

Sparse-to-dense Large Displacement Motion Optical Flow Estimation Based on Deep Matching
-
摘要: 针对非刚性大位移运动场景的光流计算准确性与鲁棒性问题, 提出一种基于深度匹配的由稀疏到稠密大位移运动光流估计方法. 首先利用深度匹配模型计算图像序列相邻帧的初始稀疏运动场; 其次采用网格化邻域支持优化模型筛选具有较高置信度的图像网格和匹配像素点, 获得鲁棒的稀疏运动场; 然后对稀疏运动场进行边缘保护稠密插值, 并设计全局能量泛函优化求解稠密光流场. 最后分别利用MPI-Sintel和KITTI数据库提供的测试图像集对本文方法和Classic + NL, DeepFlow, EpicFlow以及FlowNetS等变分模型、匹配策略和深度学习光流计算方法进行综合对比与分析, 实验结果表明本文方法相对于其他方法具有更高的光流计算精度, 尤其在非刚性大位移和运动遮挡区域具有更好的鲁棒性与可靠性.Abstract: In order to improve the accuracy and robustness of optical flow estimation under the non-rigid large displacement motion, we propose a sparse-to-dense large displacement motion optical flow estimation method based on deep matching. First, we utilize the deep matching model to compute an initial sparse motion field from the consecutive two frames of the image sequence. Second, we adopt the gridded neighborhood support optimization scheme to extract the image grids and matching pixels which have the high confidence, and acquire the robust sparse motion field. Third, we interpolate the sparse motion field to obtain the dense motion field and plan a global energy function to estimate the optimized dense optical flow. Finally, we respectively employ the MPI-Sintel and KITTI datasets to compare the performance of the proposed method with several variational, region matching and deep-learning based optical flow approaches including Classic + NL, DeepFlow, EpicFlow and FlowNetS models. The experimental results indicate that the proposed method has the higher computational accuracy compared with those of the other state-of-the-art approaches, especially owns the better robustness and reliability in the areas of non-rigid large displacements and motion occlusions.
-
Key words:
- Dense optical flow /
- deep matching /
- neighborhood support /
- image grid /
- global optimization
-
表面肌电信号 (Surface electromyography, sEMG) 是动作电位沿着肌纤维方向传播引起的生物电信号, 可用于反映人体肌肉收缩、关节力矩等运动信息[1]. 由于非侵入、测量技术相对成熟等特点, sEMG被广泛用于估计人体的运动状态和运动意图[2], 在人机协作、智能假肢、康复医疗和运动评估等领域有重要的应用价值[3-5].
基于sEMG的人体运动估计中的重要问题之一, 即如何建立sEMG与人体运动之间的映射模型. 其中, 生理学建模是一种常用的方法, 该方法从运动生理学和生物力学出发, 将sEMG转换为动力, 并依据关节动力学得出人体运动信息[6]. 生理学模型符合运动生理规律且具有较好的可解释性, 但计算复杂且涉及大量不易测量的生理参数, 限制了该类模型的应用[7]. 近年来, 随着深度学习技术的迅速发展, 深度神经网络逐渐成为人体运动估计领域中应用最为广泛的方法[8-14]. 在基于sEMG的人体运动估计中, 深度学习模型设计的核心在于如何利用深度神经网络从sEMG数据中学习出sEMG与人体运动之间的映射关系. Lu等[15]提出了一种堆叠卷积长短期记忆网络(Stacked convolutional and long-short term memory networks, Conv-LSTM)用于人体下肢关节角度估计. Chai等[16]结合长短期记忆网络 (Long short-term memory, LSTM) 和离散时间归零神经算法的闭环控制模型来实现人体上肢运动意图的准确估计. 尽管这类方法取得了较好的准确性, 但深度神经网络作为一种 “黑箱” 模型含有大量不可见状态且可解释性欠缺, 限制了其估计性能的进一步提升[17].
基于卡尔曼滤波的状态估计方法通过显式描述表示系统状态的转换关系, 具有良好的噪声处理能力. 为处理深度神经网络含有噪声的估计输出[18-21], Zhang等[18]设计LSTM-UKF算法, 利用LSTM网络提供量测预测值, 解决量测缺失引起的误差增大问题. Jondhale等[19]利用无迹卡尔曼滤波 (Unscented Kalman filter, UKF) 进一步提高广义回归神经网络的估计精度. Lim等[20]提出利用TCN (Temporal convolutional network) 将各类信号合成后辅助UKF进行状态估计的方法. 然而, 卡尔曼滤波方法的应用需要大量先验知识来设计人体运动模型和调整参数, 尤其是肌肉运动引起的sEMG与人体运动状态之间物理关系涉及大量复杂转换以及大量难以测量的生理学参数. 同时, sEMG噪声的复杂性和人体运动的随机性又增加了人体运动估计的建模难度. 为了克服这些限制, 已有学者尝试将卡尔曼滤波与神经网络相结合, 从测量数据中使用神经网络来学习卡尔曼滤波参数[17, 22-25]. Coskun等[22]提出了LSTM-KF (LSTM-based Kalman filter process), 用于处理任意黑盒估计器输出的含有噪声的人体姿态估计, 通过三个LSTM模块分别学习卡尔曼滤波的状态模型、观测模型以及噪声模型. Bao等[23]提出了深度卡尔曼滤波网络(Deep Kalman filter network, DKFN), 利用卷积神经网络 (Convolutional neural network, CNN) 提取sEMG高维特征后输入LSTM-KF, DKFN在LSTM-KF的基础上, 增加了一个LSTM模块用于学习卡尔曼增益. Zhao等[24]提出学习卡尔曼网络 (Learning Kalman network, LKN), 由全连接层学习其状态模型和量测模型参数, 由LSTM模块学习得到卡尔曼增益. 这种结合深度神经网络的卡尔曼滤波方法称作卡尔曼滤波网络 (Kalman filter network, KFN). 通过结合深度学习与卡尔曼滤波的优势, KFN具有较好的模型适应性和抗噪能力. 然而, 非线性的深度神经网络使得滤波过程中引入较大的线性化误差, 影响了KFN的估计精度和系统的稳定性[26-27], 因此目前与卡尔曼滤波结合的神经网络结构较简单. 由于结构限制, KFN的估计能力有限, 通常在其他估计模型之后用于进一步处理含有噪声的状态估计或高阶特征[22-24].
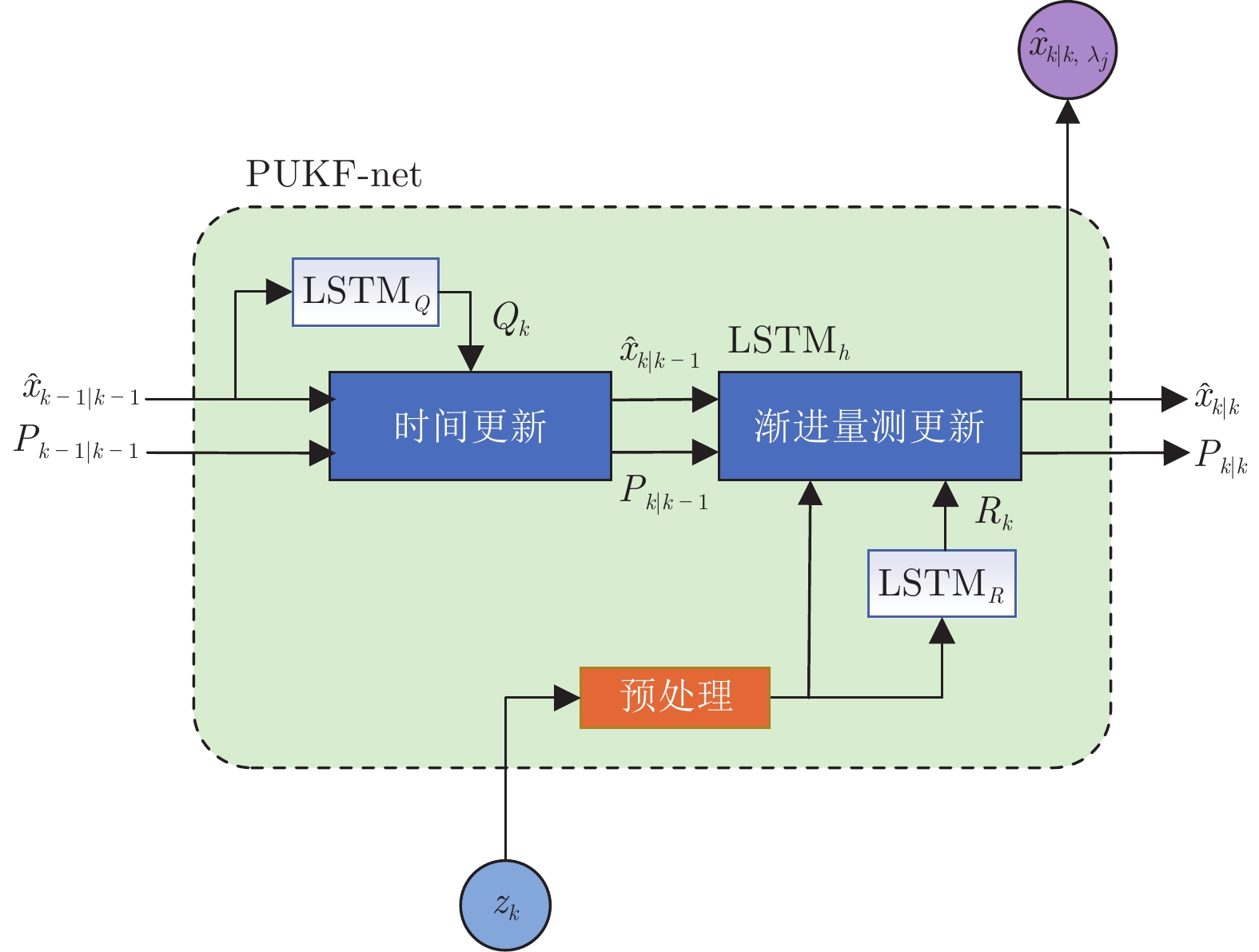
针对以上问题, 本文提出了一种渐进无迹卡尔曼滤波网络 (Progressive unscented Kalman filter network, PUKF-net) 端到端地实现基于sEMG的人体运动状态估计, 其结构如图1所示. 首先, 根据人体运动过程建立非线性状态转移模型和量测模型, 设计了三个LSTM模块直接从sEMG数据中学习人体运动状态与sEMG量测的映射关系, 以及模型的噪声统计特性; 其次, 利用UT (Unscented transformation)变换和渐进量测更新方法减小线性化误差, 提高PUKF-net模型的稳定性; 最后, 通过实验采集肢体运动过程关节角度变化和相关肢体sEMG, 验证了PUKF-net模型的有效性和优越性.
1. 问题描述
sEMG是一种反映肌群潜在变化的表征方式, 其有效信号频带范围为10 ~ 500 Hz, 信号幅度一般为0 ~ 5 mV. 基于sEMG的人体肢体运动状态估计的主要难点在于: 1) 人体运动涉及多块肌肉活动, sEMG信号实际上是多层次肌肉活动引起的动作电位在皮肤表面叠加的结果; 2) 由于sEMG的非平稳、微弱等特性, 同时受体内电解质水平等生理因素以及外部环境因素干扰[28], sEMG信号通常包含大量复杂的观测噪声. 因此, 传统解析的方法难以精确描述肌肉运动引起的sEMG与肢体姿态之间的转换关系. 特别地, 肢体运动的随机性又增加了人体运动的建模难度. 以人体上肢运动为例
$$ x_k = f(x_{k-1})+w_{k} $$ (1) 其中, $ x_{k}\in {\bf{R}}^{n} $表示$ k $时刻$ n $维上肢关节状态向量, $ {{w}_{k}} $表示$ k $时刻系统噪声, $ f\left( \cdot \right) $表示系统状态转移函数. 上肢运动状态的初始估计满足
$$ \left\{\begin{aligned} & {{\hat{x}}_{0|0}} = \text{E}\left( {{{x}}_{0}} \right) \\ & {{{P}}_{0|0}} = \text{E}\left( \left( x_0-\hat x_{0|0} \right){\left( x_{0}-\hat{x}_{0|0} \right)}^\text{T} \right) \end{aligned}\right. $$ (2) 其中, $ {{\hat{x}}_{0|0}} $和$ {{{P}}_{0|0}} $表示初始状态估计及其方差. 考虑到sEMG与上肢关节角度之间的复杂映射关系, 设计LSTM模块直接从sEMG中学习系统的非线性量测函数, $ {z}_{k}\in {\bf{R}}^{m} $表示$ m $维的sEMG量测向量, $ {{v}_{k}} $表示$ k $时刻的量测噪声, 系统的量测模型表示如下
$$ z_k = \text{LSTM}_{h}\left( {{x}_{k}} \right)+{{v}_{k}} $$ (3) 其中, $ \text{LSTM}_{h} $表示用于学习量测函数的LSTM模型, 过程噪声$ {{w}_{k}} $和量测噪声$ {{v}_{k}} $分别是均值为零、协方差为$ {{Q}_{k}} $和$ {{R}_{k}} $的互不相关的高斯白噪声
$$ \begin{align} w_{k}\sim\ \text{N} \left( {\bf{0}}, Q_{k} \right) \end{align} $$ (4) $$ \begin{align} v_{k}\sim\ \text{N} \left( {\bf{0}}, R_{k} \right) \end{align} $$ (5) 其中, $ {{Q}_{k}} $和$ {{R}_{k}} $分别表示$ k $时刻过程噪声$ {{w}_{k}} $和量测噪声$ {{v}_{k}} $的协方差. 针对肢体运动的随机性和sEMG量测噪声的复杂性, 利用LSTM模块从系统状态和sEMG测量中学习当前时刻的$ {{Q}_{k}} $和$ {{R}_{k}} $
$$ \begin{align} Q_{k}& = \text{LSTM}_{Q}\left( x_{k-1}, c_{k-1}^{Q} \right) \end{align} $$ (6) $$ \begin{align} R_{k}& = \text{LSTM}_{R}\left( z_{k}, c_{k-1}^{R} \right) \end{align} $$ (7) 其中, $ \text{LSTM}_{Q} $和$ \text{LSTM}_{R} $表示用于学习过程噪声和量测噪声统计特性的LSTM模块, $ c_{k-1}^{Q} $和$ c_{k-1}^{R} $是上一时刻$ \text{LSTM}_{Q} $和$ \text{LSTM}_{R} $输出的隐藏单元, 由其对应的LSTM模块得到[22]
$$ \begin{align} {{{f}}_{k}}& = \sigma ( {{{W}}_{fh}}{{{h}}_{k-1}}+{{{W}}_{fx}}{{{x}}_{k}}+{{{b}}_{f}} ) \end{align} $$ (8) $$ \begin{align} {{{i}}_{k}}& = \sigma \left( {{{W}}_{ih}}{{{h}}_{tk-1}}+{{{W}}_{ix}}{{{x}}_{k}}+{{{b}}_{i}} \right) \end{align} $$ (9) $$ \begin{align} {{{o}}_{k}}& = \sigma \left( {{{W}}_{oh}}{{{h}}_{k-1}}+{{{W}}_{ox}}{{{x}}_{k}}+{{{b}}_{o}} \right) \end{align} $$ (10) $$ \begin{align} {{\widetilde{{c}}}_{k}}& = \tanh \left( {{{W}}_{ch}}{{{h}}_{k-1}}+{{{W}}_{cx}}{{{x}}_{k}}+{{{b}}_{c}} \right) \end{align} $$ (11) $$ \begin{align} {{{c}}_{k}}& = {{{f}}_{k}}{{{c}}_{k-1}}+{{{i}}_{k}}{{\widetilde{{c}}}_{k}} \end{align} $$ (12) $$ \begin{align} {{{h}}_{k}}& = {{{o}}_{k}}\tanh \left( {{{c}}_{k}} \right) \end{align} $$ (13) 其中, $ \sigma ( \cdot ) $表示Sigmod函数, $ x_k $表示$ k $时刻输入, $ h_{k-1} $表示上一时刻LSTM隐藏单元输出, 通过计算遗忘门$ f_k $, 输入门$ i_k $, 输出门$ o_k $以及记忆单元$ c_k $, 最终输出隐藏状态$ h_k $. $ W_\# $表示门控单元权重, $ b_\# $表示门控单元偏置.
所设计的PUKF-net内部结构如图1所示. 该模型将基于sEMG的肢体运动估计任务拆分成三个LSTM模块. 其中, $ \text{LSTM}_{Q} $和$ \text{LSTM}_{R} $分别用于从sEMG数据中学习噪声协方差矩阵$ Q_k $和$ R_k $, $ \text{LSTM}_h $模块用于学习人体运动状态与sEMG之间的映射关系. 特别地, 在量测更新过程中采用渐进量测更新方式来提高系统估计的稳定性. 最后, 在损失函数中增加了偏差项以提高PUKF-net训练效率.
2. 运动估计方法
2.1 时间更新
根据$ k $时刻输入的sEMG, 通过PUKF-net估计当前人体上肢运动状态$ {x}_{k} $. 首先, 根据上一时刻运动状态$ {{x}_{k-1}} $和当前时刻的量测$ {{z}_{k}} $学习噪声统计特性$ {{Q}_{k}} $和$ {{R}_{k}} $. $ \text{LSTM}_{Q} $和$ \text{LSTM}_{R} $内部结构如图2所示. 对$ \text{LSTM}_{Q} $和$ \text{LSTM}_{R} $模块的输出取幂使得$ {{Q}_{k}} $和$ {{R}_{k}} $为正定矩阵. $ k $时刻$ n $维状态$ {{x}_{k}} $的均值和协方差用$ 2n+1 $个传播点近似表示
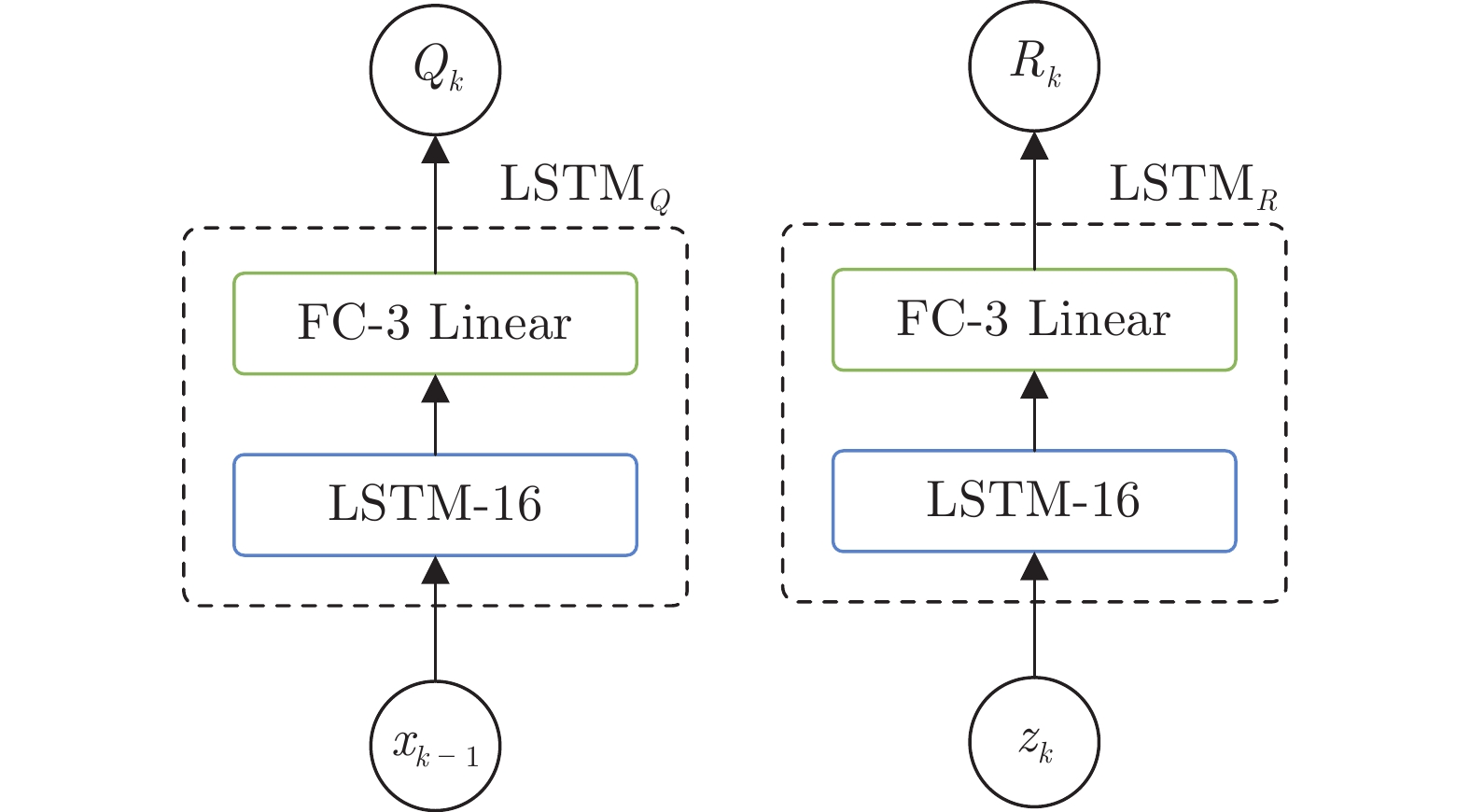 图 2 $ \text{LSTM}_Q$, $ \text{LSTM}_R$网络结构Fig. 2 Network structure of $ \text{LSTM}_Q$ and $ \text{LSTM}_R$
图 2 $ \text{LSTM}_Q$, $ \text{LSTM}_R$网络结构Fig. 2 Network structure of $ \text{LSTM}_Q$ and $ \text{LSTM}_R$$$ \left\{\begin{aligned} &\chi _{k-1|k-1}^{i} = {{\hat{x}}_{k-1|k-1}}, i = 0 \\ &\chi _{k-1|k-1}^{i} = {{\hat{x}}_{k-1|k-1}}+{{\left( \sqrt{(n+\kappa ){{P}_{k-1|k-1}}}\right)}_{i}}, \\ & i = 1, 2, \cdots , n\\ &\chi _{k-1|k-1}^{i} = {{\hat{x}}_{k-1|k-1}}-{{\left( \sqrt{(n+\kappa ){{P}_{k-1|k-1}}}\right)}_{i}}, \\ & i = n+1, \cdots , 2n \end{aligned}\right. $$ (14) 其中, $ {{\hat{x}}_{k-1|k-1}} $和$ {{P}_{k-1|k-1}} $是系统$ k-1 $时刻的状态估计及其协方差, $ n $表示系统状态$ x $的维度, $ \kappa $是系统状态$ x $的Sigma传播点间距比例因子. 通过调节比例因子$ \kappa $的取值大小, 决定Sigma传播点之间的距离和其比重的大小, 从而调整采样点所描述非线性状态函数后验分布的统计特性. 在满足高斯分布假设的条件下, 为使得UKF对称采样获取的后验分布效果最好, $ n+\kappa = 3 $被选择[29]. 根据系统状态模型, 由采样点集$\{ {{\chi }^{i}_{k-1|k-1}} \}, i = 0, 1, \cdots , 2n $可得状态预测的传播点
$$ X_{k|k-1}^{i} = f\left( \chi _{k-1|k-1}^{i} \right), i = 0, 1, \cdots , 2n $$ (15) 预测状态及其协方差表示如下
$$ \begin{align} &{\hat{x}_{k|k-1}} = \sum\limits_{i = 0}^{2n}{W_{i}^{m}X_{k|k-1}^{i}} \end{align} $$ (16) $$ \begin{split} {{P}_{k|k-1}} =\;& \underset{i = 0}{\overset{2n}{\mathop \sum }} W_{i}^{c}\left( X _{k|k-1}^{i}-{\hat{x}_{k|k-1}} \right)\times\\ &{{\left( X _{k|k-1}^{i}-{\hat{x}_{k|k-1}} \right)}^{\text{T}}}+{{Q}_{k}} \end{split} $$ (17) 其中, $ {{Q}_{k}} $是由$ \text{LSTM}_{Q} $模块得到的系统噪声协方差, 均值权重$ W_{i}^{m} $和方差权重$ W_{i}^{c} $取值如下
$$ W_{i}^{m} = W_{i}^{c} = \left\{\begin{aligned} &\frac{\kappa} {n+\kappa }, & i = 0 \qquad\qquad\;\;\;\\ &\frac{1}{2\left( n+\kappa \right)}, & i = 1, 2, \cdots , 2n \end{aligned}\right. $$ (18) 2.2 渐进量测更新方法
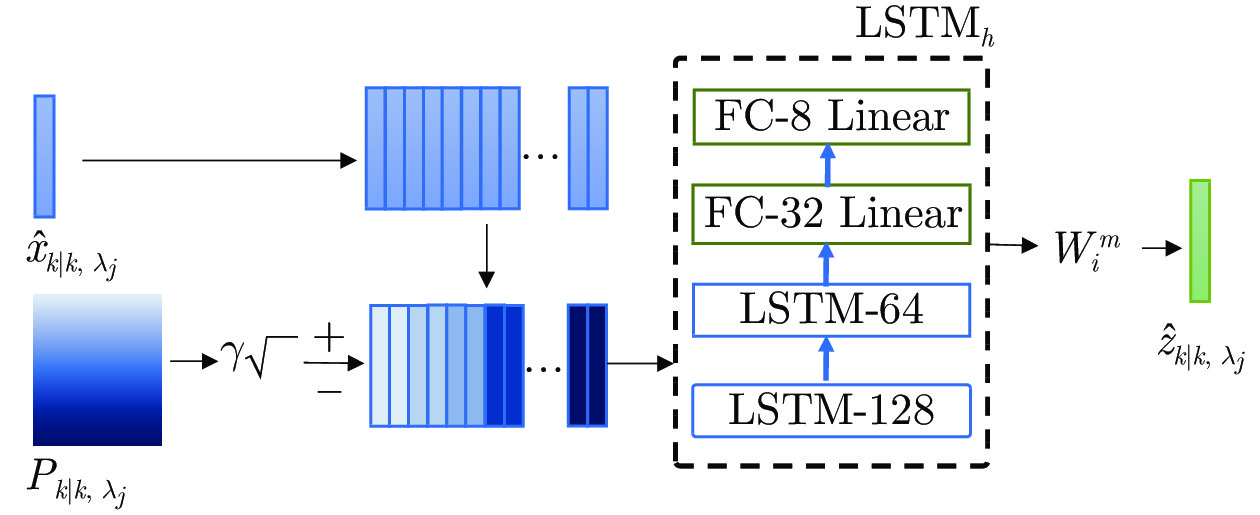
由于人体肢体运动与sEMG之间的非线性映射关系复杂, 且肢体运动估计器的稳定性不足, 将采用渐进量测更新方法[30-31]来修正人体肢体的运动估计. 根据非线性卡尔曼滤波稳定性分析, 不难发现人为增大测量噪声的协方差有助于提高估计器的稳定性[30]. 将量测更新分解成$ N $步, 同时每次渐进量测更新时测量噪声协方差被人为放大$ {1}/{\Delta }_{j} $倍, $ {\Delta }_{j} $表示第$ j $步的迭代步长[31-32]. 令渐进更新的伪时间点为$ {\lambda }_{j}\in \left[ 0, 1 \right], j = 0, 1, \cdots, N $, 第$ j $步的伪时间点$ {\lambda}_{j} = {{\lambda}_{j-1}}{+}{\Delta}_{j} $, 且满足$ {\lambda}_{0} = 0 $和$ {\lambda}_{N} = 1 $. 根据状态预测中得到的$ \hat{x}_{k|k-1} $和$ {P}_{k|k-1} $, 令 $ {{{\hat{x}}}_{k|k, {{\lambda }_{0}}}} = {{{\hat{x}}}_{k|k-1}}, {{P}_{k|k, {{\lambda }_{0}}}} = {{P}_{k|k-1}} $, 可得伪时间$ {{\lambda}_{j}} $, 传播点集$ \{ \chi _{k|k, {{\lambda }_{j-1}}}^{i} \}, i = 1, 2, \cdots , 2n $经过量测模型$ \text{LSTM}_h $传递可得量测预测的传播点及其均值
$$ Z_{k|k, {{\lambda }_{j}}}^{i} = \text{LST}{{\text{M}}_{h}}\left( \chi _{k|k, {{\lambda }_{j-1}}}^{i} \right)\\ $$ (19) $$ {\hat z_{k|k,{\lambda _j}}} = \mathop {\mathop \sum \limits^{2n} }\limits_{i = 0} W_i^mZ_{k|k,{\lambda _j}}^i $$ (20) 其中, 预测状态估计的传播点表示如下
$$ \left\{\begin{aligned} & \chi _{k|k, {{\lambda }_{j-1}}}^{i} = {\hat{x}_{k|k, {{\lambda }_{j-1}}}}, i = 0 \\ & \chi _{k|k, {{\lambda }_{j-1}}}^{i} = {\hat{x}_{k|k, {{\lambda }_{j-1}}}}+{{\left( \sqrt{(n+\kappa ){{P}_{k|k, {{\lambda }_{j-1}}}}} \right)}_{i}}, \\ & i = 1, 2, \cdots , n \\ & \chi _{k|k, {{\lambda }_{j-1}}}^{i} = {\hat{x}_{k|k, {{\lambda }_{j-1}}}}-{{\left( \sqrt{(n+\kappa ){{P}_{k|k, {{\lambda }_{j-1}}}}} \right)}_{i}}, \\ & i = n+1, \cdots , 2n \end{aligned}\right. $$ (21) 其中, $ {\hat{x}_{k|k, {\lambda}_{j-1}}} $和$ {P}_{k|k, {\lambda}_{j-1}} $表示系统$ k $时刻下, 伪时间步$ j-1 $的状态估计及其协方差, 量测函数由$ \text{LSTM}_h $模块学习得到, 其内部结构及计算过程如图3所示, 其中, $\lambda=\sqrt{\kappa+n}$, 系统状态协方差及其状态与量测的互协方差如下
$$ \begin{split} {{P}_{zz, k|k, {{\lambda }_{j}}}} = \;&\underset{i = 0}{\overset{2n}{\mathop \sum }} W_{i}^{c}\left( Z_{k|k, {{\lambda }_{j}}}^{i}-{\hat{z}_{k|k, {{\lambda }_{j}}}} \right)\times\\ &{{\left( Z_{k|k, {{\lambda }_{j}}}^{i}-{\hat{z}_{k|k, {{\lambda }_{j}}}} \right)}^\text{T}}+ \frac{{R}_{k}}{\Delta_{j}}\\[-10pt] \end{split} $$ (22) $$ \begin{split} {{P}_{xz, k|k, {{\lambda }_{j}}}} = \;& \underset{i = 0}{\overset{2n}{\mathop \sum }} W_{i}^{c}\left( \chi _{k|k, {{\lambda }_{j-1}}} ^{i}-{\hat{x}_{k|k, {{\lambda }_{j-1}}}} \right)\times\\ &{{\left( Z_{k|k, {{\lambda }_{j}}}^{i}-{\hat{z}_{k|k, {{\lambda }_{j}}}} \right)}^{\text{T}}} \end{split} $$ (23) 滤波增益$ K $以及当前伪时间点下的状态估计和估计方差如下
$$ {{K}_{k|k, {{\lambda }_{j}}}} = {{P}_{xz, k|k, {{\lambda }_{j}}}}{{({{P}_{zz, k|k, {{\lambda }_{j}}}})}^{-1}} $$ (24) $$ \left\{\begin{aligned} & {{{\hat{x}}}_{k|k, {{\lambda }_{j}}}} = {{{\hat{x}}}_{k|k, {{\lambda }_{j-1}}}}+{{K}_{k|k, {{\lambda }_{j}}}}\left( {{z}_{k}}-{\hat{z}_{k|k, {{\lambda }_{j}}}} \right) \\ & {{P}_{k|k, {{\lambda }_{j}}}} = {{P}_{k|k, {{\lambda }_{j-1}}}}-{{K}_{k|k, {{\lambda }_{j}}}}{{P}_{zz, k|k, {{\lambda }_{j}}}}K_{k|k, {{\lambda }_{j}}}^\text{T} \end{aligned}\right. $$ (25) 在第$ N $次更新后$ {{\lambda}_{N}} = 1 $, 最终得到当前时刻目标后验状态向量$ {{\hat{x}}_{k|k}} $和协方差$ {{P}_{k|k}} $. 由此, 完成PUKF-net的预测和渐进量测更新. 最后, PUKF-net算法流程如算法1所示. 用于描述量测模型的$ \text{LSTM}_h $网络具有较强非线性, 线性化误差对滤波器稳定性的破坏风险较大. 根据UKF、PUKF等稳定性分析不难发现, 渐进量测更新过程将有助于降低滤波器稳定性的破坏风险, 同时减少了滤波过程中的线性化误差. 本文利用渐进高斯滤波方法的优势, 引入先验到后验的渐变过程, “放大” 量测噪声协方差来渐进地包含传感器量测, 从而提升了滤波的稳定性.
算法1. PUKF-net算法
1)初始化
2) while do
3) 时间更新: 式 (15) ~ (17)
4) for $ i = 1:N $ do
5) 量测更新: 式(19) ~ (25)
6) end for
7) end while
2.3 损失函数
计算真值$ {{x}_{k}} $与预测值$ {{\hat{x}}_{k|k, {{\lambda }_{j}}}} $的偏差作为$ \text{LSTM}_{h} $和$ \text{LSTM}_{R} $的模型损失, 增加了偏差项以确保$ \text{LSTM}_{Q} $的梯度流通过反向传播被增强[22], 关节角度$ \theta $的损失函数$ L\left( \theta \right) $表示如下
$$ L\left( \theta \right) = \frac{1}{T}\mathop {\mathop \sum \limits^T }\limits_{k = 1} \left({\left\| {{x_k} - {{\hat x}_{k|k - 1}}} \right\|^2} + {\left\| {{x_k} - {{\hat x}_{k|k}}} \right\|^2} \right)$$ (26) 其中, $ T $表示单个训练样本的时间步长, $ {{x}_{k}} $为系统真值, $ {\hat{x}_{k|k-1}} $和$ {{\hat{x}}_{k|k}} $分别为肢体状态预测值和更新值.
3. 实验分析
以人体上肢肘关节运动为例, 设计实验采集肢体sEMG以及关节角度真值, 通过所提出的PUKF-net实现基于sEMG的肢体运动估计, 并与其他方法进行比较, 证明该模型的有效性.
3.1 数据采集
为验证PUKF-net的有效性, 搭建了一套sEMG和肘关节角度采集系统. 使用Myo手环采集上肢在肘关节运动中的sEMG, Myo手环采样频率为200 Hz, 能够同时采集8通道数据. 如图4(a)所示, Myo佩戴在受试者右侧大臂用于采集运动过程的sEMG. 在肘关节角度采集部分, 采用Optitrack视觉捕捉系统分析上肢关节运动特性. Optitrack系统通过12台200 Hz高速相机捕捉发光标记点位置, 并根据预先标定的相机坐标和世界坐标输出标记点在世界坐标系内的三维坐标. 在大臂和小臂上分别放置多个标记点, 防止运动过程中单个标记点丢失. 如图4(b)所示, 将大臂小臂的方向向量映射在三维坐标系中, AB表示受试者大臂, BC表示受试者小臂, 夹角$ \theta $即为上肢肘关节角度.
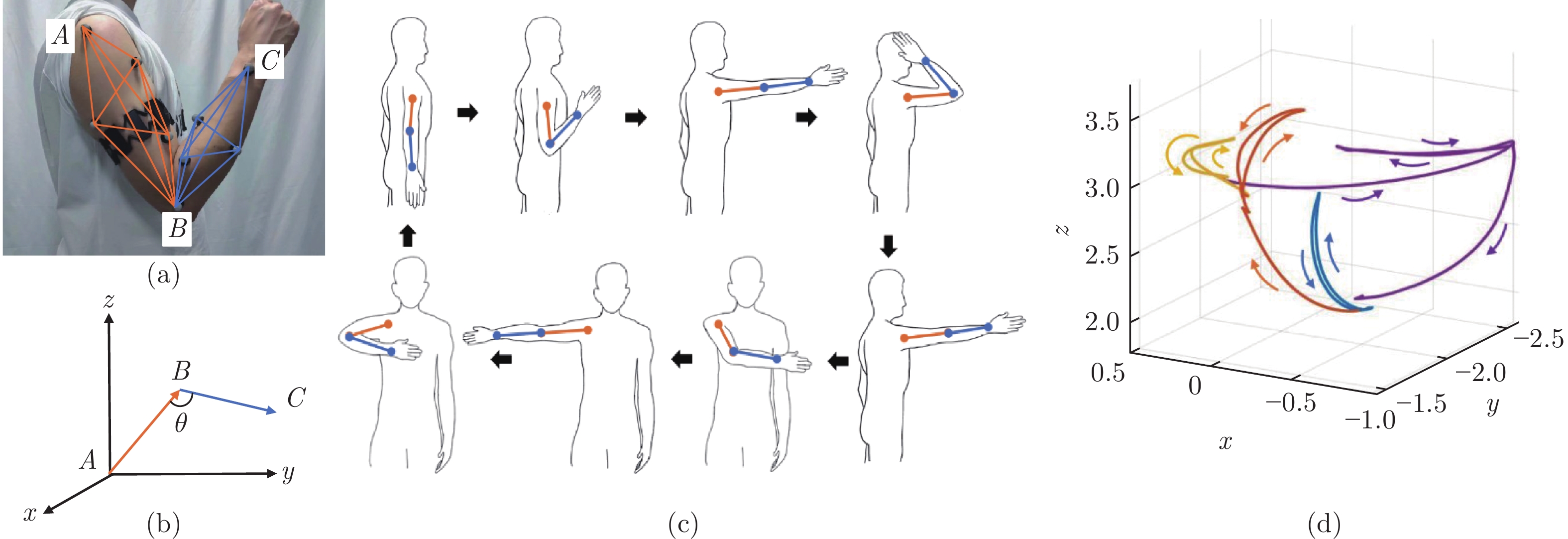 图 4 实验设计 ((a) 传感器布局; (b) 关节角度坐标; (c) 轨迹规划; (d) Optitrack采集到手腕关节点轨迹)Fig. 4 Experiment design ((a) Sensor layout; (b) Joint angle coordinates; (c) Trajectory planning; (d) Track of wrist joint collected by Optitrack)
图 4 实验设计 ((a) 传感器布局; (b) 关节角度坐标; (c) 轨迹规划; (d) Optitrack采集到手腕关节点轨迹)Fig. 4 Experiment design ((a) Sensor layout; (b) Joint angle coordinates; (c) Trajectory planning; (d) Track of wrist joint collected by Optitrack)12名肢体健康的测试者参与实验, 测试者的身体参数如表1所示. 实验时测试者站在Optitrack工作空间, 按照图4(c)规划轨迹依次完成4组肘关节屈伸动作. 肘关节屈伸动作需要肘关节屈曲至最大角度, 停顿后缓慢伸展. 每个位置进行10组肘关节的屈曲和伸展. 测试者充分休息后再次进行10组运动. 为了防止肌肉疲劳, 每组实验之间有3 min的休息时间, 实验持续约30 min. 图4(d)展示了实验过程中Optitrack捕捉到的手腕标记点在三维空间中的轨迹.
表 1 测试者身体参数Table 1 Physiological information of subjects测试者 年龄 身高 (cm) 体重 (kg) 性别 S1 31 155 65 女 S2 24 161 53 女 S3 29 182 85 男 S4 20 177 61 男 S5 25 173 75 男 S6 28 175 65 男 S7 30 160 47 女 S8 25 171 72 男 S9 22 175 70 男 S10 24 162 50 女 S11 32 159 54 女 S12 29 170 78 男 3.2 实验结果
人体上肢肘关节屈伸运动分为肘关节屈曲和肘关节伸展两个过程, 根据解剖学知识, 肘关节屈曲运动主要由肱二头肌、肱肌和肱桡肌协同完成, 肘关节伸展运动则主要与肱三头肌的肌肉活动相关. 测试者均按照图5(a)、图5(b)方式佩戴Myo手环, 然而实际采集到的信号 (如图5(d)) 表明, 肘关节伸展过程中肱三头肌部分sEMG变化并不明显. 为了排除冗余信号的干扰, 利用非负矩阵分解方法[33]得到协同矩阵$ W $(图5(c)), 矩阵中数值越大则表示该通道信号协同性越强, 选取协同性较强的4个通道, 即通道4 ~ 7作为sEMG有效信号.
 图 5 sEMG分析 ((a) 人体大臂肌肉分布; (b) Myo位置肌肉横截面; (c)协同矩阵$ W$; (d) sEMG原始信号)Fig. 5 sEMG analysis ((a) Muscle distribution of human upper arm; (b) Cross-section of Myo wearing position; (c) Non-negative matrix factorization comatrix $ W$; (d) Original signal of sEMG)
图 5 sEMG分析 ((a) 人体大臂肌肉分布; (b) Myo位置肌肉横截面; (c)协同矩阵$ W$; (d) sEMG原始信号)Fig. 5 sEMG analysis ((a) Muscle distribution of human upper arm; (b) Cross-section of Myo wearing position; (c) Non-negative matrix factorization comatrix $ W$; (d) Original signal of sEMG)在获取sEMG有效信号后, 采用均方根欠采样方法[34]对有效sEMG通道进行预处理, 然后将预处理后的信号输入PUKF-net进行训练. 本文建立了LSTM、LSTM-KF[22]、以及本文所设计的PUKF-net模型, 并在PyTorch框架中实现了所有网络的训练和测试. 在初始化阶段, 对于所有网络的LSTM以及LSTM-cell单元采用Xavier初始化. 初始学习率设为0.001, 通过ADAM优化器在统一批量中进行200次迭代训练. 特别地, 由于LSTM隐藏层数量和节点个数会直接影响网络性能, 因此用于对比的LSTM和LSTM-KF采用与PUKF-net相同的隐藏层. 随机选取所有样本中的50% 作为训练集, 其余数据作为测试集.
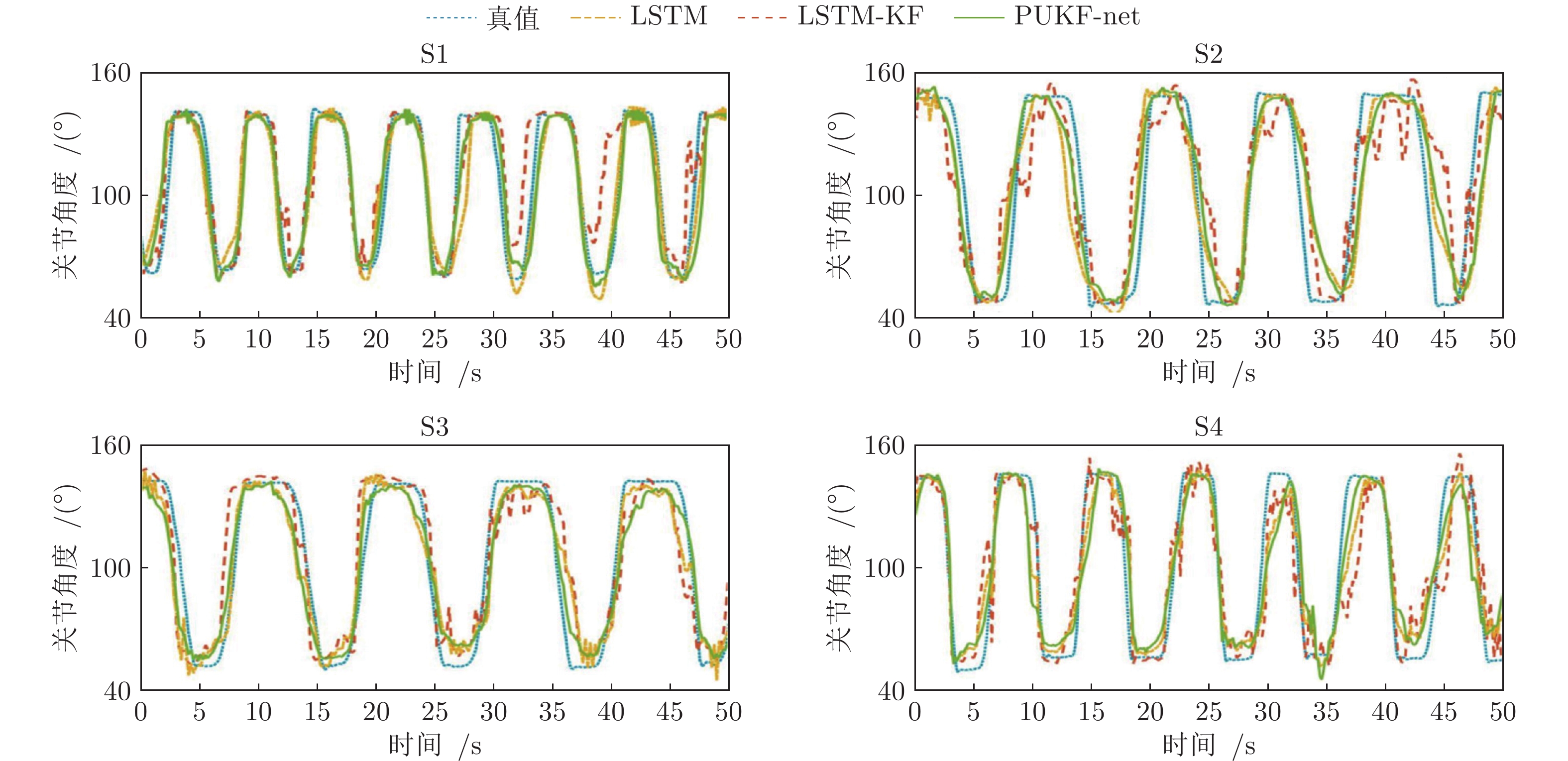
以测试者S1 ~ S4的数据为例, 三种模型基于sEMG估计的人体肘关节角度曲线如图6所示, 可以看出, 通过PUKF-net估计的肘关节角度比其他两个模型的估计值更接近真实值. 特别地, LSTM模型的估计值波动较明显, 在不同测试者数据集上表现差异较大, 这是由于测试者的sEMG存在较大的个体差异. 得益于卡尔曼滤波的抗噪性, LSTM-KF和PUKF-net的预测值波动平缓, PUKF-net整体上更接近真实值.
通过相关系数$ \text{R}^2 $和RMSE评估各个模型性能. $ \text{R}^2 $表示估计结果与真实值的相关性, RMSE计算真实值与估计值之间的幅值差异. 三种模型均能得到有效的人体肘关节角度估计, 且测试者身体参数差异与估计结果没有明显关联, 表2列出了LSTM、LSTM-KF和PUKF-net在12名测试者测试数据集上的相关系数和均方根误差. LSTM、LSTM-KF和PUKF-net的平均RMSE分别为$20.422\;\pm 3.442, 16.069\pm 2.640, 13.668\pm 1.793$, PUKF-net能够在相同隐藏层条件下取得最小的RMSE. 平均$ \text{R}^2 $为$ 0.709\pm 0.057, 0.823\pm 0.041, 0.865\pm 0.024 $, 相比于LSTM和LSTM-KF, PUKF-net通过UT变换和渐进量测方法使得模型估计精度更高, 模型稳定性也有所提高, 在关节角度估计中的RMSE下降了14.9%, $ \text{R}^2 $ 提高了5.1%, 验证了本文提出的PUKF-net模型的有效性.
表 2 LSTM、LSTM-KF、PUKF-net在测试集上的RMSE和$ \text{R}^2 $Table 2 RMSE and $ \text{R}^2 $ of LSTM, LSTM-KF, PUKF-net测试者 RMSE $ \text{R}^2$ LSTM LSTM-KF PUKF-net LSTM LSTM-KF PUKF-net S1 15.913 12.668 11.940 0.823 0.896 0.906 S2 24.568 18.677 15.473 0.622 0.748 0.829 S3 19.736 16.996 14.044 0.737 0.825 0.872 S4 20.653 13.315 12.668 0.679 0.863 0.876 S5 26.746 20.675 16.448 0.629 0.761 0.824 S6 16.793 13.664 11.588 0.803 0.880 0.905 S7 22.193 17.164 14.187 0.699 0.852 0.868 S8 17.984 15.241 12.294 0.748 0.827 0.880 S9 22.537 18.464 15.624 0.710 0.817 0.861 S10 24.142 18.555 16.165 0.655 0.809 0.848 S11 14.601 11.271 10.545 0.682 0.792 0.844 S12 19.196 16.137 13.044 0.721 0.804 0.865 平均值 20.422 16.069 13.668 0.709 0.823 0.865 4. 结论
通过结合LSTM与UKF的优势, 本文设计了PUKF-net模型实现了基于sEMG的上肢运动估计. PUKF-net利用数据驱动的思想解决肢体运动估计中的建模难问题. 同时, 采用渐进量测更新方法来解决运动状态估计过程中线性化误差引起的不稳定问题. 实验表明, 所提出的PUKF-net模型在基于sEMG的上肢关节角度估计中的效果优于LSTM和LSTM-KF模型. 在未来的工作中, 将使用所提出的PUKF-net实现基于多源异构传感器融合的运动估计. 通过整合多源传感器的物理信息和生理信息, 提高机器人柔性感知能力和估计精度.
-
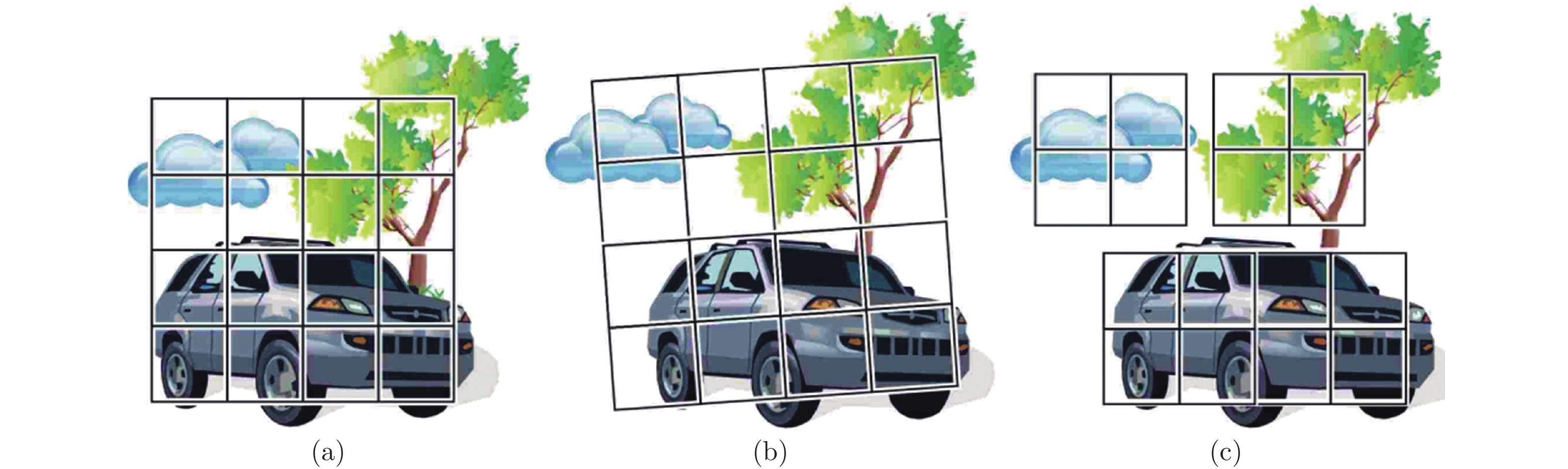
图 1 基于区域划分的深度匹配采样窗口示意图 ((a)参考帧采样窗口; (b)传统匹配方法采样窗口;(c)深度匹配算法采样窗口)
Fig. 1 Illustration of the deep matching sample window based on the regional division ((a) Sample window of the reference frame; (b) Sample window of the traditional matching method; (c) Sample window of the deep matching method)
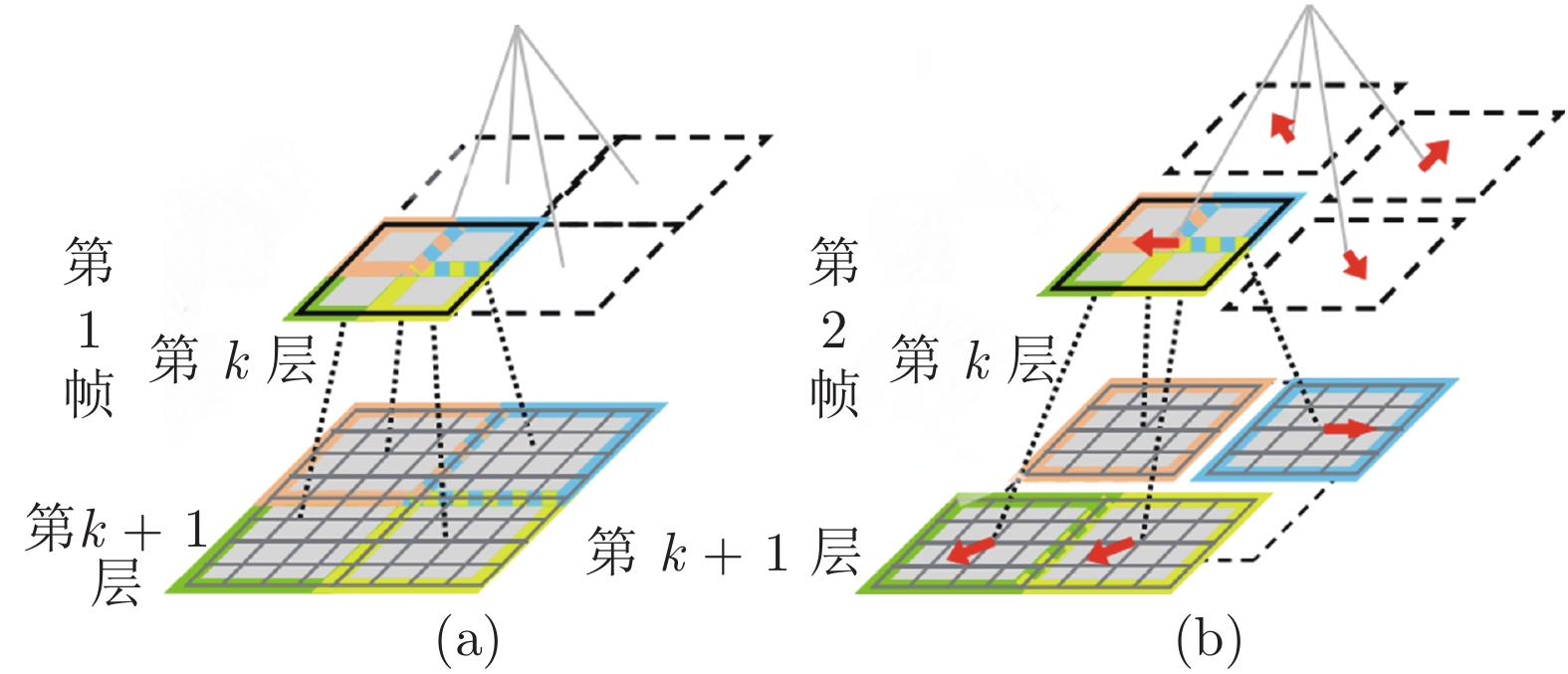
图 2 深度匹配金字塔采样示意图 ((a)第1帧子区域聚合; (b)第2帧子区域聚合)
Fig. 2 Illustration of the pyramid sampling based deep matching ((a) Subregion polymerization of the first frame; (b) Subregion polymerization of the second frame)

图 3 本文邻域支持模型运动场优化效果 (蓝色标记符表示匹配正确像素点, 红色标记符表示匹配错误像素点)
Fig. 3 Optimization effect of the motion field by using the proposed neighborhood supporting model (The blue mark indicates the correct matching pixels, the red mark denotes the false matching pixels)
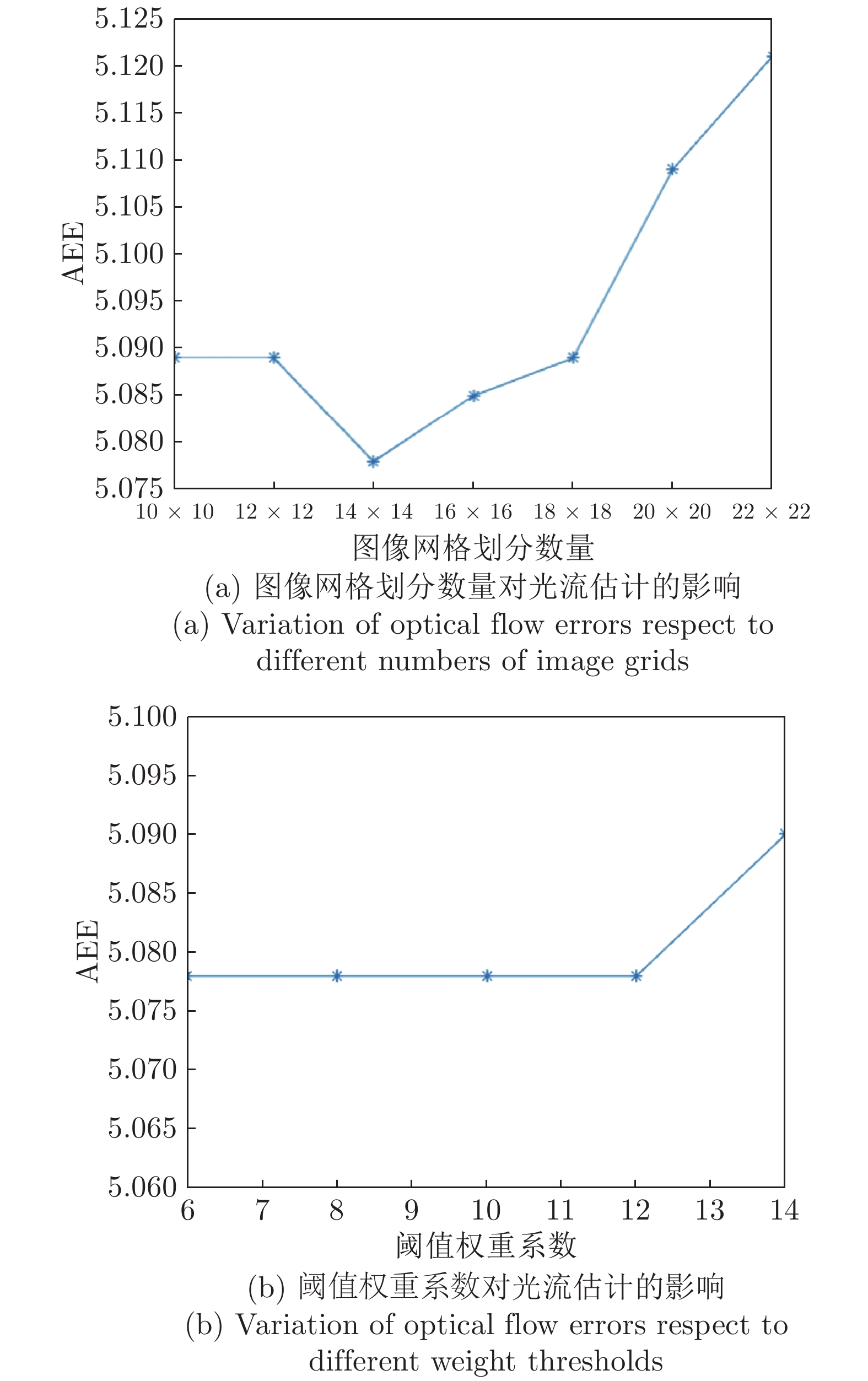
图 4 不同参数设置对本文光流估计精度的影响
Fig. 4 Variation of optical flow estimation results respect to different parameters

图 5 非刚性大位移与运动遮挡图像序列光流估计结果
Fig. 5 Optical flow results of the image sequences including non-rigidly large displacements and motion occlusions

图 7 MPI-Sintel数据库消融实验光流图
Fig. 7 Optical flow results of the ablation experiment tested on MPI-Sintel database
表 1 MPI-Sintel数据库光流估计误差对比
Table 1 Comparison results of optical flow errors on MPI-Sintel database
 下载: 导出CSV
下载: 导出CSV
表 2 非刚性大位移与运动遮挡图像序列光流估计误差对比
Table 2 Comparison results of optical flow errors on the image sequences including non-rigidly large displacements and motion occlusions
对比方法 平均误差 Ambush_5 Cave_2 Market_2 Market_5 Temple_2 AAE/AEE AAE/AEE AAE/AEE AAE/AEE AAE/AEE AAE/AEE Classic+NL[7] 14.71/9.28 22.53/11.06 15.78/14.03 7.64/0.98 18.93/16.59 8.39/3.72 DeepFlow[18] 10.89/6.66 18.86/8.75 9.23/9.30 8.00/0.85 12.19/11.89 6.15/2.50 EpicFlow[21] 10.64/6.47 19.19/8.48 7.45/7.81 7.91/0.89 12.15/12.47 6.48/2.72 FlowNetS[12] 15.63/9.77 25.37/12.43 17.24./15.66 8.56/1.26 16.56/15.24 10.45/4.24 本文方法 9.77/6.12 18.43/8.43 6.98/7.49 7.05/0.78 10.58/11.35 5.83/2.56
下载: 导出CSV
表 4 本文方法消融实验结果对比
Table 4 Comparison results of the ablation experiment
消融模型 Alley_2 Cave_4 Market_6 本文方法 0.07 1.16 3.72 无匹配优化 0.09 1.28 5.07 无稠密插值 0.14 1.31 5.85 无全局优化 0.09 1.21 3.84
下载: 导出CSV
-
[1] 潘超, 刘建国, 李峻林. 昆虫视觉启发的光流复合导航方法. 自动化学报, 2015, 41(6): 1102-1112.PAN Chao, LIU Jian-Guo, LI Jun-Lin. An optical flow-based composite navigation method inspired by insect vision. Acta Automatica Sinica, 2015, 41(6): 1102-1112 (in Chinese). [2] Colque R, Caetano C, Andrade M, Schwartz W. Histograms of optical flow orientation and magnitude and entropy to detect anomalous events in Videos. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(3): 673-682. doi: 10.1109/TCSVT.2016.2637778 [3] 王飞, 崔金强, 陈本美, 李崇兴. 一套完整的基于视觉光流和激光扫描测距的室内无人机导航系统. 自动化学报, 2013, 39(11): 1889-1900.WANG Fei, CUI Jin-Qiang, CHEN Ben-Mei, LEE Tong H. A comprehensive uav indoor navigation system based on vision optical flow and laser fastSLAM. Acta Automatica Sinica, 2013, 39(11): 1889-1900 (in Chinese). [4] 张桂梅, 孙晓旭, 刘建新, 储珺. 基于分数阶微分的TV-L1光流模型的图像配准方法研究. 自动化学报, 2017, 43(12): 2213-2224.ZHANG Gui-Mei, SUN Xiao-Xu, LIU Jian-Xin, CHU Jun. Research on TV-L1 optical flow model for image registration based on fractional-order differentiation. Acta Automatica Sinica, 2017, 43(12): 2213-2224 (in Chinese). [5] Horn B K P, Schunck B G. Determining optical flow. Artificial Intelligence, 1980, 17(1): 185- 203. [6] Brox T, Bruhn A, Papenberg N, Weickert J. High accuracy optical flow estimation based on a theory for warping. In: Proceedings of the 2004 European Conference on Computer Vision. Prague, Czech Republic: Springer, 2004. 25−36 [7] Sun D, Roth S, Black M J. A quantitative analysis of current practices in optical flow estimation and the principles behind them. International Journal of Computer Vision, 2014, 106(2): 115-137. doi: 10.1007/s11263-013-0644-x [8] Drulea M, Nedevschi S. Total variation regularization of local-global optical flow. In: Proceedings of the 2011 International Conference on Intelligent Transportation Systems. Washington DC, USA: IEEE, 2011. 318−323 [9] Perona P, Malik J. Scale-space and edge detection using anisotropic diffusion. IEEE Transactions on pattern analysis and machine intelligence, 1990, 12(7): 629-639. doi: 10.1109/34.56205 [10] Weickert J, Schnörr C. A theoretical framework for convex regularizers in PDE-based computation of image motion. International Journal of Computer Vision, 2001, 45(3): 245- 264. doi: 10.1023/A:1013614317973 [11] Zimmer H, Bruhn A, Weickert J. Optic flow in harmony. International Journal of Computer Vision, 2011, 93(3): 368-388. doi: 10.1007/s11263-011-0422-6 [12] Dosovitskiy A, Fischer P, Ilg E, Häusser P, Hazirbas C, Golkov V, et al. Flownet: Learning optical flow with convolutional networks. In: Proceedings of the 2015 International Conference on Computer Vision and Pattern Recognition. Santiago, Chile: IEEE, 2015. 2758−2766 [13] Ilg E, Mayer N, Saikia T, Keuper M, Dosovitskiy A, Brox T. FlowNet 2.0: Evolution of optical flow estimation with deep networks. In: Proceedings of the 2017 International Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 1647−1655 [14] Ranjan A, Black M J. Optical flow estimation using a spatial pyramid network. In: Proceedings of the 2017 International Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 4161−4170 [15] Hui T W, Tang X, Loy C. LiteFlowNet: A lightweight convolutional neural network for optical flow estimation. In: Proceedings of the 2018 International Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 8981−8989 [16] Ilg E, Saikia T, Keuper M, Brox T. Occlusions, motion and depth boundaries with a generic network for disparity, optical flow or scene flow estimation. In: Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: Springer, 2018. 614−630 [17] Brox T, Malik J. Large displacement optical flow: descriptor matching in variational motion estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(3): 500-513. doi: 10.1109/TPAMI.2010.143 [18] Weinzaepfel P, Revaud J, Harchaoui Z, Schmid C. DeepFlow: Large displacement optical flow with deep matching. In: Proceedings of the 2013 International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 1385−1392 [19] 张聪炫, 陈震, 熊帆, 黎明, 葛利跃, 陈昊. 非刚性稠密匹配大位移运动光流估计. 电子学报, 2019, 47(6): 1316-1323. doi: 10.3969/j.issn.0372-2112.2019.06.019ZHANG Cong-xuan, CHEN Zhen, XIONG Fan, LI Ming, GE Li-yue, CHEN Hao. Large displacement motion optical flow estimation with non-rigid dense patch matching. Acta Electronica Sinica, 2019, 47(6): 1316-1323 (in Chinese). doi: 10.3969/j.issn.0372-2112.2019.06.019 [20] Hu Y L, Song R, Li Y S. Efficient coarse-to-fine patch match for large displacement optical flow. In: Proceedings of the 2016 International Conference on Computer Vision and Pattern Recognition, Las Vegas, USA: IEEE, 2016. 5704−5712 [21] Revaud J, Weinzaepfel P, Harchaoui Z, Schmid C. Epicflow: Edge-preserving interpolation of correspondences for optical flow. In: Proceedings of the 2015 International Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 1164−1172 [22] Hu Y L, Li Y S, Song R. Robust interpolation of correspondences for large displacement optical flow. In: Proceedings of the 2017 International Conference on Computer Vision and Pattern Recognition, Honolulu, USA: IEEE, 2017. 481−489 [23] Revaud J, Weinzaepfel P, Harchaoui Z, Schmid C. DeepMatching: Hierarchical deformable dense matching. International Journal of Computer Vision, 2016, 120(3): 300-323. doi: 10.1007/s11263-016-0908-3 [24] Bian J W, Lin W Y, Matsushita Y, Yeung S K, Nguyen T D, Cheng M M. GMS: Grid-based motion statistics for fast, ultra- robust feature correspondence. In: Proceedings of the 2017 International Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 4181−4190 -

 下载:
下载:

计量
- 文章访问数: 543
- HTML全文浏览量: 547
- PDF下载量: 147
- 被引次数: 0
