

-
摘要: 近年来, 基于卷积神经网络的目标检测研究发展十分迅速, 各种检测模型的改进方法层出不穷. 本文主要对近几年内目标检测领域中一些具有借鉴价值的研究工作进行了整理归纳. 首先, 对基于卷积神经网络的主要目标检测框架进行了梳理和对比. 其次, 对目标检测框架中主干网络、颈部连接层、锚点等子模块的设计优化方法进行归纳, 给出了各个模块设计优化的基本原则和思路. 接着, 在COCO数据集上对各类目标检测模型进行测试对比, 并根据测试结果分析总结了不同子模块对模型检测性能的影响. 最后, 对目标检测领域未来的研究方向进行了展望.Abstract: In recent years, research on object detection based on convolutional neural network has developed rapidly, and various improved algorithms and models have emerged one after another. This paper mainly summarizes some recent valuable research work in the field of object detection. Firstly, main object detection framework based on convolutional neural network is analyzed and compared. Secondly, the optimization methods of backbone, neck, anchors and other sub-modules are summarized, and the basic principles and ideas for the design and optimization of each modules are given. Thirdly, various objection detection models are tested and compared on the COCO dataset, effects of different sub-modules on the detector performance were analyzed according to the test results. Finally, future research direction in object detection is prospected.
-
Key words:
- Convolutional neural network /
- object detection /
- sub-module optimization
-
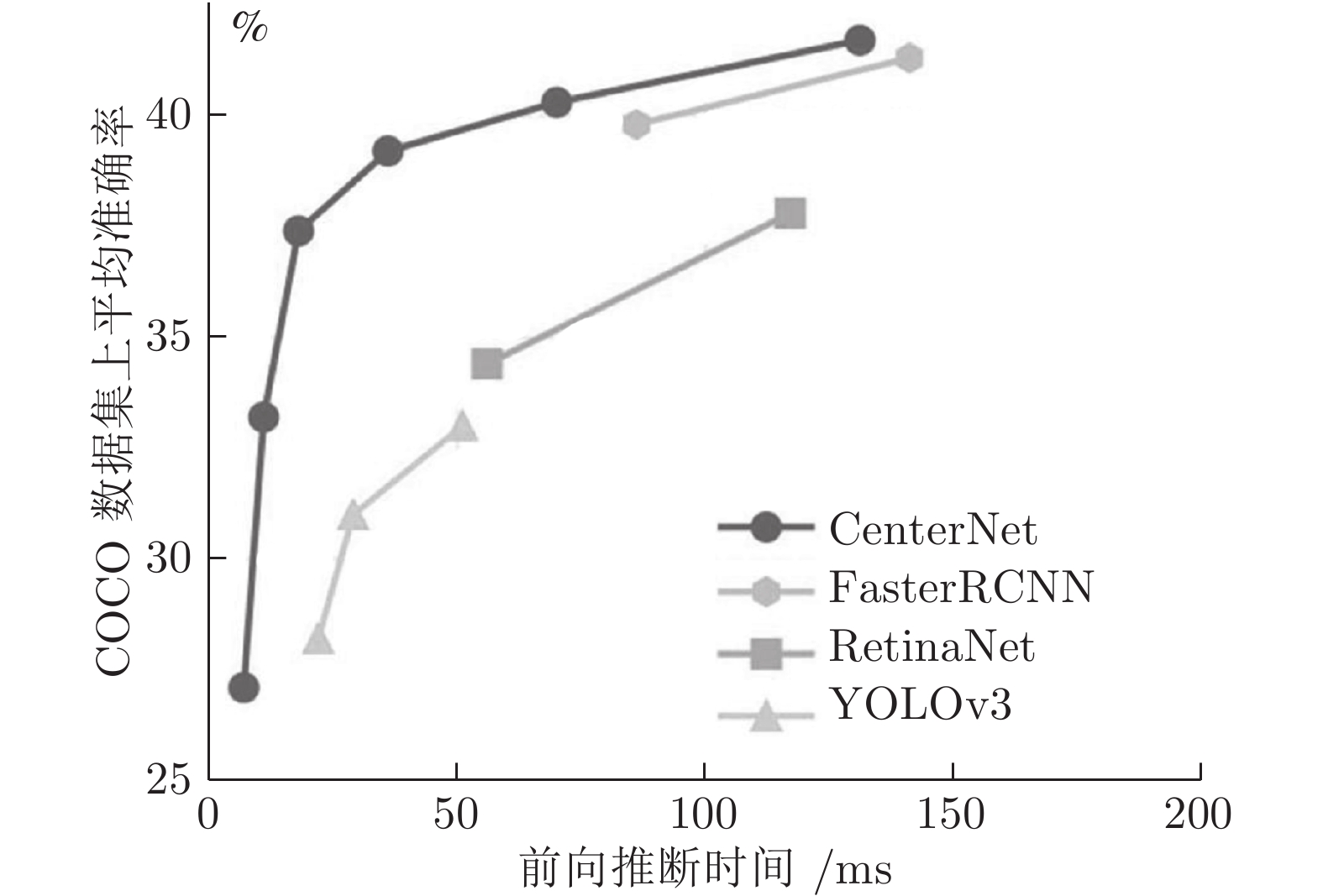
图 3 典型目标检测算法速度−准确率对比
Fig. 3 Speed-accuracy comparison of typical object detection algorithms
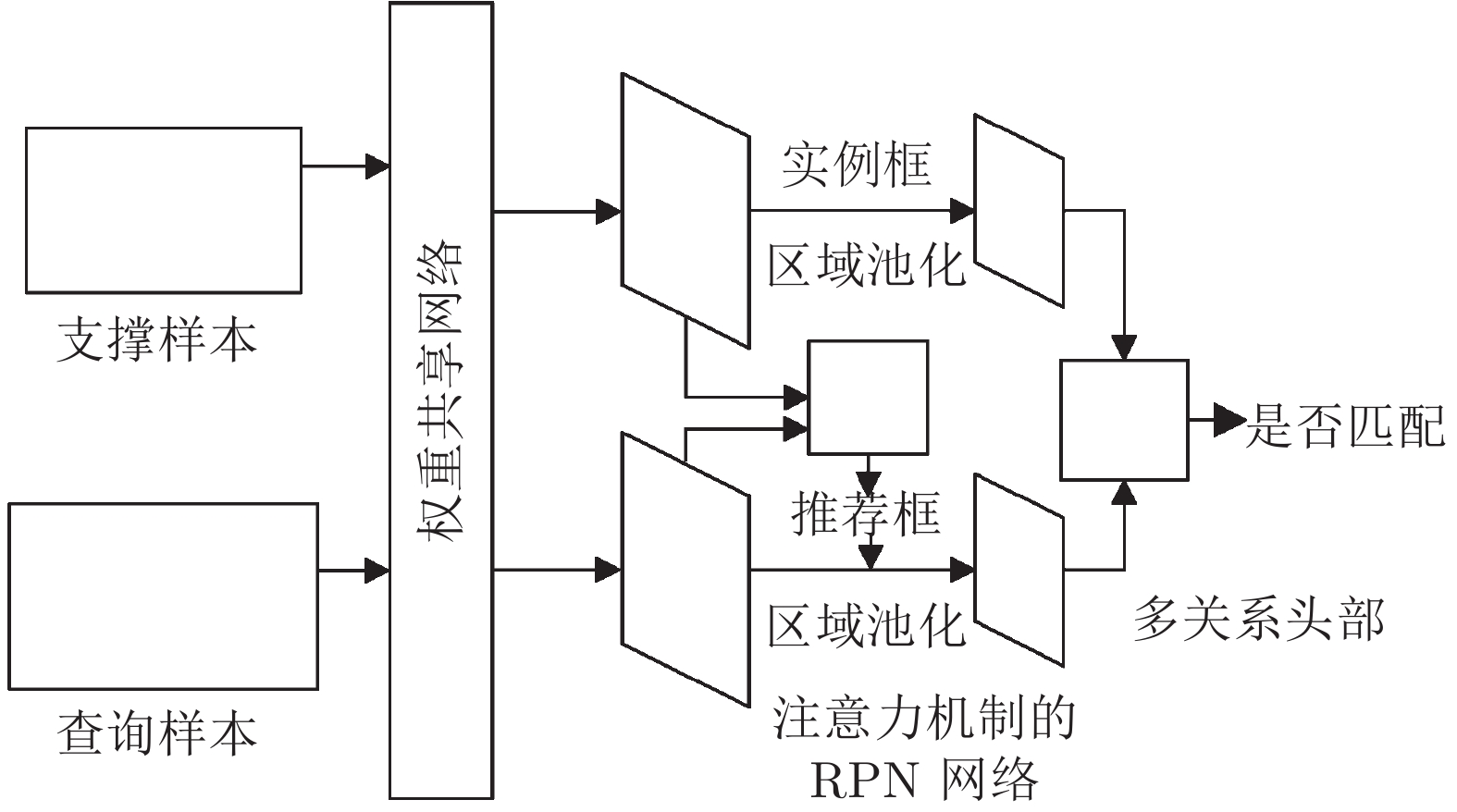
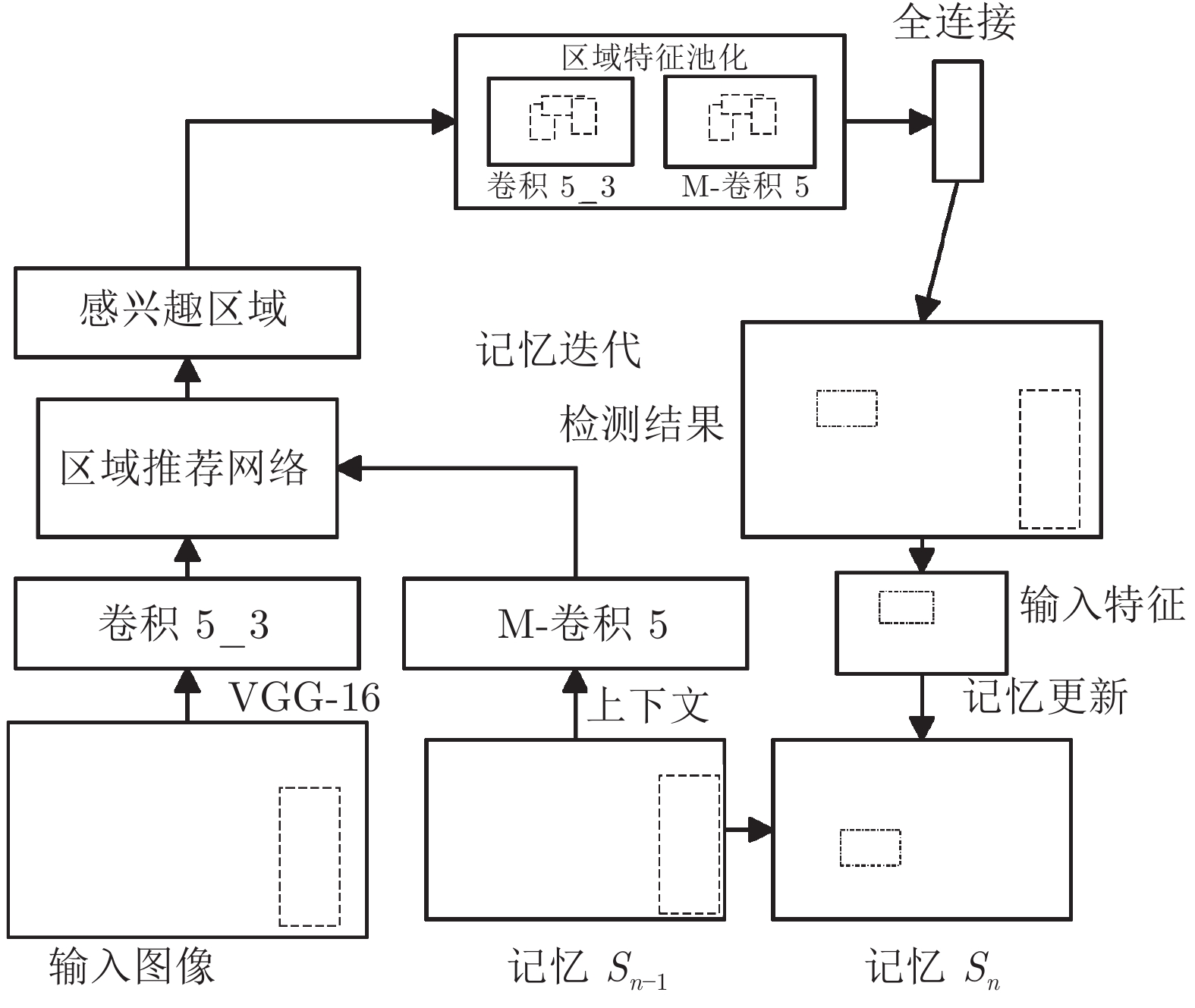
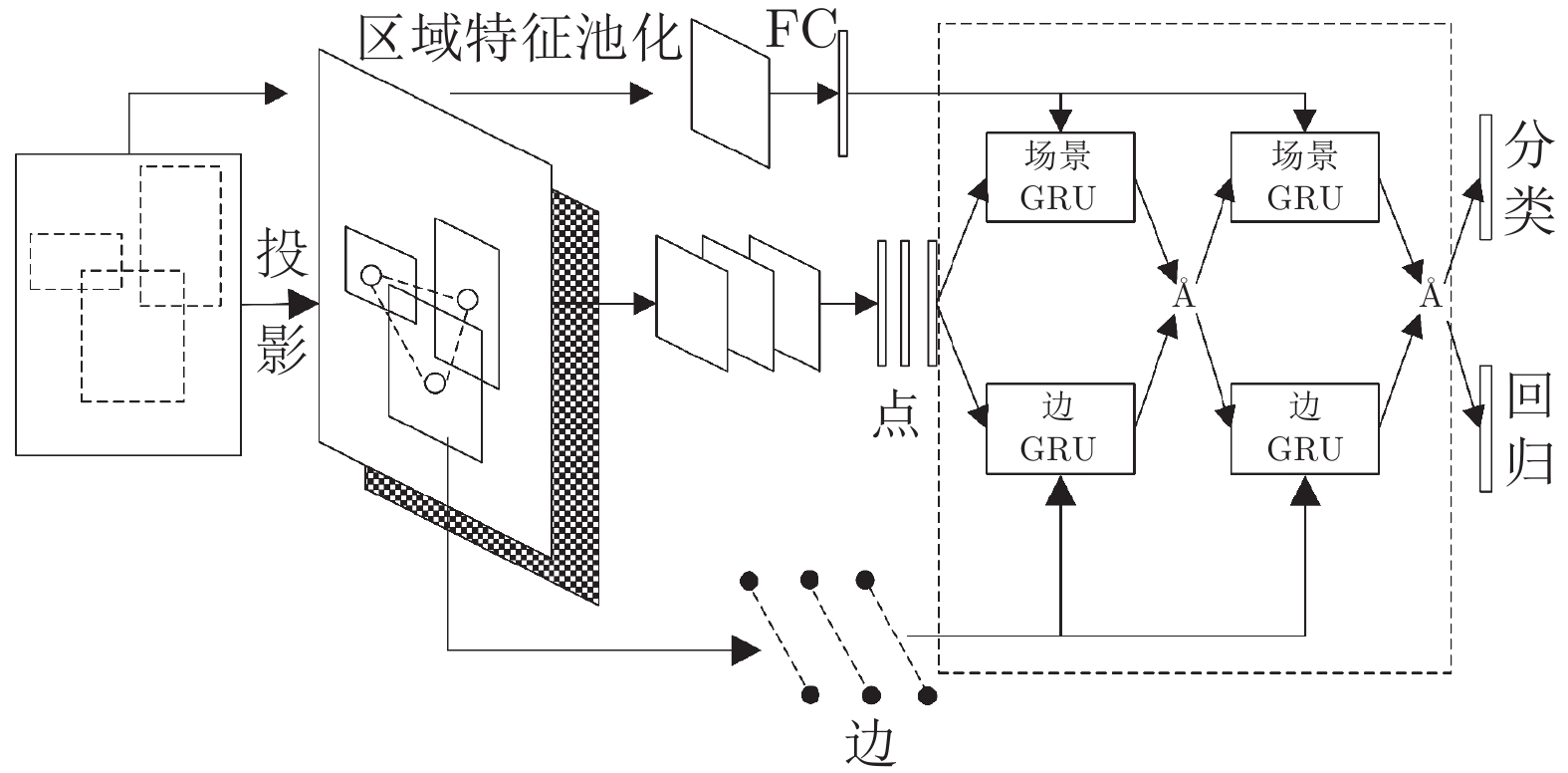
图 31 基于注意力机制RPN与多关系头部的少样本检测
Fig. 31 Attention-RPN and multi-relation head based few-shot detection
表 1 各检测模型的性能对比
Table 1 Performance comparison of different object detection models
模型 主干网络 AP AP50 AP75 APS APM APL Faster R-CNN VGG-16 21.9 42.7 — — — — Faster R-CNN R-101* 29.1 48.4 30.7 12.9 35.5 50.9 Faster R-CNN R-101-CBAM 30.8 50.5 32.6 — — — Faster R-CNN++ R-101-FPN 36.2 59.1 39.0 18.2 39.0 48.2 Faster R-CNN++ HR-W32 39.5 61.0 43.1 23.6 42.9 51.0 Faster-DCR V2 R-101 34.3 57.7 35.8 13.8 36.7 51.1 OHEM VGG-16 22.6 42.5 22.2 5.0 23.7 37.9 SIN VGG-16 23.2 44.5 22.0 7.3 24.5 36.3 ION VGG-16 23.6 43.2 22.6 6.4 24.1 38.3 Mask R-CNN R-101-FPN 38.2 60.3 41.7 20.1 41.1 50.2 Mask R-CNN HR-32 40.7 61.8 44.7 25.2 44.4 51.8 Mask R-CNN R-101-FPN+GC 40.8 62.1 45.5 24.4 43.7 51.9 SN-Mask R-CNN R-101-FPN 40.4 58.7 42.5 — — — IN-Mask R-CNN R-101-FPN 40.6 59.4 43.6 24.3 43.9 52.6 R-FCN R-101 29.9 51.9 — 10.8 32.8 45.0 CoupleNet R-101 34.4 54.8 37.2 13.4 38.1 50.8 Cascade R-CNN R-101 42.8 62.1 46.3 23.7 45.5 55.2 Libra R-CNN R-101-FPN 41.1 62.1 44.7 23.4 43.7 52.5 Grid R-CNN[100] X-101* 43.2 63.0 46.6 25.1 46.5 55.2 Light-Head R-CNN R-101 38.2 60.9 41.0 20.9 42.2 52.8 M2Det800 VGG-16 41.0 59.7 45.0 22.1 46.5 53.8 SSD512 VGG-16 28.8 48.5 30.3 10.9 31.8 43.5 GHM SSD X-101 41.6 62.8 44.2 22.3 45.1 55.3 YOLOV3 D-53* 33.0 57.9 34.4 18.3 35.4 41.9 YOLOV3 D-53 34.3 — 36.2 — — — RetinaNet X-101-FPN 39.0 59.4 41.7 22.6 43.4 50.9 GA-RetinaNet X-101-FPN 40.3 60.9 43.5 23.5 44.9 53.5 RefineDet512++ R-101-FPN 41.8 62.9 45.7 25.6 45.1 55.3 FCOS X-101-FPN 42.1 62.1 45.2 25.6 44.9 52.0 FoveaBox X-101-FPN 42.1 61.9 45.2 24.9 46.8 55.6 FSFA X-101-FPN 42.9 63.8 46.3 26.6 46.2 52.7 CornerNet HG-104* 40.5 56.5 43.1 19.4 42.7 53.9 ExtremeNet HG-104 40.2 55.5 43.2 20.4 43.2 53.1 CenterNet HG-104 42.1 61.1 45.9 24.1 45.5 52.8 RepPoints R-101 41.0 62.9 44.3 23.6 44.1 51.7 SNIP++ R-101 43.1 65.3 48.1 26.1 45.9 55.2 SNIPER++ R-101 46.1 67.0 51.6 29.6 48.9 58.1 TridentNet R-101 42.7 63.6 46.5 23.9 46.6 56.6 *注: R-ResNet, X-ResNeXt, HR-HRNet, D-DarkNet, HG-Hourglass. ++表示使用了多尺度、水平翻转等策略  下载: 导出CSV
下载: 导出CSV
表 2 部分检测模型的速度、显存消耗、参数量与计算量对比(基于Titan Xp)
Table 2 Speed, VRAM consumption, parameters and computation comparison of some object detection models (on Titan Xp)
模型 主干网络 训练速度 (s/iter) 显存消耗 (GB) 推理速度 (fps) 参数量 运算次数 Faster R-CNN++ R-101-FPN 0.465 5.7 11.9 60.52×106 283.14×109 Faster R-CNN++ HR-W32 0.593 5.9 8.5 45.0×106 245.3×109 Mask R-CNN R-101-FPN 0.571 5.8 9.4 62.81×106 351.65×109 Mask R-CNN x-101-FPN 0.759 7.1 8.3 63.17×106 355.4×109 Mask R-CNN R-101-FPN+GC 0.731 7.0 8.6 82.13×106 352.8×109 R-FCN R-101 0.400 5.6 14.6 — — Cascade R-CNN R-101-FPN 0.584 6.0 10.3 87.8×106 310.78×109 Cascade R-CNN X-101-FPN 0.770 8.4 8.9 88.16×106 314.53×109 Libra R-CNN R-101-FPN 0.495 6.0 10.4 60.79×106 284.19×109 Grid R-CNN X-101-FPN 1.214 6.7 10.0 82.95×106 409.19×109 M2Det800 VGG-16 — — 11.8 — — SSD512 VGG-16 0.412 7.6 20.7 36.04×106 386.02×109 GHM RetinaNet X-101-FPN 0.818 7.0 7.6 56.74×106 319.14×109 RetinaNet X-101-FPN 0.632 6.7 9.3 56.37×106 319.04×109 GA-RetinaNet X-101-FPN 0.870 6.7 7.5 56.01×106 283.13×109 FCOS R-101-FPN 0.558 9.4 11.6 50.96×106 276.53×109 CornerNet HG$-104^*$ — — 4.9 — — ExtremeNet HG-104 — — 3.1 — — CenterNet HG-104 — 11.91 8.5 — — RepPoints R-101 0.558 5.6 10.9 55.62×106 266.23×109 SNIP++ R-101 — — < 1.0 — — SNIPER++ R-101 — — 4.8 — — TridentNet R-101 0.985 6.6 2.1 — — *注: R-ResNet, X-ResNeXt, HR-HRNet, D-DarkNet, HG-Hourglass. ++表示使用了多尺度、水平翻转等策略
下载: 导出CSV
-
[1] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2): 91−110 doi: 10.1023/B:VISI.0000029664.99615.94 [2] Viola P, Jones M. Rapid object detection using a boosted cascade of simple features. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). Kauai, HI, USA: IEEE, 2001. I−511−I−518 [3] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). San Diego, CA, USA: IEEE, 2005. 886−893 [4] Girshick R, Donahue J, Darrell T, Malik J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 38(1): 142−158 [5] Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1440−1448 [6] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137−1149 [7] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y, et al. SSD: Single shot MultiBox detector. In: Proceedings of the 2016 European Conference on Computer Vision (ECCV). Amsterdam, The Netherlands: Springer, 2016. 21−37 [8] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 779−788 [9] Redmon J, Farhadi A. YOLO9000: Better, faster, stronger. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 6517−6525 [10] Redmon J, Farhadi A. YOLOv3: An incremental improvement. arXiv: 1804.02767, 2018 [11] Law H, Deng J. CornerNet: Detecting objects as paired keypoints. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 765−781 [12] Zhou X Y, Zhuo J C, Krähenbühl P. Bottom-up object detection by grouping extreme and center points. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 850−859 [13] Zhou X Y, Wang D Q, Krähenbühl P. Objects as points. arXiv: 1904.07850, 2019 [14] Yang Z, Liu S H, Hu H, Wang L W, Lin S. RepPoints: Point set representation for object detection. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 9656−9665 [15] Zhang S F, Wen L Y, Bian X, Lei Z, Li S Z. Single-shot refinement neural network for object detection. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 4203−4212 [16] Chi C, Zhang S F, Xing J L, Lei Z, Li S Z, Zou X D. Selective refinement network for high performance face detection. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI). Honolulu, Hawaii, USA: AAAI, 2019. 8231−8238 [17] Li Z M, Peng C, Yu G, Zhang X Y, Deng Y D, Sun J. Light-head R-CNN: In defense of two-stage object detector. arXiv: 1711.07264, 2017 [18] Simonyan K, Zisseman A. Very deep convolutional networks for large-scale image recognition. arXiv: 1409.1556, 2014 [19] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 770−778 [20] Xie S N, Girshick R, Dollár P, Tu Z W, He K M. Aggregated residual transformations for deep neural networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 5987−5995 [21] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 1−9 [22] Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 7132−7141 [23] Wang X L, Girshick R, Gupta A, He K M. Non-local neural networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 7794−7803 [24] Cao Y, Xu J R, Lin S, Wei F Y, Hu H. GCNet: Non-local networks meet squeeze-excitation networks and beyond. arXiv: 1904.11492, 2019 [25] Woo S, Park J, Lee J Y, So Kweon I. CBAM: Convolutional block attention module. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 3−19 [26] Lin T Y, Dollár P, Girshick R, He K M, Hariharan B, Belongie S. Feature pyramid networks for object detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 936−944 [27] Pan J M, Chen K, Shi J P, Feng H J, Ouyang W N, Lin D H. Libra R-CNN: Towards balanced learning for object detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 821−830 [28] Liu S, Qi L, Qin H F, Shi J P, Jia J Y. Path aggregation network for instance segmentation. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 8759−8768 [29] Zhao Q J, Sheng T, Wang Y T, Tang Z, Chen Y, Cai L, et al. M2det: A single-shot object detector based on multi-level feature pyramid network. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI). Honolulu, Hawaii, USA: AAAI, 2019. 9259−9266 [30] Tan M X, Pang R M, Le Q V. EfficientDet: Scalable and efficient object detection. arXiv: 1911.09070, 2020 [31] Newell A, Yang K Y, Deng J. Stacked hourglass networks for human pose estimation. In: Proceedings of the 2016 European Conference on Computer Vision (ECCV). Amsterdam, The Netherlands: Springer, Cham, 2016. 483−499 [32] Sun K, Xiao B, Liu D, Wang J D. Deep high-resolution representation learning for human pose estimation. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 5686−5696 [33] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions. arXiv: 1511.07122, 2016 [34] Zhu C C, Tao R, Luu K, Savvides M. Seeing small faces from robust anchor' s perspective. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 5127−5136 [35] Xie L L, Liu Y L, Jin L W, Xie Z C. DeRPN: Taking a further step toward more general object detection. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI). Honolulu, Hawaii, USA: AAAI, 2019. 9046−9053 [36] Zhong Y Y, Wang J F, Peng J, Zhang L. Anchor box optimization for object detection. arXiv: 1812.00469, 2020 [37] Wang J Q, Chen K, Yang S, Loy C C, Lin D H. Region proposal by guided anchoring. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 2960−2969 [38] Dai J F, Qi H Z, Xiong Y W, Zhang G D, Hu H, Wei Y C. Deformable convolutional networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 764−773 [39] Zhu X Z, Hu H, Lin S, Dai J F. Deformable ConvNets V2: More deformable, better results. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 9300−9308 [40] Tian Z, Shen C H, Chen H, He T. FCOS: Fully convolutional one-stage object detection. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 9626−9635 [41] Kong T, Sun F C, Liu H P, Jiang Y N, Li L, Shi J B. FoveaBox: Beyond anchor-based object detector. arXiv: 1904.03797, 2020 [42] Zhu C C, He Y H, Savvides M. Feature selective anchor-free module for single-shot object detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 840−849 [43] Zhu C C, Chen F Y, Shen Z Q, Savvides M. Soft anchor-point object detection. arXiv: 1911.12448, 2020 [44] Bodla N, Singh B, Chellappa R, Davis L S. Soft-NMS-improving object detection with one line of code. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICVV). Venice, Italy: IEEE, 2017. 5562−5570 [45] He Y H, Zhang X Y, Savvides M, Kitani K. Softer-NMS: Rethinking bounding box regression for accurate object detection. arXiv: 1809.08545, 2019 [46] Jiang B R, Luo R X, Mao J Y, Xiao T T, Jiang Y N. Acquisition of localization confidence for accurate object detection. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 816−832 [47] Liu Y, Liu L Q, Rezatofighi H, Do T T, Shi Q F, Reid I. Learning pairwise relationship for multi-object detection in crowded scenes. arXiv: 1901.03796, 2019 [48] Rezatofighi H, Tsoi N, Gwak J Y, Sadeghian A, Reid L, Savarese S. Generalized intersection over union: A metric and a loss for bounding box regression. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 658−666 [49] Cai Z W, Vasconcelos N. Cascade R-CNN: Delving into high quality object detection. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 6154−6162 [50] Shrivastava A, Gupta A, Girshick R. Training region-based object detectors with online hard example mining. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 761−769 [51] Yu H, Zhang Z N, Qin Z, Wu H, Li D S, Zhao J, et al. Loss Rank Mining: A general hard example mining method for real-time detectors. In: Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN). Rio de Janeiro, Brazil: IEEE, 2018. 1−8 [52] He K M, Gkioxari G, Dollár P, Girshick R. Mask R-CNN. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2020, 42(2): 386−397 [53] Dai J F, Li Y, He K M, Sun J. R-FCN: Object detection via region-based fully convolutional networks. In: Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS). Barcelona, Spain: Curran Associates Inc., 2016. 379−387 [54] Zhu Y S, Zhao C Y, Wang J Q, Zhao X, Wu Y, Lu H Q. CoupleNet: Coupling global structure with local parts for object detection. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 4146−4154 [55] Zhai Y, Fu J J, Lu Y, Li H Q. Feature selective networks for object detection. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 4139−4147 [56] Chen Y T, Han C X, Wang N Y, Zhang Z X. Revisiting feature alignment for one-stage object detection. arXiv: 1908.01570, 2019 [57] Cheng B W, Wei Y C, Shi H H, Feris R, Xiong J J, Huang T. Revisiting RCNN: On awakening the classification power of faster RCNN. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV). Munich, Germany: Springer. 2018. 473−490 [58] Cheng B W, Wei Y C, Feris R, Xiong J J, Hwu W M, Huang T, et al. Decoupled classification refinement: Hard false positive suppression for object detection. arXiv: 1810.04002, 2020 [59] Bell S, Zitnick C L, Bala K, Girshick R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 2874−2883 [60] Ouyang W L, Luo P, Zeng X Y, Qiu S, Tian Y L, Li H S, et al. DeepID-Net: Multi-stage and deformable deep convolutional neural networks for object detection. arXiv: 1409.3505, 2014 [61] Chen X L, Gupta A. Spatial memory for context reasoning in object detection. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 4106−4116 [62] Liu Y, Wang R P, Shan S G, Chen X L. Structure inference net: Object detection using scene-level context and instance-level relationships. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 6985−6994 [63] Hu H, Gu J Y, Zhang Z, Dai J F, Wei Y C. Relation networks for object detection. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 3588−3597 [64] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS). Long Beach, California, USA: Curran Associates Inc., 2017. 6000−6010 [65] Gidaris S, Komodakis N. Object detection via a multi-region and semantic segmentation-aware CNN model. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1134−1142 [66] Zeng X Y, Ouyang W L, Yang B, Yan J J, Wang X G. Gated bi-directional CNN for object detection. In: Proceedings of the 2016 European Conference on Computer Vision (ECCV). Amsterdam, The Netherlands: Springer, 2016. 354−369 [67] Luo W J, Li Y J, Urtasun R, Zemek R. Understanding the effective receptive field in deep convolutional neural networks. In: Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS). Barcelona, Spain: Curran Associates Inc., 2016. 4905−4913 [68] Lin T Y, Goyal P, Girshick R, He K M, Dollár P. Focal loss for dense object detection. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2999−3007 [69] Cai Z W, Fan Q F, Feris R S, Vasconcelos N. A unified multi-scale deep convolutional neural network for fast object detection. In: Proceedings of the 2016 European Conference on Computer Vision (ECCV). Amsterdam, The Netherlands: Springer, 2016. 354−370 [70] Yang F, Choi W, Lin Y Q. Exploit all the layers: Fast and accurate CNN object detector with scale dependent pooling and cascaded rejection classifiers. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 2129−2137 [71] Singh B, Davis L S. An analysis of scale invariance in object detection - SNIP. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 3578−3587 [72] Singh B, Najibi M, Davis L S. SNIPER: Efficient multi-scale training. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS). Montreal, Canada: Curran Associates Inc., 2018. 9333−9343 [73] Najibi M, Singh B, Davis L S. AutoFocus: Efficient multi-scale inference. arXiv: 1812.01600, 2018 [74] Li Y H, Chen Y T, Wang N Y, Zhang Z X. Scale-aware trident networks for object detection. arXiv: 1901.01892, 2019 [75] Chen L C, Papandreou G, Schroff F, Adam H. Rethinking atrous convolution for semantic image segmentation. arXiv: 1706.05587, 2017 [76] Chen K, Li J G, Lin W Y, See J, Wang J, Duan L Y, et al. Towards accurate one-stage object detection with AP-Loss. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 5114−5122 [77] Li B Y, Liu Y, Wang X G. Gradient harmonized single-stage detector. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI). Honolulu, Hawaii, USA: AAAI, 2019. 8577−8584 [78] Wang X L, Xiao T T, Jiang Y N, Shao S, Sun J, Shen C H. Repulsion loss: Detecting pedestrians in a crowd. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 7774−7783 [79] Yu J H, Jiang Y N, Wang Z Y, Cao Z M, Huang T. UnitBox: An advanced object detection network. In: Proceedings of the 24th ACM International Conference on Multimedia. Amsterdam, The Netherlands: ACM, 2016. 516−520 [80] Tychsen-Smith L, Petersson L. Improving object localization with fitness NMS and bounded IoU loss. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 6877−6885 [81] Ma J Q, Shao W Y, Ye H, Wang L, Wang H, Zheng Y B, et al. Arbitrary-oriented scene text detection via rotation proposals. IEEE Transactions on Multimedia, 2018, 20(11): 3111−3122 doi: 10.1109/TMM.2018.2818020 [82] Liao M H, Shi B G, Bai X. TextBoxes++: A single-shot oriented scene text detector. IEEE Transactions on Image Processing, 2018, 27(8): 3676−3690 doi: 10.1109/TIP.2018.2825107 [83] Zhou X Y, Yao C, Wen H, Wang Y Z, Zhou S C, He W R, et al. EAST: An efficient and accurate scene text detector. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 2642−2651 [84] Huang L C, Yang Y, Deng Y F, Yu Y N. DenseBox: Unifying landmark localization with end to end object detection. arXiv: 1509.04874, 2015 [85] Deng D, Liu H F, Li X L, Cai D. PixelLink: Detecting scene text via instance segmentation. arXiv: 1801.01315, 2018 [86] Xie E Z, Zang Y H, Shao S, Yu G, Yao C, Li G Y. Scene text detection with supervised pyramid context network. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI). Honolulu, Hawaii, USA: AAAI, 2019. 9038−9045 [87] Wang W H, Xie E Z, Li X, Hou W B, Lu T, Yu G, et al. Shape robust text detection with progressive scale expansion network. arXiv: 1903.12473, 2019 [88] Xia G S, Bai X, Ding J, Zhu Z, Belongie S, Luo J B, et al. DOTA: A large-scale dataset for object detection in aerial image. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 3974−3983 [89] Li K, Wan G, Cheng G, Meng L Q, Han J W. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159: 296−307 doi: 10.1016/j.isprsjprs.2019.11.023 [90] Yang F, Fan H, Chu P, Blasch E, Ling H B. Clustered object detection in aerial images. arXiv: 1904.08008, 2019 [91] Ding J, Xue N, Long Y, Xia G S, Lu Q K. Learning RoI transformer for oriented object detection in aerial images. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 2844−2853 [92] Qian W, Yang X, Peng S L, Guo Y, Yan J C. Learning modulated loss for rotated object detection. arXiv: 1911.08299, 2019 [93] Zhu Y X, Wu X Q, Du J. Adaptive period embedding for representing oriented objects in aerial images. arXiv: 1906.09447, 2019 [94] Zhang S S, Benenson R, Schiele B. CityPersons: A diverse dataset for pedestrian detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 4457−4465 [95] Shao S, Zhao Z J, Li B X, Xiao T T, Yu G, Zhang X Y, et al. CrowdHuman: A benchmark for detecting human in a crowd. arXiv: 1805.00123, 2018 [96] Pang Y W, Xie J, Khan M H, Anwer R M, Khan F S, Shao L. Mask-guided attention network for occluded pedestrian detection. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 4966−4974 [97] Zhang S F, Wen L Y, Bian X, Lei Z, Li S Z. Occlusion-aware R-CNN: Detecting pedestrians in a crowd. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 657−674 [98] Liu T R, Luo W H, Ma L, Huang J J, Stathaki T, Dai T H. Coupled network for robust pedestrian detection with gated multi-layer feature extraction and deformable occlusion handling. arXiv: 1912.08661, 2019 [99] Liu S T, Huang D, Wang Y H. Adaptive NMS: Refining pedestrian detection in a crowd. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 6452−6461 [100] Lu X, Li B Y, Yue Y X, Li Q Q, Yan J J. Grid R-CNN. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 7355−7364 [101] Zoph B, Vasudevan V, Shlens J, Le Q V. Learning transferable architectures for scalable image recognition. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 8697−8710 [102] Chen Y K, Yang T, Zhang X Y, Meng G F, Xiao X Y, Sun J. DetNAS: Backbone search for object detection. In: Proceedings of the 33rd Conference on Neural Information Processing Systems (NIPS). Vancouver, Canada: Margan Kaufmann Publishers, 2019. 6638−6648 [103] Ghiasi G, Lin T Y, Le Q V. NAS-FPN: Learning scalable feature pyramid architecture for object detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 7029−7038 [104] Wang N, Gao Y, Chen H, Wang P, Tian Z, Shen C H, et al. NAS-FCOS: Fast neural architecture search for object detection. arXiv: 1906.04423, 2020 [105] Fang J M, Sun Y Z, Peng K J, Zhang Q, Li Y, Liu W Y, et al. Fast neural network adaptation via parameter remapping and architecture search. arXiv: 2001.02525, 2020 [106] Karlinsky L, Shtok J, Harary S, Schwartz E, Aides A, Feris R, et al. RepMet: Representative-based metric learning for classification and few-shot object detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 5192−5201 [107] Fan Q, Zhuo W, Tang C K, Tai Y W. Few-shot object detection with attention-RPN and multi-relation detector. arXiv: 1908.01998, 2020 [108] Wang T, Zhang X P, Yuan L, Feng J S. Few-shot adaptive faster R-CNN. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 7166−7175 [109] Yan X P, Chen Z L, Xu A N, Wang X X, Liang X D, Lin L. Meta R-CNN: Towards general solver for instance-level low-shot learning. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 9576−9585 [110] Kang B Y, Liu Z, Wang X, Yu F, Feng J S, Darrell T. Few-shot object detection via feature reweighting. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 8419−8428 [111] Inoue N, Furuta R, Yamasaki T, Aizawa K. Cross-domain weakly-supervised object detection through progressive domain adaptation. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 5001−5009 [112] RoyChowdhury A, Chakrabarty P, Singh A, Jin S Y, Jiang H Z, Cao L L, et al. Automatic adaptation of object detectors to new domains using self-training. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 780−790 [113] Kim S, Choi J, Kim T, Kim C. Self-training and adversarial background regularization for unsupervised domain adaptive one-stage object detection. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 6091−6100 [114] Chen Y H, Li W, Sakaridis C, Dai D X, van Gool L. Domain adaptive faster R-CNN for object detection in the wild. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 3339−3348 [115] Saito K, Ushiku Y, Harada T, Saenko K. Strong-Weak distribution alignment for adaptive object detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 6949−6958 [116] Zhu X G, Pang J M, Yang C Y, Shi J P, Lin D H. Adapting object detectors via selective cross-domain alignment. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 687−696 [117] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2242−2251 [118] Howard A G, Zhu M L, Chen B, Kalenichenko D, Wang W J, Weyand T, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv: 1704.04861, 2017 [119] Sandler M, Howard A, Zhu M L, Zhmoginov A, Chen L C. MobileNetV2: Inverted residuals and linear bottlenecks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 4510−4520 [120] Howard A, Sandler M, Chen B, Wang W J, Chen L C, Tan M X, et al. Searching for MobileNetV3. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 1314−1324 [121] Zhang X Y, Zhou X Y, Lin M X, Sun J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 6848−6856 [122] Ma N N, Zhang X Y, Zheng H T, Sun J. ShuffleNet V2: Practical guidelines for efficient CNN architecture design. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 122−138 [123] Zhang T, Qi G J, Xiao B, Wang J D. Interleaved group convolutions. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 4383−4392 [124] Qin Z, Li Z M, Zhang Z N, Bao Y P, Yu G, Peng Y X, et al. ThunderNet: Towards real-time generic object detection on mobile devices. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 6717−6726 [125] Zhang P Y, Zhong Y X, Li X Q. SlimYOLOv3: Narrower, faster and better for real-time UAV applications. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). Seoul, Korea: IEEE, 2019. 37−45 [126] Bilen H, Vedaldi A. Weakly supervised deep detection networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 2846−2854 [127] Kantorov V, Oquab M, Cho M, Laptev I. ContextLocNet: Context-aware deep network models for weakly supervised localization. In: Proceedings of the 2016 European Conference on Computer Vision (ECCV). Amsterdam, The Netherlands: Springer, 2016. 350−365 [128] Tang P, Wang X G, Bai S, Shen W, Bai X, Liu W Y, et al. PCL: Proposal cluster learning for weakly supervised object detection. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2020, 42(1): 176−191 [129] Diba A, Sharma V, Pazandeh A, Pirsiavash H, van Gool L. Weakly supervised cascaded convolutional networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 5131−5139 [130] Li Y, Liu L Q, Shen C H, van den Hengel A. Image co-localization by mimicking a good detector' s confidence score distribution. In: Proceedings of the 2016 European Conference on Computer Vision (ECCV). Amsterdam, The Netherlands: Springer, 2016. 19−34 [131] Yang K, Li D S, Dou Y. Towards precise end-to-end weakly supervised object detection network. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea: IEEE, 2019. 8371−8380 [132] Wan F, Wei P X, Jiao J B, Han Z J, Ye Q X. Min-entropy latent model for weakly supervised object detection. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 1297−1306 [133] Zhou B L, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 2921−2929 [134] Zhang X L, Wei Y C, Feng J S, Yang Y, Huang T. Adversarial complementary learning for weakly supervised object localization. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, Utah, USA: IEEE, 2018. 1325−1334 [135] Choe J, Shim H. Attention-based dropout layer for weakly supervised object localization. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019. 2214−222 -

 下载:
下载:











计量
- 文章访问数: 3926
- HTML全文浏览量: 4201
- PDF下载量: 1681
- 被引次数: 0
