

-
摘要: 为了模拟人眼的视觉注意机制, 快速、高效地搜索和定位图像目标, 提出了一种基于循环神经网络(Recurrent neural network, RNN)的联合回归深度强化学习目标定位模型. 该模型将历史观测信息与当前时刻的观测信息融合, 并做出综合分析, 以训练智能体快速定位目标, 并联合回归器对智能体所定位的目标包围框进行精细调整. 实验结果表明, 该模型能够在少数时间步内快速、准确地定位目标.Abstract: To simulate the visual attention mechanism of the human eye, search and locate image objection quickly and efficiently, this paper proposes a union regression deep reinforcement learning object localization model based on recurrent neural network (RNN), which fuses the historical observation information with the observation information at the current time, then makes a comprehensive analysis to train the agent to quickly locate the object, and combine with the regressor to fine-tune the object bounding box positioned by the agent. Experiments show that the proposed model can accurately and rapidly locate the object in a few time steps.
-
受震动冲击、工况切换、机械磨损、化学侵蚀、负载变化以及能量消耗等因素影响, 设备的健康性能水平将不可避免地劣化, 最终导致其失效, 甚至引起系统故障与事故, 造成人员与财产的损失[1-3]. 作为预测与健康管理的关键技术之一, 寿命与剩余寿命(Remaining useful life, RUL)预测技术能够为设备维修管理提供有效的信息支持与理论支撑[4-5]. 因此, 准确地预测设备寿命及剩余寿命具有重要的理论研究和工程应用价值.
随着传感技术与监测方法的进步, 系统的健康水平可通过状态监测数据, 也就是退化数据来体现. 另外, 由于运行环境、测量误差、样本差异性以及固有随机性等影响, 退化过程往往具有随机性与不确定性[6-7]. 因此, 基于随机退化过程建模的设备寿命与剩余寿命预测方法在近些年得到了广泛关注, 并成为国内外研究的热点问题, 如Gamma退化过程模型、Wiener退化过程模型、逆高斯退化过程模型等[8-9]. 相比于Gamma过程与逆高斯过程等单调退化过程模型, Wiener退化过程模型不仅能够描述非单调的退化数据, 还具有良好的数学计算特性[8-11]. 鉴于此, 本文主要关注基于Wiener过程的退化建模与寿命预测问题.
目前, 对于非单调退化过程模型, 其寿命及剩余寿命往往定义为随机退化过程首次达到失效阈值的时刻, 即首达时间(First passage time, FPT)[8-9, 12]. 也就是说, 退化过程一旦达到给定的失效阈值, 便认为该设备发生了失效. 这种寿命定义方式虽然适用于一些安全性要求较高的关键设备, 但是相对保守. 例如, 当退化过程具有较大的随机性与波动性时, 基于首达时间的定义方式可能就会导致退化过程较早达到给定阈值而引起设备提前终止运行, 造成较大的浪费. 迄今为止, 鲜有文献考虑了这一实际问题.
实际上, 退化数据是设备健康状态水平的内在变化的外在表现. 具体来说, 设备的性能水平与健康状态会随使用次数以及时间的累积而不可避免地发生退化, 表现为退化数据呈现出递增或者递减的变化趋势, 例如电池的电容量减少[13]、陀螺仪漂移系数的增长[14]、轴承振动幅度的变大[15] 等. 这些退化数据会随着时间或使用次数的累积, 最终超过并远离所给定的阈值. 众所周知, 首达时间表示退化过程首次达到阈值的时刻, 而最后逃逸时间(Last exit time, LET)则表示退化过程最后一次离开阈值的时刻[16-17], 反映了设备最后一次恢复到正常状态的时刻, 也就是说从此以后退化过程彻底远离了失效阈值. 首达时间对数据的动态随机性十分敏感, 相比之下, 最后逃逸时间具有更强的鲁棒性, 能够避免由于退化过程动态随机性与数据波动性所导致的设备过早终止运行.
鉴于此, 本文提出一种基于最后逃逸时间的随机退化设备寿命与剩余寿命定义方式. 在新框架下, 以线性Wiener过程模型为研究对象, 首先建立了首达时间与最后逃逸时间之间的关系, 然后推导得到了最后逃逸时间下寿命与剩余寿命分布的表达形式. 此外, 通过数值仿真验证了所得结论的理论正确性, 并进一步完成了模型参数敏感度分析. 最后, 通过实例说明了最后逃逸时间描述随机退化设备寿命具有一定可行性与有效性.
1. 问题描述
1.1 首达时间与最后逃逸时间
首达时间与最后逃逸时间的定义均来自随机过程理论中的概念, 反映了非单调随机过程首次通过和最后一次离开某一给定边界的时刻[16-19]. 受随机过程的不确定性与动态随机性影响, 随机过程的轨迹可能多次往返于某一个给定边界, 如图1所示.
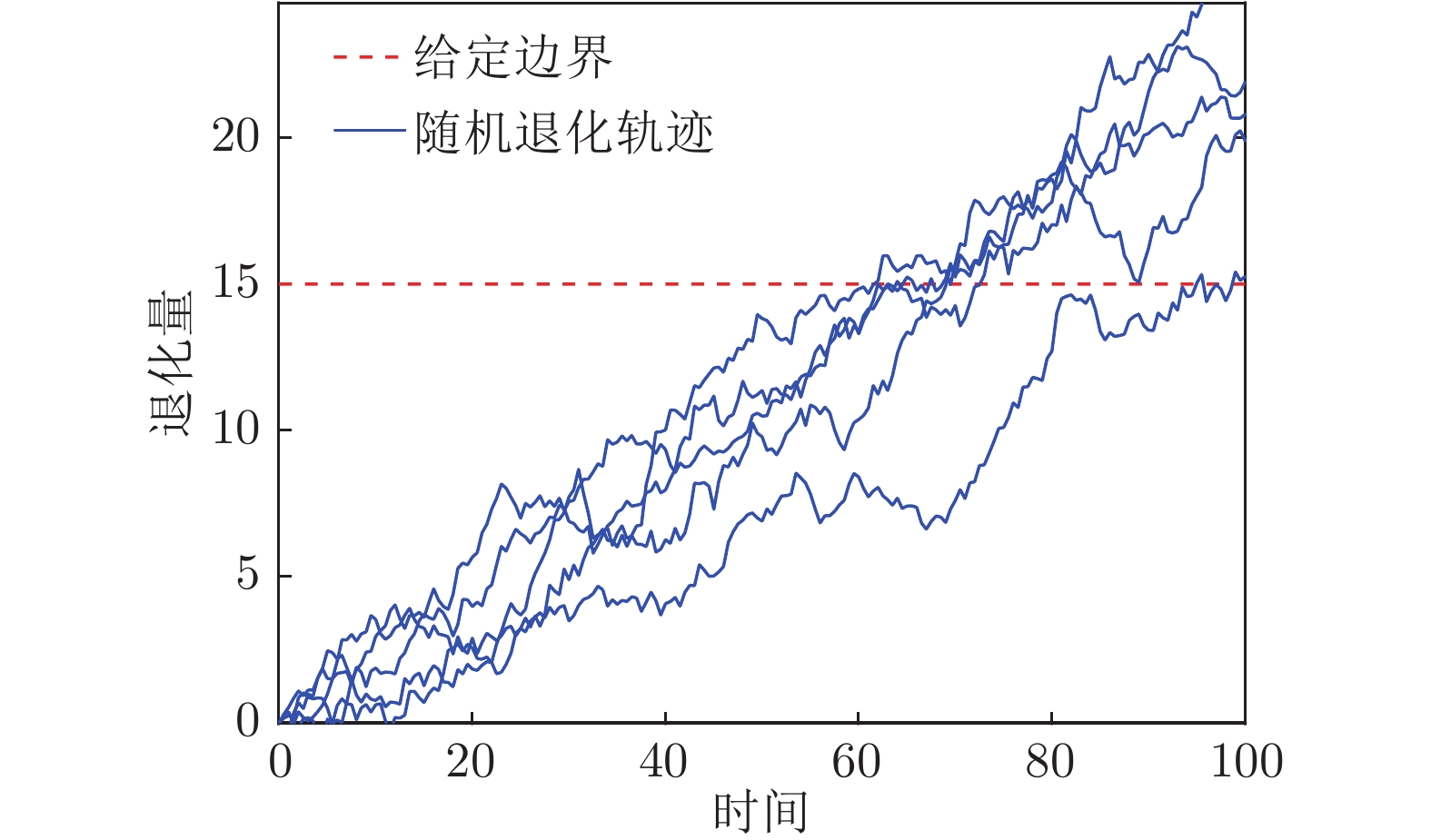 图 1 随机过程中首达时间与最后逃逸时间Fig. 1 The first passage time and last exit time of the stochastic process
图 1 随机过程中首达时间与最后逃逸时间Fig. 1 The first passage time and last exit time of the stochastic process图1为仿真生成的一组非单调随机退化轨迹. 从图中可以发现, 受模型的随机性与不确定性影响, 相同数学模型下的随机过程其退化轨迹也会存在明显的差异, 这会导致首达时间与最后逃逸时间存在差异. 因此, 以下几点需要注意:
1) 对于连续时间随机退化过程, 首达时间与最后逃逸时间均是一个随机变量, 反映了其取值范围的各种可能性;
2) 对于随机过程产生的某一退化轨迹而言, 如果首达时间和最后逃逸时间已出现, 那么其首达时间和最后逃逸时间则是一个具体的特定时刻;
3) 如果该随机过程具有马尔科夫性, 那么其首达时间、最后逃逸时间与过去状态无关, 仅与当前状态相关.
1.2 问题来源
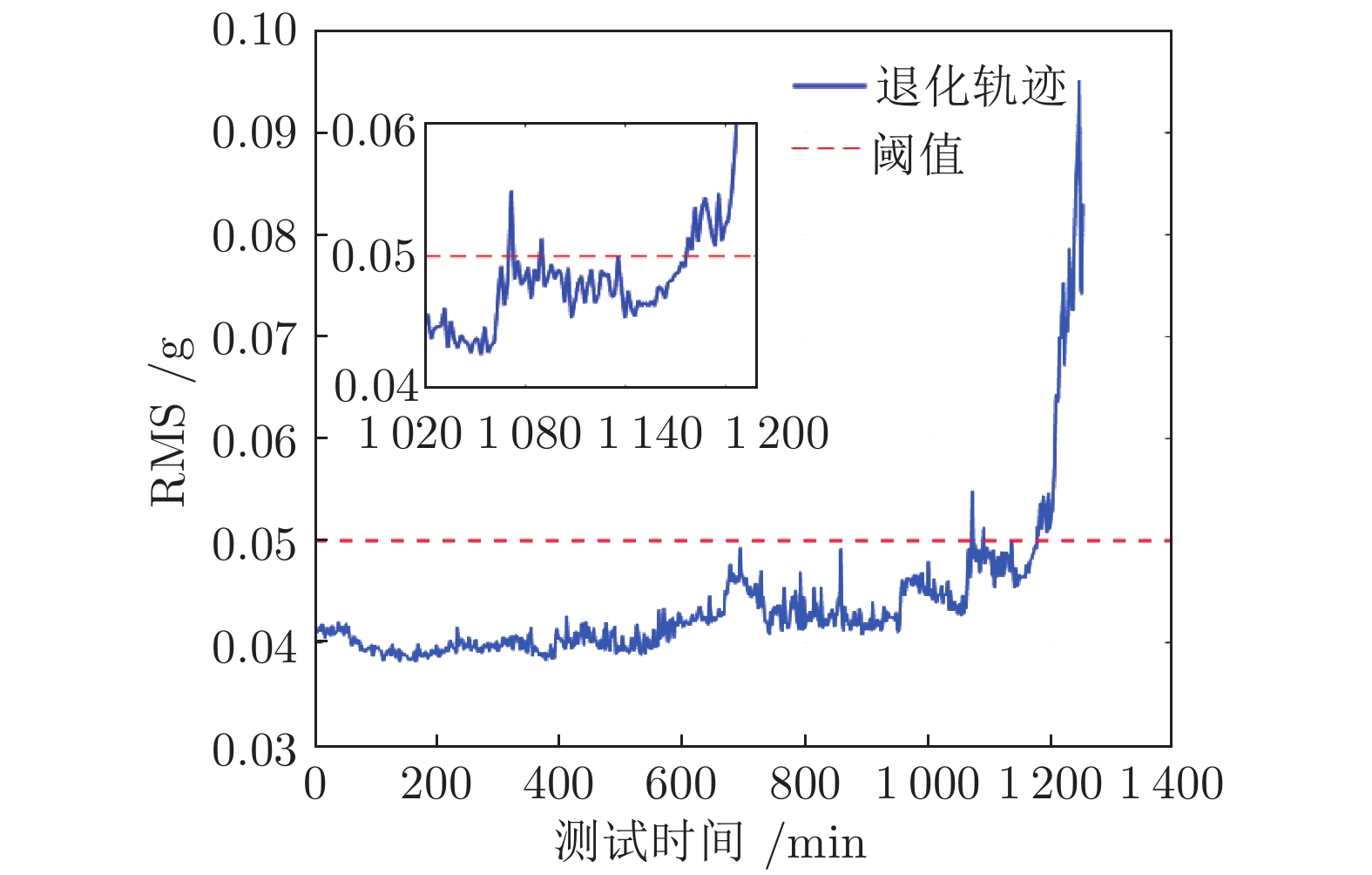
图2表示某一轴承振动退化数据的均方根值(Root mean square, RMS). 从图中可以看出, 受退化过程的随机性与波动性影响, 退化过程在超过某一给定阈值后, 仍可能会回到阈值之下, 并经过较长时间后才会最终离开阈值. 因此, 若直接用首达时间来定义该轴承的寿命与剩余寿命, 预测结果对退化过程的随机性和波动性十分敏感, 得到的结果过于保守, 将导致设备提前终止运行或过早维护, 造成较大浪费.
以西安交通大学雷亚国教授[15, 20]课题组所完成的全寿命周期轴承退化实验为例, 若按照文献[15]中所给出的轴承寿命定义方式(即令轴承最大振动幅值小于20 g), 首达时间下得到的寿命会明显小于实际寿命, 如表1所示. 相比之下, 最后逃逸时间下得到的寿命则更加接近轴承的实际寿命.
注 1. 需要注意的是, 轴承数据1_4与3_2的退化过程不明显, 其退化数据突然超过给定阈值, 可视为突发失效, 因此本文不讨论这两组数据.
表 1 轴承真实寿命对比(min)Table 1 Comparison of bearings' actual lifetime (min)轴承数据 实际寿命 首达时间下寿命 最后逃逸时间下寿命 1_1 123 91 110 1_2 161 74 110 1_3 159 149 149 1_5 52 47 49 2_1 491 488 488 2_2 161 144 161 2_3 533 478 533 2_4 42 38 38 2_5 399 199 284 3_1 2538 2524 2529 3_3 371 352 362 3_4 1515 1456 1461 3_5 114 74 98 1.3 模型描述
本文主要研究基于最后逃逸时间的寿命与剩余寿命预测问题. 假设设备的退化过程为X(t), 那么首达时间下的寿命
$\tilde T$ 与在${t_k}$ 时刻处的剩余寿命${\tilde L_k}$ 表示如下$$\tilde T = \inf \{ t:X(t) \geq \xi |{x_0} < \xi \} $$ (1) $${\tilde L_k} = \inf \{ {l_k}:X({t_k} + {l_k}) \geq \xi |{x_k} < \xi \} $$ (2) 其中,
$\xi $ 表示给定的阈值,${x_0}$ 表示退化过程的初值,$l_k$ 表示剩余寿命在$t_k $ 时刻处的取值,${x_k}$ 表示在${t_k}$ 时刻处的退化值, inf表示下确界.与式(1)、式(2)类似, 基于最后逃逸时间的寿命
$T $ 与在tk时刻处的剩余寿命Lk可表示为$$T = \sup \{ t:X(t) \leq \xi |{x_0} < \xi \} $$ (3) $${L_k} = \sup \{ {l_k}:X({t_k} + {l_k}) \leq \xi |{x_k}\} $$ (4) 其中, sup表示上确界. 需要注意的是, 不同于首达时间, 即使
${x_k}$ 大于阈值$\xi ,$ 最后逃逸时间仍可能存在.此外, 对于单调退化过程(如Gamma过程模型、逆高斯过程模型等),
$X(t + \Delta t) > $ $ X(t)$ 恒成立. 因此, 单调退化过程首达时间下寿命与剩余寿命和最后逃逸时间下一致, 即有$$\tilde T = T = \inf \{ t:X(t) \geq \xi |{x_0} < \xi \} $$ (5) $${\tilde L_k} = {L_k} = \inf \{ {l_k}:X({t_k} + {l_k}) \geq \xi |{x_k} < \xi \} $$ (6) 目前, 已有很多文章(如文献[21-22])给出了单调退化过程的寿命与剩余寿命预测方法. 因此, 本文主要以Wiener过程为例, 研究最后逃逸时间下非单调退化过程的寿命与剩余寿命预测问题.
2. 寿命分布与剩余寿命分布推导
2.1 基于最后逃逸时间的寿命分布推导
一般来说, 传统线性Wiener过程模型可表示为
$$X(t) = {x_0} + \mu t + {\sigma _B}B(t)$$ (7) 其中,
$X(t)$ 表示在t时刻的退化状态,${x_0}$ 表示退化过程的初值,$\mu > 0$ 和${\sigma _B} > 0$ 分别表示漂移系数与扩散系数,$B(t)$ 表示标准布朗运动, 令退化过程的阈值为$\xi > $ 0.不同于传统基于首达时间下的寿命分布推导方法, 最后逃逸时间下的寿命与剩余寿命分布难以通过直接求解式(3)与式(4)得到. 因此, 为求解式(3)与式(4), 本文先给出以下定义
$${T_0} = \sup \{ t:X(t) \leq \xi |{x_0} = \xi \} $$ (8) 其中,
${T_0}$ 为一个随机变量, 用于描述首达时间下寿命与最后逃逸时间下寿命之间的差异, 也就是$${T_0} = T - {\tilde T}$$ (9) 这样, 便可通过
${T_0}$ 建立最后逃逸时间下寿命分布与传统基于首达时间下寿命分布之间的联系, 如式(9)所示. 需要注意的是,${T_0}$ 为一个非负随机变量. 那么, 根据式(9)可知, 首达时间下的寿命分布期望和方差均会小于最后逃逸时间下的结果. 为求解$T $ 的表达形式, 首先给出${T_0}$ 的求解方式, 如定理1所示.定理 1. 若退化过程如式(7)所示, 且退化初值等于给定阈值, 即
${x_0} = \xi ,$ 那么${T_0}$ 的概率密度函数(Probability density function, PDF)有如下形式$$\begin{split} {f_{{T_0}}}(t;s) = \;&\dfrac{1}{{2\sqrt {2\pi t} }}\exp \left( { - \dfrac{{{\mu ^2}t}}{{\sigma _B^2}}} \right) \times \\ &\left\{ {\dfrac{{\exp \left[ { - \dfrac{{2{\mu ^2}(s - t)}}{{\sigma _B^2}}} \right](s - t)}}{{\sqrt {2\pi } {{(s - t)}^{\frac{3}{2}}}}}} \right.{\rm{ + }} \\ &\left. {\dfrac{{\dfrac{{\mu \sqrt {2\pi } {{(s - t)}^{{\frac{3}{2}}}}}}{{{\sigma _B}}}{\rm{Erf}}\left[ {\sqrt {\dfrac{{{\mu ^2}(s - t)}}{{2\sigma _B^2}}} } \right]}}{{\sqrt {2\pi } {{(s - t)}^{\frac{3}{2}}}}}} \right\} \end{split} $$ (10) 其中,
$s $ 表示${T_0}$ 的最大取值范围, 即${T_0} \leq s;$ ${\rm{Erf}}$ 表示误差函数.证明. 首先定义一个新的随机变量
$\kappa _h^s$ 如下所示$$\kappa _h^s = \sup \{ t \leq s:B(t) = h(t)\} $$ (11) 其中, B(0) = h(0) = 0. 那么
$\kappa _h^s$ 则表示在时间s前, 标准布朗运动B(t)通过一个时变边界h(t)的逃逸时间.类似于式(11), 定义一个新的随机变量
$\gamma _h^s$ 如下$$\gamma _h^s = \inf \{ t \leq s:B(t) = h(t)\} $$ (12) 其中,
$\gamma _h^s$ 表示在时间s前, 标准布朗运动B(t)通过一个时变边界h(t)的首达时间.根据文献[19]可知,
$\kappa _h^s$ 与$\gamma _h^s$ 的PDF有如下关系$${f_{\kappa _h^s}}(t) = p\left(t;\;0,\;h(t)\right)\int_{ - \infty }^{ + \infty } 2 {\nu _\chi }\left(s - t,\;\hat h\right){\rm{d}}\chi $$ (13) 其中,
$${\nu _\chi }\left(t,\;\hat h\right) = {f_{\gamma _{\hat h}^s}}\left(t|B(0) = \chi \right)$$ (14) $$p(t;\;x,\;y) = \frac{1}{{2\sqrt {2\pi t} }}\exp \left[ { - \frac{{{{(x - y)}^2}}}{{2t}}} \right]$$ (15) 在式(14)中,
$\hat h(t) = h(s - t) = - \mu /{\sigma _B} (s - t)$ 表示$ h(t)$ 的时间反函数.那么, 令
$h(t) = - \mu /{\sigma _B}t ,$ 式(12)等价于式(8), 即有$\kappa _h^s = {T_0}.$ 因此, 可以通过计算式(12)来求解${T_0}.$ 接下来, 根据h(t)的函数形式和式(15),$p(t;\;0,\;h(t))$ 的表达形式很容易得到, 即$$p(t;\;0,\;h(t)) = \frac{1}{{2\sqrt {2\pi t} }}\exp \left( { - \frac{{{\mu ^2}t}}{{2\sigma _B^2}}} \right)$$ (16) 实际上, 式(14), 即
${f_{\gamma _{\hat h}^s}}(t|B(0) = \chi )$ 描述了随机过程$B(t) + \chi $ 通过一个时变边界$\hat h(t) = $ $ - \mu /{\sigma _B} (s - t)$ 首达时间的PDF. 根据模型变换可以发现, 这等价于随机过程${\sigma _B}B(t) - \mu t$ 通过给定阈值$ - \mu s - {\sigma _B}\chi $ 的首达时间. 因此, 根据Wiener过程的性质可得到如下结果$$ \begin{split} {\nu _\chi }\left(t,\;\hat h\right) =\; &{f_{\gamma _{\hat h}^s}}(t|B(0) = \chi )= \\ & \dfrac{{|\mu s + {\sigma _B}\chi |}}{{\sqrt {2\pi \sigma _B^2{t^3}} }}\exp \left[ { - \dfrac{{{{( - \mu s - {\sigma _B}\chi + \mu t)}^2}}}{{2\sigma _B^2t}}} \right] \end{split} $$ (17) 进一步, 将s − t代入式(17)可以得到式(13)中函数
${\nu _\chi }(s - t,\;\hat h)$ 的具体表示形式如下$$\begin{split} &{\nu _\chi }(s - t,\;\hat h) = \dfrac{{|\mu s + {\sigma _B}\chi |}}{{\sqrt {2\pi \sigma _B^2{{(s - t)}^3}} }} \;\times \\ & \qquad \exp \left[ { - \dfrac{{{{( - \mu s - {\sigma _B}\chi + \mu (s - t))}^2}}}{{2\sigma _B^2(s - t)}}} \right] = \\ & \qquad \dfrac{{|\mu s + {\sigma _B}\chi |}}{{\sqrt {2\pi \sigma _B^2{{(s - t)}^3}} }}\exp \left[ { - \dfrac{{{{( - {\sigma _B}\chi - \mu t)}^2}}}{{2\sigma _B^2(s - t)}}} \right] \end{split} $$ (18) 那么, 根据式(18)和式(16),
$\kappa _h^s$ 的概率密度函数, 即式(13)为$$\begin{split} &{f_{\kappa _h^s}}(t) = p(t;\;0,\;h(t))\int_{ - \infty }^{ + \infty } 2 {\nu _\chi }(s - t,\;\hat h){\rm{d}}\chi = \\ &\qquad \dfrac{1}{{2\sqrt {2\pi t} }}\exp \left( { - \dfrac{{{\mu ^2}t}}{{2\sigma _B^2}}} \right)\int_{ - \infty }^{ + \infty } 2 {\nu _\chi }\left(s - t,\;\hat h\right){\rm{d}}\chi = \\ & \qquad \dfrac{1}{{\sqrt {2\pi t} }}\exp \left( { - \dfrac{{{\mu ^2}t}}{{2\sigma _B^2}}} \right) \times \left\{ {\dfrac{{2\exp \left[ { - \dfrac{{2{\mu ^2}(s - t)}}{{\sigma _B^2}}} \right]}}{{\sqrt {2\pi } {{(s - t)}^{\frac{1}{2}}}}}} \right. {\rm{ + }}\\ & \qquad \left. {\dfrac{{\dfrac{{\mu \sqrt {2\pi } }}{{{\sigma _B}}}{\rm{Erf}}\left[ {\sqrt {\dfrac{{{\mu ^2}(s - t)}}{{2\sigma _B^2}}} } \right]}}{{\sqrt {2\pi } }}} \right\} \\[-33pt] \end{split} $$ (19) 其中,
$${\rm{Erf}}\left[ {\sqrt {\dfrac{{{\mu ^2}(s- t)}}{{2\sigma _B^2}}} } \right] = \dfrac{{\smallint _0^{\sqrt {\dfrac{{{\mu ^2}(s- t)}}{{2\sigma _B^2}}} }2\exp ( -\; {\eta ^2}){\rm{d}}\eta }}{{\sqrt \pi }}$$ (20) □
进一步, 根据定理1的结论以及式(9), 便可得到最后逃逸时间下的寿命分布PDF表达形式如推论1所示.
推论 1. 若退化过程如式(7)所示, 其阈值为
$\xi $ 以及退化初值为${x_0} = 0,$ 同时给定寿命的取值范围为$(0,\;{T_{\max }}),$ 那么基于最后逃逸时间的寿命分布PDF为$${f_T}(t;\;{T_{\max }}) = \int_0^t {{f_{{T_0}}}(t - \tau ;\;{T_{\max }} - \tau )} {f_{\tilde T}}(\tau ){\rm{d}}\tau $$ (21) 其中,
${f_{{T_0}}}(t - \tau ;\;{T_{\max }} - \tau )$ 的表达形式可由式(10)直接得到,${f_{\tilde T}}(\tau )$ 为Wiener过程的首达时间下寿命分布PDF, 即$${f_{\tilde T}}(\tau ) = \frac{\xi }{{\sqrt {2\pi \sigma _B^2\tau _{}^3} }}\exp \left[ { - \frac{{{{(\xi - \mu \tau )}^2}}}{{2\sigma _B^2\tau }}} \right]$$ (22) 这样, 便得到了基于最后逃逸时间的寿命分布表示形式. 需要注意的是, 推论1中
${T_{\max }}$ 需要事先给定, 当且仅当${T_{\max }}$ 趋于无穷大时, 式(21)完全等价于式(3).2.2 基于最后逃逸时间的剩余寿命分布推导
假设退化过程如式(7)所示, 且当前退化时刻为
${t_k},$ 退化量为${x_k}.$ 不同于首达时间下剩余寿命的求解, 基于最后逃逸时间的剩余寿命需要分以下三种情况进行讨论.情况 1. 当前退化量
${x_k}$ 小于阈值$\xi, $ 当前时刻下剩余寿命可等价于求解初值为${x_k}$ 的寿命, 那么可根据推论1中寿命预测的结果直接得到, 结果如下所示$${f_L}({l_k};\;{T_{\max }}) = \int_0^{{l_k}} {{f_{{T_0}}}({l_k} - \tau ;\;{T_{\max }} - \tau )} {f_{\tilde L}}(\tau ){\rm{d}}\tau $$ (23) 其中,
$L $ 表示给定$T_{\max} $ 条件下剩余寿命分布的PDF.$${f_{\tilde L}}(\tau ) = \dfrac{{\xi - {x_k}}}{{\sqrt {2\pi \sigma _B^2\tau _{}^3} }}\exp \left[ { - \dfrac{{{{(\xi - \mu \tau - {x_k})}^2}}}{{2\sigma _B^2\tau }}} \right]$$ (24) 情况 2. 当前退化量
${x_k}$ 等于阈值$\xi, $ 剩余寿命直接等于${T_0},$ 其分布可由定理1直接计算得到, 结果如式(10)所示.情况 3. 当前退化量
${x_k}$ 大于阈值$\xi, $ 需要分别讨论两种可能性, 并分别计算概率分布, 具体结果如下.1)退化过程再也不回到阈值, 前一次达到阈值的时刻即是最后逃逸时间, 这意味着寿命早已终止. 假设最后一次达到阈值的时刻为
${\omega _k},$ 那么有剩余寿命${L_k}$ 为${\omega _k} - {t_k},$ 其概率等于退化过程回不到阈值的概率$$\begin{split} \Pr& \left\{ {{L_k} = {\omega _k} - {t_k}} \right\} = \\ &1 - \int_0^{ + \infty } {\dfrac{{|\xi - {x_k}|}}{{\sqrt {2\pi \sigma _B^2l_k^3} }}} \exp \left[ { - \dfrac{{{{(\xi - \mu {l_k} - {x_k})}^2}}}{{2\sigma _B^2{l_k}}}} \right]{\rm{d}}{l_k} = \\ & 1 - \exp \left( { - \dfrac{{2|\xi - {x_k}|\mu }}{{\sigma _B^2}}} \right) = \\ &1 - \exp \left[ { - \dfrac{{2({x_k} - \xi )\mu }}{{\sigma _B^2}}} \right] \\[-10pt] \end{split} $$ (25) 2)退化过程会回到阈值, 最后逃逸时间下的剩余寿命
${L_k}$ 大于0. 此时可根据情况1的方式进行求解, 结果如下$${f_L}({l_k};\;{T_{\max }}) = \int_0^{{l_k}} {{f_{{T_0}}}({l_k} -\tau ;\;{T_{\max }} -\tau )} {f_{\tilde L}}(\tau ){\rm{d}}\tau $$ (26) 其中,
$${f_{\tilde L}}(\tau ) = \frac{{{x_k} - \xi }}{{\sqrt {2\pi \sigma _B^2\tau _{}^3} }}\exp \left[ { - \frac{{{{(\xi - \mu \tau - {x_k})}^2}}}{{2\sigma _B^2\tau }}} \right]$$ (27) 从上式中可以看出, 当退化量超过阈值后, 存在两种可能的情况, 即退化过程回到阈值之下与退化过程彻底远离阈值. 需要注意的是, 这两种情况均有可能发生, 可通过式(25)计算得到退化过程回不到阈值的概率为
$\Pr {\{} {L_k} = $ $ {\omega _k} - {t_k} {\}},$ 而能回到阈值的概率等于$1 - \Pr {\{} {L_k} = {\omega _k} - {t_k} {\}} .$ 综上, 基于最后逃逸时间下的剩余寿命预测结果便已经推导得到. 由于退化过程的随机性, 退化过程即使超过阈值后仍有可能返回阈值之下. 因此, 不同于首达时间下剩余寿命预测问题, 最后逃逸时间下的剩余寿命预测需要考虑退化量是否大于阈值, 进而需分以上三种情况进行讨论.
2.3 考虑随机效应影响下的寿命分布推导
在实际工程中, 受样本间差异性的影响, 退化过程的初值往往存在差异性, 即
${x_0}$ 取值不同. 为描述样本差异性所带来的影响, 通常在退化过程中引入随机效应, 也就是假设${x_0}$ 服从某种随机分布. 鉴于高斯混合模型能够近似逼近任意分布, 本文假设${x_0}$ 服从高斯混合模型, 其中每个高斯分布间相互独立, 且第i个高斯分布期望为${u_i},$ 标准差为${\sigma _i},$ 以及权重为${\varpi _i}.$ 那么这种情况下的寿命分布如定理2所示.定理 2. 若退化过程如式(7)所示, 其阈值为
$\xi $ , 给定寿命的取值范围为$(0,\;{T_{\max }}),$ 且退化初值为${x_0}$ 存在随机效应, 服从期望为${u_i},$ 标准差为${\sigma _i},$ 以及权重为${\varpi _i}$ 的高斯混合模型(i = 1, 2,···, N), 那么基于最后逃逸时间的寿命分布PDF为$${f_T}(t;\;{T_{\max }}) = \int_0^t {{f_{{T_0}}}(t - \tau ;\;{T_{\max }} - \tau )} {f_{\tilde T}}(\tau ){\rm{d}}\tau $$ (28) 其中,
${f_{{T_0}}}(t - \tau ;\;{T_{\max }} - \tau )$ 的表达形式可由式(10)直接得到,${f_{\tilde T}}(\tau )$ 为Wiener过程的首达时间下寿命分布PDF, 即$$\begin{split} {f_{\tilde T}}(\tau ) = &\sum\limits_{i = 1}^N {{\varpi _i}\dfrac{{\mu \sigma _i^2 + \sigma _B^2(\xi - {u_i})}}{{\sqrt {2\pi (\sigma _B^2\tau + \sigma _i^2)_{}^3} }}}\; \times \\ &\exp \left[ { - \dfrac{{{{(\xi - {u_i} - \mu \tau )}^2}}}{{2(\sigma _B^2\tau + \sigma _i^2)}}} \right] \\[-10pt] \end{split} $$ (29) 证明. 与第2.1节中推导过程类似, 可以得到
${T_0} = $ $ T- \tilde T ,$ 因此首先计算${T_0}$ 的表达形式. 根据${T_0}$ 的定义可知, 式(8)等价于$${T_0} = \sup \{ t:\mu t + {\sigma _B}(t) \leq 0\} $$ (30) 由式(30)可以发现,
${T_0}$ 的取值与退化初值以及阈值无关, 其分布形式仅取决于退化过程的漂移系数与扩散系数. 因此,${T_0}$ 的概率密度函数仍为式(10)所示.另一方面, 受随机初值的影响, 式(1)可以等价为初值为0的退化过程通过一个随机阈值的首达时间问题, 即
$$\begin{split} \tilde T = &\inf \{ t:X(t) \geq \xi |{x_0} < \xi \}= \\ & \inf \{ t:\mu t + {\sigma _B}(t) \geq \xi - {x_0}\} \\ \end{split} $$ (31) 因此, 根据全概率公式,
$\tilde T$ 的概率密度函数${f_{\tilde T}}(\tau )$ 为$$\begin{split} {f_{\tilde T}}(\tau ) = &\int_{ - \infty }^{ + \infty } {\dfrac{{\xi - {x_0}}}{{\sqrt {2\pi \sigma _B^2\tau _{}^3} }}\exp \left[ { - \dfrac{{{{(\xi - {x_0} - \mu \tau )}^2}}}{{2\sigma _B^2\tau }}} \right]} \times\\ & \left\{ {\sum\limits_{i = 1}^N {\dfrac{{{\varpi _i}}}{{\sqrt {2\pi \sigma _i^2} }}\exp \left[ { - \dfrac{{{{({x_0} - {\mu _i})}^2}}}{{2\sigma _i^2}}} \right]} } \right\}{\rm{d}}{x_0} \\[-20pt] \end{split} $$ (32) 为便于求解式(32), 根据文献[23]给出如下引理1.
引理 1[23]. 若
$Z\sim {\rm N}(\alpha ,\;{\beta ^2}),\;$ 且$C \in {\mathbb{{\bf{R}}}^ + }, \;$ ${\omega _1},\;{\omega _2}, $ $ \;A, B \in \mathbb{{\bf{R}}},$ 则有$$\begin{split} {{{\rm{E}}}_Z} &\left[ {\left( {{\omega _1} - AZ} \right){\rm{exp}}\left( { - \dfrac{{{{({\omega _2} - BZ)}^2}}}{{2C}}} \right)} \right] =\\ & \sqrt {\dfrac{C}{{{B^2}{\beta ^2} + C}}} \left( {{\omega _1} - A\dfrac{{B{\omega _2}{\beta ^2} + \alpha C}}{{{B^2}{\beta ^2} + C}}} \right) \times\\ & {\rm{exp}}\left( { - \dfrac{{{{({\omega _2} - B\alpha )}^2}}}{{2{B^2}{\beta ^2} + 2C}}} \right) \end{split} $$ (33) 其中,
${{{\rm{E}}}_Z}\left[ \cdot \right]$ 表示关于Z的期望.根据引理1, 便可得到如下结果
$$\begin{split} \int_{ - \infty }^{ + \infty } & {\dfrac{{\xi - {x_0}}}{{\sqrt {2\pi \sigma _B^2\tau _{}^3} }}\exp \left[ { - \dfrac{{{{(\xi - {x_0} - \mu \tau )}^2}}}{{2\sigma _B^2\tau }}} \right]} \times \\ & \left\{ {\dfrac{{{\varpi _i}}}{{\sqrt {2\pi \sigma _i^2} }}\exp \left[ { - \dfrac{{{{({x_0} - {\mu _i})}^2}}}{{2\sigma _i^2}}} \right]} \right\}{\rm{d}}{x_0} = \\ &\dfrac{{\mu \sigma _i^2 + \sigma _B^2(\xi - {u_i})}}{{\sqrt {2\pi (\sigma _B^2\tau + \sigma _i^2)_{}^3} }} \times \exp \left[ { - \dfrac{{{{(\xi - {u_i} - \mu \tau )}^2}}}{{2(\sigma _B^2\tau + \sigma _i^2)}}} \right] \end{split} $$ (34) 进一步, 根据高斯混合模型的性质,
$\tilde T$ 的概率密度函数${f_{\tilde T}}(\tau )$ 为式(29)所示. □注 2. 需要注意的是, Wiener退化过程模型的参数估计问题在很多文献中已经得到了广泛研究, 例如文献[9-11], 受篇幅所限本文不再讨论.
3. 数值仿真
3.1 寿命分布
首先根据定理1和定理2中所得结论验证寿命分布的正确性. 为验证定理1, 假设退化过程的漂移系数
$\mu $ 与扩散系数${\sigma _B}$ 分别为1和2, 阈值$\xi $ 为5, 退化初值${x_0}$ 为0, 最大取值范围${T_{\max }} = $ 500. 那么便可得到寿命分布的PDF如图3所示.从图3中可以发现, 本文所得理论结果与蒙特卡洛得到的仿真结果一致, 说明了本文方法在理论上的正确性. 此外, 与首达时间下的结果进行对比可以发现, 最后逃逸时间下寿命期望和方差都要明显大于首达时间下的结果, 这也和第2.1节中分析结果一致.
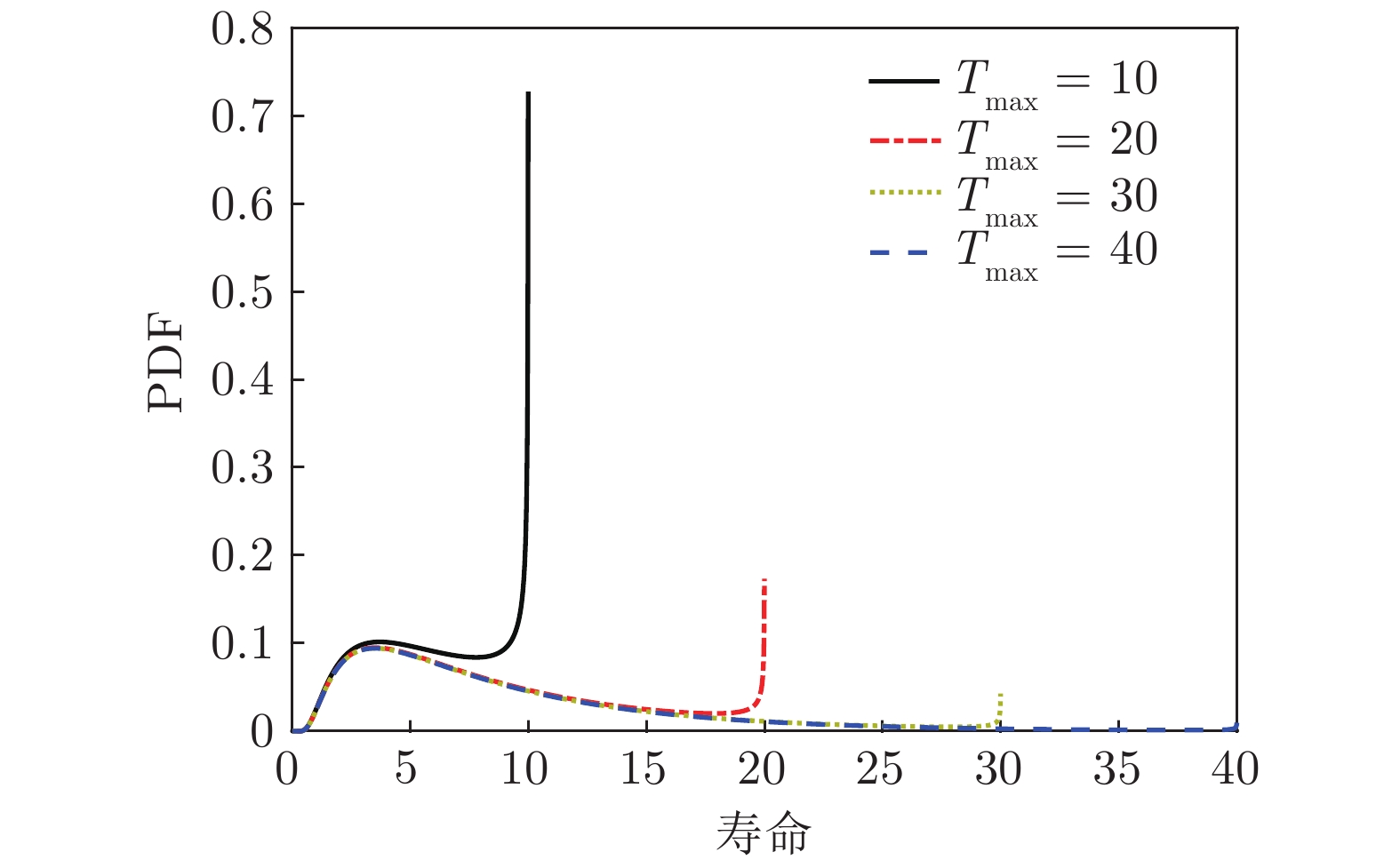
若分别令
${T_{\max }}$ 为20和50, 得到结果如图4所示. 由图4可见, 若${T_{\max }}$ 的取值过小, 得到寿命分布在接近${T_{\max }}$ 的取值部分存在明显的误差. 为了更好地对比${T_{\max }}$ 的取值对寿命分布的影响, 图5展示了4种${T_{\max }}$ 下寿命分布PDF. 从图5中可以发现, 当${T_{\max }}$ 取值较小时, 估计得到寿命分布与式(3)所定义寿命分布之间的误差随着寿命取值的增大而增大, 而${T_{\max }}$ 的取值越大越接近式(3)中所定义的寿命分布.对于定理2的验证, 假设退化过程的漂移系数
$\mu $ 与扩散系数${\sigma _B}$ 分别为1和2, 阈值$\xi $ 为5, 最大取值范围${T_{\max }} = $ $ 500,$ 退化初值${x_0}$ 服从期望为${u_1}\;{\rm{ = 1,}} $ $ {u_2}\;{\rm{ = 2,}}\;{u_3}\;{\rm{ = 3,}}$ 标准差为${\sigma _1} = 1,\;{\sigma _2} = 1/2, \;{\sigma _3} = 1/3$ , 以及权重为${\varpi _1} = 0.2, $ $ \; {\varpi _2} = 0.6,\;{\varpi _3} = 0.2$ 的高斯混合模型. 那么便可得到寿命分布的PDF如图6所示. 从图6中可见, 本文方法能够很好地拟合蒙特卡洛得到的结果, 证明了本文方法理论正确性.3.2 敏感度分析
实际上, 退化过程的参数不同, 也会导致得到的寿命分布存在较大差异性. 为更好地体现模型参数对寿命分布的影响, 进一步分析模型参数的敏感性. 假设退化过程模型如式(7)所示, 模型参数漂移系数
$\mu $ 与扩散系数${\sigma _B}$ 分别为1和2, 阈值$\xi $ 为5, 退化初值${x_0}$ 为0, 最大取值范围${T_{\max }} = $ 500.首先, 改变漂移系数
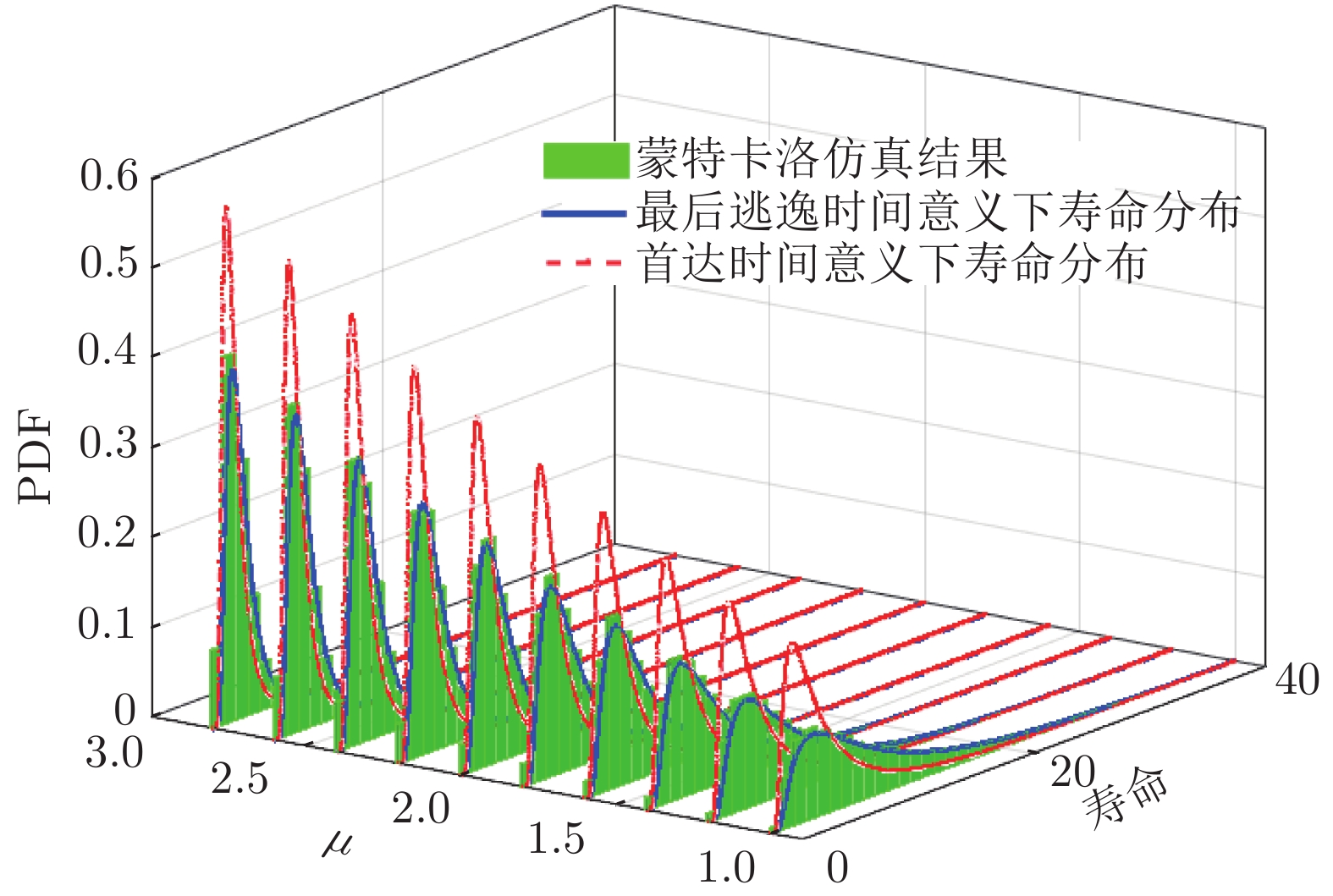
$\mu $ 的取值, 并得到了不同取值下寿命分布PDF如图7所示. 在图7中, 柱状图表示通过蒙特卡洛数值仿真得到的寿命分布, 实线和虚线分别表示最后逃逸时间下和首达时间下的寿命分布PDF. 从图7中可以发现,$\mu $ 取值越大, 寿命分布的期望和方差越小, 并且越接近首达时间下寿命分布.类似地, 图8显示了不同扩散系数
${\sigma _B}$ 取值下寿命分布的PDF. 从图8中可以发现,${\sigma _B}$ 的取值越小, 越接近首达时间下的结果. 图 8 不同
图 8 不同${\sigma _B}$ 取值下寿命分布PDFFig. 8 PDF of the lifetime distribution with different${\sigma _B}$ 由此可见, 漂移系数
$\mu$ 与扩散系数${\sigma _B}$ 的比值越大, 最后逃逸时间下的寿命分布PDF越接近首达时间下的结果; 反之, 则偏差越大. 需要注意的是, 漂移系数$\mu$ 与扩散系数${\sigma _B}$ 的比值反映了退化过程的动态特性与波动性. 也就是说, 退化过程的动态特征和波动性越强, 最后逃逸时间下寿命结果与首达时间下的结果差异越大. 实际上, 退化过程的动态特征和波动性越强, 退化过程越容易在早期超过给定阈值, 在这种情况下, 若仍采用首达时间来定义寿命或剩余寿命, 很可能导致预测得到的寿命远小于实际寿命.4. 实例验证
本节将通过滚动轴承与激光器的两组实际退化数据, 分别说明本文方法在数据波动较大与较小两种情况下的有效性. 需要注意的是, 由第2节可知, 本文仅考虑了线性Wiener退化过程模型的寿命预测问题. 因此, 在本节中主要将本文所得到结果与首达时间下基于线性Wiener过程模型的寿命预测结果(见文献[9, 24-25])进行对比.
4.1 滚动轴承实例
滚动轴承是一种典型的退化元件, 其广泛应用于武器装备、航空航天、生产制造等关键系统的旋转机械设备中. 研究表明滚动轴承的退化失效是引起旋转机械发生故障的重要原因[26]. 通常采用其振动信号的最大振幅或均方根来反映滚动轴承的健康性能状态. 因此, 本文采用轴承最大振幅数据来描述其退化状态.
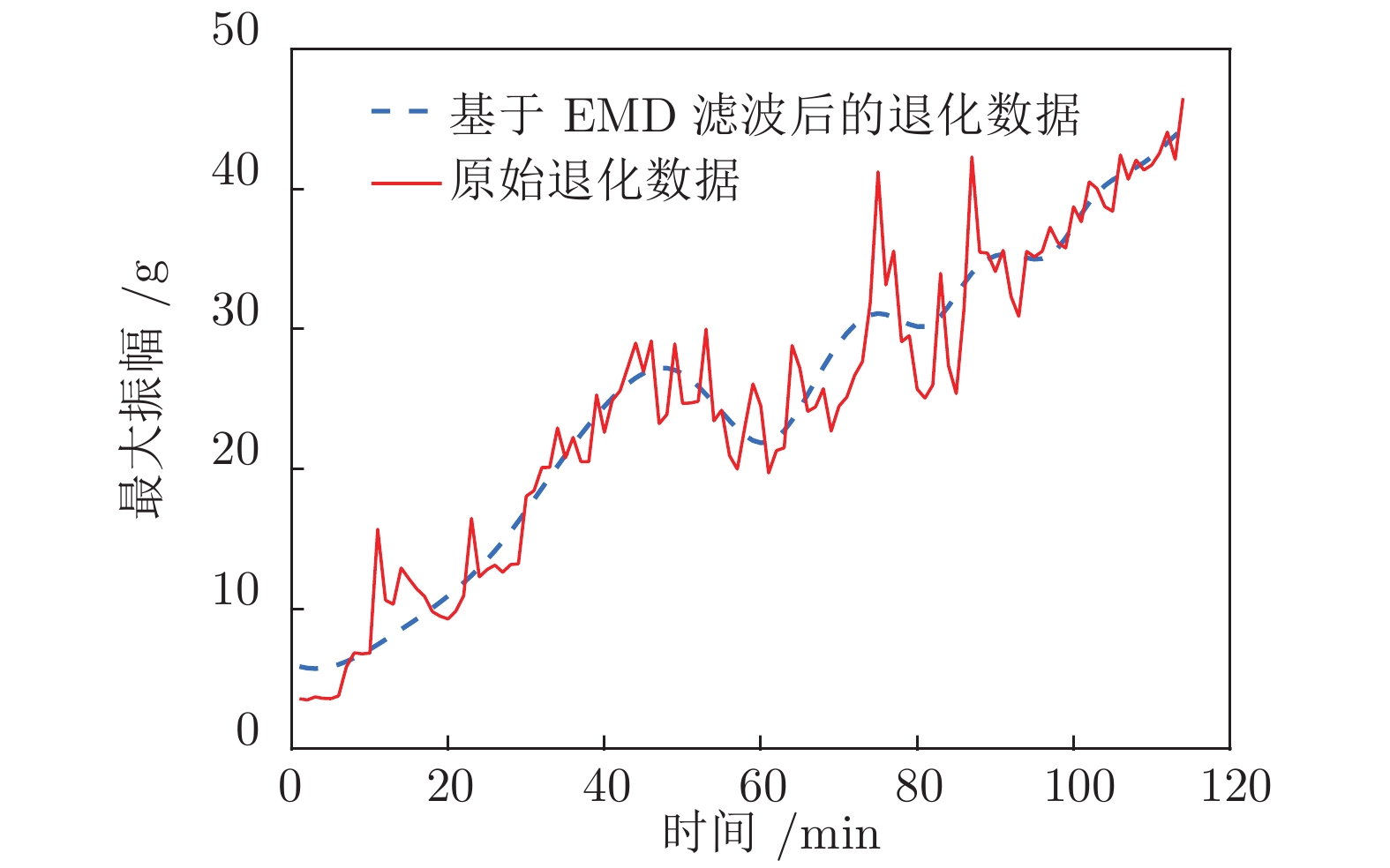
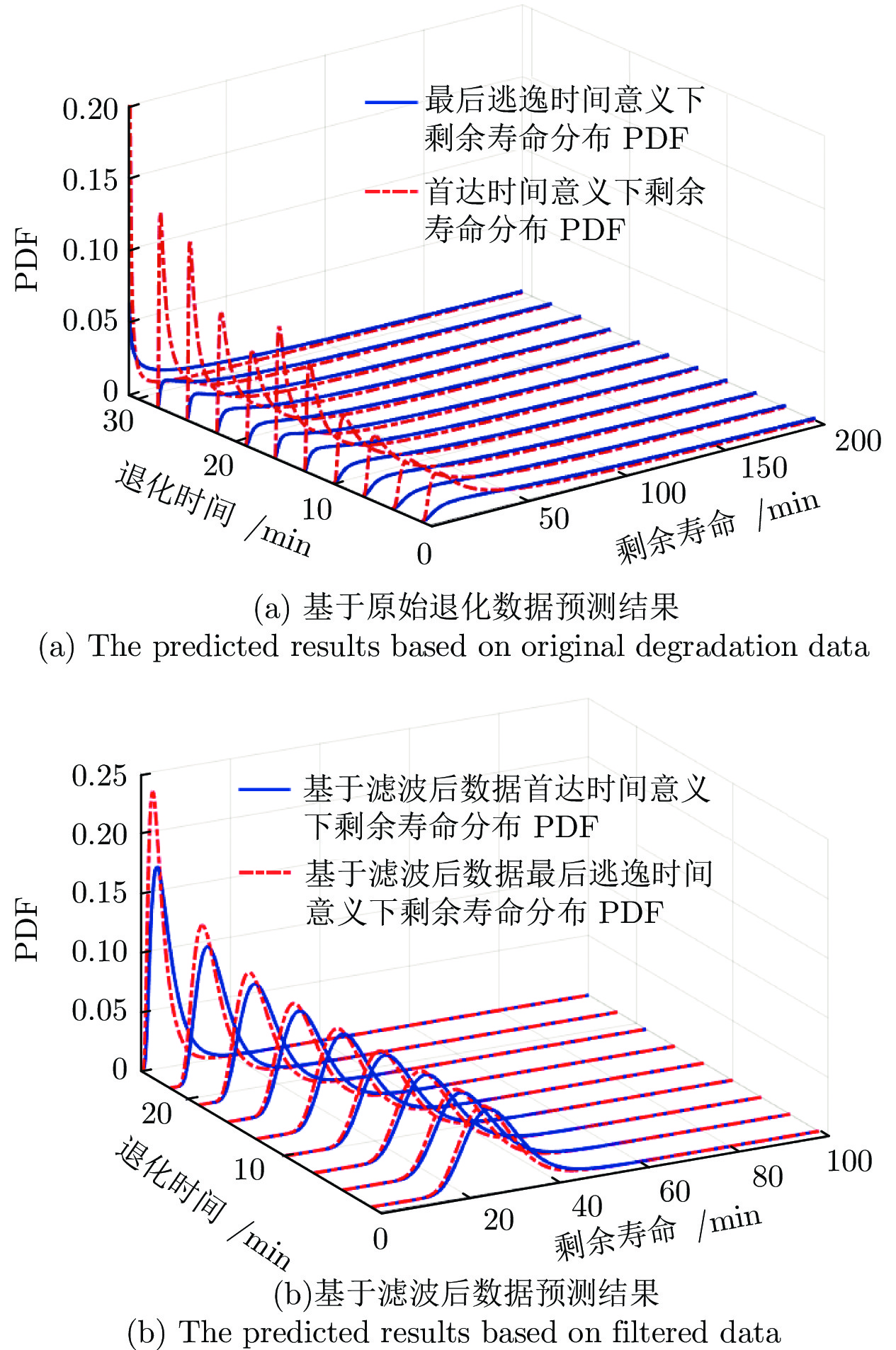
本文采用西安交通大学雷亚国教授[15, 20]课题组的轴承全寿命周期数据对本文方法进行验证. 由第2节可知, 受算法复杂性和计算复杂度所限, 本文仅考虑了线性退化模型的寿命与剩余寿命分布求解问题. 因此, 本文仅对具有线性特征的退化数据进行分析, 3_5轴承的最大振幅退化轨迹如图9所示. 从图9中可以发现, 该退化过程具有较为明显的线性趋势, 且该数据具有较强的动态随机特性. 为更好地进行对比实验, 本文采用经验模态分解算法(Empirical mode decomposition, EMD)对该轴承数据进行滤波处理, 图9中虚线即为滤波后的轴承退化数据, 可以发现滤波后的数据更加平稳, 也更具有线性特征.
根据线性Wiener过程模型的特性, 采用极大似然估计算法即可得到退化模型的参数估计值. 接下来, 根据文献[20]中轴承失效定义方式, 给定失效阈值为
$\xi = 20$ g, 采用第2.1节中所得到的结论便可计算出首达时间和最后逃逸时间下剩余寿命分布PDF. 基于原始退化数据和滤波后数据的预测结果分别如图10 (a)和图10 (b)所示.从图10 (a)中可以发现, 首达时间下的剩余寿命分布PDF与最后逃逸时间下的剩余寿命分布PDF存在明显差异. 由图10 (a)估计当退化时间接近35 min时, 退化过程能够达到给定阈值, 说明首达时间下的剩余寿命已经接近为0 min, 这远远小于真实寿命114 min. 图10 (b)则反映了滤波后的剩余寿命预测结果, 可以发现通过滤波的方法可以降低数据的波动性(如图9所示), 使得计算得到的首达时间下结果与最后逃逸时间下结果几乎一致.
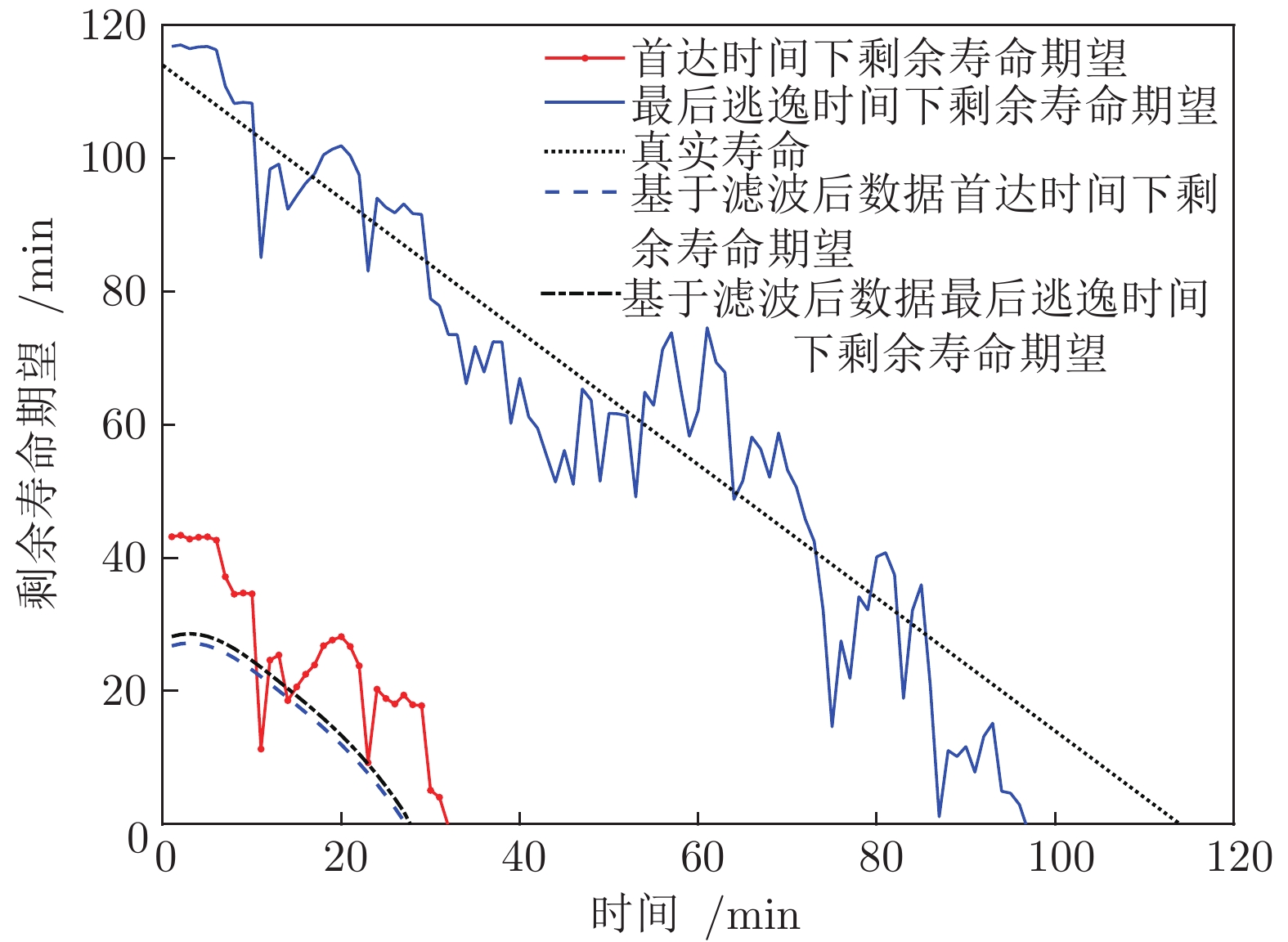
为更好地对比, 图11给出了两种不同定义方式下剩余寿命期望的对比. 在图11中, 分别给出了实验室获取的真实寿命以及基于原始数据、滤波数据下根据两种不同寿命定义方式计算得到的剩余寿命预测值. 从图11中可以发现, 首达时间下的寿命预测值为35 min, 与真实寿命相差79 min, 而基于最后逃逸时间计算得到的寿命为97 min, 更加接近全寿命周期实验中得到的实际寿命. 相比之下, 通过滤波后数据得到的结果, 仍然远远偏离真实剩余寿命, 并不能有效改善剩余寿命预测的准确度.
通过以上对比可以发现, 当退化的随机性和波动性比较强, 退化过程很容易在退化的初始阶段就超过阈值, 若仍采用首达时间来定义寿命与剩余寿命, 则可能会导致设备提前终止运行或过早维护, 引起不必要的浪费. 与之相反, 基于最后逃逸时间的定义, 可以克服这一局限性, 具有较好的鲁棒性与适应性. 另外, 通过与滤波后结果对比可以发现, 虽然采用滤波、平滑等方法可以减小数据的随机性与波动性, 但并未有效改善剩余寿命预测结果; 此外, 通过滤波、平滑等方法也可能会消除退化以及数据本身的随机性与不确定性, 可能会导致预测结果出现偏差.
需要注意的是, 由于其他几组轴承数据具有较强非线性而不适用于线性Wiener过程模型, 因此未采用第2.1节中所提方法进行分析. 但是从表1中可以看出, 其他几组轴承数据首达时间下寿命明显短于实际寿命, 相比之下, 最后逃逸时间下寿命更加接近真实值.
4.2 激光器实例
注意到, 轴承退化数据的波动性与随机性较强, 导致两种定义下剩余寿命预测结果存在较大差异. 接下来, 本文以激光器的公开退化数据说明当退化过程随机性与数据波动性较小时, 两种定义方式的剩余寿命预测情况.
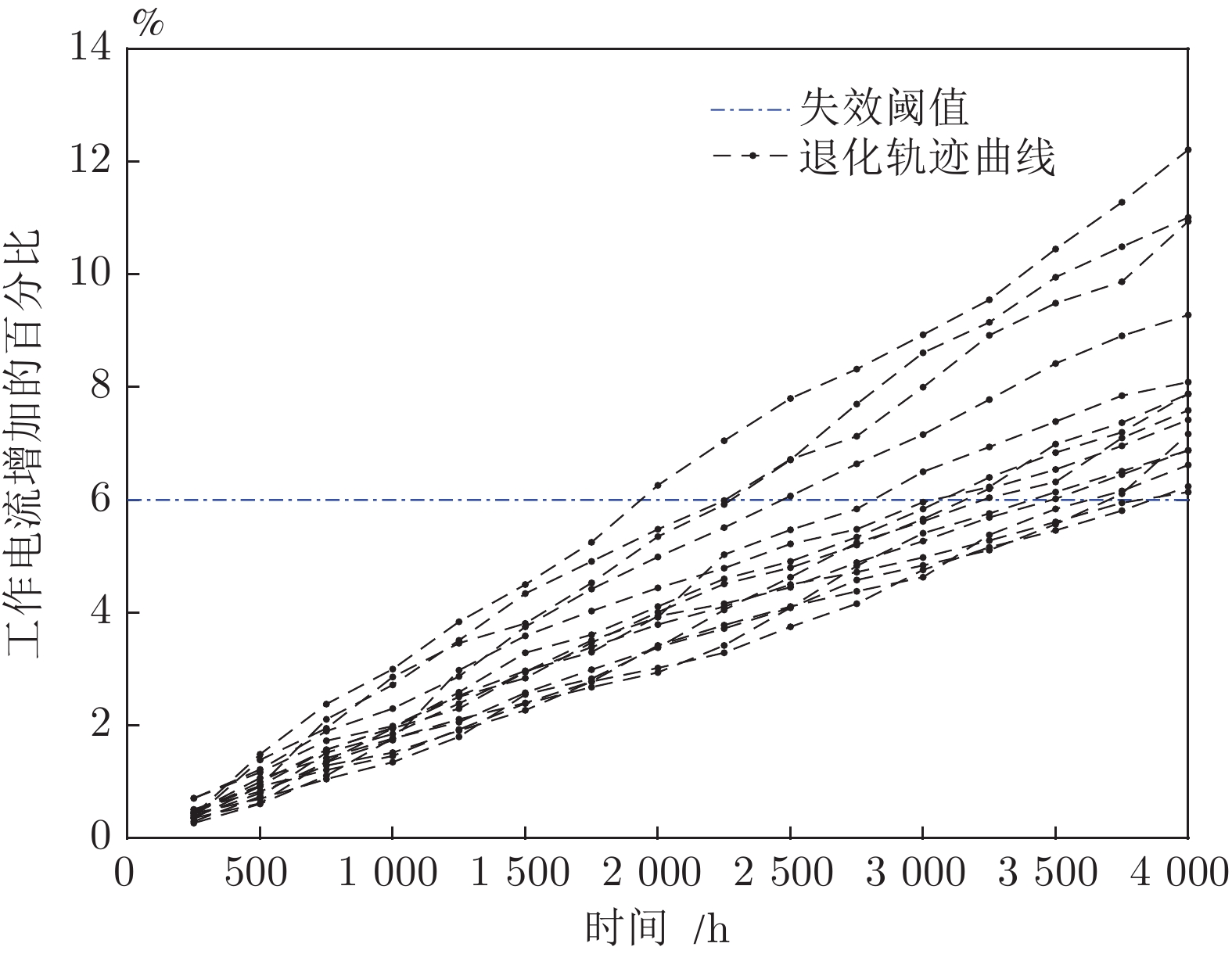
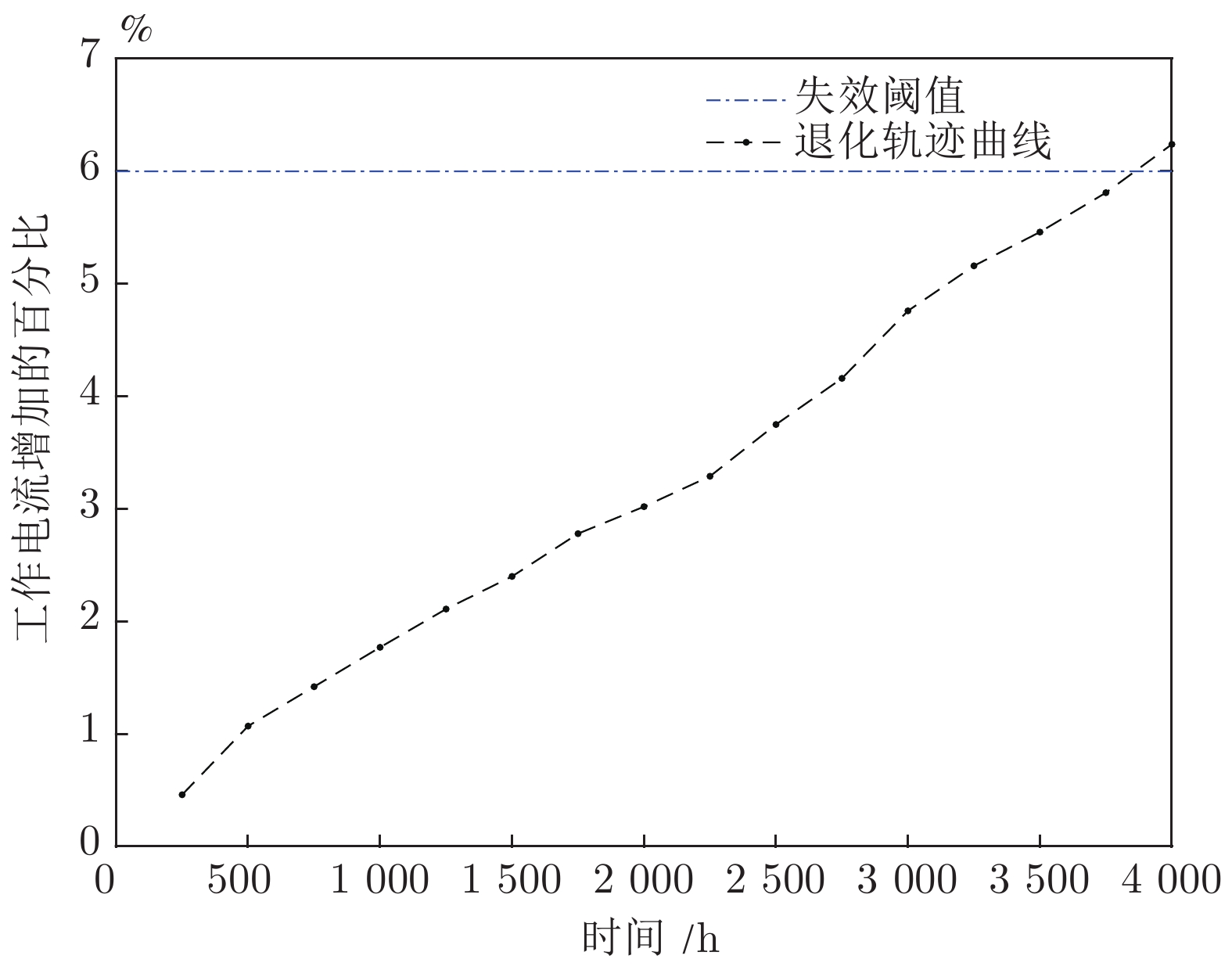
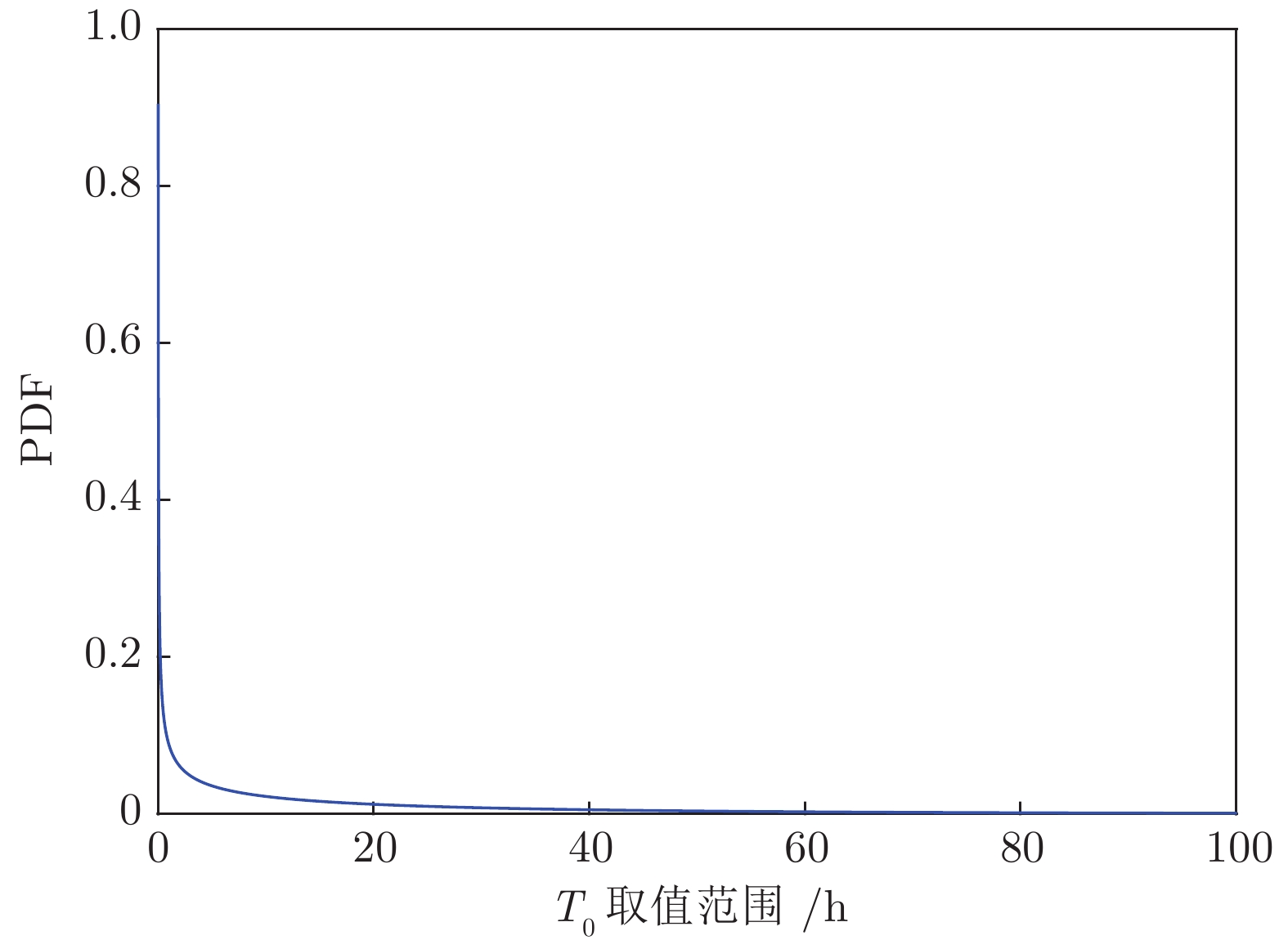
图12描述了文献[27]中15组激光器的退化轨迹, 其中虚线为给定的失效阈值. 本节中采用第8组数据予以说明, 其退化轨迹如图13所示. 类似地, 根据极大似然估计得到, 退化模型的参数为
$\hat \mu = $ 0.0015以及${\hat \sigma _B} = $ 0.0068. 给定失效阈值$\xi = $ 6, 那么可以得到剩余寿命预测结果如图14所示.从图14中可以发现, 两种定义下的剩余寿命分布PDF非常接近, 这说明两种定义下的剩余寿命预测结果几乎没有差别. 也就是说, 当数据的波动性较小时, 两种定义下的寿命及剩余寿命没有太大差别. 如图15所示,
${T_0}$ 的期望和标准差分别为20 h和29 h. 而$\tilde T$ 的期望和标准差分别为4000 h和286 h, 因此${T_0}$ 相对较小, 由式(9)可知,$T \approx \tilde T.$ 综上所述, 从两个实际案例中可以发现, 相比于首达时间下寿命及剩余寿命的定义, 最后逃逸时间的定义方式具有更好的鲁棒性. 当退化过程具有较强动态随机特性时, 能够避免由于退化值偶然超过阈值而低估和误算其实际寿命; 当退化过程动态随机性较弱时, 也能得到与首达时间下几乎一样的结果. 这说明采用最后逃逸时间来描述随机退化设备的寿命具有可行性与有效性, 存在潜在的工程应用价值.
5. 结论
本文针对随机退化设备的寿命预测问题中, 传统首达时间下的寿命与剩余寿命预测结果存在较为保守的缺陷, 基于最后逃逸时间提出了一种新的寿命与剩余寿命定义框架. 在这个新框架下, 给出了基于线性Wiener过程模型的寿命与剩余寿命分布解析表示, 并进一步扩展至随机效应影响下的退化模型. 最后分别通过数值仿真与工程实例证实了本文所提理论的正确性与有效性, 说明了采用最后逃逸时间来定义寿命或剩余寿命具有一定的可行性. 通过对比可以发现, 相比于传统基于首达时间下的寿命预测方法, 基于最后逃逸时间的寿命预测方法具有更好的鲁棒性. 但本文方法仍有一些问题值得进一步研究.
1) 本文仅给出了线性Wiener过程模型下的寿命与剩余寿命预测结果, 但迄今为止国内外学者已提出了很多新的退化模型, 例如非线性Wiener过程模型等. 这些模型更具一般性与普适性, 有待进一步研究其最后逃逸时间下寿命分布推导方法.
2) 相比于首达时间定义的‘‘保守”, 最后逃逸时间较为‘‘激进”, 对于一些高可靠性要求的关键设备, 容易导致预测结果大于真实寿命, 如何在首达时间‘‘保守”与最后逃逸时间‘‘激进”中选取一个‘‘折中”的方案是一个值得研究的问题.
3) 迄今为止, 首达时间和最后逃逸时间主要用于基于随机退化过程建模的剩余寿命预测方法中, 目前基于机器学习的寿命预测方法考虑相对较少, 有待进一步研究.
4) 由于退化随机性的影响, 当退化过程离开阈值时, 无法立刻判定该退化过程之后是否能再次返回阈值之下, 这会导致计算得到的最后逃逸时间与真实逃逸时间存在一定的滞后.
5) 由式(9)与前面分析可知, 最后逃逸时间下的寿命分布方差大于传统首达时间下的结果, 这会给维护决策带来一定的挑战, 如何减小预测结果的方差也是一个值得研究的问题.
-
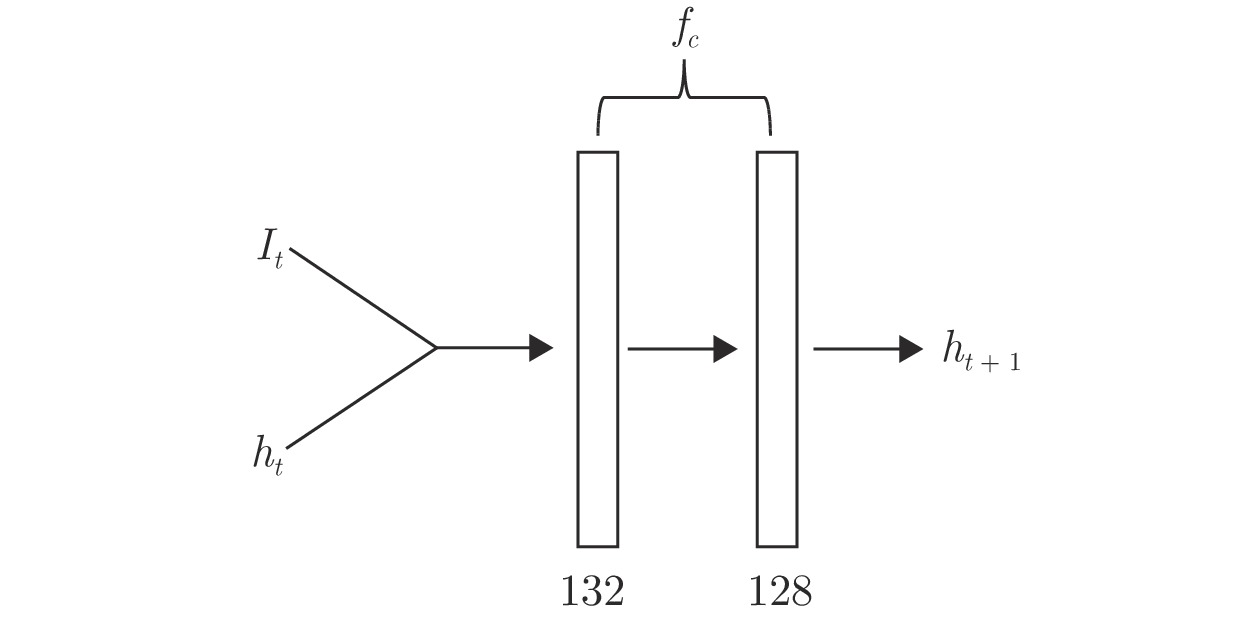
图 4 融合网络
${f}_{c}\left({\theta }_{c}\right)$ Fig. 4 Integration network
$ {f}_{c}\left({\theta }_{c}\right) $ 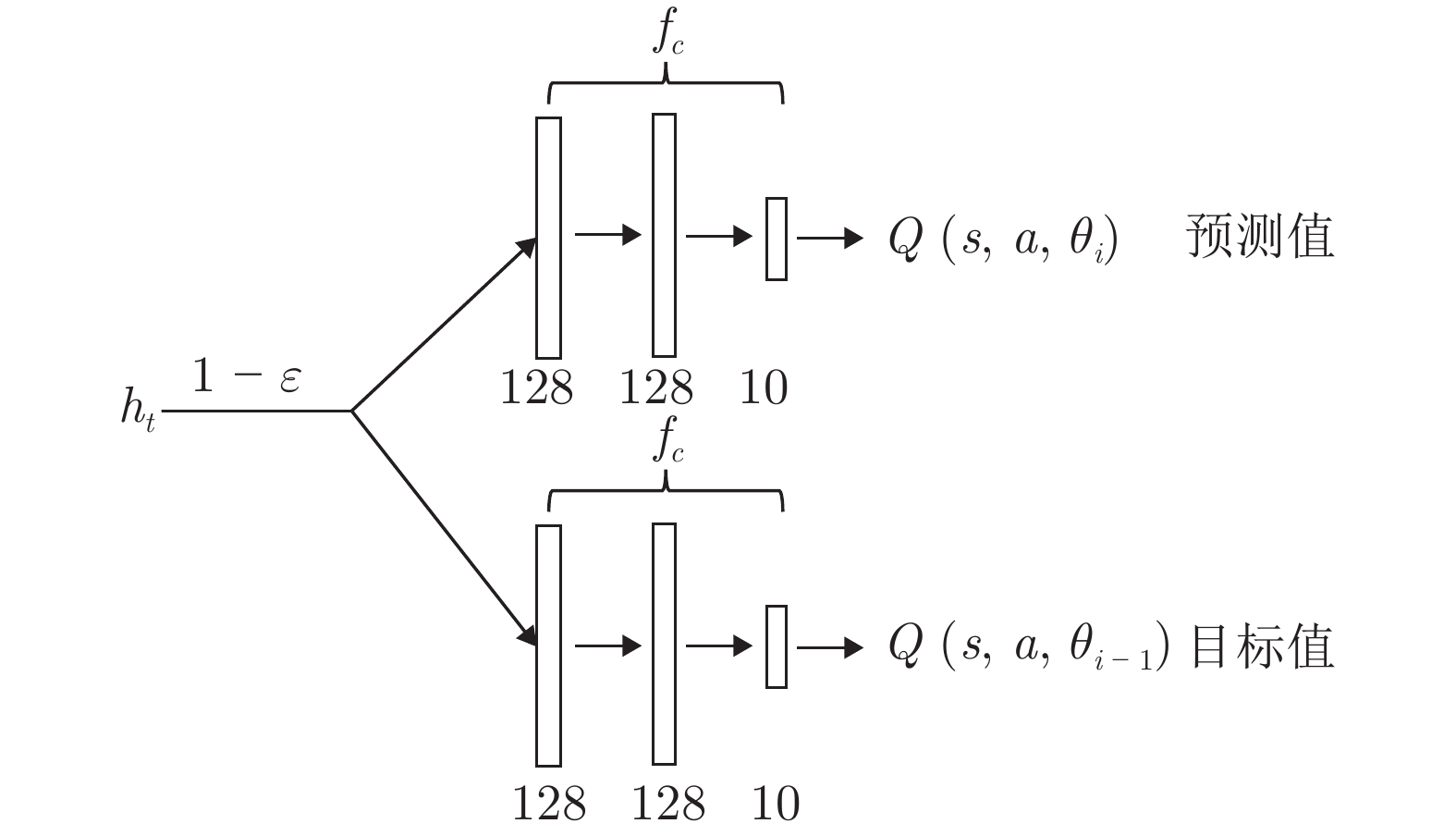
图 5 动作网络
$ {f}_{a}\left({\theta }_{a}\right) $ Fig. 5 Action network
$ {f}_{a}\left({\theta }_{a}\right) $ 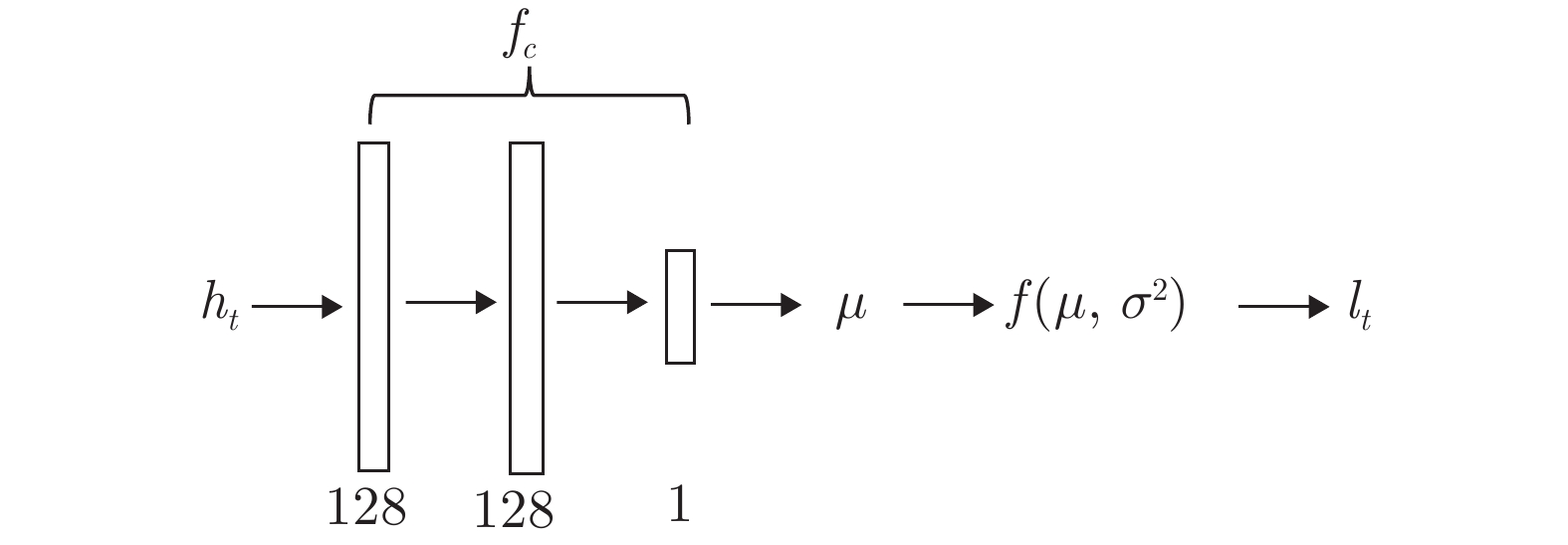
图 6 位置网络
$ {f}_{l}\left({\theta }_{l}\right) $ Fig. 6 Location network
$ {f}_{l}\left({\theta }_{l}\right) $ 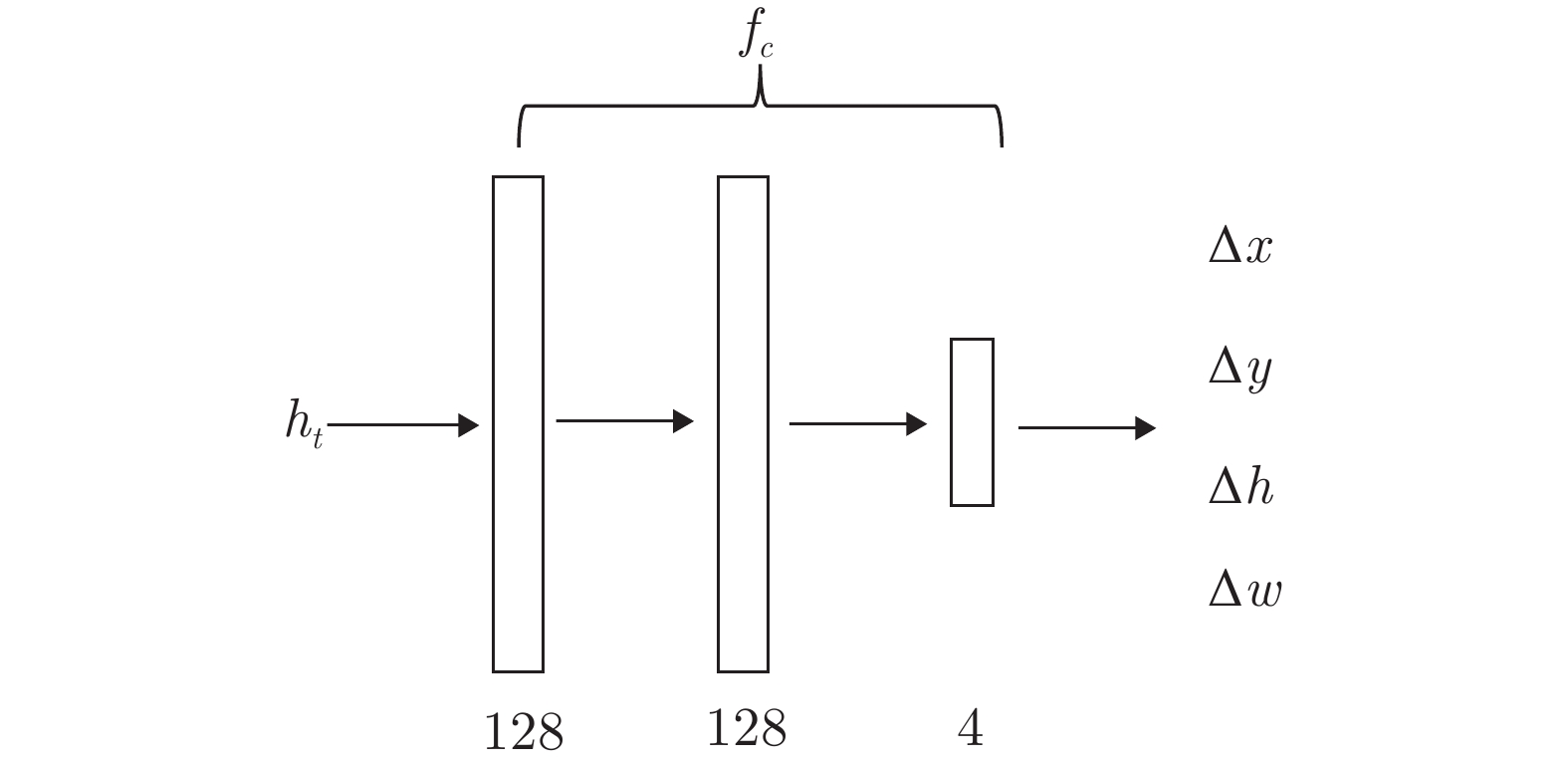
图 7 回归网络
$ {f}_{g}\left({\theta }_{g}\right) $ Fig. 7 Regression network
$ {f}_{g}\left({\theta }_{g}\right) $ 
图 19 回归器精调后IoU交叠区域示意图
Fig. 19 Schematic diagram of IoU overlapping area after fine adjustment of regressor
表 1 不同算法在VOC 2007测试集上的定位精度表现(节选部分种类)
Table 1 Positioning accuracy performance of different algorithms on VOC 2007 test set (category of excerpts)
算法 Aero Bike Bird Boat Bottle Bus Car Cat mAP Faster R-CNN 86.5 81.6 77.2 58.0 51.0 78.6 76.6 93.2 75.3 Caicedo 57.9 56.7 38.4 33.0 17.5 51.1 52.7 53.0 45.0 Bueno 56.1 52.0 42.2 38.4 22.1 46.7 42.2 52.6 44.0 UR-DRQN 59.4 58.7 44.6 36.1 28.3 55.3 48.4 52.4 47.9  下载: 导出CSV
下载: 导出CSV
表 2 不同算法平均每个轮次的定位耗时
Table 2 The average location time of each epoch in different algorithms
算法 Faster R-CNN Caicedo Bueno UR-DRQN 定位耗时 (s/轮次) 372 271 251 219
下载: 导出CSV
-
[1] 王亚珅, 黄河燕, 冯冲, 周强. 基于注意力机制的概念化句嵌入研究. 自动化学报, 2020, 46(7): 1390-1400WANG Ya-Shen, HUANG He-Yan, FENG Chong, ZHOU Qiang. Conceptual Sentence Embeddings Based on Attention Mechanism. Acta Automatica Sinica, 2020, 46(7): 1390-1400. [2] Sherstinsky A. Fundamentals of recurrent neural network (rnn) and long short-term memory (lstm) network. Physica D: Nonlinear Phenomena, 2020, 404: 132306.. doi: 10.1016/j.physd.2019.132306 [3] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301-1312Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301-1312. [4] Hasselt H, Guez A, Silver D. Deep reinforcement learning with double Q-learning. In: Proceedings of the 13th AAAI Conference on Artificial Intelligence. Arizona, USA: 2016. 2094−2100 [5] Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou I, Wierstra D, et al. Playing atari with deep reinforcement learning. arXiv preprint arXiv: 1312.5602, 2013. [6] Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529. doi: 10.1038/nature14236 [7] Rahman M A, Wang Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In: Proceedings of the International Symposium on Visual Computing. Cham, Sw-itzerland: 2016. 234−244 [8] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 580−587 [9] Girshick R. Fast R-CNN. In: Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1440−1448 [10] Ren S, He K, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. In: Proceedings of the Advances in Neural Information Processing Systems. Vancouver, Canada: MIT Press. 2015. 91−99 [11] Mnih V, Heess N, Graves A. Recurrent models of visual attention. In: Proceedings of the Advances in Neural Information Pro-cessing Systems. Vancouver, Canada: 2014. 2204−2212 [12] Caicedo J C, Lazebnik S. Active object localization with deep reinforcement learning. In: Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 2488−2496 [13] Bueno M B, Giró-i-Nieto X, Marqués F, et al. Hierarchical object detection with deep reinforcement learning. Deep Learning for Image Processing Applications, 2017, 31(164): 3. [14] Hara K, Liu M Y, Tuzel O, Farahmand A M. Attentional network for visual object detection. arXiv preprint arXiv: 1702.01478, 2017. [15] Shah S M, Borkar V S. Q-learning for Markov decision processes with a satisfiability criterion. Systems & Control Letters, 2018. 113: 45-51. [16] Garcia F, Thomas P S. A meta-MDP approach to exploration for lifelong reinforcement learning. In: Proceedings of the Advances in Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2019. 5691−5700 [17] Sutton R S, Barto A G. Reinforcement Learning: An Introduction. Cambridge: MIT Press, 2018. [18] March J G. Exploration and exploitation in organizational learning. Organization Science, 1991, 2(1): 71-87. doi: 10.1287/orsc.2.1.71 [19] Bertsekas D P. Dynamic Programming and Optimal Control. Belmont: Athena Scientific, 1995. 期刊类型引用(4)
1. 乔宏霞,杜杭威,李元可,杨安. 氯氧镁水泥混凝土中涂层钢筋的锈蚀劣化模型研究. 建筑结构. 2024(03): 65-70 .  百度学术
百度学术2. 康守强,邢颖怡,王玉静,王庆岩,谢金宝,MIKULOVICH Vladimir Ivanovich. 基于无监督深度模型迁移的滚动轴承寿命预测方法. 自动化学报. 2023(12): 2627-2638 . 本站查看3. 严帅,熊新. 基于KPCA和TCN-Attention的滚动轴承退化趋势预测. 电子测量技术. 2022(15): 28-34 . 百度学术4. 张伟涛,纪晓凡,黄菊,楼顺天. 航发轴承复合故障诊断的循环维纳滤波方法. 西安电子科技大学学报. 2022(06): 139-151 . 百度学术其他类型引用(12)
-

 下载:
下载:
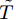
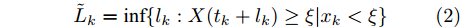
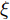
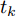
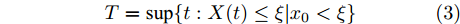
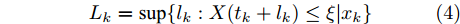
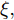
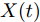
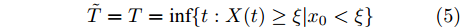
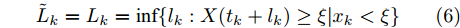
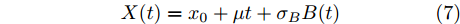
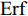
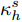
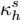
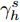
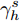
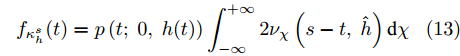
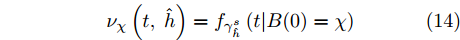
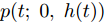
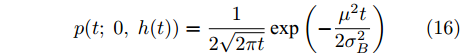
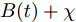
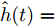
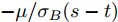
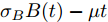
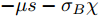
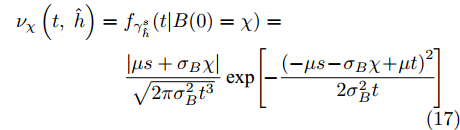
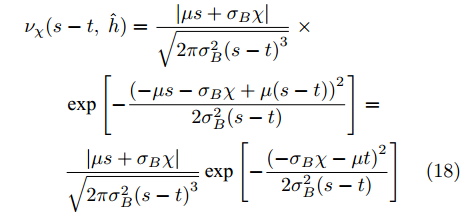
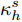
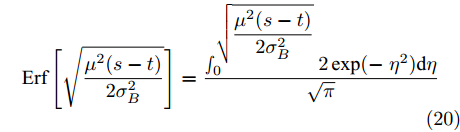
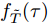
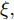
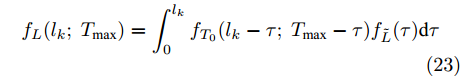
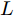
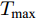
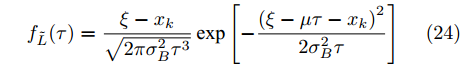
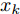

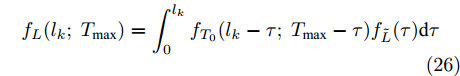
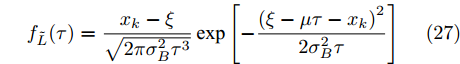
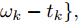
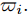
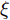
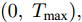
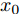
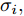

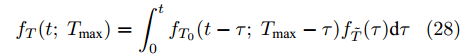
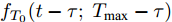
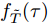
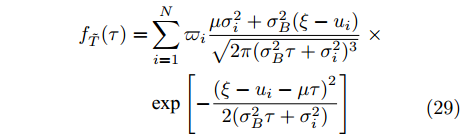
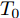
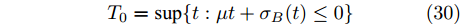
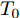
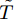
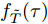
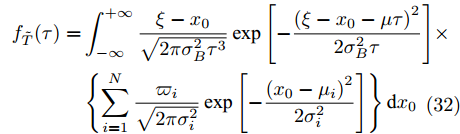
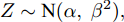
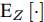
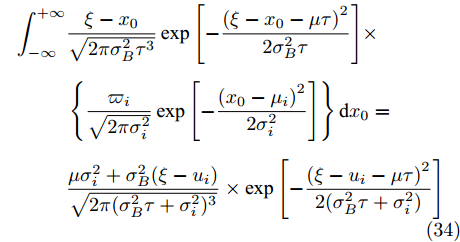
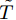
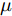
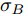
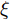
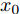
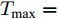


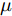
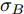
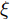
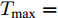
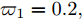
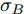
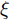
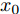
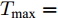
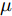
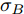
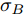
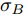
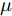
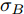
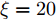
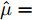
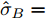
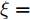












计量
- 文章访问数: 1739
- HTML全文浏览量: 811
- PDF下载量: 319
- 被引次数: 16
