

A Survey of Attack, Defense and Related Security Analysis for Deep Reinforcement Learning
-
摘要: 深度强化学习是人工智能领域新兴技术之一, 它将深度学习强大的特征提取能力与强化学习的决策能力相结合, 实现从感知输入到决策输出的端到端框架, 具有较强的学习能力且应用广泛. 然而, 已有研究表明深度强化学习存在安全漏洞, 容易受到对抗样本攻击. 为提高深度强化学习的鲁棒性、实现系统的安全应用, 本文针对已有的研究工作, 较全面地综述了深度强化学习方法、对抗攻击、防御方法与安全性分析, 并总结深度强化学习安全领域存在的开放问题以及未来发展的趋势, 旨在为从事相关安全研究与工程应用提供基础.Abstract: Deep reinforcement learning is one of the emerging technologies in the field of artificial intelligence. It combines the powerful feature extraction capabilities of deep learning with the decision-making capabilities of reinforcement learning to achieve an end-to-end framework from status input to the decision output, which also makes it regarded as an important way to general artificial intelligence. However, existing studies have shown that deep reinforcement learning has security vulnerabilities and is vulnerable to adversarial sample attacks. In order to improve the robustness of deep reinforcement learning and realize the security application of the system, this article comprehensively summarizes deep reinforcement learning methods, adversarial attacks, defense methods and security analysis based on existing research work, and summarizes deep reinforcement learning security The open problems in the field and future development trends are intended to provide a basis for relevant safety research and engineering applications.
-
Key words:
- Deep reinforcement learning /
- adversarial attack /
- defense /
- policy attack /
- security
-
表 1 经典深度强化学习算法对比
Table 1 Comparison of classic deep reinforcement learning algorithm
分类 算法 原理 贡献 不足 基于
值函数深度Q网络(DQN)[1-2] 使用经验回放机制打破样本相关性; 使用目标网络稳定训练过程 第一个能进行端到端学习的
深度强化学习框架训练过程不稳定; 无法处理
连续动作任务双重深度Q网络(DDQN)[3] 用目标网络来评估价值, 用评估网络选择动作 缓解了DQN对价值的过估计问题 训练过程不稳定; 无法
处理连续动作优先经验回放Q网络
(Prioritized DQN)[4]对经验池中的训练样本设立优先级进行采样 提高对稀有样本的使用效率 训练过程不稳定; 无法
处理连续动作对偶深度Q网络
(Dueling DQN)[5]对偶网络结构, 使用状态价值函数, 与相对动作价值函数来评估Q值 存在多个价值相仿的动作时
提高了评估的准确性无法处理连续动作 深度循环Q网络(DRQN)[27] 用长短时记忆网络替换全连接层 缓解了部分可观测问题 完全可观测环境下性能表现不
足; 无法处理连续动作注意力机制深度循环Q
网络(DARQN)[28]引入注意力机制 减轻网络训练的运算代价 训练过程不稳定; 无法
处理连续动作噪声深度Q网络
(Noisy DQN)[29]在网络权重中加入参数噪声 提高了探索效率; 减少了参数设置; 训练过程不稳定; 无法
处理连续动作循环回放分布式深度
Q网络(R2D2)[30]RNN隐藏状态存在经验池中; 采样部分序列产生RNN初始状态 减缓了RNN状态滞后性 状态滞后和表征漂移
问题仍然存在演示循环回放分布式深度
Q网络(R2D3)[32]经验回放机制; 专家演示回放缓冲区; 分布式优先采样 解决了在初始条件高度可变
的部分观察环境中的
稀疏奖励任务无法完成记住和越过
传感器的任务基于策
略梯度REINFORCE[35] 使用随机梯度上升法; 累计奖励作为动作价值函数的无偏估计 策略梯度是无偏的 存在高方差;收敛速度慢 自然策略梯度(Natural PG)[36] 自然梯度朝贪婪策略方向更新 收敛速度更快; 策略更新变化小 自然梯度未达到有效最大值 行动者−评论者(AC)[37] Actor用来更新策略; Critic用来评估策略 解决高方差的问题 AC算法中策略梯度存
在较大偏差确定性策略梯度(DDPG)[38] 确定性策略理论 解决了连续动作问题 无法处理离散动作问题 异步/同步优势行动者−评
论者(A3C/A2C)[6]使用行动者评论者网络结构; 异步更新公共网络参数 用多线程提高学习效率;
降低训练样本的相关性;
降低对硬件的要求内存消耗大; 更新策略
时方差较大信任域策略优化(TRPO)[7] 用KL散度限制策略更新 保证了策略朝着优化的方向更新 实现复杂; 计算开销较大 近端策略优化(PPO)[39] 经过裁剪的替代目标函数自适应的KL惩罚系数 比TRPO更容易实现;
所需要调节的参数较少用偏差大的大数据批进行学
习时无法保证收敛性K因子信任域行动者评
论者算法(ACKTR)[8]信任域策略优化; Kronecker因子
算法; 行动者评论者结构采样效率高; 显著减少计算量 计算依然较复杂  下载: 导出CSV
下载: 导出CSV
表 2 深度强化学习的攻击方法
Table 2 Attack methods toward deep reinforcement learning
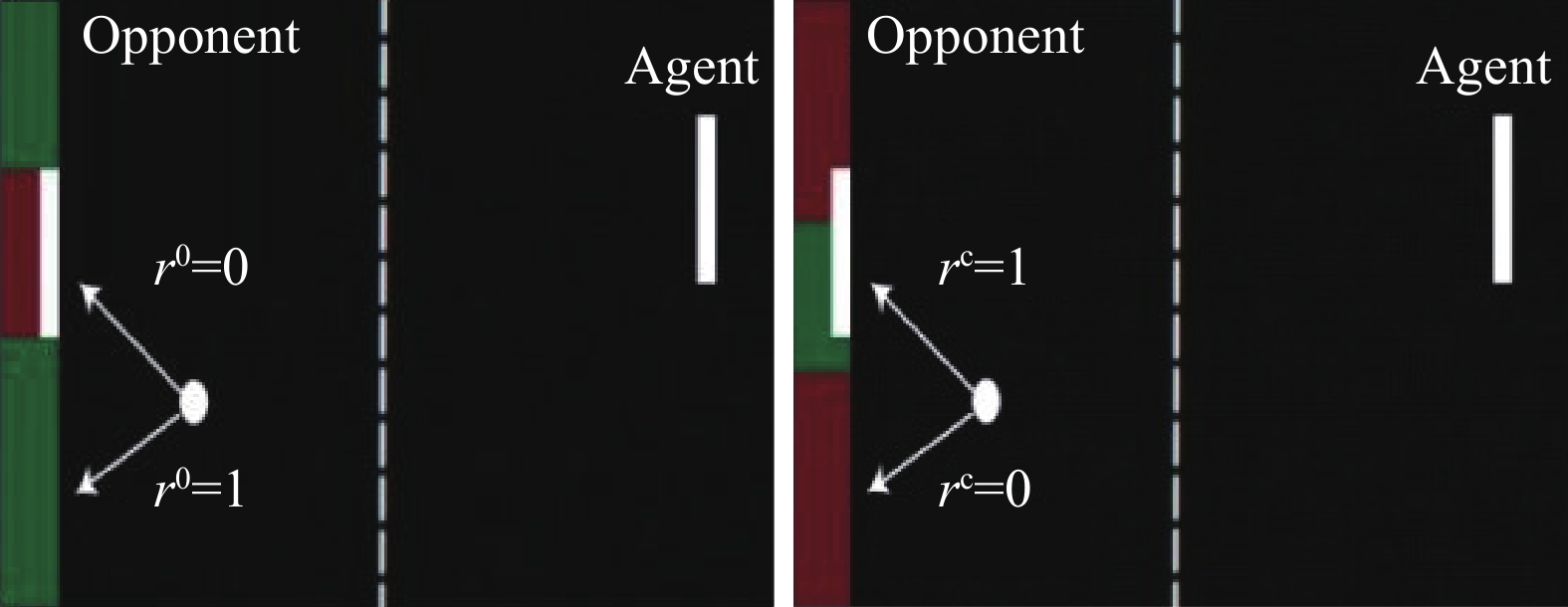
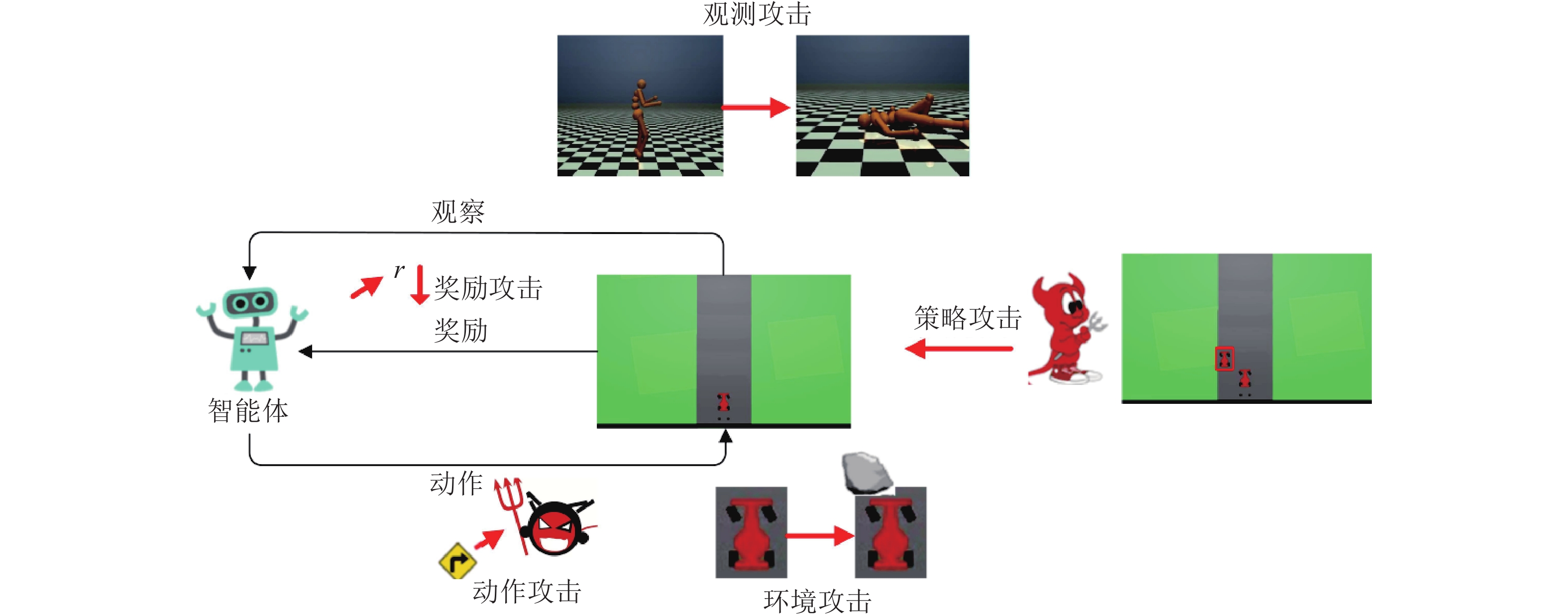
分类 攻击方法 攻击模型 攻击策略 攻击阶段 对手知识 观测攻击(见2.1) FGSM[19] DQN[1-2]、TRPO[7]、A3C[6] 在观测上加上FGSM攻击 测试阶段 白盒/黑盒 策略诱导攻击[41] DQN[1-2] 训练敌手策略; 对抗样本的转移性 训练阶段 黑盒 战略时间攻击[42] DQN[1-2]、A3C[6] 在一些关键时间步进行攻击 测试阶段 白盒 迷惑攻击[42] DQN[1-2]、A3C[6] 通过预测模型诱导智能体做出动作 测试阶段 白盒 基于值函数的对抗攻击[44] A3C[6] 在值函数的指导下选择部分观测进行攻击 测试阶段 白盒 嗅探攻击[45] DQN[1-2]、PPO[39] 用观测以及奖励、动作信号来获取代理模型并进行攻击 测试阶段 黑盒 基于模仿学习的攻击[46] DQN[1-2]、A2C[6]、PPO[39] 使用模仿学习提取的专家模型信息进行攻击 测试阶段 黑盒 CopyCAT算法[47] DQN[1-2] 使用预先计算的掩码对智能体的观测做出实时的攻击 测试阶段 白盒/黑盒 奖励攻击(见2.2) 基于对抗变换网络的对抗攻击[21] DQN[1-2] 加入一个前馈的对抗变换网络使策略追求对抗奖励 测试阶段 白盒 木马攻击[48] A2C[6] 在训练阶段用特洛伊木马进行中毒攻击 训练阶段 白盒/黑盒 翻转奖励符号攻击[49] DDQN[3] 翻转部分样本的奖励值符号 训练阶段 白盒 环境攻击(见2.3) 路径脆弱点攻击[50] DQN[1-2] 根据路径点Q值的差异与直线的夹角找出脆弱点 训练阶段 白盒 通用优势对抗样本生成方法[20] A3C[6] 在梯度上升最快的横断面上添加障碍物 训练阶段 白盒 对环境模型的攻击[51] DQN[1-2]、DDPG[38] 在环境的动态模型上增加扰动 测试阶段 黑盒 动作攻击(见2.4) 动作空间扰动攻击[52] PPO[39]、DDQN[3] 通过奖励函数计算动作空间扰动 训练阶段 白盒 策略攻击(见2.5) 通过策略进行攻击[53] PPO[39] 采用对抗智能体防止目标智能体完成任务 测试阶段 黑盒
下载: 导出CSV
表 3 深度强化学习的攻击和攻击成功率
Table 3 Attack success rate toward deep reinforcement learning
攻击模型 攻击方法 攻击阶段 攻击策略 平台 成功率 DQN[1] CopyCAT算法[47] 测试阶段 使用预先计算的掩码对智能体的观测做出实时的攻击 OpenAI Gym[77] 60%~100% FGSM攻击[19] 训练阶段 在观测上加上FGSM攻击 OpenAI Gym[77] 90% ~ 100% 策略诱导攻击[41] 训练阶段 训练敌手策略; 对抗样本的转移性 Grid-World map[40] 70%~95% 战略时间攻击[42] 测试阶段 在一些关键时间步进行攻击 OpenAI Gym[77] 40步以内达到70% PPO[37] 通过策略进行攻击[53] 测试阶段 采用对抗智能体防止目标智能体完成任务 OpenAI Gym[77] 玩家智能体成功率下降至62%和45%
下载: 导出CSV
表 4 深度强化学习的防御方法
Table 4 Defense methods of deep reinforcement learning
分类 防御方法 防御机制 防御目标 攻击方法 对抗训练(见3.1) 使用FGSM与随机噪声重训练[44, 55] 对正常训练后的策略使用对抗样本
与随机噪声进行重训练状态扰动 FGSM、经值函数指导的对抗攻击
(见2.1)基于梯度带的对抗训练[50] 用单一的优势对抗样本进行对抗训练 环境扰动 通用优势对抗样本生成方法(见2.3) 非连续扰动下的对抗训练[23] 以一定的攻击概率在训练样本中加入对抗扰动 状态扰动 战略时间攻击、经值函数指导的
对抗攻击(见2.1)基于敌对指导探索的对抗训练[56] 根据对抗状态动作对的显著性调整对 状态扰动 战略时间攻击、嗅探攻击(见2.1) 鲁棒学习(见3.2) 基于代理奖励的鲁棒训练[57] 通过混淆矩阵得到代理奖励值以
更新动作价值函数奖励扰动 结合对抗变换网络的对抗攻击(见2.2) 鲁棒对抗强化学习[58] 在有对抗智能体的情境下利用
博弈原理进行鲁棒训练不同场景下的不稳定因素 在多智能体环境下的对抗策略(见2.5) 二人均衡博弈[59] 博弈、均衡原理 奖励扰动 结合对抗变换网络的对抗攻击(见2.2) 迭代动态博弈框架[60] 用迭代的极大极小动态博弈
框架提供全局控制状态扰动 FGSM、战略时间攻击、经值函数指导
的对抗攻击、迷惑攻击(见2.1)对抗A3C[24] 在有对抗智能体的情境下
进行博弈鲁棒训练不同场景下的不稳定因素 在多智能体环境下的对抗策略(见2.5) 噪声网络[61] 使用参数空间噪声减弱对
抗样本的迁移能力状态扰动 FGSM、策略诱导攻击、利用模仿
学习的攻击(见2.1)方差层[62] 用权重遵循零均值分布, 并且仅
由其方差参数化的随机层进行训练状态扰动 FGSM、战略时间攻击、经值函数
指导的对抗攻击、迷惑攻击(见2.1)对抗检测(见3.3) 基于元学习的对抗检测[63] 学习子策略以检测对抗扰动的存在 状态扰动 FGSM、战略时间攻击、经值函数
指导的对抗攻击、迷惑攻击(见2.1)基于预测模型的对抗检测[25] 通过比较预测帧与当前帧之间
的动作分布来检测对抗扰动状态扰动 FGSM、战略时间攻击、经值函数指导
的对抗攻击、迷惑攻击(见2.1)水印授权[54] 在策略中加入特有的水印以
保证策略不被非法修改策略篡改 CopyCAT攻击、策略诱导攻击(见2.1) 受威胁的马尔科夫决策过程[68] 在马尔科夫决策过程中加入攻击者
动作集并使用K级思维模式进行学习奖励扰动 翻转奖励符号攻击(见2.2) 在线认证防御[69] 在输入扰动范围内选择最优动作 状态扰动 FGSM、战略时间攻击、经值函数指导
的对抗攻击、迷惑攻击(见2.1)
下载: 导出CSV
表 6 深度强化学习的攻击指标
Table 6 Attack indicators of deep reinforcement learning
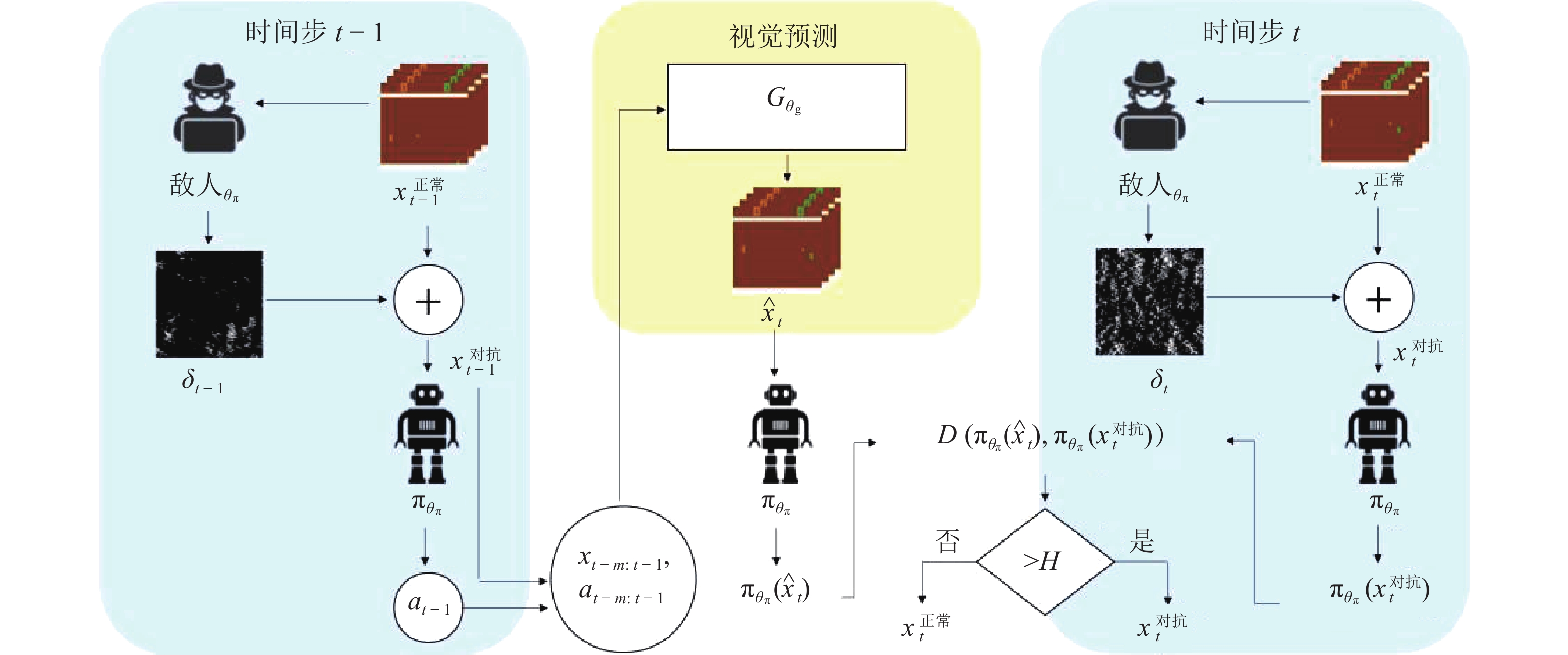
分类 攻击方法 攻击模型 平台 奖励 损失 成功率 精度 观测攻击 FGSM[19] DQN[1-2]、TRPO[7]、A3C[6] OpenAI Gym[75] √ 策略诱导攻击[41] DQN[1-2] Grid-world[40] √ √ 战略时间攻击[42] DQN[1-2]、A3C[6] OpenAI Gym[75] √ √ 迷惑攻击[42] DQN[1-2]、A3C[6] OpenAI Gym[75] √ √ 基于值函数的对抗攻击[44] A3C[6] OpenAI Gym[75] √ 嗅探攻击[45] DQN[1-2]、PPO[39] OpenAI Gym[75] √ 基于模仿学习的攻击[46] DQN[1-2]、A2C[6]、PPO[39] OpenAI Gym[75] √ CopyCAT算法[47] DQN[1-2] OpenAI Gym[75] √ √ 奖励攻击 基于对抗变换网络的对抗攻击[21] DQN[1-2] OpenAI Gym[75] √ 木马攻击[48] A2C[6] OpenAI Gym[75] √ 翻转奖励符号攻击[49] DDQN[3] SDN environment[49] √ 环境攻击 路径脆弱点攻击[50] DQN[1-2] OpenAI Gym[75] √ √ 通用优势对抗样本生成方法[20] A3C[6] Grid-world[40] √ √ 对环境模型的攻击[51] DQN[1-2]、DDPG[38] OpenAI Gym[75] √ 动作攻击 动作空间扰动攻击[52] PPO[37]、DDQN[3] OpenAI Gym[75] √ 策略攻击 通过策略进行攻击[53] PPO[39] OpenAI Gym[75] √
下载: 导出CSV
表 7 深度强化学习的防御指标
Table 7 Defense indicators of deep reinforcement learning
分类 防御方法 实验平台 平均回报 成功率 每回合步数 对抗训练 使用FGSM与随机噪声重训练[44-45] OpenAI Gym[75] √ 基于梯度带的对抗训练[50] Grid-world[40] √ 非连续扰动下的对抗训练[56] OpenAI Gym[75] √ 基于敌对指导探索的对抗训练[57] OpenAI Gym[75] √ 鲁棒学习 基于代理奖励的鲁棒训练[58] OpenAI Gym[75] √ √ 鲁棒对抗强化学习[59] OpenAI Gym[75] √ 二人均衡博弈[60] Grid-world[40] √ 迭代动态博弈框架[61] KUKA youbot[60] √ 对抗A3C[24] OpenAI Gym[75] √ 噪声网络[62] OpenAI Gym[75] √ 方差层[63] OpenAI Gym[75] √ 对抗检测 基于元学习的对抗检测[64] OpenAI Gym[75] √ 基于预测模型的对抗检测[25] OpenAI Gym[75] √ 水印授权[54] OpenAI Gym[75] √ √ 受威胁的马尔科夫决策过程[69] Grid-world[40] √ 在线认证防御[70] OpenAI Gym[75] √
下载: 导出CSV
表 5 深度强化学习的安全性评估指标
Table 5 Security evaluation indicators of deep reinforcement learning
分类 指标 评价机制 评价目的 攻击指标 奖励 根据模型策略运行多个回合, 计算累积回合奖励或者平均回合奖励 用于评估攻击方法对模型整体性能的影响 损失 通过定义含有物理意义的概念来计算其是否到达不安全或者失败场景 用于评估攻击方法对模型策略的影响 成功率 攻击方法在一定限制条件内可以达到成功攻击的次数比例 用于评估攻击方法的有效性 精度 模型输出的对抗点中可以成功干扰路径规划的比例 用于评估攻击方法对模型策略的影响 防御指标 平均回报 根据模型策略运行多个回合, 计算平均回合奖励 用于评估防御方法对提高模型性能的有效性 成功率 检测攻击者篡改的策略动作 用于评估防御方法的有效性 每回合步数 根据模型策略运行多个回合, 记录每个回合的存活步数或者平均回合步数 用于评估防御方法对提高模型性能的有效性
下载: 导出CSV
-
[1] Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou I, Wierstra D, et al. Playing atari with deep reinforcement learning. arXiv preprint arXiv: 1312.5602, 2013 [2] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533 doi: 10.1038/nature14236 [3] Van Hasselt H, Guez A, Silver D. Deep reinforcement learning with double Q-learning. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, Arizona: AAAI, 2016. 2094−2100 [4] Schaul T, Quan J, Antonoglou I, Silver D. Prioritized experience replay. arXiv preprint arXiv: 1511.05952, 2016 [5] Wang Z Y, Schaul T, Hessel M, van Hasselt H, Lanctot M, de Freitas N. Dueling network architectures for deep reinforcement learning. arXiv preprint arXiv: 1511.06581, 2016 [6] Mnih V, Badia A P, Mirza M, Graves A, Harley T, Lillicrap T P, et al. Asynchronous methods for deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning. New York, NY, USA: JMLR.org, 2016. 1928−1937 [7] Schulman J, Levine S, Moritz P, Jordan M, Abbeel P. Trust region policy optimization. In: Proceedings of the 31st International Conference on Machine Learning. Lille, France: JMLR, 2015. 1889−1897 [8] Wu Y H, Mansimov E, Liao S, Grosse R, Ba J. Scalable trust-region method for deep reinforcement learning using kronecker-factored approximation. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, California, USA: Curran Associates Inc., 2017. 5285−5294 [9] Silver D, Huang A, Maddison C J, Guez A, Sifre L, Van Den driessche G, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587): 484-489 doi: 10.1038/nature16961 [10] Berner C, Brockman G, Chan B, Cheung V, Dȩbiak P, Dennison C, et al. Dota 2 with large scale deep reinforcement learning. arXiv preprint arXiv: 1912.06680, 2019 [11] Fayjie A R, Hossain S, Oualid D, Lee D J. Driverless car: Autonomous driving using deep reinforcement learning in urban environment. In: Proceedings of the 15th International Conference on Ubiquitous Robots (UR). Honolulu, HI, USA: IEEE, 2018. 896−901 [12] Prasad N, Cheng L F, Chivers C, Draugelis M, Engelhardt B E. A reinforcement learning approach to weaning of mechanical ventilation in intensive care units. arXiv preprint arXiv: 1704.06300, 2017 [13] Deng Y, Bao F, Kong Y Y, Ren Z Q, Dai Q H. Deep direct reinforcement learning for financial signal representation and trading. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(3): 653-664 doi: 10.1109/TNNLS.2016.2522401 [14] Amarjyoti S. Deep reinforcement learning for robotic manipulation-the state of the art. arXiv preprint arXiv: 1701.08878, 2017 [15] Nguyen T T, Reddi V J. Deep reinforcement learning for cyber security. arXiv preprint arXiv: 1906.05799, 2020 [16] Oh J, Guo X X, Lee H, Lewis R, Singh S. Action-conditional video prediction using deep networks in Atari games. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2015. 2863−2871 [17] Caicedo J C, Lazebnik S. Active object localization with deep reinforcement learning. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 2488−2496 [18] Sutton R S, Barto A G. Reinforcement Learning: An Introduction (Second Edition). Cambridge, MA: MIT Press, 2018. 47−48 [19] Huang S, Papernot N, Goodfellow I, Duan Y, Abbeel P. Adversarial attacks on neural network policies. arXiv preprint arXiv: 1702.02284, 2017 [20] Chen T, Niu W J, Xiang Y X, Bai X X, Liu J Q, Han Z, et al. Gradient band-based adversarial training for generalized attack immunity of A3C path finding. arXiv preprint arXiv: 1807.06752, 2018 [21] Tretschk E, Oh S J, Fritz M. Sequential attacks on agents for long-term adversarial goals. arXiv preprint arXiv: 1805.12487, 2018 [22] Ferdowsi A, Challita U, Saad W, Mandayam N B. Robust deep reinforcement learning for security and safety in autonomous vehicle systems. In: Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC). Maui, HI, USA: IEEE, 2018. 307−312 [23] Behzadan V, Munir A. Whatever does not kill deep reinforcement learning, makes it stronger. arXiv preprint arXiv: 1712.09344, 2017 [24] Gu Z Y, Jia Z Z, Choset H. Adversary A3C for robust reinforcement learning. arXiv preprint arXiv: 1912.00330, 2019 [25] Lin Y C, Liu M Y, Sun M, Huang J B. Detecting adversarial attacks on neural network policies with visual foresight. arXiv preprint arXiv: 1710.00814, 2017 [26] Watkins C J C H, Dayan P. Q-learning. Machine learning, 1992, 8(3−4): 279−292 [27] Hausknecht M, Stone P. Deep recurrent Q-learning for partially observable MDPs. In: Proceedings of 2015 AAAI Fall Symposium on Sequential Decision Making for Intelligent Agents. Arlington, Virginia, USA: AAAI, 2015. [28] Sorokin I, Seleznev A, Pavlov M, Fedorov A, Ignateva A. Deep attention recurrent Q-network. arXiv preprint arXiv: 1512.01693, 2015 [29] Plappert M, Houthooft R, Dhariwal P, Sidor S, Chen R Y, Chen X, et al. Parameter space noise for exploration. arXiv preprint arXiv: 1706.01905, 2018 [30] Kapturowski S, Ostrovski G, Quan J, Munos R, Dabney W. Recurrent experience replay in distributed reinforcement learning. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, LA, USA, 2019. [31] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [32] Le Paine T, Gulcehre C, Shahriari B, Denil M, Hoffman M, Soyer H, et al. Making efficient use of demonstrations to solve hard exploration problems. arXiv preprint arXiv: 1909.01387, 2019 [33] Sutton R S, McAllester D A, Singh S, Mansour Y. Policy gradient methods for reinforcement learning with function approximation. In: Proceedings of the 12th International Conference on Neural Information Processing Systems. Denver, CO: MIT Press, 1999. 1057−1063 [34] Silver D, Lever G, Heess N, et al. Deterministic policy gradient algorithms. In: Proceedings of the International conference on machine learning. PMLR, 2014: 387−395 [35] Graf T, Platzner M. Adaptive playouts in monte-carlo tree search with policy-gradient reinforcement learning. In: Proceedings of the 14th International Conference on Advances in Computer Games. Leiden, The Netherlands: Springer, 2015. 1−11 [36] Kakade S M. A natural policy gradient. In: Advances in Neural Information Processing Systems 14. Vancouver, British Columbia, Canada: MIT Press, 2001. 1531−1538 [37] Konda V R, Tsitsiklis J N. Actor-critic algorithms. In: Advances in Neural Information Processing Systems 14. Vancouver, British Columbia, Canada: MIT Press, 2001. 1008−1014 [38] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y, et al. Continuous control with deep reinforcement learning. arXiv preprint arXiv: 1509.02971, 2019 [39] Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv preprint arXiv: 1707.06347, 2017 [40] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. arXiv preprint arXiv: 1412.6572, 2015 [41] Behzadan V, Munir A. Vulnerability of deep reinforcement learning to policy induction attacks. In: Proceedings of the 13th International Conference on Machine Learning and Data Mining in Pattern Recognition. New York, NY, USA: Springer, 2017. 262−275 [42] Lin Y C, Hong Z W, Liao Y H, Shih M L, Liu M Y, Sun M. Tactics of adversarial attack on deep reinforcement learning agents. arXiv preprint arXiv: 1703.06748, 2019 [43] Carlini N, Wagner D. MagNet and “efficient defenses against adversarial attacks” are not robust to adversarial examples. arXiv preprint arXiv: 1711.08478, 2017 [44] Kos J, Song D. Delving into adversarial attacks on deep policies. arXiv preprint arXiv: 1705.06452, 2017 [45] Inkawhich M, Chen Y R, Li H. Snooping attacks on deep reinforcement learning. arXiv preprint arXiv: 1905.11832, 2020 [46] Behzadan V, Hsu W. Adversarial exploitation of policy imitation. arXiv preprint arXiv: 1906.01121, 2019 [47] Hussenot L, Geist M, Pietquin O. CopyCAT: Taking control of neural policies with constant attacks. arXiv preprint arXiv: 1905.12282, 2020 [48] Kiourti P, Wardega K, Jha S, Li W C. TrojDRL: Trojan attacks on deep reinforcement learning agents. arXiv preprint arXiv: 1903.06638, 2019 [49] Han Y, Rubinstein B I P, Abraham T, Alpcan T, De Vel O, Erfani S, et al. Reinforcement learning for autonomous defence in software-defined networking. In: Proceedings of the 9th International Conference on Decision and Game Theory for Security. Seattle, WA, USA: Springer, 2018. 145−165 [50] Bai X X, Niu W J, Liu J Q, Gao X, Xiang Y X, Liu J J. Adversarial examples construction towards white-box Q table variation in DQN pathfinding training. In: Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC). Guangzhou, China: IEEE, 2018. 781−787 [51] Xiao C W, Pan X L, He W R, Peng J, Sun M J, Yi J F, et al. Characterizing attacks on deep reinforcement learning. arXiv preprint arXiv: 1907.09470, 2019 [52] Lee X Y, Ghadai S, Tan K L, Hegde C, Sarkar S. Spatiotemporally constrained action space attacks on deep reinforcement learning agents. arXiv preprint arXiv: 1909.02583, 2019 [53] Gleave A, Dennis M, Wild C, Kant N, Levine S, Russell S. Adversarial policies: Attacking deep reinforcement learning. arXiv preprint arXiv: 1905.10615, 2021 [54] Behzadan V, Hsu W. Sequential triggers for watermarking of deep reinforcement learning policies. arXiv preprint arXiv: 1906.01126, 2019 [55] Pattanaik A, Tang Z Y, Liu S J, Bommannan G, Chowdhary G. Robust deep reinforcement learning with adversarial attacks. In: Proceedings of the 17th International Conference on Autonomous Agents and Multiagent Systems. Stockholm, Sweden: International Foundation for Autonomous Agents and Multiagent Systems, 2018. 2040−2042 [56] Behzadan V, Hsu W. Analysis and Improvement of Adversarial Training in DQN Agents With Adversarially-Guided Exploration (AGE). arXiv preprint arXiv: 1906.01119, 2019 [57] Wang J K, Liu Y, Li B. Reinforcement learning with perturbed rewards. arXiv preprint arXiv: 1810.01032, 2020 [58] Pinto L, Davidson J, Sukthankar R, Gupta A. Robust adversarial reinforcement learning. In: Proceedings of the 34th International Conference on Machine Learning-Volume 70. Sydney, Australia: JMLR.org, 2017. 2817−2826 [59] Bravo M, Mertikopoulos P. On the robustness of learning in games with stochastically perturbed payoff observations. Games and Economic Behavior, 2017, 103: 41-66 doi: 10.1016/j.geb.2016.06.004 [60] Ogunmolu O, Gans N, Summers T. Minimax iterative dynamic game: Application to nonlinear robot control tasks. In: Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Madrid, Spain: IEEE, 2018. 6919−6925 [61] Behzadan V, Munir A. Mitigation of policy manipulation attacks on deep Q-networks with parameter-space noise. In: Proceedings of the International Conference on Computer Safety, Reliability, and Security. Västeras, Sweden: Springer, 2018. 406−417 [62] Neklyudov K, Molchanov D, Ashukha A, Vetrov D. Variance networks: When expectation does not meet your expectations. arXiv preprint arXiv: 1803.03764, 2019 [63] Havens A, Jiang Z, Sarkar S. Online robust policy learning in the presence of unknown adversaries. In: Proceedings of the 32nd Conference on Neural Information Processing Systems. Montreal, Canada: Curran Associates, Inc., 2018. 9916−9926 [64] Xu W L, Evans D, Qi Y J. Feature squeezing mitigates and detects Carlini/Wagner adversarial examples. arXiv preprint arXiv: 1705.10686, 2017 [65] Meng D Y, Chen H. MagNet: A two-pronged defense against adversarial examples. In: Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. Dallas, Texas, USA: ACM, 2017. 135−147 [66] Feinman R, Curtin R R, Shintre S, Gardner A B. Detecting adversarial samples from artifacts. arXiv preprint arXiv: 1703.00410, 2017 [67] Uchida Y, Nagai Y, Sakazawa S, Satoh S. Embedding watermarks into deep neural networks. In: Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval. Bucharest, Romania: ACM, 2017. 269−277 [68] Gallego V, Naveiro R, Insua D R. Reinforcement learning under threats. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 9939-9940 [69] Lütjens B, Everett M, How J P. Certified adversarial robustness for deep reinforcement learning. arXiv preprint arXiv: 1910.12908, 2020 [70] Athalye A, Carlini N, Wagner D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. arXiv preprint arXiv: 1802.00420, 2018 [71] Bastani O, Pu Y W, Solar-Lezama A. Verifiable reinforcement learning via policy extraction. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montreal, Canada: Curran Associates Inc., 2018. 2499−2509 [72] Zhu H, Xiong Z K, Magill S, Jagannathan S. An inductive synthesis framework for verifiable reinforcement learning. In: Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation. Phoenix, AZ, USA: ACM, 2019. 686−701 [73] Behzadan V, Munir A. Adversarial reinforcement learning framework for benchmarking collision avoidance mechanisms in autonomous vehicles. arXiv preprint arXiv:1806.01368, 2018 [74] Behzadan V, Hsu W. RL-based method for benchmarking the adversarial resilience and robustness of deep reinforcement learning policies. arXiv preprint arXiv: 1906.01110, 2019 [75] Brockman G, Cheung V, Pettersson L, Schneider J, Schulman J, Tang J, et al. OpenAI gym. arXiv preprint arXiv: 1606.01540, 2016 [76] Johnson M, Hofmann K, Hutton T, Bignell D. The Malmo platform for artificial intelligence experimentation. In: Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI-16). New York, USA: AAAI, 2016. 4246−4247 [77] Lanctot M, Lockhart E, Lespiau J B, Zambaldi V, Upadhyay S, Pérolat J, et al. OpenSpiel: A framework for reinforcement learning in games. arXiv preprint arXiv: 1908.09453, 2020 [78] James S, Ma Z C, Arrojo D R, Davison A J. Rlbench: The robot learning benchmark & learning environment. IEEE Robotics and Automation Letters, 2020, 5(2): 3019-3026 doi: 10.1109/LRA.2020.2974707 [79] Todorov E, Erez T, Tassa Y. MuJoCo: A physics engine for model-based control. In: Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. Vilamoura-Algarve, Portugal: IEEE, 2012. 5026−5033 [80] Dhariwal P, Hesse C, Klimov O, et al. Openai baselines. 2017. [81] Duan Y, Chen X, Houthooft R, Schulman J, Abbeel P. Benchmarking deep reinforcement learning for continuous control. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: JMLR.org, 2016. 1329−1338 [82] Castro P S, Moitra S, Gelada C, Kumar S, Bellemare M G. Dopamine: A research framework for deep reinforcement learning. arXiv preprint arXiv: 1812.06110, 2018 [83] Papernot N, Faghri F, Carlini N, Goodfellow I, Feinman R, Kurakin A, et al. Technical report on the cleverhans v2.1.0 adversarial examples library. arXiv preprint arXiv: 1610.00768, 2018 [84] Rauber J, Brendel W, Bethge M. Foolbox: A python toolbox to benchmark the robustness of machine learning models. arXiv preprint arXiv: 1707.04131, 2018 -

 下载:
下载:



计量
- 文章访问数: 3796
- HTML全文浏览量: 3508
- PDF下载量: 1350
- 被引次数: 0
