

A Method of Inpainting Ancient Yi Characters Based on Dual Discriminator Generative Adversarial Networks
-
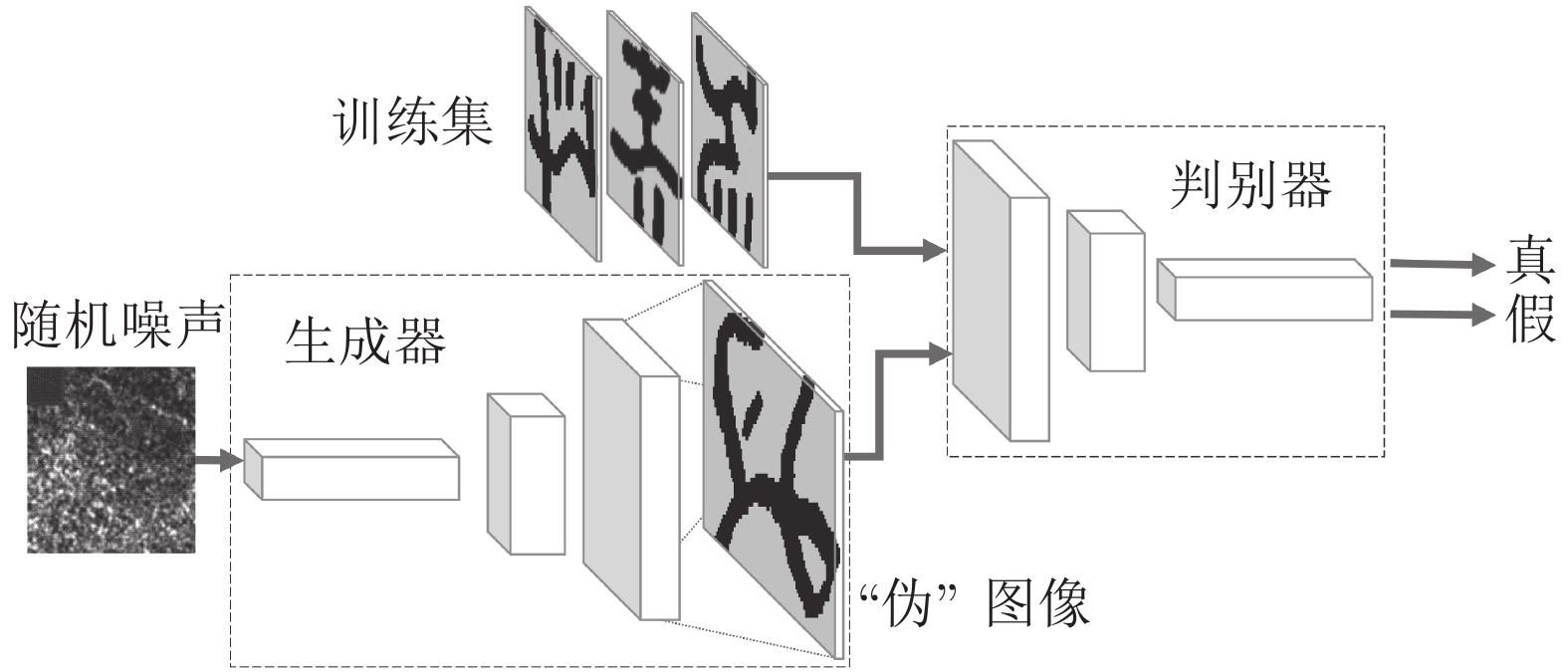
摘要: 在中国, 彝文古籍文献日益流失而且损毁严重, 由于通晓古彝文的研究人员缺乏, 使得古籍恢复工作进展十分缓慢. 人工智能在图像文本领域的应用, 为古籍文献的自动修复提供可能. 本文设计了一种双判别器生成对抗网络(Generative adversarial networks with dual discriminator,D2GAN), 以还原古代彝族字符中的缺失部分. D2GAN是在深度卷积生成对抗网络的基础上, 增加一个古彝文筛选判别器. 通过三个阶段的训练来迭代地优化古彝文字符生成网络, 以获得古彝文字符的文字生成器. 根据筛选判别器的损失结果优化D2GAN模型, 并使用生成的字符恢复古彝文中丢失的笔画. 实验结果表明, 在字符残缺低于1/3的情况下, 本文提出的方法可使文字笔画的修复率达到77.3%, 有效地加快了古彝文字符修复工作的进程.Abstract: Ancient Yi literatures are increasingly lost and damaged seriously. Due to the lack of ancient Yi researchers, the inpainting of ancient books is progressing very slowly. The application of artificial intelligence is successful in the field of image and texts, so it is possible for automatic inpainting of ancient books. In this paper, a generative adversarial networks with dual discriminator (D2GAN) is designed to restore missing part in ancient Yi characters. The D2GAN is based on the deep convolution generating adversarial network, and adds a selection discriminator. The generation networks of ancient Yi character is optimized iteratively through three-stage training, and the character generator of ancient Yi is established. The loss of selection discriminator is used to optimize the model D2GAN iteratively. So, generated characters based D2GAN can restore the missing stroke in the ancient Yi characters. The experimental results show that the method proposed has an inpainting rate of 77.3% for incomplete characters that the incomplete part does not exceed one third. Therefore, our method is effectively for the inpainting of ancient book, it can accelerate the protection progress of ancient Yi literature.
-
Key words:
- Yi characters /
- generativeadversarialnetwork(GAN) /
- deeplearning /
- gradientdescent
1) 收稿日期 2019-10-30 录用日期 2020-04-16 Manuscript received October 30, 2019; accepted April 16, 2020 国家自然科学基金 (61603310), 国家社会科学基金 (19BYY171), 重庆市自然科学基金 (cstc2019jcyj-msxm2550), 模式识别国家重点实验室开放课题 (201900010), 中央高校基本科研业务费(XDJK2018B020), 重庆市教育委员会科学技术研究计划青年项目(KJQN201801901, KJQN201801902) 资助 Supported by National Natural Science Foundation of China (61603310), National Social Science Foundation of China (19BYY171), Natural Science Foundation of Chongqing (cstc2019jcyj-msxm2550), Open Projects Program of National Laboratory of Pattern Recognition (201900010), Fundamental Research Funds for the Central Universities of China (XDJK2018B020), and Youth Project of Science and Technology Research Program of Chongqing Education Commission (KJQN201801901, KJQN201801902) 本文责任编委 金连文 Recommended by Associate Editor JIN Lian-Wen 1. 西南大学计算机与信息科学学院 重庆 400715 2. 重庆工程学院计算机与物联网学院 重庆 400056 3. 贵州工程应用技术学2) 院彝学研究院 毕节 551700 1. College of Computer and Information Science, Southwest University, Chongqing 400715 2. College of Computer and Internet of Things, Chongqing Institute of Engineering College, Chongqing 400056 3. Institute of Yi Studies, Guizhou University of Engineering Science, Bijie 551700 -
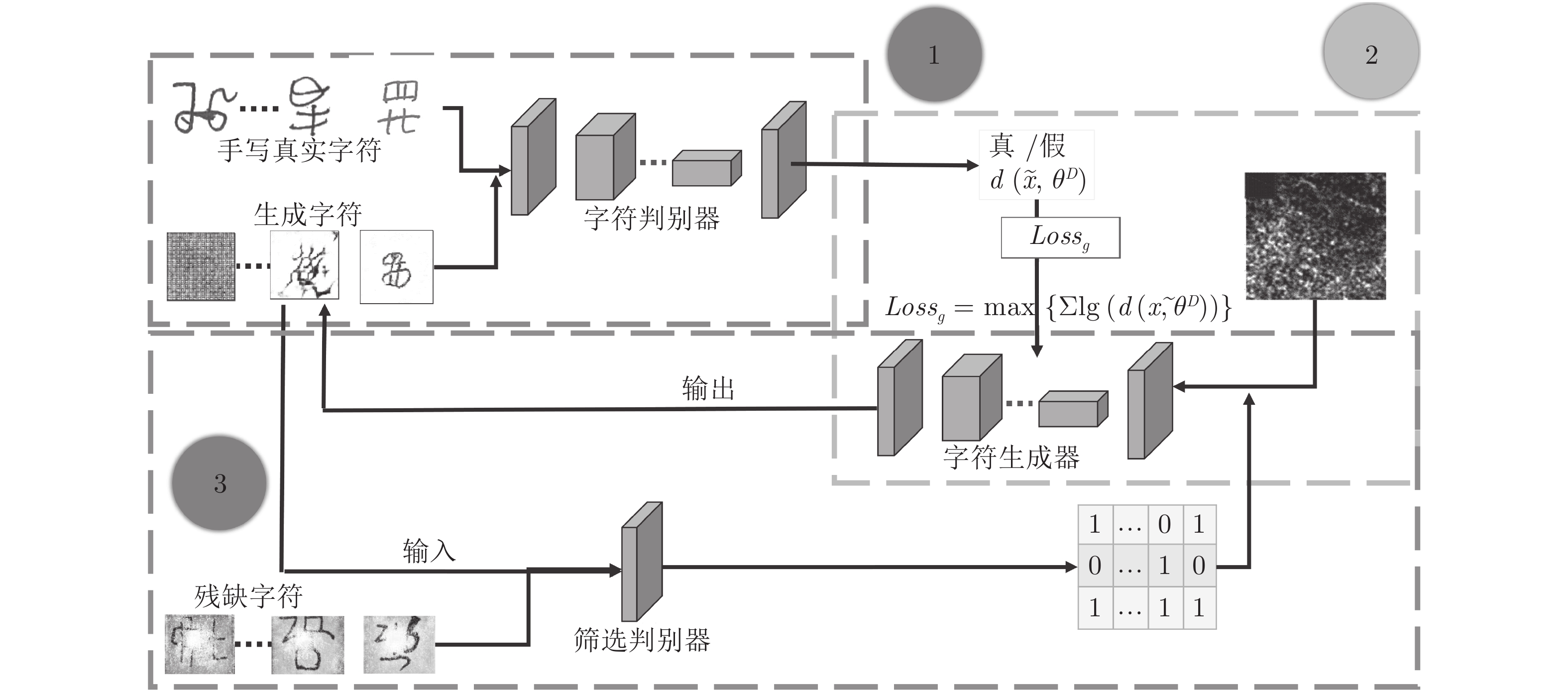
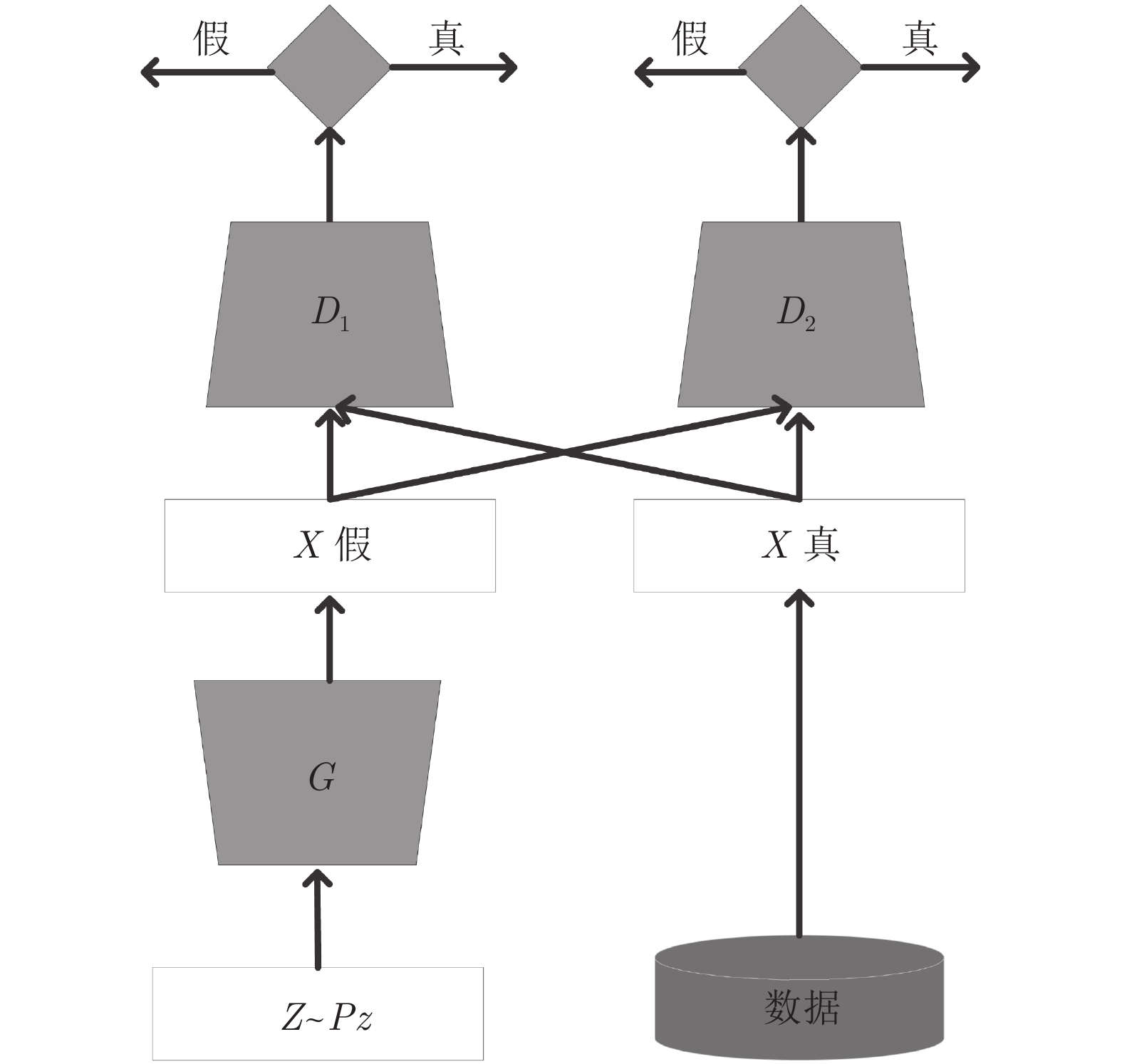
图 2 本文双判别器生成式对抗网络结构
Fig. 2 Generative adversarial networks with double discriminator in the paper
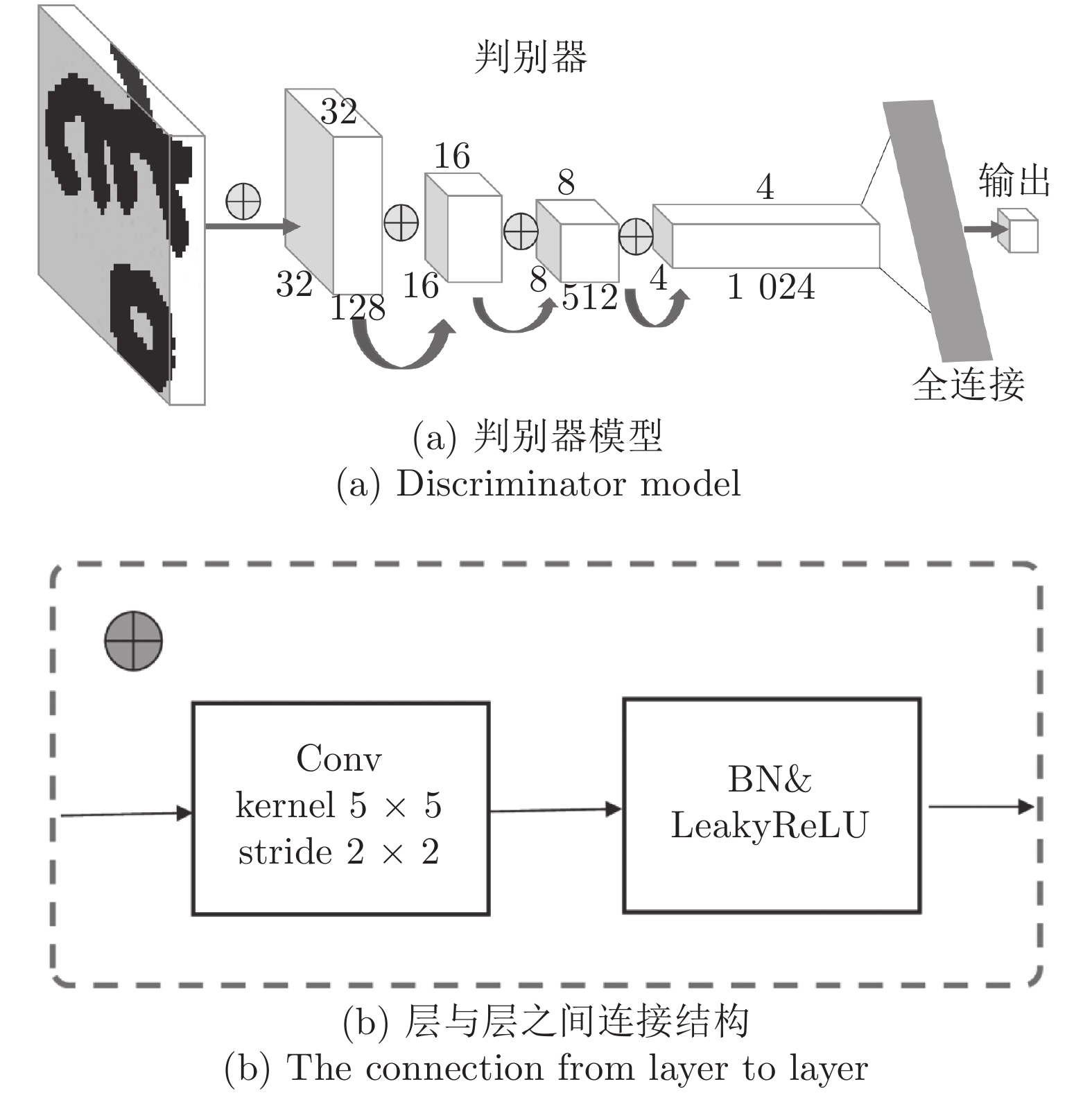
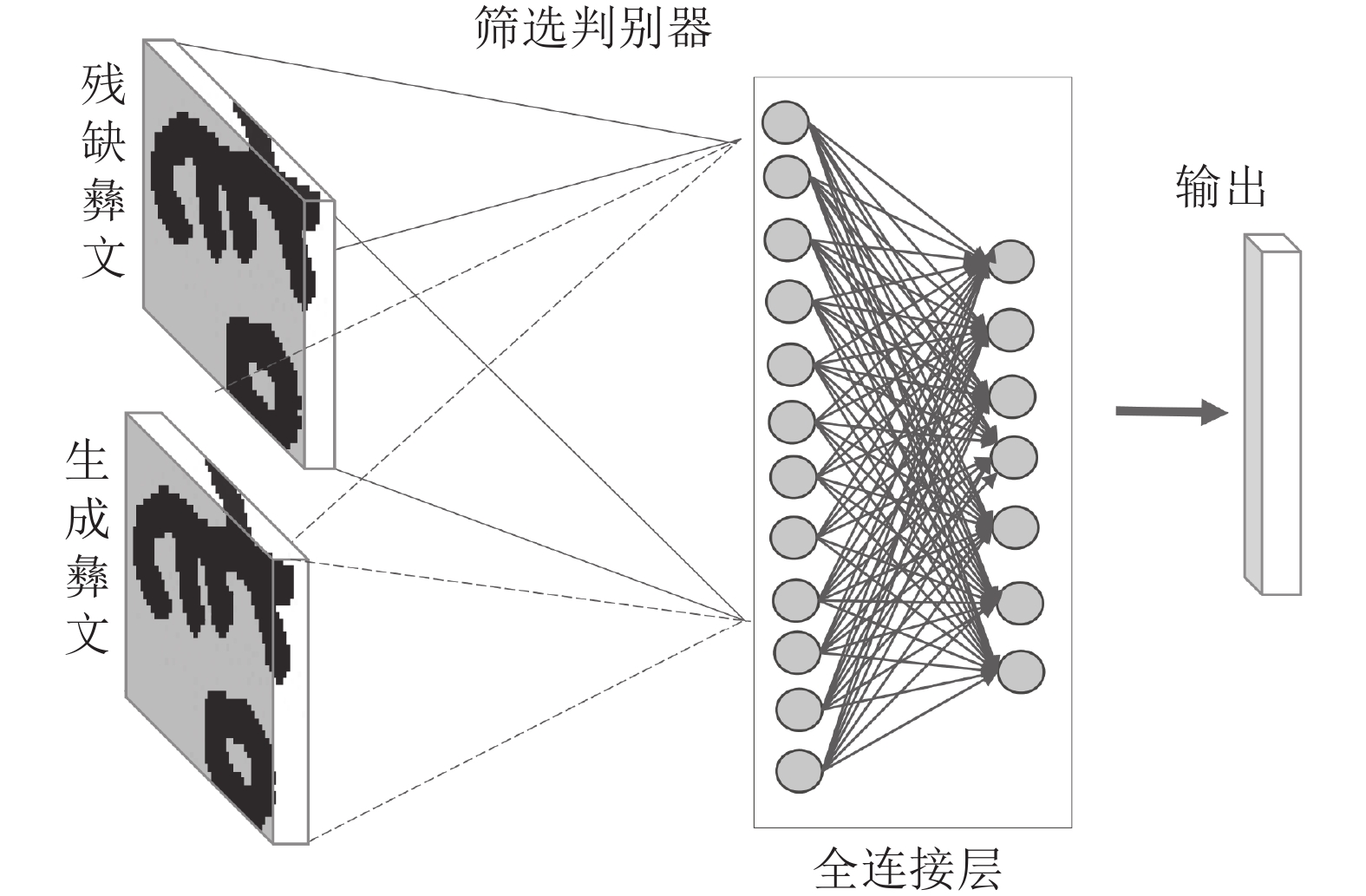
图 5 古彝文字符判别器模型详细结构
Fig. 5 Detailed structure of the ancient Yi character discriminator model
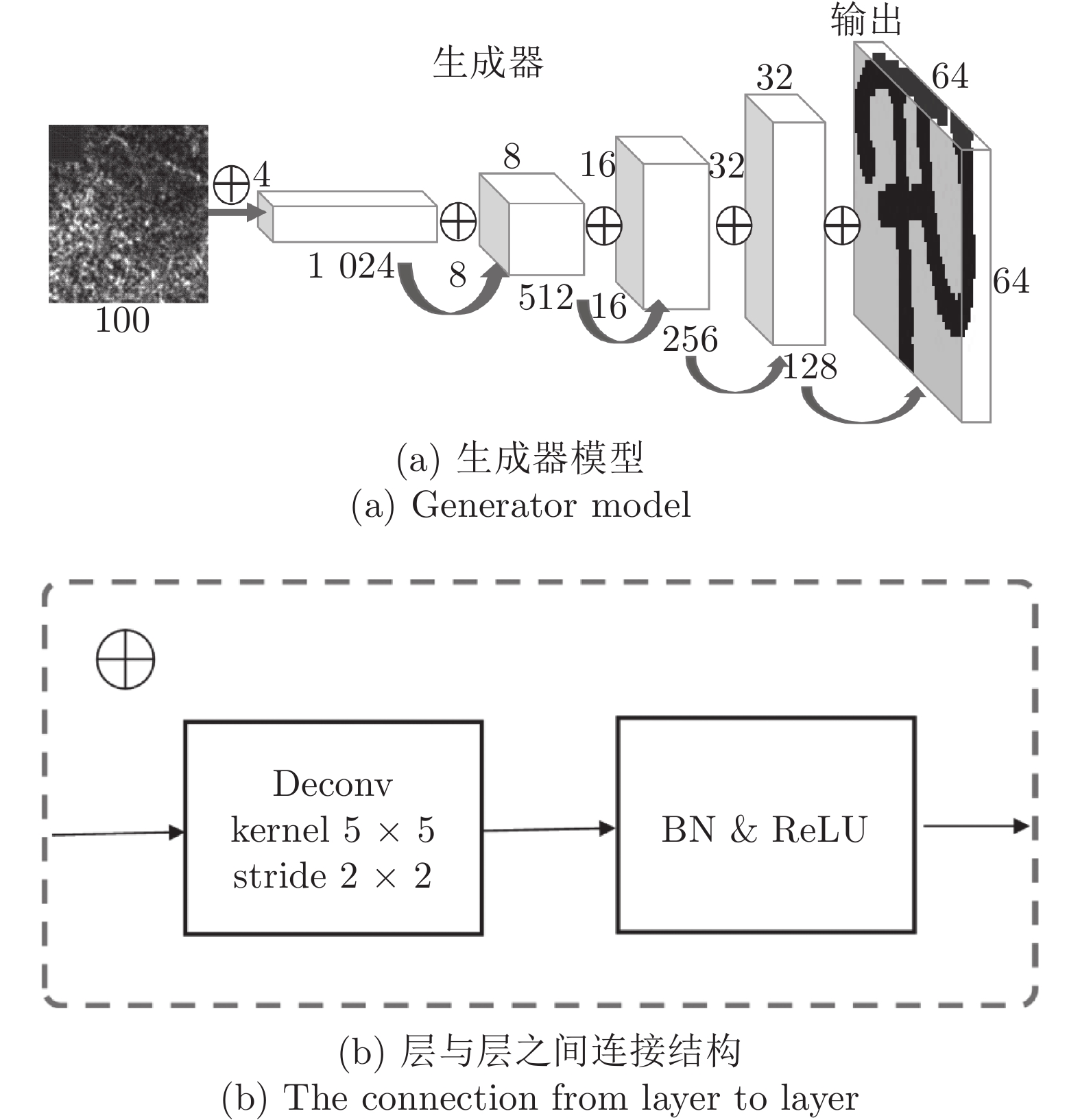
图 6 古彝文字符生成器模型详细结构
Fig. 6 Detailed structure of the ancient Yi character generator model

图 10 通过生成器模型输出图像
$G(\boldsymbol z)$ Fig. 10 Output images
$G(\boldsymbol z)$ from the generator model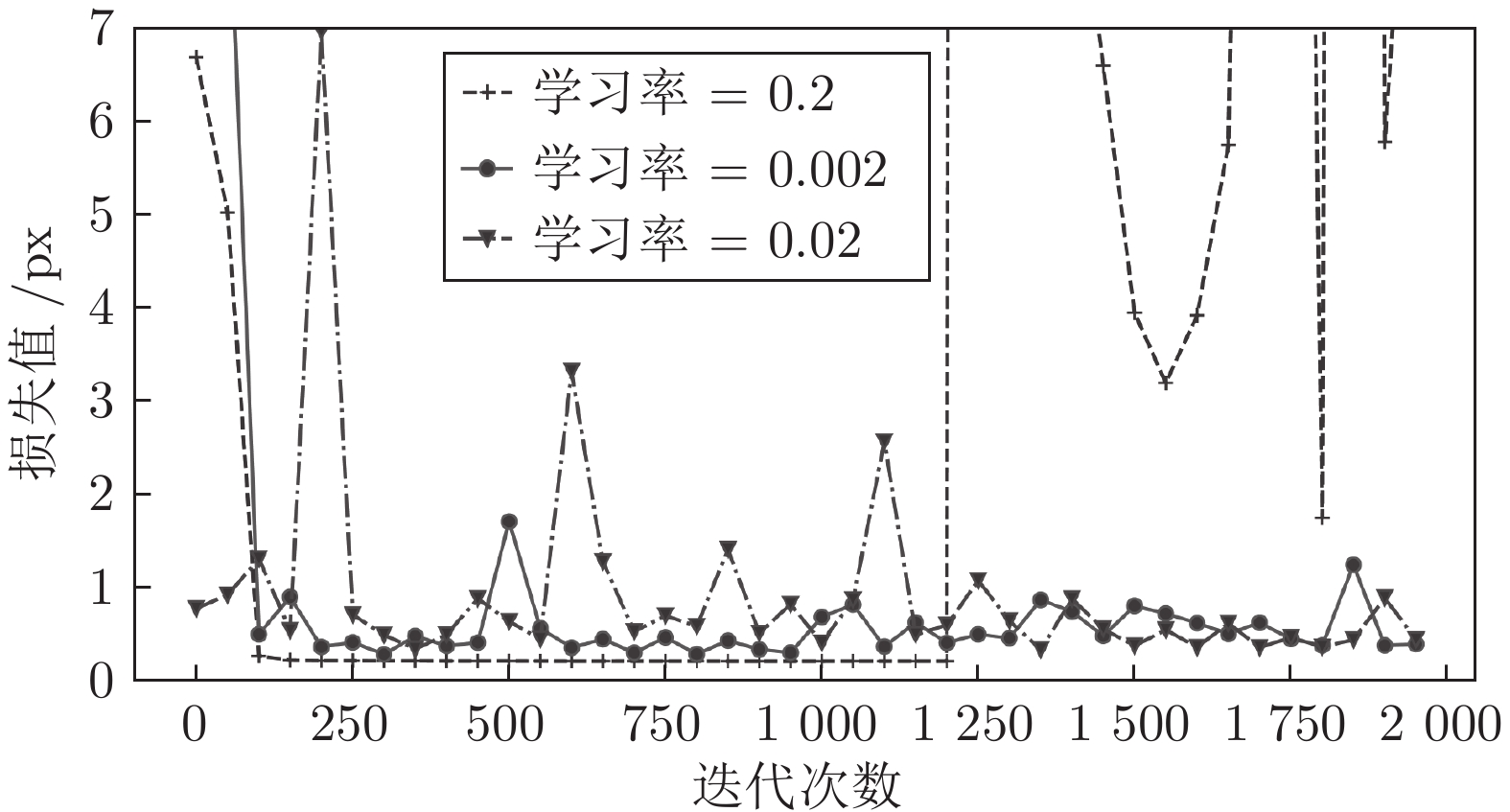
图 15 学习率0.2, 0.02, 0.002的损失值变化曲线
Fig. 15 The loss variation of the learning rate involving 0.2, 0.02 and 0.002
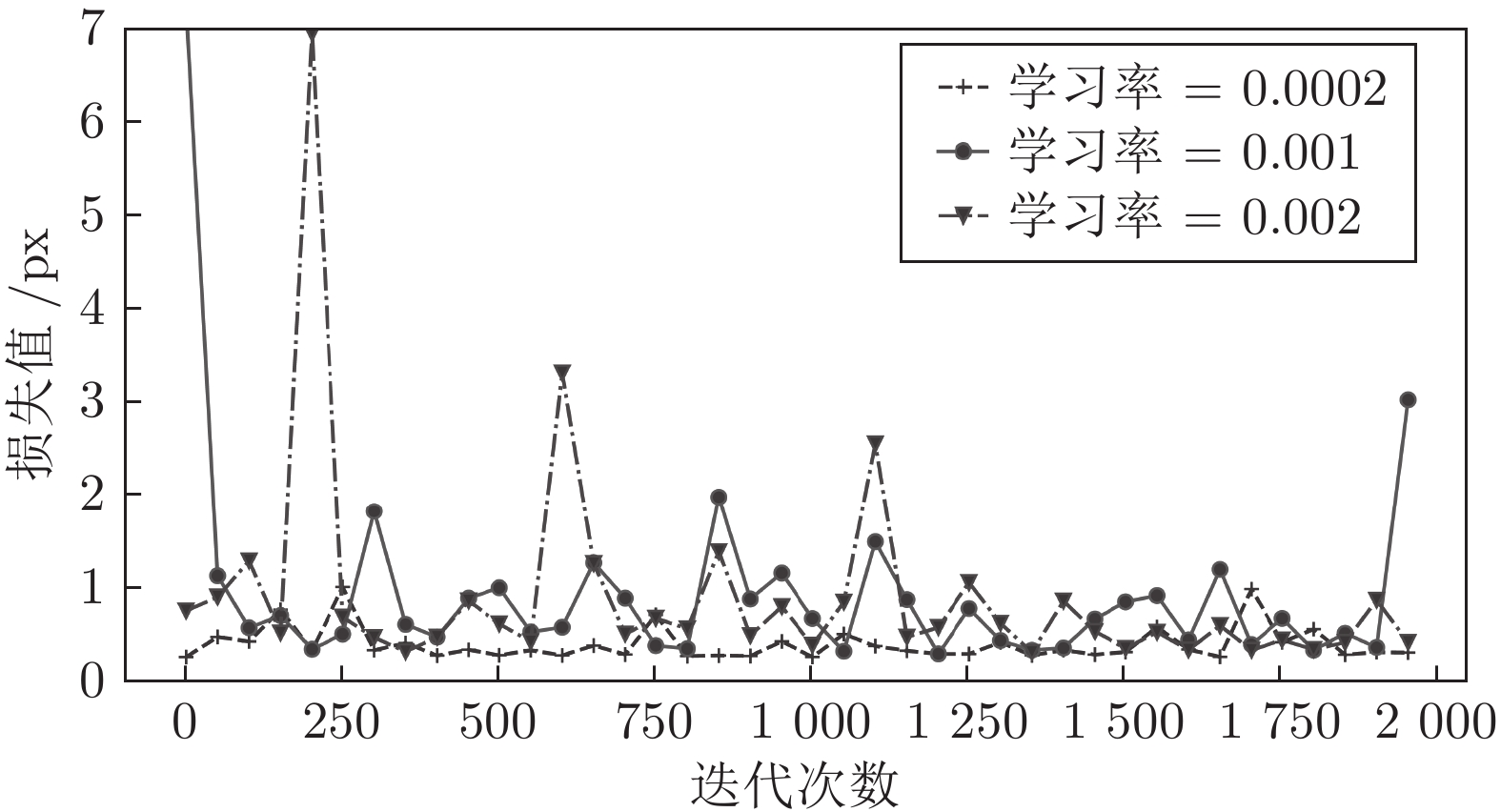
图 16 学习率为0.0002, 0.001, 0.002的损失值变化曲线
Fig. 16 The loss variation of the learning rate involving 0.0002, 0.001 and 0.002
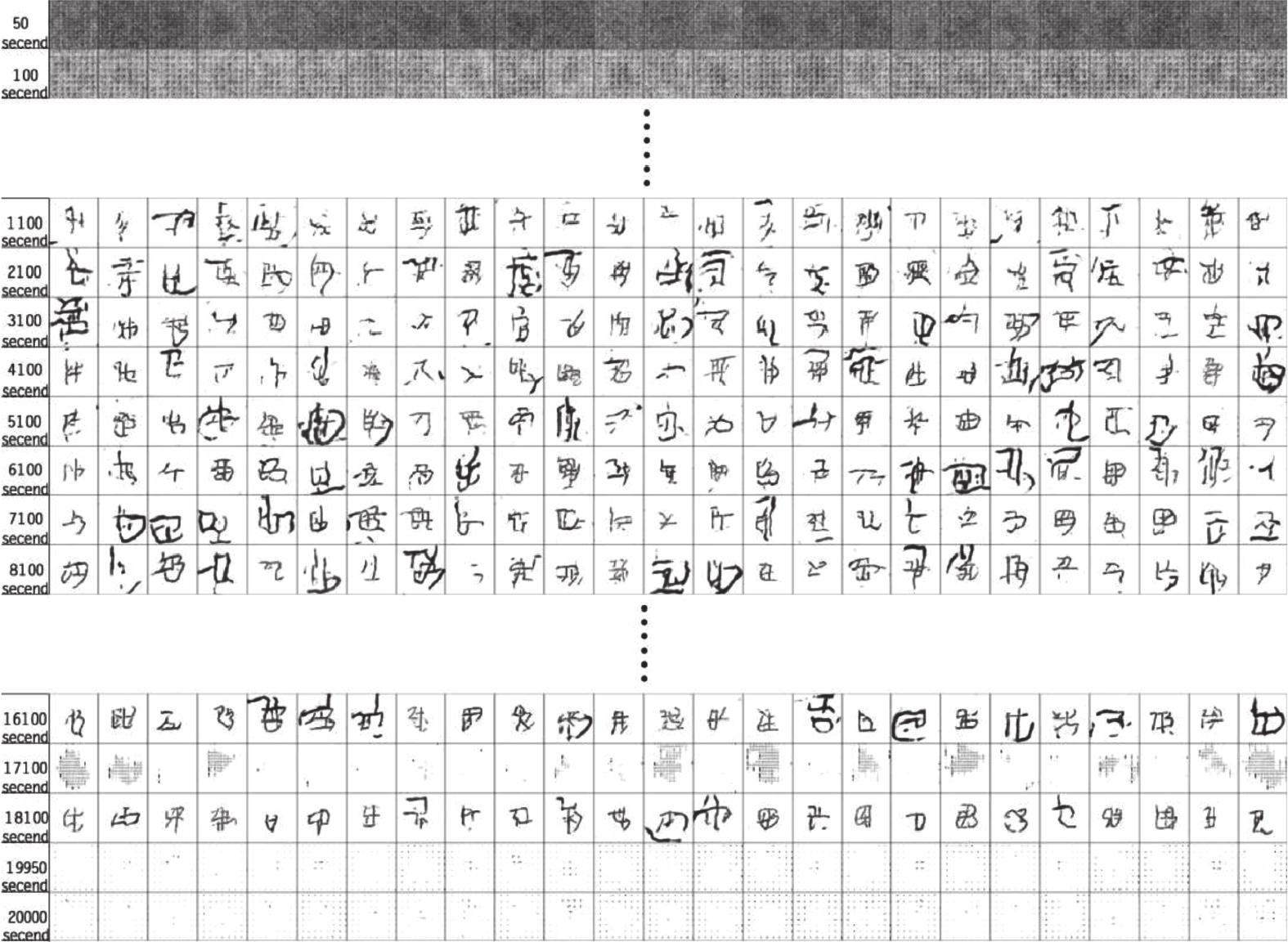
图 17 不同训练次数下生成器生成图像
Fig. 17 The generator generates image under different training times
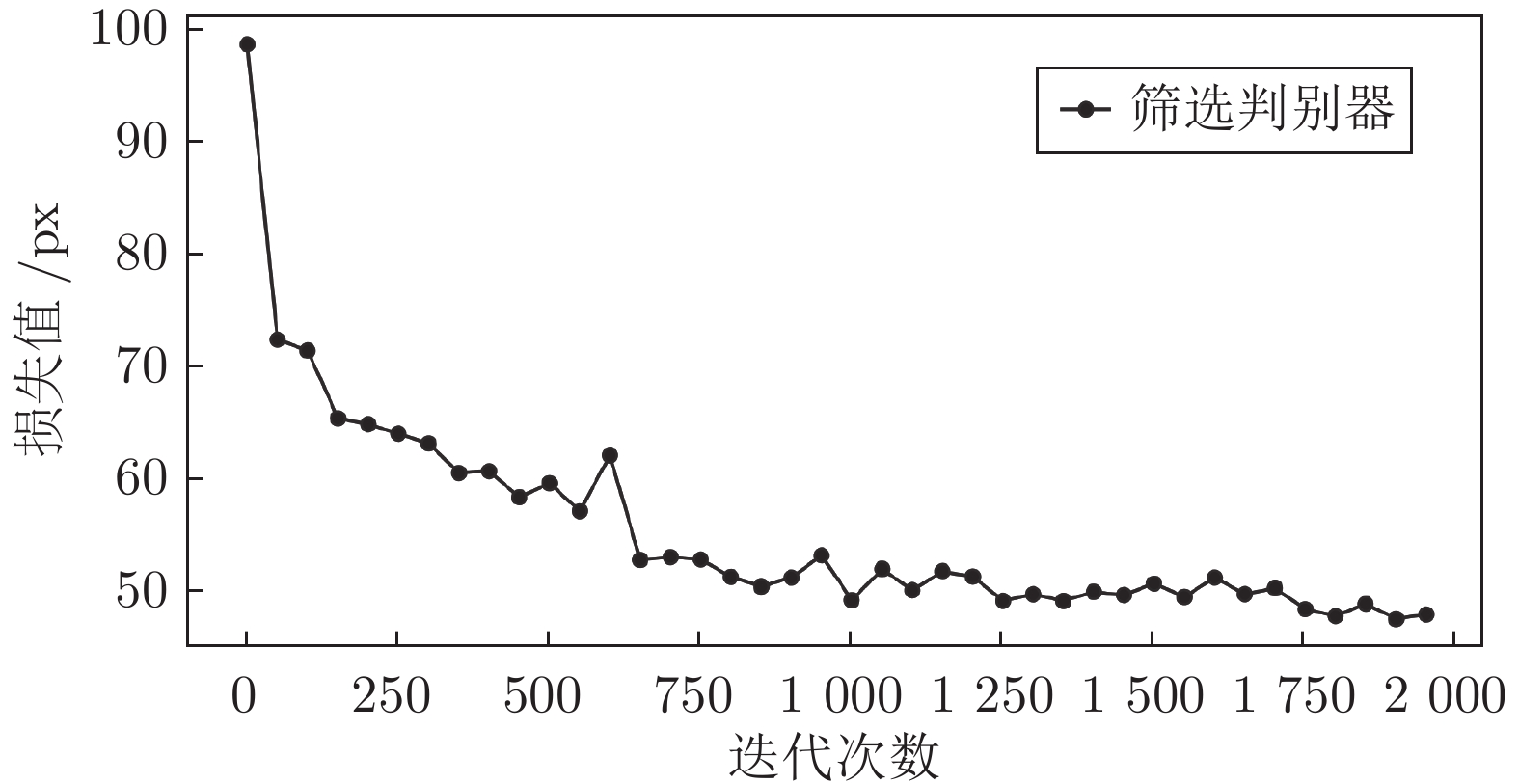
图 20 筛选判别器的训练过程中损失值变化曲线
Fig. 20 The loss curve in process of the training of the selecting discriminator
图 21 训练得到
$\boldsymbol z',$ 然后输入$\boldsymbol z'$ 到生成器得到的图像Fig. 21 After trainning,
$\boldsymbol z'$ is generated, and then input$\boldsymbol z'$ to the generator to get the image
图 24 多形状残缺修复结果
Fig. 24 The repair effect of ancient Yi characterof multiple shape occlusion

图 25 彝文古籍文献中残缺字符修复效果
Fig. 25 The repair effect of incomplete characters in ancient Yi literature

图 26 古彝文残缺字符修复失败效果
Fig. 26 The failed repair effect of ancient Yi incomplete characters
表 1 判别器模型参数表
Table 1 Parameter table of the discriminator model
层信息 卷积核
个数卷积核
大小步长 特征图
大小参数个数 C1层 (卷积层) 128 5×5 2 32×32 3328 C2层 (卷积层) 256 5×5 2 16×16 819456 C3层 (卷积层) 512 5×5 2 8×8 3277312 C4层 (卷积层) 1024 5×5 2 4×4 13108224 OUTPUT层 (输出层) 1×1 16385  下载: 导出CSV
下载: 导出CSV
表 2 生成器模型参数表
Table 2 Parameter table of the generator model
层信息 卷积核
个数卷积核
大小步长 特征图
大小参数个数 C1层 (卷积层) 1654784 C2层 (卷积层) 512 5×5 2 8×8 13107712 C3层 (卷积层) 256 5×5 2 16×16 3277056 C4层 (卷积层) 128 5×5 2 32×32 819328 OUTPUT层 (输出层) 1 5×5 2 64×64 3201
下载: 导出CSV
表 3 古彝文字符修复比例
Table 3 Restoration proportion of ancient Yi characters
个数 占比 (%) 时间消耗 (ms) 完全修复 523 52 52 部分修复 246 25 61 未完成修复 231 23 56 合计 1000 100
下载: 导出CSV
-
[1] 王正贤. 彝文金石述略. 贵州民族研究, 2002, 20(2): 156-163 doi: 10.3969/j.issn.1002-6959.2002.02.028Wang Zhen-Xian. Brief introduction to Yiwen and gold stone language. Guizhou Ethnic Studies, 2002, 20(2): 156-163 doi: 10.3969/j.issn.1002-6959.2002.02.028 [2] 吴勰, 禄玉萍, 王明贵. 论贵州古彝文编码字符集构建. 中文信息学报, 2014, 28(4): 153-158 doi: 10.3969/j.issn.1003-0077.2014.04.021Wu Xie, Lu Yu-Ping, Wang Ming-Gui. On the construction of ancient Yi coded character sets in Guizhou. Journal of Chinese Information, 2014, 28(4): 153-158 doi: 10.3969/j.issn.1003-0077.2014.04.021 [3] 史金波. 当代少数民族文字历史文献整理与研究刍议. 青海民族研究, 2018, 29(3): 108-115Shi Jin-Bo. On the collation and research of historical literature of contemporary minority characters. Qinghai Nationalities Research, 2018, 29(3): 108-115 [4] 滇川黔桂彝文协作组, 滇川黔桂彝文字典. 云南民族出版社, 2001, 1(1): 278−286Yunnan Sichuan Guizhou Guangxi Yi Language Cooperation Group. Yunnan Sichuan Guizhou Guangxi Yi Dictionary. Yunnan Nationalities Publishing House, 2001, 1(1): 278−286 [5] 陈善雄, 王小龙, 韩旭等. 一种基于深度学习的古彝文识别方法, 浙江大学学报(理学版), 2019, 46(3): 261-269Chen Shan-Xiong, Wang Xiao-Long, Han Xu. A recognition method of ancient Yi based on deep learning. Journal of Zhejiang University (SCIENCE EDITION), 2019, 46(3): 261-269 [6] Bouillon M, Ingold R, Liwicki M. Grayification: A meaningful grayscale conversion to improve handwritten historical documents analysis. Pattern Recognition Letters, 2018, 121(15): 46-51 [7] Cao XY, Zhou F, Lin X, et al. Hyperspectral image classification with markov random fields and a convolutional neural network. IEEE Transactions on Image Processing, 2018, 27(5): 2354-2367 doi: 10.1109/TIP.2018.2799324 [8] Danilla C, Persello C, Tolpekin V, Bergado J R. Classification of multitemporal sar images using convolutional neural networks and Markov random fields. In: Proceedings of the 2017 Geoscience and Remote Sensing Symposium (IGARSS), IEEE International Symposium. Fort Worth, TX, USA: IEEE, 2017. 2231−2234 [9] Huang X, Belongie S. Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017(1): 1510−1519 [10] Cireşan D C, Meier U, Schmidhuber J. Transfer learning for Latin and Chinese characters with deep neural networks. In: Proceedings of the 2012 International Joint Conference on Neural Networks. Brisbane, QLD, Australia: IEEE, 2012. 1−6 [11] Goodfellow L, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Kuching, Malaysia: MIT Press, 2014, 2672−2680 [12] Chen S M, Wang W J, Xia B H, You X G, Peng Q M, Cao Z H, et al. CDE-GAN: Cooperative dual evolution-based generative adversarial network, IEEE Transactions on Evolutionary Computation, 2021, 25(5): 986−1000 [13] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. In: Proceedings of the 4th International Conference on Learning Representations (ICLR ). San Juan, Puerto Rico: OpenReview.net, 2016. [14] 赵树阳, 李建武. 基于生成对抗网络的低秩图像生成方法. 自动化学报, 2018, 44(5): 829-839Zhao Shu-Yang, LI Jian-Wu. Generative adversarial network for generating low-rank images. ACTA AUTOMATICA SINICA, 2018, 44(5): 829-839 [15] Wei P, Li H, Hu P. Inverse discriminative networks for handwritten signature verification. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVRP). Long Beach, CA, USA: IEEE, 2019. 5764−5772 [16] Li X W, Shen H Q, Yu M, Wei X, Han J, Zhu J L, et al. Blind image inpainting using pyramid GAN on thyroid ultrasound images. In: Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). San Diego, CA, USA: IEEE, 2019. 678−683 [17] Chang J, Gu Y J, Zhang Y, Wang Y F. Chinese handwriting imitation with hierarchical generative adversarial network. In: Proceedings of the 2018 British Machine Vision Conference (BMVC). Newcastle, UK: BMVA, 2018. [18] Chang B, Zhang Q, Pan S Y, Meng L L. Generating handwritten Chinese characters using cyclegan. In: Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Tahoe, NV, USA: IEEE, 2018. 199−207 [19] Yeh R A, Chen C, Lim T Y, Schwing A G, Hasegawa-Johnson M, Do M N. Semantic image inpainting with deep generative models. In: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 6882−6890 [20] 付晓, 沈远彤, 李宏伟, 程晓梅. 基于半监督编码生成对抗网络的图像分类模型. 自动化学报, 2020, 46(3): 531-539Fu Xiao, Shen Yuan-Tong, Li Hong-Wei, Cheng Xiao-Mei. A Semi-supervised encoder generative adversarial networks model for image classification. ACTA AUTOMATICA SINICA, 2020, 46(3): 531-539 [21] Gao Y P, Gao L, Li X Y. A generative adversarial network based deep learning method for low-quality defect image reconstruction and recognition. IEEE Transactions on Industrial Informatics, 2021, 17(5): 3231−3240 [22] You C Y, Cong W X, Vannier M W, Saha P K, Hoffman E A, Wang G, et al. CT super-resolution GAN constrained by the identical, residual, and cycle learning ensemble (GAN-CIRCLE). IEEE Transactions on Medical Imaging, 2020, 39(1): 188−203 [23] Liu M, Ding Y K, Xia M, Liu X, Ding E R, Zuo W M, Weng S L. Stgan: A unified selective transfer network for arbitrary image attribute editing. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVRP). Long Beach, CA, USA: IEEE, 2019. 3668−3677 [24] Zhong Z L, Li J, Clausi D A, Wong A. Generative adversarial networks and conditional random fields for hyperspectral image classification. IEEE Transactions on Cybernetics, 2020, 50(7): 3318−3329 [25] Nguyen T D, Le T, Vu H T, Phung D. Dual discriminator generative adversarial nets. In: Proceedings of the 31st Internation Conference on Neural Information Processing Systems (NIPS). Long Beach, CA, USA: Curran Associates, 2017. 2671−2681 [26] Memisevic R. Gradient-based learning of the 2011 higher-order image features. In: Proceedings of the 2011 International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011, 1591−1598 [27] Zhang S, Wang M, Xiong J, Liu S, Chen P Y. Improved linear convergence of training CNNs with generalizability guarantees: A one-hidden-layer case, IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(6): 2622−2635 [28] Shi Y, Davaslioglu K, Sagduyu Y E. Generative adversarial network in the air: deep adversarial learning for wireless signal spoofing. IEEE Transactions on Cognitive Communications and Networking, 2021, 7(1): 294−303 [29] Chang J, Scherer S. Learning representations of emotional speech with deep convolutional generative adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Acoustic, Speech and Signal Processing. New Orleans, LA USA: IEEE, 2017. 2746−2750 [30] Meng Y Y, Kong D Q, Zhu Z F, Zhao Y. From night to day: GANs based low quality image enhancement. Neural Processing Letters, 2019, 50(1): 799−814 [31] 马锦卫, 彝文起源及其发展考论 [博士学位论文], 西南大学, 中国, 2010.Ma Jin-Wei. On the Origin and Development of Yi Language [Ph.D. dissertation]. Southwest University, China, 2010. [32] Arcos-García, álvaro, álvarez-García, Juan A, Soria-Morillo L M. Deep neural network for traffic sign recognition systems: an analysis of spatial transformers and stochastic optimisation methods. Neural Networks, 2018, 99: 158−165 [33] Shin H C, et al. Deep convolutional neural networks for computer-aided detection: cnn architectures, dataset characteristics and transfer learning. IEEE Transactions on Medical Imagings, 2016, 35(5): 1285-1297 doi: 10.1109/TMI.2016.2528162 [34] Chen S X, Han X, Gao W Z, Liu X X, Mo B F. A classification method of oracle materials based on local convolutional neural network framework. IEEE Computer Graphics and Applications, 2020, 40(3): 32−44 -

 下载:
下载:
















计量
- 文章访问数: 1245
- HTML全文浏览量: 692
- PDF下载量: 190
- 被引次数: 0
