

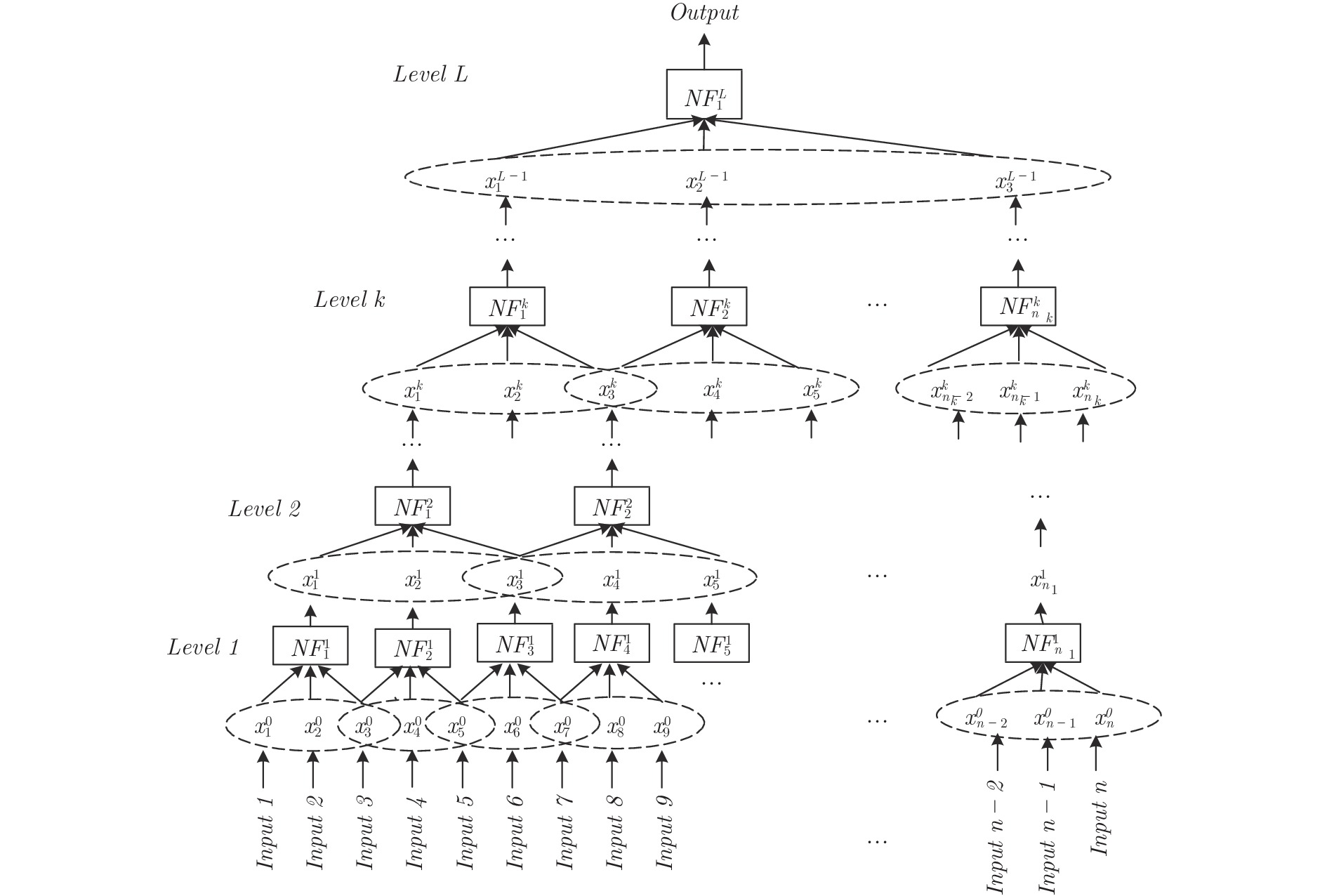
Deep Neural Fuzzy System Algorithm and Its Regression Application
-
摘要: 深度神经网络是人工智能的热点, 可以很好处理高维大数据, 却有可解释性差的不足. 通过IF-THEN规则构建的模糊系统, 具有可解释性强的优点, 但在处理高维大数据时会遇到“维数灾难”问题. 本文提出一种基于ANFIS (Adaptive network based fuzzy inference system)的深度神经模糊系统(Deep neural fuzzy system, DNFS)及两种基于分块和分层的启发式实现算法: DNFS1和DNFS2. 通过四个面向回归应用的数据集的测试, 我们发现: 1)采用分块、分层学习的DNFS在准确度与可解释性上优于BP、RBF、GRNN等传统浅层神经网络算法, 也优于LSTM和DBN等深度神经网络算法; 2)在低维问题中, DNFS1具有一定优势; 3)在面对高维问题时, DNFS2表现更为突出. 本文的研究结果表明DNFS是一种新型深度学习方法, 不仅可解释性好, 而且能有效解决处理高维数据时模糊规则数目爆炸的问题, 具有很好的发展前景.Abstract: Deep neural network is a hot spot of artificial intelligence, which can deal with high-dimensional big data well, but has the disadvantage of poor interpretability. The fuzzy system constructed by if-then rules has the advantage of strong interpretability, but it will encounter the problem of “the curse of dimension” when dealing with high dimension big data. This paper presents a DNFS (Deep neural fuzzy system) based on ANFIS (Adaptive network based fuzzy inference system) and two heuristic algorithms based on block and layer: DNFS1 and DNFS2. Through the testing of four regression-oriented data sets, we found: 1) DNFS with block and layer learning is superior to BP, RBF, GRNN and other traditional shallow neural network algorithms in accuracy and interpretability, as well as LSTM, DBN and other deep neural network algorithms; 2) In low dimensional problems, DNFS1 has certain advantages; 3) In the face of high dimensional problems, DNFS2 is more prominent. The results of this paper show that DNFS is a new deep learning method, which not only has good interpretability, but also can effectively solve the problem that the number of fuzzy rules explodes when dealing with high-dimensional data, and has a good development prospect.
-
人工交通系统是利用人工社会的基本理论与方法, 通过抽取交通环境中单个个体或局部交通行为的基本属性或动态规律, 基于Agent建模技术, 通过交通系统个体或局部Agent之间相互作用, "涌现(Emergence)"出复杂的交通现象, 这是一个"自下而上"、基于"简单一致原则"人工"培育"出来的交通系统[1-3].人工交通系统可把"仿真"结果作为现实的一个替代版本, 而把实际系统也作为可能出现的现实中的一种, 与仿真结果等价[4-6].
霍兰指出: "涌现现象是以相互作用为中心的, 它比单个行为的简单累加要复杂得多"[7].对代理、环境及规则上描述的细微差别, 在涌现过程中, 就可能出现"差之毫厘, 谬以千里"的结果, 从而仿真结果失去了对现实的指导意义, 甚至给出完全错误的指导方案.正如社会学家Helmreich所批评的一样:人工社会的模型反映的是其创造者的潜意识中的文化假设和偏见[8].
如何避免这一问题?在人工交通的建模及平行系统的研究中, 需要引入严密的量化评估体系, 建立系统"可信"或"可用"的数学描述, 并从多维度、多粒度的数据层面进行量化评估, 从理论上保证人工交通系统与现实交通系统在统计特性上、在动态演化规律上、在行为特性上的一致性.本文针对人工交通系统, 基于人工交通系统基本体系结构, 将二型模糊集合方法引入人工交通系统可信度评估中, 建立了一种适用于人工交通系统的可信度评估理论体系与具体评估方法.并利用一个"人工公交交通系统"模型, 进行了可信度评估的数据验证.
本文结构安排如下.第1节介绍了可信度研究的意义, 对可信度研究方法和成果进行了综述, 并提出了本文的可信度评估框架.第2节为可信度评估使用的核心算法介绍.第3节仿真验证.最后给出结论.
1. 可信度研究综述及评估体系
可信度定义:对于一个事物或现象为真的相信程度.可信度的量化值一般在[0, 1]之间, 值越大, 表示该事物越"真"[9].评估复杂仿真系统可信度的过程称为复杂仿真系统的可信度评估.通过开展复杂仿真系统的可信度评估研究和应用, 可以提高综合仿真系统的仿真结果的正确性, 降低其应用的风险保证仿真系统的质量.可信度评估在交通仿真、网络管理、信息管理、远程通讯以及导弹系统等各个领域都有广泛的应用[10-13].
文献[12]针对微观交通仿真模型开发者和使用者的不同需求, 研究了交通仿真模型可信度评价内容及其与仿真模型校正、校核、验证和确认的关系; 分析了三种可用于微观交通仿真模型可信度评价的方法:层次分析法、相似度法以及模糊综合评判.文献[14]使用模糊三角函数与层次分析法及网络层次分析法综合评价列车控制仿真系统的可信度, 获取定量的可信度结果.文献[15]在对当前城市交通导航系统的分析中发现, 许多共享交互的弱点会损害系统的可信度.论文提出了改进的交互机制, 以提高导航系统的可信度.在比较用户的研究中评估了所提议的机制, 并给出了确认其可信度的积极影响的结果.
从应用上分类, 可信度评估方法主要有仿真结果评估与VV & A (Verification, validation and accreditation)两种模式[16-18].基于仿真结果验证的方法主要是应用定性或定量评估方法, 并结合统计学的相关知识, 通过仿真结果与实际或预想结果的比较, 得出仿真可信度评价[16], 是交通仿真系统中主要使用的可信度评估模式.人工交通概念提出以来, 关于其建模方法及应用的研究成果较多, 但可可信度评估的研究相对较少[19]. Li等[20]在前期研究中, 建立了基于二型模糊集合方法的人工交通系统可信度评估体系.
因为一般现代综合评估方法存在: 1)因评价专家主观上的随机性和不一致性导致问题描述的混乱; 2)隶属度函数及权重难以精确确定; 3)简单的评价结果无法精确地反映评价结果与评价对象内在因素的多维关系等问题[21-22].同时考虑到人工交通系统不依赖精确数学模型、不确定性因素多、输入输出数据随机性强等特点, 本文应用二型模糊集理论, 利用其较强的处理不确定性及随机性的能力来对人工交通系统的可信度做具体的评估研究.建立了以区间二型模糊集合理论为核心数据处理算法的评估方法, 如图 1所示.评估方法的核心由三部分构成:数据处理、区间二型模糊集、Jaccard算法.
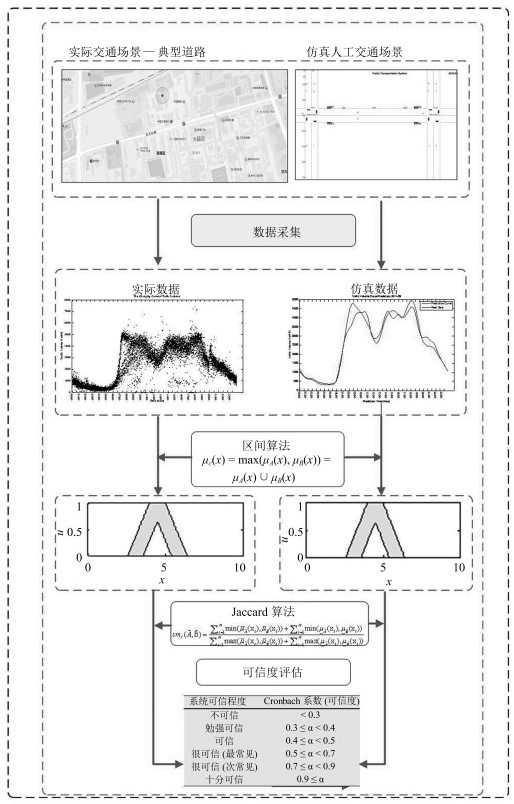 图 1 基于二型模糊集合理论的人工交通系统评估过程Fig. 1 Artificial traffic system assessment process based on type-2 fuzzy set theory
图 1 基于二型模糊集合理论的人工交通系统评估过程Fig. 1 Artificial traffic system assessment process based on type-2 fuzzy set theory该方法应用可信度概念, 描述将人工交通系统视为交通系统的现实版本的真实程度, 通过评估人工交通系统和实际交通系统输出数据的统计一致性程度, 来评估人工交通系统的可信度.即在一致输入条件下, 输出的统计特性一致.具体思路描述如下:
1) 将来自于实际交通场景的大量数据进行前期处理, 考虑到交通系统的非严格重复的周期性、随机性和不确定性, 基于置信区间概念, 将其处理为区间化数据:同理, 将相应的人工交通系统的输出数据也做同样的处理.
2) 区间化数据表达符合对开放复杂系统的输出数据不确定性和波动性的描述, 在剔除了噪声数据的同时, 也完成了二型模糊集建模的输入数据准备.
3) 应用区间二型模糊集合算法, 将处理后的区间输入进行深度加工, 得到更准确刻画系统特性的两个交通系统(实际交通系统和人工交通系统)的数据集合.
4) 基于Jaccard算法对二型模糊集输出数据集合进行一致性比较, 通过一致性结果数据, 评价人工交通系统的可信度.
上述评价方法, 有效地实现了基于Agent建模的复杂系统评估问题.该方法以系统数据为驱动, 不依赖于数学模型, 同时通过数据的波动性描述系统的不确定性特征:应用了二型模糊集处理带有噪声及不确定性数据的优越性能, 保证二次数据的精准性.
2. 核心算法
2.1 区间二型模糊集合
Zadeh[23]在1975年提出了二型模糊集合的概念, 二型模糊集合是传统模糊集合(称为一型模糊集合)的拓展.二型模糊集合由于隶属度本身是不确定的, 可以对不确定的数据进行确定描述, 在处理带有噪声及不确定性数据方面具有优越的性能[24], 这使它用于处理不确定性强、随机性强的交通流数据成为可能. 2017年, 二型模糊集合理论得到了进一步的修正[25].
定义 1. 设${C}(I)$是由单位区间$I$的全体非空闭子集构成的一个集合.论域$X$上的一个二型模糊集合$\omega $定义为
$ \omega = \ \{ {{( {x, u, z} )} |}\forall x\in X, \forall u \in {L_x} \in {C}( {{2^I}}) , \nonumber\\ \ {z = \mu _\omega ^2( {x, u} ) \in I} \} $
(1) 其中, $x$为主变量, $u$为次变量, $z$为第3变量, ${L_x}$为主隶属度, 由一个多值映射定义而得, 表示为
$ \mu _\omega ^1:\Omega \to {C}\left( {{2^I}} \right)\\ $
(2) $ x\mapsto L_x $
(3) 即$\forall x\in X$, 存在${L_x} \in {C}({{2^I}}) $, 使得$\mu _\omega ^1 (x) = L_x$.
称$\mu _\omega ^1 (x)$为主隶属度函数, 设$\mu _\omega ^2 (x)$为次隶属度函数, 定义为
$ \mu _\omega ^2:\bigcup\limits_{x \in X } {x \times {L_x}} \to I\notag \\x\times u \mapsto z $
(4) 次隶属度函数可以看成是一个以$\bigcup_{x \in X } {x \times {L_x}}$为论域上的一型模糊集合的隶属函数, 该定义称为二型模糊集合的二段式定义.
定义 2. 二型模糊集合$\omega$的支集为在$X\times I$中使次隶属度大于0的全体元素构成的集合, 记为$Supp(\omega)$, 即
$ Supp(\omega)=\left\{( {u, x})|\mu _\omega ^2 (x, u) >0 \right\} $
(5) 若$\mu _\omega ^2$为一个连续函数, 则由连续函数的性质, 可记$CoS(\omega)$为支集$Supp(\omega)$的闭包(Closure of support), 表示为
$ CoS(\omega) = \overline{\left\{( {x, u})|\mu _\omega ^2 (x, u) >0 \right\}} $
(6) 如果对$\forall x \in X$, $\forall u \in L_x$, 都有$\mu^2_\omega(x, u)=1$, 则称$\omega$为一个区间二型模糊集合.
2.2 交通数据的区间化方法
城市交通环境因其开放性、不确定性和随机性较强, 导致交通数据具有不确定性和随机性特征, 但同时, 城市交通环境作为一个大惯性系统, 其数据的非严格重复性又使其具有较好的统计特征.
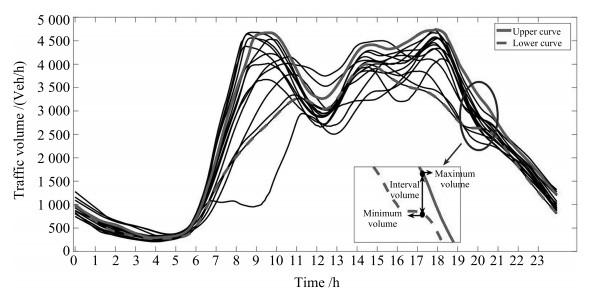
图 2以24小时交通流量数据为例, 刻画了多天交通流量的分布及区间化描述.在某一给定时刻, 区间的最大和最小值表明了该时刻交通流量可能的变化范围.
交通流量的区间化描述方式不仅能够给出交通流量丰富的分布信息, 并可以用构造内嵌一型模糊集合, 以作为二型模糊集的源数据.
本文引入置信区间的概念, 应用中心极限定理, 将交通流数据由点值数据转化为区间描述[26].
置信区间是指由样本统计量所构造的总体参数的估计区间:
设$\theta $是总体的一个参数, 该参数空间为$\Theta $, ${x_1}$, 是来自该总体的样本, $n$为样本量.对于给定的一个$\alpha$ $(0<\alpha<1)$, 若有两个统计量: ${\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\theta } _L}={\mathord{\buildrel{\lower3pt\hbox{}} \over\theta } _L}({x_1}, {x_2}, \cdots, {x_n})$和, 对任意的$\theta\in\Theta$, 有${P_\theta }({{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\theta } }_L}\le\theta\le {{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\theta } }_H})\ge 1 - \alpha $.称随机区间为$\theta $的置信水平为$1-\alpha $的置信区间.
构造未知参数$\theta $的置信区间最常用的方法是轴枢量法.考虑到对于非正态分布的随机序列总体, 一般难以求出其总体的轴枢量, 因此利用中心极限定理将其近似分布转化为正态分布, 从而求得参数的置信区间估计[27].
勒维-林德伯格定理如下:
设${x_1}, {x_2}, \cdots, {x_n}$为相互独立同分布的随机序列, 且$E\left({{x_i}} \right) = \mu $, $D\left({{x_i}} \right) = {\sigma ^2} > 0$, $i = 1, 2, 3, \cdots, $则服从正态分布, 即.
针对这样一个正态分布, 可按照式(7)构造轴枢量
$ G = G\left( {{x_1}, {x_2}, \cdots , {x_n}, \mu } \right) = \frac{{\bar x - \mu }}{{\frac{\sigma }{\sqrt n} }} \sim \rm N \left( {0, 1}\right) $
(7) 经过不等式变形, 方差${\sigma ^2}$已知条件下, 期望$\mu $的置信区间为
$ \left( {\bar x - {\mu _{\frac{\alpha }{2}}}\frac{\sigma }{{\sqrt n }}, \bar x + {u_{\frac{\alpha }{2}}}\frac{\sigma }{{\sqrt n }}} \right) $
(8) 这是一个以样本均值$\overline x $为中心, 半径为${\mu _{\frac{\alpha }{2}}}\frac{\sigma }{{\sqrt n }}$的对称区间.之所以取${\mu _{\frac{\alpha }{2}}}$, 是因为$\frac{\alpha }{2}$分位点很好地处理了置信区间区间可靠性和精度的关系.
2.3 基于Jaccard算法的集合相似性计算
Jaccard算法是由Jaccard在1908年提出的, 用于对两个集合的相似度进行比较[28].其中被广泛使用的参数为Jaccard相似系数(Jaccard similarity coefficient), 用于比较有限样本集之间的相似性与差异性, Jaccard相似系数越大, 样本相似度越高.
从20世纪初到现在, Jaccard算法已经在生物学、经济和社会研究领域中被广泛运用并取得了较好的效果. Bell等[29]在评估植物图像分割的子集匹配时采用了Jaccard算法, 对分割图像和地面实际图像这两个像素集合进行相似度的计算. Rinartha等[30]在文章搜索中运用Jaccard相似度对关键词的处理时间和搜索文章的结果精确性进行了比较分析.结果发现Jaccard相似性查询建议将产生更加准确的搜索结果.研究表明, Jaccard相似度的平均绝对误差(Mean absolute error, MAE)相较于皮尔逊相关系数法、对数似然值相似度和余弦相似度等误差较低, 且算法简单, 运算速度快.在通常情况下, Jaccard系数值越大, 样本相似度越高, 本文采用Wu等[31]提出的针对二型模糊集合Jaccard算法, 如式(9)所示.
$ s{m_J} \left( {\tilde A, \tilde B} \right) =\notag\\ {\frac{ \sum\limits_{i = 1}^N {\min ( {{{\bar \mu }_{\tilde A}}( {{x_i}} ), {{\bar \mu }_{\tilde B}}( {{x_i}} )} )}+ \sum\limits_{i = 1}^N {\min ( {{{\underline{\mu } }_{\tilde A}}( {{x_i}} ), {\underline{\mu } }_{\tilde B}( {{x_i}} )} )} }{ \sum\limits_{i = 1}^N {\max ( {{{\bar \mu }_{\tilde A}}( {{x_i}} ), {{\bar \mu }_{\tilde B}}( {{x_i}} )} )} + \sum\limits_{i = 1}^N {\max ( {{{\underline{\mu } }_{\tilde A}}( {{x_i}} ), {\underline{\mu } }_{\tilde B}( {{x_i}} )} )} }} $
(9) 3. 人工交通系统可信度评估实例验证
3.1 系统建模
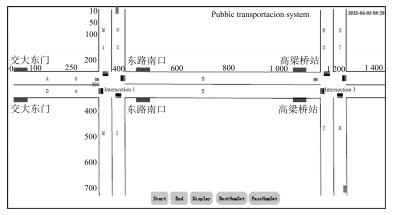
本文选择北京海淀区某道路为典型建模场景进行可信度实验研究, 该路段双向2车道, 包含三个公交车站、两个定时控制的信号灯路口和3条公交线路, 全长约为1.4公里.
研究者以2015年3月至4月中旬的每周二、周三、周四共计六周18天, 在每一天的上午8点到下午8点进行数据调研, 以调研数据作为人工交通系统的数据来源.包括双方向车流量、车辆类型、多点车辆速度等.因为在该场景中, 有比较繁忙的公交线路, 公交线路的参与者又受到周边环境的影响, 具有复杂系统典型性数据特征.因此本文特别对参与公共交通运输的数据:包括上下车乘客数、公交车到、发站时间等也进行了数据调研, 完成了该典型交通场景的人工交通系统建模的数据准备.并选取随机性较强、对公共交通调度规划具有重要影响的乘客上车人数作为人工交通系统可信度评估参数, 进行可信度验证.该路段上三个公交车站在调研时段的乘客等车调研数据如表 1所示(实际系统).限于篇幅, 关于人工交通建模的研究内容将在另文进行阐述.
表 1 三个公交车站上车人数的实际调研数据和人工交通系统运行数据Table 1 The actual data and simulation data of people get on the three bus stops时段 实际系统第1站 仿真系统第1站 实际系统第2站 仿真系统第2站 仿真系统第3站 实际系统第3站 3:00 $\sim$ 3:05 9 13 8 15 4 5 3:06 $\sim$ 3:10 10 15 10 13 0 1 3:11 $\sim$ 3:15 14 9 5 8 3 3 3:16 $\sim$ 3:20 0 25 6 9 1 2 3:21 $\sim$ 3:25 29 20 16 0 6 3 3:26 $\sim$ 3:30 25 3 11 19 3 5 3:31 $\sim$ 3:35 15 17 5 6 4 8 3:36 $\sim$ 3:40 10 0 7 6 3 2 3:41 $\sim$ 3:45 15 9 8 0 5 1 3:46 $\sim$ 3:50 19 15 6 11 1 0 3:51 $\sim$ 3:55 9 21 10 9 4 4 3:56 $\sim$ 4:00 19 4 16 18 0 2 搭建的人工交通系统运行界面如图 3所示.根据实际调研数据, 在人工交通系统中设置该路段初始计划乘车人数为50人, 系统将这50个人随机分布在路段的不同地方, 然后各自判断自己离哪个公交车站更近, 从而选择自己的前进方向.多次运行人工交通系统, 得到三个车站等车乘客人数的仿真数据, 其均值也列入表 1 (仿真系统).
3.2 数据处理
为了对数据进行统一处理, 把每个参数的输入数据除以一个比例因子进行"归十化"到区间$[0, 1]$.对"归十化"得到的数据进行一型模糊化处理, 由式(8)将交通流数据由点数据转化为区间数据, 表 2展示了区间化数据结果.基于此数据基础, 即可构造内嵌的一型隶属度模糊集.设每一个区间左端点为$b$, 右端点为$c$, 左右端点的中间值为$a$, 本仿真中, 用区间数据构造三角型隶属度函数, 则
表 2 三个公交车站上车人数模糊化以后的实际数据和仿真数据Table 2 The actual data and simulation data after fuzzified of people get on the three bus stops时段 实际系统第1站 仿真系统第1站 实际系统第2站 仿真系统第2站 仿真系统第3站 实际系统第3站 3:00 $\sim$ 3:05 2 4 3 5 3 5 6 8 3 5 4 6 3:06 $\sim$ 3:10 2 4 4 6 4 6 6 8 0 1 0 2 3:11 $\sim$ 3:15 3 5 2 4 1 3 3 5 2 4 2 4 3:16 $\sim$ 3:20 0 1 7 9 2 4 3 5 0 2 1 3 3:21 $\sim$ 3:25 6 8 6 8 7 9 0 1 5 7 2 4 3:26 $\sim$ 3:30 6 8 0 2 4 6 5 7 2 4 4 6 3:31 $\sim$ 3:35 4 6 5 7 1 3 2 4 3 5 7 9 3:36 $\sim$ 3:40 2 4 0 1 3 5 2 4 2 4 1 3 3:41 $\sim$ 3:45 4 6 2 4 3 5 0 1 4 6 0 2 3:46 $\sim$ 3:50 5 7 4 6 2 4 4 6 0 2 0 1 3:51 $\sim$ 3:55 2 4 6 8 4 6 4 6 3 5 3 5 3:56 $\sim$ 4:00 5 7 0 2 7 9 8 9 0 1 1 3 $ {\mu _F}\left( x \right) = \begin{cases} \frac{{x - b}}{{a - b}}, &b \leq x \leq a \\ \frac{{c - x}}{{c - a}}, &a < x \leq c \\ 0, &x < b ~\mbox{或}~ x > c \end{cases} $
(10) 因此, 每一个区间都对应着一个一型模糊集.运用式(10)进行集合并运算:
$ {\mu _C}\left( x \right) = \max \left( {{\mu _A}\left( x \right), {\mu _B}\left( x \right)} \right) = {\mu _A}\left( x \right) \cup {\mu _B}\left( x \right) $
(11) 其中, ${\mu _A}\left(x \right)$和${\mu _B}\left(x \right)$为一型模糊集合$A$和$B$的隶属度函数, ${\mu _C}\left(x \right)$为集合并运算得到的新集合${ C}$的隶属度函数, 即二型模糊集合$CoS$.本文将某5分钟的前两个时段和本时段及后一个时段共四个时段进行了并运算, 得$CoS$如图 4所示.
对实际交通系统和人工交通系统, 研究时间轴为每一天的上午8点到下午8点, 共12个小时.因为按照5分钟进行数据统计, 所以得到144个$CoS$, 限于篇幅, 仅列出一个5分钟数据采样时段, 两个系统的二型模糊集合图例, 结果如图 5所示.
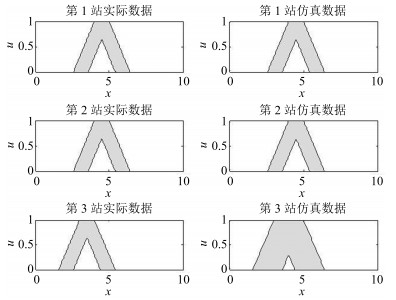 图 5 三个候车站实际候车乘客数据和对应的人工交通系统候车乘客人数数据的二型模糊集合Fig. 5 Two-type fuzzy set of three stations actual data and corresponding simulation data
图 5 三个候车站实际候车乘客数据和对应的人工交通系统候车乘客人数数据的二型模糊集合Fig. 5 Two-type fuzzy set of three stations actual data and corresponding simulation data经过解模糊化处理, 可以得到两个系统分别由144个重心组成的上限重心和下限重心值构造出来的144个集合, 根据式(9)可计算出两个系统三个站点各144个集合的相似度值, 记为$Jsm(x)$ $(x=1$, $2$, $3)$.
3.3 模型评估
由式(9)可计算得到人工公共交通系统可信度评估结果:
第1站的评估结果为$Jsm (1) = 1$
第2站的评估结果为$Jsm (2) = 1$
第3站的评估结果为$Jsm (3) = 0.6331$
整个系统的评估结果为
$ Jsm = \frac{1}{3}\sum\limits_{x = 1}^3 {Jsm(x) =0.88} $
针对这一结果, 本文使用克朗巴哈系数(Cronbach$'$s alpha)进行评价, 通常Cronbach系数的值在0和1之间.如果系数不超过0.6, 一般认为内部一致可信度不足:达到0.7 $\sim$ 0.8时表示量表具有相当的可信度, 达到0.8 $\sim$ 0.9时说明量表可信度非常好, 如表 3所示[32].本文所建立的人工交通系统, 以车站候车人数为计算指标, 得到的可信度为0.88, 表明人工交通系统很可信.
表 3 可信度值与Cronbach系数的关系Table 3 The relationship between the value of credibility and Cronbach coefficient系统可信程度 Cronbach系数(可信度) 不可信 $ < 0.3$ 勉强可信 $0.3 \leq\alpha < 0.4$ 可信 $0.4 \leq\alpha < 0.5$ 很可信(最常见) $0.5 \leq\alpha < 0.7$ 很可信(次常见) $0.7 \leq\alpha < 0.9$ 十分可信 $0.9 \leq\alpha$ 4. 结束语
本文进行了人工交通系统模型可信度评估的研究:针对交通数据的不确定性和随机性特性, 在可可信度评估中引入区间二型模糊集理论, 利用基于统计的数据一致性分析思想, 构建了基于区间二型模糊集方法的人工系统可信度评估方法.本文核心思想是对实际系统和人工系统的输出数据进行了二重处理, 一重处理通过置信区间获取数据的统计特征, 同时区间化得到二重处理的输入数据:二重处理通过二型模糊集方法处理不确定性数据、随机性数据以及噪声数据的能力, 获得更细致刻画系统特性的输出数据集, 通过两个数据集的相似性程度评估系统的可信度.
本文使用人工交通系统中候车乘客人数这一类易受周边环境影响的数据进行了计算验证, 结果表明了基于区间二型模糊集合的可信度评估方法的有效性和合理性.
本文的研究过程中还存在着如下一些问题: 1)在建模过程中没有完全提取交通系统的所有参数及特性; 2)在案例研究中, 也只针对公交运行过程中乘客上车人数数据进行评估, 相对单一.后续的研究工作要继续完善人工交通系统模型, 获得更多类型的数据, 通过更多案例研究实现系统的可信度评估.同时, 也将研究如何通过可信度评估过程及结果对人工交通系统建模过程提出优化建议.
-
表 1 实验数据集
Table 1 Experimental data set
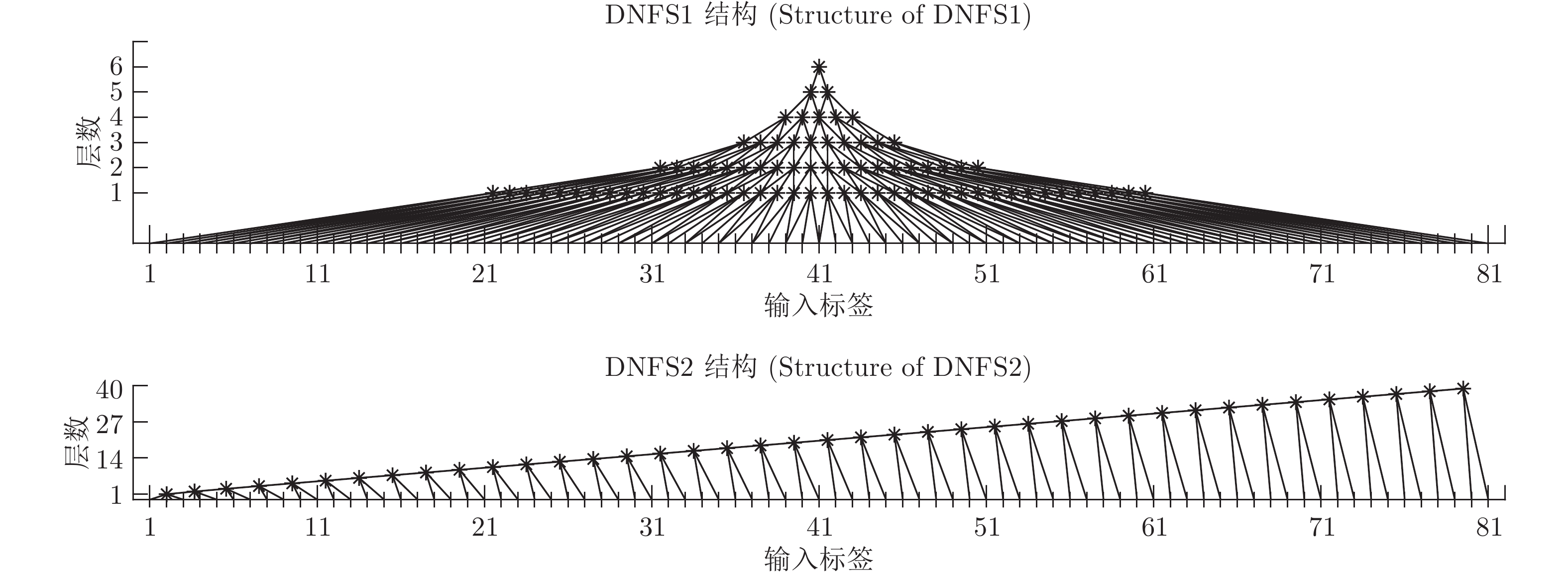
项目编号 数据集 输入维度 输出维度 样本数 DNFS1总层数 DNFS2总层数 1 Smartwatch_sens (SMW) 12 1 12000 15 30 2 Online News Popularity (ONP) 59 1 20000 25 145 3 Superconductivty (SUP) 81 1 10000 30 200 4 BlogFeedback (BF) 271 1 15000 40 675  下载: 导出CSV
下载: 导出CSV
表 2 SMW测试集评价指标
Table 2 Evaluation index of SMW test set
BP RBF GRNN LSTM DBN ANFIS DNFS1 DNFS2 STD 0.038869 0.038510 0.038441 0.039385 0.038596 0.039398 0.037643 0.040971 RMSE 0.038865 0.038506 0.038437 0.040219 0.038592 0.039397 0.037640 0.040970 MAE 0.017789 0.018355 0.017081 0.020928 0.017088 0.017965 0.016639 0.016834 SMAPE 3.5849 % 3.7368 % 3.4864 % 4.2653 % 3.4872 % 3.6510 % 3.3553 % 3.5535 % Score 16 16 27 7 21 11 32 14
下载: 导出CSV
表 3 ONP测试集评价指标
Table 3 Evaluation index of ONP test set
BP RBF GRNN LSTM DBN ANFIS DNFS1 DNFS2 STD 0.040148 0.017565 0.016941 0.016321 0.016217 0.234585 0.025012 0.016195 RMSE 0.040173 0.017567 0.016941 0.018827 0.016216 0.263966 0.025011 0.016195 MAE 0.005824 0.005347 0.004060 0.011639 0.004153 0.123609 0.004400 0.003975 SMAPE 83.1325 % 110.4412 % 77.8989 % 136.6059 % 88.0204 % 106.8444 % 78.3964 % 79.4094 % Score 12 15 26 13 24 6 18 30
下载: 导出CSV
表 4 SUP测试集评价指标
Table 4 Evaluation index of SUP test set
BP RBF GRNN LSTM DBN ANFIS DNFS1 DNFS2 STD 0.12385 0.13038 0.17493 0.15997 0.21074 0.16866 0.13415 0.12293 RMSE 0.12384 0.13038 0.17527 0.16004 0.21076 0.16972 0.13418 0.12293 MAE 0.08786 0.10038 0.14956 0.12958 0.18245 0.12657 0.10165 0.08735 SMAPE 30.1760 % 32.4668 % 43.0296 % 38.5752 % 51.2832 % 37.7120 % 31.2728 % 28.7900 % Score 28 23 8 14 4 14 21 32
下载: 导出CSV
表 5 BF测试集评价指标
Table 5 Evaluation index of BF test set
BP RBF GRNN LSTM DBN ANFIS DNFS1 DNFS2 STD 0.10900 0.04217 0.04322 0.03355 0.04457 0.09683 0.04465 0.03155 RMSE 0.10973 0.04259 0.04324 0.03398 0.04457 0.33922 0.04466 0.03156 MAE 0.02304 0.01112 0.01120 0.01409 0.01607 0.32630 0.01028 0.00859 SMAPE 54.675 % 76.842 % 81.804 % 96.684 % 102.462 % 142.341 % 64.263 % 54.162 % Score 12 23 19 21 13 5 19 32
下载: 导出CSV
-
[1] Mcclloch W S, Pitts W. A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biology, 1943, 10(5): 115−133 [2] Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 1958, 65: 386−408 doi: 10.1037/h0042519 [3] Minsky M L, Papert S A. Perceptrons. American Journal of Psychology, 1969, 84(3): 449−452 [4] Hopfield J J. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences of the United States of America, 1982, 79(8): 2554−2558 doi: 10.1073/pnas.79.8.2554 [5] Lv Y S, Chen Y Y, Zhang X Q, Duan Y J, Li N Q. Social media based transportation research: The state of the work and the networking. IEEE/CAA Journal of Automatica Sinica, 2017, 4(1): 19−26 doi: 10.1109/JAS.2017.7510316 [6] Rumelhart, David E, Hinton, Geoffrey E, Williams, Ronald J. Learning representations by back-propagating errors. Nature, 1986, 323(6088): 533−536 doi: 10.1038/323533a0 [7] Cortes C, Vapnik V. Support-vector networks. Machine Learning, 1995, 20(3): 273−297 [8] Hinton, G. E. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504−507 doi: 10.1126/science.1127647 [9] Lecun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436−444 doi: 10.1038/nature14539 [10] Sabour S, Frosst N, Hinton G E. Dynamic routing between capsules. In: Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. 2017. 1−11 [11] Guha A, Ghosh S, Roy A, Chatterjee S. Epileptic seizure recognition using deep neural network. Emerging Technology in Modelling and Graphics. Springer, Singapore, 2020. 21−28 [12] Kantz E D, Tiwari S, Watrous J D, Cheng S. Deep neural networks for classification of lc-ms spectral peaks. Analytical Chemistry, 2019, 91(19): 12407−12413. DOI: 10.1021/acs.analchem.9b02983 [13] Liu B S, Chen X M, Han Y H, Li J J, Xu H B, Li X W. Accelerating DNN-based 3D point cloud processing for mobile computing. Science China. Information Sciences, 2019, 32(11): 36−46 [14] Mercedes E. Paoletti. Deep pyramidal residual networks for spectral–spatial hyperspectral image classification. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(2): 740−754 doi: 10.1109/TGRS.2018.2860125 [15] Yang H, Luo L, Chueng L P, Ling D, Chin F. Deep learning and its applications to natural language processing. Deep Learning: Fundamentals, Theory and Applications. Springer, Cham, 2019. 89−109 [16] Zadeh, L.A. Fuzzy sets. Information & Control, 1965, 8(3): 338−353 [17] Mamdani E H, Baaklini N. Prescriptive method for deriving control policy in a fuzzy-logic controller. Electronics Letters, 1975, 11(25): 625−626 [18] Wang L X. Fuzzy systems are universal approximators. In: Proceedings of the 1992 IEEE International Conference on Fuzzy Systems. San Diego, CA, USA: IEEE, 1992.1163−1170 [19] Wang L X, Mendel J M. Generating fuzzy rules by learning from examples. IEEE Transactions on Systems, Man and Cybernetics, 1992, 22(6): 1414−1427 doi: 10.1109/21.199466 [20] Jang J S R. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Transactions on Systems Man and Cybernetics, 1993, 23(3): 665−685 [21] Sun B X, Gao K, Jiang J C, Luo M, He T T, Zheng F D, Guo H Y. Research on discharge peak power prediction of battery based on ANFIS and subtraction clustering. Transactions of China Electrotechnical Society, 2015, 30(4): 272−280 [22] 陈伟宏, 安吉尧, 李仁发, 李万里. 深度学习认知计算综述. 自动化学报, 2017, 43(11): 1886−1897Chen Wei-Hong, An Ji-Yao, Li Ren-Fa, Li Wan-Li. Review on deep-learning-based cognitive computing. Acta Automatica Sinica, 2017, 43(11): 1886−1897 期刊类型引用(0)
其他类型引用(3)
-

 下载:
下载:





计量
- 文章访问数: 2090
- HTML全文浏览量: 384
- PDF下载量: 464
- 被引次数: 3
