

-
摘要: 近年来, 智能便携设备和移动互联网的迅速发展促使网络空间中积累了海量的数据信息, 从而影响了众多领域的研究与发展. 本文针对在以社会信号为主的数据对交通领域的影响下产生的跨学科领域−社会交通, 从数据及相应技术方法和研究应用方面对物理和网络空间信息的感知、挖掘、分析与利用的研究成果进行综述, 并分析、总结与展望该领域的未来研究趋势.Abstract: In recent years, the rapid development of smart portable devices and mobile Internet has led to the accumulation of massive data information in cyberspace, and has affected research and development in many fields. This paper focuses on an emerging interdisciplinary research field named social transportation, which derived from transportation under the impact of data based mainly on social signals. The perception, mining, analysis and utilization upon information of physical and cyber space in related work are introduced according to data, corresponding technical methods, and research applications. The research trends of social transportation is also analyzed and summarized.
-
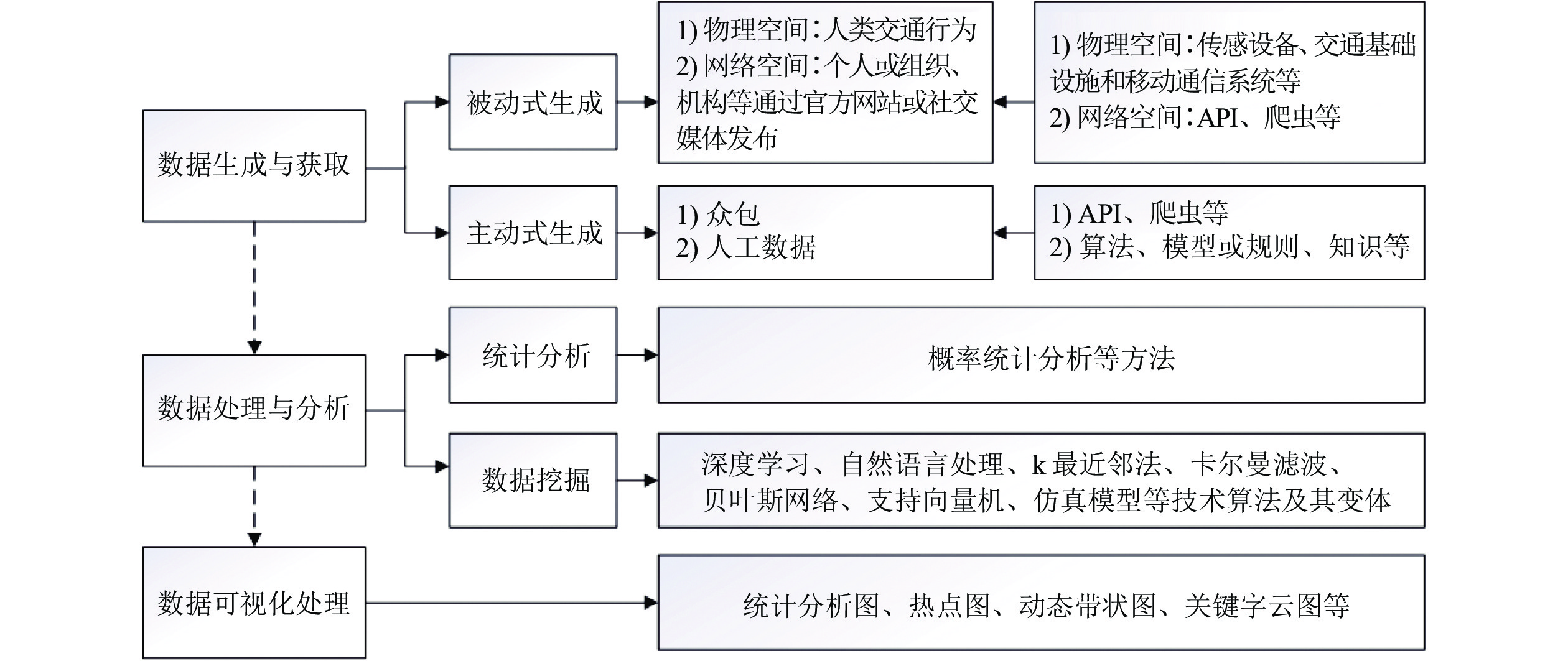
图 1 常规数据研究流程及相应典型技术方法
Fig. 1 Routine data research process and corresponding typical technical methods

图 5 社会交通研究与应用的发展趋势及分类
Fig. 5 The development trend and classification of social transportation research and application

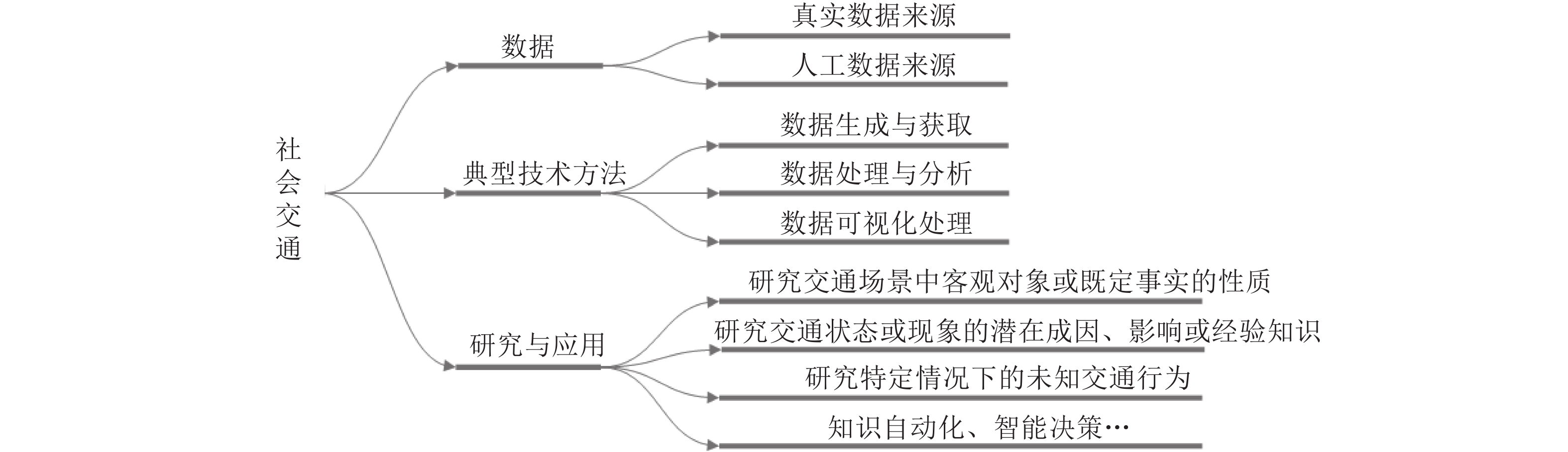
图 7 社会交通领域研究的基本要素
Fig. 7 Basic elements of research in the field of social transportation
表 1 影响城市交通状况变化的因素
Table 1 Factors affecting the change of urban traffic conditions
既定因素 非既定因素 天气 实时路况 节假日 交通舆情 体育赛事、文艺演出等大型集会活动 交通拥堵、事故等非既定交通事件 道路施工、管制等既定交通事件 其他突发特殊事件 交通方式及其运行安排 $\vdots $ 环境、经济、土地、人口等相关信息 $\vdots $  下载: 导出CSV
下载: 导出CSV
表 2 可用真实数据的类别、来源、类型、信息及研究实例
Table 2 The categories, sources, data types, information and examples of available data
类别 来源 主要数据类型及信息 典型研究实例 物理空间 传感设备、浮动车和移动通讯终端以及共享单车、公交巴士和地铁等媒介 1) 数值: 日期、 时间、 GPS定位、速度、加速度等 文献 [8, 10-11, 13-14, 17-19, 21, 23-35] 2) 文本: 方向、起点、终点、地址、站点、车牌号码、基站编号等 文献 [17, 21-23, 25-27] 3) 图像/视频/语音: 图像、视频等 文献 [18] 网络空间 非社交类 在线地图服务提供商、签到网站、政府部门和公共场所或科研组织机构等官方机构或组织的公开信息发布网站 1) 数值: 时间、气温、速度、流量、GPS定位等 文献 [19, 21, 31, 33-43] 2) 文本: 地址、 站点、事件类型及描述、天气情况等 文献 [19, 21-22, 28-30, 32, 38-39, 41, 45-50] 3) 图像/视频/语音: 图像、视频等 文献 [12, 27] 社交类 Twitter、微博、贴吧、论坛和出行服务等媒介 1) 数值: 时间、GPS定位、手机号码等 文献 [12, 15, 18, 40, 51-61] 2) 文本: 用户名称、出行方式、地址、事件及描述、评论、天气情况等 文献 [1, 4, 12, 24, 28, 31, 36, 38-39, 41-43, 48-50, 52-58, 60, 62-78] 3) 图像/视频/语音: 图像、视频等 文献 [79]
下载: 导出CSV
-
[1] 王飞跃. 社会计算与情报和安全信息学原型系统的研发. 中国科学院重大项目报告, 2004.Wang Fei-Yue. Social computing and prototype systems development for key projects in CAS. Chinese Academy of Sciences Reports of Major Projects, 2004. [2] 王飞跃. 社会信号处理与分析的基本框架: 从社会传感网络到计算辩证解析方法. 中国科学: 信息科学, 2013, 43(12): 1598−1611 doi: 10.1360/N112013-00094Wang Fei-Yue. A framework for social signal processing and analysis: From social sensing networks to computational dialectical analytics. Scientia Sinica (Informationis), 2013, 43(12): 1598−1611 doi: 10.1360/N112013-00094 [3] Lau R Y K. Toward a social sensor based framework for intelligent transportation. In: Proceedings of the 18th IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks. Macau, China: IEEE, 2017. 1−6 [4] Sasaki K, Nagano S, Ueno K, Cho K. Feasibility study on detection of transportation information exploiting twitter as a sensor. In: Proceedings of the 6th International AAAI Conference on Weblogs and Social Media. Dublin, Ireland: AAAI, 2012. 30−35 [5] Wang F-Y. Scanning the issue and beyond: Real-time social transportation with online social signals. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(3): 909−914 doi: 10.1109/TITS.2014.2323531 [6] Zheng X H, Chen W, Wang P, Shen D Y, Chen S H, Wang X, et al. Big data for social transportation. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(3): 620−630 doi: 10.1109/TITS.2015.2480157 [7] Lv Y S, Chen Y Y, Zhang X Q, Duan Y J, Li N Q. Social media based transportation research: The state of the work and the networking. IEEE/CAA Journal of Automatica Sinica, 2017, 4(1): 19−26 doi: 10.1109/JAS.2017.7510316 [8] 陶汉卿, 李文勇. 基于感应线圈车辆检测器的车辆转弯信息获取. 桂林电子科技大学学报, 2008, 28(5): 387−391 doi: 10.3969/j.issn.1673-808X.2008.05.002Tao Han-Qing, Li Wen-Yong. Acquisition of turning vehicles information based on induction loop detector. Journal of Guilin University of Electronic Technology, 2008, 28(5): 387−391 doi: 10.3969/j.issn.1673-808X.2008.05.002 [9] 王川童. 基于视频处理的城市道路交通拥堵判别技术研究 [硕士学位论文], 重庆大学, 中国, 2010.Wang Chuan-Tong. Study on Video-based Traffic Congestion Identiflcation Technology of City Road [Master thesis], Chongqing University, China, 2010. [10] Paul R, Hamilton M, D'Souza D. A cloud model for distributed transport system integration. In: Proceedings of the 4th IEEE International Conference on Big Data and Cloud Computing. Sydney, Australia: IEEE, 2014. 77−84 [11] Zhou T, Gao L X, Ni D H. Road traffic prediction by incorporating online information. In: Proceedings of the 23rd International Conference on World Wide Web. Seoul, Korea: ACM, 2014. 1235−1240 [12] Zhang Y, Lu Y W, Zhang D L, Shang L Y, Wang D. Risksens: A multi-view learning approach to identifying risky traffic locations in intelligent transportation systems using social and remote sensing. In: Proceedings of the 2018 IEEE International Conference on Big Data. Seattle, USA: IEEE, 2018. 1544−1553 [13] 董均宇. 基于GPS浮动车的城市路段平均速度估计技术研究 [硕士学位论文], 重庆大学, 中国, 2006.Dong Jun-Yu. Study on Link Speed Estimation in Urban Arteries Based on GPS Equipped Floating Vehicle [Master thesis], Chongqing University, China, 2006. [14] 翁剑成, 荣建, 于泉, 任福田. 基于浮动车数据的行程速度估计算法及优化. 北京工业大学学报, 2007, 33(5): 459−464Weng Jian-Cheng, Rong Jian, Yu Quan, Ren Fu-Tian. Optimization on estimation algorithms of travel speed based on the real-time floating car data. Journal of Beijing University of Technology, 2007, 33(5): 459−464 [15] Zheng Y, Liu Y C, Yuan J, Xie X. Urban computing with taxicabs. In: Proceedings of the 13th International Conference on Ubiquitous Computing. Beijing, China: ACM, 2011. 89−98 [16] Koukoumidis E, Peh L S, Martonosi M R. Signalguru: Leveraging mobile phones for collaborative traffic signal schedule advisory. In: Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services. Bethesda, USA: ACM, 2011. 127−140 [17] Yin P F, Ye M, Lee W C, Li Z H. Mining GPS data for trajectory recommendation. In: Proceedings of the 18th Pacific-Asia Conference on Knowledge Discovery and Data Mining. Tainan, China: Springer, 2014. 50−61 [18] Parsafard M, Chi G Q, Qu X B, Li X P, Wang H Z. Error measures for trajectory estimations with geo-tagged mobility sample data. IEEE Transactions on Intelligent Transportation Systems, 2019, 20(7): 2566−2583 doi: 10.1109/TITS.2018.2868182 [19] Yang Z D, Hu J, Shu Y C, Cheng P, Chen J M, Moscibroda T. Mobility modeling and prediction in bike-sharing systems. In: Proceedings of the 14th Annual International Conference on Mobile Systems, Applications, and Services. Singapore, Singapore: ACM, 2016. 165−178 [20] He T F, Bao J, Li R Y, Ruan S J, Li Y H, Tian C, et al. Detecting vehicle illegal parking events using sharing bikes' trajectories. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. London, UK: ACM, 2018. 340−349 [21] Rodrigues F, Borysov S S, Ribeiro B, Pereira F C. A Bayesian additive model for understanding public transport usage in special events. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(11): 2113−2126 doi: 10.1109/TPAMI.2016.2635136 [22] Lu Y, Wu H Y, Xin L, Chen P H, Zhang J Y. Toursense: A framework for tourist identification and analytics using transport data. IEEE Transactions on Knowledge and Data Engineering, 2019, 31(12): 2407−2422 doi: 10.1109/TKDE.2019.2894131 [23] Itoh M, Yokoyama D, Toyoda M, Tomita Y, Kawamura S, Kitsuregawa M. Visual fusion of mega-city big data: An application to traffic and tweets data analysis of metro passengers. In: Proceedings of the 2014 IEEE International Conference on Big Data. Washington, USA: IEEE, 2014. 431−440 [24] Itoh M, Yokoyama D, Toyoda M, Tomita Y, Kawamura S, Kitsuregawa M. Visual exploration of changes in passenger flows and tweets on mega-city metro network. IEEE Transactions on Big Data, 2016, 2(1): 85−99 doi: 10.1109/TBDATA.2016.2546301 [25] Zhao J J, Qu Q, Zhang F, Xu C Z, Liu S Y. Spatio-temporal analysis of passenger travel patterns in massive smart card data. IEEE Transactions on Intelligent Transportation Systems, 2017, 18(11): 3135−3146 doi: 10.1109/TITS.2017.2679179 [26] Mashhadi A, Quattrone G, Capra L. Putting ubiquitous crowd-sourcing into context. In: Proceedings of the 2013 Conference on Computer Supported Cooperative Work. San Antonio, USA: ACM, 2013. 611−622 [27] Morgul E F, Yang H, Kurkcu A, Ozbay K, Bartin B, Kamga C, et al. Virtual sensors: Web-based real-time data collection methodology for transportation operation performance analysis. Transportation Research Record: Journal of the Transportation Research Board, 2014, 2442(1): 106−116 doi: 10.3141/2442-12 [28] Cui J, Fu R, Dong C H, Zhang Z. Extraction of traffic information from social media interactions: Methods and experiments. In: Proceedings of the 17th IEEE International Conference on Intelligent Transportation Systems. Qingdao, China: IEEE, 2014. 1549−1554 [29] Kurkcu A, Morgul E F, Ozbay K. Extended implementation method for virtual sensors: Web-based real-time transportation data collection and analysis for incident management. Transportation Research Record: Journal of the Transportation Research Board, 2015, 2528(1): 27−37 doi: 10.3141/2528-04 [30] Meng C S, Cui Y, He Q, Su L, Gao J. Travel purpose inference with GPS trajectories, POIs, and geo-tagged social media data. In: Proceedings of the 2017 IEEE International Conference on Big Data. Boston, USA: IEEE, 2017. 1319−1324 [31] Santos B P, Rettore P H L, Ramos H S, Vieira L F M, Loureiro A A F. Enriching traffic information with a spatiotemporal model based on social media. In: Proceedings of the 2018 IEEE Symposium on Computers and Communications. Natal, Brazil: IEEE, 2018. 464−469 [32] Cui Y, Meng C S, He Q, Gao J. Forecasting current and next trip purpose with social media data and Google places. Transportation Research Part C: Emerging Technologies, 2018, 97: 159−174 doi: 10.1016/j.trc.2018.10.017 [33] Cranshaw J, Schwartz R, Hong J I, Sadeh N. The livehoods project: Utilizing social media to understand the dynamics of a city. In: Proceedings of the 6th International AAAI Conference on Weblogs and Social Media. Dublin, Ireland: ACM, 2012. 58−65 [34] Zhang A X, Noulas A, Scellato S, Mascolo C. Hoodsquare: Modeling and recommending neighborhoods in location-based social networks. In: Proceedings of the 2013 IEEE International Conference on Social Computing. Alexandria, USA: IEEE, 2013. 69−74 [35] Peng X F, Pan Y M, Luo J B. Predicting high taxi demand regions using social media check-ins. In: Proceedings of the 2017 IEEE International Conference on Big Data. Boston, USA: IEEE, 2017. 2066−2075 [36] Çelikten E, Le Falher G, Mathioudakis M. Modeling urban behavior by mining geotagged social data. IEEE Transactions on Big Data, 2017, 3(2): 220−233 doi: 10.1109/TBDATA.2016.2628398 [37] Hasan S, Ukkusuri S V. Reconstructing activity location sequences from incomplete check-in data: A semi-markov continuous-time Bayesian network model. IEEE Transactions on Intelligent Transportation Systems, 2018, 19(3): 687−698 doi: 10.1109/TITS.2017.2700481 [38] He J R, Shen W, Divakaruni P, Wynter L, Lawrence R. Improving traffic prediction with tweet semantics. In: Proceedings of the 23rd International Joint Conference on Artificial Intelligence. Beijing, China: IJCAI/AAAI, 2013. 1387−1393 [39] Georgiou T, El Abbadi A, Yan X F, George J. Mining complaints for traffic-jam estimation: A social sensor application. In: Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015. Paris, France: ACM, 2015. 330−335 [40] Zhang P, Deng Q, Liu X D, Yang R, Zhang H. Emergency-oriented spatiotemporal trajectory pattern recognition by intelligent sensor devices. IEEE Access, 2017, 5: 3687−3697 doi: 10.1109/ACCESS.2017.2678471 [41] Bichu N, Panangadan A. Analyzing social media communications for correlation with freeway vehicular traffic. In: Proceedings of the 2017 IEEE SmartWorld, Ubiquitous Intelligence and Computing, Advanced and Trusted Computed, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People and Smart City Innovation. San Francisco, USA: IEEE, 2017. 1−7 [42] Wang S Z, Zhang X M, Li F X, Yu P S, Huang Z Q. Efficient traffic estimation with multi-sourced data by parallel coupled hidden Markov model. IEEE Transactions on Intelligent Transportation Systems, 2019, 20(8): 3010−3023 doi: 10.1109/TITS.2018.2870948 [43] Lin L, Li J X, Chen F, Ye J P, Huai J P. Road traffic speed prediction: A probabilistic model fusing multi-source data. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(7): 1310−1323 doi: 10.1109/TKDE.2017.2718525 [44] Moriya K, Matsushima S, Yamanishi K. Traffic risk mining from heterogeneous road statistics. IEEE Transactions on Intelligent Transportation Systems, 2018, 19(11): 3662−3675 doi: 10.1109/TITS.2018.2856533 [45] 张献力. 互联网网页蕴含高动态交通信息的实时搜索与语义理解技术研究 [硕士学位论文], 浙江工业大学, 中国, 2014.Zhang Xian-Li. The Research of Real-time Search and Semantic Understanding of Dynamic Traffic Information Internet Web Page Contains [Master thesis], Zhejiang University of Technology, China, 2014. [46] 仇培元, 张恒才, 陆锋. 互联网文本蕴含道路交通信息抽取的模式匹配方法. 地球信息科学学报, 2015, 17(4): 416−422Qiu Pei-Yuan, Zhang Heng-Cai, Lu Feng. A pattern matching method for extracting road traffic information from internet texts. Journal of Geo-information Science, 2015, 17(4): 416−422 [47] Abidin A F, Kolberg M. Towards improved vehicle arrival time prediction in public transportation: Integrating SUMO and Kalman filter models. In: Proceedings of the 17th UKSim-AMSS International Conference on Modelling and Simulation. Cambridge, UK: IEEE, 2015. 147−152 [48] Semwal D, Patil S, Galhotra S, Arora A, Unny N. Star: Real-time spatio-temporal analysis and prediction of traffic insights using social media. In: Proceedings of the 2nd IKDD Conference on Data Sciences. Bangalore, India: ACM, 2015. Article No. 7 [49] Ali F, EI-Sappagh S, Khan P, Kwak K S. Feature-based transportation sentiment analysis using fuzzy ontology and sentiwordnet. In: Proceedings of the 2018 IEEE International Conference on Information and Communication Technology Convergence. Jeju, Korea: IEEE, 2018. 1350−1355 [50] Neuhold R, Gursch H, Kern R, Cik M. Driver' s dashboard-using social media data as additional information for motorway operators. IET Intelligent Transport Systems, 2018, 12(9): 1116−1122 doi: 10.1049/iet-its.2018.5337 [51] Hasnat M, Hasan S. Understanding tourist destination choices from geo-tagged tweets. In: Proceedings of the 21st IEEE International Conference on Intelligent Transportation Systems. Maui, USA: IEEE, 2018. 3391−3396 [52] Wang D, Al-Rubaie A, Davies J, Clarke S S. Real time road traffic monitoring alert based on incremental learning from tweets. In: Proceedings of the 2014 IEEE Symposium on Evolving and Autonomous Learning Systems. Orlando, USA: IEEE, 2014. 50−57 [53] Wang D, Al-Rubaie A, Clarke S S, Davies J. Real-time traffic event detection from social media. ACM Transactions on Internet Technology, 2017, 18(1): Article No. 9 [54] Hsiao H J, Huang Y F, Deng H S, Hsu Y F, Hu C L. Intelligent bus information service with the support of mobile social community on the internet. In: Proceedings of the 8th IEEE International Conference on Ubi-Media Computing. Colombo, Sri Lanka: IEEE, 2015. 61−65 [55] Sinnott R O, Yin S C. Accident black spot identification and verification through social media. In: Proceedings of the 2015 IEEE International Conference on Data Science and Data Intensive Systems. Sydney, Australia: IEEE, 2015. 17−24 [56] Chen S M, Yuan X R, Wang Z H, Guo C, Liang J, Wang Z C, et al. Interactive visual discovering of movement patterns from sparsely sampled geo-tagged social media data. IEEE Transactions on Visualization and Computer Graphics, 2016, 22(1): 270−279 doi: 10.1109/TVCG.2015.2467619 [57] Zhang S X, Wang Y, Zhang S Y, Zhu G L. Building associated semantic representation model for the ultra-short microblog text jumping in big data. Cluster Computing, 2016, 19(3): 1399−1410 doi: 10.1007/s10586-016-0602-9 [58] Maghrebi M, Abbasi A, Waller S T. Transportation application of social media: Travel mode extraction. In: Proceedings of the 19th IEEE International Conference on Intelligent Transportation Systems. Rio de Janeiro, Brazil: IEEE, 2016. 1648−1653 [59] Pimpale P, Panangadan A, Abellera L V. Analyzing spread of influence in social networks for transportation applications. In: Proceedings of the 8th IEEE Annual Computing and Communication Workshop and Conference. Las Vegas, USA: IEEE, 2018. 763−768 [60] Yao H X, Wu F, Ke J T, Tang X F, Jia Y T, Lu S Y, et al. Deep multi-view spatial-temporal network for taxi demand prediction. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: IEEE, 2018. 2588−2595 [61] Liao Y, Yeh S. Predictability in human mobility based on geographical-boundary-free and long-time social media data. In: Proceedings of the 21st IEEE International Conference on Intelligent Transportation Systems. Maui, USA: IEEE, 2018. 2068−2073 [62] Zeng K, Liu W L, Wang X, Chen S H. Traffic congestion and social media in China. IEEE Intelligent Systems, 2013, 28(1): 72−77 [63] Wayasti R A, Surjandari I, Zulkamain. Mining customer opinion for topic modeling purpose: Case study of ride-hailing service provider. In: Proceedings of the 6th IEEE International Conference on Information and Communication Technology. Bandung, Indonesia: IEEE, 2018. 305−309 [64] 崔健, 冯璇, 张佐. 基于微博的交通事件提取与文本分析系统. 交通信息与安全, 2013, 31(6): 132−135 doi: 10.3963/j.issn.1674-4861.2013.06.025Cui Jian, Feng Xuan, Zhang Zuo. Extraction and analysis system of traffic incident based on microblog. Journal of Transport Information and Safety, 2013, 31(6): 132−135 doi: 10.3963/j.issn.1674-4861.2013.06.025 [65] Pan B, Zheng Y, Wilkie D, Shahabi C. Crowd sensing of traffic anomalies based on human mobility and social media. In: Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. Orlando, USA: ACM, 2013. 344−353 [66] Cao J P, Zeng K, Wang H, Cheng J J, Qiao F C, Wen D, et al. Web-based traffic sentiment analysis: Methods and applications. IEEE Transactions on Intelligent Transportation systems, 2014, 15(2): 844−853 doi: 10.1109/TITS.2013.2291241 [67] Grant-Muller S M, Gal-Tzur A, Minkov E, Nocera S, Kuflik T, Shoor I. Enhancing transport data collection through social media sources: Methods, challenges and opportunities for textual data. IET Intelligent Transport Systems, 2015, 9(4): 407−417 doi: 10.1049/iet-its.2013.0214 [68] Gutiérrez C, Figuerias P, Oliveira P, Costa R, Jardim-Goncalves R. Twitter mining for traffic events detection. In: Proceedings of the 2015 IEEE Science and Information Conference. London, UK: IEEE, 2015. 371−378 [69] D'Andrea E, Ducange P, Lazzerini B, Marcelloni F. Real-time detection of traffic from twitter stream analysis. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(4): 2269−2283 doi: 10.1109/TITS.2015.2404431 [70] Fu K Q, Lu C T, Nune R, Tao J X. Steds: Social media based transportation event detection with text summarization. In: Proceedings of the 18th IEEE International Conference on Intelligent Transportation Systems. Gran Canaria, Spain: IEEE, 2015. 1952−1957 [71] Maghrebi M, Abbasi A, Rashidi T H, Waller S T. Complementing travel diary surveys with twitter data: Application of text mining techniques on activity location, type and time. In: Proceedings of the 18th IEEE International Conference on Intelligent Transportation Systems. Gran Canaria, Spain: IEEE, 2015. 208−213 [72] Salas A, Georgakis P, Petalas Y. Incident detection using data from social media. In: Proceedings of the 20th IEEE International Conference on Intelligent Transportation Systems. Yokohama, Japan: IEEE, 2017. 751−755 [73] Saragih M H, Girsang A S. Sentiment analysis of customer engagement on social media in transport online. In: Proceedings of the 2017 IEEE International Conference on Sustainable Information Engineering and Technology. Malang, Indonesia: IEEE, 2017. 24−29 [74] Kulkarni G, Abellera L, Panangadan A. Unsupervised classification of online community input to advance transportation services. In: Proceedings of the 8th IEEE Annual Computing and Communication Workshop and Conference. Las Vegas, USA: IEEE, 2018. 261−267 [75] 郑治豪, 吴文兵, 陈鑫, 胡荣鑫, 柳鑫, 王璞. 基于社交媒体大数据的交通感知分析系统. 自动化学报, 2018, 44(4): 656−666Zheng Zhi-Hao, Wu Wen-Bing, Chen Xin, Hu Rong-Xin, Liu Xin, Wang Pu. A traffic sensing and analyzing system using social media data. Acta Automatica Sinica, 2018, 44(4): 656−666 [76] Abalı G, Karaarslan E, Hürriyetoğlu A, Dalkılıç F. Detecting citizen problems and their locations using twitter data. In: Proceedings of the 6th IEEE International Istanbul Smart Grids and Cities Congress and Fair. Istanbul, Turkey: IEEE, 2018. 30−33 [77] Alamsyah A, Rizkika W, Nugroho D D A, Renaldi F, Saadah S. Dynamic large scale data on twitter using sentiment analysis and topic modeling. In: Proceedings of the 6th IEEE International Conference on Information and Communication Technology. Bandung, Indonesia: IEEE, 2018. 254−258 [78] Alkouz B, Al Aghbari Z. Leveraging cross-lingual tweets in location recognition. In: Proceedings of the 2018 IEEE International Conference on Electro/Information Technology. Rochester, USA: IEEE, 2018. 84−89 [79] Giancristofaro G T, Panangadan A. Predicting sentiment toward transportation in social media using visual and textual features. In: Proceedings of the 19th IEEE International Conference on Intelligent Transportation Systems. Rio de Janeiro, Brazil: IEEE, 2016. 2113−2118 [80] Elevant K. Trust-networks for changing driver behaviour during severe weather. IET Intelligent Transport Systems, 2013, 7(4): 415−424 doi: 10.1049/iet-its.2012.0042 [81] Huang C, Zou Z Y. People' s intention towards public bicycle system in Wuhan. In: Proceedings of the 8th IEEE International Symposium on Computational Intelligence and Design. Hangzhou, China: IEEE, 2015. 148−151 [82] Chaniotakis E, Antoniou C, Grau J M S, Dimitriou L. Can social media data augment travel demand survey data? In: Proceedings of the 19th IEEE International Conference on Intelligent Transportation Systems. Rio de Janeiro, Brazil: IEEE, 2016. 1642−1647 [83] Panadea H, Handayani P W, Pinem A A. The analysis of tourism information to enhance information quality in e-tourism. In: Proceedings of the 2nd IEEE International Conference on Informatics and Computing. Jayapura, Indonesia: IEEE, 2017. 1−6 [84] Peng Y X, Zhu W W, Zhao Y, Xu C S, Huang Q M, Lu H Q, et al. Cross-media analysis and reasoning: Advances and directions. Frontiers of Information Technology and Electronic Engineering, 2017, 18(1): 44−57 [85] Shrivastava A, Pfister T, Tuzel O, Susskind J, Wang W D, Webb R. Learning from simulated and unsupervised images through adversarial training. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 2242−2251 [86] Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, et al. Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 105−114 [87] Yeh R A, Chen C, Lim T Y, Schwing A G, Johnson M H, Do M N. Semantic image inpainting with deep generative models. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 6882−6890 [88] Isola P, Zhu J Y, Zhou T H, Efros A A. Image-to-image translation with conditional adversarial networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 5967−5976 [89] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2242−2251 [90] Wang K F, Gou C, Zheng N N, Rehg J M, Wang F-Y. Parallel vision for perception and understanding of complex scenes: Methods, framework, and perspectives. Artificial Intelligence Review, 2019, 48(3): 299−329 [91] Cao Y J, Jia L L, Chen Y X, Lin N, Yang R, Zhang H, et al. Recent advances of generative adversarial networks in computer vision. IEEE Access, 2019, 7: 14985−15006 doi: 10.1109/ACCESS.2018.2886814 [92] Wang X, Zheng X H, Zhang Q P, Wang T, Shen D Y. Crowdsourcing in its: The state of the work and the networking. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(6): 1596−1605 doi: 10.1109/TITS.2015.2513086 [93] Zimmerman J, Tomasic A, Garrod C, Yoo D, Hiruncharoenvate C, Aziz R, et al. Field trial of tiramisu: Crowd-sourcing bus arrival times to spur co-design. In: Proceedings of the 2011 SIGCHI Conference on Human Factors in Computing Systems. Vancouver, Canada: ACM, 2011. 1677−1686 [94] Xu Z, Zhang H, Sugumaran V, Choo K K R, Mei L, Zhu Y W. Participatory sensing-based semantic and spatial analysis of urban emergency events using mobile social media. EURASIP Journal on Wireless Communications and Networking, 2016, 2016(1): 44 doi: 10.1186/s13638-016-0553-0 [95] 王飞跃, 史蒂夫·兰森. 从人工生命到人工社会——复杂社会系统研究的现状和展望. 复杂系统与复杂性科学, 2004, 1(1): 33−41 doi: 10.3969/j.issn.1672-3813.2004.01.007Wang Fei-Yue, Lansing J S. From artificial life to artificial societies — new methods for studies of complex social systems. Complex Systems and Complexity Science, 2004, 1(1): 33−41 doi: 10.3969/j.issn.1672-3813.2004.01.007 [96] 王飞跃, 汤淑明. 人工交通系统的基本思想与框架体系. 复杂系统与复杂性科学, 2004, 1(2): 52−59 doi: 10.3969/j.issn.1672-3813.2004.02.008Wang Fei-Yue, Tang Shu-Ming. Concepts and frameworks of artificial transportation systems. Complex Systems and Complexity Science, 2004, 1(2): 52−59 doi: 10.3969/j.issn.1672-3813.2004.02.008 [97] 王飞跃. 计算实验方法与复杂系统行为分析和决策评估. 系统仿真学报, 2004, 16(5): 893−897 doi: 10.3969/j.issn.1004-731X.2004.05.009Wang Fei-Yue. Computational experiments for behavior analysis and decision evaluation of complex systems. Journal of System Simulation, 2004, 16(5): 893−897 doi: 10.3969/j.issn.1004-731X.2004.05.009 [98] 王飞跃. 平行系统方法与复杂系统的管理和控制. 控制与决策, 2004, 19(5): 485−489, 514 doi: 10.3321/j.issn:1001-0920.2004.05.002Wang Fei-Yue. Parallel system methods for management and control of complex systems. Control and Decision, 2004, 19(5): 485−489, 514 doi: 10.3321/j.issn:1001-0920.2004.05.002 [99] 王飞跃. 关于复杂系统研究的计算理论与方法. 中国基础科学, 2004, 6(5): 3−10 doi: 10.3969/j.issn.1009-2412.2004.05.001Wang Fei-Yue. Computational theory and method on complex system. China Basic Science, 2004, 6(5): 3−10 doi: 10.3969/j.issn.1009-2412.2004.05.001 [100] Wang F-Y, Tang S M. A framework for artificial transportation systems: From computer simulations to computational experiments. In: Proceedings of the 2005 IEEE Intelligent Transportation Systems. Vienna, Austria: IEEE, 2005. 1130−1134 [101] Tang S M, Wang F-Y. A preliminary study for basic approaches in artificial transportation systems. Journal of the Graduate School of the Chinese Academy of Sciences, 2006, 23(4): 569−575 [102] Zhu F H, Wang Z X, Wang F-Y, Tang S M. Modeling interactions in artificial transportation systems using petri net. In: Proceedings of the 2006 IEEE Intelligent Transportation Systems Conference. Toronto, Canada: IEEE, 2006. 1131−1136 [103] He F, Miao Q H, Li Y T, Wang F-Y, Tang S M. Modeling and analysis of artificial transportation system based on multi-agent technology. In: Proceedings of the 2006 IEEE Intelligent Transportation Systems Conference. Toronto, Canada: IEEE, 2006, 1120−1124 [104] Li J Y, Tang S M, Wang X Q, Wang F-Y. A software architecture for artificial transportation systems-principles and framework. In: Proceedings of the 2007 IEEE Intelligent Transportation Systems Conference. Bellevue, USA: IEEE, 2007. 229−234 [105] Wang F-Y. Parallel control and management for intelligent transportation systems: Concepts, architectures, and applications. IEEE Transactions on Intelligent Transportation Systems, 2010, 11(3): 630−638 doi: 10.1109/TITS.2010.2060218 [106] Li J Y, Tang S M, Wang X Q, Duan W, Wang F-Y. Growing artificial transportation systems: A rule-based iterative design process. IEEE Transactions on Intelligent Transportation Systems, 2011, 12(2): 322−332 doi: 10.1109/TITS.2011.2110646 [107] Miao Q H, Zhu F H, Lv Y S, Cheng C J, Chen C, Qiu X G. A game-engine-based platform for modeling and computing artificial transportation systems. IEEE Transactions on Intelligent Transportation Systems, 2011, 12(2): 343−353 doi: 10.1109/TITS.2010.2103400 [108] Smith M, Duncan G, Druitt S. PARAMICS: Microscopic traffic simulation for congestion management. In: Proceedings of the 1995 IEE Colloquium on Dynamic Control of Strategic Inter-Urban Road Networks. London, UK: IET, 1995. 8/1−8/3 [109] Fellendorf M, Vortisch P. Microscopic traffic flow simulator VISSIM. Fundamentals of Traffic Simulation. New York: Springer, 2010. 63−93 [110] 李力, 林懿伦, 曹东璞, 郑南宁, 王飞跃. 平行学习 — 机器学习的一个新型理论框架. 自动化学报, 2017, 43(1): 1−8Li Li, Lin Yi-Lun, Cao Dong-Pu, Zheng Nan-Ning, Wang Fei-Yue. Parallel learning — a new framework for machine learning. Acta Automatica Sinica, 2017, 43(1): 1−8 [111] Lv Y S, Chen Y Y, Li L, Wang F-Y. Generative adversarial networks for parallel transportation systems. IEEE Intelligent Transportation Systems Magazine, 2018, 10(3): 4−10 doi: 10.1109/MITS.2018.2842249 [112] Chen Y Y, Lv Y S, Wang X, Wang F-Y. Traffic flow prediction with parallel data. In: Proceedings of the 21st IEEE International Conference on Intelligent Transportation Systems. Maui, USA: IEEE, 2018. 614−619 [113] Han J W, Pei J, Kamber M. Data mining: Concepts and techniques. Amsterdam, the Netherlands: Elsevier, 2011. [114] 姜桂艳, 李琦, 董硕. 基于k-NN和SCATS交通数据的路段行程时间估计方法. 西南交通大学学报, 2013, 48(2): 343−349 doi: 10.3969/j.issn.0258-2724.2013.02.024Jiang Gui-Yan, Li Qi, Dong Shuo. Travel time estimation method using SCATS traffic data based on k-NN algorithm. Journal of Southwest Jiaotong University, 2013, 48(2): 343−349 doi: 10.3969/j.issn.0258-2724.2013.02.024 [115] Zheng Z D, Su D C. Short-term traffic volume forecasting: A k-nearest neighbor approach enhanced by constrained linearly sewing principle component algorithm. Transportation Research Part C: Emerging Technologies, 2014, 43: 143−157 doi: 10.1016/j.trc.2014.02.009 [116] Abidin A F, Kolberg M, Hussain A. Improved traffic prediction accuracy in public transport using trusted information in social networks. In: Proceedings of the 7th York Doctoral Symposium on Computer Science and Electronics. York, UK: University of York, 2014. Article No. 19 [117] Zhang Z H. Fusing Social Media and Traditional Traffic Data for Advanced Traveler Information and Travel Behavior Analysis [Ph.D. dissertation], State University of New York at Buffalo, USA, 2017. [118] Lv Y S, Duan Y J, Kang W W, Li Z X, Wang F-Y. Traffic flow prediction with big data: A deep learning approach. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(2): 865−873 [119] Duan Y J, Lv Y S, Wang F-Y. Travel time prediction with lstm neural network. In: Proceedings of the 19th IEEE International Conference on Intelligent Transportation Systems. Rio de Janeiro, Brazil: IEEE, 2016. 1053−1058 [120] Chen Y Y, Lv Y S, Li Z J, Wang F-Y. Long short-term memory model for traffic congestion prediction with online open data. In: Proceedings of the 19th IEEE International Conference on Intelligent Transportation Systems. Rio de Janeiro, Brazil: IEEE, 2016. 132−137 [121] Kang D Q, Lv Y S, Chen Y Y. Short-term traffic flow prediction with LSTM recurrent neural network. In: Proceedings of the 20th IEEE International Conference on Intelligent Transportation Systems. Yokohama, Japan: IEEE, 2017. 1−6 [122] Chen Y Y, Lv Y S, Wang X, Wang F-Y. A convolutional neural network for traffic information sensing from social media text. In: Proceedings of the 20th IEEE International Conference on Intelligent Transportation Systems. Yokohama, Japan: IEEE, 2017. 1−6 [123] Chen Y Y, Lv Y S, Wang X, Li L X, Wang F-Y. Detecting traffic information from social media texts with deep learning approaches. IEEE Transactions on Intelligent Transportation Systems, 2019, 20(8): 3049−3058 doi: 10.1109/TITS.2018.2871269 [124] 叶佩军, 吕宜生, 吉竟初. 基于社会网络视角的交通仿真和计算实验研究文献分析. 自动化学报, 2013, 39(9): 1402−1412Ye Pei-Jun, Lv Yi-Sheng, Ji Jing-Chu. Literature analysis for traffic simulation and computational experiments based on social networks. Acta Automatica Sinica, 2013, 39(9): 1402−1412 [125] Zheng Y, Capra L, Wolfson O, Yang H. Urban computing: Concepts, methodologies, and applications. ACM Transactions on Intelligent Systems and Technology, 2014, 5(3): Article No. 38 [126] 孟祥冰, 王蓉, 张梅, 王飞跃. 平行感知: ACP理论在视觉SLAM技术中的应用. 指挥与控制学报, 2018, 3(4): 350−358Meng Xiang-Bing, Wang Rong, Zhang Mei, Wang Fei-Yue. Parallel perception: An ACP-based approach to visual SLAM. Journal of Command and Control, 2018, 3(4): 350−358 [127] 刘昕, 王晓, 张卫山, 汪建基, 王飞跃. 平行数据: 从大数据到数据智能. 模式识别与人工智能, 2017, 30(8): 673−681Liu Xin, Wang Xiao, Zhang Wei-Shan, Wang Jian-Ji, Wang Fei-Yue. Parallel data: From big data to data intelligence. Pattern Recognition and Artificial Intelligence, 2017, 30(8): 673−681 [128] Chen M, Yu X H, Liu Y. PCNN: Deep convolutional networks for short-term traffic congestion prediction. IEEE Transactions on Intelligent Transportation Systems, 2018, 19(11): 3550−3559 doi: 10.1109/TITS.2018.2835523 [129] Perhac J, Zeng W, Asada S, Arisona S M, Schubiger S, Burkhard R, et al. Urban fusion: Visualizing urban data fused with social feeds via a game engine. In: Proceedings of the 21st IEEE International Conference Information Visualization. London, UK: IEEE, 2017. 312−317 [130] Endarnoto S K, Pradipta S, Nugroho A S, Purnama J. Traffic condition information extraction and visualization from social media twitter for android mobile application. In: Proceedings of the 2011 IEEE International Conference on Electrical Engineering and Informatics. Bandung, Indonesia: IEEE, 2011. 1−4 [131] Zhang S, Tang J J, Wang H, Wang Y H. Enhancing traffic incident detection by using spatial point pattern analysis on social media. Transportation Research Record: Journal of the Transportation Research Board, 2015, 2528(1): 69−77 doi: 10.3141/2528-08 [132] Zhang S. Using twitter to enhance traffic incident awareness. In: Proceedings of the 18th IEEE International Conference on Intelligent Transportation Systems. Gran Canaria, Spain: IEEE, 2015. 2941−2946 [133] Tejaswin P, Kumar R, Gupta S. Tweeting traffic: Analyzing twitter for generating real-time city traffic insights and predictions. In: Proceedings of the 2nd IKDD Conference on Data Sciences. Bangalore, India: ACM, 2015. 1−4 [134] Ulloa D, Saleiro P, Rossetti R J F, Silva E R. Mining social media for open innovation in transportation systems. In: Proceedings of the 19th IEEE International Conference on Intelligent Transportation Systems. Rio de Janeiro, Brazil: IEEE, 2016. 169−174 [135] Guo W S, Gupta N, Pogrebna G, Jarvis S. Understanding happiness in cities using twitter: Jobs, children, and transport. In: Proceedings of the 2016 IEEE International Smart Cities Conference. Trento, Italy: IEEE, 2016. 1−7 [136] Singh B S R B J. Real Time Prediction of Road Traffic Condition in London via Twitter and Related Sources [Master thesis], Middlesex University, UK, 2012. [137] Lécué F, Tallevi-Diotallevi S, Hayes J, Tucker R, Bicer V, Sbodio M L, et al. Star-city: Semantic traffic analytics and reasoning for city. In: Proceedings of the 19th International Conference on Intelligent User Interfaces. Haifa, Israel: ACM, 2014. 179−188 [138] Lécué F, Tucker R, Bicer V, Tommasi P, Tallevi-Diotallevi S, Sbodio M. Predicting severity of road traffic congestion using semantic web technologies. In: Proceedings of the 11th European Semantic Web Conference. Anissaras, Crete: Springer, 2014. 611−627 [139] Ye J C, Sun L L, Du B W, Fu Y J, Tong X R, Xiong H. Co-prediction of multiple transportation demands based on deep spatio-temporal neural network. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Anchorage, USA: ACM, 2019. 305−313 [140] Zhao L, Chen F, Lu C T, Ramakrishnan N. Spatiotemporal event forecasting in social media. In: Proceedings of the 2015 SIAM International Conference on Data Mining. Vancouver, Canada: SIAM, 2015. 963−971 [141] Ye B L, Wu W M, Ruan K Y, Li L X, Chen T H, Gao H M, et al. A survey of model predictive control methods for traffic signal control. IEEE/CAA Journal of Automatica Sinica, 2019, 6(3): 623−640 doi: 10.1109/JAS.2019.1911471 [142] 马亮, 杨妹, 艾川, 朱正秋, 陈海亮, 朱蒙娜, 等. 基于ACP方法的新型冠状病毒肺炎疫情管控措施效果评估. 智能科学与技术学报, 2020, 2(1): 88−98 doi: 10.11959/j.issn.2096-6652.202010Ma Liang, Yang Mei, Ai Chuan, Zhu Zheng-Qiu, Chen Hai-Liang, Zhu Meng-Na, et al. The evaluation of the control measures for COVID-19 based on ACP approach. Chinese Journal of Intelligent Science and Technology, 2020, 2(1): 88−98 doi: 10.11959/j.issn.2096-6652.202010 [143] 熊佳茜. 基于CRF的中文微博交通信息事件抽取 [硕士学位论文], 上海交通大学, 中国, 2014.Xiong Jia-Xi. Civil transportation event extraction from Chinese microblogs based on CRF [Master thesis], Shanghai Jiao Tong University, China, 2014. [144] Lécué F, Tucker R, Tallevi-Diotallevi S, Nair R, Gkoufas Y, Liguori G, et al. Semantic traffic diagnosis with STAR-CITY: Architecture and lessons learned from deployment in Dublin, bologna, Miami and Rio. In: Proceedings of the 13th International Semantic Web Conference. Riva del Garda, Italy: Springer, 2014. 292−307 [145] Lécué F, Tallevi-Diotallevi S, Hayes J, Tucker R, Bicer V, Sbodio M, et al. Smart traffic analytics in the semantic web with star-city: Scenarios, system and lessons learned in Dublin city. Journal of Web Semantics, 2014, 27-28: 26−33 doi: 10.1016/j.websem.2014.07.002 [146] Bajaj G, Bouloukakis G, Pathak A, Singh P, Georgantas N, Issarny V. Toward enabling convenient urban transit through mobile crowdsensing. In: Proceedings of the 18th IEEE International Conference on Intelligent Transportation Systems. Gran Canaria, Spain: IEEE, 2015. 290−295 [147] Ngai E C H, Brandauer S, Shrestha A, Vandikas K. Personalized mobile-assisted smart transportation. In: Proceedings of the 2016 IEEE Digital Media Industry and Academic Forum. Santorini, Greece: IEEE, 2016. 158−160 [148] Akilesh B, Kumar N, Reddy B, Singh M. TRAFAN: Road traffic analysis using social media web pages. In: Proceedings of the 10th IEEE International Conference on Communication Systems and Networks. Bengaluru, India: IEEE, 2018. 655−659 [149] Wang F-Y, Yang L Q, Yang J, Zhang Y L, Han S S, Zhao K. Urban intelligent parking system based on the parallel theory. In: Proceedings of the 2016 IEEE International Conference on Computing, Networking and Communications. Kauai, USA: IEEE, 2016. 1−5 [150] 吕宜生, 陈圆圆, 金峻臣, 李镇江, 叶佩军, 朱凤华. 平行交通: 虚实互动的智能交通管理与控制. 智能科学与技术学报, 2019, 1(1): 21−33 doi: 10.11959/j.issn.2096-6652.201908Lv Yi-Sheng, Chen Yuan-Yuan, Jin Jun-Chen, Li Zhen-Jiang, Ye Pei-Jun, Zhu Feng-Hua. Parallel transportation: Virtual-real interaction for intelligent traffic management and control. Chinese Journal of Intelligent Science and Technology, 2019, 1(1): 21−33 doi: 10.11959/j.issn.2096-6652.201908 [151] Xiong G, Zhu F H, Liu X W, Dong X S, Huang W L, Chen S H, et al. Cyber-physical-social system in intelligent transportation. IEEE/CAA Journal of Automatica Sinica, 2015, 2(3): 320−333 doi: 10.1109/JAS.2015.7152667 [152] Wang F-Y. Scanning the issue and beyond: Computational transportation and transportation 5.0. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(5): 1861−1868 doi: 10.1109/TITS.2014.2353831 [153] Xiong G, Dong X S, Lu H, Shen D Y. Research progress of parallel control and management. IEEE/CAA Journal of Automatica Sinica, 2020, 7(2): 355−367 doi: 10.1109/JAS.2019.1911792 [154] Wang F-Y, Zhang J J. Transportation 5.0 in CPSS: Towards ACP-based society-centered intelligent transportation. In: Proceedings of the 20th IEEE International Conference on Intelligent Transportation Systems. Yokohama, Japan: IEEE, 2017. 762−767 [155] 王飞跃, 曹东璞, 魏庆来. 强化学习: 迈向知行合一的智能机制与算法. 智能科学与技术学报, 2020, 2(2): 101−106Wang Fei-Yue, Cao Dong-Pu, Wei Qing-Lai. Reinforcement learning: Toward action-knowledge merged intelligent mechanisms and algorithms. Chinese Journal of Intelligent Science and Technology, 2020, 2(2): 101−106 -

 下载:
下载:


计量
- 文章访问数: 1339
- HTML全文浏览量: 964
- PDF下载量: 481
- 被引次数: 0
