

A Review of Single Image Super-resolution Reconstruction Algorithms Based on Deep Learning
-
摘要: 单幅图像超分辨率(Single image super-resolution, SISR)重建是计算机视觉领域上的一个重要问题, 在安防视频监控、飞机航拍以及卫星遥感等方面具有重要的研究意义和应用价值. 近年来, 深度学习在图像分类、检测、识别等诸多领域中取得了突破性进展, 也推动着图像超分辨率重建技术的发展. 本文首先介绍单幅图像超分辨率重建的常用公共图像数据集; 然后, 重点阐述基于深度学习的单幅图像超分辨率重建方向的创新与进展; 最后, 讨论了单幅图像超分辨率重建方向上存在的困难和挑战, 并对未来的发展趋势进行了思考与展望.Abstract: Single image super-resolution (SISR) reconstruction is an important problem in the field of computer vision. It has important research significance and application value in security video surveillance, aircraft aerial photography and satellite remote sensing. In recent years, deep learning has made a breakthrough in many fields such as image classification, detection and recognition, and promoted the development of image super-resolution reconstruction technology. This paper first introduces the common public image datasets for single image super-resolution reconstruction. Then, the innovation and progress of single image super-resolution reconstruction based on deep learning are emphasized. Finally, the difficulties and challenges in the single image super-resolution reconstruction are discussed, and the future development trend is discussed.
-
Key words:
- Single image super-resolution (SISR) /
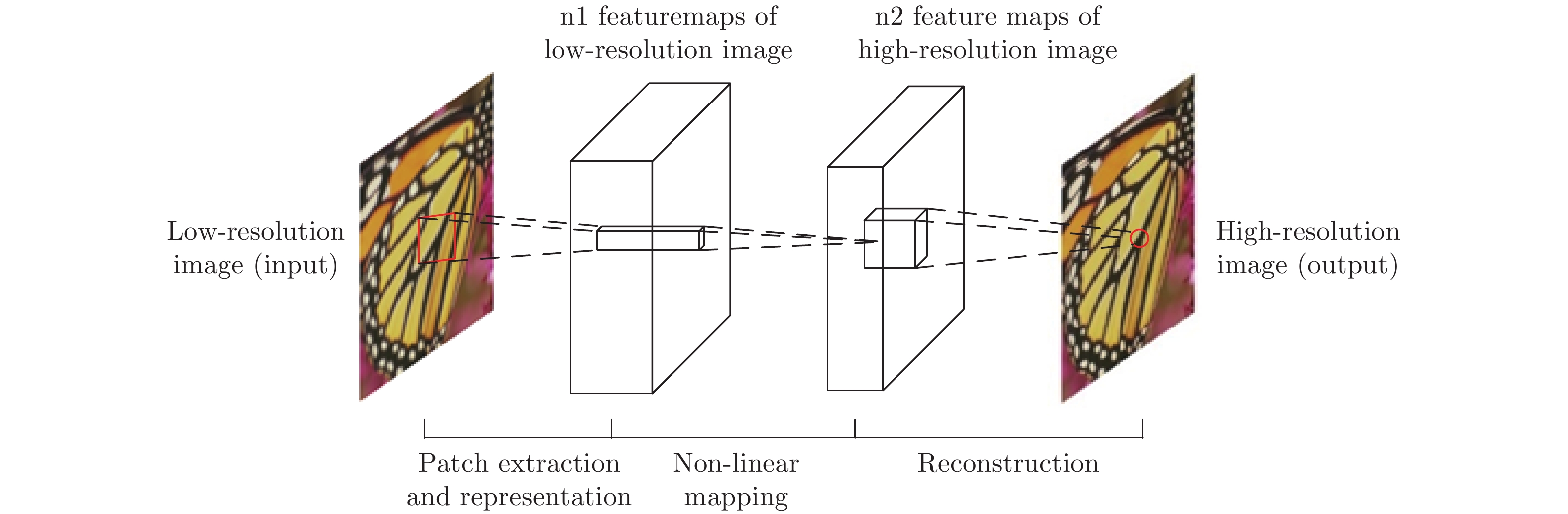
- computer vision /
- deep learning /
- neural network
-
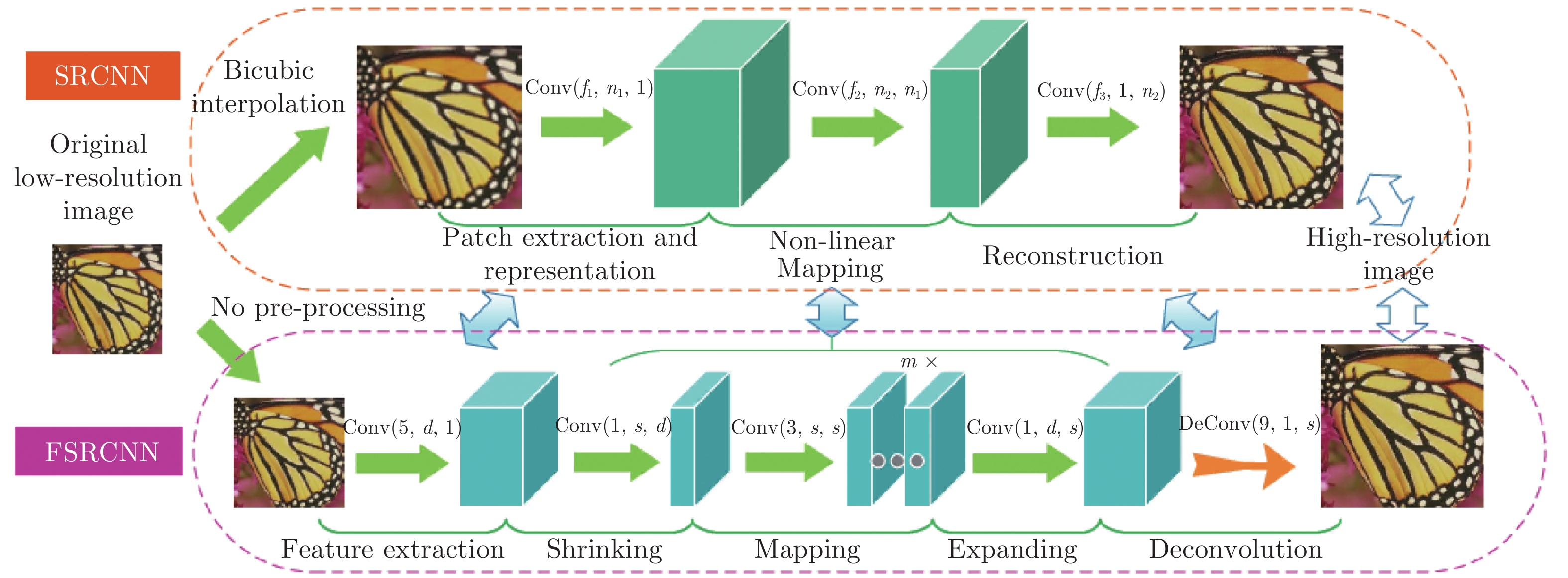


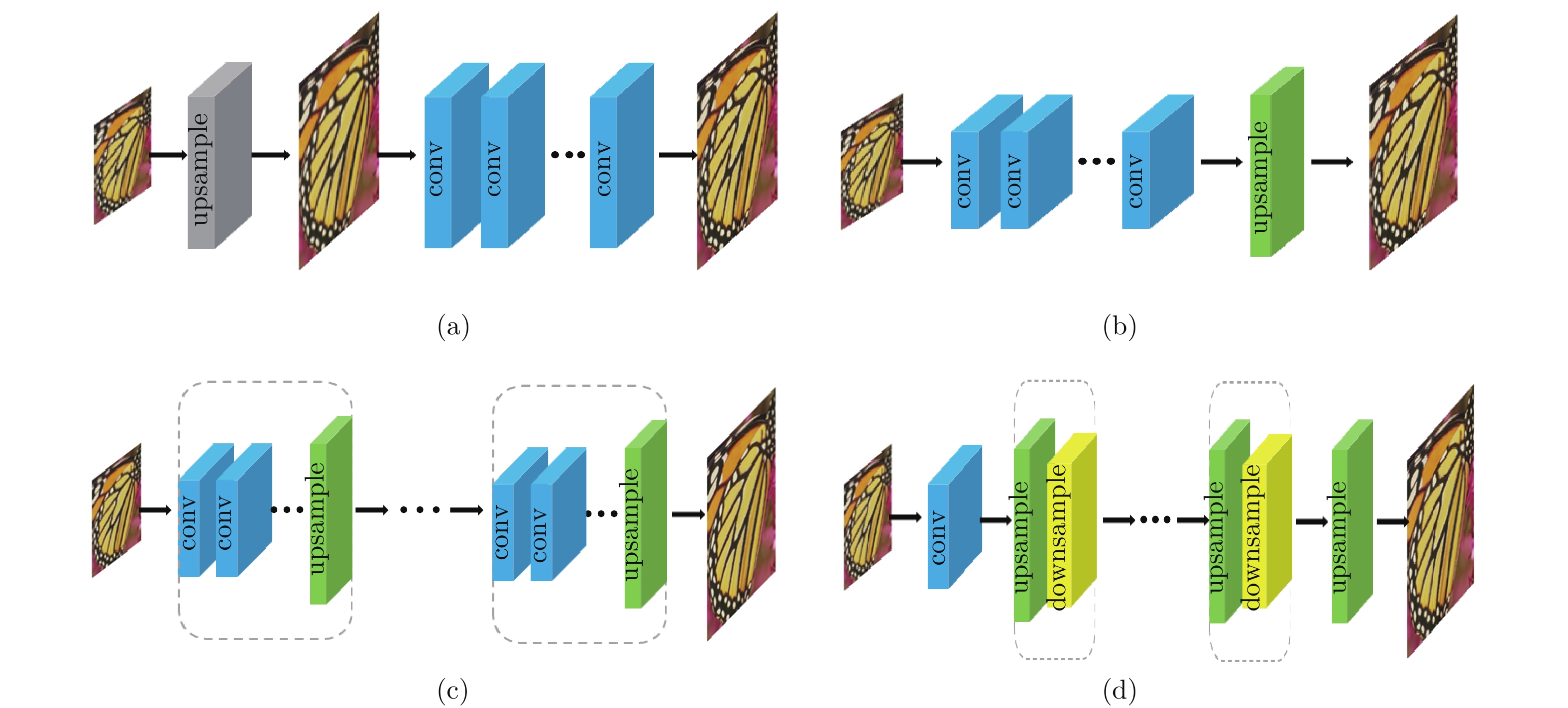
图 15 主流上采样方法
((a) 预上采样SR网络; (b) 后上采样SR网络; (c) 渐进上采样SR网络; (d) 迭代上下采样SR网络)
Fig. 15 Mainstream upsampling methods
((a) Pre-upscaling SR network; (b) Post-upscaling SR network; (c) Progressive upscaling SR network; (d) Iterative up-and-down sampling network)

图 23 部分模型的主观视觉与PSNR的比较
Fig. 23 Comparison of subjective vision and PSNR of partial models
表 3 MOS评估准则
Table 3 The MOS assessment
分数 绝对评估 相对评估 1 图像质量非常差 该组中最差 2 图像质量较差 差于该组中平均水平 3 图像质量一般 该组中的平均水平 4 图像质量较好 好于该组中的平均水平 5 图像质量非常好 该组中最好  下载: 导出CSV
下载: 导出CSV
表 4 部分网络模型在基准数据集Set5、Set14的平均PSNR对比
Table 4 The average PSNR comparison of some network models on the Set5 and Set14 benchmark datasets
Set5 Set14 方法 ×2 ×3 ×4 ×8 ×2 ×3 ×4 ×8 Bicubic[2] 33.66 30.39 28.42 24.39 30.23 27.54 26.00 23.19 SRCNN[6] 36.66 32.75 30.49 25.33 32.45 29.30 27.50 23.85 VDSR[7] 37.10 32.89 30.84 25.72 32.97 29.77 28.03 24.21 ESPCN[33] — 33.13 30.90 — — 29.49 27.73 — SRGAN[8] — — 30.64 — — — 26.92 — LapSRN[47] 37.52 33.82 31.54 26.14 33.08 29.87 28.19 24.44 SRDenseNet[38] — — 32.02 — — — 28.50 — EDSR[43] 38.20 34.76 32.62 26.96 34.02 30.66 28.94 24.91 EnhanceNet[44] — — 31.74 — — — 28.42 — DBPN[53] 38.09 — 32.47 27.21 33.85 — 28.82 25.13 RCAN[55] 38.33 34.85 32.73 27.47 34.23 30.76 28.98 25.40 SRMD[61] 37.79 34.12 31.96 — 33.32 30.04 28.35 — ZSSR[77] 37.37 33.42 31.13 — 33.00 29.80 28.01 — Meta-SR[72] — — — — 34.04 30.55 28.84 — OISR[85] 38.12 34.56 32.33 — 33.80 30.46 28.73 —
下载: 导出CSV
表 5 部分网络模型在基准数据集Set5、Set14的平均SSIM对比
Table 5 The comparison of average SSIM of partial network models on the Set5 and Set14 benchmark datasets
Set5 Set14 方法 ×2 ×3 ×4 ×8 ×2 ×3 ×4 ×8 Bicubic[2] 0.9299 0.8682 0.8104 0.657 0.8687 0.7736 0.7019 0.568 SRCNN[6] 0.9542 0.9090 0.8628 0.689 0.9067 0.8215 0.7513 0.593 VDSR[7] 0.9587 0.9213 0.8838 0.711 0.9124 0.8314 0.7674 0.609 FSRCNN[13] 0.9558 0.9140 0.8657 0.682 0.9088 0.8242 0.7535 0.592 SRGAN[8] — — 0.8472 — — — 0.7397 — LapSRN[47] 0.959 0.9227 0.885 0.738 0.913 0.8320 0.772 0.623 SRDenseNet[38] — — 0.8934 — — — 0.7782 — EDSR[43] 0.9606 0.9290 0.8984 0.775 0.9204 0.8481 0.7901 0.640 MemNet[36] 0.9597 0.9248 0.8893 0.7414 0.9142 0.8350 0.7723 0.6199 DBPN[53] 0.960 — 0.898 0.784 0.919 — 0.786 0.648 RCAN55] 0.9617 0.9305 0.9013 0.7913 0.9225 0.8494 0.7910 0.6553 SRMD[61] 0.960 0.925 0.893 — 0.915 0.837 0.777 — ZSSR[77] 0.9570 0.9188 0.8796 — 0.9108 0.8304 0.7651 — Meta-SR[72] — — — — 0.9213 0.8466 0.7872 — OISR[85] 0.9609 0.9284 0.8968 — 0.9196 0.8450 0.7845 —
下载: 导出CSV
表 6 部分网络模型在基准数据集Set5、Set14和BSDS100的×4尺度上的MOS对比
Table 6 The MOS comparison of some network models at ×4 of the benchmark datasets Set5, Set14 and BSDS100
下载: 导出CSV
表 7 部分网络模型在各测试数据集上的运行时间对比
Table 7 The comparison of running time of partial network models on each testing datasets
方法 深度学习框架 CPU/GPU 测试数据集 上采样因子 运行时间 (s) SRCNN[6] Caffe CPU Set5 ×3 2.23 VDSR[7] MatConvNet CPU Set5 ×3 0.13 ESPCN[33] Theano CPU Set14 ×3 0.26 FSRCNN[13] Caffe CPU Set14 ×3 0.061 LapSRN[47] MatConvNet GPU Set14 ×4 0.04 MemNet[36] Caffe GPU Set5 ×3 0.4 EnhanceNet[44] Tensorflow GPU Set5 ×4 0.009 MS-LapSRN[69] MatConvNet GPU Urban100 ×4 0.06 ZSSR[77] — GPU BSDS100 ×2 9 Meta-SR[72] — GPU BSDS100 ×2 0.033
下载: 导出CSV
-
[1] Duchon C E. Lanczos filtering in one and two dimensions. Journal of Applied Meteorology, 1979, 18(8): 1016−1022 doi: 10.1175/1520-0450(1979)018<1016:LFIOAT>2.0.CO;2 [2] Keys R. Cubic convolution interpolation for digital image processing. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1981, 29(6): 1153−1160 doi: 10.1109/TASSP.1981.1163711 [3] Freeman W T, Jones T R, Pasztor E C. Example-based super-resolution. IEEE Computer Graphics and Applications, 2002, 22(2): 56−65 doi: 10.1109/38.988747 [4] Chang H, Yeung D Y, Xiong Y M. Super-resolution through neighbor embedding. In: Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). Washington, DC, USA: IEEE, 2004. [5] Sun J, Xu Z B, Shum H Y. Image super-resolution using gradient profile prior. In: Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Anchorage, AK, USA: IEEE, 2008. 1−8 [6] Dong C, Loy C C, He K M, Tang X O. Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295−307 doi: 10.1109/TPAMI.2015.2439281 [7] Kim J, Lee J K, Lee K M. Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 1646−1654 [8] Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, et al. Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 105−114 [9] Ignatov A, Kobyshev N, Timofte R, Vanhoey K, Van Gool L. WESPE: Weakly supervised photo enhancer for digital cameras. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Salt Lake City, USA: IEEE, 2018. [10] Bevilacqua M, Roumy A, Guillemot C, Morel M L A. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: Proceedings of the 2012 British Machine Vision Conference. Surrey, UK: BMVA Press, 2012. 135.1−135.10 [11] Zeyde R, Elad M, Protter M. On single image scale-up using sparse-representations. In: Proceedings of the 7th International Conference on Curves and Surfaces. Avignon, France: Springer, 2010. 711−730 [12] Huang J B, Singh A, Ahuja N. Single image super-resolution from transformed self-exemplars. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 5197−5206 [13] Dong C, Loy C C, Tang X O. Accelerating the super-resolution convolutional neural network. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 391−407 [14] Martin D, Fowlkes C, Tal D, Malik J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings of the 8th IEEE International Conference on Computer Vision (ICCV). Vancouver, BC, Canada: IEEE, 2001. 416−423 [15] Arbeláez P, Maire M, Fowlkes C, Malik J. Contour detection and hierarchical image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(5): 898−916 doi: 10.1109/TPAMI.2010.161 [16] Fujimoto A, Ogawa T, Yamamoto K, Matsui Y, Aizawa K. Manga109 dataset and creation of metadata. In: Proceedings of the 1st International Workshop on coMics ANalysis, Processing and Understanding. Cancun, Mexico: ACM, 2016. 1−5 [17] Yang J C, Wright J, Huang T S, Ma Y. Image super-resolution via sparse representation. IEEE Transactions on Image Processing, 2010, 19(11): 2861−2873 doi: 10.1109/TIP.2010.2050625 [18] Agustsson E, Timofte R. NTIRE 2017 challenge on single image super-resolution: Dataset and study. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Honolulu, HI, USA: IEEE, 2017. 1122−1131 [19] Timofte R, Rothe R, Van Gool L. Seven ways to improve example-based single image super resolution. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 1865−1873 [20] Wang X T, Yu K, Dong C, Loy C C. Recovering realistic texture in image super-resolution by deep spatial feature transform. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 606−615 [21] Blau Y, Mechrez R, Timofte R, Michaeli T, Zelnik-Manor L. The 2018 PIRM challenge on perceptual image super-resolution. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 334−355 [22] Deng J, Dong W, Socher R, Li L J, Li K, Li F F. ImageNet: A large-scale hierarchical image database. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Miami, FL, USA: IEEE, 2009. 248−255 [23] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision (ECCV). Zurich, Switzerland: Springer, 2014. 740−755 [24] Everingham M, Eslami S M A, Van Gool L, Williams C K I, Winn J, Zisserman A. The PASCAL visual object classes challenge: A retrospective. International Journal of Computer Vision, 2015, 111(1): 98−136 doi: 10.1007/s11263-014-0733-5 [25] Liu Z W, Luo P, Wang X G, Tang X O. Deep learning face attributes in the wild. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 3730−3738 [26] Yu F, Zhang Y D, Song S R, Seff A, Xiao J X. Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv: 1506.03365, 2016. [27] Ma K D, Duanmu Z F, Wu Q B, Wang Z, Yong H W, Li H L, et al. Waterloo exploration database: New challenges for image quality assessment models. IEEE Transactions on Image Processing, 2017, 26(2): 1004−1016 doi: 10.1109/TIP.2016.2631888 [28] Timofte R, Agustsson E, Van Gool L, Yang M H, Zhang L, Lim B, et al. NTIRE 2017 challenge on single image super-resolution: Methods and results. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Honolulu, HI, USA: IEEE, 2017. 1110−1121 [29] Chen C, Xiong Z W, Tian X M, Zha Z J, Wu F. Camera lens super-resolution. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 1652−1660 [30] Ignatov A, Kobyshev N, Timofte R, Vanhoey K, Van Gool L. DSLR-quality photos on mobile devices with deep convolutional networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 3297−3305 [31] Wang Z H, Chen J, Hoi S C H. Deep learning for image super-resolution: A survey. arXiv preprint arXiv: 1902.06068, 2020. [32] 胡长胜, 詹曙, 吴从中. 基于深度特征学习的图像超分辨率重建. 自动化学报, 2017, 43(5): 814−821Hu Chang-Sheng, Zhan Shu, Wu Cong-Zhong. Image super-resolution based on deep learning features. Acta Automatica Sinica, 2017, 43(5): 814−821 [33] Shi W Z, Caballero J, Huszár F, Totz J, Aitken A P, Bishop R, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 1874−1883 [34] Mao X J, Shen C H, Yang Y B. Image restoration using convolutional auto-encoders with symmetric skip connections. arXiv preprint arXiv: 1606.08921, 2016. [35] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 770−778 [36] Tai Y, Yang J, Liu X M, Xu C Y. MemNet: A persistent memory network for image restoration. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 4549−4557 [37] Kim J, Lee J K, Lee K M. Deeply-recursive convolutional network for image super-resolution. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 1637−1645 [38] Huang G, Liu Z, Van Der Maaten L, Weinberger K Q. Densely connected convolutional networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 2261−2269 [39] Tong T, Li G, Liu X J, Gao Q Q. Image super-resolution using dense skip connections. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 4809−4817 [40] Zhang Y L, Tian Y P, Kong Y, Zhong B N, Fu Y. Residual dense network for image super-resolution. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 2472−2481 [41] Yu J H, Fan Y C, Yang J C, Xu N, Wang Z W, Wang X C, et al. Wide activation for efficient and accurate image super-resolution. arXiv preprint arXiv: 1808.08718, 2018. [42] Timofte R, Gu S H, Wu J Q, Van Gool L, Zhang L, Yang M H, et al. NTIRE 2018 challenge on single image super-resolution: Methods and results. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City, USA: IEEE, 2018. [43] Lim B, Son S, Kim H, Nah S, Lee K M. Enhanced deep residual networks for single image super-resolution. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Honolulu, HI, USA: IEEE, 2017. 1132−1140 [44] Sajjadi M S M, Schölkopf B, Hirsch M. EnhanceNet: Single image super-resolution through automated texture synthesis. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 4501−4510 [45] Soh J W, Park G Y, Jo J, Cho N I. Natural and realistic single image super-resolution with explicit natural manifold discrimination. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 8114−8123 [46] Tai Y, Yang J, Liu X M. Image super-resolution via deep recursive residual network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 2790−2798 [47] Lai W S, Huang J B, Ahuja N, Yang M H. Deep laplacian pyramid networks for fast and accurate super-resolution. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 5835−5843 [48] 周登文, 赵丽娟, 段然, 柴晓亮. 基于递归残差网络的图像超分辨率重建. 自动化学报, 2019, 45(6): 1157−1165Zhou Deng-Wen, Zhao Li-Juan, Duan Ran, Chai Xiao-Liang. Image super-resolution based on recursive residual networks. Acta Automatica Sinica, 2019, 45(6): 1157−1165 [49] Han W, Chang S Y, Liu D, Yu M, Witbrock M, Huang T S. Image super-resolution via dual-state recurrent networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 1654−1663 [50] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA, USA: MIT Press, 2014. 2672−2680 [51] Wang X T, Yu K, Wu S X, Gu J J, Liu Y H, Dong C, et al. ESRGAN: Enhanced super-resolution generative adversarial networks. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 63−79 [52] Jolicoeur-Martineau A. The relativistic discriminator: A key element missing from standard GAN. arXiv preprint arXiv: 1807.00734, 2018. [53] Haris M, Shakhnarovich G, Ukita N. Deep back-projection networks for super-resolution. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 1664−1673 [54] Li Z, Yang J L, Liu Z, Yang X M, Jeon G, Wu W. Feedback network for image super-resolution. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 3862−3871 [55] Zhang Y L, Li K P, Li K, Wang L C, Zhong B N, Fu Y. Image super-resolution using very deep residual channel attention networks. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 286−301 [56] Dai T, Cai J R, Zhang Y B, Xia S T, Zhang L. Second-order attention network for single image super-resolution. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 11057−11066 [57] 周登文, 马路遥, 田金月, 孙秀秀. 基于特征融合注意网络的图像超分辨率重建[Online], 自动化学报, 获取自: https://doi.org/10.16383/j.aas.c190428, 2019年11月7日Zhou Deng-Wen, Ma Lu-Yao, Tian Jin-Yue, Sun Xiu-Xiu. Feature fusion attention network for image super-resolution [Online], Acta Automatica Sinica, available: https://doi.org/10.16383/j.aas.c190428, November 7, 2019 [58] Johnson J, Alahi A, Li F F. Perceptual losses for real-time style transfer and super-resolution. In: Proceedings of the 14th European Conference on Computer Vision (ECCV). Amsterdam, The Netherlands: Springer, 2016. 694−711 [59] Gatys L A, Ecker A S, Bethge M. A neural algorithm of artistic style. arXiv preprint arXiv: 1508.06576, 2015. [60] Wang Y F, Perazzi F, McWilliams B, Sorkine-Hornung A, Sorkine-Hornung O, Schroers C. A fully progressive approach to single-image super-resolution. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Salt Lake City, USA: IEEE, 2018. [61] Yuan Y, Liu S Y, Zhang J W, Zhang Y B, Dong C, Lin L. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Salt Lake City, USA: IEEE, 2018. [62] Mao X D, Li Q, Xie H R, Lau R Y K, Wang Z, Smolley S P. Least squares generative adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2813−2821 [63] Gatys L A, Ecker A S, Bethge M. Texture synthesis using convolutional neural networks. arXiv preprint arXiv: 1505.07376, 2015. [64] Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 2414−2423 [65] Rudin L I, Osher S, Fatemi E. Nonlinear total variation based noise removal algorithms. Physica D: Nonlinear Phenomena, 1992, 60(1−4): 259−268 doi: 10.1016/0167-2789(92)90242-F [66] Mechrez R, Talmi I, Shama F, Zelnik-Manor L. Maintaining natural image statistics with the contextual loss. In: Proceedings of the 14th Asian Conference on Computer Vision (ACCV). Perth, Australia: Springer, 2018. 427−443 [67] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv: 1409.1556, 2015. [68] Lempitsky V, Vedaldi A, Ulyanov D. Deep image prior. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 9446−9454 [69] Lai W S, Huang J B, Ahuja N, Yang M H. Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(11): 2599−2613 doi: 10.1109/TPAMI.2018.2865304 [70] Kim J H, Lee J S. Deep residual network with enhanced upscaling module for super-resolution. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Salt Lake City, USA: IEEE, 2018. [71] Wang Z, Bovik A C, Sheikh H R, Simoncelli E P. Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Processing, 2004, 13(4): 600−612 doi: 10.1109/TIP.2003.819861 [72] Hu X C, Mu H Y, Zhang X Y, Wang Z L, Tan T N, Sun J. Meta-SR: A magnification-arbitrary network for super-resolution. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 1575−1584 [73] Bulat A, Yang J, Tzimiropoulos G. To learn image super-resolution, use a GAN to learn how to do image degradation first. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 187−202 [74] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2242−2251 [75] Zontak M, Irani M. Internal statistics of a single natural image. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Colorado Springs, CO, USA: IEEE, 2011. 977−984 [76] Mosseri I, Zontak M, Irani M. Combining the power of internal and external denoising. In: Proceedings of the 2013 IEEE International Conference on Computational Photography (ICCP). Cambridge, MA, USA: IEEE, 2013. 1−9 [77] Shocher A, Cohen N, Irani M. Zero-shot super-resolution using deep internal learning. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 3118−3126 [78] Glasner D, Bagon S, Irani M. Super-resolution from a single image. In: Proceedings of the 12th International Conference on Computer Vision (ICCV). Kyoto, Japan: IEEE, 2009. 349−356 [79] Zhang K, Zuo W M, Zhang L. Learning a single convolutional super-resolution network for multiple degradations. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 3262−3271 [80] Gu J J, Lu H N, Zuo W M, Dong C. Blind super-resolution with iterative kernel correction. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 1604−1613 [81] Zhang K, Zuo W M, Zhang L. Deep plug-and-Play super-resolution for arbitrary blur kernels. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 1671−1681 [82] Xu X Y, Ma Y R, Sun W X. Towards real scene super-resolution with raw images. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 1723−1731 [83] Coffin D. Dcraw: Decoding raw digital photos in linux [Online], available: http://www.cybercom.net/dcoffin/dcraw/ [84] Szegedy C, Ioffe S, Vanhoucke V, Alemi A A. Inception-v4, inception-ResNet and the impact of residual connections on learning. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence (AAAI). San Francisco, USA: AAAI Press, 2017. 4278−4284 [85] He X Y, Mo Z T, Wang P S, Liu Y, Yang M Y, Cheng J. ODE-inspired network design for single image super-resolution. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 1732−1741 [86] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2): 91−110 doi: 10.1023/B:VISI.0000029664.99615.94 [87] Fischler M A, Bolles R C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM, 1981, 24(6): 381−395 doi: 10.1145/358669.358692 [88] Zhang X E, Chen Q F, Ng R, Koltun V. Zoom to learn, learn to zoom. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 3757−3765 [89] Chen Y, Tai Y, Liu X M, Shen C H, Yang J. FSRNet: End-to-end learning face super-resolution with facial priors. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 2492−2501 [90] Bulat A, Tzimiropoulos G. Super-FAN: Integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with GANs. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 109−117 [91] Sheikh H R, Bovik A C, de Veciana G. An information fidelity criterion for image quality assessment using natural scene statistics. IEEE Transactions on Image Processing, 2005, 14(12): 2117−2128 doi: 10.1109/TIP.2005.859389 [92] Sheikh H R, Bovik A C. Image information and visual quality. IEEE Transactions on Image Processing, 2006, 15(2): 430−444 doi: 10.1109/TIP.2005.859378 [93] Damera-Venkata N, Kite T D, Geisler W S, Evans B L, Bovik A C. Image quality assessment based on a degradation model. IEEE Transactions on Image Processing, 2000, 9(4): 636−650 doi: 10.1109/83.841940 [94] Wang Z, Simoncelli E P, Bovik A C. Multiscale structural similarity for image quality assessment. In: Proceedings of the 37th Asilomar Conference on Signals, Systems & Computers. Pacific Grove, CA, USA: IEEE, 2003. 1398−1402 [95] Chandler D M, Hemami S S. VSNR: A wavelet-based visual signal-to-noise ratio for natural images. IEEE Transactions on Image Processing, 2007, 16(9): 2284−2298 doi: 10.1109/TIP.2007.901820 [96] Zhang L, Zhang L, Mou X Q, Zhang D. FSIM: A feature similarity index for image quality assessment. IEEE Transactions on Image Processing, 2011, 20(8): 2378−2386 doi: 10.1109/TIP.2011.2109730 [97] Blau Y, Michaeli T. The perception-distortion tradeoff. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 6228−6237 [98] Mittal A, Soundararajan R, Bovik A C. Making a “completely blind” image quality analyzer. IEEE Signal Processing Letters, 2013, 20(3): 209−212 doi: 10.1109/LSP.2012.2227726 [99] Ma C, Yang C Y, Yang X K, Yang M H. Learning a no-reference quality metric for single-image super-resolution. Computer Vision and Image Understanding, 2017, 158: 1−16 doi: 10.1016/j.cviu.2016.12.009 [100] Michaeli T, Irani M. Nonparametric blind super-resolution. In: Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV). Sydney, NSW, Australia: IEEE, 2013. 945−952 -

 下载:
下载:










计量
- 文章访问数: 5094
- HTML全文浏览量: 2933
- PDF下载量: 1072
- 被引次数: 0
