

-
摘要:
基于自表示子空间聚类的多视图聚类引起越来越多的关注. 大多数现有算法假设每个样本的所有视图都可获得, 然而在实际应用中, 由于各种因素, 可能会导致某些视图缺失. 为了对视图不完整数据进行聚类, 本文提出了一种在统一框架下同时执行缺失视图补全和多视图子空间聚类的方法. 具体地, 缺失视图是由已观测视图数据约束的隐表示生成的. 此外, 多秩张量应用于挖掘不同视图之间的高阶相关性. 这样通过隐表示和高阶张量同时挖掘了不同视图以及所有样本(即使是不完整视图样本)之间的相关性. 本文使用增广拉格朗日交替方向最小化(AL-ADM)方法求解优化问题. 在真实数据集上的实验结果表明, 我们的方法优于最新的多视图聚类算法, 具有更好的聚类准确度和鲁棒性.
Abstract:There has been a growing interest in multi-view clustering over self-representation-based subspace clustering. Most existing algorithms assume that all views for each sample are available. However, in real applications, some views may be missing which produces data with partial views. To cluster the incomplete data, we propose a generative model to simultaneously perform view imputation and multi-view subspace clustering in a unified framework. Specifically, the missing views are generated by a latent representation which is constrained by the observed views. Moreover, multi-rank tensor is employed to explore the higher-order correlations across different views. In this way, the correlations across different views and all samples even with incomplete views are simultaneously explored by the latent representation and high-order tensor. We solve the optimization problem by using augmented Lagrangian alternating direction minimization (AL-ADM) method. Experimental results on real-world datasets demonstrate the superior performance and robustness of our method over state-of-the-art multi-view clustering algorithms.
-
Key words:
- View missing /
- multi-view clustering /
- tensor /
- generative model
1) 1http://cvc.yale.edu/projects/yalefacesB/yalefacesB.html 2http://www.uk.research.att.com/facedatabase.html 3http://www.cs.columbia.edu/CAVE/software/softlib/ 4http://mlg.ucd.ie/datasets/ 2) 2http://www.uk.research.att.com/facedatabase.html3) 3http://www.cs.columbia.edu/CAVE/software/softlib/4) 4http://mlg.ucd.ie/datasets/ -
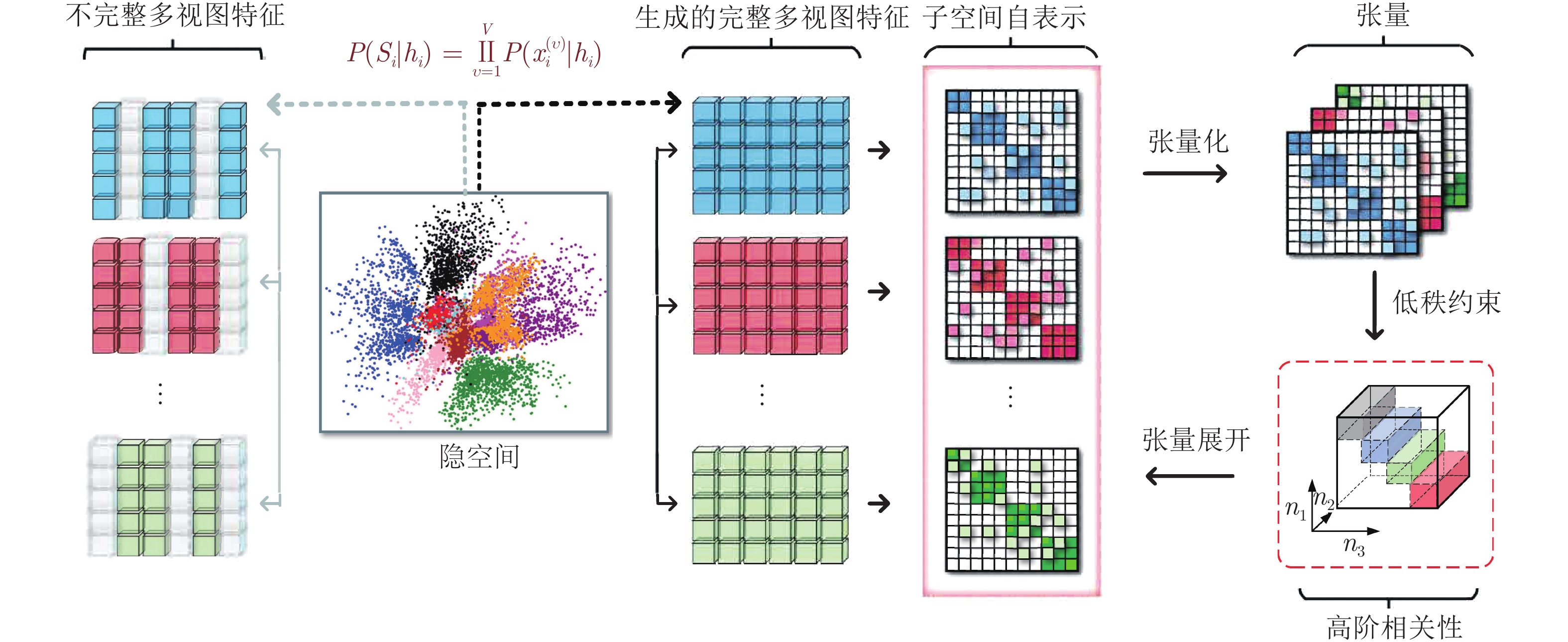
图 1 同时用
$P(X|H)$ 对隐空间$H$ 进行建模, 并基于隐表示生成完整特征. 根据完整的数据, GM-PMVC将子空间表示集成到一个张量中, 可以挖掘多视图数据高阶相关性Fig. 1 Illustration of generative model for partial multi-view clustering (GM-PMVC). Given incomplete multi-view data, we simultaneously model latent space
$H$ by$P(X|H)$ and generate complete feature based on latent representation. According to the completed data, GM-PMVC integrates subspace representation into a tensor which can effectively explores higher-order correlations equipped with low-rank constraint
图 2 在四个数据集上不同缺失率的准确度(ACC)和归一化互信息(NMI) (平均值 ± 标准差)
Fig. 2 Results (mean ± std) in terms of accuracy and NMI on four datasets with different missing rate

图 3 YaleB数据集上缺失率为10 %时的模型分析: (a) 参数调整对NMI指标的影响; (b)迭代过程中的收敛条件数值和聚类指数曲线(收敛条件数值已归一化)
Fig. 3 Model analysis on YaleB with missing rate: 10 %: (a) Performence with parameter tuning; (b) Convergence and clustering index curves during iteration (convergence values are normlized)
表 1 符号与定义
Table 1 Notations and definitions
$b$ 标量 $B$ 矩阵 ${\boldsymbol{b}}$ 向量 ${\cal{B}}$ 张量 ${\cal{I}}$ 单位张量 $fft$ 快速傅里叶变换 ${\cal{B}}_{ijk}$ 张量${\cal{B}}$第$(i,j,k)$元素 ${\cal{Q}}$ 正交张量 ${\cal{B}}(i,:,:)$ 第$i$水平切片 ${\cal{B}}^{\rm T}$ ${\cal{B}}$的转置 ${\cal{B}}(:,i,:)$ 第$i$侧面切片 ${\cal{B}}_{f}$ $fft({\cal{B}},[],3)$ ${\cal{B}}(:,:,i)$ 第$i$正面切片 $B^{(i)}$ ${\cal{B}}(:,:,i)$ $||B||_{F}$ $\sqrt{\sum\nolimits_{i,j}|B_{ij}|^{2}}$ $||B||_{*}$ 矩阵$B$奇异值之和 $||{\cal{B}}||_{F}$ $\sqrt{\sum\nolimits_{i,j,k}|{\cal{B}}_{ijk}|^{2}}$ $||{\cal{B}}||_{1}$ $\sum\nolimits_{i,j,k}|{\cal{B}}_{ijk}|$  下载: 导出CSV
下载: 导出CSV
表 2 算法运行时间对比(秒)
Table 2 Algorithm running time comparison (s)
Algorithms ORL yaleB MIC 84.67 143.30 IMG 83.02 169.38 PVC 120.68 404.82 DAIMC 157.76 191.27 SRLCs 93.21 193.36 t-SVD-MSC 56.77 107.03 Ours 180.90 288.50
下载: 导出CSV
-
[1] Sun S. A survey of multi-view machine learning. Neural Computing and Applications, 2013, 23(7-8): 2031-2038 doi: 10.1007/s00521-013-1362-6 [2] Yang Y, Wang H. Multi-view clustering: A survey. Big Data Mining and Analytics, 2018, 1(2): 83-107 doi: 10.26599/BDMA.2018.9020003 [3] Baltrusaitis T, Ahuja C, Morency L P. Multimodal machine learning: A survey and taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(2): 423-443 [4] 张祎, 孔祥维, 王振帆, 付海燕, 李明. 基于多视图矩阵分解的聚类分析. 自动化学报, 2018, 44(12): 2160-2169Zhang Yi, Kong Xiang-Wei, Wang Zhen-Fan, Fu Hai-Yan, Li Ming. Matrix Factorization for Multi-view Clustering. Acta Automatica Sinica, 2018, 44(12): 2160-2169 [5] 王海艳. 一种基于多视图学习的群组发现方法. 自动化学报, 2019, 39(4): 80-89Wang Hai-Yan. Group discovery method based on multi view learning. Acta Automatica Sinica, 2019, 39(4): 80-87 [6] 李霞, 卢官明, 闫静杰, 张正言. 多模态维度情感预测综述. 自动化学报, 2018, 44(12): 2142-2159.Li Xia, Lu Guan-Ming, Yan Jing-Jie, Zhang Zheng-Yan. A Survey of Dimensional Emotion Prediction by Multimodal Cues. Acta Automatica Sinica, 2018, 44(12): 2142-2159 [7] Li Z Y, Wang Q Q, Tao Z Q, Gao Q X, Yang Z H. Deep adversarial multi-view clustering network. In: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. Macau, China: Morgan Kaufmann, 2019. 2952−2958 [8] Xie Y, Tao D C, Zhang W S, Liu Y, Zhang L, Qu Y Y. On unifying multi-view self-representations for clustering by tensor multi-rank minimization. International Journal of Computer Vision, 2018, 126(11): 1157-1179 doi: 10.1007/s11263-018-1086-2 [9] Zhang C Q, Fu H Z, Liu S, Liu G C, Cao X C. Low-rank tensor constrained multiview subspace clustering. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1582−1590 [10] Cao X C, Zhang C Q, Fu H Z, Liu S, Zhang H. Diversity-induced multi-view subspace clustering. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 586−594 [11] Zhang C Q, Fu H Z, Hu Q H, Cao X C, Xie Y, Tao D C, et al. Generalized latent multi-view subspace clustering. IEEE transactions on pattern analysis and machine intelligence, 2018, 42(1): 86-99 [12] Li R H, Zhang C Q, Hu Q H, Zhu P F, Wang Z. Flexible multi-View representation learning for subspace clustering. In: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. Macau, China: Morgan Kaufmann, 2019. 2916−2922 [13] Kang Z, Shi G X, Huang S, Chen W Y, Pu X R, Zhou T Y, et al. Multi-graph fusion for multi-view spectral clustering. Knowledge-Based Systems, 2020, 189: 105102 doi: 10.1016/j.knosys.2019.105102 [14] Kang Z, Zhao X J, Peng C, Zhu H Y, Zhou T Y, Peng X, et al. Partition level multiview subspace clustering. Neural Networks, 2020, 122: 279-288 doi: 10.1016/j.neunet.2019.10.010 [15] Huang Z Y, Zhou T Y, Peng X, Zhang C Q, Zhu H Y, Lv J C. Multi-view spectral clustering network. In: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. Macau, China: Morgan Kaufmann, 2019. 2563−2569 [16] Cai J F, Candès E J, Shen Z. A singular value thresholding algorithm for matrix completion. SIAM Journal on Optimization, 2010, 20(4): 1956-1982 doi: 10.1137/080738970 [17] Mazumder R, Hastie T, Tibshirani R. Spectral regularization algorithms for learning large incomplete matrices. Journal of machine learning research, 2010, 11(80): 2287-2322 [18] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2223−2232 [19] Choi Y, Choi M, Kim M, Ha J W, Kim S, Choo J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 8789−8797 [20] Kim T, Cha M, Kim H, Lee J K, Kim J. Learning to discover cross-domain relations with generative adversarial networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: ACM, 2017. 1857−1865 [21] Lee D, Kim J, Moon W J, Ye J C. CollaGAN: Collaborative GAN for missing image data imputation. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 2487−2496 [22] 孙亮, 韩毓璇, 康文婧, 葛宏伟. 基于生成对抗网络的多视图学习与重构算法. 自动化学报, 2018, 44(5): 819-828Sun Liang, Han Yu-Xuan, Kang Wen-Jing, Ge Hong-Wei. Multi-view Learning and Reconstruction Algorithms via Generative Adversarial Networks. Acta Automatica Sinica, 2018, 44(5): 819-828 [23] Li S Y, Jiang Y, Zhou Z H. Partial multi-view clustering. In: Proceedings of Twenty-Eighth the Association for the Advance of Artificial Intelligence Conference. Québec Convention Center, Canada: AAAI, 2014. 1968−1974 [24] Zhao H D, Liu H F, Fu Y. Incomplete multi-modal visual data grouping. In: Proceedings of the 25th International Joint Conference on Artificial Intelligenc. New York, USA: Morgan Kaufmann, 2016. 2392−2398 [25] Zhuge W Z, Hou C P, Liu X W, Tao H, Yi D Y. Simultaneous representation learning and clustering for incomplete multi-view data. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macau, China: Morgan Kaufmann, 2019. 4482−4488 [26] Kilmer M E, Martin C D. Factorization strategies for third-order tensors. Linear Algebra and its Applications, 2011, 435(3): 641-658 doi: 10.1016/j.laa.2010.09.020 [27] Semerci O, Hao N, Kilmer M E, Miller E L. Tensor-based formulation and nuclear norm regularization for multienergy computed tomography. IEEE Transactions on Image Processing, 2014, 23(4): 1678-1693 doi: 10.1109/TIP.2014.2305840 [28] Zhang Z M, Ely G, Aeron S, Hao N, Kilmer M. Novel methods for multilinear data completion and de-noising based on tensor-SVD. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 3842−3849 [29] Zhang C Q, Adeli E, Wu Z W, Li G, Lin W L, Shen D G. Infant brain development prediction with latent partial multi-view representation learning. IEEE Transaction on Medical Imaging, 2019, 38(4): 909-918 doi: 10.1109/TMI.2018.2874964 [30] Liu G C, Lin Z C, Yan S C, Sun J, Yu Y, Ma Y. Robust recovery of subspace structures by low-rank representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 35(1): 171-184 [31] Lin Z C, Liu R S, Su Z X. Linearized alternating direction method with adaptive penalty for low-rank representation. In: Proceedings of Advances in Neural Information Processing Systems. Granada Congress and Exhibition Centre, SPAIN: MIT Press, 2011. 612−620 [32] Greene D, Cunningham P.A matrix factorization approach for integrating multiple data views. In: Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Bled, Slovenia: Springer, 2009. 423−438 [33] Shao W X, He L F, Philip S Y. Multiple Incomplete Views Clustering via Weighted Nonnegative Matrix Factorization with L2, 1 Regularization. In: Proceedings of Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Porto, Portugal: Springer, 2015. 318−334 [34] Hu M L, Chen S C. Doubly aligned incomplete multi-view clustering. In: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence. Stockholm, Sweden: AAAI, 2018. 2262−2268 -





 下载:
下载:

计量
- 文章访问数: 2894
- HTML全文浏览量: 1283
- PDF下载量: 407
- 被引次数: 0
