

-
摘要: 为快速构建一个大规模、多领域的高质树库, 提出一种基于短语功能与句法角色组块的、便于标注多层次结构的标注体系, 在篇章中综合利用标点、句法结构、表述功能作为句边界判断标准, 确立合理的句边界与层次; 在句子中以组块的句法功能为主, 参考篇章功能、人际功能, 以4个性质标记、8个功能标记、4个句标记来描写句中3类5种组块, 标注基本句型骨架, 突出中心词信息. 目前已初步构建有质量保证的千万汉字规模的浅层结构分析树, 包含60余万小句的9千余条句型结构库, 语料涉及百科、新闻、专利等应用领域文本1万余篇; 同时, 也探索了高效的标注众包管理模式.Abstract: In order to provide a large scale annotation of Chinese functional chunk for linguistic research and syntactic parsing, we present a method to quickly build a discourse based Chinese chunkbank with high quality in multi-domain: Firstly, we use punctuations, syntax, expression functions of VP and NP, to segment complex sentences into several independent simple sentences; Secondly, based on the syntactic function, textual function, discourse function and interpersonal function of the chunks, we design 4 phrase tags, 8 functional tags, 4 sentence boundary tags to depict the chunks, which was classified into 3 types and 5 kinds. the annotators annotated the skeleton structure and highlighted the head word of the predicate for every simple sentence. Until now, we have been annotating more than 10 million of Chinese characters, including 9 thousand of skeleton structures for 60 thousand sentences. The chunkbank covers a range of text genres, including baidubaike, internet news, patent, etc. At the same time, we explored an effective model of crowdsourced data management.
-
Key words:
- Corpus annotation /
- treebank /
- chunk /
- syntactic parsing
-
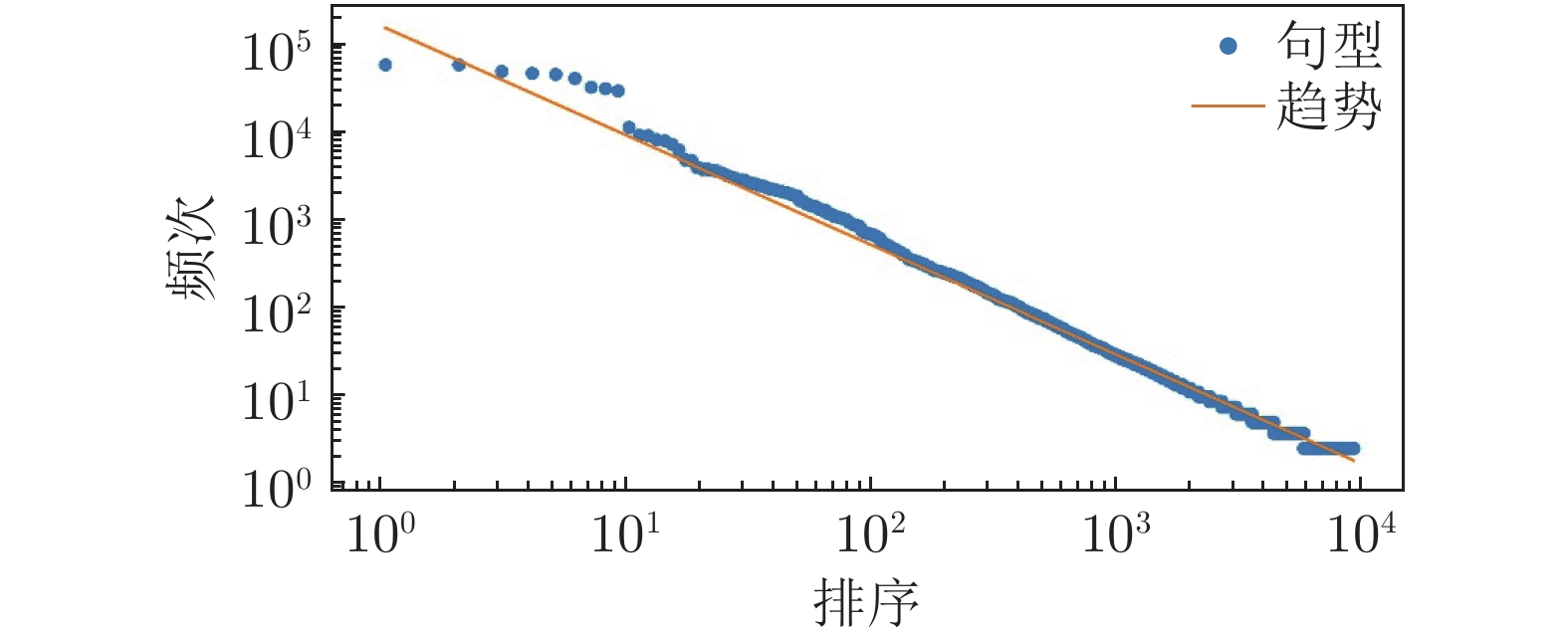
图 4 基本句型随机法齐夫对数分布
Fig. 4 The rank-frequency random logarithmic distribution for the sentence patterns
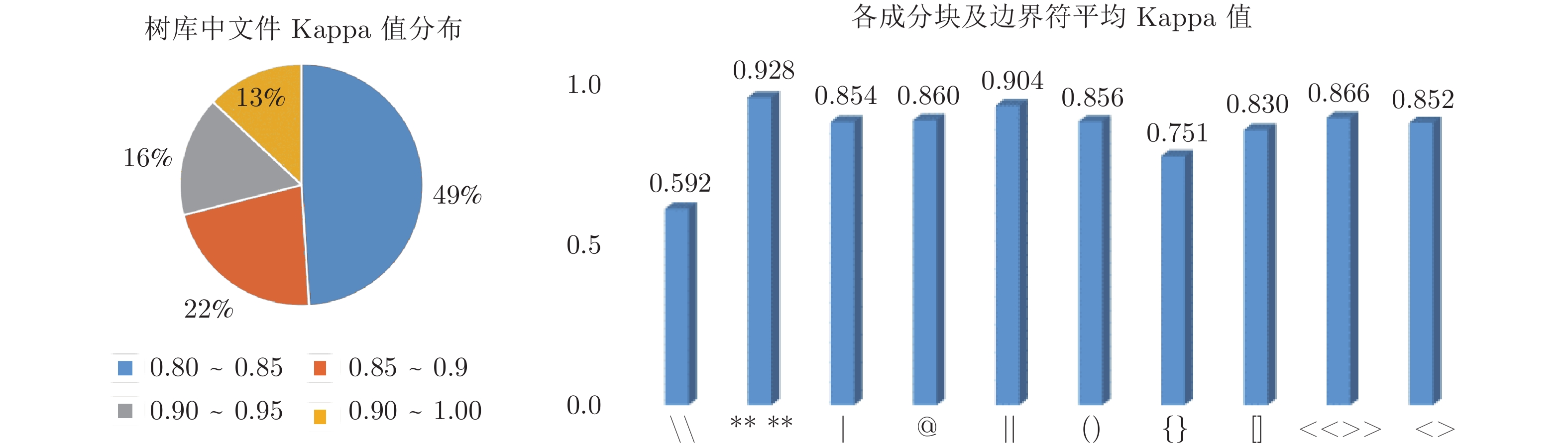
图 6 树库全文本Kappa值分布与各标注符号Kappa平均值
Fig. 6 The distribution of Kappa coefficient of the text in the Treebank, and the mean of every kind of label's Kappa
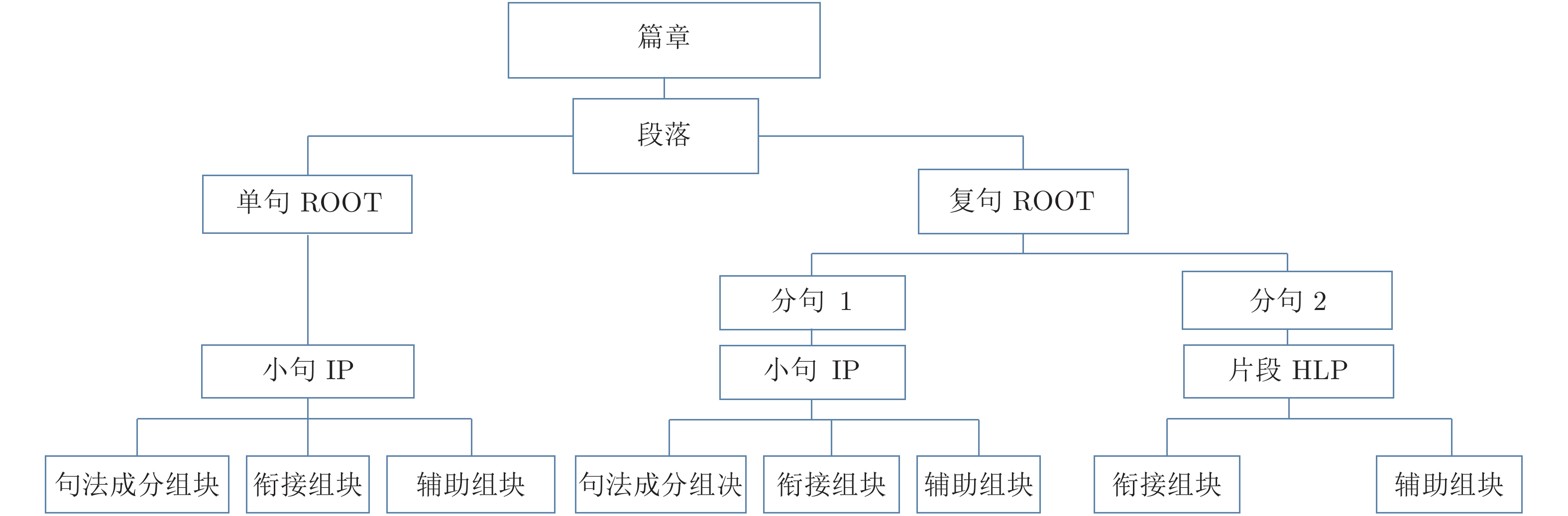
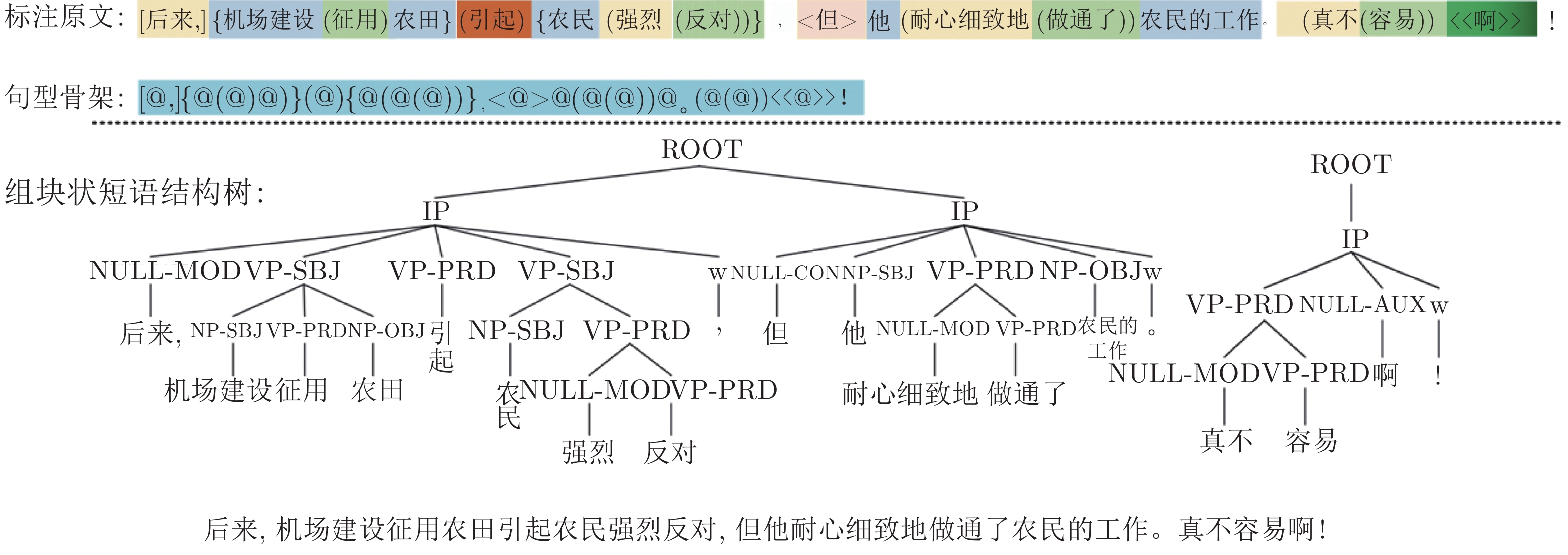
表 1 树库标记集
Table 1 Tags for chunk-tree
序号 符号 标记类型 1 VP 谓词性组块 2 NP 体词性组块 3 UNK 谓词与体词并列的组块 4 NULL 其它性质组块 5 PRD 述语 6 NPRE 名词谓语 7 MOD 状语、补语 8 SBJ 主语 9 OBJ 宾语 10 CON 衔接组块 11 AUX 辅助组块 12 ROOT 单复句 13 IP 完整小句 14 HLP 独词句或片段 15 W 标点  下载: 导出CSV
下载: 导出CSV
表 2 目前有效标注语料分布
Table 2 The data distribution of the valid annotated data
类别 ROOT IP HLP 汉字数 文件数 说明 新闻 132009 359373 50378 4920170 4813 新浪 2006、新华社新闻 2012 ~ 2018 年新闻 百科 76595 149097 14823 2376151 2982 自动化控制系统、电子学与计算机、轻工、大气与海洋及
水文科学、航空航天、经济学专利 69260 166462 16966 2839935 3915 2018 年国家专利申请文书描述与权利申明部分 ROOT 中汉字字长分布 IP 中字长分布 类别 平均 最大 最小 中位数 众数 平均 新闻 37 837 1 33 1 13.69 百科 31 251 0 27 20 15.94 专利 40 819 0 29 16 17.06
下载: 导出CSV
-
[1] Zhang X, Xue N. Extending and scaling up the Chinese treebank annotation. In: Proceedings of the 2nd CIPS-SIGHAN Joi-nt Conference on Chinese Language Processing. Tianjin, China: 2012: 27−34. [2] 周强, 张伟, 俞士汶. 汉语树库的构建. 中文信息学报, 1997, 11(4): 43-52Zhou Qiang, Zhang Wei, Yu Shiwen. The Building of Chinese Treebank. Journal of Chinese Information Processing, 1997, 11(4): 43-52. [3] 周强. 汉语句法树库标注体系. 中文信息学报, 2004, 18(4): 2-9Zhou Qiang. Annotation Scheme for Chinese Treebank. Journal of Chinese Information Processing, 2004, 18(4): 2-9 [4] Chen K J, Luo C C, Chang M C, Chen F Y, Chen C J, Huang C R. Sinica Treebank: Design criteria, representational issues and implementation, Chapter 13 [Online], available: https:// link.springer.com/chapter/10.1007%2F978-94-010-0201-1_13, April 16, 2019. [5] Che W, Li Z, Liu T. Chinese dependency treebank1.0 (LDC-2012T05) [DB/OL].Philadelphia: Linguistic Data Consortium [Online], available: https://catalog.ldc.upenn.edu/LDC2012 T05, April 16, 2019. [6] 郭丽娟, 彭雪, 李正华, 张民. 面向多领域多来源文本的汉语依存句法树库构建. 中文信息学报, 2019, 33(02): 34-42 doi: 10.3969/j.issn.1003-0077.2019.02.005Guo Lijuan, Pen Xue, Li Zhenghua, Zhang Min. Construction of Chinese Dependency Syntax Treebanks for Multi-domain and Multi-source Texts. Journal of Chinese Information Processing, 2019, 33(02): 34-42. doi: 10.3969/j.issn.1003-0077.2019.02.005 [7] Brody M. Phrase structure and dependence [Online], available: http://real-eod.mtak.hu/8176/1/WorkingPapersInTheTheoryOfGrammar_01-1_1994.pdf, April 16, 2019. [8] 邱立坤, 金澎, 王厚峰. 基于依存语法构建多视图汉语树库. 中文信息学报, 2015, 29(3): 9-15 doi: 10.3969/j.issn.1003-0077.2015.03.002Qiu Likun, Jin Peng, Wang Houfeng. A Multi-view Chinese Treebank Based on Dependency Grammar. Journal of Chinese Information Processing, 2015, 29(3): 9-15. doi: 10.3969/j.issn.1003-0077.2015.03.002 [9] 周强. 构建大规模的汉语语块库. 自然语言理解与机器翻译—全国第六届计算语言学联合学术会议. 太原, 中国: 2001. 6Zhou Qiang. Build a large scale Chinese functional chunkbank. In: Proceedings of the 6th National Conference on Computational Linguistics-natural Language Understanding and Machine Tra-nslation. Taiyuan, China: 2001. 6 [10] Xue N, Palmer M. Adding semantic roles to the Chinese Treebank. Natural Language Engineering, 2009, 15(1): 143-172. doi: 10.1017/S1351324908004865 [11] Kong F, Wang HL, Zhou GD. Suvery on Chinese Discourse Understanding. Journal of Software, 2019, 30(7): 2052-2072(in Chinese). [12] 钱小飞. 组块分析研究综述. 现代语文, 2018, 2018(06): 166-170Qian Xiaofei. Research Review on Chunk Parsing. Modern Chinese, 2018, 2018(06): 166-170. [13] Chu C, Nakazawa T, Kawahara D, et al. SCTB: A Chinese treebank in scientific domain. In: Proceedings of the 12th Worksh-op on Asian Language Resources. Osaka, Japan: 2016. 59−67 [14] 赵春利, 石定栩. 语气、情态与句子功能类型. 外语教学与研究, 2011, 43(04): 483-500+639Zhao Chunli, Shi Dingxu. Mood, modality and sentence typ. Foreign Language Teaching and Research, 2011, 43(04): 483-500+639. [15] 胡壮麟. 语篇的衔接与连贯. 上海: 上海外语教育出版社, 1994: 108−109Hu Zhuang-Lin. Discourse Cohesion and Coherence. Shanghai: Shanghai Foreign Language Education Press, 1994: 108−109 [16] 邢福义. 汉语复句研究. 北京: 商务印书馆, 2001: 2−6, 26−31, 38−56, 546−548Xing Fu-Yi. The Research on Chinese Sentences With Two or Mo-re Clause. Beijing: The Commercial Press, 2001: 2−6, 26−31, 38−56, 546−548 [17] 徐赳赳. 现代汉语篇章语言学. 北京: 商务印书馆, 2010: 218−222Xu Jiu-Jiu. The Text Linguistics of Modern Chinese. Beijing: The Commercial Press, 2010: 218−222 [18] 李秀明. 汉语元话语标记研究. 复旦大学, 中国, 2006Li Xiu-Ming. The Research of Chinese Metadiscourse Marker [Ph.D. dissertation], Fudan University, China, 2006 [19] 杨一飞. 语篇中的连接手段. 复旦大学, 中国, 2011Yang Yi-Fei. Connection in Modern Chinese Discourses [Ph.D. dissertation], Fudan University, China, 2011 [20] 宋柔, 葛诗利, 尚英, 卢达威. 面向文本信息处理的汉语句子和小句. 中文信息学报, 2017, 31(02): 18-24+35Song Rou, Ge Shili, Shang Ying, Lu Dawei. Chinese Sentence and Clause for Text Information Processing. Journal of Chinese Information Processing, 2017, 31(02): 18-24+35. [21] 陈荣春. 从句子的表述性谈单句复句的划分. 语文研究, 1981, 1981(01): 46-51Chen Rongchun. Talk about Chinese compound sentence from declarability. Linguistic Researches, 1981, 1981(01): 46-51. [22] 董秀芳. 汉语词汇化和语法化的现象与规律. 上海: 学林出版社, 2017: 143−144Dong Xiu-Fang. The Phenomenon and Regularity of Chinese Lexicalization and Grammaticalization. Shanghai: Akademia Pre-ss, 2017: 143−144 [23] Holle H, Robert R. Understanding Body Movement: A Guide to Empirical Research on Nonverbal Behaviour With an Introduction to the NEUROGES Coding System. Frankfurt am Main: Peter Lang GmbH Internationaler Verlag der Wissenschaffen, 2013. 261−277 [24] Kitaev N, Cao S, Klein D. Multi-lingual constituency parsing with self-attention and pretraining [Online], available: https://arxiv.org/abs/1812.11760, April 16, 2019. [25] Mitchell S, Jacob A, Dan K. A minimal spanbased neural constituency parser. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Can-ada: 2017, 818–827 [26] Devlin J, Chang M W, Lee K, Toutanova K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint, 2018, arXiv: 1810.04805 -

 下载:
下载:


计量
- 文章访问数: 2142
- HTML全文浏览量: 1380
- PDF下载量: 165
- 被引次数: 0
