

-
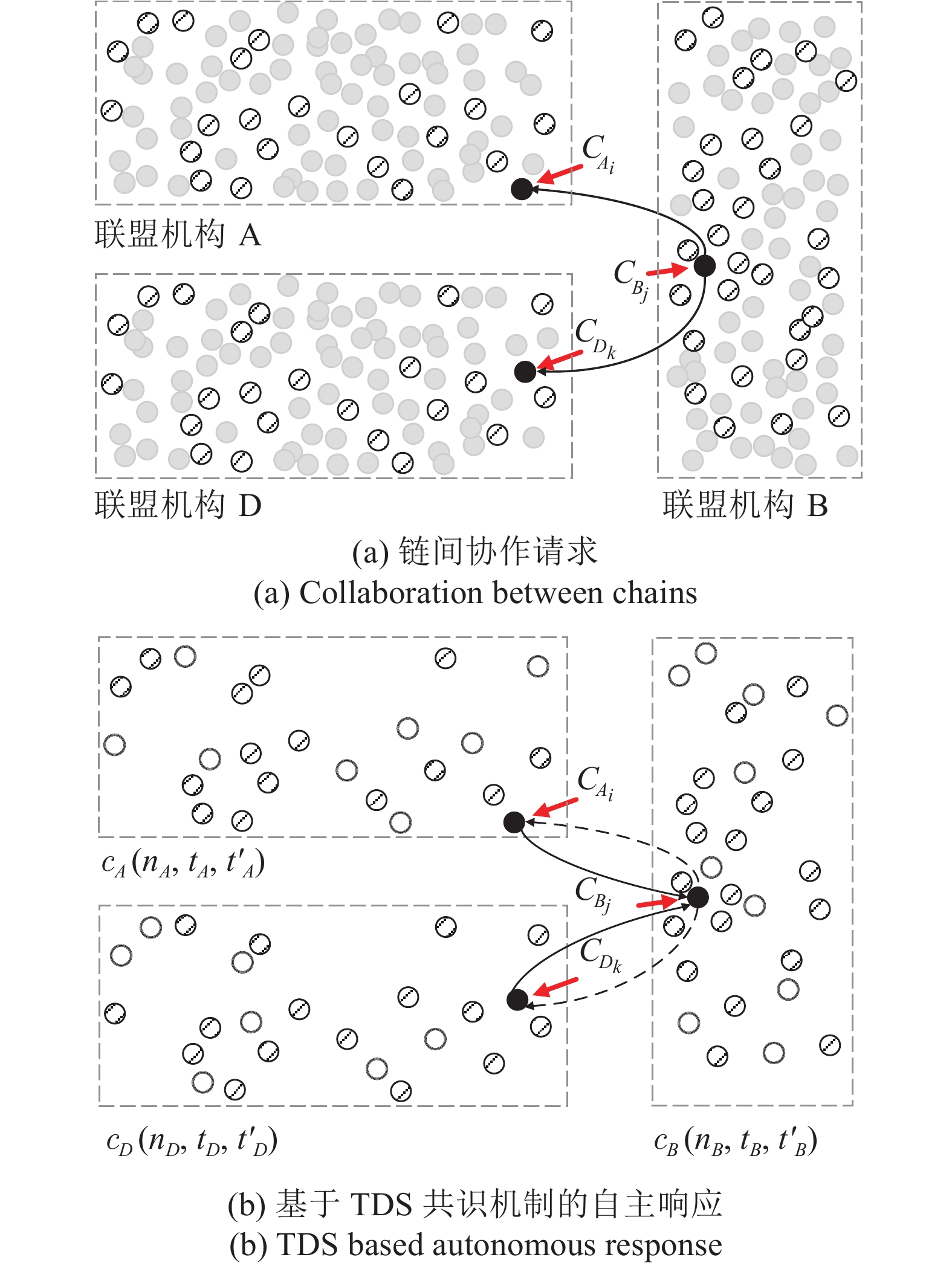
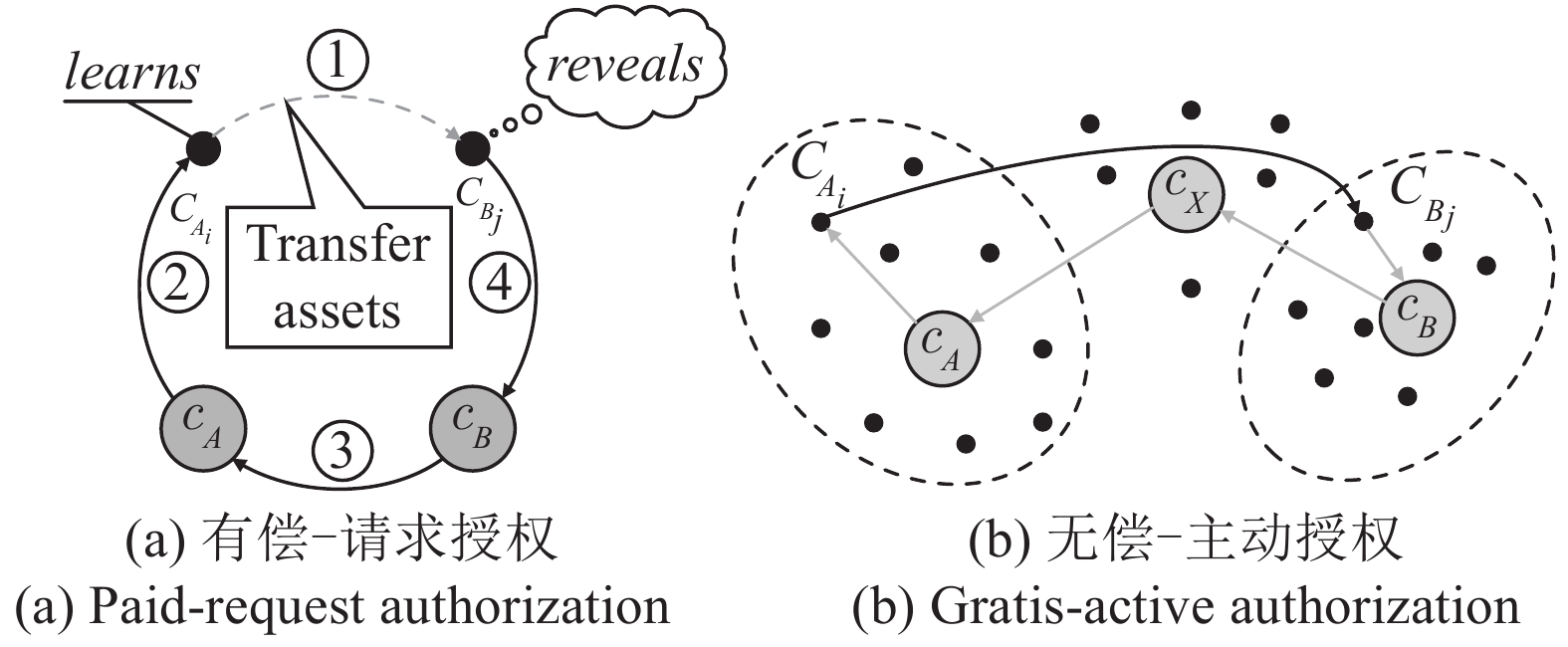
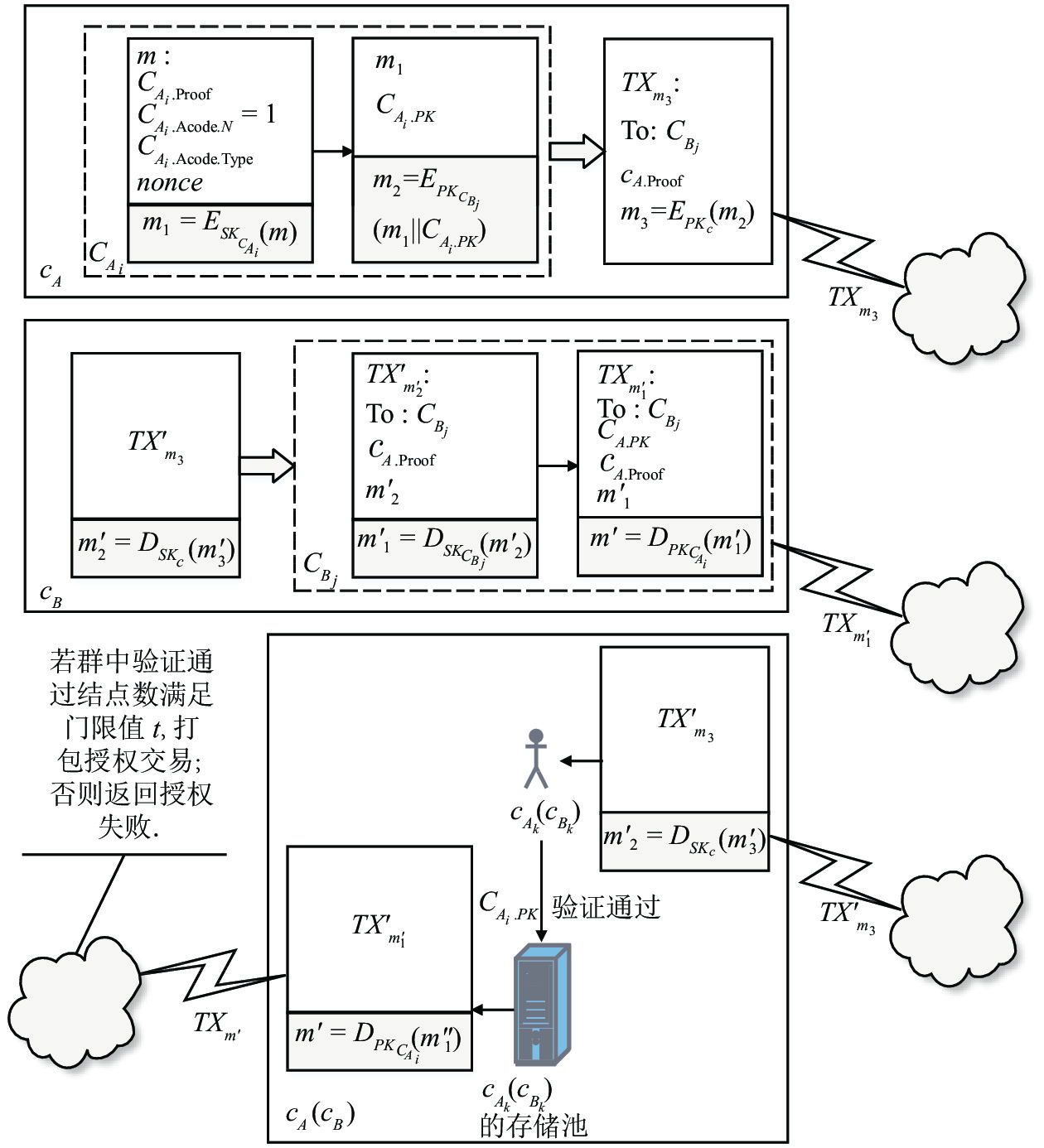
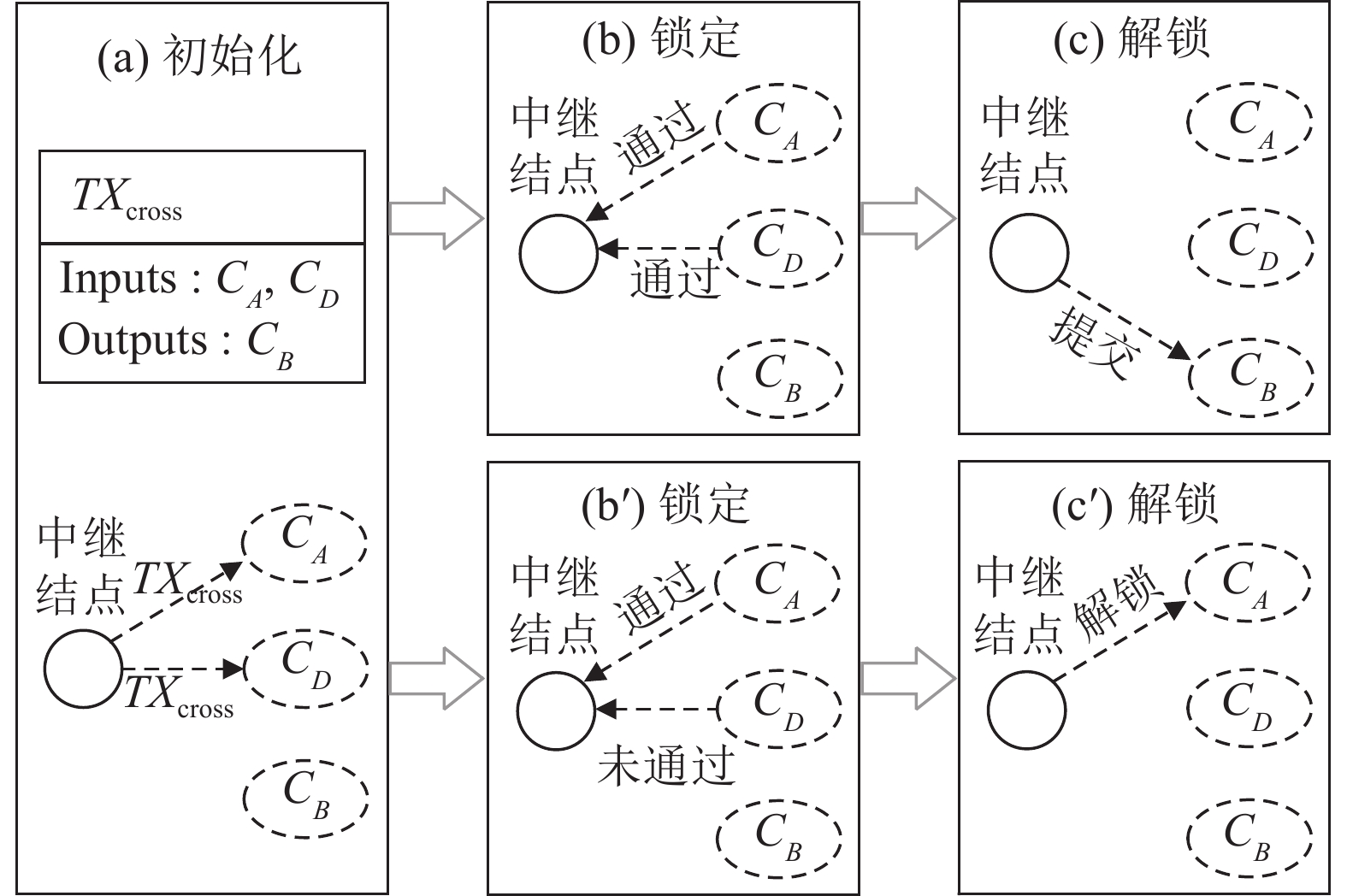
摘要: 联盟链具有公有链固有的安全性, 其许可准入机制允许对网络结点及规模进行控制, 恰好迎合了物联网(Internet of things, IoT)向规模化、智能化发展的需要, 成为物联网学术界研究的热点. 然而, 联盟链在一定程度上违背了区块链去中心化价值和信任体系, 产生了多中心化的复杂区块链生态体系, 为使物联网数字资产在不同联盟链间安全、自主、动态流转, 迫切需要对涉及多个联盟链的复杂系统通信机制进行研究. 基于存在多个特权子群的门限数字签名机制建立多联盟链链间合作共识, 利用授权码构造身份证明, 实现链间实体自主授权过程; 构建跨联盟链交易原子提交协议, 确保异步授权状态同步; 提出多级混合可选信任—验证交易共识机制. 实验表明, 上述机制能够在优化系统性能的同时确保系统的安全性.Abstract: Consortium chain has the inherent security of public chain, and its permission and access mechanism allows institutions to control network nodes and scale, which exactly meets the need of scale and intelligent development of internet of things (IoT), and has become a hotspot in the research of the internet of things. However, the consortium chain violates the decentralized blockchain to some extent, resulting in multi-centralized complex consortium chain ecosystem. In order to make the digital assets of the internet of things safe, autonomous and dynamic transfer between different consortium chains, it is urgent to research on the communication mechanism of IoT consortium chain in complex scenarios. In this paper a method for establishing cooperation consensus among multiple consortium chains based on the threshold digital signature mechanism is proposed. On this basis, a multi-layer hybrid optional trust-verified transaction consensus mechanism is proposed. Then, the authorization code is used to construct an identity certificate, thereby the autonomous authorization between entities is realized. After that, the cross-consortium chain transaction atomic submission protocol is constructed to ensure that the asynchronous authorization status is synchronized, as well as multiple mixed optional trust-verification transaction consensus mechanism is proposed. Experimental results show that the above mechanism optimizes system performance while ensuring system security a lot.
-
[1] Díaz M, Martín C, Rubio B. State-of-the-art, challenges, and open issues in the integration of internet of things and cloud computing. Journal of Network and Computer Applications, 2016, 67: 99-117 doi: 10.1016/j.jnca.2016.01.010 [2] McKinsey & Company. Tech-enabled transformation: The trillion-dollar opportunity for industrials [Online], available: https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/tech-enabled-transformation, December 20, 2018 [3] Li H X, Zhu H J, Du S G, Liang X H, Shen X M. Privacy leakage of location sharing in mobile social networks: Attacks and defense. IEEE Transactions on Dependable and Secure Computing, 2018, 15(4): 646-660 doi: 10.1109/TDSC.2016.2604383 [4] Zhou L, Du S G, Zhu H J, Chen C L, Ota K, Dong M X. Location privacy in usage-based automotive insurance: Attacks and countermeasures. IEEE Transactions on Information Forensics and Security, 2019, 14(1): 196-211 doi: 10.1109/TIFS.2018.2848227 [5] 李继蕊, 李小勇, 高雅丽, 高云全, 方滨兴. 物联网环境下数据转发模型研究. 软件学报, 2018, 29(1): 196-224Li Ji-Rui, Li Xiao-Yong, Gao Ya-Li, Gao Yun-Quan, Fang Bin-Xing. Review on data forwarding model in Internet of things. Journal of Software, 2018, 29(1): 196-224 [6] Bertino E. Data security and privacy in the IoT. In: Proceedings of the 19th International Conference on Extending Database Technology. Bordeaux, France: OpenProceedings, 2016. 3−10 [7] 张玉清, 王晓菲, 刘雪峰, 刘玲. 云计算环境安全综述. 软件学报, 2016, 27(6): 1328-1348Zhang Yu-Qing, Wang Xiao-Fei, Liu Xue-Feng, Liu Ling. Survey on cloud computing security. Journal of Software, 2016, 27(6): 1328-1348 [8] Chung K, Park R C. P2P cloud network services for IoT based disaster situations information. Peer-to-Peer Networking and Applications, 2016, 9(3): 566-577 doi: 10.1007/s12083-015-0386-3 [9] Teing Y Y, Dehghantanha A, Choo K K R, Yang L T. Forensic investigation of P2P cloud storage services and backbone for IoT networks: bitTorrent sync as a case study. Computers & Electrical Engineering, 2017, 58: 350-363 [10] Hussein D, Bertin E, Frey V. A community-driven access control approach in distributed IoT environments. IEEE Communications Magazine, 2017, 55(3): 146-153 doi: 10.1109/MCOM.2017.1600611CM [11] 袁勇, 周涛, 周傲英, 段永朝, 王飞跃. 区块链技术: 从数据智能到知识自动化. 自动化学报, 2017, 43(9): 1485-1490Yuan Yong, Zhou Tao, Zhou Ao-Ying, Duan Yong-Chao, Wang Fei-Yue. Blockchain technology: From data intelligence to knowledge automation. Acta Automatica Sinica, 2017, 43(9): 1485-1490 [12] 朱建明, 丁庆洋, 高胜. 基于许可链的SWIFT系统分布式架构. 软件学报, 2019, 30(6): 1594-1613Zhu Jian-Ming, Ding Qing-Yang, Gao Sheng. Distributed framework of SWIFT system based on permissioned blockchain. Journal of Software, 2019, 30(6): 1594-1613 [13] Landau S. Making sense from Snowden: What’s significant in the NSA surveillance revelations. IEEE Security & Privacy, 2013, 11(4): 54-63 [14] 袁勇, 王飞跃. 区块链技术发展现状与展望. 自动化学报, 2016, 42(4): 481-494Yuan Yong, Wang Fei-Yue. Blockchain: The state of the art and future trends. Acta Automatica Sinica, 2016, 42(4): 481-494 [15] 祝烈煌, 高峰, 沈蒙, 李艳东, 郑宝昆, 毛洪亮, 等. 区块链隐私保护研究综述. 计算机研究与发展, 2017, 54(10): 2170-2186 doi: 10.7544/issn1000-1239.2017.20170471Zhu Lie-Huang, Gao Feng, Shen Meng, Li Yan-Dong, Zheng Bao-Kun, Mao Hong-Liang, et al. Survey on privacy preserving techniques for blockchain technology. Journal of Computer Research and Development, 2017, 54(10): 2170-2186 doi: 10.7544/issn1000-1239.2017.20170471 [16] Fraga-Lamas P, Fernández-Caramés T M. A review on blockchain technologies for an advanced and cyber-resilient automotive industry. IEEE Access, 2019, 7: 17578-17598 doi: 10.1109/ACCESS.2019.2895302 [17] Fernández-Caramés T M, Fraga-Lamas P. Design of a fog computing, blockchain and IoT-based continuous glucose monitoring system for crowdsourcing mHealth. In: Proceedings of the 5th International Electronic Conference on Sensors and Applications. MDPI, 2018. 37 [18] Conoscenti M, Vetro A, De Martin J C. Blockchain for the internet of things: A systematic literature review. In: Proceedings of the 13th International Conference of Computer Systems and Applications. Agadir, Morocco: IEEE, 2017. 1−6 [19] 朱立, 俞欢, 詹士潇, 邱炜伟, 李启雷. 高性能联盟区块链技术研究. 软件学报, 2019, 30(6): 1575-1593Zhu Li, Yu Huan, Zhan Shi-Xiao, Qiu Wei-Wei, Li Qi-Lei. Research on high-performance consortium blockchain technology. Journal of Software, 2019, 30(6): 1575-1593 [20] Miraz M H, Donald D C. Atomic cross-chain swaps: Development, trajectory and potential of non-monetary digital token swap facilities. Annals of Emerging Technologies in Computing, 2019, 3(1): 42-50 doi: 10.33166/AETiC.2019.01.005 [21] 曾帅, 袁勇, 倪晓春, 王飞跃. 面向比特币的区块链扩容: 关键技术, 制约因素与衍生问题. 自动化学报, 2019, 45(6): 1015-1030Zeng Shuai, Yuan Yong, Ni Xiao-Chun, Wang Fei-Yue. Scaling blockchain towards Bitcoin: Key technologies, constraints and related issues. Acta Automatica Sinica, 2019, 45(6): 1015-1030 [22] Redman J. Engineers demonstrate Zcash/Bitcoin atomic swaps [Online], available: https://news.bitcoin.com/engineers-demonstrate-zcashbitcoin-atomic-swaps/, October 1, 2017 [23] 刘敖迪, 杜学绘, 王娜, 李少卓. 基于区块链的大数据访问控制机制. 软件学报, 2019, 30(9): 2636-2654Liu Ao-Di, Du Xue-Hui, Wang Na, Li Shao-Zhuo. Blockchain-based access control mechanism for big data. Journal of Software, 2019, 30(9): 2636-2654 [24] 刘敖迪, 杜学绘, 王娜, 李少卓. 区块链技术及其在信息安全领域的研究进展. 软件学报, 2018, 29(7): 2092-2115Liu Ao-Di, Du Xue-Hui, Wang Na, Li Shao-Zhuo. Research progress of blockchain technology and its application in information security. Journal of Software, 2018, 29(7): 2092-2115 [25] 乔蕊, 曹琰, 王清贤. 基于联盟链的物联网动态数据溯源机制. 软件学报, 2019, 30(6): 1614-1631Qiao Rui, Cao Yan, Wang Qing-Xian. Traceability mechanism of dynamic data in internet of things based on consortium blockchain. Journal of Software, 2019, 30(6): 1614-1631 [26] Qiao R, Zhu S F, Wang Q X, Qin J. Optimization of dynamic data traceability mechanism in internet of things based on consortium blockchain. International Journal of Distributed Sensor Networks, 2018, 14(12): 1-15 [27] Qiao R, Luo X Y, Zhu S F, Liu A D, Yan X Q, Wang Q X. Dynamic autonomous cross consortium chain mechanism in e-healthcare. IEEE Journal of Biomedical and Health Informatics, 2020, 24(8): 2157-2168 doi: 10.1109/JBHI.2019.2963437 [28] Adamik F, Kosta S. SmartExchange: Decentralised trustless cryptocurrency exchange. In: Proceedings of the 2018 International Conference on Business Information Systems. Berlin, Germany: Springer, 2018. 356−367 [29] Buterin V. Chain interoperability [Online], available: https://static1.squarespace.com/static/55f73743e4b051cfcc0b02cf/t/5886800ecd0f68de303349b1/1485209617040/Chain+Interoperability.pdf, September 9, 2018 [30] Wang H, Cen Y Y, Li X F. Blockchain router: A cross-chain communication protocol. In: Proceedings of the 6th International Conference on Informatics, Environment, Energy and Applications. Jeju, South Korea: ACM, 2017. 94−97 [31] Liu X, Zhu Q K. An intelligent value chain model with internet enterprises based on blockchain. In: Proceedings of the 2018 IEEE Advanced Information Technology, Electronic and Automation Control Conference. Chongqing, China: IEEE, 2018. 1845−1849 [32] Borkowski M, McDonald D, Ritzer C, Schulte S. Towards atomic cross-chain token transfers: State of the art and open questions within TAST [Online], available: http://www.borkowski.at/pub/tast-white-paper-1.pdf, October 7, 2018 [33] 李芳, 李卓然, 赵赫. 区块链跨链技术进展研究. 软件学报, 2019, 30(6): 1649-1660Li Fang, Li Zhuo-Ran, Zhao He. Research on the progress in cross-chain technology of blockchains. Journal of Software, 2019, 30(6): 1649-1660 [34] Poon J, Dryja T. The bitcoin lightning network: Scalable off-chain instant payments [Online], available: https://lightning.network/lightning-network-paper.pdf, December 14, 2019 [35] Piatkivskyi D, Axelsson S, Nowostawski M. Digital forensic implications of collusion attacks on the lightning network. In: Proceedings of the 13th IFIP International Conference on Digital Forensics. Orlando, USA: Springer, 2017. 133−147 [36] BlockStream [Online], available: https://blockstream.com/, December 5, 2019 [37] Back A, Corallo M, Dashjr L, Friedenbach M, Maxwell G, Miller A, et al. Enabling blockchain innovations with pegged sidechains [Online], available: https://www.blockstream.com/sidechains.pdf, November 23, 2019 [38] RootStock [Online], available: https://www.rsk.co/, October 11, 2019 [39] Lisk [Online], available: https://lisk.io/, October 15, 2019 [40] Asch [Online], available: https://www.asch.io/, November 2, 2018 [41] Vitalik B. Ethereum sharding faq [Online], available: https://github.com/ethereum/wiki/wiki/Sharding-FAQs, November 17, 2018 [42] Thomas S, Schwartz E. A protocol for interledger payments [Online], available: https://interledger.org/interledger.pdf, December 18, 2019 [43] Pointnity Network [Online], available: http://pointnity.network/, December 22, 2018 [44] Wood G. Polkadot: Vision for a heterogeneous multi-chain framework [Online], available: https://polkadot.network/PolkaDotPaper.pdf, October 22, 2018 [45] Fusion [Online], available: https://fusion.org/, November 29, 2018 [46] Buterin V. A next generation smart contract & Decentralized application platform [Online], available: https://cryptorating.eu/whitepapers/Ethereum/Ethereum_white_paper.pdf, December 11, 2017 [47] 贺海武, 延安, 陈泽华. 基于区块链的智能合约技术与应用综述. 计算机研究与发展, 2018, 55(11): 2452-2466 doi: 10.7544/issn1000-1239.2018.20170658He Hai-Wu, Yan An, Chen Ze-Hua. Survey of smart contract technology and application based on blockchain. Journal of Computer Research and Development, 2018, 55(11): 2452-2466 doi: 10.7544/issn1000-1239.2018.20170658 [48] Etherscan. Ethereum unique address growth chart [Online], available: https://etherscan.io/chart/address/, December 28, 2019 [49] Park D, Zhang Y, Saxena M, Daian P, Rosu G. A formal verification tool for ethereum VM bytecode. In: Proceedings of the 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. Lake Buena Vista, USA: ACM, 2018. 912−915 [50] Warren W, Bandeali A. 0x: An open protocol for decentralized exchange on the Ethereum blockchain [Online], available: https://deepai.org/publication/enabling-cross-chain-transactions-a-decentralized-cryptocurrency-exchange-protocol, December 18, 2017 [51] Aeternity [Online], available: https://aeternity.com/, November 22, 2018 [52] Cui L Z, Yang S, Chen Z T, Pan Y, Xu M W, Xu K. An efficient and compacted DAG-based blockchain protocol for industrial internet of things. IEEE Transactions on Industrial Informatics, 2020, 16(6): 4134-4145 doi: 10.1109/TII.2019.2931157 -

 下载:
下载:






图(12)
计量
- 文章访问数: 959
- HTML全文浏览量: 357
- PDF下载量: 170
- 被引次数: 0
