

A New Nonlinear Adaptive Switching Control Method Based on Data Driven
-
摘要: 针对一类非线性离散时间动态系统, 提出了一种新的非线性自适应切换控制方法. 该方法首先把非线性项分解为前一拍可测部分与未知增量和的形式, 并充分利用被控对象的大数据信息和知识, 把非线性项前一拍可测数据与未知增量都用于控制器设计, 分别设计了线性自适应控制器, 带有非线性项前一拍可测数据补偿的非线性自适应控制器以及带有非线性项未知增量估计与补偿的非线性自适应控制器. 三个自适应控制器通过切换函数和切换规则来协调控制被控对象. 既保证了闭环系统的稳定性, 同时又提高了闭环系统的性能. 分析了闭环切换系统的稳定性和收敛性. 最后, 通过水箱液位系统的物理实验, 实验结果验证了所提算法的有效性.Abstract: In this paper, a new nonlinear adaptive switching control method is proposed for a class of nonlinear discrete time dynamical systems. The proposed method firstly decomposes the nonlinear term into the form of the measurable part at the previous sampling instant plus its unknown increment part, and makes full use of the big data information and knowledge of the controlled plant, both the measurable part and the unknown increment of the nonlinear term are used in the controller design, the linear adaptive controller, nonlinear adaptive controller with nonlinear term measurable data compensation and nonlinear adaptive controller with nonlinear unknown increment estimation are designed respectively. Three adaptive controllers are used to the controlled plant coordinately through switching functions and switching rules, which not only ensures the stability of the closed-loop system but also improves the performance of the closed-loop system. The stability and convergence of the closed-loop switching system are analyzed. Finally, through the physical experiment of the level control system of the tank, the experimental results verify the effectiveness of the proposed algorithm.
-
Key words:
- Data driven /
- nonlinear systems /
- adaptive control /
- switching system
-
基因突变是由DNA分子中碱基对发生增添、缺失或替换而引起的基因结构变化. 基因突变具有随机性, 是一种可遗传的变异现象. 致病基因突变通过阻止一种或多种蛋白质正常工作扰乱正常发育过程或导致疾病. 癌症是由控制细胞功能的基因突变引起的一系列相关疾病的统称. 导致癌症的基因突变可能遗传自父母, 也可能是人体自身受致癌环境或致癌物质刺激导致细胞分裂时产生的错误. 一般来说, 癌细胞比正常细胞有更多的基因突变. 乳腺癌是世界上最常见的疾病之一, 2018年新增乳腺癌患者约20亿人[1]. 医学领域的多项研究表明, BRCA1、BRCA2和PALB2基因的突变会导致乳腺癌风险增加, 其他与乳腺癌患病风险相关的基因突变包括ATM、TP53、PTEN等. 因此, 从乳腺癌组学数据中挖掘出与其密切相关的致病基因对乳腺癌的临床诊断、预后和治疗有着深远意义.
在生物信息学中, 癌症致病基因预测通过基因排序方法实现. 基于网络相似度的基因排序算法通过分析多种基因−疾病网络中的局部、全局信息, 计算基因与疾病之间的相似性, 从而对基因进行排序. 例如, Kohler等[2]提出重启随机游走算法利用网络全局拓扑信息对致病基因进行预测; Xu等[3]提出多路径随机游走的网络嵌入模型对异构网络进行致病基因预测. 这些方法过度依赖网络拓扑信息, 不能对网络外的基因进行预测, 且对癌症数据中的噪声比较敏感. 随着机器学习理论的发展, 基于机器学习的基因排序方法利用监督学习或非监督学习方式实现基因预测, 能够挖掘到与癌症相关的致病基因, 被广泛应用于癌症致病基因的预测. 例如Han等[4]将图卷积网络和矩阵分解结合提出一种疾病基因关联任务框架; Natarajan等[5]将推荐系统中的归纳矩阵补全用于预测基因与疾病的相关性.
在乳腺癌致病基因预测方面, 自然启发式算法应用较广, 例如粒子群优化 (Particle swarm optimization, PSO)、遗传算法等. Sahu等[6]提出一种基于PSO的基因选择算法, 首先采用
$ k $ 均值聚类方法对数据集进行聚类, 利用信噪比评分对聚类簇中的基因进行排序, 然后从每个聚类簇中收集得分最高的基因生成新的特征子集, 最后将新特征子集作为PSO的输入, 生成优化后的特征子集. Malar等[7]通过将关联特征选择方法和改进的二进制PSO结合选择致病基因, 同时解决了微阵列数据的高维性问题. 为了消除对乳腺癌无意义的基因, AliazKovic等[8]将遗传算法用于提取乳腺癌数据中的重要信息, 挖掘与乳腺癌生物过程相关的致病基因. Sangaiah等[9]将特征加权和基于熵的遗传算法结合起来, 提出一种乳腺癌致病基因预测的混合方法. Alzubaidi等[10]将遗传算法与互信息结合应用于乳腺癌致病基因选择. 通过遗传算法将基于互信息的基因选择算法转化为全局优化算法, 能够有效选择基因. 避免算法陷入局部最优. Alomari等[11]结合最小冗余、最大关联算法和花授粉算法来确定包含更多癌症信息的基因子集. Hamim等[12]提出一种基于决策树模型的乳腺癌致病基因选择策略, 该策略包括两个阶段: 基于Fisher评分的过滤阶段和基于C5.0算法的基因选择阶段. Liu等[13]为了提高基因选择效率, 将基因评分与深度神经网络产生的基因重要性相结合, 同时考虑癌症亚型间的差异性和亚型内基因间的相关性来选择乳腺癌三阴性亚型的最优致病基因子集. Zhao等[14]基于信息熵的不确定性系数被用来定义基因间是否存在逻辑关系, 进而构建基因逻辑网络, 最终通过比较对照组与实验组网络之间的差异程度, 提取乳腺癌致病基因.上述预测方法都是基于已有癌症组学数据进行基因预测, 这些组学数据来源于对癌症患者的测序. 换言之, 这些方法仅能根据目前已发病患者的基因突变状态来分析基因与癌症之间的关联, 无法预知患者发病前的基因突变状态, 而发病前的基因突变状态与发病基因突变状态之间的差异才是癌症发生的关键.
强化学习[15]是一类结合了优化控制思想和生命体学习行为的机器学习方法, 其要求待处理的问题环境拥有马尔可夫性质, 即当前状态仅受上一状态的影响, 与其余状态无关. 强化学习希望智能体在指定的状态能够得到让回报最大化的动作, 并通过智能体与环境的交互进行学习, 从而改变特定状态选择某个动作的趋势. 强化学习还是一种拥有自主决策能力的算法, 它使智能体通过在环境中的不断试错得到回报值和下一时刻状态的观测值, 最终学习到一个能够获取较大折扣累积回报的策略. 强化学习已被成功应用于多个研究领域, 例如, 数据驱动控制[16]、多机协同决策[17]、交通控制[18]等.
本文通过分析基因突变, 发现其过程满足马尔可夫过程, 且基因突变与癌症之间的关联性可以通过强化学习中累计回报函数构建的方式进行计算. 因此, 基于乳腺癌突变数据, 本文设计一套强化学习环境与算法对患者从正常基因突变状态至死亡基因突变状态的过程进行评估、决策, 旨在为癌症致病基因预测提供新思路, 并挖掘出导致乳腺癌死亡状态的致病基因. 实验结果表明, 提出的强化学习算法能够挖掘出与乳腺癌密切相关的致病基因.
1. 问题描述
由于基因突变并非确定性事件, 在非人为干涉的前提下, 基因突变可视为一个随机过程. 设任意
$ t $ 时刻基因突变状态(后文简称状态)为$ {{\boldsymbol{s}}_t} $ , 下一时刻状态为$ {{\boldsymbol{s}}_{t+1}} $ , 则在$ t+1 $ 时刻状态发生的变化只与$ t $ 时刻的状态有关, 与之前$ 0 \sim t-1 $ 的状态并无关联, 即$$ \begin{equation} P\left( {{{\boldsymbol{s}}_{t + 1}}\left| {{{\boldsymbol{s}}_0},{{\boldsymbol{s}}_1}, \cdots ,{{\boldsymbol{s}}_t}} \right.} \right) = P\left( {{{\boldsymbol{s}}_t}} \right) \end{equation} $$ (1) 其中,
$ P\left( \cdot \right) $ 为概率. 基于上述考虑, 可以认为基因突变对应的随机过程为马尔可夫过程.本文根据乳腺癌患者生存数据中患者的临床信息来定义死亡状态和非死亡状态. 患者生存数据兼有时间和结局两种属性信息. 时间描述的是患者由观察起点至观察终点的时间间隔, 通常称为生存时间. 患者生存数据的结局即为观察终点, 观察终点分为死亡和存活两种, 在生存数据中记为1和0. 在本文中, 如果某患者的观察终点为死亡, 则将该患者在乳腺癌数据中的基因突变状态定义为死亡状态. 值得注意的是, 具有相同基因突变状态的患者, 观察终点并不一定相同, 因此通过定义死亡率来更加精细地对数据进行描述. 若基因突变状态使所有癌症患者死亡, 则该状态的死亡率为100%; 若基因突变状态有一定概率导致患者死亡, 例如100个患者有相同的状态, 其中有10个患者死亡, 则死亡率为10%. 这里将有概率死亡的基因突变状态统称为死亡状态. 设一个基因与
$ t $ 时刻状态$ {{\boldsymbol{s}}_t} $ 之间的关联性为$ r\left( {{{\boldsymbol{s}}_t}} \right) $ , 已有基因排序算法更关注对历史病例数据的数理统计, 通过计算$ r\left( {{{\boldsymbol{s}}_t}} \right) $ 的大小来评价某个基因突变与癌症患者之间的联系强弱. 然而这类方法没有充分考虑患者的死亡状态, 且忽视了癌症的发生过程, 比如死亡状态$ {\boldsymbol{s}}_\alpha $ 虽然死亡率不高, 且$ r\left( {{{\boldsymbol{s}}_t}} \right) $ 值较小, 但可能在一定时期内突变成死亡率很高的其他状态, 这类状态$ {\boldsymbol{s}}_\alpha $ 中的基因与癌症患者死亡之间的应该有很强的关联性. 因此, 对基因与癌症患者之间关联的评估不应只关注状态$ {{\boldsymbol{s}}_t} $ 中基因与癌症关联性, 更应从一个正常状态经历漫长基因突变过程至死亡状态的角度, 评估突变基因与某个死亡状态的关联性, 即$ \sum\nolimits_i {r\left( {{{\boldsymbol{s}}_i}} \right)} $ .乳腺癌突变数据中, 每个患者的所有基因突变状态是一个样本, 每个基因在所有患者上的突变状况是一个特征, 如图1所示. 患者的某个基因发生突变, 则记为1 (图1中黑色格子), 不发生突变则记为0 (图1中非黑色格子). 本文构建强化学习环境如下: 将基因作为智能体 (Agent),
$ t $ 时刻基因突变状况作为状态$ {{\boldsymbol{s}}_t} $ , 基因突变作为动作$ {{\boldsymbol{a}}_t} $ , 根据死亡状态的死亡率设计回报函数$ r\left( {{{\boldsymbol{s}}_t}} \right) $ , 当智能体达到死亡状态时获得最优策略, 停止与环境交互, 给予高回报值. 基因突变数据中的基因数目成百上千, 在一个状态中, 使用单智能体进行强化学习时, 状态−动作空间复杂度极高, 需要大量计算成本. 为此, 考虑利用多智能体深度Q网络 (Deep Q network, DQN)[19]对乳腺癌突变数据进行强化学习. 一方面, 相比于Q学习方法, DQN通过训练更新值函数神经网络的参数, 减小状态高维度对算法训练效果的影响; 另一方面, 使用多智能体进行强化学习, 可降低动作空间复杂度, 大大减少强化学习的计算量.多智能体DQN使得学习任务的复杂度减小, 但多智能体的动作维度并没有下降, 智能体探索到最优策略的概率很低. 由于所有死亡状态均来自乳腺癌突变数据, 可将死亡状态作为专家意见指导强化学习过程, 根据演示学习理论, 提出两种多智能体DQN: 基于行为克隆的多智能体DQN (Behavioral cloning-based multi-agent DQN, BCDQN)和基于预训练记忆的多智能体DQN (Pre-training memory-based multi-agent DQN, PMDQN). 设置探索经验池
$ {B_1} $ 和演示经验池$ {B_2} $ 两个经验池 , 更好地实现演示学习. 当智能体数量较少时, BCDQN使智能体在每一步探索时都给出专家意见, 保证$ {B_1} $ 和$ {B_2} $ 在状态上同分布, 实现探索策略对专家策略的完全克隆; 当智能体数量较大时, PMDQN通过预训练将一定数量的专家经验保存在$ {B_2} $ 中, 再使智能体随机探索填充$ {B_1} $ , 并通过训练最终实现$ {B_1} $ 和$ {B_2} $ 同分布, 这能够使$ {B_2} $ 中样本之间的相关性下降, 从而加快算法的学习.2. 环境设计
设基因数为
$ N $ , 构建一个状态、动作维度都为$ N $ 的状态−动作空间, 则状态空间$ S $ 中任一状态$ {{\boldsymbol{s}}_t} = \left[ {s_t^1,s_t^2, \cdots ,s_t^N} \right] $ 为$ N $ 维二进制向量, 其中$s_t^k( k = $ $ 1,2, \cdots ,N )$ 的取值满足: 基因在$ s_t^k $ 上发生突变则$ s_t^k = 1 $ , 不发生突变则$ s_t^k = 0 $ . 动作空间$ A $ 中动作$ {{\boldsymbol{a}}_t} = \left[ {a_t^1,a_t^2, \cdots ,a_t^N} \right] $ 为$ N $ 维二进制向量, 其中$a_t^k( k = $ $ 1,2, \cdots ,N )$ 满足: 基因在$ s_t^k $ 下一状态发生突变则调整$ a_t^k = 1 $ , 不发生突变则保持$ a_t^k = 0 $ . 状态间的状态转移$ {{\boldsymbol{s}}_{t+1}} $ 满足$$ {{\boldsymbol{s}}_{t + 1}} = {{\boldsymbol{s}}_t} \oplus {{\boldsymbol{a}}_t} = \left[ {s_t^k \oplus a_t^k, \cdots ,s_t^k \oplus a_t^k} \right] $$ (2) 其中,
$ \oplus $ 为异或运算. 定义汉明距离$ D $ 为:$$ D\left( {{{\boldsymbol{s}}_t},{{\boldsymbol{s}}_{t + 1}}} \right) = \sum\limits_{i = 1}^N {s_t^k \oplus s_{t + 1}^k} = {\left\| {{{\boldsymbol{a}}_t}} \right\|_1} $$ (3) 回报函数
$ r\left( {{{\boldsymbol{s}}_t}} \right) $ 定义为:$$ r\left( {{{\boldsymbol{s}}_t}} \right) = \left\{ \begin{aligned} &- 1 - \eta D\left( {{{\boldsymbol{s}}_t},{{\boldsymbol{s}}_{t + 1}}} \right),\; {\rm{Alive}}\\ &- \eta D\left( {{{\boldsymbol{s}}_t},{{\boldsymbol{s}}_{t + 1}}} \right),\qquad {\rm{Dead}} \end{aligned} \right. $$ (4) 式中, 设死亡状态(Dead)的死亡率为
$ P_d $ , 即若状态对应的死亡率不为0, 则智能体在该状态有$ P_d $ 的概率死亡. 若智能体触发死亡事件, 则停止智能体与环境的交互. 智能体在环境中探索时, 智能体如果存活则给予智能体负的回报, 智能体在环境中存活的时间越长, 对应的累积回报$ \sum\nolimits_{i = t}^\infty {{\gamma ^{i - t}}r\left( {{{\boldsymbol{s}}_i}} \right)} $ 就越低, 其中,$ \gamma \left( {0 < \gamma < 1} \right) $ 为折扣因子. 式(4)中的$ D $ 则限制了状态的变化幅度, 以避免违背基因突变的客观规律, 即智能体要想获得更高的回报则必须要用较小动作幅度触发死亡事件. 由于$ D $ 值在$ N $ 足够大情况下会远大于1, 由霍夫丁不等式可知, 随机变量总和与其期望值之间的偏差上限与随机变量取值区间大小正相关. 因此, 使用常数$ \eta \left( {0 < \eta < 1} \right) $ 限制回报变化幅度, 降低学习任务的复杂度.3. 基于多智能体强化学习的乳腺癌致病基因预测
强化学习目标是找到最优策略
$ {\pi ^*} = P\left( {{{\boldsymbol{a}}_t}\left| {{{\boldsymbol{s}}_t}} \right.} \right) $ , 即最大化期望折扣回报$$ \begin{equation} {\rm{E}}\left[ {\sum\limits_{i\; =\; t}^\infty {{\gamma ^{i - t}}} r\left( {{{\boldsymbol{s}}_i}} \right)} \right] \end{equation} $$ (5) 常用的强化学习算法为异步策略的Q学习方法[6]. 对于当前的学习问题, Q学习方法的迭代公式为
$$ \begin{split} &Q\left( {{{\boldsymbol{s}}_t},{{\boldsymbol{a}}_t}} \right) = Q\left( {{{\boldsymbol{s}}_t},{{\boldsymbol{a}}_t}} \right) + \\ &\qquad\alpha \left( {r\left( {{{\boldsymbol{s}}_t}} \right) + \gamma \mathop {\max }\limits_{\boldsymbol{a}} Q\left( {{{\boldsymbol{s}}_{t + 1}},{\boldsymbol{a}}} \right) - Q\left( {{{\boldsymbol{s}}_t},{{\boldsymbol{a}}_t}} \right)} \right) \end{split} $$ (6) 从式(6)可以看出, Q学习方法要求智能体使用贪心算法进行动作选择, 从而刚性保证算法的收敛. Q学习方法倾向于直接估计状态−动作值矩阵. 在所设计的环境中, 状态、动作都是二进制向量, 所以动作空间复杂度为
$ {2^{N + 1}} $ , 状态空间复杂度为$ {2^N} $ . 如果使用Q学习方法, 则需要估计复杂度为$ {2^{2N + 1}} $ 的值函数矩阵. Q学习方法在$ N $ 很大时, 需要耗费大量时间遍历求解值函数矩阵. 为此, 本文选择使用DQN通过神经网络训练更新值函数的参数, 减小状态维度对算法训练效果的影响. DQN的更新目标为$$ \begin{equation} Y_t^{} = r\left( {{{\boldsymbol{s}}_t}} \right) + \gamma \mathop {\max }\limits_{\boldsymbol{a}} Q\left( {{{\boldsymbol{s}}_{t + 1}},{\boldsymbol{a}}} \right) \end{equation} $$ (7) 相应的损失函数为
$$ \begin{equation} L\left( {{{\boldsymbol{\theta}}^k}} \right) = {\rm{E}}\left[ {{{\left( {Y - Q\left( {{\boldsymbol{s}},{\boldsymbol{a}};{\boldsymbol{\theta}} } \right)} \right)}^2}} \right] \end{equation} $$ (8) 其中,
$ {\boldsymbol{\theta}} $ 为值函数网络参数. DQN采用经验回放技术, 训练值函数网络所用的数据需要从环境交互得到的经验信息中随机采样得到, 以消除训练数据之间的相关性, 从而满足深度学习对训练集数据独立同分布的前提条件. DQN可以高效处理状态−动作空间维度较大的学习问题, 并通过经验回放技术提高经验数据的利用效率.3.1 多智能体DQN
本文实验环境如果使用单智能体深度强化学习算法, 则其状态−动作空间复杂度为
$ {2^{2N + 1}} $ ; 如果使用多智能框架, 则会使$ {2^{N + 1}} $ 的动作空间复杂度变为$ 2N $ , 整体上的状态−动作空间复杂度则变为$ N{2^{N + 1}} $ . 环境所使用的基因数$ N $ 一般很大, 因此$N{2^{N + 1}} \ll {2^{2N + 1}}$ , 多智能体框架可以大幅降低学习问题的复杂程度, 减少了设计单智能体所需的网络参数.多智能体强化学习框架如图2所示. 首先, 将
$ {{\boldsymbol{s}}_t} = \left[ {s_t^1,s_t^2, \cdots ,s_t^N} \right] $ 输入到具有$ N $ 个智能体的值网络中, 根据$ t $ 时刻每个基因的突变状态, 分别输出动作$ a_t^k $ , 并将输出的$ a_t^k $ 组合成$ {\boldsymbol{a}}_t $ , 进而生成新状态$ {\boldsymbol{s}}_{t+1} $ . 之后, 根据乳腺癌突变数据中患者的死亡状态, 判断是否停止与环境交互, 如果不停止, 则将$ {\boldsymbol{s}}_{t+1} $ 输入网络继续上述迭代过程.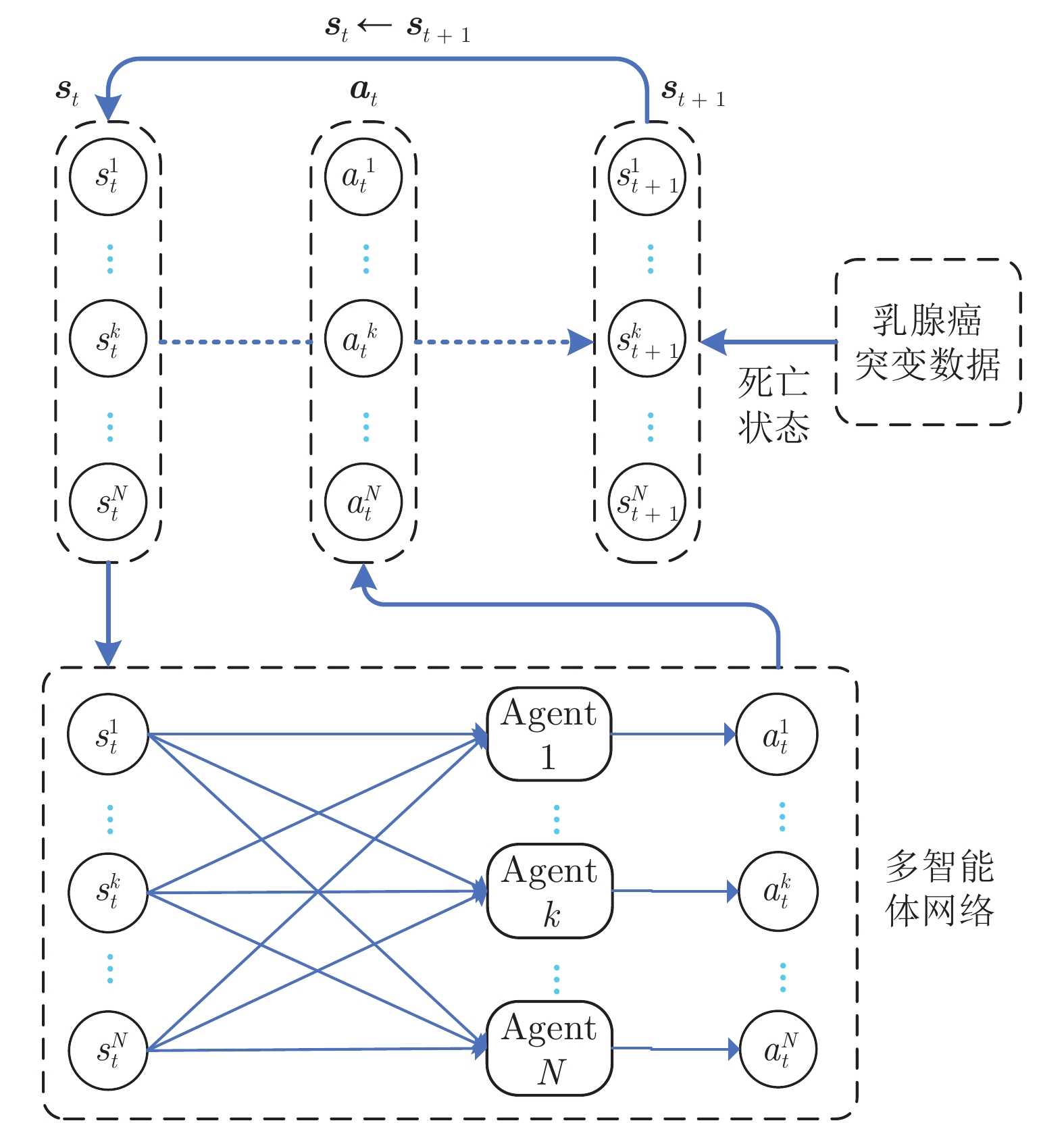 图 2 多智能体强化学习框架(以第k个智能体为例)Fig. 2 Multi-agent reinforcement learning framework (Take the k-th agent as an example)
图 2 多智能体强化学习框架(以第k个智能体为例)Fig. 2 Multi-agent reinforcement learning framework (Take the k-th agent as an example)每个智能体的更新目标为
$$ \begin{equation} Y_t^k = r\left( {{{\boldsymbol{s}}_t}} \right) + \gamma \mathop {\max }\limits_{a_{}^k} {Q^k}\left( {{{\boldsymbol{s}}_{t + 1}},a_{}^k;{{\boldsymbol{\theta}} ^k}} \right) \end{equation} $$ (9) 其中, 第
$ k $ 个智能体的动作$ {a_{}^k} $ 属于各自的动作空间$ {A^k} $ ,$ {{\boldsymbol{\theta}} ^k} $ 则为第$ k $ 个智能体的值函数网络参数. 第$ k $ 个智能体系统的损失函数为$$ \begin{equation} L\left( {{{\boldsymbol{\theta}}^k}} \right) = {\rm{E}}\left[ {\sum\limits_{k \;=\; 1}^N {{{\left( {{Y^k} - {Q^k}\left( {{\boldsymbol{s}},a_{}^k;{{\boldsymbol{\theta}}^k}} \right)} \right)}^2}} } \right] \end{equation} $$ (10) 多智能体DQN的伪代码如算法1所示.
算法1. 多智能体DQN
输入: 最大迭代次数
$ {I_{\max }} $ , 折扣因子$ \gamma $ , 学习率$ \eta $ , 智能体个数$ N $ .输出: 网络参数
$ {{\boldsymbol{\theta}} ^k}\left( {k = 1,2, \cdots ,N} \right) $ .1) 初始化网络参数
${{\boldsymbol{\theta}} ^k}\left( {k = 1,2, \cdots ,N} \right) ;$ 2) While
$I < {I_{\max }};$ 3)
$t = 0;$ 4) 随机初始化状态
$ {\boldsymbol{s}}_t $ ;5) While
$ t \le {t_{\max }} $ or 患者死亡;6) For
$k = 1:N ;$ 7) 计算动作:
$ a_t^k = \arg \mathop {\max }\limits_{{a^k}} {Q^k}\left( {{{\boldsymbol{s}}_t},a_{}^k;{{\boldsymbol{\theta}} ^k}} \right) $ ;8) end For;
9) 环境中应用动作
$ {{\boldsymbol{a}}_t} = \left[ {a_t^1,a_t^2, \cdots ,a_t^N} \right] $ , 并返回回报$ r\left( {{{\boldsymbol{s}}_t}} \right) $ 和下一时刻状态$ {{\boldsymbol{s}}_{t + 1}} $ ;10)
$t \leftarrow t + 1 ;$ 11) end While;
12)
$I \leftarrow I + 1;$ 13) For
$k = 1:N ;$ 14) 随机采样并更新
$ {{\boldsymbol{\theta}} ^k} $ :${{\boldsymbol{\theta}}^k} \leftarrow {{\boldsymbol{\theta}}^k} + \eta {\nabla _{{{\boldsymbol{\theta}} ^k}}}{\rm{E}}\left[ {\sum\limits_{k = 1}^N {{{\left( {{Y^k} - {Q^k}\left( {{\boldsymbol{s}},{\boldsymbol{a}}_{}^k;{{\boldsymbol{\theta}} ^k}} \right)} \right)}^2}} } \right]$ ;15) end For;
16) end While.
3.2 多智能体演示学习
本文环境中的基因数目
$ N $ 很大, 则对应的动作维度也很大, 这使得智能体通过随机探索找到最优路径的概率很低. 单纯使用多智能体框架也无法完全避免难以探索得到最优路径的问题, 这是因为: 多智能体框架可以使得学习任务的复杂度下降, 但动作的维数并没有下降, 因而随机探索得到最优策略的概率还是很低. 考虑到环境中包含的所有死亡状态和状态转移均已知, 本文将死亡状态视为专家意见, 采用演示学习[20]方式加快算法的学习.在计算专家意见对应的回报
$ {r^e}\left( {{{\boldsymbol{s}}_t}} \right) $ 时, 需要考虑死亡概率, 即$$ \begin{equation} \begin{array}{l} {r^e}\left( {{{\boldsymbol{s}}_t}} \right) = {\rm{E}}\left[ {r\left( {{{\boldsymbol{s}}_t}} \right)} \right] = - 1 + {P_d}\left( {{{\boldsymbol{s}}^*}} \right) - \eta D\left( {{{\boldsymbol{s}}_t},{{\boldsymbol{s}}^*}} \right) \end{array} \end{equation} $$ (11) 其中,
$ {\boldsymbol{s}}^* $ 为目标状态,$ {P_d}\left( {{{\boldsymbol{s}}^*}} \right) $ 为目标状态的死亡概率. 每个智能体的更新目标为$$ \begin{equation} Y_t^{e,k} = r_{}^e\left( {{{\boldsymbol{s}}_t}} \right) + \gamma \mathop {\max }\limits_{{a^k}} \left( {Q\left( {{{\boldsymbol{s}}_{t + 1}},{a^k};{{\boldsymbol{\theta}} ^k}} \right)} \right) \end{equation} $$ (12) 如果专家意见对应的回报和环境的期望回报
$ E\left[ {r\left( {{{\boldsymbol{s}}_t}} \right)} \right] $ 不相符, 值估计将不收敛, 这时专家系统给出的动作$ {{\boldsymbol{a}}^*} $ 即为最优动作. 为了更好地实现演示学习, 单独设计一个经验池$ B_2 $ 来保存演示经验. 将随机探索得到的经验池$ B_1 $ 和演示经验池$ B_2 $ 的经验按照$ P_s $ 的概率进行采样, 即用于网络训练的Batch有$ P_s $ 的概率从$ B_1 $ 采样,$ 1-P_s $ 的概率从$ B_2 $ 采样. 基于值的强化学习问题本质上是对值函数的拟合问题, 所以无论是专家经验还是智能体随机探索得到的非最优解经验, 都需要应用于值迭代.3.3 基于行为克隆的多智能体DQN (BCDQN)
启发于行为克隆[21]思想, 在智能体随机探索的同时, 对应每一步都给出相应的专家意见, 专家意见即为最优策略, 以保证
$ B_1 $ 和$ B_2 $ 在状态上同分布. 算法的每一次迭代训练都会拉近$ B_1 $ 和$ B_2 $ 之间对应动作的分布差异, 当算法收敛时,$ B_1 $ 和$ B_2 $ 将完全同分布, 从而实现了智能体探索策略对专家策略的完全克隆. BCDQN的优势是算法会收敛到与专家策略完全相同的策略上.令
$ {L^o} $ 和$ {L^e} $ 分别为智能体探索系统和专家演示系统的损失函数, 则有$$ {L^o}\left( {{{\boldsymbol{\theta}} ^k}} \right) = {{\rm{E}}_{{\boldsymbol{s}}\sim\psi ,{\boldsymbol{a}}\sim\varphi }} \left[ {\sum\limits_{k = 1}^N {{{\left( {{Y^k} - {Q^k}\left( {{\boldsymbol{s}},a_{}^k;{{\boldsymbol{\theta}} ^k}} \right)} \right)}^2}} } \right] $$ (13) $$ \begin{split} &{L^e}\left( {{{\boldsymbol{\theta}} ^k}} \right) = \\ &{{\rm{E}}_{{\boldsymbol{s}}\sim\psi ,{\boldsymbol{a}}\sim\varphi ',\varphi '\sim{\pi ^*}\left( \psi \right)}}\left[ {\sum\limits_{k = 1}^N {{{\left( {Y_{}^{e,k} - {Q^k}\left( {{\boldsymbol{s}},a_{}^k;{{\boldsymbol{\theta}} ^k}} \right)} \right)}^2}} } \right] \end{split} $$ (14) 其中,
$ \psi $ 和$ \varphi $ 分别为探索路径下的状态空间和动作空间. 最终BCDQN的损失函数为$$ \begin{equation} L\left( {{{\boldsymbol{\theta}} ^k}} \right) = {P_s}{L^o}\left( {{{\boldsymbol{\theta}} ^k}} \right) + \left( {1 - {P_s}} \right){L^e}\left( {{{\boldsymbol{\theta}} ^k}} \right) \end{equation} $$ (15) 综上所述, BCDQN的伪代码如下:
算法2. BCDQN算法
输入: 最大迭代次数
$ {I_{\max }} $ , 折扣因子$ \gamma $ , 学习率$ \eta $ , 智能体个数$ N $ , 采样概率$ P_s $ , 初始化探索经验池$ B_1 $ 和演示经验池$ B_2 $ .输出: 网络参数
$ {{\boldsymbol{\theta}} ^k}\left( {k = 1,2, \cdots ,N} \right) $ .1) 初始化网络参数
$ {{\boldsymbol{\theta}} ^k}\left( {k = 1,2, \cdots ,N} \right) $ ;2) While
$I < {I_{\max }} ;$ 3)
$t = 0 ;$ 4) 随机初始化状态
$ {\boldsymbol{s}}_t $ ;5) While
$ t \le {t_{\max }} $ or 患者死亡;6) For
$k = 1:N ;$ 7) 计算动作:
$ a_t^k = \arg \mathop {\max }\limits_{{a^k}} {Q^k}\left( {{{\boldsymbol{s}}_t},a_{}^k;{{\boldsymbol{\theta}} ^k}} \right) $ ;8) 计算专家动作
$ a_t^{*k} $ ;9) end For;
10) 环境中应用动作
$ {{\boldsymbol{a}}_t} = \left[ {a_t^1,a_t^2, \cdots ,a_t^N} \right] $ , 并返回回报$ r\left( {{{\boldsymbol{s}}_t}} \right) $ 和下一时刻状态$ {{\boldsymbol{s}}_{t + 1}} $ , 存入$ B_1 $ ;11) 环境中应用动作
$ {{\boldsymbol{a}}_t^*} = \left[ {a_t^{*1},a_t^{*2}, \cdots ,a_t^{*N}} \right] $ , 并返回回报$ r^e\left( {{{\boldsymbol{s}}_t}} \right) $ 和下一时刻状态$ {{\boldsymbol{s}}_{t + 1}} $ , 存入$ B_2 $ ;12)
$t \leftarrow t + 1;$ 13) end While;
14)
$I \leftarrow I + 1 ;$ 15) For
$k = 1:N ;$ 16) 随机采样并更新
$ {{\boldsymbol{\theta}} ^k} $ :$ {{\boldsymbol{\theta}} ^k} \leftarrow {{\boldsymbol{\theta}} ^k} + \eta {\nabla _{{{\boldsymbol{\theta}} _k}}}\left( {{P_s}{L^o}\left( {{{\boldsymbol{\theta}} ^k}} \right) + \left( {1 - {P_s}} \right){L^e}\left( {{{\boldsymbol{\theta}} ^k}} \right)} \right) $ ;17) end For;
18) end While.
3.4 基于预训练记忆的多智能体DQN (PMDQN)
随着
$ N $ 的增大, BCDQN中$ B_1 $ 和$ B_2 $ 状态上同分布反而会使得智能体难以找到最优路径.$ N $ 越大, 智能体的随机探索得到最优路径的概率就越低, 经验池里经验向量来自同一条路径的概率就越高, 这间接增加了训练样本间的相关性. 而深度强化学习要求训练样本间要尽可能独立, 所以提出基于预训练记忆的多智能体DQN (PMDQN)先使智能体在环境中进行预训练, 并将数量$ T $ 的专家经验保存在$ B_2 $ 中, 然后不再对$ B_2 $ 进行更新. 随后使智能体进行随机探索填充$ B_1 $ , 并继续智能体的训练. 由于最终算法收敛时,$ B_1 $ 和$ B_2 $ 不一定会完全同分布, 因此, 智能体不能保证学习到最优策略. 但PMDQN可以使专家经验池提供的样本间的相关性下降, 并加快了算法的学习速度.这时, 智能体探索系统和专家演示系统的损失函数分别为
$ {L^o} $ 和$ {L^e} $ , 则有$$ \begin{split} &{L^o}\left( {{{\boldsymbol{\theta}} ^k}} \right) = \\ &\qquad {\rm{E}}_{{\boldsymbol{s}}\sim\psi ,{\boldsymbol{a}}\sim\varphi } \left[ {\sum\limits_{k = 1}^N {{{\left( {{Y^k} - {Q^k}\left( {{\boldsymbol{s}},a_{}^k;{{\boldsymbol{\theta}} ^k}} \right)} \right)}^2}} } \right] \end{split} $$ (16) $$ \begin{split} &{L^e}\left( {{{\boldsymbol{\theta}} ^k}} \right) = \\ &\qquad{{\rm{E}}_{\left( {{\boldsymbol{s}},{\boldsymbol{a}}} \right)\sim{B_2}}}\left[ {\sum\limits_{k = 1}^N {{{\left( {Y_{}^{e,k} - {Q^k}\left( {{\boldsymbol{s}},a_{}^k;{{\boldsymbol{\theta}} ^k}} \right)} \right)}^2}} } \right] \end{split} $$ (17) 最终PMDQN的损失函数为
$$ \begin{equation} L\left( {{{\boldsymbol{\theta}} ^k}} \right) = {P_s}{L^o}\left( {{{\boldsymbol{\theta}} ^k}} \right) + \left( {1 - {P_s}} \right){L^e}\left( {{{\boldsymbol{\theta}} ^k}} \right) \end{equation} $$ (18) PMDQN的伪代码如下:
算法3. PMDQN算法
输入: 最大迭代次数
$ {I_{\max }} $ , 折扣因子$ \gamma $ , 学习率$ \eta $ , 智能体个数$ N $ , 采样概率$ P_s $ , 专家经验数量$ T $ , 初始化探索经验池$ B_1 $ 和演示经验池$ B_2 $ .输出: 网络参数
$ {{\boldsymbol{\theta}} ^k}\left( {k = 1,2, \cdots ,N} \right) $ .1) While
$I < T;$ 2) 随机生成状态
$ {{\boldsymbol{s}}_t} $ , 并计算专家动作$ a_t^{*k} $ ;3) 环境中应用动作
$ {{\boldsymbol{a}}_t^*} = \left[ {a_t^{*1},a_t^{*2}, \cdots ,a_t^{*N}} \right] $ , 并返回回报$ r^e\left( {{{\boldsymbol{s}}_t}} \right) $ 和下一时刻状态$ {{\boldsymbol{s}}_{t + 1}} $ , 存入$ B_2 $ ;4) 初始化网络参数
$ {{\boldsymbol{\theta}} ^k}\left( {k = 1,2, \cdots ,N} \right) $ ;5) While
$I < {I_{\max }};$ 6)
$t = 0 ;$ 7) 随机初始化状态
$ {\boldsymbol{s}}_t $ ;8) While
$ t \le {t_{\max }} $ or 患者死亡;9) For
$k = 1:N ;$ 10) 计算动作:
$ a_t^k = \arg \mathop {\max }\limits_{{a^k}} {Q^k}\left( {{{\boldsymbol{s}}_t},a_{}^k;{{\boldsymbol{\theta}} ^k}} \right) $ ;11) end For;
12) 环境中应用动作
$ {{\boldsymbol{a}}_t} = \left[ {a_t^1,a_t^2, \cdots ,a_t^N} \right] $ , 并返回回报$ r\left( {{{\boldsymbol{s}}_t}} \right) $ 和下一时刻状态$ {{\boldsymbol{s}}_{t + 1}} $ , 存入$ B_1 $ ;13)
$t \leftarrow t + 1 ;$ 14) end While;
15)
$I \leftarrow I + 1 ;$ 16) For
$k = 1:N ;$ 17) 随机采样并更新
$ {{\boldsymbol{\theta}} ^k} $ ;${{\boldsymbol{\theta}} ^k} \leftarrow {{\boldsymbol{\theta}} ^k} + \eta {\nabla _{{{\boldsymbol{\theta}} _k}}}\left( {{P_s}{L^o}\left( {{{\boldsymbol{\theta}} ^k}} \right) + \left( {1 - {P_s}} \right){L^e}\left( {{{\boldsymbol{\theta}} ^k}} \right)} \right);$ 18) end For;
19) end While.
3.5 基于多智能体DQN的乳腺癌致病基因排序
通过比较每个基因突变状态
$ s^k $ 的值$ F\left( {{s^k}} \right) $ 进行乳腺癌致病基因排序.$ F\left( {{s^k}} \right) $ 可表示为$$ \begin{split} F\left( {{s^k}} \right) =\;& {\rm{E}}\left[ {Q\left( {{\boldsymbol{s}}\left| {_{{s^k} = 0}} \right.,{a^k} = 1;{{\boldsymbol{\theta}} ^k}} \right)} \right]+\\ &{\rm{E}}\left[ {Q\left( {{\boldsymbol{s}}\left| {_{{s^k} = 1}} \right.,{a^k} = 0;{{\boldsymbol{\theta}} ^k}} \right)} \right] \end{split} $$ (19) 式中, 由于第
$ k $ 个智能体从未突变状态($ s^k = 0 $ )到最终突变状态($ s^k = 1 $ )采取的动作为$ a^k = 1 $ ; 从突变状态($ s^k = 1 $ )到最终突变状态($ s^k = 1 $ )采取的动作为$ a^k = 0 $ , 所以$ F\left( {{s^k}} \right) $ 可以用于表示某个基因突变对患者死亡贡献度的高低. 这里默认最终状态为未突变状态($ s^k = 0 $ )时, 对乳腺癌突变基因的分析无意义.在多智能体框架中, 每一个智能体只处理动作空间为2、状态空间为
$ 2^N $ 的强化学习问题, 并使用基于值的强化学习来进行训练, 这时输入为$ N $ 维二进制向量, 输出为2维的Q值. 这时的多智能框架对神经网络结构的要求不高. 为了加快多智能体的训练速度, 所有DQN仅使用单层神经网络, 即第$ k $ 个网络参数$ {\boldsymbol{\theta}} ^k $ 只包含权值向量$ {\boldsymbol{w}} ^k $ 和偏置向量$ {\boldsymbol{b}} ^k $ , 则有$$ \begin{split} &{2^{N - 1}}\left( {{{\left\| {{{\boldsymbol{w}}^k}} \right\|}_1} + {{\left\| {{{\boldsymbol{b}}^k}} \right\|}_1}} \right) =\\ &\qquad {\rm{E}}\left[ {Q\left( {{\boldsymbol{s}}\left| {_{{s^k} = 0}} \right.,{a^k} = 1;{{\boldsymbol{\theta}} ^k}} \right)} \right]+\\ &\qquad {\rm{E}}\left[ {Q\left( {{\boldsymbol{s}}\left| {_{{s^k} = 1}} \right.,{a^k} = 0;{{\boldsymbol{\theta}} ^k}} \right)} \right] \end{split} $$ (20) 由于
$ \mathop {\arg \max \limits_k} \left( {F\left( {{s^k}} \right)} \right) $ 与$ \mathop {\arg \max \limits_k } \left( {{{\left\| {{{\boldsymbol{w}}^k}} \right\|}_1} + {{\left\| {{{\boldsymbol{b}}^k}} \right\|}_1}} \right) $ 相等, 所以最终使用下式进行致病基因排序$$ \begin{equation} F\left( {{s^k}} \right) = {\left\| {{{\boldsymbol{w}}^k}} \right\|_1} + {\left\| {{{\boldsymbol{b}}^k}} \right\|_1} \end{equation} $$ (21) 深度强化学习方法主要通过评估状态−动作值的高低来决定动作: 如果某个基因在式(21)中的值越大, 说明智能体在任意状态下发生突变的状态−动作值越大, 即该基因发生突变导致病人死亡的概率越高. 因此, 通过式(21)指标可以排序出基因突变与患者死亡之间的关联性. 最后, 根据需求选择排序靠前的
$ n $ 个基因作为致病基因.4. 实验结果与分析
4.1 实验设置
本文通过在乳腺癌基因突变数据构建的环境来预测乳腺癌的致病基因. 乳腺癌突变数据和生存数据由TCGA数据官网下载得到(
网址: https://portal.gdc.cancer.gov) . 深度强化学习的训练时间与环境的状态−动作空间复杂度正相关. 一般环境的状态−动作空间复杂度越高, 需要的神经网络越复杂, 训练时间越长. 受限于实验设备的计算效率, 实验中需要通过一定的规则来限制状态、动作的维度, 因此通过基因突变率来筛选基因数目.根据乳腺癌突变数据中的基因突变率将实验设置为2组: 第1组选择基因突变率
$\ge 50\%$ 的基因, 得到$ N = 188 $ 个基因, 其中包含53种不同的死亡状态; 第2组选择基因突变率$\ge 30\%$ 的基因, 得到$ N = 420 $ 个基因, 其中包含81种不同的死亡状态. 由于BCDQN比PMDQN更稳定, 所以$ N = 188 $ 时使用BCDQN进行训练. 当$ N = 420 $ 时, BCDQN需耗费大量时间进行训练, 为了使算法快速收敛, 使用PMDQN进行训练.本文将基因突变视为多智能体的动作, 若基因突变率太低, 则基因/智能体数目增多, 而死亡状态中突变基因的占比急剧减小, 多智能体很难通过动作学习到死亡状态, 所以选择使用30%、50%的基因突变率来确保构建环境所用的基因数满足智能体对乳腺癌死亡状态的学习. 当然, 也可以选择其他突变率的基因数目, 例如突变率
$ \ge 40$ %, 理论上在合理的基因突变率范围内, 本文提出的算法都能够适用. 不同基因突变率数据集的选择会对实验结果产生影响, 这体现在两个方面: 1) 突变率越低得到的基因数目越大, 状态−动作空间维度也越大, 导致模型收敛速度变慢, 无法学习到最优策略; 突变率越高, 则得到的基因越少, 使得强化学习任务更简单, 且过高突变率的基因使乳腺癌致病基因预测任务无意义. 2) 突变率改变将会产生不同的患者死亡率, 影响智能体完成任务情况. 因此, 在实验设备的允许的情况下, 建议基因突变率的选择范围为10% ~ 50%.4.2 实验结果
当
$ N = 188 $ 时, 使用BCDQN进行训练. 多智能体在53个死亡状态上的回报值如图3所示, 其中, 横坐标表示episode, 纵坐标表示回报值. 由图3可以看出, 所有的策略处于收敛状态, 在每个死亡状态上, 多智能体在每个episode都可以取得稳定的回报. 由于策略收敛, BCDQN可以完成所有学习任务, 具备较好的鲁棒性. 图4表示当$ N = 188 $ 时, 多智能体完成任务情况 (达到死亡状态), 其中, 横坐标表示episode, 纵坐标表示完成任务的次数. 图4中除0、1、6、7四个死亡状态外, 智能体能够稳定学习到死亡状态的最优策略. 智能体在0、1、6、7四个死亡状态产生波动是由于这几个死亡状态的死亡率较低 (死亡率分别为4.60%、9.7%、7.69%和9.09%), 使得智能体在上限步数内虽然停留在死亡状态却无法触发死亡事件, 导致智能体无法完全保证稳定学习到最优策略. BCDQN在状态−动作空间维度较小环境中可以确保找到最优策略. 而在较复杂的状态−动作空间维度中, 若存在充足的专家经验, 则算法一定可以收敛至最优策略, 但需要耗费的训练时间难以估计. 图 3 当
图 3 当$ N = 188$ 时, BCDQN在53个死亡状态上的回报值Fig. 3 The rewards of BCDQN at 53 death states under the condition of$ N = 188$  图 4 当
图 4 当$ N = 188$ 时, BCDQN在53个死亡状态上的完成任务情况Fig. 4 The task completion status of BCDQN at 53 death states under the condition of$ N = 188$ 当
$ N = 420 $ 时, 使用PMDQN进行训练. 多智能体在81个死亡状态上的回报值如图5所示. 除61、62、67、69、71五个死亡状态外, 多智能体可在其余所有死亡状态上学习到最高的回报值. 图6是当$ N = 420 $ 时, 多智能体完成任务情况. 除61、62、67、69、71五个死亡状态外, 智能体能够学习到死亡状态的最优策略. 产生这种结果的原因是由于智能体增多导致动作−状态空间复杂度增大, 智能体训练时间不够长, 暂时没有学习到最优策略. PMDQN虽然保证了采样效率, 提供了大量有效的专家经验, 加快了算法的训练, 却不可避免地会因为环境的太过复杂而遇到专家经验不足的问题. 此时通过专家经验的扩充可在一定程度上的减少这种陷入局部最优现象的发生. 当$ N = 420 $ 时, 状态−空间维度较大且复杂, 多智能体在一个情节内经历的轨迹较长, 这也会导致智能体无法探索到上述五个死亡状态. 因此, 也可以尝试利用增强探索的强化学习方法解决此问题. 图 5 当
图 5 当$ N = 420$ 时, PMDQN在81个死亡状态上的回报值Fig. 5 The rewards of PMDQN at 81 death states under the condition of$ N = 420$  图 6 当
图 6 当$ N = 420$ 时, PMDQN在81个死亡状态上的完成任务情况Fig. 6 The task completion status of PMDQN at 81 death states under the condition of$ N = 420$ 根据上述结果, 总结BCDQN和PMDQN的特点和适用情况如下: BCDQN在状态−动作空间维度较小时, 能够保证智能体探索到与专家策略相同的策略, 稳定找到最优策略; 在状态−动作空间维度大且复杂时, PMDQN可以减小样本间的相关性, 满足更多智能体快速进行强化学习, 但不能保证智能体学习到最优策略. 综上所述, 在实验设备允许情况下, 建议在
$ N<420 $ 时使用BCDQN, 在$ N \ge 420 $ 时使用PMDQN.4.3 致病基因分析
$当N = 188$ 和$ N = 420 $ 时, BCDQN和PMDQN预测的前10个致病基因如表1所示. 在这两种情况下, 预测的致病基因有重叠部分, 例如TP53、MYC和PVT1.表 1 BCDQN和PMDQN预测的前10个致病基因Table 1 Top 10 pathogenic genes predicted by BCDQN and PMDQN序号 BCDQN PMDQN 1 TP53 TP53 2 FAM91A1 PIK3CA 3 TNFRSF11B TG 4 KCNQ3 HHLA1 5 MYC ASAP1 6 COL14A1 CASC8 7 CCDC26 SNORA12 8 CCN3 MYC 9 PVT1 PVT1 10 DSCC1 RN7SL329 肿瘤抑制基因TP53在控制细胞增殖、细胞存活和基因组完整性的许多细胞通路中发挥着关键作用. 当细胞经历应激条件 (如DNA损伤、缺氧或致癌基因激活)时, TP53作为细胞增殖的制动器, 几乎在所有类型的癌症中发生突变. Silwal-Pandit等[22]分析了1420名乳腺癌患者体细胞的TP53突变, 研究结果表明TP53突变谱在乳腺癌中具有亚型特异性和明显的预后相关性. Funda等[23]对257例转移性乳腺癌患者的202个基因进行了高通量测序, 研究表明TP53在乳腺癌的三种亚型中都存在显著突变, 且与无复发生存期、无进展生存期和总生存期相关. Han等[24]分析了187例转移性乳腺癌患者的血液样本, 研究表明TP53突变转移性乳腺癌患者的预后明显低于TP53野生型患者, 特别是激素受体阳性/表皮生长因子受体2阴性和三阴性队列患者. 在TP53突变的患者中, DNA结合域中非错义突变的乳腺癌患者的相关生存率更低.
MYC是细胞生长、增殖、代谢、分化和凋亡的关键调控因子, 它的扩增或过表达常见于多种恶性肿瘤. 乳腺癌中MYC的解除涉及多种机制, 包括基因扩增、转录调节、mRNA和蛋白质稳定, 这与肿瘤抑制子的缺失和致癌途径的激活相关. Xu等[25]报道了肿瘤抑制因子BRCA1能够抑制MYC的转录和转化活性, 并且BRCA1缺失和MYC过表达导致乳腺癌的发生, 特别是基底细胞样亚型的乳腺癌. Terunuma等[26]发现乳腺癌中2-羟戊二酸水平升高与MYC通路激活之间存在关联, 并在人类乳腺上皮细胞和乳腺癌细胞中MYC的过表达和敲低进一步证实了这一关系. Camarda等[27]通过靶向代谢组学方法, 发现脂肪酸氧化中间体在MYC驱动的三阴性乳腺癌模型中显著上调.
PVT1在多种恶性肿瘤中高表达, 是潜在的癌基因, 它还可与MYC基因相互作用, 通过多种途径参与恶性肿瘤细胞的增殖、凋亡等调控. Cho等[28]证明了PVT1启动子具有独立于PVT1 lncRNA的肿瘤抑制功能, 且PVT1启动子CRISPR增强了乳腺癌细胞在体内的竞争和生长. Tang等[29]报道了PVT1在临床三阴性乳腺癌中上调, 并促进KLF5/beta-catenin信号通路以驱动三阴性乳腺癌的发生. Wang等[30]的研究表明, PVT1的表达增加与乳腺癌患者的临床分期、淋巴结转移和总生存率有关.
为进一步验证预测得到的致病基因与乳腺癌密切相关, 首先利用ToppGene工具(网址:
https://toppgene.cchmc.org/ )进行基因富集分析. 基因富集分析是指将一组基因按照基因组注释信息进行分类的过程, 能够发现基因间是否具有某方面的共性. 基因组注释信息存储于基因注释数据库(Gene anotation database), 能够帮助理解基因功能, 发现基因与疾病之间的关联等. 本文采用的基因注释数据库是基因本体数据库(Gene ontology, GO), 其涵盖多种语义分类, 如分子功能、生物学过程、细胞组分等. GO术语 (GO term) 是GO数据库中的基本描述单元, 可描述基因产物的功能, 例如: GO术语: regulation of DNA biosynthetic process描述的是一组基因在生物过程中对DNA生物合成过程起调节作用.在富集分析圈图(图7 ~ 8)中, 圆形的左半圆部分表示基因, 右半边表示GO术语, 基因与GO术语之间有连线表示基因产物与GO术语相关, 一个基因与越多GO术语相连, 则表示该基因的产物功能越多. 图7是在
$ N = 188 $ 时, 前10个致病基因的富集分析圈图, 其中基因CCDC26无法与其他基因得到富集结果. 图7中的GO术语是从富集结果的众多GO术语中与乳腺功能密切相关的15个GO术语, 基因MYC与最多数目的GO术语相连, 且与多个乳腺癌相关的GO术语有关, 表示MYC与乳腺癌的发生、发展最为密切, 其次是基因TP53, 以此类推. 由此可见, 图7中的9个基因的产物都与乳腺癌的发病过程相关. 虽然CCDC26无法与其他基因得到富集结果, 但在文献[31]中, CCDC26作为下调基因, 可在多种癌症的发生过程产生作用, 例如白血病、胶质瘤等. 图 7 当
图 7 当$ N = 188$ 时, BCDQN预测的前10个致病基因的富集分析圈图Fig. 7 The enrichment analysis circle diagram of the top 10 pathogenic genes predicted by BCDQN under the condition of$ N = 188$  图 8 当
图 8 当$ N = 420$ 时, PMDQN预测的前10个致病基因的富集分析圈图Fig. 8 The enrichment analysis circle diagram of the top 10 pathogenic genes predicted by PMDQN under the condition of$ N = 420$ 图8是在
$ N = 420 $ 时, 前10个致病基因的富集分析圈图, 本文从富集结果的众多GO术语中选择了与乳腺功能密切相关的18个GO术语. 基因TP53、MYC、PIK3CA、PVT1和TG与这18个GO术语相关, 表明与乳腺癌有关联. 虽然基因HHLA1、ASAP1与上述18个GO术语无关, 但与基因MYC、PVT1、TG一起与GO术语: Human Leukemia Schoch05 1052genes相关, 即与白血病相关. 基因SNORA12在文献[32]中被验证为宫颈癌的8个过表达基因之一. 通过RNA测序结果, 基因RN7SL329P是前列腺癌中前10位差异表达的IncRNAs[33].值得注意的是, 生命科学是一门实验科学, 由人类在长期的科学探究中不断积累知识逐步完善. 本文预测的部分致病基因现阶段虽与乳腺癌无直接关联, 但都参与了其他癌症的发生过程, 可作为乳腺癌的候选致病基因以待临床验证. 导致乳腺癌风险增加最常见的突变基因BRCA1、BRCA2和PALB2没有出现在本实验中, 这是由于这些基因的突变率没有达到实验设置要求, 即在
$ N = 188 $ 和$ N = 420 $ 的实验中不包含这些基因. 受篇幅限制, 这里仅提供两种方法预测的前10个基因, 排名靠后的基因不再进行分析, 但是, 这并不代表这些基因与乳腺癌无关, 例如,$ N = 420 $ 的实验结果中, 基因PIK3CA排在第2位, 但在$ N = 188 $ 的实验结果中, 其排在第23位.5. 结束语
本文基于乳腺癌突变数据, 构建多智能体强化学习环境, 并根据突变数据特性设计了两种基于演示学习的多智能体DQN. 借鉴行为克隆思想提出BCDQN, 将患者死亡状态作为专家信息, 对智能体的每一步探索都给予指导, 最终实现探索经验池与专家经验池完全同分布. 为了满足更多智能体快速进行强化学习, 并减小样本间的相关性, 提出PMDQN通过预训练方式将一定数量的专家经验保存在专家经验池中, 然后令智能体进行随机探索, 加快智能体探索到与专家策略相同的策略. 最后, 通过基因富集分析对预测得到的致病基因进行分析, 实验结果表明, 本文方法能够挖掘出乳腺癌致病基因. 同时, 该算法也挖掘出一些与其他癌症的发生过程相关的基因, 可作为乳腺癌的候选致病基因.
未来的研究工作包括设计癌症连续数据的强化学习环境, 进一步提出适用于连续数据的多智能体强化学习算法.
-
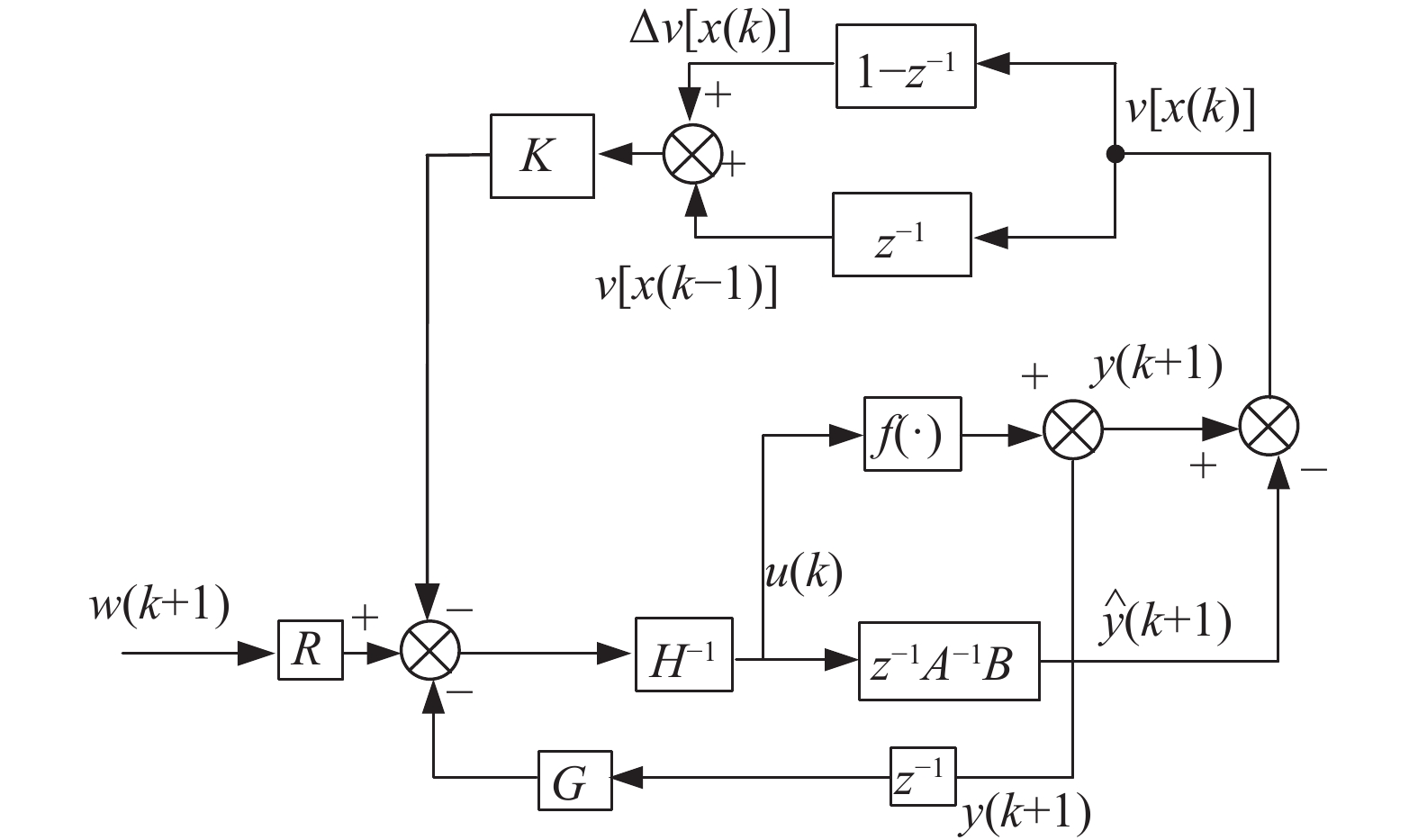
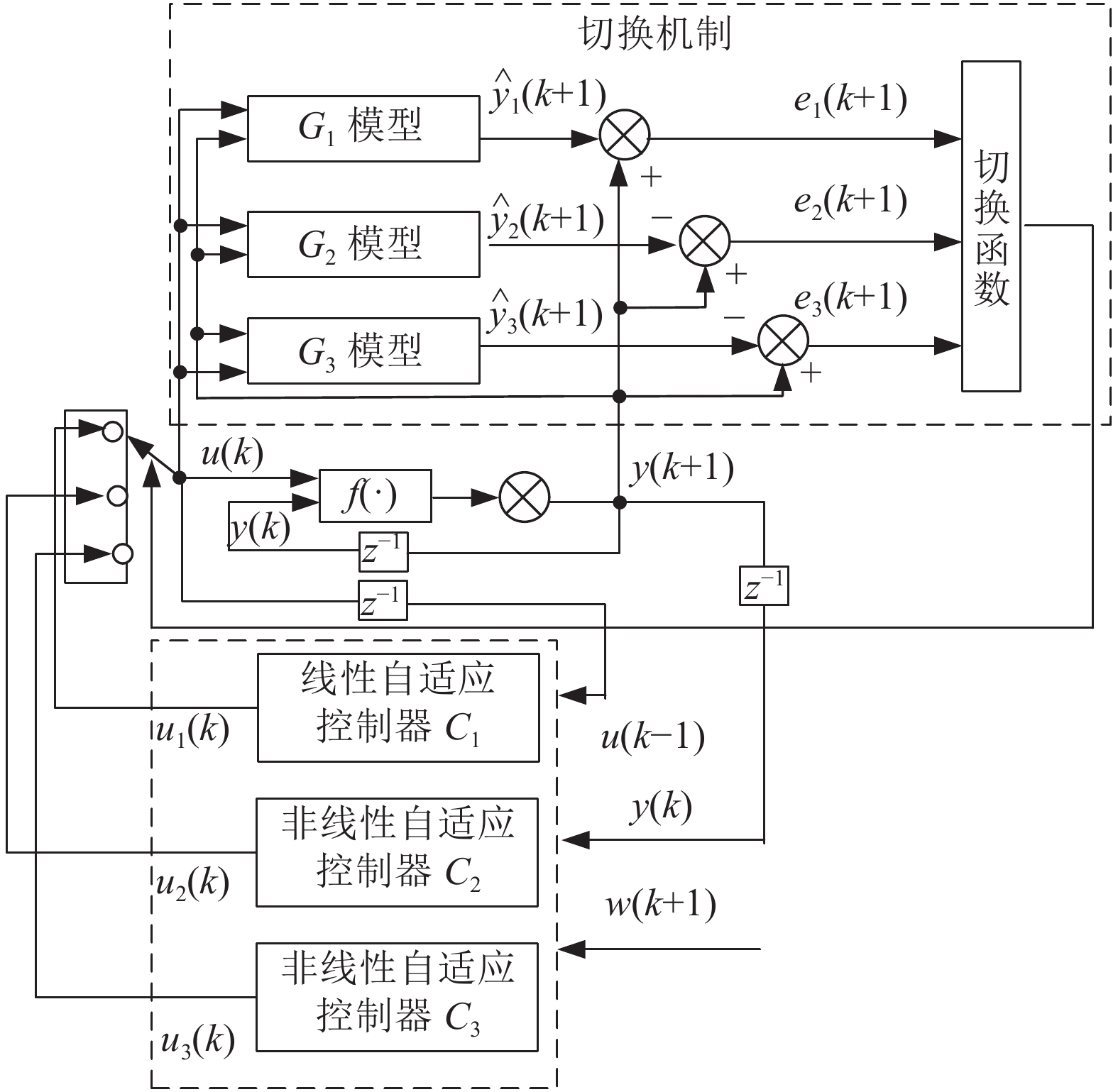
图 1 带有
$v[{{x}}(k)]$ 前一拍数据及其未知增量补偿的非线性控制器Fig. 1 Nonlinear controller with
$v[{{x}}(k)]$ previous step data and its unknown incremental compensation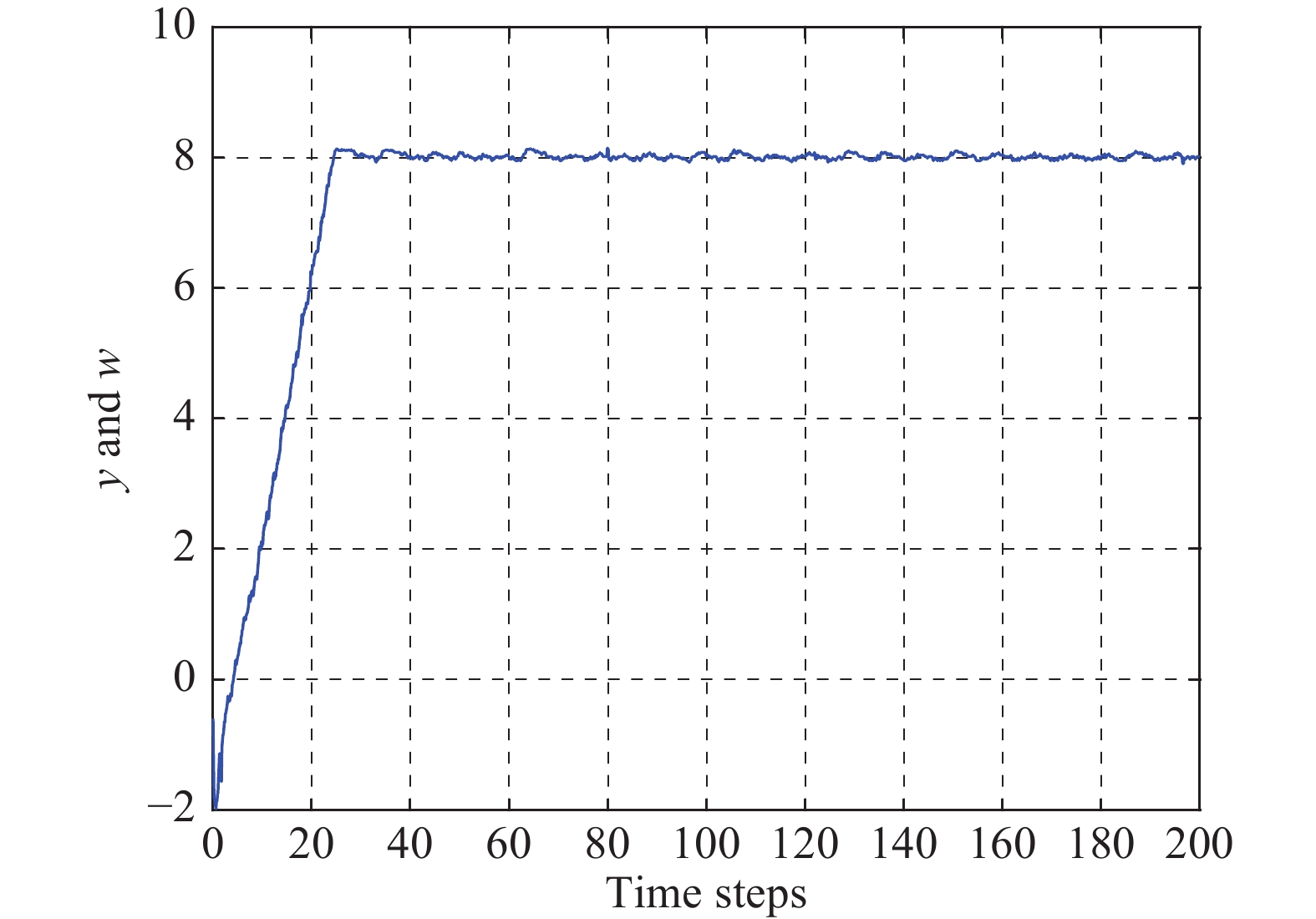
图 4 采用本文方法时水箱液位的实际响应曲线(输出y)
Fig. 4 The actual response curve of tank level by the proposed method (output y)
-
[1] Lainiotis D G. Optimal adaptive estimation structure and parameter adaption. IEEE Transactions on Automatic Control, 1971, 16(2): 160−170 doi: 10.1109/TAC.1971.1099684 [2] Narendra K S, Parthasarathy K. Identification and control of dynamical systems using neural networks. IEEE Transactions on Neural Network, 1990, 1(1): 4−27 doi: 10.1109/72.80202 [3] Narendra K S, Balakrishnan J. Improving transient response of adaptive control systems using multiple models and switching. IEEE Transactions on Automatic Control, 1994, 39(9): 1861−1866 doi: 10.1109/9.317113 [4] Narendra K S, Balakrishnan J. Adaptive control using multiple models. IEEE Transactions on Automatic Control, 1997, 42(2): 171−187 doi: 10.1109/9.554398 [5] Narendra K S, Cheng X. Adaptive control of discrete-time systems using multiple models. IEEE Transactions on Automatic Control, 2000, 45(9): 1669−1686 doi: 10.1109/9.880617 [6] Chen L J, Narendra K S. Nonlinear adaptive control using neural networks and multiple models. Automatic, 2001, 37(8): 1245−1255 doi: 10.1016/S0005-1098(01)00072-3 [7] Fu Y, Chai T Y. Nonlinear multivariable adaptive control using multiple models and neural networks. Automatic, 2007, 43(8): 1101−1110 [8] 石宇静, 柴天佑. 基于神经网络与多模型的非线性自适应广义预测控制. 自动化学报, 2007, 33(5): 540−545Shi Yu-Jing, Chai Tian-You. Neural networks and multiple models based nonlinear adaptive generalized predictive control. Acta Automatica Sinica, 2007, 33(5): 540−545 [9] 柴天佑, 张亚军. 基于非线性项补偿的非线性自适应切换控制方法. 自动化学报, 2010, 37(7): 773−786Chai Tian-You, Zhang Ya-Jun. Nonlinear adaptive switching control method based on un-modeled dynamics compensation. Acta Automatica Sinica, 2010, 37(7): 773−786 [10] Chai T Y, Zhai L F, Yue H. Multiple models and neural networks based decoupling control of ball mill coal-pulverizing systems. Journal of Process Control, 2011, 21(3): 351−366 doi: 10.1016/j.jprocont.2010.11.007 [11] Wang Y, Chai T Y, Fu Y, Sun J, Wang H. Adaptive decoupling switching control of the forced-circulation evaporation system using neural networks. IEEE Transactions on Control Systems Technology, 2013, 21(3): 964−974 doi: 10.1109/TCST.2012.2193883 [12] 董泽, 尹二新, 韩璞. 基于迟延估计与Kalman状态跟踪的热工过程动态数据驱动建模. 动力工程学报, 2018, 38(3): 203−210Dong Ze, Yin Er-Xin, Han Pu. Dynamic data driven modeling for thermal processes based on delay estimation and Kalman state tracking. Journal of Chinese Society of Power Engineering, 2018, 38(3): 203−210 [13] Hou Z S and Xu J X. On data-driven control theory: The state of the art and perspective. Acta Automatica Sinica, 2009, 35(6): 650−667 doi: 10.3724/SP.J.1004.2009.00650 [14] Hou Z S, Wang Z. From model-based control to data-driven control: Survey, classification and perspective. Information Science, 2013, 235: 3−35 doi: 10.1016/j.ins.2012.07.014 [15] Ma Y J, Zhao S Y, Huang B. Multiple-model state estimation based on variational bayesian inference. IEEE Transactions on Automatic Control, 2018, 64(4): 1679−1685 [16] 张亚军, 柴天佑, 杨杰. 一类非线性离散时间动态系统的交替辨识算法及应用. 自动化学报, 2017, 43(1): 101−113Zhang Ya-Jun, Chai Tian-You, Yang Jie. Alternating identi?cation algorithm and its application to a class of nonlinear discrete-time dynamical systems. Acta Automatica Sinica, 2017, 43(1): 101−113 [17] He W, Meng T, He X, Ge S S. Unified iterative learning control for flexible structures with input constraints. Automatica, 2018, 96: 326−336 doi: 10.1016/j.automatica.2018.06.051 [18] Dornheim J, Link N, Gumbsch P. Model-free adaptive optimal control of sequential manufacturing processes using reinforcement learning. arXiv preprint arXiv, 2018, 1809.06646. [19] Ma Y J, Zhao S Y, Huang B. Feature extraction of constrained dynamic latent variables. IEEE Transactions on Industrial Informatics, 2019, DOI: 10.1109/TII.2019.2901934. [20] Na J, Li G, Wang B, Herrmann G, Zhan S. Robust optimal control of wave energy converters based on adaptive dynamic programming. IEEE Transactions on Sustainable Energy, 2019, 10(2): 961−970 doi: 10.1109/TSTE.2018.2856802 [21] Chai T Y, Zhang Y J, Wang H, Su C Y, Sun J. Data based virtual un-modeled dynamics driven multivariable nonlinear adaptive switching control. IEEE Transactions on Neural Network, 2011, 22(12): 2154−2172 doi: 10.1109/TNN.2011.2167685 [22] Tong S C, Sui S, Li Y M. Observed-based adaptive fuzzy tracking control for switched nonlinear systems with dead-zone. IEEE Transactions on Cybernetics, 2015, 45(12): 2816−2826 doi: 10.1109/TCYB.2014.2386912 [23] Tong S C, Li Y M. Adaptive fuzzy output feedback control for switched nonlinear systems with unmodeled dynamics. IEEE Transactions on Cybernetics, 2017, 47(2): 295−305 [24] Li Y M, Sui S, Tong S C. Adaptive fuzzy control design for stochastic nonlinear switched systems with arbitrary switchings and unmodeled dynamics. IEEE Transactions on Cybernetics, 2017, 47(2): 403−414 [25] Ma R C and Zhao J. Backstepping design for global stabilization of switched nonlinear systems in lower triangular form under arbitrary switchings. Automatica, 2010, 46(11): 1819−1823 doi: 10.1016/j.automatica.2010.06.050 [26] Liu Y J, Gao Y, Tong S C, Li Y M. Fuzzy approximation-based adaptive backstepping optimal control for a class of nonlinear discretetime systems with dead-zone. IEEE Transactions on Fuzzy Systems, 2016, 24(1): 16−28 doi: 10.1109/TFUZZ.2015.2418000 [27] Long L J, Zhao J. Adaptive output-feedback neural control of switched uncertain nonlinear systems with average dwell time. IEEE Transactions on Neural Network and Learning Systems, 2015, 26(7): 1350−1362 doi: 10.1109/TNNLS.2014.2341242 [28] Sun K K, Mou S H, Qiu J B, Wang T, Gao H J. Adaptive fuzzy control for nontriangular structural stochastic switched nonlinear systems with full state constraints. IEEE Transactions on Fuzzy Systems, 2019, 27(8): 1587−1601 doi: 10.1109/TFUZZ.2018.2883374 [29] Qiu J B, Sun K K, Imre J Rudas, Gao H J. Command filter-based adaptive NN control for MIMO nonlinear systems with full-state constraints and actuator hysteresis. IEEE Transactions on Cybernetics, 2019, 99:1-11. DOI: 10.1109/TCYB.2019.2944761 [30] Goodwin G C, Ramadge P J, Caines P E. Discrete-time multivariable adaptive control. IEEE Transactions on Automatic Control, 1980, 25(3): 449−456 期刊类型引用(7)
1. 顾扬,程玉虎,王雪松. 基于优先采样模型的离线强化学习. 自动化学报. 2024(01): 143-153 .  本站查看
本站查看2. 王雪松,王荣荣,程玉虎. 基于表征学习的离线强化学习方法研究综述. 自动化学报. 2024(06): 1104-1128 . 本站查看3. 程玉虎,黄龙阳,侯棣元,张佳志,陈俊龙,王雪松. 广义行为正则化离线Actor-Critic. 计算机学报. 2023(04): 843-855 . 百度学术4. 王雪松,王荣荣,程玉虎. 安全强化学习综述. 自动化学报. 2023(09): 1813-1835 . 本站查看5. Jinying Yang,Yongjun Zhang,Tanju Yildirim,Jiawei Zhang. A Model Predictive Control Algorithm Based on Biological Regulatory Mechanism and Operational Research. IEEE/CAA Journal of Automatica Sinica. 2023(11): 2174-2176 . 必应学术6. 满坚平,黄国立,赖聪,陈子怡,周毅. 智能体在医疗健康领域的研究与应用. 医学信息学杂志. 2022(04): 20-26 . 百度学术7. 江雨龙,胡文峰,彭涛,阳春华. 基于重置控制的一般线性多智能体系统无领导者一致性问题. 厦门大学学报(自然科学版). 2022(06): 954-960 . 百度学术其他类型引用(11)
-


















 下载:
下载:
























































































































































































































 下载:
下载:
计量
- 文章访问数: 1502
- HTML全文浏览量: 360
- PDF下载量: 435
- 被引次数: 18
