

-
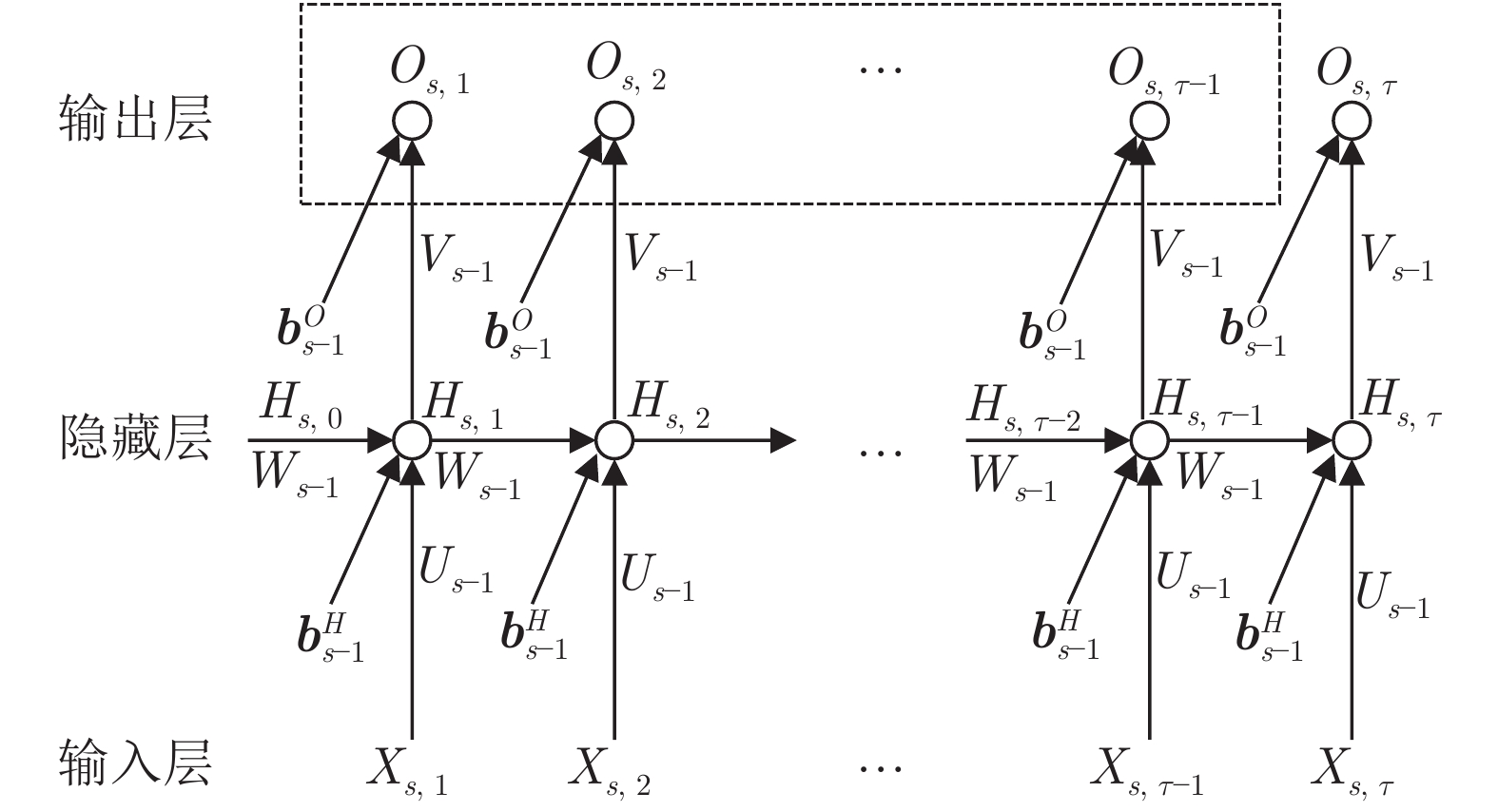
摘要: 针对循环神经网络(Recurrent neural networks, RNNs)一阶优化算法学习效率不高和二阶优化算法时空开销过大, 提出一种新的迷你批递归最小二乘优化算法. 所提算法采用非激活线性输出误差替代传统的激活输出误差反向传播, 并结合加权线性最小二乘目标函数关于隐藏层线性输出的等效梯度, 逐层导出RNNs参数的迷你批递归最小二乘解. 相较随机梯度下降算法, 所提算法只在RNNs的隐藏层和输出层分别增加了一个协方差矩阵, 其时间复杂度和空间复杂度仅为随机梯度下降算法的3倍左右. 此外, 本文还就所提算法的遗忘因子自适应问题和过拟合问题分别给出一种解决办法. 仿真结果表明, 无论是对序列数据的分类问题还是预测问题, 所提算法的收敛速度要优于现有主流一阶优化算法, 而且在超参数的设置上具有较好的鲁棒性.Abstract: In recurrent neural networks (RNNs), the first-order optimization algorithms usually converge slowly, and the second-order optimization algorithms commonly have high time and space complexities. In order to solve these problems, a new minibatch recursive least squares (RLS) optimization algorithm is proposed. Using the inactive linear output error to replace the conventional activation output error for backpropagation, together with the equivalent gradients of the weighted linear least squares objective function with respect to linear outputs of the hidden layer, the proposed algorithm derives the minibatch recursive least squares solutions of RNNs parameters layer by layer. Compared with the stochastic gradient descent algorithm, the proposed algorithm only adds one covariance matrix into each layer of RNNs, and its time and space complexities are almost three times as much. Furthermore, in order to address the adaptive problem of the forgetting factor and the overfitting problem of the proposed algorithm, two approaches are also presented, respectively, in this paper. The simulation results, on the classification and prediction problems of sequential data, show that the proposed algorithm has faster convergence speed than popular first-order optimization algorithms. In addition, the proposed algorithm also has good robustness in the selection of hyperparameters.
-
水下光学图像探测技术是海洋开发、探测常用的关键技术之一, 是水下机器人(Autonomous underwater vehicle/Remote operated vehicle, AUV/ROV)进行深海目标监测与生物资源考察的重要方法[1-3], 在海洋工程、海洋军事以及海洋环境保护等方面具有重要应用前景[4].
图像的颜色信息作为反映物体特性的重要信息, 对于水下目标的识别和分类起到重要的作用. 但是水下光线的衰减和散射效应会导致水下图像呈现对比度低、散射模糊和颜色失真现象, 为后续的基于机器视觉的自动识别和理解带来了严重困难. 为此, 本文的目的就是研究基于改进循环生成对抗神经网络的水下图像颜色校正与增强新方法.
根据是否基于水下成像物理模型, 目前水下图像的颜色校正方法可分为基于成像模型的图像复原算法和基于非成像模型的图像增强算法两类.
1)基于成像物理模型的图像复原方法[5-9]是对水下图像的退化过程建立数学模型, 并估算出模型的基本参数, 然后通过该模型反演图像的退化过程, 并获得理想状态下的未退化图像. 如He等[5]提出了暗通道先验(Dark channel prior, DCP)算法, 该算法通过寻找雾化图像的局部最暗点并结合图像物理模型进行图像复原. 该类算法的共同点是需要建立水下成像模型, 并估计散射光成分和衰减系数. 由于水下环境复杂多变, 水下成像模型很难建立, 所以参数估计精度和模型稳健性都受到一定限制.
2)图像增强算法不需要对成像过程进行建模和参数估计, 而是直接对降质图像进行增强处理. 主要的代表性方法有以下两种:
a) 传统的图像处理方法. 通过图像处理技术, 直接调整或改变图像的像素值分布以达到改善图像质量的目的[10-13]. 如基于灰度世界(Gray world, GW)假设的算法[11], 利用颜色恒常性原理, 将自然场景颜色的平均值设为定值, 并应用于水下图像增强. UCM (Unsupervised color correction method)算法[12]先将水下图像在RGB空间进行色彩均衡, 然后再在HSV空间进行对比度校正. 这类算法虽然简单, 但是易存在噪声过增强、以及引入伪影和颜色失真等问题.
b) 基于深度学习的水下图像颜色校正增强算法. 该类算法通过深度卷积神经网络的学习, 来建立水下降质图像和真实图像之间的复杂非线性映射关系, 进而达到对水下退化图像颜色校正的目的. 目前主要的代表性方法都是基于生成对抗网络(Generative adversarial networks, GANs)[14]和循环一致性生成对抗网络(Cycle-consistent generative adversarial networks, CycleGANs)[15]. 如Li等[16]首先利用生成对抗神经网络WaterGAN以非监督方式生成一个训练集, 该网络的输入是空气中的彩色图像和该图像的深度图, 输出为对应深度的水下生成图像. 然后基于生成的训练集, 利用双级卷积全连接网络进行水下实际图像的颜色校正. 这种方法的特点是必须利用深度图像进行训练学习, 这在实际应用场景中难以实现, 此外深度估计一旦存在误差, 也会影响颜色的校正效果. 此外, Li等[17]提出了一种基于循环生成对抗网络(CycleGAN)的水下图像颜色校正方法, 该方法利用CycleGAN以弱监督方式学习非成对空气图像集和水下图像集之间的颜色映射关系. 为了保留水下图像的内容和结构信息, 在网络训练损失函数中, 新加入了结构相似性损失函数(Structural similarity index, SSIM). 在缺乏水下成对图像样本集的条件下, 对于校正水下图像的偏色效应取得了较好的实验结果, 并具有普适性强、效率高的优点. 但该方法仍然存在两个问题: 1)采用的结构相似性损失函数在图像亮度信息、对比度信息、结构信息三方面进行了相似性限制, 这与实际情况不相符合. 因为原始的模糊图像和校正后的清晰图像在亮度、对比度上本应不相似, 若强制相似, 反而起不到对比度增强的目的. 2)对于校正后图像的颜色没有客观的定量指标进行约束或评价, 故很难保证校正后图像和真实理想图像颜色的一致性.
为了克服文献[17]存在的以上两个问题, 本文提出了一种基于改进CycleGAN的水下图像颜色校正与增强算法. 该方法的主要贡献体现在两方面: 1)为了保证在CycleGAN学习中, 既能保留原始水下图像的边缘、纹理结构信息, 又能提高增强后图像的对比度, 提出了基于图像强边缘结构相似度(Strong edge and structure similarity, SESS)损失函数的SESS-CycleGAN; 2)为了保证校正后图像的颜色和真实图像颜色的一致性, 提出了弱监督SESS-CycleGAN和强监督生成网络相结合的网络结构并提出了两阶段学习策略. 并通过实验验证了提出方法在颜色校正和对比度增强方面的有效性.
1. 提出的方法
本节分别从网络结构组成、网络损失函数确定、和网络学习过程三方面介绍本文提出的基于改进CycleGAN的水下图像增强方法.
1.1 网络结构组成
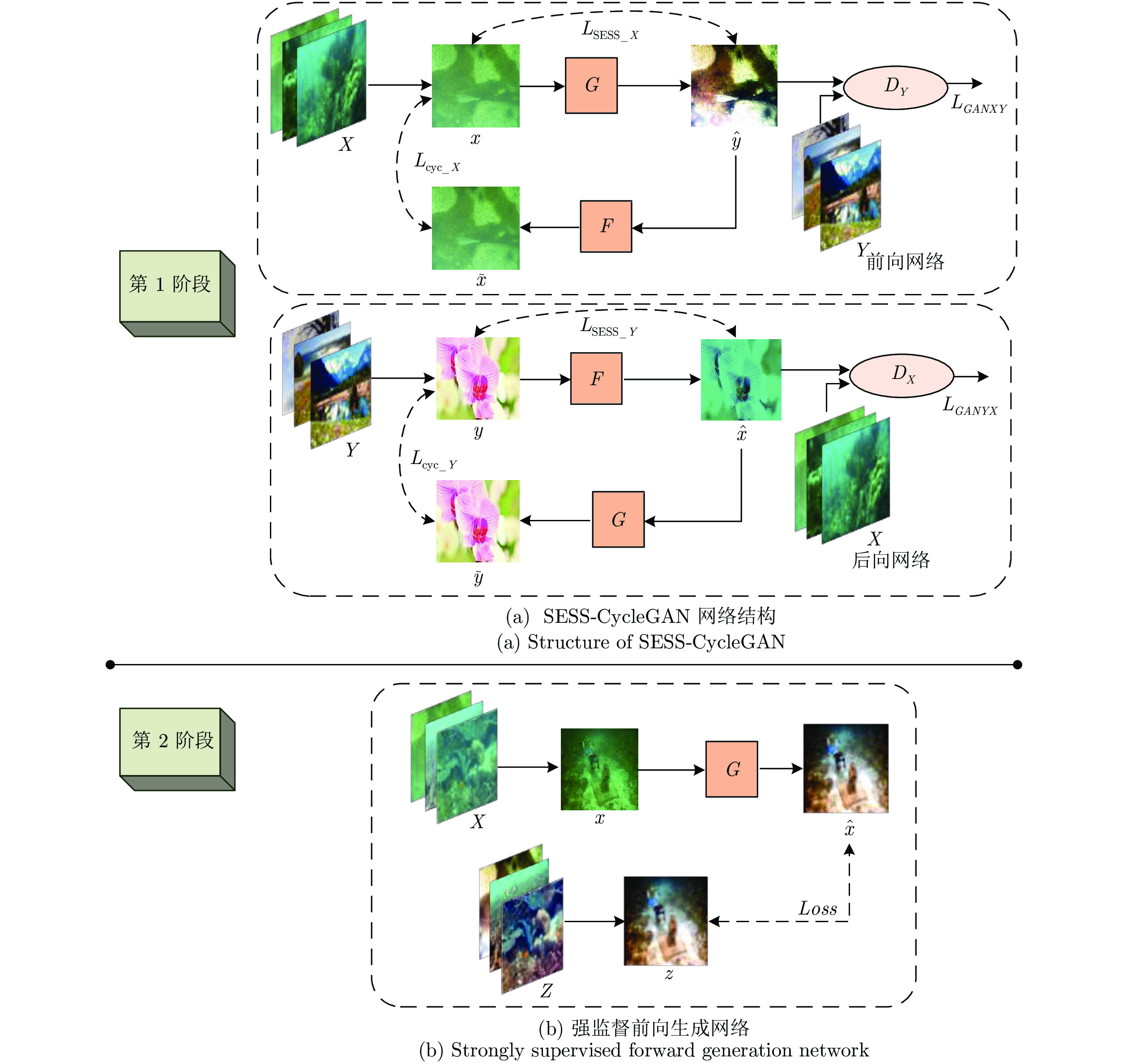
本文提出算法的网络结构组成如图1所示. 该网络主要由两部分组成.
1)图1中第1阶段的改进CycleGAN网络, 即基于图像强边缘结构相似度(SESS)损失函数的CycleGAN, 本文称之为SESS-CycleGAN. 该网络的作用是通过对非成对训练集的弱监督学习, 实现由水下图像到空气中脱水图像颜色风格的转换. 图1中, 前向网络的
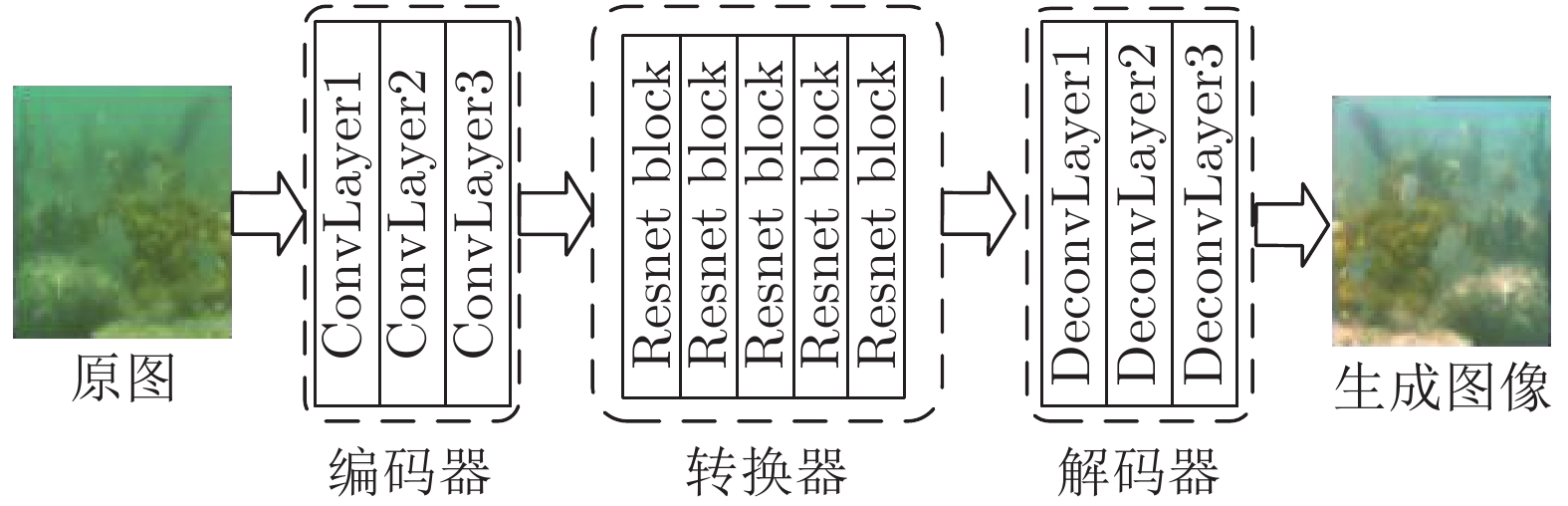
$L_{{\rm SESS}\_X} $ 代表水下图像$x $ 与经过生成器$G $ 生成的脱水图像$\hat y $ 之间的差别,$L_{{\rm cyc}\_X} $ 代表原水下图像$x $ 与$\hat y $ 经过生成器$F $ 生成的水下图像$\tilde x$ 之间的差别,$L_{GANXY} $ 代表生成的脱水图像$\hat y $ 与真实的脱水图像域Y之间分布的差别; 后向网络同理. 由图1可知: SESS-CycleGAN由两个镜像GAN网络构成一个环形循环网络, 包含两个生成器($G $ 和$F $ )以及两个判别器$(D_X $ 和$D_Y) $ . 为了实现从水下图像域X到空气脱水图像域Y的风格转换, 需要训练生成器G和F, 即学习一个映射G: X→Y, 使生成的样本$\hat y = G(x)$ 尽可能与真实空气脱水图像域Y的分布达到一致; 以及G的逆向映射F: Y→X, 使$\tilde x = F(G(x))$ 尽可能与真实水下图像集X的分布一致, 由此保持循环一致性, 即$F(G(x)) \approx x$ , 以防止$X $ 的所有图像都被映射为Y中的某一幅图像, 与此同时, 还引入了判别器DY来判别生成图像的类别. 更新G和DY, 直到DY的输出结果接近0.5, 达到纳什平衡, 学习映射完成. Y域到X域的风格转换与此同理.生成器的组成如图2所示, 主要包含3个部分: 编码器、转换器、解码器. 编码器主要用来提取水下图像的不同特征, 将其转化为特征向量; 转换器作用是组合图像的不同相近特征; 解码器和编码器过程完全相反, 通过特征向量重构低级特征, 输出生成的空气脱水图像.
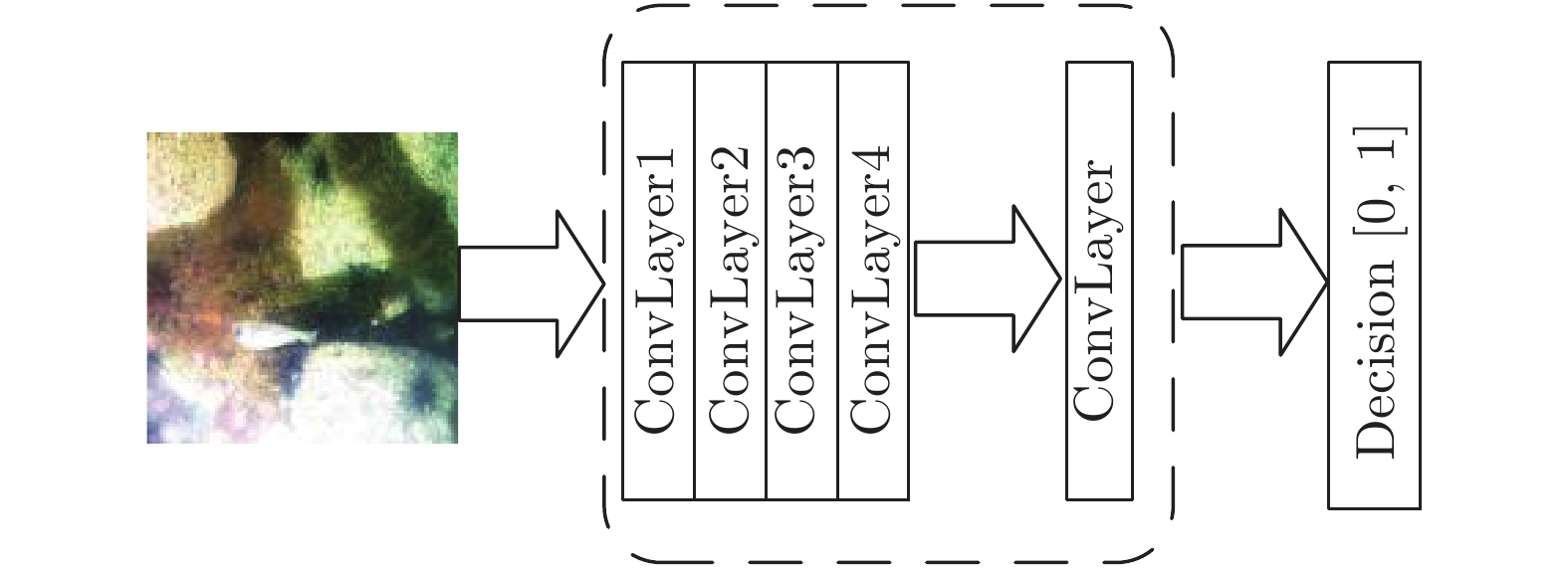
而判别器的网络结构如图3所示, 由5层卷积层构成, 其中前四层用来提取图像特征, 最后一层用来辨别图像的真假. 它将生成的图像作为输入, 对其提取特征并进行图像类型识别, 输出预测图像为真实图像的概率.
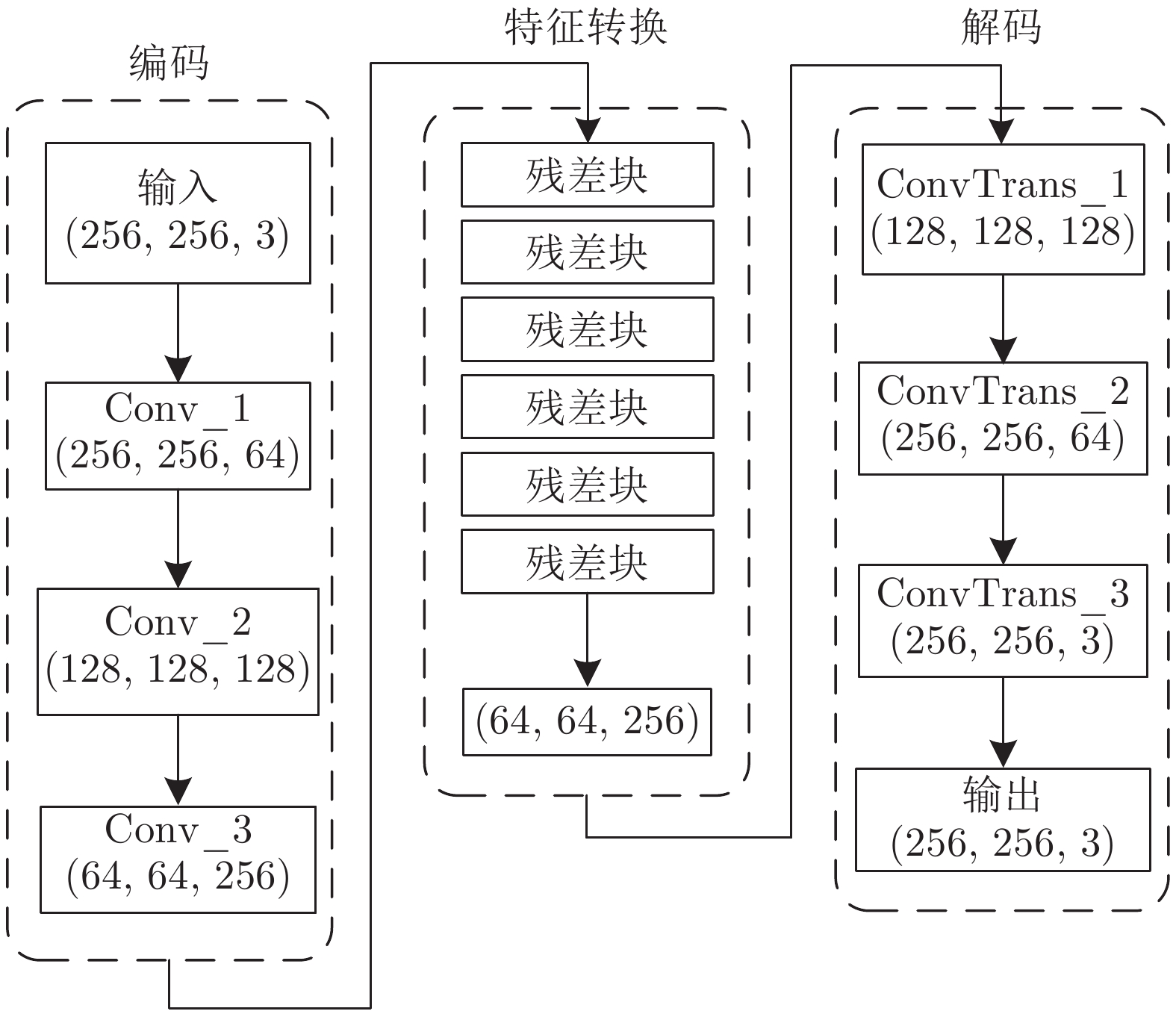
2)图1中第2阶段的强监督生成网络, 其目的是为了生成真实的脱水图像. 利用少量成对的水下图像集X和真实脱水图像集Z, 对该生成网络G进行一对一训练, 其网络结构为Encoder-Transformer-Decoder框架, 图4为该生成器的网络特征流程图.
图4中编码器由3层卷积层构成, 从
$256\times 256\times 3 $ 的图像中提取$64\times 64\times 256 $ 维特征. 转换器由6个残差块实现, 将水下图像域$X $ 图像的$64\times 64\times 256 $ 特征向量转换得到对应脱水图像域$Z $ 图像的$64\times 64\times 256 $ 特征向量. 解码器和编码器过程完全相反, 由3层反卷积层构成, 将$64\times 64\times 256 $ 特征向量输出为$256\times 256\times 3 $ 的目标域图像.1.2 网络损失函数确定
损失函数是卷积神经网络的优化准则, 为网络权重提供更新方向, 整个网络的损失函数包括第1阶段SESS-CycleGAN的对抗损失、循环一致性损失、边缘损失三部分; 以及第2阶段生成网络的一致性损失函数.
1)对抗损失. 对抗损失主要是为了更准确地提取并融合水下失真图像的特征, 其定义如式(1)所示, 代表生成的空气脱水图像
$\hat y$ 与真实的空气脱水图像域Y之间分布的差别.$$\begin{split} \;&{L_{{\rm{GAN}}}}(G,{D_Y},X,Y) = {{\rm{E}}_{y \sim P_{\rm{data}}(y)}}[{({D_Y}(y) - 1)^2}] \;+ \\ &\qquad{{\rm{E}}_{x \sim P_{\rm{data}}(x)}}[{D_Y}{(G(x))^2}]\\[-10pt] \end{split}$$ (1) 式中,
$X, Y $ 分别代表水下图像域和空气脱水图像域,$x\in X$ ,$y\in Y $ ,$P_{{\rm{data}}}(x) $ 代表数据集$X $ 的分布,${{\rm{E}}_{x \sim P_{\rm{data}}(x)}}$ 代表在$x $ 服从$P _ {\rm{data}}(x)$ 的情况下求均值. 式(1)表示X→Y的过程, 同理, 式(2)表示Y→X的过程, 为生成的水下图像$\hat x$ 与真实的水下图像域X之间的损失.$$\begin{split} \;&{L_{{\rm{GAN}}}}(F,{D_X},Y,X) = {{\rm{E}}_{x \sim P_{\rm{data}}(x)}}[{({D_X}(x) - 1)^2}] \;+ \\ &\qquad{{\rm{E}}_{y \sim P_{\rm{data}}(y)}}[{D_X}{(G(y))^2}] \\[-10pt] \end{split}$$ (2) 2)循环一致性损失. 式(3)为循环一致性损失的定义, 其作用是为了保持转换后的图像与原始图像内容的一致性. 为
$F(G(x)) $ 与$x $ ,$G(F(y)) $ 与$y $ 之间的损失, 起到保留图像内容信息的作用.$$\begin{split} {L_{{\rm{cyc}}}}(G,F) =\;& {{\rm{E}}_{x\sim P_{\rm{data}}(x)}}[||F(G(x)) - x|{|_1}]\; + \\ &{{\rm{E}}_{y\sim P_{\rm{ data}}(y)}}[||G(F(y)) - y|{|_1}] \end{split} $$ (3) 3)图像强边缘结构相似度(SESS)损失. 对于水下图像的颜色校正与增强来说, 该损失函数的作用至关重要. 因为一般的CycleGAN网络, 只能实现图像不同风格的转换, 例如输入是马, 输出的是斑马, 在这种不同风格图像的转换中, 原始图像的结构纹理等都发生改变. 而本文的目的是利用CycleGAN网络实现由水下图像到其对应脱水图像的转换, 这里的风格转变主要体现在图像颜色和对比度的变化, 即图像颜色校正和对比度的增强.
为了达到以上目的, 文献[17]提出了基于结构相似性SSIM的结构性损失函数. SSIM是通过对比两幅图像在对比度
$l(x,y) $ 、结构$s(x,y) $ 、亮度$c(x,y) $ 三方面的差异的组合来衡量两幅图像相似性的指标, 将均值作为亮度的估计, 标准差作为对比度的估计, 协方差作为结构相似程度的度量. 对于两幅图像$x $ ,$y $ , 其SSIM指标定义为$$SSIM(x,y) = {l^\alpha }(x,y){c^\beta }(x,y){s^\lambda }(x,y)$$ (4) $$l(x,y) = \frac{{2{\mu _x}{\mu _y} + {C_1}}}{{\mu _x^2 + \mu _y^2 + {C_1}}}$$ (5) $$\qquad\qquad c(x,y) = \frac{{2{\sigma _x}{\sigma _y} + {C_2}}}{{\sigma _x^2 + \sigma _y^2 + {C_2}}}$$ (6) $$\qquad\qquad s(x,y) = \frac{{{\sigma _{xy}} + {C_3}}}{{{\sigma _x}{\sigma _y} + {C_3}}}$$ (7) 式中,
$l(x,y) $ ,$s(x,y) $ ,$c(x,y) $ 分别代表$x $ 与$y $ 的亮度、结构和对比度因子;$\mu_x $ 为$x $ 的均值,$\mu_y $ 为$y $ 的均值,$\sigma _{xy} $ 为$x,y $ 的协方差,$\sigma _x^2 $ 为x的方差,$\sigma _y^2 $ 为$y $ 的方差,$C_1 $ ,$C_2 $ ,$C_3 $ 为常数, 为了防止出现分母为零的情况,$C_1=0.01 $ ,$C_2=0.03 $ ,$C_3=C_2/2 $ , 参数$\alpha, \beta ,\lambda$ 均大于0, 用来调节亮度, 结构和对比度因子三者之间的重要性, 当$\alpha=\beta=\lambda=1 $ 时, SSIM指标函数变为$$SSIM(x,y) = \frac{{(2{\mu _x}{\mu _y} + {c_1})(2{\sigma _{xy}} + {c_2})}}{{(\mu _x^2 + \mu _y^2 + {c_1})(\sigma _x^2 + \sigma _y^2 + {c_2})}}$$ (8) 文献[17]为了保证水下图像转换到空气脱水图像的过程中保留图像原有的内容和结构信息, 只实现颜色转换, 而不改变结构, 通过加入结构性损失函数, 式(9)对生成器网络进行约束.
$${L_{{\rm{SSIM}}}}(x,G(x)) = 1 - \frac{1}{N}\sum\limits_{p = 1}^{N - 1} {({{SSIM}}(p))} $$ (9) 由SSIM的定义式(4)可知, 该损失函数可使CycleGAN网络生成的脱水图像和输入的水下降质图像, 在亮度、对比度上和纹理结构保持一定的一致性. 从水下图像颜色校正和对比度增强的角度看, 保持图像的纹理结构是必须的, 但是若同时限制图像亮度和对比度的一致性, 显然不合理. 因为输入的水下降质图像一般比较暗且呈现对比度较低的模糊现象, 我们希望生成的图像不仅颜色得到校正, 而且对比度也要得到增强, 即清晰化且颜色不失真. 为克服文献[17]中 SSIM损失函数的缺点, 本文提出了新的基于图像强边缘结构相似度(SESS)的损失函数, 该损失函数只是限制输入水下图像和生成脱水图像在边缘纹理结构上保持一致性.
图像强边缘结构相似度(SESS)的计算步骤如下:
步骤 1. 对原始图像X和生成图像fake_Y分别用Sobel算子求梯度图像
$G_1 $ 、$G_2 $ , Sobel算子为$${G_x} = \left[ {\begin{array}{*{20}{r}} { - 1}&0&1 \\ { - 2}&0&2 \\ { - 1}&0&1 \end{array}} \right],\;\;{G_y} = \left[ {\begin{array}{*{20}{r}} 1&2&1 \\ 0&0&0 \\ { - 1}&{ - 2}&{ - 1} \end{array}} \right]$$ (10) 步骤 2. 采用Otsu算法[18]自适应确定梯度图像
$G_1 $ 的阈值$T_1 $ , 将梯度图像$G_1 $ 分为背景和强边缘前景两部分. 设前景像素点数占整幅图像的比例记为$r_1 $ , 前景平均梯度为$u_1 $ ; 背景像素点数占整幅图像的比例记为r2, 背景平均梯度为u2, 则图像总体均值为$$u = {r_1}{u_1} + {r_2}{u_2}$$ (11) 关于阈值t的最大类间方差表达式为
$$f(t) = {r_1}{({u_1} - u)^2} + {r_2}{({u_2} - u)^2}$$ (12) 当
$f(t) $ 取最大值时, 对应的t即为最佳阈值$T_1 $ .步骤 3. 按照最佳阈值
$T_1 $ 对梯度图像$G_1 $ 进行二值分割得到原始强边缘图像${{image}}_1 $ ; 并计算强边缘像素个数所占整幅图像的比率$rate $ .步骤 4. 因为要求原始强边缘比率
$rate $ 和生成图像的强边缘比率相同, 所以由$rate $ 可确定出生成梯度图像$G_2 $ 的最佳分割阈值$T_2 $ , 并得到生成图像的强边缘图像$image_2 $ .步骤 5. 对得到的强边缘图像
$image_1 $ 和$image_2 $ , 计算边缘结果相似度损失$L_{{\rm{SESS}}} $ 为$$\begin{split} {L_{{\rm{SESS}}}} =\;& {{\rm{E}}_{x\sim P_{\rm{data}}(x)}}[||G{(x)_1} - {\overset{\frown} x} |{|_1}] \;+ \\ & {{\rm{E}}_{y\sim P_{\rm{data}}(y)}}[||F{(y)_1} - {\overset{\frown} y} |{|_1}] \\ \end{split} $$ (13) 其中, 第1项为前向网络的边缘损失,
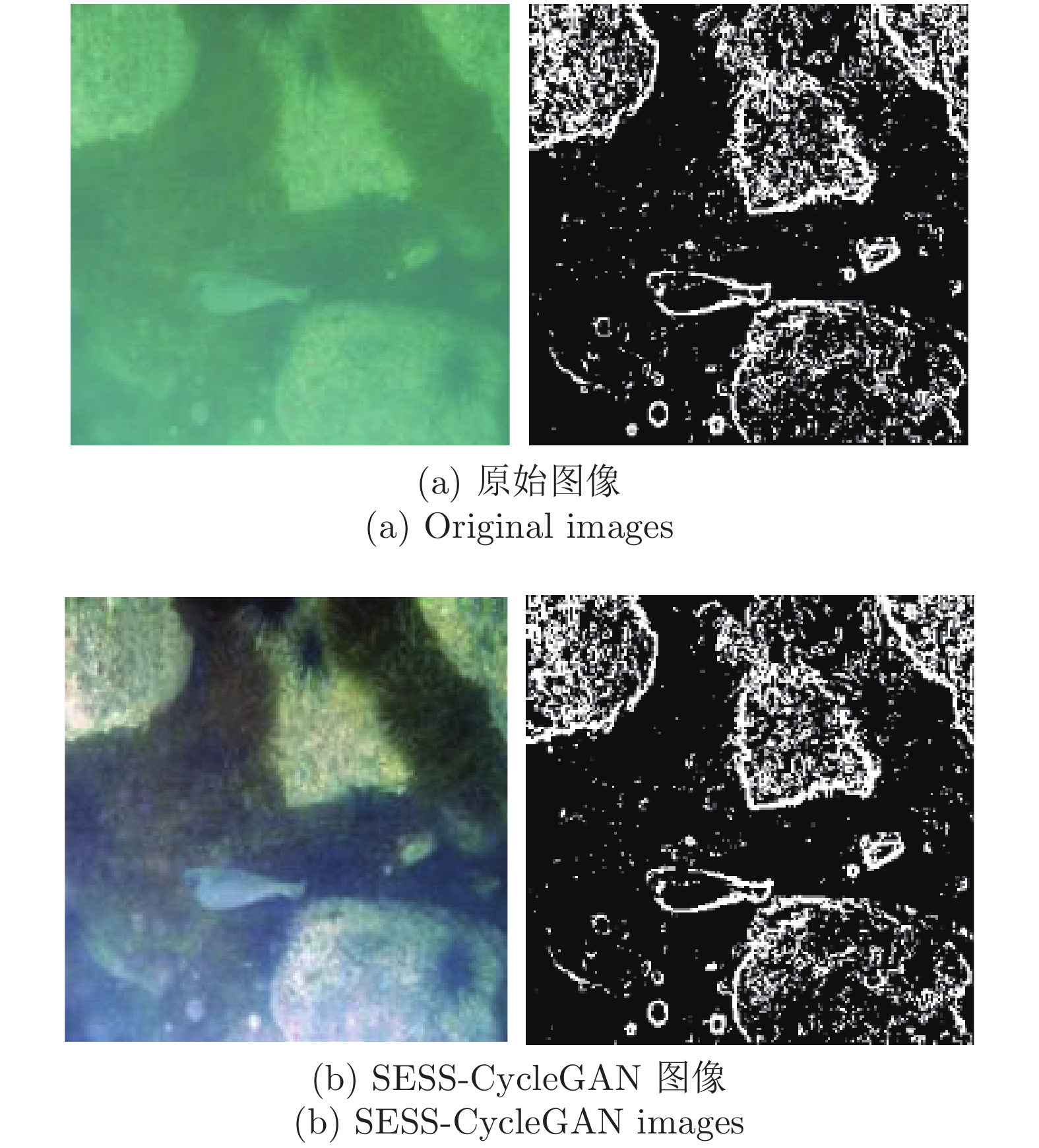
${\overset{\frown} x} $ 代表image1, G(x)1代表image2, 第2项为后向网络的边缘损失.图5是经过SESS-CycleGAN算法得到的脱水图像与原始水下图像的强边缘图像对比, 其中, 图5(a)是原始水下图像和其对应的强边缘图像; 图5(b)是生成的脱水图像和其对应的强边缘图像. 可见, 两幅图像的强边缘图像基本一致, 即含有类似结构和边缘信息, 但生成脱水图像的对比度和亮度都得到了增强, 颜色也得到了校正, 这说明本文提出的图像强边缘结构相似度(SESS)损失函数是有效的.
4) SESS-CycleGAN 的总损失. 总损失函数为对抗损失、循环一致性损失、边缘结构损失三部分的加权组合, 即
$$\begin{split} L(G,F,{D_X},{D_Y}) =\;& {L_{{\rm{GAN}}}}(G,{D_Y},X,Y) \;+ \\ & {L_{{\rm{GAN}}}}(F,{D_X},Y,X) \;+ \\ &\lambda {L_{{\rm{cyc}}}}(G,F) + \omega {L_{{\rm{SESS}}}} \end{split} $$ (14) 式中, 权系数
$\lambda $ ,$\omega $ 体现了各个损失函数之间的相对重要性, 为了保证该网络的对抗损失、循环一致性损失和图像强边缘结构相似度损失值在同一数量级, 即对于模型的训练具有同等的重要性, 通过考察计算各损失值的范围, 将权系数设为:$\lambda $ = 10,$\omega $ =10. 式中前向网络的生成器G的目标是使生成图像G(x)尽可能与Y域图像更相似, 判别器D的目标是将G生成的图像G(x)尽可能与真实Y域图像区别开来. 为了能够达到相应的生成功能和鉴别功能, G尝试最小化这个损失, 而D将尝试最大化该损失, 即:${\min _G}\;{\max _{{D_Y}}}\;{L_{{\rm{GAN}}}}(G,{D_Y},X,Y)$ , 后向网络同理, 因此, 该网络的训练目标为$${G^*},{F^*} = \arg \mathop {\min }\limits_{G,F} \mathop {\max }\limits_{{D_X},{D_Y}} L(G,F,{D_X},{D_Y})$$ (15) 5)第2阶段正向生成网络的一致性损失. 这是强监督学习的损失函数, 利用正向生成器生成的脱水图像
$\hat z$ = G(x)和与$\hat z $ 相对应的真实脱水图像z的差来进行正向生成器的二次监督式学习, 因此, 该阶段损失函数为$$M_{\rm{LOSS}} = {{\rm{E}}_{z\sim P_ {\rm{data}}(z)}}[||G(x) - z|{|_1}]$$ (16) 式中,
$z\in Z $ ,$Z $ 为真实脱水图像集,$G(x) $ 为生成的脱水图像,$z $ 为与之对应的真实脱水图像.1.3 网络学习过程
整个网络的学习过程分为两个阶段: 第1阶段为SESS-CycleGAN网络非成对样本集的弱监督学习; 第2阶段为正向生成网络少量成对样本集的强监督学习. 在训练过程中为了减小振荡, 我们使用缓存的50幅历史生成图像而不是最新生成图片来进行判别器的训练. 采用Adam优化器, 其利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率, 经过偏置校正之后, 每次迭代的学习率都有一个确定的范围, 能够计算不同参数的自适应学习率, 从而保证网络快速收敛, 稳定高效地完成训练.
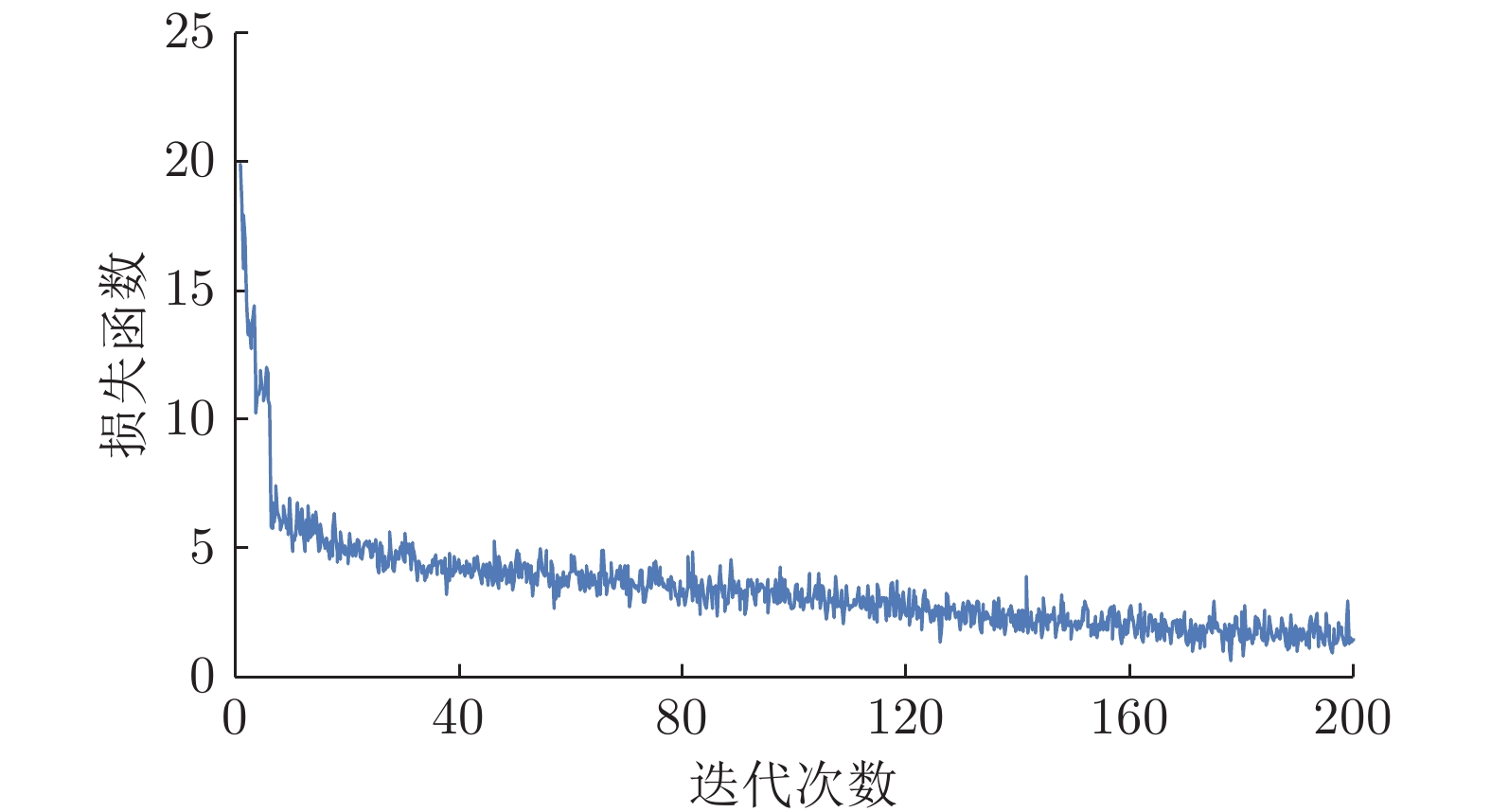
图6为第1阶段SESS-CycleGAN网络训练过程中整体损失函数式(14)的变化曲线. 可以看出, 该网络在训练开始时的损失函数值较大, 随后迅速收敛至基本稳定的范围, 并且期间波动幅度很小, 由此可以看出该网络具有较强的稳定性.
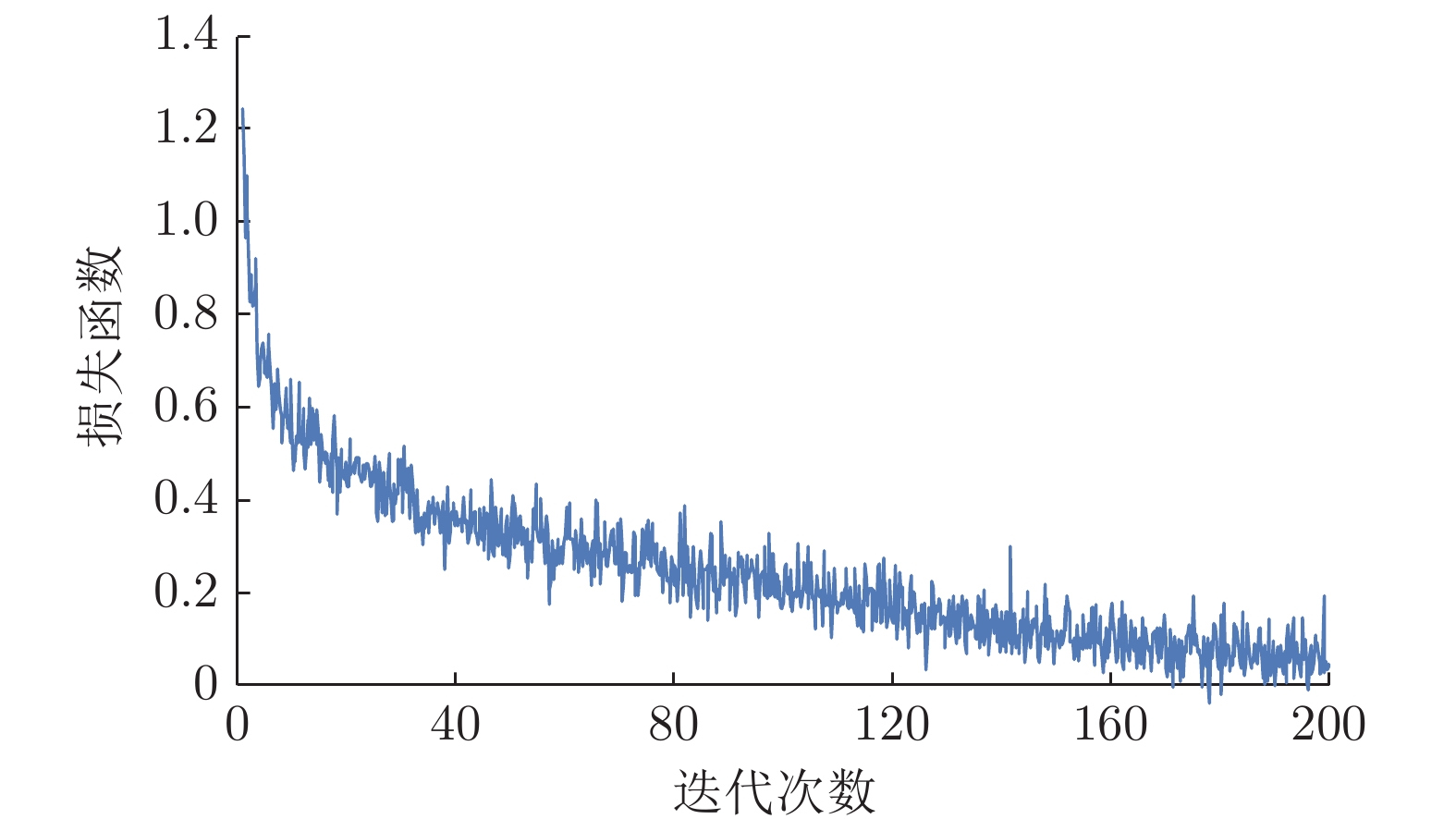
图7为第2阶段强监督网络损失函数式(16)的变化曲线, 该阶段为利用成对数据对第1阶段前向生成网络的进一步训练, 计算生成图像与真实脱水图像误差. 由图7可以看出, 该阶段网络亦能够快速稳步收敛, 达到训练目标.
SESS-CycleGAN网络的生成器和判别器结构与原CycleGAN结构相同, 训练参数如下: 批次(Batch size)为1, 训练样本尺寸为
$256\times 256 $ 像素, 动量为 0.5, Epoch为迭代次数, 将整个数据集每训练一次, Epoch便增加一次, 一共有200个Epoch. 其中, 前100个Epoch, 学习率为0.0002; 后100个Epoch, 学习率按照线性递减为0. 第1阶段学习图像集为网络收集到的非成对3000幅水下图像和3000幅空气图像. 其中水下图像集基本涵盖了所有的水下图像风格, 包括不同水下场景以及水下物种等. 第2阶段成对图像集为800幅水下图像和对应的800幅真实脱水图像, 该图像集来自于文献[19]. 在以上学习图像集中, 通过其中存在的少量异常数据, 以确保模型训练的鲁棒性; 而模型的泛化性是指网络模型对于未知数据的预测能力, 本文通过数据集的多样性以及CycleGAN网络从$X $ 域到$X $ 域, 从$Y $ 域到$Y $ 域的一致性训练过程来实现网络的泛化性. 测试集为从成对图像中随机抽取的200幅水下图像. 本文算法在Pytorch下运行, Adam优化器的其余超参数均为其默认值. 服务器的配置参数为: NVIDIA Quadro P600 GPU、Ubuntu16.4 操作系统.值得注意的是, 第2阶段监督生成网络的训练有利于生成器学习到水下图像和真实脱水图像更多特征之间的对应关系, 加入真实输出样本对生成器参数的更新方向进行指导, 使生成的脱水图像域图像更加真实、自然、清晰, 亦为生成图像的真实性提供了可靠性的依据.
2. 实验结果与分析
为了验证本文算法的有效性, 通过主观视觉评价和客观指标评价对校正结果进行分析. 主观上, 将本文算法与暗通道先验算法(DCP)[5]、GW算法[11]、循环生成对抗网络(CycleGAN)[15]、SSIM-CycleGAN[17]进行视觉效果上的比较; 客观上, 通过信息熵(Entropy)[20]、水下彩色图像质量评价指标(Underwater color image quality evaluation, UCIQE)[21]和峰值信噪比(Peak signal to noise ratio, PSNR)[13]作为衡量标准, 对测试集中原始水下图像和经各算法增强后的图像进行质量对比评价.
2.1 主观评价
为了显示各种算法的增强效果, 将水下降质图像与5种算法的增强结果进行对比, 部分结果图如图8所示. 综合两幅图像效果可见, DCP算法对于水下失真图像颜色校正效果最差, 整体呈现偏蓝色, 但清晰化效果较好, 原因是由于该算法采用了去雾算法, 能够提高图像的对比度, 但对于颜色校正方面没有太大的贡献. GW算法增强后图像颜色偏红并出现了局部颜色过亮或过暗, 原因是水下环境复杂多变, 但该算法应用颜色恒常性以灰度世界假设为基础, 将物体对于光线的反射均值设为定值, 强制应用于待处理图像, 没有考虑图像局部的颜色的变化, 故对于水下图像的校正效果较差. 由于CycleGAN算法旨在实现水下图像和空气图像的风格转换, 因此对于水下图像颜色校正效果一般, 图像清晰度较差.
SSIM-CycleGAN算法对于原始水下失真图像来说效果较好, 但校正后颜色和空气图像颜色仍有偏差, 由于其使用了SSIM损失函数, 学习过程中使损失值趋向于零. 对于校正后图像的结构和纹理信息有了保证, 但水下图像和空气图像亮度和对比度的区别会使其结果出现偏差. 而本文算法对此提出SESS损失函数, 并提出了弱监督SESS-CycleGAN与强监督生成网络相结合的网络结构和两阶段训练方式. 在保证图像内容和结构不变的情况下, 还提高了对比度和亮度, 得到的图像颜色更加真实自然, 清晰度也更高, 图像的视觉质量最高.
图9是本文的SESS-CycleGAN算法结果与原图像以及真实脱水图像的对比. 由图9可见, 本文算法的增强结果对原图像增强效果明显, 与真实脱水图像的视觉效果几乎相同, 由此证明了本文算法的有效性.
2.2 客观评价
首先, 为了对增强结果的质量进行客观分析比较, 下面将根据信息熵(Entropy)、UCIQE和峰值信噪比(PSNR)三个方面的指标进行定量分析.
Entropy体现的是图像信息的丰富度, 其定义为
$$ N_{\rm{Entropy}}= - \sum\limits_{t = 0}^L {p(t){{\log }_2}p(t)} $$ (17) 其中,
$p(t) $ 为直方图中灰度值为$t $ 的概率密度,$L $ 为灰度级, 信息熵的值越大代表图像信息越丰富, 图像越清晰, 质量越好.UCIQE是用CIELab空间的色度、饱和度、清晰度三者的加权组合来评价图像质量, 其定义为
$${V_{{\rm{UCIQE}}}} = {c_1}{C_V} + {c_2}{S_V} + {c_3}{Q_V}$$ (18) 式中,
$c_1,c_2,c_3 $ 为加权系数, 分别为0.4680, 0.2745, 0.2576;$C_V $ 为色调方差,$S_V $ 为饱和度方差,$Q_V $ 为清晰度方差, UCIQE的值与图像质量成正比关系.PSNR反映了两幅图像之间的相似性, 其定义为
$$L_{\rm{MSE}}=\frac{{\rm{1}}}{{m \times n}}\sum\limits_{i = 0}^{m - 1} {\sum\limits_{j = 0}^{n - 1} {{{(X[i,j] - Y[i,j])}^2}} } $$ (19) $$K_{\rm{PSNR}} = 10{\lg }\left(\frac{{MAX_I^2}}{{L_{\rm{MSE}}}}\right)$$ (20) 式中,
$L_{\rm{MSE}}$ 为真实脱水图像与增强后图像像素之间的累计平方差,$m $ ,$n $ 分别为图像的长和宽,$X $ 为真实脱水图像,$Y $ 为增强后图像,$X[i,j],Y[i,j] $ 为该位置的像素值.$MAX_I $ 代表图像像素点的最大值.$L_{\rm{MSE}}$ 值越小、$K_{\rm{PSNR}}$ 值越大表示增强后图像与真实脱水图像越接近, 即真实性越高.为了显示本文算法增强结果的客观性, 在成对数据集中随机抽取200幅水下图像作为测试集. 分别得到5种算法的处理结果. 表1为5种算法对于测试集图像增强结果的3个参数的平均测评值. 由表1可知, 本文算法的信息熵平均值在5种算法中均为最高值, 说明本文算法保留了更多的信息量, 并具有更好的清晰度. 本文的UCIQE平均分数在5种算法中也为最高, 说明本文算法在均衡水下降质图像的色度、饱和度以及提高清晰度方面有更好的表现, 能够得到整体颜色更自然的增强图像. 不难看出, 与其他算法相比, 本文算法的PSNR指标更高. 说明本文算法增强后的图像与真实的脱水图像, 在颜色和对比度等方面更加接近, 即增强效果更佳且真实性更强.
表 1 增强图像的指标对比Table 1 Comparison of enhanced images方法 信息熵 UCIQE PSNR (dB) 原始图像 6.546 0.437 — DCP 6.940 0.540 19.537 GW 6.621 0.493 16.491 CycleGAN 7.592 0.613 19.690 SSIM-CycleGAN 7.598 0.541 20.670 本文方法 7.714 0.631 24.594 3. 结束语
本文利用深度学习的方法, 提出了一种基于改进循环生成对抗网络的水下图像颜色校正与增强算法. 通过改进循环生成对抗网络的损失函数结构, 提出了基于水下失真图像和生成脱水图像的强边缘结构相似度损失函数的SESS-CycleGAN, 保证了网络输入图像与输出图像的边缘结构不发生改变. 采用弱监督SESS-CycleGAN网络和强监督生成网络相结合的网络结构和双阶段学习模式, 保证了生成图像和真实脱水图像颜色的一致性. 实验结果表明, 本文算法有较高的颜色保真度, 在校正水下图像颜色失真的同时还提高了图像的对比度. 在未来工作中, 我们将进一步研究基于循环生成对抗网络的水下模糊图像清晰化算法研究, 以期达到利用改进的循环生成对抗网络同时实现颜色校正和清晰化增强的目标.
-
表 1 SGD-RNN与RLS-RNN复杂度分析
Table 1 Complexity analysis of SGD-RNN and RLS-RNN
SGD-RNN RLS-RNN 时间复杂度 $O_{s}$ ${\rm{O}}(\tau mdh)$ — $Z_{s}$ — ${\rm{O}}(\tau mdh)$ $H_{s}$ ${\rm{O}}(\tau mh(h+a))$ ${\rm{O}}(\tau mh(h+a))$ ${\Delta}^O_{s}$ ${\rm{O}}(4\tau md)$ ${\rm{O}}(3\tau md)$ ${\Delta}^H_{s}$ ${\rm{O}}(\tau mh(h+d))$ ${\rm{O}}(\tau mh(h+d))$ ${P}_{s}^O$ — ${\rm{O}}(2\tau mh^2)$ ${P}_{s}^H$ — ${\rm{O}}(2\tau m(h+a)^2)$ ${\Theta}_{s}^O$ ${\rm{O}}(\tau mdh)$ ${\rm{O}}(\tau mdh)$ ${\Theta}_{s}^H$ ${\rm{O}}(\tau mh(h+a))$ ${\rm{O}}(\tau mh(h+a))$ 合计 ${\rm{O}}(\tau m(3dh+3h^2+2ha))$ ${\rm{O}}(\tau m(7h^2+2a^2+3dh+6ha))$ 空间复杂度 $\Theta_{s}^O$ ${\rm{O}}(hd)$ ${\rm{O}}(hd)$ $\Theta_{s}^H$ ${\rm{O}}(h(h+a))$ ${\rm{O}}(h(h+a))$ ${P}_{s}^H$ — ${\rm{O}}((h+a)^2)$ ${P}_{s}^O$ — ${\rm{O}}(h^2)$ 合计 ${\rm{O}}(h^2+hd+ha)$ ${\rm{O}}(hd+3ha+a^2+3h^2)$  下载: 导出CSV
下载: 导出CSV
表 2 初始化因子
$\alpha$ 鲁棒性分析Table 2 Robustness analysis of the initializing factor
$\alpha$ $\alpha$ 0.01 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 MNIST分类准确率 (%) 97.10 97.36 97.38 97.35 97.57 97.70 97.19 97.27 97.42 97.25 97.60 IMDB分类准确率 (%) 72.21 73.50 73.24 73.32 74.02 73.01 73.68 73.25 73.20 73.42 73.12 股价预测MSE ($\times 10^{-4}$) 5.32 5.19 5.04 5.43 5.42 5.30 4.87 4.85 5.32 5.54 5.27 PM2.5预测MSE ($\times 10^{-3}$) 1.58 1.55 1.53 1.55 1.61 1.55 1.55 1.54 1.57 1.58 1.57
下载: 导出CSV
表 3 比例因子
$\eta$ 鲁棒性分析Table 3 Robustness analysis of the scaling factor
$\eta$ $\eta$ 0.1 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0 10.0 MNIST分类准确率 (%) 97.80 97.59 97.48 97.61 97.04 97.62 97.44 97.33 97.38 97.37 97.45 IMDB分类准确率 (%) 73.58 73.46 73.62 73.76 73.44 73.82 73.71 72.97 72.86 73.12 73.69 股价预测MSE ($\times 10^{-4}$) 5.70 5.32 5.04 5.06 5.61 4.73 5.04 5.14 4.85 4.97 5.19 PM2.5预测MSE ($\times 10^{-3}$) 1.53 1.55 1.56 1.59 1.56 1.53 1.58 1.55 1.54 1.50 1.52
下载: 导出CSV
-
[1] Mikolov T, Karafiát M, Burget L, Cernockỳ J, Khudanpur S. Recurrent neural network based language model. In: Proceedings of the 11th Annual Conference of the International Speech Communication Association. Chiba, Japan: ISCA, 2010. 1045−1048 [2] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks. In: Proceeding of the 27th International Conference on Neural Information Processing Systems. Montréal, Canada: MIT Press, 2014. 3104−3112 [3] Graves A, Mohamed A R, Hinton G. Speech recognition with deep recurrent neural networks. In: Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, Canada: IEEE, 2013. 6645−6649 [4] Pascanu R, Mikolov T, Bengio Y. On the difficulty of training recurrent neural networks. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, USA: JMLR.org, 2013. 1310−1318 [5] Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 1994, 5(2): 157−166 doi: 10.1109/72.279181 [6] Bottou L. On-line learning and stochastic approximations. On-Line Learning in Neural Networks. New York: Cambridge University Press, 1999. 9−42 [7] Polyak B T. Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics, 1964, 4(5): 1−17 doi: 10.1016/0041-5553(64)90137-5 [8] Sutskever I, Martens J, Dahl G, Hinton G. On the importance of initialization and momentum in deep learning. In: Proceedings of the 30th International Conference on International Conference on Machine Learning. Atlanta, USA: JMLR.org, 2013. 1139−1147 [9] Duchi J, Hazan E, Singer Y. Adaptive subgradient methods for online learning and stochastic optimization. The Journal of Machine Learning Research, 2011, 12: 2121−2159 [10] Tieleman T, Hinton G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude [Online], available: https://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf, February 19, 2020 [11] Zeiler M D. ADADELTA: An adaptive learning rate method [Online], available: https://arxiv.org/abs/1212.5701\newblock, February 19, 2020 [12] Kingma D P, Ba J. Adam: A method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [13] Keskar N S, Socher R. Improving generalization performance by switching from adam to SGD [Online], available: https://arxiv.org/abs/1712.07628, February 19, 2020 [14] Reddi S J, Kale S, Kumar S. On the convergence of Adam and beyond. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: OpenReview.net, 2018. [15] Martens J. Deep learning via hessian-free optimization. In: Proceedings of the 27th International Conference on Machine Learning. Haifa, Israel: Omnipress, 2010. 735−742 [16] Keskar N S, Berahas A S. adaQN: An adaptive quasi-newton algorithm for training RNNs. In: Proceedings of the 2016 Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Riva del Garda, Italy: Springer, 2016. 1−16. [17] Martens J, Grosse R. Optimizing neural networks with kronecker-factored approximate curvature. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: JMLR.org, 2015. 2408−2417 [18] Shanno D F. Conditioning of quasi-newton methods for function minimization. Mathematics of Computation, 1970, 24(111): 647−656 doi: 10.1090/S0025-5718-1970-0274029-X [19] Liu D C, Nocedal J. On the limited memory BFGS method for large scale optimization. Mathematical Programming, 1989, 45(1−3): 503−528 doi: 10.1007/BF01589116 [20] Le Q V, Ngiam J, Coates A, Lahiri A, Prochnow B, Ng A Y. On optimization methods for deep learning. In: Proceedings of the 28th International Conference on Machine Learning. Bellevue, USA: Omnipress, 2011. 265−272 [21] Azimi-Sadjadi M R, Liou R J. Fast learning process of multilayer neural networks using recursive least squares method. IEEE Transactions on Signal Processing, 1992, 40(2): 446−450 doi: 10.1109/78.124956 [22] 谭永红. 多层前向神经网络的RLS训练算法及其在辨识中的应用. 控制理论与应用, 1994, 11(5): 594−599Tan Yong-Hong. RLS training algorithm for multilayer feedforward neural networks and its application to identification. Control Theory and Applications, 1994, 11(5): 594−599 [23] Xu Q, Krishnamurthy K, McMillin B, Lu W. A recursive least squares training algorithm for multilayer recurrent neural networks. In: Proceedings of the 1994 American Control Conference-ACC’94. Baltimore, USA: IEEE, 1994. 1712−1716 [24] Peter T, Pospíchal J. Neural network training with extended Kalman filter Using graphics processing unit. In: Proceedings of the 18th International Conference on Artificial Neural Networks. Berlin, Germany: Springer, 2008. 198−207 [25] Jaeger H. Adaptive nonlinear system identification with echo state networks. In: Proceedings of the 15th International Conference on Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2002. 609−616 [26] Werbos P J. Backpropagation through time: What it does and how to do it. Proceedings of the IEEE, 1990, 78(10): 1550−1560 doi: 10.1109/5.58337 [27] Sherman J, Morrison W J. Adjustment of an inverse matrix corresponding to a change in one element of a given matrix. The Annals of Mathematical Statistics, 1950, 21(1): 124−127 doi: 10.1214/aoms/1177729893 [28] Paleologu C, Benesty J, Ciochina S. A robust variable forgetting factor recursive least-squares algorithm for system identification. IEEE Signal Processing Letters, 2008, 15: 597−600 doi: 10.1109/LSP.2008.2001559 [29] Albu F. Improved variable forgetting factor recursive least square algorithm. In: Proceedings of the 12th International Conference on Control Automation Robotics and Vision (ICARCV). Guangzhou, China: IEEE, 2012. 1789−1793 [30] Ekșioğlu E M. RLS adaptive filtering with sparsity regularization. In: Proceedings of the 10th International Conference on Information Science, Signal Processing and Their Applications (ISSPA 2010). Kuala Lumpur, Malaysia: IEEE, 2010. 550−553 [31] LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278−2324 doi: 10.1109/5.726791 [32] Gawlik D. New York stock exchange [Online], available: https://www.kaggle.com/dgawlik/nyse, February 19, 2020 [33] Liang X, Zou T, Guo B, Li S, Zhang H Z, Zhang S Y, et al. Assessing Beijing's PM2.5 pollution: Severity, weather impact, APEC and winter heating. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 2015, 471(2182): Article No. 20150257 [34] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1026−1034 [35] Pennington J, Socher R, Manning C. GloVe: Global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: ACL, 2014. 1532−1543 期刊类型引用(1)
1. 刘奇,梁智昊,訾建潇. SMOGN过采样下导水裂隙带高度的MPSO-BP预测模型. 煤田地质与勘探. 2024(11): 72-85 .  百度学术
百度学术其他类型引用(7)
-

 下载:
下载:




































































































































计量
- 文章访问数: 823
- HTML全文浏览量: 213
- PDF下载量: 323
- 被引次数: 8
