

-
摘要: 前额皮层是哺乳动物环境认知能力的重要神经生理基础, 许多研究基于皮层网络结构对前额皮层进行计算建模, 使机器人能够完成环境认知与导航任务. 但是, 对皮层网络模型神经元噪声(一种干扰神经元规律放电的内部电信号)鲁棒性方面的研究不多, 传统模型采用的奖励扩散方法存在着导航性能随噪声增大而下降过快的问题, 同时其路径规划方法效果不好, 无法规划出全局最短路径. 针对上述问题, 本文在皮层网络的基础上引入波前传播算法, 结合全局抑制神经元来设计奖励传播回路, 同时将时间细胞和位置偏好细胞引入模型的路径规划回路以改善路径规划效果. 为了验证模型的有效性, 本文复现了心理学上两个经典的环境认知实验. 实验结果表明, 本模型与其他皮层网络模型相比表现出更强的神经元噪声鲁棒性. 同时, 模型保持了较好的路径规划效果, 与传统路径规划算法相比具有较高的效率.Abstract: Prefrontal cortex is important physiological foundation of environment cognition ability in mammals. Many research seek to make computation model of prefrontal cortex based on cortical network structure, in order to enable robots realize tasks related to environment cognition and navigation. However, there are few works involving in cortical network model's robustness to neuron noise, which is an internal electric signal that generally impedes regular spiking of neurons. Tradition models using reward diffusion method have problem of rapid deterioration of navigation performance under increasing neuron noise. To solve this problem, on the basis of cortical network, this paper recruits wavefront propagation method combined with globally inhibitory neuron to design reward propagating circuit, and introduces time cell and position preference cell into path planning circuit. Two classic environment cognition experiments were reproduced to verify the model. Results show that comparing to other cortical network model, our model exhibits more robustness to neuron noise. Meanwhile, this model keeps good results of environment cognition, and has higher path planning efficiency comparing to traditional path planning algorithms.
-

图 3 机器人探索迷宫后建立的皮层网络拓扑图 (m)
Fig. 3 Cortical column topological map after exploring the maze (m)

图 4 噪声标准差对导航结果的影响
Fig. 4 Influence of neuron noise standard variation on navigation results
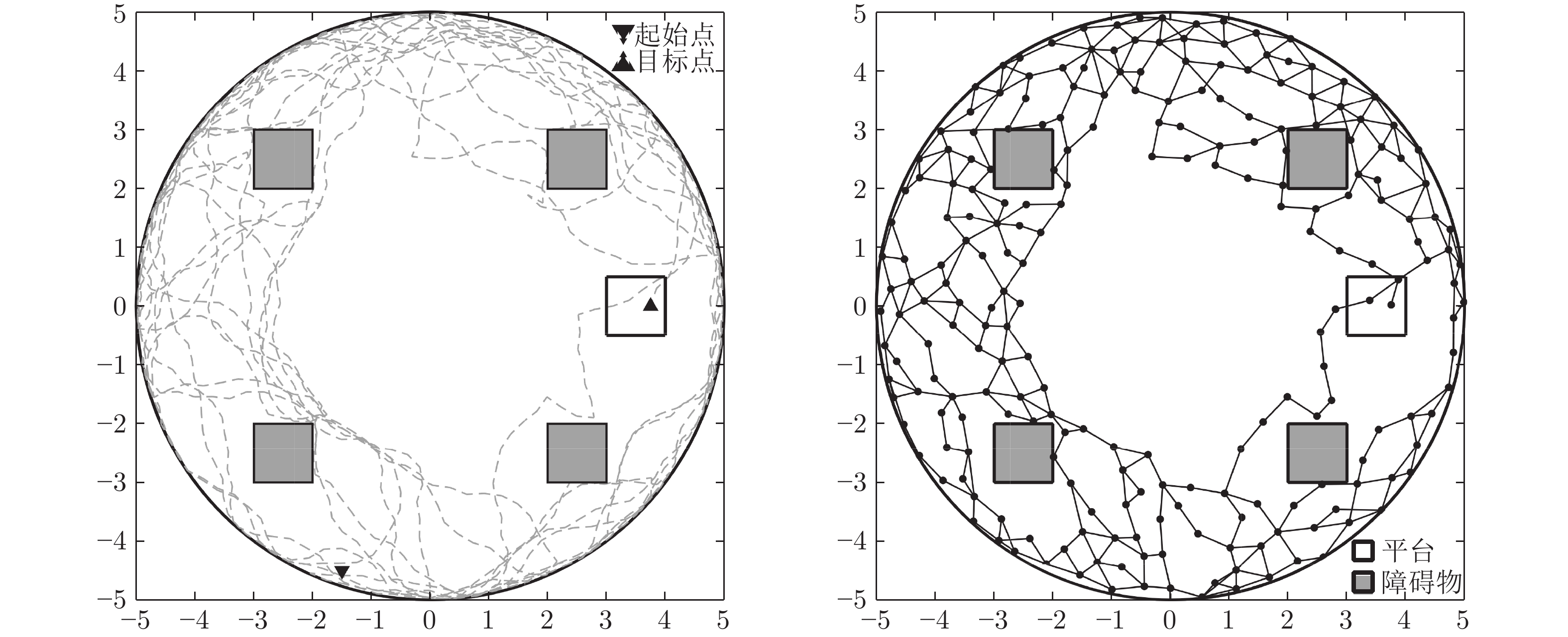
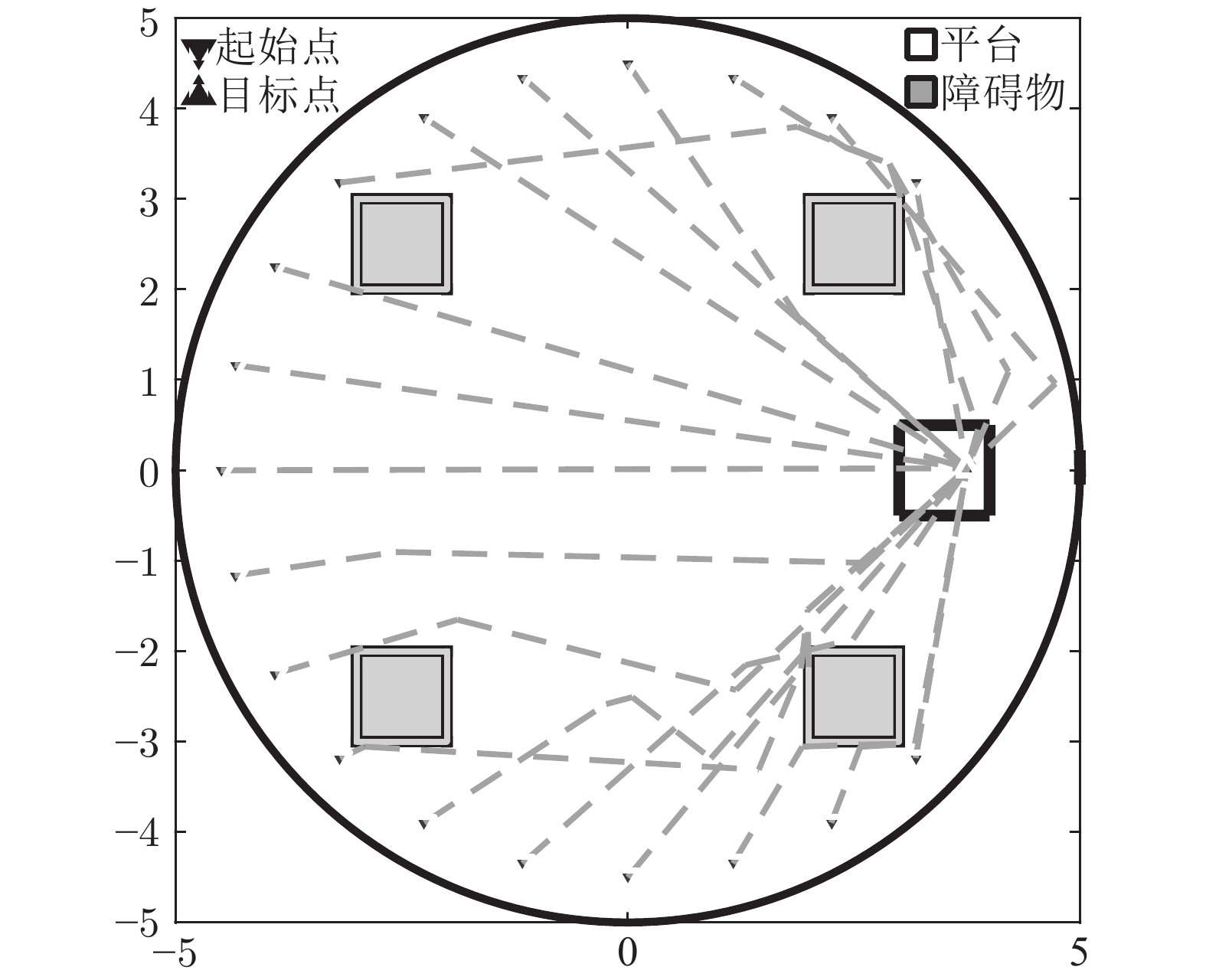
图 7 Morris水迷宫路逃生实验中的移动轨迹(左)和建立的皮层网络拓扑图(右) (m)
Fig. 7 Moving trace on the preparing stage (left) and the established cortical column network (right) (m)
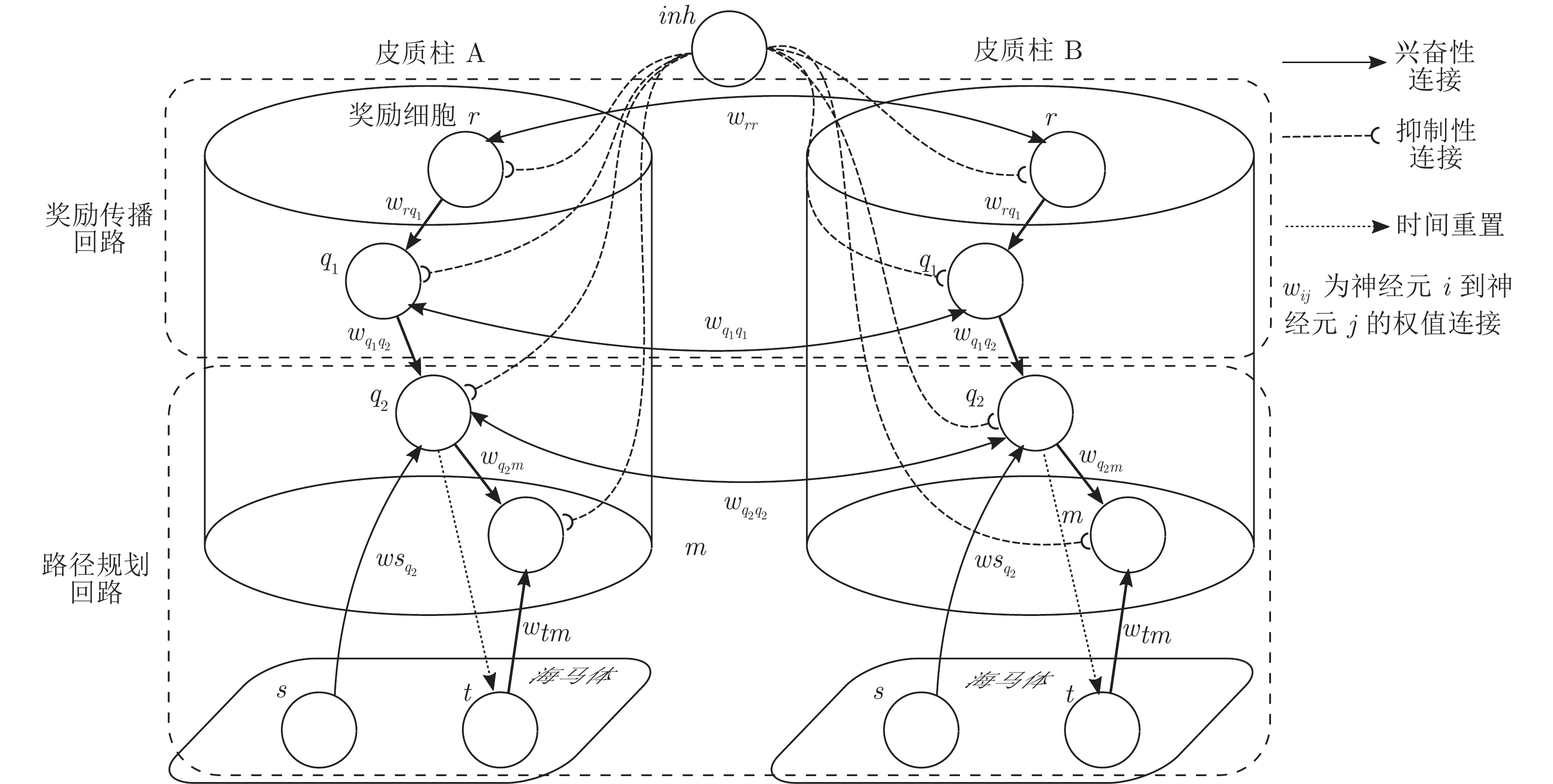
表 1 模型参数值设定
Table 1 Parameter setting of the model
神经元 类型 参数 奖励细胞$r$ 整合放电型 $w_{rr}=1,w_{rq_1}=1$ 中间神经元$q_1$ 整合放电型 $w_{q_1q_2}=0.1,\tau_{STDP}=0.02,{M }=1$ 中间神经元$q_2$ 整合放电型 $w_{q_2q_2}=w_{q_1q_1},w_{sq_2}=0.1$ 位置偏好细胞$m$ 非放电型 $w_{q_2m}=1,w_{tm}=1$ 位置细胞$s$ 非放电型 $\sigma_{s} = 0.35,V_{s,thr}=0.5$ 时间细胞$t$ 非放电型 $\tau_t=10,\eta=2,V_{t,thr}=0.95$ 全局抑制神经元 非放电型 $V_{inh}=0.1$  下载: 导出CSV
下载: 导出CSV
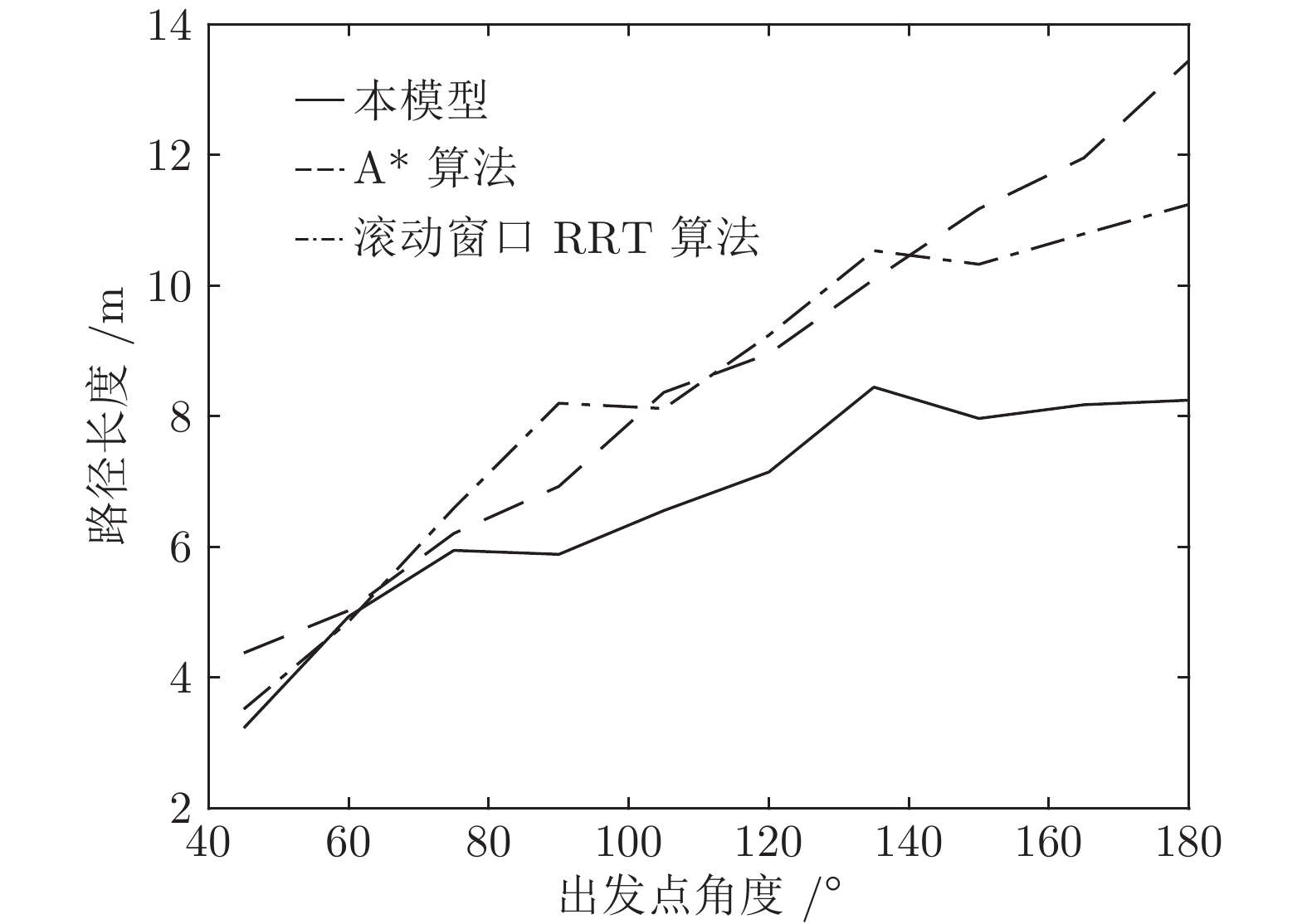
表 2 不同方法规划路径的转弯次数及转弯角度对比
Table 2 Comparison of turning counts and angle of path planned by different path planning methods
神经元 平均转弯次数 平均累计转弯角度 本模型 1.9 $28.36^{\circ}$ A* 算法 17.55 $331.9^{\circ}$ 滚动窗口 RRT 算法 12.46 $177.25^{\circ}$
下载: 导出CSV
-
[1] Contreras M, Pelc T, Llofriu M, Weitzenfeld A. The ventral hippocampus is involved in multi-goal obstacle-rich spatial navigation. Hippocampus, 2018, 28: 853−866 doi: 10.1002/hipo.22993 [2] Vorhees C, Williams M. Assessing spatial learning and memory in rodents. ILAR Journal, 2014, 55(2): 310−332 doi: 10.1093/ilar/ilu013 [3] Bucci D, Chiba A, Gallagher M. Spatial learning in male and female long-evans rats. Behavioral Neuroscience, 1995, 109(1): 180−183 doi: 10.1037/0735-7044.109.1.180 [4] Granon S, Poucet B. Medial prefrontal lesions in the rat and spatial navigation: Evidence for impaired planning. Behavioral Neuroscience, 1995, 109(3): 474−484 doi: 10.1037/0735-7044.109.3.474 [5] Martinet L E, Sheynikhovich D, Benchenane K, Arleo A. Spatial learning and action planning in a prefrontal cortical network model. Public Library of Science Computational Biology, 2011, 7(5): 1−21 [6] Martinet L E, Passot J B, Fouque B, Meyer J A. Map-based spatial navigation: A cortical column model for action planning. In: Proceedings of International Conference Spatial Cognition, Freiburg, Germany: Springer, 2008. 39−55. [7] Erdem U M, Hasselmo M E. A biologically inspired hierarchical goal directed navigation model. Journal of Physiology-Paris, 2014, 108(1): 28−37 doi: 10.1016/j.jphysparis.2013.07.002 [8] Chersi F, Pezzulo G. Using hippocampal-striatal loops for spatial navigation and goal-directed decision-making. Cognitive Processing, 2012, 13(1): 125−129 [9] Kaplan R, Friston K J. Planning and navigation as active inference. Biological Cybernetics, 2018, 112(4): 323−343 doi: 10.1007/s00422-018-0753-2 [10] Destexhe A, Rudolph-Lilith M. Neuronal Noise. New York: Springer, 2012, 1−2 [11] Arleo A, Smeraldi F, Gerstner W. Cognitive navigation based on nonuniform gabor space sampling, unsupervised growing networks, and Reinforcement learning. IEEE Transactions on Neural Networks, 2004, 15(3): 639−652 doi: 10.1109/TNN.2004.826221 [12] Strosslin T, Sheynikhovich D, Chavarriaga, Gerstner W. Robust self-localisation and navigation based on hippocampal place cells. Neural Networks, 2012, 18(9): 1125−1140 [13] Forster D J, Morris R G, Dayan P. A model of hippocampally dependent navigation, using the temporal difference learning rule. Hippocampus, 2000, 10(1): 1−16 [14] Tolman E C, Honzik C H. “Insight” in rats. University of California Publications in Psychology, 1931, 4: 215−232 [15] Edvardsen V, Bicanski A, Burgess N. Navigating with grid and place cells in cluttered environments. Hippocampus, 2019: 1−13 [16] Erdem U M, Hasselmo M. A goal-directed spatial navigation model using forward trajectory planning based on grid cells. European Journal of Neuroscience, 2012, 35: 916−931 doi: 10.1111/j.1460-9568.2012.08015.x [17] Gonner L, Vitay J, Hamker F H. Predictive place-cell sequences for goal-finding emerge from goal memory and the cognitive map: a computational model. Frontiers in Computational Neuroscience, 2017, 11(84): 1−19 [18] Tejera G, Llofriu M, Barrera A, Weitzenfeld A. Bio-inspired robotics: A spatial cognition model integrating place cells, grid cells and head direction cells. Journal of Intelligent and Robotic Systems, 2018, 91(3): 85−99 [19] Bicanski A, Burgess N. A neural-level model of spatial memory and imagery. eLife, 2018, 7: e33752 doi: 10.7554/eLife.33752 [20] Ponulak F, Hopfield J J. Rapid, parallel path planning by propagating wavefronts of spiking neural activity. Frontiers in Computational Neuroscience, 2013, 7(98): 1−14 [21] Bi G Q, Poo M M. Synaptic modifications in cultured hippocampal neurons: dependence on spike timing, synaptic strength, and postsynaptic cell type. Journal of Neuroscience, 1998, 18: 10464−10472 doi: 10.1523/JNEUROSCI.18-24-10464.1998 [22] Kang L, DeWeese M R. Replay as wavefronts and theta sequences as bump oscillations in a grid cell attractor network. eLife, 2019, 8: e46351 [23] Ellender T J, Nissen W, Colgin L L, Mann E O, Paulsen O. Priming of hippocampal population bursts by individual perisomatic-targeting interneurons. Journal of Neuroscience, 2010, 30(17): 5979−5991 doi: 10.1523/JNEUROSCI.3962-09.2010 [24] Zennir M, Benmohammed M, Martinez D. Robust path planning by propagating rhythmic spiking activity in a hippocampal network model. Biologically Inspired Cognitive Architectures, 2017, 20: 47−58 doi: 10.1016/j.bica.2017.02.001 [25] Khajeh-Alijani A, Urbanczik R, Senn W. Scale-free navigational planning by neuronal traveling waves. Public Library of Science One, 2015, 10(7): 1−15 [26] Palmer J, Keane A, Gong P. Learning and executing goal directed choices by internally generated sequences in spiking neural circuits. Public Library of Science Computational Biology, 2017, 13(7): e1005669 [27] Hok V, Save E, Lenck-Santini P P, Poucet B. Coding for spatial goals in the prelimbic/infralimbic area of the rat frontal cortex. Proceedings of the National Academy of Sciences, 2005, 102(12): 4602−4607 doi: 10.1073/pnas.0407332102 [28] Preston A R, Eichenbaum H. Interplay of hippocampus and prefrontal cortex in memory. Current Biology, 2013, 23(17): 764−773 doi: 10.1016/j.cub.2013.05.041 [29] O' Keefe J. Place units in the hippocampus of the freely moving rat. Experimental Neurology, 1976, 51(1): 78−109 doi: 10.1016/0014-4886(76)90055-8 [30] Eichenbaum H. Memory on Time. Trends in Cognitive Sciences, 2013, 17: 81−88 doi: 10.1016/j.tics.2012.12.007 [31] Ramakrishnan A, Byun Y W, Rand K, Pedersen C E, Levedev M A, Nicolelis M A. Interplay of hippocampus and prefrontal cortex in memory. Proceedings of the National Academy of Sciences of the United States of America, 2017, 114(24): 4841−4850 doi: 10.1073/pnas.1703668114 [32] Dorst L, Trovato K. Optimal path planning by cost wave propagation in metric configuration space. In: SPIE Advances in Intelligent Robotics Systems, Cambridge, USA: SPIE, 1989. 186−197. [33] Tolman E C. Cognitive maps in rats and men. The Psychological Review, 1948, 55(4): 189−208 doi: 10.1037/h0061626 [34] Morris R, Garrud P, Rawlins J, O' Keefe J. Place navigation impaired in rats with hippocampal lesions. Nature, 1982, 297: 681−683 doi: 10.1038/297681a0 [35] Dechter R, Pearl J. Generalized best-first search strategies and the optimality of A*. Journal of the ACM, 1985, 32(3): 505−536 doi: 10.1145/3828.3830 [36] 康亮, 赵春霞, 郭剑辉. 未知环境下改进的基于RRT算法的移动机器人路径规划. 模式识别与人工智能, 2009, 22(3): 337−343 doi: 10.3969/j.issn.1003-6059.2009.03.001Kang Liang, Zhao Chun-Xia, Guo Jian-Hui. Improved path planning based on rapidly exploring random tree for mobile robot in unknown environment. Pattern Recognition and Artificial Intelligence, 2009, 22(3): 337−343 doi: 10.3969/j.issn.1003-6059.2009.03.001 [37] 卜新苹, 苏虎, 邹伟, 王鹏, 周海. 基于非均匀环境建模与三阶Bezier曲线的平滑路径规划. 自动化学报, 2017, 43(5): 710−724Bu Xin-Ping, Su Hu, Zou Wei, Wang Peng, Zhou Hai. Smooth path planning based on non-uniformly modeling and cubic bezier curves. Acta Automatica Sinica, 2017, 43(5): 710−724 -

 下载:
下载:



计量
- 文章访问数: 1021
- HTML全文浏览量: 269
- PDF下载量: 161
- 被引次数: 0
