

One-shot Learning Classification and Recognition of Gesture Expression From the Egocentric Viewpoint in Intelligent Human-computer Interaction
-
摘要: 在智能人机交互中, 以交互人的视角为第一视角的手势表达发挥着重要作用, 而面向第一视角的手势识别则成为最重要的技术环节. 本文通过深度卷积神经网络的级联组合, 研究复杂应用场景中第一视角下的一次性学习手势识别(One-shot learning hand gesture recognition, OSLHGR)算法. 考虑到实际应用的便捷性和适用性, 运用改进的轻量级SSD (Single shot multibox detector)目标检测网络实现第一视角下手势目标的快速精确检测; 进而, 以改进的轻量级U-Net网络为主要工具进行复杂背景下手势目标的像素级高效精准分割. 在此基础上, 以组合式3D深度神经网络为工具, 研究提出了一种第一视角下的一次性学习手势动作识别的网络化算法. 在Pascal VOC 2012数据集和SoftKinetic DS325采集的手势数据集上进行的一系列实验测试结果表明, 本文所提出的网络化算法在手势目标检测与分割精度、分类识别准确率和实时性等方面都有显著的优势, 可为在复杂应用环境下实现便捷式高性能智能人机交互提供可靠的技术支持.Abstract: In intelligent human-computer interaction (HCI), the expression of gestures with the perspective of the interactive person as the egocentric viewpoint plays an important role, while gesture recognition from the egocentric viewpoint becomes the most important technical link. In this paper, one-shot learning hand gesture recognition (OSLHGR) algorithm under the egocentric viewpoint in complex application scenarios is studied through the cascade combination of deep convolutional neural networks (CNN). Considering the convenience and applicability of practical applications, the improved lightweight SSD (single shot multibox detector) detection network was utilized to achieve rapid and accurate gesture object detection. Furthermore, the improved lightweight U-Net network is used as the main tool to perform pixel-level efficient and accurate segmentation of gesture targets in complex backgrounds. On the basis of U-Net results, a networked algorithm for OSLHGR from the egocentric viewpoint is proposed by using the combined 3D deep neural network. A series of experimental results on the Pascal VOC 2012 dataset and the gesture dataset collected by SoftKinetic DS325 show that the proposed networked algorithm has significant advantages in gesture target detection and segmentation precision, classification accuracy and real-time performance. It can provide reliable technical support for the realization of convenient and high-performance intelligent HCI in complex application environment.
-
水面无人艇是一种无需人工操作的自主水面舰艇, 具有自主性强、成本低、灵活性高等优势. 它可以在危险或人类难以进入的水域执行任务, 广泛应用于民用和军事领域. 例如, 在环境监测、渔业管理、海上搜救、物流运输、通信中继、侦察监视及巡逻防御等方面发挥重要作用[1-6]. 然而, 由于单个无人艇的执行能力有限, 往往难以胜任复杂水域任务. 在此背景下, 多无人艇(Multiple unmanned surface vehicle, Multi-USV)协同作业正逐渐成为未来的发展趋势. 在协同作业中, 多艘无人艇通过协同工作, 共同完成复杂水域任务, 如大范围的海洋协同监测、搜索与救援、水下地形协同测绘和水下目标协同探测等. 值得注意的是, 在某些实际应用场景中, 通过引入无人艇之间的竞争交互机制, 可以有效提升多无人艇协同作业的能力[7-8]. 在这种情形下, 底层信息交互拓扑图往往被建模为符号图. 特别地, 二分编队跟踪控制是符号图下多无人艇系统编队控制领域的基础研究课题之一, 旨在设计一组分布式控制协议, 使得多无人艇系统能够以预设的二分编队构型跟踪参考轨迹[8].
在多无人艇系统编队控制领域, 基于反推控制方法的研究成果丰硕[5, 9-12]. 反推控制是一种基于Lyapunov 理论的递归控制方案设计方法, 自20世纪90年代起便受到系统与控制领域学者们的广泛关注[13-15]. 该方法通过将高阶非线性系统拆分为多个较为简单的低阶系统, 并引入虚拟控制器和参数自适应更新律, 以确保闭环系统的稳定性, 从而逐步推导出实际控制器[14]. 然而, 反推控制方法在控制器设计过程中通常需要使用参考轨迹的高阶导数, 并对系统动力学模型的要求较高. 为了克服这些挑战, 文献[16] 引入命令滤波技术, 避免对虚拟控制器求导, 显著降低了计算负担, 简化了控制律的设计和形式, 从而使得该方法能够适用于更广泛的非线性系统. 然而, 基于命令滤波反推方法的多无人艇系统二分编队跟踪控制的研究目前见诸文献的结果还相对较少.
如文献[17-18] 所述, 无人艇在执行实际任务时, 往往会受到风、浪、水流等环境因素的干扰, 这些因素可能导致无人艇的运行不稳定甚至引发事故. 为了增强控制系统的稳定性和鲁棒性, 考虑模型不确定性变得尤为重要. 在处理具有模型不确定性的非线性系统控制问题时, 确保参数收敛性是一个核心环节, 因为它能够提升闭环系统的整体稳定性和鲁棒性. 传统基于梯度下降法的参数自适应律设计方法, 存在参数漂移的潜在威胁. 在此基础上, 添加阻尼项可以有效抑制其影响, 但是在这种参数自适应律设计方法下人们往往难以证明闭环系统的渐近稳定性. 此外, 在传统的自适应控制中, 必须满足一个严格的持续激励 (Persistent excitation, PE) 条件, 以保证参数的收敛性. 然而, 在实际场景下, PE条件通常难以验证. 为了放松PE条件, 在文献[19]和文献[20]中分别提出了并行学习和复合学习技术, 在较弱的区间激励(Interval excitation, IE) 条件下, 确保了参数的收敛性. 此外, 与并行学习方法相比, 由于复合学习自适应律的设计不依赖于系统状态的导数, 在实际应用中往往更具有优势. 另一方面, 无人艇在执行任务时通常要求快速的控制响应. 引入有限时间或固定时间控制技术[21-22] 可以使受控系统在有限时间内达成目标. 此外, 有限时间及固定时间控制技术不仅可以保证跟踪误差的快速收敛, 而且对不确定性具有良好的鲁棒性.
基于以上讨论, 本文针对模型参数不确定下多无人艇系统的固定时间二分编队跟踪控制问题, 提出一组融合命令滤波、复合学习及反推控制技术的分布式控制协议. 本文的贡献可以概括为以下两个方面: 在反推控制方法中引入命令滤波, 有效地避免了对虚拟控制器求导, 极大地降低了计算负担, 且简化了分布式控制协议的形式; 在反推控制方法中引入复合学习, 使得提出的控制协议在不满足PE条件的情况下, 不仅能够确保编队误差的固定时间收敛性, 也能够确保参数估计误差的固定时间收敛性.
本文使用的符号: $ {\bf{R}}^n $和$ {\bf{R}}^{n\times m} $分别表示 $ n $ 维向量空间和$ n\times m $ 阶实矩阵的集合; $ {\rm diag}\{R_i\}= {\rm diag}\{R_1,\;\cdots,\;R_N\} $表示块对角矩阵, 其中矩阵$ R_1,\;\cdots,\;R_N\in{\bf{R}}^{n\times n} $ 在该矩阵的对角线上; $ \varnothing $ 表示空集; $ \Vert\cdot\Vert $ 表示向量的$ 2 $ 范数; $ {\rm sign}(\cdot) $ 表示符号函数; $ |\cdot| $ 表示标量的绝对值; $ \otimes $ 表示Kronecker积; 给定向量函数$ \delta(t)=(\delta_1(t),\;\cdots,\;\delta_N(t))^{\mathrm{T}}\in{\bf{R}}^{N} $和常数$ \gamma > 0 $, 定义$ {\rm sig}\{\delta(t)\}^{\gamma} = (|\delta_1(t)|^{\gamma}{\rm sign}(\delta_1(t)),\; \cdots,$ $ |\delta_N(t)|^{\gamma}{\rm sign}(\delta_N(t)))^{\rm T} $; 给定对称矩阵$ Q\in{\bf{R}}^{m\times m} $, $ Q>{\bf{0}} $ 表示$ Q $ 是正定矩阵, $ \lambda_{\min}(Q),\; $ $ \lambda_{\max}(Q) $ 分别表示对称矩阵$ Q $ 的最小和最大特征值; $ I_n $ 表示$ n $ 维单位矩阵.
1. 预备知识和问题描述
1.1 代数图论
给定一个符号无向图$ {\cal{G}}=({\cal{I}},\; {\cal{E}},\; {\cal{A}}) $ 用以描述多无人艇系统的通信情况, 其中, $ {\cal{I}}=\{1,\; 2,\; \cdots,\; N\} $, $ {\cal{E}}=\{(i,\; j): i,\;j\in{\cal{I}}\} \subseteq{\cal{I}}\times{\cal{I}} $ 和$ {\cal{A}}=[a_{ij}]\in {\bf{R}}^{N\times N} $分别表示节点集、边集和符号邻接矩阵, 满足: 若$ (j,\;i)\in{\cal{E}} $ 则表示智能体$ i $可以接收到智能体 $ j $的信息, 否则表示不能接收到; 若$ i\neq j $ 且$ (j,\; i)\in{\cal{E}} $ 则$ a_{ij}\neq 0 $, 否则$ a_{ij}=0 $. 节点 $ i $ 的邻居集定义为$ {\cal{N}}_i=\{j: a_{ij}\neq 0\} $. 通信拓扑图的 Laplacian 矩阵定义为$ {\cal{L}}={\rm diag}\Big\{\sum\nolimits_{j\in{\cal{N}}_i}|a_{ij}|\Big\}-{\cal{A}} $. 给定一个包含$ N+1 $ 个节点的符号有向图$ {\cal{\bar{G}}}=({\cal{\bar{I}}},\;{\cal{\bar{E}}}) $, 其中, $ {\cal{\bar{I}}}= {\cal{I}}\cup\{0\} $; $ {\cal{\bar{E}}}\subseteq {\cal{I}} \times{\cal{I}} $; 节点0表示领航无人艇, 它仅向跟随无人艇传递信息而不接收信息. 牵引矩阵记为$ {\cal{B}}={\rm diag}\{b_i\} $, 满足: 若无人艇$ i $能接收到领航者的信息则$ b_i>0 $; 否则, $ b_i=0 $.
定义 1[23]. 若存在节点集的划分$ {\cal{I}}_1,\; {\cal{I}}_2 $ 满足: 1) $ {\cal{I}}_1\cup{\cal{I}}_2={\cal{I}} $; 2) $ {\cal{I}}_1\cap{\cal{I}}_2=\varnothing $; 3) 若$ i,\;j $ 同属于一个集合$ {\cal{I}}_1 $或$ {\cal{I}}_2 $, 则$ a_{ij}\geq 0 $, 否则$ a_{ij}\leq 0 $, 则符号图$ {\cal{G}} $被称作结构平衡的.
引入对角矩阵$ E={\rm diag}\{\varepsilon_i\} $, 其中, $ \varepsilon_i=1,\; i\in {\cal{I}}_1 $; $ \varepsilon_i=-1,\; i\in{\cal{I}}_2 $. 定义$ {\cal{\tilde{L}}}=E{\cal{L}}E $.
1.2 固定时间稳定性
定义2[24]. 给定如下非线性系统
$$ \dot{x}(t)=f(t,\;x(t)) $$ 式中, $ x(t)\in{\bf{R}}^n,\; f(t,\;x(t))\in{\bf{R}}^n $分别表示系统状态和局部 Lipschitz 连续函数. 若该系统的原点是全局渐进稳定的, 且存在与状态初值无关的时刻$ T $满足$ x(t)=0,\; \forall t\geq T $, 则称原点是固定时间稳定的.
引理 1[25]. 若存在常数$ c_1,\;c_2,\; m_1,\; m_2 $和连续径向无界标量函数$ {\cal{V}}(x(t)) $, 满足$ c_1>0,\; c_2>0 $, $ 0< m_1<1<m_2 $ 以及
$$ \dot{{\cal{V}}}(x(t))\leq -c_1{\cal{V}}^{m_1}(x(t))-c_2{\cal{V}}^{m_2}(x(t)) $$ 则原点是固定时间稳定的, 且稳定时间$ T_s $满足
$$ T_s\leq\frac{1}{c_1(1-m_1)}+\frac{1}{c_2(m_2-1)} $$ 进一步地, 若下式成立
$$ \dot{{\cal{V}}}(x(t))\leq -c_1{\cal{V}}^{m_1}(x(t))-c_2{\cal{V}}^{m_2}(x(t))+{\cal{C}} $$ 式中, $ {\cal{C}}>0 $为常参数, 则称原点是实用固定时间稳定的, 且稳定时间$ T_s $满足
$$ T_s\leq\frac{1}{c_1c(1-m_1)}+\frac{1}{c_2c(m_2-1)},\;\quad c\in(0,\;1) $$ 1.3 问题描述
考虑由$ N $艘无人艇组成的集群二分编队跟踪系统. 第$ i,\; i\in{\cal{I}} $艘跟随无人艇的运动学与动力学模型描述为[8]
$$ \dot{\eta}_i(t)=R(\psi_i(t))v_i(t) $$ (1) $$ M_i \dot{v}_i(t)=f_i(v_i(t))+\tau_i(t)+\phi_{i}(v_i(t))\Theta_i $$ (2) 式中, $ \eta_i(t)\;=\;(x_i(t),\; y_i(t),\; \psi_i(t))^{\rm T}\in{\bf{R}}^3 $, $ (x_i(t),\; y_i(t))^{\rm T}\in {\bf{R}}^2 $ 和$ \psi_i(t)\in{\bf{R}} $ 分别表示第$ i $艘无人艇在地面坐标系下的位置向量和偏航角; $ v_i(t)=(u_i^1(t),\; u_i^2(t),\; u_i^3(t))^{\rm T}\in{\bf{R}}^3 $表示第$ i $艘无人艇在体坐标系下的速度向量, $ u_i^1(t),\; u_i^2(t) $和$ u_i^3(t) $分别表示前向速度、横向速度和转向角速度; $ \tau_i(t)\in{\bf{R}}^3 $表示第$ i $艘无人艇的控制输入; $ R(\psi_i(t))\in{\bf{R}}^{3\times 3} $是转换矩阵, 形式如下
$$ R(\psi_i(t))= \left[\begin{array}{ccc} \cos(\psi_i(t))& -\sin(\psi_i(t))& 0\\ \sin(\psi_i(t))& \cos(\psi_i(t))& 0\\ 0 & 0 & 1 \end{array}\right] $$ $ f_i(v_i(t))=(f_{i1}(v_i(t)),\, f_{i2}(v_i(t)),\, f_{i3}(v_i(t)))^{\mathrm{T}}\in{\bf{R}}^{3} $ 是一个非线性向量函数; $M_i\in{\bf{R}}^{3\times 3}>{\bf{0}} $表示惯性矩阵; $ \phi_{i}(v_i(t))\Theta_i\in{\bf{R}}^{3} $表示参数不确定性, $ \phi_{i}(v_i(t))\in {\bf{R}}^{3\times m} $是已知的非线性函数, $ \Theta_i\in{\bf{R}}^{m} $是未知的常参数. 领航无人艇0的状态信号记为$ \eta_0(t)=(x_0(t),\; y_0(t),\; \psi_0(t))\in{\bf{R}}^3 $和$ v_0(t)\in{\bf{R}}^3 $.
期望编队向量记为$ h=(h_{1}^{\mathrm{T}},\;\cdots,\;h_{N}^{\mathrm{T}})^{\mathrm{T}}\in{\bf{R}}^{3N} $, 其中, $ h_{i}=(h_{i}^1,\;h_{i}^2,\;h_{i}^3)^{\mathrm{T}}\in{\bf{R}}^3,\; i\in{\cal{I}} $表示无人艇$ i $与领航无人艇$ 0 $之间期望的位置差. $ h_{i} $仅用于描述期望编队构型, 不用于为跟随无人艇提供参考轨迹. 本文的控制目标是: 设计一组分布式控制器, 使得遭受模型参数不确定性影响的多无人艇系统 (1) ~ (2) 实现固定时间二分编队跟踪, 即
$$ \lim_{t\rightarrow T_i}\Vert e_i(t) \Vert=0,\;\quad \forall i\in{\cal{I}} $$ 式中, $ T_i>0 $ 是一个常参数; $ e_i(t)=\eta_i(t)-h_i\;- \varepsilon_i\eta_0(t)\in{\bf{R}}^3 $ 是编队误差. 为设计控制器, 给出以下假设、引理和定义.
假设 1. 有向图$ {\cal{\bar{G}}} $ 具有有向生成树, $ 0 $是其根节点; 无向图$ {\cal{G}} $是连通的且结构平衡的.
假设 2. 参考轨迹$ \eta_0(t) $及其一阶导数$ \dot{\eta}_0(t) $是有界的, 即, 存在正常数$ \bar{\eta}_0\in {\bf{R}} $, 使得$ \Vert\eta_0(t)\Vert\leq \bar{\eta}_0 $和$ \Vert\dot{\eta}_0(t)\Vert\leq \bar{\eta}_0 $成立. 此外, $ \bar{\eta}_0 $仅部分和领航无人艇有通信的无人艇可知.
引理 2[26]. 给定标量函数$ z_1(t),\; \cdots,\; z_{\bar{\rho}}(t) $ 和常数$ \vartheta $, 以下不等式成立
$$ \left\{\begin{split} &\left(\sum_{\rho=1}^{\bar{\rho}} z_{\rho}(t)\right)^{\vartheta}\leq \sum_{\rho=1}^{\bar{\rho}}z_{\rho}^{\vartheta}(t),\;\quad 0 <\vartheta\leq 1\\ & \bar{\rho}^{1-\vartheta}\left(\sum_{\rho=1}^{\bar{\rho}} z_{\rho}(t)\right)^{\vartheta}\leq \sum_{\rho=1}^{\bar{\rho}}z_{\rho}^{\vartheta}(t),\; \quad \vartheta > 1 \end{split}\right. $$ 定义 3[27]. 给定一个矩阵函数$ \Delta(t)\in{\bf{R}}^{n\times m} $, 若存在常数$ \tilde{t},\; \mu $满足$ 0<\tilde{t}<t,\; \mu>0 $使$ \int_{t-\tilde{t}}^t\Delta^{\rm T} (\sigma)\;\times \Delta(\sigma) {\mathrm{d}}\sigma\geq \mu I_m,\; \forall t\geq 0 $ 成立, 则 $ \Delta(t) $ 被称作PE信号.
定义 4[27]. 给定一个矩阵函数$ \Delta(t)\in{\bf{R}}^{n\times m} $, 若存在常数$ \hat{t},\; \tilde{t},\; \mu $满足$ 0<\tilde{t}<\hat{t},\; \mu>0 $使$ \int_{\hat{t}-\tilde{t}}^{\hat{t}}\Delta^{\rm T} (\sigma) \times \; \Delta(\sigma){\mathrm{d}}\sigma\geq \mu I_m $成立, 则$ \Delta(t) $被称作IE信号.
注 1. 在分布式场景下, 无人艇$ i,\; i\in{\cal{I}} $仅能获得相对信息$ \eta_i(t)-{\rm sign}(a_{ij})\eta_j(t) $和 $ h_{ij}=h_i- {\rm sign} (a_{ij})h_j $; 部分与领航无人艇有通信连接的无人艇能获得全局信息$ \eta_0(t) $和$ h_i $.
注 2. 对比定义3和定义4, IE条件明显弱于PE条件.
2. 复合学习固定时间二分编队控制协议设计
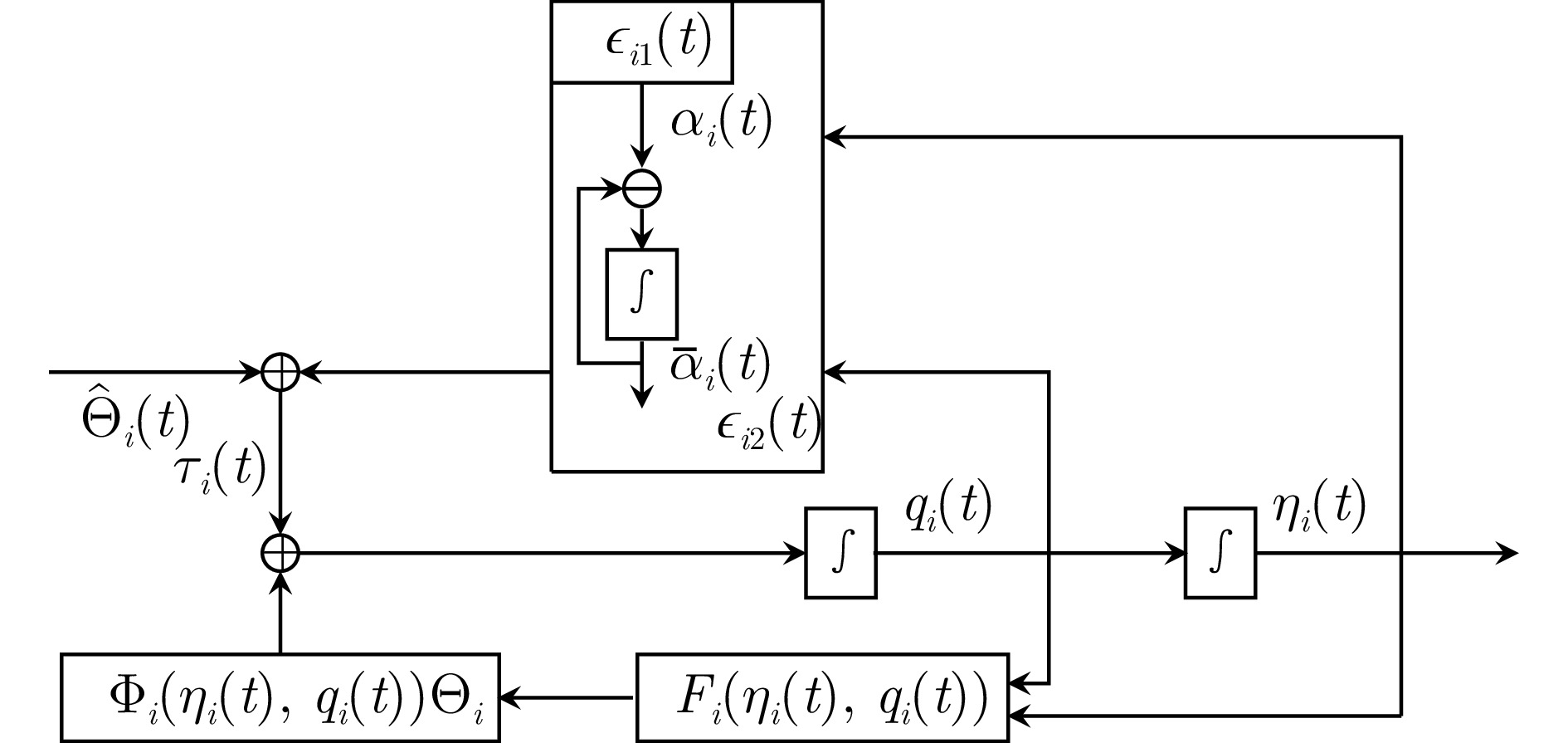
在本节中, 提出了一组复合学习固定时间二分编队控制协议, 图1中给出了控制程序和控制信号框图.
2.1 控制器设计
令$ q_i(t)=R(\psi_i(t))v_i(t) $, 则系统(1) ~ (2)可转化为
$$ \dot{\eta}_i(t)= q_i(t) $$ (3) $$ \begin{split} \dot{q}_i(t)=&\; F_i(\eta_i(t),\;q_i(t)) +g_i(\eta_i(t),\;q_i(t))\tau_i(t)\;+\\ & \Phi_{i}(\eta_i(t),\;q_i(t))\Theta_i \end{split} $$ (4) 式中, $ F_i(\eta_i(t),\,q_i(t))\;\;=\;\;R(\psi_i(t))M_i^{-1}f_i(v_i(t))\;+ \dot{R} (\psi_i(t)) v_i(t) $, $ g_i(\eta_i(t),\;q_i(t))\;\;=\;\;R(\psi_i(t))M_i^{-1} $ 以及$ \Phi_{i} (\eta_i(t),\; q_i(t))= R(\psi_i(t))M_i^{-1}\phi_{i}(v_i(t)) $.
对于第$ i,\; i\in{\cal{I}} $ 艘无人艇, 定义如下的局部跟踪误差信号
$$ \begin{split} \epsilon_{i1}(t)=&\;\sum\limits_{j\in{\cal{N}}_i}|a_{ij}|\left(\eta_i(t)-{\rm sign}(a_{ij})\eta_j(t)-h_{ij}\right)+\\ & b_i\left(\eta_i(t)-\varepsilon_i\eta_0(t)-h_i\right)\\[-1pt] \end{split} $$ (5) $$ \epsilon_{i2}(t)= q_i(t)-\bar{\alpha}_i(t) $$ (6) 式中, $ \alpha_i(t)\in{\bf{R}}^{3} $ 为虚拟控制输入, $ \bar{\alpha}_i(t)\in{\bf{R}}^{3} $ 为$ \alpha_i(t) $ 的命令滤波对应量, 其满足
$$ \dot{\bar{\alpha}}_i(t)=-w_i\tilde{\alpha}_i(t) $$ (7) 其中, $ \tilde{\alpha}_i(t)=\bar{\alpha}_i(t)-\alpha_i(t) $ 为滤波误差, $ w_i>0 $ 为常参数. 接下来, 介绍无人艇控制协议的具体设计程序.
步骤 1. 定义$ \epsilon_{1}(t)=(\epsilon_{11}^{\rm T}(t),\;\cdots,\;\epsilon_{N1}^{\rm T}(t))^{\rm T} $. 根据(3)、(5)和(6)可得
$$ \dot{\epsilon}_{1}(t)=\left(({\cal{L}}+{\cal{B}})\otimes I_3\right)\Xi(t)$$ (8) 式中, $ \Xi(t)= \begin{pmatrix} \epsilon_{12}(t)+\tilde{\alpha}_1(t)+\alpha_1(t)-\varepsilon_1\dot{\eta}_0(t)\\ \vdots\\ \epsilon_{N2}(t)+\tilde{\alpha}_N(t)+\alpha_N(t)-\varepsilon_N\dot{\eta}_0(t)\\ \end{pmatrix} . $虚拟控制输入设计为:
$$ \begin{split} \alpha_i(t)=\;&-\left(k_{i1}+\frac{1}{2}+\nu_i\right)\epsilon_{i1}(t)\;-\\ & \eta_{0i}(t)\frac{\epsilon_{i1}(t)}{\sqrt{\|\epsilon_{i1}(t)\|^2+\rho_i^2(t)}}\;-\\ & \sum_{l=1}^2c_l{\rm sig}\{\epsilon_{i1}(t)\}^{m_l} \end{split} $$ (9) 式中, $ k_{i1}>0,\; c_l>0,\; 0<m_1<1<m_2,\; \nu_i>0 $为待设计的常参数; $ \rho_i(t)\in{\bf{R}}>0 $满足$ \int_0^{+\infty}\rho_i(t){\mathrm{d}}t< +\infty $和$ |\rho_i(t)|\leq\bar{\rho}_i $; $ \eta_{0i}(t)\in{\bf{R}} $是对$ \bar{\eta}_0 $的估计, 根据下式更新:
$$ \dot{\eta}_{0i}(t)=-\sum_{l=1}^2c_l{\rm sig}\{\xi_i(t)\}^{m_l} $$ (10) 其中, $ \xi_i(t) = \sum\nolimits_{j\in {\cal{N}}_i}|a_{ij}|(\eta_{0i}(t)-\eta_{0j}(t))+b_i(\eta_{0i}(t)\;- \bar{\eta}_0) $.
将 (9) 代入 (8) 可得闭环误差系统
$$ \dot{\epsilon}_{1}(t)=\left(({\cal{L}}+{\cal{B}})\otimes I_3\right)\tilde{\Xi}(t) $$ (11) 式中
$$\begin{split} &\tilde{\Xi}(t)=\epsilon_{2}(t)+\tilde{\alpha}(t)-{\rm diag}\left\{\left(k_{i1}+\frac{1}{2}+ \nu_i\right)\otimes I_3\right\}\times \\ &\;\;\;\; \epsilon_{1}(t) - \begin{pmatrix} \displaystyle\frac{\eta_{01}(t)\epsilon_{11}(t)}{\sqrt{\|\epsilon_{11}(t)\|^2+\rho_1^2(t)}}+\varepsilon_1\dot{\eta}_0(t)\\\vdots\\ \displaystyle\frac{\eta_{0N}(t)\epsilon_{N1}(t)}{\sqrt{\|\epsilon_{N1}(t)\|^2+\rho_N^2(t)}}+\varepsilon_N\dot{\eta}_0(t)\\ \end{pmatrix} -\\ &\;\;\;\; \sum\limits_{l=1}^2c_l{\rm sig}\{\epsilon_{1}(t)\}^{m_l}\end{split} $$ 其中, $ \epsilon_{2}(t) = (\epsilon_{12}^{\rm T}(t),\;\cdots,\; \epsilon_{N2}^{\rm T}(t))^{\rm T}$和 $ \tilde{\alpha}(t) = (\tilde{\alpha}_1^{\rm T}(t),\; \cdots,\;\tilde{\alpha}_N^{\rm T}(t))^{\rm T} $.
选择如下的 Lyapunov 函数
$$ V_{1}(t)=\frac{1}{2}\epsilon_{1}^{\mathrm{T}}(t)\left(({\cal{L}}+{\cal{B}})\otimes I_3\right)^{-1}\epsilon_{1}(t) $$ 由 (11) 可推出
$$ \begin{split} \dot{V}_{1}(t) \leq\;& -\epsilon_{1}^{\mathrm{T}}(t){\rm diag}\left\{\left(k_{i1}+\nu_i\right)\otimes I_3\right\}\epsilon_{1}(t)\ +\\ & \frac{1}{2}\epsilon_{2}^{\mathrm{T}}(t)\epsilon_{2}(t) -\sum\limits_{l=1}^2c_l\epsilon_{1}^{\mathrm{T}}(t){\rm sig}\{\epsilon_{1}(t)\}^{m_l}\ -\\ & \sum\limits_{i=1}^N\frac{\tilde{\eta}_{0i}(t)\|\epsilon_{i1}(t)\|^2}{\sqrt{\|\epsilon_{i1}(t)\|^2+\rho_i^2(t)}} +\sum\limits_{i=1}^N\bar{\eta}_0\rho_i(t)\ +\\ & \epsilon_{1}^{\mathrm{T}}(t)\tilde{\alpha}(t)\\[-1pt] \end{split} $$ (12) 式中, $ \tilde{\eta}_{0i}(t)=\eta_{0i}(t)-\bar{\eta}_0 $ 表示参数估计误差. 定义全局参数估计误差$ \tilde{\eta}_{0}(t)=(\tilde{\eta}_{01}^{\rm T}(t),\;\cdots,\;\tilde{\eta}_{0N}^{\rm T}(t))^{\rm T} $.
步骤 2. 利用 (4)、(6) 和 (7) 可得
$$ \begin{split} \dot{\epsilon}_{i2}(t)=\;& g_i(\eta_i(t),\;q_i(t))\Big(g_i^{-1}(\eta_i(t),\;q_i(t))w_i\tilde{\alpha}_i(t)\ +\\ & \tau_i(t) +g_i^{-1}(\eta_i(t),\;q_i(t))\Phi_{i}(\eta_i(t),\;q_i(t))\Theta_i\ +\\ & g_i^{-1}(\eta_i(t),\;q_i(t))F_i(\eta_i(t),\;q_i(t))\Big)\\[-1pt] \end{split} $$ (13) 控制输入可以设计为
$$ \begin{split} \tau_i(t)=&\;-g_i^{-1}(\eta_i(t),\;q_i(t))\Big(\Big(k_{i2}+\frac{1}{2}\Big)\epsilon_{i2}(t)\ +\\ & F_i(\eta_i(t),\;q_i(t)) +\sum_{l=1}^2c_l{\rm sig}\{\epsilon_{i2}(t)\}^{m_l}\ +\\ & w_i\tilde{\alpha}_i(t) +\Phi_{i}(\eta_i(t),\;q_i(t))\hat{\Theta}_i(t)\Big)\end{split} $$ (14) 式中, $ k_{i2}>0 $为待设计的常参数, $ \hat{\Theta}_i(t)\in{\bf{R}}^{m} $是对$ \Theta_i $的估计.
将 (14) 代入 (13) 可得闭环误差系统
$$ \begin{split} \dot{\epsilon}_{i2}(t)=&-\left(k_{i2}+\frac{1}{2}\right)\epsilon_{i2}(t)-\Phi_{i}(\eta_i(t),\;q_i(t))\tilde{\Theta}_i(t)\ -\\ & \sum_{l=1}^2c_l{\rm sig}\{\epsilon_{i2}(t)\}^{m_l}\\[-1pt]\end{split} $$ (15) 式中, $ \tilde{\Theta}_i(t)=\hat{\Theta}_i(t)-\Theta_i $ 为参数估计误差.
为了自适应地估计未知参数$ \Theta_i $, 给出滤波信号$ q_{i}^{f}(t)\in{\bf{R}}^3,\; H_{i}^{f}(t)\in{\bf{R}}^3,\; \Phi_{i}^{f}(t)\in{\bf{R}}^{3\times m} $和辅助变量$ \Lambda_i(t)\in{\bf{R}}^{m\times m},\; \Upsilon_i(t)\in{\bf{R}}^{m} $, 其按下式更新
$$ \left\{ \begin{array}{l} \beta_i\dot{q}_{i}^{f}(t)+q_{i}^{f}(t)=q_i(t)\\ \beta_i\dot{H}_{i}^{f}(t)+H_{i}^{f}(t)= H_{i}(t) \\ \beta_i\dot{\Phi}_{i}^{f}(t)+\Phi_{i}^{f}(t)=\Phi_{i}(\eta_i(t),\;q_i(t)) \end{array}\right. $$ (16) $$ \left\{\begin{split} &\Lambda_{i}(t)=\int_{t-o_i}^t\Phi_{i}^{f{\mathrm{T}}}(\sigma)\Phi_{i}^{f}(\sigma){\mathrm{d}}\sigma\\ &\Upsilon_{i}(t)=\int_{t-o_i}^t\Phi_{i}^{f{\mathrm{T}}}(\sigma) \left(\frac{q_{i}(\sigma)- q_{i}^{f}(\sigma)} {\beta_i}-H_{i}^{f}(\sigma)\right){\mathrm{d}}\sigma \end{split}\right. $$ (17) 式中, $ \beta_i>0 $, $ t>o_i\geq0 $是常数, $ H_{i}(t)\;=\;F_i (\eta_i(t), q_i(t))+g_i(\eta_i(t),\;q_i(t))\tau_i(t) $. 联立 (4)、(16) 和 (17) 可得
$$ \Lambda_{i}(t)\Theta_{i}=\Upsilon_{i}(t) $$ (18) 定义如下的预测误差函数$ {\cal{P}}_i(t)\in{\bf{R}}^{m} $:
$$ \begin{aligned} {\cal{P}}_i(t)= \begin{cases} \Lambda_{i}(t)\hat{\Theta}_i(t),\;& t<p_i\;\\ \Lambda_{i}(p_i)\hat{\Theta}_i(t)-\Upsilon_{i}(p_i),\;& t\geq p_i\; \end{cases} \end{aligned} $$ (19) 式中, $ p_i $是矩阵$ \Lambda_{i}(t)>{\bf{0}} $的时刻. 参数估计$ \hat{\Theta}_i(t) $的更新律设计如下:
$$ \begin{split} \dot{\hat{\Theta}}_i(t)=\ &\Gamma_i\Phi_{i}^{\mathrm{T}}(\eta_i(t),\;q_i(t))\epsilon_{i2}(t)\ -\\ & \Gamma_i\Lambda_{i}^{\mathrm{T}}(t)\sum_{l=1}^2c_l{\rm sig}\{{\cal{P}}_i(t)\}^{m_l} \end{split} $$ (20) 式中, $ \Gamma_i\in{\bf{R}}^{m\times m}>{\bf{0}} $ 代表参数学习率.
选择如下的 Lyapunov 函数:
$$ V_{2}(t)=\frac{1}{2}\epsilon_{2}^{\mathrm{T}}(t)\epsilon_{2}(t)+\frac{1}{2}\sum_{i=1}^N\tilde{\Theta}_i^{\mathrm{T}}(t)\Gamma_i^{-1}\tilde{\Theta}_i(t) $$ 根据 (15) 和 (20), 对于$ t\geq \max _{i\in{\cal{I}}}\{p_i\} $有
$$ \begin{split} \dot{V}_{2}(t)=\ &-\epsilon_{2}^{\rm T}(t){\rm diag}\left\{\left(k_{i2}+\frac{1}{2}\right)\otimes I_3\right\}\epsilon_{2}(t)\ -\\& \sum_{l=1}^2c_l\epsilon_{2}^{\rm T}(t){\rm sig}\{\epsilon_{2}(t)\}^{m_l}\ -\\& \sum_{l=1}^2c_l{\cal{P}}^{\rm T}(t){\rm sig}\{{\cal{P}}(t)\}^{m_l}\\[-1pt] \end{split} $$ (21) 式中, $ {\cal{P}}(t)=({\cal{P}}_1^{\rm T}(t),\;\cdots,\;{\cal{P}}_N^{\rm T}(t))^{\rm T} $.
注 3. 由 (5) 可推出, $ \epsilon_{1}(t)=(({\cal{L}}+{\cal{B}})\otimes I_3)e(t) $, 其中, $ e(t)=(e_1^{\rm T}(t),\;\cdots,\;e_N^{\rm T}(t))^{\mathrm{T}} $. 此外, 在假设1满足时, 有$ {\cal{L}}+{\cal{B}}>{\bf{0}} $和$ {\cal{\tilde{L}}}+{\cal{B}}>{\bf{0}} $成立.
2.2 稳定性分析
在给出最终稳定性结果之前, 首先给出如下引理.
引理 3. 在假设1和假设2满足时, 全局参数估计误差$ \tilde{\eta}_{0}(t) $在固定时间内收敛到零, 收敛时间$ T_{\eta} $满足$ T_{\eta}\leq\frac{1}{\kappa_1(1-\iota_1)}+\frac{1}{\kappa_2(\iota_2-1)} $.
证明. 根据 (10) 有
$$ \dot{\tilde{\eta}}_{0}(t)=-\sum_{l=1}^2c_l{\rm sig}\{(({\cal{\tilde{L}}}+{\cal{B}})\otimes I_3)\tilde{\eta}_{0}(t)\}^{m_l}$$ (22) 选择如下的 Lyapunov 函数
$$ L(t)=\frac{1}{2}\tilde{\eta}_{0}^{\rm T}(t)(({\cal{\tilde{L}}}+{\cal{B}})\otimes I_3)\tilde{\eta}_{0}(t)$$ (23) 由 (22) 可推出
$$ \dot{L}(t)=-\kappa_1L^{\iota_1}(t)-\kappa_2L^{\iota_2}(t) $$ (24) 式中, $ \iota_1 = \frac{1+m_1}{2},\; \iota_2 = \frac{1+m_2}{2},\; \kappa_1 = c_1(2\lambda_{\min}({\cal{\tilde{L}}} + {\cal{B}}))^{\iota_1},\; \kappa_2=c_2(2\lambda_{\min}({\cal{\tilde{L}}}+{\cal{B}}))^{\iota_2}(3N)^{1-\iota_2} $. 根据引理1可知, $ \tilde{\eta}_{0}(t) $固定时间收敛到零, 收敛时间 $ T_{\eta} $满足$ T_{\eta}\leq \frac{1}{\kappa_1(1-\iota_1)}+\frac{1}{\kappa_2(\iota_2-1)} $. 因此, 存在时刻$ \tilde{t}\geq T_{\eta} $有$ \tilde{\eta}_{0}(t)= {\bf{0}},\; \forall t\geq \tilde{t} $.
□ 注 4. 在实际情形下, 无人艇系统状态信号$ \eta_i(t),\; $$ \eta_0(t) $是有界的; 根据假设2, 信号$ \dot{\eta}_0(t) $也是有界的. 因此, 根据 (5) 可推出$ \epsilon_{i1}(t) $是有界的. 此外, 根据引理3可知, $ \eta_{0i}(t) $是有界的. 综上, 由 (9) 可推断出$ \alpha_i(t) $是有界的. 注意, 如果$ \alpha_i(t) $是有界的, 那么$ \tilde{\alpha}_i(t) $是有界的. 在此情况下, 存在常数$ \check{\alpha}_i>0 $使得$ \Vert\tilde{\alpha}_i(t)\Vert\leq\check{\alpha}_i $.
定理1给出了本文的稳定性结果.
定理 1. 在假设1和假设2满足时, 多无人艇系统 (3) ~ (4) 在控制协议 (14) 和参数自适应律 (20) 的驱动下可以实现实用固定时间二分编队跟踪控制, 收敛时间$ T_{{\cal{P}}} $满足$ T_{{\cal{P}}}\leq\max_{i\in{\cal{I}}}\;\{\;\tilde{t},\;p_i\;\}\ + \frac{1}{\bar{\kappa}_1c(1-\bar{\iota}_1)}+\frac{1}{\bar{\kappa}_2c(\bar{\iota}_2-1)} $.
证明. 选择如下的 Lyapunov 函数$ V(t)= V_{1}(t) + \; V_{2}(t) $. 根据 (12) 和 (21), 对于$ t\;\geq\; \max_{i\in{\cal{I}}} \{\tilde{t}, p_i\}, \nu_i\geq o_i $ 有
$$ \begin{split} \dot{V}(t) \leq\;&\ \epsilon_{1}^{\rm T}(t)\tilde{\alpha}(t) -\sum\limits_{l=1}^2c_l\epsilon_{1}^{\rm T}(t){\rm sig}\{\epsilon_{1}(t)\}^{m_l}\ -\\ & \epsilon_{1}^{\rm T}(t){\rm diag}\left\{\nu_i\otimes I_3\right\}\epsilon_{1}(t) +\sum\limits_{i=1}^N\bar{\eta}_0\rho_i(t)\ -\\ & \sum_{l=1}^2c_l\epsilon_{2}^{\rm T}(t){\rm sig}\{\epsilon_{2}(t)\}^{m_l}\ -\\ & \sum_{l=1}^2c_l{\cal{P}}^{\rm T}(t){\rm sig}\{{\cal{P}}(t)\}^{m_l}\leq\\ & -\sum_{l=1}^2c_l\epsilon_{{\cal{P}}}^{\rm T}(t){\rm sig}\{\epsilon_{{\cal{P}}}(t)\}^{m_l}+\iota \end{split} $$ 式中, $ \epsilon_{{\cal{P}}}(t) = (\epsilon_{1}^{\rm T}(t),\;\epsilon_{2}^{\rm T}(t),\; {\cal{P}}^{\rm T}(t))^{\rm T} $, $ \iota = \sum\nolimits_{i=1}^N\frac{1}{4o_i}\check{\alpha}_i^2 + \; \sum\nolimits_{i=1}^N\bar{\eta}_0\bar{\rho}_i $, $ o_i>0 $是合适的常参数, 通过选取$ o_i $和$ \rho_i(t) $可以使残差集任意小. 因为对于$ t\;\geq \;\max _{i\in{\cal{I}}} \{\tilde{t}, p_i\} $有
$$ \zeta_1\epsilon_{{\cal{P}}}^{\rm T}(t)\epsilon_{{\cal{P}}}(t)\leq V(t) \leq\zeta_2\epsilon_{{\cal{P}}}^{\rm T}(t)\epsilon_{{\cal{P}}}(t) $$ 式中, $ \zeta_1=\min\limits_{i\in{\cal{I}}}\left\{\frac{1}{2},\;\frac{1}{2\lambda_{\min}\left(\Lambda_{i}^{\mathrm{T}}(t)\Gamma_i\Lambda_{i}(t)\right)},\;\frac{1}{2\lambda_{\max}\left({\cal{L}}+{\cal{B}}\right)}\right\},\; $ $ \zeta_2=\min\limits_{i\in{\cal{I}}}\left\{\frac{1}{2},\;\frac{1}{2\lambda_{\max}\left(\Lambda_{i}^{\mathrm{T}}(t)\Gamma_i\Lambda_{i}(t)\right)},\;\frac{1}{2\lambda_{\min}\left({\cal{L}}+{\cal{B}}\right)}\right\} $. 因此, 根据引理2可以推断出
$$ \begin{split} &-c_1\epsilon_{{\cal{P}}}^{\rm T}(t){\rm sig}\{\epsilon_{{\cal{P}}}(t)\}^{m_1} \leq -\bar{\kappa}_1V^{\bar{\iota}_1}(t)\\ & -c_2\epsilon_{{\cal{P}}}^{\rm T}(t){\rm sig}\{\epsilon_{{\cal{P}}}(t)\}^{m_2} \leq -\bar{\kappa}_2V^{\bar{\iota}_2}(t) \end{split} $$ 式中, $ \bar{\iota}_1 = \frac{m_1+1}{2},\; \bar{\kappa}_1=c_1\left(\frac{1}{\zeta_2}\right)^{\bar{\iota}_1},\; \bar{\iota}_2 = \frac{m_2+1}{2} $ 和$ \bar{\kappa}_2= c_2((6+m)N)^{1-\bar{\iota}_2}\left(\frac{1}{\zeta_2}\right)^{\bar{\iota}_2} $. 进一步有
$$ \dot{V}(t) \leq -\sum_{l=1}^2\bar{\kappa}_lV^{\bar{\iota}_l}(t)+\iota,\;\quad t\geq \max\limits_{i\in{\cal{I}}}\{\tilde{t},\;p_i\} $$ 根据引理1可知, 误差向量$ \epsilon_1(t),\; \epsilon_2(t),\; {\cal{P}}(t) $固定时间收敛到原点的任意小邻域, 收敛时间$ T_{{\cal{P}}} $满足$ T_{{\cal{P}}}\leq\max_{i\in{\cal{I}}}\{\tilde{t},\;p_i\}+\frac{1}{\bar{\kappa}_1c(1-\bar{\iota}_1)}+\frac{1}{\bar{\kappa}_2c(\bar{\iota}_2-1)} $. 根据 (19), 当$ t\geq \max_{i\in{\cal{I}}}\{\tilde{t},\;p_i\} $时, 有$ {\cal{P}}_i(t)=\Lambda_i(p_i)\tilde{\Theta}_i(t) $且$ \Lambda_i(p_i) $可逆. 因此, 参数估计误差$ \tilde{\Theta}_i(t),\; i\in{\cal{I}} $也固定时间收敛到原点的任意小邻域. 综上, 多无人艇系统 (3) ~ (4) 在控制协议 (14) 和参数自适应律 (20) 的驱动下可以实现实用固定时间二分编队跟踪控制.
□ 注 5. 根据定理1可知, 所设计的控制器不仅能使得误差信号$ \epsilon_{i1}(t),\; \epsilon_{i2}(t),\; i\in{\cal{I}} $ 固定时间收敛到原点的任意小邻域, 而且能使得参数估计误差$ \tilde{\Theta}_i(t) $ 收敛到零的任意小邻域.
注 6. 根据 (18) 可知, 通过引入滤波信号$ q_{i}^{f}(t)$, $ H_{i}^{f}(t) $, $ \Phi_{i}^{f}(t) $ 和辅助变量$ \Lambda_i(t) $, $ \Upsilon_i(t) $, 并联立 (4) 可以推导出$ \Theta_{i} $ 与$ \Lambda_{i}(t),\; \Upsilon_{i}(t) $ 的关系. 进一步地, 可以构建包含$ \tilde{\Theta}_i(t) $ 的参数更新律 (20). 此外, 由定理1的证明过程可知, 当参数更新律设计为 (20) 且信号$ \Lambda_{i}(t) $ 满足较弱的 IE 条件时, 参数估计误差的收敛性可以确保.
3. 仿真实验
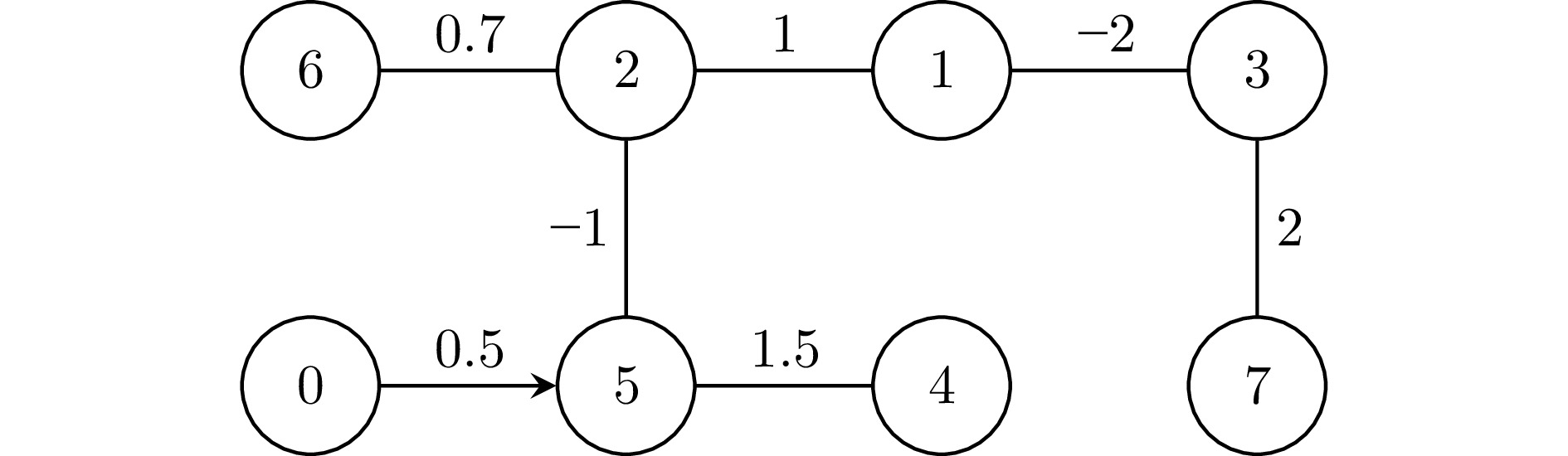
本节给出一个仿真实例以验证提出的控制协议的可行性. 考虑一个无人艇二分编队集群, 包含$ 7 $ 艘跟随无人艇和$ 1 $ 艘领航无人艇. 无人艇间的通信互动在图2中描述, 且$ E={\rm diag}\{1,\;1,\;-1,\; -1,\;-1,\; 1,\;-1\} $. 期望编队构型如下所示:
$$ \begin{split} &h_{1}=(1,\;1,\;0)^{\rm T},\;\ \ \qquad h_{2}=(3,\;1,\;0)^{\rm T},\;\\ & h_{3}=(-1,\;-1,\;0)^{\rm T},\;\quad h_{4}=(-3,\;-1,\;0)^{\rm T},\;\\ & h_{5}=(-3,\;-3,\;0)^{\rm T},\;\quad h_{6}=(2,\;3,\;0)^{\rm T},\;\\ & h_{7}=(-1,\;-3,\;0)^{\rm T} \end{split} $$ 跟随无人艇$ i,\; i=1,\;2,\;\cdots,\;7 $的动力学信息如下所示:
$$ \begin{split} &M_i= \left[\begin{array}{ccc} 26&0&0\\ 0&34&1.1\\ 0&1.1&2.8 \end{array}\right]\\& f_i(v_i(t))=-C_i(v_i(t))-D_i(v_i(t)) \end{split} $$ 式中,
$$ C_i(v_i(t))= \left[\begin{array}{c} C_i^{1}(v_i(t))u_i^3(t)\\ C_i^{2}(v_i(t))u_i^3(t)\\ -C_i^{1}(v_i(t))u_i^1(t)-C_i^{2}(v_i(t))u_i^2(t) \end{array} \right]$$ $$ D_i(v_i(t))= \left[\begin{array}{c} D_i^1(v_i(t))u_i^1(t)\\ D_i^2(v_i(t))u_i^2(t)+D_i^3(v_i(t))u_i^3(t)\\ D_i^4(v_i(t))u_i^2(t)+D_i^5(v_i(t))u_i^3(t) \end{array}\right] $$ $$ C_i^{1}(v_i(t))=-34u_i^2(t)-1.1u_i^3(t) $$ $$ C_i^{2}(v_i(t))=26u_i^1(t)$$ $$ D_i^{1}(v_i(t))=0.73+1.33|u_i^1(t)|+5.87(u_i^1(t))^2 $$ $$ D_i^{2}(v_i(t))=0.86+36.3|u_i^2(t)|+8.1|u_i^3(t)| $$ $$ D_i^{3}(v_i(t))=-0.11+0.85|u_i^2(t)|+3.5|u_i^3(t)| $$ $$ D_i^{4}(v_i(t))=-0.11-5.1|u_i^2(t)|-0.13|u_i^3(t)| $$ $$ D_i^{5}(v_i(t))=-1.9-0.1|u_i^2(t)|+0.75|u^3_i(t)| $$ 未知参数设置为$ \Theta_1=(1,\; 1.5,\; 5)^{\rm T},\; \Theta_2=(2.5,\; 3 ,$ $3.5)^{\rm T},\; \Theta_3\;=\;(0.5,\; 1.0,\; 8)^{\rm T},\; $ $ \Theta_4\;=\;(3.7,\; $ $ 3.7,\; $ $ 6)^{\rm T}, $ $ \Theta_5\;=\;-(0.7,\; $ $ 0.8,\; $ $ 5)^{\rm T},\; $ $ \Theta_6\;=\;-(1.1,\; $ $ 2.1,\; $ $ 7)^{\rm T} $和$ \Theta_7\;=\;-(2,\; $ $ 3,\; $ $ 6)^{\rm T} $. 已知函数选取为$ \phi_{i}\;(v_i\;(t))= \begin{pmatrix}\phi_{i}^{1}(v_i(t))& 0 &\phi_{i}^{2}(v_i(t))\\ 0& \phi_{i}^{3}(v_i(t)) &0\\ 0& 0 &\phi_{i}^{4}(v_i(t))\end{pmatrix}. $ 式中, $ \phi_{i}^{1}(v_i(t))= $ $\sin(u_i^1(t))\cos(1.5u_i^2(t)) + 2 $, $ \phi_{i}^{2}(v_i(t)) = ||\sin^{\rm T}(v_i(t))\;\times $$ \sin(v_i(t))|| $, $ \phi_{i}^{3}(v_i(t)) $ $ =\,\sin(2u_i^2(t))\cos(u_i^3(t))+2 $ 和$ \phi_{i}^{4}(v_i(t))= $ $ \sin(0.2u_i^1(t))\cos(0.2u_i^3(t))+2 $.
领航无人艇参考轨迹如下:
$$ \eta_0(t)= \left[\begin{array}{c} 3\sin(0.025\pi t)\\ 2\sin(0.05\pi t)\\ \pi\cos(0.02\pi t) \end{array}\right]$$ 无人艇系统状态初始值设置为$ \eta_1(0)\,=\,5(-1, -2.1,\;1.3)^{\rm T} $, $ v_1(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $, $ \eta_2(0)\,=\,0.1(-1, -2.1,\;1.3)^{\rm T} $, $ v_2(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $, $ \eta_3(0)\,=\,(-1, -2.1,\;1.3)^{\rm T} $, $ v_3(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $, $ \eta_4(0) $ $ =\;(-1, -2.1,\;1.3)^{\rm T} $, $ v_4(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $, $ \eta_5(0)\,=\,(-1, -2.1,\; 1.3)^{\rm T} $, $ v_5(0)\,=\,3(1,\;2,\;-1.3)^{\rm T} $, $ \eta_6(0)\,=\,10(-1, -2.1,\;1.3)^{\rm T} $, $ v_6(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $, $ \eta_7(0)\,=\,(-1, -2.1,\;1.3)^{\rm T} $ 和$ v_7(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $. 参数估计初值选取为$ \eta_{01}(t)=4 $, $ \eta_{02}(t)=5 $, $ \eta_{03}(t)\,=\,6 $, $ \eta_{04}(t)\,=\, 7 $, $ \eta_{05}(t)\,=\,8 $, $ \eta_{06}(t)\,=\,9 $, $ \eta_{07}(t)\,=\,10 $, $ \hat{\Theta}_1(0)\,=\,(6, $ $ 6 $, $ 9)^{\rm T} $, $ \hat{\Theta}_2(0)\,=\,(7.5 $, $ 13.5 $, $ 7.5)^{\rm T} $, $ \hat{\Theta}_3(0)\,=\, (9.9 $, $ 5.1 $, $ 6.9)^{\rm T} $, $ \hat{\Theta}_4(0)\;=\;3(-4.1 $, $ -2.2 $, $ -3.7)^{\rm T} $, $ \hat{\Theta}_5(0)\,=\, 3(-3.5 $, $ 2.7 $, $ 0.7)^{\rm T} $, $ \hat{\Theta}_6(0)\,=\,3(7.1 $, $ 5 $, $ -1.7)^{\rm T} $ 和$ \hat{\Theta}_7(0)\,=\,3(1.3 $, $ 7.2 $, $ 1.7)^{\rm T} $. 命令滤波对应量的初始值设置为$ \bar{\alpha}_i(0)\,=\,i(0.5,\;1,\;0.75)^{\rm T} $. 控制器参数选取为$ c_1=c_2=10,\; m_1=0.5,\; m_2 = 1.5,\; w_i=1.6,\; k_{i1}= k_{i2}=25 $ 和$ \beta_i=0.1 $.
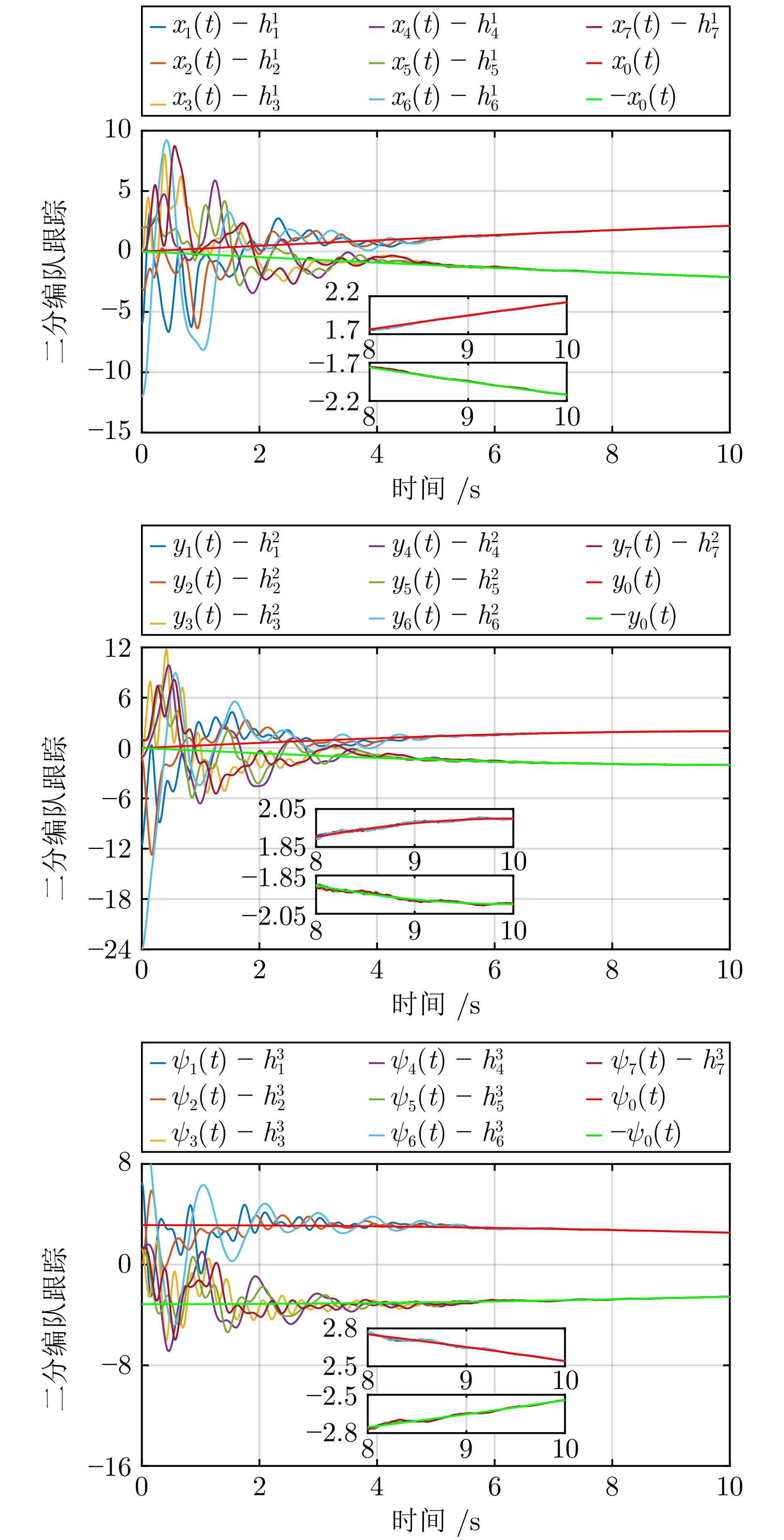
记$ \epsilon_{i1}(t) = (\epsilon_{i1}^1(t),\,\epsilon_{i1}^2(t),\,\epsilon_{i1}^3(t))^{\rm T}, $ $ \epsilon_{i2}(t) = $ $ (\epsilon_{i2}^1(t),\, \epsilon_{i2}^2(t),\,\epsilon_{i2}^3(t))^{\rm T}, $ $ \Theta_i = (\Theta_i^1,\,\Theta_i^2,\,\Theta_i^3)^{\rm T} $ 和$ \hat{\Theta}_i\,(t) = $ $(\hat{\Theta}_i^1(t), \hat{\Theta}_i^2(t) $, $ \hat{\Theta}_i^3(t))^{\rm T} $. 参数估计误差轨迹分别在图3和图4中描述. 观察图3和图4可知, 参数估计误差信号$ \tilde{\eta}_{0i}(t),\, i = 1,\,2,\,\cdots,\,7 $ 在 2 ($ 2 < \frac{1}{\kappa_1(1-\iota_1)} + \frac{1}{\kappa_2(\iota_2-1)} = 17.73 $) s内收敛到零; 参数估计误差信号$ \tilde{\Theta}_{i}(t), i=1,\;2,\;\cdots,\;7 $ 在 4 ($ 4 < \frac{1}{\bar{\kappa}_1c(1-\bar{\iota}_1)} + \frac{1}{\bar{\kappa}_2c(\bar{\iota}_2-1)} > 26.1 $) s内收敛到零的小邻域. 局部跟踪误差轨迹$ \epsilon_{i1}(t), \epsilon_{i2}(t),\; i=1,\;2,\;\cdots,\;7 $ 在图5中给出, 它们在5 ($ 5< 26.1 $) s内收敛到零的小邻域. 图6揭示了在提出的控制协议下, 多无人艇系统可实现固定时间二分编队跟踪控制.
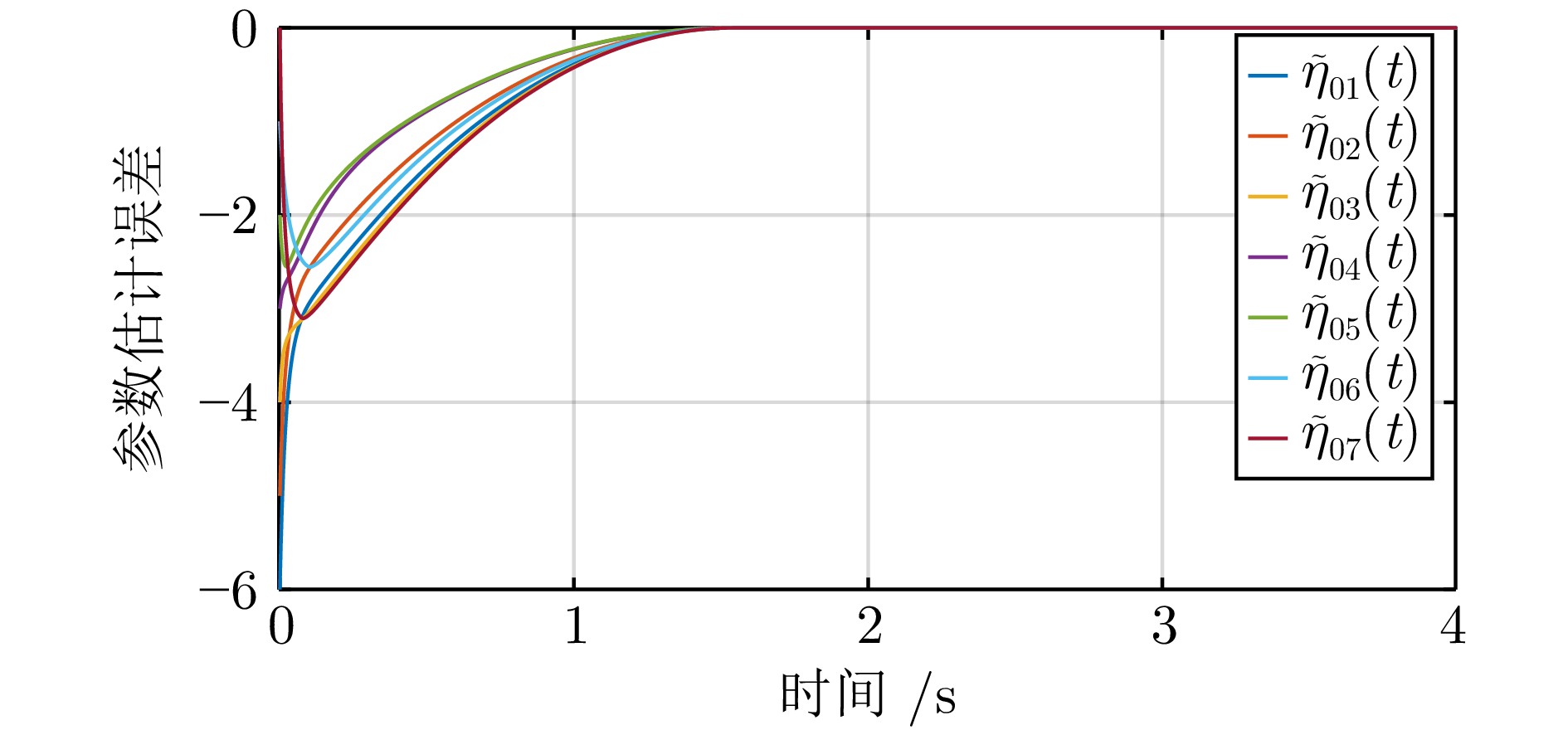 图 3 参数估计误差 $\tilde{\eta}_{0i}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 3 Parameter estimation errors $\tilde{\eta}_{0i}(t),\; i=1,\;2,\;\cdots,\;7$
图 3 参数估计误差 $\tilde{\eta}_{0i}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 3 Parameter estimation errors $\tilde{\eta}_{0i}(t),\; i=1,\;2,\;\cdots,\;7$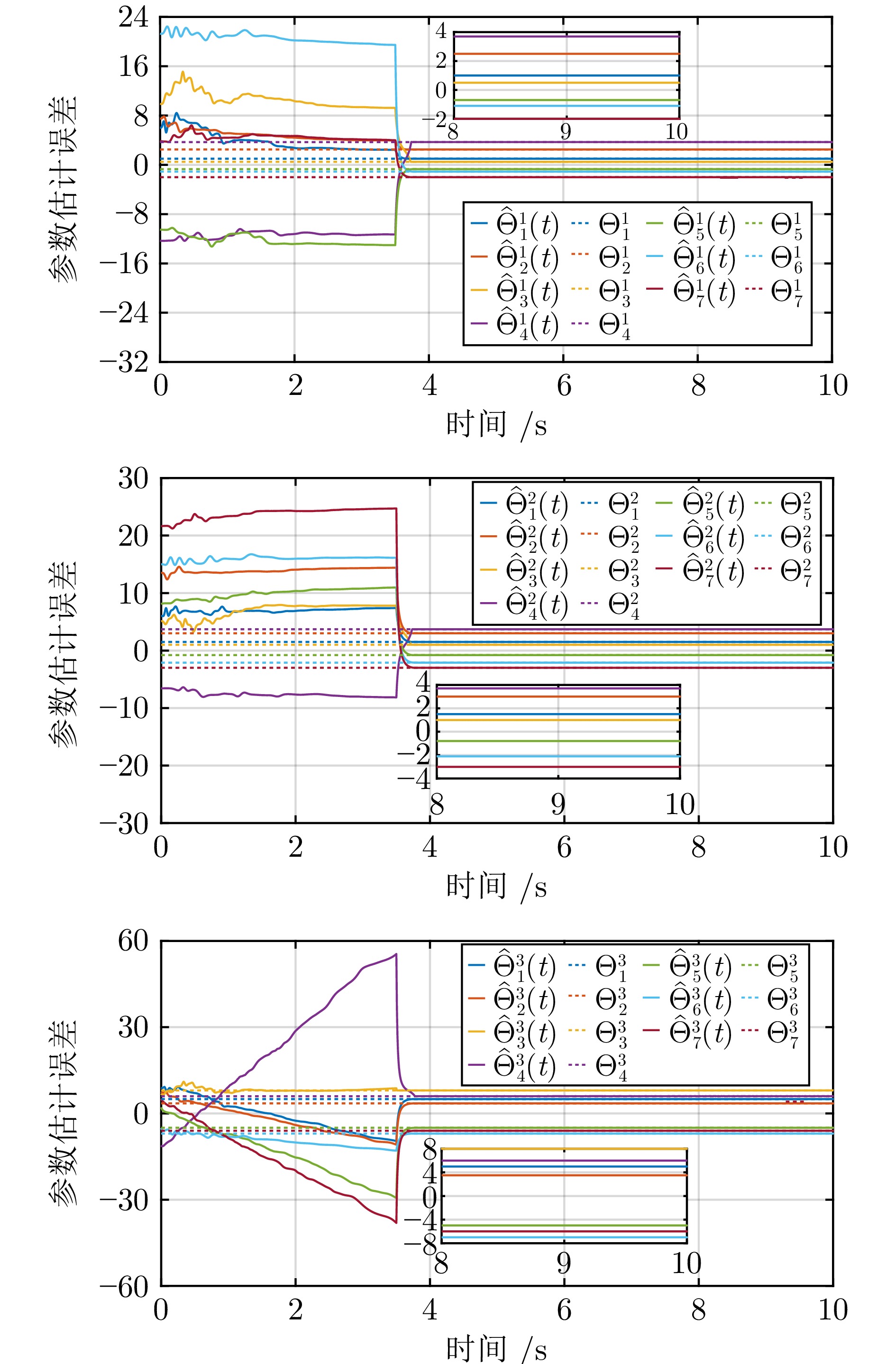 图 4 参数估计误差$\tilde{\Theta}_{i}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 4 Parameter estimation errors $\tilde{\Theta}_{i}(t),\; i=1,\;2,\;\cdots,\;7$
图 4 参数估计误差$\tilde{\Theta}_{i}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 4 Parameter estimation errors $\tilde{\Theta}_{i}(t),\; i=1,\;2,\;\cdots,\;7$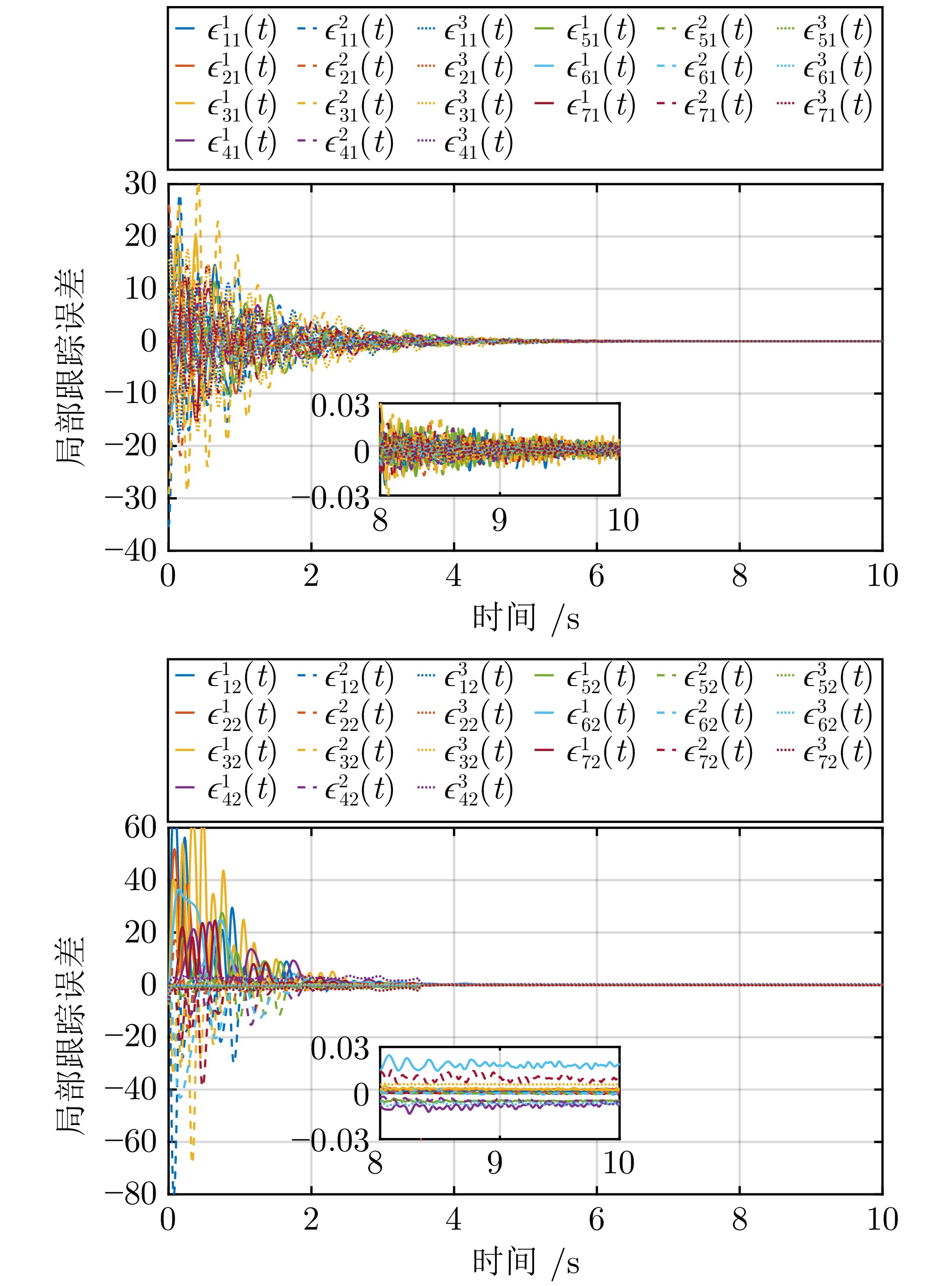 图 5 局部跟踪误差$\epsilon_{i1}(t),\; \epsilon_{i2}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 5 Local tracking errors $\epsilon_{i1}(t),\;$ $\epsilon_{i2}(t),\;$ $i=1,\;2,\;\cdots,\;7$
图 5 局部跟踪误差$\epsilon_{i1}(t),\; \epsilon_{i2}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 5 Local tracking errors $\epsilon_{i1}(t),\;$ $\epsilon_{i2}(t),\;$ $i=1,\;2,\;\cdots,\;7$4. 结束语
通过设计基于命令滤波与复合学习的反推控制协议, 解决了模型参数不确定下多无人艇系统的固定时间二分编队跟踪控制问题. 与已有的相关工作相比, 本文具有以下优势: 通过引入命令滤波技术, 提出的控制协议避免了计算虚拟控制输入的导数, 极大地简化了分布式控制器的设计; 通过引入复合学习技术, 在不需要 PE 条件的情况下, 保证了跟踪误差和参数估计误差的固定时间收敛性. 未来主要关注有向符号图下具有时变参数不确定性影响的多无人艇系统固定时间分布式控制问题, 以及多无人机−无人艇跨域协同控制问题.
-

图 1 不同场景下第一视角手势人机交互图示
Fig. 1 HCI demonstration of gestures from the egocentric viewpoint in different scenarios
图 2 第一视角下智能人机交互的活动区域图示
Fig. 2 Demonstration of active area of intelligent HCI from the egocentric viewpoint

图 4 第一视角下手势样本数据的标注结果
Fig. 4 Annotation results of gesture samples from the egocentric viewpoint
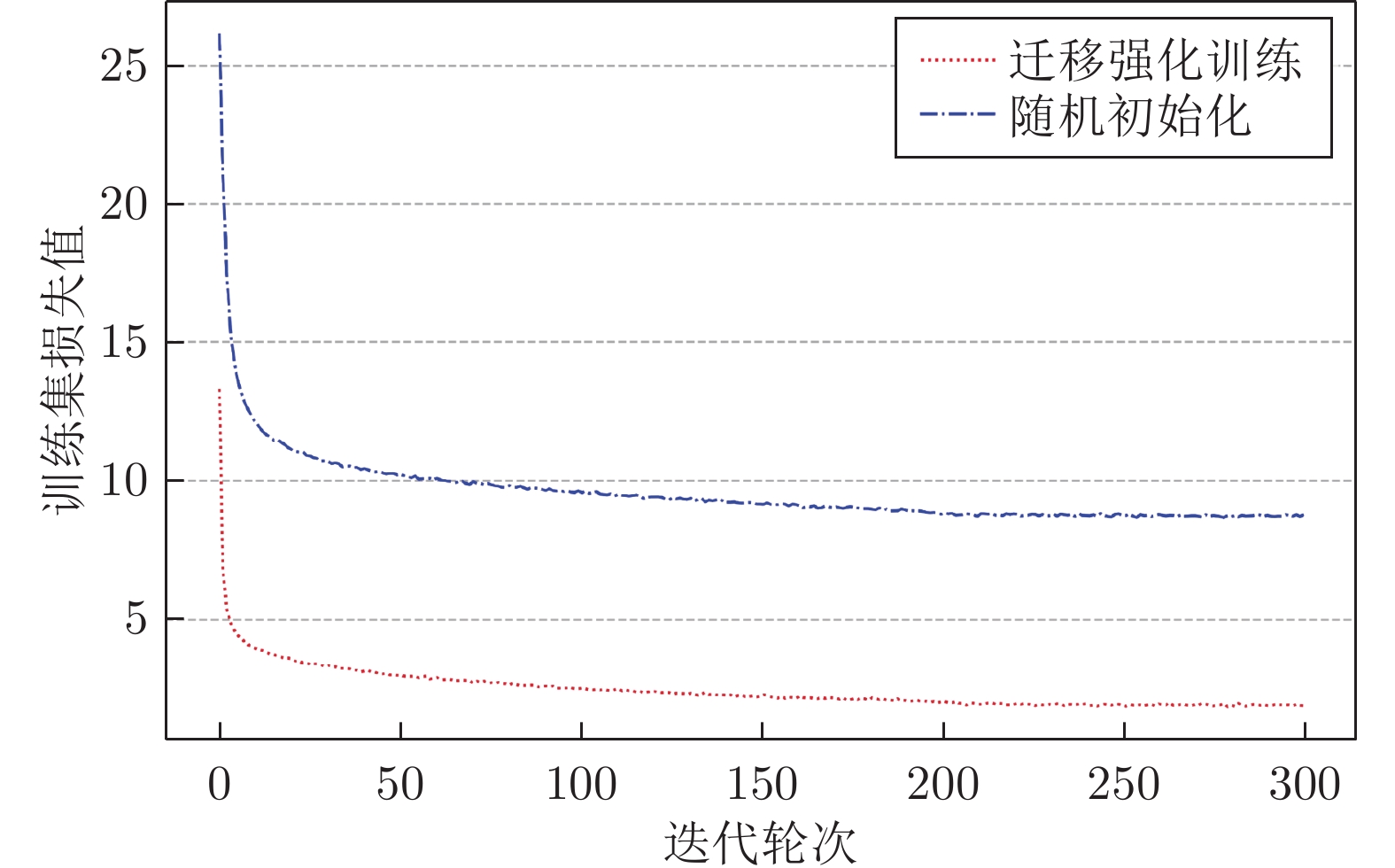
图 5 迁移强化训练和随机初始化两种方式下损失函数变化曲线对比
Fig. 5 Comparison of loss function change curves between transfer reinforcement training and random initialization
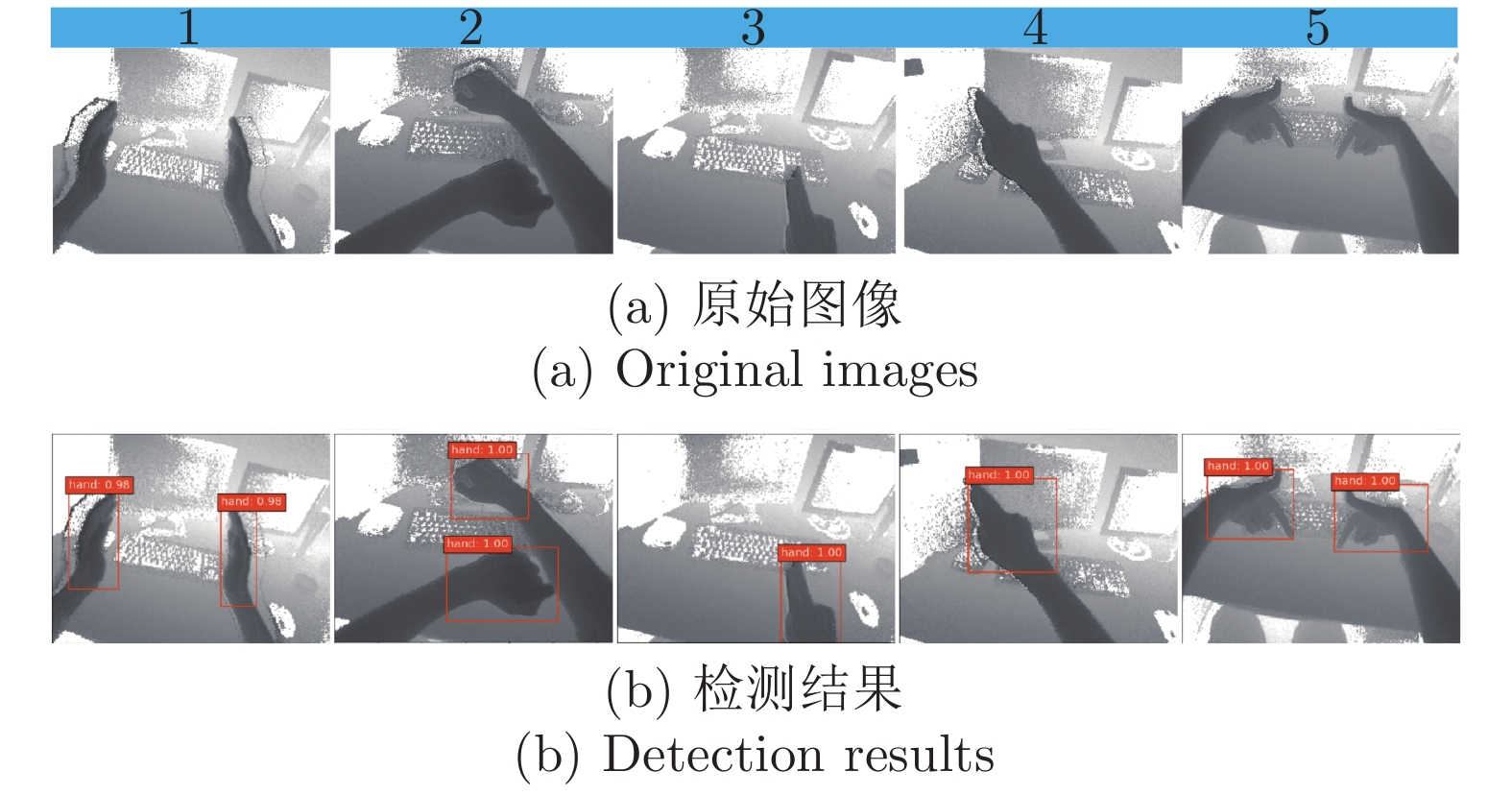
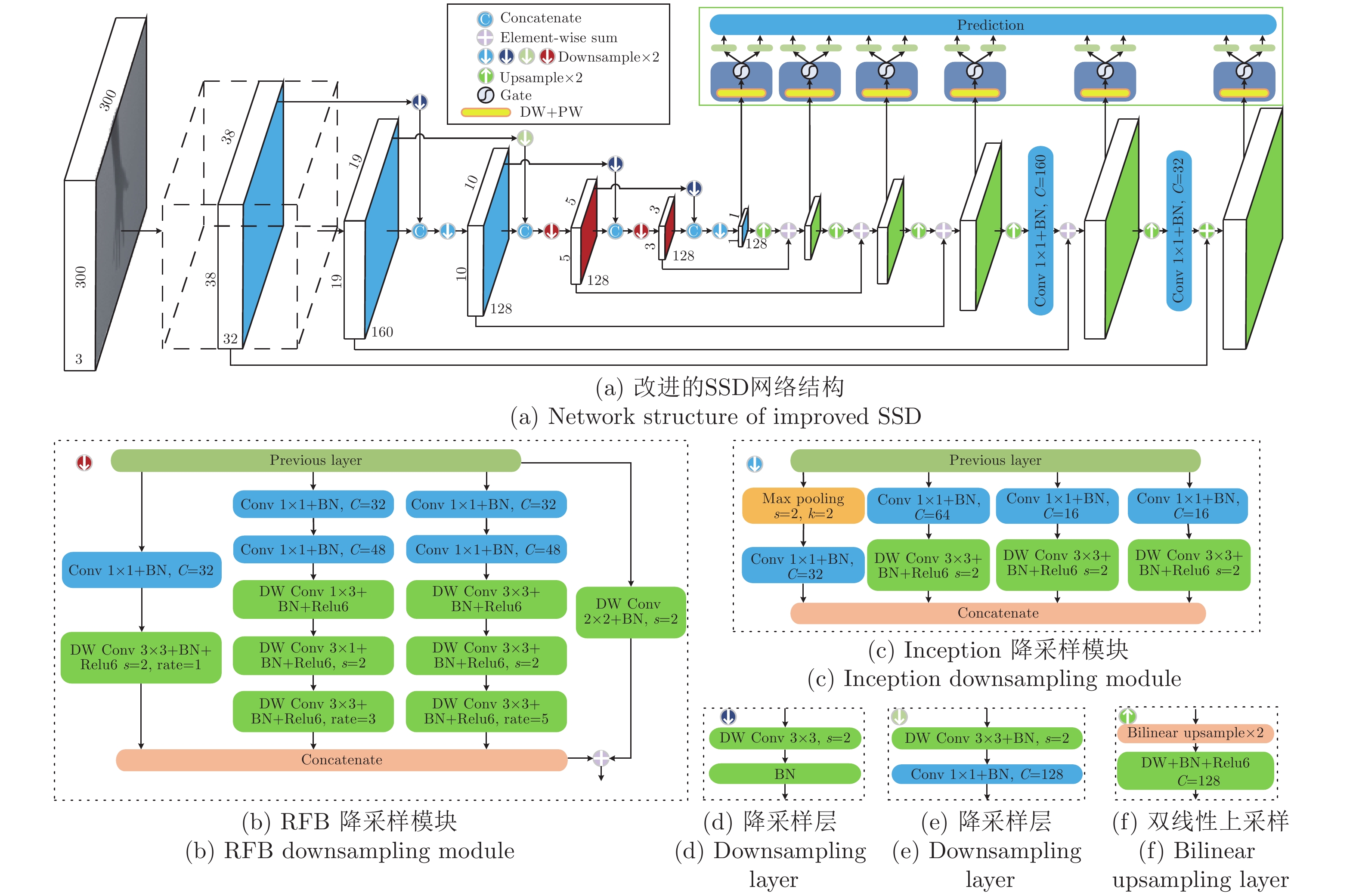
图 6 第一视角下改进SSD目标检测网络的检测结果
Fig. 6 The detection results of improved SSD target detection network from the egocentric viewpoint
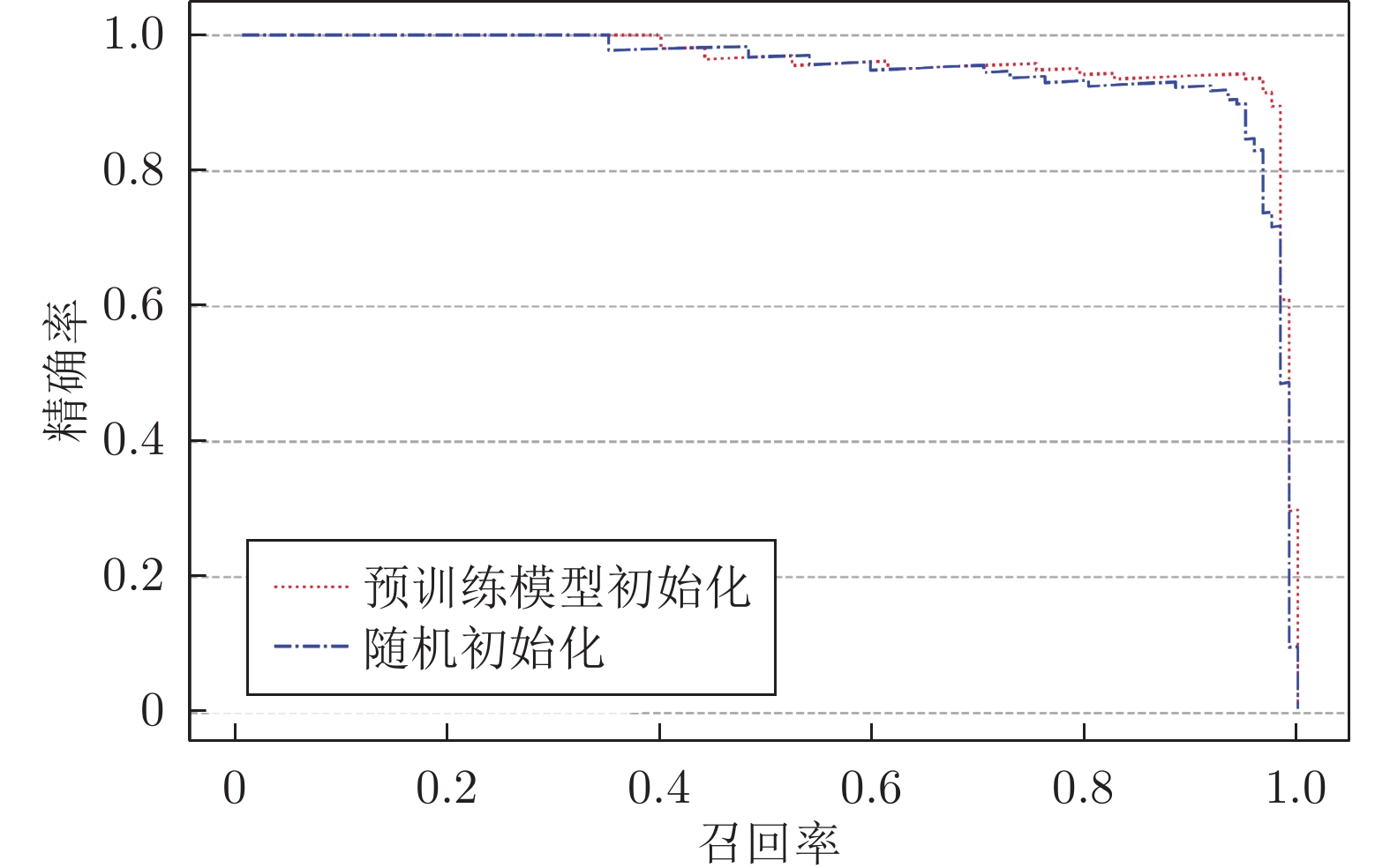
图 7 第一视角下手势目标检测结果的召回率−精确率变化曲线
Fig. 7 Recall and precision curves of gesture target detection results from the egocentric viewpoint

图 9 第一视角下手势目标轮廓的人工标注结果
Fig. 9 Manual annotation results of gesture target contours from the egocentric viewpoint
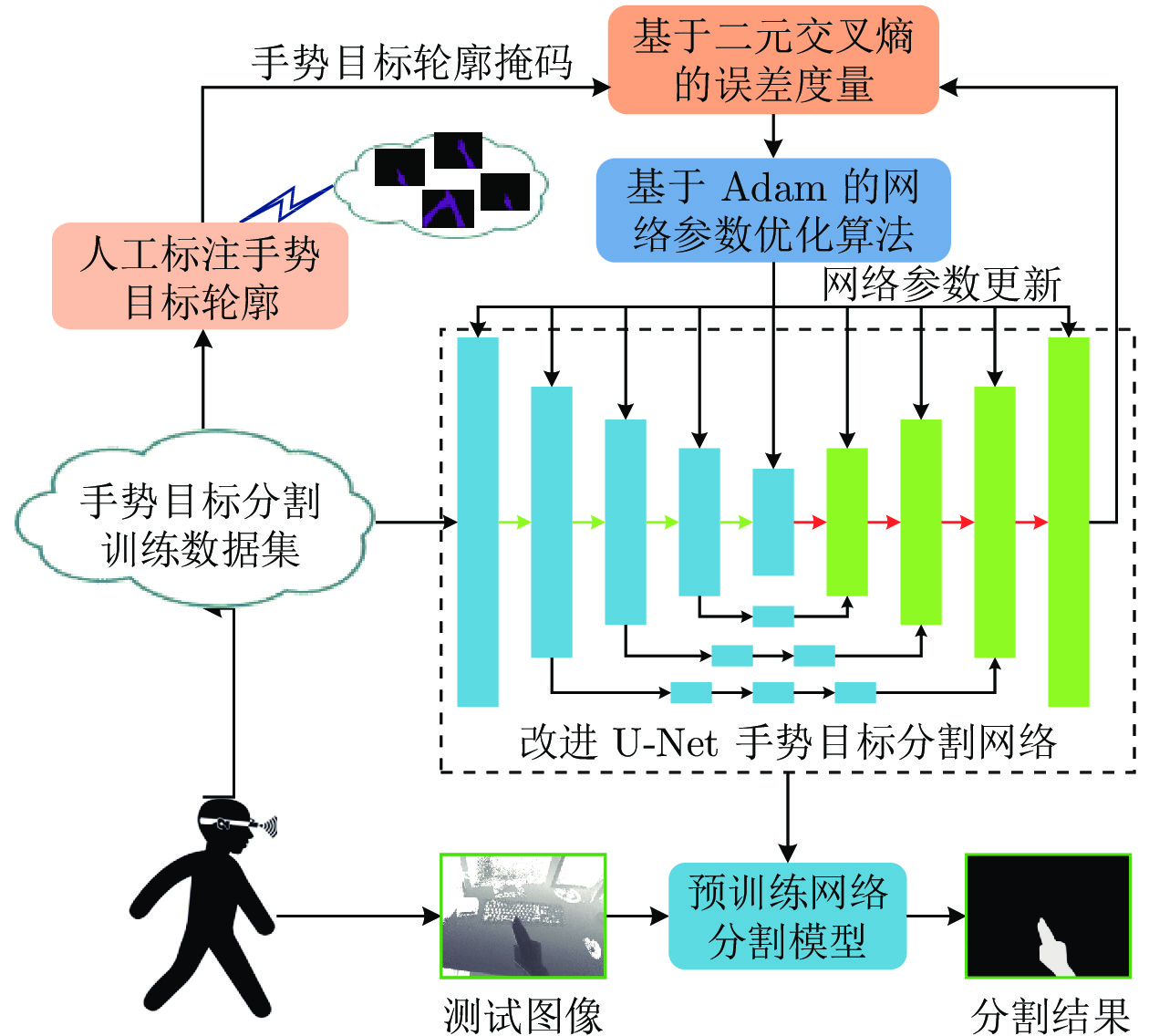
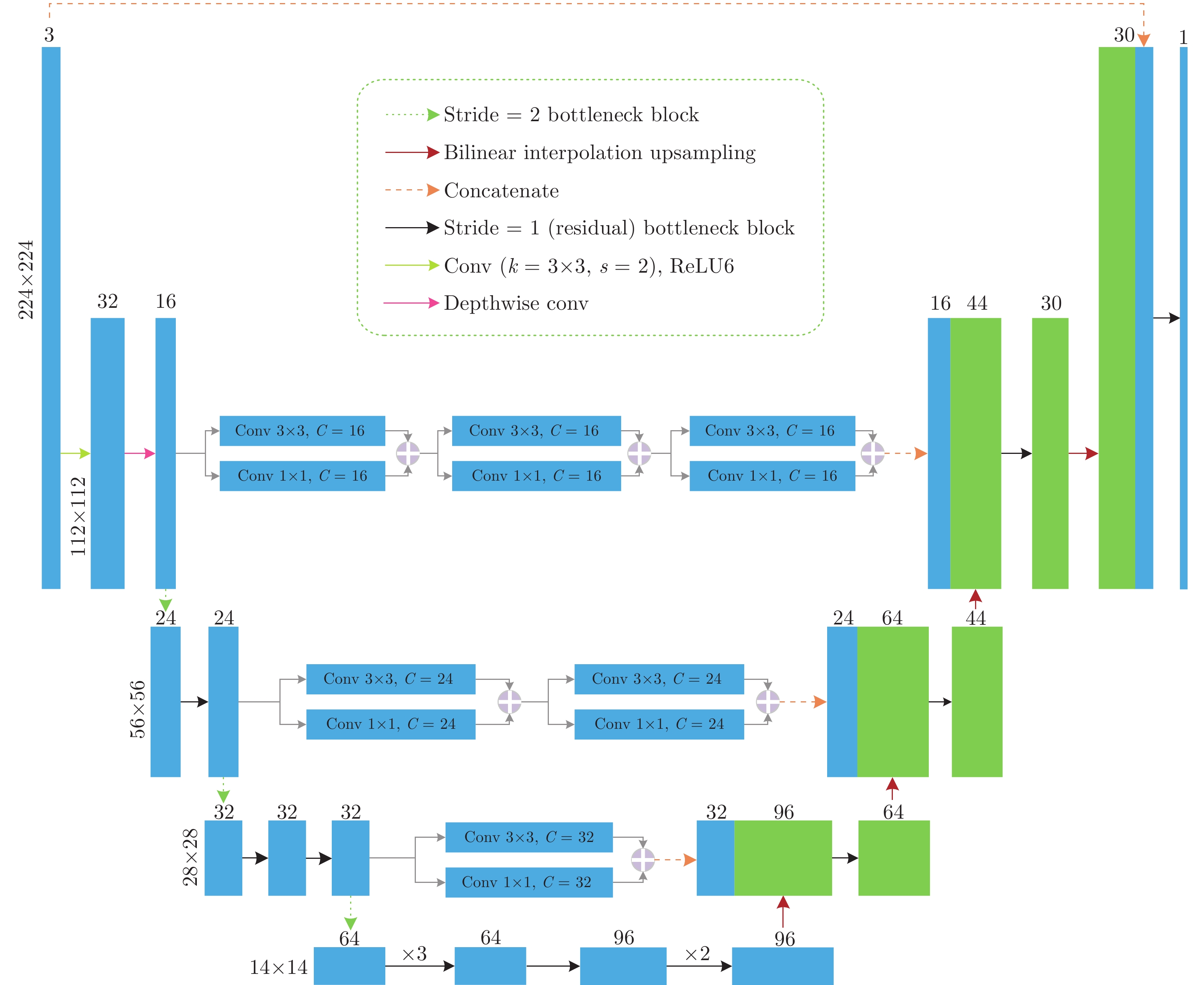
图 10 基于改进U-Net的手势目标快速分割和提取算法系统架构
Fig. 10 Architecture of fast segmentation and extraction algorithm of gesture targets based on improved U-Net
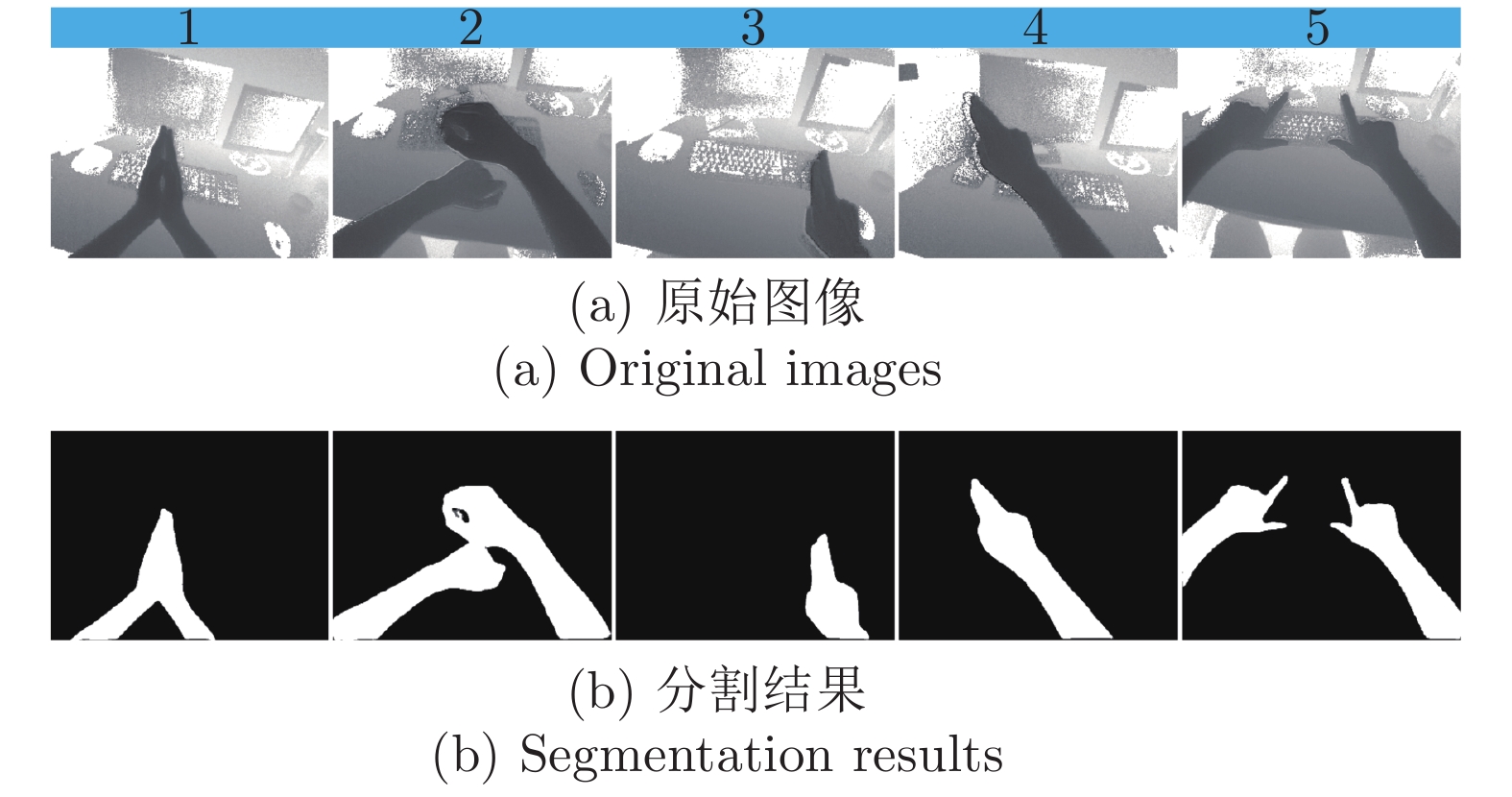
图 11 第一视角下改进U-Net网络模型的分割结果
Fig. 11 The segmentation results of improved U-Net network model from the egocentric viewpoint
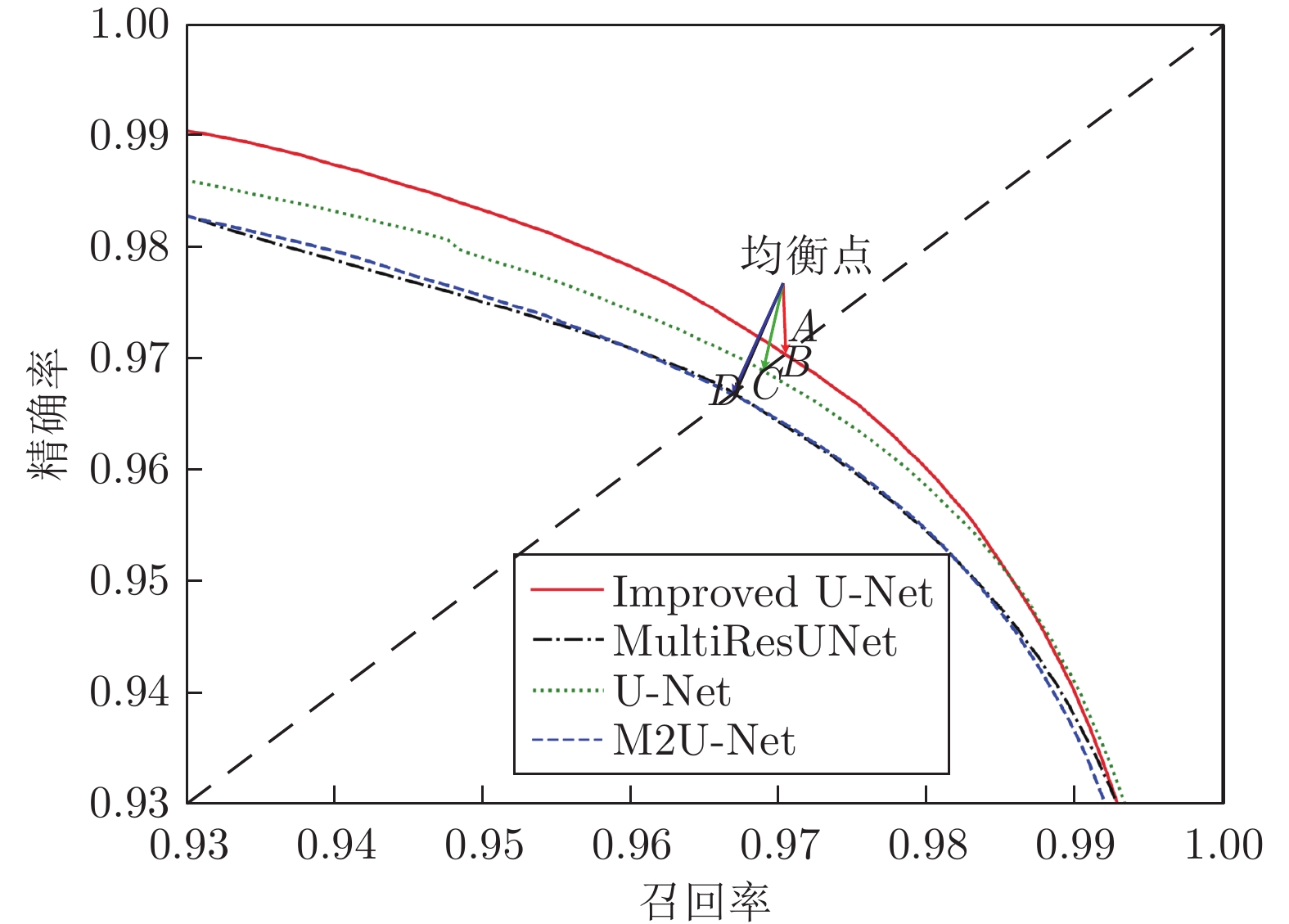
图 12 第一视角下手势目标分割结果的召回率−精确率变化曲线
Fig. 12 Recall and precision curves of gesture target segmentation results from the egocentric viewpoint

图 13 本文提出的SSD + U-Net组合方法与Mask R-CNN v3检测和分割结果对比
Fig. 13 Comparison of detection and segmentation results between SSD + U-Net and Mask R-CNN v3
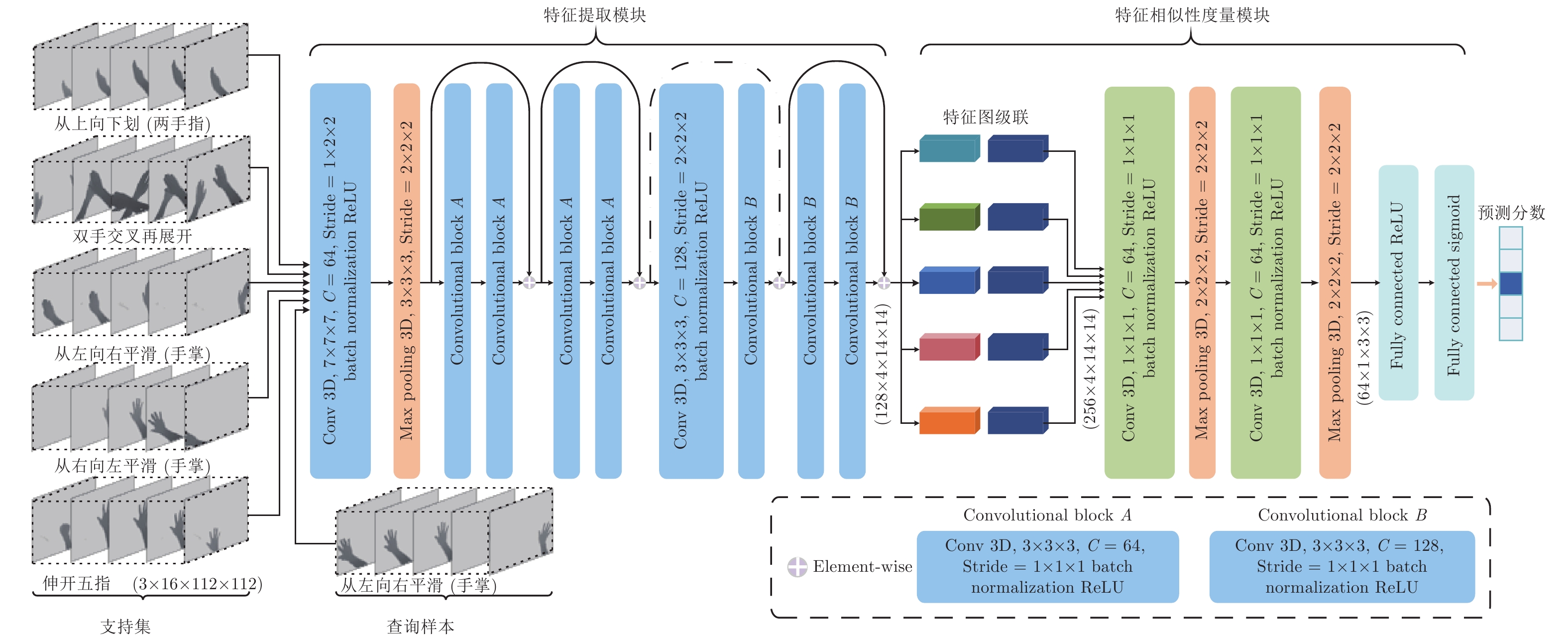
图 14 5-way 1-shot 3D关系神经网络系统架构
Fig. 14 5-way 1-shot 3D relation neural network system architecture

图 17 10种用于验证OSLHGR算法性能的动态手势数据集. 每一列从上向下表示手势核心阶段从起始到结束的变化过程. 图中箭头用于描述动态手势运动的方向
Fig. 17 Ten dynamic gesture datasets to verify the classification performance of OSLHGR algorithm. From top to bottom, each column represents the change process from the beginning to the end of the core phase of gestures. The arrows are used to describe the motion direction of dynamic gestures
表 1 轻量级目标检测模型在VOC 2007测试集上的检测结果对比 (
$ \dagger$ 表示引用文献[34]中的实验结果)Table 1 Comparison of detection results of lightweight target detection model on VOC 2007 test set (
$ \dagger$ represents the experimental results in [34])目标检测算法 输入图像大小 训练数据集 测试数据集 ${\rm{mAP} }$(%) 计算复杂度 (M) 参数量 (M) Tiny YOLO$\dagger$ 416$\times$416 2007 + 2012 2007 57.1 6970 15.12 Tiny SSD[35] 300$\times$300 2007 + 2012 2007 61.3 571 1.13 SqueezeNet-SSD$\dagger$ 300$\times$300 2007 + 2012 2007 64.3 1180 5.50 MobileNet-SSD$\dagger$ 300$\times$300 2007 + 2012 2007 68.0 1140 5.50 Fire SSD[36] 300$\times$300 2007 + 2012 2007 70.5 2670 7.13 Pelee[37] 300$\times$300 2007 + 2012 2007 70.9 1 210 5.98 Tiny DSOD[34] 300$\times$300 2007 + 2012 2007 72.1 1060 0.95 SSD 300$\times$300 2007 + 2012 2007 74.3 34360 34.30 改进的 SSD 300$\times$300 2007 + 2012 2007 73.6 710 1.64  下载: 导出CSV
下载: 导出CSV
表 2 不同网络模型分割结果和模型参数对比
Table 2 Comparison of segmentation results and model parameters of different network models
分割网络
模型输入图像
大小IoU (%) 计算复
杂度 (G)参数量(M) 计算时间(ms/f) U-Net 224$\times$224 94.29 41.84 31.03 67.50 MultiResUNet 224$\times$224 94.01 13.23 6.24 119.50 M2U-Net 224$\times$224 93.94 0.38 0.55 36.25 改进的U-Net 224$\times$224 94.53 0.52 0.61 53.75
下载: 导出CSV
表 3 本文提出的目标检测和分割方法与Mask R-CNN v3的性能对比
Table 3 Performance comparison of the proposed object detection and segmentation method and Mask R-CNN v3
检测与分割算法 输入图像大小 参数量 (M) ${\rm{mAP} }$(%) IoU (%) 目标检测时间 (ms/f) Mask R-CNN v3 (ResNet-101) 300$\times$300 21.20 98.00 83.45 219.73 改进的SSD+U-Net (MobileNetV2) 300$\times$300 2.25 96.30 94.53 31.04
下载: 导出CSV
表 4 OSLHGR算法的分类结果和模型性能对比
Table 4 Comparison of classification results and model performance of OSLHGR algorithms
下载: 导出CSV
-
[1] Betancourt A, López M M, Regazzoni C S, Rauterberg M. A sequential classifier for hand detection in the framework of egocentric vision. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Columbus, Ohio, USA: IEEE, 2014. 600−605 [2] Thalmann D, Liang H, Yuan J. First-person palm pose tracking and gesture recognition in augmented reality. Computer Vision, Imaging and Computer Graphics Theory and Applications, 2015, 598: 3−15 [3] Serra G, Camurri M, Baraldi L, Benedetti M, Cucchiara R. Hand segmentation for gesture recognition in EGO-vision. In: Proceedings of the 3rd ACM International Workshop on Interactive Multimedia on Mobile and Portable Devices. Barcelona, Spain: ACM, 2013. 31−36 [4] Cao C Q, Zhang Y F, Wu Y, Lu H Q, Cheng J. Egocentric gesture recognition using recurrent 3D convolutional neural networks with spatiotemporal transformer modules. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 3763−3771 [5] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y, Berg A C. SSD: Single shot multiBox detector. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 21−37 [6] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich, Germany: Springer, 2015. 234−241 [7] Sung F, Yang Y X, Zhang L, Xiang T, Torr P H S, Hospedales T M. Learning to compare relation network for few-shot learning. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 1199−1208 [8] Sandler M, Howard A, Zhu M, Zhmoginov A, Chen L C. MobileNetV2: Inverted residuals and linear bottlenecks. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 4510−4520 [9] Laibacher T, Weyde T, Jalali S. M2U-Net: Effective and efficient retinal vessel segmentation for resource-constrained environments. arXiv preprint, arXiv: 1811.07738, 2018. [10] Ibtehaz N, Rahman M S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Networks, 2020, 121: 74−87 doi: 10.1016/j.neunet.2019.08.025 [11] 彭玉青, 赵晓松, 陶慧芳, 刘宪姿, 李铁军. 复杂背景下基于深度学习的手势识别. 机器人, 2019, 41(4): 534−542Peng Yu-Qing, Zhao Xiao-Song, Tao Hui-Fang, Liu Xian-Zi, Li Tie-Jun. Hand gesture recognition against complex background based on deep learning. Robot, 2019, 41(4): 534−542 [12] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 779−788 [13] Yip H M, Navarro-Alarcon D, Liu Y. Development of an eye-gaze controlled interface for surgical manipulators using eye-tracking glasses. In: Proceedings of the 2016 IEEE International Conference on Robotics and Biomimetics. Qingdao, China: IEEE, 2016. 1900−1905 [14] Wanluk N, Visitsattapongse S, Juhong A, Pintavirooj C. Smart wheelchair based on eye tracking. In: Proceedings of the 9th Biomedical Engineering International Conference. Luang Prabang, Laos: IEEE, 2016. 1−4 [15] 杨观赐, 杨静, 苏志东, 陈占杰. 改进的YOLO特征提取算法及其在服务机器人隐私情境检测中的应用. 自动化学报, 2018, 44(12): 2238−2249Yang Guan-Ci, Yang Jing, Su Zhi-Dong, Chen Zhan-Jie. An improved YOLO feature extraction algorithm and its application to privacy situation detection of social robots. Acta Automatica Sinica, 2018, 44(12): 2238−2249 [16] 李昌岭, 李伟华. 面向战场的多通道人机交互模型. 火力与指挥控制, 2014, 39(11): 110−114 doi: 10.3969/j.issn.1002-0640.2014.11.027Li Chang-Ling, Li Wei-Hua. A multimodal interaction model for battlefield. Fire Control and Command Control, 2014, 39(11): 110−114 doi: 10.3969/j.issn.1002-0640.2014.11.027 [17] Zhang Y F, Cao C Q, Cheng J, Lu H Q. EgoGesture: A new dataset and benchmark for egocentric hand gesture recognition. IEEE Transactions on Multimedia, 2018, 20(5): 1038−1050 doi: 10.1109/TMM.2018.2808769 [18] Hegde S, Perla R, Hebbalaguppe R, Hassan E. GestAR: Real time gesture interaction for AR with egocentric view. In: Proceedings of the 2016 IEEE International Symposium on Mixed and Augmented Reality. Merida, Mexico: IEEE, 2016. 262−267 [19] Bambach S, Bambach S, Crandall D J, Yu C. Lending a hand: Detecting hands and recognizing activities in complex egocentric interactions. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1949−1957 [20] Pandey R, White M, Pidlypenskyi P, Wang X, Kaeser-Chen C. Real-time egocentric gesture recognition on mobile head mounted displays. In: Proceedings of the 31st Conference on Neural Information Processing Systems. Long Beach, CA, USA: IEEE, 2017. 1−4 [21] Howard A G, Zhu M L, Chen B, Kalenichenko D, Wang W J, Weyamd T, Andreetto M, Adam H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint, arXiv: 1704.04861, 2017. [22] 张慧, 王坤峰, 王飞跃. 深度学习在目标视觉检测中的应用进展与展望. 自动化学报, 2017, 43(8): 1289−1305Zhang Hui, Wang Kun-Feng, Wang Fei-Yue. Advances and perspectives on applications of deep learning in visual object detection. Acta Automatica Sinica, 2017, 43(8): 1289−1305 [23] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, Ohio. USA: IEEE, 2014. 580−587 [24] Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1440−1448 [25] Ren S, He K, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137−1149 doi: 10.1109/TPAMI.2016.2577031 [26] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 2015 International Conference on Learning Representations. San Diego, USA: ICLR, 2015. 1−14 [27] Fu C Y, Liu W, Tyagi A, Berg A C. DSSD: Deconvolutional single shot detector. arXiv preprint, arXiv: 1701.06659, 2017. [28] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA: IEEE, 2015. 1−9 [29] Liu S T, Huang D, Wang Y H. Receptive field block net for accurate and fast object detection. In: Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: Springer, 2018. 385−400 [30] Shen Z Q, Shi H, Feris R, Cao L L, Yan S C, Liu D, et al. Learning object detectors from scratch with gated recurrent feature pyramids. arXiv preprint, arXiv: 1712.00886, 2017. [31] Hu J, Shen L, Albanie S, Sun G, Wu E H. Squeeze-and-excitation networks. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 7132−7141 [32] 张雪松, 庄严, 闫飞, 王伟. 基于迁移学习的类别级物体识别与检测研究与进展. 自动化学报, 2019, 45(7): 1224−1243Zhang Xue-Song, Zhuang Yan, Yan Fei, Wang Wei. Status and development of transfer learning based category-level object recognition and detection. Acta Automatica Sinica, 2019, 45(7): 1224−1243 [33] Wang T, Chen Y, Zhang M Y, Chen J, Snoussi H. Internal transfer learning for improving performance in human action recognition for small datasets. IEEE Access, 2017, 5(1): 17627−17633 [34] Li Y X, Li J W, Lin W Y, Li J G. Tiny-DSOD: Lightweight object detection for resource-restricted usages. In: Proceedings of the 2018 British Machine Vision Conference. Newcastle, UK: BMVC, 2018. 1−12 [35] Wong A, Shafiee M J, Li F, Chwyl B. Tiny SSD: A tiny single-shot detection deep convolutional neural network for real-time embedded object detection. In: Proceedings of 15th Conference on Computer and Robot Vision. Toronto, Canada: IEEE, 2018. 95−101 [36] Liau H, Yamini N, Wong Y L. Fire SSD: Wide fire modules based single shot detector on edge device. arXiv preprint, arXiv: 1806.05363, 2018. [37] Wang R J, Li X, Ling C X. Pelee: A real-time object detection system on mobile devices. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: IEEE, 2018. 1967−1976 [38] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1026−1034 [39] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 39(4): 640−651 [40] Badrinarayanan V, Kendall A, Cipolla R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481−2495 doi: 10.1109/TPAMI.2016.2644615 [41] He K M, Gkioxari G, DollárP, Girshick R. Mask R-CNN. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2961−2969 [42] Lu Z, Qin S Y, Li X J, Li L W, Zhang D H. One-shot learning hand gesture recognition based on modified 3D convolutional neural networks. Machine Vision and Application, 2019, 30(7–8): 1157−1180 doi: 10.1007/s00138-019-01043-7 [43] Lu Z, Qin S Y, Li L W, Zhang D H, Xu K H, Hu Z Y. One-shot learning hand gesture recognition based on lightweight 3D convolutional neural networks for portable applications on mobile systems. IEEE Access, 2019, 7: 131732−131748 doi: 10.1109/ACCESS.2019.2940997 期刊类型引用(6)
1. 谢雪梅,王明慧. 基于依存句法分析的智能人机交互产品用户体验研究. 数字图书馆论坛. 2024(06): 44-53 .  百度学术
百度学术2. 张文安,林安迪,杨旭升,俞立,杨小牛. 融合深度学习的贝叶斯滤波综述. 自动化学报. 2024(08): 1502-1516 . 本站查看3. 陈仁钧,费敏锐,杨傲雷. 面向人机交互的手势指向估计方法. 仪器仪表学报. 2023(03): 200-208 . 百度学术4. 白煜,李香萍,张雨菡. 基于机器视觉的静态手势识别实验设计. 实验技术与管理. 2023(06): 187-191+198 . 百度学术5. 张晓俊,李长勇. 基于深度学习多特征融合的手势分割识别算法. 济南大学学报(自然科学版). 2022(03): 286-291 . 百度学术6. 刘勇,马鹏飞,薛国庆,陶迎婷. 人机交互技术在智能矿山设备中的应用. 工矿自动化. 2021(S1): 45-47 . 百度学术其他类型引用(9)
-

 下载:
下载:




计量
- 文章访问数: 1687
- HTML全文浏览量: 1993
- PDF下载量: 300
- 被引次数: 15
