N}$, SCN模型的预测值$ {{\hat{y}}_{n}} $与真实值$ y_{n} $之间的关系可表示为:
$$ \begin{align} y_{n}^{{}}=\hat{y}_{n}+\varepsilon_{n}={\boldsymbol{h}}({{{\boldsymbol{x}}}_{n}}){\boldsymbol{\beta}}+\varepsilon_{n} \end{align} $$ (23) 其中, $ \varepsilon_{n} $表示建模误差. 假设$ \varepsilon_{n} $服从混合Laplace分布, 其概率分布可表示为:
$$ \begin{align} p(\varepsilon )=\sum\limits_{k=\text{1}}^{K}{{{\omega }_{k}}{\cal{L}}(\varepsilon |\text{0},{{\sigma }_{k}})} \end{align} $$ (24) 其中, $ k=1, 2, \cdot\cdot\cdot, K $; $ K $表示混合Laplace分布的数量; $ {\boldsymbol{\omega}}=\{{\omega}_{1}, {\omega}_{2},\cdot\cdot\cdot,{\omega}_{K}\} $表示混合Laplace分布的权值, $ {\omega}_{k} \geq0 $且$ \sum\nolimits_{k\text{=1}}^{K}{\omega}_{k}=\text{1} $; ${\boldsymbol{\sigma}}=\{\sigma_{1}, \sigma_{2},\cdot\cdot\cdot, \sigma_{K}\}$表示混合Laplace分布的参数. 此时, $ y_{n} $的概率分布可表示为:
$$ \begin{align} p({{y}_{n}}|{{{\boldsymbol{x}}}_{n}},{\boldsymbol{\beta}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}})=\sum\limits_{k=\text{1}}^{K}{{{\omega}_{k}}{\cal{L}}({{y}_{n}}|{\boldsymbol{h}}({{{\boldsymbol{x}}}_{n}}){\boldsymbol{\beta}},{{\sigma }_{k}})} \end{align} $$ (25) 令$ {\boldsymbol{v}}=\{{{v}_{n}}\}_{n=1}^{N} $, 基于新数据集$ {\boldsymbol{R}}=\{{{\boldsymbol{X}}, {\boldsymbol{y}}, {\boldsymbol{v}}}\} $, 式(25)可以改写为:
$$ \begin{split} &p({{y}_{n}},{{v}_{n}}|{\boldsymbol{X}},{\boldsymbol{\beta}}, {\boldsymbol{\omega}},{\boldsymbol{\sigma}})= \\ &\quad\quad\sum\limits_{k=\text{1}}^{K}{{{\omega }_{k}}{\cal{L}}({{y}_{n}},{{v}_{n}}|{\boldsymbol{h}}({{{\boldsymbol{x}}}_{n}}){\boldsymbol{\beta}} ,{{\sigma}_{k}})} \end{split} $$ (26) 假设$ {\boldsymbol{R}} $中的数据均为独立同分布, 其似然函数可表示为:
$$ \begin{split} &p({\boldsymbol{y}},{\boldsymbol{v}}|{\boldsymbol{X}},{\boldsymbol{\beta}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}})=\\ &\quad\quad\prod\limits_{n=\text{1}}^{N}{\sum\limits_{k=\text{1}}^{K}{{\omega }_{k}}{\cal{L}}({{y}_{n}},{{v}_{n}}|{\boldsymbol{h}}({{{\boldsymbol{x}}}_{n}}){\boldsymbol{\beta}},{\sigma}_{k})} \end{split} $$ (27) 此外, 假设每个目标的输出权值服从高斯分布[35]:
$$ \begin{align} p({\boldsymbol{\beta}}|{\sigma}_{\boldsymbol{\beta}}^{\text{2}})=\frac{\text{1}}{{{({2}\pi\sigma _{\boldsymbol{\beta}}^{\text{2}})}^{L/\text{2}}}}\exp \left(-\frac{{{\| {\boldsymbol{\beta}}\|}_{2}^{\text{2}}}}{\text{2}\sigma _{\boldsymbol{\beta}}^{\text{2}}}\right) \end{align} $$ (28) 基于贝叶斯理论, 输出权值$ {\boldsymbol{\beta}} $的后验分布可表示为:
$$ \begin{align} p({\boldsymbol{\beta}}|{\boldsymbol{R}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2})\propto p({\boldsymbol{y}},{\boldsymbol{v}}|{\boldsymbol{X}},{\boldsymbol{\beta}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}})p({\boldsymbol{\beta}}{ }|\sigma_{\boldsymbol{\beta}}^{2}) \end{align} $$ (29) 对上式两边取对数可得:
$$ \begin{split} &\ln p({\boldsymbol{\beta}}|{\boldsymbol{R}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2})= \\ &\quad\quad\ln p({\boldsymbol{y}},{\boldsymbol{v}}|{\boldsymbol{X}},{\boldsymbol{\beta}},{\boldsymbol{\omega}}, {\boldsymbol{\sigma}})+\ln p({\boldsymbol{\beta}}|\sigma_{\boldsymbol{\beta}}^{2})+\text{c} \end{split} $$ (30) 其中, $ \text{c} $表示常数. 参数$ \{{\boldsymbol{\beta}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2}\} $可通过EM算法[37]计算式(31)的最大后验估计获得:
$$ \begin{split} &{\{\boldsymbol{\beta}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2}\}^{*}=\\ &\quad\quad{\text{arg}}\underset{{\boldsymbol{\beta}},{\boldsymbol{\omega}} ,{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2}}{\text{max}}\,\{\text{ln}\; p({\boldsymbol{\beta}}|{\boldsymbol{R}},{\boldsymbol{\omega}} ,{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2})\} \end{split} $$ (31) EM算法求解式(31)主要包括E-step与M-step两步, 如下所示:
E-step:
通过引入潜变量$ {{\boldsymbol{z}}}_{n}=\{z_{kn}\}_{k=1}^{K} $, 在完整数据集$ {\boldsymbol{G}}=\{{\boldsymbol{X}}, {\boldsymbol{y}}, {\boldsymbol{v}}, {\boldsymbol{z}}\} $下, 式(27)可改写为:
$$ \begin{split} &p({\boldsymbol{y}},{\boldsymbol{v}},{\boldsymbol{z}}|{\boldsymbol{X}},{\boldsymbol{\beta}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}}) = \\ &\quad\quad\prod\limits_{n=\text{1}}^{N}{\prod\limits_{k=\text{1}}^{K}{{{[{{\omega }_{k}}{\cal{L}}({{y}_{n}},{{v}_{n}}|{\boldsymbol{h}}({{\boldsymbol{x}}_{n}}){\boldsymbol{\beta}},{{\sigma}_{k}})]}^{{{z}_{kn}}}}}} \end{split} $$ (32) 于是, 式(30)可改写为:
$$ \begin{split} &\ln p({\boldsymbol{\beta}}|{\boldsymbol{G}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2})=\\ &\quad\quad\ln p({\boldsymbol{y}},{\boldsymbol{v}},{\boldsymbol{z}}|{\boldsymbol{X}},{\boldsymbol{\beta}}, \boldsymbol{{\omega}},{\boldsymbol{\sigma}})+\ln p({\boldsymbol{\beta}}|\sigma_{\boldsymbol{\beta}}^{2})+\text{c} \end{split} $$ (33) 综合式(28)与式(32), 式(33)的对数似然函数期望可表示为(省去了与参数$ \{{\boldsymbol{\beta}} ,{\boldsymbol{\omega}} ,{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2}\} $无关项):
$$ \begin{split} &\text{E}[\ln p({\boldsymbol{\beta}}|{\boldsymbol{G}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}}, \sigma_{\boldsymbol{\beta}}^{2})|{\boldsymbol{D}}]=\\ &\qquad \sum\limits_{n=1}^{N}\sum\limits_{k=1}^{K}\left\{\text{E}[{{z}_{kn}}|({{{\boldsymbol{x}}}_{n}},{y_{n}})](\ln {\omega}_{k}-\frac{1}{2}\ln\sigma _{k}^{2})\right\} - \\ &\qquad \sum\limits_{n=\text{1}}^{N}{\sum\limits_{k=\text{1}}^{K}{\Bigg\{\text{E}[{{z}_{kn}}|({{{\boldsymbol{x}}}_{n}},{{y}_{n}})]}}\;\times\end{split} $$ $$ \begin{align} \begin{split} &\qquad\frac{\text{E}[v_{n}^{\text{2}}|({{{\boldsymbol{x}}}_{n}}, {{y}_{n}})]{{({{y}_{n}}-{\boldsymbol{h}}({{{\boldsymbol{x}}}_{n}}){\boldsymbol{\beta}})}^{2}}}{\sigma_{k}^{2}}\Bigg\} - \\ &\qquad\frac{L}{\text{2}}\ln \sigma _{\boldsymbol{\beta}}^{2}-\frac{{{\| {\boldsymbol{\beta}}\|}_{2}^{2}}}{2\sigma_{\boldsymbol{\beta}}^{2}}+{{\text{c}}_{1}} \end{split} \end{align} $$ (34) 其中, $ \text{E}[\cdot] $表示期望算子; $ \text{c}_{1} $表示常数. $ \text{E}[{{z}_{kn}}|({{{\boldsymbol{x}}}_{n}},{{y}_{n}})] $与$ \text{E}[v_{n}^{2}|({{{\boldsymbol{x}}}_{n}},{{y}_{n}})] $的计算公式如下所示[36-37]:
$$ \begin{split} {{\gamma }_{kn}}=\;& \text{E}[{{z}_{kn}}|({{{\boldsymbol{x}}}_{n}},{{y}_{n}})]=\\ &\frac{{{\omega }_{k}}{\cal{L}}({{y}_{n}}|{\boldsymbol{h}}({{\boldsymbol{x}}_{n}}){\boldsymbol{\beta}},{{\sigma }_{k}})}{\sum\limits_{k=1}^{K}{{{\omega }_{k}}{\cal{L}}({{y}_{n}}|{\boldsymbol{h}}({{{\boldsymbol{x}}}_{n}}){\boldsymbol{\beta}},{{\sigma}_{k}})}} \end{split} $$ (35) $$ \begin{align} \begin{aligned} {{\chi }_{kn}}= \text{E}[v_{n}^{2}|({{{\boldsymbol{x}}}_{n}},{{y}_{n}})]=\frac{{{\sigma}_{k}}}{\sqrt{2}| {{y}_{n}}-{\boldsymbol{h}}({{{\boldsymbol{x}}}_{n}}){\boldsymbol{\beta}}|} \end{aligned} \end{align} $$ (36) 其中, $ {\gamma }_{kn} $与$ {\chi}_{kn} $分别表示$ {z}_{kn} $与$ v_{n}^{2} $的期望.
M-step:
令$ \frac{\partial \text{E}[\ln p({\boldsymbol{\beta}}|{\boldsymbol{G}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2})|{\boldsymbol{D}}]}{\partial \{{\boldsymbol{\beta}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}}, \sigma_{\boldsymbol{\beta}}^{2}\}}=0 $, 参数$ \{{\boldsymbol{\beta}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2}\} $的更新公式如下所示:
$$ \begin{align} \omega _{k}^{(l+1)}=\frac{\sum\limits_{n=1}^{N}{\gamma _{_{kn}}^{(l)}}}{N} \end{align} $$ (37) $$ \begin{align} \sigma _{k}^{(l+\text{1)}}=\sqrt{\frac{\text{2}\sum\limits_{n=\text{1}}^{N}{\gamma _{kn}^{(l)}\chi _{kn}^{(l)}{{({{y}_{n}}-{\boldsymbol{h}}({{{\boldsymbol{x}}}_{n}}){{\boldsymbol{\beta}}^{(l)}})}^{\text{2}}}}}{\sum\limits_{n=\text{1}}^{N}{\gamma _{kn}^{(l)}}}} \end{align} $$ (38) $$ \begin{align} \sigma_{\boldsymbol{\beta}}^{\text{2}(l+\text{1)}}=\frac{{{\| {{\boldsymbol{\beta}}^{(l)}}\|}_{2}^{\text{2}}}}{L} \end{align} $$ (39) $$ {{\boldsymbol{\beta}}^{(l+\text{1})}}={{[{{{\boldsymbol{H}}}^{\text{T}}}({\boldsymbol{X}}){{{{\boldsymbol{\Phi}}}}^{(l+\text{1})}}{\boldsymbol{H}}({\boldsymbol{X}})+{\boldsymbol{I}}]}^{-\text{1}}} {{{\boldsymbol{H}}}^{\text{T}}} ({\boldsymbol{X}}){{{{\boldsymbol{\Phi}}}}^{(l+\text{1})}}{\boldsymbol{y}} $$ (40) $$ \begin{align} {{\phi }^{(l+{1})}}={2}\sigma _{\boldsymbol{\beta}}^{\text{2}}\sum\limits_{k={1}}^{K}{\frac{\gamma _{kn}^{(l+{1})}\chi _{kn}^{(l+{1})}}{\sigma{{_{k}^{{2}}}^{(l+\text{1})}}}} \end{align} $$ (41) 其中, $ {{{{\boldsymbol{\Phi}}}}^{(l+{1})}}=\text{diag}\{\phi_{n}^{(l+{1})}\}_{n={1}}^{N} $表示惩罚矩阵. EM算法的收敛条件如下所示:
$$ \left|{\frac{\text{E}[\ln p({{\boldsymbol{\beta}}^{(l+1)}}|{\boldsymbol{G}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}}, \sigma_{\boldsymbol{\beta}}^{2})|{\boldsymbol{D}}]}{\text{E}[\ln p({{\boldsymbol{\beta}}^{(l)}}|{\boldsymbol{G}},{\boldsymbol{\omega}},{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^{2})|{\boldsymbol{D}}]}-{1} }\right |<\kappa $$ (42) 2.4 MRI-SCN算法伪代码
基于上述, 本节给出MRI-SCN算法伪代码, 如下所示:
算法 1. MRI-SCN算法伪代码
输入. 训练集$ {\boldsymbol{D}}=\{{\boldsymbol{X}},{\boldsymbol{Y}}\}=\{{\boldsymbol{x}}_{n}, {\boldsymbol{y}}_{n}\}_{n=1}^N. $
输出. MRI-SCN模型与参数$ {\boldsymbol{\beta}}^*,{\boldsymbol{w}}^*,{b}^{*},{{\boldsymbol{q}}^*} $.
1) 设置隐含层最大节点数量$ L_{\text{max}} $, 最大配置次数$ T_{\text{max}} $, 容忍误差$ \tau $, 隐含层参数选择区间$ \Upsilon $, 正则化系数$ \lambda $与$ \alpha $, 约束参数$ P $, 混合Laplace分布数量$ K $以及参数$ \{{\boldsymbol{\omega}},{\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^2\} $;
2) 初始化$ {{\boldsymbol{e}}_0 ={[{\boldsymbol{y}}_1, {\boldsymbol{y}}_2,\cdot\cdot\cdot, {\boldsymbol{y}}_N]}^{\rm T}, {{\Omega}}, {\boldsymbol{Q}}, {\boldsymbol{W}}= [\; ];} $
3) while $ L\leq L_{\text{max}} \ \text{and }\ \|{\boldsymbol{e}}_0\|_{ \text{F}}>\tau $ do
4) 在区间$ \Upsilon $内随机生成权值$ {\boldsymbol{w}}_k $, $ {\boldsymbol{q}}_k $与偏置$ b_k $;
5) 根据式(2), 式(6) ~ 式(8)计算$ \xi_L $, 分别将$ {\boldsymbol{w}}_L $, $ b_L $存入$ {\boldsymbol{W}} $, 将$ {\boldsymbol{q}}_L $存入$ {\boldsymbol{Q}} $, 将$ \xi_L $存入$ {{\Omega}} $;
6) 将$ {{\Omega}} $中$ \xi_L $最大值对应的$ {\boldsymbol{w}}_L^* $, $ b_L^* $, $ {\boldsymbol{q}}_L^* $作为新增节点参数, 并令$ {\boldsymbol{H}}_L=[{\boldsymbol{h}}_1^*,{\boldsymbol{h}}_2^{*},\cdot\cdot\cdot ,{\boldsymbol{h}}_L^*] $;
7) 根据式(4)计算输出权值${\boldsymbol{\beta}}^*$;
8) while 式(19)所示条件未被满足 do
9) 根据式(17)、式(18)更新$ {\boldsymbol{\beta}}^* $与$ {\boldsymbol{U}} $;
10) end while
11) 更新$ {\boldsymbol{e}}_0 ={\boldsymbol{H}}_L{\boldsymbol{\beta}}^*-{\boldsymbol{Y}}, L=L+1 $;
12) end while
13) for $ i=1 $ to $ m $ do
14) while 式(42)所示条件未被满足 do
15) E-step: 根据式(35)、式(36)计算$ \gamma_{kn} $与$ \chi_{kn} $;
16) M-step: 根据式(37) ~ 式(39)计算参数$ \{{\boldsymbol{\omega}}, $ ${\boldsymbol{\sigma}},\sigma_{\boldsymbol{\beta}}^2\} $;
17) 根据式(40)、式(41)更新$ {\boldsymbol{\beta}}^{*} $与$ {{{\boldsymbol{\Phi}}}} $;
18) end while
19) end for
20) 返回MRI-SCN模型与参数$ {\boldsymbol{\beta}}^{*},{\boldsymbol{w}}^{*},{b}^{*},{{\boldsymbol{q}}}^{*} $.
3. 实验测试与结果分析
为便于表述, 将2.1节改进的方法记为I-SCN, 将2.1节与2.2节共同改进的方法记为MI-SCN. 实验数据来自北京市某固废焚烧厂2021年的历史运行数据, 分别从春、夏、秋、冬4个季节中选取, 从而获得4组数据集. 每组数据集中训练集的样本数量为1000, 验证集与测试集的样本数量均为200, 样本采样时间为1 min. 所有数据均归一化至[0, 1] 区间内. 本节实验主要包括3部分: 实验一是在原始数据集上, 将MRI-SCN与误差反传网络(BP)、径向基神经网络(RBF)、随机向量函数链网络(RVFL)[11] 以及多输出最小二乘支持向量回归机(MLS-SVR)[38] 等不同类型的建模方法进行对比实验; 实验二是在原始数据集上, 将MRI-SCN与多目标SCN (MT-SCN)[39], 混合高斯−拉普拉斯分布的鲁棒SCN (MoGL-SCN)[35]、MI-SCN以及SCN等同类型的建模方法进行对比实验; 实验三是在实验二的基础上, 向训练集中引入比例为$ \zeta =\{10\%, 15\%, 20\%, 25\%, 30\%\} $的异常值, 即将所选样本对应的输出替换为[−0.5, 1.5] 上的随机数, 从而获得4组噪声数据集以验证MRI-SCN在不同异常值比例下的建模性能. 每种方法独立运行30次, 采用平均均方根误差(Average root mean squared error, aRMSE)、平均绝对误差(Mean absolute error, MAE) 以及平均确定系数(Average $ \text{R}^2 $, $ \text{aR}^2 $) 评价模型性能, 计算公式如下所示:
$$ \begin{align} \text{aRMSE}=\frac{1}{m}\sum\limits_{i=1}^{m}{\sqrt{\frac{\sum\limits_{j=1}^ {{{N}_{\text{t}}}}{{{(y_{ij}^{{}}-\hat{y}_{ij}^{{}})}^{2}}}}{{{N}_{\text{t}}}}}}\times 100\% \end{align} $$ (43) $$ \begin{align} \text{MAE}=\frac{1}{m}\sum\limits_{i=1}^{m}{\frac{\sum\limits_{j=1}^ {{{N}_{\text{t}}}}{\left| y_{ij}^{{}}-\hat{y}_{ij}^{{}} \right|}}{{{N}_{\text{t}}}}}\times 100\% \end{align} $$ (44) $$ \begin{align} \text{a}{{\text{R}}^{\text{2}}}=\frac{1}{m}\sum\limits_{i=1}^{m}\left(1-\frac{\sum\limits_{j=1}^ {{{N}_{\text{t}}}}{{{({{y}_{ij}}-{{{\hat{y}}}_{ij}})}^{2}}}}{\sum\limits_{j=1}^ {{{N}_{\text{t}}}}{{{({{y}_{ij}}-{{{\bar{y}}}_{ij}})}^{2}}}}\right)\times 100\% \end{align} $$ (45) 其中, $ N_{\text{t}} $表示测试集数量; $ {y}_{ij} $表示真实值; $ {\hat{y}}_{ij} $表示预测值; $ {{\bar{y}}_{ij}} $表示$ {{y}_{ij}} $的均值.
实验参数设置如下: 在实验一中, BP的训练次数为200, 学习率为0.01; RBF采用MATLAB工具箱中的newrb函数实现, 隐含层最大节点数量$ L_{\text{max}}=60 $, 其余参数默认设置; RVFL隐含层参数区间$ \Upsilon=1 $; MLS-SVR的正则化参数在区间$ [2^{-10:1:10}]\; $内选择. 每种建模方法的容忍误差$ \tau =10^{-3} $, BP与RVFL的隐含层最大节点数量与RBF一致, 激活函数为sigmoid. 在实验二中, 最大配置次数$ T_{\text{max}}=50 $, 隐含层参数区间$ \Upsilon=[1:1:10] $, 隐含层最大节点数量、激活函数以及容忍误差与实验一保持一致; MT-SCN的正则化参数选择区间与MLS-SVR一致; MRI-SCN与MI-SCN的正则化参数$ \lambda=2^{-5} $、$ \alpha=0.2 $, 约束参数$ P=10 $; MRI-SCN与MoGL-SCN的混合分布数量$ K=3 $, 对应的权重与分布参数分别为$ \omega_{1}=0.40,\; \omega_{2}=0.30,\; \omega_{3}=0.30,\; \sigma_{1}= 0.10,\; \sigma_{2}=0.13,\; \sigma_{3}=0.12 $, $ \sigma_{\boldsymbol{\beta}}^{2}=0.15 $. 在实验三中, MRI-SCN与MI-SCN的正则化参数$ \lambda=1.00 $、$ \alpha=0.4 0$, 其余参数设置保持不变. 以上超参数由验证集获得.
表1与表2统计了MRI-SCN与其他建模方法在原始数据集上的实验结果. 从表1中可以看出, MLS-SVR与MRI-SCN通过对模型参数进行稀疏约束, 利用多目标间的相关性提升了建模精度, 但MLS-SVR未考虑到异常数据对模型性能的负面影响, 所以其模型精度低于MRI-SCN. 从表2中可以看出, 由于SCN未利用多目标间相关性且对训练集中的正常样本与异常样本进行无差别学习, 所以MT-SCN、MoGL-SCN等建模方法的表现均优于SCN. 综合对比表1与表2可知, 与BP、RBF相比, SCN的预测精度相对较高; 与RVFL相比, SCN通过监督不等式选择优质节点添加至隐含层, 从而提升了建模质量. 而MRI-SCN在进行多目标建模的同时兼顾模型鲁棒性, 其在3个评价指标上的表现均优于其他对比方法, 以春季数据集为例, MRI-SCN在aRMSE评价指标上比RVFL、MLS-SVR分别下降31.43%、8.50%; 比SCN、MT-SCN、MoGL-SCN分别下降14.99%、9.83%、13.57%.
表 1 MRI-SCN与不同类型建模方法在原始数据集上的对比实验结果Table 1 Results of experiments comparing MRI-SCN with the different type of modeling methods on the original dataset数据集 BP RBF RVFL MLS-SVR MRI-SCN 春季 5.80; 4.57; 86.57 5.40; 3.74; 89.14 4.55; 3.59; 92.36 3.41; 2.38; 95.70 3.12; 2.34; 96.38 夏季 5.63; 4.33; 87.48 4.85; 3.75; 91.49 4.60; 3.63; 92.14 3.37; 2.52; 95.90 3.16; 2.26; 96.25 秋季 5.39; 4.27; 89.03 4.92; 3.73; 91.25 4.52; 3.55; 92.44 3.44; 2.69; 95.41 3.08; 2.31; 96.48 冬季 5.30; 4.19; 89.93 5.72; 4.42; 89.14 4.96; 3.91; 91.46 3.52; 2.53; 95.61 3.10; 2.33; 96.68 表 2 MRI-SCN 与同类型建模方法在原始数据集上的对比实验结果Table 2 Results of experiments comparing MRI-SCN with the same type of modeling methods on the original dataset数据集 SCN MI-SCN MT-SCN MoGL-SCN MRI-SCN 春季 3.67; 2.86; 95.07 3.45; 2.64; 95.62 3.46; 2.67; 95.59 3.61; 2.68; 94.50 3.12; 2.34; 96.38 夏季 3.70; 2.80; 95.40 3.43; 2.55; 95.65 3.32; 2.57; 95.84 3.40; 2.67; 95.63 3.16; 2.26; 96.25 秋季 3.63; 2.73; 95.17 3.31; 2.56; 95.91 3.34; 2.61; 95.92 3.52; 2.76; 95.42 3.08; 2.31; 96.48 冬季 3.74; 2.94; 95.23 3.56; 2.73; 95.33 3.49; 2.81; 95.84 3.55; 2.31; 95.82 3.10; 2.33; 96.68 为测试不同范数约束对模型性能的影响, 以2.1节改进的方法I-SCN为基础, 将F范数约束的I-SCN记为I-SCN-F, 将$ L_{2,1} $范数约束的I-SCN记为I-SCN-L21, MI-SCN则表示F范数与$ L_{2,1} $范数共同约束的I-SCN. 由图3可知, 相对于F范数约束, $ L_{2,1} $范数约束由于具有稀疏性, 其利用炉温与烟气含氧量间的相关性来提升模型质量, 所以I-SCN-L21的建模精度高于I-SCN-F. 而将上述两种范数约束相结合构成矩阵弹性网, 可使模型输出权值具有稀疏性且相对较小, 从而进一步降低了模型过拟合的风险, 所以MI-SCN的预测精度相对较高.
 图 3 不同范数约束在原始数据集上的实验结果Fig. 3 Results of experiments with different paradigm constraints on the original dataset
图 3 不同范数约束在原始数据集上的实验结果Fig. 3 Results of experiments with different paradigm constraints on the original dataset为进一步验证MRI-SCN的鲁棒性, 表3统计了SCN、MI-SCN、MT-SCN、MoGL-SCN以及MRI-SCN等建模方法在4组噪声数据集上的实验结果. 由表3可知, 由于SCN对正常样本与异常样本进行无差别学习, 所以模型质量相对较差. MI-SCN与MT-SCN利用炉温与烟气含氧量间的相关性来提升模型精度, 所以它们的建模性能均优于SCN. 但随着异常值比例的增加, MI-SCN与MT-SCN的模型性能退化较大, 缺乏鲁棒性. 虽然MoGL-SCN采用基于混合分布的建模策略提升了模型鲁棒性, 但其未利用多目标间的相关性来提升建模精度, 而MRI-SCN利用矩阵弹性网将炉温与烟气含氧量间的相关性假设转化为对模型参数的稀疏约束, 并在此基础上利用混合Laplace分布作为每个目标建模误差的先验分布, 通过最大后验估计优化模型输出权值, 从而有效提升了模型精度与鲁棒性, 所以MRI-SCN在4组噪声数据集上的表现优于其他对比方法.
表 3 四组噪声数据集上的实验结果Table 3 Results of experiments on the four noisy datasets数据集 $ \zeta $ SCN MI-SCN MT-SCN MoGL-SCN MRI-SCN 10% 6.62; 5.15; 83.95 5.80; 4.57; 87.67 5.59; 4.40; 88.55 3.86; 2.87; 94.43 3.65; 2.74; 95.07 15% 7.59; 5.97; 78.84 6.39; 5.07; 84.97 6.35; 5.05; 85.16 4.00; 2.95; 94.02 3.87; 2.89; 94.45 春季 20% 8.96; 7.11; 70.38 7.33; 5.80; 80.14 7.36; 5.88; 79.99 4.26; 3.11; 93.21 4.03; 3.02; 93.95 25% 10.38; 8.05; 60.18 8.26; 6.46; 74.83 8.58; 6.74; 72.80 4.48; 3.26; 92.53 4.34; 3.24; 92.95 30% 11.17; 8.71; 53.98 8.70; 6.86; 72.21 9.40; 7.41; 67.46 4.82; 3.50; 91.25 4.56; 3.38; 92.28 10% 6.31; 4.90; 85.43 5.77; 4.56; 87.74 5.50; 4.30; 88.88 4.00; 2.93; 93.81 3.76; 2.78; 94.66 15% 7.38; 5.71; 79.98 6.48; 5.13; 84.56 6.24; 4.89, 85.75 4.38; 3.14; 92.66 3.96; 2.92; 94.07 夏季 20% 8.91; 7.00; 70.13 7.45; 5.94; 79.13 7.49; 5.96; 78.73 4.38; 3.17; 92.55 4.22; 3.13; 93.10 25% 9.40; 7.48; 66.62 7.89; 6.34; 76.58 7.93; 6.35; 76.22 4.68; 3.33; 91.83 4.45; 3.27; 92.43 30% 10.39; 8.21; 59.58 8.61; 6.90; 72.39 8.85; 7.09; 70.72 5.08; 3.65; 89.94 4.65; 3.41; 91.83 10% 6.40; 5.04; 85.18 5.98; 4.79; 86.83 5.57; 4.43; 88.69 3.73; 2.75; 94.76 3.46; 2.60; 95.53 15% 7.33; 5.72; 80.40 6.33; 5.01; 85.27 6.10; 4.78; 86.37 3.80; 2.80; 94.63 3.61; 2.72; 95.11 秋季 20% 8.90; 6.85; 71.15 7.19; 5.66; 80.85 7.40; 5.74; 79.96 4.03; 2.95; 94.02 3.86; 2.88; 94.45 25% 9.82; 7.52; 65.08 7.62; 6.00; 78.77 8.00; 6.20; 76.81 4.11; 2.98; 93.71 3.96; 2.96; 94.16 30% 10.79; 8.25; 57.89 8.28; 6.44; 74.97 8.75; 6.73; 72.24 4.50; 3.22; 92.52 4.26; 3.18; 93.28 10% 6.86; 5.34; 83.29 6.55; 5.16; 84.72 6.22; 4.86; 86.29 4.10; 3.04; 94.20 3.93; 2.98; 94.56 15% 7.94; 6.20; 78.14 7.27; 5.76; 81.77 6.97; 5.50; 83.25 4.40; 3.21; 93.30 4.27; 3.18; 93.73 冬季 20% 9.40; 7.36; 69.16 8.05; 6.32; 77.44 7.91; 6.20; 78.23 4.55; 3.33; 92.83 4.37; 3.28; 93.32 25% 10.56; 8.18; 60.47 8.81; 6.94; 72.48 8.90; 6.97; 71.96 4.88; 3.56; 91.40 4.62; 3.45; 92.41 30% 11.26; 8.74; 55.94 9.50; 7.48; 68.70 9.65; 7.57; 67.57 5.02; 3.64; 91.25 4.83; 3.60; 91.72 从图4的曲线中可以看出, MI-SCN与MT-SCN由于缺乏鲁棒性, 随着异常值比例的增加, MI-SCN与MT-SCN的建模误差增长幅度较快, 难以实现炉温与烟气含氧量的准确预测. 而MoGL-SCN与MRI-SCN采用鲁棒建模策略提升了模型鲁棒性, 所以建模误差增长幅度较为缓慢, 尤其是MRI-SCN在不同异常值比例下的模型精度相对较好, 这充分说明了在异常数据影响下建立炉温与烟气含氧量鲁棒预测模型的必要性.
从图5中可以看出, 当$ \zeta $=20% 时, MRI-SCN的预测结果比SCN更加靠近对角线, 这验证了本文所提改进策略的有效性. 从预测误差概率分布曲线中可以看出, 由于MoGL-SCN与MRI-SCN采用鲁棒建模策略来抑制异常数据对模型准确性的负面影响, 所以它们预测误差小于SCN、MI-SCN以及MT-SCN. 此外, MRI-SCN的预测误差概率分布曲线在0附近的尖峰特征比MoGL-SCN更加明显, 所以MRI-SCN的预测精度相对较高.
 图 5 炉温与烟气含氧量散点图及预测误差概率分布曲线$(\zeta$ = 20%)Fig. 5 Scatterplot of furnace temperature, flue gas oxygen content and probability distribution curves of prediction error $(\zeta$ = 20%)
图 5 炉温与烟气含氧量散点图及预测误差概率分布曲线$(\zeta$ = 20%)Fig. 5 Scatterplot of furnace temperature, flue gas oxygen content and probability distribution curves of prediction error $(\zeta$ = 20%)图6是在$ \zeta $=30% 的情况下, SCN与MRI-SCN在4组噪声数据集上的炉温与烟气含氧量预测误差曲线及其模型输出权值. 从图6中可以看出, 在异常数据影响下, 采用MRI-SCN建立的模型对炉温与烟气含氧量的预测精度相对较高且模型输出权值较小, 这在一定程度上可以提升模型的泛化能力.
 图 6 炉温与烟气含氧量预测误差曲线及模型输出权值$(\zeta$ = 30%)Fig. 6 Furnace temperature, flue gas oxygen content prediction error curves and model output weights $(\zeta$ = 30%)
图 6 炉温与烟气含氧量预测误差曲线及模型输出权值$(\zeta$ = 30%)Fig. 6 Furnace temperature, flue gas oxygen content prediction error curves and model output weights $(\zeta$ = 30%)表4统计了BP、SCN以及MRI-SCN等建模方法运行30次所花费的时间. 从表4中可以看出, MI-SCN、MRI-SCN的建模速度均比MT-SCN与MoGL-SCN快, 这说明利用参数自适应变化的监督机制可以提升MI-SCN与MRI-SCN隐含层参数的配置效率.
表 4 不同建模方法运行 30 次的时间对比Table 4 Comparison of time for 30 runs of different modeling methods方法 BP RBF SCN MI-SCN MT-SCN MoGL-SCN MRI-SCN 时间(s) 21.43 31.70 5.23 16.29 36.22 37.78 28.17 4. 结束语
为准确预测MSWI过程的炉温与烟气含氧量, 提出了一种基于改进SCN的多目标鲁棒建模方法(MRI-SCN), 并通过实验验证了MRI-SCN建模方法的有效性与优越性. 主要贡献总结如下:
第一, 将标准前馈与级联构造相融合, 在参数自适应的不等式监督机制下分配隐含层参数, 从而增强了SCN隐含层映射多样性, 并提高了模型参数的配置效率.
第二, 利用F范数与$ L_{2,1} $范数正则项构建矩阵弹性网对模型输出权值进行稀疏约束, 利用炉温与烟气含氧量之间的相关性进一步提升了建模精度.
第三, 将混合Laplace分布作为每个目标建模误差的先验分布, 并采用最大后验估计重新评估SCN模型的输出权值, 使学习到的模型具有良好的鲁棒性.
实验结果表明, 在异常数据影响下, 基于MRI-SCN建立的预测模型可以较为准确地预测炉温与烟气含氧量的变化趋势, 从而为MSWI过程的多目标协同优化控制奠定了良好的基础, MRI-SCN建模方法在工业过程参数预测建模领域具有一定的应用潜力. 考虑到MSWI过程的参数变化具有时变性, 提升MRI-SCN模型对复杂工况的自适应能力是后续研究工作的重点.
附录A
表 A1 多目标鲁棒预测模型输入变量明细Table A1 Input variable details of multi-target robust prediction model序号 变量名称 单位 1 进料器左内侧速度 % 2 进料器左外侧速度 % 3 进料器右内侧速度 % 4 进料器右外侧速度 % 5 干燥炉排左内侧速度 % 6 干燥炉排左外侧速度 % 7 干燥炉排右内侧速度 % 8 干燥炉排右外侧速度 % 9 干燥炉排左1空气流量 $ {\rm {km^3N/h}} $ 10 干燥炉排右1空气流量 $ {\rm {km^3N/h}} $ 11 干燥炉排左2空气流量 $ {\rm {km^3N/h}} $ 12 干燥炉排右2空气流量 $ {\rm {km^3N/h}} $ 13 燃烧炉排左1-1段空气流量 $ {\rm {km^3N/h}} $ 14 燃烧炉排右1-1段空气流量 $ {\rm {km^3N/h}} $ 15 燃烧炉排左1-2段空气流量 $ {\rm {km^3N/h}} $ 16 燃烧炉排右1-2段空气流量 $ {\rm {km^3N/h}} $ 17 燃烧炉排左2-1段空气流量 $ {\rm {km^3N/h}} $ 18 燃烧炉排右2-1段空气流量 $ {\rm {km^3N/h}} $ 19 燃烧炉排左2-2段空气流量 $ {\rm {km^3N/h}} $ 20 燃烧炉排右2-2段空气流量 $ {\rm {km^3N/h}} $ 21 燃烬炉排左空气流量 $ {\rm {km^3N/h}} $ 22 燃烬炉排右空气流量 $ {\rm {km^3N/h}} $ 23 二次风量 $ {\rm {km^3N/h}} $ 24 一次风机出口空气压力 kPa 25 一次空气加热器出口空气温度 ℃ 26 干燥炉排左内侧温度 ℃ 27 干燥炉排左外侧温度 ℃ 28 干燥炉排右内侧温度 ℃ 29 干燥炉排右外侧温度 ℃ 30 燃烧炉排1-1段左内侧温度 ℃ 31 燃烧炉排1-1段左外侧温度 ℃ 32 燃烧炉排1-1段右内侧温度 ℃ 33 燃烧炉排1-1段右外侧温度 ℃ 34 燃烧炉排1-2段左内侧温度 ℃ 35 燃烧炉排1-2段左外侧温度 ℃ 36 燃烧炉排1-2段右内侧温度 ℃ 37 燃烧炉排1-2段右外侧温度 ℃ 38 燃烧炉排2-1段左内侧温度 ℃ 39 燃烧炉排2-1段左外侧温度 ℃ 40 燃烧炉排2-1段右内侧温度 ℃ 41 燃烧炉排2-1段右外侧温度 ℃ 42 燃烧炉排2-2段左内侧温度 ℃ 43 燃烧炉排2-2段左外侧温度 ℃ 44 燃烧炉排2-2段右内侧温度 ℃ 45 燃烧炉排2-2段右外侧温度 ℃ 46 当前时刻的炉温 ℃ 47 当前时刻的烟气含氧量 % -

图 1 风箱废气温度和烧结带分布
Fig. 1 Temperature of exhaust gas in bellows andsintering zone distribution
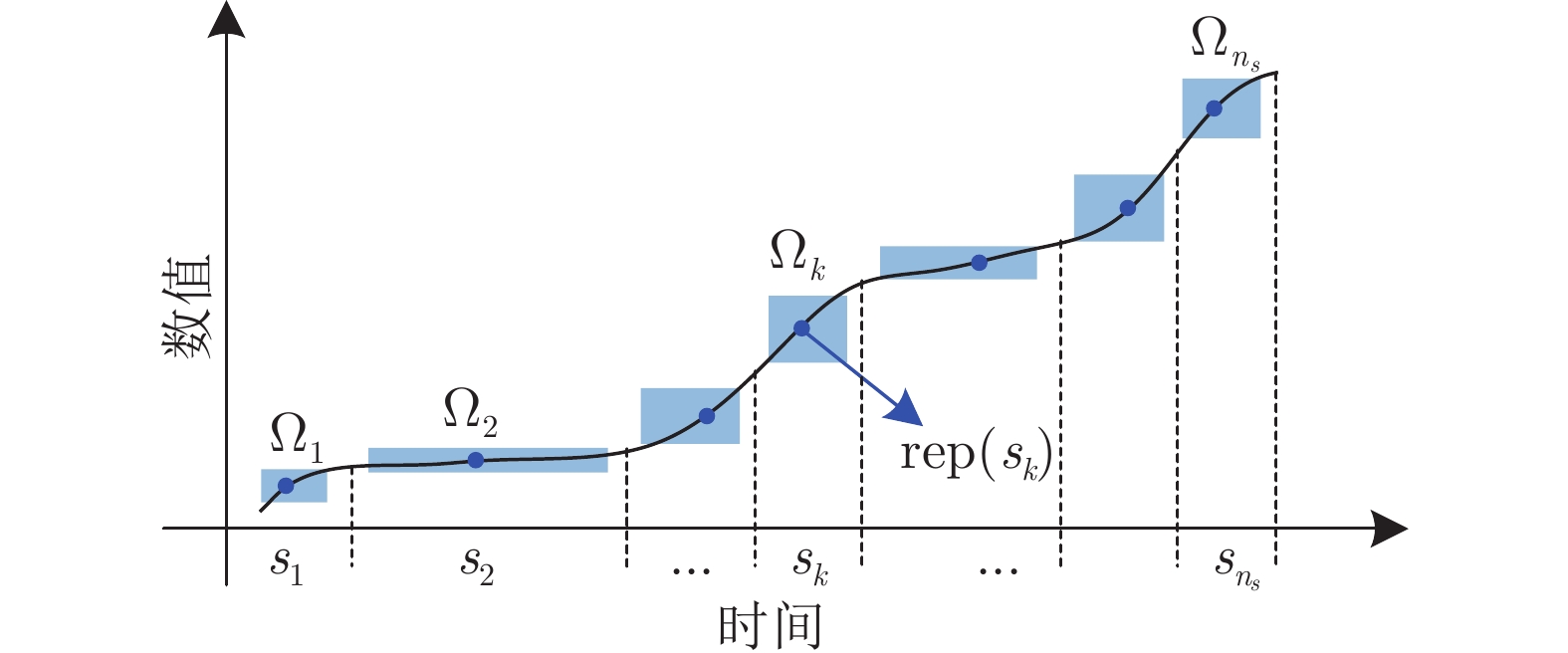
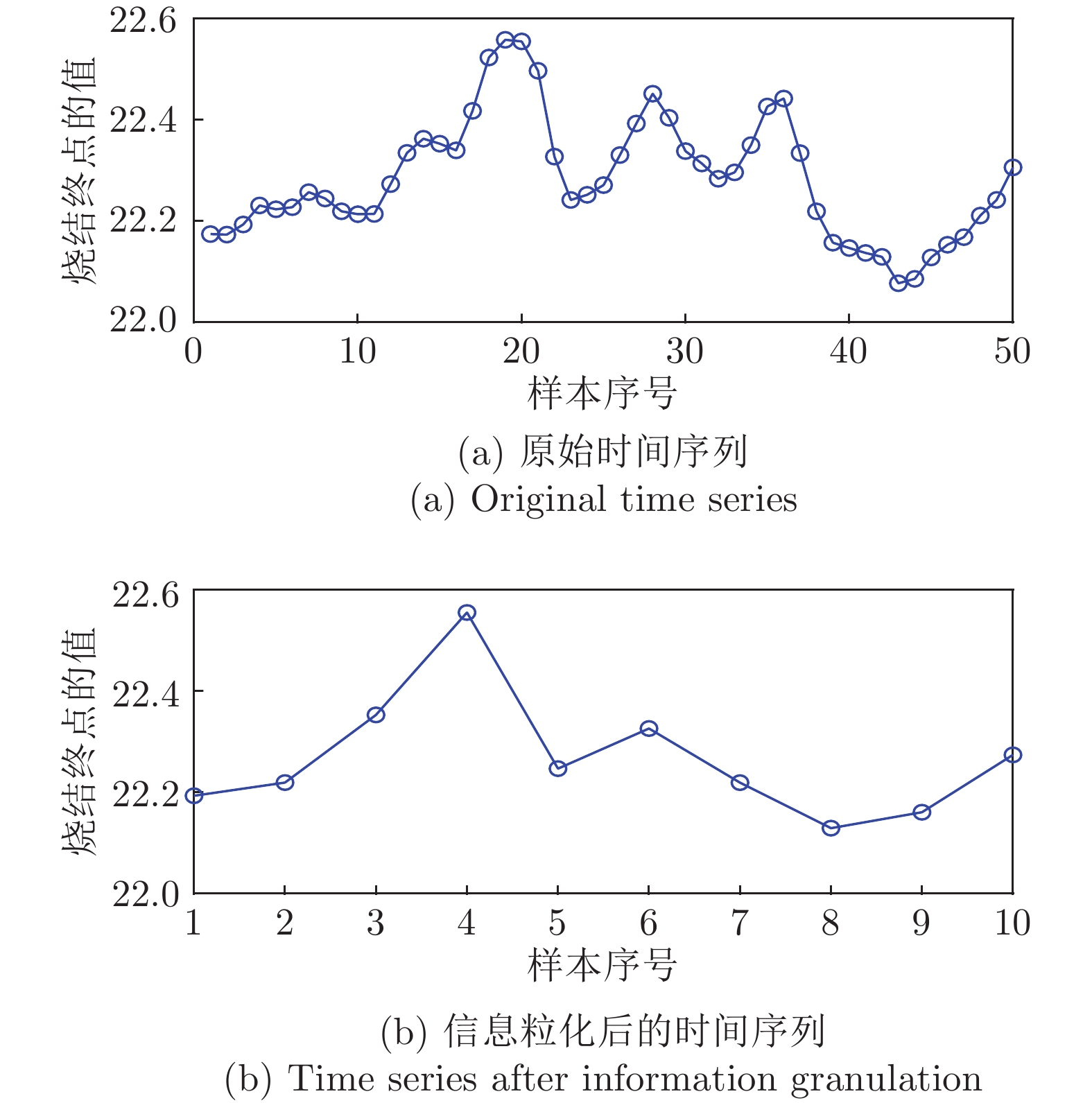
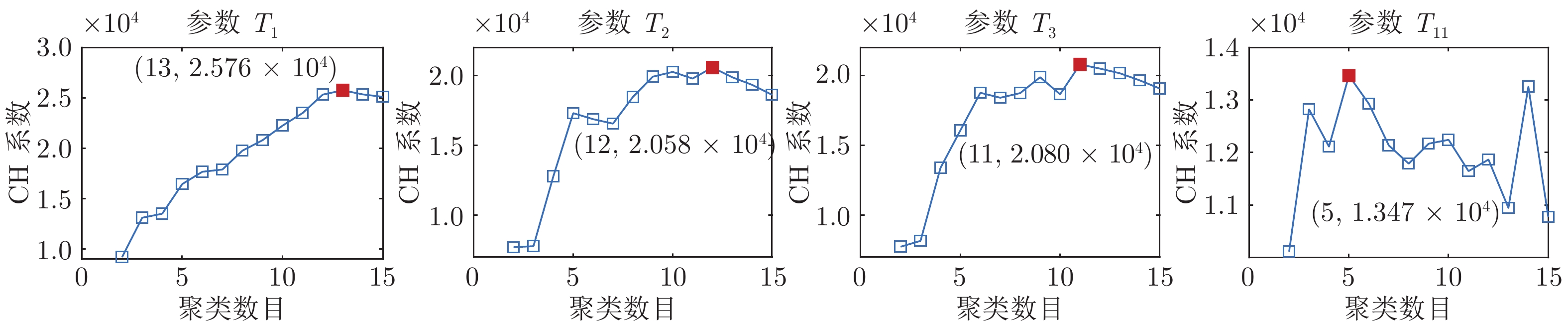
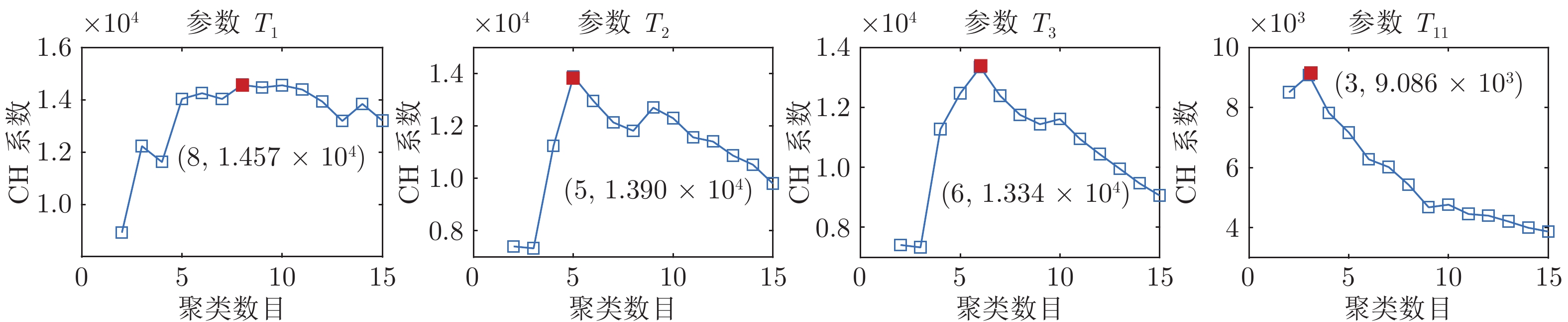
$T_{BTP} $ 烧结终点(Burn-through point, BTP)温度(℃) $L_{BTP} $ 烧结终点位置 $T_{i} $ 第i个风箱废气温度(℃) $P_{N} $ 主风箱负压(kPa) $H_{M} $ 料层厚度(mm) $C_{pm} $ 田口过程能力指数 ${V_T} $ 台车速度 (m/min) $P_i $ 第i个检测参数 $L_i $ 第i个聚类标签 $G_i $ 第i个运行性能等级 $F_T $ 检验统计量 $\rho $ 检验概率 $X $ 时间序列 $s_k $ 第k个时间序列片段 $\Omega_k $ 第k个信息粒 ${\rm{rep}}(s_k) $ $\Omega_k$的数值代表 ${\rm{rep}}(X) $ 粒时间序列 $c $ 聚类数目 $C_i $ 第i个簇的聚类中心 $u_{ij} $ 属于第i个簇的隶属度 $C_H(c) $ Calinski-Harabasz系数  下载: 导出CSV
下载: 导出CSV
表 1 运行性能等级划分
Table 1 Operating performance grade division
运行性能等级 描述 优 (Perfect, Pe) $C_{pm}\geq$ 1.67 良 (Good, Go) 1.67 $>C_{pm}\geq \;$1.33 一般 (General, Ge) 1.33 $>C_{pm}\geq$1.00 差 (Poor, Po) 1.00 $> C_{pm}\geq$ 0.67 不可接受 (Unacceptable, Un) 0.67 $>C_{pm}$
下载: 导出CSV
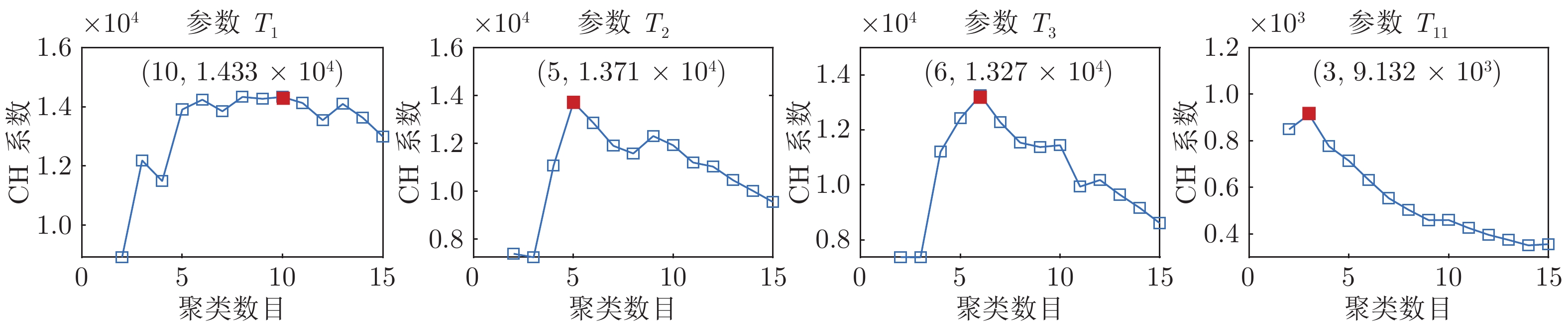
表 2 单因素方差分析结果
Table 2 Results of one-way analysis of variance
参数 $\rho$ $T_{1}$ 6.76 × 10–8 $T_{2}$ 1.56 × 10–5 $T_{3}$ 8.26 × 10–5 $T_{5}$ 6.40 × 10–2 $T_{7}$ 1.90 × 10–2 $T_{9}$ 4.26 × 10–3 $T_{11}$ 2.47 × 10–25 $T_{13}$ 5.85 × 10–20 $T_{15}$ 6.43 × 10–20 $T_{17}$ 4.17 × 10–15 $~~T_{18}$ 9.39 × 10–25 $T_{19}$ 2.89 × 10–18 $T_{20}$ 1.84 × 10–21 $~~T_{21}$ 6.53 × 10–18 $T_{22}$ 3.59 × 10–20 $T_{23}$ 1.24 × 10–16 $T_{24}$ 2.35 × 10–35 $P_N$ 2.46 × 10–26 $H_M$ 1.46 × 10–13 $V_T$ 6.25 × 10–2
下载: 导出CSV
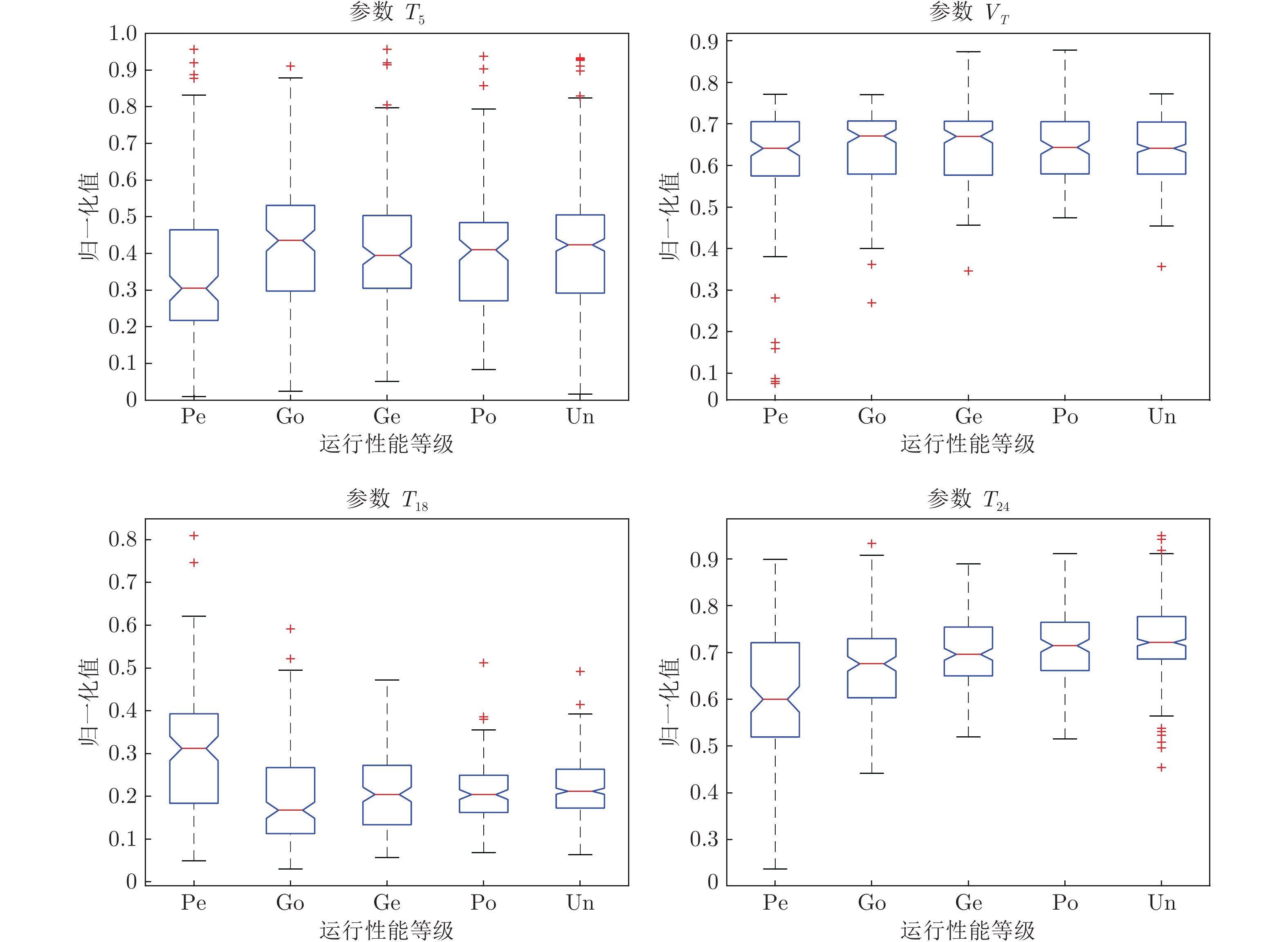
表 3 运行性能评价结果 (%)
Table 3 Results of operating performance assessment (%)
评估等级 实际等级 精度 Pe Go Ge Po Un TSDC Pe 89.08 7.96 1.20 0.70 1.06 79.70 Go 8.97 75.41 9.21 3.38 3.03 Ge 4.58 8.50 66.45 13.73 6.75 Po 2.29 4.30 14.61 67.34 11.46 Un 1.53 4.81 5.03 8.10 80.53 TSFC Pe 90.08 7.08 1.20 0.64 0.99 80.28 Go 8.84 75.55 8.96 3.90 2.76 Ge 4.43 9.09 67.63 11.31 7.54 Po 1.37 5.75 13.97 66.85 12.05 Un 1.22 4.22 5.22 8.10 81.24 TSGC Pe 94.24 5.04 0.14 0.36 0.22 83.40 Go 8.35 79.52 10.41 1.37 0.34 Ge 0.44 12.66 67.03 12.45 7.42 Po 0 1.15 11.17 74.50 13.18 Un 0 0.54 5.59 11.60 82.28
下载: 导出CSV
-
[1] Chen X, Lan T, Shi X, Tong C. A semi-supervised linear–nonlinear least-square learning network for prediction of carbon efficiency in iron ore sintering process. Control Engineering Practice, 2020, DOI: 10.1016/j.conengprac.2020.104454. [2] Huang X, Fan X, Chen X, Gan M, Zhao X. Soft-measuring models of thermal state in iron ore sintering process. Measurement, 2018, 130: 145-150. doi: 10.1016/j.measurement.2018.07.095 [3] Wang S, Li H, Zhang Y, Zou Z. A hybrid ensemble model based on ELM and improved AdaBoost.RT algorithm for predicting the iron ore sintering characters. Computational Intelligence and Neuroscience, 2019, DOI: 10.1155/2019/4164296. [4] Du S, Wu M, Chen X, Lai X, Cao W. Intelligent coordinating control between burn-through point and mixture bunker level in an iron ore sintering process. Journal of Advanced Computational Intelligence and Intelligent Informatics, 2017, 21(1): 139-147. doi: 10.20965/jaciii.2017.p0139 [5] Chen X, Shi X, Tong C. Multi-time-scale TFe prediction for iron ore sintering process with complex time delay. Control Engineering Practice, 2019, 89: 84-93. doi: 10.1016/j.conengprac.2019.05.012 [6] Liu Y, Wang F, Chang Y, Ma R. Comprehensive economic index prediction based operating optimality assessment and nonoptimal cause identification for multimode processes. Chemical Engineering Research and Design, 2015, 97: 77-90. doi: 10.1016/j.cherd.2015.03.008 [7] Liu Y, Chang Y, Wang F. Online process operating performance assessment and nonoptimal cause identification for industrial processes. Journal of Process Control, 2014, 24(10): 1548-1555. doi: 10.1016/j.jprocont.2014.08.001 [8] 邹筱瑜, 王福利, 常玉清, 王敏, 蔡庆宏. 基于分层分块结构的流程工业过程运行状态评价及非优原因追溯. 自动化学报, 2019, 45(2): 315-324.Zou X, Wang F, Chang Y, Wang M, Cai Q. Plant-wide process operating performance assessment and non-optimal cause identification based on hierarchical multi-block structure. Acta Automatica Sinica, 2019, 45(2): 315-324. [9] 邹筱瑜, 王福利, 常玉清, 郑伟. 基于两层分块GMM-PRS的流程工业过程运行状态评价. 自动化学报, 2019, 45(11): 2071-2081.Zou X, Wang F, Chang Y, Zheng W. Plant-wide process operating performance assessment based on two-level multiblock GMM-PRS. Acta Automatica Sinica, 2019, 45(11): 2071-2081. [10] Zou X, Zhao C. Concurrent assessment of process operating performance with joint static and dynamic analysis. IEEE Transactions on Industrial Informatics, 2020, 16(4): 2776- 2786. doi: 10.1109/TII.2019.2934757 [11] Zou X, Wang F, Chang Y. Assessment of operating performance using cross-domain feature transfer learning. Control Engineering Practice, 2019, 89: 143-153. doi: 10.1016/j.conengprac.2019.05.007 [12] Du S, Wu M, Chen L, Cao W, Pedrycz W. Operating mode recognition of iron ore sintering process based on the clustering of time series data. Control Engineering Practice, 2020, DOI: 10.1016/j.conengprac.2020.104297. [13] Cho H, Choi N, Lee B. Oscillation recognition using a geometric feature extraction process based on periodic timeseries approximation. IEEE Access, 2020, 8: 34375-34386. doi: 10.1109/ACCESS.2020.2974259 [14] Guo H, Wang L, Liu X, Pedrycz W. Information granulation-based fuzzy clustering of time series. IEEE Transactions on Cybernetics, 2020, DOI: 10.1109/TCYB.2020.2970455. [15] Pedrycz W, Bargiela A. Granular clustering: a granular signature of data. IEEE Transactions on Systems, Man, and Cybernetics−Part B: Cybernetics, 2002, 32(2): 212-224. doi: 10.1109/3477.990878 [16] Lu W, Chen X, Pedrycz W, Liu X, Yang J. Using interval information granules to improve forecasting in fuzzy time series. International Journal of Approximate Reasoning, 2015, 57: 1-18. doi: 10.1016/j.ijar.2014.11.002 [17] Boyles R A. The Taguchi capability index. Journal of Quality Technology. 1991, 23(1): 17-26. doi: 10.1080/00224065.1991.11979279 [18] Du S, Wu M, Chen L, Zhou K, Hu J, Cao W, Pedrycz W. A fuzzy control strategy of burn-through point based on the feature extraction of time-series trend for iron ore sintering process. IEEE Transactions on Industrial Informatics, 2020, 16(4): 2357-2368. doi: 10.1109/TII.2019.2935030 [19] Wu C W. An efficient inspection scheme for variables based on Taguchi capability index. European Journal of Operational Research, 2012, 223(1): 116-122. doi: 10.1016/j.ejor.2012.06.023 [20] Booker J M, Raines M, Swift K G. Designing Capable and Reliable Products. Oxford: Butterworth-Heinemann, 2001. [21] 卢伟. 基于粒计算的时间序列分析与建模方法研究 [博士论文], 大连理工大学, 中国, 2015Lu Wei. Time Series Analysis and Modeling Method Research Based on Granular Computing [Ph.D. dissertation], Dalian University of Technology, China, 2015 [22] Wang W, Pedrycz W, Liu X. Time series long-term forecasting model based on information granules and fuzzy clustering. Engineering Applications of Artificial Intelligence. 2015, 41: 17-24. doi: 10.1016/j.engappai.2015.01.006 [23] Bezdek J C, Ehrlich R, Full W. FCM: The fuzzy c-means clustering algorithm. Computers & Geosciences, 1984, 10(2- 3): 191-203. [24] Caliński T, Harabasz J. A dendrite method for cluster analysis. Communications in Statistics-theory and Methods, 1974, 3(1): 1-27. doi: 10.1080/03610927408827109 [25] Chai Z, Zhao C. Enhanced random forest with concurrent analysis of static and dynamic nodes for industrial fault classification. IEEE Transactions on Industrial Informatics, 2020, 16(1): 54-66. doi: 10.1109/TII.2019.2915559 [26] Räsänen T, Kolehmainen M. Feature-based clustering for electricity use time series data. In: Proceedings of the 9th International Conference on Adaptive and Natural Computing Algorithms. Kuopio, Finland: 2009. 401−412 -


 下载:
下载:


计量
- 文章访问数: 1991
- HTML全文浏览量: 411
- PDF下载量: 174
- 被引次数: 0
