

-
摘要:
信息时代产生的大量数据使机器学习技术成功地应用于许多领域. 大多数机器学习技术需要满足训练集与测试集独立同分布的假设, 但在实际应用中这个假设很难满足. 域适应是一种在训练集和测试集不满足独立同分布条件下的机器学习技术. 一般情况下的域适应只适用于源域目标域特征空间与标签空间都相同的情况, 然而实际上这个条件很难满足. 为了增强域适应技术的适用性, 复杂情况下的域适应逐渐成为研究热点, 其中标签空间不一致和复杂目标域情况下的域适应技术是近年来的新兴方向. 随着深度学习技术的崛起, 深度域适应已经成为域适应研究领域中的主流方法. 本文对一般情况与复杂情况下的深度域适应的研究进展进行综述, 对其缺点进行总结, 并对其未来的发展趋势进行预测. 首先对迁移学习相关概念进行介绍, 然后分别对一般情况与复杂情况下的域适应、域适应技术的应用以及域适应方法性能的实验结果进行综述, 最后对域适应领域的未来发展趋势进行展望并对全文内容进行总结.
Abstract:The large amount of data generated in the information age enables machine learning to be successfully applied in many fields. Most machine learning techniques need to meet the assumption that the training set and the test set are independent and identically distributed, but in practice this assumption is difficult to meet. Domain adaptation is a machine learning technology in which the training set and test set do not need to satisfy the condition of independent and identical distribution. The general domain adaptation is only applicable to the case where feature space and label space of the source domain and target domain are the same, but in fact this condition is difficult to meet. In order to enhance the applicability of domain adaptation, domain adaptation under complex conditions has gradually become a research hotspot. Domain adaptation under the condition of inconsistent label space and complex target domain is an emerging direction in recent years. With the rise of deep learning technology, deep domain adaptation has become the mainstream method in the field of domain adaptation research. This article reviews the research progress of deep domain adaptation in general and complex situations, summarizes their shortcomings, and predicts their future development trends. This article firstly introduces the concepts of transfer learning, and then summarizes domain adaptation in general and complex situations, the application of domain adaptation technology and the performance of domain adaptation methods, finally prospects the development trend of the domain adaptation field and summarizes the content of the full text.
-
Key words:
- Domain adaptation /
- transfer learning /
- deep domain adaptation /
- deep learning /
- machine learning
-
图像密集描述是基于自然语言处理和计算机视觉两大研究领域的任务, 是一个由图像到语言的跨模态课题. 其主要工作是为图像生成多条细节描述语句, 描述对象从整幅图像扩展到图中局部物体细节. 近年来, 该任务颇受研究者关注. 一方面, 它具有实际的应用场景[1], 如人机交互[2]、导盲等; 另一方面, 它促进了众多研究任务的进一步发展, 如目标检测[3-4]、图像分割[5]、图像检索[6]和视觉问答[7]等.
作为图像描述的精细化任务, 图像密集描述实现了计算机对图像的细粒度解读. 同时, 该任务沿用了图像描述的一般网络架构. 受机器翻译[8]启发, 目前的图像描述网络[9-11]大多为编码器−解码器(Encoder-decoder, ED)框架, 因此图像密集描述任务也大多基于该传统结构. 该框架首先将卷积神经网络(Convolutional neural network, CNN)作为编码器来提取图像视觉信息[12], 得到一个全局视觉向量, 然后输入到基于长短期记忆网络(Long-short term memory, LSTM)[13]的解码器中, 最后逐步输出相应的描述文本单词.
基于上述编码−解码框架, 为实现图像区域密集描述, Karpathy等[14]试图在区域上运行图像描述模型, 但无法在同一模型中同时实现检测和描述. 在此基础上, Johnson等[15]实现了模型的端到端训练, 并首次提出了图像密集描述概念. 该工作为同时进行检测定位和语言描述提出了一种全卷积定位网络架构, 通过单一高效的前向传递机制处理图像, 不需要外部提供区域建议, 并且可实现端到端的优化. 虽然全卷积定位网络架构可实现端到端密集描述, 但仍存在两个问题:
1)模型送入解码器的视觉信息仅为感兴趣区域的深层特征向量, 忽略了浅层网络视觉信息和感兴趣区域间的上下文信息, 从而导致语言模型预测出的单词缺乏场景信息的指导, 所生成的描述文本缺乏细节信息, 甚至可能偏离图像真实内容.
2)对于单一图像的某个区域而言, 描述文本的生成过程即为一次图像描述. 图像描述中, 由于网络仅使用单一LSTM来预测每个单词, 故解码器未能较好地捕捉到物体间的空间位置关系[16], 从而造成描述文本的句式简单, 表述不够丰富.
为解决上下文场景信息缺失问题, Yang等[17]基于联合推理和上下文融合思想提出了一种多区域联合推理模型. 该模型将图像特征和区域特征进行集成, 实现了较为准确的密集描述. 但是提出的上下文信息过于粗糙, 且尚不完整. Yin等[18]通过相邻区域与目标区域间的多尺度信息传播, 提出一种上下文信息传递模块. 该模块引入了局部、邻居和全局信息, 从而获取较细粒度的上下文信息. 此外, Li等[19]通过目标检测技术揭示了描述区域与目标间的密切关系, 提出一种互补上下文学习架构, 也可实现上下文信息的细粒度获取. 在图像密集描述任务的最新进展中, Shao等[20]提出一种基于Transformer的图像密集描述网络, 打破了传统的编码−解码框架, 致力于改进LSTM网络和关注信息丰富区域. 上述工作在一定程度上解决了上下文场景信息的缺失问题, 但尚未有研究能解决浅层特征信息利用不完全和区域内空间位置信息获取不完备的问题.
为提高图像区域描述的准确性, 本文提出一种基于多重注意结构的图像密集描述生成方法 —MAS-ED (Multi-attention structure-encoder decoder). 该方法通过构建多尺度特征环路融合(Multi-scale feature loop fusion, MFLF)机制, 为解码器提供多尺度有效融合特征, 增加比较细节的几何信息; 并设计多分支空间分步注意力(Multi-branch spatial step attention, MSSA)解码器, 通过提取目标间的空间维度信息, 以加强文本中目标间的位置关系描述. 模型训练过程中, MFLF机制和MSSA解码器之间交替优化、相互促进. 实验结果表明, 本文的MAS-ED方法在Visual Genome数据集上获得了具有竞争力的结果.
1. 基于多重注意结构的密集描述
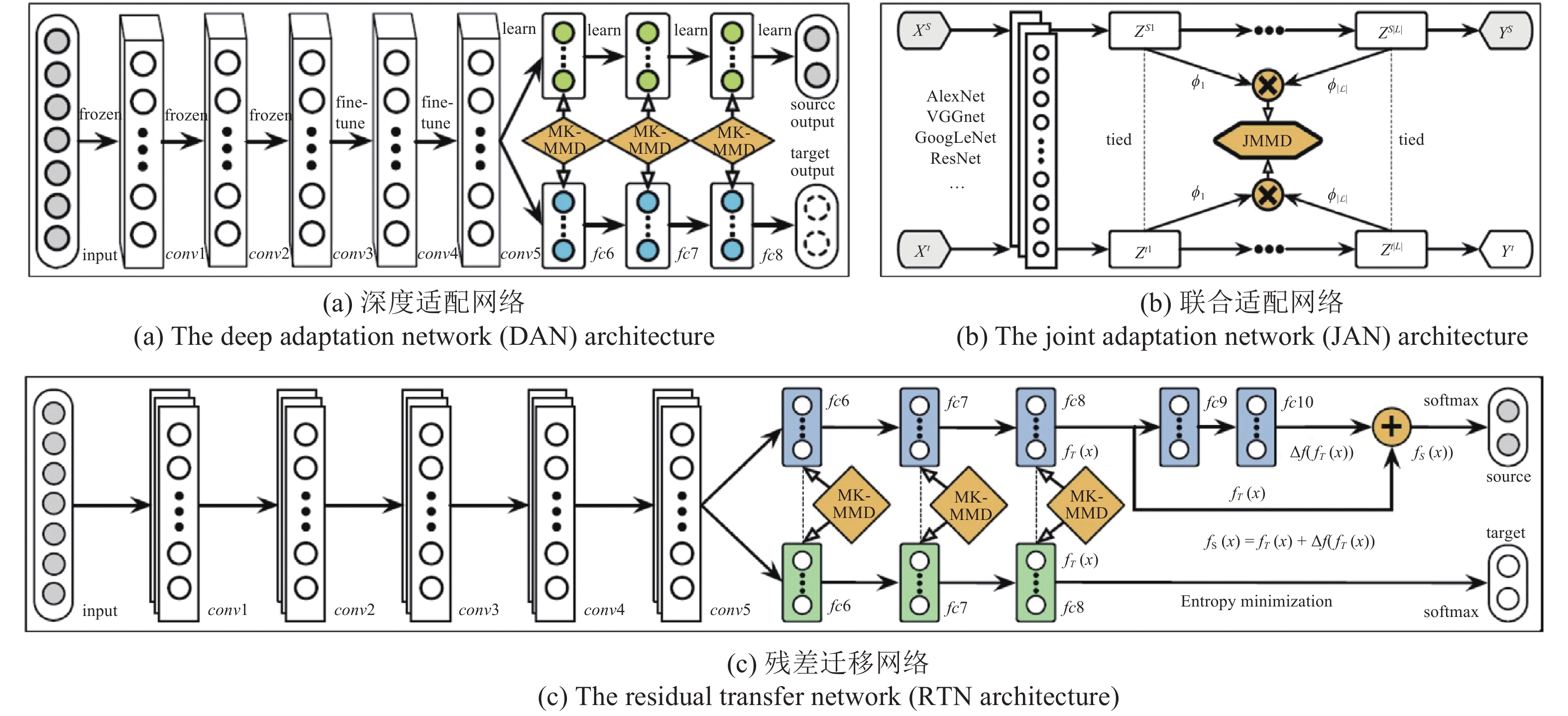
1.1 算法模型
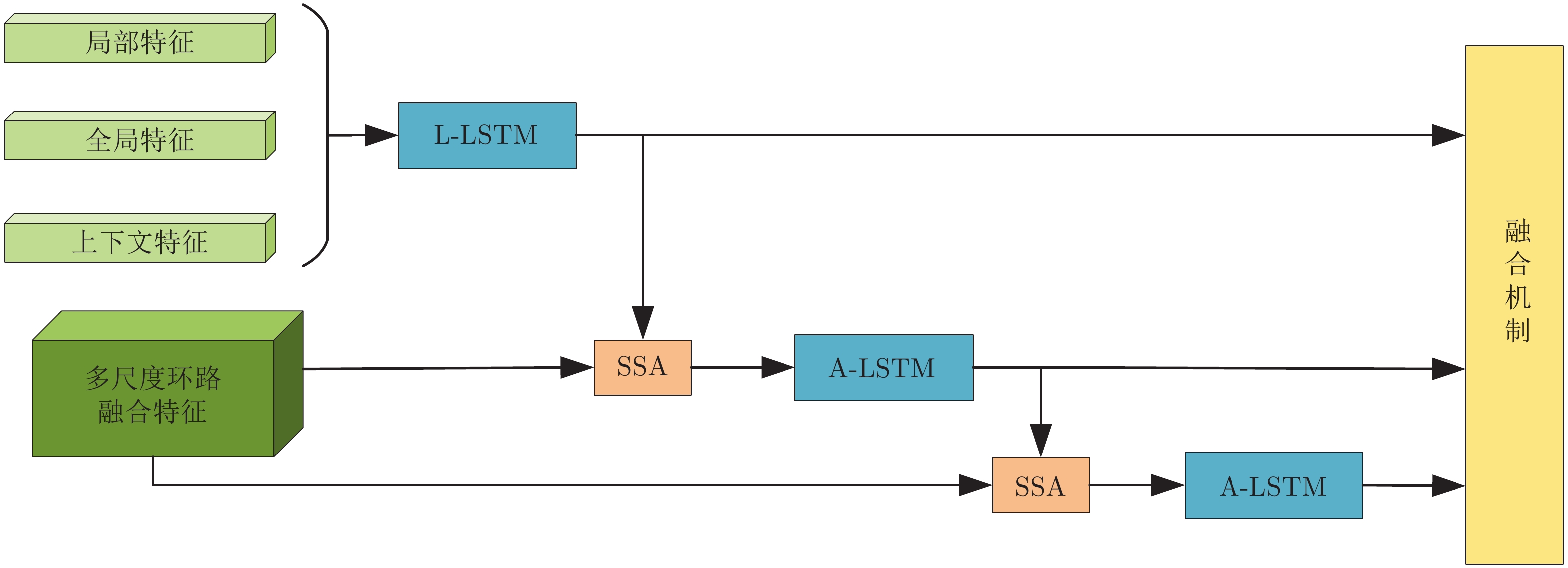
本文提出的基于多重注意结构的密集描述生成方法网络框架如图1所示. 模型是一个端到端的网络模型. 据图1可知, MAS-ED模型是基于残差网络和LSTM网络的编码−解码架构, 总体可分解为以下几个阶段.
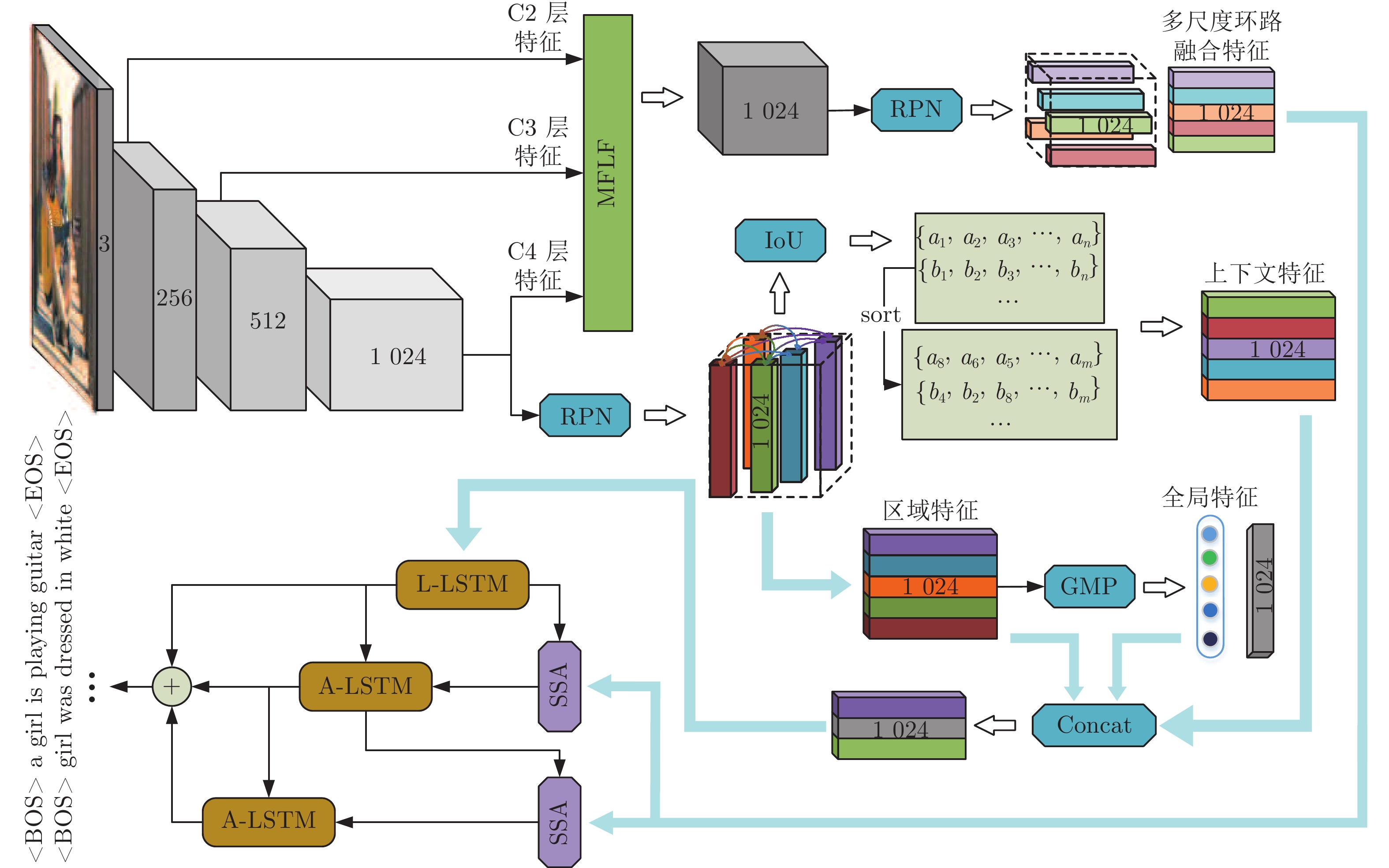 图 1 基于多重注意结构的图像密集描述生成方法Fig. 1 Dense captioning method based on multi-attention structure
图 1 基于多重注意结构的图像密集描述生成方法Fig. 1 Dense captioning method based on multi-attention structure1)区域视觉特征获取. 选用在ImageNet数据集上预训练过的ResNet-152网络作为特征提取器, 用来获取含有整幅图像视觉信息的全局视觉向量, 然后将其送入区域建议网络(Region proposal network, RPN), 得到高质量的区域建议候选框.
2)上下文信息处理. 通过交并比(Intersection over union, IoU)计算两个区域图像块间的交并比分数, 并进行排序. 将分值最高的相邻图像块特征作为当前图像块的上下文特征. 全局特征的获取由全局池化层(Global pooling layer, GAP)来完成.
3)多尺度环路融合特征提取. MFLF机制会从残差网络的各Block层视觉特征中提取各向量上包含的几何信息和语义信息, 然后将其中显著性视觉信息编码进一个和Block层视觉特征维度相同的特征向量中. 最后将该向量送入RPN层, 以得到含有几何细节和语义信息丰富的多尺度环路融合特征.
4)空间位置信息提取. 空间分步注意力(Spatial step attention, SSA)模块会根据上一解码器当前的隐含层状态, 动态决定从多尺度环路融合特征中获取哪些位置信息, 同时决定位置信息在当前单词预测时刻的参与比例, 从而向语言模型提供对预测本时刻单词最有用的位置关系特征.
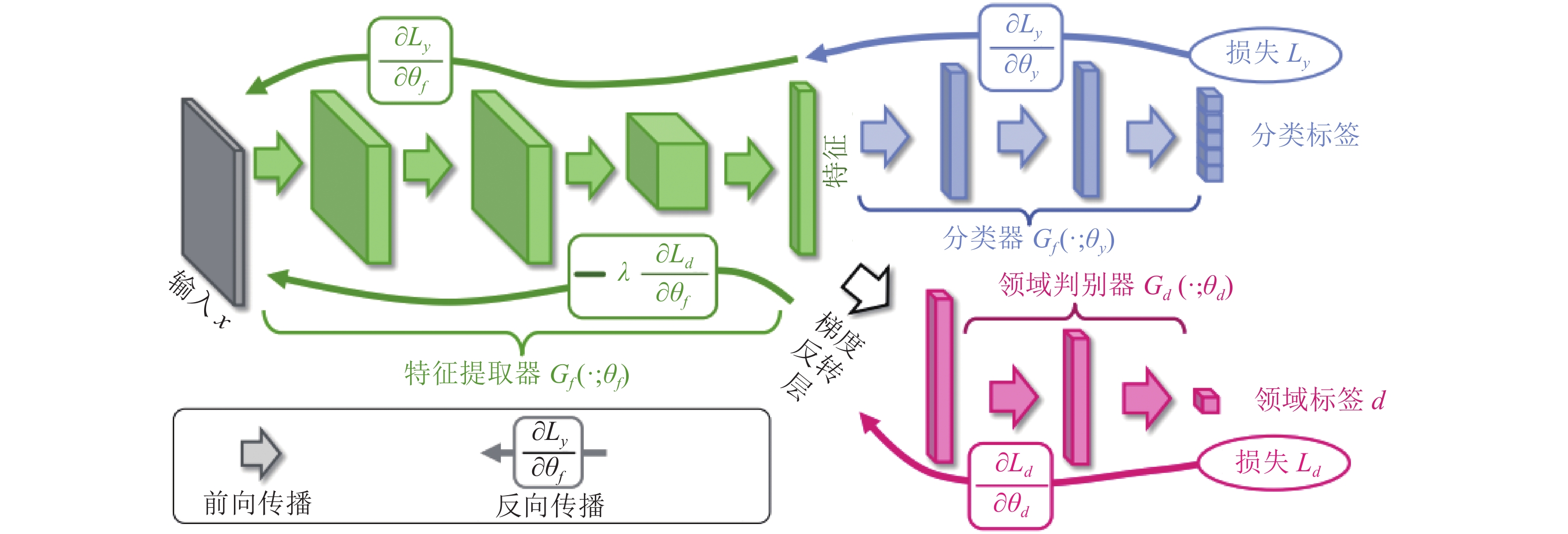
5)单词预测. 本文采用表示物体间空间位置关系的注意力特征来引导LSTM网络的单词序列建模过程. 图1中L-LSTM表示Language-LSTM, 输入的视觉特征由区域特征、上下文特征和全局特征组成; A-LSTM表示Attention-LSTM, 输入的视觉特征是注意力引导的多尺度环路融合特征. 为使空间位置信息更好地融入到解码器的输出中, 本文将SSA模块和三个LSTM网络组成图1所示结构, 以形成选择和融合的反馈连接, 并称为多分支空间分步注意力(MSSA)解码器.
1.2 多尺度特征环路融合机制
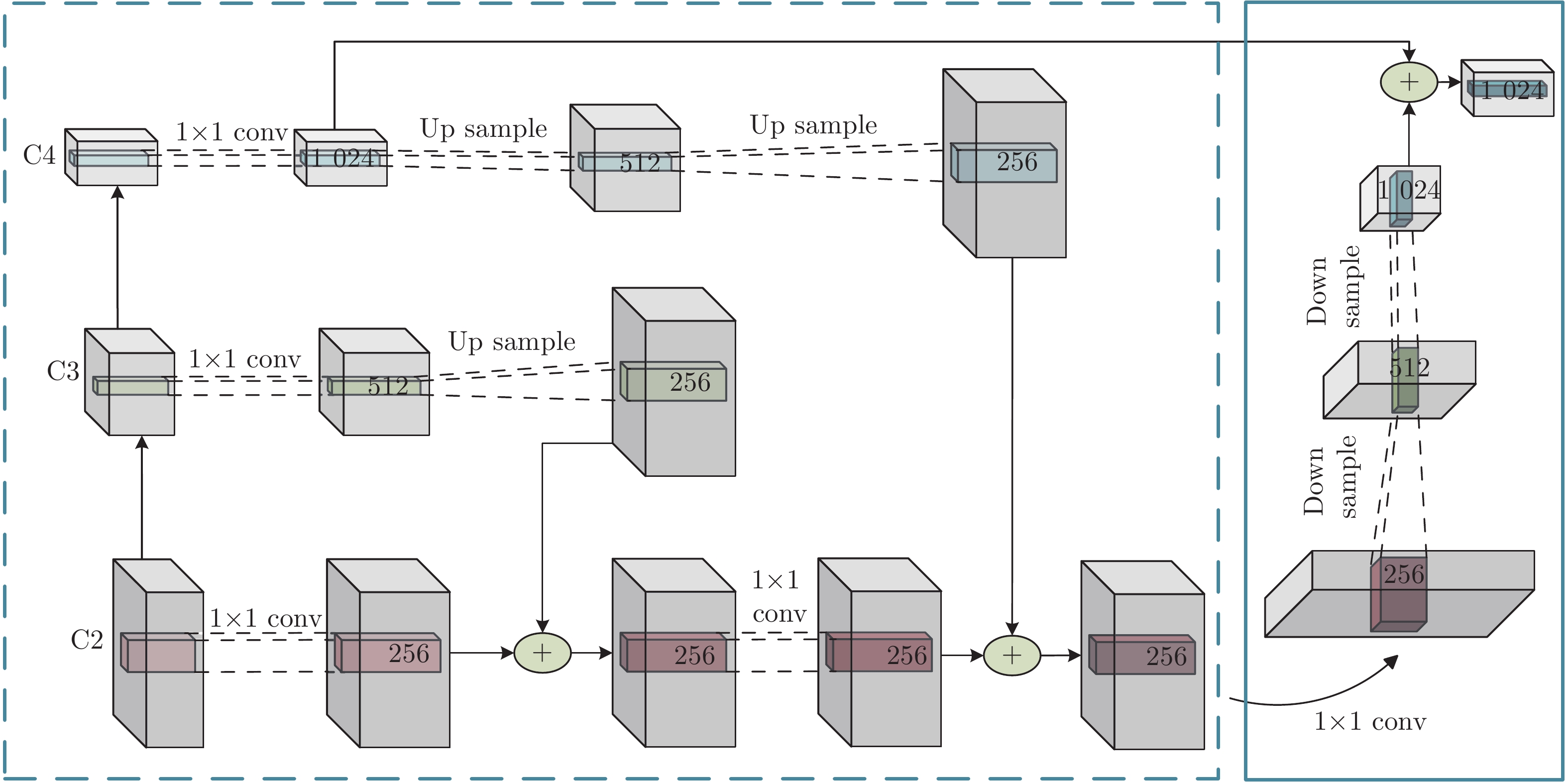
图像密集描述兼具标签密度大和复杂性高两大难点, 其任务网络模型较为庞大. 现有研究方法仅将深层网络特征用于文本生成, 而浅层网络特征并未有效利用. 虽然深层网络特征语义信息表征能力强, 但其特征图分辨率低, 几何信息含量少. 而浅层网络特征的特征图分辨率高, 几何信息表征能力强. 故本文在增加少许网络参数量和计算量的情况下, 提出一种多尺度特征环路融合机制, 即MFLF机制, 将同一网络的深层和浅层特征进行多尺度融合, 使模型可更完备地提取出图中含有的几何信息和语义信息. 其结构如图2所示.
受到特征金字塔算法[21]启发, MFLF机制效仿其实现过程, 改进逐层流向结构, 以减少计算资源开支. MFLF机制让高层网络输出特征流向低层网络输出特征, 以实现在低层特征图中加权有效的语义信息. 本文将此过程称为语义流, 其实现过程如图2中虚线子图框所示. 经几次语义流向过程后, 最底层特征图完成了全部有效语义信息的加权. 为使模型有效利用语义加权优化后低层特征图中的有效几何信息, MFLF机制设计了从低层特征流向高层的网络结构, 以实现在高层特征图中加权有效几何信息的目的. 此过程称为几何流, 其实现过程如图2中实线子图框所示. 需要注意的是, 几何流的初始特征是经语义信息加权后的, 故可削弱冗杂信息的比重. 由图2可知, 语义流和几何流构成了闭合回路, 组成了多尺度特征环路融合(MFLF)机制.
ResNet-152网络可分为4个Block, 第1个Block层的网络层数较少, 其特征图含有较多冗杂信息[22]. 因此在构建MFLF机制时, 仅考虑后3个Block的输出特征, 即图2中所示的C2、C3和C4. 此外, 语义流和几何流的组合具有多种可能. 本文将在消融实验部分阐述如何选择语义流分支和几何流分支. 本文确定的最佳组合为语义流分支选择C3-C2和C4-C2, 几何流分支选择C2-C4, 其中C3-C2表示C3层特征信息流向C2 层, 以此类推.
如图2所示, 单条语义流分支实现过程为: 1)将两个不同尺度的特征图送入1×1卷积层, 以保留原有平面结构, 达到通道数统一; 2)通过上采样将高层特征表示映射到低层特征表示空间; 3)将上采样后的高层特征与低层特征进行元素级相加操作, 得到融合特征; 4)将融合特征送入1×1卷积层完成通道数调整. 实际操作中, 若残差网络Block层输出特征通道数统一, 则不需要完成步骤1)和步骤4). 本文为提高MFLF机制的健壮性和可迁移性, 特意增加这两个步骤. 单条几何流分支实现过程同单条语义流分支, 仅将其中的上采样操作更改为下采样操作即可. 最终, MFLF机制将语义流分支和几何流分支融合形成一组多尺度视觉特征. 随着训练过程中网络参数的逐步优化, 各Block层的输出视觉特征也随之优化, 使MFLF机制动态调整几何信息和语义信息在输出特征中的比例, 为解码器提供了可动态优化的多尺度融合特征, 从而使模型能够准确生成含有丰富细节的文本描述.
1.3 多分支空间分步注意力解码器
1.3.1 空间分步注意力模块
注意力机制在各个研究领域中得到广泛应用[23-25]. 本文引入注意力机制获取目标位置信息, 并借鉴卷积块注意模块(Convolutional block attention module, CBAM)[26] 模型方法, 同时考虑通道和空间两个维度, 以获得更好的注意效果. 如图3所示, 空间分步注意力模块(SSA)的类通道注意力模块(Channel-like attention module, CLAM)由维度变换操作和通道注意力模块[27]共同组成, 且通道注意与空间注意交叉进行.
给定视觉特征
$ F \in {\mathbf R ^{H \times W \times C}} $ 和预测单词$ {\boldsymbol w} \in {\mathbf R ^ {C}} $ , 其中$ H,W,C $ 分别表示特征图的高、宽和通道. 首先扩充预测单词的空间维度$ S \in {\mathbf R ^ {H \times W \times C}} $ , 并与视觉特征进行元素级加和及非线性$ {\rm ReLu} $ 函数激活, 得到携带预测单词信息的加和特征图$ F_S \in {\mathbf R ^ {H \times W \times C}} $ :$$ \begin{equation} F_S = {\rm ReLu}(F + S) \end{equation} $$ (1) 由图3可知, SSA模块包含上下两支路, 其作用过程类似. 以上支路为例, 先考虑预测单词在特征图height维度的加权, 后考虑width维度. SSA模块将加和特征
$ F_S $ 输入CLAM中, 得到预测单词在特征图height维度的注意力权重图$ A^{H} $ :$$ \begin{equation} \begin{split} A^{H} = \;&{\rm CLAM}(F_S) = \\ &\sigma({\rm Maxpool}({f^{\rm T}}(F_S)) + {\rm Avgpool}({f^{\rm T}}(F_S))) \end{split} \end{equation} $$ (2) 其中,
$ {f^{\rm T}} $ 是维度变换函数, 目的是将特征图空间维度中的height维度信息映射到通道维度所在空间. 利用式(3)将注意力权重图$ A^{H} $ 与视觉特征$ F $ 相乘进行自适应特征优化, 得到经预测单词加权height维度后的特征矩阵向量$ F^{H} $ :$$ \begin{equation} F^{H} = {\rm Matmul}(F,A^{H}) \end{equation} $$ (3) 其中,
$ {\rm Matmul} $ 函数表示两个矩阵的乘积.接下来介绍上支路中第二步空间注意, 即考虑预测单词在特征图width维度的加权. 将经预测单词加权height维度后的特征矩阵
$ F^{H} $ 送入式(2), 得到预测单词在width维度各向量上的注意权重分布图$ A^{H \& W} $ ($ H \& W $ 表示先考虑height维度, 后考虑width维度). 特别注意, 此次$ {f^ {\rm T}} $ 函数是将特征图中的width维度信息映射到通道维度所在空间. 由此得到基于预测单词加权特征空间height, width两维度的特征图表示:$$ \begin{equation} F^{H \& W} = {\rm Matmul}(F, A^{H \& W}) \end{equation} $$ (4) 图3中下支路的作用流程与上支路类似, 加和特征
$ F_{S} $ 经式(2) ~ 式(4)操作后, 可得到基于预测单词加权特征空间width, height两维度的特征图$ F^{W \& H} $ . 最后, SSA模块将优化后的上、下两分支特征图进行元素级加和, 得到预测单词调整后的视觉特征:$$ \begin{equation} F = F^{H \& W} + F^{W \& H} \end{equation} $$ (5) 综上, SSA模块通过结合解码器上一时刻的预测单词, 实现了在空间维度和通道维度的交叉注意, 以加权视觉特征中的位置信息, 并将其用于指导解码器下一时刻的单词预测. 在解码器序列建模过程中, 模型可根据当前单词的预测结果, 完成有选择性地关注视觉特征中的空间位置关系.
1.3.2 多分支解码器
一般来说, 若只将单一LSTM网络作为语言模型, 则在本时刻的单词预测仅可根据前几个时刻的信息来推断. 然而, 随着时间轴的不断延长, 解码器较大概率会出现错误累积现象[16]. 因此在当前时刻采用纠正手段来缓解错误累积, 可在一定程度上提高密集描述的准确率. 由第1.3.1节可知, SSA模块可结合解码器上一时刻的预测单词, 来指导下一时刻的单词预测. 基于此, 本文设计如图4所示的多分支解码器结构以实现在当前时刻对预测单词的及时纠正. 多分支解码器结构由两个SSA模块、一个L-LSTM网络和两个A-LSTM网络组成. 三个LSTM网络的输入构成级联以实现同一时刻的错误纠正, 其输出构成并联以完成本时刻预测单词的反复验证.
三个LSTM网络的初始化向量均为局部特征、全局特征及上下文特征的串行连接向量
$ F_{\rm concat} $ . 在密集描述文本生成前, 网络初始化过程为:$$ \begin{equation} F_{\rm concat} = {\rm concat}(F_{\rm local},F_{\rm global},F_{\rm context}) \end{equation} $$ (6) $$ \begin{equation} \left\{ \begin{aligned} &h_1^{L} = {\rm{ L}} \text{-} {\rm{LSTM}}(F_{\rm concat},h_0^{L}) \\ &h_1^{A1} = {\rm{ A}} \text{-} {\rm{LSTM}}(F_{\rm concat},h_0^{A1}) \\ &h_1^{A2} = {\rm{ A}} \text{-} {\rm{LSTM}}(F_{\rm concat},h_0^{A2}) \end{aligned} \right. \end{equation} $$ (7) 其中,
$ F_{\rm local} $ ,$ F_{\rm global} $ 和$ F_{\rm context} $ 分别表示描述区域特征, 全局信息特征和上下文信息特征;$ F_{\rm concat} $ 表示特征向量的拼接. 在$ t $ 时刻下, 为生成预测单词$ y_t $ , 解码器${\rm{ L}} \text{-} {\rm{LSTM}} $ 的向量转化如下:$$ \begin{equation} h_t^{L} = {\rm{ L}} \text{-} {\rm{LSTM}}(F_{\rm concat},y_{t-1},h_{t-1}^{L}) \end{equation} $$ (8) 其中,
$ h_{t}^{L} $ 代表${\rm{ L}} \text{-} {\rm{LSTM}} $ 网络在$ t $ 时刻预测的单词向量. 为避免错误累积, 多分支解码器采用两个${\rm{ A}} \text{-} {\rm{LSTM}} $ 网络对单词向量进行纠正:$$ \begin{equation} \left\{ \begin{aligned} &F_1 = {\rm SSA}(F,h_t^{L}) \\ &h_t^{A1} = {\rm{ A}} \text{-} {\rm{LSTM}}(F_1,y_{t-1},h_{t-1}^{A1}) \\ &F_2 = {\rm SSA}(F,h_t^{A1}) \\ &h_t^{A2} = {\rm{ A}} \text{-} {\rm{LSTM}}(F_2,y_{t-1},h_{t-1}^{A2}) \end{aligned} \right. \end{equation} $$ (9) 其中,
$ h_{t}^{A1} $ 和$ h_{t}^{A2} $ 表示经过${\rm{ L}} \text{-} {\rm{LSTM}} $ 解码器一次纠正和二次纠正后的预测单词向量,$ F_{1} $ 和$ F_{2} $ 表示经SSA模块优化后的多尺度环路融合特征. 由此可知, 多分支解码器不仅可实现当前时刻预测单词的及时纠正, 还为单词预测过程引入了几何信息和空间位置信息, 从而使模型生成的描述文本更为精细. 最后, 多分支解码器更新当前隐藏状态$ h_{t} $ :$$ \begin{equation} h_t = {\rm Add}(h_{t}^{L} + h_{t}^{A1} + h_{t}^{A2}) \end{equation} $$ (10) 1.4 算法复杂度分析
MAS-ED方法主要包括多尺度特征环路融合、空间位置注意权重获取和多分支解码器建模几个步骤. 在多尺度特征环路融合中, 由于本文模型无需调整特征图通道数, 因此可去除MFLF机制的1×1卷积层, 故MFLF机制共有3次加法运算、3次上采样和2次下采样. 实验中上采样和下采样由双线性插值函数来完成, 因此每个像素点坐标需完成8次乘法和11次加法运算. 因此MFLF机制的乘法运算次数为
$ 40 \times (w \times h) $ , 加法运算次数为$ 55 \times (w \times h) + 3 $ . 新增8个输出特征图, 故空间、时间复杂度分别为$ {\rm O}(8 \times (w \times h \times C)) $ 、$ {\rm O}(95 \times (w \times h) + 3) $ . 而将同等$ w \times h $ 分辨率的高维特征图送入单个卷积层后, 其时间和空间复杂度可达到${\rm O}(k^{2} \times w \times h \times C_{\rm in} \times C_{\rm out})$ 和$ {\rm O}(k^{2} \times C_{\rm in} \times C_{\rm out}) $ . 由此可知, MFLF机制增加的计算量和参数量尚不如一个卷积操作.用SSA模块获取空间位置注意权重时, 模型需要完成3次加法运算、4次矩阵乘法运算、2次
$ {\rm ReLu} $ 非线性变换和4次CLAM模块. 每个CLAM模块包含2次池化、2次$ {\rm ReLu} $ 变换、4 次卷积和1次Sigmoid变换. 其中, 仅卷积操作和中间新增特征图涉及空间复杂度计算, 故SSA模块增加的参数量为$ {\rm O}(k^{2} \times C_{\rm in} \times C_{\rm out} + w \times h \times C) $ , 增加的计算量为$ {\rm O}(k^{2} \times w \times h \times C_{\rm in} \times C_{\rm out} + C + C^{2}) $ . 此外, 构建多分支解码器建模时, 模型仅增加了1 次加法运算, 可以忽略.基于编码器−解码器框架下, CAG-Net[18]方法采用VGG16网络进行特征提取, 并将3个LSTM网络用于文本序列解码; 而MAS-ED则采用ResNet-152网络, 同样使用3个LSTM网络用于解码. VGG16和ResNet-152的计算复杂度大致等同[23], 但前者参数量超出后者约21 MB. 暂不考虑CAG-Net所提出的CFE和CCI这两个模块, 仅基础架构模型的参数量就已超MAS-ED所有参数量; 而且两者计算复杂度基本持平. TDC (Transformer-based dense captioner)[20]模型同样采用参数量较少的ResNet-152网络, 但其后端解码网络使用了Transformer[28]. 与3个LSTM网络相比, Transformer网络增加的计算量和参数量相对较大. 综上可知, 相对于CAG-Net和TDC, MAS-ED虽然增加了MFLF机制和MSSA解码器两个模块, 但是增加的计算量和参数量均很小.
2. 实验与分析
2.1 数据集和评估指标
本文使用标准数据集Visual Genome对MAS-ED方法进行测试. 该数据集有V1.0和V1.2两个版本, V1.2比V1.0标注重复率更低, 标注语句也更符合人类习惯. 对数据集的处理同文献[15], 将出现次数少于15的单词换为 <UNK> 标记, 得到一个包含10 497个单词的词汇表; 将超过10个单词的注释语句去除, 来提高运行效率. 本文的数据划分方式同基线方法, 77 398张图片用于训练, 5 000张图片用于验证和测试. 本文基于V1.0和V1.2两个版本的数据集来验证方法的有效性.
与目标检测任务的平均准确均值(Mean average precision, mAP)指标不同, 本文所用的mAP指标专门用来评估图像密集描述任务, 由文献[15]首次提出. 该指标的计算过程为: 首先, 利用交并比函数(IoU), 将区域间重叠分值处于
$\{0.2, 0.3, 0.4, 0.5, 0.6\}$ 的几种精度均值(Average precision, AP) 作为预测区域性定位的准确性度量; 之后, 使用METEOR指标[29]将语义相似度处于$\{0, 0.05, 0.10, 0.15, 0.20, 0.25\}$ 的几种精度均值(AP), 作为预测文本和真值标注间的语义相似度度量; 最后, 计算这几组AP的平均值作为最终的mAP分值.2.2 实验设置
本文采用文献[17]的近似联合训练方法来实现模型的端到端训练, 并使用随机梯度下降来优化模型, 其学习率和迭代数的设置均与基线方法相同. 训练过程中, 图像批大小设为1, 且每次前向训练中为单个图像生成256个感兴趣区域. 实验使用具有512个隐藏节点的LSTM单元, 并将单词序列长度设为12. 对于测试评估, 将高度重叠的框合并为具有多个参考标题的单个框, 来预处理验证/测试集中的真值标注区域. 具体地, 对于每个图像, 迭代选择具有最多重叠框的框(基于阈值为0.7的IoU), 将它们合并在具有多个标注的单个框中. 之后排除该组, 并重复以上过程.
2.3 MAS-ED评估
为验证MAS-ED方法的有效性和可靠性, 本文选取几种典型的基线方法来完成对比实验. 基线方法根据网络框架分为两组: 基于LSTM解码网络框架和基于Transformer解码网络框架. 其中, 仅TDC[20]模型为基于Transformer解码网络框架. 密集描述模型性能由mAP分值来评估.
基于LSTM解码网络框架下的各模型性能如表1所示. 针对V1.0数据集, 与FCLN相比, MAS-ED的mAP分值提高了98.01%, 性能提升明显; 与T-LSTM和COCG相比, MAS-ED的mAP分别提升了14.64%和8.76%. 由于T-LSTM和COCG模型仅致力于上下文信息的改进, 而MAS-ED不仅考虑到上下文关系, 还有效利用浅层特征和空间位置关系, 所以本文mAP性能得到有效提升. 与最先进的CAG-Net方法相比, 为公平起见, MAS-ED未使用ResNet-152网络而使用VGG16网络, 其mAP性能仍提升1.55%. 这表明, MAS-ED优于CAG-Net. 针对V1.2数据集, MAS-ED性能同样优于基线方法, 与最先进的COCG相比, MAS-ED获得了6.26%的性能优势.
表 1 基于LSTM解码网络密集描述算法mAP性能Table 1 mAP performance of dense caption algorithms based on LSTM decoding network表2所示为基于Transformer解码网络框架下的模型性能. 由表2可见, MAS-ED方法的mAP分值优于TDC方法, 在V1.2数据集上mAP分值达到了11.04; 而与TDC + ROCSU模型相比, MAS-ED性能稍差. 但TDC + ROCSU模型算法复杂度远高于MAS-ED. 具体来说, TDC + ROCSU模型选用Transformer作为序列解码器, 而本文选用LSTM网络, 前者所增加的计算量和参数量远远大于后者; 其次, TDC + ROCSU模型在使用ROCSU模块获取上下文时, 部分网络不能进行on-line训练, 无法实现整个网络的端到端训练, 而MAS-ED却可实现端到端的网络优化; 最后, TDC + ROCSU致力于获取准确的文本描述, 而MAS-ED不仅考虑文本描述的准确性, 还试图为文本增加几何细节和空间位置关系, 在一定程度上增加了文本的丰富度. 所以相比于TDC + ROCSU模型, 本文方法MAS-ED算法复杂度低, 可端到端优化且能提高文本丰富性.
表 2 基于非LSTM解码网络密集描述算法mAP性能Table 2 mAP performance of dense caption algorithms based on non-LSTM decoding network模型 V1.0 V1.2 TDC 10.64 10.33 TDC + ROCSU 11.49 11.90 MAS-ED 10.68 11.04 2.4 消融实验
本文共实现了三种基于注意结构的密集描述模型: 1)多尺度特征环路融合模型(MFLF-ED), 使用深、浅层网络的融合特征作为视觉信息, 由标准三层LSTM解码; 2)多分支空间分步注意力模型(MSSA-ED), 仅使用深层网络特征作为视觉信息, 由多分支空间分步注意力解码器解码; 3)多重注意结构模型(MAS-ED), 使用深、浅层网络的融合特征作为视觉信息, 由多分支空间分步注意力解码器解码. 为验证两个模块的有效性, 在相同实验条件下, 本文设置了如表3所示的对比实验.
表 3 VG数据集上密集描述模型mAP性能Table 3 mAP performance of dense caption models on VG dataset模型 VGG16 ResNet-152 Baseline[17] 9.31 9.96 MFLF-ED 10.29 10.65 MSSA-ED 10.42 11.87 MAS-ED 10.68 11.04 由表3可知, 在两种不同网络框架下, MSSA-ED模型和MFLF-ED模型的性能表现均优于基线模型, 这表明浅层细节信息和空间位置信息都利于图像的密集描述. 此外, MSSA-ED模型要比MFLF-ED模型表现更优. 这是因为在MSSA解码器中, SSA模块通过上一解码器的预测单词指导下一解码器的单词生成时, 模块有额外视觉特征输入, 所以MSSA-ED模型除了可获取物体的空间位置信息, 还在一定程度上利用了视觉特征中区域目标的相关信息. 而MFLF-ED模型仅使用MFLF机制来融合多尺度特征, 增加几何信息, 以此提升小目标的检测精度和增加大目标的描述细节. 因此相对而言, MSSA-ED模型的改进方法较为多元, 实验效果较好.
此外, MAS-ED模型性能优于两个单独模型. 这是因为在MAS-ED模型训练过程中, MSSA解码器通过反向传播机制, 促使MFLF机制不断调整视觉融合特征中语义信息和几何信息的参与比例; 同时, MFLF机制通过提供优质融合特征, 来辅助MSSA解码器尽最大可能地获取区域实体间的空间位置关系. 最后, 由表3可知, 基于ResNet-152的三个消融模型性能比基于VGG16更优越. 说明密集描述模型不仅需要具有几何细节的浅层特征, 也需要包含丰富语义的深层特征, 从而也证明本文将深层残差网络ResNet-152作为特征提取网络的正确性.
2.4.1 MFLF-ED
为探索MFLF机制的最佳实现方式, 本文设计了不同语义流和几何流支路组合的性能对比实验, 实验结果如表4所示. 由MFLF机理可知, 语义流的源特征层应为最高的C4层, 以保证最优的语义信息可流向低层特征图; 其目的特征层应为最低的C2层, 以确保较完整的几何细节可流向高层特征图. 而几何流的源特征层和目的特征层应与语义流相反, 从而几何流和语义流构成环路融合. 语义流有4种情况: C4-C2, C4-C3 & C3-C2, C4-C2+(C3-C2), C4-C2+(C4-C3 & C3-C2), 同样几何流有C2-C4, C2-C3 & C3-C4, C2-C4+(C3-C4)和C2-C4+(C2-C3 & C3-C4). 本文将从源特征层直接流向目的特征层的分支(如C4-C2)称为直接流向分支, 而将途经其他特征层的分支(如C4-C3 & C3-C2)称为逐层流向分支.
表 4 不同分支组合模型的mAP性能比较Table 4 Comparison of mAP performance of different branch combination models语义流 几何流 C2-C4 C2-C3 & C3-C4 C2-C4 + (C3-C4) C2-C4 + (C2-C3 & C3-C4) C3-C2 9.924 10.245 10.268 7.122 C4-C2 10.530 10.371 9.727 8.305 C4-C3 & C3-C2 10.125 10.349 10.474 10.299 C4-C2+(C3-C2) 10.654 10.420 10.504 10.230 C4-C2+(C4-C3&C3-C2) 10.159 10.242 10.094 7.704 由表4可知, 当语义流和几何流均采用单条直接流向分支[C4-C2]+[C2-C4]时, 其性能(10.530)优于两者均采用单条逐层流向分支[C4-C3 & C3-C2]+ [C2-C3 & C3-C4](10.349), 更优于两者均采用逐层流向分支和直接流向分支[C4-C2+(C4-C3 & C3-C2)]+[C2-C4+(C2-C3 & C3-C4)](7.704). 这是由于直接流向结构可确保源特征图信息完整地融入目的特征图, 而逐层流向结构会造成信息丢失. 此外, 若同时使用两种结构进行信息传播, 由于信息含量过多且较为冗杂, 会造成显著性信息缺失, 从而性能表现最差.
当语义流和几何流均选用单条直接流向分支和部分逐层流向分支[C4-C2+(C3-C2)]+[C2-C4+(C3-C4)] 时, 其模型性能(10.504)虽优于逐层流向结构模型(10.349), 但劣于直接流向结构模型(10.530). 为进一步提高模型性能, 本文选择分开考虑语义流和几何流配置. 当语义流选用直接流向分支, 而几何流选用直接流向分支和部分逐层流向分支[C4-C2]+[C2-C4+(C3-C4)]时, 其模型性能较差(9.727). 而当语义流选用直接流向分支和部分逐层流向分支, 几何流选用直接流向分支[C4-C2+(C3-C2)]+[C2-C4]时, 其模型性能(10.654)要优于直接流向结构模型(10.530).
除此之外, 由表4中前2行数据可知, C4层中的优质语义信息多于C3层, C2层中的几何细节信息也比C3层多, 从而进一步证明了MFLF机制将C4层和C2层作为源特征层和目的特征层的正确性.
综上, [C4-C2+(C3-C2)]+[C2-C4]是MFLF机制的最优组合方式. 为了更加直观, 本文将各模型的描述结果可视化如图5所示. 当语义流和几何流均采用直接流向和逐层流向的双通路实现时, 由于信息冗杂, 语句中含有的信息量少, 甚至出现错误信息, 如“A shelf of a shelf”. 当单独采用直接流向或逐层流向时, 语句中含有的语义和几何信息有所提升, 如“wood”和“yellow”. 随着网络结构不断优化, 生成语句中的语义信息更抽象, 如“kitchen room”, 几何信息也更加具体, 如“many items”.
 图 5 不同分支组合模型结果可视化(图中每行上面“[·]”表示语义流, 下面“[·]”表示几何流)Fig. 5 Visualization of results of different semantic flow branching models (The upper “[·]” of each line in the figure represents the semantic flow, and the lower “[·]” represents the geometric flow)
图 5 不同分支组合模型结果可视化(图中每行上面“[·]”表示语义流, 下面“[·]”表示几何流)Fig. 5 Visualization of results of different semantic flow branching models (The upper “[·]” of each line in the figure represents the semantic flow, and the lower “[·]” represents the geometric flow)2.4.2 MSSA-ED
1) SSA模块. 基于相同实验条件下, 本文在模型MSSA-ED上对SSA模块中上下两分支进行冗余性分析, 实验结果如表5所示. 表中Up-ED表示仅使用SSA模块上支路, 即先考虑预测单词在特征图height维度的加权, 后考虑width维度; Down-ED则仅使用SSA模块下支路, 维度加权顺序与上支路相反. 由表5可知, 两个单支路模型的性能相差不大, 而采用双支路的MSSA-ED性能优于两个单支路模型. 这是因为每个支路对两个空间维度(height维度和width维度)都进行加权考虑, 加权先后顺序对模型性能影响并不大, 若将上下两支路所得到的加权信息融合, 模型便可获得更加准确的空间位置信息.
表 5 SSA模块支路模型的mAP性能Table 5 mAP performance of SSA module branch model模型 Up-ED Down-ED MSSA-ED mAP 10.751 10.779 10.867 各模型的可视化效果如图6所示. Up-ED能检测出“sign”与“wall”的左右关系, Down-ED则捕捉到目标物体与“refrigerator”的高低关系, 而MSSA-ED则通过融合两个位置信息得出最符合真值标注的预测语句.
2)多分支解码器. 本文通过设计对比实验来确定多分支解码器的支路数, 实验结果见表6. 其中单支路表示仅添加一条A-LSTM通路, 依此类推两支路与三支路表示. 由表6可知, 基于三种不同SSA模块, 两支路模型的性能都优于单支路模型和三支路模型. 这是因为采用A-LSTM对预测单词进行实时纠正时, 过少支路的模型不能在复杂特征信息中准确定位描述目标; 而过多支路的模型, 虽对单目标区域十分友好, 但在多目标区域描述时, 会过度关注每个目标, 导致模型忽略目标间的语义关系.
表 6 不同支路数对多分支解码器性能的影响Table 6 Effects of different branch numbers on the performance of multi-branch decoders模型 单支路 两支路 三支路 Up-ED 10.043 10.751 10.571 Down-ED 10.168 10.779 10.686 MSSA-ED 10.347 10.867 10.638 为了更加直观, 图7将基于MSSA-ED的三种不同支路模型的注意权重可视化. 图中从左到右依次为原图、单支路注意图、两支路注意图和三支路注意图, 图下方为各模型的预测语句. 其中单支路模型的注意权重分布较分散, 无法准确捕捉到目标; 三支路对单目标注意相对集中, 但对多目标注意权重图成点簇状; 而两支路不仅能突出描述区域内的目标, 并且可关注到区域内目标间的空间位置关系.
2.5 可视化分析
为进一步直观表明各个模块实验效果, 图8给出了多个密集描述模型的定性表现. 由图中的描述语句可得, MFLF-ED模型可以描述出灌木丛“bush”的“small”和“green”, 建筑物“building”和公交车“bus”的颜色“red”等细节信息, 说明MFLF机制能为密集描述增加有效几何信息, 但描述语句均为简单句, 较少体现物体间的逻辑关系; MSSA-ED模型能够捕捉到建筑物“building”与植物“plants”、树“trees”与大象“elephant”间的空间位置关系, 证明MSSA解码器能为密集描述获取有效位置关系, 但因缺乏几何细节, 左子图中“bush”的信息表述模糊, 采用了广泛的“plant”来表述; 而MAS-ED模型不仅可检测出灌木丛“bush”、建筑物“building”以及公交车“bus”的颜色、大小细节, 而且还在一定程度上能够表达出各物体间的空间位置关系, 如“side”, “behind”等.
值得注意的是, MAS-ED模型的预测语句沿用了MSSA-ED中的“growing on”词组, 这表明“bush”的一种生长状态, 是基准描述语句中未体现的. 类似地, 右子图中的“beard man”也没有存在于基准语句中, 这些都体现了MAS-ED方法可为密集描述增加丰富度, 能够生成灵活多样的描述语句.
特殊地, 对于大目标物体的细节信息, 如“build-ing”, MAS-ED模型指出了该物体的颜色“red”和组成“brick”. 但GT和MFLF-ED模型的语句中仅体现了颜色这一细节, 因此“brick” 是MAS-ED模型自适应添加的几何细节, 且该几何细节完全符合图中物体. 此外, MAS-ED还一定程度上增加了小目标物体的精确检测, 如GT语句中未体现“beard man”. 该目标是MAS-ED模型在描述语句中自适应增加的, 并且由图8可知当前描述区域中的确含有这一目标. 此外, 图8中间子图的密集描述语句体现了MAS-ED模型可自适应加入位置信息. 在该子图中, MSSA-ED模型捕捉到了“tress”与“elephant”间的位置关系, 但MAS-ED模型中却未体现, 而是指出了“building”与“elephant”间的关系. 这是由于MAS-ED模型经训练后, 有选择地筛选出了最为突出的目标间位置信息.
3. 结论
本文提出了一种基于多重注意结构的图像密集描述生成方法, 该方法通过构建一个多尺度特征环路融合机制, 为文本描述增加了较为细节的几何信息; 并设计了多分支空间分步注意力解码器, 以加强描述目标间的空间位置关系. 实验结果表明, 基于LSTM解码网络框架, 本文MAS-ED方法的性能优于其他图像密集描述方法.
-

图 7 CycleGAN的训练过程((a)源域图像通过翻译网络G变换到目标域, 目标域图像通过翻译网络F变换到源域;(b)在源域中计算循环一致性损失; (c)在目标域中计算循环一致性损失)
Fig. 7 The training process of CycleGAN ((a) source images are transformed to target domain through translation network G, target images are transformed to source domain through translation network F; (b) calculate the cycle-consistency loss in source domain; (c) calculate the cycle-consistency loss in target domain.)
表 4 在Office31数据集上各深度域适应方法的准确率 (%)
Table 4 Accuracy of each deep domain adaptation method on Office31 dataset (%)
方法 ${\rm{A}}\to {\rm{W}}$ ${\rm{D}}\to {\rm{W}}$ ${\rm{W}}\to {\rm{D}}$ ${\rm{A}}\to {\rm{D}}$ ${\rm{D}}\to {\rm{A}}$ ${\rm{W}}\to {\rm{A}}$ 平均 ResNet50[26] 68.4 96.7 99.3 68.9 62.5 60.7 76.1 DAN[20] 80.5 97.1 99.6 78.6 63.6 62.8 80.4 DCORAL[42] 79.0 98.0 100.0 82.7 65.3 64.5 81.6 RTN[39] 84.5 96.8 99.4 77.5 66.2 64.8 81.6 DANN[27] 82.0 96.9 99.1 79.7 68.2 67.4 82.2 ADDA[75] 86.2 96.2 98.4 77.8 69.5 68.9 82.9 JAN[23] 85.4 97.4 99.8 84.7 68.6 70.0 84.3 MADA[2] 90.1 97.4 99.6 87.8 70.3 66.4 85.2 GTA[99] 89.5 97.9 99.8 87.7 72.8 71.4 86.5 CDAN[22] 94.1 98.6 100.0 92.9 71.0 69.3 87.7  下载: 导出CSV
下载: 导出CSV
表 5 在OfficeHome数据集上各深度域适应方法的准确率 (%)
Table 5 Accuracy of each deep domain adaptation method on OfficeHome dataset (%)
方法 ${\rm{A}}\to {\rm{C}}$ ${\rm{A}}\to {\rm{P}}$ ${\rm{A}}\to {\rm{R}}$ ${\rm{C}}\to {\rm{A}}$ ${\rm{C}}\to {\rm{P}}$ ${\rm{C}}\to {\rm{R}}$ ResNet50[26] 34.9 50.0 58.0 37.4 41.9 46.2 DAN[20] 43.6 57.0 67.9 45.8 56.5 60.4 DANN[27] 45.6 59.3 70.1 47.0 58.5 60.9 JAN[23] 45.9 61.2 68.9 50.4 59.7 61.0 CDAN[22] 50.7 70.6 76.0 57.6 70.0 70.0 方法 ${\rm{P}}\to {\rm{A}}$ ${\rm{P}}\to {\rm{C }}$ ${\rm{P}}\to {\rm{R}}$ ${\rm{R}}\to {\rm{A}}$ ${\rm{R}}\to {\rm{C }}$ ${\rm{R}}\to {\rm{P}}$ 平均 ResNet50[26] 38.5 31.2 60.4 53.9 41.2 59.9 46.1 DAN[20] 44.0 43.6 67.7 63.1 51.5 74.3 56.3 DANN[27] 46.1 43.7 68.5 63.2 51.8 76.8 57.6 JAN[23] 45.8 43.4 70.3 63.9 52.4 76.8 58.3 CDAN[22] 57.4 50.9 77.3 70.9 56.7 81.6 65.8
下载: 导出CSV
表 6 在Office31数据集上各部分域适应方法的准确率 (%)
Table 6 Accuracy of each partial domain adaptation method on Office31 dataset (%)
方法 ${\rm{A}}\to {\rm{W}}$ ${\rm{D}}\to {\rm{W}}$ ${\rm{W}}\to {\rm{D}}$ ${\rm{A}}\to {\rm{D}}$ ${\rm{D}}\to {\rm{A}}$ ${\rm{W}}\to {\rm{A}}$ 平均 ResNet50[26] 75.5 96.2 98.0 83.4 83.9 84.9 87.0 DAN[20] 59.3 73.9 90.4 61.7 74.9 67.6 71.3 DANN[27] 73.5 96.2 98.7 81.5 82.7 86.1 86.5 IWAN[109] 89.1 99.3 99.3 90.4 95.6 94.2 94.6 SAN[1] 93.9 99.3 99.3 94.2 94.1 88.7 94.9 PADA[107] 86.5 99.3 100.0 82.1 92.6 95.4 92.6 ETN[108] 94.5 100.0 100.0 95.0 96.2 94.6 96.7
下载: 导出CSV
表 7 在Office31数据集上各开集域适应方法的准确率 (%)
Table 7 Accuracy of each open set domain adaptation method on Office31 dataset (%)
方法 ${\rm{A}}\to {\rm{W}}$ ${\rm{A}}\to {\rm{D}}$ ${\rm{D}}\to {\rm{W}}$ OS OS* OS OS* OS OS* ResNet50[26] 82.5 82.7 85.2 85.5 94.1 94.3 RTN[39] 85.6 88.1 89.5 90.1 94.8 96.2 DANN[27] 85.3 87.7 86.5 87.7 97.5 98.3 OpenMax[145] 87.4 87.5 87.1 88.4 96.1 96.2 ATI-$ \lambda $[110] 87.4 88.9 84.3 86.6 93.6 95.3 OSBP[111] 86.5 87.6 88.6 89.2 97.0 96.5 STA[105] 89.5 92.1 93.7 96.1 97.5 96.5 方法 ${\rm{W}}\to {\rm{D}}$ ${\rm{D}}\to {\rm{A}}$ ${\rm{W}}\to {\rm{A}}$ 平均 OS OS* OS OS* OS OS* OS OS* ResNet50[26] 96.6 97.0 71.6 71.5 75.5 75.2 84.2 84.4 RTN[39] 97.1 98.7 72.3 72.8 73.5 73.9 85.4 86.8 DANN[27] 99.5 100.0 75.7 76.2 74.9 75.6 86.6 87.6 OpenMax[145] 98.4 98.5 83.4 82.1 82.8 82.8 89.0 89.3 ATI-$ \lambda $[110] 96.5 98.7 78.0 79.6 80.4 81.4 86.7 88.4 OSBP[111] 97.9 98.7 88.9 90.6 85.8 84.9 90.8 91.3 STA[105] 99.5 99.6 89.1 93.5 87.9 87.4 92.9 94.1
下载: 导出CSV
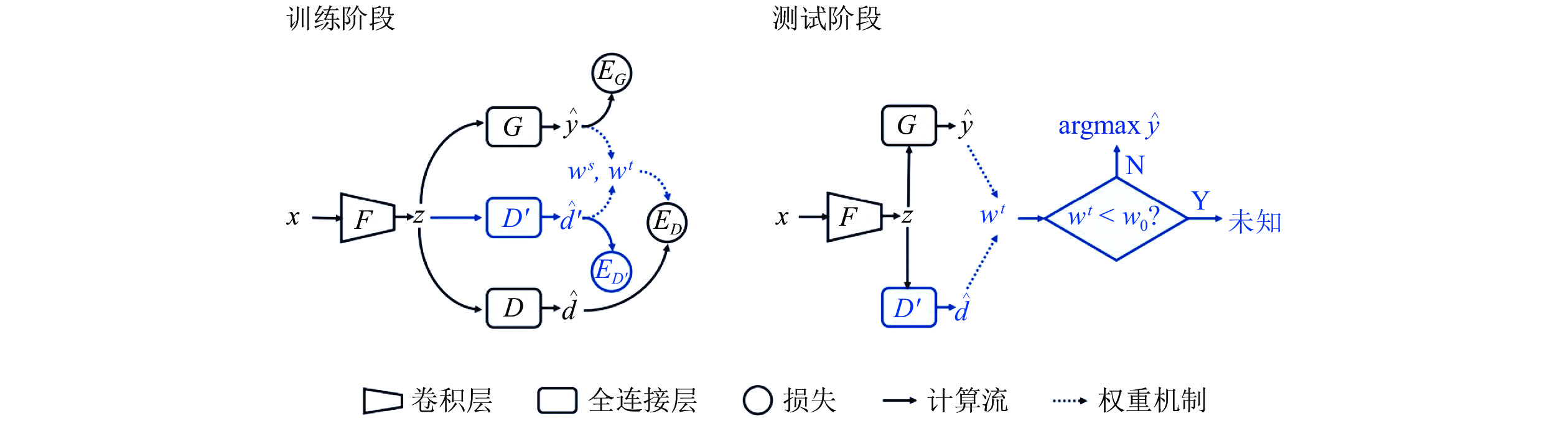
表 8 在OfficeHome数据集上通用域适应及其他方法的准确率 (%)
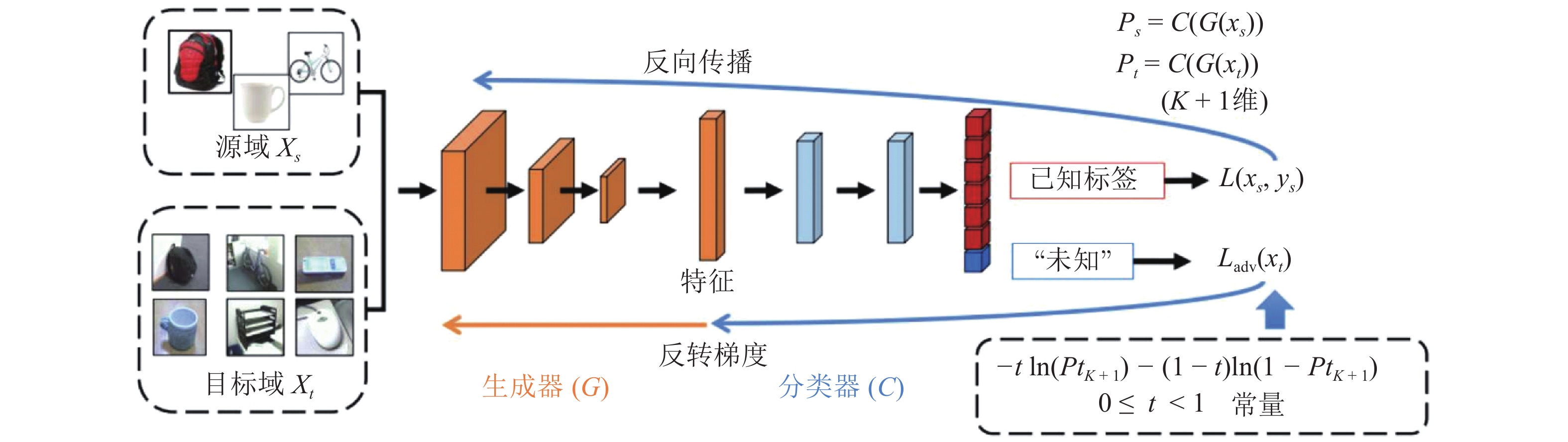
Table 8 Accuracy of universal domain adaptation and other methods on OfficeHome dataset (%)
方法 ${\rm{A}}\to {\rm{C}}$ ${\rm{A}}\to {\rm{P}}$ ${\rm{A}}\to {\rm{R}}$ ${\rm{C}}\to {\rm{A}}$ ${\rm{C}}\to {\rm{P}}$ ${\rm{C}}\to {\rm{R}}$ ResNet[26] 59.4 76.6 87.5 69.9 71.1 81.7 DANN[27] 56.2 81.7 86.9 68.7 73.4 83.8 RTN[39] 50.5 77.8 86.9 65.1 73.4 85.1 IWAN[109] 52.6 81.4 86.5 70.6 71.0 85.3 PADA[107] 39.6 69.4 76.3 62.6 67.4 77.5 ATI-$ \lambda $[110] 52.9 80.4 85.9 71.1 72.4 84.4 OSBP[111] 47.8 60.9 76.8 59.2 61.6 74.3 UAN[106] 63.0 82.8 87.9 76.9 78.7 85.4 方法 ${\rm{P}}\to {\rm{A}}$ ${\rm{P}}\to {\rm{C}}$ ${\rm{P}}\to {\rm{R}}$ ${\rm{R}}\to {\rm{A}}$ ${\rm{R}}\to {\rm{C}}$ ${\rm{R}}\to {\rm{P}}$ 平均 ResNet[26] 73.7 56.3 86.1 78.7 59.2 78.6 73.2 DANN[27] 69.9 56.8 85.8 79.4 57.3 78.3 73.2 RTN[39] 67.9 45.2 85.5 79.2 55.6 78.8 70.9 IWAN[109] 74.9 57.3 85.1 77.5 59.7 78.9 73.4 PADA[107] 48.4 35.8 79.6 75.9 44.5 78.1 62.9 ATI-$ \lambda $[110] 74.3 57.8 85.6 76.1 60.2 78.4 73.3 OSBP[111] 61.7 44.5 79.3 70.6 55.0 75.2 63.9 UAN[106] 78.2 58.6 86.8 83.4 63.2 79.4 77.0
下载: 导出CSV
表 9 在Office31数据集上AMEAN及其他方法的准确率 (%)
Table 9 Accuracy of AMEAN and other methods on Office31 dataset (%)
下载: 导出CSV
表 10 在Office31数据集上DADA及其他方法的准确率 (%)
Table 10 Accuracy of DADA and other methods on Office31 dataset (%)
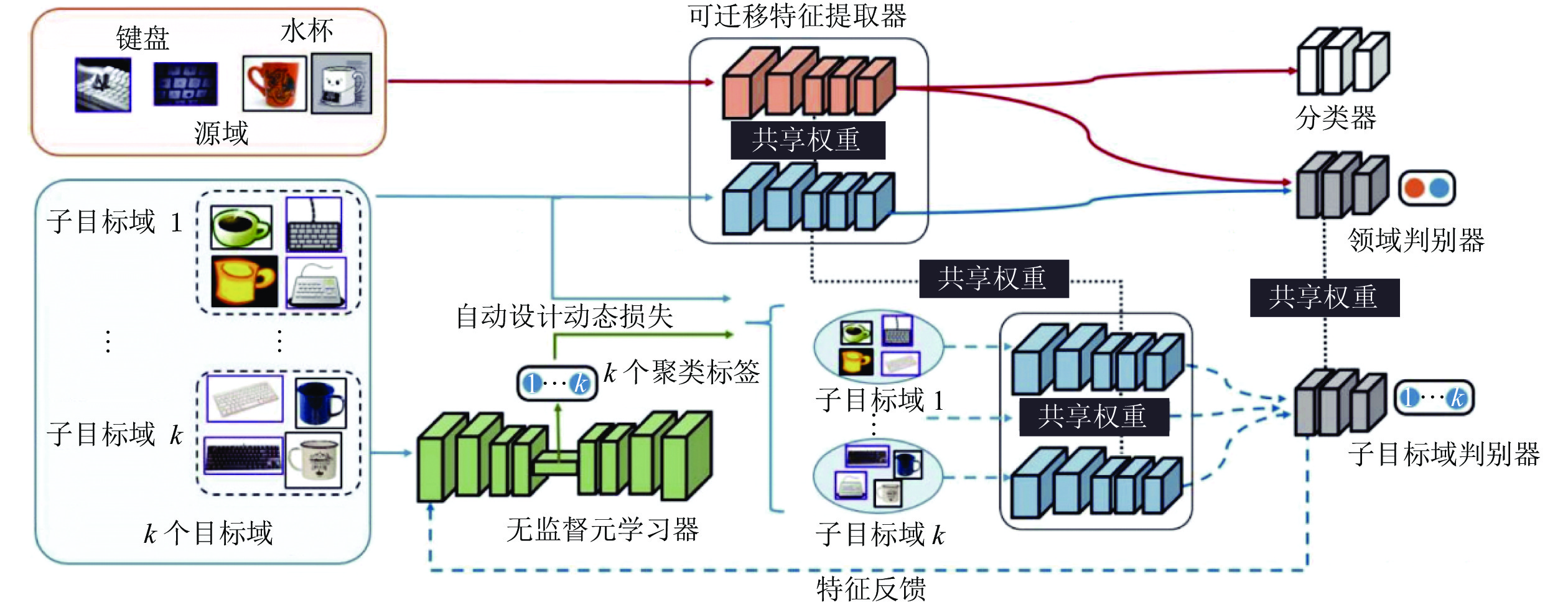
方法 ${\rm{A} }\to {\rm{C} }, $$ \;{\rm{ D},\;\rm{W} }$ ${\rm{C} }\to {\rm{A} }, $$ \; {\rm{D},\;\rm{W} }$ ${\rm{D} }\to {\rm{A} },\; $$ {\rm{C},\;{\rm{W} } }$ ${\rm{W} }\to {\rm{A} }, $$ \;{\rm{C},\;\rm{D} }$ 平均 ResNet[26] 90.5 94.3 88.7 82.5 89.0 MCD[28] 91.7 95.3 89.5 84.3 90.2 DANN[27] 91.5 94.3 90.5 86.3 90.6 DADA[4] 92.0 95.1 91.3 93.1 92.9
下载: 导出CSV
表 11 在MNIST数据集上领域泛化方法的准确率 (%)
Table 11 Accuracy of domain generalization methods on MNIST dataset (%)
源域 目标域 DAE DICA D-MTAE MMD-AAE ${M}_{ {15} },\;{M}_{30},\;{M}_{45},\;{M}_{60},\;{M}_{75}$ $ {M}_{0} $ 76.9 70.3 82.5 83.7 ${M}_{ {0} },\;{M}_{30},\;{M}_{45},\;{M}_{60},\;{M}_{ {75} }$ $ {M}_{15} $ 93.2 88.9 96.3 96.9 ${M}_{ {0}},\;{M}_{15},\;{M}_{45},\;{M}_{60},\;{M}_{{75} }$ $ {M}_{30} $ 91.3 90.4 93.4 95.7 ${M}_{ {0}},\;{M}_{15},\;{M}_{30},\;{M}_{60},\;{M}_{{75} }$ $ {M}_{45} $ 81.1 80.1 78.6 85.2 ${M}_{ {0}},\;{M}_{15},\;{M}_{30},\;{M}_{45},\;{M}_{{75} }$ $ {M}_{60} $ 92.8 88.5 94.2 95.9 ${M}_{ {0}},\;{M}_{15},\;{M}_{30},\;{M}_{45},\;{M}_{{60} }$ $ {M}_{75} $ 76.5 71.3 80.5 81.2 平均 85.3 81.6 87.6 89.8
下载: 导出CSV
-
[1] Cao Z J, Long M S, Wang J M, Jordan M I. Partial transfer learning with selective adversarial networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 2724−2732 [2] Pei Z Y, Cao Z J, Long M S, Wang J M. Multi-adversarial domain adaptation. In: Proceedings of the 32nd Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 3934−3941 [3] Gholami B, Sahu P, Rudovic O, Bousmalis K, Pavlovic V. Unsupervised multi-target domain adaptation: An information theoretic approach. IEEE Transactions on Image Processing, 2020, 29: 3993−4002 doi: 10.1109/TIP.2019.2963389 [4] Peng X C, Huang Z J, Sun X M, Saenko K. Domain agnostic learning with disentangled representations. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: ICML, 2019. 5102−5112 [5] Bousmalis K, Trigeorgis G, Silberman N, Krishnan D, Erhan D. Domain separation networks. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 343−351 [6] Pan S J, Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345−1359 doi: 10.1109/TKDE.2009.191 [7] Shao L, Zhu F, Li X L. Transfer learning for visual categorization: A survey. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(5): 1019−1034 doi: 10.1109/TNNLS.2014.2330900 [8] Liang H, Fu W L, Yi F J. A survey of recent advances in transfer learning. In: Proceedings of the 2019 IEEE 19th International Conference on Communication Technology. Xi' an, China: IEEE, 2019. 1516−1523 [9] Chu C H, Wang R. A survey of domain adaptation for neural machine translation. In: Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe, New Mexico, USA: COLING, 2018. 1304−1319 [10] Ramponi A, Plank B. Neural unsupervised domain adaptation in NLP: A survey. In: Proceedings of the 28th International Conference on Computational Linguistics. Barcelona, Spain: COLING, 2020. 6838−6855 [11] Day O, Khoshgoftaar T M. A survey on heterogeneous transfer learning. Journal of Big Data, 2017, 4: Article No. 29 doi: 10.1186/s40537-017-0089-0 [12] Patel V M, Gopalan R, Li R N, Chellappa R. Visual domain adaptation: A survey of recent advances. IEEE Signal Processing Magazine, 2015, 32(3): 53−69 doi: 10.1109/MSP.2014.2347059 [13] Weiss K, Khoshgoftaar T M, Wang D D. A survey of transfer learning. Journal of Big Data, 2016, 3: Article No. 9 doi: 10.1186/s40537-016-0043-6 [14] Csurka G. Domain adaptation for visual applications: A comprehensive survey. arXiv: 1702.05374, 2017. [15] Wang M, Deng W H. Deep visual domain adaptation: A survey. Neurocomputing, 2018, 312: 135−153 doi: 10.1016/j.neucom.2018.05.083 [16] Tan C Q, Sun F C, Kong T, Zhang W C, Yang C, Liu C F. A survey on deep transfer learning. In: Proceedings of the 27th International Conference on Artificial Neural Networks. Rhodes, Greece: Springer, 2018. 270−279 [17] Wilson G, Cook D J. A survey of unsupervised deep domain adaptation. ACM Transactions on Intelligent Systems and Technology, 2020, 11(5): Article No. 51 [18] Zhuang F Z, Qi Z Y, Duan K Y, Xi D B, Zhu Y C, Zhu H S, et al. A comprehensive survey on transfer learning. Proceedings of the IEEE, 2021, 109(1): 43−76 doi: 10.1109/JPROC.2020.3004555 [19] Ben-David S, Blitzer J, Crammer K, Kulesza A, Pereira F, Vaughan J W. A theory of learning from different domains. Machine Learning, 2010, 79(1-2): 151−175 doi: 10.1007/s10994-009-5152-4 [20] Long M S, Cao Y, Wang J M, Jordan M I. Learning transferable features with deep adaptation networks. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: ICML, 2015. 97−105 [21] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2242−2251 [22] Long M S, Cao Z J, Wang J M, Jordan M I. Conditional adversarial domain adaptation. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: NeurIPS, 2018. 1647−1657 [23] Long M S, Zhu H, Wang J M, Jordan M I. Deep transfer learning with joint adaptation networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: ICML, 2017. 2208−2217 [24] Zhao H, Des Combes R T, Zhang K, Gordon G J. On learning invariant representations for domain adaptation. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: ICML, 2019. 7523−7532 [25] Liu H, Long M S, Wang J M, Jordan M I. Transferable adversarial training: A general approach to adapting deep classifiers. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: ICML, 2019. 4013−4022 [26] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 770−778 [27] Ganin Y, Lempitsky V S. Unsupervised domain adaptation by backpropagation. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: ICML, 2015. 1180−1189 [28] Saito K, Watanabe K, Ushiku Y, Harada T. Maximum classifier discrepancy for unsupervised domain adaptation. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 3723−3732 [29] Wang Z R, Dai Z H, Póczos B, Carbonell J. Characterizing and avoiding negative transfer. In: Proceedings of the 2019 Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 11285−11294 [30] Chen C Q, Xie W P, Huang W B, Rong Y, Ding X H, Xu T Y, et al. Progressive feature alignment for unsupervised domain adaptation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 627−636 [31] Tan B, Song Y Q, Zhong E H, Yang Q. Transitive transfer learning. In: Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney, Australia: KDD, 2015. 1155−1164 [32] Tan B, Zhang Y, Pan S J, Yang Q. Distant domain transfer learning. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, USA: AAAI, 2017. 2604−2610 [33] Yosinski J, Clune J, Bengio Y, Lipson H. How transferable are features in deep neural networks? In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: NIPS, 2014. 3320−3328 [34] Ghifary M, Kleijn W B, Zhang M J. Domain adaptive neural networks for object recognition. In: Proceedings of the 13th Pacific Rim International Conference on Artificial Intelligence. Gold Coast, Australia: Springer, 2014. 898−904 [35] Tzeng E, Hoffman J, Zhang N, Saenko K, Darrell T. Deep domain confusion: Maximizing for domain invariance. arXiv: 1412.3474 , 2014. [36] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, USA: NIPS, 2012. 1097−1105 [37] Zhang X, Yu F X, Chang S F, Wang S J. Deep transfer network: Unsupervised domain adaptation. arXiv: 1503.00591, 2015. [38] Yan H L, Ding Y K, Li P H, Wang Q L, Xu Y, Zuo W M. Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 945−954 [39] Long M S, Zhu H, Wang J M, Jordan M I. Unsupervised domain adaptation with residual transfer networks. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 136−144 [40] 皋军, 黄丽莉, 孙长银. 一种基于局部加权均值的领域适应学习框架. 自动化学报, 2013, 39(7): 1037−1052Gao Jun, Huang Li-Li, Sun Chang-Yin. A local weighted mean based domain adaptation learning framework. Acta Automatica Sinica, 2013, 39(7): 1037−1052 [41] Sun B C, Feng J S, Saenko K. Return of frustratingly easy domain adaptation. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, USA: AAAI, 2016. 2058−2065 [42] Sun B C, Saenko K. Deep CORAL: Correlation alignment for deep domain adaptation. In: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 443−450 [43] Chen C, Chen Z H, Jiang B Y, Jin X Y. Joint domain alignment and discriminative feature learning for unsupervised deep domain adaptation. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI, 2019. 3296−3303 [44] Li Y J, Swersky K, Zemel R S. Generative moment matching networks. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: ICML, 2015. 1718−1727 [45] Zellinger W, Grubinger T, Lughofer E, Natschläger T, Saminger-Platz S. Central moment discrepancy (CMD) for domain-invariant representation learning. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: ICLR, 2017. [46] Courty N, Flamary R, Tuia D, Rakotomamonjy A. Optimal transport for domain adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(9): 1853−1865 doi: 10.1109/TPAMI.2016.2615921 [47] Courty N, Flamary R, Habrard A, Rakotomamonjy A. Joint distribution optimal transportation for domain adaptation. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: NIPS, 2017. 3733−3742 [48] Damodaran B B, Kellenberger B, Flamary R, Tuia D, Courty N. Deepjdot: Deep joint distribution optimal transport for unsupervised domain adaptation. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 467−483 [49] Lee C Y, Batra T, Baig M H, Ulbricht D. Sliced wasserstein discrepancy for unsupervised domain adaptation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 10277−10287 [50] Shen J, Qu Y R, Zhang W N, Yu Y. Wasserstein distance guided representation learning for domain adaptation. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 4058−4065 [51] Arjovsky M, Chintala S, Bottou L. Wasserstein generative adversarial networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: ICML, 2017. 214−223 [52] Herath S, Harandi M, Fernando B, Nock R. Min-max statistical alignment for transfer learning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 9280−9289 [53] Rozantsev A, Salzmann M, Fua P. Beyond sharing weights for deep domain adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(4): 801−814 doi: 10.1109/TPAMI.2018.2814042 [54] Shu X B, Qi G J, Tang J H, Wang J D. Weakly-shared deep transfer networks for heterogeneous-domain knowledge propagation. In: Proceedings of the 23rd ACM international conference on Multimedia. Brisbane, Australia: ACM, 2015. 35−44 [55] 许夙晖, 慕晓冬, 柴栋, 罗畅. 基于极限学习机参数迁移的域适应算法. 自动化学报, 2018, 44(2): 311−317Xu Su-Hui, Mu Xiao-Dong, Chai Dong, Luo Chang. Domain adaption algorithm with elm parameter transfer. Acta Automatica Sinica, 2018, 44(2): 311−317 [56] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: JMLR.org, 2015. 448−456 [57] Chang W G, You T, Seo S, Kwak S, Han B. Domain-specific batch normalization for unsupervised domain adaptation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 7346−7354 [58] Roy S, Siarohin A, Sangineto E, Buló S R, Sebe N, Ricci E. Unsupervised domain adaptation using feature-whitening and consensus loss. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 9463−9472 [59] Li Y H, Wang N Y, Shi J P, Liu J Y, Hou X D. Revisiting batch normalization for practical domain adaptation. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: OpenReview.net, 2017. [60] Ulyanov D, Vedaldi A, Lempitsky V. Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 4105−4113 [61] Carlucci F M, Porzi L, Caputo B, Ricci E, Bulò S R. AutoDIAL: Automatic domain alignment layers. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 5077−5085 [62] Xiao T, Li H S, Ouyang W L, Wang X G. Learning deep feature representations with domain guided dropout for person re-identification. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1249−1258 [63] Wu S, Zhong J, Cao W M, Li R, Yu Z W, Wong H S. Improving domain-specific classification by collaborative learning with adaptation networks. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI, 2019. 5450−5457 [64] Zhang Y B, Tang H, Jia K, Tan M K. Domain-symmetric networks for adversarial domain adaptation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 5026−5035 [65] Gopalan R, Li R N, Chellappa R. Domain adaptation for object recognition: An unsupervised approach. In: Proceedings of the 2011 International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 999−1006 [66] Gong B Q, Shi Y, Sha F, Grauman K. Geodesic flow kernel for unsupervised domain adaptation. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 2066−2073 [67] Chopra S, Balakrishnan S, Gopalan R. Dlid: Deep learning for domain adaptation by interpolating between domains. International Conference on Machine Learning Workshop on Challenges in Representation Learning, 2013, 2(6 [68] Gong R, Li W, Chen Y H, van Gool L. DLOW: Domain flow for adaptation and generalization. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 2472−2481 [69] Xu X, Zhou X, Venkatesan R, Swaminathan G, Majumder O. d-SNE: Domain adaptation using stochastic neighborhood embedding. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 2492−2501 [70] Yang B Y, Yuen P C. Cross-domain visual representations via unsupervised graph alignment. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI, 2019. 5613−5620 [71] Ma X H, Zhang T Z, Xu C S. GCAN: Graph convolutional adversarial network for unsupervised domain adaptation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 8258−8268 [72] Yang Z L, Zhao J J, Dhingra B, He K M, Cohen W W, Salakhutdinov R, et al. GLoMo: Unsupervised learning of transferable relational graphs. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: NeurIPS, 2018. 8964−8975 [73] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: NIPS, 2014. 2672−2680 [74] Chen X Y, Wang S N, Long M S, Wang J M. Transferability vs. Discriminability: Batch spectral penalization for adversarial domain adaptation. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019, 1081−1090 [75] Tzeng E, Hoffman J, Saenko K, Darrell T. Adversarial discriminative domain adaptation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 2962−2971 [76] Volpi R, Morerio P, Savarese S, Murino V. Adversarial feature augmentation for unsupervised domain adaptation. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 5495−5504 [77] Vu T H, Jain H, Bucher M, Cord M, Pérez P. ADVENT: Adversarial entropy minimization for domain adaptation in semantic segmentation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 2512−2521 [78] Tzeng E, Hoffman J, Darrell T, Saenko K. Simultaneous deep transfer across domains and tasks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 4068−4076 [79] Kurmi V K, Kumar S, Namboodiri V P. Attending to discriminative certainty for domain adaptation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 491−500 [80] Wang X M, Li L, Ye W R, Long M S, Wang J M. Transferable attention for domain adaptation. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI, 2019. 5345−5352 [81] Luo Y W, Zheng L, Guan T, Yu J Q, Yang Y. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 2502−2511 [82] Springenberg J T, Dosovitskiy A, Brox T, Riedmiller M A. Striving for simplicity: The all convolutional net. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [83] Selvaraju R R, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 618−626 [84] Chattopadhay A, Sarkar A, Howlader P, Balasubramanian V N. Grad-CAM++: Generalized gradient-based visual explanations for deep convolutional networks. In: Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Lake Tahoe, USA: IEEE, 2018. 839−847 [85] Bengio Y. Learning deep architectures for AI. Foundations and Trends® in Machine Learning, 2009, 2(1): 1−127 [86] Glorot X, Bordes A, Bengio Y. Domain adaptation for large-scale sentiment classification: A deep learning approach. In: Proceedings of the 28th International Conference on Machine Learning. Bellevue, USA: Omnipress, 2011. 513−520 [87] Chen M M, Xu Z E, Weinberger K Q, Sha F. Marginalized denoising autoencoders for domain adaptation. In: Proceedings of the 29th International Conference on Machine Learning. Edinburgh, UK: Omnipress, 2012. [88] Ghifary M, Kleijn W B, Zhang M J, Balduzzi D, Li W. Deep reconstruction-classification networks for unsupervised domain adaptation. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 597−613 [89] Zhuang F Z, Cheng X H, Luo P, Pan S J, He Q. Supervised representation learning: Transfer learning with deep autoencoders. In: Proceedings of the 24th International Joint Conference on Artificial Intelligence. Buenos Aires, Argentina: AAAI, 2015. 4119−4125 [90] Sun R Q, Zhu X G, Wu C R, Huang C, Shi J P, Ma L Z. Not all areas are equal: Transfer learning for semantic segmentation via hierarchical region selection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 4355−4364 [91] Tsai J C, Chien J T. Adversarial domain separation and adaptation. In: Proceedings of the 27th International Workshop on Machine Learning for Signal Processing. Tokyo, Japan: IEEE, 2017. 1−6 [92] Zhu P K, Wang H X, Saligrama V. Learning classifiers for target domain with limited or no labels. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 7643−7653 [93] Zheng H L, Fu J L, Mei T, Luo J B. Learning multi-attention convolutional neural network for fine-grained image recognition. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 5219−5227 [94] Zhao A, Ding M Y, Guan J C, Lu Z W, Xiang T, Wen J R. Domain-invariant projection learning for zero-shot recognition. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: NeurIPS, 2018. 1027−1038 [95] Liu M Y, Tuzel O. Coupled generative adversarial networks. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 469−477 [96] He D, Xia Y C, Qin T, Wang L W, Yu N H, Liu T Y, et al. Dual learning for machine translation. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 820−828 [97] Yi Z, Zhang H, Tan P, Gong M L. DualGAN: Unsupervised dual learning for image-to-image translation. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2868−2876 [98] Kim T, Cha M, Kim H, Lee J K, Kim J. Learning to discover cross-domain relations with generative adversarial networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 1857−1865 [99] Sankaranarayanan S, Balaji Y, Castillo C D, Chellappa R. Generate to adapt: Aligning domains using generative adversarial networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 8503−8512 [100] Yoo D, Kim N, Park S, Paek A S, Kweon I S. Pixel-level domain transfer. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 517−532 [101] Chen Y C, Lin Y Y, Yang M H, Huang J B. CrDoCo: Pixel-level domain transfer with cross-domain consistency. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 1791−1800 [102] Shrivastava A, Pfister T, Tuzel O, Susskind J, Wang W D, Webb R. Learning from simulated and unsupervised images through adversarial training. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 2242−2251 [103] Li Y S, Yuan L, Vasconcelos N. Bidirectional learning for domain adaptation of semantic segmentation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 6929−6938 [104] Bousmalis K, Silberman N, Dohan D, Erhan D, Krishnan D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 95−104 [105] Liu H, Cao Z J, Long M S, Wang J M, Yang Q. Separate to adapt: Open set domain adaptation via progressive separation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 2922−2931 [106] You K C, Long M S, Cao Z J, Wang J M, Jordan M I. Universal domain adaptation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 2715−2724 [107] Cao Z J, Ma L J, Long M S, Wang J M. Partial adversarial domain adaptation. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 139−155 [108] Cao Z J, You K C, Long M S, Wang J M, Yang Q. Learning to transfer examples for partial domain adaptation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 2980−2989 [109] Zhang J, Ding Z W, Li W Q, Ogunbona P. Importance weighted adversarial nets for partial domain adaptation. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 8156−8164 [110] Busto P P, Gall J. Open set domain adaptation. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 754−763 [111] Saito K, Yamamoto S, Ushiku Y, Harada T. Open set domain adaptation by backpropagation. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 156−171 [112] Li Y Y, Yang Y X, Zhou W, Hospedales T M. Feature-critic networks for heterogeneous domain generalization. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 3915−3924 [113] Chen Z L, Zhuang J Y, Liang X D, Lin L. Blending-target domain adaptation by adversarial meta-adaptation networks. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 2243−2252 [114] Shankar S, Piratla V, Chakrabarti S, Chaudhuri S, Jyothi P, Sarawagi S. Generalizing across domains via cross-gradient training. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: OpenReview.net, 2018. [115] Volpi R, Namkoong H, Sener O, Duchi J, Murino V, Savarese S. Generalizing to unseen domains via adversarial data augmentation. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: NeurIPS, 2018. 5339−5349 [116] Muandet K, Balduzzi D, Schölkopf B. Domain generalization via invariant feature representation. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, USA: JMLR.org, 2013. 10−18 [117] Li D, Yang Y X, Song Y Z, Hospedales T M. Learning to generalize: Meta-learning for domain generalization. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 3490−3497 [118] Li H L, Pan S J, Wang S Q, Kot A C. Domain generalization with adversarial feature learning. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 5400−5409 [119] Carlucci F M, D'Innocente A, Bucci S, Caputo B, Tommasi T. Domain generalization by solving jigsaw puzzles. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 2224−2233 [120] Ghifary M, Kleijn W B, Zhang M J, Balduzzi D. Domain generalization for object recognition with multi-task autoencoders. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 2551−2559 [121] Xu Z, Li W, Niu L, Xu D. Exploiting low-rank structure from latent domains for domain generalization. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: IEEE, 2014. 628−643 [122] Niu L, Li W, Xu D. Multi-view domain generalization for visual recognition. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 4193−4201 [123] Niu L, Li W, Xu D. Visual recognition by learning from web data: A weakly supervised domain generalization approach. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 2774−2783 [124] Chen Y H, Li W, Sakaridis C, Dai D X, Van Gool L. Domain adaptive faster R-CNN for object detection in the wild. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 3339−3348 [125] Inoue N, Furuta R, Yamasaki T, Aizawa K. Cross-domain weakly-supervised object detection through progressive domain adaptation. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 5001−5009 [126] Xu Y H, Du B, Zhang L F, Zhang Q, Wang G L, Zhang L P. Self-ensembling attention networks: Addressing domain shift for semantic segmentation. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI, 2019. 5581−5588 [127] Chen C, Dou Q, Chen H, Qin J, Heng P A. Synergistic image and feature adaptation: Towards cross-modality domain adaptation for medical image segmentation. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI, 2019. 865−872 [128] Agresti G, Schaefer H, Sartor P, Zanuttigh P. Unsupervised domain adaptation for ToF data denoising with adversarial learning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 5579−5586 [129] Yoo J, Hong Y J, Noh Y, Yoon S. Domain adaptation using adversarial learning for autonomous navigation. arXiv: 1712.03742, 2017. [130] Choi D, An T H, Ahn K, Choi J. Driving experience transfer method for end-to-end control of self-driving cars. arXiv: 1809.01822, 2018. [131] Bąk S, Carr P, Lalonde J F. Domain adaptation through synthesis for unsupervised person re-identification. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 193−209 [132] Deng W J, Zheng L, Ye Q X, Kang G L, Yang Y, Jiao J B. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 994−1003 [133] Li Y J, Yang F E, Liu Y C, Yeh Y Y, Du X F, Wang Y C F. Adaptation and re-identification network: An unsupervised deep transfer learning approach to person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City, USA: IEEE, 2018. 172−178 [134] 吴彦丞, 陈鸿昶, 李邵梅, 高超. 基于行人属性先验分布的行人再识别. 自动化学报, 2019, 45(5): 953−964Wu Yan-Cheng, Chen Hong-Chang, Li Shao-Mei, Gao Chao. Person re-identification using attribute priori distribution. Acta Automatica Sinica, 2019, 45(5): 953−964 [135] Côté-Allard U, Fall C L, Drouin A, Campeau-Lecours A, Gosselin C, Glette K, et al. Deep learning for electromyographic hand gesture signal classification using transfer learning. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2019, 27(4): 760−771 doi: 10.1109/TNSRE.2019.2896269 [136] Ren C X, Dai D Q, Huang K K, Lai Z R. Transfer learning of structured representation for face recognition. IEEE Transactions on Image Processing, 2014, 23(12): 5440−5454 doi: 10.1109/TIP.2014.2365725 [137] Shin H C, Roth H R, Gao M C, Lu L, Xu Z Y, Nogues I, et al. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Transactions on Medical Imaging, 2016, 35(5): 1285−1298 doi: 10.1109/TMI.2016.2528162 [138] Byra M, Wu M, Zhang X D, Jang H, Ma Y J, Chang E Y, et al. Knee menisci segmentation and relaxometry of 3D ultrashort echo time (UTE) cones MR imaging using attention U-Net with transfer learning. arXiv: 1908.01594, 2019. [139] Cao H L, Bernard S, Heutte L, Sabourin R. Improve the performance of transfer learning without fine-tuning using dissimilarity-based multi-view learning for breast cancer histology images. In: Proceedings of the 15th International Conference Image Analysis and Recognition. Póvoa de Varzim, Portugal: Springer, 2018. 779−787 [140] Kachuee M, Fazeli S, Sarrafzadeh M. ECG heartbeat classification: A deep transferable representation. In: Proceedings of the 2018 IEEE International Conference on Healthcare Informatics. New York, USA: IEEE, 2018. 443−444 [141] 贺敏, 汤健, 郭旭琦, 阎高伟. 基于流形正则化域适应随机权神经网络的湿式球磨机负荷参数软测量. 自动化学报, 2019, 45(2): 398−406He Min, Tang Jian, Guo Xu-Qi, Yan Gao-Wei. Soft sensor for ball mill load using damrrwnn model. Acta Automatica Sinica, 2019, 45(2): 398−406 [142] Zhao M M, Yue S C, Katabi D, Jaakkola T S, Bianchi M T. Learning sleep stages from radio signals: A conditional adversarial architecture. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 4100−4109 [143] Saenko K, Kulis B, Fritz M, Darrell T. Adapting visual category models to new domains. In: Proceedings of the 11th European Conference on Computer Vision. Crete, Greece: Springer. 2010. 213−226 [144] Venkateswara H, Eusebio J, Chakraborty S, Panchanathan S. Deep hashing network for unsupervised domain adaptation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 5385−5394 [145] Bendale A, Boult T E. Towards open set deep networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. [146] Shu Y, Cao Z J, Long M S, Wang J M. Transferable curriculum for weakly-supervised domain adaptation. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI, 2019. 4951−4958 -

 下载:
下载:

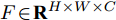
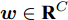
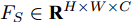
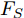
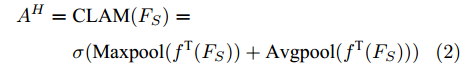
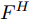


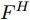
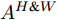
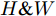
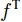

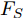
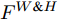
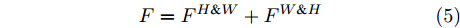
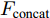
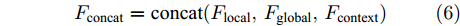
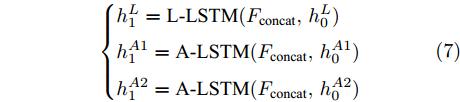
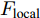
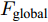
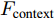
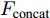
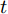
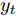
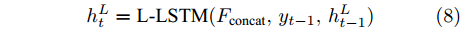
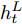
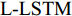
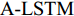
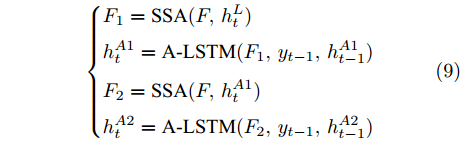
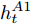
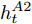

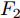
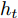
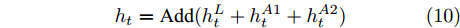
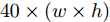
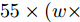
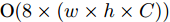
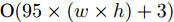

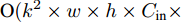
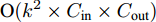
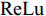
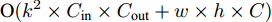
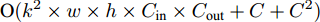
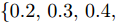
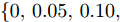




计量
- 文章访问数: 4754
- HTML全文浏览量: 2769
- PDF下载量: 1495
- 被引次数: 0
