

Fault Detection and Diagnosis Based on Residual Dissimilarity in Dynamic Principal Component Analysis
-
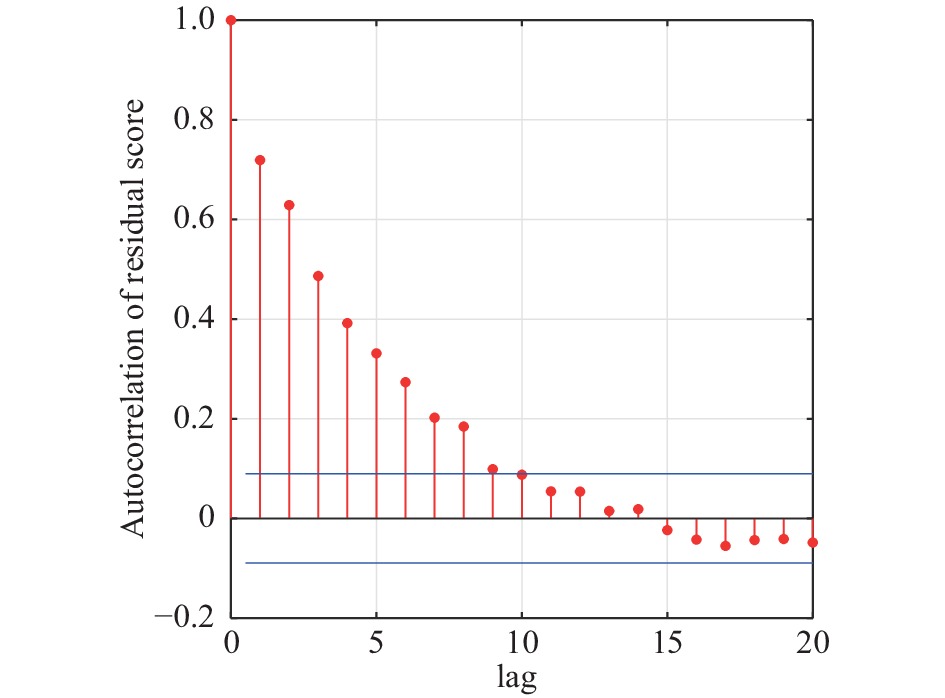
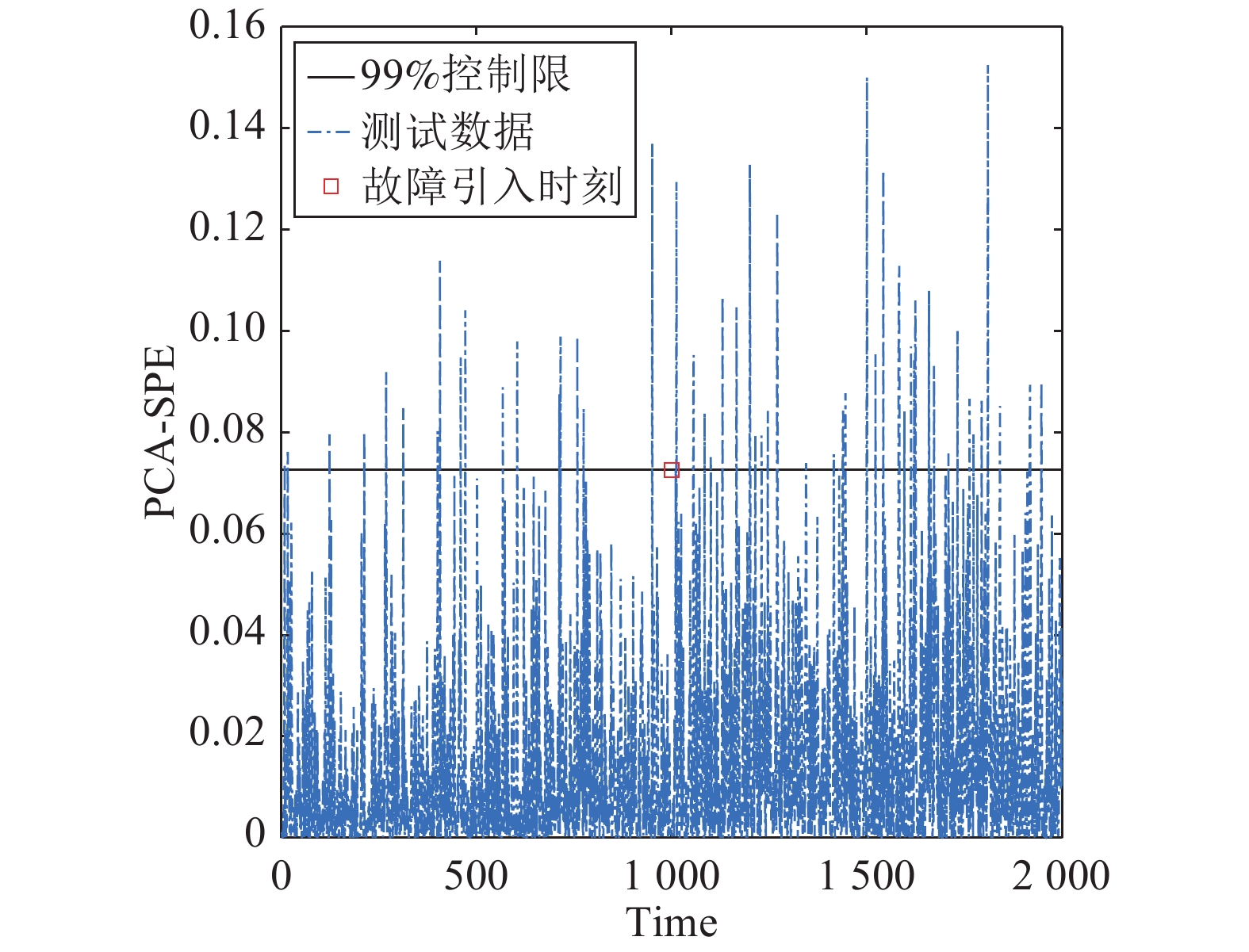
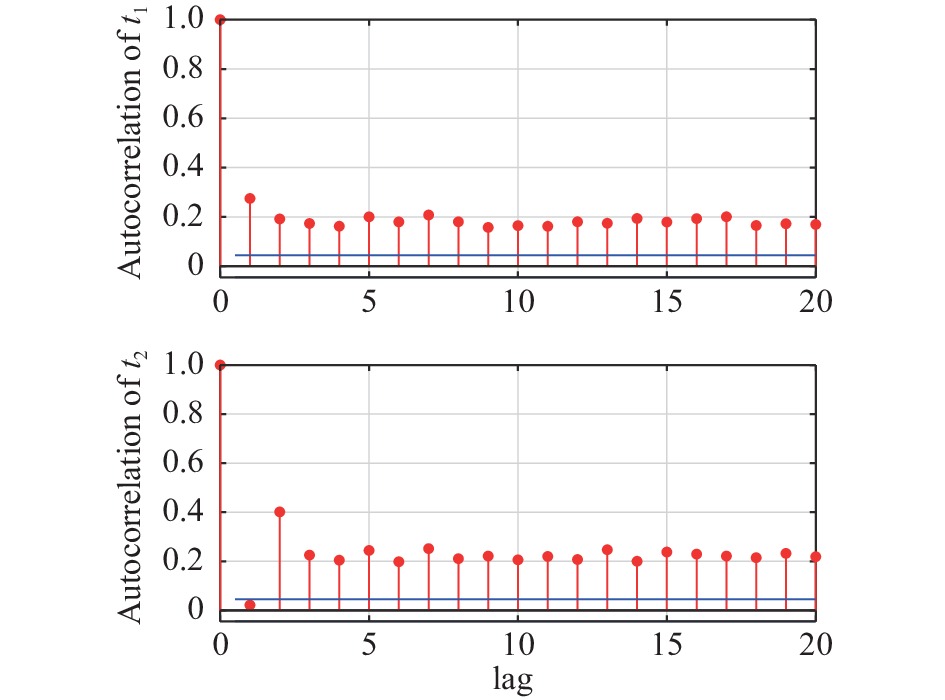
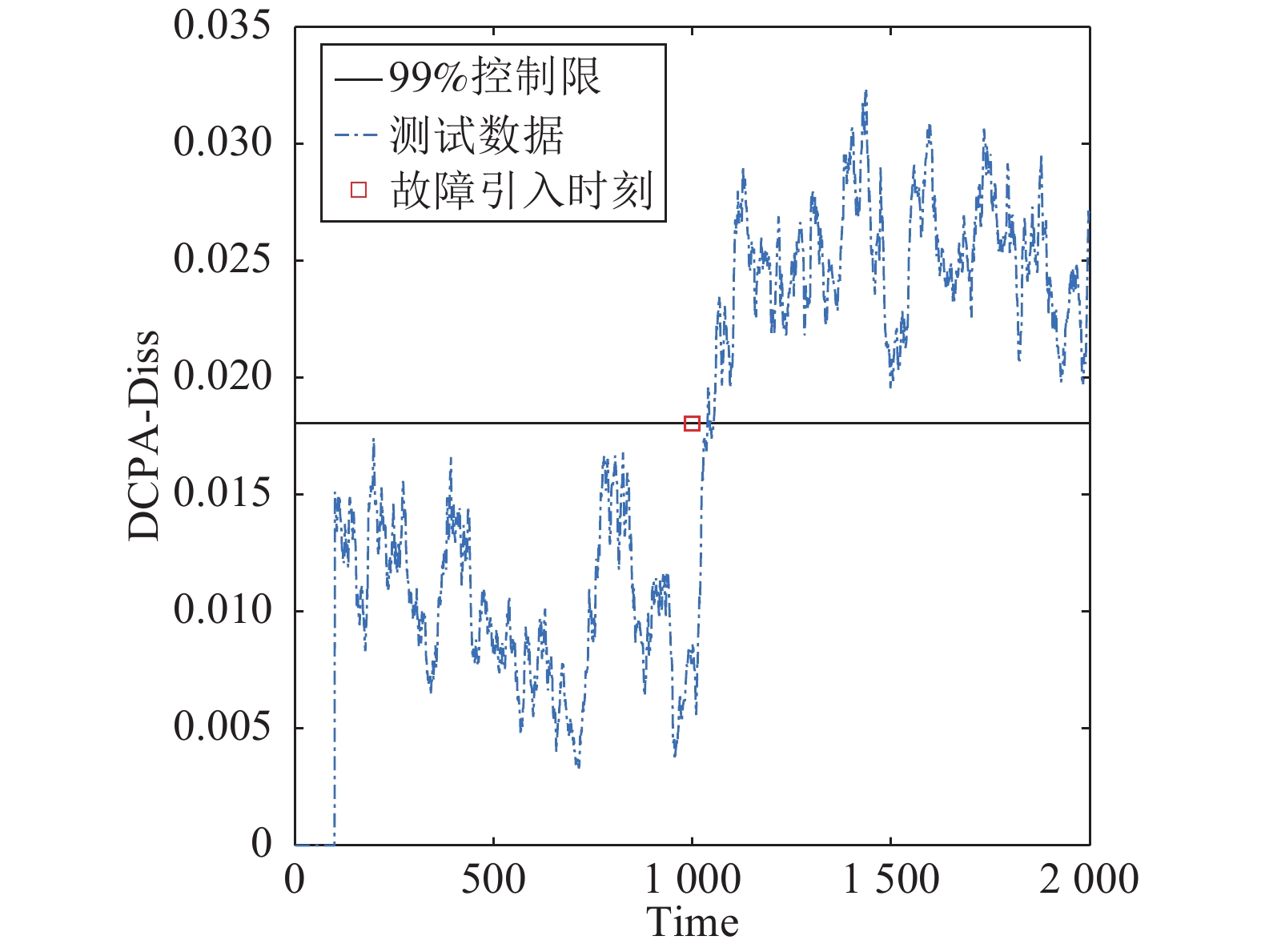
摘要: 针对动态主元分析方法中残差自相关性降低过程故障检测率问题, 提出基于动态主元分析残差互异度的故障检测与诊断方法. 首先, 应用动态主元分析(Dynamic principal component analysis, DPCA)计算动态过程数据的残差得分; 接下来, 应用滑动窗口技术并结合互异度指标(Dissimilarity)来监控过程残差得分状态; 最后, 利用基于变量贡献图的方法进行过程故障诊断分析. 本文方法通过DPCA捕获过程的动态特征, 同时互异度指标区别于传统的平方预测误差(Square prediction error, SPE), 它可以有效地对具有自相关性的残差得分进行过程状态监控. 通过一个数值例子和Tennessee Eastman (TE)过程的仿真实验并与传统方法对比分析, 仿真结果进一步证实了本文方法的有效性.Abstract: Aiming at the problem of reducing process fault detection rate because of residual autocorrelation in dynamic principal component analysis, a novel fault detection and diagnosis based on residual dissimilarity in dynamic principal component analysis is proposed in this paper. Firstly, Dynamic principal component analysis (DPCA) is used to calculate residual score of a dynamic process. Next, moving window technology and dissimilarity index are utilized to monitor the status of this process in residual score. Finally, a fault diagnosis method based on contribution chart of monitored variables is used for discovering the reason causing abnormal change of this process. The proposed method to capture dynamic characteristics of a process through DPCA, meanwhile, the proposed dissimilarity index, which is different from the conventional squared prediction error (SPE), can effectively monitor the process in which the residual scores contain significant autocorrelation. The effectiveness of DPCA-Diss is tested in a numerical case and the Tennessee Eastman (TE) process.
-
表 1 各种方法故障检测率
Table 1 Fault detection rates using different methods
检测方法 FDR (%) PCA-SPE 4.4 DPCA-SPE 16.6 DPCA-Diss 95.1  下载: 导出CSV
下载: 导出CSV
表 2 各种方法故障检测率(%)
Table 2 Fault detection rates using different methods (%)
故障号 PCA-SPE KPCA-SPE DPCA-SPE Diss DPCA-Diss 1 99.75 93.75 98.88 34.25 96.13 2 91.88 94.50 91.75 8.88 93.63 4 99.88 53.88 4.25 9.75 21.63 5 64.25 7.50 100.00 14.13 99.38 6 100.00 63.38 100.00 96.38 99.88 7 34.25 98.63 20.00 30.25 48.75 8 79.38 40.25 65.25 70.25 96.75 10 56.50 3.63 90.13 30.88 96.63 11 67.38 53.00 7.75 76.75 91.00 12 87.00 57.75 97.75 98.88 99.75 13 94.50 62.00 93.13 65.75 93.50 14 89.13 88.13 7.75 62.00 94.38 15 3.25 3.13 2.50 2.50 77.50 16 56.63 2.88 89.63 54.25 98.38 17 94.88 74.00 71.88 88.50 96.63 18 90.38 85.75 89.50 87.00 89.00 19 51.88 6.00 46.25 73.13 97.13 20 60.13 21.63 87.38 71.00 90.00 21 37.00 5.25 16.75 22.50 33.88
下载: 导出CSV
-
[1] Qin S J. Survey on data-driven industrial process monitoring and diagnosis. Annual Reviews in Control, 2012, 36(2): 220-234 doi: 10.1016/j.arcontrol.2012.09.004 [2] 刘强, 卓洁, 郎自强, 秦泗钊. 数据驱动的工业过程运行监控与自优化研究展望. 自动化学报, 2018, 44(11): 1944-1956 doi: 10.16383/j.aas.2018.c180207Liu Qiang, Zhuo Jie, Lang Zi-Qiang, Qin S. Joe. Perspectives on Data-driven Operation Monitoring and Self-optimization of Industrial Processes. Acta Automatica Sinica, 2018, 44(44): 1944-1956 doi: 10.16383/j.aas.2018.c180207 [3] Ge Z Q, Song Z H, Gao F R. Review of recent research on data-based process monitoring. Industrial & Engineering Chemistry Researchl, 2013, 52(10): 3543-3562 [4] 张成, 高宪文, 李元. 基于k近邻主元得分差分的故障检测策略. 自动化学报, 待发表 doi: 10.16383/j.aas.c180163Zhang Cheng, Gao Xian-Wen, LI Yuan. Perspectives on Data-driven Operation Monitoring and Self-optimization of Industrial Processes. Acta Automatica Sinica, to be published doi: 10.16383/j.aas.c180163 [5] 冯立伟, 张成, 李元, 谢彦红. 基于双近邻标准化和PCA的多阶段过程故障检测. 化工学报, 2018, 69(07): 3159-3166Feng Li-Wei, Zhang Cheng. Li Yuan, Xie Yan-Hong. DLNS-PCA-based fault detection for multimode batch process. CIESC Journal, 2018, 69(07): 3159-3166 [6] 胡益, 王丽, 马贺贺, 侍洪波. 基于核 PLS 方法的非线性过程在线监控. 化工学报, 2011, 62(09): 2555-2561 doi: 10.3969/j.issn.0438-1157.2011.09.025Hu Yi, Wang Li, Ma He-He, Shi Hong-Bo. Online nonlinear process monitoring using kernel partial least squares CIESC Journal, 2011, 62(09): 2555-2561 doi: 10.3969/j.issn.0438-1157.2011.09.025 [7] Wang L, Shi H B. Improved kernel PLS-based fault detection approach for nonlinear chemical processes. Chinese Journal of Chemical Engineering, 2014, 22(06): 657-663 doi: 10.1016/S1004-9541(14)60088-4 [8] 张成, 郭青秀, 冯立伟, 李元. 基于局部保持投影-加权k近邻规则的多模态间歇过程故障检测策略. 控制理论与应用, 2019, 36(10): 1682-1689 doi: 10.7641/CTA.2019.80858Zhang Cheng, Guo Qing-Xiu, Feng Li-Wei, Li Yuan. Fault detection strategy based on locality preserving projections-weighted k nearest neighbors in multimodal batch processes. Control Engineering of China, 2019, 36(10): 1682-1689 doi: 10.7641/CTA.2019.80858 [9] Lee J M, Yoo C K, Choi S W, Vanrolleghem P A, Lee I B. Nonlinear process monitoring using kernel principal component analysis. Chemical Engineering Science, 2004, 59(1): 223-234 doi: 10.1016/j.ces.2003.09.012 [10] 赵孝礼, 赵荣珍. 全局与局部判别信息融合的转子故障数据集降维方法研究. 自动化学报, 2017 43(4): 560-567Zhao Xiao-Li, Zhao Rong-Zhen. A Method of Dimension Reduction of Rotor Faults Data Set Based on Fusion of Global and Local Discriminant Information. Acta Automatica Sinica, 2017, 43(4): 560-567 [11] Zhang Y W, Ma C. Fault diagnosis of nonlinear processes using multiscale KPCA and multiscale KPLS. Chemical Engineering Science, 2011, 66(1): 64-72 doi: 10.1016/j.ces.2010.10.008 [12] 张成, 郭青秀, 李元, 高宪文. 基于主元分析得分重构差分的故障检测策略. 控制理论与应用, 2019, 36(05): 774-782Zhang Cheng, Guo Qing-Xiu, Li Yuna, Gao Xian-Wen. Fault detection strategy based on difference of score reconstruction associated with principal component analysis. Control Theory & Application, 2019, 36(05): 774-782 [13] 彭开香, 马亮, 张凯. 复杂工业过程质量相关的故障检测与诊断技术综述. 自动化学报, 2017, 43(3): 349-365Peng Kai-Xiang, Ma Liang, Zhang Kai. Review of Quality-related Fault Detection and Diagnosis Techniques for Complex Industrial Processes. Acta Automatica Sinica, 2017, 43(3): 349-365 [14] Ku W, Storer R H, Georgakis C. Disturbance detection and isolation by dynamic principal component analysis. Chemom. Intell. Lab. Syst. , 1995, 30(1): 179-196 doi: 10.1016/0169-7439(95)00076-3 [15] Kano M. Statistical process monitoring based on dissimilarity of process data. AIChE Journal, 2002, 48(6): 1231-1240 doi: 10.1002/aic.690480610 [16] Wang G Z, Liu J C, Li Y. A progressive fault detection and diagnosis method based on dissimilarity of process data. In: Proceedings of the 2014 IEEE International Conference on Information and Automation. Hailar, China: IEEE, 2014. 1211-1216 [17] Zhao C H, Wang F L, Jia M X. Dissimilarity analysis based batch process monitoring using moving windows. AIChE Journal, 2007, 53(5): 1267-1277 doi: 10.1002/aic.11164 [18] Zhang C, Guo Q X, Li Y. Fault detection method based on principal component difference associated with DPCA. Journal of Chemometrics, 2019, 33(1) [19] Rato T J, Reis M S. Fault detection in the Tennessee Eastman benchmark process using dynamic principal components analysis based on decorrelated residuals. Chemom Intel Lab Syst, 2013, 125(7): 101-108 [20] 石怀涛, 刘建昌, 丁晓迪, 谭帅, 王雪梅. 基于混合动态主元分析的故障检测方法. 控制工程, 2012, 19(1): 152-155 doi: 10.3969/j.issn.1671-7848.2012.01.038Shi Huai-Tao, Liu Jian-Chang, Ding Xiao-Di, Tan Shuai, Wang Xue-Mei. Fault detection based on hybrid dynamic principal component analysis. Control Engineering of China, 2012, 19(1): 152-155 doi: 10.3969/j.issn.1671-7848.2012.01.038 [21] Rato T J, Reis M S. Advantage of using decorrelated residuals in dynamic principal component analysis for monitoring large-scale systems. Industrial & Engineering Chemistry Research, 2013, 52(38): 13685-13698 [22] Wang J, He Q P. Multivariate statistical process monitoring based on statistics pattern analysis. Industrial & Engineering Chemistry Research, 2010, 49(17): 7858-7869 [23] Li G, Alcala C F, Qin S J, Zhou D H. Generalized reconstruction-based contributions for output-relevant fault diagnosis with application to the Tennessee Eastman process. IEEE Transactions on Control Systems Technology, 2011, 19(5): 1114-1127 doi: 10.1109/TCST.2010.2071415 [24] Yu H, Khan F. Improved latent variable models for nonlinear and dynamic process monitoring. Chemical Engineering Science, 2017, 168: 325-338 doi: 10.1016/j.ces.2017.04.048 [25] Jiang Q C, Yan X F. Non-Gaussian chemical process monitoring with adaptively weighted independent component analysis and its applications. Journal of Process Control, 2013, 23(9): 1320-131 doi: 10.1016/j.jprocont.2013.09.008 [26] Zhang M G, Ge Z Q, Song Z H, Fu R W. Global-Local structure analysis Model and its application for fault detection and identification. Industrial & Engineering Chemistry Research, 2011, 50(11): 6837-6848 -

 下载:
下载:

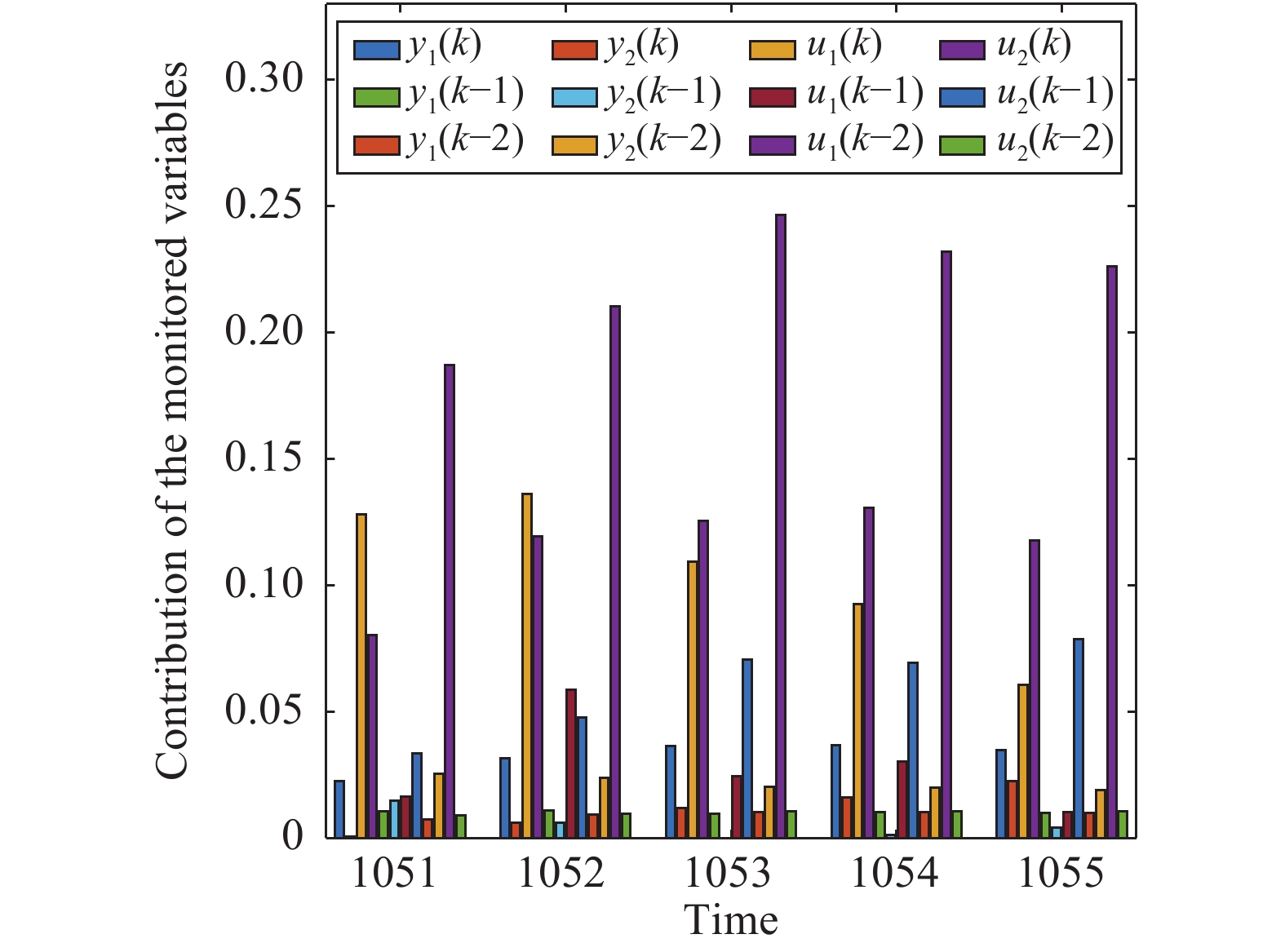


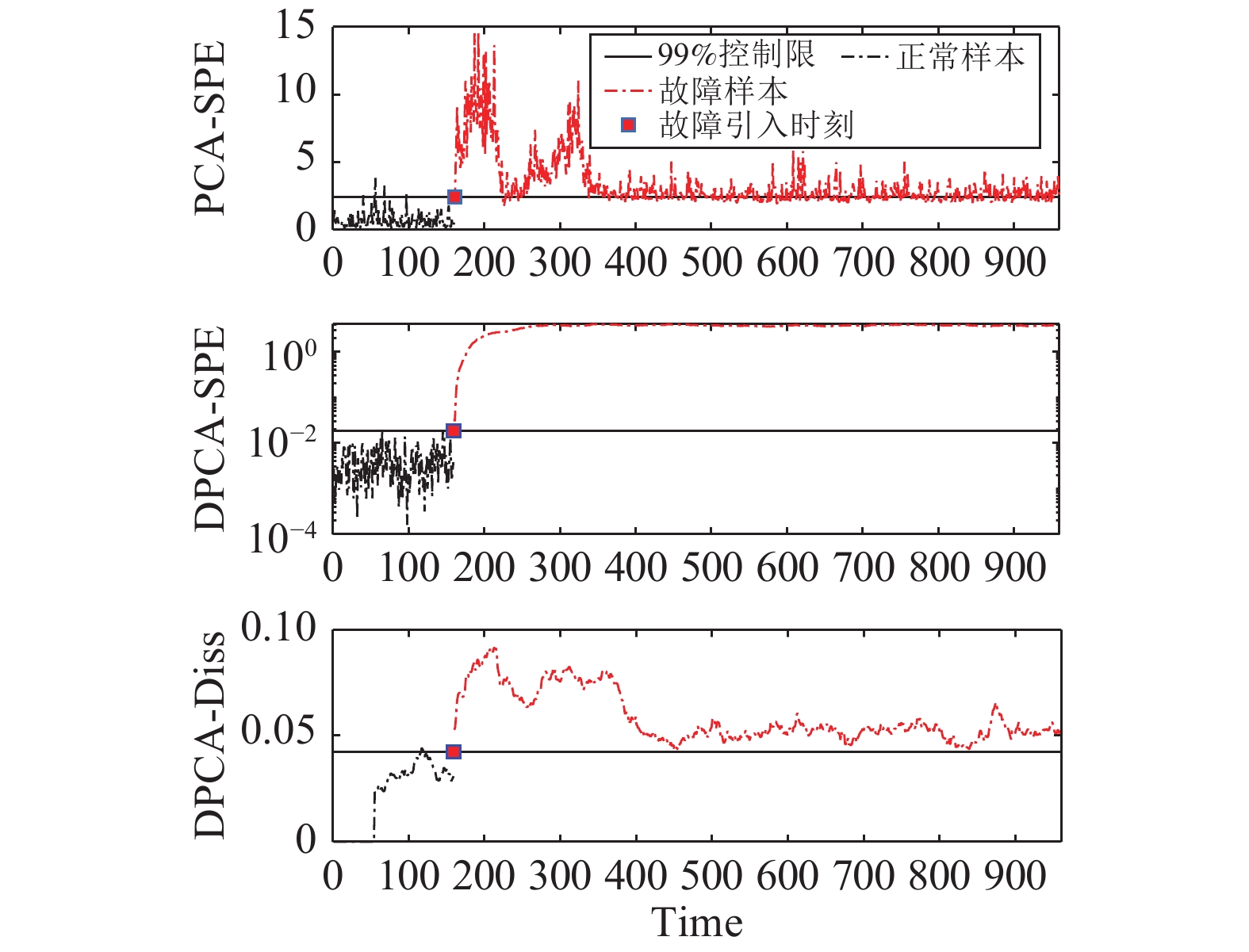
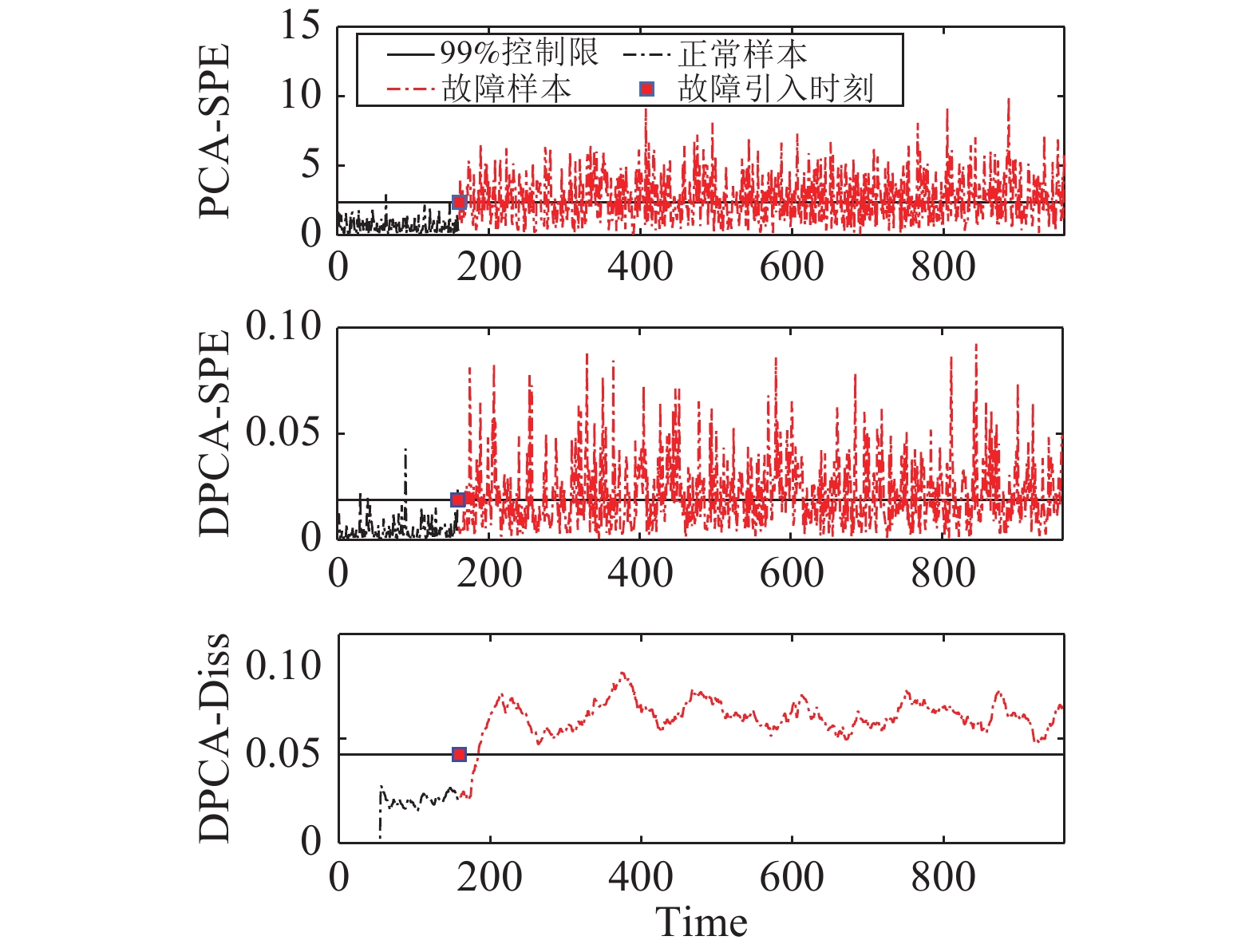
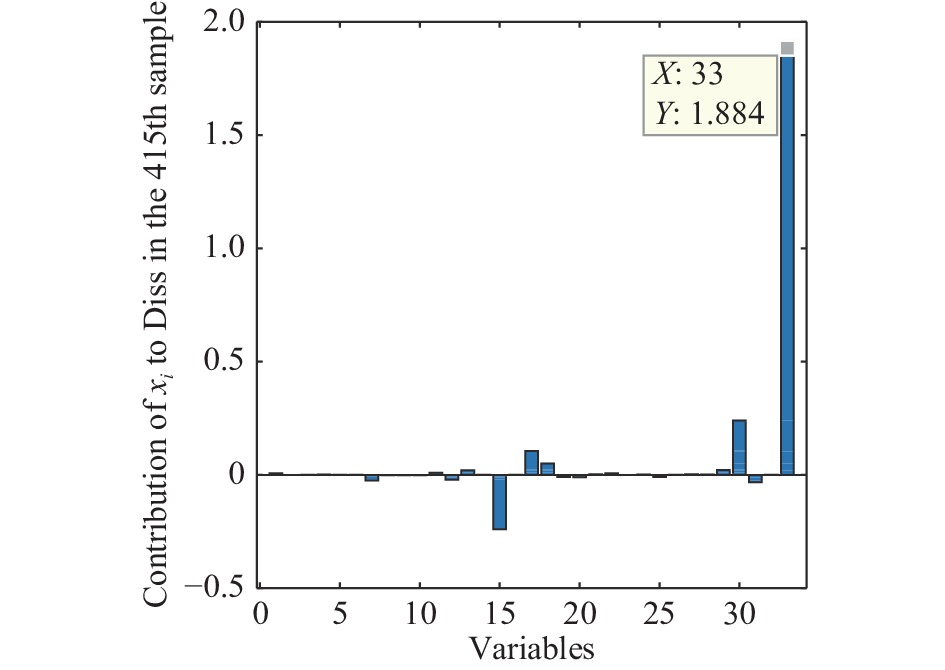
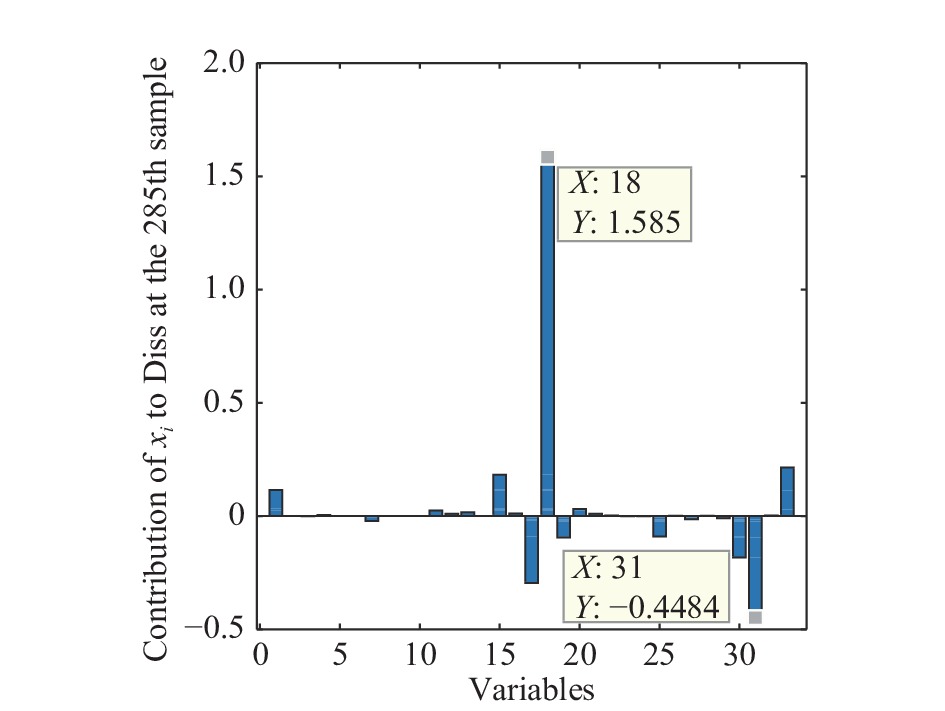
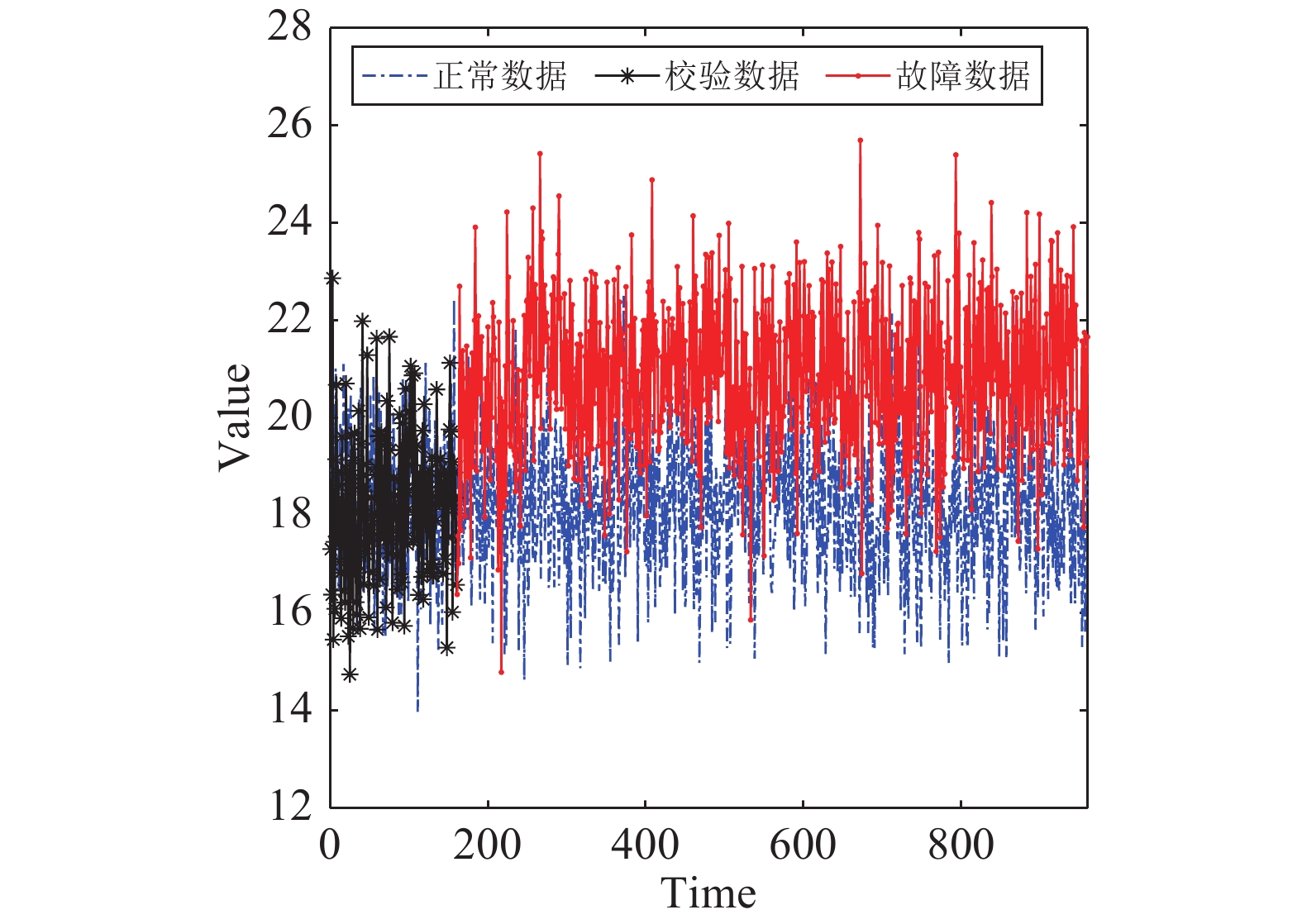


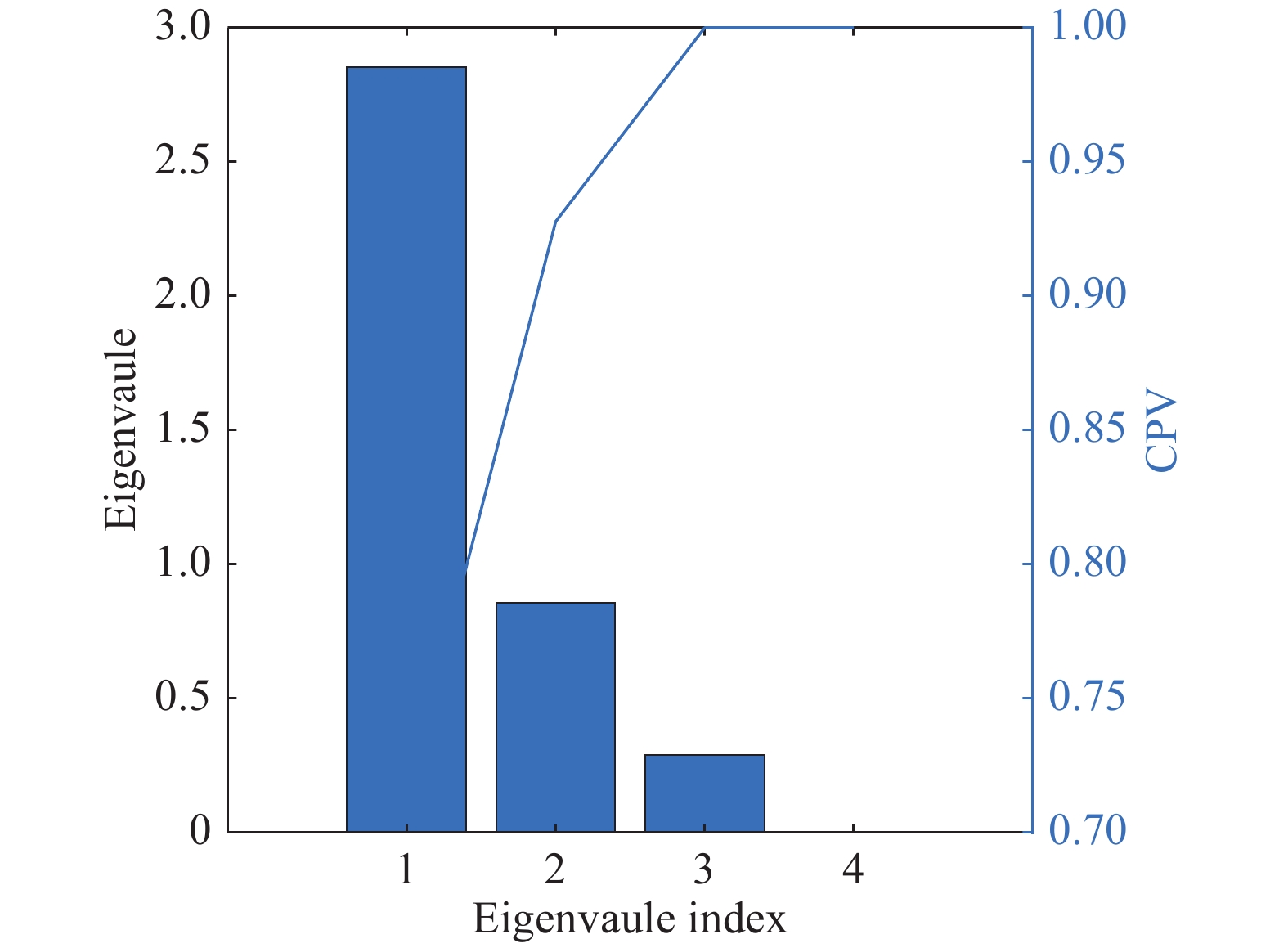
图(15) / 表(2)
计量
- 文章访问数: 1455
- HTML全文浏览量: 452
- PDF下载量: 238
- 被引次数: 0
