

-
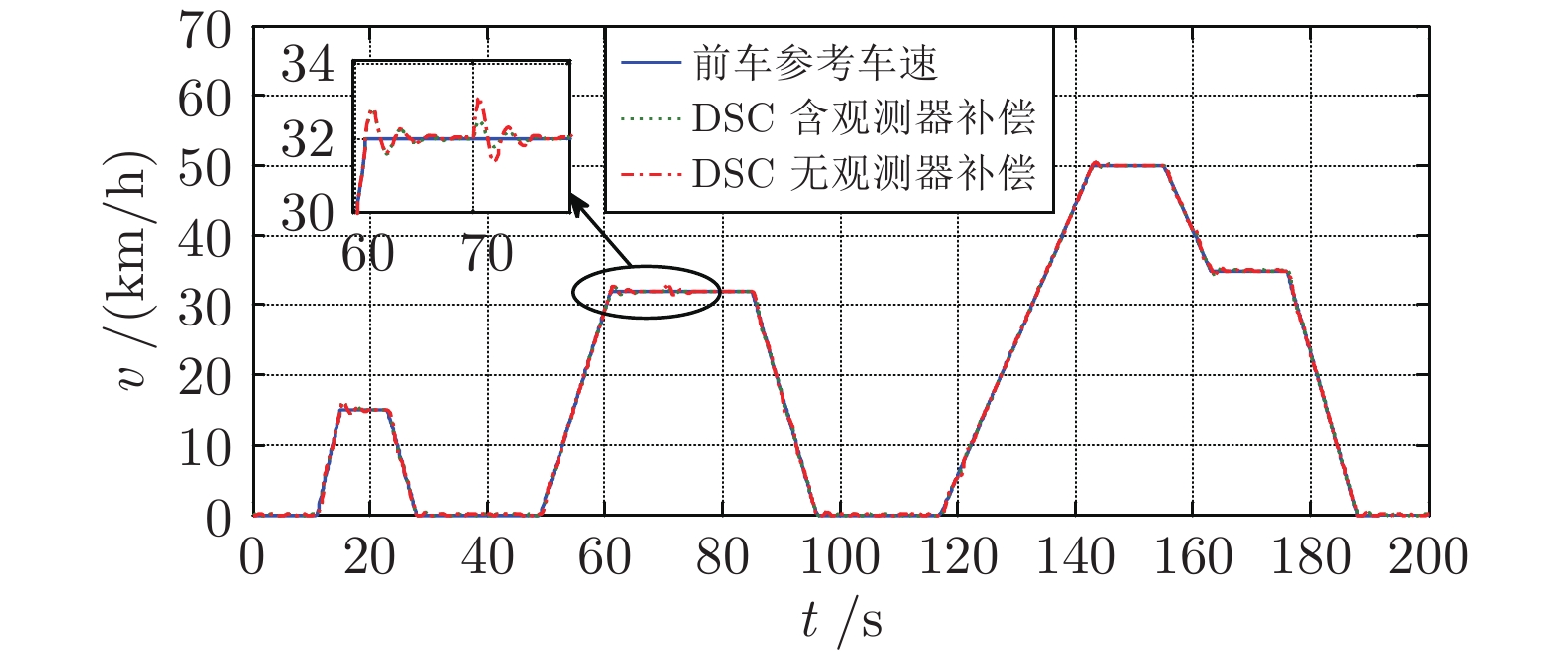
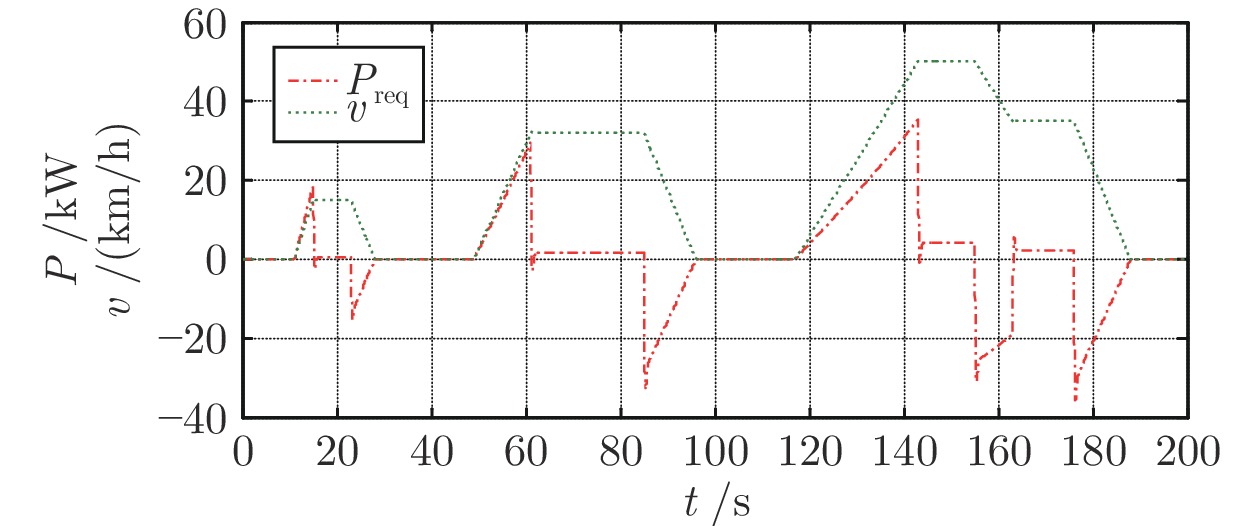
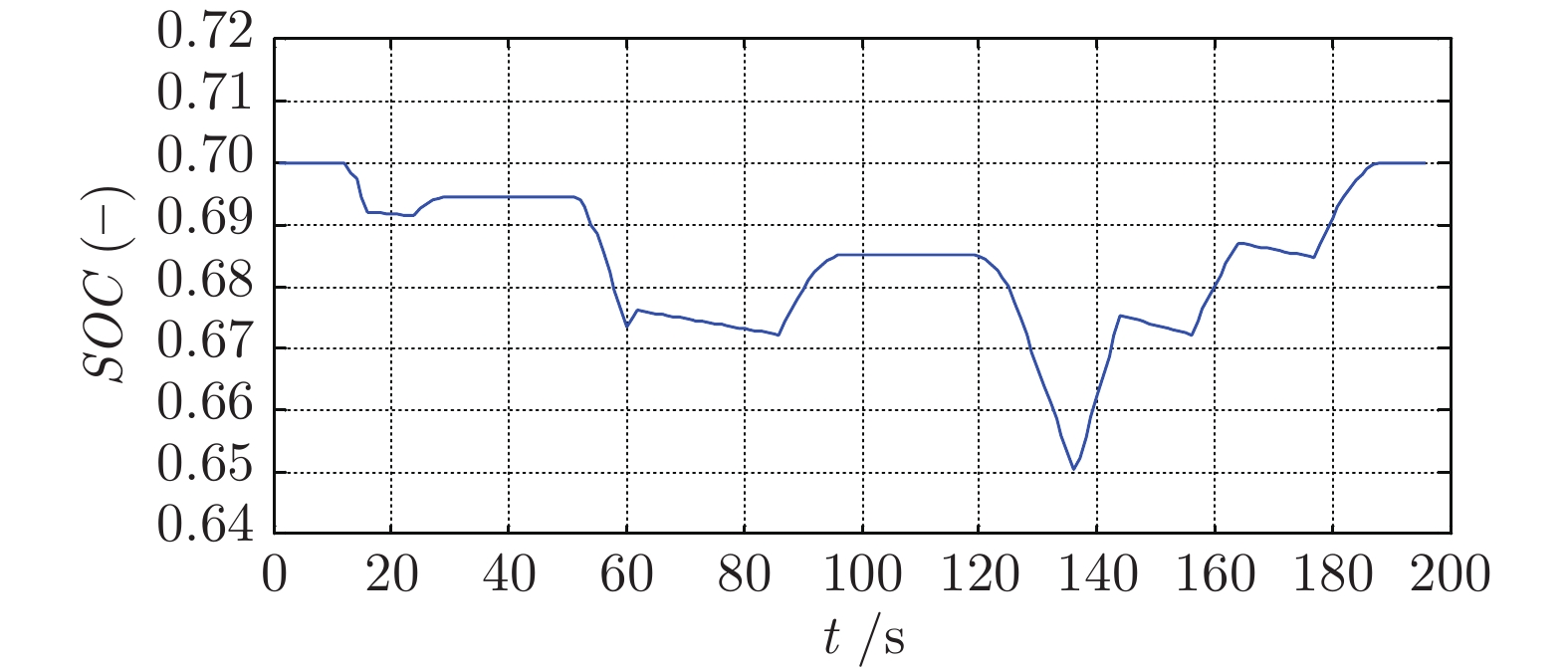
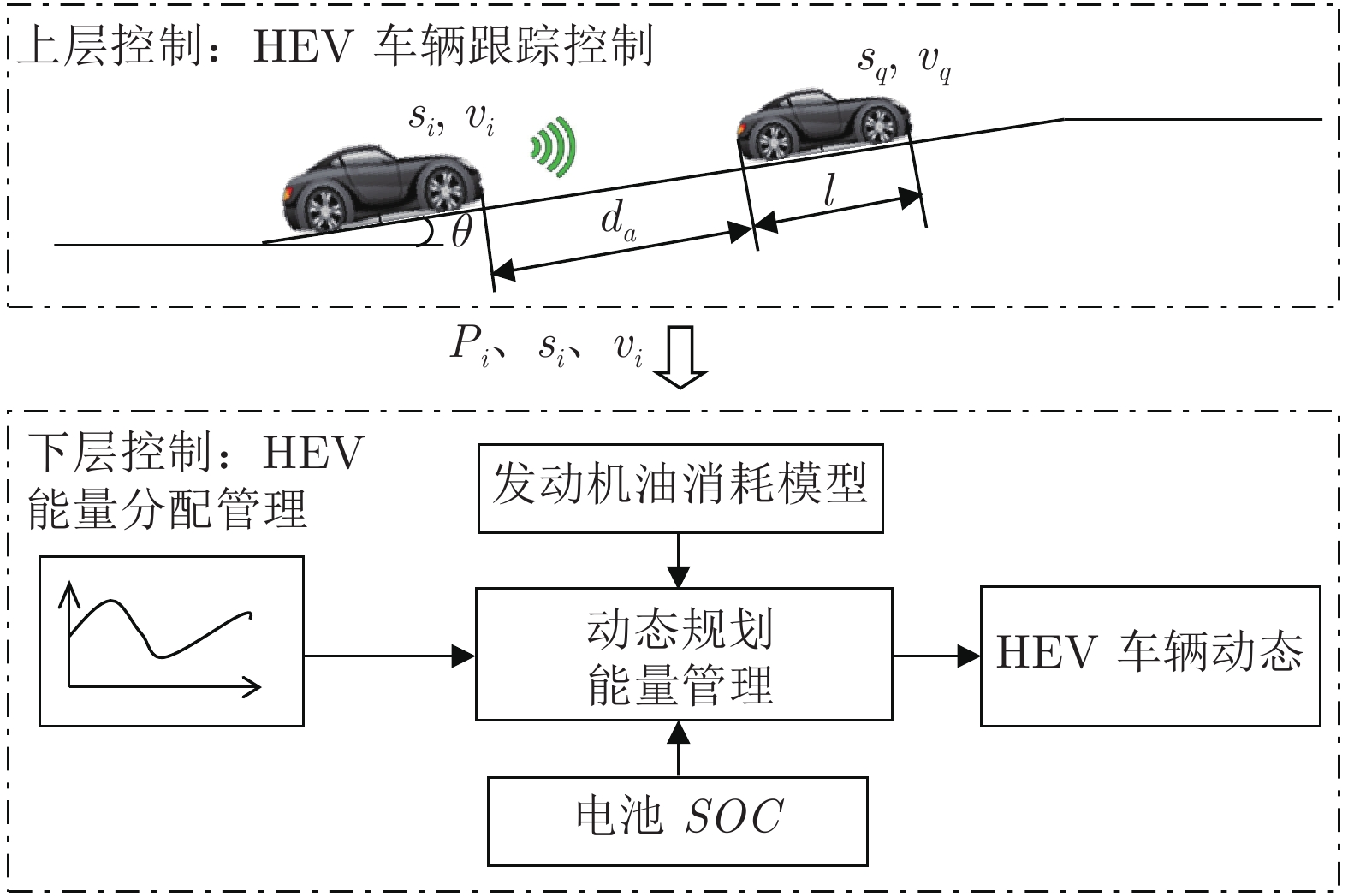
摘要: 混合动力电动汽车(Hybrid electric vehicles, HEVs)的能量管理问题至关重要, 而混合动力电动汽车的跟车控制不仅涉及跟车效果与安全性, 也影响着能量的高效利用. 将HEVs的跟车控制与能量管理相结合, 提出一种基于安全距离的HEVs车辆跟踪与能量管理控制方法. 首先, 考虑坡度、载荷变动建立了HEVs车辆跟车系统的非线性模型, 并基于安全距离, 提出一种基于道路观测器的动态面控制(Dynamic surface control, DSC)进行车辆跟踪控制. 然后, 结合跟踪控制下工况循环, 采用滚动动态规划(Dynamic programming, DP)算法进行混合动力电动汽车能量实时优化控制. 最后, 通过仿真研究进行验证.Abstract: The energy management of hybrid electric vehicles (HEVs) is very important. The tracking control of hybrid electric vehicles not only involves tracking and safety, but also affects the energy efficiency. Integrated with the problem of vehicle tracking control, an energy management control method based on safety distance for hybrid electric vehicles (HEVs) is proposed in this paper. Firstly, the nonlinear model of vehicle tracking system is established considering the change of slope and load. Considering the safety distance, a dynamic surface control (DSC) based on road observer is proposed for vehicle tracking control. Then, combined with the driving cycle under tracking control, the dynamic programming (DP) algorithm is used to optimize the energy real-time control of hybrid electric vehicles. Finally, the effectiveness is verified by simulations.
-
表 1 HEV车辆主要参数
Table 1 Parameters of HEV
参数 数值 单位 参数 数值 单位 整车质量 1332 kg 车轮半径 0.287 m 重力加速度 9.81 N/kg 迎风面积 1.746 m2 车身长度 3 m 空气密度 1.29 kg/m3 风阻系数 0.3 — 滚动阻力系数 0.3 m/s  下载: 导出CSV
下载: 导出CSV
表 2 燃油消耗对比
Table 2 Comparison of fuel consumption
优化方法 (ECE 工况) 燃油消耗 (l/100 km) 提高 (%) Advisor 6.3 — 本文算法 4.68 12
下载: 导出CSV
-
[1] Li L, Wang X Y, Song J. Fuel consumption optimization for smart hybrid electric vehicle during a car-following process. Mechanical Systems and Signal Processing, 2017, 87: 17-29 [2] 赵秀春, 郭戈. 混合动力电动汽车能量管理策略研究综述. 自动化学报, 2016. 42(3): 321-334Zhao Xiu-Chun, Guo Ge. Survey on energy management strategies for hybrid electric vehicles. Actaautomatic sincia, 2016, 42(3): 321-334 [3] Li X, Evangelou S. Torque-leveling threshold-changing rule-based control for parallel hybrid electric vehicles. IEEE Transactions on Vehicular Technology, 2019, 68(7): 6509-6523 doi: 10.1109/TVT.2019.2916720 [4] Anbaran S A, Idris N R N, Jannati M, Aziz M J, Alsofyani I. Rule-based supervisory control of split-parallel hybrid electric vehicle. In: Proceedings of the 2014 IEEE Conference on Energy Conversion. Johor Bahru, Malaysia: IEEE Press, 2014. 7−12 [5] Denis N, Dubois M R, Desrochers A. Fuzzy-based blended control for the energy management of a parallel plug-in hybrid electric vehicle. IET Intelligent Transport Systems, 2015, 9(1): 30-37 doi: 10.1049/iet-its.2014.0075 [6] Murphey Y L, Park J, Chen Z H, Kuang M L, Masrur M A, Phillips A M. Intelligent hybrid vehicle power control Part I: machine learning of optimal vehicle power. IEEE Transactions on Vehicular Technology, 2012, 61(8): 3519-3530 doi: 10.1109/TVT.2012.2206064 [7] Zhang R D and Tao J L. GA-based fuzzy energy management system for FC/SC-powered HEV considering H2 consumption and load variation. IEEE Transactions on Fuzzy Systems, 2018, 26(4): 1833-1843 doi: 10.1109/TFUZZ.2017.2779424 [8] Liu J C, ChenY Z, Zhan J Y, Shang F. Heuristic dynamic programming based online energy management strategy for plug-in hybrid electric vehicles. IEEE Transactions on Vehicular Technology, 2019, 68(5): 4479-4493 doi: 10.1109/TVT.2019.2903119 [9] 常远. 基于动态规划的并联混合动力动车组能量管理策略研究. 内燃机与配件, 2019. 8: 114-119 doi: 10.3969/j.issn.1674-957X.2019.10.055Chang Yuan. Research on energy management strategy of parallel hybrid electric multiple unit based on dynamic programming. Internal combustion engine and parts, 2019. 8: 114-119 doi: 10.3969/j.issn.1674-957X.2019.10.055 [10] Larsson V, Johannesson M L, Egardt B, Karlsson S. Commuter route optimized energy management of hybrid electricvehicles. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(3): 1145-1154 doi: 10.1109/TITS.2013.2294723 [11] Ko J, Ko S, Son H, Yoo B, Cheon J, Kim H. Development of brake system and regenerative braking cooperative control algorithm for automatic-transmission-based hybrid electric vehicles. IEEE Transactions on Vehicular Technology, 2015, 64(2): 431-440 doi: 10.1109/TVT.2014.2325056 [12] Li G Q, Görges D. Ecological adaptive cruise control and energy management strategy for hybrid electric vehicles based on heuristic dynamic programming. IEEE Transactions on Intelligent Transportation Systems, 2019, 20(9): 3526-3535 doi: 10.1109/TITS.2018.2877389 [13] Zeng X R, Wang J M. A parallel hybrid electric vehicle energy management strategy using stochastic model predictive control with road grade preview. IEEE Transactions on Control Systems Technology, 2015, 23(6): 2416-2423 doi: 10.1109/TCST.2015.2409235 [14] Yan F J, Wang J M, Huang K S. Hybrid electric vehicle model predictive control torque-split strategy incorporating engine transient characteristics. IEEE Transactions on Vehicular Technology, 2012, 61(6): 2458-2467 [15] Moon S, Moon I, Yi K. Design, tuning, and evaluation of a full-range adaptive cruise control system with collision avoidance. Control Engineering Practice, 2017, 5: 442-455 [16] Chen J Z, Zhou Y, Liang H. Effects of ACC and CACC vehicles on traffic flow based on an improved variable time headway spacing strategy. IET Intelligent Transport Systems, 2019, 13(9): 1365-1373 doi: 10.1049/iet-its.2018.5296 [17] 陈虹, 郭露露, 宫洵等. 智能时代的汽车控制. 自动化学报, 2020. 46(7): 1313-1332Chen Hong, Guo Lu-Lu, Gong Xun, et al. Automotive control in intelligent era. Actaautomatic sincia, 2020. 46(7): 1313-1332 [18] Stefania S, Alessandro S, Antonio S V, et al. Platooning maneuvers in vehicular networks: a distributed and consensus-based approach. IEEE Transactions on Intelligent Vehicles, 2019, 4(1): 59-72 doi: 10.1109/TIV.2018.2886677 [19] Wang C, Nijmeijer H. String stable heterogeneous vehicle platoon using cooperative adaptive cruise control. In: Proceedings of the 18th International Conference on Intelligent Transportation Systems. Las Palmas, Spain: IEEE, 2015. 1977−1982 [20] Li Y F, Chen W B, Peeta S, Wang Y B. Platoon control of connected multi-vehicle systems under V2X communications: design and experiments. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(5): 1891-1902 doi: 10.1109/TITS.2019.2905039 [21] Zheng Y, Li S E, Wang J Q, Cao D P, Li K Q. Stability and scalability of homogeneous vehicular platoon: study on the influence of information flow topologies. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(1): 14-26 doi: 10.1109/TITS.2015.2402153 [22] Luo Y, Chen T, and Li K. Multi-objective decoupling algorithm for active distance control of intelligent hybrid electric vehicle. Mechanical Systems and Signal Processing, 2015, 64-65: 29-45 doi: 10.1016/j.ymssp.2015.02.025 [23] Di Cairano S, Bernardini D, Bemporad A, Kolmanovsky IV. Stochastic MPC with learning for driver-predictive vehicle control and its application to HEV energy management. IEEE Transactions on Control Systems Technology, 2014, 22(3): 1018-1031 doi: 10.1109/TCST.2013.2272179 [24] Tajeddin S, Vajedi M, Azad N. A newton/GMRES approach to predictive ecological adaptive cruise control of a plug-in hybrid electric vehicle in carfollowing scenarios. IFAC-Papers Online, 2016, 49(21): 59-65 doi: 10.1016/j.ifacol.2016.10.511 [25] Luo Y, Chen T, Zhang S W, Li K Q. Intelligent hybrid electric vehicle ACC with coordinated control of tracking ability, fuel economy, and ride comfort. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(4): 2303-2308 doi: 10.1109/TITS.2014.2387356 [26] Yu K J, Yang H Z, et al. Model predictive control for hybrid electric vehicle platooning using slope information. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(7): 1894-1909 doi: 10.1109/TITS.2015.2513766 [27] Guo G, Yue W. Autonomous platoon control allowing range-limited sensors. IEEE Transactions on Vehicular Technology, 2012, 61(7): 2901-2912. [28] 王琼, 郭戈. 车队速度滚动时域动态规划及非线性控制. 自动化学报, 2019. 45(5): 888-896 doi: 10.1109/TVT.2012.2203362Wang Qiong, Guo Ge. Platoon speed receding horizon dynamic programming and nonlinear control. Acta Automatica Sinica, 2019, 45(5): 888-896 doi: 10.1109/TVT.2012.2203362 [29] Qu Z, Dawson D M, Lim S Y, Dorsey J F. A new class of robust control laws for tracking of robots. International Journal of Robotics Research, 1994, 13(4): 355-363 doi: 10.1177/027836499401300407 -

 下载:
下载:



图(10) / 表(2)
计量
- 文章访问数: 1311
- HTML全文浏览量: 731
- PDF下载量: 319
- 被引次数: 0
