

-
摘要: 针对稀疏自动编码器(Sparse auto encoder, SAE)采用sigmoid激活函数容易造成梯度消失的问题, 用一种新的Tan函数替代原有的sigmoid函数; 针对SAE采用Kullback-Leibler (KL) 散度进行稀疏性约束在回归预测方面的局限性, 以dropout机制替代KL散度实现网络的稀疏性. 利用改进SAE对滚动轴承振动信号进行无监督深层特征自适应提取, 无需人工设计标签进行有监督微调. 同时, 考虑到滚动轴承剩余使用寿命(Remaining useful life, RUL)预测方法一般仅考虑过去信息而忽略未来信息, 引入双向长短时记忆网络(Bi-directional long short-term memory, Bi-LSTM)构建滚动轴承RUL的预测模型. 在2个轴承数据集上的实验结果均表明, 所提基于改进SAE和Bi-LSTM的滚动轴承RUL预测方法不仅可以提高模型的收敛速度而且具有较低的预测误差.Abstract: Since the sigmoid activation function of sparse auto-encoder (SAE) is easy to cause the gradient to disappear, a new Tan function is used to replace the original sigmoid function. In SAE, for the limitations in regression prediction when Kullback-Leibler (KL) divergence is used for sparseness constraints, KL divergence is replaced with the dropout mechanism to achieve network sparsity. And the improved SAE is used to perform unsupervised adaptive deep feature extraction for the vibration signals of rolling bearings, without designing labels manually for supervised fine adjustment. Meanwhile, for the remaining useful life (RUL) prediction method of rolling bearing, generally only the past information is considered and the future information is ignored, the bi-directional long short-term memory (Bi-LSTM) is introduced to construct an RUL prediction model of the rolling bearing. Using two bearing data sets, experimental results both show that the proposed RUL prediction method of a rolling bearing based on improved sparse auto encoder and Bi-LSTM can improve the convergence speed of the model and has lower prediction error.
-
近年来, 深度神经网络在解决机器学习任务时取得了巨大的成功. 2012年, Krizhevsky等[1]首次使用深度神经网络, AlexNet在ILSVRC (ImageNet large scale visual recognition competition)[2]分类任务上获得了冠军, 他们的结果相比传统的机器学习算法在识别精度上提升了近10个百分点, 引起学术界和工业界巨大轰动.从那时起, 各种不同结构的深度神经网络模型如雨后春笋般不断涌现. 2014年英国牛津大学的Visual Geometry Group提出了VGG[3]模型, 同时谷歌的研究人员提出了GoolgLeNet[4], 2015年He等提出了ResNet[5-6].这些模型的网络结构越来越深, 从而能学习到更好的特征以提升模型的性能.然而, 由于内存和计算能力有限, 随着网络变得越来越深, 对包括移动设备在内的有严格时延要求的有限资源平台而言, 随之增加的模型参数需要消耗更多的计算和存储资源, 难以直接应用于手机等移动嵌入式设备.
虽然将深度神经网络部署到云服务器端, 移动端将数据上传服务端处理, 能很好解决上述问题, 但服务器需要耗费昂贵的硬件成本, 导致计算成本过高, 其次移动端在使用的过程对网络要求高, 需要将移动端本地的数据上传到云端服务器进行保存, 在处理一些隐私数据时, 还会存在信息的泄露.所以将深度学习算法部署到移动端本地非常有意义, 但常用的深度模型具有大量的储存量, 比如AlexNet的模型大小量超过200 MB, VGG的模型大小量超过500 MB, 如果将这些网络结构直接运用到手机APP中, 用户需要大量的流量下载APP文件, 还会占用用户手机的大量内存.同时, 巨大的模型文件会带来另外一个问题, 手机设备的能源消耗问题, 手机在调用这些文件时会存在大量的能源消耗, 会让手机设备产生大量的热量, 因此深度模型压缩是非常有必要的.
为了解决这一问题, 各种深度模型压缩方法被提出, 这些方法主要有:模型剪枝、知识精炼(Knowledge distillation)、低秩分解、精细化的模型结构以及权重共享.本文主要关注基于权重共享的方法来压缩模型, 权重共享是通过卷积滤波器中相近的权重共享同一量化值从而达到对深度神经网络压缩的目的.权重共享的方法大致可以分为三类:聚类编码法、二值/三值量化编码和指数量化编码.
聚类编码法, 指使用聚类的方法, 将权重聚类为若干类, 取每类的聚类中心作为共享的权重.例如, Gong等[7]通过对全连接层参数进行聚类, 取聚类中心作为量化编码, 可以将深度模型AlexNet压缩20倍, 而Top-5准确率仅仅下降1 %.类似的, Chen等[8]提出了HashedNets对全连接层进行量化, 利用哈希函数随机的将权重分到不同的哈希桶(Hash bucket), 同一哈希桶的权重具有相同的量化值. Han等[9]提出了一种深度压缩(Deep compression)方法, 通过对卷积层和全连接层的权重进行剪枝, 然后通过K-Means聚类进行量化, 最后使用霍夫曼编码(Huffman coding)对模型进行保存, 极大的压缩了模型的规模.但是, 聚类编码法需要大量额外的计算开销用于聚类分析, 算法的训练效率低.
二值/三值量化编码, 将网络的权重、激活值量化为二值或者三值.例如, Courbariaux等[10]提出了一种二值连接(Binary connect)方法, 将权重进行二值量化(量化为${-1, 1}$), 可以将一个深度模型直接压缩32倍; 他们随后提出了Binarized neural networks[11], 将权重和激活值同时进行二值量化, 在压缩网络的同时还可以提高运算效率. Rastegari等[12]提出的二值权重网络(Binary weight networks)和XNOR-Net, 在把权重量化为+1和$-1$的基础上乘以一个尺度因子, 在大数据集ImageNet上取得了不错的压缩效果. Li等[13]提出的HORQ, 相对于XNOR只使用到一阶阈值, HORQ还用到二阶阈值, 让二阶阈值逼近一阶阈值的残差, HORQ在对准确率影响很小的情况下能将模型缩小32倍, 同时加速30倍左右. Li等[14]提出的TWN (Ternary weight networks), 在二值网络的基础中引入0作为量化权重值. Zhu等[15]提出的TTQ (Trained ternary quantization), 将网络的权重量化为+1和$-1$的基础上, 分别乘上两个不同的尺度因子. Cai等[16]提出HWGQ-Net通过改变网络的激活函数, 将权重量化1个比特网络的激活值量化为2个比特, 网络只有微小的性能损失.尽管这类方法将模型中的每一个权重、激活值压缩为一到两位来表示, 但是模型的识别精度也有一定幅度的下降.
指数量化编码, 将权重量化为2的(为整数)次幂, 以便于嵌入式系统进行二进制移位操作.该方法由Zhou等[17]首次提出, 利用预训练模型获取固定的指数量化的码本, 然后通过增量量化过程来逐渐量化整个网络.在使用5-bit量化时, 压缩模型的识别率能够保持与原模型一致.这种方法在量化时, 可以高效率对深度神经网络量化, 但在网络重训练时, 他们提出的增量网络量化方法需要分多个阶段训练, 训练效率较低.
鉴于以上几点, 本文提出一种基于动态量化的深度模型压缩方法, 不同与从预训练模型获取固定码本, 动态量化在训练的过程中也更新码本.这种量化方式在保证模型性能的同时, 还加快了效率.同时为了方便嵌入式系统进行移位操作, 本文对所有网络的权值采用指数量化编码, 并通过理论证明得出, 绝对值较大权值参数的量化对模型的精度影响越大.因此, 本研究通过动态编码使得码本能自适应网络中绝对值较大的权值参数.本文的主要贡献有以下三点:
1) 提出动态更新码本自适应网络中绝对值较大的权值参数, 尽可能减小这些参数的量化对模型精度的影响;
2) 提出交替迭代算法用于模型训练, 使得权值参数和码本交替更新, 加快训练过程的收敛速度;
3) 大量的对比实验表明, 本文所提的基于动态编码的模型压缩方法总体上优于静态编码的方法.
本文剩余部分的组织结构如下:第1节介绍现有的深度神经网络压缩方法; 第2节介绍本文提出的方法, 包括基于权重的动态编码过程以及压缩模型的训练过程; 第3节通过大量的对比实验验证本文方法的有效性; 第4节总结与展望.
1. 相关的工作
本节主要介绍不同的深度神经网络压缩方法.除了上一节重点介绍的权重共享的方法, 深度神经网络压缩的方法还包括:模型的剪枝、知识精炼(Knowledge distillation)、低秩分解以及精细化的模型结构.
模型的剪枝, 通过评定预训练模型中参数的重要性, 剔除网络中不重要的网络连接, 主要有权重剪枝和滤波器剪枝两种方法.权重剪枝主要通过判断权重的大小来决定重要性, 一般设定一个阈值进行剔除, 或者根据设定剪切比例进行剔除, 优先将那些权重较小的值剔除例如Song等[18]采用此方法将AlexNet模型的参数量减少了9倍, VGG模型的参数量减少13倍, 而并没有造成模型精度的下降; Anwar等[19]按照一定的比例对每层中的权重随机裁剪, 统计多种随机剪裁下局部最优的作为最终剪裁.滤波器剪枝则是剔除网络中那些对网络影响较小的卷积滤波器, Li等[20]通过对卷积滤波器所有元素绝对值求和, 剔除那些求和较小的滤波器, 从而实现对模型的剪枝; Luo等[21]对卷积滤波器剪切前和剪切后激活值的损失进行评定, 剪切那些对损失影响不大的滤波器; Hu等[22]通过判定卷积录波器中权重为0的参数量来评定剪切标准; Luo等[23]提出了一种基于熵值的裁剪方式, 通过特征层的概率分布来评价卷积滤波器的重要性; Yang等[24]通过每层需要消耗的能量来进行裁剪, 优先修剪那些消耗大的层.相对而言, 滤波器剪枝会产生规则的稀疏矩阵, 而权重剪枝则会产生大量不规则的稀疏矩阵, 因此, 在加速方面滤波器剪枝更加有效.
知识精炼, 利用大模型指导小模型, 从而让小模型学到大模型相似的函数映射. Hinton等[25]利用训练好的复杂模型指导小模型的训练, 小模型通过优化复杂模型的输出交叉熵和自身的交叉熵, 在模型性能和训练速度上均有所提高. Romero等[26]提出的FitNets通过添加网络模型中间层的特征作为监督信号, 有效解决由于网络层数过深造成的学习困难. Zagoruyko等[27]同样采用大模型的中间特征作对小模型进行监督学习, 让小模型同时学到低、中、高层三个层次的特征输出.
低秩分解, 将原来的矩阵分解成若干个小矩阵, 对分解的小矩阵进行优化调整. Zhang等[28]将卷积矩阵变换为二维的矩阵, 结合SVD分解, 将VGG-16模型加速4倍而精度只有微小的下降. Lebedev等[29]使用CP分解的方法, 将每层网络分解成若干个低复杂度的网络层, 将AlexNet的第二个卷积层的速度提升了4倍却只增加1 %的分类误差.
精细化的模型结构, 通过使用小的卷积单元或者改变卷积方式对模型进行压缩和加速. Iandola等[30]提出的SqueezeNet使用$1 \times 1$卷积核对上层特征进行卷积降维, 然后使用$1 \times 1$和$3 \times 3$卷积进行特征堆叠, 大大减小了卷积的参数数量. Howard等[31]提出的MobileNets对每个通道的特征单独卷积, 之后再使用$1 \times 1$卷积对不同通道特征进行拼接. Zhang等[32]提出的ShuffleNet则是对多通道特征先进行分组后再执行卷积, 避免信息流不通畅的问题.这些轻量化的模型设计, 极大了减小了模型的参数量和计算量.
这些方法在对深度神经网络的压缩, 使得网络的性能在一定程度上有所下降, 有些压缩算法实现步骤繁琐, 甚至有些方法还对原始的网络结构进行了改变.而与这些方法相比, 权重共享的方法只对深度神经网络中的权重进行量化, 实现简单, 不会改变模型的网络结构, 本文对深度神经网络的压缩采用了权重共享的方式.
2. 动态量化编码的深度神经网络
本文提出的方法由两部分组成:权重量化与动态编码, 以及基于动态编码的量化模型训练, 本节将详述这两部分内容.
2.1 权重量化与动态编码
为了方便嵌入式系统进行移位运算, 本文采用类似文献[15]中的方法, 采用2的$n$次幂的形式对神经网络中的权值进行量化, 即当权重量化为$b$比特时, 码本最多有$2^{b}$个取值.码本可以表示为:
$ \begin{equation} P_{l}=\left \{ \pm 2^{n} \right \}, n\in [n_{1}, n_{2}], n\in {\bf Z} \end{equation} $
(1) 式中, $l$代表深度神经网络的第$l$层, $n_{1}$和$n_{2}$是两个整数, 满足$n_{1} < n_{2}$.由于$n_{1}$和$n_{2}$之间有$n_{2}-n_{1}+1$个整数, 且码本中正负整数的个数是相等的, 因此码本中总的取值有$2\times (n_{2}-n_{1}+1)=2^{b}$个, 即:
$ \begin{equation} n_{2}-n_{1}+1=2^{b-1} \end{equation} $
(2) 亦可引入0作为量化值对权重进行编码, 具体形式为:
$ \begin{equation} P_{l}=\left \{ \pm 2^{n}, 0 \right \}, n\in [n_{1}, n_{2}], n\in {\bf Z} \end{equation} $
(3) 由于0无法表示成2的$n\ (n$为整数)次幂, 需要额外的一个比特来表示0这个量化值.当$n_{1}$和$n_{2}$保持不变时, 式(3)需要$b+1$比特来量化权重.即:
$ \begin{equation} n_{2}-n_{1}+1=2^{b} \end{equation} $
(4) 虽然将0作为量化值引入码本需要增加一个比特, 但是会让网络中产生大量的稀疏矩阵, 有利于网络的正则化, 能在一定程度上抑制过拟合.
无论是否引入0进行编码, 当量化的位数确定时, 只要确定$n_{1}$或$n_{2}$中任意一个的值, 根据式(2)或式(4)求得另外一个参数, 从而根据式(1)或式(3)得到码本.假设给定预训练的模型, 并将此模型中的网络权值量化为2的$n$次幂.可采用以下式(5)使量化误差最小化:
$ \begin{equation} \begin{split} &\underset{n}{\min}\ err =\underset{n}{\min}(|w^{+}-2^{n}|), w^{+}\in |W_{l}|\\ &{\rm s. t.}\quad{\ n\in [n_{1}, n_{2}], n\in Z} \end{split} \end{equation} $
(5) 式中, $err$为量化误差, $W_{l}$为预训练模型的第$l$层权重, $w^{+}$为$|W_{l}|$中的任一正值权重.假设$|W_{l}|$中的两个值$w_{1}^{+}$和$w_{2}^{+}$, $w_{1}^{+} < w_{2}^{+}$, 同时近似满足$2^{q}w_{1}^{+}\approx w_{2}^{+}$, $q$为正整数. $w_{1}^{+}$和$w_{2}^{+}$分别量化为$2^{m_{1}}$和$2^{m_{2}}$, $2^{m_{1}}$和$2^{m_{2}}$应满足$2^{q}2^{m_{1}}=2^{m_{2}}$, 则$w_{1}^{+}$和$w_{2}^{+}$的量化误差$err_{1}$和$err_{2}$满足以下关系:
$ \begin{align} err_{1}= &|w_{1}^{+}-2^{m_{1}}|\rightarrow \Delta \approx 0\nonumber\\ err_{2}= &\left|w_{2}^{+}-2^{m_{2}}\right|=2^{q}\times \left|\frac{1}{2^{q}}w_{2}^{+}-2^{m_{1}}\right|\approx\nonumber\\ & 2^{q}\times |w_{1}^{+}-2^{m_{1}}|=2^{q}err_{1}\geq err_{1} \end{align} $
(6) 由于量化模型的权值调整大小是由反向传播的梯度和学习率的乘积来决定, 而这两个量都非常的小, 因此$2^{q}w_{1}^{+}\approx w_{2}^{+}$这一假设是容易满足的, 从而可以根据式(6)得出当模型进行指数量化时, 量化权值的绝对值越大, 量化误差也越大.
基于这一结论, 我们在量化的过程中优先量化那些权重绝对值较大的值, 即根据$|W_{l}|$中的最大值确定上限$n_{2}$的取值.具体的计算过程如下:
$ \begin{equation} n_{2}=~{\bf floor}({\rm log}_{2}(\max(|W_{l}|))) \end{equation} $
(7) 其中, floor$(\cdot)$表示的是向下取整操作, max$(\cdot)$表示的取最大值操作.确定了$n_{2}$, 就可以通过式(2)或式(4)得到下限$n_{1}$的取值, 从而确定码本$P_{l}$.
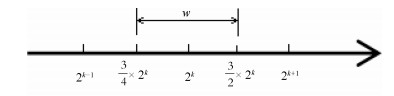
对于式(1)定义的码本, 每个网络权值用码本中最近的量化值进行编码, 具体量化规则如图 1所示.
可用如下的公式来计算:
$ \begin{equation} \hat{w} = \begin{cases} 2^{n_{2}}\times I(w), &|w|\geq \dfrac{3}{2}\times 2^{n_{2}}\\ 2^{k}\times I(w), &\dfrac{3}{4}\times 2^{k}\leq |w| < \dfrac{3}{2} \times 2^{k}, \\ & k\in [n_{1}, n_{2}], k\in {\bf Z}\\ 2^{n_{1}}\times I(w), &|w|\leq \dfrac{3}{4}\times 2^{n_{1}} \end{cases} \end{equation} $
(8) 式中, $\hat{w}$为量化后的权重, $2^{k}$为权重$w$的绝对值$|w|$的量化值; $I(w)$为指示函数, 用于区分网络中的正负权值.当$w$大于0时, $I(w)$为1; $w$为小于或等于0时, $I(w)$为$-1.$
对于式(3)定义的码本, 只需要根据码本下限进行截断取0值即可, 对应的量化公式如下:
$ \begin{equation} \hat{w} = \begin{cases} 2^{n_{2}}\times I(w), &|w|\geq \dfrac{3}{2}\times 2^{n_{2}}\\ 2^{k}\times I(w), &\dfrac{3}{4}\times 2^{k}\leq |w| < \dfrac{3}{2}\times 2^{k}, \\ & k\in [n_{1}, n_{2}], k\in {\bf Z}\\ 0, &|w| < \dfrac{3}{4}\times 2^{n_{1}} \end{cases} \end{equation} $
(9) 2.2 基于动态编码的量化模型训练
本节主要介绍量化模型的训练过程.对于初始的深度神经网络模型, 首先基于式(7)根据网络中的最大权值确定码本, 然后根据码本对网络权值采用式(8)或式(9)进行量化, 量化的深度神经网络通过前向传播过程计算网络的损失.再根据网络损失通过反向传播过程, 对网络权值进行更新.网络权值的更新会破坏原有的量化, 因此有必要对码本进行更新, 然后使用新的码本对网络权值进行再一次的量化.整个训练过程码本和权重交替迭代更新, 直到网络损失收敛为止.在整个迭代过程中, 码本根据网络权值的变化进行动态的更新, 码本的更新和深度神经网络的训练交替进行, 训练流程如图 2所示.以下介绍量化模型训练的具体实现细节.
对于普通的深度神经网络, 其训练由两个基本过程构成, 即前向传播过程和反向传播过程.在前向传播过程中, 分层网络的前一层的输出作为后一层的输入, 直到传入网络的最后一层得到整个深度神经网络的输出.根据输出和标签之间的差异计算损失函数, 其中损失函数的定义如下:
$ \begin{equation} \begin{split} &\underset{w_{l}}{\min}\ E(\hat{w_{l}})=L(\hat{w_{l}})+\lambda R(\hat{w_{l}})\\ &{\rm s. t.}\quad\ \hat{w_{l}}\in P_{l}, 1\leq l\leq L \end{split} \end{equation} $
(10) 式中, $E(\hat{w_{l}})$是网络的损失, $R(\hat{w_{l}})$是正则项, 本文采用$L_{2}$正则项, $\lambda$是正则项的权值系数.在反向传播过程中, 网络的残差由后一层逐层向前传递, 网络的权重根据残差计算的梯度进行更新:
$ \begin{equation} w_{l}^{k+1}\leftarrow w_{l}^{k}-\gamma \frac{\partial E}{\partial w_{l}^{k}} \end{equation} $
(11) 式中, $w_{l}^{k+1}$是更新后的权重, $\gamma$是学习率.但是, 对于量化模型来说, 对式(8)或式(9)中指示函数$I(w)$进行求导会导致得到的梯度为0, 无法更新参数.需采用STE (Straight-through estimator)方法[33]来处理:
$ \begin{equation} \begin{split} &\mbox{前向过程:}\ q\sim {\rm Bernoulli}(p)\\ &\mbox{反向过程:}\ \frac{\partial E}{\partial p}=\frac{\partial E}{\partial q} \end{split} \end{equation} $
(12) 其中, $q$是二项分布函数, $p\in [0, 1]$的概率.根据$STE$的处理方法, 在反向求导的过程中, 我们可以这样处理模型中的权重$w_{l}^{k}$:
$ \begin{equation} \frac{\partial E}{\partial w_{l}^{k}}=\frac{\partial E} {\partial \hat{w}_{l}^{k}} \end{equation} $
(13) 因此在进行反向传播过程时, 式(11)可以写成:
$ \begin{equation} w_{l}^{k+1}\leftarrow {w}_{l}^{k}-\gamma \frac{\partial E}{\partial\hat{w}_{l}^{k}} \end{equation} $
(14) 采用动态量化编码的方式对深度神经网络压缩, 使得网络的权重在一个动态更新的范围量化.与静态量化的码表相比, 动态量化后的权重与模型最新更新的权重之间误差更小.另外, 由于动态更新的码本在训练过程会随着网络的训练误差而间接更新, 所以动态更新码本的方法无需一个预训练的模型作为初始化也能最终使模型收敛.
3. 实验与分析
为了验证本文方法的有效性, 我们在标准数据集MNIST[34]、CIFAR-10[35]上进行了实验.其中, MNIST数据集是一个手写字符数据集, 大小为$28\times 28$的单通道图像, 包含训练集60 000张, 测试集为10 000张; CIFAR-10是一个图像分类数据集, 所有的图像都是大小为$32\times 32$的三通道彩色图像, 包含60 000张图片, 其中训练集为50 000, 验证集为10 000.
3.1 MNIST实验设置
在MNIST数据集上, 先使用LeNet[35]在不同的损失函数下训练全精度32位的模型.在压缩过程中, 使用预训练的全精度模型作为压缩模型的初始化.使用的三种损失函数为Softmax-loss、Softmax-loss加上L1正则项、Softmax-loss加上L2正则项, 分别对应码本中有无0两种情况, 实验过程中正则项系数为0.001, 具体实验结果如下:
通过表 1~表 3可以看到, 无论在码本中是否引入0, 本文的方法均能有效地对网络进行压缩.同时还可以看到, 在损失函数中引入L2正则项有比较好的结果, 因此在后续的实验中只使用Softmax-loss加上L2正则项作为损失函数.
表 1 LeNet在Softmax-loss下量化效果Table 1 Quantization performance of LeNet under Softmax-loss位宽 码本无0 码本有0 3 99.29 % 99.22 % 4 99.30 % 99.25 % 5 99.35 % 99.32 % 表 2 LeNet在Softmax-loss+L1下量化效果Table 2 Quantization performance of LeNet under Softmax-loss and L1位宽 码本无0 码本有0 3 98.69 % 99.25 % 4 99.09 % 99.25 % 5 99.14 % 99.27 % 表 3 LeNet在Softmax-loss+L2下量化效果Table 3 Quantization performance of LeNet under Softmax-loss and L2位宽 码本无0 码本有0 3 99.26 % 99.29 % 4 99.29 % 99.28 % 5 99.36 % 99.28 % 3.2 CIFAR-10实验设置
为了清晰地看到压缩前和压缩后的变化, 我们先使用不同深度的ResNet训练了全精度32位的模型.在压缩过程中, 为了尽量避免初始化不同对最终实验结果的影响, 以及加快量化模型的训练收敛速度, 均使用预训练好的32位模型作为量化模型的初始化.在预训练和量化压缩过程中, 数据预处理都使用了数据增强的方法, 在原32 $\times $ 32的图像边界上填补0扩充为36 $\times $ 36的图像, 再随机的裁剪为32 $\times $ 32的图像, 然后随机左右翻转.在训练过程中, 都迭代了80 000轮, 每轮送进网络一个批次的数据是128, 初始的学习率为0.1, 当训练达到40 000次学习率为0.01, 达到60 000次之后学习率为0.001, 训练中使用正则项, 其权值系数设置为0.001.
3.2.1 对比不同码本的性能
本文在第3.1节引入了两种码本, 在量化同样的位数下, 一种在码本中引入了0另外一种没有.将0作为量化值引入码表, 会使滤波器产生大量的稀疏矩阵, 这会在一定程度抑制过拟合.但由于0不能表示为2的$n$ (为整数)次幂这种形式, 需要额外的一个比特来表示, 会影响码表的丰富性.为了说明这两种量化的差别, 我们做了如下实验:
从表 4~7中可以看到, 两种量化方式均能有效压缩深度神经网络.当量化位数一定时, 网络越深量化效果越好:当网络深度一定时, 量化位数越大量化效果越好.特别在量化位数较大且网络较深时, 采用这种动态量化编码的方法, 甚至可以提升网络的性能.
表 4 ResNet-20在不同码本下量化效果Table 4 Quantization performance of ResNet-20 under different codebook位宽 码本无0 码本有0 3 90.07 % 90.78 % 4 91.71 % 91.91 % 5 92.63 % 92.82 % 表 5 ResNet-32在不同码本下量化效果Table 5 Quantization performance of ResNet-32 under different codebook位宽 码本无0 码本有0 3 91.44 % 92.11 % 4 92.53 % 92.36 % 5 92.87 % 92.33 % 表 6 ResNet-44在不同码本下量化效果Table 6 Quantization performance of ResNet-44 under different codebook位宽 码本无0 码本有0 3 92.68 % 92.53 % 4 93.14 % 93.37 % 5 93.28 % 93.14 % 表 7 ResNet-56在不同码本下量化效果Table 7 Quantization performance of ResNet-56 under different codebook位宽 码本无0 码本有0 3 92.72 % 92.69 % 4 93.54 % 93.39 % 5 93.21 % 93.24 % 3.2.2 对比静态量化编码(SQC)方法
本文使用的是动态的码本(Static quantitative coding, DQC), 每次迭代都会对码本进行更新.为了说明DQC的有效性, 我们比较了基于SQC和DQC的模型性能.其中, SQC方法与DQC方法不同的地方在于量化模型的训练过程中不对码本进行更新.基于SQC方法的实验结果如表 8, 通过表 8可以看到深度模型的网络结构越深, 量化的位数越大, 量化效果越好.
表 8 固定码本下量化效果Table 8 Quantization performance of SQC网络 3 bits码本 3bits码本 3 bits码本 3 bits码本 3 bits码本 3 bits码本 SQC无0 SQC有0 SQC无0 SQC有0 SQC无0 SQC有0 ResNet-20 92.72 % 92.69 % 92.72 % 92.69 % 92.72 % 92.69 % ResNet-32 93.54 % 93.39 % 92.72 % 92.69 % 92.72 % 92.69 % ResNet-44 93.21 % 93.24 % 92.72 % 92.69 % 92.72 % 92.69 % ResNet-56 93.21 % 93.24 % 92.72 % 92.69 % 92.72 % 92.69 % 为了更加清楚地显示SQC和DQC两种方法训练得到模型性能的差异, 我们将静态码表的结果减去动态码表的结果, 具体结果如图 3和图 4所示.
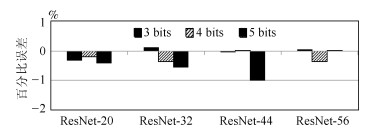 图 3 码本中无0, SQC和DQC的量化比较Fig. 3 Quantization performance of SQC and DQC with 0 in codebook
图 3 码本中无0, SQC和DQC的量化比较Fig. 3 Quantization performance of SQC and DQC with 0 in codebook 图 4 码本中有0, SQC和DQC的量化效果比较Fig. 4 Quantization performance of SQC and DQC without 0 in codebook
图 4 码本中有0, SQC和DQC的量化效果比较Fig. 4 Quantization performance of SQC and DQC without 0 in codebook从图 3和图 4中可以看到, 除了个别情况, 绝大数情况动态变化的码本比固定码本对深度神经网络的压缩效果更好, 特别是在网络较浅时, 动态量化编码的效果比静态量化的效果更加明显.在使用动态更新的码本方法时, 码本随着权重的更新而更新, 深度神经网络的权重在新的码本内量化, 这会在一定程度上减小由于量化造成的误差; 而固定的码本只与预训练的权重有关系, 量化得到的模型权重与预训练模型中权重误差较小.显然, 采用动态量化编码的方式, 能更好的减小由于量化造成的影响.
3.3 对比现有方法
本文与Deep compression[9]做了对比, 由于文献[9]是对网络进行了剪枝之后再进行量化.为了对比的公平性, 我们在此处做了和文献[9]同样的处理, 使用的数据集是MNIST, 将LeNet第一个卷积层66 %的小权重置为0, 第二个卷积层12 %较小权重置为0, 第一个全连接层8 %的小权重置为0, 第二个全连接层19 %的小权重置为0.对于这些置为0的权重, 在更新过程中不进行求导运算.此处本文的方法码本中没有引入0, 具体实验结果如下:
从表 9可以看到, 在相同条件下, 我们的方法有一定的优势.
表 9 Deep compression与DQC的实验比较Table 9 Comparison of deep compression and DQC压缩方法 位宽 准确率 Deep compression 5 99.20 % DQC 5 99.70 % 为了进一步说明我们的方法, 本文与INQ[15]的结果做了比较.这里主为了实验的客观性, 只与INQ做了对比实验, 由于本文的量化方法与INQ相近, 都是将权重量化为2的$n~(n$为整数)次幂这种形式, 从而在对比实验时避免编码形式的影响.我们使用相同的数据、初始网络结构, 压缩到同样的位数, INQ使用4个步骤进行量化, 每次量化比例: 0.50, 0.75, 0.85, 1.00, 两种方法均量化5 bits, 结果如下:
从表 10可知, 无论网络的层数多深, 码本中是否引入0, 使用动态量化编码的结果均优于INQ的方法, 进一步说明了我们方法的有效性.
表 10 量化为5 bits时INQ和DQC在CIFAR-10上的准确率比较Table 10 Compare the accuracy of INQ and DQC on CIFAR-10 with 5 bits网络 INQ DQC码本无0 DQC码本有0 ResNet-20 91.01 % 92.63 % 92.82 % ResNet-32 91.78 % 92.87 % 92.33 % ResNet-44 92.30 % 93.28 % 93.14 % ResNet-56 92.29 % 93.21 % 93.24 % 4. 总结与展望
本文提出了一种基于动态量化编码的深度神经网络压缩方法.为了方便在嵌入式系统采用移位操作, 本文对网络中的权值采用指数量化编码, 通过理论推导得出, 将模型量化为指数形式时, 绝对值较大权值参数的量化对模型引起的误差也越大.为此, 本文采用动态量化编码, 在反向传播更新网络权值后, 对码本进行更新以自适应模型中的绝对值较大的权值参数, 减小这些参数的量化对模型精度的影响.本文还讨论了静态和动态两种不同码本进行编码时压缩模型的性能.通过实验表明, 深度神经网络越深, 压缩位数越大, 压缩效果越好; 动态量化编码的方法优于静态量化的方法; 本文方法在网络压缩10.67倍时准确率还有提升.虽然本文为了说明动态量化的优越性能, 使用不同深度和量化位宽对深度神经网络压缩进行了大量实验, 但目前只对小数据集进行实验, 后续将在更大的数据集上进行实验.
-

图 7 轴承1_1时域振动信号及归一化后的频域幅值谱
Fig. 7 The time domain vibration signal and normalized amplitude spectrum of the bearing1_1

图 9 本文方法预测轴承1_7的当前p值
Fig. 9 The current p value of bearing 1_7 predicted by the proposed method

图 10 本文方法对轴承1_7的RUL预测结果
Fig. 10 RUL prediction result of bearing 1_7 by the proposed method

图 11 特征提取所消耗时间的对比(PHM2012轴承数据集)
Fig. 11 Comparison of the time consuming of feature extraction (PHM2012 bearing datasets)

图 12 3种方案对轴承1_7的RUL预测结果
Fig. 12 RUL prediction results of bearing 1_7 by three schemes

图 13 特征提取所消耗时间的对比(XJTU-SY轴承数据集)
Fig. 13 Comparison of the time consuming of feature extraction (XJTU-SY bearing datasets)
表 1 实验数据(PHM2012轴承数据集)
Table 1 Experimental data (PHM2012 bearing datasets)
数据集划分 不同轴承 非全寿数据 (组) 全寿数据 (组) 训练集 1_1 — 2803 1_2 — 871 2_1 — 911 2_2 — 797 3_1 — 515 3_2 — 1637 测试集 1_3 1802 2375 1_4 1139 1428 1_5 2302 2463 1_6 2302 2448 1_7 1502 2259 2_3 1202 1955 2_4 612 751 2_5 2002 2311 2_6 572 701 2_7 172 230 3_3 352 434  下载: 导出CSV
下载: 导出CSV
表 2 3种优化算法的训练误差
Table 2 Training error of three optimization algorithms
不同优化算法 Adam RMSProp SGDM MSE 0.0008 0.0011 0.0009 MAE 0.0450 0.0794 0.0485 MAPE 0.2292 0.3302 0.3394 MSPE 0.0183 0.0213 0.0406 RMSE 0.0624 0.0985 0.0651 误差之和 0.3557 0.5304 0.4945
下载: 导出CSV
表 3 本文预测方法与其他3种方案的构成
Table 3 The composition of the proposed prediction method and other three schemes
预测方法 特征提取模型 预测模型 本文方法 改进 SAE Bi-LSTM 方案 1 SAE Bi-LSTM 方案 2 改进 SAE LSTM 方案 3 SAE LSTM
下载: 导出CSV
表 4 不同轴承RUL预测误差结果对比(PHM2012轴承数据集) (%)
Table 4 Comparison of RUL prediction results of different bearings (PHM2012 bearing datasets) (%)
不同轴承 本文方法 方案 1 方案 2 方案 3 文献[20] 文献[21] 1_3 8.03 0.52 0.70 −6.98 43.28 −31.76 1_4 −8.30 0.70 −3.81 2.42 67.55 62.76 1_5 −44.72 −26.09 −45.34 −110.56 −22.98 −136.03 1_6 −2.74 −23.29 21.92 −13.70 21.23 −32.88 1_7 −3.04 7.13 −9.51 −33.03 17.83 −11.09 2_3 −4.12 −20.85 −15.94 −1.73 37.84 44.22 2_4 0.72 −3.60 −0.72 −27.30 −19.42 −55.40 2_5 −6.15 16.83 −38.51 12.62 54.37 68.61 2_6 3.10 −37.21 −13.95 −6.20 −13.95 −51.94 2_7 1.72 −1.72 5.17 −1.72 −55.17 −68.97 3_3 −15.85 2.44 2.44 17.07 3.66 −21.96 平均误差 −6.49 −7.74 −9.81 −15.37 32.48 53.24 平均得分 0.576 0.522 0.477 0.425 0.263 0.065
下载: 导出CSV
表 5 实验数据(XJTU-SY轴承数据集)
Table 5 Experimental data (XJTU-SY bearing datasets)
数据集划分 不同轴承 非全寿数据 (组) 全寿数据 (组) 训练集 1_1 — 123 1_2 — 161 2_1 — 491 2_2 — 161 3_1 — 2538 3_2 — 2496 测试集 1_3 126 158 1_4 98 122 1_5 42 52 2_3 426 533 2_4 34 42 2_5 271 339 3_3 297 371 3_4 1212 1515 3_5 91 114
下载: 导出CSV
表 6 不同轴承 RUL 预测误差结果对比(XJTU-SY 轴承数据集) (%)
Table 6 Comparison of RUL prediction results of different bearings (XJTU-SY bearing datasets) (%)
不同轴承 本文方法 方案 1 方案 2 方案 3 1_3 15.63 21.88 12.50 18.75 1_4 8.33 −8.33 −4.17 20.83 1_5 −10.00 −30.00 20.00 −10.00 2_3 −24.30 −21.78 15.89 −23.36 2_4 −12.50 −25.00 −25.00 −12.50 2_5 10.29 27.94 14.71 22.06 3_3 31.08 23.78 17.57 22.97 3_4 −18.25 5.83 −50.83 −36.96 3_5 4.35 −26.09 −8.70 −39.13 平均误差 0.51 −3.53 −0.89 −4.15 平均得分 0.419 0.282 0.418 0.267
下载: 导出CSV
-
[1] 刘建昌, 权贺, 于霞, 何侃, 李镇华. 基于参数优化VMD和样本熵的滚动轴承故障诊断. 自动化学报, 2022, 48(3): 808−819 doi: 10.16383/j.aas.190345Liu Jian-Chang, Quan He, Yu Xia, He Kan, Li Zhen-Hua. Rolling bearing fault diagnosis based on parameter optimization VMD and sample entropy. Acta Automatica Sinica, 2022, 48(3): 808−81 doi: 10.16383/j.aas.190345 [2] 张正新, 胡昌华, 司小胜, 张伟. 双时间尺度下的设备随机退化建模与剩余寿命预测方法. 自动化学报, 2017, 43(10): 1789-1798Zhang Zheng-Xin, Hu Chang-Hua, Si Xiao-Sheng, Zhang Wei. Degradation modeling and remaining useful life prediction with bivariate time scale. Acta Automatica Sinica, 2017, 43(10): 1789-1798 [3] 赵光权, 刘小勇, 姜泽东, 胡聪. 基于深度学习的轴承健康因子无监督构建方法. 仪器仪表学报, 2018, 39(6): 82-88Zhao Guang-Quan, Liu Xiao-Yong, Jiang Ze-Dong, Hu Cong. Unsupervised health indicator of bearing based on deep learning. Chinese Journal of Scientific Instrument, 2018, 39(6): 82-88 [4] 杨宇, 张娜, 程军圣. 全参数动态学习深度信念网络在滚动轴承寿命预测中的应用. 振动与冲击, 2019, 38(10): 199-205+249Yang Yu, Zhang Na, Cheng Jun-Sheng. Global parameters dynamic learning deep belief networks and its application in rolling bearing life prediction. Journal of Vibration and Shock, 2019, 38(10): 199-205+249 [5] Hinchi A Z, Tkiouat M. Rolling element bearing remaining useful life estimation based on a convolutional long-short-term memory network. Procedia Computer Science, 2018, 127: 123-132 doi: 10.1016/j.procs.2018.01.106 [6] Li X, Zhang W, Ding Q. Deep learning-based remaining useful life estimation of bearings using multi-scale feature extraction. Reliability Engineering and System Safety, 2019, 182: 208-218 doi: 10.1016/j.ress.2018.11.011 [7] Cheriyadat A M. Unsupervised feature learning for aerial scene classification. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(1): 439-451 doi: 10.1109/TGRS.2013.2241444 [8] 孙文珺, 邵思羽, 严如强. 基于稀疏自动编码深度神经网络的感应电动机故障诊断. 机械工程学报, 2016, 52(9): 65-71 doi: 10.3901/JME.2016.09.065Sun Weng-Jun, Shao Si-Yu, Yan Ru-Qiang. Induction motor fault diagnosis based on deep neural network of sparse auto-encoder. Journal of Mechanical Engineering, 2016, 52(9): 65-71 doi: 10.3901/JME.2016.09.065 [9] 陈宇, 温欣玲, 刘兆瑜, 马鹏阁. 稀疏自动编码器视觉特征融合的多弹分类算法研究. 红外与激光工程, 2018, 47(8): 386-393Chen Yu, Wen Xin-Ling, Liu Zhao-Yu, Ma Peng-Ge. Research of multi-missile classification algorithm based on sparse auto-encoder visual feature fusion. Infrared and Laser Engineering, 2018, 47(8): 386-393 [10] 朱宵珣, 周沛, 苑一鸣, 徐博超, 韩中合. 基于KL-HVD的转子振动故障诊断方法研究. 振动与冲击, 2018, 37(16): 250-255Zhu Xiao-Xun, Zhou Pei, Yuan Yi-Ming, Xu Bo-Chao, Han Zhong-He. A study on the method of rotor vibration fault diagnosis based on KL-HVD. Journal of Vibration and Shock, 2018, 37(16): 250-255 [11] Wang S X, Wang X, Wang S M, Wang D. Bi-directional long short-term memory method based on attention mechanism and rolling update for short-term load forecasting. Electrical Power and Energy Systems, 2019, 109: 470-479 doi: 10.1016/j.ijepes.2019.02.022 [12] Bin Y, Yang Y, Shen F M, Xie N, Shen H T, Li X L. Describing video with attention-based bidirectional LSTM. IEEE Transactions on Cybernetics, 2019, 49(7): 2631-2641 doi: 10.1109/TCYB.2018.2831447 [13] 刘国梁, 余建波. 知识堆叠降噪自编码器. 自动化学报, 2022, 48(3): 774−786 doi: 10.16383/j.aas.c190375Liu Guo-Liang, Yu Jian-Bo. Knowledge-based stacked denoising Autoencoder. Acta Automatica Sinica, 2022, 48(3): 774−786 doi: 10.16383/j.aas.c190375 [14] Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 2014, 15: 1929-1958 [15] Wu S, Gebraeel N, Lawley M A. A neural network integrated decision support system for condition-based optimal predictive maintenance policy. IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, 2007, 37(2): 226-236. doi: 10.1109/TSMCA.2006.886368 [16] 史加荣, 王丹, 尚凡华, 张鹤于. 随机梯度下降算法研究进展. 自动化学报, 2020: https://doi.org/10.16383/j.aas.c190260 doi: 10.16383/j.aas.c190260Shi Jia-Rong, Wang Dan, Shang Fan-Hua, Zhang He-Yu. Research advances on stochastic gradient descent algorithms. Acta Automatica Sinica, 2020: https://doi.org/10.16383/j.aas.c190260 doi: 10.16383/j.aas.c190260 [17] Nectoux P, Gouriveau R, Medjaher K, Ramasso E, Morello B, Zerhouni N, et al. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In: Proceedings of the Conference on Prognostics and Health Management. Denver, Colorado, USA: IEEE, 2012. 1−8 [18] 石晓辉, 阳新华, 张向奎, 李文礼. 改进的形态差值滤波器在滚动轴承故障诊断中的应用. 重庆理工大学学报(自然科学), 2018, 32(1): 1-6Shi Xiao-Hui, Yang Xin-Hua, Zhang Xiang-Kui, Li Weng-Li. Application of improved morphological difference filter in fault diagnosis of rolling bearings. Journal of Chongqing University of Technology(Natural Science), 2018, 32(1): 1-6 [19] Singleton R K, Strangas E G, Aviyente S. Extended kalman filtering for remaining-useful-life estimation of bearings. IEEE Transactions on Industrial Electronics, 2015, 62(3): 1781-1790 doi: 10.1109/TIE.2014.2336616 [20] Guo L, Li N P, Jia F, Lei Y G, Lin J. A recurrent neural network based health indicator for remaining useful life prediction of bearings. Neurocomputing, 2017, 240: 98-109 doi: 10.1016/j.neucom.2017.02.045 [21] Sheng H, Zheng Z, Enrico Z, Kan H. Condition assessment for the performance degradation of bearing based on a combinatorial feature extraction method. Digital Signal Processing, 2014, 27: 159-166 doi: 10.1016/j.dsp.2013.12.010 [22] 雷亚国, 韩天宇, 王彪, 李乃鹏, 闫涛, 杨军. XJTU-SY滚动轴承加速寿命试验数据集解读. 机械工程学报, 2019, 55(16): 1-6 doi: 10.3901/JME.2019.16.001Lei Yang-Guo, Han Tian-Yu, Wang Biao, Li Nai-Peng, Yan Tao, Yang Jun. XJTU-SY rolling element bearing accelerated life test datasets: a tutorial. Journal of Mechanical Engineering, 2019, 55(16): 1-6 doi: 10.3901/JME.2019.16.001 期刊类型引用(26)
1. 朱亮,李晓明,纪慧,楼一珊. 基于SAE和LSTM神经网络的深部未钻地层可钻性预测方法. 西安石油大学学报(自然科学版). 2025(01): 39-46+64 .  百度学术
百度学术2. 王思远,陈荣辉,顾凯,任密蜂,阎高伟. 基于SA-TCN的轴承短期故障预测方法. 太原理工大学学报. 2024(01): 214-222 . 百度学术3. 刘雨蒙,郑旭,田玲,王宏安. 基于时序图推理的设备剩余使用寿命预测. 自动化学报. 2024(01): 76-88 . 本站查看4. 李家豪,王青于,范玥霖,史石峰,彭宗仁,曹培,徐鹏. 鲸鱼优化算法-双向长短期记忆神经网络用于断路器机械剩余寿命的预测研究. 高电压技术. 2024(01): 250-262 . 百度学术5. 刘康宁,徐遵义,李晨,闫春相. 基于NLMS和Autoformer的滚动轴承RUL预测. 计算机技术与发展. 2024(03): 177-184 . 百度学术6. 毕金茂,张朋,张洁,赵春财,崔利. 不完备数据下的聚酯熔体特性黏度预测方法. 上海交通大学学报. 2024(04): 534-544 . 百度学术7. 张翠翠,刘竹. 基于深度学习的电气控制系统故障诊断与容错技术. 自动化应用. 2024(08): 35-37 . 百度学术8. 秦娅,马军,熊新,朱江艳. 基于形态波动一致性偏移距离的滚动轴承剩余寿命预测方法. 电子测量与仪器学报. 2024(03): 32-44 . 百度学术9. 曹洁,陈泽阳,王进花. Multi-GAT:基于多度量衡构建图的故障诊断方法. 控制理论与应用. 2024(05): 931-940 . 百度学术10. 丁国荣,王文波,赵姣姣. 基于KPCA-PSO-LSSVM的轴承寿命预测研究. 计算机与数字工程. 2024(03): 945-949 . 百度学术11. 刘静涛,邱明,李军星,刘志卫,高锐. 数据缺失下SGAIN融合TCN预测滚动轴承剩余寿命. 兵器装备工程学报. 2024(08): 240-247 . 百度学术12. 刘小峰,亢莹莹,柏林. 轴承自驱式独立退化轨迹构建与剩余寿命灰色预测. 中国机械工程. 2024(09): 1613-1621+1652 . 百度学术13. 谷妙春. 基于噪声统计的EMD-LSTM网络流量预测方法. 计算机测量与控制. 2023(02): 21-27 . 百度学术14. 杨智杰,王刚,赵瑞杰,王春洁,赵军鹏. 火星进入舱配平翼机构展开冲击动力学分析. 北京航空航天大学学报. 2023(02): 422-429 . 百度学术15. 周哲韬,刘路,宋晓,陈凯. 基于Transformer模型的滚动轴承剩余使用寿命预测方法. 北京航空航天大学学报. 2023(02): 430-443 . 百度学术16. 张荣升,吴燕生,秦旭东,张普卓. 基于深度学习的高空风在线估计及预报方法. 航空学报. 2023(13): 164-179 . 百度学术17. 赵志宏,张然,孙诗胜. 基于关系网络的轴承剩余使用寿命预测方法. 自动化学报. 2023(07): 1549-1557 . 本站查看18. 陈东楠,胡昌华,郑建飞,裴洪,张建勋,庞哲楠. 状态划分下基于Bi-LSTM-Att的轴承剩余寿命预测. 空间控制技术与应用. 2023(04): 29-39 . 百度学术19. 曹正志,叶春明. 考虑转动周期的轴承剩余使用寿命预测. 计算机集成制造系统. 2023(08): 2743-2750 . 百度学术20. 薛林,王豪,王云森,陆尧,何群,张德健. 基于Autoformer的滚动轴承剩余使用寿命预测. 电子测量技术. 2023(13): 169-175 . 百度学术21. 康守强,邢颖怡,王玉静,王庆岩,谢金宝,MIKULOVICH Vladimir Ivanovich. 基于无监督深度模型迁移的滚动轴承寿命预测方法. 自动化学报. 2023(12): 2627-2638 . 本站查看22. 郑建飞,牟含笑,胡昌华,赵瑞星,张博玮. 考虑多性能指标相关性的退化设备剩余寿命预测. 哈尔滨工程大学学报. 2022(05): 620-629 . 百度学术23. 牟含笑,郑建飞,胡昌华,赵瑞星,董青. 基于CDBN与BiLSTM的多元退化设备剩余寿命预测. 航空学报. 2022(07): 308-319 . 百度学术24. 严帅,熊新. 基于KPCA和TCN-Attention的滚动轴承退化趋势预测. 电子测量技术. 2022(15): 28-34 . 百度学术25. 郭浩雨,冯秀芳. 基于Bi-LSTM的CSI手势识别算法. 计算机工程与设计. 2022(09): 2614-2621 . 百度学术26. 郭晓静,殷宇萱,贠玉晶. 基于改进LSTM的航空发动机寿命预测方法研究. 机床与液压. 2022(20): 185-193 . 百度学术其他类型引用(51)
-

 下载:
下载:








计量
- 文章访问数: 1179
- HTML全文浏览量: 374
- PDF下载量: 313
- 被引次数: 77
