

Combining Global and Local Variation for Image Quality Assessment
-
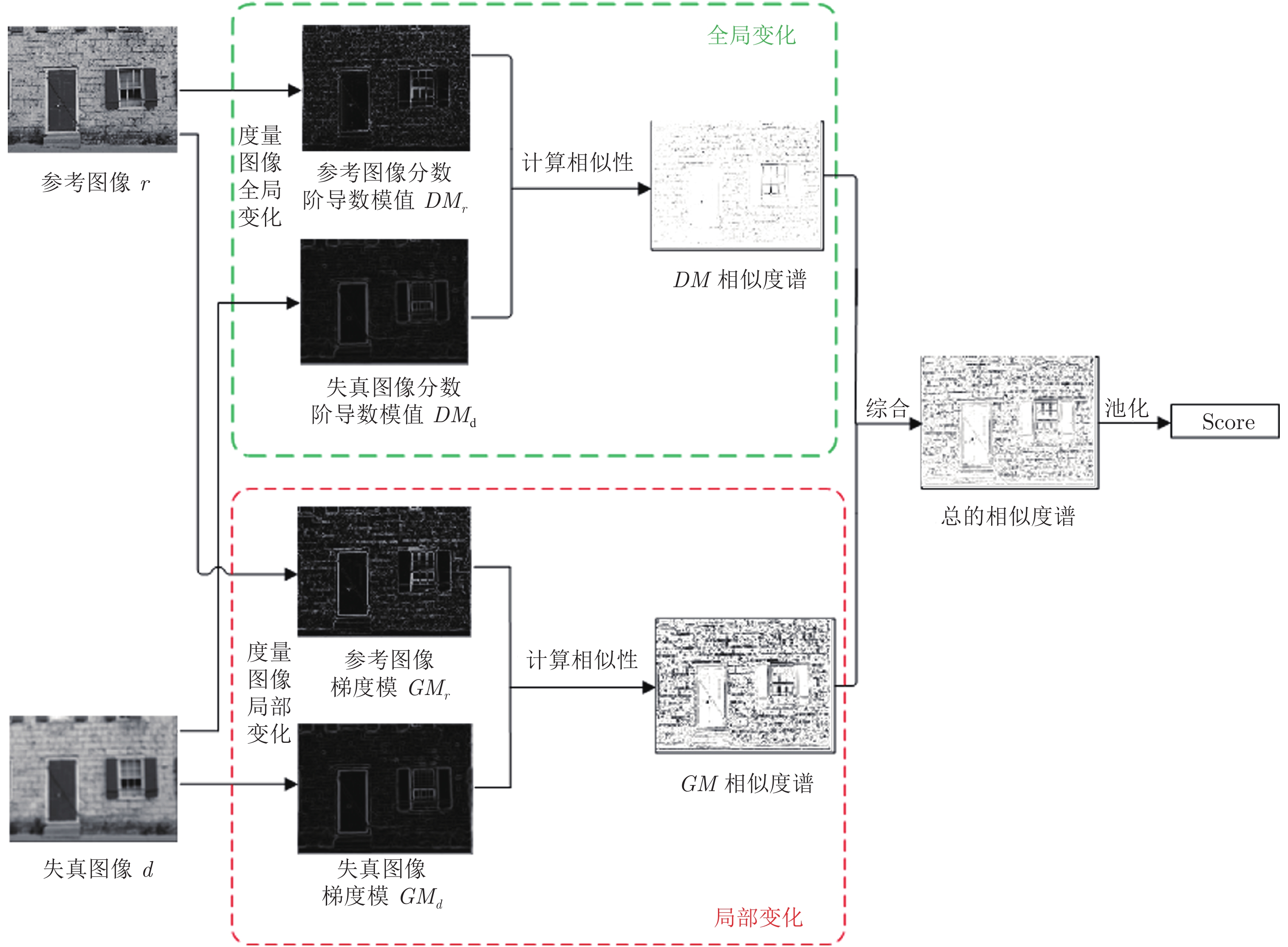
摘要: 图像所包含的信息是通过灰度值在空域的变化呈现的. 梯度是度量变化的基本工具, 这使得梯度成为了目前大多数图像质量评价算法的重要组成部分. 但是梯度只能度量局部变化, 而当人类视觉系统(Human visual system, HVS)感知一幅图像时, 既能感知到局部变化, 也能感知到全局变化. 基于HVS的这一特性, 本文提出了一种结合全局与局部变化的图像质量评价算法(Global and local variation similarity, GLV-SIM). 该算法利用Grünwald-Letnikov分数阶导数来度量图像的全局变化, 利用梯度模来度量图像的局部变化. 然后结合二者计算参考图像和退化图像之间的相似度谱(Similarity map), 进而得到图像的客观评分. 在TID2013、TID2008、CSIQ与LIVE四个数据库上的仿真实验表明, 较之单一度量局部变化的方法, 本文算法能更准确地模拟HVS对图像质量的感知过程, 给出的客观评分与主观评分具有较好的一致性.
-
关键词:
- 图像质量评价 /
- 全局与局部 /
- Grünwald-Letnikov分数阶导数 /
- 梯度模
Abstract: The information contained in an image is presented by the changes of gray value in spatial domain. Gradient is the basic tool to measure changes, which makes gradient become an important ingredient of most image quality assessment algorithms. However, gradient can only measure local changes, while when human visual system (HVS) perceives an image, it can perceive both local and global changes. Based on this characteristic of HVS, this paper proposes an image quality assessment algorithm by combining global and local variations similarity (GLV-SIM). The algorithm uses Grünwald-Letnikov fractional derivative to measure the global changes and uses gradient magnitude to measure the local changes of the image. Synthesizing the two aspect changes, similarity map between reference image and distorted image is calculated, and then objective score of the image is obtained. Simulation experiments on four databases TID2013, TID2008, CSIQ and LIVE show that, comparing with the algorithm only considering local changes, the proposed algorithm can more accurately simulate the perception process of HVS on image quality and can obtain better consistency between objective scores and subjective scores. -
一个切换系统是由一个切换信号和一组子系统所构成的特殊混杂系统[1-2].在切换系统的研究中, 切换信号具有双重角色.如果切换信号选择地合适, 那么切换系统可以继承子系统的性质[3-6]甚至产生子系统没有的性质[7-8].如果切换信号选择地不合适, 那么切换时刻可能出现大的控制信号抖振行为[9-10].这种控制信号抖振行为是切换系统特有的暂态行为.考虑到控制信号抖振的存在通常会引发系统性能降级甚至失稳问题, 因此, 抑制控制信号抖振行为变得尤为重要.目前, 切换系统的研究成果多数是关于稳态性质的, 而关于暂态性能, 特别是由切换引起的暂态性能的研究成果极少.因此, 本文将考虑如何设计切换信号以减轻由切换引发的不希望的控制信号抖振这种暂态行为.
无扰切换控制有效地抑制了切换系统在切换时刻可能出现的不希望的控制信号抖振[11].无扰切换性能是对切换时刻控制信号抖振抑制水平的刻画.典型的无扰切换控制策略是对已经事先设计好的控制器进行修正[12-16].对已有控制器修正方法的应用要求切换系统具有事先已知的切换时间或者切换顺序.对一般切换系统而言, 由于切换时间和切换顺序都是事先未知的, 所以, 上面提到的控制器修正策略[12-16]很难应用于解决一般切换系统的无扰切换控制问题.为了解决这一问题, 文献[17]提出了一种控制信号受限的方法, 其主要思想是对控制器增益的幅值施加限制.这种增益受限的思想相当于对控制信号在全状态空间内进行限制.就无扰切换控制目标而言, 文献[17]增加了过多的限制.为了减轻这种限制, 最近, 文献[18-20]对文献[17]的无扰切换控制方法进行了改进, 只要求控制信号幅值在子系统激活区间内受限即可.但是, 文献[18-20]中的无扰切换控制仍然具有额外的限制, 与无扰切换控制本旨不完全吻合.应该指出的是, 无扰切换控制的本旨是减小或者抑制切换时刻处的控制信号抖振.因此, 对切换时刻处的控制信号抖振进行抑制是本文的一个主要研究动机.
众所周知, 跟踪问题是控制领域的一个经典控制问题.关于切换系统跟踪控制问题的研究, 已经存在大量的研究成果[21-26].一个主要成果是利用多Lyapunov函数方法设计切换律和控制器实现切换系统的跟踪控制目标[27-29].有必要说明的是, 目前, 关于切换系统跟踪控制问题的研究都没有考虑如何减轻切换时刻可能出现的大的控制信号抖振问题.然而, 切换时刻处剧烈的控制信号抖振往往会降低系统的跟踪效果, 甚至引发系统故障.因此, 在实现跟踪控制目标的同时, 有必要对切换时刻处大的控制信号抖振进行抑制.但是, 同时实现跟踪和切换时刻处的控制信号抖振抑制是一个艰巨的任务.主要原因在于已有的跟踪控制方法不能直接用于实现无扰切换控制, 并且已有的无扰切换控制方法很难用来实现跟踪控制.所以, 解决跟踪无扰切换控制问题具有重要意义.这也正是本文研究的另一个主要动机.
航空发动机控制系统是高度复杂的非线性系统[30].随着航天业的飞速发展, 航空发动机的精度要求变得越来越高.航空发动机的高精度要求势必导致高精度要求的控制设计.切换控制在航空发动机控制系统中具有着重要的意义.该意义主要体现在航空发动机的控制任务特点与模型特点上.一方面, 从航空发动机的控制任务角度讲, 多目标控制是航空发动机的一个主要特点[30-32].由于航空发动机在实际工作过程中要受到多种安全边界的限制, 所以航空发动机的控制目标必须是多目标.由于单一的控制器设计很难满足航空发动机的多目标要求, 所以对航空发动机控制系统实施切换控制是非常有必要的.另一方面, 从航空发动机的模型描述角度讲, 航空发动机是高精度、高复杂度的非线性控制系统, 单一的线性模型几乎不可能描述其动态特性[33-34].因此, 有必要对航空发动机建立多个线性模型.切换线性模型因为具有额外的设计自由度与较容易的设计工具而经常被用来刻画发动机控制系统.通过利用切换线性系统的控制方法为每个子系统分别设计线性控制器, 然后利用切换信号将子系统的控制器联系在一起形成切换控制器进而控制航空发动机[35].
另外, 在航空发动机的控制设计中, 无扰切换是至关重要的, 因为大的控制信号抖振可能会降低发动机的安全性, 致使发动机出现喘振、超温和熄火等危险.基于切换线性模型, 许多学者对航空发动机的控制设计进行了研究并取得了一定的研究成果, 如火箭冲压发动机的推力调节[36]、超燃冲压发动机的进气道安全保护[37]与涡扇发动机的预测控制器设计[38]等.然而, 关于航空发动机的无扰切换控制问题的研究结果却非常少.文献[39]和[40]分别应用跟踪控制方法和重置技术对已经事先设计好的控制器进行修正, 进而解决了航空发动机控制设计中的无扰切换控制问题.但是, 文献[39]和[40]却要求子系统的工作顺序是事先已知的, 这意味着文献[39]和[40]中的无扰切换控制方法对于子系统工作顺序事先未知的航空发动机是不适用的.因此, 设计一般性的无扰切换控制方法解决航空发动机控制设计中的无扰切换控制问题是非常有必要的.
针对一类切换线性系统, 本文基于多Lyapunov函数方法提出了状态跟踪无扰切换控制问题的一个解决方案.与已有结果相比, 本文主要具有以下4方面的贡献:
1) 给出一个新的无扰切换性能定义.与文献[17-20]相比, 本文的无扰切换性能描述更加符合无扰切换的本旨.本文只对切换时刻处的控制信号抖振进行了限制, 然而, 在文献[17-20]中, 不仅对切换时刻处的控制信号抖振进行了限制, 而且在子系统激活区间甚至整个状态空间内, 也对控制信号进行了限制.从无扰切换的本旨来看, 只对切换时刻处的控制信号抖振进行限制即可.因此, 本文的无扰切换性能描述更加符合无扰切换的本旨.
2) 同时实现状态跟踪和无扰切换控制.由于状态跟踪性能与无扰切换性能通常是相互冲突的, 所以已有的仅用来实现状态跟踪性质的状态空间分割方法[27-29]不能直接用来保证无扰切换性能, 已有的仅用来实现无扰切换控制的控制器修正方法[12-16]很难用来保证状态跟踪性质.为了解决状态跟踪性能要求与无扰切换性能要求之间的冲突, 本文提出了能同时保证状态跟踪性能和无扰切换性能的状态空间划分方法.
3) 给出一个使切换线性系统状态跟踪无扰切换控制问题可解的充分条件.该条件不要求每个子系统的状态跟踪无扰切换控制问题可解.
4) 将所提出控制方法应用于涡扇航空发动机模型的转速调节上, 实现该模型的状态跟踪无扰切换控制设计.
本文主要包括4部分.第1节给出了切换系统状态跟踪无扰切换控制问题的描述.在第2节中, 通过多Lyapunov函数方法, 我们给出了切换系统状态跟踪无扰切换控制问题的一个解决方案.在第3节中, 通过将所提出的状态跟踪无扰切换控制方案应用于一个涡扇航空发动机模型上, 验证了所提出控制方案的有效性.最后, 在第4节中, 我们对文章内容进行了总结.
注1. 本文中$ {{\bf R}^n} $表示$ n $维欧氏空间, $ L_2[0, \infty) $表示区间$ [0, \infty) $上平方可积函数的全体, $ {\bf N} $与$ {S} $分别表示非负整数集与正整数集.符号$ * $表示对称矩阵的对称部分.设$ \pmb\zeta \in {\bf R}^n $, 则$ ||\pmb\zeta||_2 $表示$ \pmb\zeta $的欧氏范数.
1. 问题描述
考虑切换系统
$$ \begin{equation} \dot{{\pmb x}}(t) = A_{\sigma(t)} {\pmb x}(t)+B_{\sigma(t)} {\pmb u}(t)+F_{\sigma(t)}{\pmb d}(t) \end{equation} $$ (1) 其中, $ {\pmb x}(t)\in {\bf R}^n $表示系统的状态, $ \pmb u(t)\in {\bf R}^q $表示系统的控制输入, $ \pmb d(t)\in L_2[0, \infty) $表示系统的外部干扰输入, $ \sigma(t):[0, \infty)\rightarrow S = \{1, 2, \cdots, s\} $表示系统的切换信号, $ s $为子系统个数.切换信号$ \sigma(t) $可以用由序列$ \{ {\pmb x_0};({i_0}, {t_0}), ({i_1}, {t_1}), \cdots , ({i_n}, {t_n}), \cdots |{i_n} \in S, n \in {\bf N}\} $进行描述, 式中, $ x_0 $为系统的初始状态, $ t_0 $为系统的初始时间, $ t_n $为第$ n $个切换时刻, $ \sigma(t) = i_n $表示第$ i_n $个子系统工作.文中假设切换信号$ \sigma(t) $在有限时间内只发生有限次切换, 且矩阵$ B_i $为列满秩矩阵.
考虑参考模型
$$ \begin{equation} \dot{\pmb x}_r(t) = G\pmb x_r(t)+H\pmb r(t) \end{equation} $$ (2) 其中, $ \pmb x_r(t)\in {\bf R}^n $表示参考模型的状态, $ \pmb r(t)\in {\bf R}^p $表示参考模型的输入.
定义状态跟踪误差$ \pmb e(t) = \pmb x(t)-\pmb x_r(t) $, 对于第$ i $个子系统, 考虑如下形式的控制器
$$ \begin{equation} \pmb u(t) = M_{1i}\pmb e(t)+M_{2i}\pmb x_r(t)+M_{3i}\pmb r(t) \end{equation} $$ (3) 其中, $ M_{1i}, M_{2i} $与$ M_{3i} $为待设计的控制器增益矩阵.
联立式(1)~(3)可得
$$ \begin{align} \dot{\pmb e}(t) = &\dot{\pmb x}(t)-\dot{\pmb x}_r(t) = \nonumber\\ &X_{1\sigma(t)}\pmb e(t)+X_{2\sigma(t)}\pmb x_r(t)+\nonumber\\ &X_{3\sigma(t)}\pmb r(t)+F_{\sigma(t)}\pmb d(t) \end{align} $$ (4) 其中, $ X_{1i} = A_{i}+B_{i}M_{1i}, X_{2i} = B_{i}M_{2i}+A_{i}-G, X_{3i} = B_{i}M_{3i}-H, i\in S $.
首先, 给出无扰切换性能的定义.
定义1. 对于给定的非负常值$ \alpha_1, \alpha_2 $和$ \alpha_3 $, 如果
$$ \begin{align} &||\pmb u(t_n^+)-\pmb u(t_n^-)||_2^2\leq\nonumber\\ &\qquad \alpha_1||\pmb e(t_n)||_2^2+\alpha_2||\pmb x_r(t_n)||_2^2+\alpha_3||\pmb r(t_n)||_2^2 \end{align} $$ (5) 在任意的切换时刻$ t_n $处均成立, 则称切换系统(1)在控制器(3)下关于$ (\alpha_1, \alpha_2, \alpha_3, \sigma(t)) $具有无扰切换性能.此外, 称$ \alpha_1, \alpha_2, \alpha_3 $为无扰切换性能水平.
注2. 式(5)左侧的项表示控制信号$ \pmb u(t) $在切换时刻$ t_n $处的抖振幅值.值得注意的是在式(5)左侧出现了$ t_n^+ $与$ t_n^- $, 但是在式(5)右侧却没有出现$ t_n^+ $与$ t_n^- $.这是因为控制信号$ \pmb u(t) $在切换时刻$ t_n $处通常是不连续的, 而变量$ \pmb e(t), \pmb x_r(t) $与$ \pmb r(t) $在切换时刻$ t_n $处是连续的.式(5)刻画了切换时刻处控制信号抖振的抑制水平.定义1的主要理论参考依据为文献[17-20].在文献[17-20]的无扰切换性能描述中, 控制信号受限的时间为子系统激活时间区间或者整个状态空间.而无扰切换的本旨是抑制切换时刻处的控制信号抖振.因此, 在文献[17-20]的无扰切换性能描述中存在多余的控制信号受限时间.也就是说, 除了切换时刻外, 控制信号在其他时间受限均是不必要的.定义1则改进了这一不足, 只对切换时刻处的控制信号抖振进行限制.所以定义1比文献[17-20]中的无扰切换性能定义更符合无扰切换控制的本旨.
接下来, 给出系统(1)状态跟踪无扰切换控制问题的定义.
定义2. 考虑具有参考模型(2)和控制器(3)的切换系统(1).若存在一个切换规则$ \sigma(t) $和一组具有式(3)形式的控制器使切换系统(1)满足定义1的无扰切换性能和下面的状态跟踪性能:
1) 当$ \pmb d(t)\equiv0 $时, 有$ \mathop {\lim }\nolimits_{t\to\infty}\pmb e(t) = 0 $;
2) 当$ \pmb d(t)\neq0 $时, 在零初始条件下, 对于任意的$ \pmb d(t)\in\; L_2[0, \infty) $, 有
$$ \begin{equation} \int_0^\infty {{\pmb e^\text{T}}(\tau )} \pmb e(\tau ){\rm d}\tau \le \lambda^2 \int_0^\infty {{\pmb d^\text{T}}(\tau )} \pmb d(\tau ){\rm d}\tau \end{equation} $$ (6) 其中, $ {\lambda} $为一个给定的非负常值称为$ L_2 $-增益水平, 则称切换系统(1)的状态跟踪无扰切换控制问题可解.
本文的控制目标为:通过设计切换律$ \sigma(t) $和控制器(3)为切换系统(1)的状态跟踪无扰切换控制问题提供一个解决方案.
在建立本文主要结果之前, 给出一个需要用到的引理.
引理1[41]. 对于任意的正定矩阵$ V $和矩阵$ U $, 有
$$ \begin{equation*} UV^{-1}U\geq U+U^\text{T}-V \end{equation*} $$ 2. 主要结果
为实现切换系统(1)的状态跟踪无扰切换控制目标, 通过多Lyapunov函数方法建立如下定理1.
定理1. 考虑切换系统(1).对于给定的非负常值$ \alpha_1 $, $ \alpha_2 $, $ \alpha_3 $, $ \lambda $, 如果存在正定矩阵$ R_i $, 矩阵$ M_{2i}, M_{3i}, N_{1i}, Z_{ip} $, 非正常值$ \rho_{ij}, \beta_{ij} $, $ i\in S $满足:
$$ \begin{equation} X_{2i} = 0 \end{equation} $$ (7) $$ \begin{equation} X_{3i} = 0 \end{equation} $$ (8) $$ \begin{equation} \left[ {\begin{array}{*{20}{c}} {{\Lambda _{11i}}} & {{F_i}} & {R_i} & {{J_i}{R_i}} \\ * & { - \lambda^2 I} & 0 & 0 \\ * & * & { - I} & 0 \\ * & * & * & { - {Q_i}} \\ \end{array}} \right] < 0 \end{equation} $$ (9) $$ \begin{equation} \left[ {\begin{array}{*{20}{c}} { - {\alpha _2}I} & {{{(\Delta M_{ip}^2)}^\text{T}}} \\ * & { - { {1 \over 3}}I} \\ \end{array}} \right] < 0 \end{equation} $$ (10) $$ \begin{equation} \left[ {\begin{array}{*{20}{c}} { - {\alpha _3}I} & {{{(\Delta M_{ip}^3)}^\text{T}}} \\ * & { - { {1 \over 3}}I} \\ \end{array}} \right] < 0 \end{equation} $$ (11) $$ \begin{equation} \left[ {\begin{array}{*{20}{c}} {{\Phi _{11i}}} & {N_{1i}^\text{T} - {{Z_{ip}}^\text{T}}} & {{L_i}{R_i}} \\ * & { - { {1 \over 3}}I} & 0 \\ * & * & { - {O_i}} \\ \end{array}} \right] \le 0, i \neq p, p\in S \end{equation} $$ (12) 其中
$$ \begin{equation*} \begin{aligned} &{\Lambda _{11i}} = {\bar \Lambda _{11i}}+ \bar \Lambda _{11i}^\text{T}+ \sum\limits_{j = 1}^s {{\rho _{ij}}} {R_i}\\ &{\bar \Lambda _{11i}} = {R_i}A_i^\text{T} + N_{1i}^T{B_i}^\text{T}\\ & \Delta M_{ip}^2 = {M_{2i}} - {M_{2p}}, i \neq p, p \in S\\ & \Delta M_{ip}^3 = {M_{3i}} - {M_{3p}}, i \neq p , p \in S\\ &{\Phi _{11i}} = - 3{R_i} +R_p+ \sum\limits_{j = 1}^s {{\beta _{ij}}} {R_i}+ \alpha _1^{ - 1}I\\ &{J_i} = [\sqrt { - {\rho _{i1}}}, \sqrt { - {\rho _{i2}}}, \cdots, \sqrt { - {\rho _{ii - 1}}}, \\ &\; \; \; \; \sqrt { - {\rho _{ii + 1}}}, \cdots , \sqrt { - {\rho _{is}}} ], \\ &{L_i} = [\sqrt { - {\beta _{i1}}}, \sqrt { - {\beta _{i2}}}, \cdots, \sqrt { - {\beta _{ii - 1}}}, \\ &\; \; \; \; \sqrt { - {\beta _{ii + 1}}}, \cdots, \sqrt { - {\beta _{is}}} ] \\ &{Q_i} = {\rm{diag}}\{ {R_1}, {R_2}, \cdots , {R_{i - 1}}, {R_{i + 1}}, \cdots, {R_s}\} \end{aligned} \end{equation*} $$ 那么, 在控制器(3)与切换律
$$ \begin{equation} \sigma (t) = \arg \mathop {\min }\limits_{i \in S} \{{\pmb e^\text{T}}{R_i^{-1}}\pmb e\} \end{equation} $$ (13) 下, 切换系统(1)的状态跟踪无扰切换控制问题可解.
证明. 本证明分为状态跟踪性质的证明和无扰切换性能的证明两部分.首先, 证明状态跟踪性质.根据式(7)和(8)将系统(4)描述为
$$ \begin{align} \dot{\pmb e}(t) = &X_{1\sigma(t)}\pmb e(t)+X_{2\sigma(t)}\pmb x_r(t)+\nonumber\\ &X_{3\sigma(t)}\pmb r(t)+F_{\sigma(t)}\pmb d(t) = \nonumber\\ &X_{1\sigma(t)}\pmb e(t)+F_{\sigma(t)}\pmb d(t) \end{align} $$ (14) 为系统(14)的第$ i $个子系统选择Lyapunov函数$ W_i = \pmb e^\text{T}R_i^{-1}\pmb e $.沿着系统(14)的状态轨线, 对Lyapunov函数求导数可得:
$$ \begin{align} \label{p1.1} \dot{W}_i(\pmb e(t)) = &2\dot{\pmb e}^\text{T}(t)R_i^{-1}\pmb e(t) = \\ &\pmb e^\text{T}(t)({X_{1i}^\text{T}R_i^{-1} + R_i^{-1}{X_{1i}}})\pmb e(t)+\\ &2\pmb e^\text{T}(t)R_i^{-1}F_i\pmb d(t) \end{align} $$ (15) 于是, 有
$$ \begin{align} \dot{W}_i(\pmb e(t))+\pmb e^\text{T}(t)\pmb e(t)-\lambda^2 \pmb d^\text{T}(t)\pmb d(t) = \pmb\eta^\text{T}(t)\Omega_i\pmb \eta(t) \end{align} $$ (16) 其中, $ \pmb\eta^\text{T}(t) = [\pmb e^\text{T}(t)\; \pmb d^\text{T}(t)] $,
$$ \begin{equation*} \begin{aligned} {\Omega _i} = & \left[ {\begin{array}{*{20}{c}} {{\Omega _{11i}}} & {R_i^{-1}{F_i}} \\ * & { - \lambda^2 I} \\ \end{array}} \right] \\ {\Omega _{11i}} = & X_{1i}^\text{T}R_i^{-1} + R_i^{-1}{X_{1i}} +I \end{aligned} \end{equation*} $$ 由切换规则(13)可知, 当第$ i $个子系统工作时, 有
$$ \begin{equation} \pmb e^\text{T}(t)R_i^{-1}\pmb e(t) \leq \pmb e^\text{T}(t)R_j^{-1}\pmb e(t), \quad j = 1, 2, \cdots, s \end{equation} $$ (17) 联立式(16)与(17)可得, 当第$ i $个子系统工作时, 有
$$ \begin{align} \label{p1.4} &\dot{W}_i(\pmb e(t))+\pmb e^\text{T}(t)\pmb e(t)-\lambda^2 \pmb d^\text{T}(t)\pmb d(t) = \\ &\; \; \; \; \; \pmb\eta^\text{T}(t)\Omega_i\pmb\eta(t)\leq\\ & \pmb\eta^\text{T}(t)\Omega_i\pmb\eta(t)+\pmb e^\text{T}(t)\sum\limits_{j = 1}^s {{\rho _{ij}}} (R_i^{-1} - R_j^{-1})\pmb e(t) = \\ &\; \; \; \; \; \; \pmb\eta^\text{T}(t)\Psi_i\pmb\eta(t) \end{align} $$ (18) 其中
$$ \begin{equation*} \begin{aligned} {\Psi _i} = & \left[ {\begin{array}{*{20}{c}} {{\Psi _{1i}}} & {{R_i^{-1}}{F_i}} \\ * & { - \lambda^2 I} \\ \end{array}} \right]\\ {\Psi _{1i}} = & {\Omega _{11i}} + \sum\limits_{j = 1}^s {{\rho _{ij}}} (R_i^{-1} - R_j^{-1}) \\ \end{aligned} \end{equation*} $$ 于是, 如果$ {\Psi _i}<0 $, 那么在第$ i $个子系统的工作时间区间内, 有
$$ \begin{equation} \dot{W}_i(\pmb e(t))+\pmb e^\text{T}(t)\pmb e(t)-\lambda^2 \pmb d^\text{T}(t)\pmb d(t)\leq 0 \end{equation} $$ (19) 成立.令$ N_{1i} = M_{1i}R_i $并对式(9)应用Schur引理得:
$$ \begin{equation} {\Xi _i} = \left[ {\begin{array}{*{20}{c}} {{\Xi _{1i}}} & {{F_i}} \\ * & { - \lambda^2 I}\\ \end{array}} \right] < 0 \end{equation} $$ (20) 其中
$$ \begin{equation*} \begin{aligned} {\Xi _{1i}} = & {X_{1i}}{R_i} + {R_i}X_{1i}^\text{T} + {R_i}{R_i}+ \\ &\; \; \; \; \; \; \sum\limits_{j = 1}^s {{\rho _{ij}}} ({R_i} - {R_i}R_j^{ - 1}{R_i}) \end{aligned} \end{equation*} $$ 对式(20)两边同时分别乘以$ \text{diag}\{R_i^{-1}, I\} $得$ \Psi_i<0 $, 从而得式(19).对于$ d(t)\neq0 $, 当第$ i $个子系统工作时, 从$ \tau = t_n $到$ t_{n+1} $对式(17)两边的函数同时进行积分得:
$$ \begin{align} \label{p1.8} &\int_{{t_n}}^{{t_{n + 1}}} {[{\pmb e^\text{T}}(\tau)\pmb e(\tau) - {\lambda^2}} {\pmb d^\text{T}}(\tau)\pmb d(\tau)]{\rm d}\tau\le \\ &\qquad\qquad W_i(\pmb e({t_n})) - W_i(\pmb e({t_{n + 1}})) \end{align} $$ (21) 利用切换规则(13)可得:
$$ \begin{equation} W_{i_n}(\pmb e(t_{n+1})) = W_{i_{n+1}}(\pmb e(t_{n+1})) \end{equation} $$ (22) 联立式(21)和式(22)有
$$ \begin{equation*} \begin{aligned} &\int_0^t {[{\pmb e^\text{T}}(\tau )\pmb e(\tau ) - \lambda^2 {\pmb d^\text{T}}(\tau )\pmb d(\tau )]{\rm d}\tau }\le\nonumber\\ &\qquad\qquad {W_{\sigma (0)}}(\pmb e(0)) - {W_{\sigma (t)}}(\pmb e(t)) \end{aligned} \end{equation*} $$ 因为$ {W_{i}}(\pmb e(t))\geq0 $, 所以, 在零初始条件下, 当$ t\rightarrow\infty $时, $ L_2 $-增益性质(6)成立.当$ \pmb d(t)\equiv0 $时, 易知
$$ \begin{align*} \dot{W}_i(\pmb e(t)) = &2\dot{\pmb e}^\text{T}(t)R_i^{-1}\pmb e(t) = \nonumber\\ &\pmb e^\text{T}(t)(X_{1i}^\text{T}R_i^{-1}+R_i^{-1}X_{1i})\pmb e(t) \end{align*} $$ 根据式(17), 当第$ i $个子系统激活时, 有
$$ \begin{align} \dot{W}_i(\pmb e(t)) = &\pmb e^\text{T}(t)(X_{1i}^\text{T}R_i^{-1}+R_i^{-1}X_{1i})\pmb e(t)\leq\\ & \pmb e^\text{T}(t)(X_{1i}^\text{T}R_i^{-1}+R_i^{-1}X_{1i})\pmb e(t)+\\ &\pmb e^\text{T}(t)\sum\limits_{j = 1}^s {{\rho _{ij}}} (R_i^{-1} - R_j^{-1})\pmb e(t) = \\ &\pmb e^\text{T}(t)\Upsilon_i\pmb e(t), \end{align} $$ (23) 其中, $ \Upsilon_i = X_{1i}^\text{T}R_i^{-1}+R_i^{-1}X_{1i}+\sum\limits_{j = 1}^s {{\rho _{ij}}} (R_i^{-1} - R_j^{-1}) $.由于$ \Psi_i<0 $, 在第$ i $个子系统的工作时间区间内, 有$ \dot{W}_i(\pmb e(t))<0, \forall \pmb e(t) \neq 0 $.与式(19)联立, 可得$ \mathop {\lim }\nolimits_{t \to \infty } \pmb e(t) = 0 $
接下来, 证明切换切换系统(1)满足无扰切换性能(5).假设在切换时刻$ t_n $处, 第$ p $个子系统代替第$ i $个子系统开始工作, 对于任意的$ i, p \in S, i \neq p $, 在切换时刻$ t_n $处, 设$ \mathcal{U}_{ip}(t_n) = ||\Delta M_{ip}^1\pmb e(t_n) + \Delta M_{ip}^2{\pmb x_r}(t_n) + \Delta M_{ip}^3\pmb r(t_n)||_2^2- {\alpha _1}||\pmb e(t_n)||_2^2 - {\alpha _2}||{\pmb x_r}(t_n)||_2^2 - {\alpha _3}||\pmb r(t_n)||_2^2 $, 其中, $ \Delta M_{ip}^1 = {M_{1i}} - {M_{1p}} $.于是, 有
$$ \begin{align} \mathcal{U}_{ip}(t_n) = & ||\Delta M_{ip}^1\pmb e(t_n) + \Delta M_{ip}^2{\pmb x_r}(t_n)+ \\ &\Delta M_{ip}^3\pmb r(t_n)||_2^2- {\alpha _1}||\pmb e(t_n)||_2^2\\ & - {\alpha _2}||{\pmb x_r}(t_n)||_2^2 - {\alpha _3}||\pmb r(t_n)||_2^2\le \\ & {\pmb e^\text{T}}(t_n)[3{(\Delta M_{ip}^1)^\text{T}}\Delta M_{ip}^1 - {\alpha _1}I]\pmb e(t_n)+\\ & \pmb x_r^\text{T}(t_n)[3{(\Delta M_{ip}^2)^\text{T}}\Delta M_{ip}^2 - {\alpha _2}I]{\pmb x_r}(t_n)+\\ & {\pmb r^\text{T}}(t_n)[3{(\Delta M_{ip}^3)^\text{T}} \Delta M_{ip}^3 - {\alpha _3}I]\pmb r(t_n) \end{align} $$ (24) 根据式(10)、(11)和式(24)得:
$$ \begin{align} \mathcal{U}_{ip}(t_n)\leq & {\pmb e^\text{T}}(t_n)[3{(\Delta M_{ip}^1)^\text{T}}\Delta M_{ip}^1 - {\alpha _1}I]\pmb e(t_n)+\\ & \pmb x_r^\text{T}(t_n)[3{(\Delta M_{ip}^2)^\text{T}}\Delta M_{ip}^2 - {\alpha _2}I]{\pmb x_r}(t_n)+\\ & {\pmb r^\text{T}}(t_n)[3{(\Delta M_{ip}^3)^\text{T}}\Delta M_{ip}^3 - {\alpha _3}I]\pmb r(t_n)\leq \\ &{\pmb e^\text{T}}(t_n)[3{(\Delta M_{ip}^1)^\text{T}}\Delta M_{ip}^1 - {\alpha _1}I]\pmb e(t_n) \end{align} $$ (25) 根据式(17)和(25)知, 当第$ i $个子系统工作时, 有
$$ \begin{align} \mathcal{U}_{ip}(t_n)&\leq {\pmb e^\text{T}}(t_n)[3{(\Delta M_{ip}^1)^\text{T}}\Delta M_{ip}^1 - {\alpha _1}I]\pmb e(t_n)\leq\\ & \; \; \; \; \; {\pmb e^\text{T}}(t_n)[3{(\Delta M_{ip}^1)^\text{T}}\Delta M_{ip}^1 - {\alpha _1}I]\pmb e(t_n)+\\ &\; \; \; \; \; \pmb e^\text{T}(t_n)\sum\limits_{j = 1}^s {{\beta _{ij}}} (R_i^{-1} - R_j^{-1})\pmb e(t_n) = \\ &\; \; \; \; \; \pmb e^\text{T}(t_n)\Pi_{ip}\pmb e(t_n) \end{align} $$ (26) 其中, $ \Pi_{ip} = 3{(\Delta M_{ip}^1)^\text{T}}\Delta M_{ip}^1 - {\alpha _1}I+\sum\nolimits_{j = 1}^s {{\beta _{ij}}} (R_i^{-1} - R_j^{-1}). $令$ Z_{ip} = M_{1p}R_i $并对式(12)应用Schur补引理得
$$ \begin{align} &3{R_i}{(\Delta M_{ip}^1)^\text{T}}\Delta M_{ip}^1{R_i} - 3{R_i}+R_p+ \\ &\qquad\alpha _1^{ - 1}I + \sum\limits_{j = 1}^s {{\beta _{ij}}} ({R_i} - {R_i}R_j^{ - 1}{R_i}) \le 0 \end{align} $$ (27) 通过引理1可知
$$ \begin{eqnarray} \alpha_1R_iR_i\geq2R_i-\alpha_1^{-1}I \end{eqnarray} $$ (28) $$ \begin{eqnarray} R_iR_p^{-1}R_i\geq 2R_i-R_p \end{eqnarray} $$ (29) 联立式(27)、(28)和式(29)得:
$$ \begin{align} &3{R_i}{(\Delta M_{ip}^1)^\text{T}}\Delta M_{ip}^1{R_i} - {\alpha _1}{R_i}{R_i}+R_i+ \\ &\qquad \sum\limits_{j = 1}^s {{\beta _{ij}}} ({R_i} - {R_i}R_j^{ - 1}{R_i}) - {R_i}R_p^{ - 1}{R_i} \le 0 \end{align} $$ (30) 对式(27)左右两边分别同时乘以$ R_i^{-1} $得:
$$ \begin{equation} \Pi_{ip}+R_i^{-1}-R_p^{-1}\leq0 \end{equation} $$ (31) 联立式(26)和式(31)得:
$$ \begin{align} \mathcal{U}_{ip}(t_n)\leq & \pmb e^\text{T}(t_n)\Pi_{ip}\pmb e(t_n)\leq\\ &\pmb e^\text{T}(t_n)(R_p^{-1}-R_i^{-1})\pmb e(t_n) \end{align} $$ (32) 根据式(22)和式(32)可知
$$ \begin{equation} \mathcal{U}_{ip}(t_n)\leq \pmb e^\text{T}(t_n)(R_p^{-1}-R_i^{-1})\pmb e(t_{n}) = 0 \end{equation} $$ (33) 因此, 切换系统(1)满足无扰切换性能(5). \hfill$ \square $
注3. 定理1给出了一个充分条件用来实现切换系统(1)的状态跟踪性质和无扰切换性能.在式(7)和式(8)成立的前提下, 式(9)保证了状态跟踪性质, 式(10) $ \sim $ (12)保证了无扰切换性能(5).如果式(7) $ \sim $ (12)可解, 就可以求解出控制器(3)的增益矩阵$ M_{1i} $, $ M_{2i} $与$ M_{3i} $.进而, 在控制器(3)与切换律(13)的共同作用下, 就可以同时保证切换系统(1)的状态跟踪性质与无扰切换性能.
注4. 切换信号(13)可能产生滑模现象.下面说明即使产生滑模现象, 在$ d(t)\equiv0 $的情形下, 任意的滑动模态是稳定的.不失一般性, 假设只有两个子系统$ i, j $.由切换律(13)可知, 滑模产生的条件为
$$ \begin{equation} [\dot{W}_i(t)-\dot{W}_j(t)]\big|_{\sigma(t) = i}\geq0 \end{equation} $$ (34) 与
$$ \begin{equation} [\dot{W}_{j}(t)-\dot{W}_i(t)]\big|_{\sigma(t) = j} \geq 0 \end{equation} $$ (35) 其中, $ \dot{W}_i(t)\big|_{\sigma(t) = j} $表示$ W_i(t) $沿着子系统$ j $的时间导数.式(34)和式(35)可以分别等价描述为
$$ \begin{equation} {\pmb e}^\text{T}(t)[X_{1i}^\text{T}(R_i^{-1}-R_j^{-1})+(R_i^{-1}-R_j^{-1})X_{1i}]\pmb e(t)\geq0 \end{equation} $$ (36) 与
$$ \begin{equation} \pmb e^\text{T}(t)[X_{1j}^\text{T}(R_j^{-1}-R_{i}^{-1})+(R_{j}^{-1}-R_i^{-1})X_{1j}]\pmb e(t) \geq 0 \end{equation} $$ (37) 下面说明任一子系统的Lyapunov函数沿着Filippov解都是下降的.对于任意的$ i \in S $, $ \mu \in (0, 1) $, 有
$$ \begin{align} \dot{W}_i(\pmb e(t)) = &\pmb e^\text{T}(t)\{[\mu X_{1i}+(1-\mu)X_{1j}]^\text{T}R_i^{-1}+\\ &R_{i}^{-1}[\mu X_{1i}+(1-\mu)X_{1j}]\}\pmb e(t) = \\ &\mu \pmb e^\text{T}(t)(X_{1i}^\text{T}R_i^{-1}+R_i^{-1}X_{1i})\pmb e(t)+\\ &(1-\mu)\pmb e^\text{T}(t)(X_{1j}^\text{T}R_i^{-1}+R_i^{-1}X_{1j})\pmb e(t) \end{align} $$ (38) 由式(37)可知
$$ \begin{align} &\pmb e^\text{T}(t)(X_{1j}^\text{T}R_i^{-1}+R_i^{-1}X_{1j})\pmb e(t)\leq\\ &\qquad \pmb e^\text{T}(t)(X_{1j}^\text{T}R_j^{-1}+R_j^{-1}X_{1j})\pmb e(t) \end{align} $$ (39) 于是, 由式(9), (38)和式(39)可知, 对于$ \forall \pmb e(t)\neq 0 $, 有
$$ \begin{equation*} \begin{aligned} \dot{W}_i(\pmb e(t)) = &\mu \pmb e^\text{T}(t)(X_{1i}^\text{T}R_i^{-1}+R_i^{-1}X_{1i})\pmb e(t)+\nonumber\\ &(1-\mu)\pmb e^\text{T}(t)(X_{1j}^\text{T}R_i^{-1}+R_i^{-1}X_{1j})\pmb e(t)\leq\nonumber\\ &\mu \pmb e^\text{T}(t)(X_{1i}^\text{T}R_i^{-1}+R_i^{-1}X_{1i}) \pmb e(t)+\nonumber\\ &(1-\mu) \pmb e^\text{T}(t)(X_{1j}^\text{T}R_j^{-1}+\nonumber\\ &R_j^{-1}X_{1j})\pmb e(t)<0 \end{aligned} \end{equation*} $$ 所以, 当$ \pmb d(t)\equiv0 $时, 任意的滑动模态都是渐近稳定的.
3. 应用
本节采用文献[30]中航空发动机切换线性模型来验证所提出状态跟踪无扰切换控制方法的有效性.
所采用的模型为90k级涡扇航空发动机模型.如文献[42]所述, 利用循环平台数据模型的构建方法与基于系统辨识的方法, 可以得到由以下微分方程进行描述的航空发动机模型:
$$ \begin{align} \left[ {\begin{array}{*{20}{c}} {\Delta {{\dot N}_f}(t)} \\ {\Delta {{\dot N}_c}(t)} \\ \end{array}} \right] = & {A_{\sigma (t)}} \left[ {\begin{array}{*{20}{c}} {\Delta { N_f}(t)} \\ {\Delta { N_c}(t)} \\ \end{array}} \right] +\\ & {B_{\sigma (t)}}\Delta {Q_f}(t)+ {F_{\sigma (t)}} d(t) \end{align} $$ (40) 其中, $ {\Delta { N_f}(t)} $和$ {\Delta {N_c}(t)} $分别为航空发动机的风扇转速变化量与核心机转速变化量, $ \Delta{ Q}_f(t) $为燃油流量变化量, $ d(t) $是航空发动机退化参数, $ \sigma(t):[0, \infty)\rightarrow \{1, 2\} $为切换信号, 当$ \sigma(t) = i\in\{1, 2\} $时, 称第$ i $个子模态工作.
参考模型由以下微分方程描述:
$$ \begin{align} \left[ {\begin{array}{*{20}{c}} {\Delta {{\dot N}_{fr}}(t)} \\ {\Delta {{\dot N}_{cr}}(t)} \\ \end{array}} \right] = & G\left[ {\begin{array}{*{20}{c}} {\Delta { N_{fr}}(t)} \\ {\Delta { N_{cr}}(t)} \\ \end{array}} \right] +Hr(t) \end{align} $$ (41) 其中, $ {\Delta { N_{fr}}(t)} $与$ {\Delta { N_{cr}}(t)} $分别为航空发动机的参考风扇转速变化量与核心机转速变化量, $ r(t) $为参考输入信号.
设$ e_f(t) = \Delta{ N}_f(t)-\Delta{ N}_{fr}(t) $和$ e_c(t) = \Delta{ N}_c(t)-\Delta{N}_{cr}(t) $分别为风扇转速跟踪误差与核心机转速跟踪误差.
对于航空发动机模型(37)中的第$ i $个子模型, 考虑其燃油流量变化量
$$ \begin{align} \Delta{ Q}_f(t) = &M_{1i}\left[ {\begin{array}{*{20}{c}} {{ e_f}(t)} \\ {{ e_c}(t)} \\ \end{array}} \right]+M_{2i}\left[ {\begin{array}{*{20}{c}} {\Delta { N_{fr}}(t)} \\ {\Delta { N_{cr}}(t)} \\ \end{array}} \right]+\\ &M_{3i} r(t) \end{align} $$ (42) 其中, $ M_{1i}, M_{2i} $和$ M_{3i} $为待设计的增益矩阵.
如文献[42]所述, 为了实时得到更精确的数学模型, 对于航空发动机模型(37), 设计切换信号
$$ \begin{equation} \sigma (t) = \arg \mathop {\min }\limits_{i \in S}\left \{\left[ {\begin{array}{*{20}{c}} e_f(t) \\ e_c(t) \\ \end{array}} \right]{R_i^{-1}}\left[ {\begin{array}{*{20}{c}} e_f(t) \\ e_c(t) \\ \end{array}} \right]\right\}, \end{equation} $$ (43) 式中, $ R_i $为待求的正定矩阵.
模型(40)和(41)中的数据如下:
$$ \begin{align*} A_1 = &\left[ {\begin{array}{*{20}{c}} -3.8557 &1.4467\\ 0.4690 &-4.7081\\ \end{array}} \right], B_1 = \left[ {\begin{array}{*{20}{c}} 230.6739\\ 653.5547\\ \end{array}} \right]\\ A_2 = &\left[ {\begin{array}{*{20}{c}} -3.7401 &1.4001\\ 0.4752 &-4.5586\\ \end{array}} \right], B_2 = \left[ {\begin{array}{*{20}{c}} 231.5508\\ 657.3084\\ \end{array}} \right]\\ F_1 = &\left[ {\begin{array}{*{20}{c}} 1\\ 0.5\\ \end{array}} \right], F_2 = \left[ {\begin{array}{*{20}{c}} 0.8\\ 0.1\\ \end{array}} \right], H = \left[ {\begin{array}{*{20}{c}} 225.5204\\ 627.2142\\ \end{array}} \right]\\ G = &\left[ {\begin{array}{*{20}{c}} -4.0334 & 1.4777\\ 0.5872 & -4.6338\\ \end{array}} \right] \end{align*} $$ $$ \begin{align*} d(t) = &{\rm e}^{-0.3t}\\ r(t) = & \begin{cases} -0.5t, &0 \le t \le 5\\ 0.2t, &5 < t \le 10\\ 0, &\text{其他} \end{cases}\\ \Delta{ N}_f(0) = &\Delta{N}_{ fr}(0) = 0.5\\ \Delta{N}_c(0) = &\Delta{N}_{ cr}(0) = -2 \end{align*} $$ 针对航空发动机模型(40), 制定如下控制任务:通过设计燃油流量变化量(42)和切换信号(43)使航空发动机的风扇转速$ \Delta{N}_f(t) $跟踪上参考风扇转速$ \Delta{N}_{fr}(t) $, 核心机转速跟踪上参考核心机转速$ \Delta{N}_{cr}(t) $, 同时燃油流量变化量$ \Delta{Q}_f(t) $执行无扰切换控制.
由于定理1中保证状态跟踪性质的条件与保证无扰切换性能的条件是相互耦合的, 所以不能同时追求最好的状态跟踪性质与无扰切换性能.因此, 为了说明所提方法的有效性, 下面给出两组仿真对比:第一组为在保证无扰切换性能的前提下, 追求最好的状态跟踪性质, 第二组为在保证跟踪性质的前提下, 追求最好的无扰切换性能.
首先, 给出第一组仿真对比.考虑如下两种情形:
1) 同时考虑状态跟踪性能和无扰切换性能
给定$ \beta_{12} = \beta_{21} = -1 $, $ \alpha_1 = 1 $, 通过求解定理1中的式(7) $ \sim $ (12)得到控制器增益矩阵
$$ \begin{equation*} \begin{aligned} M_{11} = &[-0.0022 \; \; -0.0041]\\ M_{12} = &[ -0.0018 \; \; -0.0043]\\ M_{21} = &10^{-3}\times[0.0755 \; \; 0.1160], M_{31} = 0.9617\\ M_{22} = &10^{-4}\times[0.1175 \; \; -0.6478], M_{32} = 0.9564 \end{aligned} \end{equation*} $$ Lyapunov矩阵
$$ \begin{equation*} \begin{aligned} R_1^{-1} = &\left[ {\begin{array}{*{20}{c}} 0.2340 & 0.2188\\ 0.2188 & 0.6682\\ \end{array}} \right]\\ R_2^{-1} = &\left[ {\begin{array}{*{20}{c}} 0.2630 & 0.0482\\ 0.0482 & 0.3373\\ \end{array}} \right] \end{aligned} \end{equation*} $$ 最小$ L_2 $-增益水平$ \lambda = 0.3080 $, $ \rho_{12} = -0.0015 $, $ \rho_{21} = -0.1251 $.
2) 只考虑状态跟踪性质, 不考虑无扰切换性能
选择相同的$ \rho_{12}, \rho_{21} $, 通过求解定理1中的式(7) $ \sim $ (9)得相同的控制器增益矩阵$ M_{2i}, M_{3i} $和不同的控制器增益矩阵$ M_{11} = [-1.2397 \; \; -1.5590], M_{12} = [-1.5224 \; \; -1.9083] $, Lyapunov矩阵
$$ \begin{equation*} \begin{aligned} R_1^{-1} = &\left[ {\begin{array}{*{20}{c}} 0.1955 & -0.0688\\ -0.0688 & 0.0245\\ \end{array}} \right]\\ R_2^{-1} = &\left[ {\begin{array}{*{20}{c}} 0.1565 & -0.0550\\ -0.0550 & 0.0196\\ \end{array}} \right] \end{aligned} \end{equation*} $$ 此时, 最小$ L_2 $-增益水平为$ \lambda = 0.1620 $.
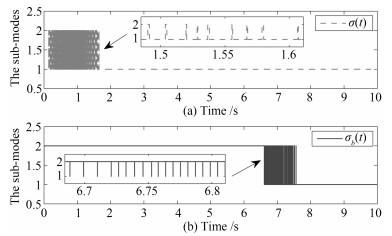
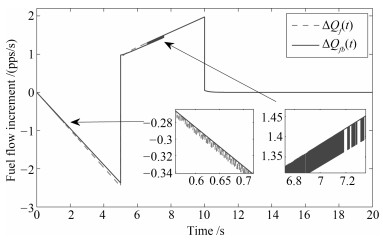
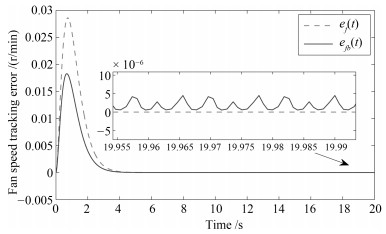
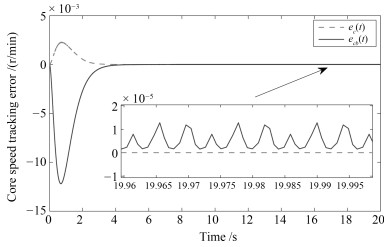
两种情形下得到的仿真效果如图 1~4所示.图中有角标$ b $的信号表示第二种情形下得到的信号, 无角标$ b $的信号为第一种情形下得到的信号.
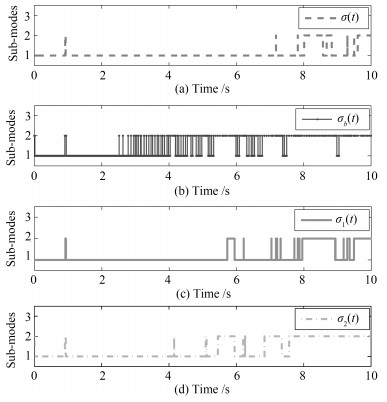
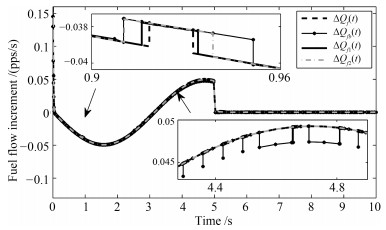
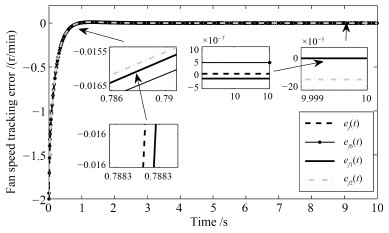
图 1表示不同情形下的切换信号.从图 1中可以看到当时间$ t $大于8 s以后便不再发生切换了.这是因为控制系统在实际运行中是允许有一定的误差的, 所以当系统状态轨迹满足误差精度要求后, 子系统的Lyapunov函数就不再进行比较, 相应地, 该控制系统也不会再发生切换. 图 2表示不同情形下的燃油流量变化情况. 图 2表明第一种情形下得到的燃油流量变化$ \Delta{Q}_f(t) $具有更小的抖振幅值. 图 3和图 4反映了转速跟踪情况, 其中, 图 3为风扇转速跟踪误差, 图 4为核心机转速跟踪误差.通过图 3和4不难发现, 第一种情形下得到的状态跟踪误差具有更快的收敛速度与更小的抖振幅值.
仿真结果表明在考虑无扰切换性能的情况下, 切换模型(40)的状态跟踪误差具有更好的效果.因此, 可以说明所提出的无扰切换控制策略能改善状态跟踪性能.
下面给出第二组仿真对比.为了充分说明无扰切换的效果, 我们考虑不同的参考信号$ r(t) $与不同的初始状态值.
取
$$ \begin{equation*} r(t) = \begin{cases} -0.5\sin(t), &0 \le t \leq 5\\ 0, &\text{其他} \end{cases} \end{equation*} $$ 初始状态值$ \Delta{N}_{f}(0) = -2.1, \Delta{N}_{c}(0) = -0.9, $ $ \Delta{N}_{fr}(0) = -0.1, \Delta{N}_{cr}(0) = 0.1. $
考虑如下4种情形: 1)同时考虑状态跟踪性能和无扰切换性能(5); 2)只考虑状态跟踪性能, 不考虑无扰切换性能; 3)同时考虑状态跟踪性能和文献[20]中的无扰切换性能; 4)同时考虑状态跟踪性能和文献[17]中的无扰切换性能.
由定理1可知, 控制器增益$ M_{2i} $和$ M_{3i} $仅由式(7)和(8)决定, 与切换无关.于是, 通过求解得到控制器增益矩阵
$$ \begin{equation*} \begin{aligned} M_{21} = &10^{-3}\times[0.0755 \; \; 0.1160] M_{31} = 0.9617, \\ M_{22} = &10^{-4}\times[0.1175 \; \; -0.6478], M_{32} = 0.9564 \end{aligned} \end{equation*} $$ 为了便于比较, 在以下4种对比情形中, 选取相同的参数$ \rho_{12} = \rho_{21} = -1 $, $ \lambda = 3 $与相同的控制器增益矩阵$ M_{2i} $, $ M_{3i} $.
接下来进行具体说明.
1) 同时考虑状态跟踪性能和无扰切换性能(5).
通过求解定理1中的式(9) $ \sim $ (12)得到控制器增益矩阵
$$ \begin{equation*} \begin{aligned} &M_{11} = [-0.0367 \; \; -0.0878]\\ &M_{12} = [ -0.0308 \; \; -0.0819] \end{aligned} \end{equation*} $$ Lyapunov矩阵
$$ \begin{equation*} \begin{aligned} R_1^{-1} = &\left[ {\begin{array}{*{20}{c}} 77.1877 & 28.5031\\ 28.5031 & 127.4399\\ \end{array}} \right]\\ R_2^{-1} = &\left[ {\begin{array}{*{20}{c}} 109.0347 & 8.7740\\ 8.7740 & 126.1410\\ \end{array}} \right] \end{aligned} \end{equation*} $$ 最小无扰切换性能水平$ \alpha_1 = 67.4393, \alpha_2 = 10^{-6}\times0.1102, \alpha_3 = 10^{-5}\times8.3987 $, 参数$ \beta_{12} = -2.2034, \beta_{21} = -1.3080 $.
2) 只考虑状态跟踪性质, 不考虑无扰切换性能.
通过求解定理1中的式(9)得到控制器增益矩阵
$$ \begin{equation*} \begin{aligned}& M_{11} = [-0.0900\; -0.2146]\\&M_{12} = [-0.0311\; -0.0826], \end{aligned} \end{equation*} $$ Lyapunov矩阵
$$ \begin{equation*} \begin{aligned} R_1^{-1} = &\left[ {\begin{array}{*{20}{c}} 109.0927 & 95.5283\\ 95.5283 & 290.1846\\ \end{array}} \right]\\ R_2^{-1} = &\left[ {\begin{array}{*{20}{c}} 105.7225 & 10.4722\\ 10.4722 & 126.9379\\ \end{array}} \right] \end{aligned} \end{equation*} $$ 3) 同时考虑状态跟踪性能和文献[20]中的无扰切换性能
此时, 无扰切换性能由条件为定理1中的式(10)和(11)以及
$$ \begin{equation} \left[ {\begin{array}{*{20}{c}} \tilde{G}_i&{N_{1i}^T - {R_i}{{(M_1^*)}^T}}&{{U_i}{R_i}}\\ *&{ - I}&0\\ *&*&{ - {O_i}} \end{array}} \right] \le 0 \end{equation} $$ (44) 保证, 其中, $ M_1^* $为控制器增益$ M_{1i} $的参考值, $ \alpha_4 $表示无扰切换性能水平, $ \tilde{\mu}_{ij}\leq0 $为待求参数, $ \tilde{G}_i = $ $ {\sum\limits_{j = 1}^s {{\tilde{\mu} _{ij}}{R_i} - 2{R_i} + { {1 \over {{\alpha _4}}}}I} } $, $ U_i = [\sqrt { - {\tilde{\mu} _{i1}}}, $ $ \sqrt { - {\tilde{\mu} _{i2}}}, \cdots, \sqrt { - {\tilde{\mu} _{ii - 1}}}, \sqrt { - {\tilde{\mu} _{ii + 1}}}, \cdots \sqrt { - {\tilde{\mu} _{is}}} ] $.
设$ M_{1}^* = [1\; 2] $, 通过求解定理1中的式(9) $ \sim $ (11), 式(41), 得到控制器增益矩阵
$$ \begin{equation*} \begin{aligned} &M_{11} = [-0.0396\; -0.0946]\\ &M_{12} = [-0.0310\; -0.0824] \end{aligned} \end{equation*} $$ Lyapunov矩阵
$$ \begin{equation*} \begin{aligned} R_1^{-1} = &\left[ {\begin{array}{*{20}{c}} 78.6785 & 32.2596\\ 32.2596 & 136.6087\\ \end{array}} \right]\\ R_2^{-1} = &\left[ {\begin{array}{*{20}{c}} 109.1470 & 9.0616\\ 9.0616 & 126.8886\\ \end{array}} \right] \end{aligned} \end{equation*} $$ 非正参数$ \tilde{\mu}_{12} = -5.4996, \tilde{\mu}_{21} = -262.0396 $, 最小无扰切换性能水平$ \alpha_4 = 5.4768 $.
4) 同时考虑状态跟踪性能和文献[17]中的无扰切换性能
此时, 保证无扰切换性能的条件为定理1中的式(10)和(11)以及
$$ \begin{equation} (M_{1i}-M_{1}^*)^T(M_{1i}-M_{1}^*) \leq \alpha_5 I \end{equation} $$ (45) 其中, $ \alpha_5 $为无扰切换性能水平.
与情形3)选择相同的$ M_{1}^* $, 通过求解得到控制器增益矩阵
$$ \begin{align*} &M_{11} = [-0.0396\; -0.0946]\\ &M_{12} = [-0.0310\; -0.0824] \end{align*} $$ Lyapunov矩阵
$$ \begin{equation*} \begin{aligned} R_1^{-1} = &\left[ {\begin{array}{*{20}{c}} 92.1229 & 60.6710\\ 60.6710 & 201.1888\\ \end{array}} \right]\\ R_2^{-1} = &\left[ {\begin{array}{*{20}{c}} 111.0222 & 10.4278\\ 10.4278 & 131.8623\\ \end{array}} \right] \end{aligned} \end{equation*} $$ 最小无扰切换性能水平$ \alpha_5 = 5.7335 $.
以上4种情形下的系统响应曲线如图 5~8所示.为便于区分, 情形1)中的得到的响应曲线没有额外标记, 情形2)中得到的响应曲线用角标$ b $进行区分, 情形3)中得到的响应曲线用角标$ 1 $进行区分, 情形4)中得到的响应曲线用角标$ 2 $进行区分.
图 5表示不同情形下的切换信号. 图 6表示不同情形下的燃油流量变化情况. 图 7和8反映了转速跟踪情况, 其中, 图 7为风扇转速跟踪误差, 图 8为核心机转速跟踪误差.
由图 5可知, 情形2)中的切换信号$ \sigma_b(t) $发生切换的次数最为频繁, 情形1)中的切换信号$ \sigma(t) $与情形4)中的切换信号$ \sigma_2(t) $比情形3)中的切换信号$ \sigma_3(t) $具有更少的切换频率.从图 6可以观察到, 在4.4 s$ \sim $4.8 s的时间段内, 情形2)中得到的燃油流量变化$ \Delta{Q}_{fb}(t) $还有明显的抖振, 在0.9 s$ \sim $0.96 s的时间段内, 情形1)中的燃油流量变化$ \Delta{Q}_f(t) $比情形2)$ \sim $4)中的燃油流量变化$ \Delta{Q}_{fb}(t) $, $ \Delta{Q}_{f1}(t) $与$ \Delta{Q}_{f2}(t) $的抖振更小.通过图形7与8可知, 第一种情形下得到的状态跟踪误差具有更小的幅值和更快的收敛速度.
仿真结果表明本文所提出的无扰切换控制策略优于文献[17]和[20]中的无扰切换控制策略.因此, 可以说明所提出的状态跟踪无扰切换控制方法是有效的, 可以进一步考虑应用于真实的涡扇航空发动机上以指导其控制设计.
4. 结论
本文针对一类切换线性系统利用多Lyapunov函数方法研究了状态跟踪无扰切换控制问题.从无扰切换的本旨出发, 给出了一个无扰切换性能的描述.通过切换律和控制器的双重设计, 建立了一个实现状态跟踪与切换时刻控制信号抖振抑制目标的充分条件.通过将所提出的状态跟踪无扰切换控制方法应用于涡扇航空发动机模型上实现了该发动机模型的转速调节, 验证了所提出状态跟踪无扰切换控制方法的有效性和合理性.此外, 本文考虑的跟踪性质为状态跟踪, 未来可以考虑输出跟踪无扰切换控制问题.
-

图 3 参考图像(a)及其不同类型退化图像(b)~(f) (右下角为矩形区域局部放大图)
Fig. 3 Reference image (a) and different types of distorted images (b)~(f)
(The lower right corner is a enlarged view of the rectangular region)
评价方法 图3(b) 图3(c) 图3(d) 图3(e) 图3(f) MOS 5.0000 3.8387 4.1875 4.7667 6.2903 PSNR 30.5304 30.5784 26.1303 27.4808 27.3498 VSNR 29.7301 21.1480 20.5342 30.7072 20.2681 IFC 4.7389 3.4351 4.9319 2.9956 11.3746 SSIM 0.9250 0.8461 0.9459 0.9475 0.9568 MS-SSIM 0.9606 0.9159 0.9738 0.9727 0.9821 IW-SSIM 0.9684 0.9075 0.9645 0.9704 0.9661 GSIM 0.9958 0.9888 0.9953 0.9966 0.9979 FSIM 0.9831 0.9462 0.9538 0.9699 0.9707 GLV-SIM 0.9959 0.9845 0.9927 0.9957 0.9961  下载: 导出CSV
下载: 导出CSV
下载: 导出CSV
下载: 导出CSV
表 3 不同IQA算法在TID2013和TID2008数据库的实验结果比较
Table 3 Comparison the performance results of different IQA algorithms on TID2013 and TID2008 databases
数据库 性能指标 PSNR VSNR IFC SSIM MS-SSIM IW-SSIM GSIM FSIM GLV-SIM TID 2013 SROCC 0.6396 0.6812 0.5389 0.7417 0.7859 0.7779 0.7946 0.8015 0.8068 KROCC 0.4698 0.5084 0.3939 0.5588 0.6047 0.5977 0.6255 0.6289 0.6381 PLCC 0.7017 0.7402 0.5538 0.7895 0.8329 0.8319 0.8464 0.8589 0.8580 RMSE 0.8832 0.8392 1.0322 0.7608 0.6861 0.6880 0.6603 0.6349 0.6368 TID 2008 SROCC 0.5531 0.7046 0.5675 0.7749 0.8542 0.8559 0.8504 0.8805 0.8814 KROCC 0.4027 0.5340 0.4236 0.5768 0.6568 0.6636 0.6596 0.6946 0.6956 PLCC 0.5734 0.6820 0.7340 0.7732 0.8451 0.8579 0.8422 0.8738 0.8648 RMSE 1.0994 0.9815 0.9113 0.8511 0.7173 0.6895 0.7235 0.6525 0.6739
下载: 导出CSV
表 4 不同IQA算法在CSIQ和LIVE数据库的实验结果比较
Table 4 Comparison the performance results of different IQA algorithms on CSIQ and LIVE databases
数据库 性能指标 PSNR VSNR IFC SSIM MS-SSIM IW-SSIM GSIM FSIM GLV-SIM CSIQ SROCC 0.8058 0.8106 0.7671 0.8756 0.9133 0.9213 0.9108 0.9242 0.9264 KROCC 0.6084 0.6247 0.5897 0.6907 0.7393 0.7529 0.7374 0.7567 0.7605 PLCC 0.8000 0.8002 0.8384 0.8613 0.8991 0.9144 0.8964 0.9120 0.9082 RMSE 0.1575 0.1575 0.1431 0.1334 0.1149 0.1063 0.1164 0.1007 0.1099 LIVE SROCC 0.8756 0.9274 0.9259 0.9479 0.9513 0.9567 0.9561 0.9634 0.9521 KROCC 0.6865 0.7616 0.7579 0.7963 0.8045 0.8175 0.8150 0.8337 0.8179 PLCC 0.8723 0.9231 0.9268 0.9449 0.9489 0.9522 0.9512 0.9597 0.9368 RMSE 13.359 10.505 10.264 8.9445 8.6188 8.3473 8.4327 7.6780 8.0864
下载: 导出CSV
表 5 不同IQA算法在TID2008数据库单一失真评价性能(SROCC)比较
Table 5 Comparison SROCC for individual distortion of different IQA algorithms on TID2008 database
数据库 失真类型 PSNR VSNR IFC SSIM MS-SSIM IW-SSIM GSIM FSIM GLV-SIM TID 2008 AWN 0.9073 0.7728 0.5806 0.8107 0.8094 0.7869 0.8573 0.8566 0.9125 ANMC 0.8994 0.7793 0.5460 0.8029 0.8064 0.7920 0.8095 0.8527 0.8979 SCN 0.9175 0.7665 0.5958 0.8144 0.8195 0.7714 0.8902 0.8483 0.9167 MN 0.8520 0.7295 0.6732 0.7795 0.8156 0.8087 0.7403 0.8021 0.8087 HFN 0.9273 0.8811 0.7318 0.8729 0.8685 0.8662 0.8932 0.9093 0.9175 IMN 0.8725 0.6470 0.5345 0.6732 0.6868 0.6465 0.7721 0.7452 0.7864 QN 0.8702 0.8271 0.5857 0.8531 0.8537 0.8177 0.8750 0.8564 0.8865 GB 0.8704 0.9330 0.8559 0.9544 0.9607 0.9636 0.9585 0.9472 0.9587 DEN 0.9422 0.9286 0.7973 0.9530 0.9571 0.9473 0.9723 0.9603 0.9666 JPEG 0.8723 0.9174 0.8180 0.9252 0.9348 0.9184 0.9391 0.9279 0.9534 JP2K 0.8131 0.9515 0.9437 0.9625 0.9736 0.9738 0.9755 0.9773 0.9751 JGTE 0.7525 0.8056 0.7909 0.8678 0.8736 0.8588 0.8832 0.8708 0.8793 J2TE 0.8312 0.7909 0.7301 0.8577 0.8522 0.8203 0.8925 0.8544 0.9021 NEPN 0.5812 0.5716 0.8418 0.7107 0.7336 0.7724 0.7372 0.7491 0.7271 BLOCK 0.6194 0.1926 0.6770 0.8462 0.7617 0.7623 0.8865 0.8492 0.8960 MS 0.6966 0.3715 0.4250 0.7231 0.7374 0.7067 0.7174 0.6698 0.6994 CTC 0.5867 0.4239 0.2713 0.5246 0.6398 0.6301 0.6736 0.6481 0.6689
下载: 导出CSV
-
[1] Mohammadi P, Ebrahimi-Moghadam A, Shirani S. Subjective and objective quality assessment of image: a survey. Majlesi Journal of Electrical Engineering, 2015, 9(1): 419−423 [2] Yang X C, Sun Q S, Wang T S. Image quality assessment improvement via local gray-scale fluctuation measurement. Multimedia Tools and Applications, 2018, 77(18): 24185−24202 doi: 10.1007/s11042-018-5740-z [3] 高敏娟, 党宏社, 魏立力, 张选德. 基于非局部梯度的图像质量评价算法. 电子与信息学报, 2019, 41(5): 1122−1129 doi: 10.11999/JEIT180597Gao Min-Juan, Dang Hong-She, Wei Li-Li, Zhang Xuan-De. Image quality assessment algorithm based on non-local gradient. Journal of Electronics and Information Technology, 2019, 41(5): 1122−1129 doi: 10.11999/JEIT180597 [4] 许丽娜, 肖奇, 何鲁晓. 考虑人类视觉特征的融合图像评价方法. 武汉大学学报(信息科学版), 2019, 44(4): 546−554Xu Li-Na, Xiao Qi, He Lu-Xiao. Fused image quality asssessment based on human visual characterisyics. Geomatics and Information Science of Wuhan University, 2019, 44(4): 546−554 [5] 曹清洁, 史再峰, 张嘉平, 李杭原, 高静, 姚素英. 分区域多标准的全参考图像质量评价算法. 天津大学学报(自然科学与工程技术版), 2019, 52(6): 625−630Cao Qing-Jie, Shi Zai-Feng, Zhang Jia-Ping, Li Hang-Yuan, Gao Jing, Yao Su-Ying. Sub-regional and multiple criteria full-reference image quality assessment. Journal of Tianjin University (Science and Technology), 2019, 52(6): 625−630 [6] Wang Z, Bovik A C. Mean squared error: love it or leave it? A new look at signal fidelity measures. IEEE Signal Processing Magazine, 2009, 26(1): 98−117 doi: 10.1109/MSP.2008.930649 [7] Huynh-Thu Q, Ghanbari M. Scope of validity of PSNR in image/video quality assessment. Electronics Letters, 2008, 44(13): 800−801 doi: 10.1049/el:20080522 [8] Wang Z, Bovik A C, Sheikh H R, Simoncelli E P. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on image processing, 2004, 13(4): 600−612 doi: 10.1109/TIP.2003.819861 [9] Wang Z, Simoncelli E P, Bovik A C. Multiscale structural similarity for image quality assessment. In: Proceedings of the 37th IEEE Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, USA, 2003. 1398−1402 [10] Wang Z, Li Q. Information content weighting for perceptual image quality assessment. IEEE Transactions on Image Processing, 2011, 20(5): 1185−1198 doi: 10.1109/TIP.2010.2092435 [11] Li C F, Bovik A C. Three-component weighted structural similarity index. In: Proceedings of the 2009 SPIE Conference on Image Quality and System Performance, San Jose, California, USA, 2009. 7242: 72420Q−72420Q-9 [12] 刘大瑾, 叶建兵, 刘家骏. SSIM框架下基于SVD的灰度图像质量评价算法研究. 南京师大学报(自然科学版), 2017, 40(1): 73−78Liu Da-Jin, Ye Jian-Bing, Liu Jia-Jun. SVD-based gray-scale image quality assessmentalgorithms in the SSIM perspective. Journal of Nanjing Normal University (Natural Science Edition), 2017, 40(1): 73−78 [13] 闫乐乐, 李辉, 邱聚能, 梁平. 基于区域对比度和SSIM的图像质量评价方法. 应用光学, 2015, 36(1): 58−63 doi: 10.5768/JAO201536.0102002Yan Le-Le, Li Hui, Qiu Ju-Neng, Liang Ping. Image qualty assessment method based on regional contrast and structural similarity. Journal of Applied Optics, 2015, 36(1): 58−63 doi: 10.5768/JAO201536.0102002 [14] Jin X, Jiang G Y, Chen F, Yu M, Shao F, Peng Z J, et al. Adaptive image quality assessment method based on structural similarity. Journal of Optoelectronics. Laser, 2014, 25(2): 378−385 [15] 田浩南, 李素梅. 基于边缘的SSIM图像质量客观评价方法. 光子学报, 2013, 42(1): 110−114 doi: 10.3788/gzxb20134201.0110Tian Hao-Nan, Li Su-Mei. Objective evaluation method for image quality based on edge structural similarity. Acta Photonica Sinca, 2013, 42(1): 110−114 doi: 10.3788/gzxb20134201.0110 [16] Zhang L, Zhang L, Mou X Q, Zhang D. FSIM: a feature similarity index for image quality assessment. IEEE Transactions on Image Processing, 2011, 20(8): 2378−2386 doi: 10.1109/TIP.2011.2109730 [17] Liu A M, Lin W S, Narwaria M. Image quality assessment based on gradient similarity. IEEE Transactions on Image Processing, 2012, 21(4): 1500−1512 doi: 10.1109/TIP.2011.2175935 [18] Zhang X D, Feng X C, Wang W W, Xue W F. Edge strength similarity for image quality assessment. IEEE Signal Processing Letters, 2013, 20(4): 319−322 doi: 10.1109/LSP.2013.2244081 [19] Sun W, Liao Q M, Xue J H, Zhou F. SPSIM: a superpixel-based similarity index for full-reference image quality assessment. IEEE Transactions on Image Processing, 2018, 27(9): 4232−4244 doi: 10.1109/TIP.2018.2837341 [20] Ding L, Huang H, Zang Y. Image quality assessment using directional anisotropy structure measurement. IEEE Transactions on Image Processing, 2017, 26(4): 1799−1809 doi: 10.1109/TIP.2017.2665972 [21] Xue W F, Zhang L, Mou X Q, Bovik A C. Gradient magnitude similarity deviation: a highly efficient perceptual image quality index. IEEE Transactions on Image Processing, 2014, 23(2): 684−695 doi: 10.1109/TIP.2013.2293423 [22] Pei S C, Chen L H. Image quality assessment using human visual DOG model fused with random forest. IEEE Transactions on Image Processing, 2015, 24(11): 3282−3292 doi: 10.1109/TIP.2015.2440172 [23] Reisenhofer R, Bosse S, Kutyniok G, Wiegand T. A haar wavelet-based perceptual similarity index for image quality assessment. Signal Processing: Image Communication, 2018, 61: 33−43 doi: 10.1016/j.image.2017.11.001 [24] 薛定宇. 分数阶微积分学与分数阶控制. 北京: 科学出版社, 2018. 31−72Xue Ding-Yu. Fractional Calculus and Fractional-order Control. Beijing: Publishing House of Science, 2018. 31−72 [25] 张桂梅, 孙晓旭, 刘建新, 储珺. 基于分数阶微分的TV-L1光流模型的图像配准方法研究. 自动化学报, 2017, 43(12): 2213−2224Zhang Gui-Mei, Sun Xiao-Xu, Liu Jian-Xin, Chun Jun. Research on TV-L1 optical flow model for image registration based on fractional-order differentiation. Acta Automatica Sinica, 2017, 43(12): 2213−2224 [26] 陈云, 郭宝裕, 马祥园. 基于分数阶微积分正则化的图像处理. 计算数学, 2017, (39): 393−406Chen Yun, Guo Bao-Yu, Ma Xiang-Yuan. Image processing based on regularization with fractional clculus. Mathematica Numerica Sinica, 2017, (39): 393−406 [27] Ponomarenko N, Jin L, Ieremeiev O, Lukin V, Egiazarian K, Astola J, et al. Image database TID2013: peculiarities, results and perspectives. Image Communication, 2015, 30(C): 57−77 [28] Ponomarenko N, Lukin V, Zelensky A, Egiazarian K, Astola J, Carli M, et al. TID2008: a database for evaluation of full-reference visual quality assessment metrics [Online], available: http://www.ponomarenko.info/papers/mre, November 1, 2016 [29] Larson E C, Chandler D. Categorical subjective image quality (CSIQ) database [Online], available: http://vision.okstate.edu/csiq, November 1, 2016 [30] Sheikh H R, Wang Z, Bovik A C. Image and video quality assessment research at LIVE. [Online], available: http://live.ece.utexas.edu/rese-arch/quality/, November 1, 2016 [31] Chandler D M, Hemami S S. VSNR: a wavelet-based visual signal-to-noise ratio for natural images. IEEE Transactions on Image Processing, 2007, 16(9): 2284−2298 doi: 10.1109/TIP.2007.901820 [32] Sheikh H R, Bovik A C, Veciana G D. An information fidelity criterion for image quality assessment using natural scene statistics. IEEE Transactions on Image Processing, 2005, 14(12): 2117−2128 doi: 10.1109/TIP.2005.859389 -

 下载:
下载:





计量
- 文章访问数: 4659
- HTML全文浏览量: 2025
- PDF下载量: 316
- 被引次数: 0
