

-
摘要: 深度卷积神经网络显著提升了单图像超分辨率的性能. 通常, 网络越深, 性能越好. 然而加深网络往往会急剧增加参数量和计算负荷, 限制了在资源受限的移动设备上的应用. 提出一个基于轻量级自适应级联的注意力网络的单图像超分辨率方法. 特别地提出了局部像素级注意力模块, 给输入特征的每一个特征通道上的像素点都赋以不同的权值, 从而为重建高质量图像选取更精确的高频信息. 此外, 设计了自适应的级联残差连接, 可以自适应地结合网络产生的层次特征, 能够更好地进行特征重用. 最后, 为了充分利用网络产生的信息, 提出了多尺度全局自适应重建模块. 多尺度全局自适应重建模块使用不同大小的卷积核处理网络在不同深度处产生的信息, 提高了重建质量. 与当前最好的类似方法相比, 该方法的参数量更小, 客观和主观度量显著更好.Abstract: Deep convolutional neural networks have significantly improved the performance of single image super-resolution. Generally, the deeper the network, the better the performance. However, deepening network often increases the number of parameters and computational cost, which limits its application on resource constrained mobile devices. In this paper, we propose a single image super-resolution method based on a lightweight adaptive cascading attention network. In particular, we propose a local pixel-wise attention block, which assigns different weights to pixels on each channel, so as to select high-frequency information for reconstructing high quality image more accurately. In addition, we design an adaptive cascading residual connection, which can adaptively combine hierarchical features and is propitious to reuse feature. Finally, in order to make full use of all hierarchical features, we propose a multi-scale global adaptive reconstruction block. Multi-scale global adaptive reconstruction block uses convolution kernels of different sizes to process different hierarchical features, hence can reconstruct high-resolution image more effectively. Compared with other state-of-the-art methods, our method has fewer parameters and achieves superior performance.
-
Key words:
- Super-resolution /
- lightweight /
- attention mechanism /
- multi-scale reconstruction /
- adaptive parameter
-
如今利用现代设备采集高维数据变得方便和容易, 但是获得的高维数据可能包含不相关和冗余的信息. 这不仅增加了学习模型的计算量和存储量, 而且可能导致学习模型的性能下降. 为了解决这些问题, 线性降维[1-4]通常用于从数据中提取重要和有用的信息. 线性降维的目的是通过优化一些准则函数对原始特征空间进行适当的线性变换. 主成分分析(Principal component analysis, PCA)和线性判别分析(Linear discriminant analysis, LDA)是两种流行的线性降维方法. 由于PCA和LDA的简单性和有效性, 它们已经被广泛应用于许多领域, 如人脸识别[5]、手写体字符识别[6]和缺陷诊断[7]等.
当样本的类别信息可用时, 通常情况下LDA在提取数据的鉴别特征方面比PCA更有效. 线性判别分析的目标是在变换空间中通过最大化类间距离和最小化类内距离来寻找投影矩阵. 从概率的观点来看, 假设每类样本服从高斯分布且具有不同的类中心以及相同的协方差, 则从Bayes最优准则可推导出LDA.
为了改善线性判别分析的特征提取性能, 各种LDA的改进算法[8-10]已经被提出. 使用最优向量替换各类中心[8]能提高LDA的类信息鉴别能力. 分数阶的LDA[11]通过在一系列分数阶中引入加权函数来改善LDA, 但这增加了获得投影向量的代价. 与Bayes错误率相关的近似成对精度准则[12]在原空间计算各类的权重, 从而改善LDA的性能. 几何平均[13], 调和平均[14]以及加权调和平均[15]被用来定义判别分析的准则函数. 最不利情况下的线性判别分析[16]考虑了最近的两个类中心和具有最大方差的类来寻找投影方向. 基于最大−最小距离的目标函数[17]探索了最近的数据对的性质来取得投影方向. Wasserstein判别分析[18]利用正则化Wasserstein距离获取类之间的全局和局部信息并优化目标函数取得最佳投影方向.
线性判别分析存在小样本的奇异性[19]以及非线性数据特征提取[20-21]等问题. 为了克服LDA的小样本奇异性问题, 典型的方法包括PCA+LDA, 正则化LDA, 伪逆LDA 以及张量判别分析[22]等. 为了有效地处理非线性数据, 各种线性判别分析已被拓宽到基于核函数的判别分析[7, 20-21]. 当训练集随着新数据的加入而变化时或处理的数据量大时, 各种增量学习[23-24]或在线学习方式被用来获得鉴别分析的投影方向. 文献[24]提出了两种形式的增量LDA : 序列增量LDA和块增量LDA, 它们能有效地获取大数据流的特征空间.
数据在采集或传输过程中可能受到污染, 这使得处理的数据包含噪声或离群点. 但经典线性判别分析对噪声数据具有敏感性, 即获得的投影方向偏离真正的投影方向. 为了降低LDA对噪声数据的敏感性, 许多工作致力于用鲁棒的目标函数替换LDA的原有目标函数[25-26]. 已有的诸多研究发现, 基于L1范数的目标函数比基于L2范数的目标函数在抑制异常点或噪声方面更有效[27-29]. 因此基于L1范数的判别分析方法近年来备受关注. L1范数的LDA[28]的类内距离和类间距离的定义依赖于L1范数, 这在某种程度上能抑制噪声. L1范数的核LDA不仅能抑制噪声, 而且能捕捉数据的非线性鉴别特征[28]. L1范数的两维LDA[30]拓宽了L1范数的LDA, 这种方法可直接处理图像数据, 而不需要把图像转化为向量形式. 通常L1范数的判别分析通过贪婪算法获取多个投影方向, 而非贪婪迭代算法[31]被用来直接获取L1范数的LDA的多个投影向量. 广义弹性网[32]通过Lp范数定义的目标函数来改善判别分析抑制噪声的能力, 而通过优化Bhattacharyya的L1范数误差界[33]可设计出新的鉴别分析模型. 最近提出的基于L21范数的LDA方法[34]通过同时优化类中心和投影方向从而在噪声数据方面表现出良好的性能.
在大多数判别分析中, 通常假定类内各个样本以相等的概率(均匀分布)取得的, 但是位于类中心附近的样本一般远远多于位于类边界附近的样本. 为了增加类内样本采样的多样性, 可令类内样本的采样概率在均匀分布的概率附近变化, 这种变化有利于区分类中心附近的样本或类边界附近的样本. 不确定优化中的不确定集能描述概率分布的变化范围. 因此本文借助KL散度定义的不确定集对类内样本信息进行概率建模. 此外, 为了更好描述各类中心的信息, 本文也利用KL散度定义的不确定集对其进行概率建模. 基于此, 本文提出了基于KL散度不确定集的线性判别分析方法, 从而进一步改善已有线性判别分析方法. 与以往的方法不同, 本文不仅考虑了一般范数的目标函数, 而且利用不确定集对训练样本信息进行了刻画. 本文采用的不确定集为围绕均匀分布的KL散度球且约束中的不确定集被转化为目标函数的正则化项. 本文的主要贡献表现为:
1) 提出了正则化对抗LDA和正则化乐观LDA. 正则化对抗LDA优先考虑了难以区分的样本, 而正则化乐观LDA优化考虑了易于区分的样本.
2) 采用了广义Dinkelbach算法求解正则化对抗LDA或正则化乐观LDA. 对正则化对抗LDA运用投影梯度法求解优化子问题, 而对正则化乐观LDA运用交替优化求解优化子问题.
3) 在数据集上表明了当数据没有被污染时, 两种判别分析模型取得可竞争的性能, 但在污染数据的情况下, 正则化乐观LDA取得更好的性能. 这也从另一方面说明了本文提供两种模型的目的, 即如果在某些验证数据集上正则化乐观LDA的最好性能明显优于正则化对抗LDA的最好性能, 那说明训练集包含离群点. 因此通过检查正则化对抗LDA和正则化乐观LDA的性能可判断训练集是否包含离群点.
1. 相关工作
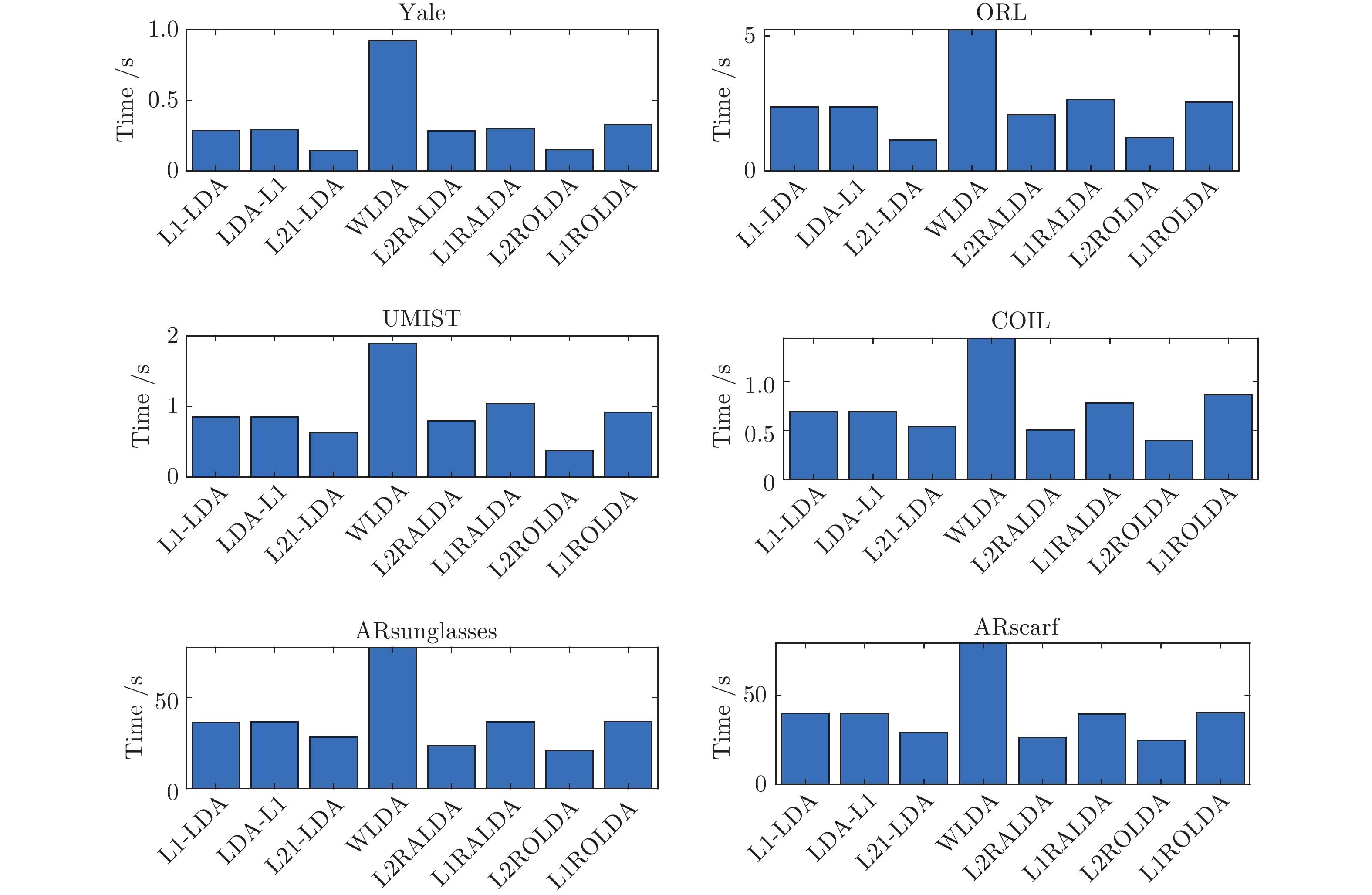
假设维数为
$ d $ 的$ n $ 个数据点表示为$\{{\boldsymbol{x}}_1 ,\cdots, $ $ {\boldsymbol{x}}_n \}$ , 其中$ {\boldsymbol{x}}_i\in {\bf{R}}^d $ $ (i = 1,\cdots,n) $ . 数据集中每个数据点属于$ c $ 类中的一类, 第$ i $ 类的样本数为$ n_i $ , 这样$ n = \sum\nolimits_{i = 1}^c {n_i} $ 为总的样本数. 定义向量${\boldsymbol{a}} = (a_1,\cdots, $ $ a_n )^{\rm{T}}$ 的Ls范数为$\| {\boldsymbol{a}} \|_s = ( {\sum\nolimits_{i = 1}^n {| {a_i } |^s} } )^{\frac{1}{s}}$ , 其中$ s>0 $ . 当$ 0<s<1 $ 时,$ \| {\boldsymbol{a}} \|_s $ 并不是严格意义上的范数.线性判别分析的类间离差矩阵和类内离差矩阵分别被定义为:
$$ {\boldsymbol{S_b}} = \sum\limits_{i = 1}^c {\frac{n_i }{n}} ({\boldsymbol{m}}_i -\bar {{\boldsymbol{m}}})({\boldsymbol{m}}_i -\bar {{\boldsymbol{m}}})^{\rm{T}} $$ (1) $$ {\boldsymbol{S_w}} = \frac{1}{n}\sum\limits_{i = 1}^c {\sum\limits_{k = 1}^{n_i } {({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )} } ({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )^{\rm{T}} $$ (2) 其中
$ \bar{{\boldsymbol{m}}} = \frac{1}{n}\sum\nolimits_{i = 1}^n {{\boldsymbol{x}}_i } $ 表示所有样本的均值,${\boldsymbol{m}}_i = $ $ \frac{1}{n_i}\sum\nolimits_{k = 1}^{n_i } {{\boldsymbol{x}}_k^i }$ 是第$ i $ 类样本的均值,$ {\boldsymbol{x}}_k^i $ 表示第$ i $ 类的第$ k $ 个样本. 线性判别分析在矩阵对$ ({\boldsymbol{S_b}}, {\boldsymbol{S_w}} ) $ 上执行广义特征值分解取得多个投影方向.1.1 最不利情况的线性判别分析
在文献[16]中, 类间离差矩阵(1)被改写成下面形式:
$$ {\boldsymbol{S_b}} = \sum\limits_{i = 1}^c \sum\limits_{j = i+1}^c \omega _{ij} ({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )^{\rm{T}} $$ (3) 其中
$ \omega _{ij} = \omega _i\omega _j $ ,$ i,j = 1,\cdots,c $ 以及$\omega _i = \dfrac{n_i}{n}$ 表示第$ i $ 类样本的先验概率. 在此基础上, 文献[16]定义了如下的线性判别分析:$$ \begin{split} &\max\limits_{{\boldsymbol{W}}} \frac{\min _{ij} \{\omega _{ij} \|{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )\|_2^2 \}}{\max _i \displaystyle\left\{\frac{1}{n_i }\sum\limits_{k = 1}^{n_i } {\|{\boldsymbol{W}}^{\rm{T}}} ({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )\|_2^2 \right\}}\\ &{\rm{s.t.}} \ {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split} $$ (4) 其中
$ {\boldsymbol{W}} $ 是一个$ d\times m $ 投影矩阵以及${\boldsymbol{I}}_m$ 表示单位矩阵. 在投影空间中, 模型(4)通过优化距离最近的两个类中心和具有最大类内距离的类取得最优投影矩阵. 这种方法实际上寻找不利区分样本的最优投影方向. 这种设计思想来源于分类器的设计. 在分类器设计中, 设计的分类器对难以分类的样本(边界样本)进行优先考虑, 即赋予较大的采样概率, 从而使设计的分类器具有更好的泛化性能. 模型(4)通过优先考虑难以区分的样本取得最优投影矩阵. Zhang和Yeung[16]提出了两种算法求解模型(4). 一种方法是将(4)转化为度量学习问题, 另一种方法是设计了一种基于约束的凹凸优化算法.1.2 基于L1范数的线性判别分析
在文献[28]中,下面优化模型被用来取得投影矩阵
$ {\boldsymbol{W}} $ :$$ \begin{split} &\max\limits_{{\boldsymbol{W}}} \frac{\displaystyle\sum\limits_{i = 1}^c {n_i } \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -\bar {{\boldsymbol{m}}})} \|_1 }{\displaystyle\sum\limits_{i = 1}^c {\sum\limits_{{\boldsymbol{x}}_j \in l_i } {\| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_j -{\boldsymbol{m}}_i )} \|_1 } } }\\ &{\rm{s.t}}.\ {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split} $$ (5) 其中
$\|\cdot\|_1$ 表示向量的L1范数,$ l_i $ 表示第$ i $ 类样本的集合. 优化问题(5)的目标函数关于变量$ {\boldsymbol{W}} $ 是非平滑和非凸的. 文献[28]首先利用梯度上升法取得一个投影向量, 然后设计了一个贪婪方法来取得多个投影向量.1.3 基于L21范数的线性判别分析
为了改善线性判别分析模型在投影空间的鉴别能力, 文献[34]提出了下面的优化模型:
$$ \begin{split} &\min\limits_{{\boldsymbol{W}},{\boldsymbol{m}}_i } \frac{\sum\limits_{i = 1}^c {\displaystyle\sum\limits_{{\boldsymbol{x}}_j \in l_i } {\| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_j -{\boldsymbol{m}}_i )} \|_2 } } }{\displaystyle\frac{1}{n}\sum\limits_{i = 1}^n {\| {{\boldsymbol{W}}^{\rm{T}}{\boldsymbol{x}}_i } \|_2 } }\\ &{\rm{s.t}}. \ {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split} $$ (6) 与以前的一些模型不同, 式(6)的类平均
${{{\boldsymbol m}_i}}\;(i = $ $ 1,\cdots,c)$ 是优化变量. 模型(6)的目标函数实际上对不同样本采用了L1范数, 而对每个样本的约简特征采用了L2范数, 这通常被称为L21范数的线性判别分析. 如果数据包含离群点, 基于算术平均取得的类中心可能偏离样本的真正类中心, 而优化的类中心接近真正的类中心. 模型(6)比模型(5)包含更多的优化变量. 文献[34]设计了一个有效的框架求解模型(6).2. 基于不确定集的正则化线性判别分析
2.1 正则化对抗LDA
为了度量两个具有公共支集的离散概率分布之间的差异, 文献[35]定义了KL散度. 假设给定两个离散概率分布
$ {\boldsymbol{p}} = (p_1,\cdots, p_n) $ 和$ {\boldsymbol{q}} = (q_1,\cdots, q_n) $ , 那么这两个概率分布之间的KL散度被定义为:$$ KL({\boldsymbol{p}}\vert {\boldsymbol{q}}) = \sum\limits_{i = 1}^n {p_i } \ln \frac{p_i }{q_i } $$ (7) 如果两个离散概率分布相同, 则KL散度的值为零. 由于KL散度不满足三角不等式, 它实际上不是一个真正的距离度量. 注意到KL散度是非对称的, 即
$ KL({\boldsymbol{p}}\vert {\boldsymbol{q}})\ne KL({\boldsymbol{q}}\vert {\boldsymbol{p}}) $ . KL散度是非负的, 即$ KL({\boldsymbol{p}}\vert {\boldsymbol{q}})\ge 0 $ . 在鲁棒优化中, 基于KL散度的不确定集被定义为[36-37]:$$ { K} = \{{\boldsymbol{p}}| {KL({\boldsymbol{p}}\vert {\boldsymbol{q}})} \le \varepsilon \} $$ (8) 式(8)的不确定集表明, 离散概率分布
$ {\boldsymbol{p}} $ 在给定的离散概率分布$ {\boldsymbol{q}} $ 附近变化, 其变化范围由一个非负参数$ \varepsilon $ 控制. 参数$ \varepsilon $ 越大, 不确定集的变化范围越大. 单个$ {\boldsymbol{p}} $ 是不确定集内的一个具体的概率分布.为了探索样本的类间信息, 模型(4)试图在低维投影空间中最大化最近的两个类中心, 而且它利用L2范数定义了类间距离. 在Ls范数的距离测度下, 与式(4)相似的类间信息的优化问题
$\max _{{\boldsymbol{W}}} \min _{i < j} \omega _{ij} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )} \|_s^s$ 在${\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m$ 约束条件下被写成下面形式:$$ \begin{split} &\max\limits_{{\boldsymbol{W}}} \min\limits_{p_{ij} } \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} } } \omega _{ij} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )} \|_s^s\\ &{\rm{s.t}}. \ \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} = 1} }, p_{ij} \ge 0, {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split} $$ (9) 模型(9)不仅引入了优化变量
$ p_{ij} $ , 而且在投影后的类间距离使用了Ls范数. 如果$ s = 1 $ , 那么使用了L1范数定义了类间距离. 如果$ s = 2 $ , 那么使用了L2范数定义了类间距离. 模型(9)说明了优化变量$ p_{ij} $ 在概率单纯形内变化, 即在这个单纯形中寻找距离最近的类中心对, 并试图取得最优投影矩阵. 因此在提取鉴别特征时, 距离最近的两个类中心所起的作用最大. 显然, 它忽略了其他类中心的信息, 使得这种模型利用类中心的信息不完整. 为了解决这个问题, 本文首先将离散概率分布$ p_{ij} $ 看作类中心$ {\boldsymbol{m}}_i $ 和$ {\boldsymbol{m}}_j $ 之间的采样概率, 然后将离散概率分布$ p_{ij} $ 限制在一定的范围内, 使得模型变得更加灵活. 这里使用式(8)定义的不确定集, 这个不确定集是由离散概率分布定义的. 因此根据KL散度定义的不确定集和各类中心信息, 以下优化问题被提出:$$ \begin{split} &\max\limits_{{\boldsymbol{W}}} \min\limits_{p_{ij} } \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} } } \omega _{ij} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )} \|_s^s\\ &{\rm{s.t}}.\ \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} = 1} },p_{ij} \ge 0\\ &\sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c} {p_{ij} } \ln \frac{p_{ij} }{q_{ij} }\le \varepsilon, {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split} $$ (10) 模型(10)引入了满足条件
$ \sum\nolimits_{i<j}^c {q_{ij} } = 1 $ 的参数$ q_{ij} $ , 该参数$ q_{ij} $ 表示第$ i $ 类中心和第$ j $ 类中心所提供的先验知识. 如果事先没有提供先验知识, 可令$q_{ij} = \dfrac{2}{c(c-1)}$ , 即它服从均匀概率分布, 这是因为不同类中心构成的数据对的数目为$\dfrac{ c(c-1)}{2}$ . 参数$ q_{ij} $ 并不是优化变量. 模型(10)允许参数$ p_{ij} $ 在给定$ q_{ij} $ 的邻域内变化. 根据正则化理论, 通过引入一个非负参数$ \eta $ 可将(10)的不确定集转化为目标函数的正则化项. 因此模型(10)等价于下面的模型:$$ \begin{split} &\max\limits_{{\boldsymbol{W}}} \min\limits_{p_{ij} } F_1 (W,p_{ij} ): = \eta KL({\boldsymbol{p}}|{\boldsymbol{q}})+\\ &\qquad\sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} } } \omega _{ij} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )}\|_s^s\\ &{\rm{s.t}}. \ \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} = 1} },p_{ij} \ge 0,{\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split} $$ (11) 在模型(11)中, KL散度作为正则化项使用了非负参数
$ \eta $ . 参数$ \eta $ 越大, 对应的不确定集越小. 参数$ \eta $ 越小, 对应的不确定集就越大. KL散度是非负的, 因此$ F_1 ({\boldsymbol{W}},p_{ij} ) $ 是非负的. 模型(11)仅仅考虑了类间样本的分布信息. 对于类内样本的分布信息, 遵循同样的思想, 这里考虑类边界附近的样本, 在投影矩阵的半正交约束下,$\min _{\boldsymbol{W}} \sum\nolimits_{i = 1}^c {\max _j } \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_j^i -{\boldsymbol{m}}_i )} \|_r^r$ 被改写成下面的形式:$$ \begin{split} &\min\limits_{{\boldsymbol{W}}} \max\limits_{u_{ik} } \sum\limits_{i = 1}^c {\sum\limits_{k = 1}^{n_i } {u_{ik} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )}\|_r^r } }\\ &{\rm{s.t}}. \ \sum\limits_{k = 1}^{n_i } {u_{ik} = 1} , u_{ik} \ge 0, {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split} $$ (12) 模型(12)采用了Lr范数定义类内距离, 参数
$ r $ 是正的实数. 模型(4)中分式的分母考虑了低维空间中具有最大类内距离的类, 而模型(12)考虑了每一类中远离其类中心的那些样本, 那些样本可能位于类之间的交界处. 换言之, 它搜索一些样本, 使它们在类内信息中起主导作用. 这样$ u_{ik} $ 可看成第$ i $ 类的第$ k $ 个样本的采样概率. 通过将$ u_{ik} $ 限制在一个不确定集内, 使样本的采样概率发生变化. 根据(12)和不确定集可定义如下的优化问题:$$ \begin{split} &\min\limits_{{\boldsymbol{W}}} \max\limits_{u_{ik} } F_2 ({\boldsymbol{W}},u_{ik} ): = \\ &\qquad\sum\limits_{i = 1}^c{\sum\limits_{k = 1}^{n_i } {u_{ik} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )} \|_r^r } } -\\ &\qquad\sum\limits_{i = 1}^c {\sum\limits_{k = 1}^{n_i } {\lambda _i } u_{ik} } \ln \frac{u_{ik} }{v_{ik} }\\ &{\rm{s.t}}.\ {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m,\sum\limits_{k = 1}^{n_i } {u_{ik} = 1}, u_{ik} \ge 0 \end{split} $$ (13) 模型(13)为每类引入了非负参数
$\lambda _i\;(i = 1,\cdots, $ $ c)$ , 这些非负参数在类内信息和不确定集之间作出适当的折衷. 参数$ v_{ik} $ 表示不确定集的中心, 并满足$ \sum\nolimits_{k = 1}^{n_i } {v_{ik} = 1} $ ,$ v_{ik} \ge 0 $ . 通常每类的$ v_{ik} $ 为均匀分布, 即$v_{ik} = \dfrac{1}{n_i}, k = 1,\cdots, n_i$ . 模型(11)通过对各类中心进行概率建模探索了类间信息, 而模型(13)通过对类内样本的采样概率进行建模探索了类内信息. 为了同时利用类内信息和类间信息, 从式(11)和(13)可建立如下单目标优化模型:$$ \begin{split} &\min\limits_{{\boldsymbol{W}}} \frac{\max _{u_{ik} } F_2 ({\boldsymbol{W}},u_{ik} )}{\min _{p_{ij} } F_1 ({\boldsymbol{W}},p_{ij} )}\\ &{\rm{s.t.}} \ {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m , \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} = 1} }\\ &p_{ij} \ge 0, u_{ik} \ge 0, \sum\limits_{k = 1}^{n_i } {u_{ik} = 1} \end{split} $$ (14) 式(14)的内层优化是关于变量
$ u_{ik} $ 和$ p_{ij} $ 的优化问题以及外层优化是关于变量$ {\boldsymbol{W}} $ 的优化问题. 模型的内层优化优先考虑了可分离性不好的样本(边界附近的样本有大的采样概率), 而外层优化使得它们在投影空间的可分离性变好. 从(12), (13)以及(14)知, 内层优化和外层优化的目标具有不一致(对抗)的性质. 本文将模型(14)称为正则化对抗LDA(Regularized adversarial LDA, RALDA). 式(14)的内层优化取得的概率分布被称为不确定集的对抗概率分布. 模型(14)是一个非凸优化问题. 模型(14)包含三组优化变量, 即$ {\boldsymbol{W}} $ ,$ u_{ik} $ 和$ p_{ij} $ . 如果同时考虑这三组优化变量, 这实际上是一个鞍点优化问题. 如果令$ u_{ik}^\ast({\boldsymbol{W}}) = \arg \max _{u_{ik} } F_2 ({\boldsymbol{W}},u_{ik} ) $ , 那么从$ u_{ik}^\ast(W) $ 可得到关于$ {\boldsymbol{W}} $ 的梯度信息[38], 这是因为$ F_2 ({\boldsymbol{W}},u_{ik}) $ 是变量$ u_{ik} $ 的严格凸函数. 同样地令$ p_{ij}^\ast (W) = \arg \max _{p_{ij} }F_1({\boldsymbol{W}},p_{ij} ) $ , 从$ p_{ij}^\ast ({\boldsymbol{W}}) $ 可得到关于$ {\boldsymbol{W}} $ 的梯度信息. 换句话说, 此情况下可计算$ u_{ik}^\ast ({\boldsymbol{W}}) $ 和$ p_{ij}^\ast(W) $ 关于$ {\boldsymbol{W}} $ 的(次)梯度. 注意非可微函数采用了次梯度. 通过下面两个优化问题可取得$ u_{ik}^\ast ({\boldsymbol{W}}) $ 和$ p_{ij}^\ast({\boldsymbol{W}}) $ :$$ \begin{split} &\max\limits_{u_{ik} } F_2 ({\boldsymbol{W}},u_{ik} )\\ &{\rm{s.t}}.\ \sum\limits_{k = 1}^{n_i } {u_{ik} = 1} , u_{ik} \ge 0 \end{split}$$ (15) $$ \begin{split} &\min\limits_{p_{ij} } F_1 ({\boldsymbol{W}},p_{ij} )\\ &{\rm{s.t}}.\ \sum\limits_{i<j}^c {p_{ij} = 1}, p_{ij} \ge 0 \end{split}$$ (16) 优化问题(15)对应模型(14)中分式的分子, 优化问题(16)对应模型(14)中分式的分母. 注意到函数
$ F_1({\boldsymbol{W}},p_{ij} ) $ 是变量$ p_{ij} $ 的强凸函数以及$ F_2 ({\boldsymbol{W}},u_{ik} ) $ 是变量$ u_{ik} $ 的强凹函数, 这说明优化问题(15)和(16)分别存在唯一解. 式(15)和(16)的唯一解分别表示为:$$ u_{ik}^\ast = \frac{v_{ik} \exp (\| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )} \|_r^r /\lambda _i )}{\sum\limits_{k = 1}^{n_i } {v_{ik} \exp (\| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )} \|_r^r /\lambda _i } )} $$ (17) $$ p_{ij}^\ast = \frac{q_{ij} \exp (-\omega _{ij} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )} \|_s^s /\eta )}{\sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {q_{ij} } \exp (-\omega _{ij} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )} \|_s^s /\eta } )} $$ (18) 把式(17)代入
$ \max _{u_{ik} } F_2 ({\boldsymbol{W}},u_{ik} ) $ 可取得:$$ \begin{split} &\tilde {F}_2 ({\boldsymbol{W}}) = \max\limits_{u_{ik} } F_2 ({\boldsymbol{W}},u_{ik} ) = \\ &\qquad\sum\limits_{i = 1}^c {\lambda _i } \ln \sum\limits_{k = 1}^{n_i } {v_{ik} \exp (\| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )} \|_r^r /\lambda _i } ) \end{split} $$ (19) 把式(18)代入
$ \min _{p_{ij} } F_1 ({\boldsymbol{W}},p_{ij} ) $ 可取得:$$ \begin{split} &\tilde {F}_1 ({\boldsymbol{W}}) = \min\limits_{p_{ij} } F_1 ({\boldsymbol{W}},p_{ij} ) = \\ &\quad-\eta \ln \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {q_{ij} } \exp (-\omega _{ij}\| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )} \|_s^s /\eta } ) \end{split} $$ (20) 式(19)和(20)实际上求解模型(14)的内层优化问题. 利用式(19)和(20), 优化模型(14)被改写成下面形式:
$$ \begin{split} &\min\limits_W F({\boldsymbol{W}}): = \frac{\tilde {F}_2 ({\boldsymbol{W}})}{\tilde {F}_1 ({\boldsymbol{W}})}\\ &{\rm{s.t}}. \ {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split}$$ (21) 模型(21)仅包含优化变量
$ {\boldsymbol{W}} $ . 它是一个非常复杂的非线性优化问题. 从模型(21)的约束来看, 它属于Stiefel流形上的优化问题[41].2.2 求解优化模型(21)
式(21)是一个比率优化问题. 从
$ F_1({\boldsymbol{W}},p_{ij}) $ 的非负性和式(20)可得出$ \tilde {F}_1 ({\boldsymbol{W}}) $ 是非负的. 从(19)可推导出$ \tilde {F}_2 ({\boldsymbol{W}}) $ 是非负的. 这样式(21)中的函数$ F({\boldsymbol{W}}) $ 是非负的. 尽管存在求解模型(21)的诸多优化算法, 但本文采用了广义Dinkelbach算法[39]求解模型(21). 算法1描述了求解式(21)的主要步骤.算法1. 求解模型(21)的广义Dinkelbach算法
1) 令
$ {\boldsymbol{W}}^1 $ 是满足$({\boldsymbol{W}}^1)^{\rm{T}} {\boldsymbol{W}}^1 = {\boldsymbol{I}}_m$ 的初始可行解, 设定参数$ \lambda _i $ ,$ \eta $ ,$ q_{ij} = 2/(c(c-1)), u_{ik} = 1/n_i $ ,$ \gamma _1 = F({\boldsymbol{W}}^1) $ ,2) 对于
$ t = 1 $ to$ T $ 执行a) 求解
$\bar {F}(\gamma _t ) = \min _{{\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m\\ } \{\tilde {F}_2 ({\boldsymbol{W}})-\gamma _t \tilde {F}_1 ({\boldsymbol{W}})\}$ , 其解表示为$ {\boldsymbol{W}}^{t+1} $ ,b) 如果
$ \bar {F}(\gamma _t ) = 0 $ , 停止且$ {\boldsymbol{W}}^{t+1} $ 是最优解, 否则取得$ \gamma _{t+1} = F({\boldsymbol{W}}^{t+1}) $ ,3) 输出投影矩阵
$ {\boldsymbol{W}} $ .算法1把比率优化问题(21)归结为两个函数差的优化问题. 文献[27]已采用这种思想求解L1范数的LDA, 从而避免矩阵逆的计算, 这也克服小样本的奇异性问题. 文献[27]的方法实际上是广义Dinkelbach算法的一种形式. 这样本文的算法也不会出现矩阵逆计算问题. 如果KL散度的值不为0,
$ F_1 ({\boldsymbol{W}},p_{ij} ) $ 作为式(14)的分母也不为零. 这些因素促使了提出的算法克服了小样本的奇异性问题.算法1的停止条件是
$ \bar {F}(\gamma _t ) = 0 $ . 在实际应用中, 由于受浮点数计算精度的影响, 这通常是不可行的. 通常采用最大迭代次数或目标函数的相对变化小于一个数作为停止条件. 如文献[39]所述, 如果约束集是闭有界集且优化子问题取得精确解, 则算法1将在有限次迭代中结束, 或者它将产生一个无穷序列, 其极限点是式(21)的平稳点. 注意到投影矩阵$ W $ 位于一个闭有界集中, 并且模型(21)的目标函数是连续的. 因此式(21)的目标函数是有上下界的. 在实际求解中可能无法取得优化子问题的精确解. 如果采用闭映射的下降算法求解优化子问题, 那么算法1在这种情况下也收敛[39]. 因此本文利用梯度下降算法解决优化子问题以确保算法1的收敛性. 从算法1可看出, 其关键问题是如何求解优化子问题. 算法1中的子问题被表示如下:$$ \begin{array}{l}\bar {F}(\gamma _t ) = \min\limits_{{\boldsymbol{W}}^{\rm{T}} {\boldsymbol{W}} = {{{\boldsymbol I}_m}}} \{\tilde {F}_2 ({\boldsymbol{W}})-\gamma _t \tilde {F}_1 ({\boldsymbol{W}})\} \end{array} $$ (22) 从
$ F({\boldsymbol{W}}^1) $ 的非负性可知$ \gamma _t $ 是非负的. 如文献[39]所述, 函数$ \bar {F}(\gamma _t ) $ 是变量$ \gamma _t $ 的凹函数和递减函数, 并且$ \bar {F}(\gamma _t ) = 0 $ 有唯一解. 算法1的优点在于不需要取得优化子问题的精确解, 只要$ {\boldsymbol{W}} $ 满足$\{\tilde {F}_2 ({\boldsymbol{W}})- $ $ \gamma_t\tilde {F}_1({\boldsymbol{W}})\} < 0$ , 那么$ {\boldsymbol{W}} $ 比前一次的解更接近目标函数$ F({\boldsymbol{W}}) $ 的最优解. 这样可采用简单的梯度投影法求解优化问题(22). 本文采用了基于Armijo线搜索的投影次梯度法求解模型(22). 为了方便描述算法, 这里定义了梯度$\dfrac{\partial \tilde {F}({\boldsymbol{W}})}{\partial {\boldsymbol{W}}} = \dfrac{\partial \tilde {F}_2 ({\boldsymbol{W}})-\lambda _t \tilde {F}_1 ({\boldsymbol{W}})}{\partial {\boldsymbol{W}}}$ . 算法2描述了求解模型(22)的主要步骤.算法2. 求解模型(22)的投影次梯度法
1) 初始的
$ W $ , Armijo参数$ 0<\beta <1 $ ,2) 重复直到收敛
a) 计算(次)梯度
$\dfrac{\partial \tilde {F}({\boldsymbol{W}})}{\partial {\boldsymbol{W}}}$ 和$ g = 1 $ ,b) 计算
${{{\boldsymbol W}_{n}}} = P({\boldsymbol{W}}-\beta ^g\dfrac{\partial \tilde {F}({\boldsymbol{W}})}{\partial {\boldsymbol{W}}})$ ,c) 计算
$\tilde {F}({{{\boldsymbol W}_{n}}} )$ ; 如果$\tilde {F}({{{\boldsymbol W}_{n}}} ) < \tilde {F}({\boldsymbol{W}})$ , 那么${\boldsymbol{W}} = {{{\boldsymbol W}_{n}}}$ ; 否则$ g = g+1 $ , 转到b).算法2定义了保证投影矩阵半正交性的投影算子
$P({\boldsymbol{W}}) = {\boldsymbol{W}}({\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}})^{-\frac{1}{2}}$ , 即$(P({\boldsymbol{W}}))^{\rm{T}} P({\boldsymbol{W}}) = {{{\boldsymbol I}_m}}$ . 从算法1可知, 算法1涉及函数$ F({\boldsymbol{W}}) $ 的计算和算法2的运行. 计算$ F({\boldsymbol{W}}) $ 的复杂度为${\rm{O}}(c^2dm+ndm)$ 以及算法2的复杂度在于梯度的计算. 梯度计算的复杂度为${\rm{ O}}(c^2dm+ndm)$ . 这样算法1的计算复杂度为${\rm{O}}(T_1 ((c^2dm+ndm)+T_2 (c^2dm+ndm)))$ , 其中$ T_2 $ 为算法2的迭代次数以及$ T_1 $ 为算法1的迭代次数.2.3 正则化乐观判别分析
正则化对抗判别分析探索了不确定集中的对抗概率分布, 这实际上优化考虑了训练集中位于类边界附近的样本(远离类中心的样本). 然而当数据集包含离群点时, 这些离群点可能远离各类中心. 在这种情况下, 优先考虑类中心附近的样本是有益的, 即对接近类中心附近的样本分配大的采样概率. 不同于第2.1节中的模型, 本小节试图在不确定集中寻找另外一种概率分布, 这对应于优先考虑类中心附近的样本点. 因此借助不确定集以及类内和类间信息可定义以下优化问题:
$$ \begin{split} &\max\limits_{{\boldsymbol{W}}} \max\limits_{p_{ij} } H_1 ({\boldsymbol{W}},p_{ij} ): = -\eta KL({\boldsymbol{p}}| {\boldsymbol{q}})+\\ &\qquad\sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} } } \omega _{ij} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )} \|_s^s \\ &{\rm{s. t.}} \ \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} = 1} } , p_{ij} \ge 0, {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split} $$ (23) $$ \begin{split} &\min\limits_{{\boldsymbol{W}}, u_{ik}} H_2 ({\boldsymbol{W}},u_{ik} ): = \sum\limits_{i = 1}^c {\sum\limits_{k = 1}^{n_i } {\lambda _i } u_{ik} } \ln \frac{u_{ik} }{v_{ik} }+\\ &\qquad\sum\limits_{i = 1}^c {\sum\limits_{k = 1}^{n_i } {u_{ik} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )} \|_r^r }} \\ &{\rm{s.t}}. \ {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m , \sum\limits_{k = 1}^{n_i } {u_{ik} = 1}, u_{ik} \ge 0 \end{split} $$ (24) 模型(23)优先考虑了距离大的类中心对, 这实际上优先考虑区分性比较好的类. 因为
$ KL(p|q) $ 取非负值, 这不能从$ H_1({\boldsymbol{W}},p_{ij} ) $ 的定义得出其非负性. 对于模型(24), 它优先考虑区分性比较好的样本, 即对类中心附近的样本赋予大的采样概率和类边界附近的样本赋予小的采样概率. 当处理的数据包含异常点或噪声时, 它优先考虑了那些可能不是异常点的样本, 即对异常点赋予小的采样概率. 因为KL散度是非负的, 从式(24)知,$ H_2 ({\boldsymbol{W}},u_{ik} ) $ 不小于零. 根据(23)和(24)可建立以下单目标函数:$$ \begin{split} &\min\limits_{{\boldsymbol{W}}} H({\boldsymbol{W}}): = \frac{\min _{u_{ik} } H_2 ({\boldsymbol{W}},u_{ik} )}{\max _{p_{ij} } H_1 ({\boldsymbol{W}},p_{ij} )}\\ &{\rm{s.t}}. \ {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m, \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} = 1} } \\ &p_{ij} \ge 0, u_{ik} \ge 0, \sum\limits_{k = 1}^{n_i } {u_{ik} = 1} \end{split} $$ (25) 从(23), (24)和(25)知, 外层优化(优化
$ {\boldsymbol{W}} $ )和内层优化(优化$ u_{ik},p_{ij}) $ 的目标有一致的性质. 根据不确定规划中的乐观模型的概念, 本文将模型(25)称为正则化乐观LDA(Regularized optimistic LDA, ROLDA). 内层优化取得的概率分布被称为不确定集的乐观概率分布. 模型(25)利用不确定集优先考虑类中心附近的样本点. 对训练集而言, 模型(25)优先考虑了区分性好的类和样本. 如果数据集包含异常点或噪声, 那么这些异常点或噪声可能远离类中心且具有较低的采样概率. 因此模型(25)在某种程度上能抑制异常点或噪声. 模型(25)是非凸优化问题, 同样地也采用了广义Dinkelbach算法求解模型(25). 求解式(25)涉及下面优化子问题:$$ \begin{split} &\bar {H}(\gamma _t ) = \min\limits_{{\boldsymbol{W}}} \{\min\limits_{u_{ik} } H_2 ({\boldsymbol{W}},u_{ik} )-\\ &\qquad\gamma _t \max\limits_{p_{ij} } H_1 ({\boldsymbol{W}},p_{ij} )\}\\ &{\rm{s.t}}.\ \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} = 1} } ,\sum\limits_{k = 1}^{n_i } {u_{ik} = 1}\\ &p_{ij} \ge 0, u_{ik} \ge 0, {\boldsymbol{W}}^{\rm{T}} {\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split} $$ (26) 其中
$ \gamma_t $ 是来源于$ H({\boldsymbol{W}}) $ 的值. 函数$ H_1({\boldsymbol{W}},p_{ij}) $ 关于变量$ p_{ij} $ 是强凹函数, 函数$ H_2({\boldsymbol{W}},u_{ik}) $ 关于变量$ u_{ik} $ 是强凸函数. 这样$ p_{ij} $ 和$ u_{ik} $ 存在唯一解, 分别表示为:$$ p_{ij} = \frac{q_{ij} \exp (\omega _{ij} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )} \|_s^s /\eta )}{\sum\limits_{i<j} {q_{ij} \exp (\omega _{ij} \| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{m}}_i -{\boldsymbol{m}}_j )} \|_s^s /\eta } )} $$ (27) $$ u_{ik} = \frac{v_{ik} \exp (-\left\| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )} \right\|_r^r /\lambda _i )}{\sum\limits_{k = 1}^{n_i } {v_{ik} \exp (-\| {{\boldsymbol{W}}^{\rm{T}}({\boldsymbol{x}}_k^i -{\boldsymbol{m}}_i )} \|_r^r /\lambda _i } )} $$ (28) 因为简化
$ H_1({\boldsymbol{W}},p_{ij} ) $ 和$ H_2({\boldsymbol{W}},u_{ik} ) $ 会导致模型是复杂的非线性问题, 所以没有借助式(27)和(28)简化$ H_1({\boldsymbol{W}},p_{ij} ) $ 和$ H_2({\boldsymbol{W}},u_{ik}) $ . 注意到如果把式(27)代入$ H_1 ({\boldsymbol{W}},p_{ij} ) $ , 那么可得出$ \max _{p_{ij} } H_1 ({\boldsymbol{W}},p_{ij} ) $ 是非负的. 如果把式(28)代入$ H_2 ({\boldsymbol{W}},u_{ik}) $ , 那么可得出$ min _{u_{ik} }H_2({\boldsymbol{W}},u_{ik}) $ 是非负的. 因此$ \gamma_t $ 是非负的. 考虑到$ \gamma _t $ 的非负性, 模型(26)可转化为下面的优化问题:$$ \begin{split} &\min\limits_{{\boldsymbol{W}}} \min\limits_{u_{ik}, p_{ij} } \{H_2 ({\boldsymbol{W}},u_{ik} )-\gamma _t H_1 ({\boldsymbol{W}},p_{ij} )\}\\ &{\rm{s.t}}. \ \sum\limits_{i = 1}^c {\sum\limits_{j = i+1}^c {p_{ij} = 1} } , \sum\limits_{k = 1}^{n_i }{u_{ik} = 1}\\ &p_{ij} \ge 0, u_{ik}\ge 0, {\boldsymbol{W}}^{\rm{T}}{\boldsymbol{W}} = {\boldsymbol{I}}_m \end{split} $$ (29) 模型(29)属于约束的最小化问题. 因为约束集是闭有界集且目标函数是连续的, 模型(29)存在解. 注意到优化变量
$ u_{ik} $ ,$ p_{ij} $ 以及$ {\boldsymbol{W}} $ 的约束是独立的, 这样交替优化算法能有效地求解模型(29). 模型(22)仅涉及优化变量$ {\boldsymbol{W}} $ 且目标函数是复杂的非线性优化问题, 但模型(29)涉及三组优化变量, 每一组优化变量对应一个优化子问题. 算法3概括了求解模型(29)的过程.算法3. 求解式(29)的交替优化算法
1) 给定初始
$ p_{ij} $ 和$ u_{ik} $ ,2) 重复直到收敛
a) 固定
$ p_{ij}\; $ 和$ u_{ik} $ , 更新$ {\boldsymbol{W}} $ ,b) 固定
$ u_{ik} $ 和$ {\boldsymbol{W}} $ , 通过(27)更新$ p_{ij} $ ,c) 固定
$ p_{ij} $ 和$ {\boldsymbol{W}} $ , 通过(28)更新$ u_{ik} $ .如果
$ s = r = 2 $ , 算法1中的步骤a)可通过特征值分解取得投影矩阵$ {\boldsymbol{W}} $ . 在其他情况下, 可通过在Stiefel流形上的梯度下降法取得投影矩阵$ {\boldsymbol{W}} $ . 不同于正则化对抗LDA的求解, 如果采用Stiefel流形上的梯度下降法取得$ {\boldsymbol{W}} $ [41], 此时函数的梯度并不包含指数函数, 这实际上把指数函数放在了$ p_{ij} $ 和$ u_{ik} $ 的更新上. 在$ s = r = 2 $ 情况下, 取得$ W $ 的计算复杂度为${\rm{O}}(d^3)$ . 当样本的维数较大时, 执行特征值分解可能比较耗时, 那么可采用流形上的梯度下降法取得$ {\boldsymbol{W}} $ . 采用Stiefel流形上的梯度下降法取得$ {\boldsymbol{W}} $ 的复杂度为${\rm{O}}(T_g(c^2dm+ndm))$ , 其中$ T_g $ 为梯度下降法的迭代次数. 更新$ p_{ij} $ 和$ u_{ik} $ 的计算复杂度分别为${\rm{ O}}(c^2dm)$ 和${\rm{O}}(ndm)$ . 这样如果$ s = r = 2 $ 且采用特征值分解取得投影矩阵$ {\boldsymbol{W}} $ , 那么算法的计算复杂度为${\rm{O}}(T_3 (c^2dm+ndm+d^3))$ , 其中$ T_3 $ 为算法3的迭代次数. 如果采用Stiefel流形上的梯度下降法取得投影矩阵$ {{\boldsymbol{W}}} $ , 那么算法3的计算复杂度为${\rm{O}}(T_3 (c^2dm+ndm+T_g (c^2dm+ndm)))$ .2.4 与其他线性判别分析的关系
从式(17)和(18)可得到如下推论.
推论 1. 假定
$ p_{ij}^\ast $ 和$ u_{ik}^\ast $ 如式(17)和(18)那样定义, 那么可得出$$ \mathop {\lim }\limits_{\eta \to \infty } p_{ij}^\ast = q_{ij} , \quad \mathop {\lim }\limits_{\lambda _i \to \infty } u_{ik}^\ast = v_{ik} $$ 推论1说明了当参数
$ \eta $ 和$ \; \lambda _i $ 趋向正无穷大时,$ p_{ij} $ 和事先定义的$ q_{ij} $ 一致, 以及$ u_{ik} $ 和事先定义的$ v_{ik} $ 一致. 在这种情况下, 根据$ q_{ij} $ 和$ v_{ik} $ 定义可得出$ p_{ij} = 2/(c(c-1)) $ 和$ u_{ik} = 1/n_i $ . 此时正则化对抗LDA退化为不同范数的LDA. 即当$ s = r = 2 $ 时, 模型(14)成为L2范数的LDA; 当$ s = r = 1 $ 时, 模型(14)成为L1范数的LDA. 当参数$ \eta $ 和$ \lambda _i $ 趋向0时, 模型(14)变成了最强对抗概率分布下的线性判别分析. 这样参数$ \eta $ 和$ \lambda_i $ 的变化为模型(14)和各种范数的LDA建立了联系. 因此RALDA推广了以前的模型.从式(27)和(28)可知: 当参数
$ \eta $ 和$ \lambda_i $ 趋向正无穷大时,$ p_{ij} = 2/(c(c-1)) $ 和$ u_{ik} = 1/n_i $ . 此时正则化乐观LDA退化为不同范数的LDA. 即$ s = r = 2 $ 时, 模型(25)成为L2范数的LDA; 当$ s = r = 1 $ 时, 模型(25)成为L1范数的LDA. 当参数$ \eta $ 和$ \lambda _i $ 趋向0时, 模型(25)变成了最乐观概率分布下的线性判别分析. 从式(17)和(18), 以及式(27)和(28)可知, RALDA和ROLDA中的$ p_{ij} $ 和$ u_{ik} $ 是不同的. 从(17)可知类边界附近的样本具有大的采样概率; 从(28)可知类中心附近的样本具有大的采样概率. 这样模型(14)优先考虑那些不利区分的样本, 而模型(25)优先考虑了那些有利区分的样本. 尽管这两种模型的机制是不同的, 但是当参数趋向无穷时, 它们是等价的.3. 实验结果
本节通过在数据集上的一系列实验来评估所提出模型的有效性. 当涉及到分类问题时, 本文采用了最近邻分类器且度量准则采用了欧氏范数. 为了进行比较, 本文编程实现了几种鲁棒的特征提取方法, 包括L1-LDA[6]、最不利LDA (Worst-case LDA, WLDA[16])、LDA-L1[28]和L21-LDA[34]. L1-LDA 和LDA-L1的参数设置与文献[34]中的相同. 注意到提出的模型涉及多个参数. 为了简单起见, 令参数
$ \lambda = \lambda _1 = \cdots = \lambda _c $ , 即所有的类都被赋予了相同的参数$ \lambda $ , 这样模型的参数被约简为两个参数$ \lambda $ 和$ \eta $ , 两个参数取自集合$ {\{}10^{-3},10^{-2},10^{-1},1,10,10^2,10^3{\}} $ . 对于参数$ r $ 和$ s $ , 本文只考虑参数取特殊值的情况, 即把$ s = r = 1 $ 和$ s = r = 2 $ 的RALDA分别简记为L1RALDA和L2RALDA,以及把$ s = r = 1 $ 和$ s = r = 2 $ 的ROLDA分别简记为L1ROLDA和L2ROLDA. 迭代方法的初始解采用了LDA的正交化投影矩阵. 实验环境是一台内存为8 GB的奔腾1.6 GHz计算机和Matlab (7.0.0)编程语言.3.1 人脸和物体数据集的实验
本小节在四个人脸数据库(Yale、ORL、UMIST和AR)上和一个物体数据库(COIL)上测试了提出的模型. ORL人脸数据库包含40个人, 每个人都有10幅不同的图像, 所有的图像都是在一个均匀背景下拍摄的. UMIST人脸数据库包含20个人的564幅人脸图像, 每个人都有不同的种族、性别和外貌, 例如不同的表情、照明、戴眼镜/不戴眼镜、留胡须/不留胡须、不同的发型. 耶鲁大学的人脸数据库包含15个人的165幅灰度图像, 其人脸图像涉及光照条件和面部表情的变化. AR人脸数据库包含4000多幅彩色人脸图像, 每个人有不同的面部表情、光照条件和遮挡. AR人脸图像在两个不同的时间段拍摄且时间间隔是两周, 每阶段获取每个人的13幅图像. COIL数据库包含1440幅灰度图像和20个物体的黑色背景, 每个物体有72幅不同的图像. 为了提高计算效率, 将所有图像归一化为
$ 32\times32 $ 大小的灰度图像.考虑到提出的算法是一种迭代算法, 第一组实验测试了算法的收敛性. 实验数据来自Yale数据集. 我们随机选取每个人的四幅图像组成训练集, 其它图像用于测试. 假设约简维数为14. 训练集中有一半的样本被矩形噪声污染. 矩形噪声包含等概率的白点和黑点, 它们在图像中的位置是随机的且块的大小是
$ 32\times32 $ 像素. 在实施算法2时, 令$ \beta = 0.5 $ . 图1列出了L2RALDA, L1RALDA, L2ROLDA和L1ROLDA四种方法的收敛性. 为了简单性, 在这组实验中令$ \lambda = \eta $ .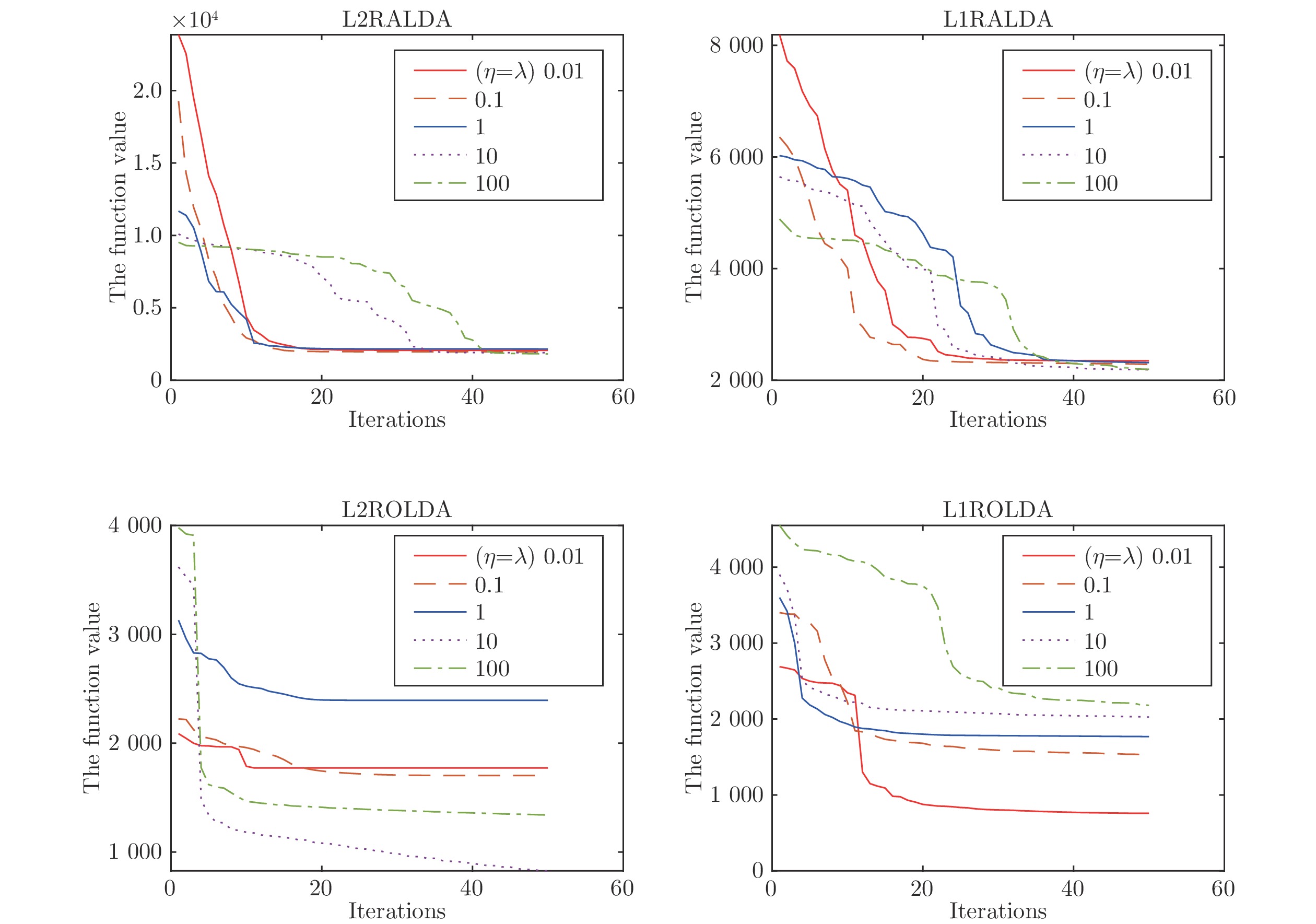 图 1 L2RALDA, L1RALDA, L2ROLDA和L1ROLDA的收敛性分析Fig. 1 Convergence analysis of L2RALDA, L1RALDA, L2ROLDA and L1ROLDA
图 1 L2RALDA, L1RALDA, L2ROLDA和L1ROLDA的收敛性分析Fig. 1 Convergence analysis of L2RALDA, L1RALDA, L2ROLDA and L1ROLDA从图1可知, 四种算法的目标函数值随着迭代次数的增加而递减. 当迭代次数超过某一数值时, 目标函数值几乎保持稳定. 文献[27]指出: 当出现小样本的奇异性问题时, 采用梯度上升法求解L1范数的判别分析(目标函数为最大化问题)可能使得目标函数值发生振荡现象. 在这组实验中, 图像的维数远远大于训练样本的个数, 这存在奇异性问题, 但图1显示了提出的算法的目标函数值并没有出现振荡的情况, 这意味着提出的算法在某种程度上避免了小样本的奇异性问题. 从图1可观察到基于L1范数的模型比基于L2范数的模型一般需要更多的迭代次数, 这是因为基于L1范数的模型有不可微的目标函数. 注意到不同的参数也影响算法的收敛速度. 因此在后面的实验中, 本文设定算法的停止条件为最大迭代次数为50或目标函数值的相对改变不超过
$ 10^{-4} $ .在约简的参数下提出的模型有两个重要参数
$ \lambda $ 和$ \eta $ . 这组实验探索了参数$ \lambda $ 和$ \eta $ 对识别性能的影响. 对于图像识别问题, 为了降低计算代价, 采用主成分分析降维但保持图像的百分之九十九的能量. 对于耶鲁数据集, 随机选取每个人的四幅图像组成训练集, 其他样本用于测试. 假设约简维数为14, 固定$ r = s = 1 $ 或$ r = s = 2 $ , 参数$ \lambda $ 和$ \eta $ 从集合${\{}10^{-3}, $ $ 10^{-2},10^{-1},1,10,10^2,10^3{\}}$ 中取值. 因此每个参数取七个值. 实验结果来自十次的平均实验. 图2显示了每种算法随参数变化的错误率. 在图2的每个子图中, 其中$ x $ 轴表示对数尺度的参数$ \lambda $ ,$ y $ 轴表示对数尺度的参数$ \eta $ , 以及$ z $ 轴表示算法的错误率.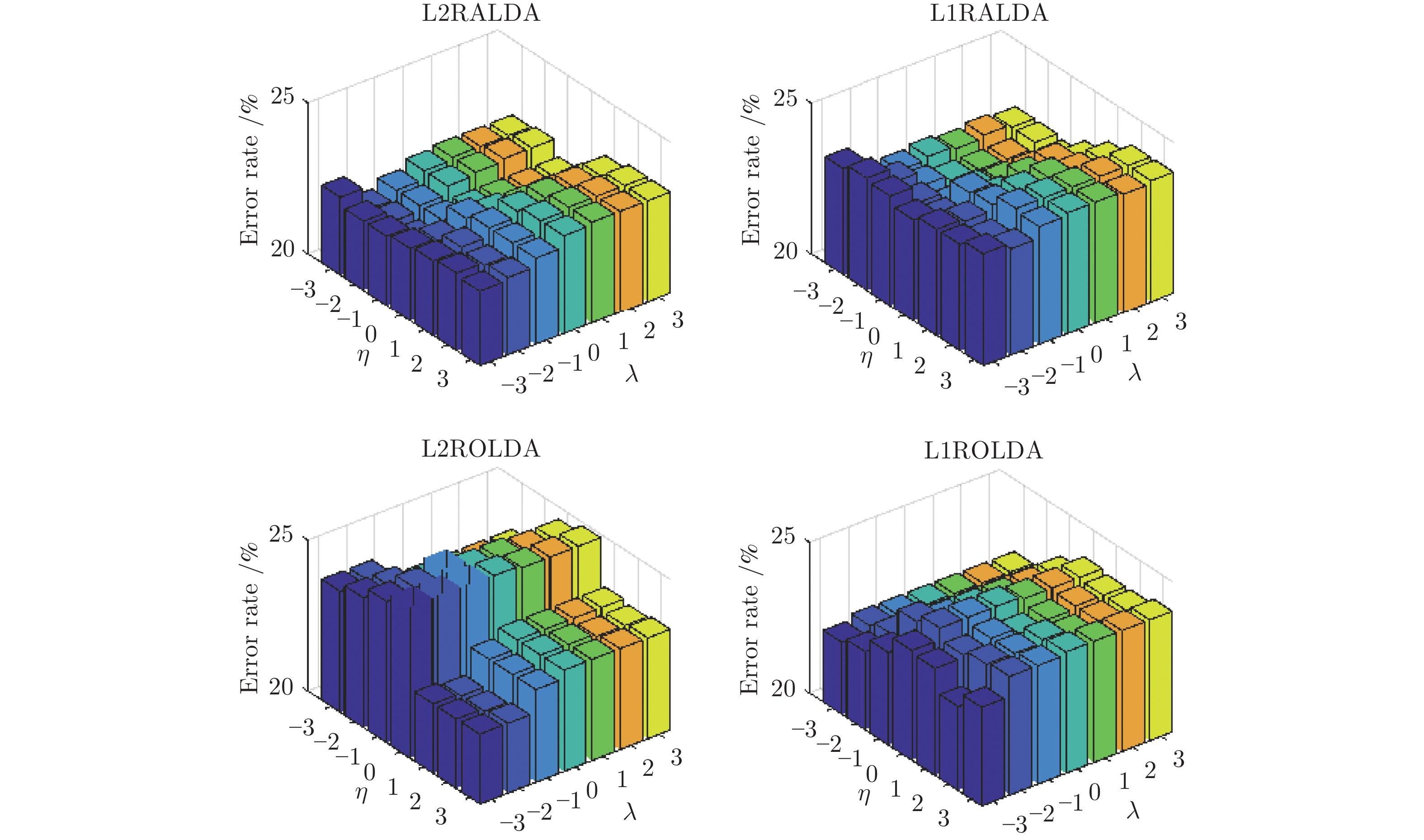 图 2 L2RALDA, L1RALDA, L2ROLDA和L1ROLDA的错误率与参数的关系Fig. 2 Error rates of L2RALDA, L1RALDA, L2ROLDA and L1ROLDA versus the parameters
图 2 L2RALDA, L1RALDA, L2ROLDA和L1ROLDA的错误率与参数的关系Fig. 2 Error rates of L2RALDA, L1RALDA, L2ROLDA and L1ROLDA versus the parameters从图2可看出, 模型的错误率随着参数的变化而变化. 当参数
$ \lambda $ 和$ \eta $ 取较小值时, L1ROLDA的错误率较低. 对于L2ROLDA, 如果参数$ \eta $ 取较大值且参数$ \lambda $ 取较小值, 则分类性能较好. 对于L1RALDA, 如果参数$ \eta $ 取较小值且参数$ \lambda $ 取较大值, 则在很大范围内获得较低的错误率. 对于L2RALDA, 其参数也影响算法的性能. 这组实验表明了L1ROLDA和L1RALDA的作用机理是不同的. 因此在实际应用中需要选择合适的参数才能获得最佳的分类性能, 这可通过交叉验证等方法来获得最佳参数.为了比较各种模型的特征提取性能, 在Yale、ORL、UMIST和COIL数据集上随机选取每个人的4幅图像构成训练集, 其余图像用作测试目的. 为了评价算法的鲁棒性, 在Yale、ORL、UMIST和COIL数据集上人工模拟了遮挡图像, 那就是训练集中有一半的样本被矩形噪声污染. 矩形噪声包含等概率的白点和黑点, 它们在图像中的位置是随机的, 块的大小是
$ 20 \times 20 $ 像素. 由于AR数据集包含实际遮挡的情况, 本文考虑了120个人的两种遮挡情况: 其一是太阳镜遮挡, 其二是围巾遮挡. 在AR数据集上, 对于太阳镜遮挡, 从第一时间段的7幅无遮挡图像中随机选择3幅图像, 然后将这些图像与随机选择的3幅太阳镜遮挡的图像构成训练集. 第二时间段得到的7幅无遮挡的图像被用做测试集. 因此每个人的训练样本数为6. 对于围巾遮挡, 从第一时间段的7幅无遮挡图像中随机选择3幅图像, 然后将这些图像与随机选择的3幅围巾遮挡图像构成训练集, 第二时间段得到的7幅无遮挡的图像被用做测试集.图3显示了在Yale数据库上几种算法的错误率随约简特征变化的情况. 表1列出了各种方法的最好性能. 另外表1中给出了各个人脸数据集上和COIL数据集上的最好性能. 每种方法的参数在额外的五次运行上得到. 表1的实验结果来自20次随机运行的平均, 其中C- 表示污染的数据集.
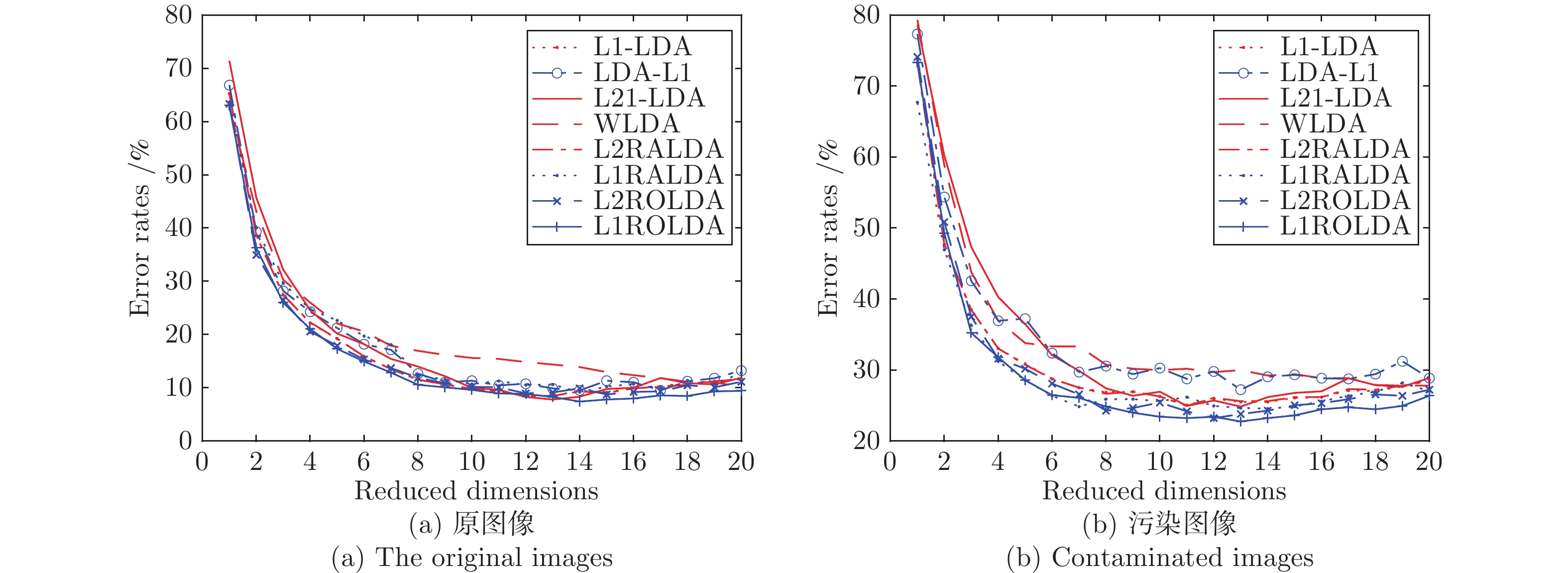 图 3 数据集上不同方法随维数变化的错误率Fig. 3 Error rates of various methods with varying dimensions on the Yale database表 1 各种方法在原始数据集和污染数据集上的平均错误率(%)和标准偏差Table 1 Average error rates (%) of various methods and their standard deviations on the original and contaminated data sets
图 3 数据集上不同方法随维数变化的错误率Fig. 3 Error rates of various methods with varying dimensions on the Yale database表 1 各种方法在原始数据集和污染数据集上的平均错误率(%)和标准偏差Table 1 Average error rates (%) of various methods and their standard deviations on the original and contaminated data setsData sets L1-LDA LDA-L1 L21-LDA WLDA L2RALDA L1RALDA L2ROLDA L1ROLDA Yale 8.48 (3.42) 9.52 (3.47) 7.81 (4.21) 10.19 (3.24) 8.48 (4.25) 9.19 (3.96) 8.76 (3.84) 7.46 (3.10) C-Yale 24.95 (4.76) 25.05 (5.05) 24.86 (4.98) 27.81 (4.87) 27.24 (4.92) 24.57 (4.58) 23.24 (4.49) 22.76 (4.12) ORL 9.89 (2.13) 0.21 (2.06) 8.86 (2.45) 10.33 (2.02) 8.98 (2.15) 8.34 (2.12) 9.66 (2.18) 9.19 (1.92) C-ORL 14.62 (2.41) 15.27 (2.32) 13.98 (2.73) 15.92 (2.85) 15.82 (2.67) 13.13 (2.63) 13.45 (2.49) 12.58 (2.52) UMIST 8.99 (2.09) 9.23 (2.07) 8.87 (2.75) 10.15 (2.02) 9.42 (2.15) 8.83 (2.12) 9.07 (2.18) 8.98 (1.99) C-UMIST 24.52 (3.89) 26.33 (3.93) 22.98 (3.85) 29.23 (3.84) 23.39 (4.04) 23.52 (3.92) 23.22 (3.88) 21.90 (3.72) COIL 18.45 (2.02) 19.46 (1.64) 18.21 (1.65) 19.97 (1.79) 19.05 (1.64) 17.98 (1.46) 18.31 (2.12) 17.42 (2.14) C-COIL 28.34 (3.41) 29.66 (3.49) 27.35 (3.55) 29.01 (3.15) 28.46 (3.43) 27.65 (2.43) 28.32 (3.01) 26.22 (3.32) AR-sunglasses 9.26 (1.73) 9.38 (1.46) 8.05 (1.57) 10.02 (1.70) 9.21 (1.53) 9.01 (1.25) 8.25 (1.23) 7.33 (1.79) AR-scarf 21.29 (1.10) 20.81 (1.25) 19.03 (1.28) 28.02 (0.92) 26.35 (0.89) 20.34 (1.34) 19.38 (1.24) 17.24 (1.34) 从图3可知, 随着约简维数的增加各种方法的错误率下降, 但过多的特征反而使得错误率上升. 这表明特征的维数是一个重要的参数. 从表1可看出, 对于原图像集, L1RALDA在ORL和UMIST数据集上可获得很好的分类效果, 这表明在适当的条件下, 优先考虑边界点的判别分析算法是合理的. 当部分图像被污染后, L1ROLDA在大多数情况下优于其他方法. 在实际遮挡的AR数据上, 围巾遮挡比太阳镜遮挡导致更大的错误率.
同其他方法比较, L1ROLDA不仅采用了L1范数的损失函数, 而且考虑了样本的采样概率, 其采样概率在不确定集中自适应地变化, 从而得到较好的效果. 从表1可知, 当部分图像被污染后, 各种方法错误率的标准偏差一般大于原始图像上各种方法错误率的标准偏差. 这表明污染的数据使得各种方法的性能具有更大的不确定性.
这组实验比较了各种算法在五个图像数据集上的时间消耗. 提出算法的停止条件如前面所述. 在ORL, UMIST, Yale和COIL数据集上假定约简维数为40. 由于AR数据集包含更多的类数, 其约简维数设定为80. 图4显示了各种算法在五个数据集上的运行时间(单位: 秒).
从图4可看出, WLDA的运行时间远远高于其它算法的运行时间, 这是因为这种方法采用了二阶锥规划. L1-LDA和LDA-L1都采用了贪婪算法取得多个投影向量, 它们的运行时间相差不大. 在Yale和ORL数据集上, L21LDA的运行时间是最少的, 但在UMIST和COIL数据集上, L2ROLDA需要的时间最少. 由于在AR数据集上的约简维数为80且类数较多, 每种方法的训练时间明显大于在其他数据集上的训练时间. 一般来说, L1RALDA和L1ROLDA训练时间分别大于L2RALDA和L2ROLDA的训练时间, 这是因为L1RALDA和L1ROLDA采用了L1范数导致其目标函数是不可微的, 而L2RALDA和L2ROLDA的目标函数是可微函数.
3.2 UCI数据集上的实验
这组实验使用的数据集来自UCI机器学习库. 这些数据集已被广泛用于评估一些学习算法的性能. 本文在8个数据集上测试了提出的模型. 这8个数据集分别是Australia (690样本/14特征/2类), Diabetes (768/8/2), German (1000/24/2), Heart (270/13/2), Liver(345/6/2), Sonar (208/60/2), WPBC (198/33/2)和Waveform (5000/21/3). 不同于图像数据集, 对于这些数据集, 训练样本的维数远远小于训练样本的个数, 即小样本的奇异性问题不会出现. 每个数据集样本的属性被转化为[−1, 1]区间. 对于每个数据集, 随机选取70% 的样本构成训练集, 剩下的样本作为测试集. 除了原始数据集, 我们也模拟了训练集中样本的某些特征被污染的情况. 具体来说, 训练集中一半样本的50% 特征被替换为由−1和1组成的随机噪声.
每种方法的参数在训练集上通过五叠交叉验证方法学习得到. 实验性能取自十次随机实验的平均结果. 为了比较两种算法在同一个数据集上的性能, 在显著性水平0.05的情况下计算L1ROLDA和其他算法的配对
$ t $ 检验的$ p $ -值. 如果$ p $ - 值大于0.05时, 这表明L1ROLDA和其他算法没有显著的差别. 当$ p $ -值小于0.05时, 这表明L1ROLDA和其他算法存在显著差别. 表2和表3列出在原始数据集和污染数据集上的实验结果, 其实验结果包括平均正确率(Average correct rates, ACR)和标准偏差(standard deviations,SD)以及L1ROLDA和其他方法的配对$ t $ 检验的$ p $ -值.表 2 各种方法在原始数据集上的平均正确率(ACR(%)), 标准偏差(SD)和$ p $ -值Table 2 Average correct rates (ACR(%)), standard deviations (SD), and$ p $ -values of various methods on the original data setsData sets L1-LDA LDA-L1 L21-LDA WLDA L2RALDA L1RALDA L2ROLDA L1ROLDA ACR (SD) ACR (SD) ACR (SD) ACR (SD) ACR (SD) ACR (SD) ACR (SD) ACR (SD) $ p $-值 $ p $-值 $ p $-值 $ p $-值 $ p $-值 $ p $-值 $ p $-值 $ p $- 值 Australian 82.22 (3.44) 80.15 (3.36) 83.44 (3.57) 80.12 (3.29) 79.15 (3.61) 82.99 (3.46) 79.77 (3.27) 84.12 (3.63) 7.98$ \times 10^{-3} $ 3.13$ \times 10^{-5} $ 0.43 3.00$ \times 10^{-5} $ 1.45$ \times 10^{-5} $ 0.028 1.78$ \times 10^{-5} $ — Diabetes 72.55 (4.51) 71.68 (4.62) 73.28 (4.33) 70.19 (4.40) 71.18 (4.71) 72.87 (4.26) 71.99 (4.27) 72.68 (4.39) 0.22 0.15 0.84 0.0084 0.10 0.46 0.19 — German 74.45 (3.66) 72.02 (3.69) 74.68 (3.88) 69.34 (3.77) 72.06 (3.54) 74.99 (3.49) 72.67 (3.66) 73.74 (3.48) 0.03 1.30$ \times 10^{-3} $ 0.04 6.39$ \times 10^{-4} $ 7.84$ \times 10^{-3} $ 0.04 0.01 — Heart 75.89 (5.11) 74.36 (5.13) 77.32 (5.16) 73.53 (5.17) 74.22 (5.22) 77.52 (5.34) 75.67 (5.54) 78.98 (5.19) 8.94$ \times 10^{-4} $ 5.99$ \times 10^{-5} $ 0.012 3.72$ \times 10^{-6} $ 4.81$ \times 10^{-5} $ 0.043 1.14$ \times 10^{-4} $ — Liver 65.25 (4.33) 63.27 (4.78) 64.34 (4.99) 62.87 (4.60) 62.99 (4.71) 64.12 (4.37) 63.01 (4.48) 64.54 (4.29) 0.52 0.89 0.28 0.074 0.08 0.68 0.51 — Sonar 72.11 (4.98) 70.99 (4.96) 73.16 (5.52) 70.21 (5.43) 70.68 (5.06) 72.45 (5.21) 70.99 (5.29) 73.22 (5.16) 0.06 6.07$ \times 10^{-4} $ 0.72 3.80$ \times 10^{-4} $ 4.45$ \times 10^{-4} $ 0.074 6.69$ \times 10^{-4} $ — Waveform 83.27 (1.99) 82.18 (2.12) 85.12 (1.88) 81.23 (1.94) 81.53 (2.15) 83.69 (2.22) 81.49 (2.10) 86.28 (1.98) 1.93$ \times 10^{-5} $ 8.97$ \times 10^{-6} $ 0.08 1.42$ \times 10^{-6} $ 1.83$ \times 10^{-6} $ 7.10$ \times 10^{-5} $ 1.57$ \times 10^{-6} $ — WPBC 77.89 (5.19) 75.32 (5.23) 78.23 (5.44) 72.12 (5.37) 73.14 (5.21) 79.33 (5.36) 72.99 (5.28) 77.89 (5.29) 0.47 1.67$ \times 10^{-4} $ 0.17 1.19$ \times 10^{-5} $ 1.58$ \times 10^{-5} $ 4.76$ \times 10^{-3} $ 6.08$ \times 10^{-6} $ — 表 3 各种方法在污染数据集上的平均正确率(ACR(%)), 标准偏差(SD)和$ p $ -值Table 3 Average correct rates (ACR(%)), standard deviations (SD), and$ p $ -values of various methods on the contaminated data setsData sets L1-LDA LDA-L1 L21-LDA WLDA L2RALDA L1RALDA L2ROLDA L1ROLDA ACR (SD) ACR (SD) ACR (SD) ACR (SD) ACR (SD) ACR (SD) ACR (SD) ACR (SD) $ p $-值 $ p $-值 $ p $-值 $ p $- 值 $ p $-值 $ p $-值 $ p $-值 Australian 80.45 (3.56) 78.34 (3.77) 81.65 (3.46) 75.22 (3.89) 77.26 (3.45) 81.78 (3.66) 79.62 (3.78) 82.51 (3.52) 1.99$ \times 10^{-4} $ 7.89$ \times 10^{-6} $ 0.025 6.02$ \times 10^{-7} $ 5.17$ \times 10^{-6} $ 0.04 2.10$ \times 10^{-5} $ — Diabetes 70.63 (4.22) 69.44 (4.29) 70.32 (4.35) 65.26 (4.65) 69.37 (4.60) 70.65 (4.05) 70.38 (4.30) 70.37 (4.41) 0.41 0.055 0.29 7.55$ \times 10^{-5} $ 0.037 0.49 0.39 — German 71.34 (3.48) 70.08 (3.55) 71.76 (3.22) 64.45 (3.79) 70.05 (3.86) 71.09 (3.94) 71.39 (3.68) 72.36 (3.77) 5.08$ \times 10^{-3} $ 0.92$ \times 10^{-3} $ 1.41$ \times 10^{-2} $ 1.30$ \times 10^{-7} $ 1.80$ \times 10^{-3} $ 0.027 0.099 — Heart 72.05 (5.26) 72.24 (5.45) 72.44 (5.13) 66.53 (4.98) 70.22 (5.26) 70.35 (5.39) 71.51 (4.99) 74.88 (5.10) 3.06$ \times 10^{-3} $ 1.58$ \times 10^{-3} $ 8.12$ \times 10^{-3} $ 2.03$ \times 10^{-6} $ 0.35$ \times 10^{-4} $ 1.06$ \times 10^{-4} $ 0.67$ \times 10^{-3} $ — Liver 62.67 (4.33) 60.67 (4.59) 62.53 (4.25) 59.36 (4.78) 60.08 (4.32) 62.04 (4.64) 61.01 (4.13) 63.98 (4.31) 0.047 9.79$ \times 10^{-4} $ 0.039 1.51$ \times 10^{-4} $ 2.75$ \times 10^{-4} $ 0.032 7.22$ \times 10^{-3} $ — Sonar 70.56 (5.71) 68.89 (5.96) 71.37 (5.34) 66.19 (5.39) 68.34 (5.30) 70.32 (5.41) 69.82 (5.27) 71.02 (5.19) 0.17 9.16$ \times 10^{-4} $ 0.55 6.18$ \times 10^{-5} $ 2.34$ \times 10^{-4} $ 0.12 6.99$ \times 10^{-2} $ — Waveform 80.46 (1.89) 79.04 (2.03) 81.08 (1.96) 79.28 (1.89) 80.56 (1.95) 81.75 (2.02) 80.73 (2.11) 82.28 (2.03) 4.47$ \times 10^{-3} $ 1.54$ \times 10^{-5} $ 0.03 4.69$ \times 10^{-5} $ 5.27$ \times 10^{-3} $ 0.18 6.33$ \times 10^{-3} $ — WPBC 73.44 (5.10) 71.35 (5.15) 73.31 (5.27) 70.25 (5.29) 70.21 (5.33) 72.21 (5.39) 70.82 (5.42) 74.76 (5.22) 0.49 2.30$ \times 10^{-2} $ 0.34 3.17$ \times 10^{-3} $ 2.96$ \times 10^{-3} $ 3.59$ \times 10^{-2} $ 8.34$ \times 10^{-3} $ — 从表2可知, L21-LDA在Diabetes数据集上取得最好的性能, L1RALDA在German和WPBC数据集上取得最好的性能, L1ROLDA在Australian, Heart和Waveform数据集上取得最好的性能, L1-LDA在Liver数据集上取得最好的性能, 这表明了没有一种方法在这些数据集上取得一致好的性能. 从表3可知, 当特征被污染后, 每种方法的性能都会存在某种程度的下降. 一般来说基于L2范数方法不比基于L1范数方法好. 从表2和表3的
$ p $ -值可知, L1ROLDA和其它方法是否存在明显的差别. 例如: 从$ p $ -值可知在特征没有被污染的情况下, L1ROLDA和L21LDA在German和Heart数据集上存在统计意义上的差别, 但当特征被污染后, L1ROLDA和L21LDA在Australian, German, Heart, Liver和Waveform数据集上存在统计意义上的差别.当特征被污染后, L1ROLDA方法在多数情况下优于其他方法, 这是因为在不确定集下, 优先考虑了那些有利区分的样本, 这些样本可能不是污染的数据点, 而对离群点赋予较低的采样概率. 因此当数据被污染后, 应当优先选择L1ROLDA方法. 实际上, 当测试RALDA和ROLDA时, 如果在验证数据集上ROLDA的性能远远好于RALDA的性能, 那么说明训练集包含离群点. 在这种情况下, 我们可采用一些去离群点的方法去除训练集中的离群点, 然后再执行特征提取算法.
尽管配对
$ t $ 检验能比较两种算法在同一个数据集上的性能差别, 但是它不能取得多种算法在多个数据集上的性能排序问题. 由于在多个数据集上测试了多种方法, 本文采用Friedman检验[40]评估多种算法的性能. 在Friedman检验中, 如果零假设成立, 即假设所有的算法在性能上是相等的, Friedman统计量可用概率分布来计算. 本文使用关键差别(Critical difference, CD)图[40]比较不同算法的性能. 图5表示了在原始数据和污染数据上的性能分析的CD图. CD图的平均秩提供了算法的性能的排序. 平均秩越小, 算法的性能越好. 从图5(a)可知, L1ROLDA给出了最小的平均秩, 但是L21-LDA的平均秩和L1ROLDA的平均秩相差不大. WLDA有最大的平均秩. 从图5(b)可知, 当数据被污染后, L1ROLDA仍然取得了最小的平均秩, 但L21-LDA的平均秩明显大于L1ROLDA的平均秩. 总的来说, 由于采用了L1范数和优先考虑了类中心附近的样本, 当数据被污染后, 正则化乐观线性判别分析取得最好的性能.4. 结论
本文提出了基于不确定集和混合范数的线性判别分析方法. 不同于以前的方法, 本文借助Kullback-Leibler不确定集描述样本的变化信息, 这样可探索不确定集中的概率分布. 由于样本或类中心的采样概率在不确定集中灵活变化, 从而使得模型适应数据的内在特性. 模型是比率优化和非凸优化问题. 广义Dinkelbach算法被用来求解优化模型. 本文利用投影梯度法或交替优化技术求解算法的优化子问题. 这样算法的收敛性直接来自广义Dinkelbach算法的收敛性. 在图像数据集和UCI数据集上做了一系列实验. 实验结果表明: 在没有污染的数据集上, 由于RALDA考虑了类边界附近的样本, RALDA应当被优先考虑, 但在污染数据集上, ROLDA应当被优先考虑. 由于本文简化了模型中一些参数, 这些参数对模型的性能会产生一定的影响. 今后我们将重点研究如何自动学习多个参数, 并将本文的基本思想推广到其它基于核函数的非线性判别分析和张量判别分析.
-
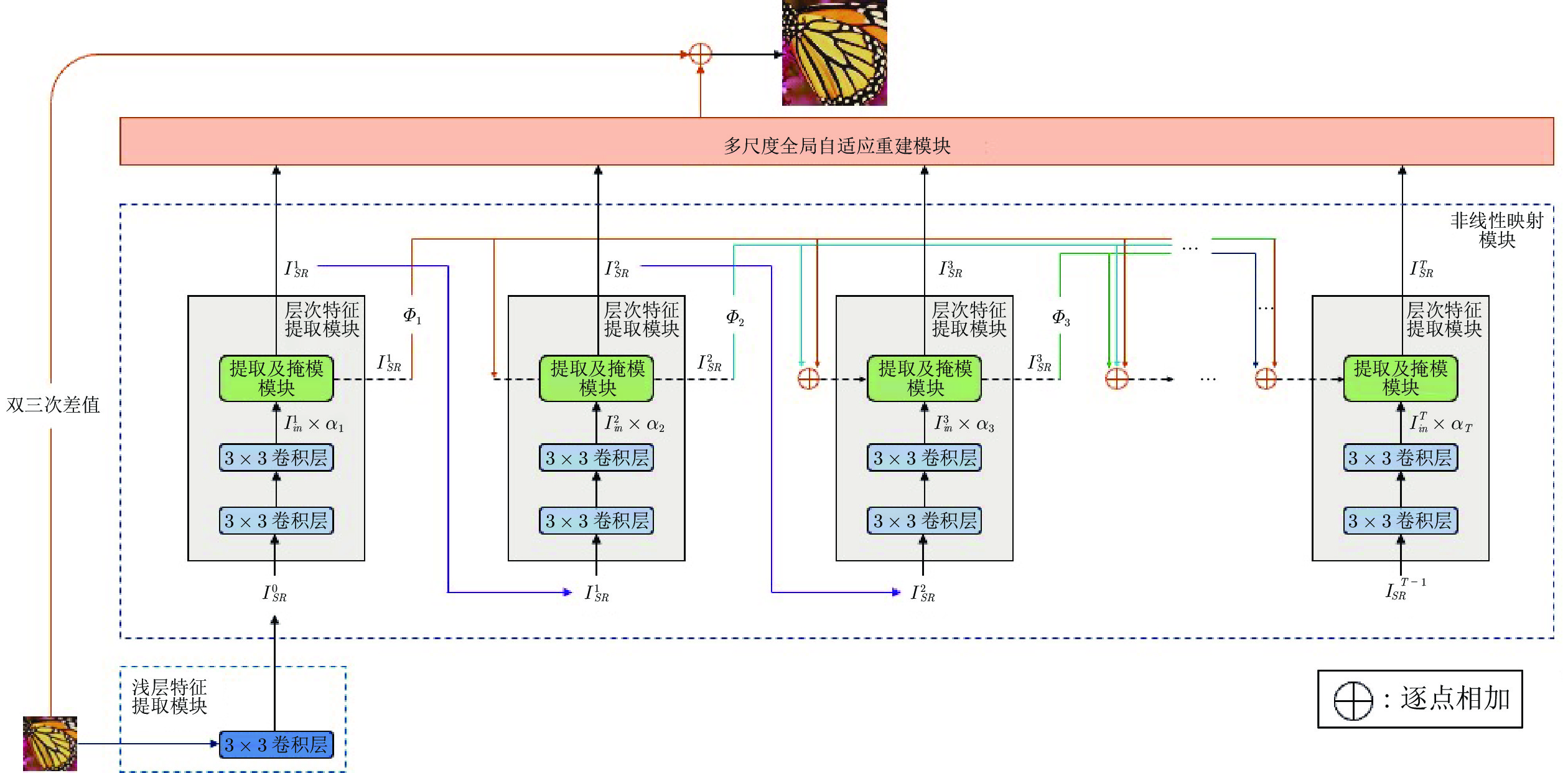
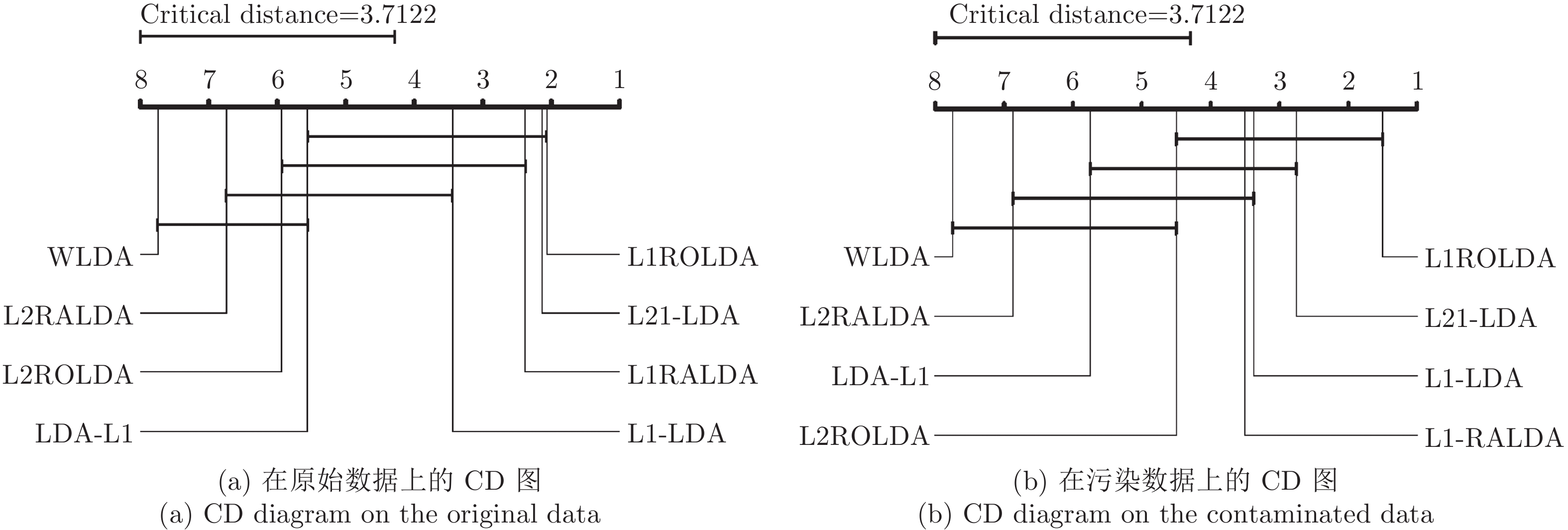
图 1 自适应级联的注意力网络架构(ACAN)
Fig. 1 Adaptive cascading attention network architecture (ACAN)

图 6 非线性映射模块中每个HFEB输出特征的可视化结果
Fig. 6 Visual results of each HFEB's output feature in non-linear mapping
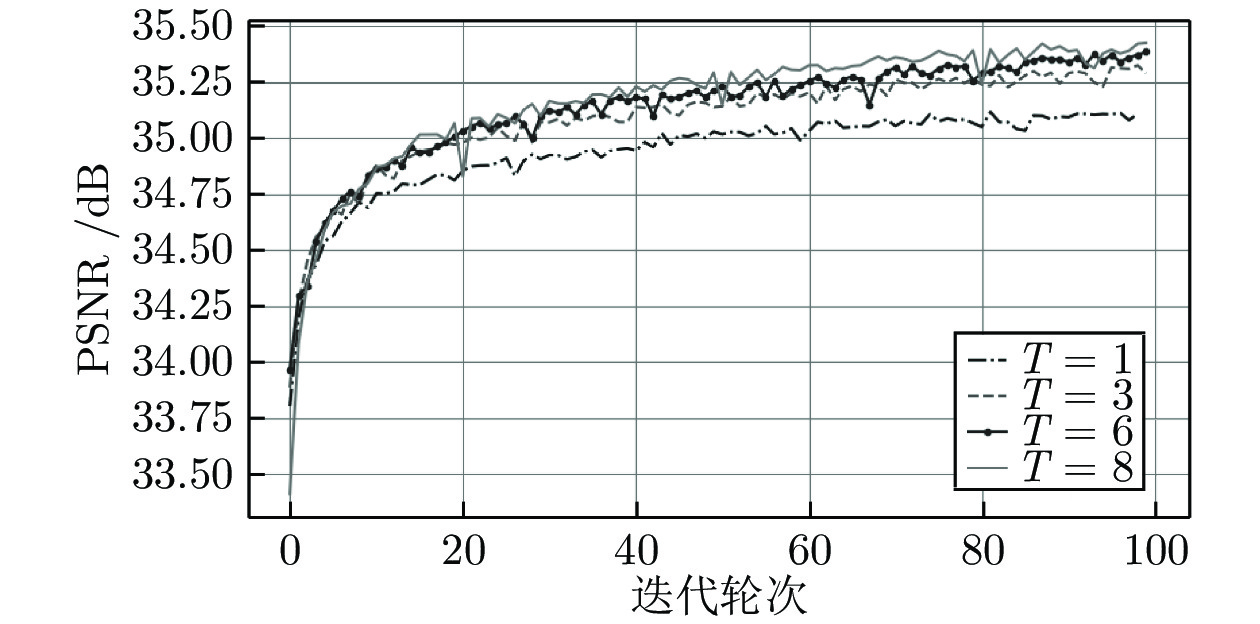
图 7 包含不同个数的HFEB的ACAN在验证集上的性能比较
Fig. 7 Performance comparison of ACAN on validation set with different numbers of HFEB
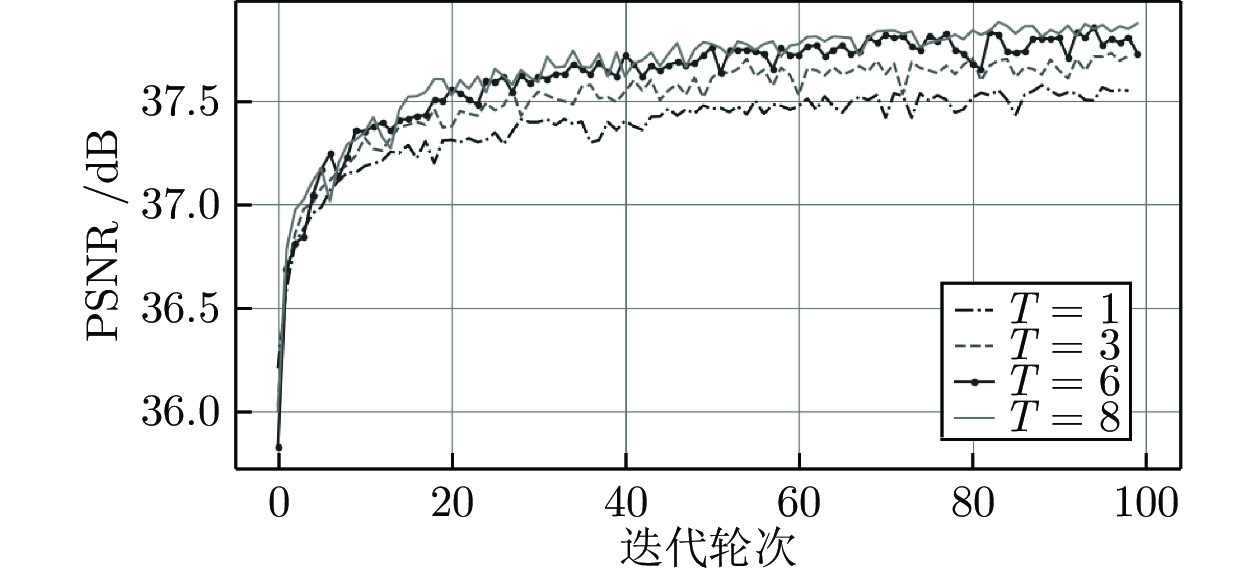
图 8 包含不同个数的HFEB的ACAN在Set5测试集上的性能比较
Fig. 8 Performance comparison of ACAN on Set5 testing set with different number of HFEB
表 1 不同卷积核的排列顺序对重建效果的影响
Table 1 Effect of convolution kernels with different order on reconstruction performance
卷积组排列顺序 9753 3579 3333 9999 PSNR (dB) 35.569 35.514 35.530 35.523  下载: 导出CSV
下载: 导出CSV
表 2 不同层次特征对重建效果的影响
Table 2 Impact of different hierarchical features on reconstruction performance
移除的卷积组大小 3 5 7 9 PSNR (dB) 35.496 35.517 35.541 35.556
下载: 导出CSV
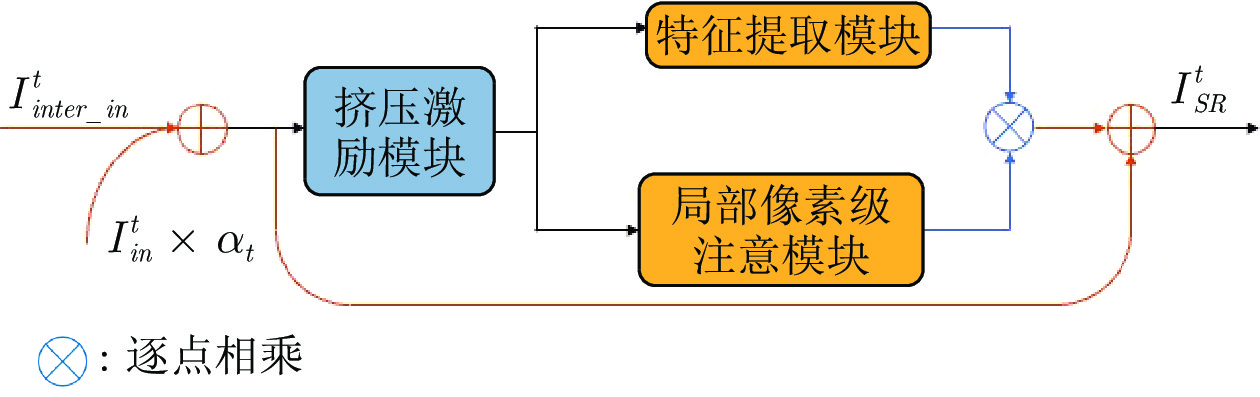
表 3 原始DBPN (O-DBPN)和使用MGAR模块的DBPN (M-DBPN)的客观效果比较
Table 3 Objective comparison between original DBPN (O-DBPN) and DBPN (M-DBPN) using MGAR module
使用不同重建模块的DBPN PSNR (dB) O-DBPN 35.343 M-DBPN 35.399
下载: 导出CSV
表 4 Sigmoid门函数的有无对LPA模块性能的影响
Table 4 Influence of Sigmoid gate function to LPA block
Sigmoid门函数 PSNR (dB) $有$ 35.569 $无$ 35.497
下载: 导出CSV
表 5 不同残差的连接方式对重建效果的影响
Table 5 Effect of different residual connection methods on reconstruction performance
不同种类的残差连接 PSNR (dB) 残差连接 35.515 无残差连接 35.521 带自适应参数的残差连接 35.569
下载: 导出CSV
表 6 使用和未使用LPA模块的客观效果比较
Table 6 Comparison of objective effects of ACAN with and without LPA module
LPA模块 PSNR (dB) $使用$ 35.569 $未使用$ 35.489
下载: 导出CSV
表 7 NLMB使用3种不同连接方式对重建效果的影响
Table 7 Impact of using three different connection methods on NLMB on reconstruction performance
使用的跳跃连接 PSNR (dB) 残差连接 35.542 级联连接 35.502 自适应级联残差连接 35.569
下载: 导出CSV
表 8 不同网络模型深度对重建性能的影响
Table 8 Impact of different network depths on reconstruction performance
T 6 7 8 9 PSNR (dB) 35.530 35.538 35.569 35.551
下载: 导出CSV
表 9 各种SISR方法的平均PSNR值与SSIM值
Table 9 Average PSNR/SSIM of various SISR methods
放大倍数 模型 参数量 Set5
PSNR / SSIMSet14
PSNR / SSIMB100
PSNR / SSIMUrban100
PSNR / SSIMManga109
PSNR / SSIM$\times$2 SRCNN 57 K 36.66 / 0.9524 32.42 / 0.9063 31.36 / 0.8879 29.50 / 0.8946 35.74 / 0.9661 FSRCNN 12 K 37.00 / 0.9558 32.63 / 0.9088 31.53 / 0.8920 29.88 / 0.9020 36.67 / 0.9694 VDSR 665 K 37.53 / 0.9587 33.03 / 0.9124 31.90 / 0.8960 30.76 / 0.9140 37.22 / 0.9729 DRCN 1774 K 37.63 / 0.9588 33.04 / 0.9118 31.85 / 0.8942 30.75 / 0.9133 37.63 / 0.9723 LapSRN 813 K 37.52 / 0.9590 33.08 / 0.9130 31.80 / 0.8950 30.41 / 0.9100 37.27 / 0.9740 DRRN 297 K 37.74 / 0.9591 33.23 / 0.9136 32.05 / 0.8973 31.23 / 0.9188 37.92 / 0.9760 MemNet 677 K 37.78 / 0.9597 33.28 / 0.9142 32.08 / 0.8978 31.31 / 0.9195 37.72 / 0.9740 SRMDNF 1513 K 37.79 / 0.9600 33.32 / 0.9150 32.05 / 0.8980 31.33 / 0.9200 38.07 / 0.9761 CARN 1592 K 37.76 / 0.9590 33.52 / 0.9166 32.09 / 0.8978 31.92 / 0.9256 38.36 / 0.9765 SRFBN-S 282K 37.78 / 0.9597 33.35 / 0.9156 32.00 / 0.8970 31.41 / 0.9207 38.06 / 0.9757 本文 ACAN 800 K 38.10 / 0.9608 33.60 / 0.9177 32.21 / 0.9001 32.29 / 0.9297 38.81 / 0.9773 本文 ACAN+ 800 K 38.17 / 0.9611 33.69 / 0.9182 32.26 / 0.9006 32.47 / 0.9315 39.02 / 0.9778 $\times$3 SRCNN 57 K 32.75 / 0.9090 29.28 / 0.8209 28.41 / 0.7863 26.24 / 0.7989 30.59 / 0.9107 FSRCNN 12 K 33.16 / 0.9140 29.43 / 0.8242 28.53 / 0.7910 26.43 / 0.8080 30.98 / 0.9212 VDSR 665 K 33.66 / 0.9213 29.77 / 0.8314 28.82 / 0.7976 27.14 / 0.8279 32.01 / 0.9310 DRCN 1774 K 33.82 / 0.9226 29.76 / 0.8311 28.80 / 0.7963 27.15 / 0.8276 32.31 / 0.9328 DRRN 297 K 34.03 / 0.9244 29.96 / 0.8349 28.95 / 0.8004 27.53 / 0.8378 32.74 / 0.9390 MemNet 677 K 34.09 / 0.9248 30.00 / 0.8350 28.96 / 0.8001 27.56 / 0.8376 32.51 / 0.9369 SRMDNF 1530 K 34.12 / 0.9250 30.04 / 0.8370 28.97 / 0.8030 27.57 / 0.8400 33.00 / 0.9403 CARN 1592 K 34.29 / 0.9255 30.29 / 0.8407 29.06 / 0.8034 27.38 / 0.8404 33.50 / 0.9440 SRFBN-S 376 K 34.20 / 0.9255 30.10 / 0.8372 28.96 / 0.8010 27.66 / 0.8415 33.02 / 0.9404 本文ACAN 1115 K 34.46 / 0.9277 30.39 / 0.8435 29.11 / 0.8055 28.28 / 0.8550 33.61 / 0.9447 本文 ACAN+ 1115 K 34.55 / 0.9283 30.46 / 0.8444 29.16 / 0.8065 28.45 / 0.8577 33.91 / 0.9464 $\times$4 SRCNN 57 K 30.48/0.8628 27.49 / 0.7503 26.90 / 0.7101 24.52 / 0.7221 27.66 / 0.8505 FSRCNN 12 K 30.71 / 0.8657 27.59 / 0.7535 26.98 / 0.7150 24.62 / 0.7280 27.90 / 0.8517 VDSR 665 K 31.35 / 0.8838 28.01 / 0.7674 27.29 / 0.7251 25.18 / 0.7524 28.83 / 0.8809 DRCN 1774 K 31.53 / 0.8854 28.02 / 0.7670 27.23 / 0.7233 25.14 / 0.7510 28.98 / 0.8816 LapSRN 813 K 31.54 / 0.8850 28.19 / 0.7720 27.32 / 0.7280 25.21 / 0.7560 29.09 / 0.8845 DRRN 297 K 31.68 / 0.8888 28.21 / 0.7720 27.38 / 0.7284 25.44 / 0.7638 29.46 / 0.8960 MemNet 677 K 31.74 / 0.8893 28.26 / 0.7723 27.40 / 0.7281 25.50 / 0.7630 29.42 / 0.8942 SRMDNF 1555 K 31.96 / 0.8930 28.35 / 0.7770 27.49 / 0.7340 25.68 / 0.7730 30.09 / 0.9024 CARN 1592 K 32.13 / 0.8937 28.60 / 0.7806 27.58 / 0.7349 26.07 / 0.7837 30.47 / 0.9084 SRFBN-S 483 K 31.98 / 0.8923 28.45 / 0.7779 27.44 / 0.7313 25.71 / 0.7719 29.91 / 0.9008 本文ACAN 1556 K 32.24 / 0.8955 28.62 / 0.7824 27.59 / 0.7366 26.17 / 0.7891 30.53 / 0.9086 本文 ACAN+ 1556 K 32.35 / 0.8969 28.68 / 0.7838 27.65 / 0.7379 26.31 / 0.7922 30.82 / 0.9117
下载: 导出CSV
-
[1] Freeman W T, Pasztor E C, Carmichael O T. Learning lowlevel vision. International Journal of Computer Vision, 2000, 40(1): 25-47 doi: 10.1023/A:1026501619075 [2] PeyréG, Bougleux S, Cohen L. Non-local regularization of inverse problems. In: Proceedings of the European Conference on Computer Vision. Berlin, Germany: Springer, Heidelberg, 2008. 57−68 [3] LeCun Y, Bengio Y, Hinton G. Deep learning. nature, 2015, 521(7553): 436-444 doi: 10.1038/nature14539 [4] Dong C, Loy C C, He K, Tang X. Learning a deep convolutional network for image super-resolution. In: Proceedings of the European Conference on Computer Vision. Zurich, Switzerland: Springer, Cham, 2014. 184−199 [5] Li Z, Yang J, LiuLi Z, Yang J, Liu Z, Yang X, et al. Feedback network for image superresolution. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 3867−3876 [6] Kim J, Kwon Lee J, Mu Lee K. Deeply-recursive convolutional network for image super-resolution. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1637−1645 [7] Tai Y, Yang J, Liu X. Image super-resolution via deep recursive residual network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 3147−3155 [8] Tai Y, Yang J, Liu X, Xu C. Memnet: A persistent memory network for image restoration. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 4539−4547 [9] Ahn N, Kang B, Sohn K A. Fast, accurate, and lightweight super-resolution with cascading residual network. In: Proceedings of the European Conference on Computer Vision. Zurich, Switzerland: Springer, Cham, 2018. 252−268 [10] Cao C, Liu X, Yang Y, Yu Y, Wang J, Wang Z, et al. Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 2956−2964 [11] Wang F, Jiang M, Qian C, Yang S, Li C, Zhang H, et al. Residual attention network for image classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 3156−3164 [12] Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7132−7141 [13] Li K, Wu Z, Peng K C, Ernst J, Fu Y. Tell me where to look: Guided attention inference network. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 9215−9223 [14] Liu Y, Wang Y, Li N, Cheng X, Zhang Y, Huang Y, et al. An attention-based approach for single image super resolution. In: Proceedings of the 2018 24th International Conference on Pattern Recognition. Beijing, China: IEEE, 2018. 2777−2784 [15] Zhang Y, Li K, Li K, Wang L, Zhong B, Fu Y. Image super-resolution using very deep residual channel attention networks. In: Proceedings of the European Conference on Computer Vision. Zurich, Switzerland: Springer, Cham, 2018. 286−301 [16] Kim J, Kwon Lee J, Mu Lee K. Accurate image superresolution using very deep convolutional networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1646−1654 [17] Wang Z, Chen J, Hoi S C H. Deep learning for image superresolution: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020 [18] Dong C, Loy C C, Tang X. Accelerating the super-resolution convolutional neural network. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Zurich, Switzerland: Springer, Cham, 2016. 391−407 [19] Shi W, Caballero J, Huszár F, Totz J, Aitken A P, Bishop R, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1874−1883 [20] Tong T, Li G, Liu X, Gao Q. Image super-resolution using dense skip connections. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 4799−4807 [21] Li J, Fang F, Mei K, Zhang G. Multi-scale residual network for image super-resolution. In: Proceedings of the European Conference on Computer Vision. Zurich, Switzerland: Springer, Cham, 2018. 517−532 [22] Haris M, Shakhnarovich G, Ukita N. Deep back-projection networks for super-resolution. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA, 2018. 1664−1673 [23] Agustsson E, Timofte R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu, USA: IEEE, 2017. 126−135 [24] Bevilacqua M, Roumy A, Guillemot C, Alberi-Morel M L. Lowcomplexity single-image super-resolution based on nonnegative neighbor embedding. In: Proceedings of the 23rd British Machine Vision Conference. Guildford, UK: BMVA Press, 2012. (135): 1−10 [25] Zeyde R, Elad M, Protter M. On single image scale-up using sparse-representations. In: Proceedings of International Conference on Curves and Surfaces. Berlin, Germany: Springer, Heidelberg, 2010. 711−730 [26] Huang J B, Singh A, Ahuja N. Single image super-resolution from transformed self-exemplars. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 5197−5206 [27] Martin D, Fowlkes C, Tal D, Malik J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings of the 2001 International Conference on Computer Vision. Vancouver, Canada: IEEE, 2015. 416−423 [28] Matsui Y, Ito K, Aramaki Y, et al. Sketch-based manga retrieval using manga109 dataset. Multimedia Tools and Applications, 2017, 76(20): 21811-21838 doi: 10.1007/s11042-016-4020-z [29] Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv preprint, 2014, arXiv: 1412.6980 [30] Lai W S, Huang J B, Ahuja N, Yang M H. Deep laplacian pyramid networks for fast and accurate super-resolution. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 5835−5843 [31] Zhang K, Zuo W, Zhang L. Learning a single convolutional super-resolution network for multiple degradations. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 3262−3271 [32] Timofte R, Rothe R, Van Gool L. Seven ways to improve example-based single image super resolution. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1865−1873 [33] Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 2004, 13(4): 600-612 doi: 10.1109/TIP.2003.819861 [34] Wu H, Zou Z, Gui J, et al. Multi-grained Attention Networks for Single Image Super-Resolution. IEEE Transactions on Circuits and Systems for Video Technology, 2020 期刊类型引用(4)
1. 杨静,王晓,王雨桐,刘忠民,李小双,王飞跃. 平行智能与CPSS:三十年发展的回顾与展望. 自动化学报. 2023(03): 614-634 .  本站查看
本站查看2. 赵奎,闫玉芳,曹吉龙,高延军. 融合规范化判断的双向循环神经网络诊疗预测模型. 小型微型计算机系统. 2022(06): 1278-1284 . 百度学术3. 赵奎,杜昕娉,高延军,马慧敏. 融合文字与标签的电子病历命名实体识别. 计算机系统应用. 2022(10): 375-381 . 百度学术4. 高华睿,郝龙,王明明,包绍伦,康乐. 基于Att-Bi-LSTM的高速公路短时交通流预测研究. 武汉理工大学学报. 2020(09): 59-64 . 百度学术其他类型引用(5)
-

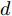
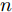
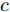

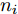
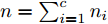
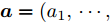
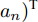
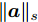
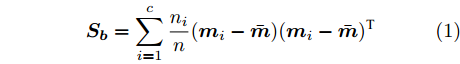
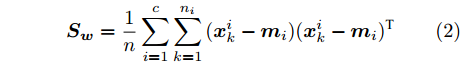
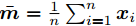
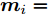
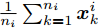

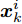
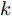
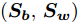
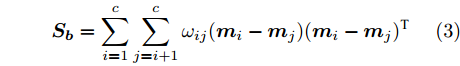
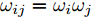
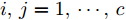
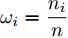

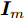
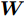
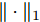
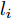

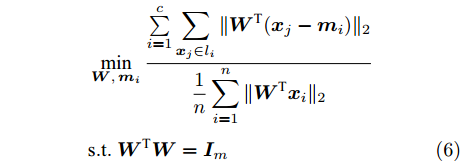
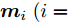
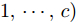
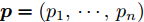
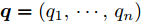
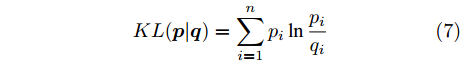
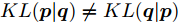
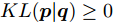
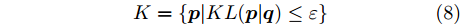
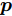
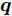


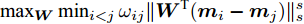
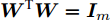
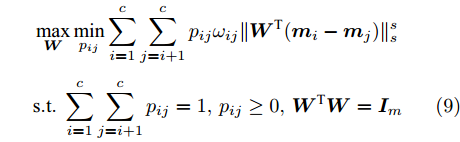
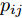


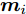
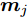
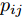
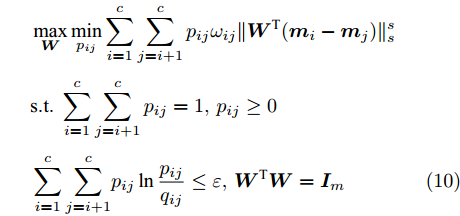

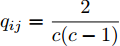
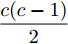
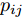
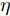
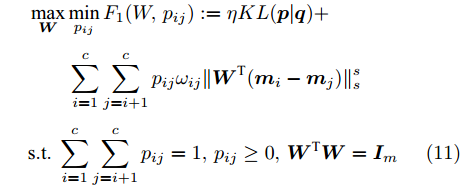
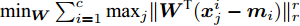
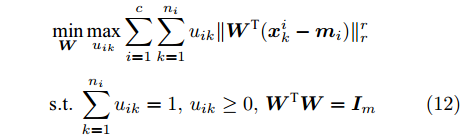

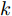
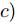
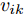
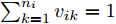
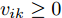
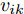
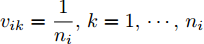
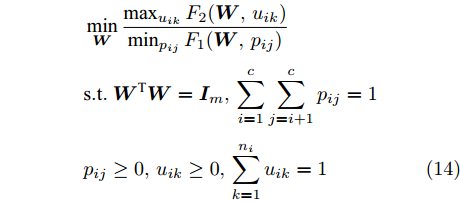
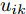
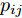
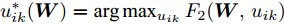
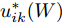
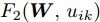
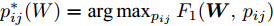
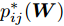
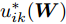
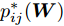
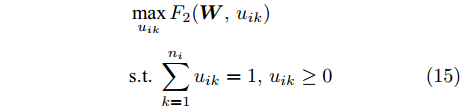
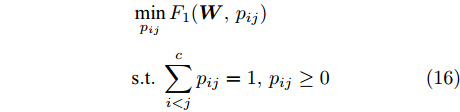
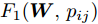
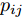
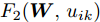
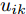
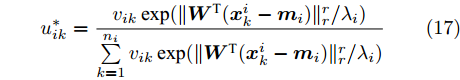
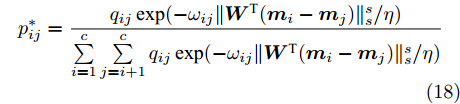
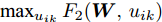
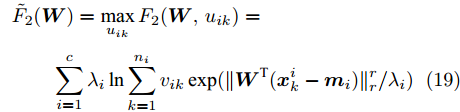
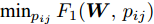
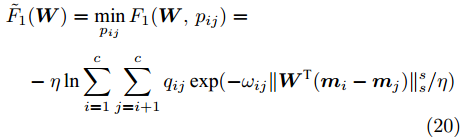
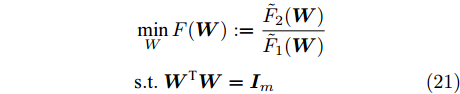
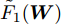
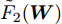
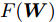
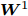
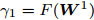

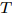
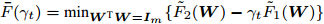
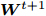
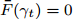
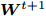
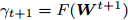
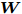
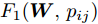
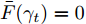
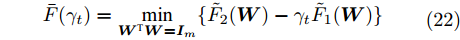
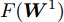
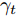
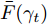
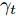
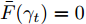
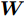
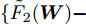
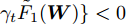
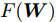
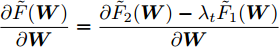
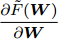
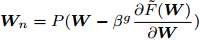
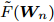
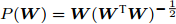
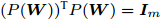
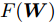
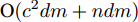
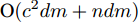
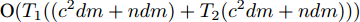
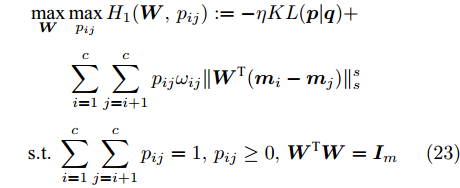
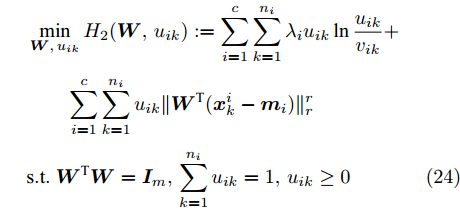
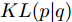
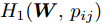
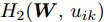
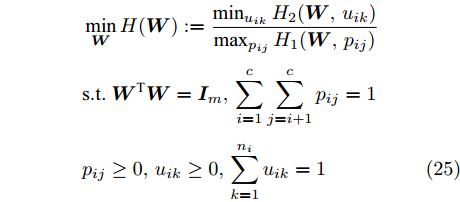
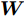
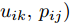
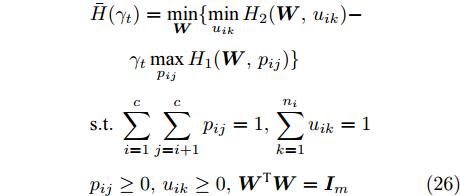
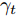
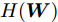
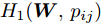
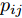
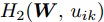
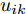
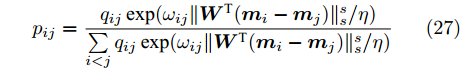
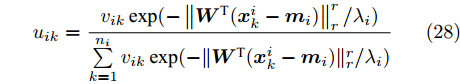
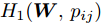
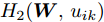
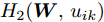
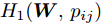
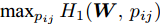
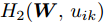
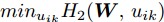
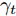
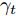
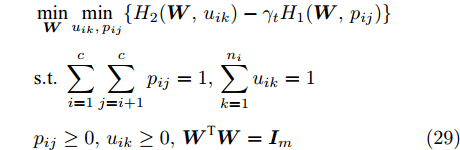
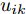
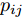
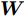
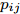

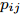

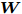

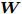
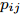
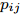

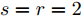
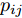
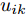
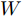
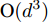
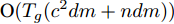
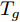
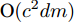
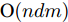
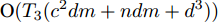

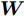
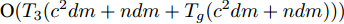
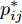
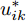
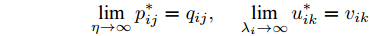
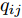
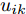
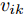
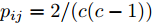
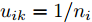
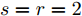
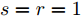
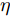
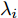
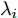
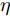
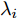
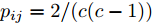
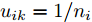
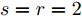
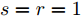
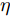
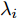
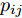
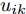
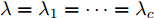
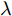
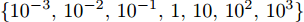
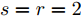
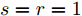
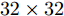
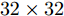
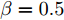
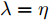
 下载:
下载:
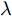
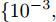
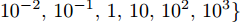
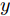
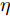
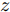
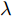
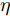
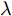
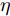
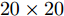
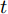




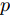
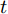



计量
- 文章访问数: 1439
- HTML全文浏览量: 480
- PDF下载量: 362
- 被引次数: 9
