

Optimized Modeling of Dynamic Process Oriented Towards Modeling Error PDF Shape and Goodness of Fit
-
摘要: 本文提出一种新的数据驱动建模思路及方法, 即面向建模误差概率密度函数(Probability density function, PDF)形状与趋势拟合优度(相似度)的动态过程多目标优化建模方法. 首先, 针对均方根误差(Root mean square error, RMSE)等常规一维性能指标不能完全刻画建模误差在时间和空间二维随机动态特性的问题, 引入PDF指标来对动态过程的建模误差在时间和空间进行二维尺度的全面刻画和评价, 并采用核密度估计技术对关于时间的建模误差序列的PDF进行估计; 其次, 为了刻画动态过程数据建模的拟合趋势, 进一步引入趋势拟合优度指标, 从而构造综合描述数据建模误差PDF形状与趋势拟合相似性的多目标性能指标; 在此基础上, 采用NSGA-II算法优化数据模型的参数集, 获取一大类满足上述多目标性能优化的智能模型参数解. 数值仿真及工业数据验证表明, 所提方法的建模误差PDF逼近设定的期望PDF, 并且模型输出与样本数据拟合趋势接近, 好于常规最小化一维RMSE指标的数据建模方法.Abstract: This paper proposes a novel data-driven modeling method, which is a multi-objective optimized modeling method for dynamic process oriented towards modeling error probability density function (PDF) shape and goodness of fit (similarity). First, aiming at the problem that the conventional modeling performance indicators such as the root mean square error (RMSE) cannot fully characterize the two-dimensional stochastic dynamic characteristics of modeling errors. The PDF index is introduced to comprehensively characterize and evaluate the modeling errors of dynamic systems in two dimensions on time and space, while the kernel density estimation technology is used to estimate the PDF of modeling error sequence. Second, in order to characterize the fitting trend of dynamic process data modeling, the goodness of fit is further introduced to construct a multi-objective performance indicator that comprehensively describes the data modeling error PDF shape and trend fitting similarity. Based on this, the parameter set of the data model is optimized using the NSGA-II algorithm to obtain the optimized parameter solutions for a large class of intelligent models. Finally, numerical simulation and industrial data verification show that the modeling error PDF of the proposed method approximates the set target PDF, and the model output is close to the actual data fitting trend, which is better than the conventional data modeling methods of minimizing the one-dimensional RMSE index.
-

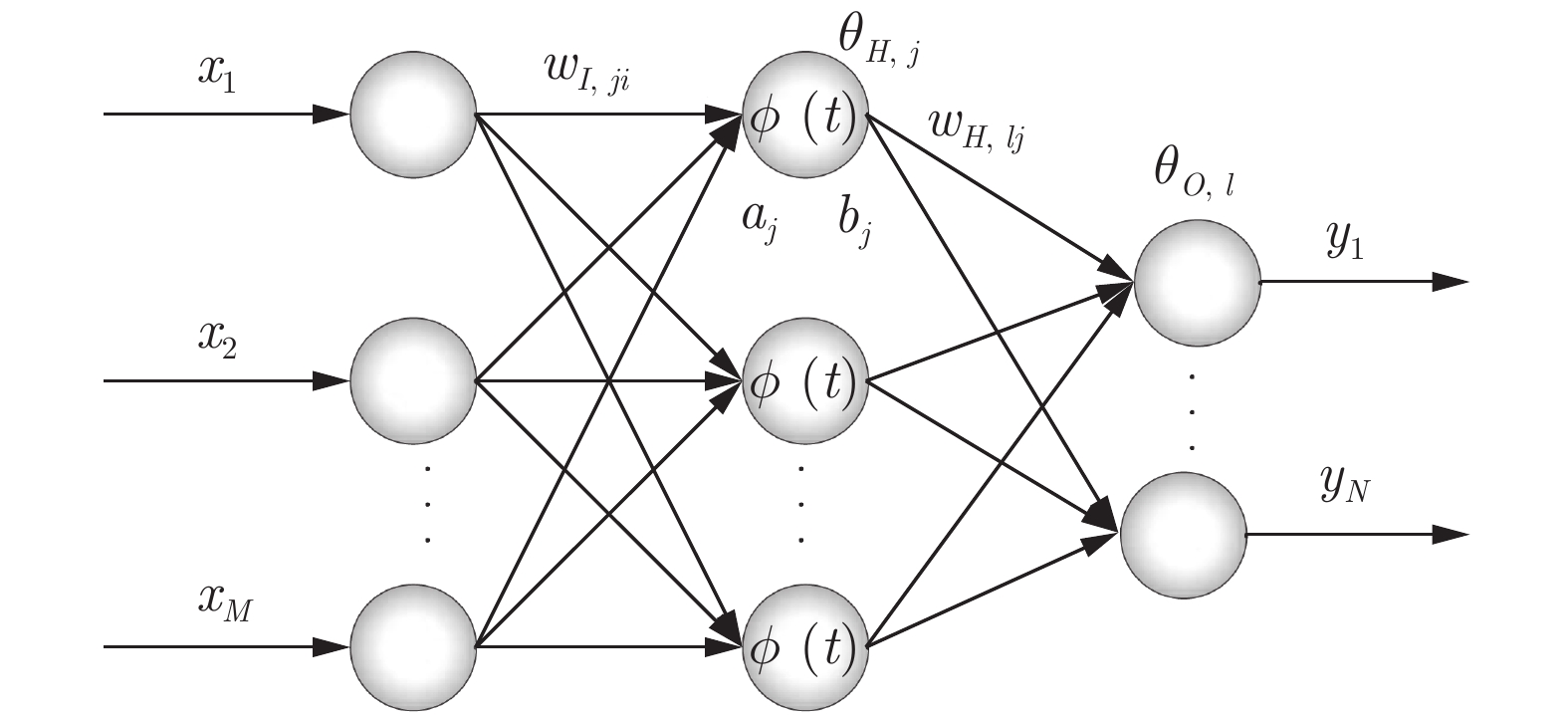
图 2 面向建模误差PDF形状与趋势拟合优度的优化建模策略
Fig. 2 Optimized modeling strategy towards modeling error PDF shape and goodness of fit

图 4 不同优化解对应的拟合优度值变化曲线
Fig. 4 Change curve of goodness of fit corresponding to different optimization solutions
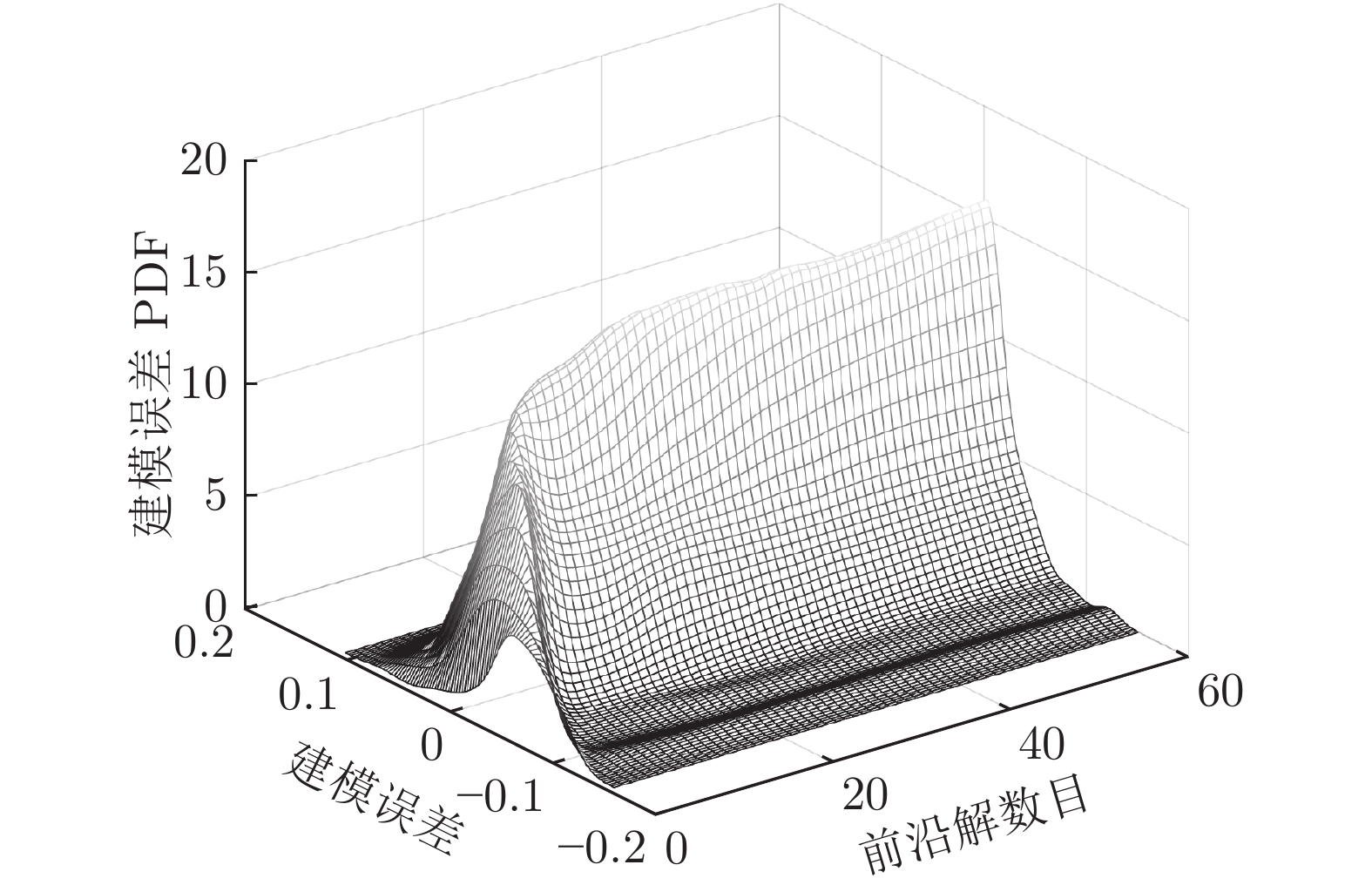
图 5 不同优化解对应的建模误差PDF变化曲面
Fig. 5 PDF changing surface corresponding to different optimization solutions

图 7 所提方法30号优化解对应的建模效果
Fig. 7 Modeling result corresponding to the 30th optimization solution of the proposed method

图 8 所提方法30号优化解对应的测试效果
Fig. 8 Testing result corresponding to the 30th optimization solution of the proposed method
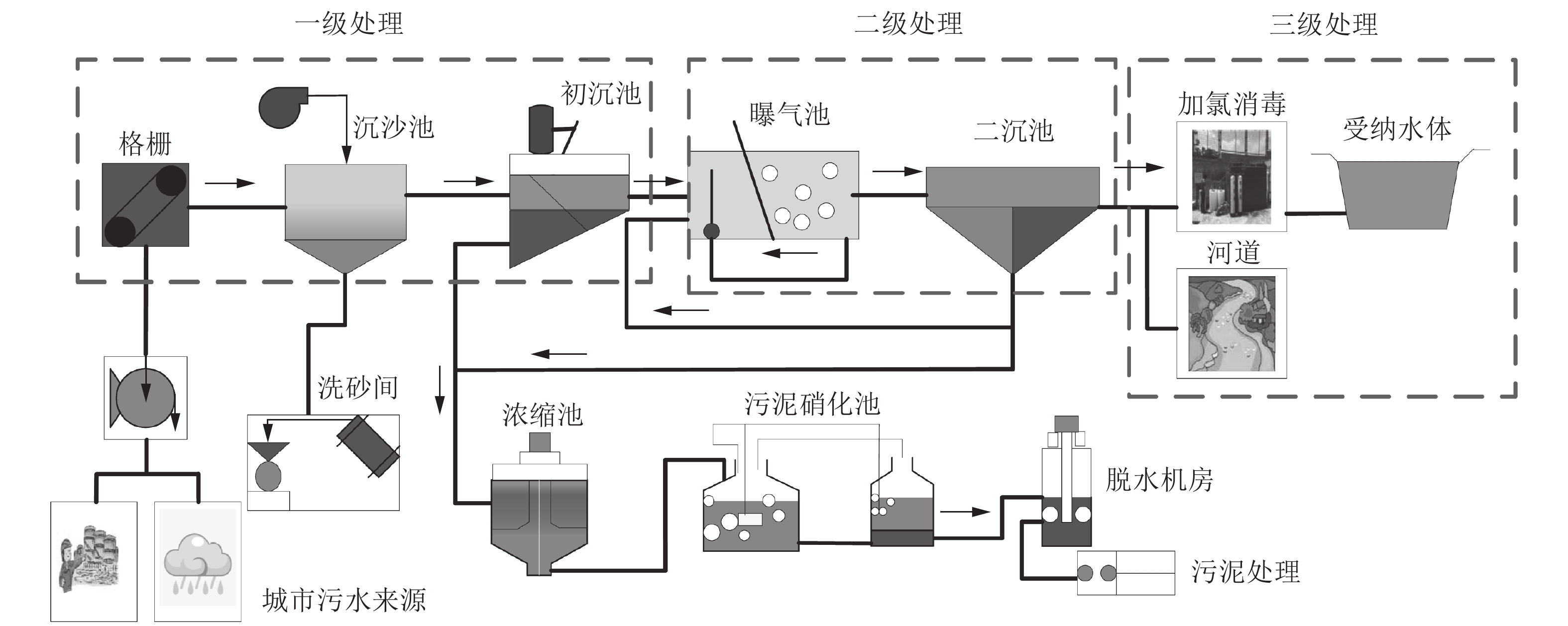
图 9 典型活性污泥法污水处理过程工艺流程图
Fig. 9 Flow chart of a typical activated sludge wastewater treatment process
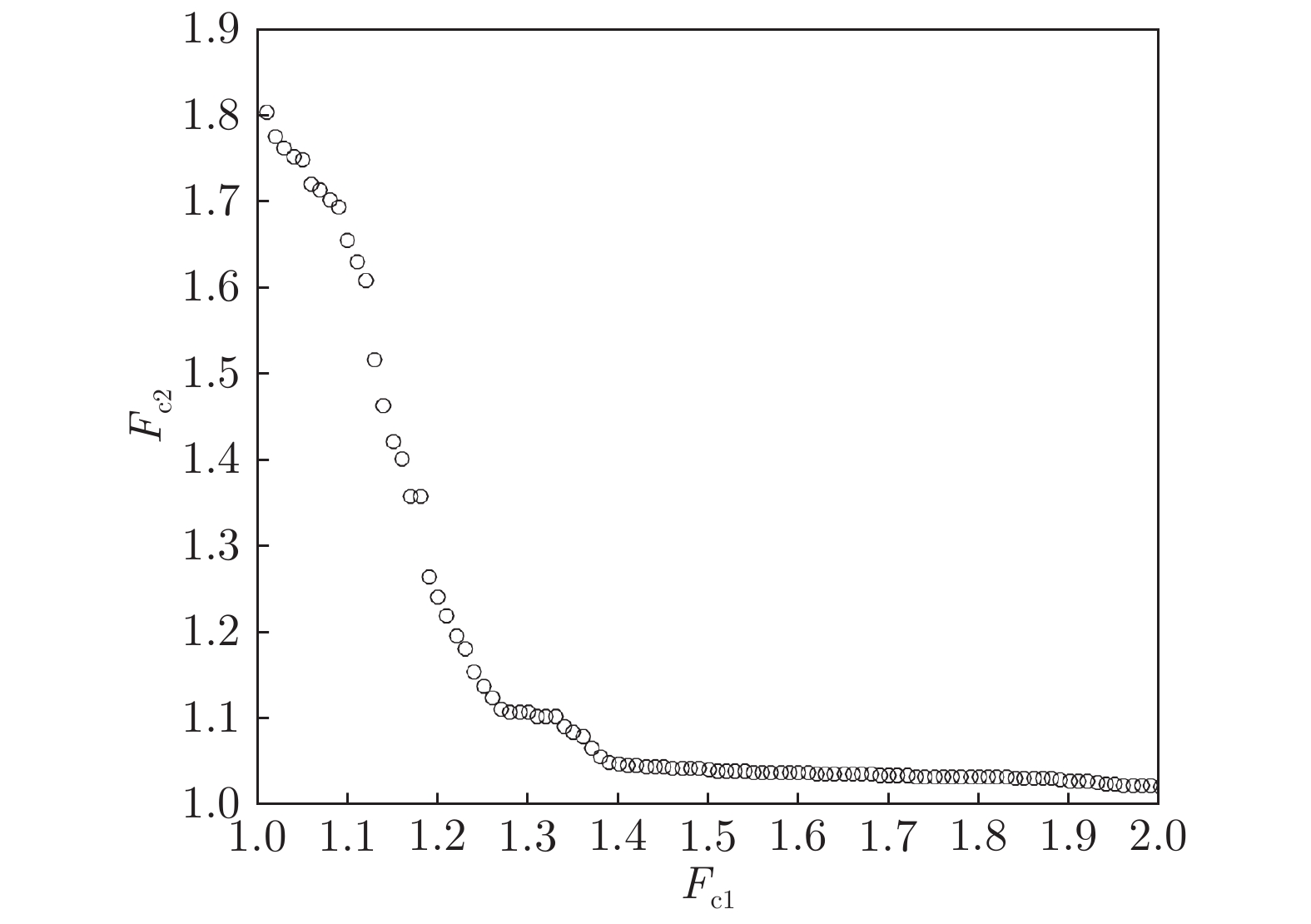
图 10 COD含量建模Pareto前沿进化过程
Fig. 10 Pareto front evolution process of COD content modeling
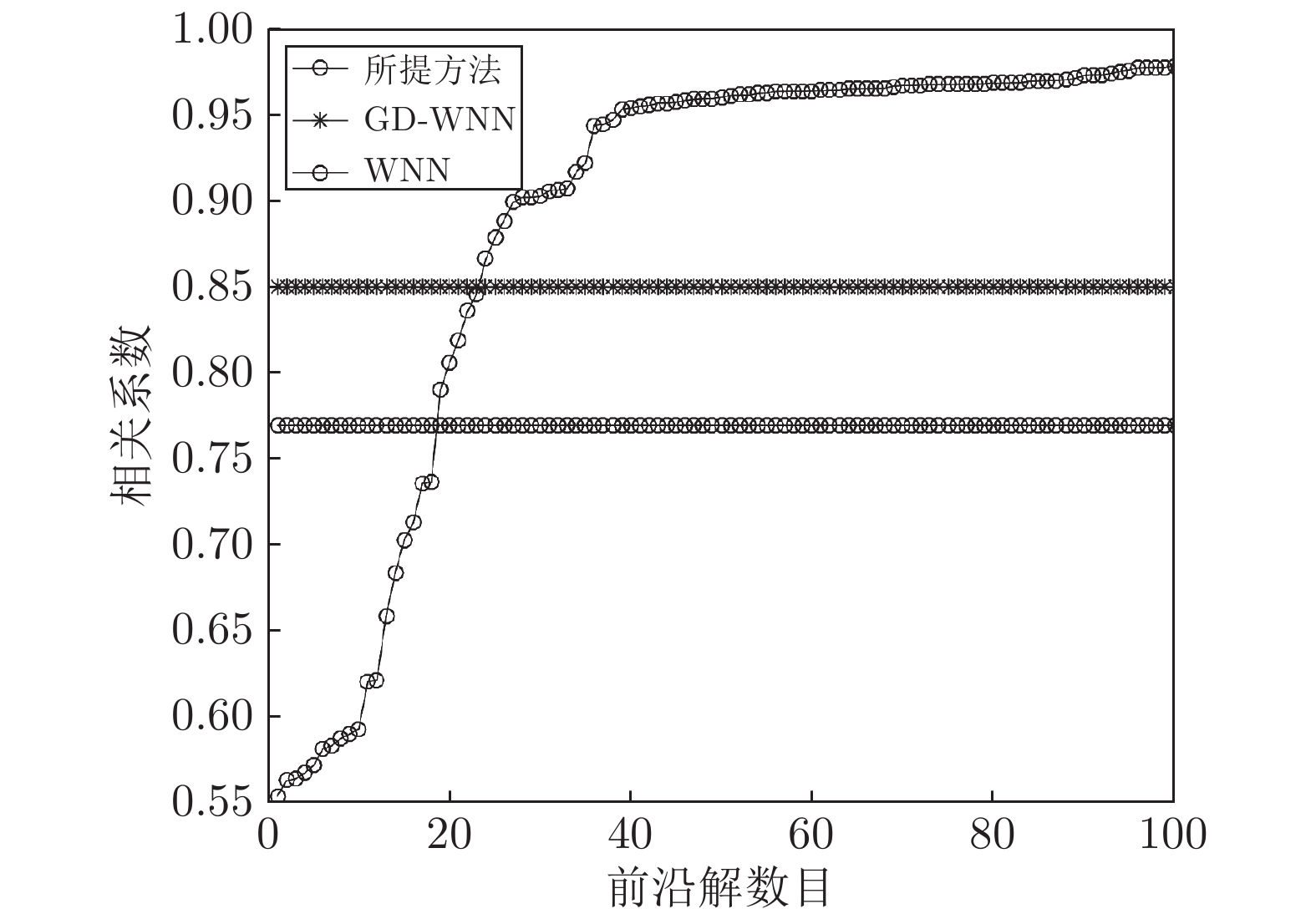
图 11 不同优化解对应的拟合优度值变化曲线
Fig. 11 Change curve of goodness of fit corresponding to different optimization solutions
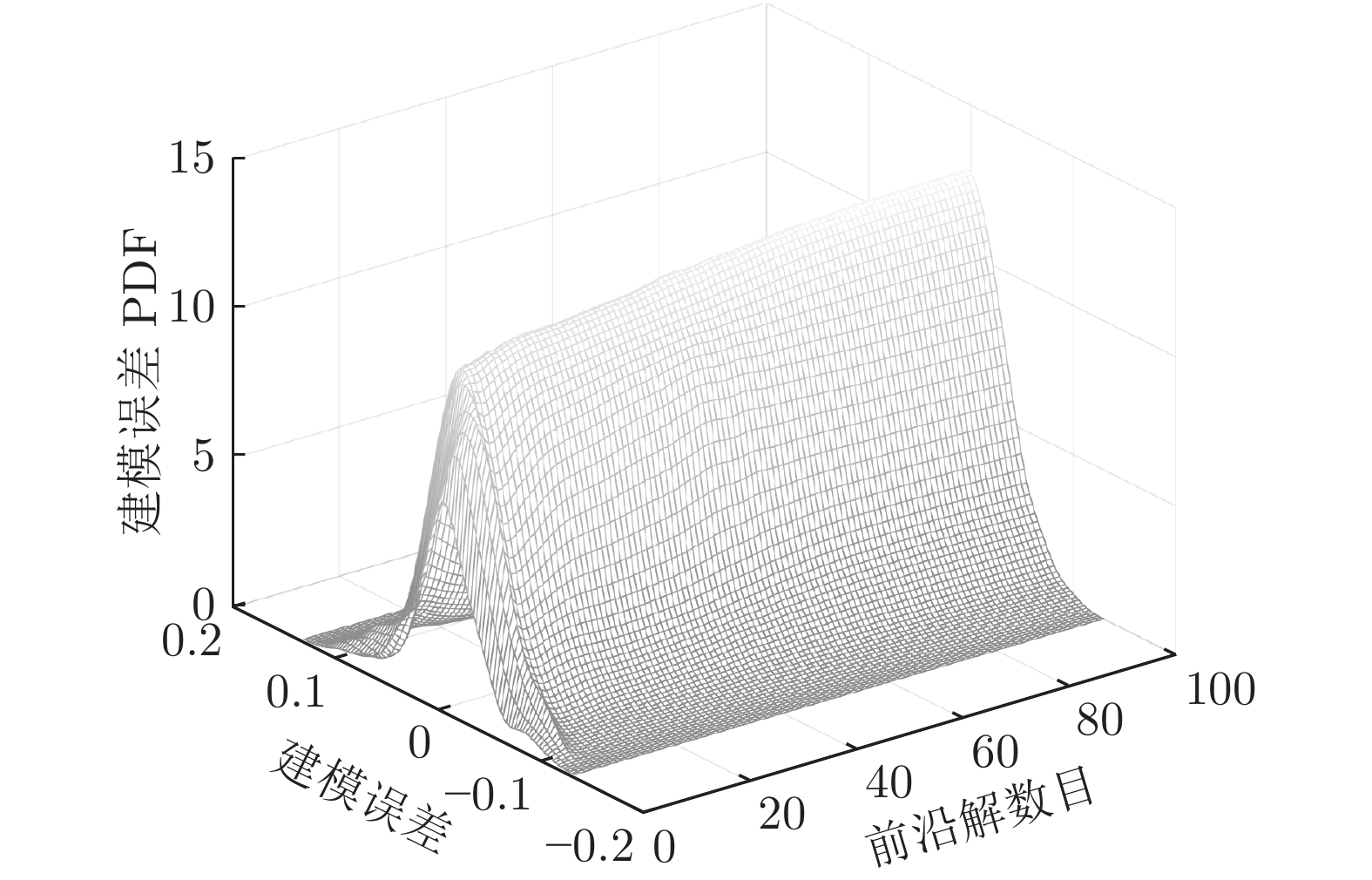
图 12 不同优化解对应的COD含量建模误差PDF变化曲面
Fig. 12 PDF changing surface of COD content modeling error corresponding to different optimization solutions
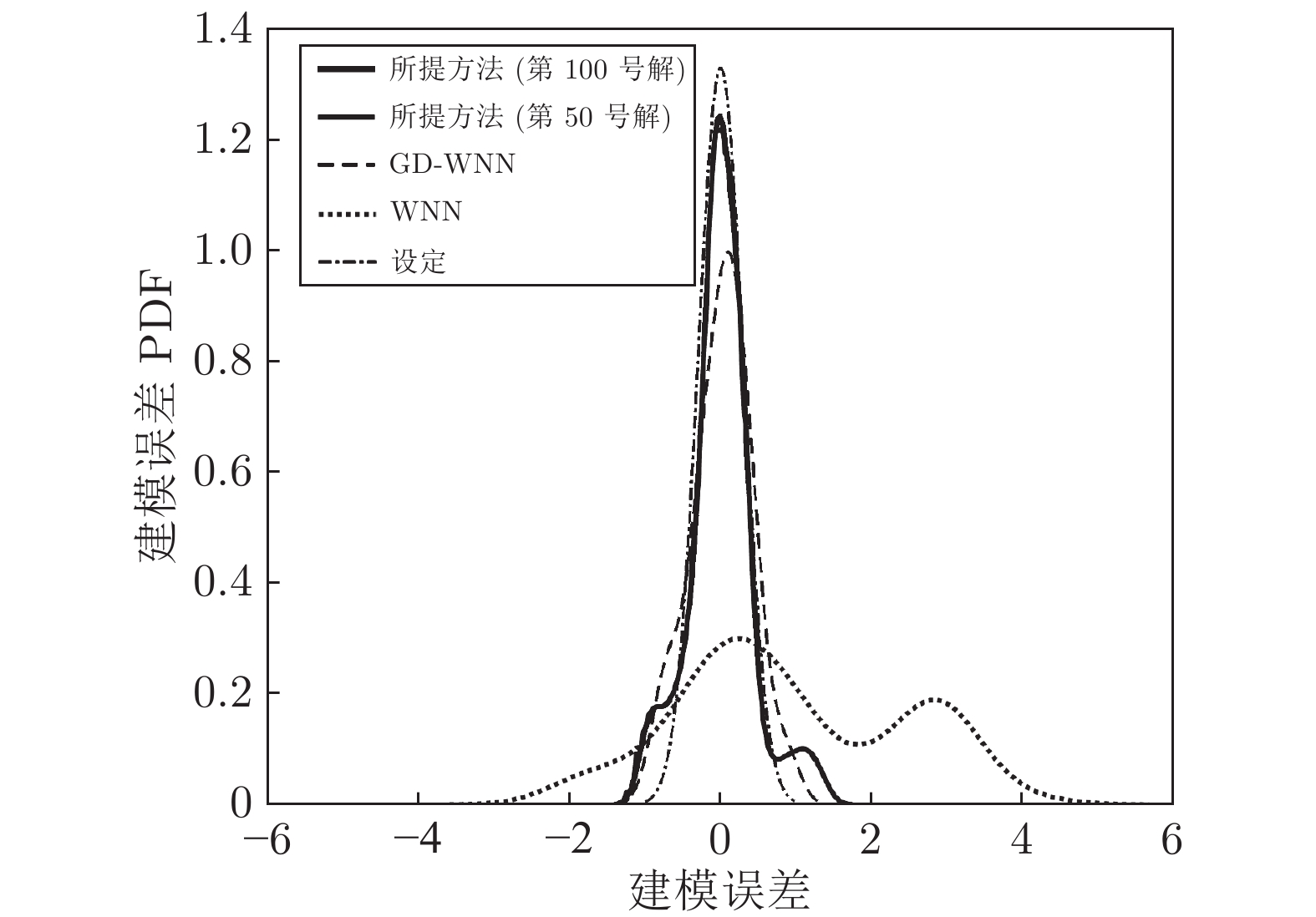
图 13 不同方法COD含量建模误差PDF比较
Fig. 13 PDF comparison of COD content modeling error with different methods
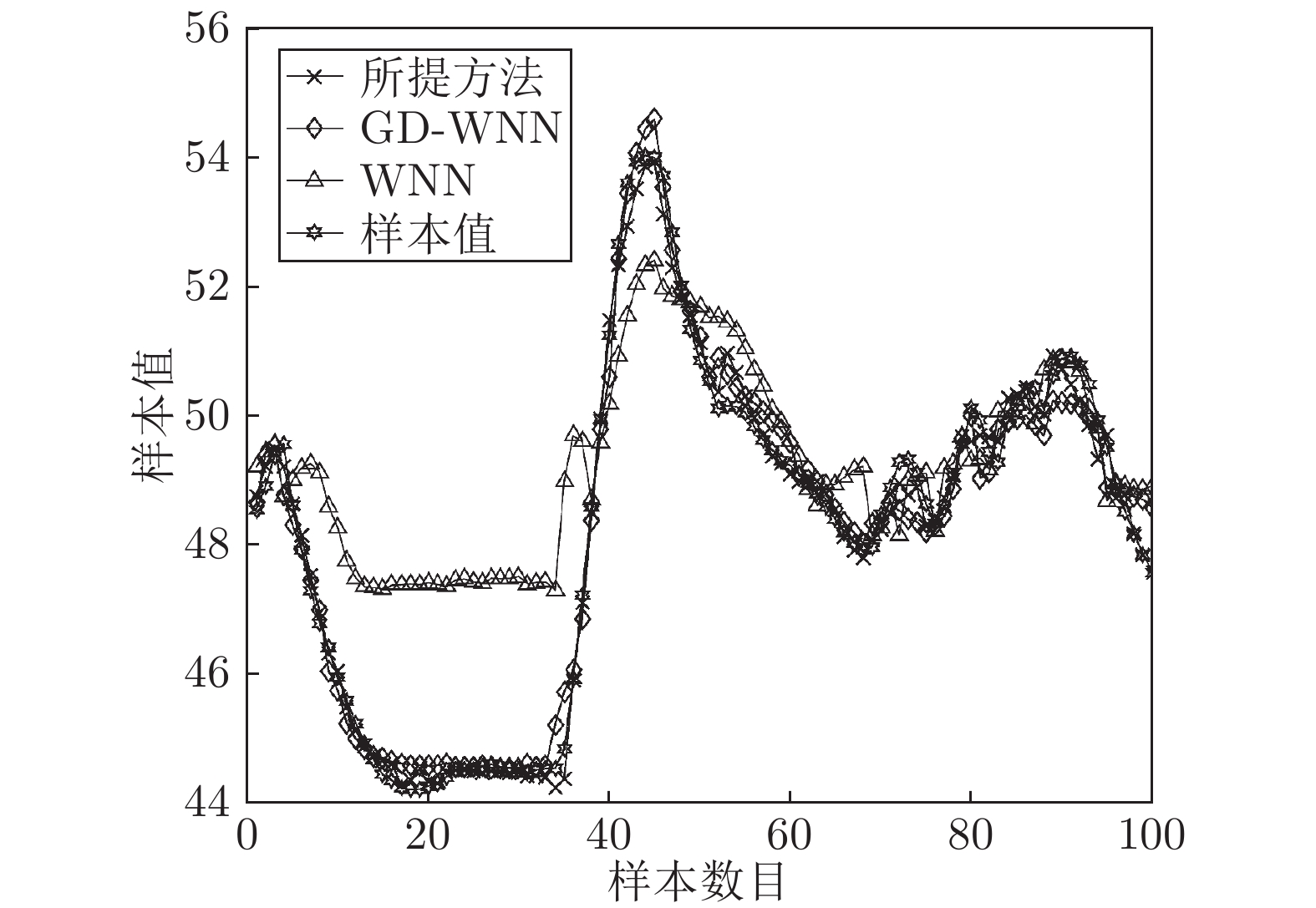
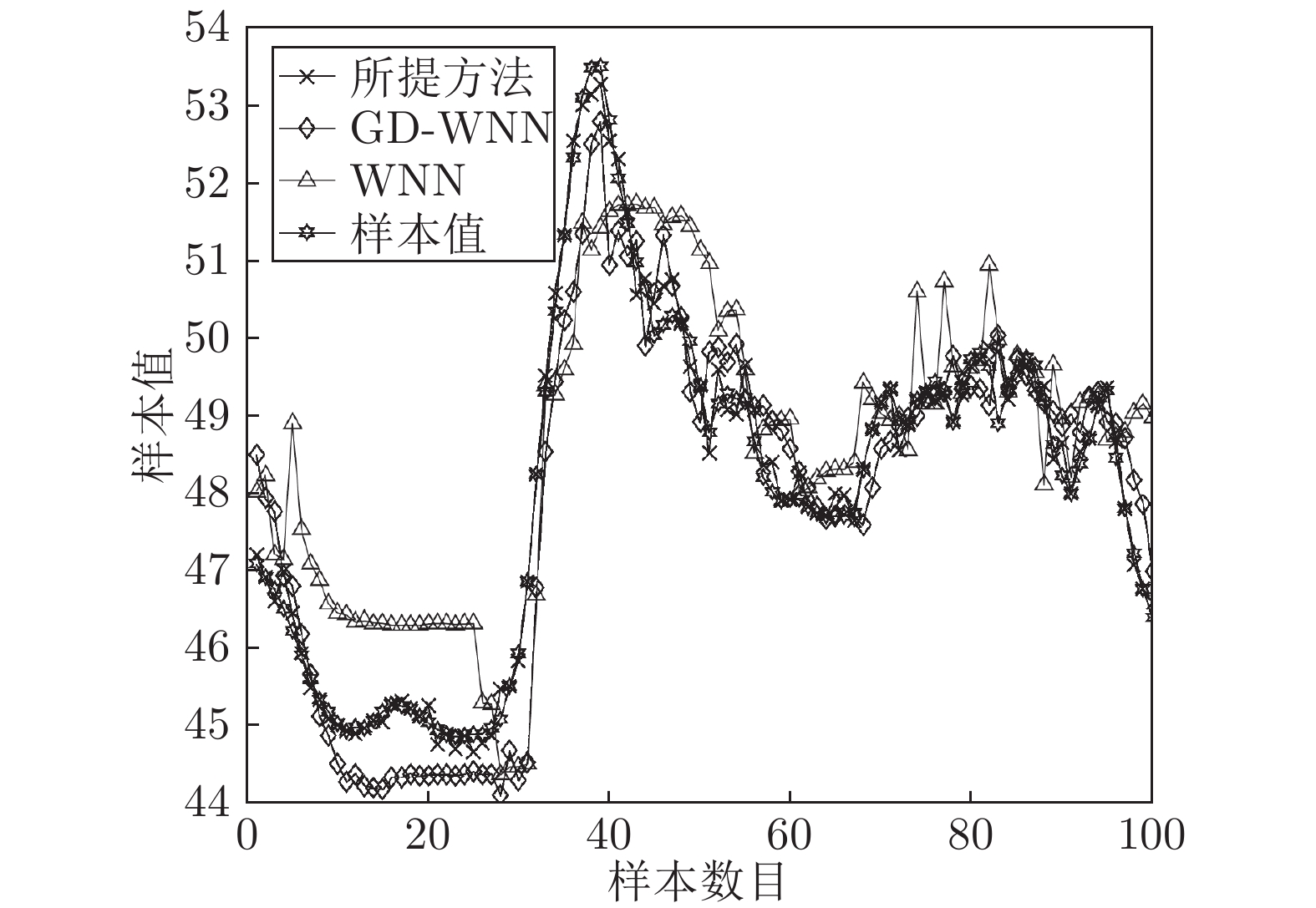
图 14 所提方法50号优化解对应的COD含量建模效果
Fig. 14 Modeling result of COD content corresponding to the 50th optimization solution of the proposed method
-
[1] 宋贺达, 周平, 王宏, 柴天佑. 高炉炼铁过程多元铁水质量非线性子空间建模及应用. 自动化学报, 2016, 42(11): 1664−1679Song He-Da, Zhou Ping, Wang Hong, Chai Tian-You. Nonlinear subspace modeling of multivariate molten iron quality in blast furnace ironmaking and its application. Acta Automatica Sinica, 2006, 42(11): 1664−1679 [2] Zhou P, Lv Y B, Wang H, Chai T Y. Data-driven robust RVFLNs modeling of blast furnace ironmaking process using Cauchy distribution weighted M-estimation. IEEE Transactions on Industrial Electronics, 2017, 64(9): 7141−7151 doi: 10.1109/TIE.2017.2686369 [3] Han H G, Qiao J F. Nonlinear model-predictive control for industrial processes: an application to wastewater treatment process. IEEE Transactions on Industrial Electronics, 2014, 61(4): 1970−1982 doi: 10.1109/TIE.2013.2266086 [4] Zhou P, Lu S W, Chai T Y.Data-driven soft-sensor modeling for product quality estimation using case-based reasoning and fuzzy-similarity rough sets. IEEE Transactions on Automation Science and Engineering, 2014. 11(4): 992−1003. doi: 10.1109/TASE.2013.2288279 [5] Janssens P, Pipeleers G, Swevers J. A data-driven constrained norm-optimal iterative learning control framework for LTI systems. IEEE Transactions on Control Systems Technology, 2013, 21(2): 546−551. doi: 10.1109/TCST.2012.2185699 [6] Zhou P, Wang C Y, Li M J, et al. Modeling error PDF optimization based wavelet neural network modeling of dynamic system and its application in blast furnace ironmaking. IEEE Neurocomputing, 2018, 285: 167−175. doi: 10.1016/j.neucom.2018.01.040 [7] Wang H. Bounded Dynamic Stochastic Systems: Modeling and control. London: Springer-Verlag Ltd, 2000. [8] Zhou Y Y, Wang A P, Zhou P, Wang H, and Chai T Y. Dynamic performance enhancement for nonlinear stochastic systems using RBF driven nonlinear compensation with extended Kalman filter. Automatica, DOI: 10.1016/j.automatica.2019.108693 [9] Ding J, Chai T, Wang H. Offline modeling for product quality prediction of mineral processing using modeling error PDF shaping and entropy minimization. IEEE Transactions on Neural Networks, 2011, 22(3):408−419. doi: 10.1109/TNN.2010.2102362 [10] Jia L, Cao L M, Chui M S. Modeling error PDF shape based data-driven model for batch processes. Chin. J. Sci. Instrum, 2012, 33(7): 1505−1512. [11] Zhou P, Guo D W, Wang H, Chai T Y. Data-driven robust M-LS-SVR-based NARX modeling for estimation and control of molten iron quality indices in blast furnace ironmaking. IEEE Trans. Neural Netw. Learn. Syst, 2018, 29(9): 4007−4021. doi: 10.1109/TNNLS.2017.2749412 [12] 李换琴, 万百五. 基于填充函数算法的工业产品小波网络质量模型[J]. 自动化学报, 2004, 30(2): 283−287Li Huan-Qin, Wan Bai-Wu. A wavelet neural network model for industrial product quality based on filled function algorithm. Acta Automatica Sinica, 2004, 30(2): 283−287. [13] Rana M, Koprinska I. Forecasting electricity load with advanced wavelet neural networks. Neurocomputing, 2016, 182(3): 118−132. [14] Wu M, Xu C H, She J H,Yokoyama R. Intelligent integrated optimization and control system for lead-zinc sintering process. Control Engineering Practice, 2009, 17(2): 280−290 doi: 10.1016/j.conengprac.2008.07.007 [15] Parzen E. On estimation of a probability density function and mode. Ann. Math. Stat., 1962, 33(3):1065−1076. doi: 10.1214/aoms/1177704472 [16] Jones M C, Marron J S, Sheather S J. A brief survey of bandwidth selection for density estimation. J. Am. Stat. Assoc, 1996, 91(433): 401−407. doi: 10.1080/01621459.1996.10476701 [17] Buch-larsen T, Nielsen J P, Guillén M. Kernel density estimation for heavy–tailed distributions using the champernowne transformation. Social Science Electronic Publishing, 2005, 39(6):503−516. [18] Deb K, Pratap A, Agarwal S and Meyarivan T. A fast and elitist multi-objective genetic algorithm: NSGA II. IEEE Trans. Evol. Comput., 2002, 6(2): 182−197. doi: 10.1109/4235.996017 [19] 张帅, 周平. 污水处理过程递推双线性子空间建模及无模型自适应控制. 自动化学报, DOI: 10.16383/j.aas.c190514Zhang Shuai, Zhou Ping. Recursive bilinear subspace modeling and model-free adaptive control of wastewater treatment. Acta Automatica Sinica, DOI: 10.16383/j.aas.c190514 [20] Han H G, Zhang L, Qiao J F. Data-based predictive control for wastewater treatment process. IEEE Access, 2018, 6: 1498−1512. doi: 10.1109/ACCESS.2017.2779175 [21] Qiao J F, Zhou H B. Modeling of energy consumption and effluent quality using density peaks-based adaptive fuzzy neural network. IEEE/CAA Journal of Automatica Sinica, 2018, 5(5): 968−976. doi: 10.1109/JAS.2018.7511168 [22] 乔俊飞, 薄迎春, 韩广. 基于ESN 的多指标DHP控制策略在污水处理过程中的应用. 自动化学报, 2013, 39(7): 146–1151.Qiao Jun-Fei, Bo Ying-Chun, Han Guang. Application of ESN-based multi indices dual heuristic dynamic programming on wastewater treatment process. Acta Automatica Sinica, 2013, 39(7): 1146−1151. -

 下载:
下载:


计量
- 文章访问数: 1042
- HTML全文浏览量: 256
- PDF下载量: 222
- 被引次数: 0
