

-
摘要: 基于深度学习的三维点云数据分析技术得到了越来越广泛的关注, 然而点云数据的不规则性使得高效提取点云中的局部结构信息仍然是一大研究难点. 本文提出了一种能够作用于局部空间邻域的卦限卷积神经网络(Octant convolutional neural network, Octant-CNN), 它由卦限卷积模块和下采样模块组成. 针对输入点云, 卦限卷积模块在每个点的近邻空间中定位8个卦限内的最近邻点, 接着通过多层卷积操作将8卦限中的几何特征抽象成语义特征, 并将低层几何特征与高层语义特征进行有效融合, 从而实现了利用卷积操作高效提取三维邻域内的局部结构信息; 下采样模块对原始点集进行分组及特征聚合, 从而提高特征的感受野范围, 并且降低网络的计算复杂度. Octant-CNN通过对卦限卷积模块和下采样模块的分层组合, 实现了对三维点云进行由底层到抽象、从局部到全局的特征表示. 实验结果表明, Octant-CNN在对象分类、部件分割、语义分割和目标检测四个场景中均取得了较好的性能.Abstract: The 3D point cloud data analysis based on deep learning has attracted increasing attention recently. However, it is still a great challenge to extract local structure information from point cloud efficiently due to its irregularity. In this paper, we propose a new network named octant convolutional neural network (Octant-CNN) which can handle local spatial neighborhoods. It consists of octant convolution module and sub-sampling module. For the input point cloud, the octant convolution module locates nearest points in eight octants of each point, and then transforms the geometric features into semantic features through a multi-layer convolution operation. The low-level geometric features are effectively fused with the high-level semantic features so that the local structure information can be efficiently extracted. The sub-sampling module groups the original point set and aggregates the features to expand the receptive field of features, and also reduce the computation overhead of the network. By stacking the octant convolution module and sub-sampling module, Octant-CNN obtains the feature representation of the 3D point cloud from low-level to abstract, and from local to global. Extensive experiments demonstrate that Octant-CNN achieves great performance in four 3D scene understanding tasks including object classification, part segmentation, semantic segmentation, and object detection.
-
表 2 ShapeNet部件分割结果(%)
Table 2 Part segmentation results on ShapeNet (%)
方法 mIoU aero bag cap car chair earphone guitar knife lamp laptop motor mug pistol rocket skateboard table PointNet[12] 83.7 83.4 78.7 82.5 74.9 89.6 73.0 91.5 85.9 80.8 95.3 65.2 93.0 81.2 57.9 72.8 80.6 PointNet++[13] 85.1 82.4 79.0 87.7 77.3 90.8 71.8 91.0 85.9 83.7 95.3 71.6 94.1 81.3 58.7 76.4 82.6 PointSIFT[14] 79.0 75.1 78.4 81.8 74.5 85.2 64.3 89.6 81.9 77.5 95.1 64.0 93.5 77.1 54.2 70.6 74.3 RGCNN[19] 84.3 80.2 82.8 92.6 75.3 89.2 73.7 91.3 88.4 83.3 96.0 63.9 95.7 60.9 44.6 72.9 80.4 DGCNN[20] 85.1 84.2 83.7 84.4 77.1 90.9 78.5 91.5 87.3 82.9 96.0 67.8 93.3 82.6 59.7 75.5 82.0 SCN[23] 84.6 83.8 80.8 83.5 79.3 90.5 69.8 91.7 86.5 82.9 96.0 69.2 93.8 82.5 62.9 74.4 80.8 Kd-Net[26] 82.3 80.1 74.6 74.3 70.3 88.6 73.5 90.2 87.2 81.0 94.9 57.4 86.7 78.1 51.8 69.9 80.3 SO-Net[27] 84.6 81.9 83.5 84.8 78.1 90.8 72.2 90.1 83.6 82.3 95.2 69.3 94.2 80.0 51.6 72.1 82.6 RS-Net[29] 84.9 82.7 86.4 84.1 78.2 90.4 69.3 91.4 87.0 83.5 95.4 66.0 92.6 81.8 56.1 75.8 82.2 Octant-CNN 85.3 83.9 83.6 88.3 79.2 91.1 70.8 91.8 87.5 82.9 95.7 72.2 94.5 83.6 60.0 75.5 81.9  下载: 导出CSV
下载: 导出CSV
表 3 S3DIS语义分割结果
Table 3 Semantic segmentation results on S3DIS
方法 mIoU OA ceiling floor wall beam column windows door chair table bookcase sofa board clutter PointNet[12] 47.7 78.6 88.0 88.7 69.3 42.4 23.1 47.5 51.6 42.0 54.1 38.2 9.6 29.4 35.2 PointNet++[13] 57.3 83.8 91.5 92.8 74.6 41.3 28.1 54.5 59.6 64.6 58.9 27.1 52.0 52.3 48.0 PointSIFT[14] 55.5 83.5 91.1 91.3 75.5 42.0 24.0 51.4 56.6 60.2 55.8 17.0 50.2 57.1 49.9 RS-Net[29] 56.5 — 92.5 92.8 78.6 32.8 34.4 51.6 68.1 59.7 60.1 16.4 50.2 44.9 52.0 Octant-CNN 58.3 84.6 92.1 94.5 76.3 48.9 30.8 56.9 62.9 65.8 55.5 28.0 48.1 50.3 48.4
下载: 导出CSV
表 4 3D目标检测对比结果(%)
Table 4 Performance compression in 3D object detection (%)
方法 Cars Pedestrians Cyclists Easy Moderate Hard Easy Moderate Hard Easy Moderate Hard Frustum PointNet v1[32] 83.75 69.37 62.83 65.39 55.32 48.62 70.17 52.87 48.27 Frustum PointNet v2[32] 83.93 71.23 63.72 64.23 56.95 50.15 74.04 54.92 50.53 Frustum PointSIFT[14] 71.56 66.17 58.97 63.13 55.08 49.05 70.36 52.56 48.53 Frustum Geo-CNN[33] 85.09 71.02 63.38 69.64 60.50 52.88 75.64 56.25 52.54 Frustum Octant-CNN 85.10 72.31 64.46 67.90 59.73 52.44 76.56 57.50 54.26
下载: 导出CSV
表 5 结构设计分析
Table 5 Analysis of the structure design
模型 多层融合 残差 投票 oAcc (%) A 90.7 B $\checkmark$ 91.2 C $\checkmark$ $\checkmark$ 91.5 D $\checkmark$ $\checkmark$ $\checkmark$ 91.9
下载: 导出CSV
表 7 不同邻点的比较
Table 7 The results of different neighbor points
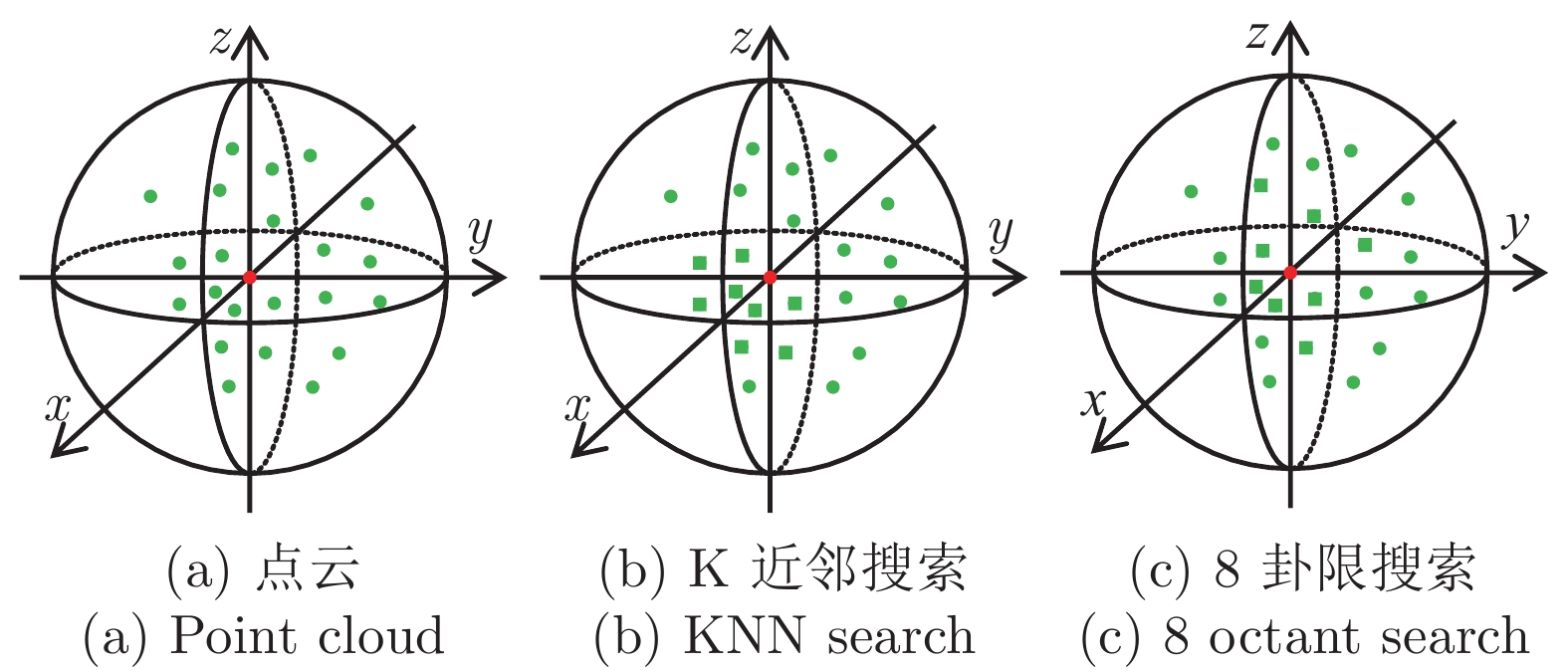
模型 邻点 准确率 (%) A K近邻 90.2 B 8 卦限搜索 91.9
下载: 导出CSV
表 8 不同搜索半径的比较
Table 8 Comparison of different search radius
模型 搜索半径 oAcc (%) A (0.25, 0.5, 1.0) 88.0 B (0.4, 0.8, 1.0) 89.2 C (0.5, 1.0, 1.0) 89.9 D None 91.9
下载: 导出CSV
表 9 不同输入通道的结果比较
Table 9 The results of different input channels
模型 输入通道 oAcc (%) A ($f_{ij}$) 90.1 B ($x_i-x_{ij}, f_{ij}$) 90.3 C ($x_i, f_{ij}$) 90.8 D ($x_i, x_i-x_{ij}, f_{ij}$) 91.9
下载: 导出CSV
-
[1] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. In: Proceedings of the 2012 Advances in Neural Information Processing Systems. Nevada, USA, 2012. 1097−1105 [2] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 770−778 [3] Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1440−1448 [4] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. In: Proceedings of the 2016 I EEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 779−788 [5] Zhu Z, Xu M D, Bai S, Huang T T, Bai X. Asymmetric non-local neural networks for semantic segmentation. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, South Korea: IEEE, 2019. 593−602 [6] Li Y, Qi H Z, Dai J F, Ji X Y, Wei Y C. Fully convolutional instance-aware semantic segmentation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 2359−2367 [7] 彭秀平, 仝其胜, 林洪彬, 冯超, 郑武. 一种面向散乱点云语义分割的深度残差−特征金字塔网络框架. 自动化学报, 2019. DOI: 10.16383/j.ass.c190063Peng Xiu-Ping, Tong Qi-Sheng, Lin Hong-Bin, Feng Chao, Zheng Wu. A deep residual-feature pyramid network for scattered point cloud semantic segmentation. Acta Automatica Sinica, 2019. DOI: 10.16383/j.aas.c190063 [8] Maturana D, Scherer S. Voxnet: A 3d convolutional neural network for real-time object recognition. In: Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems. Hamburg, Germany: IEEE, 2015. 922−928 [9] Wu Z R, Song S R, Khosla A, Yu F, Zhang L G, Tang X O, Xiao J X. 3d shapenets: A deep representation for volumetric shapes. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 1912−1920 [10] Su H, Maji S, Kalogerakis E, Learned-Miller E. Multi-view convolutional neural networks for 3d shape recognition. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 945−953 [11] Yang Z, Wang L W. Learning relationships for multi-view 3d object recognition. In: Proceedings of the 2019 IEEE International Conference on Computer Vision. Seoul, Korea (South): IEEE, 2019. 7505−7514 [12] Qi C R, Su H, Mo K, Guibas L J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 652−660 [13] Qi C R, Yi L, Su H, Guibas L J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In: Proceedings of the 2017 Advances in Neural Information Processing Systems. Long Beach, USA, 2017. 5099−5108 [14] Jiang M Y, Wu Y R, Zhao T Q, Zhao Z L, Lu C W. Pointsift: A sift-like network module for 3D point cloud semantic segmentation [Online], available: https://arxiv.org/abs/1807.00652, July 22, 2020 [15] Rao Y M, Lu J W, Zhou J. Spherical fractal convolutional neural networks for point cloud recognition. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA, 2019. 452−460 [16] Liu Y C, Fan B, Xiang S M, Pan C H. Relation-shape convolutional neural network for point cloud analysis. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA, 2019. 8895−8904 [17] Boulch A. Convpoint: continuous convolutions for point cloud processing. Computers & Graphics, 2020, 88: 24-34 [18] Simonovsky M, Komodakis N. Dynamic edge-conditioned filters in convolutional neural networks on graphs. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 3693−3702 [19] Te G, Hu W, Zheng A, Guo Z M. RGCNN: Regularized graph cnn for point cloud segmentation. In: Proceedings of the 26th ACM International Conference on Multimedia. Seoul, Korea (South): ACM, 2018. 746−754 [20] Wang Y, Sun Y, Liu Z, Sarma S E, Bronstein M M, Solomon J M. Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics (TOG), 2019, 38(5): 1-12 [21] Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 2014, 15(1): 1929-1958 [22] Yang J C, Zhang Q, Ni B, B, Li L G, Liu J X, Zhou M D, Tian Q. Modeling point clouds with self-attention and gumbel subset sampling. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA, 2019. 3323−3332 [23] Xie S N, Liu S N, Chen Z Y, Tu Z W. Attentional shapecontextnet for point cloud recognition. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 4606−4615 [24] Duan Y Q, Zheng Y, Lu J W, Zhou J, Tian Q. Structural relational reasoning of point clouds. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019. 949−958 [25] Lin H X, Xiao Z L, Tan Y, Chao H Y, Ding S Y. Justlookup: one millisecond deep feature extraction for point clouds by lookup tables. In: Proceedings of the 2019 IEEE International Conference on Multimedia and Expo. Shanghai, China: IEEE, 2019. 326−331 [26] Klokov R, Lempitsky V. Escape from cells: Deep KD-networks for the recognition of 3d point cloud models. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 863−872 [27] Li J X, Chen B M, Hee L G. So-net: Self-organizing network for point cloud analysis. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 9397−9406 [28] Yi L, Kim V G, Ceylan D, et al. A scalable active framework for region annotation in 3d shape collections. ACM Transactions on Graphics (ToG), 2016, 35(6): 1-12 [29] Huang Q G, Wang W Y, Neumann U. Recurrent slice networks for 3d segmentation of point clouds. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 2626−2635 [30] Armeni I, Sener O, Zamir A R, Jiang H, Brilakis I, Fischer M, Savarese S. 3d semantic parsing of large-scale indoor spaces. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1534−1543 [31] Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Rhode Island, USA: IEEE, 2012. 3354−3361 [32] Qi C R, Liu W, Wu C, X Su H, Guibas L J. Frustum pointnets for 3d object detection from RGB-D data. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 918−927 [33] Lan S Y, Yu R C, Yu G, Davis L S. Modeling local geometric structure of 3d point clouds using GEO-CNN. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 998−1008 -

 下载:
下载:




计量
- 文章访问数: 1823
- HTML全文浏览量: 623
- PDF下载量: 304
- 被引次数: 0
