

Research Progress, Challenge and Prospect of Local Features for Person Re-Identification
-
摘要: 行人重识别(Person re-identification, Re-ID)旨在跨区域、跨场景的视频中实现行人的检索及跟踪, 其成果在智能监控、刑事侦查、反恐防暴等领域具有广阔的应用前景. 由于真实场景下的行人图像存在光照差异大、拍摄视角不统一、物体遮挡等问题, 导致从图像整体提取的全局特征易受无关因素的干扰, 识别精度不高. 基于局部特征的方法通过挖掘行人姿态、人体部位、视角特征等关键信息, 可加强模型对人体关键区域的学习, 降低无关因素的干扰, 从而克服全局特征的缺陷, 也因此成为近几年的研究热点. 本文对近年基于局部特征的行人重识别文献进行梳理, 简述了行人重识别的发展历程, 将基于局部特征的方法归纳为基于姿势提取、基于特征空间分割、基于视角信息、基于注意力机制四类, 并详细阐述了每一类的原理及优缺点. 然后在三个主流行人数据集上对典型方法的识别性能进行了分析比较, 最后总结了目前基于局部特征算法的难点, 并对未来本领域的研究趋势和发展方向进行展望.Abstract: Person re-identification (Re-ID) aims to achieve pedestrian retrieval and tracking in cross-region and cross-scene video. Its achievements have broad application prospects in intelligent monitoring, criminal investigation, counter-terrorism and riot control. Due to pedestrian images in real scenes having problems such as large illumination differences, different shooting angles, and object occlusion, the global feature is susceptible to interference from irrelevant factors, resulting in low recognition accuracy. The local feature-based method strengthens the model's learning of key areas of the human body and reduces the interference of irrelevant factors by mining key information such as pedestrian posture, human body parts, and perspective features. Because the local feature method overcomes the defect of the global feature, it has become a research focus in recent years. In this paper, we combed the literature of Re-ID based on local features in recent years, and briefly described the development process of Re-ID. The methods based on local features can be classified into four categories: postural extraction, feature spatial partition, viewpoint information and attention mechanism. This paper first elaborates on the principles, advantages and disadvantages of each category. Then we summarize some typical methods in detail and compare their performance on three mainstream Re-ID data sets. Finally, this paper summarizes the difficulties of the method based on local features, and looks forward to the future research trend and development direction of this field.
-
Key words:
- Person re-identification (Re-ID) /
- local feature /
- deep learning /
- computer vision
-

图 1 不同视角下及遮挡场景下的行人图像
Fig. 1 Pedestrian images in different viewpoints and occlusion scenes
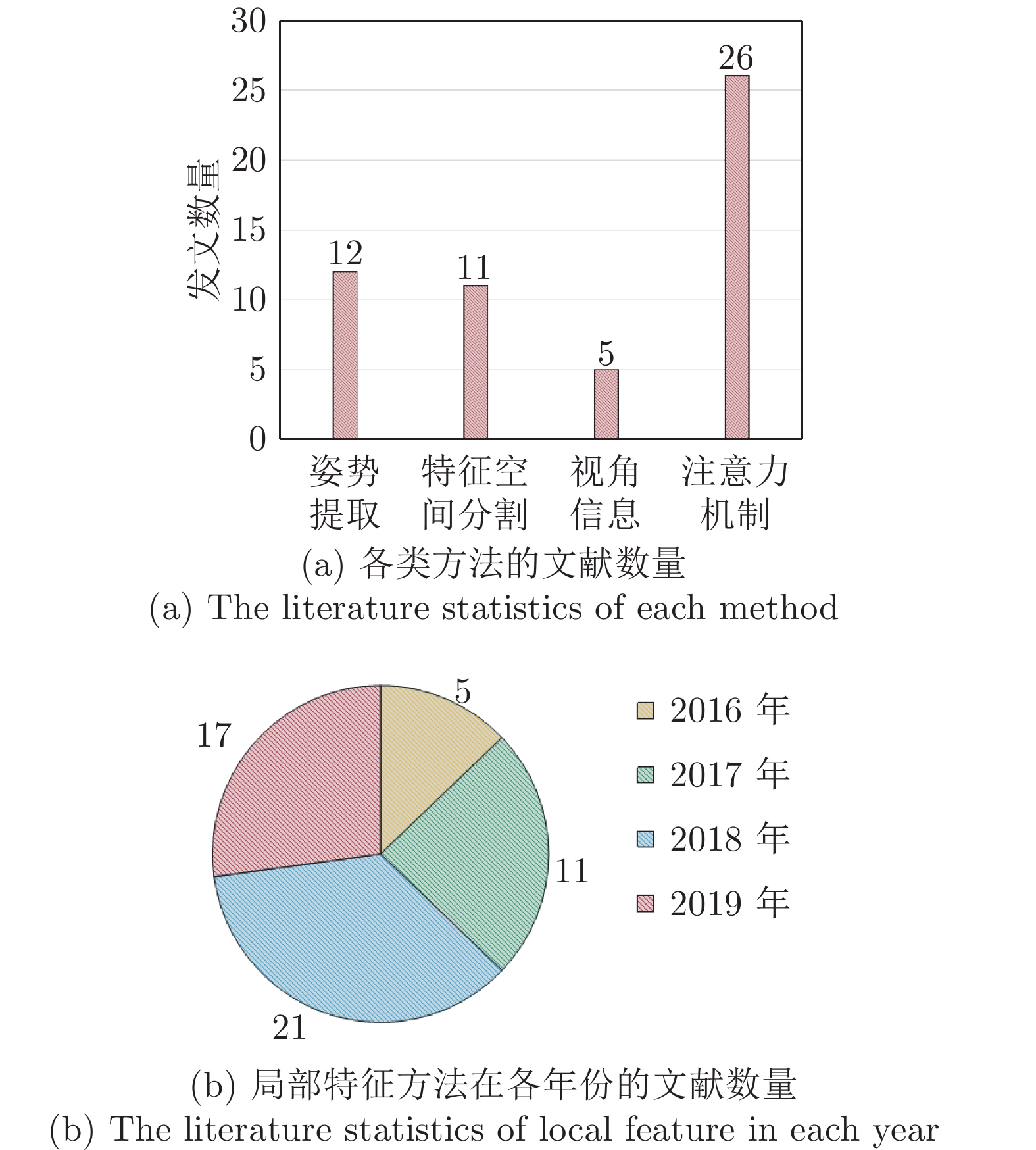
图 2 4类基于局部特征的行人重识别方法文献统计
Fig. 2 Literature statistics of four kinds of local feature-based Re-ID methods
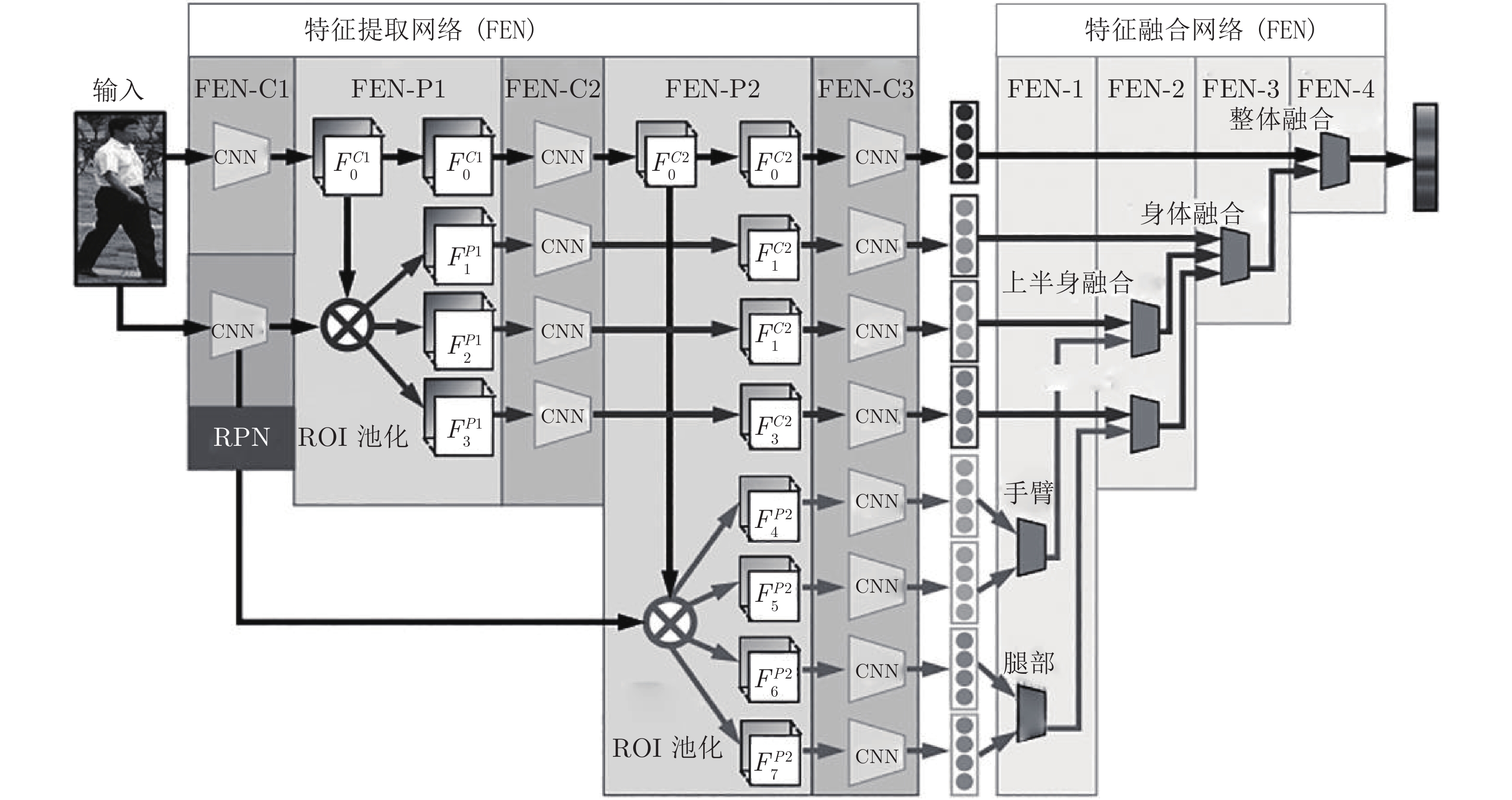
图 5 多分支融合姿态信息的SpindleNet网络流程图
Fig. 5 The pipeline of SpindleNet which fusions pose information with multiple branches

图 8 不同摄像头采集的行人特征对比示例
Fig. 8 The comparison of pedestrian feature representation captured by different cameras

图 12 MGN中不同分支的特征可视化结果
Fig. 12 The feature visualization results of the different branch of MGN
表 1 行人重识别主流数据集
Table 1 Mainstream Re-ID dataset
库名 发布机构 样本描述 类型 示例 VIPeR (2008) 加州大学圣克鲁兹分校 632 个行人, 1264 幅行人图像 单帧数据集 
PRID2011 (2011) 格拉茨技术大学 934 个行人, 24541 帧行人图像, 视频数据集 
Partial-iLIDS (2011) 伦敦玛丽女王大学 119 个行人, 238 幅行人图像 单帧遮挡数据集 
iLIDS-VID (2014) 伦敦玛丽女王大学 300 个行人, 42495 帧行人图像 视频数据集 
Duke MTMC-reID (2014) 杜克大学 1812 个行人, 36441 幅行人图像 单帧数据集 
Partial-ReID (2015) 中山大学 60 个行人, 600 帧行人图像, 单帧遮挡数据集 
Market-1501 (2015) 清华大学 1501 个行人, 33217 幅行人图像 单帧数据集 
MARS (2016) 悉尼大学 1261 个行人, 1191003 帧行人图像 视频数据集 
CHUK03 (2017) 香港中文大学 1467 个行人, 13164 幅行人图像 单帧数据集 
MSMT17 (2018) 北京大学 4101 个行人, 126441 幅行人图像 单帧数据集 
 下载: 导出CSV
下载: 导出CSV
表 2 基于姿势估计的方法总结 (rank-1为原论文在Market-1501上的实验结果)
Table 2 Summary of pose estimation based methods (rank-1 refers to the result of original paper on Market-1501)
文献 来源 方法名称 基础网络或主要方法 方法类型 姿态估计 rank-1 (%) 主要工作概述 模型 关键点数目 [5] CVPR10 SDALF 颜色相关图, 颜色矩 手工特征 — — — 设计颜色直方图等手工特征提取人体对称轴附近的局部信息. [34] CVPR17 SpindleNet GoogleNet 深度学习 CPM 14 91.5 人体关键点定位人体部件ROI, 与行人特征级联融合生成鉴别性更强的特征. [35] Arxiv17 PIE ResNet50 深度学习 CPM 14 78.6 双层全连接层提取人体部件判别向量, 指导姿态估计模型精确提取关键点. [36] ICCV19 PGFA Resnet50 深度学习 AlphaPose 18 91.2 利用姿态估计模型对遮挡的敏感性预测遮挡区域, 降低遮挡对模型判别的影响. [38] CVPR18 Pose-transfer CGAN GAN HPE 18 87.6 引入姿态估计模型定位人体结构, 优化GAN模型对人体形态的构建. [39] CVPR19 PATN CGAN GAN OpenPose 18 — 采用双判别器分别改善图像质量及姿态形体, 提升生成图像的真实感.
下载: 导出CSV
表 3 基于特征空间分割的方法总结(rank-1为原论文在Market-1501上的实验结果)
Table 3 Summary of feature spatial partition based methods (rank-1 refers to the result of original paper on Market-1501)
文献 来源 方法名称 基础网络 损失函数 分割数目统计 rank-1 (%) 主要工作概述 全局特征 局部特征 [17] ICCV18 PCB ResNet50 交叉熵损失 0 6 93.8 提出水平分割卷积特征, 提取细粒度的局部特征. [47, 53] ACM19 MGN ResNet50 交叉熵损失
三元损失3 5 95.7 多粒度网络, 结合粗粒度的全局特征及细粒度的局部特征, 使用多损失联合训练. [49] CVPR19 Pyramidal ResNet50 交叉熵损失
三元损失1 20 95.7 构建金字塔结构, 在分割特征的同时保留特征间的上下文关系. [50] PR19 AlignedReID ResNet50 交叉熵损失
三元损失1 7 91.8 设计了一种动态规划算法, 优先匹配相似度更高的局部特征, 减少了特征对齐误差. [51] CVPR19 VPM ResNet50 交叉熵损失
三元损失0 3 93.0 预定义分割区域, 使特征分割模型更稳定的提取部件特征. [52] ICCV19 SSG ResNet50 交叉熵损失
三元损失0 3 86.2 与无监督学习结合, 将每个分割区域作为一类聚类中心, 构建目标域与原域的细粒度相关性.
下载: 导出CSV
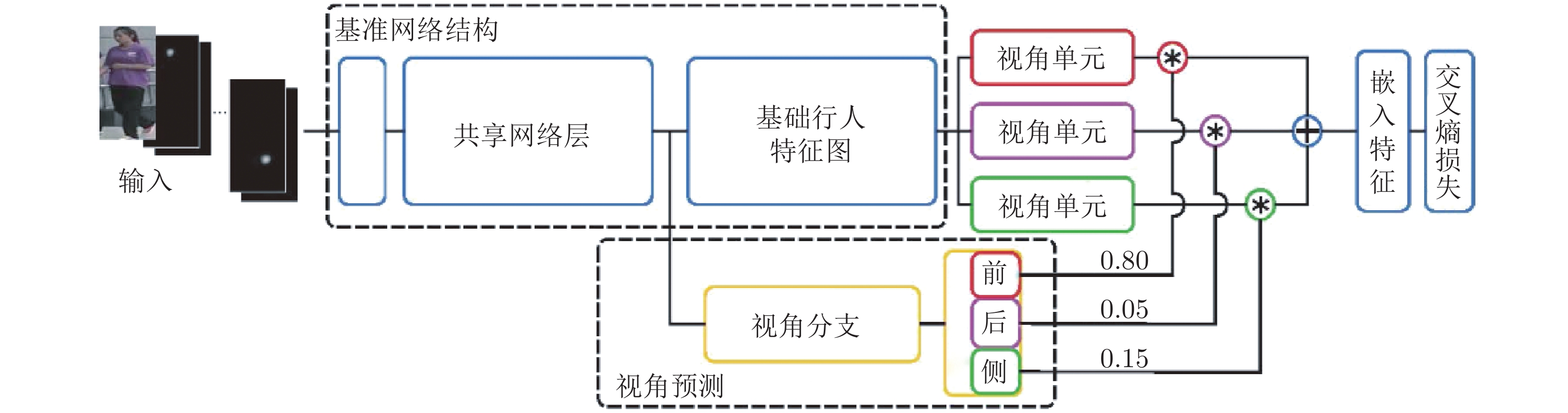
表 4 基于视角信息的方法总结
Table 4 Summary of viewpoint based methods
文献 来源 基础网络或主要方法 方法名称 损失函数 方法类型 主要工作概述 [54] CVPR19 PCB PsrsonX 交叉熵损失 深度学习 提出了一个3D行人数据集, 定量探讨了视角特征对行人重识别任务的影响. [55] AVSS14 坐标仿射变换 TA + MS + W特征 — 手工特征 挖掘人体对称性特征、角度特征, 利用仿射变换对齐图像. [57] TPAMI14 角度描述符 VIH — 手工特征 多视图构建角度描述符, 预测固定摄像头下行人姿态变化情况. [59] BMVC17 GoogleNet VeSPA 交叉熵损失 深度学习 基于行人属性集的视角标注, 训练了一个分类模型, 可预测行人视角概率. [60] CVPR18 ResNet50 PSE 交叉熵损失 深度学习 将VeSPA模型用于行人重识别任务, 结合视角概率值生成鉴别特征.
下载: 导出CSV
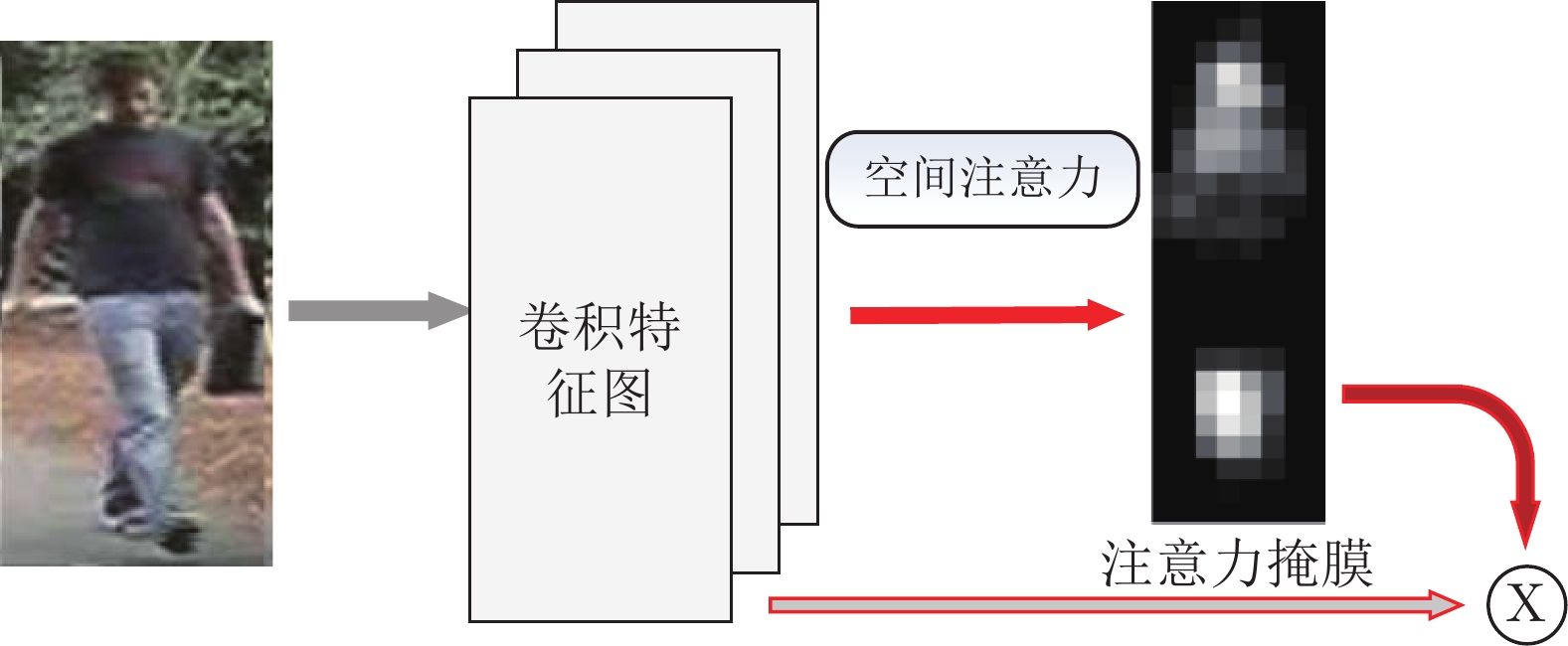
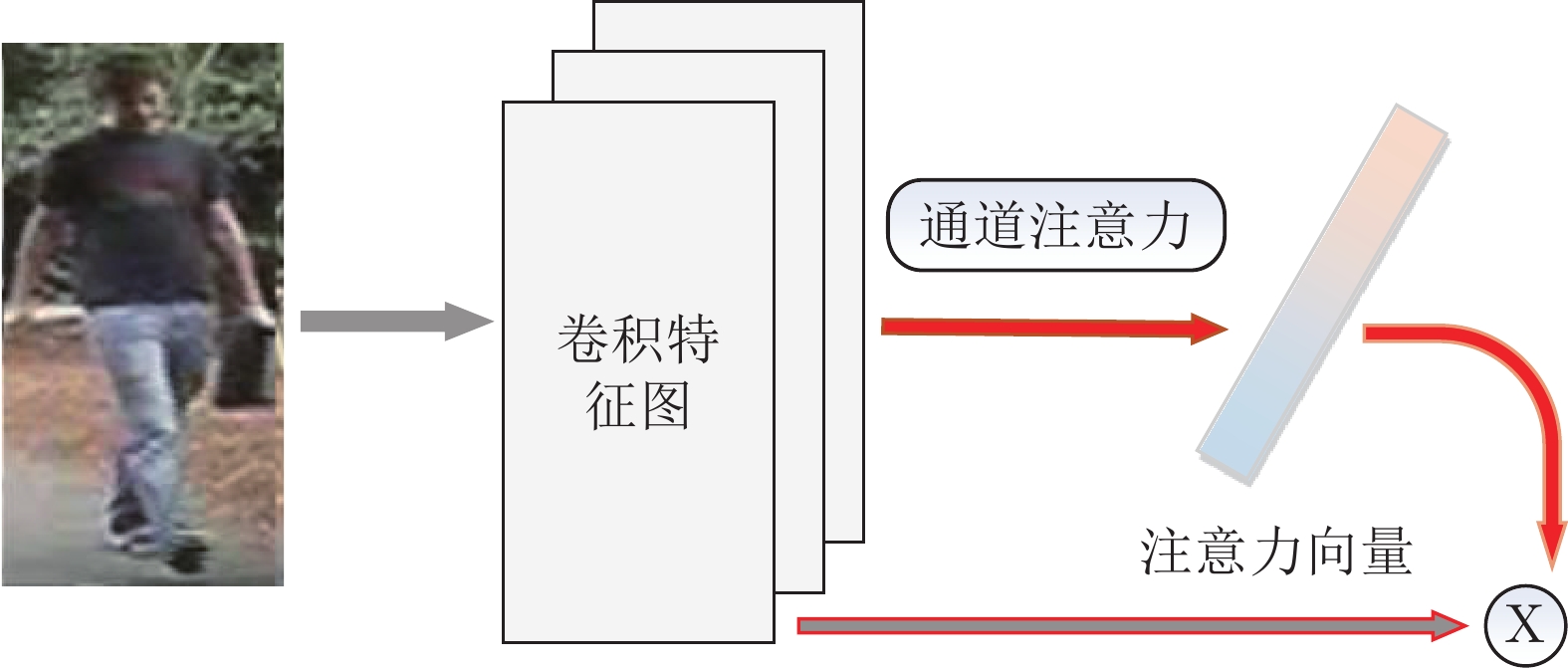
表 5 基于注意力机制的方法总结(rank-1为原论文在Market-1501上的实验结果)
Table 5 Summary of attention based methods (rank-1 refers to the result of original paper on Market-1501)
文献 来源 方法名称 基础网络 实现方法 损失函数 方法类型 rank-1 (%) 主要工作概述 [61] CVPR17 DLPAR GoogleNet 多分支的$1\times1$卷积层 三元损失 空间注意力 64.2 利用多个注意力模块作用到不同的人体部件, 多分支提取鉴别性特征. [62] CVPR18 MGCAM MGCAN 全卷积网络[69] 交叉熵损失
三元损失空间注意力 83.7 结合背景分割, 提取二值化轮廓图作为注意力图, 降低杂乱背景的干扰. [65] CVPR18 HA-CNN CNN SER结构结合多层卷积 交叉熵损失 空间注意力
通道注意力91.2 融合空间注意力学习与通道注意力, 同时学习平面像素特征与通道尺度特征. [66] ICCV19 ABD-Net ResNet50 Softmax层加权特征矩阵 交叉熵损失
三元损失空间注意力
通道注意力95.6 利用 softmax 的分类特性, 加强通道特征间的相关性. [68] ICCV19 BDBNet ResNet50 DropBlock[70]层改进 交叉熵损失
三元损失非卷积方法 95.3 特征正则化, 将随机擦除作用到特征学习, 可有效抑制过拟合.
下载: 导出CSV
表 6 DukeMTMC-ReID数据集上各种方法的对比结果 (%)
Table 6 Experimental results of various methods on DukeMTMC-ReID dataset (%)
下载: 导出CSV
表 7 Market-1501数据集上各种方法的对比结果 (%)
Table 7 Experimental results of various methods on Market-1501 dataset (%)
方法 类型 rank-1 mAP XQDA + LOMO[10] (2015) 手工特征 43.8 22.2 UMDL[73] (2016) 无监督 + 手工特征 34.5 12.4 SPGAN[74] (2018) 无监督 + GAN 58.1 26.9 SOMAne[3] (2017) 全局特征 73.9 47.9 Spindle[34] (2017) 姿势提取 76.9 — Pose-transfer[38] (2018) 姿势提取 87.6 68.9 PCB[17] (2018) 特征空间分割 92.3 77.4 MGN[47] (2018) 特征空间分割 95.7 86.9 Pyramidal[49] (2019) 特征空间分割 95.7 88.2 PSE[60] (2018) 视角信息 87.7 69.0 HA-CNN[65] (2018) 注意力机制 91.2 75.7 ABD-Net[66] (2019) 注意力机制 95.6 88.2
下载: 导出CSV
表 8 CUHK03数据集上各种方法的对比结果 (%)
Table 8 Experimental results of various methods on CUHK dataset (%)
下载: 导出CSV
表 9 各类局部特征方法比较
Table 9 Comparison of various local feature methods
方法类型 对应文献 特征学习特点 影响性能的主要因素 姿势估计 [5, 29-39] 在特征学习的过程中融合准确的关键点特征, 以学习更具鉴别性的特征, 或利用关键点处理人体定位对齐、遮挡问题. 姿态估计模型对人体关键点的检测精度、特征融合方法的有效性. 姿态估计数据集与行人重识别数据集具有较大偏差, 造成姿态估计模型在行人重识别任务中的语义分割效果不佳. 特征空间分割 [15, 47-52] 对卷积层的特征进行均匀分割, 生成的每一块特征都由单独的损失函数约束训练 输入数据的复杂程度, 特征分割区域的稳定性, 易受局部特征对齐问题的影响, 依赖质量较高的数据. 视角信息 [54-60] 需要准确的视角信息. 常利用视角信息对不同视角的图像进行仿射变换以对齐图像视角, 或融合视角信息增加特征的鉴别性. 视角信息的准确性, 目前没有专门增对视角特征的研究领域且相关数据集较少, 视角估计模型的准确度还有待提升. 注意力机制 [61-68] 学习由卷积计算生成的显著性区域, 在训练过程中提高相关程度较高区域的权重, 同时降低相关程度较低区域的权重. 注意力选择的有效性及多样性, 相关的工作表明结合多类注意力机制能够获得更好鉴别性特征.
下载: 导出CSV
表 10 DukeMTMC-reID上融合多类局部特征方法的实验结果 (%)
Table 10 Experimental results of the multiple-local feature fusion methods on DukeMTMC-reID (%)
下载: 导出CSV
-
[1] Zheng Z D, Zheng L, Yang Y. Pedestrian alignment network for large-scale person re-identification. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(10): 3037-3045 doi: 10.1109/TCSVT.2018.2873599 [2] Chen H R, Wang Y W, Shi Y M, Yan K, Geng M Y, Tian Y H, et al. Deep transfer learning for person re-identification. In: Proceedings of the 4th International Conference on Multimedia Big Data (BigMM). Xi'an, China: IEEE, 2018. 1−5 [3] Barbosa I B, Cristani M, Caputo B, Rognhaugen A, Theoharis T. Looking beyond appearances: Synthetic training data for deep CNNs in re-identification. Computer Vision and Image Understanding, 2018, 167: 50-62 doi: 10.1016/j.cviu.2017.12.002 [4] Gray D, Tao H. Viewpoint invariant pedestrian recognition with an ensemble of localized features. In: Proceedings of the 10th European Conference on Computer Vision. Marseille, France: Springer, 2008. 262−275 [5] Farenzena M, Bazzani L, Perina A, Murino V, Cristani M. Person re-identification by symmetry-driven accumulation of local features. In: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010. 2360−2367 [6] Bazzani L, Cristani M, Murino V. Symmetry-driven accumulation of local features for human characterization and re-identification. Computer Vision and Image Understanding, 2013, 117(2): 130-144 doi: 10.1016/j.cviu.2012.10.008 [7] Lowe D G. Object recognition from local scale-invariant features. In: Proceedings of the 7th IEEE International Conference on Computer Vision. Kerkyra, Greece: IEEE, 1999. 1150−1157 [8] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05). San Diego, USA: IEEE, 2005. 886−893 [9] 齐美彬, 檀胜顺, 王运侠, 刘皓, 蒋建国. 基于多特征子空间与核学习的行人再识别. 自动化学报, 2016, 42(2): 229-308Qi Mei-Bin, Tan Sheng-Shun, Wang Yun-Xia, Liu Hao, Jiang Jian-Guo. Multi-feature subspace and kernel learning for person re-identification. Acta Automatica Sinica, 2016, 42(2): 229-308 [10] Liao S C, Hu Y, Zhu X Y, Li S Z. Person re-identification by local maximal occurrence representation and metric learning. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 2197−2206 [11] Köstinger M, Hirzer M, Wohlhart P, Both P M, Bischof H. Large scale metric learning from equivalence constraints. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 2288−2295 [12] Huang T, Russell S. Object identification in a Bayesian context. In: Proceedings of the 15th International Joint Conference on Artifical Intelligence. San Francisco, USA: Morgan Kaufmann Publishers Inc., 1997. 1276−1282 [13] Zajdel W, Zivkovic Z, Krose B J A. Keeping track of humans: Have I seen this person before? In: Proceedings of the 2005 IEEE International Conference on Robotics and Automation. Barcelona, Spain: IEEE, 2005. 2081−2086 [14] Gray D, Brennan S, Tao H. Evaluating appearance models for recognition, reacquisition, and tracking. In: Proceedings of the 10th IEEE International Workshop on Performance Evaluation of Tracking and Surveillance (PETS). Rio de Janeiro, Brazil: IEEE, 2007. 1−7 [15] Li W, Zhao R, Xiao T, Wang X G. DeepReID: Deep filter pairing neural network for person re-identification. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 152−159 [16] Zheng Z D, Zheng L, Yang Y. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 3774-3782 [17] Sun Y F, Zheng L, Yang Y, Tian Q, Wang S J. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In: Proceedings of the 15th European Conference on Computer Vision (ECCV 2018). Munich, Germany: Springer, 2018. 501−518 [18] Yu H X, Zheng W S, Wu A C, Guo X W, Gong S G, Lai J H. Unsupervised person re-identification by soft multilabel learning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 2143−2152 [19] Wu A C, Zheng W S, Lai J H. Unsupervised person re-identification by camera-aware similarity consistency learning. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 6921−6930 [20] Zheng X Y, Cao J W, Shen C H, You M Y. Self-training with progressive augmentation for unsupervised cross-domain person re-identification. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 8221−8230 [21] Zheng L, Shen L Y, Tian L, Wang S J, Wang J D, Tian Q. Scalable person re-identification: A benchmark. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1116−1124 [22] Ristani E, Solera F, Zou R, Cucchiara R, Tomasi C. Performance measures and a data set for multi-target, multi-camera tracking. In: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 17−35 [23] Wei L H, Zhang S L, Gao W, Tian Q. Person transfer GAN to bridge domain gap for person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 79−88 [24] Zheng L, Bie Z, Sun Y F, Wang J D, Su C, Wang S J, et al. MARS: A video benchmark for large-scale person re-identification. In: Proceedings of the 14th European Conference on Computer Vision (ECCV 2016). Amsterdam, The Netherlands: Springer, 2016. 868−884 [25] Wang T Q, Gong S G, Zhu X T, Wang S J. Person re-identification by video ranking. In: Proceedings of the 13th European Conference on Computer Vision (ECCV 2014). Zurich, Switzerland: Springer, 2014. 688−703 [26] Hirzer M, Beleznai C, Roth P M, Bischof H. Person re-identification by descriptive and discriminative classification. In: Proceedings of the 17th Scandinavian Conference on Image Analysis. Ystad, Sweden: Springer, 2011. 91−102 [27] Zheng W S, Li X, Xiang T, Liao S C, Lai J H, Gong S G. Partial person re-identification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 4678−4686 [28] Zheng W S, Gong S G, Xiang T. Person re-identification by probabilistic relative distance comparison. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011). Colorado Springs, USA: IEEE, 2011. 649−656 [29] Cheng D S, Cristani M, Stoppa M, Bazzani L, Murino V. Custom pictorial structures for re-identification. In: Proceedings of the 22nd British Machine Vision Conference. Dundee, UK: BMVA Press, 2011. 1−11 [30] Cho Y J, Yoon K J. Improving person re-identification via pose-aware multi-shot matching. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 1354−1362 [31] Toshev A, Szegedy C. DeepPose: Human pose estimation via deep neural networks. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 1653−1660 [32] Xiao B, Wu H P, Wei Y C. Simple baselines for human pose estimation and tracking. In: Proceedings of the 15th European Conference on Computer Vision (ECCV 2018). Munich, Germany: Springer, 2018. 472−487 [33] Newell A, Yang K Y, Deng J. Stacked hourglass networks for human pose estimation. In: Proceedings of the 14th European Conference on Computer Vision (ECCV 2016). Amsterdam, The Netherlands: Springer, 2016. 483−499 [34] Zhao H Y, Tian M Q, Sun S Y, Shao J, Yan J J, Yi S, et al. Spindle net: Person re-identification with human body region guided feature decomposition and fusion. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 907−915 [35] Zheng L, Huang Y J, Lu H C, Yang Y. Pose-invariant embedding for deep person re-identification. IEEE Transactions on Image Processing, 2019, 28(9): 4500-4509 doi: 10.1109/TIP.2019.2910414 [36] Miao J X, Wu Y, Liu P, Ding Y H, Yang Y. Pose-guided feature alignment for occluded person re-identification. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 542−551 [37] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672−2680 [38] Liu J X, Ni B B, Yan Y C, Zhou P, Cheng S, Hu J G. Pose transferrable person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 4099−4108 [39] Zhu Z, Huang T T, Shi B G, Yu M, Wang B F, Bai X. Progressive pose attention transfer for person image generation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 2342−2351 [40] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 1−9 [41] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [42] Mirza M, Osindero S. Conditional generative adversarial nets. arXiv preprint arXiv: 1411.1784, 2014. [43] Wei S E, Ramakrishna V, Kanade T, Sheikh Y. Convolutional pose machines. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 4724−4732 [44] Cao Z, Simon T, Wei S E, Sheikh Y. Realtime multi-person 2D pose estimation using part affinity fields. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 1302−1310 [45] Fang H S, Xie S Q, Tai Y W, Lu C W. RMPE: Regional multi-person pose estimation. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2353−2362 [46] Cao Z, Hidalgo G, Simon T, Wei S E, Sheikh Y. OpenPose: Realtime multi-person 2D pose estimation using part affinity fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(1): 172-186. doi: 10.1109/TPAMI.2019.2929257 [47] Wang G S, Yuan Y F, Chen X, Li J W, Zhou X. Learning discriminative features with multiple granularities for person re-identification. In: Proceedings of the 26th ACM International Conference on Multimedia. Seoul, Korea (South): ACM, 2018. 274−282 [48] Cheng D, Gong Y H, Zhou S P, Wang J J, Zheng N N. Person re-identification by multi-channel parts-based CNN with improved triplet loss function. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 1335−1344 [49] Zheng F, Deng C, Sun X, Jiang X Y, Guo X W, Yu Z Q, et al. Pyramidal person re-identification via multi-loss dynamic training. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 8506−8514 [50] Luo H, Jiang W, Zhang X, Fan X, Qian J J, Zhang C. AlignedReID++: Dynamically matching local information for person re-identification. Pattern Recognition, 2019, 94: 53−61 [51] Sun Y F, Xu Q, Li Y L, Zhang C, Li Y K, Wang S J, et al. Perceive where to focus: Learning visibility-aware part-level features for partial person re-identification. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 393−402 [52] Fu Y, Wei Y C, Wang G S, Zhou Y Q, Shi H H, Uiuc U, et al. Self-Similarity grouping: A simple unsupervised cross domain adaptation approach for person re-identification. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 6111−6120 [53] Schroff F, Kalenichenko D, Philbin J. FaceNet: A unified embedding for face recognition and clustering. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 815−823 [54] Sun X X, Zheng L. Dissecting person re-identification from the viewpoint of viewpoint. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 608−617 [55] Bak S, Zaidenberg S, Boulay B, Brémond F. Improving person re-identification by viewpoint cues. In: Proceedings of the 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). Seoul, Korea (South): IEEE, 2014. 175−180 [56] Bialkowski A, Denman S, Sridharan S, Fookes C, Lucey P. A database for person re-identification in multi-camera surveillance networks. In: Proceedings of the 2012 International Conference on Digital Image Computing Techniques and Applications (DICTA). Fremantle, Australia: IEEE, 2012. 1−8 [57] Wu Z Y, Li Y, Radke R J. Viewpoint invariant human re-identification in camera networks using pose priors and subject-discriminative features. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(5): 1095-1108 doi: 10.1109/TPAMI.2014.2360373 [58] Li D W, Zhang Z, Chen X T, Huang K Q. A richly annotated pedestrian dataset for person retrieval in real surveillance scenarios. IEEE Transactions on Image Processing, 2018, 28(4): 1575−1590 [59] Sarfraz M S, Schumann A, Wang Y, Stiefelhagen R. Deep view-sensitive pedestrian attribute inference in an end-to-end model. In: Proceedings of the 2017 British Machine Vision Conference. London, UK: BMVA Press, 2017. 134.1−134.13 [60] Sarfraz M S, Schumann A, Eberle A, Stiefelhagen R. A pose-sensitive embedding for person re-identification with expanded cross neighborhood re-ranking. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 420−429 [61] Zhao L M, Li X, Zhuang Y T, Wang J D. Deeply-learned part-aligned representations for person re-identification. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 3239−3248 [62] Song C F, Huang Y, Ouyang W L, Wang L. Mask-guided con−trastive attention model for person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1179-1188 [63] Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7132−7141 [64] Nair V, Hinton G E. Rectified linear units improve restricted Boltzmann machines. In: Proceedings of the 27th International Conference on International Conference on Machine Learning. Madison, USA: Omnipress, 2010. 807−814 [65] Li W, Zhu X T, Gong S G. Harmonious attention network for person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 2285−2294 [66] Chen T L, Ding S J, Xie J Y, Yuan Y, Chen W Y, Yang Y, et al. ABD-Net: Attentive but diverse person re-identification. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 8350−8360 [67] Fu J L, Zheng H L, Mei T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 4476−4484 [68] Dai Z X, Chen M Q, Gu X D, Zhu S Y, Tan P. Batch DropBlock network for person re-identification and beyond. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 3690−3700 [69] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 3431−3440 [70] Ghiasi G, Lin T Y, Le Q V. DropBlock: A regularization method for convolutional networks. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montreal, Canada: Curran Associates Inc., 2018. 10750−10760 [71] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In: Proceedings of the 13th European Conference on Computer Vision (ECCV 2014). Zurich, Switzerland: Springer, 2014. 818−833 [72] Zhou B L, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2921−2929 [73] Peng P X, Xiang T, Wang Y W, Pontil M, Gong S G, Huang T J, et al. Unsupervised cross-dataset transfer learning for person re-identification. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 1306−1315 [74] Deng W J, Zheng L, Ye Q X, Kang G L, Yang Y, Jiao J B. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 994−1003 [75] Guo J Y, Yuan Y H, Huang L, Zhang C, Yao J G, Han K. Beyond human parts: Dual part-aligned representations for person re-identification. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 3641−3650 [76] Selvaraju R R, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 618−626 [77] 吴彦丞, 陈鸿昶, 李邵梅, 高超. 基于行人属性先验分布的行人再识别. 自动化学报, 2019, 45(5): 953-964Wu Yan-Cheng, Chen Hong-Chang, Li Shao-Mei, Gao Chao. Person re-Identification using attribute priori distribution. Acta Automatica Sinica, 2019, 45(5): 953-964 [78] Yang Q Z, Wu A C, Zheng W S. Person re-identification by contour sketch under moderate clothing change. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(6): 2029-2046 doi: 10.1109/TPAMI.2019.2960509 [79] Zhang L B, Huang S L, Liu W, Tao D C. Learning a mixture of granularity-specific experts for fine-grained categorization. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 8330−8339 [80] Simon M, Rodner E. Neural activation constellations: Unsupervised part model discovery with convolutional networks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1143−1151 [81] Xiao T J, Xu Y C, Yang K Y, Zhang J X, Peng Y X, Zhang Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 842−850 [82] Yin J H, Wu A C, Zheng W S. Fine-grained person re-identification. International Journal of Computer Vision, 2020, 128(6): 1654-1672 doi: 10.1007/s11263-019-01259-0 -

 下载:
下载:



计量
- 文章访问数: 2261
- HTML全文浏览量: 2145
- PDF下载量: 645
- 被引次数: 0
