

Generative Knowledge Question Answering Technology Based on Global Coverage Mechanism and Representation Learning
-
摘要: 针对现有生成式问答模型中陌生词汇导致答案准确率低下的问题和模式混乱导致的词汇重复问题, 本文提出引入知识表示学习结果的方法提高模型识别陌生词汇的能力, 提高模型准确率. 同时本文提出使用全局覆盖机制以平衡不同模式答案生成的概率, 减少由预测模式混乱导致的重复输出问题, 提高答案的质量. 本文在知识问答模型基础上结合知识表示学习的推理结果, 使模型具备模糊回答的能力. 在合成数据集和现实世界数据集上的实验证明了本模型能够有效地提高生成答案的质量, 能对推理知识进行模糊回答.Abstract: Aiming at the problem of low answer accuracy caused by unfamiliar words in the existing generative question answering model and the problem of vocabulary repetition caused by pattern confusion, this paper proposes a method of introducing knowledge representation learning results to improve the model's ability to recognize unfamiliar words and improve the accuracy of the model. At the same time, this paper proposes to use a global coverage mechanism to balance the probability of answer generation in different modes, reduce the repeated output problem caused by the confusion of prediction modes, and improve the quality of the answer. Based on the knowledge question answering model, this paper combines the inference results of knowledge representation learning, so that the model has the ability to answer fuzzy answers. Experiments on synthetic datasets and real-world datasets demonstrate that this model can effectively improve the quality of generated answers and can provide fuzzy answers to reasoning knowledge.
-

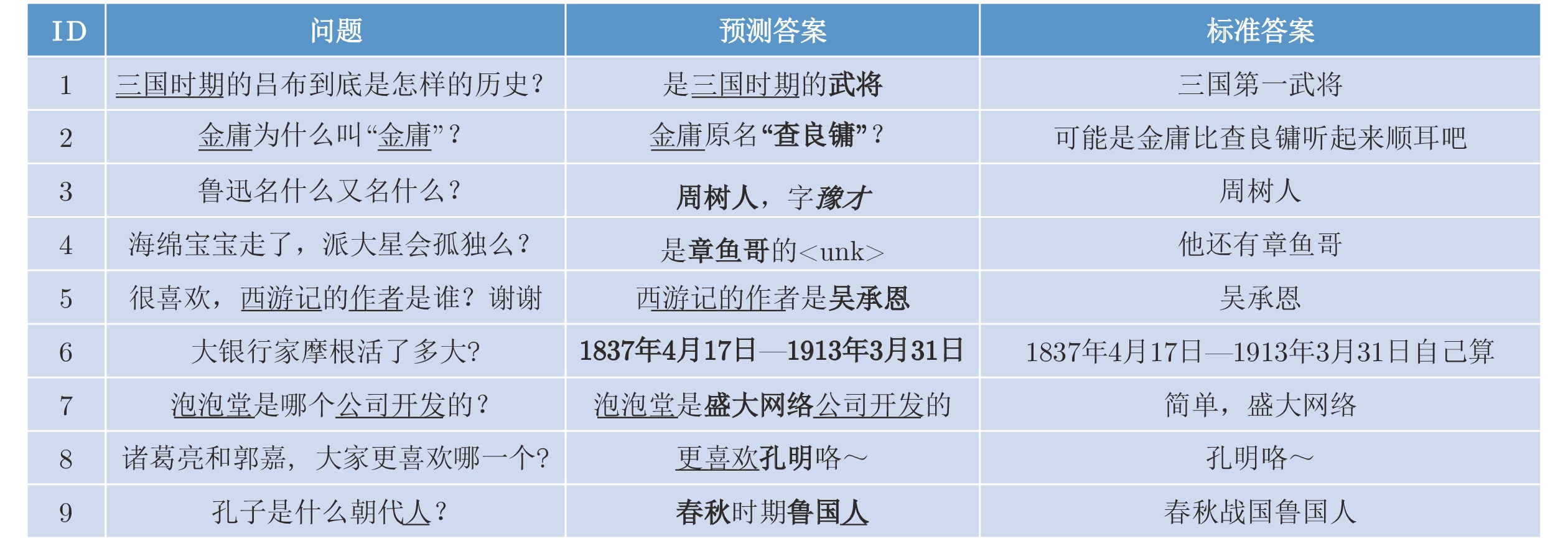
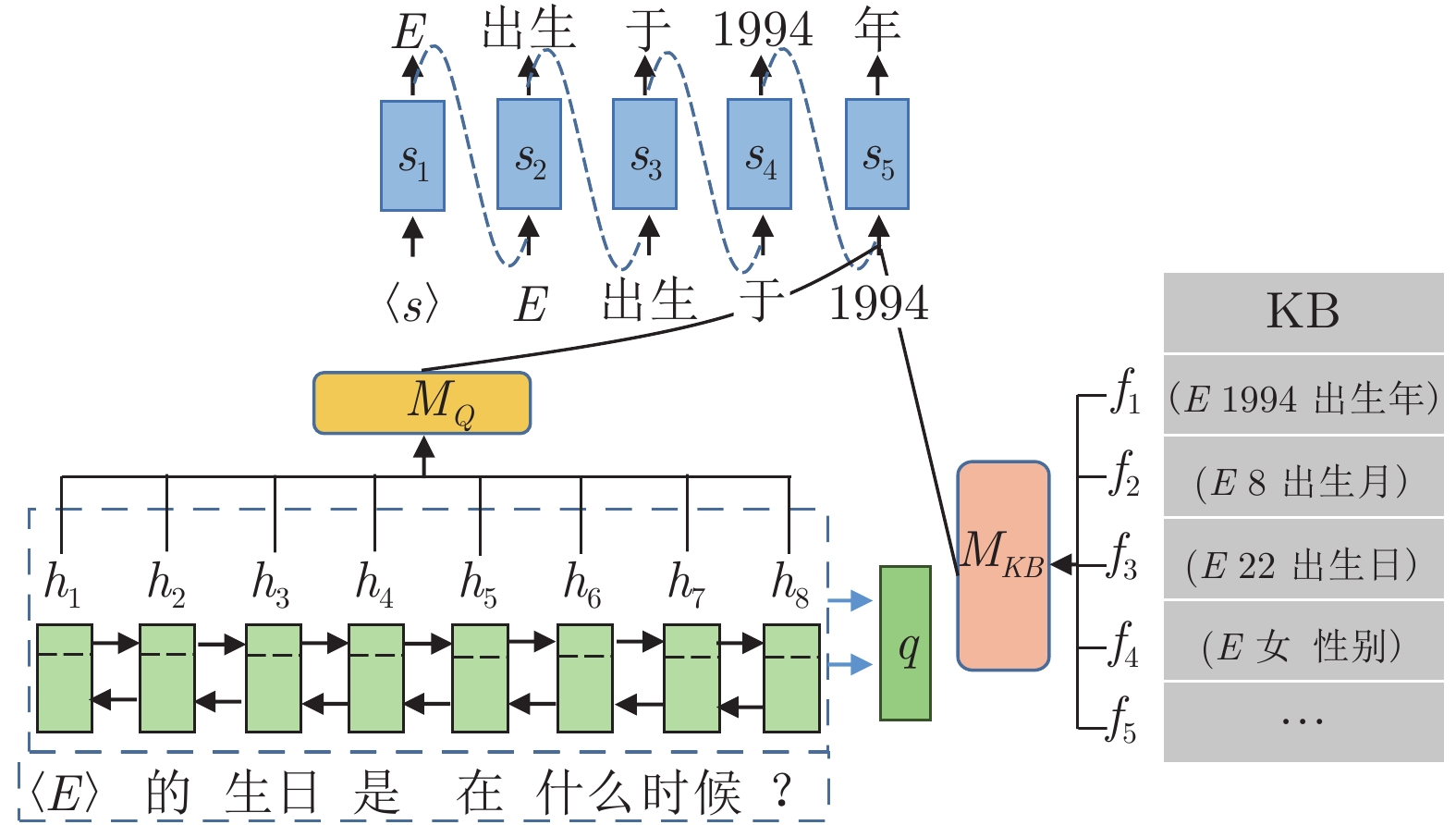
图 4 MCQA (TE, CE)与CoreQA 答案对比样例
Fig. 4 The comparison of MCQA (TE, CE) and CoreQA sample outputs
表 1 问答数据集规模
Table 1 The size of QA datasets
数据集 问答对数量 关系数量 SimpleQuestions 101 754 1 631 生日问答数据集 239 922 5 社区问答数据集 505 021 4 011  下载: 导出CSV
下载: 导出CSV
表 3 生日数据集实验结果 (%)
Table 3 The experimental results of birthday datasets (%)
方法 $ {{P}_{g}} $ $ {{P}_{y}} $ $ {{P}_{m}} $ $ {{P}_{d}} $ $ {{P}_{r}} $ Seq2Seq 67.3 — 23.4 — 37.2 NMT 71.6 — 27.1 — 54.7 CopyNet 75.2 — — — 71.9 GenQA (本文) 73.4 63.2 65.8 77.1 62.6 CoreQA 75.6 84.8 93.4 81 80.3 MCQA (WE, CE) 89.8 89.1 98.4 93.2 84.1 MCQA (TE, CE) 88.6 89.4 98.7 93.6 84.6
下载: 导出CSV
表 4 社区问答实验结果 (%)
Table 4 The experimental results of community QA datasets (%)
方法 正确性 流畅性 一致性 CopyNet — 19.4 21.3 GenQA (本文) 24.3 38.3 24.1 CoreQA 49.3 51.8 62.5 MCQA (WE, CE) 52.3 55.8 65.2 MCQA (TE, CE) 54.1 56.3 65.0
下载: 导出CSV
表 5 模糊问答推理结果 (%)
Table 5 The prediction results of ambiguously QA (%)
方法 $ {{P}_{y}} $ $ {{P}_{m}} $ $ {{P}_{d}} $ PTransE 93.2 97.4 95.0
下载: 导出CSV
表 6 模糊问答结果 (%)
Table 6 The results of ambiguously QA (%)
方法 $ {{F1}_{t}} $ $ {{P}_{y}} $ $ {{P}_{m}} $ $ {{P}_{d}} $ $ {{P}_{r}} $ MCQA (WE, CE) 87.7 78.1 88.2 90.8 80.9
下载: 导出CSV
-
[1] Vanessa L, Victoria U, Marta S, Enrico M. Is question answering fit for the semantic web?: A survey. Semantic Web, 2011, 2(2): 125-155 doi: 10.3233/SW-2011-0041 [2] Sydorova A, Poerner N, Roth B. Interpretable question answering on knowledge bases and text. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 4943−4951 [3] Cho K, Merriënboer B V, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: Association for Computational Linguistics, 2014. 1724−1734 [4] Gu J T, Lu Z D, Li H, Li V O K. Incorporating copying mechanism in sequence-to-sequence learning. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: the Association for Computational Linguistics, 2016. 1631−1640 [5] Gulcehre C, Ahn S, Nallapati R, Zhou B W, Bengio Y. Pointing the unknown words. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: the Association for Computational Linguistics, 2016. 140−149 [6] He S Z, Liu C, Liu K, Zhao J. Generating natural answers by incorporating copying and retrieving mechanisms in sequence-to-sequence learning. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: the Association for Computational Linguistics, 2017. 199−208 [7] 刘康, 张元哲, 纪国良, 来斯惟, 赵军. 基于表示学习的知识库问答研究进展与展望. 自动化学报, 2016, 42(6): 807-818Liu Kang, Zhang Yuan-Zhe, Ji Guo-Liang, Lai Si-Wei, Zhao Jun. Representation learning for question answering over knowledge base: an overview. Acta Automatica Sinica, 2016, 42(6): 807-818 [8] Tang X, Chen L, Cui J, Wei B. Knowledge representation learning with entity descriptions, hierarchical types, and textual relations. Information Processing & Management, 2019, 56(3): 809-822 [9] Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space. arXiv: 1301.3781, 2013. [10] Unger C, Freitas A, Cimiano P. An introduction to question answering over linked data. In: Proceedings of Reasoning on the Web in the Big Data Era — the 10th International Summer School. Athens, Greece: IEEE, 2014. 100−140 [11] Bast H, Haussmann E. More accurate question answering on freebase. In: Proceedings of the 24th International Conference on Information and Knowledge Management. Melbourne, VIC, Australia: ACM, 2015. 1431−1440 [12] Bordes A, Chopra S, Weston J. Question answering with subgraph embeddings. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014. 615−620 [13] Yih W, Chang M W, He X D, Gao J F. Semantic parsing via staged query graph generation: Question answering with knowledge base. In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing. Beijing, China: ACL, 2015. 1321−1331 [14] Sun Y W, Zhang L L, Cheng G, Qu Y Z. Sparqa: Skeleton-based semantic parsing for complex questions over knowledge bases. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: arXiv: 2003.13956, 2020. [15] Xu K, Wu L F, Wang Z G, Yu M, Chen L W, Sheinin V. Exploiting rich syntactic information for semantic parsing with graph-to-sequence model. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: ACL, 2018. 918−924 [16] Miller A, Fisch A, Dodge J, Karimi A H, Weston J. Key-value memory networks for directly reading documents. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas, USA: ACL, 2016. 1400−1409 [17] Bordes A, Usunier N, Chopra S, Weston J. Large-scale simple question answering with memory networks. arXiv: 1506.02075. 2015. [18] Yin J, Jiang X, Lu Z D, Shang L F, Li H, Li X M. Neural generative question answering. In: Proceedings of the 25th International Joint Conference on Artificial Intelligence. New York, USA: IJCAI/AAAI, 2016. 2972−2978 [19] Liu C, He S Z, Liu K, Zhao J. Curriculum learning for natural answer generation. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden: IJCAI/AAAI, 2018. 4223−4229 [20] Wang T Z, Cai M, Li J X. A neural conversational model using MMI-WMD decoder based on the Seq2Seq with attention mechanism. In: Proceedings of the 2019 Chinese Control and Decision Conference (CCDC). Nanchang, China: IEEE, 2019. 2696−2700 [21] Sharma A, Contractor D, Kumar H, Joshi S. Neural conversational QA: Learning to reason vs exploiting patterns. arXiv: 1909.03759, 2019. [22] Lei W Q, Jin X, Kan M Y, Ren Z C, He X N, Yin D W. Sequicity: Simplifying task-oriented dialogue systems with single sequence-to-sequence architectures. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: ACL, 2018. 1437−1447 [23] Rashkin H, Smith E M, Li M, Boureau Y L. Towards empathetic open-domain conversation models: A new benchmark and dataset. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 5370−5381 [24] Lin Y K, Liu Z Y, Sun M S. Modeling relation paths for representation learning of knowledge bases. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal: ACL, 2015. 705−714 [25] Quan W, Mao Z D, Wang B, Li G. Knowledge graph embedding: A survey of approaches and applications. IEEE Transactions on Knowledge & Data Engineering, 2017, 29(12): 2724-2743 [26] Bordes A, Weston J, Usunier N. Open question answering with weakly supervised embedding models. In: Proceedings of the 2014 Machine Learning and Knowledge Discovery in Databases European Conference. Nancy, France: Springer, 2014. 165−180 [27] Bahdanau D, Cho K Y, Bengio Y. Neural machine translation by jointly learning to align and translate. Arxiv: 1409.0473, 2014 [28] 冯冲, 石戈, 郭宇航, 龚静, 黄河燕. 基于词向量语义分类的微博实体链接方法. 自动化学报, 2016, 42(6): 915-922Feng C, Shi G, Guo YH, Gong J, Huang HY. An entity linking method for microblog based on semantic categorization by word embeddings. Acta Autom. Sinica, 2016, 42(6): 915-922 [29] Yin W P, Yu M, Xiang B, Zhou B, Schutze H. Simple question answering by attentive convolutional neural network. ArXiv: 1606.03391, 2016. [30] Yu M, Yin W P, Hasan K S, Santos C D, Xiang B, Zhou B W. Improved neural relation detection for knowledge base question answering. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: ACL, 2017. 571−581 [31] Deng Y, Xie Y X, Li Y L, Yang M, Shen Y. Multi-task learning with multi-view attention for answer selection and knowledge base question answering. In: Proceedings of the 33rd Conference on Artificial Intelligence. Honolulu, Hawaii, USA: AAAI, 2019. 6318−6325 -

 下载:
下载:


计量
- 文章访问数: 847
- HTML全文浏览量: 338
- PDF下载量: 287
- 被引次数: 0
