

Generative Knowledge Question Answering Technology Based on Global Coverage Mechanism and Representation Learning
-
摘要: 针对现有生成式问答模型中陌生词汇导致答案准确率低下的问题和模式混乱导致的词汇重复问题, 本文提出引入知识表示学习结果的方法提高模型识别陌生词汇的能力, 提高模型准确率. 同时本文提出使用全局覆盖机制以平衡不同模式答案生成的概率, 减少由预测模式混乱导致的重复输出问题, 提高答案的质量. 本文在知识问答模型基础上结合知识表示学习的推理结果, 使模型具备模糊回答的能力. 在合成数据集和现实世界数据集上的实验证明了本模型能够有效地提高生成答案的质量, 能对推理知识进行模糊回答.Abstract: Aiming at the problem of low answer accuracy caused by unfamiliar words in the existing generative question answering model and the problem of vocabulary repetition caused by pattern confusion, this paper proposes a method of introducing knowledge representation learning results to improve the model's ability to recognize unfamiliar words and improve the accuracy of the model. At the same time, this paper proposes to use a global coverage mechanism to balance the probability of answer generation in different modes, reduce the repeated output problem caused by the confusion of prediction modes, and improve the quality of the answer. Based on the knowledge question answering model, this paper combines the inference results of knowledge representation learning, so that the model has the ability to answer fuzzy answers. Experiments on synthetic datasets and real-world datasets demonstrate that this model can effectively improve the quality of generated answers and can provide fuzzy answers to reasoning knowledge.
-
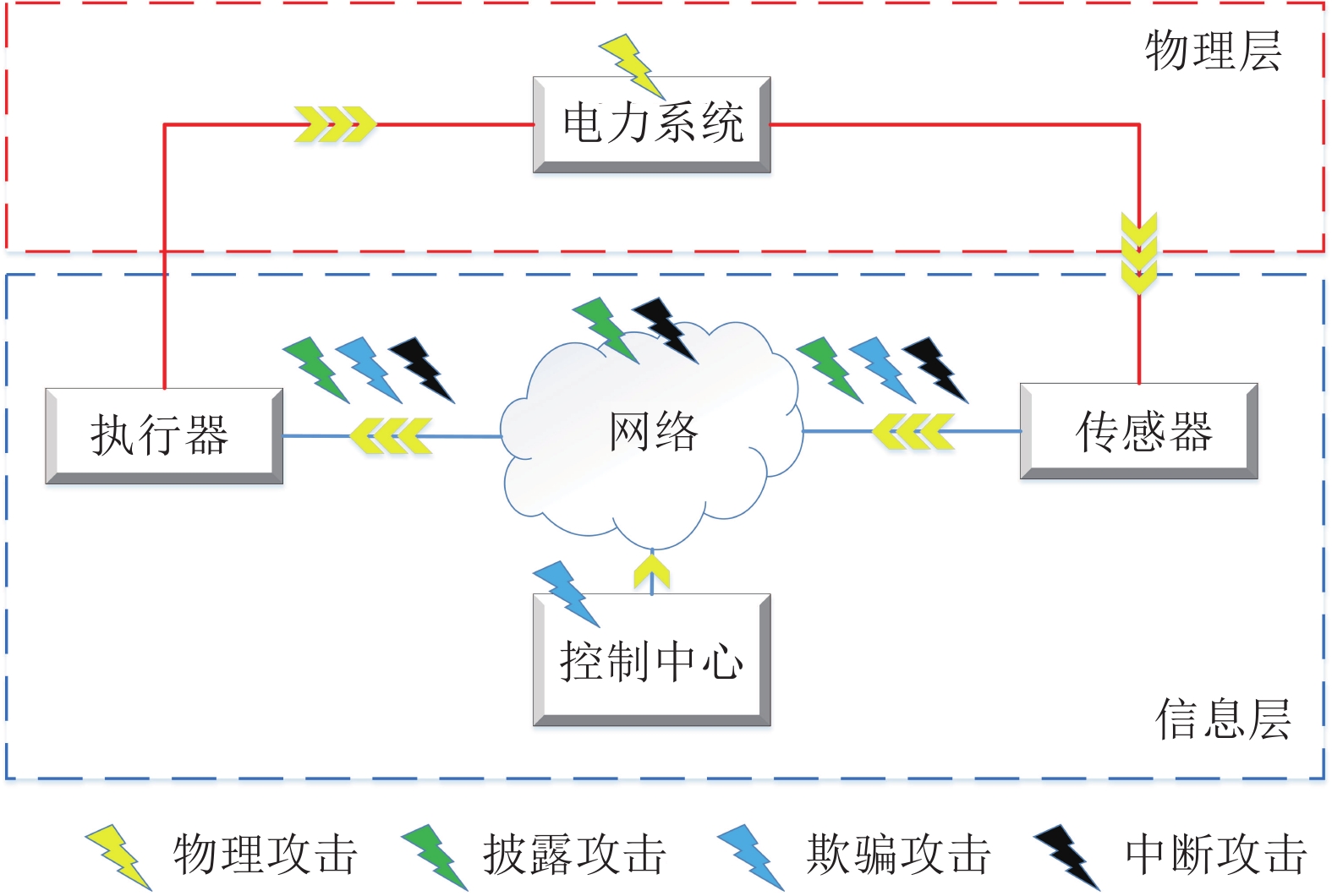
传统的电网是单向电力流网络, 缺乏信息流与电力流的信息交互. 即, 电机产生的电能通过变电、输电和配电等环节发送到负载端, 并没有形成反馈回路. 与传统的电力网络相比, 智能电网融合了先进的传感器技术、通信技术和计算机技术, 是一个典型的信息物理系统(Cyber physical system, CPS)[1-3]. 智能电网实现了信息流与电力流的双向交流, 并确保了系统更加安全、经济和高效运行. 然而, 信息物理的深度融合也使智能电网通信节点暴露, 容易遭受来自信息层的各种网络攻击. 因此, 如何确保智能电网的安全运行至关重要.
目前, 智能电网面临的攻击类型繁多且呈现出不断增长的态势. 如图1所示, 根据信息流在控制系统反馈回路中所处的核心作用, 将主要的攻击类型分为三类: 披露攻击、欺骗攻击和中断攻击[4]. 信息披露攻击[5]是指包括窃听在内的任何网络入侵行为. 欺骗攻击对应的是信号篡改与破坏, 其中虚假数据注入攻击(False data injection attack, FDIA) 最为典型[6-7]. 中断攻击对应于另一种信号可能被阻止或延迟的攻击, 如拒绝服务攻击[8]. 当前众多网络攻击之中, FDIA被认为是对安全系统操作最具挑战性的攻击[9]. 与其他攻击不同, 攻击者可以利用电网的有关信息和知识设计能够不被坏数据检测(Bad data detection, BDD)机制发现的FDIA. 因此, FDIA的隐蔽性对电力系统产生极大的威胁, 其可导致系统切负荷、线路过载、破坏电力市场等严重后果.
目前, 智能电网虚假数据注入攻击的防御研究已经成为当前研究热点. 孙凯祺等提出了一种基于攻击重组卷积神经网络的虚假数据注入攻击防御策略[10]. 刘鑫蕊等提出了一种基于SCADA和PMU混合量测的状态类空间隐蔽型恶性数据在线防御方法[11]. 为最小化系统遭受级联故障攻击时遭受的损失, Nguyen等提出了一种基于齐次等式的虚假数据注入攻击防御算法[12]. Zhang等提出了一种双利移动目标防御的防御策略以保护智能电网免受网络物理攻击[13]. 为了提高防御性能, Tian等提出了一种攻击者无法检测到的隐藏运动目标防御方法[14]. 为减少攻击对电网系统的破坏性, Xu等提出了一种基于滑模控制器的鲁棒自适应弹性防御方法[15]. 考虑攻击下电网结构的脆弱性, Hou等提出了一种基于自适应控制器的虚假数据注入攻击防御方法[16]. 考虑到FDIA的隐蔽特性和潜在威胁, Luo等提出了一种基于虚拟隐藏网络的虚假数据注入攻击弹性防御方法[17]. 对比现有研究工作[18-19], 该方法结合图论与控制论提出了基于零和博弈的竞争性互联策略, 可以有效提高智能电网的弹性防御. 然而, 文献[17]在二分图拓扑和虚拟隐含网络拓扑的选择方面, 需要满足一些限制条件. 因此, 针对二分图拉普拉斯矩阵与连接拓扑之间的拓扑优化还需进一步研究提高其防御性能.
目前, 学者们在路径拓扑优化方面已经开展了一些重要工作. 一种基于随机森林的快速搜索随机树算法被提出应用于室内复杂火场环境下路径规划[20]. 面向高层消防救援, 李鸿一等提出一种基于随机采样的多无人机协同搜索规划方法[21]. 受启发于以上路径优化方法, 本文提出了一种基于图论的拓扑结构优化算法来改善攻击防御性能. 首先, 通过Kron还原法得到一个降维模型, 进而设计了一个虚拟隐含网络与原网络互联, 间接改善智能电网的结构脆弱性; 进一步考虑图的连通度、连通图的可去边和权值的影响来提高FDIA的防御性能. 创新点如下:
1) 针对二分图连接拓扑与二分图拉普拉斯矩阵之间不能一一对应问题, 提出了权值分配法.
2) 根据图的连通度[11]与连通图的可去边原理, 给出了虚拟隐含网络拓扑和二分图连接网络拓扑的选择依据.
3) 提出了基于二分图拓扑结构的权值指标函数, 并给出了权值矩阵的选择依据. 最后, 通过在IEEE-14总线电网系统上的仿真验证了所提优化算法的有效性.
1. 图论的基础知识
考虑智能电网是双向流系统, 系统中各节点间的连接关系可以通过无向图来描述. 图$ G(V, E) $由顶点集$ V = (1, 2, \cdots, n) $和边集$ E \subset V \times V $组成, $ V, E $分别对应电力网络中节点集合和节点间的连接路径的集合. 每条边$ e \in E $由顶点对$ (i, j) $表示. 如果图$ G $的任意一个顶点对$ (i, j) $满足$\forall(i, j) \times E \Rightarrow (j, i) \times E$, 那么图$ G $是一个无向图, 反之则是有向图. 如果图$ G $中任意两个不同顶点间恰有一条边连接, 则称此图为完全图. 一个图$ G(V, E) $由它的顶点对之间的邻接关系唯一确定. 图的这种关系均可以用矩阵来刻画, 用$ m_{i, j} $表示$ G $中$ i $与$ j $之间的边数, 称矩阵$ M(G) = (m_{i, j})_{n \times n} $为$ G $的邻接矩阵. 顶点$ i $的邻域集被定义为$ N_{i} = ( j \in V | (i, j)\in E ) $, 与顶点$ i $相关联的边数, 称为顶点$ i $的度, 记为$ d(i) = \left| N_{i} \right| $, $ G $的度矩阵 $ D(G) $ 为 ${\rm{diag}}\{d(1), d(2), \cdots, d(n)\}$. 拉普拉斯矩阵$ L(G) = D(G)-M(G) $. $ L(G) $是半正定矩阵且所有行的和等于$ 0 $, 我们可以用$\lambda_{1}(G) \ge \lambda_{2}(G) \ge \cdots \ge \lambda_{n-1}(G) \ge \lambda_{n}(G) = 0$来表示$ L(G) $的特征值. 如果对图$ G $的任意两个顶点$ i $和$ j $, $ G $中存在一条路径$ (i, j) $, 则称$ G $是连通图, 否则称为非连通图. 对于一个非连通图$ G $, 我们可以把$ G $分成几个子图$ G_{1}, G_{2}, \cdots, G_{k} $, 且每个$ G_{i} $是连通的. 非连通图$ G $的这些子图称为是$ G $的连通分支.
2. 基于图论的虚假数据注入攻击弹性防御策略
2.1 基于虚拟隐含网络的控制策略
将电力网络中的平衡节点、PV节点和PQ节点等效为无向图中的顶点, 节点间的传输线路等效为无向图的边, 就得到电力网络的等效拓扑图. 通过研究电力网络的拓扑结构, 改变节点的数量或改变节点间的连接状态, 可改善智能电网的结构脆弱性, 有效防御假数据注入攻击. 考虑到现实中改变电力网络拓扑结构的高成本和复杂性, 引入了虚拟隐含网络, 并通过二分图实现原系统拓扑与虚拟隐含网络拓扑的互联, 如图2所示, $ \Sigma_{1} $表示原系统的等效拓扑, $ \Sigma_{2} $表示虚拟隐含网络等效拓扑, $ \Sigma_{{\rm{eng}}} $表示二分图连接网络等效拓扑.
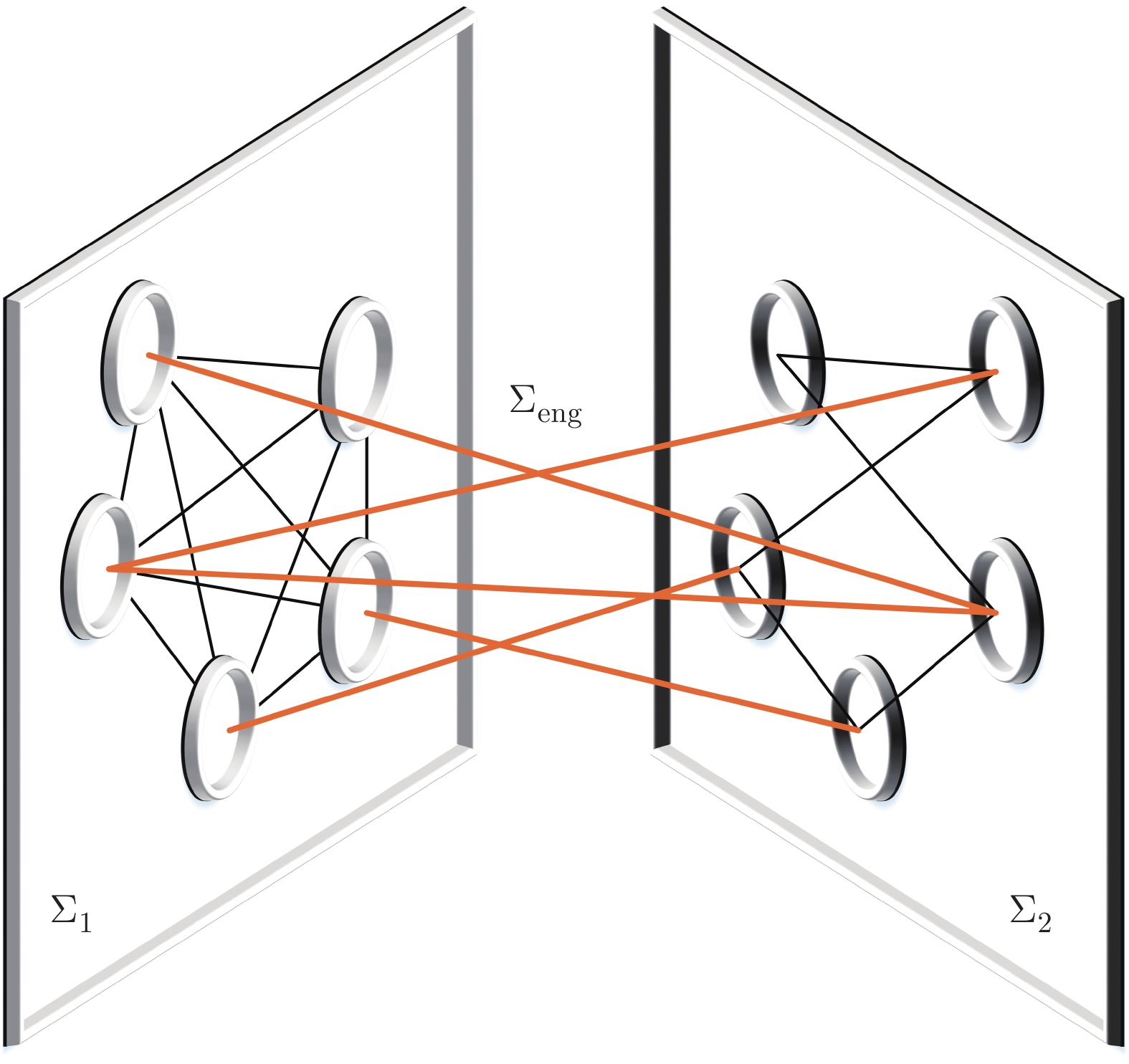 图 2 互联网络结构: ${{{\Sigma}}_{{1}}}$为电力系统拓扑, ${{{\Sigma}}_{{2}}}$为虚拟隐含网络拓扑, ${{{\Sigma}}_{\rm{eng}}}$为二分图连接拓扑Fig. 2 Connection network structure: ${{{\Sigma}}_{{1}}}$ is the power system topology, ${{{\Sigma}}_{{2}}}$ is the virtual network topology, and ${{{\Sigma}}_{\rm{eng}}}$ is the connection topology of bipartite graph
图 2 互联网络结构: ${{{\Sigma}}_{{1}}}$为电力系统拓扑, ${{{\Sigma}}_{{2}}}$为虚拟隐含网络拓扑, ${{{\Sigma}}_{\rm{eng}}}$为二分图连接拓扑Fig. 2 Connection network structure: ${{{\Sigma}}_{{1}}}$ is the power system topology, ${{{\Sigma}}_{{2}}}$ is the virtual network topology, and ${{{\Sigma}}_{\rm{eng}}}$ is the connection topology of bipartite graph优化电力系统拓扑$ \Sigma_{1} $, 等价于改变节点间的传输线路或为某些节点安装硬件保护装置, 这些做法都需要消耗大量成本且受现实条件制约. 因此, 引入虚拟隐含网络$ \Sigma_{2} $, 通过改变$ \Sigma_{2} $的拓扑结构间接改善$ \Sigma_{1} $的结构脆弱性. 此外, 选择合适的二分图拓扑$ \Sigma_{{\rm{eng}}} $, 使$ \Sigma_{1} $和$ \Sigma_{2} $形成零和博弈, 增强互联系统的弹性. 经过仿真验证, 基于虚拟隐含网络的防御方法可以有效防御FDIA. 加入虚拟隐含网络的互联系统模型如下:
$$ \left\{ \begin{aligned} \dot{x} & = Ax+\beta Kz+Bu_{0} \\ \dot{z} & = Hz-\beta Kx+\beta Kx_{0} \end{aligned} \right. $$ (1) 设$ \Sigma_{1} $和$ \Sigma_{2} $都是有$ N $个节点的图, 则$ x \in {\bf{R}}^{2N} $为$ \Sigma_{1} $的状态, $ z \in {\bf{R}}^{2N} $为$ \Sigma_{2} $的状态, $ x_{0} \in {\bf{R}}^{2N} $为稳态初始状态, $ u_{0} \in {\bf{R}}^{N} $为稳态机械输入功率, $A \in {\bf{R}}^{2N \times 2N}$和$ H \in {\bf{R}}^{2N \times 2N} $分别为$ \Sigma_{1} $和$ \Sigma_{2} $的系统矩阵, 形式为$\left[\begin{aligned} \star \;\;\; \star \\ \star L \;\; \star \end{aligned}\right]$, 其中$ L \in {\bf{R}}^{N \times N} $为$ \Sigma_{1} $和$ \Sigma_{2} $对应的拉普拉斯矩阵, $ \star $为具体内容的省略表示. $ B $为$ \Sigma_{1} $的输入矩阵, $ K \in {\bf{R}}^{2N \times 2N} $形式为$\left[\begin{aligned} L_{{\rm{eng}}} \;\; {\boldsymbol{0}}_{N \times N} \\ {\boldsymbol{0}}_{N \times N} \;\; L_{{\rm{eng}}} \end{aligned}\right]$, 其中, $L_{{\rm{eng}}} \in {\bf{R}}^{N \times N}$为二分图对应的拉普拉斯矩阵. $ \beta $为待设计的常数参数.
2.1.1 不存在攻击时的稳定性分析
在对互联系统进行稳定性分析之前, 首先分析具有$ A(\kappa) = A_{0}+\kappa A_{1} $形式的系统稳定性定理.
定理 1[22]. $ A(\kappa) = A_{0}+\kappa A_{1} $, 其中$ A_{0} $具有稳定的谱特征且为非亏损矩阵. $ V_{0} $的对角化形式为$ A_{0} = V_{0}^{-1}J_{1}V_{0} $, 其中$ V_{0} $是可逆矩阵, $ J_{1} $是对角矩阵. 令$ Y = V_{0}^{-1}A_{1}V_{0} $, 如果$ Y $的特征值的最大实部小于或等于0, 则存在区间$ \kappa \in (0, \kappa_{0}) $, $ \kappa_{0} >0 $, 使$ A(\kappa) $具有稳定的谱特征且为非亏损矩阵.
定义状态变换为$ \tilde{x} = x-x_0 $, 则将式$ (1) $重写如下
$$ \left\{ \begin{aligned} \dot{\tilde{x}} & = A \tilde{x}+\beta Kz+Ax_0+Bu_{0} \\ \dot{z} & = Hz-\beta K (\tilde{x}+x_{0})+\beta K x_{0} \end{aligned} \right. $$ (2) 基于文献[17]工作可知$ Ax_{0}+Bu_{0} = 0 $, 代入式$ (2) $得到
$$ \left\{ \begin{aligned} \dot{\tilde{x}} & = A \tilde{x}+\beta Kz \\ \dot{z} & = Hz-\beta K \tilde{x} \end{aligned} \right. $$ (3) 重写式$ (3) $可以得到
$$ \left[ \begin{array}{c} \dot{\tilde{x}}\\ \dot{z} \end{array} \right] = \left[ \begin{array}{ccc} A & \beta K \\ -\beta K & H \end{array} \right] \left[ \begin{array}{c} \tilde{x}\\ z \end{array} \right] $$ (4) 式$ (4) $的稳定性与如下方程的稳定性等价
$$ A(\kappa) = A_{0}+\kappa A_{1} $$ (5) 其中$\kappa = -1/\beta$, $A_{0} = \left[\begin{aligned} 0_{n \times n} \;\; -K\; \\ K\;\;\; \;\; 0_{n \times n} \end{aligned}\right]$, $A_{1} = \left[ \begin{aligned} A \;\;\; 0_{n \times n} \\ 0_{n \times n} \;\; H\;\; \end{aligned}\right]$.
将$ A_{0} $表示为克罗内克积的形式$ A_{0} = J \otimes K $, 其中$J = \left[\begin{aligned} 0 \; -1 \\ 1 \;\;\;\; 0\; \end{aligned}\right]$, 将矩阵$ J $和$ K $表示为二次型形式, $ J = V_{J}^{-1} D_{J} V_{J} $, $ K = V_{K}^{-1} D_{K} V_{K} $, 其中$ D_{J} $和$ D_{K} $是对应于$ J $和$ K $的对角化矩阵. 因此, 得到如下等式
$$ A_{0} = (V_{J} \otimes V_{K})^{-1}(D_{J} \otimes D_{K})(V_{J} \otimes V_{K}) $$ (6) 通过计算得到$V_{J} = \dfrac{1}{\sqrt{2}} \left[\begin{aligned} -{\rm{j}} \;\; {\rm{j}} \\ 1 \;\;\; 1 \end{aligned}\right]$, $D_{J} = \left[\begin{aligned} 0 \;\; {\rm{j}} \\{\rm{j}} \;\; 0 \end{aligned} \right]$, 其中${\rm{j}}$为虚数符号. 进一步计算得到
$$ V_{J} \otimes V_{K} = \dfrac{1}{\sqrt{2}} \begin{bmatrix} -{\rm{j}} V_{K} & {\rm{j}} V_{K} \\ V_{K} & V_{K} \end{bmatrix} $$ (7) 对式$ (7) $求逆得到
$$ (V_{J} \otimes V_{K})^{-1} = \sqrt{2} \begin{bmatrix} \dfrac{1}{2}{\rm{j}} V_{K}^{-1} & \dfrac{1}{2} V_{K}^{-1} \\ -\dfrac{1}{2}{\rm{j}} V_{K}^{-1} & \dfrac{1}{2} V_{K}^{-1} \end{bmatrix} $$ (8) 进一步得到
$$ \begin{split} &{({V_J} \otimes {V_K})^{ - 1}}({A_1})({V_J} \otimes {V_K}) = \\ &\quad\left[ {\begin{array}{*{20}{c}} {\dfrac{1}{2}V_K^{ - 1}(A + H){V_K}}&{ - \dfrac{1}{2}V_K^{ - 1}(A - H){V_K}}\\ { - \dfrac{1}{2}V_K^{ - 1}(A - H){V_K}}&{\dfrac{1}{2}V_K^{ - 1}(A + H){V_K}} \end{array}} \right] \end{split} $$ (9) 由于$ A+H $是具有一个零特征值的半负定矩阵, $-({1}/{2})V_{K}^{-1}(A+H)V_{K}$也是一个半负定矩阵, 因此将式(9)重写为
$$ \begin{split} &\left[ {\begin{array}{*{20}{c}} {\dfrac{1}{2}V_K^{ - 1}(A + H){V_K}}&{ - \dfrac{1}{2}V_K^{ - 1}(A - H){V_K}}\\ { - \dfrac{1}{2}V_K^{ - 1}(A - H){V_K}}&{\dfrac{1}{2}V_K^{ - 1}(A + H){V_K}} \end{array}} \right] = \\ &\dfrac{1}{2}\left[ {\begin{array}{*{20}{c}} {V_K^{ - 1}}&0\\ 0&{V_K^{ - 1}} \end{array}} \right]\left[ {\begin{array}{*{20}{c}} {A + H}&{H - A}\\ {H - A}&{A + H} \end{array}} \right]\left[ {\begin{array}{*{20}{c}} {{V_K}}&0\\ 0&{{V_K}} \end{array}} \right] \end{split} $$ (10) 由于$ K $为实对称拉普拉斯矩阵, 存在正交相似变换矩阵$ V_{K} $, 使得$V_{K}^{-1} = V_{K}^{{\rm{T}}}$, 因此, 式$ (10) $重写为
$$ \begin{split} &\left[ {\begin{array}{*{20}{c}} {\dfrac{1}{2}V_K^{ - 1}(A + H){V_K}}&{ - \dfrac{1}{2}V_K^{ - 1}(A - H){V_K}}\\ { - \dfrac{1}{2}V_K^{ - 1}(A - H){V_K}}&{\dfrac{1}{2}V_K^{ - 1}(A + H){V_K}} \end{array}} \right] = \\ &\dfrac{1}{2}{\left[ {\begin{array}{*{20}{c}} {{V_K}}&0\\ 0&{{V_K}} \end{array}} \right]^{\rm{T}}}\left[ {\begin{array}{*{20}{c}} {A + H}&{H - A}\\ {H - A}&{A + H} \end{array}} \right]\left[ {\begin{array}{*{20}{c}} {{V_K}}&0\\ 0&{{V_K}} \end{array}} \right] \end{split}$$ (11) 根据合同变换的理论, 由于 $\left[\begin{aligned} V_{K} \;\; 0\;\; \\ 0 \;\; V_{K} \end{aligned}\right]$ 是可逆的, $\left[\;\; {\begin{aligned} {\frac{1}{2}V_K^{ - 1}(A + H){V_K}}\;\;\;\;{ - \frac{1}{2}V_K^{ - 1}(A - H){V_K}}\\ { - \frac{1}{2}V_K^{ - 1}(A - H){V_K}}\;\;\;\;{\frac{1}{2}V_K^{ - 1}(A + H){V_K}}\; \end{aligned}} \;\;\right]$ 和 $\left[ \begin{aligned} {A + H}\;\;{H - A}\\ {H - A}\;\;{A + H} \end{aligned} \right]$的正负特征值个数相同.
引理 1.
$\left[ \begin{aligned} {A + H}\;\;{H - A}\\ {H - A}\;\;{A + H} \end{aligned} \right]$的特征值实部是非正的.
证明. 假设$\left[ {\begin{aligned} {A + H}\;\;{H - A}\\ {H - A}\;\;{A + H} \end{aligned}} \right]$的特征值为$ \lambda $, 对应的特征向量为$ [\xi_{1}^{{\rm{T}}}, \xi_{2}^{{\rm{T}}}]^{{\rm{T}}} $, 则有如下等式关系
$$ \left[ {\begin{array}{*{20}{c}} {A + H}&{H - A}\\ {H - A}&{A + H} \end{array}} \right]\left[ {\begin{array}{*{20}{c}} {{\xi _1}}\\ {{\xi _2}} \end{array}} \right] = \lambda \left[ {\begin{array}{*{20}{c}} {{\xi _1}}\\ {{\xi _2}} \end{array}} \right]$$ (12) 将式$ (12) $展开后得到
$$ \left\{ {\begin{aligned} &{(A + H){\xi _1} + (H - A){\xi _2} = \lambda {\xi _1}}\\ &{(H - A){\xi _1} + (A + H){\xi _2} = \lambda {\xi _2}} \end{aligned}} \right. $$ (13) 做差后进一步得到
$$ 2A\xi_{1}-2A\xi_{2} = 2A(\xi_{1}-\xi_{2}) = \lambda(\xi_{1}-\xi_{2}) $$ (14) 式$ (14) $说明, 特征值$ \lambda $是矩阵$ 2A $的一个特征向量, 其对应的特征向量为$ \xi_{1}-\xi_{2} $. 由于$ A $的特征值都具有非正的实部, 所以$ \lambda $也都具有非正的实部.
□ 根据定理1, 对于形式为式(1)的互联系统, 在没有攻击的情况下, 存在参数$ \beta \in (-\infty, \beta_{0}) $, 使得互联系统保持稳定.
2.1.2 有攻击时的稳定性分析
考虑到具有隐蔽性的有界的恶意攻击向量$ d $式$ (1) $可以重新整理为
$$ \left\{ \begin{aligned} &\dot x = Ax + \beta Kz + B{u_0} + d\\ &\dot z = Hz - \beta Kx + \beta K{x_0} \end{aligned} \right. $$ (15) 定义状态变换为$ \tilde{x} = x-x_{0} $, 将互联系统$ (15) $重写如下
$$ \left\{ \begin{aligned} &\dot {\tilde{x}} = A\tilde x + \beta Kz + d\\ &\dot z = Hz - \beta K\tilde x \end{aligned} \right.$$ (16) 由式$ (16) $变换, 可以得到
$$ \left[ {\begin{array}{*{20}{c}} {\dot {\tilde{x}}}\\ {\dot d}\\ {\dot z} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} A&I&{\beta K}\\ 0&0&0\\ { - \beta K}&0&H \end{array}} \right]\left[ {\begin{array}{*{20}{c}} {\tilde x}\\ d\\ z \end{array}} \right]$$ (17) 式中, $I $为单位矩阵. 式(17)的稳定性表示如下.
$$ A(\kappa) = A_{0}+\kappa A_{1} $$ (18) 其中$ \kappa = -1/\beta $, $A_{0} = \left[\begin{aligned} 0 \;\;\;\; 0 \,\; -K \\ 0 \;\;\;\; 0\;\; \;\;\;0\;\;\,\\ K \;\;\; 0 \;\;\;\;\; 0 \;\;\,\end{aligned}\right]$, $A_{1} = \left[\begin{aligned} A \;\; I\, \;\; 0 \;\\ 0\, \;\ 0\, \;\; 0 \;\\ 0\, \;\; 0 \;\; H \end{aligned} \right]$.
将$ A_{0} $表示为克罗内克积的形式$A_{0} = J \otimes K$, 其中$J = \left[\begin{aligned} 0 \;\;\;\; 0\,\; -1\, \\0 \;\; \;\;0 \;\;\; \;\;0\;\, \\1 \;\; \;\;0\;\;\;\;\; 0 \;\,\end{aligned}\right]$, 将矩阵$ J $和$ K $表示为二次型形式, $ J = V_{J}^{-1} D_{J} V_{J} $, $ K = V_{K}^{-1} D_{K} V_{K} $, 其中$ D_{J} $和$ D_{K} $是对应于$ J $和$ K $的对角化矩阵. 因此, 得到如下等式
$$ A_{0} = (V_{J} \otimes V_{K})^{-1}(D_{J} \otimes D_{K})(V_{J} \otimes V_{K}) $$ (19) 通过计算得到$V_{J} = \left[\begin{aligned} -{\rm{j}} \;\; {\rm{j}} \;\; 0\\ 0 \,\;\; 0 \;\; 1 \\ 1 \;\;\, 1 \;\; 0 \end{aligned}\right]$, $D_{J} = \left[ \begin{aligned} 0 \;\;\,\;\; \,{\rm{j}} \,\;\;\, 0 \,\\ \dfrac{1}{2}{\rm{j}}\; \;\; 0 \,\;\; \dfrac{1}{2} \\ 0\,\; -1 \;\; 0\, \end{aligned}\right]$. 进一步计算得到
$$ V_{J} \otimes V_{K} = \begin{bmatrix} -{\rm{j}} V_{K} & {\rm{j}} V_{K} & 0\\ 0 & 0 & V_{K} \\ V_{K} & V_{K} & 0 \end{bmatrix} $$ (20) 对式$ (20) $求逆, 可以得到
$$ \begin{split} &{({V_J} \otimes {V_K})^{ - 1}}({A_1})({V_J} \otimes {V_K}) = \\ &\left[ {\begin{array}{*{20}{c}} {\dfrac{1}{2}V_K^{ - 1}(A + H){V_K}}&{ - \dfrac{1}{2}V_K^{ - 1}(A - H){V_K}}&{\dfrac{1}{2}{\rm{j}}I}\\ { - \dfrac{1}{2}V_K^{ - 1}(A - H){V_K}}&{\dfrac{1}{2}V_K^{ - 1}(A + H){V_K}}&{ - \dfrac{1}{2}{\rm{j}}I}\\ 0&0&0 \end{array}} \right] \end{split} $$ (21) 进一步得到
$$ \begin{split} &{({V_J} \otimes {V_K})^{ - 1}}({A_1})({V_J} \otimes {V_K}) = \\ &\dfrac{1}{2}{\left[ {\begin{array}{*{20}{c}} {{V_K}}&0&0\\ 0&{{V_K}}&0\\ 0&0&{{V_K}} \end{array}} \right]^{\rm{T}}}\left[ {\begin{array}{*{20}{c}} {A + H}&{H - A}&{{\rm{j}}I}\\ {H - A}&{A + H}&{ - {\rm{j}}I}\\ 0&0&0 \end{array}} \right]\;\times\\ &\left[ {\begin{array}{*{20}{c}} {{V_K}}&0&0\\ 0&{{V_K}}&0\\ 0&0&{{V_K}} \end{array}} \right]\\[-25pt] \end{split} $$ (22) 根据合同变换的理论, 由于$\left[\begin{aligned} V_{K} \;\; 0\;\; \;\; 0\;\; \\0\; \;\; V_{K} \;\; 0 \;\;\\0 \;\;\;\; 0\; \;\; V_{K} \end{aligned}\right]$是可逆的, $\left[ \;{\begin{aligned} {\frac{1}{2}V_K^{ - 1}(A\; +\; H){V_K}}\;\;{ - \frac{1}{2}V_K^{ - 1}(A - H){V_K}}\;\;{\frac{1}{2}{\rm{j}}I}\;\\ { - \frac{1}{2}V_K^{ - 1}(A \;-\; H){V_K}}\;\;\;{\frac{1}{2}V_K^{ - 1}(A + H){V_K}}\;\;{ - \frac{1}{2}{\rm{j}}I}\\0\qquad\qquad\quad\;\;\;\;\;\;\;\;\;\;\;0\qquad\quad\;\;\;\;\;\;\;\;0\;\;\; \end{aligned}} \;\right]$ 和 $\left[ {\begin{aligned} {A \,+\, H}\;\;{H \,-\, A}\;\;\;\;{{\rm{j}}I}\;\\{H \,-\, A}\;\;{A\, +\, H}\;\;{ - {\rm{j}}I}\\0\;\;\;\qquad0\;\;\qquad0 \;\;\end{aligned}} \right]$的正负(实部)特征值个数相同.
引理 2.
$\left[\;\; {\begin{aligned} {A + H}\;\;\;\;{H - A}\;\;\;\;\;\;{{\rm{j}}I}\;\\ {H - A}\;\;\;\;{A + H}\;\;\;\;{ - {\rm{j}}I}\\0\;\;\;\;\;\qquad0\;\;\;\;\qquad0\;\; \end{aligned}}\;\; \right]$的特征值实部是非正的.
证明过程与引理1相似, 此处省略. 根据定理1, 对于形式为式$ (15) $的互联系统, 在存在FDIA的情况下, 存在参数$ \beta \in (-\infty, \beta_{0}) $, 使得互联系统保持稳定.
2.2 问题描述
二分图连接拓扑$ \Sigma_{{\rm{eng}}} $连接$ \Sigma_{1} $和$ \Sigma_{2} $, 涉及$ 2N $个节点, 共有$ 2^{2N} $种拓扑表示. 而二分图的拉普拉斯矩阵$ L_{{\rm{eng}}} $为$ N \times N $维, 只有$ 2^{N} $种矩阵表示. $ 2^{2N} \ne 2^{N} $, 无法实现二分图拓扑与拉普拉斯矩阵一一对应.
2.3 权值分配法
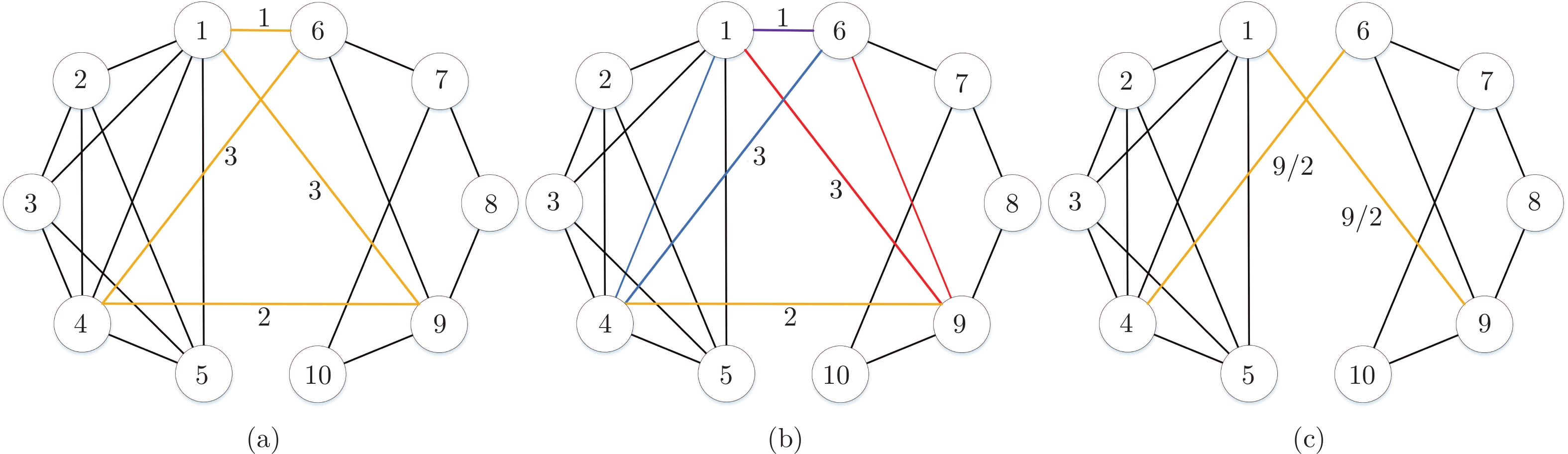
为了解决上述问题, 本节提出了权值分配法. 该方法通过将具有相同起始点的路径合并, 实现路径的消除化简. 如图3所示, 以IEEE-$ 14 $节点系统为例(经过Kron简化后, 变为$ 5 $节点), 序号为$ 1 $, $ 2 $, $ 3 $, $ 4 $, $ 5 $的节点对应$ \Sigma_{1} $中的节点, 序号为$ 6 $, $ 7 $, $ 8 $, $ 9 $, $ 10 $的节点对应$ \Sigma_{2} $中的节点. 选取$ \Sigma_{{\rm{eng}}} $如图3(a) 所示, 二分图连接拓扑结构用黄色线条表示, 相应路径的权值标在路径上(对称路径的权值大小相同). 如图3(b) 所示, 相同颜色的线构成三角形的两条路径, 由于路径$ 4\text{-}1\text{-}6 $与$ 4\text{-}6 $具有相同的功能, 所以可以把路径$ 1\text{-}6 $的权值分配到路径$ 4\text{-}6 $上. 路径$ 9\text{-}6\text{-}1 $与$ 9\text{-}1 $具有相同的功能, 所以可以把路径$ 1\text{-}6 $的权值分配到路径$ 9\text{-}1 $上. 为了保证得到对称的拉普拉斯矩阵, 将路径$ 1\text{-}6 $的权值平均分配到路径$ 4\text{-}6 $和路径$ 9\text{-}1 $上. 同理, 路径$ 4\text{-}9 $的权值也可平均分配到路径$ 4\text{-}6 $和路径$ 9\text{-}1 $上. 因此, 便可消除$ 1\text{-}6 $和$ 4\text{-}9 $这两条路径, 得到图3(c)所示的等效拓扑.
为表示方便, 作如下定义:
定义 1[23]. 当路径的一个顶点标号$ i $属于原系统, 另一个顶点标号等于$ i+5 $属于虚拟隐含网络时, 称这条路径为横路径.
定义 2[22]. 当存在回路时, 网络具有冗余度. 每个节点的度$ d(i) \ge 2 $, 当$i\text{-}j\text{-}\cdots\text{-}k\text{-}i$中的某一条路径$ i\text{-}j $消失时, 节点$ i $和$ j $能够通过$i\text{-}k\text{-}\cdots \text{-}j$继续保持连通.
推论1. 当存在一条回路时, 可以将横路径消去, 把横路径的权值分配到剩余回路中的连接拓扑中; 当存在多条回路时, 可以把横路径消去, 并把横路径的权值平均分配到其他所有剩余回路中的连接拓扑中.
证明. 根据定理$ 1 $, 当存在回路时, 横路径消失, 并不影响两节点间的连通性. 由于连接拓扑和虚拟隐含网络拓扑都是虚拟的, 所以可以采用权值平均分配的形式, 将横路径的重要性平均分配到其他连接拓扑中.
由于节点$ 1 $, $ 2 $, $ 3 $, $ 4 $, $ 5 $构成的图为完全图, 所以横路径的权值一定可以等效到其他的路径上. 但是若节点$ 6 $, $ 7 $, $ 8 $, $ 9 $, $ 10 $构成的图为非连通图, 则可能导致横路径的权值无法平均分配到其他路径上.
如图4所示, 路径$ 1\text{-}6 $与$ 1\text{-}9 $无法通过其余路径形成闭合回路, 于是路径$ 1\text{-}6 $的权值无法分配到路径$ 1\text{-}9 $上. 即使路径$ 1\text{-}6 $的权值可以分配到路径$ 4\text{-}6 $上, 但路径$ 4\text{-}6 $与$ 1\text{-}9 $的权值不相等, 无法形成对称的拉普拉斯矩阵. 因此, 要想成功消去$ 1\text{-}6 $和$ 4\text{-}9 $这样的路径, 必须保证$ \Sigma_{2} $的拓扑是连通图, 或者, 保证横路径与$ \Sigma_{2} $的连通分支部分相连. 如图5所示, 虽然$ \Sigma_{2} $是非连通图, 但是路径$ 1\text{-}6 $可以通过$ 1\text{-}6\text{-}7\text{-}8\text{-}1 $将权值分配到$ 1\text{-}8 $上, 因此也可以得到对称的拉普拉斯矩阵, 实现$ 1\text{-}6 $边的消去.
□ 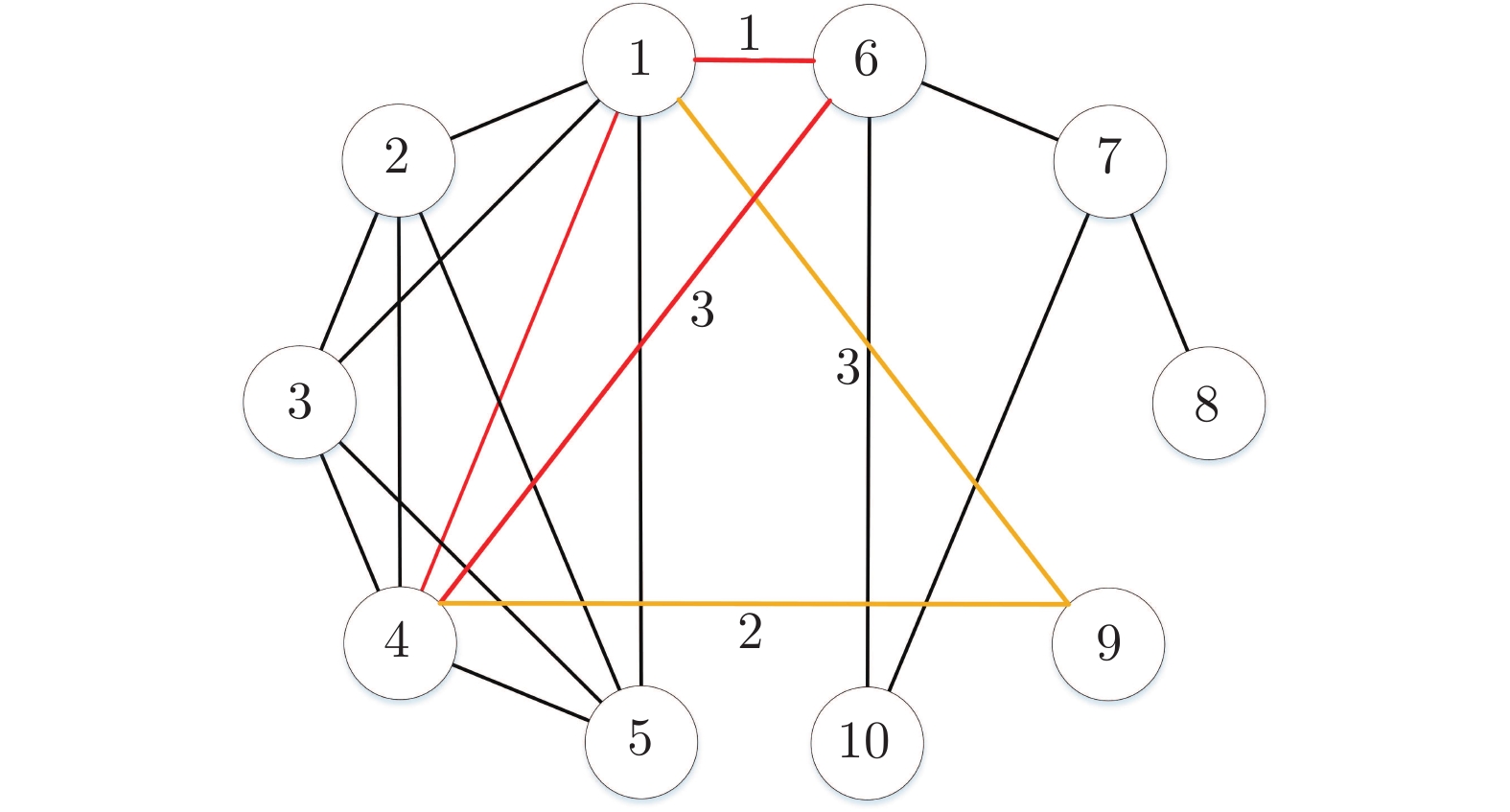 图 4 非连通图下的权值分配法无法消去横路径情形Fig. 4 The weight allocation method under disconnected graph cannot eliminate the transverse path case
图 4 非连通图下的权值分配法无法消去横路径情形Fig. 4 The weight allocation method under disconnected graph cannot eliminate the transverse path case 图 5 非连通图下存在连通分支时的权值分配法Fig. 5 Weight allocation method for connected branches in disconnected graphs
图 5 非连通图下存在连通分支时的权值分配法Fig. 5 Weight allocation method for connected branches in disconnected graphs当横路径在$ \Sigma_{2} $和$ \Sigma_{{\rm{eng}}} $中有两个或多个回路时, 横路径的权值要平均分配到其他路径. 如图6所示, 回路$ 2\text{-}6\text{-}7\text{-}2 $、回路$ 2\text{-}7\text{-}8\text{-}2 $和回路$2\text{-}7\text{-} 8\text{-}9\text{-}10\text{-}2$, 在图中标为黄色, 表明横路径$ 2\text{-}7 $可以被消去, 但路径$ 2\text{-}7 $的权值要平均分配到路径$ 2\text{-}8 $和路径$ 2\text{-}10 $上. 此时, 路径$ 2\text{-}6 $的权值变为$ 7/3 $, 路径$2\text{-}8$的权值变为$ 10/3 $, 路径$ 2\text{-}10 $的权值变为$ 16/3 $. 同理, 消去横路径$ 8\text{-}3 $后(回路$8\text{-}3\text{-}2\text{-}8 $和回路$8\text{-}3\text{-}2\text{-}6\text{-} 7)$, $ 2\text{-} 6 $的权值变为$ 17/6 $, 路径$ 2\text{-}8 $的权值变为$ 23/6 $.
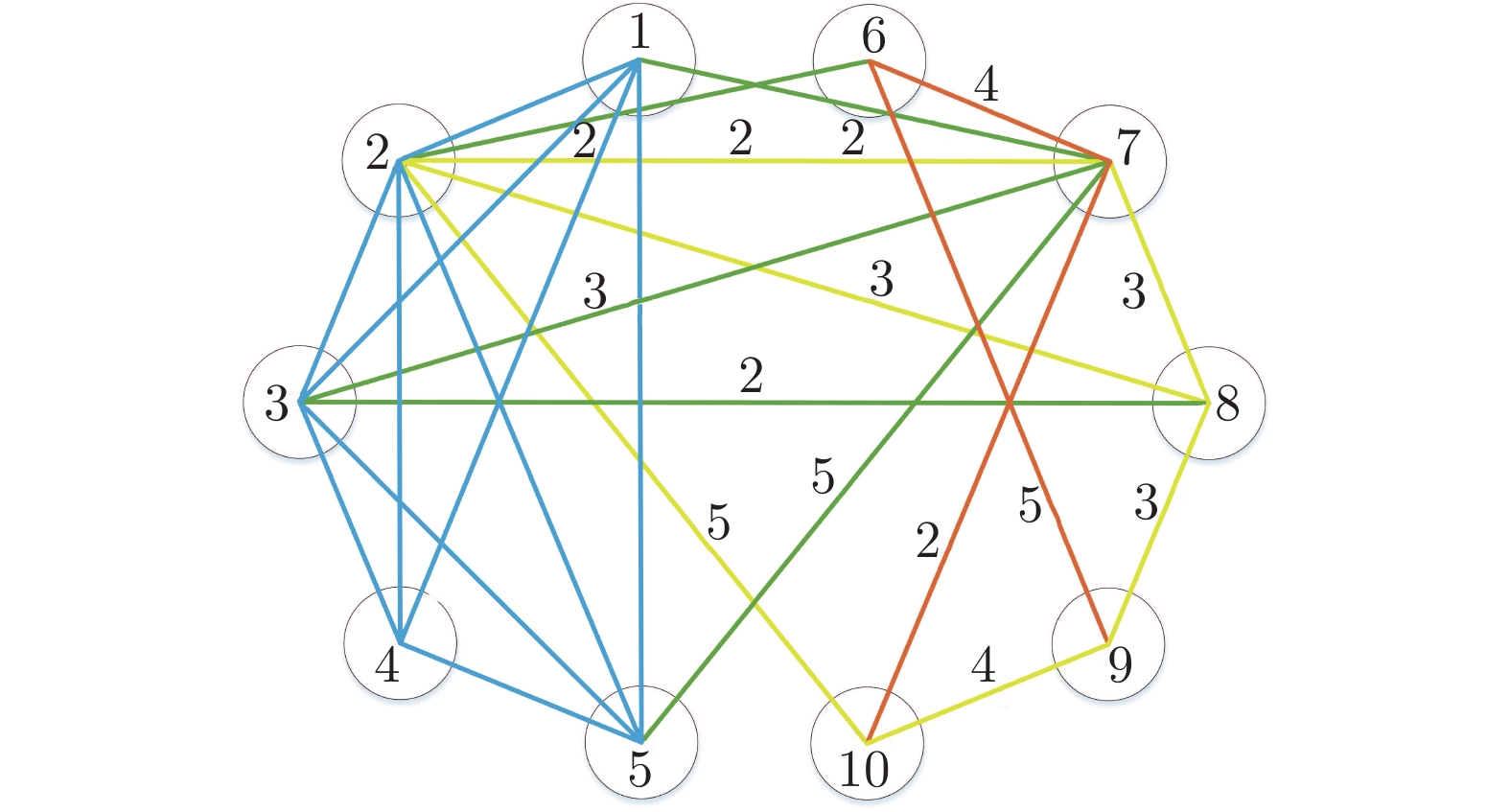 图 6 非连通图下多条横路径消去的权值分配法Fig. 6 Weight allocation method for elimination of multiple transverse paths in disconnected graphs
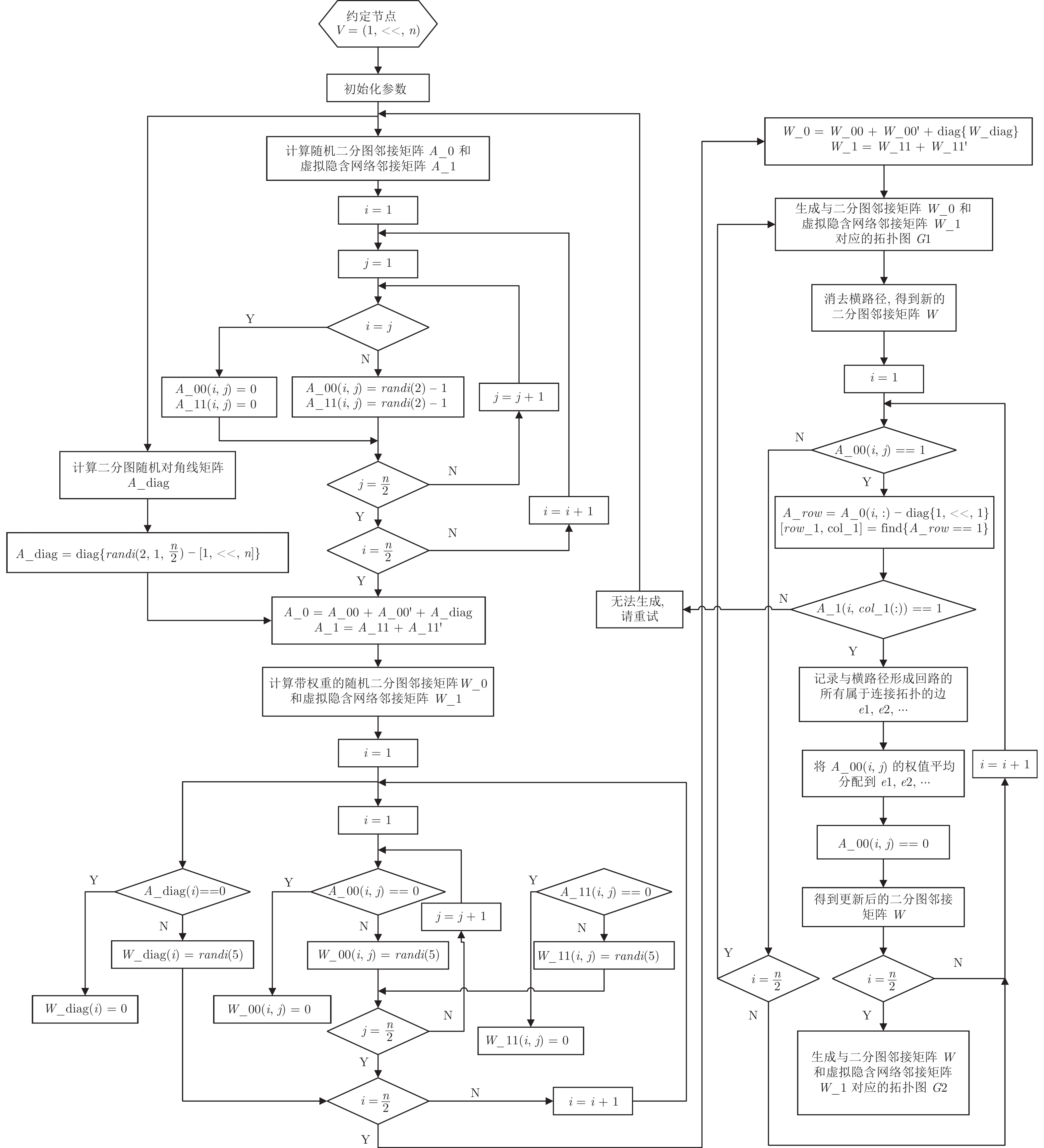
图 6 非连通图下多条横路径消去的权值分配法Fig. 6 Weight allocation method for elimination of multiple transverse paths in disconnected graphs权值分配法的流程图如图7所示.
2.4 拓扑特性
图的连通程度的高低, 在图论意义上, 是图结构性质的重要表征, 图的许多性质都与其有关; 在实际意义上, 图的连通程度的高低, 在与之对应的通信网络中, 对应于网络可靠性程度的高低. 网络可靠性, 是指网络运作的好坏程度, 即网络对某个或多个节点崩溃的容忍程度. 图的连通度和代数连通度为优化$ \Sigma_{2} $和$ \Sigma_{{\rm{eng}}} $拓扑结构, 从而为得到最优防御策略提供了依据. 为了提高智能电网通信网络的可靠性, $ \Sigma_{2} $和$ \Sigma_{{\rm{eng}}} $的选择能够使互联系统$ {\cal{G}} = (\Sigma_{1}+\Sigma_{2}+\Sigma_{{\rm{eng}}} ) $是连通图.
由于原系统的$ 5 $个发电机节点间的等效拓扑为完全图, 且FDIA仅能够对原系统产生破坏, 因此, 互联系统$ {\cal{G}} = (\Sigma_{1}+\Sigma_{2}+\Sigma_{{\rm{eng}}} ) $的连通度为$ 4 $.
定义3[24]. 设$ e $为$ 4 $连通图$ G $的一条边, 考虑如下运算:
$1)$从$ G $中去掉$ e $得到图$ G \backslash e $;
$2)$如果$ e $的某个端点在$ G \backslash e $中度为$ 3 $, 则去掉此端点, 再两两连接此端点在$ G \backslash e $中的$ 3 $个邻点;
$3)$如果经过式$ (2) $中的运算后, 有重边出现, 则用单边代替它们, 使得此图为简单图.
最后得到的图记为$ G \ominus e $, 若$ G \ominus e $为$ 4 $连通, 则称$ e $为$ G $的可去边.
对于$ 4 $连通图中可去边的分布, 有如下定理:
定理2[25]. 设$ G $为阶大于$ 5 $的$ 4 $连通图, 若$ G $的最小度大于$ 4 $, 则$ G $的任一个回路上至少有两条可去边.
由定理$ 2 $可知, 对于连通度为$ 4 $的互联系统, 若每个虚拟网络节点$ i $的度$ d(i) > 4 $, 则网络的冗余度越大, 网络可靠性越强. 当满足$ d(i) > 4 $的节点数量越多, 网络的可靠性越高.
3. 指标函数的选择
3.1 指标函数
FDIA通过篡改传感器测量参数, 干扰控制中心正确决策, 导致系统的状态偏离稳态运行值. 为了在FDIA发起情况下, 保证系统状态偏离程度在可接受范围内, 采用基于虚拟隐含网络的弹性控制方法, 通过改善系统的结构脆弱性, 将FDIA产生的影响抑制在可接受范围内, 实现攻击的有效防御. 为了评价不同的$ \Sigma_{2} $和$ \Sigma_{{\rm{eng}}} $拓扑结构对控制效果的影响, 可以选取如下的指标函数
$$ J = \frac{1}{N} \sum\limits_{n = 1}^N \Vert x-x_0 \Vert $$ (23) 式中, $ N $表示采样数据个数. 由上式可知, 指标函数的值越小, 状态偏离稳态值的程度越小, 防御效果越好.
3.2 考虑权值的指标函数
面对可以任意改变路径和路径的权值的$ \Sigma_{2} $和$ \Sigma_{{\rm{eng}}} $拓扑结构, 我们首先采用了图连通度和图的可去边理论优化边的结构. 但是, 由于边的权值表征边的重要程度, 即传输信息的能力, 一般情况下, 在拓扑结构相同的两个网络, 路径的权值越大, 控制效果越好. 因此, 在实现控制误差最小的情况下, 还要考虑权值矩阵产生的成本代价.
为此, 我们将指标函数改进如下
$$ \mathop{\min\limits_{ W_{{\rm{eng}}}, W_{2} }} J = \frac{1}{N} \sum\limits_{n = 1}^N \Vert x-x_0 \Vert + \Vert{W_{{\rm{eng}}}}\Vert_{F} + \Vert{W_{2}}\Vert_{F} $$ (24) 指标函数的第一部分表示控制误差的大小, 在稳态情况下量级很小, 在$ 1 $以内. 第二部分和第三部分分别表示攻击下$ \Vert{W_{{\rm{eng}}}}\Vert_{F} $ 和 $\Vert{W_{2}}\Vert_{F}$的权值成本, 当选定边权值上界为$ s $时, 其大小分别为$ 12.5\;{\rm{s}} $和$ 10 \;{\rm{s }}$. 当选定边权值为大于等于1的数时, 第二部分和第三部分的值远大于第一部分的值. 这与我们的预期不符. 我们的主要目标是降低控制误差, 即第一部分值的大小, 而第二部分和第三部分的值是次要的, 不能让后者占据主导地位. 为此, 我们提出倒数转化方法, 使量级很小的第一部分占据主导地位, 量级大的第二和第三部分占次要地位. 优化后的指标函数如下
$$ \mathop{\max\limits_{ W_{{\rm{eng}}}, W_{2} }} J = \frac{N}{ \sum\limits _{n = 1}^N \Vert x-x_0 \Vert} + \frac{1}{\Vert{W_{{\rm{eng}}}}\Vert_{F}} + \frac{1}{\Vert{W_{2}}\Vert_{F}} $$ (25) 综上所述, 指标函数的值越大, 说明状态偏离稳态值的程度越小, 防御效果越好.
4. 仿真验证
在本节中, 将通过IEEE-14总线系统的等效拓扑来验证拓扑优化对基于虚拟隐含网络的FDIA防御方法的性能改善. 首先, 对图的等效变换原理进行仿真验证分析; 进而给出了防御效果与拓扑选择之间的关系进行仿真分析.
4.1 图的等效变换原理仿真分析
在第$ 3 $节中, 我们介绍了图的等效变换原理和算法. 由于二分图连接拓扑表示与拉普拉斯矩阵无法一一对应, 所以需要通过权值变换的方法消去某些特定的路径, 实现二分图连接拓扑表示与拉普拉斯矩阵的一一对应.
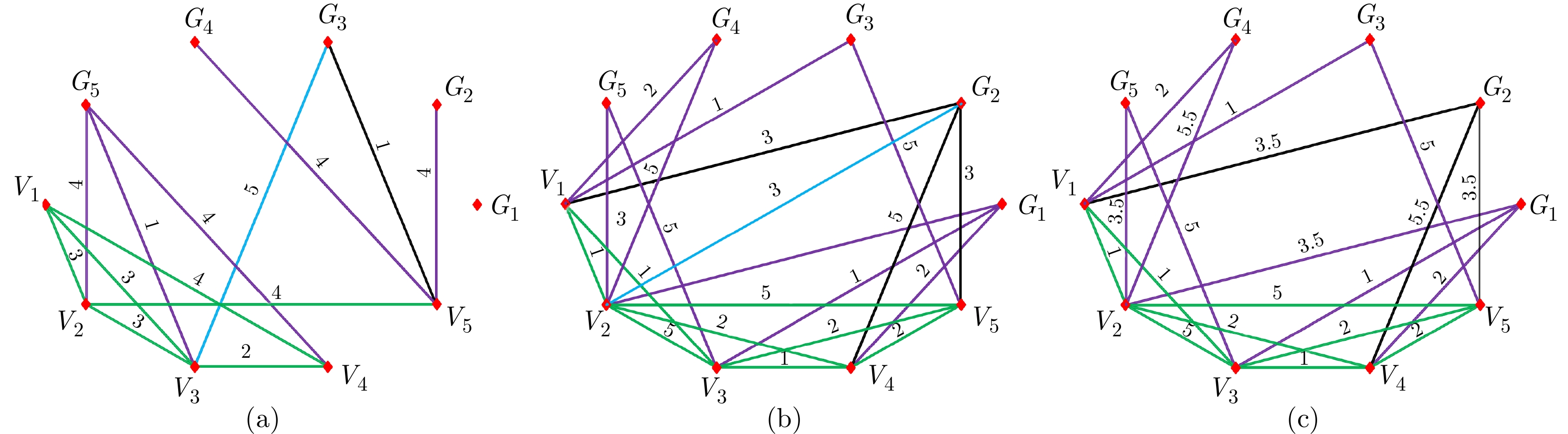
图8为图的等效变换算法的仿真结果. 图8(a)为一随机生成的图, 其中, 节点$ G_{3} $的度为$ 2 $, 路径$ G_{3}\text{-}V_{3} $只能通过路径$ G_{3}\text{-}V_{5} $实现消去, 但是在$ \Sigma_{2} $中, 节点$ V_{3} $和$ V_{5} $之间不存在一条路径, 因此, 路径$ G_{3}\text{-}V_{3} $无法消去. 图8(b)为另一随机生成的图, 其中, 节点$ G_{2} $的度为$ 4 $, 由于节点$ V_{1} $和$ V_{2} $、$ V_{2} $和$ V_{4} $以及$ V_{2} $和$ V_{5} $之间存在路径, 因此路径$ G_{2}\text{-}V_{2} $可以通过路径$ G_{2}\text{-}V_{1} $或者路径$ G_{2}\text{-}V_{4} $或者路径$ G_{2}\text{-}V_{5} $实现消去, 为此, 需要将路径$ G_{2}\text{-}V_{2} $的权值平均分配到路径$ G_{2}\text{-}V_{1} $、边$ G_{2}\text{-}V_{4} $和边$ G_{2}\text{-}V_{5} $上, 得到消去后的图如8(c)所示.
4.2 防御效果与拓扑选择关系的仿真分析
本节针对IEEE-14总线系统所遭受的FDIA, 进行基于虚拟隐含网络的弹性防御策略优化, 仿真过程中, 在60 s时对全部电机节点加入攻击.
由式(1)可知, 选择$ \Sigma_{{\rm{eng}}} $和$ \Sigma_{2} $的拓扑结构就得到了相应的参数$ K $和$ H $. 通过仿真, 可以得到不同$ \Sigma_{{\rm{eng}}} $和$ \Sigma_{2} $的拓扑结构下的转子角和角频率变化效果图.
图9(a), 9(c), 9(e)为随机生成的具有典型特征的图, 图9(b), 9(d), 9(f)分别为图9(a), 9(c), 9(e)通过权值分配法化简后的图. 图10(a), 10(c), 10(e)为随机生成的具有典型特征的图, 图10(b), 10(d), 10(f)分别为图10(a), 10(c), 10(e)通过权值分配法化简后的图. 图9和图10中的图, 全部为连通图, 但每个节点的度不相同. 对于虚拟隐含网络的节点, 其中图9(b)的度分别为$ d(6) = 5 $, $ d(7) = 7 $, $ d(8) = 6 $, $ d(9) = 5 $, $ d(10) = 5 $, 图10(f)的度分别为$ d(6) = 1 $, $ d(7) = 2 $, $ d(8) = 3 $, $ d(9) = 3 $, $ d(10) = 3 $. 由定理$2 $可知, 图9(b)的拓扑结构比图10(f)的可靠性高. 表1给出了图9(b), 9(d), 9(f), 10(b), 10(d), 10(f)的指标函数值和优化后的指标函数值. 可以看出, 一般来说, 可去边越多的拓扑选择, 优化后的指标函数值越大, 防御的效果越好. 同时, 优化后的指标函数值与未优化相比, 区分度更大, 更易判断控制效果的好坏.
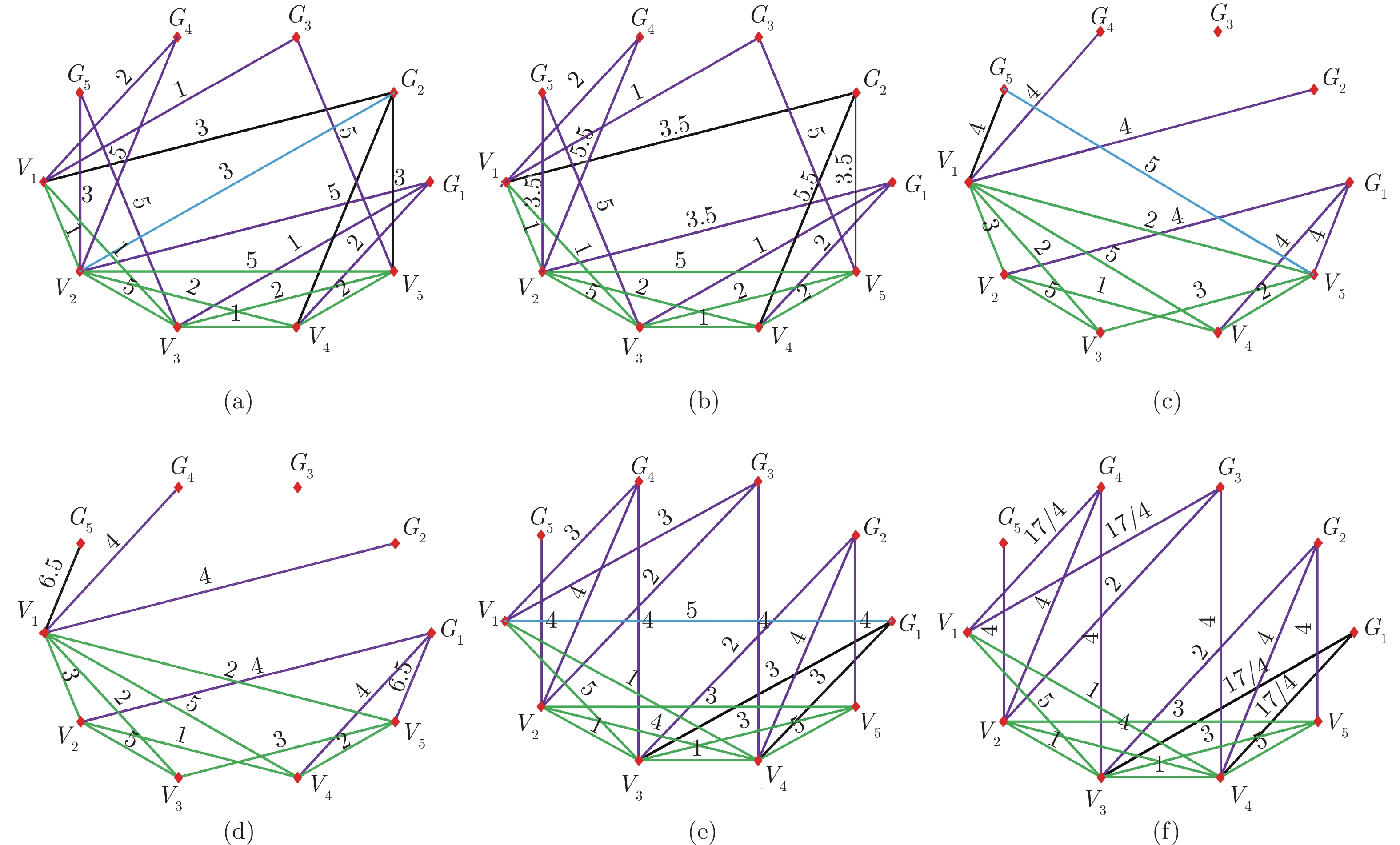 图 9 随机拓扑图及权值分配法化简后的拓扑图Fig. 9 Random topology and topology simplified by weight allocation method
图 9 随机拓扑图及权值分配法化简后的拓扑图Fig. 9 Random topology and topology simplified by weight allocation method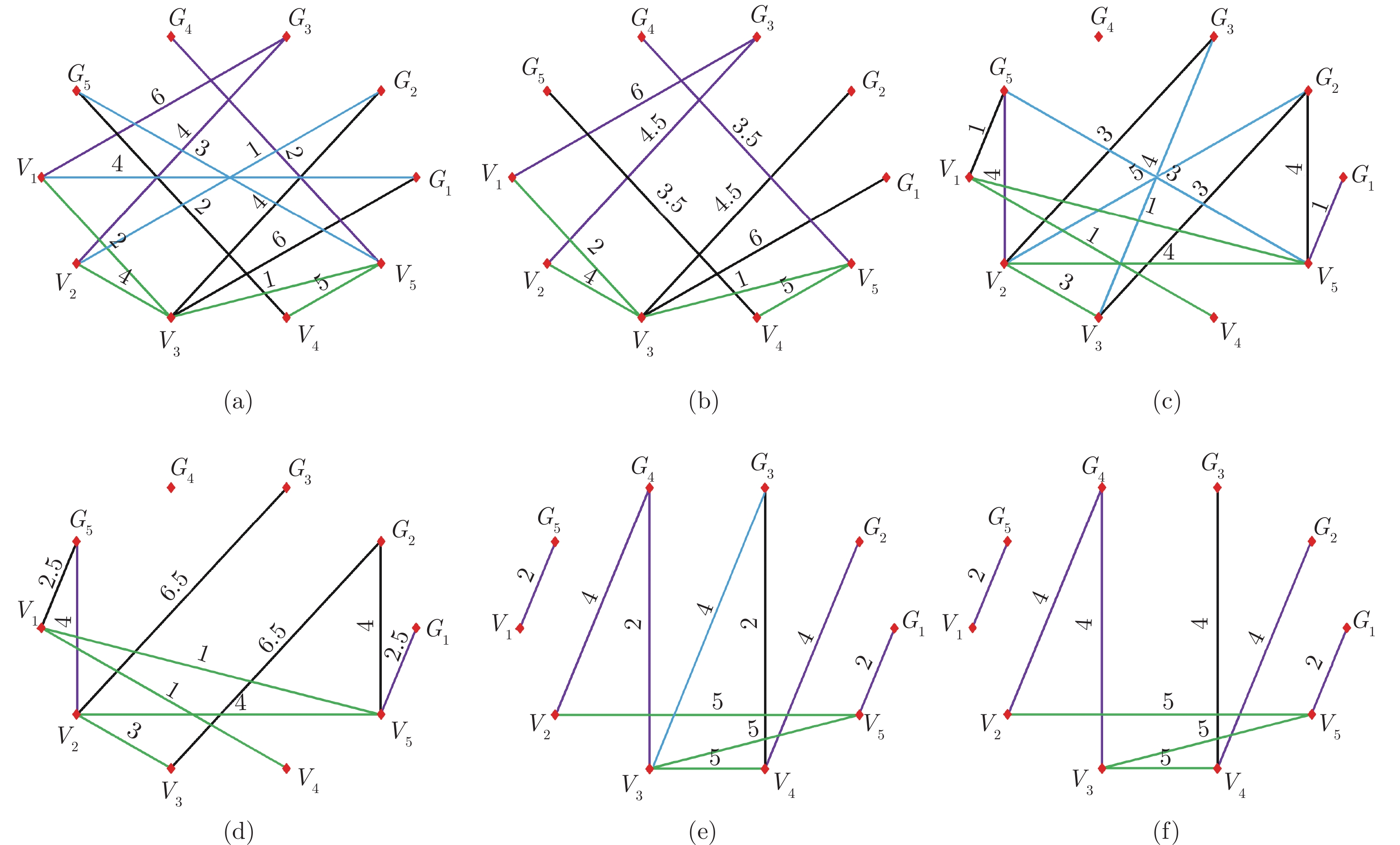 图 10 随机拓扑图及权值分配法化简后的拓扑图Fig. 10 Random topology and topology simplified by weight allocation method表 1 优化前后拓扑的指标函数值Table 1 Index function values of the topology before and after optimization
图 10 随机拓扑图及权值分配法化简后的拓扑图Fig. 10 Random topology and topology simplified by weight allocation method表 1 优化前后拓扑的指标函数值Table 1 Index function values of the topology before and after optimization仿真防御效果如图11和图12所示. 图11为IEEE-14节点系统转子角的仿真结果. 正常情况下, 在未受到FDIA时, 转子角在稳态值附近以非常小的幅值上下波动. 在不同的$ \Sigma_{2} $和$ \Sigma_{{\rm{eng}}} $选择下, 基于虚拟隐含网络的弹性防御转子角波动值不相同. 综合来说, 优化后的指标函数值越大, 防御的效果越好.
 图 12 IEEE-14节点系统角频率仿真图Fig. 12 Rotor angular frequency simulation diagram of IEEE-14 system
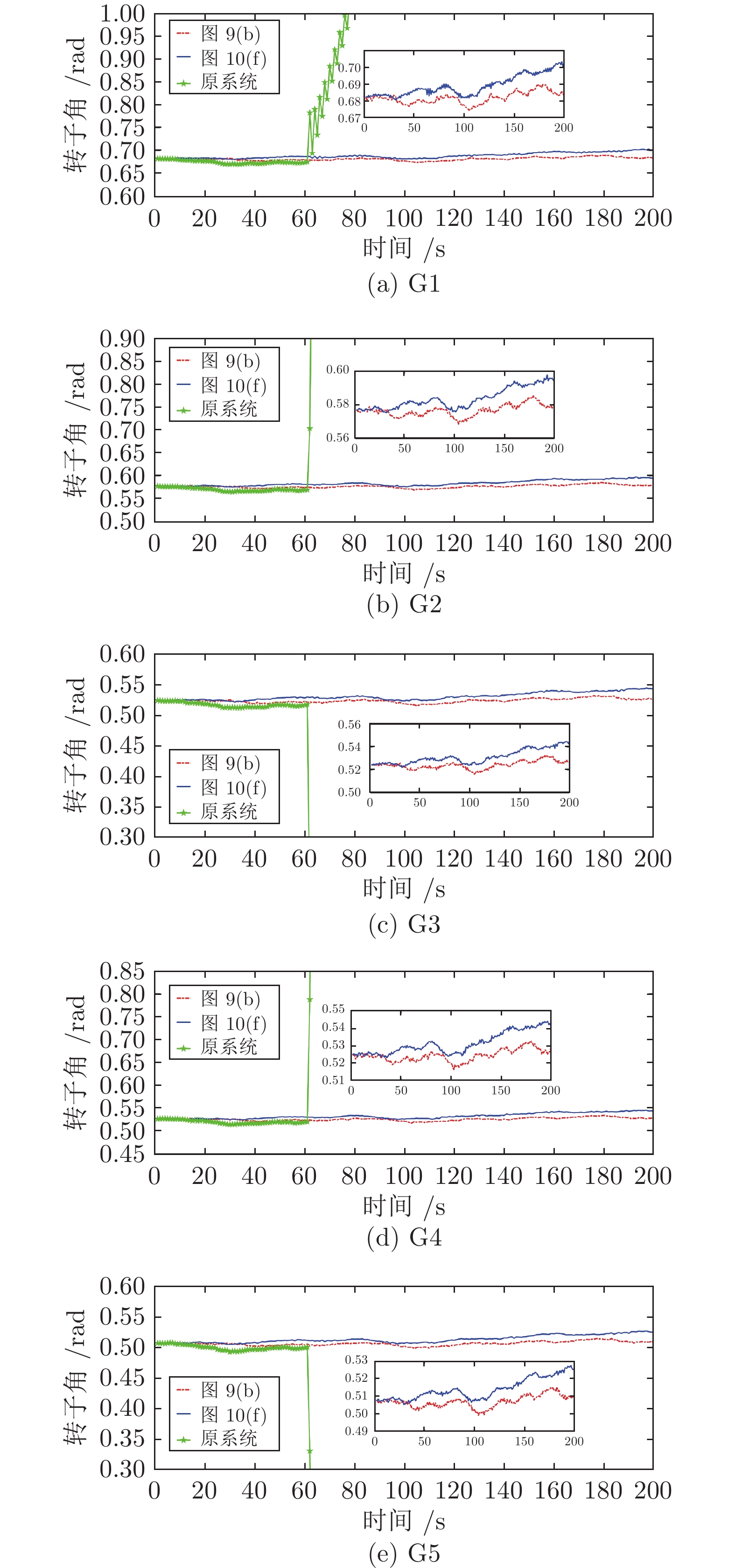
图 12 IEEE-14节点系统角频率仿真图Fig. 12 Rotor angular frequency simulation diagram of IEEE-14 system为了更好展示防御的效果, 选取优化后的指标函数值为$ 53.7803 $和$ 16.7136 $的两个具有代表性的拓扑选择进行仿真模拟. 图11(a)为发电机$ 14 $的仿真结果, 图中在第60 s受到FDIA后, 未加虚拟隐含网络防御的原系统转子角幅值剧烈变化, 智能电网处于不稳定运行状态. 应用了虚拟隐含网络的弹性防御策略后, 转子角幅值波动在允许范围内. 但由仿真结果可以看出, 采用图9(a)和图9(b)的拓扑结构, 其转子角的波动幅度比采用图10(e)和图10(f)的拓扑结构小得多. 图9(a)和图9(b)的可去边比图10(e)和图10(f)的可去边多, 且前者对应的优化指标函数值远大于后者, 因此, 可以通过可去边多少和考虑权值的指标函数优化防御效果. 图11(b)、11(c)、11(d)、11(e)分别表示发电机$ 2 $、$ 3 $、$ 4 $、$ 5 $的转子角变化, 它们的变化趋势与图11(a)是一致的.
图12为IEEE-14节点系统角频率的仿真结果. 在第60 s受到FDIA后, 未加虚拟隐含网络弹性控制器的原系统角频率剧烈震荡. 而采取虚拟隐含网络的弹性防御策略后, 有效抑制了角频率的震荡角, 角频率的波动幅值在0.1 rad/s以内, 系统运行状态在稳态范围内, 可以实现FDIA的有效防御. 图12(a)、12(b)、12(c)、12(d)、12(e)中, 在发生FDIA后, 优化后指标函数值为$ 16.7136 $的拓扑选择与值为$ 53.7803 $的拓扑选择相比, 角频率波动幅度均较大. 这表明, 图9(a)和图9(b)的拓扑结构可以更好地防御FDIA.
综上所述, 综合考虑转子角和角频率的情况, 图的可去边越多, 优化后的指标函数值越大, 防御效果越好; 图的可去边越少, 优化后的指标函数值越小, 相应的转子角或角频率波动幅度越大. 因此, 通过选择可去边多, 并且优化后的指标函数值越大的拓扑图$ \Sigma_{2} $和$ \Sigma_{{\rm{eng}}} $, 可以提高弹性防御的性能.
5. 结论和讨论
针对智能电网FDIA防御问题, 本文提出了基于连通度和权值的优化算法改善了基于虚拟隐含网络的防御性能. 首先, 针对连接网络的拓扑与二分图拉普拉斯矩阵之间无法一一对应的问题, 提出了权值分配法, 通过消除横路径, 并把横路径的权值平均分配给其他的回路边, 实现图与矩阵之间的一一对应. 其次, 分析了网络拓扑的连通度与系统可靠性之间的关系, 得出连通图可去边数量越多, 系统可靠性越高, 结构脆弱性越小的结论. 再次, 考虑了网络权值大小对控制成本的影响, 提出了考虑权值的优化指标函数, 通过最大化指标函数, 实现防御性能的优化.
本文所提的优化算法主要通过优化原电网系统与虚拟网络之间的路径来改善防御控制策略性能, 但还有一些问题需要进一步研究. 1) 本文仅仅考虑了具有双向流的电力网络, 因此, 还需进一步扩展对具有单向流−有向图的电力网络权值分配方法研究. 2) 随着电力网络规模的增大, 如何优化权值分配算法来减少其在实际应用中复杂度也是本文下一步急需解决的难点问题.
-

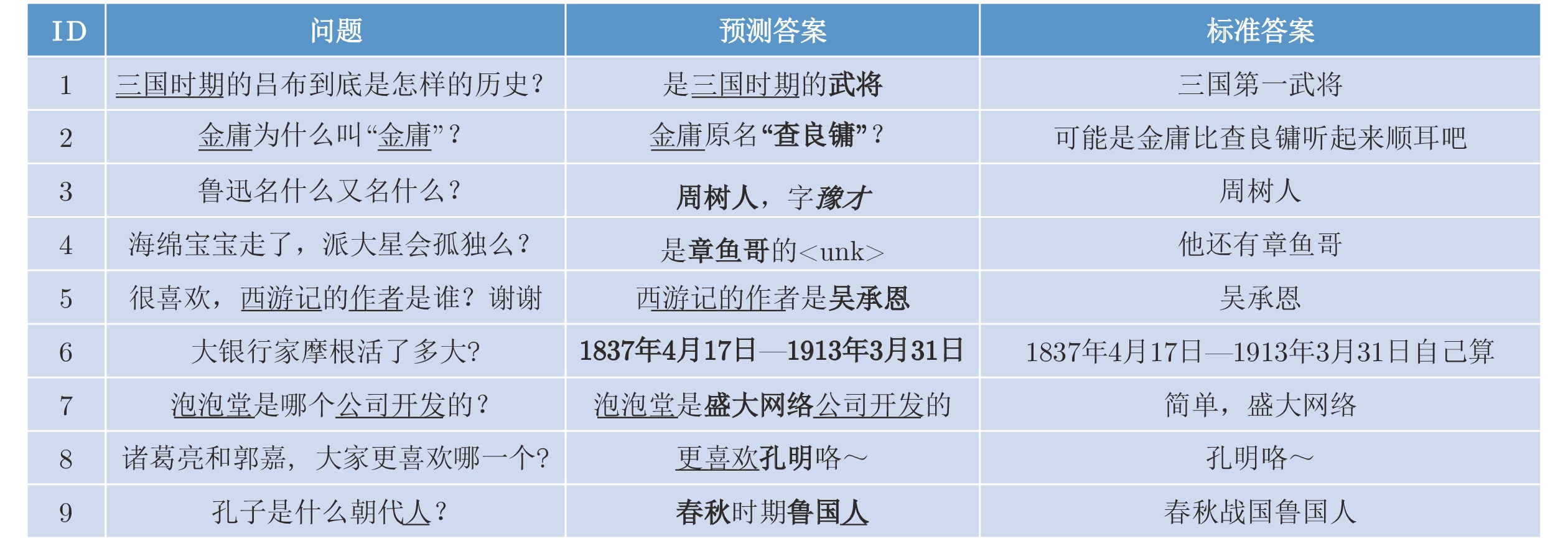
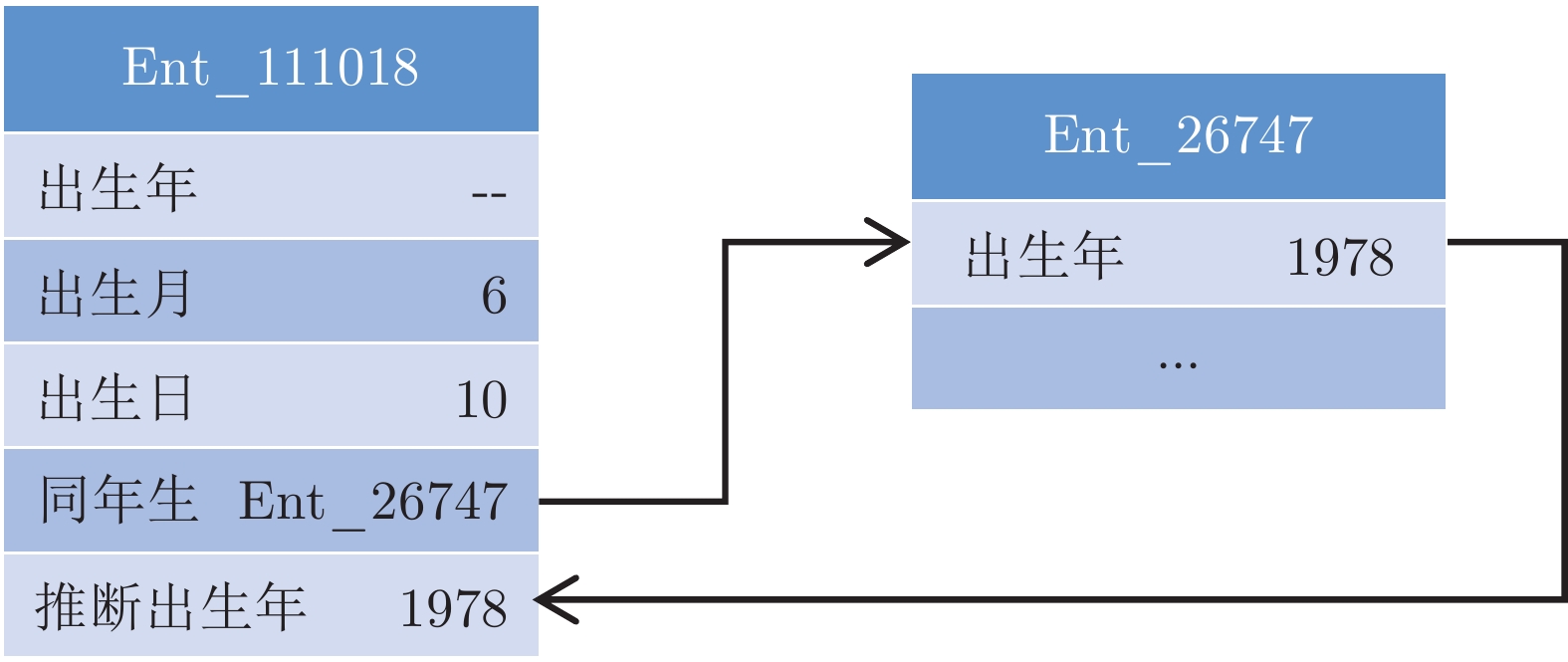
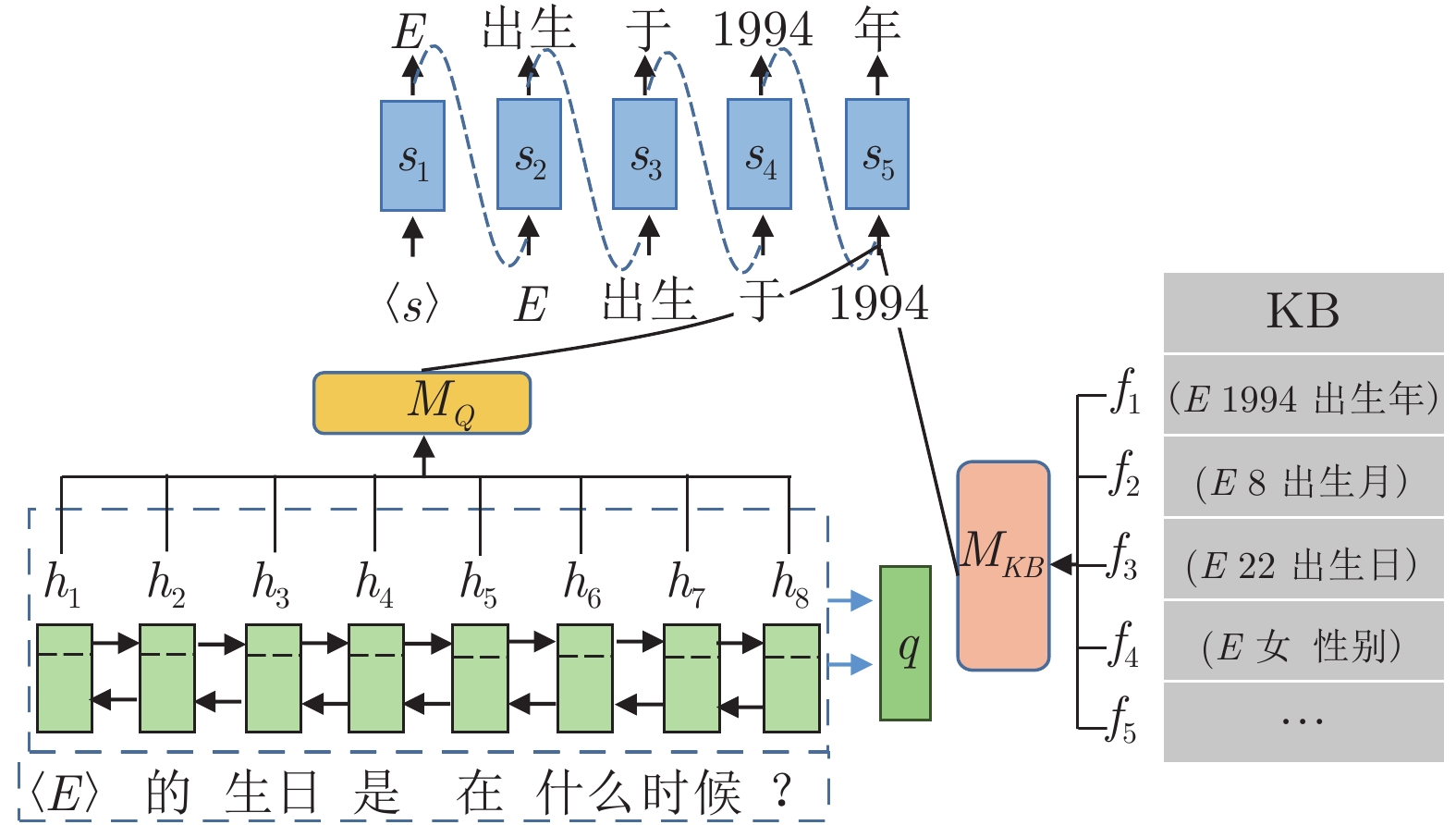
图 4 MCQA (TE, CE)与CoreQA 答案对比样例
Fig. 4 The comparison of MCQA (TE, CE) and CoreQA sample outputs
表 1 问答数据集规模
Table 1 The size of QA datasets
数据集 问答对数量 关系数量 SimpleQuestions 101 754 1 631 生日问答数据集 239 922 5 社区问答数据集 505 021 4 011  下载: 导出CSV
下载: 导出CSV
表 3 生日数据集实验结果 (%)
Table 3 The experimental results of birthday datasets (%)
方法 $ {{P}_{g}} $ $ {{P}_{y}} $ $ {{P}_{m}} $ $ {{P}_{d}} $ $ {{P}_{r}} $ Seq2Seq 67.3 — 23.4 — 37.2 NMT 71.6 — 27.1 — 54.7 CopyNet 75.2 — — — 71.9 GenQA (本文) 73.4 63.2 65.8 77.1 62.6 CoreQA 75.6 84.8 93.4 81 80.3 MCQA (WE, CE) 89.8 89.1 98.4 93.2 84.1 MCQA (TE, CE) 88.6 89.4 98.7 93.6 84.6
下载: 导出CSV
表 4 社区问答实验结果 (%)
Table 4 The experimental results of community QA datasets (%)
方法 正确性 流畅性 一致性 CopyNet — 19.4 21.3 GenQA (本文) 24.3 38.3 24.1 CoreQA 49.3 51.8 62.5 MCQA (WE, CE) 52.3 55.8 65.2 MCQA (TE, CE) 54.1 56.3 65.0
下载: 导出CSV
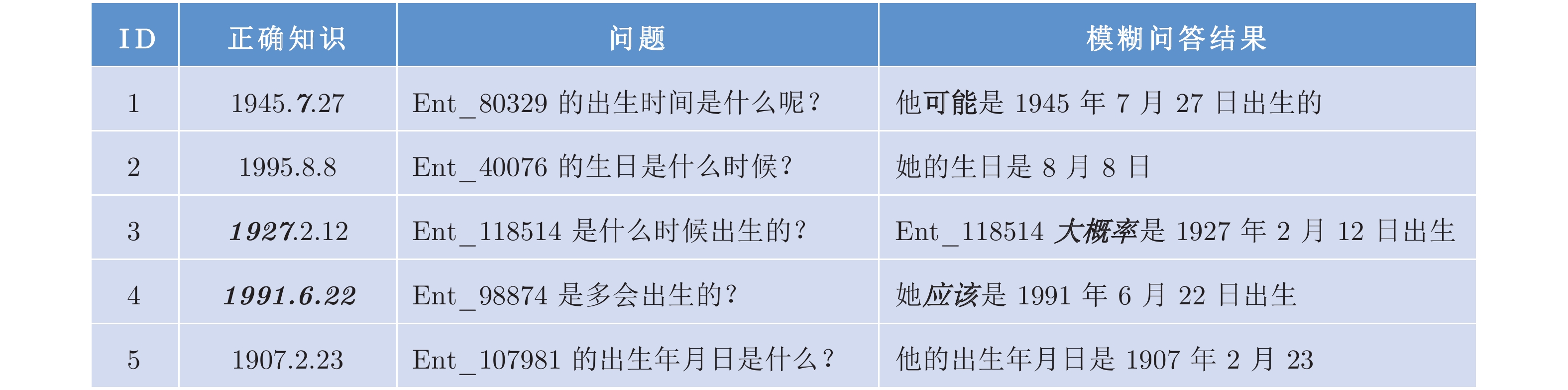
表 5 模糊问答推理结果 (%)
Table 5 The prediction results of ambiguously QA (%)
方法 $ {{P}_{y}} $ $ {{P}_{m}} $ $ {{P}_{d}} $ PTransE 93.2 97.4 95.0
下载: 导出CSV
表 6 模糊问答结果 (%)
Table 6 The results of ambiguously QA (%)
方法 $ {{F1}_{t}} $ $ {{P}_{y}} $ $ {{P}_{m}} $ $ {{P}_{d}} $ $ {{P}_{r}} $ MCQA (WE, CE) 87.7 78.1 88.2 90.8 80.9
下载: 导出CSV
-
[1] Vanessa L, Victoria U, Marta S, Enrico M. Is question answering fit for the semantic web?: A survey. Semantic Web, 2011, 2(2): 125-155 doi: 10.3233/SW-2011-0041 [2] Sydorova A, Poerner N, Roth B. Interpretable question answering on knowledge bases and text. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 4943−4951 [3] Cho K, Merriënboer B V, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: Association for Computational Linguistics, 2014. 1724−1734 [4] Gu J T, Lu Z D, Li H, Li V O K. Incorporating copying mechanism in sequence-to-sequence learning. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: the Association for Computational Linguistics, 2016. 1631−1640 [5] Gulcehre C, Ahn S, Nallapati R, Zhou B W, Bengio Y. Pointing the unknown words. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: the Association for Computational Linguistics, 2016. 140−149 [6] He S Z, Liu C, Liu K, Zhao J. Generating natural answers by incorporating copying and retrieving mechanisms in sequence-to-sequence learning. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: the Association for Computational Linguistics, 2017. 199−208 [7] 刘康, 张元哲, 纪国良, 来斯惟, 赵军. 基于表示学习的知识库问答研究进展与展望. 自动化学报, 2016, 42(6): 807-818Liu Kang, Zhang Yuan-Zhe, Ji Guo-Liang, Lai Si-Wei, Zhao Jun. Representation learning for question answering over knowledge base: an overview. Acta Automatica Sinica, 2016, 42(6): 807-818 [8] Tang X, Chen L, Cui J, Wei B. Knowledge representation learning with entity descriptions, hierarchical types, and textual relations. Information Processing & Management, 2019, 56(3): 809-822 [9] Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space. arXiv: 1301.3781, 2013. [10] Unger C, Freitas A, Cimiano P. An introduction to question answering over linked data. In: Proceedings of Reasoning on the Web in the Big Data Era — the 10th International Summer School. Athens, Greece: IEEE, 2014. 100−140 [11] Bast H, Haussmann E. More accurate question answering on freebase. In: Proceedings of the 24th International Conference on Information and Knowledge Management. Melbourne, VIC, Australia: ACM, 2015. 1431−1440 [12] Bordes A, Chopra S, Weston J. Question answering with subgraph embeddings. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014. 615−620 [13] Yih W, Chang M W, He X D, Gao J F. Semantic parsing via staged query graph generation: Question answering with knowledge base. In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing. Beijing, China: ACL, 2015. 1321−1331 [14] Sun Y W, Zhang L L, Cheng G, Qu Y Z. Sparqa: Skeleton-based semantic parsing for complex questions over knowledge bases. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: arXiv: 2003.13956, 2020. [15] Xu K, Wu L F, Wang Z G, Yu M, Chen L W, Sheinin V. Exploiting rich syntactic information for semantic parsing with graph-to-sequence model. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: ACL, 2018. 918−924 [16] Miller A, Fisch A, Dodge J, Karimi A H, Weston J. Key-value memory networks for directly reading documents. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas, USA: ACL, 2016. 1400−1409 [17] Bordes A, Usunier N, Chopra S, Weston J. Large-scale simple question answering with memory networks. arXiv: 1506.02075. 2015. [18] Yin J, Jiang X, Lu Z D, Shang L F, Li H, Li X M. Neural generative question answering. In: Proceedings of the 25th International Joint Conference on Artificial Intelligence. New York, USA: IJCAI/AAAI, 2016. 2972−2978 [19] Liu C, He S Z, Liu K, Zhao J. Curriculum learning for natural answer generation. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden: IJCAI/AAAI, 2018. 4223−4229 [20] Wang T Z, Cai M, Li J X. A neural conversational model using MMI-WMD decoder based on the Seq2Seq with attention mechanism. In: Proceedings of the 2019 Chinese Control and Decision Conference (CCDC). Nanchang, China: IEEE, 2019. 2696−2700 [21] Sharma A, Contractor D, Kumar H, Joshi S. Neural conversational QA: Learning to reason vs exploiting patterns. arXiv: 1909.03759, 2019. [22] Lei W Q, Jin X, Kan M Y, Ren Z C, He X N, Yin D W. Sequicity: Simplifying task-oriented dialogue systems with single sequence-to-sequence architectures. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: ACL, 2018. 1437−1447 [23] Rashkin H, Smith E M, Li M, Boureau Y L. Towards empathetic open-domain conversation models: A new benchmark and dataset. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 5370−5381 [24] Lin Y K, Liu Z Y, Sun M S. Modeling relation paths for representation learning of knowledge bases. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal: ACL, 2015. 705−714 [25] Quan W, Mao Z D, Wang B, Li G. Knowledge graph embedding: A survey of approaches and applications. IEEE Transactions on Knowledge & Data Engineering, 2017, 29(12): 2724-2743 [26] Bordes A, Weston J, Usunier N. Open question answering with weakly supervised embedding models. In: Proceedings of the 2014 Machine Learning and Knowledge Discovery in Databases European Conference. Nancy, France: Springer, 2014. 165−180 [27] Bahdanau D, Cho K Y, Bengio Y. Neural machine translation by jointly learning to align and translate. Arxiv: 1409.0473, 2014 [28] 冯冲, 石戈, 郭宇航, 龚静, 黄河燕. 基于词向量语义分类的微博实体链接方法. 自动化学报, 2016, 42(6): 915-922Feng C, Shi G, Guo YH, Gong J, Huang HY. An entity linking method for microblog based on semantic categorization by word embeddings. Acta Autom. Sinica, 2016, 42(6): 915-922 [29] Yin W P, Yu M, Xiang B, Zhou B, Schutze H. Simple question answering by attentive convolutional neural network. ArXiv: 1606.03391, 2016. [30] Yu M, Yin W P, Hasan K S, Santos C D, Xiang B, Zhou B W. Improved neural relation detection for knowledge base question answering. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: ACL, 2017. 571−581 [31] Deng Y, Xie Y X, Li Y L, Yang M, Shen Y. Multi-task learning with multi-view attention for answer selection and knowledge base question answering. In: Proceedings of the 33rd Conference on Artificial Intelligence. Honolulu, Hawaii, USA: AAAI, 2019. 6318−6325 期刊类型引用(7)
1. 钟林生,常玉清,王福利,高世红. 基于慢特征分析的分布式动态工业过程运行状态评价. 自动化学报. 2024(04): 745-757 .  本站查看
本站查看2. 刘金平,匡亚彬,赵爽爽,杨广益. 长短滑窗慢特征分析与时序关联规则挖掘的过渡过程识别. 智能系统学报. 2023(03): 589-603 . 百度学术3. 徐佳昀,吕立华,蒋嘉石,施逸非,姜庆超,颜学峰. 数据驱动弹簧钢脱碳影响要素分析与质量预测. 冶金自动化. 2022(05): 103-111 . 百度学术4. 赵春晖,胡赟昀,郑嘉乐,陈军豪. 数据驱动的燃煤发电装备运行工况监控——现状与展望. 自动化学报. 2022(11): 2611-2633 . 本站查看5. 苏树智,谢军,平昕瑞,高鹏连. 图强化典型相关分析及在图像识别中的应用. 电子与信息学报. 2021(11): 3342-3349 . 百度学术6. 陈路,郑丹,童楚东. 基于核函数及参数优化的KPLS质量预测研究. 电子技术应用. 2021(12): 100-104 . 百度学术7. 张化光,孙宏斌,刘德荣,王剑辉,孙秋野. “分布式信息能源系统”专题特约主编寄语. 中国电机工程学报. 2020(17): 5401-5403 . 百度学术其他类型引用(4)
-

 下载:
下载:

计量
- 文章访问数: 722
- HTML全文浏览量: 214
- PDF下载量: 279
- 被引次数: 11
