

-
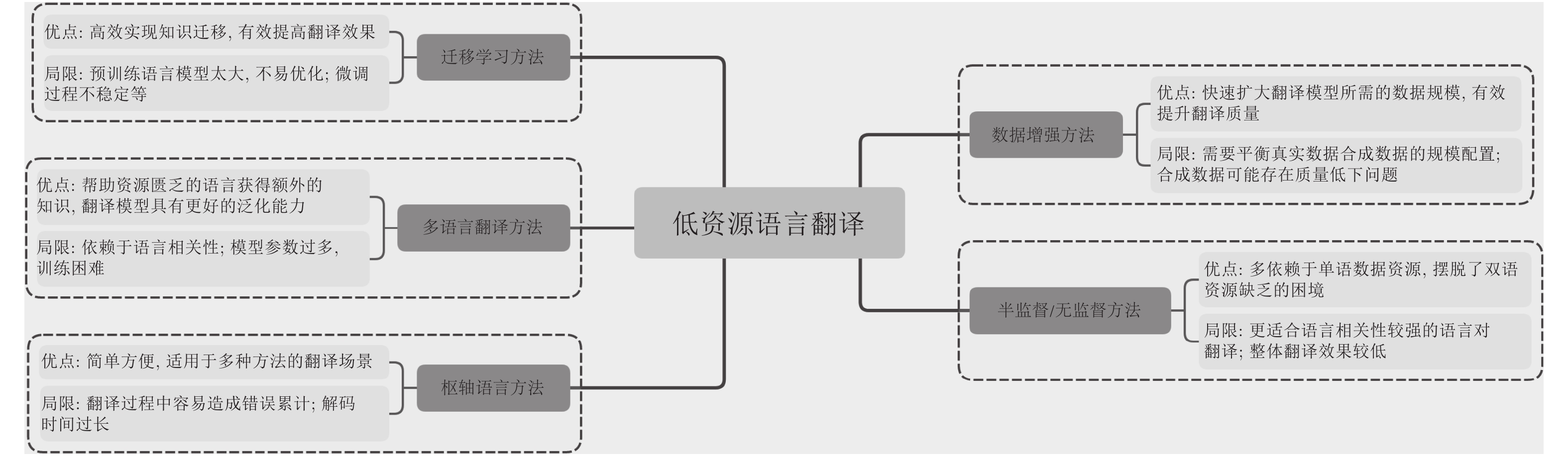
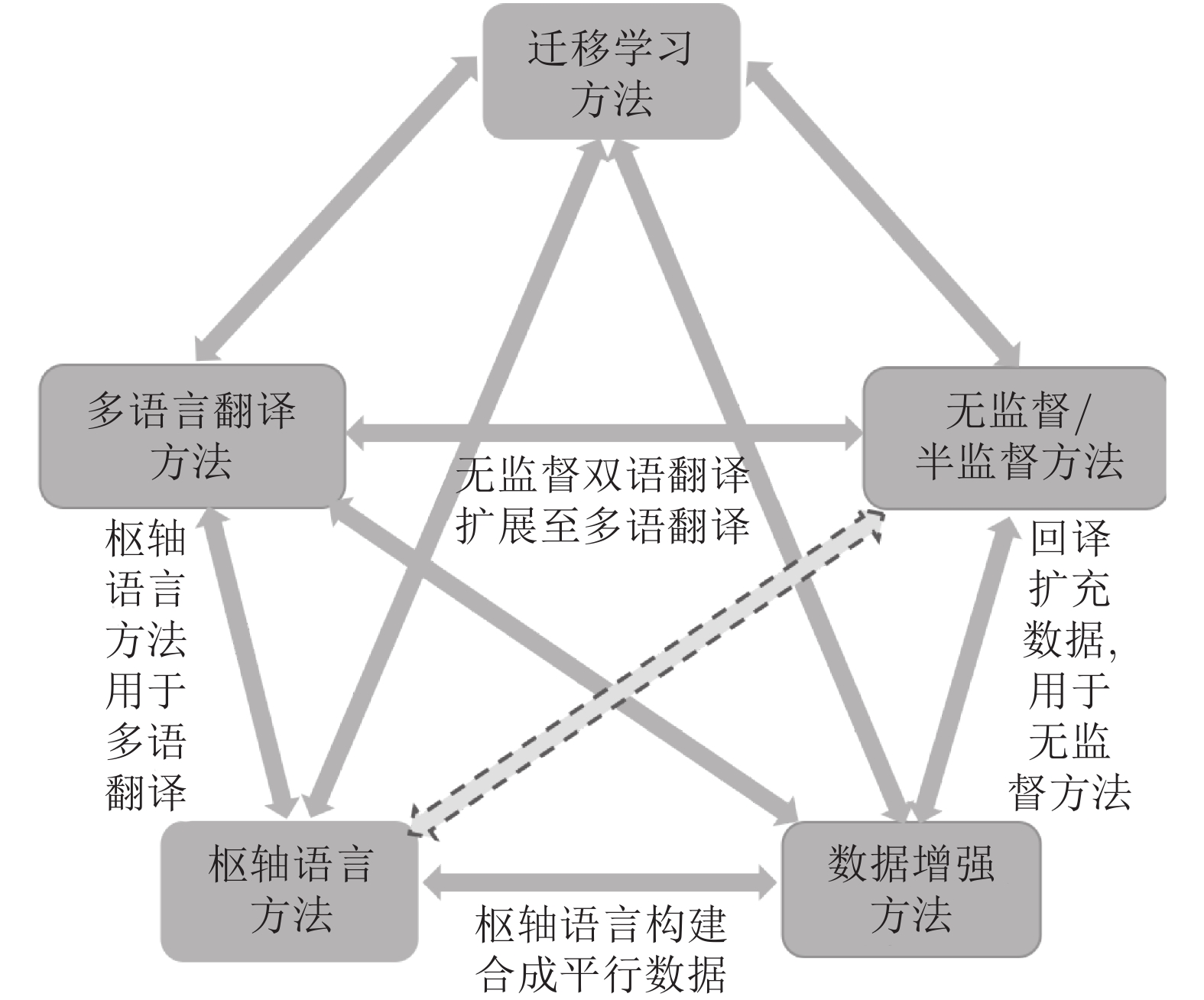
摘要: 作为目前主流翻译方法的神经网络机器翻译已经取得了很大突破, 在很多具有丰富数据资源的语言上的翻译质量也不断得到改善, 但对于稀缺资源语言的翻译效果却仍然并不理想. 稀缺资源语言机器翻译是目前机器翻译领域的重要研究热点之一, 近几年来吸引了国内外的广泛关注. 本文对稀缺资源语言机器翻译的研究进行比较全面的回顾, 首先简要介绍了与稀缺资源语言翻译相关的学术活动和数据集, 然后重点梳理了目前主要的研究方法和一些研究结论, 总结了每类方法的特点, 在此基础上总结了不同方法之间的关系并分析了目前的研究现状. 最后, 对稀缺资源语言机器翻译未来可能的研究趋势和发展方向进行了展望,并给出了相关建议.Abstract: As the mainstream approach in the field of machine translation, neural machine translation (NMT) has achieved great improvements on many rich-source languages, but performance of NMT for low-resource languages ae not very good yet. Low-resource NMT has been one of the most popular issues in MT and attracted wide attention around the world in recent years. This paper presents a survey on low-resource NMT research. We first introduce some related academic activities and feasible data sets for the translation, then categorize and summarize several types of approaches mainly used in low-resource NMT in detail, and present their features, as well as relations between them, and describe the current research status. Finally, we propose some advices on possible research trends and directions of this field in the future.
-
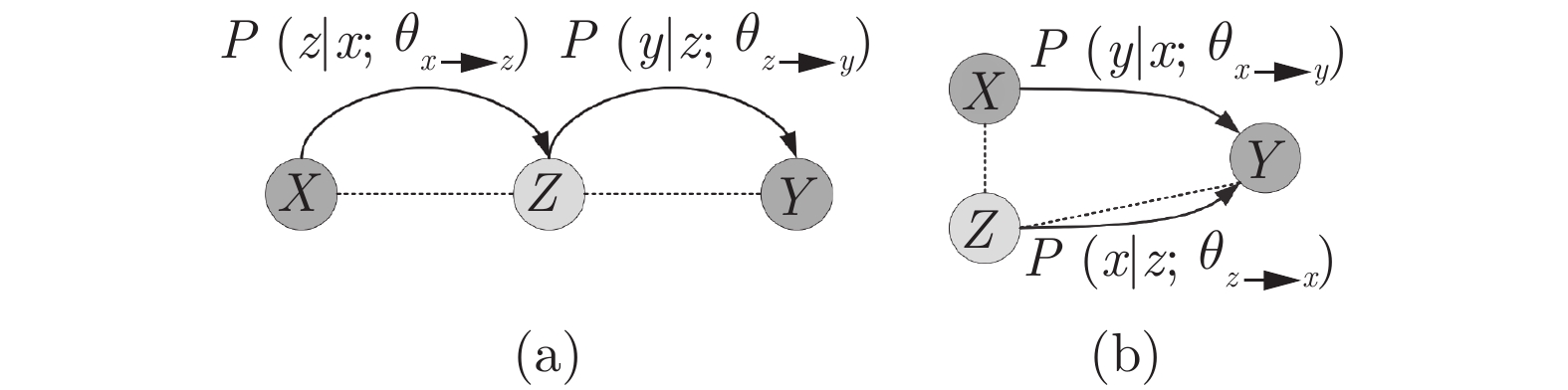
图 2 基于枢轴语言的方法(a)和“老师−学生”方法(b)
Fig. 2 Pivot-based method (a) and “Teacher-student” method (b)
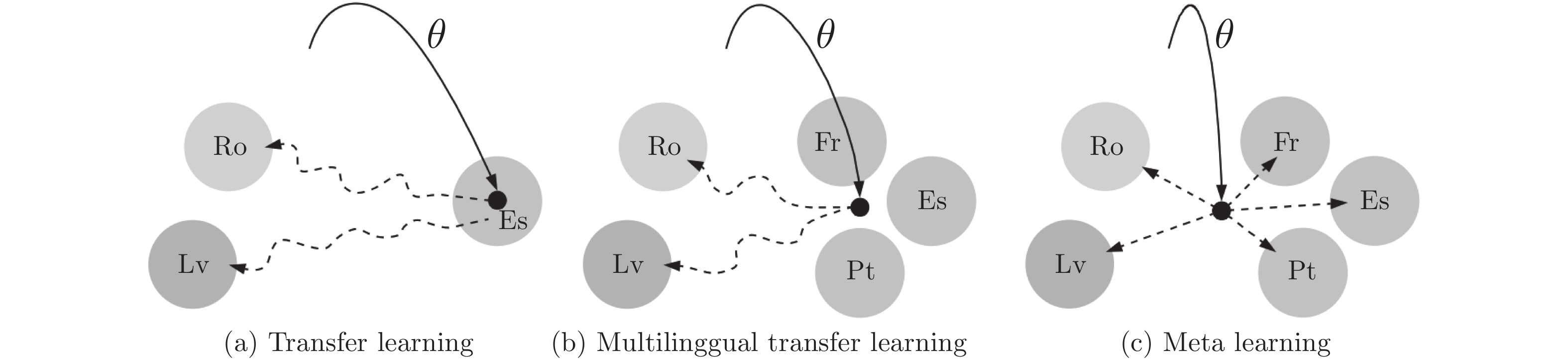
图 3 迁移学习, 多语言迁移学习与元学习
Fig. 3 Transfer learning, multilingual transfer learning and meta learning
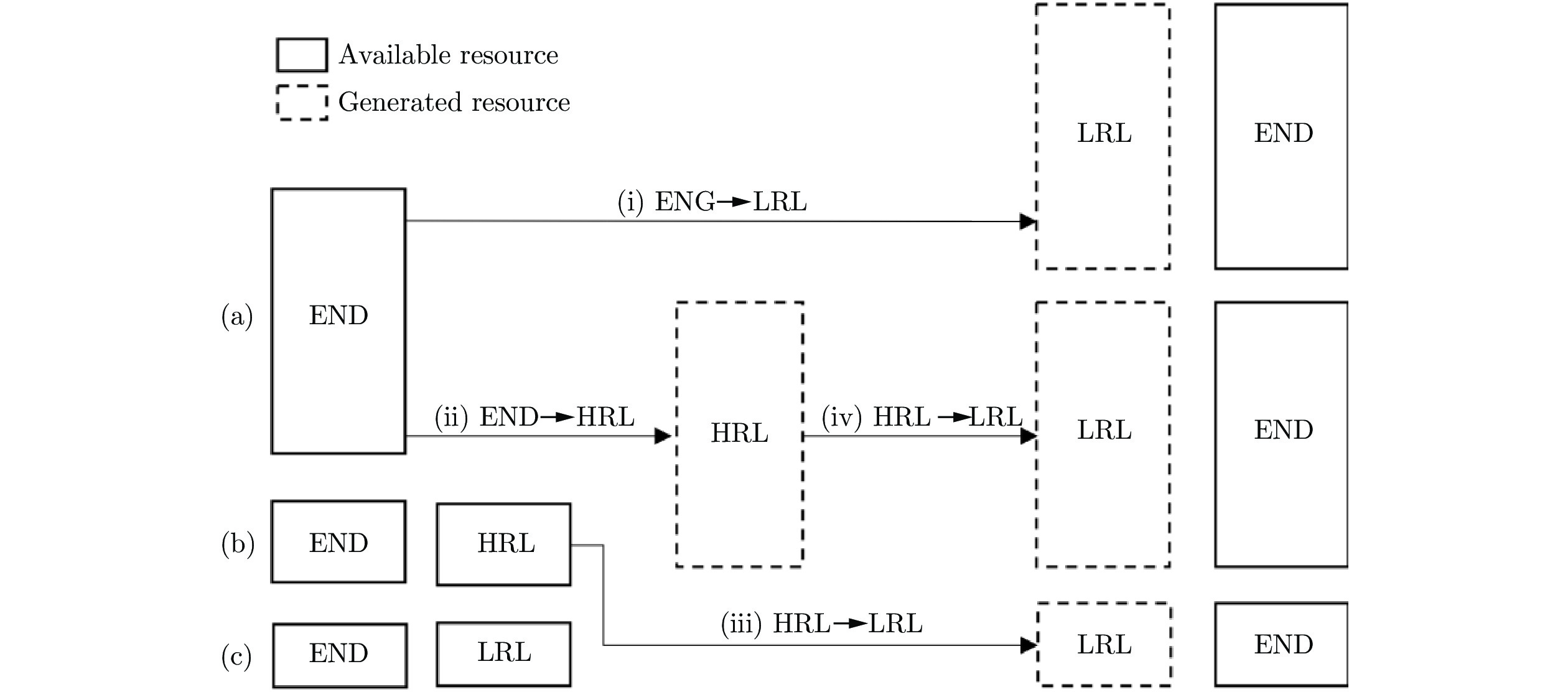
图 5 数据增强框架. 其中, (i)和(ii)是传统数据增强方法, (iii)和(iv)是新提出的方法
Fig. 5 Data augmentation method, where (i) and (ii) are traditional methods, while (iii) and (iv) are new ones
表 1 低资源语言翻译相关的数据资源
Table 1 Data for low-resource MT
数据集 描述 WMT data WMT 提供的英语−低资源语言的数据集. 这也是目前研究中使用最多的数据集. IWSLT data 面向口语翻译的 IWSLT 比赛也提供了一些低资源翻译数据集. WAT data WAT 提供亚洲低资源语言的翻译数
据集.LORELEI data7 由 DARPA 开发的低资源单语−英语双语数据集. JW300[13] 该语料库涵盖了超过 300 种语言的双语数据. WikiMatrix[14] 该语料库由 Facebook 开发构建, 包含 85 种语言的维基百科平行语料. FLORES8 由 Facebook 开发的英语−尼泊尔语和僧伽罗语的双语数据集. Indian Language Corpora Initiative (ILCI) corpus[15] 该语料库包括 11 种印度语言与英语的平行语料. Asian Language Treebank[16] 该亚洲语言树库项目包括印尼语、老挝语等 9 种东南亚语言与英语的平行语料.  下载: 导出CSV
下载: 导出CSV
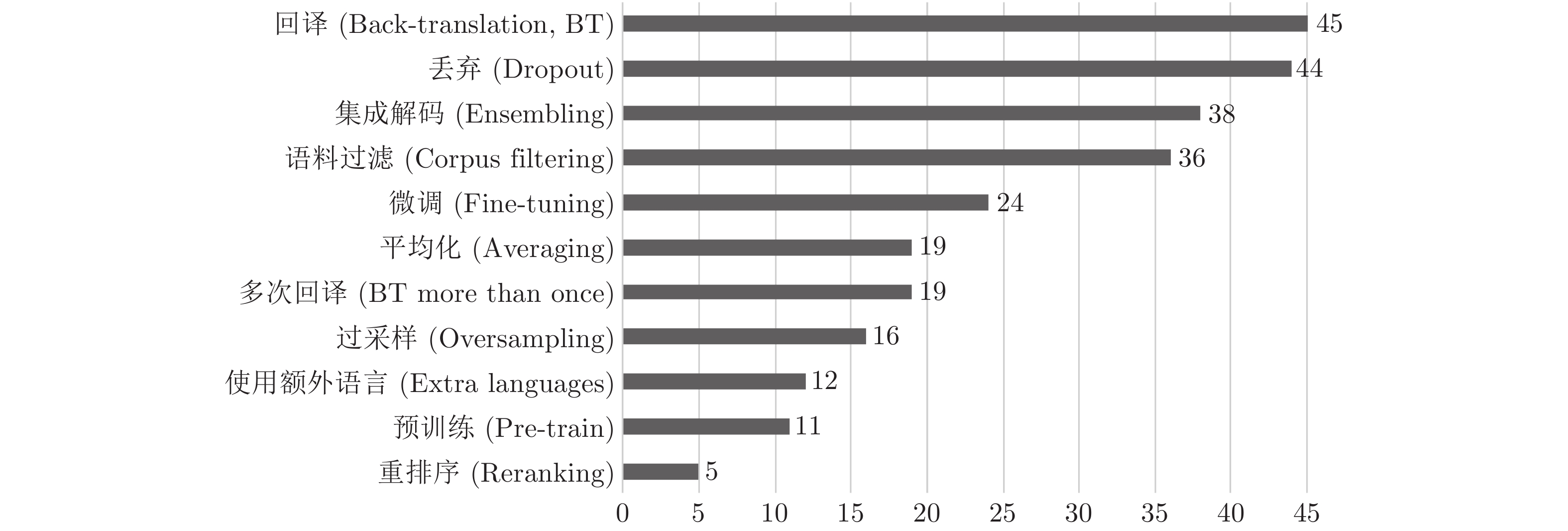
表 3 几类方法在WMT2019中的使用情况
Table 3 The methods in WMT2019
方法 频次 回译方法 45 多次回译方法 19 迁移学习和微调 24 使用额外语言(包括枢轴语言和多语种) 12 无监督方法 9
下载: 导出CSV
-
[1] Kalchbrenner N, Blunsom P. Recurrent continuous translation models. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: Association for Computational Linguistics, 2013. 1700−1709 [2] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 3104−3112 [3] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA, 2015. [4] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6000−6010 [5] 刘洋. 神经机器翻译前沿进展. 计算机研究与发展, 2017, 54(6): 1144−1149 doi: 10.7544/issn1000-1239.2017.20160805Liu Yang. Recent advances in neural machine translation. Journal of Computer Research and Development, 2017, 54(6): 1144−1149 doi: 10.7544/issn1000-1239.2017.20160805 [6] 李亚超, 熊德意, 张民. 神经机器翻译综述. 计算机学报, 2018, 41(12): 2734−2755 doi: 10.11897/SP.J.1016.2018.02734Li Ya-Chao, Xiong De-Yi, Zhang Min. A survey of neural machine translation. Chinese Journal of Computers, 2018, 41(12): 2734−2755 doi: 10.11897/SP.J.1016.2018.02734 [7] 林倩, 刘庆, 苏劲松, 林欢, 杨静, 罗斌. 神经网络机器翻译研究热点与前沿趋势分析. 中文信息学报, 2019, 33(11): 1−14 doi: 10.3969/j.issn.1003-0077.2019.11.001Lin Qian, Liu Qing, Su Jin-Song, Lin Huan, Yang Jing, Luo Bin. Focuses and frontiers tendency in neural machine translation research. Journal of Chinese Information Processing, 2019, 33(11): 1−14 doi: 10.3969/j.issn.1003-0077.2019.11.001 [8] 赵阳, 周龙, 王迁, 马聪, 刘宇宸, 王亦宁, 等. 民汉稀缺资源神经机器翻译技术研究. 江西师范大学学报(自然科学版), 2019, 43(6): 630−637Zhao Yang, Zhou Long, Wang Qian, Ma Cong, Liu Yu-Chen, Wang Yi-Ning, et al. The study on ethnic-to-Chinese scare-resource neural machine translation. Journal of Jiangxi Normal University (Natural Sciences Edition), 2019, 43(6): 630−637 [9] Bojar O, Chatterjee R, Federmann C, Graham Y, Haddow B, Huck M, et al. Findings of the 2016 conference on machine translation. In: Proceedings of the 1st Conference on Machine Translation: Volume 2, Shared Task Papers. Berlin, Germany: Association for Computational Linguistics, 2016. 131−198 [10] Bojar O, Chatterjee R, Federmann C, Graham Y, Haddow B, Huang S J, et al. Findings of the 2017 conference on machine translation (WMT17). In: Proceedings of the 2nd Conference on Machine Translation. Copenhagen, Denmark: Association for Computational Linguistics, 2017. 169−214 [11] Bojar O, Federmann C, Fishel M, Graham Y, Haddow B, Koehn P, et al. Findings of the 2018 conference on machine translation (WMT18). In: Proceedings of the 3rd Conference on Machine Translation: Shared Task Papers. Brussels, Belgium: Association for Computational Linguistics, 2018. 272−303 [12] Barrault L, Bojar O, Costa-Jussá M, Federmann C, Fishel M, Graham Y, et al. Findings of the 2019 conference on machine translation (WMT19). In: Proceedings of the 4th Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1). Florence, Italy: Association for Computational Linguistics, 2019. 1−61 [13] Agić Ž, Vulić I. JW300: A wide-coverage parallel corpus for low-resource languages. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 3204−3210 [14] Schwenk H, Chaudhary V, Sun S, Gong H Y, Guzmán F. WikiMatrix: Mining 135m parallel sentences in 1620 language pairs from Wikipedia. arXiv preprint arXiv: 1907.05791, 2019 [15] Jha G N. The TDIL program and the Indian language corpora initiative (ILCI). In: Proceedings of the 7th International Conference on Language Resources and Evaluation. Valletta, Malta, 2010. 982−985 [16] Thu Y K, Pa W P, Utiyama M, Finch A, Sumita E. Introducing the Asian language Treebank (ALT). In: Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC'16). Portorož, Slovenia: European Language Resources Association (ELRA), 2016. 1574−1578 [17] Ahmadnia B, Serrano J, Haffari G. Persian-Spanish low-resource statistical machine translation through English as pivot language. In: Proceedings of the 2017 Recent Advances in Natural Language Processing. Varna, Bulgaria, 2017. 24−30 [18] Johnson M, Schuster M, Le Q V, Krikun M, Wu Y H, Chen Z F, et al. Google' s multilingual neural machine translation system: Enabling zero-shot translation. Transactions of the Association for Computational Linguistics, 2017, 5: 339−351 doi: 10.1162/tacl_a_00065 [19] Cheng Y, Yang Q, Liu Y, Sun M S, Xu W. Joint training for pivot-based neural machine translation. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI-17). Melbourne, Australia, 2017. 3974−3980 [20] Zheng H, Cheng Y, Liu Y. Maximum expected likelihood estimation for zero-resource neural machine translation. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: AAAI Press, 2017. 4251−4257 [21] Chen Y, Liu Y, Cheng Y, Li V O K. A teacher-student framework for zero-resource neural machine translation. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vancouver, Canada: Association for Computational Linguistics, 2017. 1925−1935 [22] Ren S, Chen W H, Liu S J, Li M, Zhou M, Ma S. Triangular architecture for rare language translation. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Melbourne, Australia: Association for Computational Linguistics, 2018. 56−65 [23] Lakew S M, Lotito Q F, Negri M, Turchi M, Federico M. Improving zero-shot translation of low-resource languages. In: Proceedings of the 14th International Workshop on Spoken Language Translation. Tokyo, Japan, 2017. 113−119 [24] Nakayama H, Nishida N. Zero-resource machine translation by multimodal encoder-decoder network with multimedia pivot. Machine Translation, 2017, 31(1): 49−64 [25] Chowdhury K D, Hasanuzzaman M, Liu Q. Multimodal neural machine translation for low-resource language pairs using synthetic data. In: Proceedings of the Workshop on Deep Learning Approaches for Low-Resource NLP. Melbourne, Australia: Association for Computational Linguistics, 2018. 33−42 [26] Pan S J, Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345−1359 doi: 10.1109/TKDE.2009.191 [27] Ruder S. Neural Transfer Learning for Natural Language Processing [Ph. D. dissertation], National University of Ireland, Ireland, 2019 [28] Zoph B, Yuret D, May J, Knight K. Transfer learning for low-resource neural machine translation. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas: Association for Computational Linguistics, 2016. 1568−1575 [29] Nguyen T Q, Chiang D. Transfer learning across low-resource, related languages for neural machine translation. In: Proceedings of the 8th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Taipei, China: Asian Federation of Natural Language Processing, 2017. 296−301 [30] Dabre R, Nakagawa T, Kazawa H. An empirical study of language relatedness for transfer learning in neural machine translation. In: Proceedings of the 31st Pacific Asia Conference on Language, Information and Computation. Cebu City, Philippines: The National University, 2017. 282−286 [31] Kocmi T, Bojar O. Trivial transfer learning for low-resource neural machine translation. In: Proceedings of the 3rd Conference on Machine Translation: Research Papers. Brussels, Belgium: Association for Computational Linguistics, 2018. 244−252 [32] Gu J T, Hassan H, Devlin J, Li V O K. Universal neural machine translation for extremely low resource languages. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1(Long Papers). New Orleans, Louisiana: Association for Computational Linguistics, 2018. 344−354 [33] Gu J T, Wang Y, Chen Y, Li V O K, Cho K. Meta-learning for low-resource neural machine translation. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 3622−3631 [34] Li R M, Wang X, Yu H. MetaMT, a meta learning method leveraging multiple domain data for low resource machine translation. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 8245−8252 [35] Kim Y, Gao Y B, Ney H. Effective cross-lingual transfer of neural machine translation models without shared vocabularies. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 1246−1257 [36] Kim Y, Petrov P, Petrushkov P, Khadivi S, Ney H. Pivot-based transfer learning for neural machine translation between non-English languages. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: Association for Computational Linguistics, 2019. 866−876 [37] Ji B J, Zhang Z R, Duan X Y, Zhang M, Chen B X, Luo W H. Cross-lingual pre-training based transfer for zero-shot neural machine translation. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence (AAAI-20). New York, USA: AAAI, 2020. 115−122 [38] Cheng Y, Xu W, He Z J, He W, Wu H, Sun M S, et al. Semi-supervised learning for neural machine translation. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Berlin, Germany: Association for Computational Linguistics, 2016. 1965−1974 [39] Skorokhodov I, Rykachevskiy A, Emelyanenko D, Slotin S, Ponkratov A. Semi-supervised neural machine translation with language models. In: Proceedings of the AMTA 2018 Workshop on Technologies for MT of Low Resource Languages (LoResMT 2018). Boston, MA, USA: Association for Machine Translation in the Americas, 2018. 37−44 [40] Gulcehre C, Firat O, Xu K, Cho K, Bengio Y. On integrating a language model into neural machine translation. Computer Speech and Language, 2017, 45: 137−148 doi: 10.1016/j.csl.2017.01.014 [41] Zheng Z X, Zhou H, Huang S J, Li L, Dai X Y, Chen J J. Mirror-generative neural machine translation. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia, 2020. [42] Lample G, Conneau A, Denoyer L, Ranzato M A. Unsupervised machine translation using monolingual corpora only. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada, 2018. [43] Lample G, Ott M, Conneau A, Denoyer L, Ranzato M A. Phrase-based & neural unsupervised machine translation. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 5039−5049 [44] Artetxe M, Labaka G, Agirre E, Cho K. Unsupervised neural machine translation. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada, 2018. [45] Artetxe M, Labaka G, Agirre E. An effective approach to unsupervised machine translation. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 194−203 [46] Artetex M, Labaka G, Agirre E. A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Melbourne, Australia: Association for Computational Linguistics, 2018. 789−798 [47] Artetex M, Labaka G, Agirre E. Generalizing and improving bilingual word embedding mappings with a multi-step framework of linear transformations. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 5012−5019 [48] Yang Z, Chen W, Wang F, Xu B. Unsupervised neural machine translation with weight sharing. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Melbourne, Australia: Association for Computational Linguistics, 2018. 46−55 [49] Gu J T, Wang Y, Cho K, Li V O K. Improved zero-shot neural machine translation via ignoring spurious correlations. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 1258−1268 [50] Liu Y H, Gu J T, Goyal N, Li X, Edunov S, Ghazvininejad M, et al. Multilingual denoising pre-training for neural machine translation. arXiv preprint arXiv: 2001.08210, 2020 [51] Artetxe M, Labaka G, Agirre E. Learning bilingual word embeddings with (almost) no bilingual data. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vancouver, Canada: Association for Computational Linguistics, 2017. 451−462 [52] Conneau A, Lample G. Cross-lingual language model pretraining. In: Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019). Vancouver, Canada, 2019. [53] Pourdamghani N, Aldarrab N, Ghazvininejad M, Knight K, May J. Translating translationese: A two-step approach to unsupervised machine translation. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 3057−3062 [54] Leng Y C, Tan X, Qin T, Li X Y, Liu T Y. Unsupervised pivot translation for distant languages. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 175−183 [55] Sennrich R, Zhang B. Revisiting low-resource neural machine translation: A case study. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 211−221 [56] Zhang J J, Zong C Q. Exploiting source-side monolingual data in neural machine translation. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas: Association for Computational Linguistics, 2016. 1535−1545 [57] Gibadullin I, Valeev A, Khusainova A, Khan A. A survey of methods to leverage monolingual data in low-resource neural machine translation. In: Proceedings of the 2019 International Conference on Advanced Technologies and Humanitarian Sciences. Rabat, Morocco, 2019. [58] Sennrich R, Haddow B, Birch A. Improving neural machine translation models with monolingual data. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Berlin, Germany: Association for Computational Linguistics, 2016. 86−96 [59] Park J, Na B, Yoon S. Building a neural machine translation system using only synthetic parallel data. arXiv preprint arXiv: 1704.00253, 2017 [60] Poncelas A, Shterionov D, Way A, de Buy Wenniger G M, Passban P. Investigating backtranslation in neural machine translation. In: Proceedings of the 21st Annual Conference of the European Association for Machine Translation. Alacant, Spain, 2018. 249−258 [61] Poncelas A, Popović M, Shterionov D, de Buy Wenniger G M, Way A. Combining SMT and NMT back-translated data for efficient NMT. In: Proceedings of the 2019 Recent Advances in Natural Language Processing. Varna, Bulgaria, 2019. 922−931 [62] Edunov S, Ott M, Auli M, Grangier D. Understanding back-translation at scale. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 489−500 [63] Fadaee M, Monz C. Back-translation sampling by targeting difficult words in neural machine translation. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 436−446 [64] Hoang V C D, Koehn P, Haffari G, Cohn T. Iterative back-translation for neural machine translation. In: Proceedings of the 2nd Workshop on Neural Machine Translation and Generation. Melbourne, Australia: Association for Computational Linguistics, 2018. 18−24 [65] Imankulova A, Dabre R, Fujita A, Imamura K. Exploiting out-of-domain parallel data through multilingual transfer learning for low-resource neural machine translation. In: Proceedings of Machine Translation Summit XVⅡ Volume 1: Research Track. Dublin, Ireland: European Association for Machine Translation, 2019. 128−139 [66] Imankulova A, Sato T, Komachi M. Improving low-resource neural machine translation with filtered pseudo-parallel corpus. In: Proceedings of the 4th Workshop on Asian Translation (WAT2017). Taipei, China: Asian Federation of Natural Language Processing, 2017. 70−78 [67] Wu J W, Wang X, Wang W Y. Extract and edit: An alternative to back-translation for unsupervised neural machine translation. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1(Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics, 2019. 1173−1183 [68] Currey A, Heafield K. Zero-resource neural machine translation with monolingual pivot data. In: Proceedings of the 3rd Workshop on Neural Generation and Translation. Hong Kong, China: Association for Computational Linguistics, 2019. 99−107 [69] Fadaee M, Bisazza A, Monz C. Data augmentation for low-resource neural machine translation. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Vancouver, Canada: Association for Computational Linguistics, 2017. 567−573 [70] Wang X Y, Pham H, Dai Z H, Neubig G. SwitchOut: An efficient data augmentation algorithm for neural machine translation. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 856−861 [71] Xia M Z, Kong X, Anastasopoulos A, Neubig G. Generalized data augmentation for low-resource translation. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 5786−5796 [72] Gao F, Zhu J H, Wu L J, Xia Y C, Qin T, Cheng X Q, et al. Soft contextual data augmentation for neural machine translation. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 5539−5544 [73] Zhou C T, Ma X Z, Hu J J, Neubig G. Handling syntactic divergence in low-resource machine translation. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: Association for Computational Linguistics, 2019. 1388−1394 [74] Currey A, Barone A V M, Heafield K. Copied monolingual data improves low-resource neural machine translation. In: Proceedings of the 2nd Conference on Machine Translation. Copenhagen, Denmark: Association for Computational Linguistics, 2017. 148−156 [75] Li G L, Liu L M, Huang G P, Zhu C H, Zhao T J. Understanding data augmentation in neural machine translation: Two perspectives towards generalization. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: Association for Computational Linguistics, 2019. 5689−5695 [76] Firat O, Cho K, Bengio Y. Multi-way, multilingual neural machine translation with a shared attention mechanism. In: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego, California: Association for Computational Linguistics, 2016. 866−875 [77] Dabre R, Chu C H, Kunchukuttan A. A survey of multilingual neural machine translation. ACM Computing Surveys, to be published [78] Tan X, Ren Y, He D, Qin T, Zhao Z, Liu T Y. Multilingual neural machine translation with knowledge distillation. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA, 2019. [79] Tan X, Chen J L, He D, Xia Y C, Qin T, Liu T Y. Multilingual Neural Machine Translation with Language Clustering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: Association for Computational Linguistics, 2019. 963−973 [80] Wang X Y, Pham H, Arthur P, Neubig G. Multilingual neural machine translation with soft decoupled encoding. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA, 2019. [81] Platanios E A, Sachan M, Neubig G, Mitchell T. Contextual parameter generation for universal neural machine translation. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 425−435 [82] Arivazhagan N, Bapna A, Firat O, Lepikhin D, Johnson M, Krikun M, et al. Massively multilingual neural machine translation in the wild: Findings and challenges. arXiv preprint arXiv: 1907.05019, 2019 [83] Firat O, Sankaran B, Al-Onaizan Y, Vural F T Y, Cho K. Zero-resource translation with multi-lingual neural machine translation. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas: Association for Computational Linguistics, 2016. 268−277 [84] Zhou Z, Sperber M, Waibel A. Massively parallel cross-lingual learning in low-resource target language translation. In: Proceedings of 3rd Conference on Machine Translation: Research Papers. Brussels, Belgium: Association for Computational Linguistics, 2018. 232−243 [85] Maimaiti M, Liu Y, Luan H B, Sun M S. Multi-round transfer learning for low-resource NMT using multiple high-resource languages. ACM Transactions on Asian and Low-Resource Language Information Processing, 2019, 18(4): Article No. 38 [86] Wang X Y, Neubig G. Target conditioned sampling: Optimizing data selection for multilingual neural machine translation. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 5823−5828 [87] Dabre R, Fujita A, Chu C H. Exploiting multilingualism through multistage fine-tuning for low-resource neural machine translation. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: Association for Computational Linguistics, 2019. 1410−1416 [88] Murthy R, Kunchukuttan A, Bhattacharyya P. Addressing word-order divergence in multilingual neural machine translation for extremely low resource languages. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1(Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics, 2019. 3868−3873 [89] Imankulova A, Sato T, Komachi M. Filtered pseudo-parallel corpus improves low-resource neural machine translation. ACM Transactions on Asian and Low-Resource Language Information Processing, 2019, 19(2): Article No. 24 [90] Neubig G, Hu J J. Rapid adaptation of neural machine translation to new languages. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 875−880 [91] Lu Y C, Keung P, Ladhak F, Bhardwaj V, Zhang S N, Sun J. A neural interlingua for multilingual machine translation. In: Proceedings of the 3rd Conference on Machine Translation: Research Papers. Belgium, Brussels: Association for Computational Linguistics, 2018. 84−92 [92] Sestorain L, Ciaramita M, Buck C, Hofmann T. Zero-shot dual machine translation. arXiv preprint arXiv: 1805.10338, 2018 [93] Wang Y N, Zhou L, Zhang J J, Zhai F F, Xu J F, Zong C Q. A compact and language-sensitive multilingual translation method. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: Association for Computational Linguistics, 2019. 1213−1223 [94] Kiperwasser E, Ballesteros M. Scheduled multi-task learning: From syntax to translation. Transactions of the Association for Computational Linguistics, 2018, 6: 225−240 doi: 10.1162/tacl_a_00017 [95] Zaremoodi P, Buntine W, Haffari G. Adaptive knowledge sharing in multi-task learning: Improving low-resource neural machine translation. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Melbourne, Australia: Association for Computational Linguistics, 2018. 656−661 [96] Zaremoodi P, Haffari G. Adaptively scheduled multitask learning: The case of low-resource neural machine translation. In: Proceedings of the 3rd Workshop on Neural Generation and Translation. Hong Kong, China: Association for Computational Linguistics, 2019. 177−186 [97] Zoph B, Knight K. Multi-source neural translation. In: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego, California, USA: Association for Computational Linguistics, 2016. 30−34 [98] He D, Xia Y C, Qin T, Wang L W, Yu N H, Liu T Y, et al. Dual learning for machine translation. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates Inc., 2016. 820−828 [99] He T Y, Chen J L, Tan X, Qin T. Language graph distillation for low-resource machine translation. arXiv preprint arXiv: 1908.06258, 2019 [100] Östling R, Tiedemann J. Neural machine translation for low-resource languages. arXiv preprint arXiv: 1708.05729, 2017 [101] Nishimura Y, Sudoh K, Neubig G, Nakamura S. Multi-source neural machine translation with data augmentation. In: Proceedings of the 15th International Workshop on Spoken Language Translation. Bruges, Belgium, 2018. 48−53 [102] Garcia X, Foret P, Sellam T, Parikh A P. A multilingual view of unsupervised machine translation. arXiv preprint arXiv: 2002.02955, 2020 [103] Anastasopoulos A, Chiang D. Leveraging translations for speech transcription in low-resource settings. In: Proceedings of Interspeech 2018. Hyderabad, India, 2018. 1279−1283 [104] Stoian M C, Bansal S, Goldwater S. Analyzing ASR pretraining for low-resource speech-to-text translation. In: Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Barcelona, Spain: IEEE, 2020. 7909−7913 [105] Bansal S, Kamper H, Livescu K, Lopez A, Goldwater S. Low-resource speech-to-text translation. In: Proceedings of Interspeech 2018. Hyderabad, India, 2018. 1298−1302 [106] Anastasopoulos A, Chiang D, Duong L. An unsupervised probability model for speech-to-translation alignment of low-resource languages. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas: Association for Computational Linguistics, 2016. 1255−1263 [107] Erdmann A, Habash N, Taji D, Bouamor H. Low resourced machine translation via morpho-syntactic modeling: The case of dialectal Arabic. In: Proceedings of Machine Translation Summit XVI. Nagoya, Japan, 2017. 185−200 [108] Honnet P E, Popescu-Belis A, Musat C, Baeriswyl M. Machine translation of low-resource spoken dialects: Strategies for normalizing Swiss German. In: Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018). Miyazaki, Japan: European Language Resources Association (ELRA), 2018. 3781−3788 [109] Musleh A, Durrani N, Temnikova I, Nakov P, Vogel S, Alsaad O. Enabling medical translation for low-resource languages. In: Proceedings of the 2016 International Conference on Intelligent Text Processing and Computational Linguistics. Konya, Turkey: Springer, 2016. 3−16 [110] Ngo T V, Ha T L, Nguyen P T, Nguyen L M. Overcoming the rare word problem for low-resource language pairs in neural machine translation. In: Proceedings of the 6th Workshop on Asian Translation. Hong Kong, China: Association for Computational Linguistics, 2019. 207−214 [111] 王卓, 余正涛, 文永华, 高盛祥, 吴飞. 融合词汇翻译概率的汉越神经机器翻译方法. 昆明理工大学学报(自然科学版), 2019, 44(1): 54−60Wang Zhuo, Yu Zheng-Tao, Wen Yong-Hua, Gao Sheng-Xiang, Wu Fei. Chinese-Vietnamese neural machine translation integrated with lexicon probability. Journal of Kunming University of Science and Technology (Natural Science Edition), 2019, 44(1): 54−60 [112] 车万金, 余正涛, 郭军军, 文永华, 于志强. 融入分类词典的汉越混合网络神经机器翻译集外词处理方法. 中文信息学报, 2019, 33(12): 67−75 doi: 10.3969/j.issn.1003-0077.2019.12.009Che Wan-Jin, Yu Zheng-Tao, Guo Jun-Jun, Wen Yong-Hua, Yu Zhi-Qiang. Unknown words processing method for Chinese-Vietnamese neural machine translation based on hybrid network integrating classification dictionaries. Journal of Chinese Information Processing, 2019, 33(12): 67−75 doi: 10.3969/j.issn.1003-0077.2019.12.009 [113] 徐毓, 赖华, 余正涛, 高盛祥, 文永华. 基于深度可分离卷积的汉越神经机器翻译. 厦门大学学报(自然科学版), 2020, 59(2): 220−224Xu Yu, Lai Hua, Yu Zheng-Tao, Gao Sheng-Xiang, Wen Yong-Hua. Chinese-Vietnamese neural machine translation based on deep separable convolution. Journal of Xiamen University (Natural Science), 2020, 59(2): 220−224 [114] 贾承勋, 赖华, 余正涛, 文永华, 于志强. 基于枢轴语言的汉越神经机器翻译伪平行语料生成. 计算机工程与科学, 2021, 43(3): 542−550 doi: 10.3969/j.issn.1007-130X.2021.03.021Jia Cheng-Xun, Lai Hua, Yu Zheng-Tao, Wen Yong-Hua, Yu Zhi-Qiang. Pseudo-parallel corpus generation for Chinese-Vietnamese neural machine translation based on pivot language. Computer Engineering & Science, 2021, 43(3): 542−550 doi: 10.3969/j.issn.1007-130X.2021.03.021 [115] 于志强, 余正涛, 黄于欣, 郭军军, 高盛祥. 基于变分信息瓶颈的半监督神经机器翻译. 自动化学报, DOI: 10.16383/j.aas.c190477Yu Zhi-Qiang, Yu Zheng-Tao, Huang Yu-Xin, Guo Jun-Jun, Gao Sheng-Xiang. Improving semi-supervised neural machine translation with variational information bottleneck. Acta Automatica Sinica, DOI: 10.16383/j.aas.c190477 [116] Devlin J, Chang M W, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics, 2019. 4171−4186 [117] Clinchant S, Jung K W, Nikoulina V. On the use of BERT for neural machine translation. In: Proceedings of the 3rd Workshop on Neural Generation and Translation. Hong Kong, China: Association for Computational Linguistics, 2019. 108−117 [118] Zhu J H, Xia Y C, Wu L J, He D, Qin T, Zhou W G, et al. Incorporating BERT into neural machine translation. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia, 2020. [119] Radford A, Narasimhan K, Salimans T, Sutskever I. Improving language understanding by generative pre-training [Online], available: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf, April, 4, 2020 -

 下载:
下载:


计量
- 文章访问数: 2248
- HTML全文浏览量: 2414
- PDF下载量: 504
- 被引次数: 0
