

-
摘要: 基于深度学习的非均匀运动图像去模糊方法已经获得了较好的效果. 然而, 现有的方法通常存在对边缘恢复不清晰的问题. 因此, 本文提出一种强边缘提取网络(Strong-edge extraction network, SEEN), 用于提取非均匀运动模糊图像的强边缘以提高图像边缘复原质量. 设计的强边缘提取网络由两个子网络SEEN-1和SEEN-2组成, SEEN-1实现双边滤波器的功能, 用于提取滤除了细节信息后的图像边缘. SEEN-2实现L0平滑滤波器的功能, 用于提取模糊图像的强边缘. 本文还将对应网络层提取的强边缘特征图与模糊特征图叠加, 进一步利用强边缘特征. 最后, 本文在GoPro数据集上进行了验证实验, 结果表明: 本文提出的网络可以较好地提取非均匀运动模糊图像的强边缘, 复原图像在客观和主观上都可以达到较好的效果.Abstract: Although non-uniform motion image deblurring based on the deep learning has achieved better recovery effect, the most of the existing methods cannot recover the image edge well. In this paper, a strong edge extraction network (SEEN) is proposed for extracting the strong edges of the non-uniform motion blurry image to improve the quality of image deblurring. The designed SEEN is composed of two sub-networks, that is, SEEN-1 and SEEN-2. SEEN-1 is designed as a bilateral filter for extracting the edges of the image after filtering the image details. SEEN-2 is designed as an L0 smoothing filter for extracting strong edges of the blurry image. Meanwhile, we also combine the strong edge features map and the blurry features map for further using the strong edge features. Finally, some experiments are executed on GoPro dataset and the results demonstrate that the proposed network can better extract the strong edge of the non-uniform motion blurry image, and obtain good results in both quality of visual perception and quantitative measurement.
-
自编码器(Autoencoder, AE)[1]是一种非线性无监督神经网络, 也是一种无监督特征提取与降维方法, 通过非线性变换将输入数据投影到潜在特征空间中. AE由编码器和解码器组成, 可将输入数据编码为有意义的压缩表示, 然后对该表示进行解码使得解码输出与原始输入相同, 即解码器输出和输入数据间的重构误差最小. 当投影的潜在特征空间维数低于原始空间时, AE可视为非线性主成分分析的一种表示形式[1]. 随着深度学习的成功, 其在多个领域取得了重要突破[2], 而深度自编码器作为一种无监督深度神经网络被用于数据降维[3-4]、图像降噪[5]和信号处理[6-7]以提取数据的深层表示特征. 例如深度子空间聚类(Deep subspace clustering, DSL-l1)[8]通过深度自编码器对稀疏子空间聚类进行扩展, 在深度自编码器的编码器和解码器间引入自表达层, 用反向传播算法对编码器的输出进行自表示系数矩阵的学习, 以该自表示系数矩阵作为原始样本的相似度矩阵. DSL-l1模型是全连接卷积神经网络并使用l1范数, 求解模型的反向传播算法时间及空间复杂度较高. 为提高计算效率, 需先执行主成分分析法对数据降维.
无监督的极限学习机自编码器(Extreme learning machine autoencoder, ELM-AE)[9]是一种单隐层前馈神经网络, 其输入层到隐层的权值和偏置值随机给定, 学习过程只需通过优化最小二乘误差损失函数即可确定隐层到输出层的权值. 最小二乘损失函数的优化问题有解析解, 可转化为Moore-Penrose广义逆问题求解[10]. 因此本质上相当于直接计算网络权值而无需迭代求解, 相比反向传播和迭代求解的神经网络学习方法, 学习速度快、泛化性能好, 因此本文以ELM-AE作为基础自编码器.
极限学习机自编码器与极限学习机(Extreme learning machine, ELM)[11]类似, 主要不同之处在于ELM-AE的网络输出为输入样本的近似估计, ELM的网络输出为输入样本的类标签. 极限学习机自编码器虽然学习速度快, 但仅考虑数据全局非线性特征而未考虑面向聚类任务时数据本身固有的多子空间结构.
除极限学习机自编码器以外, 无监督极限学习机(Unsupervised extreme learning machine, US-ELM)[12]也是一种重要的无监督ELM模型, 它采用无类别信息的流形正则项替代ELM模型中含类标签的网络误差函数, 经US-ELM投影后保持样本间的近邻关系不变. US-ELM虽考虑了样本分布的流形结构, 但其流形正则项在高维空间中易出现测度“集中现象”且未考虑不同聚簇样本间的结构差异. 在US-ELM模型基础上, 稀疏和近邻保持的极限学习机降维方法(Extreme learning machine based on sparsity and neighborhood preserving, SNP-ELM)[13]引入全局稀疏表示及局部近邻保持模型,可以自适应地学习样本集的相似矩阵及不同簇样本集的子空间结构, 其不足之处在于需迭代求解稀疏优化问题, 运行时间较长.
综合上述分析, 本文以ELM-AE为基础自编码器, 引入最小二乘回归子空间模型(Least square regression, LSR)[14]对编码器的输出样本进行多子空间结构约束, 提出子空间结构保持的极限学习机自编码器(Extreme learning machine autoencoder based on subspace structure preserving, SELM-AE)及其多层版本(Multilayer SELM-AE, ML-SELM-AE), 使面向聚类任务的高维数据经过ML-SELM-AE降维后仍能保持原样本数据的多子空间结构, 并可获取数据的更深层特征.
1. 极限学习机自编码器
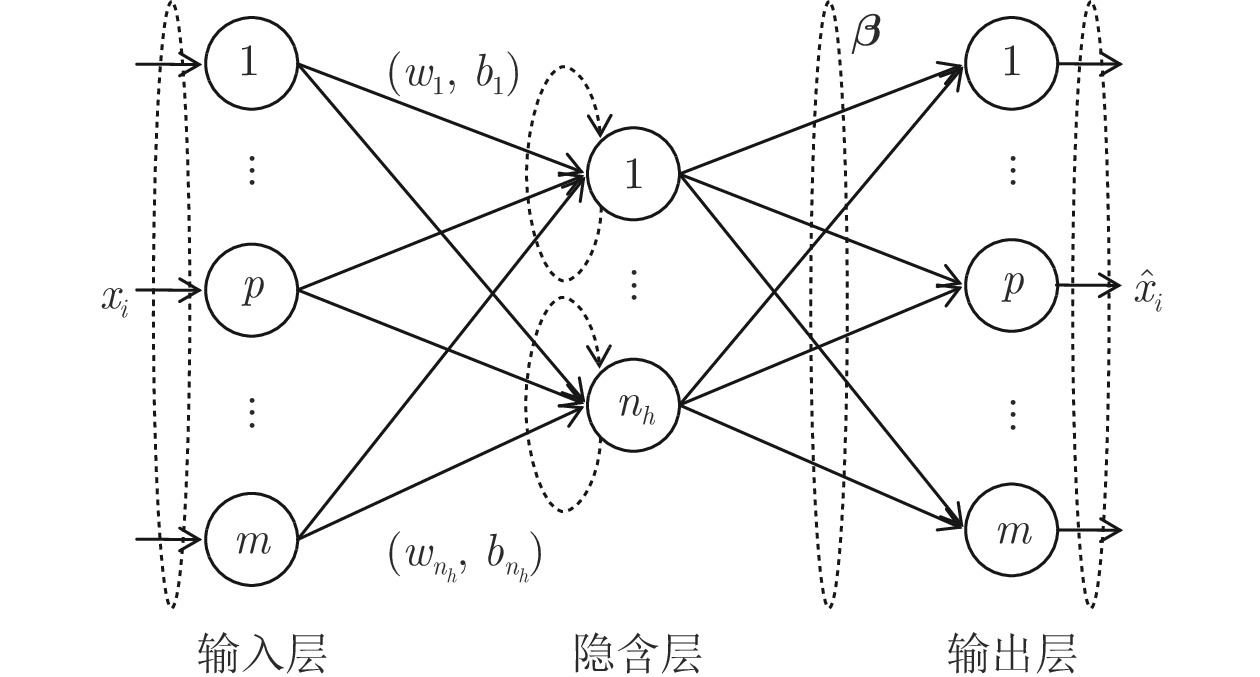
极限学习机自编码器降维方法通过将输入作为网络输出学习极限学习机网络, 其学习过程分为编码和解码过程, 学习目标是最小化重构误差. 图1给出ELM-AE模型网络结构. 对于由n个样本组成的聚类数据集S={xi |xi∈X
$\subseteq $ Rn×m, i =$1,\cdots,n $ }, xi 是网络输入变量, 网络输出${{\boldsymbol{\hat x}}_i}$ 为xi 的近似估计.ELM-AE网络的目标是计算最优的隐节点到输出节点的权值矩阵
${\boldsymbol{\beta }} $ , 使得在该权值下的网络输出${{\boldsymbol{\hat x}}_i} $ 与期望输出xi 间的误差最小. 对n个样本xi (i = 1, 2$,\cdots, $ n) 组成的数据集X, ELM-AE网络的优化模型定义为:$$\mathop {{\rm{min}}}\limits_{{\boldsymbol{\beta }} \in {{\bf{R}}^{{n_h} \times m}}} \frac{{\rm{1}}}{{\rm{2}}}||{\boldsymbol{\beta }}|{|^{\rm{2}}} + \frac{c}{{\rm{2}}}||{\boldsymbol{X}} - {\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }}|{|^2}$$ (1) 其中,
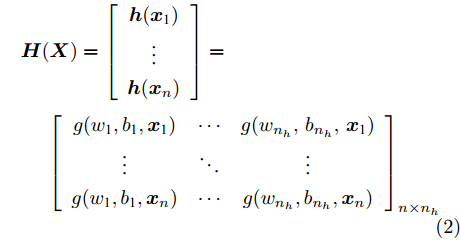
${{\boldsymbol{\beta }} \in {{\bf{R}}^{{n_h} \times m}}} $ 为隐含层到输出层的权值矩阵, H(X)${{\boldsymbol{\in {\rm{R}}}}^{n{\rm{ \times }}{{{n}}_h}}}$ 为隐层输出矩阵:$$\begin{split} &{\boldsymbol{H}}{\rm{(}}{\boldsymbol{X}}{\rm{)}} = \left[ {\begin{array}{*{20}{c}} {{\boldsymbol{h}}{\rm{(}}{{\boldsymbol{x}}_{\rm{1}}}{\rm{)}}}\\ \vdots \\ {{\boldsymbol{h}}{\rm{(}}{{\boldsymbol{x}}_{{n}}}{\rm{)}}} \end{array}} \right] = \\ &\;\;\;\;\;{\left[ {\begin{array}{*{20}{c}} {{{{{g}}(}}{{{w}}_{\rm{1}}}{\rm{,}}{{{b}}_{\rm{1}}}{\rm{,}}{{\boldsymbol{x}}_{\rm{1}}}{\rm{)}}}& \cdots &{{{g}}{\rm{(}}{{{w}}_{{n_h}}},{{{b}}_{{n_h}}},{{\boldsymbol{{{x}}}}_{\rm{1}}}{\rm{)}}}\\ \vdots & \ddots & \vdots \\ {{{g(}}{{{w}}_{\rm{1}}}{\rm{,}}{{{b}}_{\rm{1}}}{\rm{,}}{{\boldsymbol{x}}_{{n}}}{\rm{)}}}& \cdots &{{{g(}}{{{w}}_{{{{n}}_{{h}}}}}{\rm{,}}{{{b}}_{{{{n}}_{{h}}}}}{\rm{,}}{{\boldsymbol{x}}_{{n}}}{\rm{)}}} \end{array}} \right]_{{{n}} \times {{{n}}_{{h}}}}} \end{split}$$ (2) h(xi) = (g(w1, b1, xi),···, g(
$w_{n_{h}}$ ,$b_{n_{h}}$ , xi))为隐层关于xi 的输出向量, nh为隐节点个数; wj 为第j个隐节点的输入权值, bj 为第j个隐节点的偏差, 输入权值wj 和隐节点偏差bj 均随机产生, 其取值区间为[−1, 1]; g(wj, bj, xi)为第j个隐节点的激励函数, 本文采用Sigmoid函数:$$g({w_i},{b_i},{\boldsymbol{x}}) = \frac{{\rm{1}}}{{{\rm{1}} + {\rm{exp(}} - {w_i}{\boldsymbol{x}} + {b_i})}}$$ (3) 模型(1)第1项与ELM模型相同, 最小化隐层到输出层的权值矩阵β的l2范数, 以控制模型的复杂度; 模型第2项为重构误差, 表示ELM-AE 网络的输出 H(X)β 与原始输入数据X 的误差, 重构误差越小, β越优. c为平衡模型复杂度和误差项的参数. 理想情况下, ELM-AE网络的输出H(X)β与真实值X相等, 即X = H(X)β, 此时误差为零.
ELM-AE模型与ELM模型不同之处在于ELM隐层到输出层的最优权矩阵β通过最小化网络输出H(X)β与真实类标签Y的误差得到; 而ELM-AE隐层到输出层的最优权矩阵β通过最小化网络输出H(X)β与输入数据矩阵X的误差得到, 因此ELM-AE可以看成是对数据矩阵X的非线性特征表示. 为实现数据降维, 增加对输入权向量w及偏置b的正交约束. 当样本xi 原始维数m大于隐节点个数nh时, 输入样本可被投影到较低维特征空间, 其对应的隐含层输出向量h(xi)为:
$$\begin{split} & {\boldsymbol{h}}({{\boldsymbol{x}}_i}) = g({\boldsymbol{w}} \cdot {{\boldsymbol{x}}_i} + {\boldsymbol{b}}) \\ &{\rm{s}}{\rm{.t}}.\quad {{\boldsymbol{w}}^{\rm{T}}}{\boldsymbol{w}} = {\boldsymbol{I}},{{\boldsymbol{b}}^{\rm{T}}}{\boldsymbol{b}} = {\rm{1}} \end{split} $$ (4) 式(1)描述的ELM-AE模型是凸优化问题且该问题仅含单变量β, 对其目标函数关于β求导并令导数等于0, 即可得到该问题的解析解如下:
$${{\boldsymbol{\beta }}^ * } = {\left[ {{\boldsymbol{H}^{ \rm T}}{{({\boldsymbol{X}})}}{\boldsymbol{H}}({\boldsymbol{X}}) + \frac{{\rm{1}}}{c}} \right]^{ - {\rm{1}}}}{\boldsymbol{H}^{\rm T}}{({\boldsymbol{X}})}{\boldsymbol{X}}$$ (5) 其中, β*是nh×m矩阵. 据文献[9], ELM-AE通过对原始高维数据X乘以隐含层与输出层间的权值矩阵β实现降维, 即X'=X(β*)T就是所需的降维后样本.
2. 子空间结构保持多层极限学习机自编码器
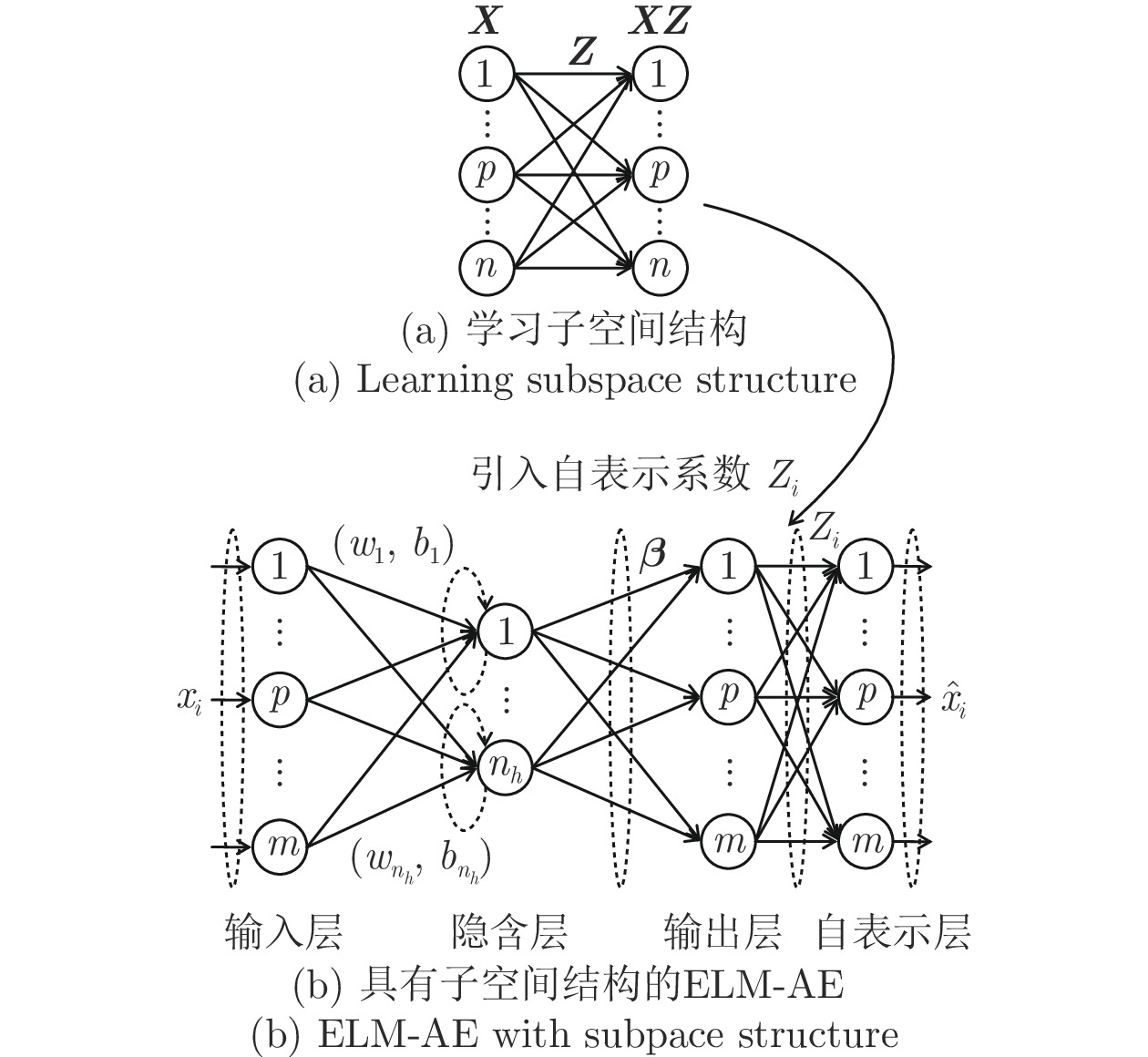
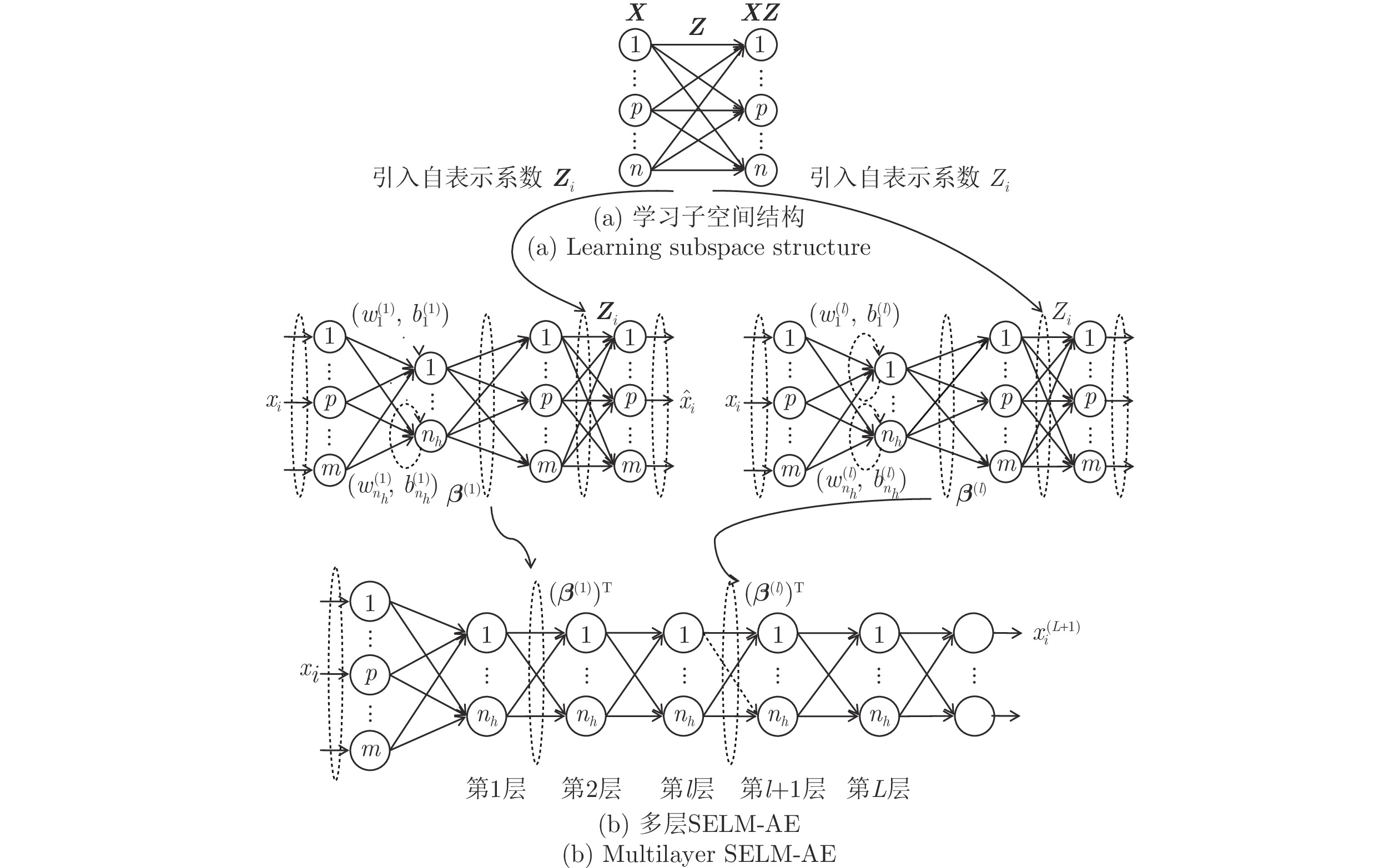
极限学习机自编码器ELM-AE虽然实现了无监督非线性降维, 但未考虑面向聚类任务的高维数据所蕴含的多子空间结构, 难以保证降维结果与聚类目标相匹配. 因此, 本文提出子空间结构保持极限学习机自编码器SELM-AE, 该模型在ELM-AE输出层之后增加自表示层, 使ELM-AE输出H(X)β保持输入数据X的多子空间结构不变.
2.1 子空间结构的获取
为获取数据的子空间结构, 通常采用样本矩阵作为字典, 得到数据自表示模型X=XZ (Z∈Rn×n), 即每一样本用所有其他样本的线性组合表示, 所有样本的组合系数构成自表示系数矩阵. 由此学习到的自表示系数矩阵Z隐含了样本间的相似关系与子空间结构, 理想情况下多簇数据的自表示系数矩阵具有块对角性.
文献[15]已证明, 在假设子空间独立情况下, 通过最小化Z的F范数, 可以保证Z具有块对角结构, 即当样本点xi和xj位于同一子空间时Zij≠0, 位于不同子空间时Zij = 0. 关于Z的自表示优化模型可采用最小二乘回归(LSR)模型, 即
$$ \begin{split} &\mathop {\min }\limits_{\boldsymbol{Z}} ||{\boldsymbol{Z}}|{|_{\rm{F}}}\\ &{\rm{s}}{\rm{.t}}{\rm{. }}\quad {\boldsymbol{X}} = {\boldsymbol{XZ}},\left( {{\rm{diag}}\left\{{\boldsymbol{Z}}\right\} = {\rm{0}}} \right) \end{split} $$ (6) 在实际应用中, 观测数据通常包含噪声, 噪声情况下该模型可扩展为:
$$\mathop {\min }\limits_{\boldsymbol{Z}} ||{\boldsymbol{X}} - {\boldsymbol{XZ}}||_{\rm{F}}^2 + \lambda ||{\boldsymbol{Z}}||_{\rm{F}}^2$$ (7) 模型(7)为凸优化问题, 有解析解, 其解为
${\boldsymbol{Z}} = {\left[ {{{\boldsymbol{X}}^{\rm{T}}}{\boldsymbol{X}} + \lambda {\boldsymbol{I}}} \right]^{ - {\rm{1}}}}{{\boldsymbol{X}}^{\rm{T}}}{\boldsymbol{X}}$ .2.2 子空间结构保持极限学习机自编码器(SELM-AE)
由式(7)学习得到的自表示系数矩阵Z = [Z1, ···, Zn] (Zi∈Rn为xi的表示系数), 包含数据的子空间结构信息. 为使极限学习机自编码器的网络输出
${\boldsymbol{{\hat X_1}}}$ =H(X)β仍保持这种子空间结构, 在极限学习机自编码器的输出层之后增加自表示层, 使得网络输出与输入的自表示系数相同, 即(H(X)β)T=(H(X)β)TZ. SELM-AE的网络结构如图2所示, 其中图2(a)用于根据式(7)学习X的自表示系数矩阵Z; 图2(b)在 ELM-AE 网络的输出层之后增加网络输出 H(X)β的自表示层, 使网络输出H(X)β与输入X有相同的子空间结构.图2(b)将输入数据X的自表示系数矩阵Z引入子空间结构保持的极限学习机自编码器(SELA-AE)的自表示层, 其优化模型如下:
$$ \begin{split} \mathop {\min }\limits_{\boldsymbol{\beta }} f({\boldsymbol{\beta }}) =\;& \frac{{\rm{1}}}{{\rm{2}}}||{\boldsymbol{\beta }}||_{\rm{F}}^{\rm{2}} + \frac{c}{{\rm{2}}}||{\boldsymbol{X}} - {\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }}||_{\rm{F}}^2 + \\ &\frac{\lambda }{2}||{({\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }})^{\rm{T}}} - {({\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }})^{\rm{T}}}{\boldsymbol{Z}}||_{\rm{F}}^{\rm{2}} \end{split} $$ (8) 模型前两项与式(1)描述的 ELM-AE 模型相同, 第3项则为自表示误差项, 也称子空间结构保持项, 用以使SELM-AE的网络输出H(X)β保持原始数据的子空间结构, c 是自编码重构误差项的平衡参数, λ是自表示误差项的平衡参数.
由于
$\left\| {{{\left( {{\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }}} \right)}^{\rm{T}}}{\rm{ - }}{{\left( {{\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }}} \right)}^{\rm{T}}}{\boldsymbol{Z}}} \right\|_{\rm{F}}^{\rm{2}} = {\rm{tr}}[ {{\boldsymbol{\beta }}^{\rm{T}}}{\boldsymbol{H}^{\rm T}}{{({\boldsymbol{X}})}} $ $ ({\boldsymbol{I}} - {\boldsymbol{Z}})({\boldsymbol{I}} - {\boldsymbol{Z}})^{\rm{T}} {\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }}]$ , 则式(8)可改写为$$\begin{split} \mathop {\min }\limits_{\boldsymbol{\beta }} f({\boldsymbol{\beta }}) =\;& \frac{{\rm{1}}}{{\rm{2}}}||{\boldsymbol{\beta }}||_{\rm{F}}^{\rm{2}} + \frac{c}{{\rm{2}}}||{\boldsymbol{X}} - {\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }}||_{\rm{F}}^{\rm{2}} + \\ &{\rm{ }}\frac{\lambda }{{\rm{2}}}{\rm{tr}}\left[ {{{\boldsymbol{\beta }}^{\rm{T}}}{\boldsymbol{H}^{\rm T}}{{({\boldsymbol{X}})}}({\boldsymbol{I}} - {\boldsymbol{Z}}){{({\boldsymbol{I}} - {\boldsymbol{Z}})}^{\rm{T}}}{\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }}} \right] \end{split} $$ (9) 2.3 模型求解
为求解SELM-AE模型即式(9), 可令A = (I-Z)(I-Z)T, 则式(9)等价表示为
$$\begin{split} \mathop {\min }\limits_{\boldsymbol{\beta }} f({\boldsymbol{\beta }}) =\;& \frac{{\rm{1}}}{{\rm{2}}}||{\boldsymbol{\beta }}||_{\rm{F}}^{\rm{2}} + {\rm{ }}\frac{c}{{\rm{2}}}||{\boldsymbol{X}} - {\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }}||_{\rm{F}}^{\rm{2}} + \\ & {\rm{ }}\frac{\lambda }{{\rm{2}}}{\rm{tr}}({{\boldsymbol{\beta }}^{\rm{T}}}{\boldsymbol{H}^{\rm T}}{({\boldsymbol{X}})}{\boldsymbol{AH}}({\boldsymbol{X}}){\boldsymbol{\beta }}) \end{split} $$ (10) 式(10)是凸优化问题, 对其目标函数f(β)关于β求导并令导数为0得到
$$\begin{split} \frac{{{\rm{d}}f}}{{{\rm{d}}{\boldsymbol{\beta }}}} =\;& {\boldsymbol{\beta }} - c{\boldsymbol{H}^{\rm T}}{({\boldsymbol{X}})}({\boldsymbol{X}} - {\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }}) + \\ & {\rm{ }} \lambda {\boldsymbol{H}^{\rm T}}{({\boldsymbol{X}})}{\boldsymbol{AH}}({\boldsymbol{X}}){\boldsymbol{\beta }} = {\rm{0}} \end{split} $$ 整理上述方程得到
$$\begin{split} & {\boldsymbol{\beta }} + c{\boldsymbol{H}^{\rm T}}{({\boldsymbol{X}})}{\boldsymbol{H}}({\boldsymbol{X}}){\boldsymbol{\beta }} + \\ &\;\;\;\;\; \lambda {\boldsymbol{H}^{\rm T}}{({\boldsymbol{X}})}{\boldsymbol{AH}}({\boldsymbol{X}}){\boldsymbol{\beta }} = c{\boldsymbol{H}^{\rm T}}{({\boldsymbol{X}})}{\boldsymbol{X}} \end{split} $$ 提取公因子β
$$\begin{split} & \left[ {{\boldsymbol{I}} + c{\boldsymbol{H}^{\rm T}}{{({\boldsymbol{X}})}}{\boldsymbol{H}}({\boldsymbol{X}}) + \lambda {\boldsymbol{H}^{\rm T}}{{({\boldsymbol{X}})}}{\boldsymbol{AH}}({\boldsymbol{X}})} \right]{\boldsymbol{\beta }}= \\ &\qquad c{\boldsymbol{H}^{\rm T}}{({\boldsymbol{X}})}{\boldsymbol{X}} \end{split} $$ 解该方程得到以下解析解
$$\begin{split} {{\boldsymbol{\beta }}^ * } =\;& [{\boldsymbol{I}} + c{\boldsymbol{H}^{\rm{T}}}{({\boldsymbol{X}})}{\boldsymbol{H}}({\boldsymbol{X}}) +\\ & \lambda {\boldsymbol{H}^{\rm{T}}{({\boldsymbol{X}})}}{\boldsymbol{AH}}({\boldsymbol{X}}){]^{ - {\rm{1}}}}c{\boldsymbol{H}^{\rm{T}}}{({\boldsymbol{X}})}{\boldsymbol{X}} \end{split} $$ (11) 最优权值矩阵β*与隐层输出H(X)相乘既可得到网络的输出H(X)β, 该输出是网络对输入X的最佳估计. 网络权值矩阵β是隐含层到网络输出层即输入数据的线性变换, 可通过最优权值矩阵β*进行降维, 降维后样本为X' = X(β*)T.
2.4 多层极限学习机自编码器(ML-SELM-AE)
由第2.3节讨论可知, 通过SELM-AE模型可以直接计算隐含层到输出层的最优权值矩阵β*, 计算速度快, 泛化性好. SELM-AE 网络以数据降维表示为目标, 其降维后样本维数与隐层节点数相等, 因此隐层节点数量通常远小于原始维数和样本数. 但作为单层神经网络, 较少的隐层节点会降低其对非线性投影函数的逼近能力. 受文献[16]的深度有监督极限学习机方法启发, 本文扩展单层子空间结构保持极限学习机自编码器SELM-AE为多层子空间结构保持极限学习机自编码器ML-SELM-AE (如图3), 以获取数据的深层特征.
图3所示的多层子空间结构保持极限学习机自编码器相当于多个SELM-AE自编码器的堆叠, 利用上述式(11)计算每一层最优权值矩阵β(l)(l = 1, 2, ···, L),将上一层输出X(l)(β(l))T作为下一层输入. ML-SELM-AE网络第l层(l = 1, 2, ..., L)随机产生正交输入权矩阵W(l)和偏置向量b(l); 第1层初始输入为原始数据X(1)=X, 第l层(l = 1, 2, ···, L)的权值矩阵β(l)根据式(11)改写为:
$$\begin{split} {{\boldsymbol{\beta }}^{(l)}} =\;& [{\boldsymbol{I}} + c{\boldsymbol{H}^{\rm T}}{({{\boldsymbol{X}}^{(l)}})}{\boldsymbol{H}}({{\boldsymbol{X}}^{(l)}}) + \\ &\lambda {\boldsymbol{H}^{\rm T}}{({{\boldsymbol{X}}^{(l)}})}{\boldsymbol{AH}}({{\boldsymbol{X}}^{(l)}}){]^{ - {\rm{1}}}}c{\boldsymbol{H}^{\rm T}}{({{\boldsymbol{X}}^{(l)}})}{{\boldsymbol{X}}^{(l)}} \end{split} $$ (12) 第l+1层输入X(l+1)可通过下式计算:
$${{\boldsymbol{X}}^{(l + 1)}} = {{\boldsymbol{X}}^{(l)}}{({{\boldsymbol{\beta }}^{(l)}})^{\rm{T}}}$$ (13) 其中, β(l)为第l层解码器的输出权矩阵. 若自编码器有L层, 则第L层的输出X(L+1)=X(L)(β(L))T, 即为降维后数据, 对降维后数据X(L+1)使用k-means算法完成聚类.
多层子空间结构保持极限学习自编码器ML-SELM-AE求解算法归纳如下:
算法1. ML-SELM-AE算法
输入. 数据矩阵{X}=
$\{ {x_i}\} _{i = 1}^n $ , 隐层节点数(维数)nh, 参数c > 0, λ > 0, 层数L输出. 降维后数据矩阵X(L+1)
1) 计算X自表示矩阵
$$\substack{ {\boldsymbol{Z}} = {[{{\boldsymbol{X}}^{\rm{T}}}{\boldsymbol{X}} + \lambda {\boldsymbol{I}}]^{ - 1}}{{\boldsymbol{X}}^{\rm{T}}}{\boldsymbol{X}};} $$ 2) 初始化第1层输入X (1) = X;
3) For l =1 to L
随机初始化第l层输入权重W(l)和偏置b(l);
通过式 (12) 计算第l 层输出权值 β(l);
通过式(13)计算第l层输出, 作为第l+1层输入, X(l+1) = X(l)(β(l))T;
end
4) 输出降维后数据矩阵X(L+1).
ML-SELM-AE算法中步骤 1)的时间开销主要用于矩阵乘法与n阶矩阵逆的计算, 时间复杂度分别为O(n2m)和O(n3); 若多层极限学习机网络层数为L, 则步骤3)需循环L次计算每一层SELM-AE的输出权值β(l)及输出X(l), 每次循环的时间开销主要用于权值β(l)的计算, 包括计算矩阵乘法与nh阶矩阵的逆, 矩阵乘法计算时间复杂度分别为O(nh2m)和O(nhnm),矩阵逆的计算时间复杂度为O(nh3). 对于高维小样本数据集, 样本数n远小于样本维数m, 故而当样本维数m小于隐层节点数nh时, 算法总时间复杂度为O(Lnh3); 当样本维数m大于隐层节点数nh时, 算法总时间复杂度为O(Lnh2m).
3. 实验
3.1 实验对比方法及参数设置
为验证本文所提的子空间结构保持单层极限学习机降维自编码器SELM-AE和多层极限学习机自编码器ML-SELM-AE的降维效果和有效性, 本文对两种方法进行数据可视化及高维数据降维聚类实验.
实验对比的其他降维方法有以下几种:
1)线性无监督降维
主成分分析法(Principal component analysis, PCA)[17]: 以最大化投影方差为目标, 方差虽可以刻画全局分布散度, 但无法描述样本间的近邻关系.
局部保持投影法(Locality preserving projections, LPP)[18]: 以保持降维前后样本间的近邻关系不变为目标.
近邻保持嵌入法(Neighborhood preserving embedding, NPE)[19]: 以最小化k近邻重构误差为目标, 旨在保持降维前后样本间的局部近邻结构.
2)传统无监督ELM
US-ELM: 无监督极限学习机, 利用无类别信息的流形正则项代替含类标签的误差函数, 将有监督极限学习机转化为无监督极限学习机, 实现原始数据向低维空间的非线性映射, 并能够得到显式的非线性映射函数. 但该方法预定义的近邻矩阵不具有数据自适应性.
ELM-AE: 极限学习机自编码器, 用原始数据替代误差函数中的类标签, 将有监督极限学习机转化为无监督式的极限学习机自编码器, 实现原始数据向低维空间的非线性映射. 但该方法仅考虑数据全局非线性特征.
ELM-AE的多层版本(Multilayer ELM-AE, ML-ELM-AE): 其多层扩展的思想与本文提出的ML-SELM-AE相同. 目的在于和ML-SELM-AE(子空间结构保持的多层极限学习机自编码器)进行对比.
3)面向聚类的子空间结构保持无监督ELM
SNP-ELM: 基于稀疏和近邻保持的极限学习机降维算法, 该方法引入稀疏及近邻保持模型学习US-ELM模型流形正则项所需的近邻矩阵, 具有较好的数据自适应性. 但需迭代求解稀疏优化问题, 运行时间较长.
SELM-AE: 本文提出的子空间结构保持极限学习机自编码器.该模型在ELM-AE模型基础上, 采用样本自表示模型刻画样本数据的子空间结构和样本间近邻关系, 使网络输出数据保持子空间结构不变, 具有较好的数据自适应性.
ML-SELM-AE:本文提出的SELM-AE模型多层版本.
3.2 实验数据集
实验采用2个脑电数据集、3个高维基因表达谱数据及UCI中的IRIS数据集[20]进行测试, 脑电数据集包括BCI竞赛II数据集IIb中的Session 10和Session 11、BCI竞赛III数据集II中的Subject A训练集[21], 基因表达数据集包括DLBCL、Prostate0和Colon[22].
研究表明, 脑电数据中C3、Cz、C4、Fz、P3、Pz、P4、PO7、PO8和Oz这10个电极的可分性更好[23], 因此选取BCI竞赛II数据集Data set IIb的该10个电极通道每轮行或列刺激后600 ms的脑电数据作为实验数据并进行0.5~30 Hz的巴特沃斯滤波; 对BCI竞赛III数据集Data set II选取相同10个电极通道每轮行或列刺激后1 s的脑电数据作为实验数据并进行0.1~20 Hz的巴特沃斯滤波. 数据集具体描述如表1所示.
表 1 数据集描述Table 1 The data set description数据集 维数 样本数 类别数 IRIS 4 150 3 Data set IIb 1440 504 2 Data set II 2400 1020 2 DLBCL 5469 77 2 Colon 2 000 62 2 Prostate0 6033 102 2 3.3 可视化实验
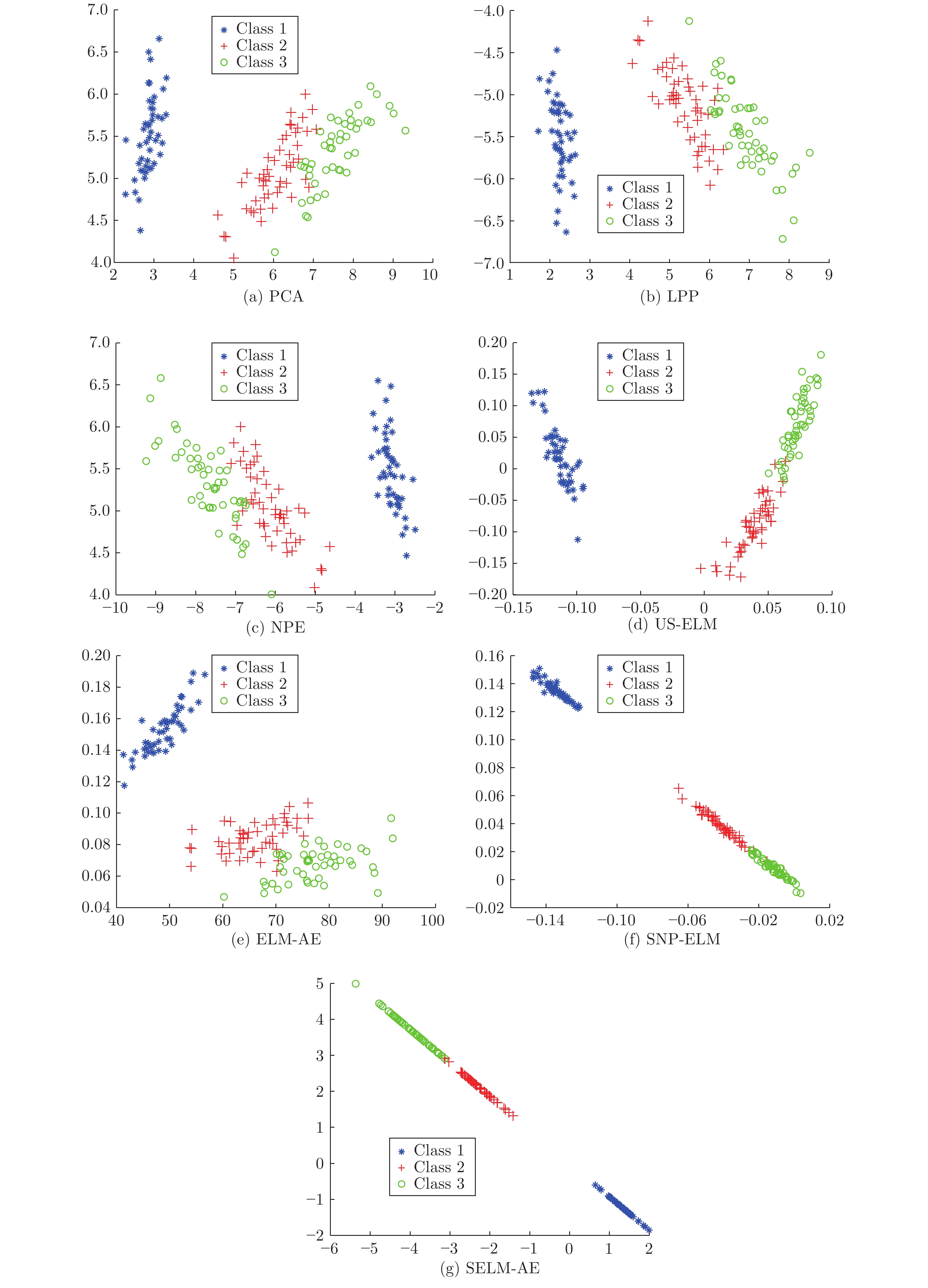
本实验分别用PCA、LPP、NPE、US-ELM、ELM-AE、SNP-ELM和SELM-AE七种方法将一个人造数据集和一个真实UCI数据集投影到一维和二维空间, 并选取每种降维方法的最优结果进行展示.
数据可视化及数据降维聚类实验采用相同的参数设置. LPP、NPE和US-ELM的近邻数k均取5. ELM-AE、SNP-ELM和SELM-AE的平衡参数c和λ均采用网格搜索策略设置, 统一参数搜索范围为{10−3, 10−2, ···, 103}. 所有极限学习机算法的激励函数均采用Sigmoid函数, 含流形正则项的极限学习机降维方法US-ELM和SNP-ELM降维后样本维数由特征方程的特征向量个数决定, 其隐层节点数设为1000. 极限学习机自编码器降维方法ELM-AE和SELM-AE隐层节点数与降维后样本维数相同.多层算法 ML-ELM-AE 和 ML-SELM-AE 中每一层的隐节点数均与第1层相同, 隐含层层数为 3.
3.3.1 一维可视化
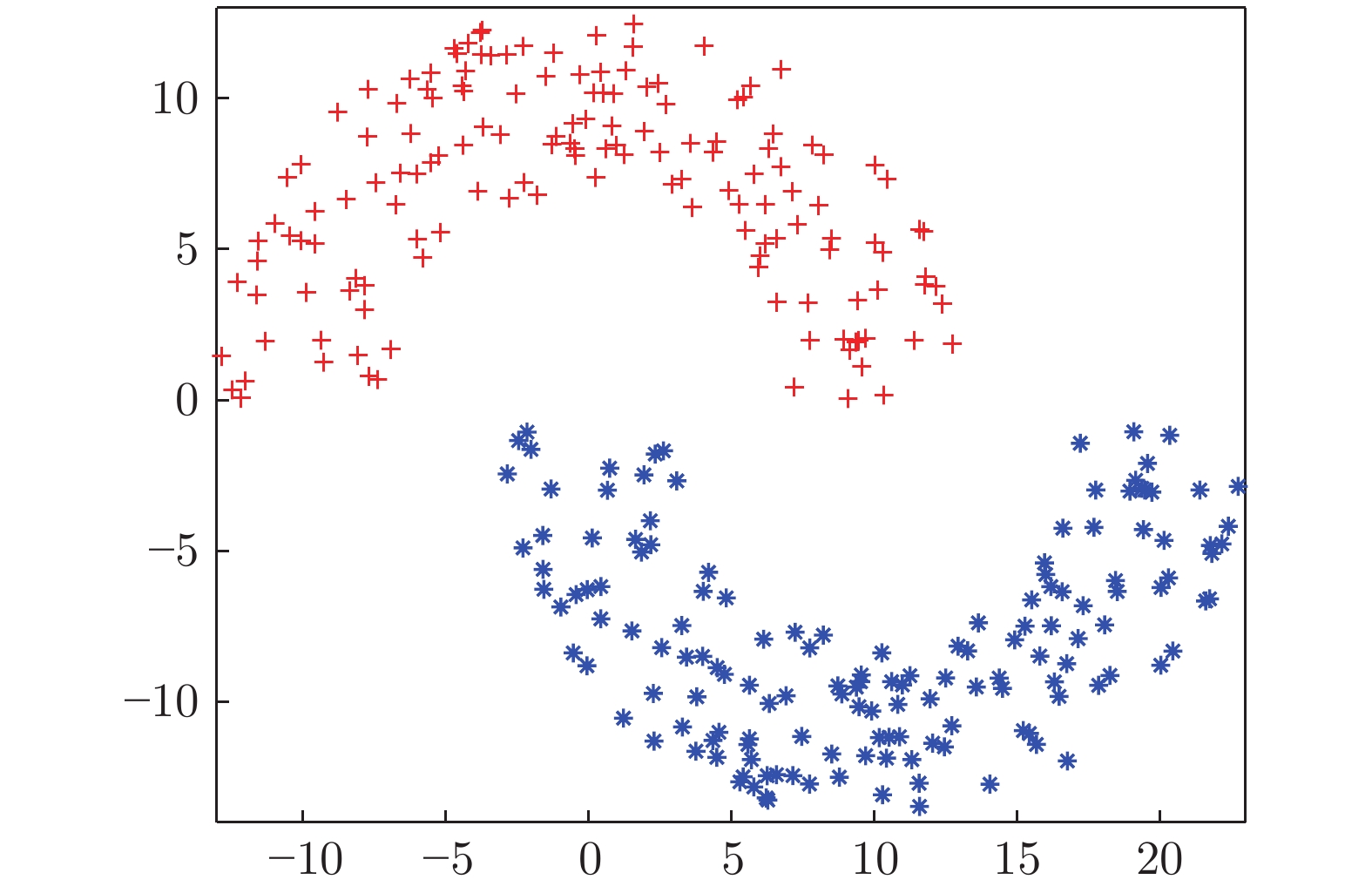
本实验使用的二维人造双月数据集如图4所示, 该数据包含2类, 每类有150个样本. 该实验将双月数据用7种不同降维方法降至一维后的结果如图5所示.
从图5可以看出, PCA以投影后的样本方差最大为目标, 其降维结果近似于把该数据投影到双月数据方差最大的 X 轴方向, 投影后2类样本交叠明显、可分性差; 基于流形思想的LPP、NPE和US-ELM均以降维后样本保持原样本的近邻结构为目的, 但US-ELM投影到 1 维后的可分性明显优于LPP和NPE, 其降维后不同类样本的交叠程度较 LPP和NPE更低. 原因在于双月数据是非线性数据, 而US-ELM包含非线性神经网络结构, 其对非线性特征的表示能力比仅采用流形思想的LPP和NPE更强. ELM-AE也是基于极限学习机的非线性降维方法, 其通过自编码网络刻画数据全局非线性特征, 较之基于数据局部流形结构的US-ELM方法, 其降维后样本的可分性进一步改善.
SNP-ELM和SELM-AE也是非线性降维方法, 均在极限学习机降维基础上引入子空间结构保持特性, SNP-ELM使降维后样本同时保持数据的近邻结构和稀疏结构, SELM-AE 使自编码网络输出数据保持子空间结构不变, 这两种方法尽可能保持原样本的潜在结构使该数据投影到1维后2类样本完全分离, 不同类样本间没有交叠, 且本文提出的 SELM-AE 方法投影后样本的内聚度较之SNP-ELM更佳, 类间可分性最优.
3.3.2 二维可视化
本实验使用的IRIS数据包含3类150个样本, 每个样本有4个特征. 分别采用PCA、LPP、NPE、US-ELM、ELM-AE、SNP-ELM和SELM-AE七种降维方法将IRIS数据投影至2维后如图6所示. 从图6可以看出, 二维可视化与一维可视化实验结论类似, 即在七种降维方法中, SELM-AE降维后样本同类聚集性最好, 不同类样本交叠程度最低、可分性最优.
3.4 降维聚类对比实验
在6个实验数据集上分别采用本文方法SELM-AE、ML-SELM-AE与对比方法PCA、LPP、NPE、US-ELM、ELM-AE、ML-ELM-AE、SNP-ELM进行降维. 其中多层极限学习机自编码器ML-ELM-AE和ML-SELM-AE的层数L设为3, 每层极限学习机的隐层节点数固定为降维维数. 所有模型的最优参数均通过网格搜索得到, 降维维数的搜索范围为{21, 22, 23, ···, 210}; 参数c和λ的搜索范围为{10−3, 10−2, ···, 103}; 模型SNP-ELM参数η和δ的搜索范围为[−1, 1], 搜索步长为0.2.
3.4.1 k-means聚类
对降维后样本进行k-means聚类, 为避免k-means随机选取初始中心导致聚类结果的随机性, 以10次聚类的平均准确率为最终准确率[24]. 3种传统降维方法PCA、LPP和NPE的聚类准确率(方差, 维数)如表2所示, 6种ELM降维方法的聚类准确率(方差, 维数)如表3所示. 表2和表3是网格搜索最优参数得到的最佳平均聚类准确率、方差及对应维数.
表 2 传统降维方法的聚类准确率(%) (方差, 维数)Table 2 Comparison of clustering accuracy of traditional methods (%) (variance, dimension)数据集 k-means 传统算法 PCA LPP NPE IRIS 89.13 (0.32) 89.07 (0.34, 4) 90.27 (0.84, 2) 88.67 (0.00, 2) Data set IIb 86.47 (2.53) 88.21 (0.61, 4) 88.69 (7.33, 4) 89.58 (6.32, 256) Data set II 72.38 (8.94) 79.31 (4.39, 2) 82.26 (0.13, 512) 82.62 (0.71, 256) DLBCL 68.83 (0.00) 68.83 (0.00, 2) 63.55 (1.86, 8) 69.09 (0.82, 32) Colon 54.84 (0.00) 54.84 (0.00, 2) 54.84 (0.00, 2) 56.45 (0.00, 2) Prostate0 56.86 (0.00) 56.83 (0.00, 2) 56.86 (0.00, 2) 56.86 (0.00, 4) 表 3 ELM降维方法聚类准确率(%) (方差, 维数)(参数)Table 3 Comparison of clustering accuracy of ELM methods (%) (variance, dimension)(parameters)数据集 k-means Unsupervised ELM Subspace + unsupervised ELM US-ELM(λ) ELM-AE(c) ML-ELM-AE (c) SNP-ELM(λ,η,δ) SELM-AE(c, λ) ML-SELM-AE(c, λ) IRIS 89.13
(0.32)93.87
(13.78, 2)
(0.1)93.93
(1.19, 2)
(10)95.20
(1.05, 2)
(0.01)98.46
(0.32, 2)
(10, 0.6, −1)98.00
(0.00, 2)
(10, 0.01)98.40
(0.56, 2)
(10, 0.01)Data set IIb 86.47
(2.53)91.59
(4.25, 4)
(0.1)91.98
(0.25, 4)
(0.1)92.46
(0.08, 16)
(1)92.06
(0.13, 16)
(0.001, 0.8, 0.2)95.29
(0.06, 8)
(0.001, 1)96.63
(0.00, 8)
(0.001, 0.1)Data set II 72.38
(8.94)83.18
(0.32, 256)
(10)82.84
(0.00, 2)
(0.001)83.03
(0.00, 2)
(0.1)83.92
(1.65, 2)
(10, 0.2, −0.2)83.14
(0.00, 2)
(0.01, 1)84.22
(0.00, 2)
(0.001, 10)DLBCL 68.83
(0.00)76.62
(0.00, 32)
(0.001)78.05
(0.73, 2)
(0.001)82.46
(0.68, 2)
(0.001)86.34
(1.78, 8)
(0.001, -0.2, 0.6)83.63
(2.51, 2)
(10, 0.1)86.71
(3.48, 2)
(10, 1)Colon 54.84
(0.00)67.06
(4.19, 32)
(0.001)69.35
(0.00, 2)
(0.001)80.32
(1.02, 2)
(0.001)85.95
(3.69, 8)
(0.001, −0.8, 1)83.87
(0.00, 4)
(10, 0.1)85.97
(0.78, 2)
(10, 0.1)Prostate0 56.86
(0.00)64.09
(5.83, 2)
(0.01)75.98
(0.51, 2)
(0.01)79.61
(1.01, 2)
(0.01)82.92
(2.19, 128)
(0.1, 0.2, 0.8)84.31
(0.00, 2)
(10, 1)85.29
(0.00, 2)
(10, 0.01)表3中粗体值代表9种降维方法中聚类准确率最高者, 下划线值代表第2高者, 第3高者采用粗体加下划线标记. 由记. 由表2 ~ 3可以看出:
1) 经3种传统方法降维后的聚类准确率明显低于6种 ELM 降维方法. 原因在于PCA、LPP和NPE是全局线性降维模型, 其对非线性数据特征的描述能力低于非线性极限学习机降维方法.
2) 本文提出的ML-SELM-AE在5个数据集上取得最高的聚类准确率, 在IRIS数据集的准确率也接近最高值. 主要原因在于子空间结构保持项和多层编码器结构分别揭示了原始数据的子空间结构和非线性特征. ML-SELM-AE对应的单层方法SELM-AE和未引入子空间结构保持项的多层自编码器ML-ELM-AE聚类准确率均低于ML-SELM-AE, SELM-AE低0.3% ~ 3.1%, ML-ELM-AE低1.6% ~ 5.6%, 说明在准确率提升方面子空间结构保持项的作用优于编码器层数的增加. 多层ML-SELM-AE与单层SELM-AE在多数数据集上的聚类准确率不相上下, 且单层SELM-AE的计算速度更快.
3) 对比方法SNP-ELM的聚类准确率略低于ML-SELM-AE, 与SELM-AE相当, 但优于未考虑子空间结构保持项的其他降维方法, 且优势明显. 进一步说明子空间结构保持的重要性.
SNP-ELM模型的局限在学习样本的近邻表示和稀疏表示存在迭代求解过程, 耗时较长. 而本文的SELM-AE模型有解析解, 计算效率明显高于SNP-ELM, 即使在多层情况下也快于SNP-ELM. 从表4给出的SNP-ELM、SELM-AE和ML-SELM-AE运行时间便可以看出, SNP-ELM的运行时间明显高于SELM-AE和ML-SELM-AE, 是二者的100倍~1000倍. 因此, 综合考虑准确率和效率, 本文提出的SELM-AE和ML-SELM-AE较之SNP-ELM更有优势.
表 4 运行时间对比(s)Table 4 Comparison of running time (s)数据集 SNP-ELM SELM-AE ML-SELM-AE IRIS 4.58 0.02 0.02 Data set IIb 4.64×103 0.16 0.33 Data set II 8.24×103 0.65 0.76 DLBCL 7.77 0.04 0.06 Colon 3.44×102 0.03 0.11 Prostate0 1.15×102 0.07 0.13 4)对比ELM-AE、SELM-AE和相应的多层版本ML-ELM-AE 、ML-SELM-AE, 多层版本聚类准确率均高于对应的单层版本, 差距普遍在0.2%~4.0%之间, 说明增加网络层数可以提取更丰富的非线性特征, 提高降维样本的聚类准确率.
3.4.2 多种聚类方法对比实验
为观察不同聚类方法的影响, 进一步对降维前后数据应用三种子空间聚类方法进行聚类, 包括最小二乘回归子空间聚类(LSR)[14]、低秩表示子空间聚类(LRR)[25]和潜在低秩表示子空间聚类(LatLRR)[26]. 为取得最优结果, 3种聚类模型的最优参数λ均通过网格搜索得到, LSR和LRR的参数搜索范围为{10−3, 10−2, ···, 103}, LatLRR的参数搜索范围为{10−5, 10−4, ···, 1}.
在6个实验数据集上对未降维数据和采用ML-SELM-AE 降至2维后数据进行聚类实验, 不同聚类方法的聚类准确率及方差如表5所示.
表 5 ML-SELM-AE降维前后数据的聚类准确率(%) (方差)Table 5 Clustering accuracy before and after ML-SELM-AE dimensionality reduction (%) (variance)数据集 k-means LSR LRR LatLRR 未降维 已降维 未降维 已降维 未降维 已降维 未降维 已降维 IRIS 89.13 (0.32) 98.40 (0.00) 82.40 (0.69) 97.33 (0.00) 90.87 (0.00) 94.00 (0.83) 81.27 (1.03) 97.33 (0.00) Data set IIb 86.47 (2.53) 93.25 (0.00) 83.13 (0.00) 86.59 (0.19) 83.13 (0.00) 86.11 (0.00) 83.13 (0.00) 86.48 (0.25) Data set II 72.38 (8.94) 84.22 (0.00) 83.24 (0.08) 83.29 (0.05) 83.24 (0.00) 83.24 (0.00) 83.24 (0.00) 83.33 (0.00) DLBCL 68.83 (0.00) 86.71 (3.48) 76.62 (0.00) 81.43 (0.63) 76.62 (0.00) 78.57 (0.68) 74.03 (0.00) 78.18 (3.23) Colon 54.84 (0.00) 85.97 (0.78) 67.74 (0.00) 74.19 (0.00) 63.39 (0.00) 69.35 (0.00) 66.13 (1.67) 75.65 (4.06) Prostate0 56.86 (0.00) 85.29 (0.00) 63.82 (1.37) 70.59 (0.00) 57.84 (0.00) 63.73 (0.00) 55.88 (0.00) 74.51 (0.00) 从表5可以看出, 对于未降维高维数据, 子空间聚类方法 LSR 和 LRR 均优于 k-means 聚类. 但经过ML-SELM-AE降维后, k-means聚类的准确率明显高于三种子空间聚类方法, 且比未降维时的聚类准确率有显著提高. 该实验结果进一步说明采用多层极限学习机和子空间结构保持可使降维数据蕴含更丰富的聚簇信息, 聚类划分更容易.
3.4.3 多层极限学习机隐层节点数对聚类结果的影响
为观察多层极限学习机隐层节点数的不同设置对聚类结果的影响, 将ML-ELM-AE和ML-SELM-AE两种三层极限学习机自编码器的隐层节点数分别设为500-100-2、500-100-10、500-100-100及2-2-2、10-10-10、100-100-100, 并对高维数据集Data set IIb、Data set II、DLBCL、Colon和Prostate0进行降维和聚类, 取得的k-means聚类准确率如表6所示.
表 6 三层极限学习机自编码器隐层节点数与聚类准确率(%) (方差)Table 6 The number of hidden layer nodes and clustering accuracy for three-layer extreme learning machine autoencoder (%) (variance)数据集 ML-ELM-AE (Multilayer ELM-AE) ML-SELM-AE (Multilayer SELM-AE) 500-100-2 500-100-10 500-100-50 500-100-100 500-100-2 500-100-10 500-100-50 500-100-100 Data set IIb 88.69 (0.00) 91.98 (0.25) 90.89 (0.06) 87.66 (0.20) 95.44 (0.00) 94.92 (0.17) 95.44 (0.00) 94.80 (0.33) Data set II 82.94 (0.00) 82.94 (0.00) 82.94 (0.00) 82.94 (0.00) 83.14 (0.00) 83.04 (0.00) 83.04 (0.00) 83.04 (0.00) DLBCL 74.03 (0.00) 72.99 (3.29) 72.73 (0.00) 69.22 (0.88) 80.52 (0.00) 80.52 (0.00) 78.57 (2.05) 76.62 (0.00) Colon 73.87 (1.67) 59.68 (0.00) 69.52 (7.35) 59.03 (0.83) 78.55 (2.53) 75.97 (7.81) 76.13 (9.46) 70.48 (4.37) Prostate0 66.67 (0.00) 60.78 (0.00) 59.80 (0.00) 62.75 (0.00) 77.16 (0.47) 82.35 (0.00) 78.33 (6.51) 80.39 (0.00) 数据集 2-2-2 10-10-10 50-50-50 100-100-100 2-2-2 10-10-10 50-50-50 100-100-100 Data set IIb 92.46 (0.08) 90.48 (0.00) 90.16 (0.17) 90.40 (0.25) 96.63 (0.00) 95.83 (0.00) 95.44 (0.00) 94.84 (0.00) Data set II 83.04 (0.00) 83.04 (0.00) 83.04 (0.00) 82.94 (0.00) 84.22 (0.00) 83.14 (0.00) 83.04 (0.00) 83.04 (0.00) DLBCL 83.12 (0.00) 77.01 (0.63) 68.83 (0.00) 68.70 (0.41) 86.75 (4.23) 80.52 (0.00) 78.96 (0.82) 76.62 (0.00) Colon 80.64 (0.00) 60.00 (2.50) 70.00 (1.36) 62.90 (0.00) 85.97 (0.78) 68.23 (0.78) 80.65 (0.00) 76.61 (9.48) Prostate0 80.39 (0.00) 57.45 (0.83) 64.41 (0.47) 63.73 (0.00) 85.29 (0.00) 69.61 (0.00) 79.12 (6.67) 84.31 (0.00) 从表6可以看出, 在5个实验数据集上, 无论是ML-ELM-AE还是ML-SELM-AE, 三层隐层节点数均取2时的聚类准确率最优. 且隐层节点数取固定值与非固定值的聚类准确率差别不明显, 固定隐层节点数的聚类准确率总体略好于不固定隐层节点数.
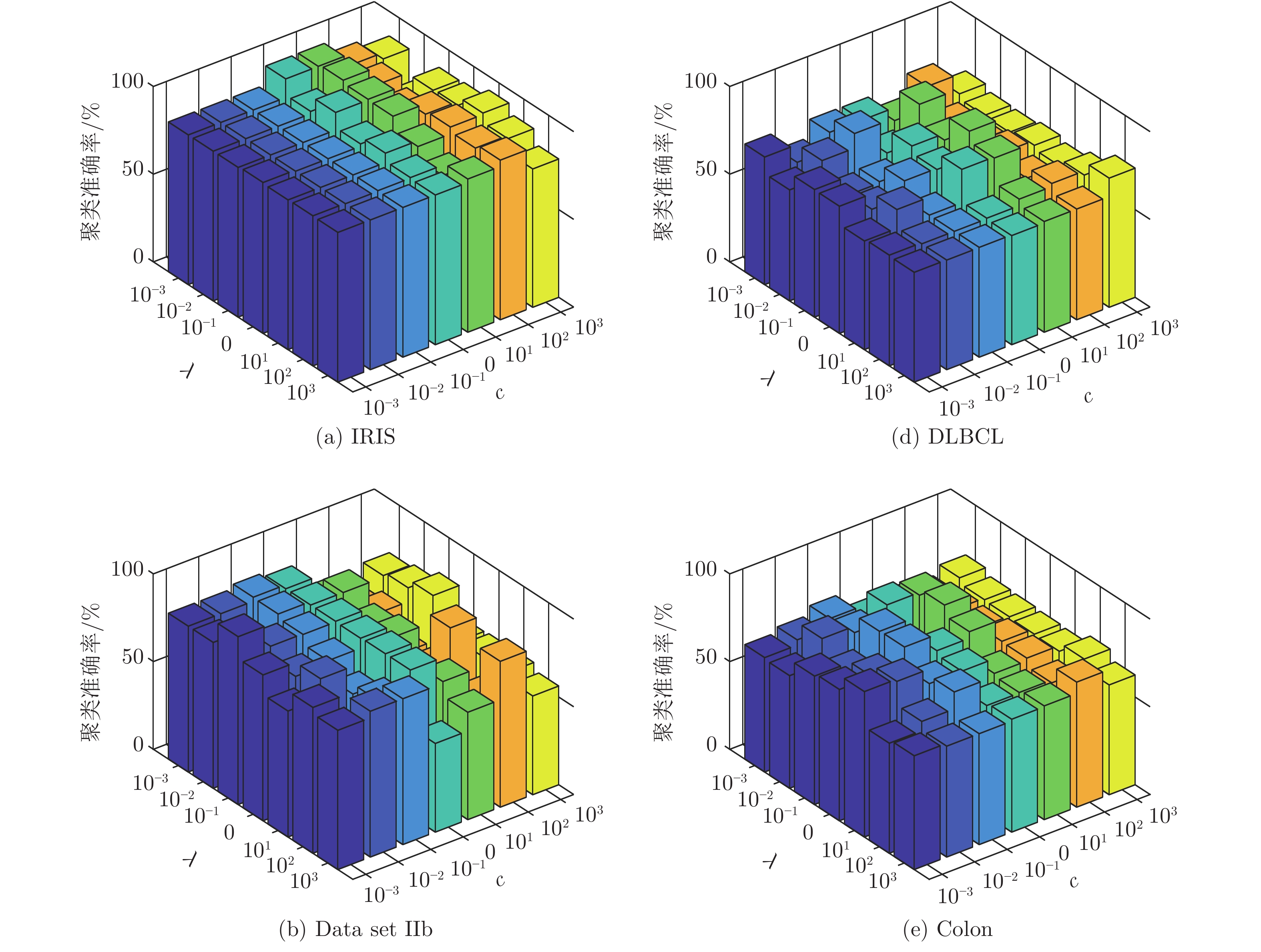
3.5 SELM-AE模型参数分析
由表5的实验结果可知, 本文提的SELM-AE模型将数据投影到2维时便能取得较高的k-means聚类准确率, 因此取固定维数2情况下进行参数分析. SELM-AE模型的参数c和λ, 分别是目标函数中自编码重构误差项和子空间结构保持项的平衡参数.
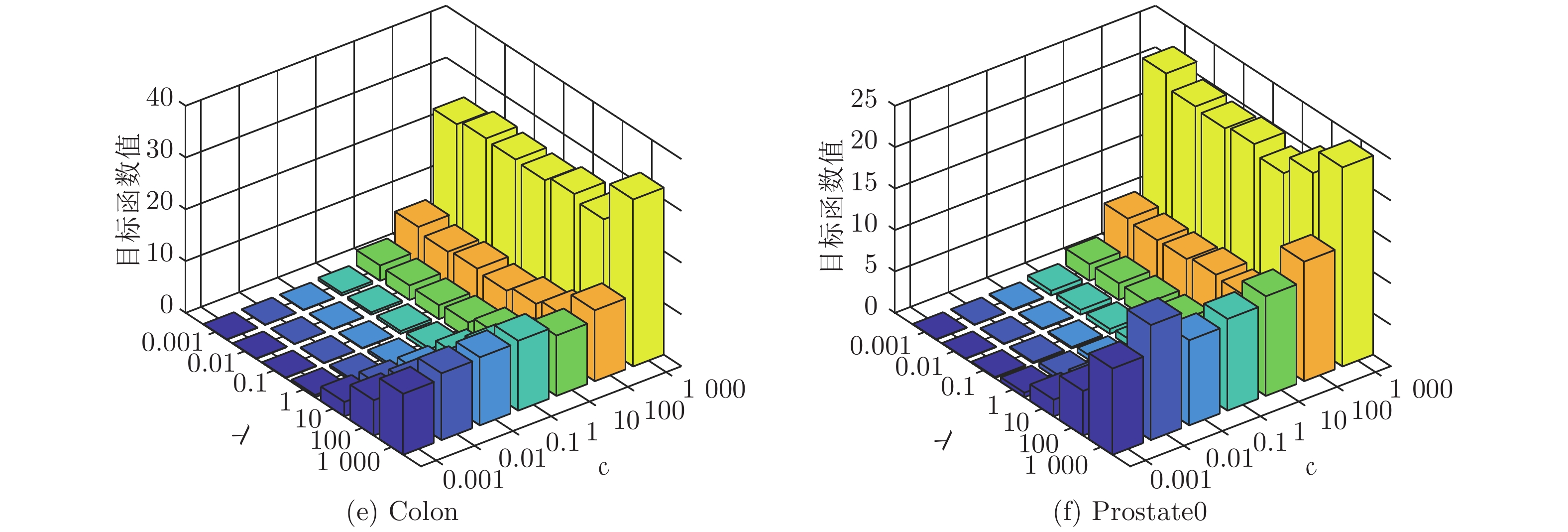
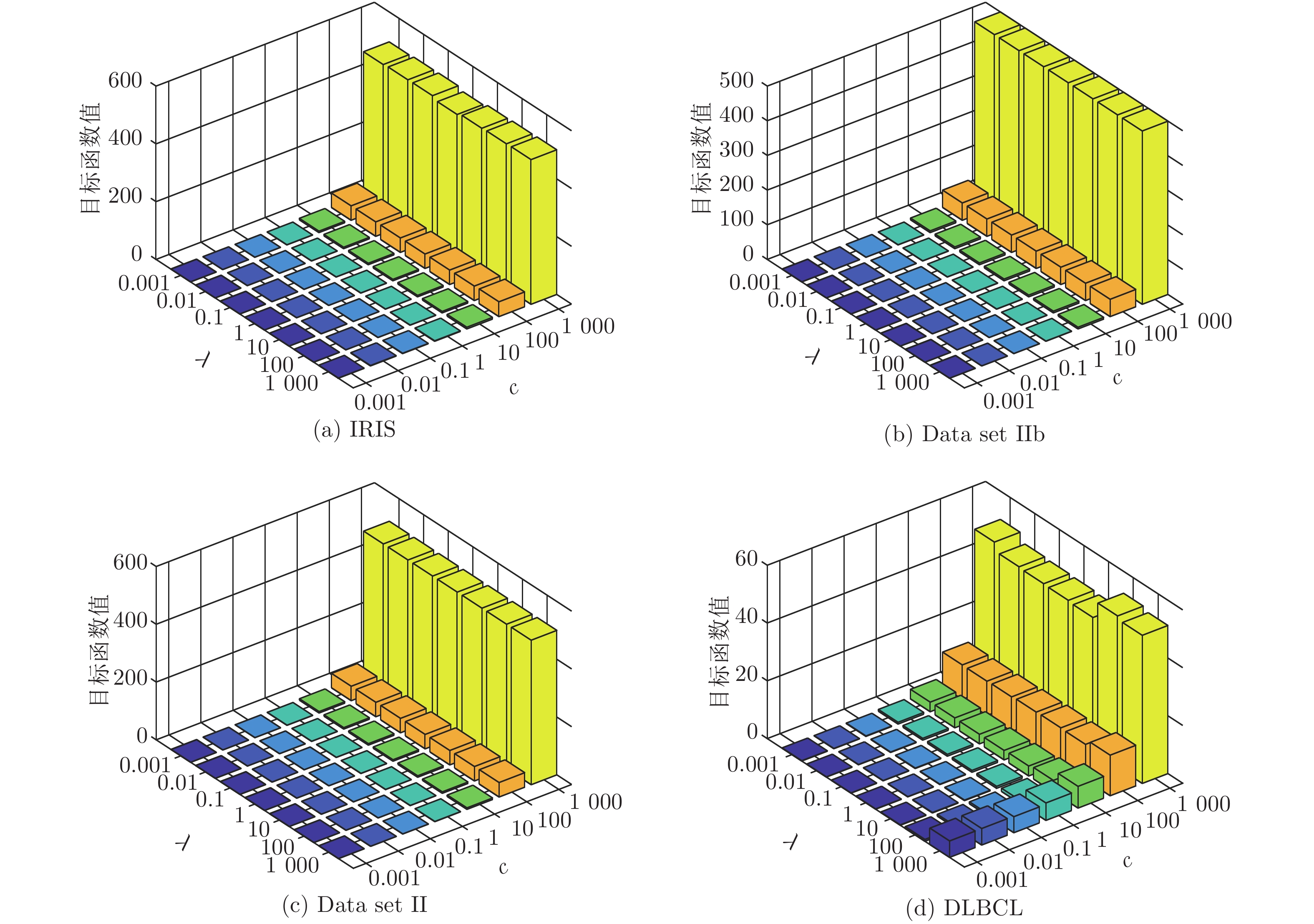
3.5.1 目标函数值随参数c与λ的变化情况
SELM-AE模型以最小化目标函数值为目标. 本实验目的在于观察模型的目标函数值随参数c和λ变化情况(如图7), c和λ的取值范围均为{10−3, 10−2, ···, 103}.
由图7可以看出, 参数λ的变化对目标函数值的影响较小, 而参数c的变化对目标函数值的影响较大. 总体来看, 参数c和λ在区间[0.001, 10]内取值时, 目标函数值最小.
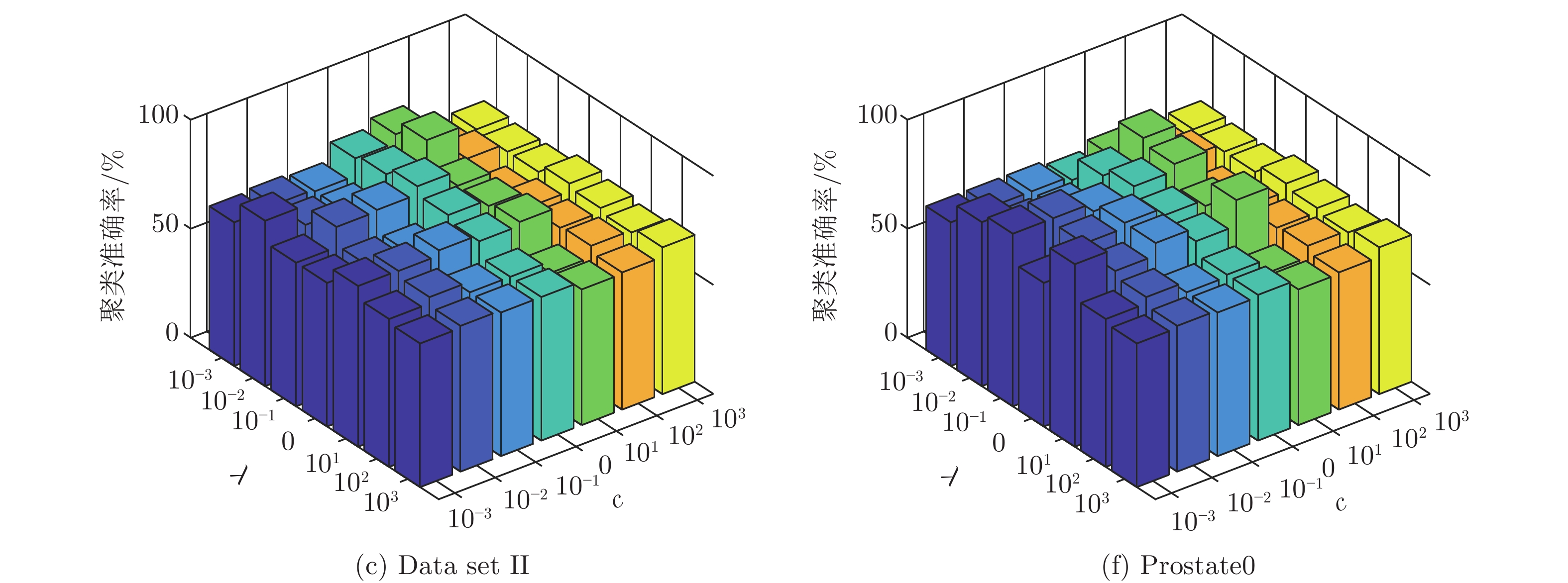
3.5.2 聚类准确率随参数c与λ的变化情况
为进一步观察SELM-AE模型聚类准确率随参数c和λ的变化情况, 图8给出参数c和λ取不同值时的k-means聚类准确率, 其中c和λ的变化范围为{10−3, 10−2, ···, 103}. 由图8可以看出, 参数c和λ在区间[0.001, 10]内取值时, 能取得最高的聚类准确率, 该参数的最佳取值区间与图7的分析结论一致.
4. 结束语
在极限学习机自编码器ELM-AE基础上, 本文提出子空间结构保持的极限学习机自编码器SELM-AE及其多层版本ML-SELM-AE. SELM-AE在极限学习机自编码器的输出层增加自表示层, 引入最小二乘回归子空间结构模型, 使自编码器输出与输入的自表示系数相同. 多层子空间结构保持极限学习自编码器ML-SELM-AE通过增加 SELM-AE自编码器层数获取数据的深层特征, 提高网络的特征提取能力. 在6个数据集上的实验结果表明, 经SELM-AE和ML-SELM-AE降维后的聚类准确率普遍优于经典降维方法和传统的ELM降维方法. 同时多层ML-SELM-AE因对非线性投影函数的逼近能力优于单层的SELM-AE模型, 其降维后数据的聚类准确率更高.
-

图 1 均匀运动模糊图像和非均匀运动模糊图像及其模糊核示意图
Fig. 1 Uniform and non-uniform motion blurry image and their blur kernel diagram

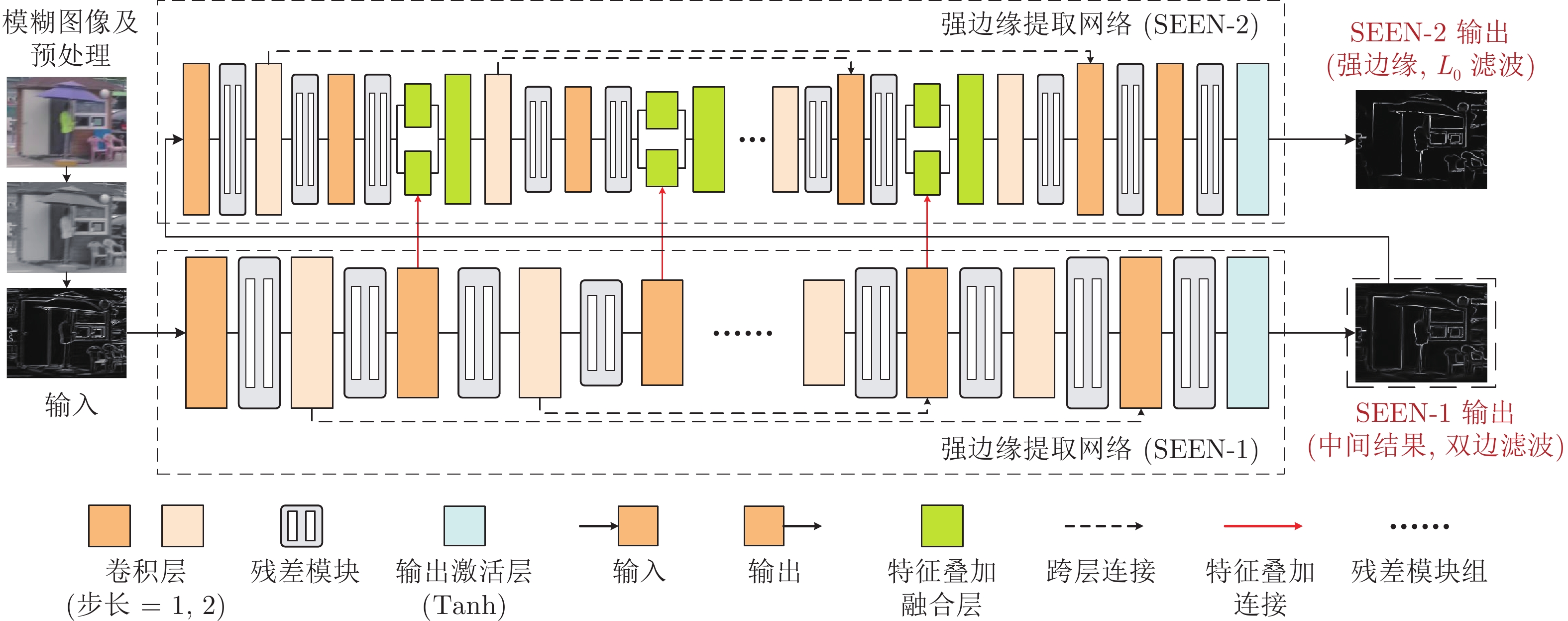
图 2 提出的非均匀运动模糊图像复原网络结构图
Fig. 2 Proposed network structure for the non-uniform motion blurry image deblurring

图 5 本文提出的双方向融合梯度计算方法示意图
Fig. 5 Diagram of gradient calculation method of two-directions fusion proposed in this paper

图 9 有无强边缘提取网络的非均匀模糊图像复原结果比较实例 ((a) 模糊图像; (b) 模糊图像梯度图;(c) SEEN-1 输出; (d) SEEN-2 输出 (强边缘); (e) 无强边缘提取网络的复原结果;(f) 有强边缘提取网络的复原结果; (g) 清晰图像)
Fig. 9 Comparison of restoration results of non-uniform motion blurry image with or without edge extraction network ((a) Blurry image; (b) Gradient of blurry image; (c) Output of SEEN-1; (d) Edge of SEEN-2 (Strong edge); (e) Restoration results of network without strong edge extraction network; (f) Restoration results of network with strong edge extraction network; (g) Clear image)

图 10 强边缘提取网络中间结果分析
Fig. 10 The intermediate results analysis of strong edge extraction network

图 11 强边缘提取网络效果分析
((i)模糊图像小块(30×30); (ii)模糊图像小块边缘(30×30); (iii) SEEN-1输出;(iv) SEEN-2输出; (v)灰度分布图; (vi)列灰度值加和曲线图)
Fig. 11 Effect analysis of strong edge extraction network
((i) Blurry image patch (30×30); (ii) Edge of blurry image patch (30×30); (iii) Output of SEEN-1; (iv) Output of SEEN-2; (v) Gray value distribution; (vi) Column gray value addition)
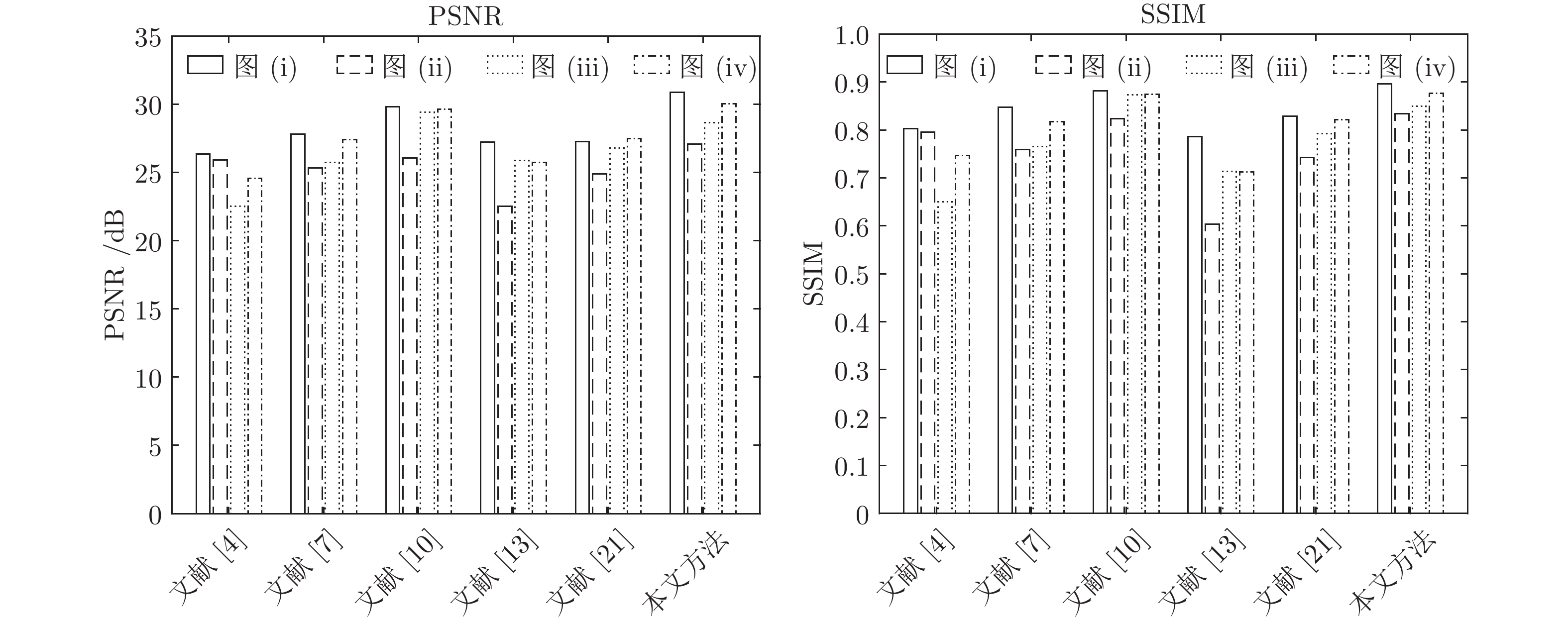
图 13 对比实验图像的PSNR和SSIM指标值柱状图
Fig. 13 Histogram of PSNR and SSIM values of comparative experimental images
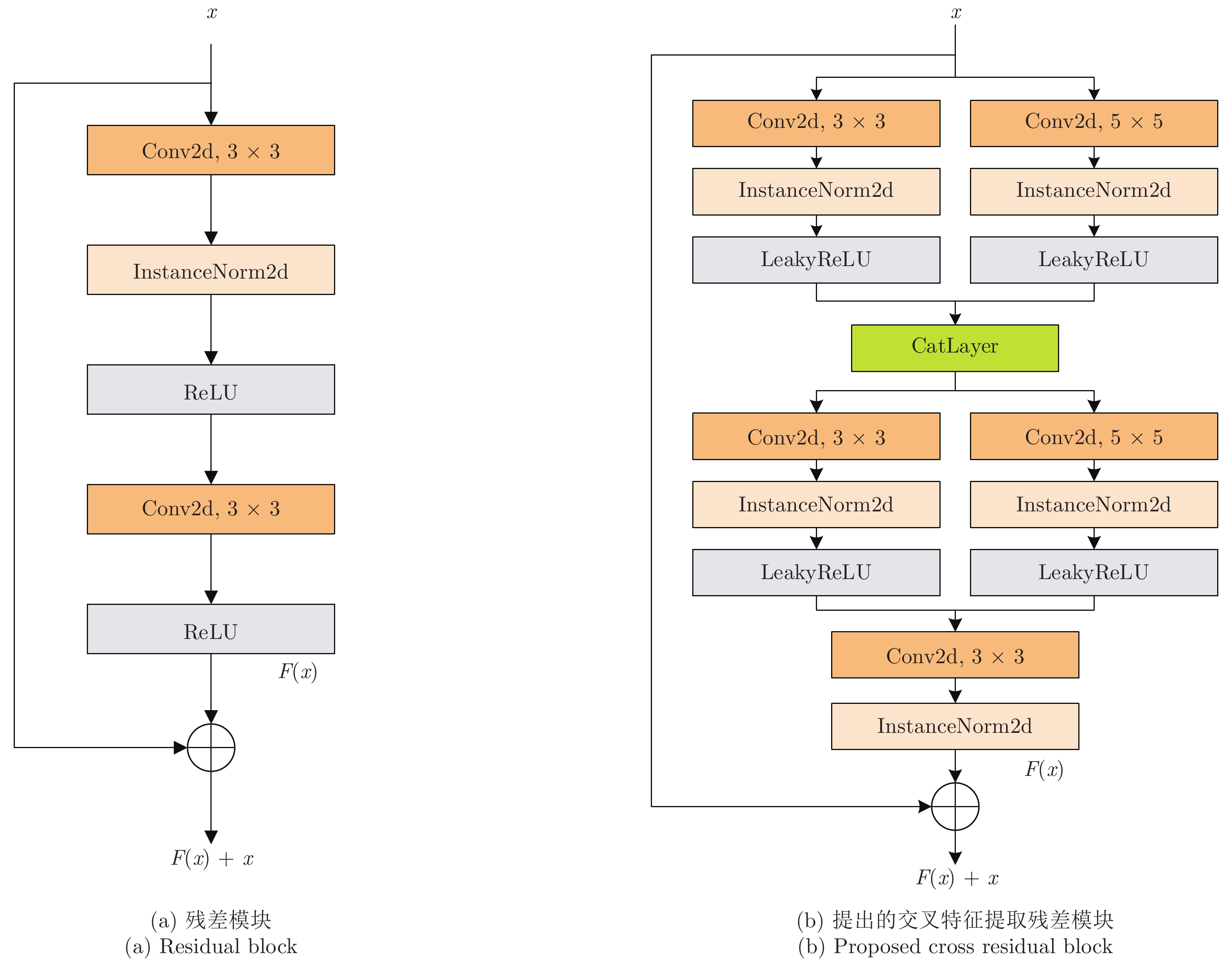
表 1 交叉特征提取残差模块有效性验证实验结果(GoPro数据集)
Table 1 Validation experiment results of cross-resnet block (GoPro dataset)
评价指标 残差模块 交叉特征提取残差模块 PSNR 29.9800 30.2227 SSIM 0.8892 0.8944  下载: 导出CSV
下载: 导出CSV
-
[1] Xu L, Jia J Y. Two-phase kernel estimation for robust motion deblurring. In: Proceedings of the 2010 European Conference on Computer Vision. Crete, Greece: Springer, 2010. 157−170 [2] Mesarovic V Z, Galatsanos N P. MAP and regularized constrained total least-squares image restoration. In: Proceedings of the 1st International Conference on Image Processing. Austin, TX, USA: IEEE, 1994. 177−181 [3] Michael K N, Robert J P, Felipe P. A New Approach to Constrained Total Least Squares Image Restoration. Linear Algebra and its Applications, 2000, 316(1-3): 237-258 doi: 10.1016/S0024-3795(00)00115-4 [4] Li W H, Chen Y Q, Chen R, Gong W G, Zhao B X. Hybrid order l0-regularized blur kernel estimation model for image blind deblurring. In: Proceedings of the 2017 International Symposium on Neural Networks. Sapporo, Japan: Springer, 2017. 239−247 [5] Li W H, Chen R, Xu S W, Gong W G. Blind motion image deblurring using nonconvex higher-order total variation model. Journal of Electronic Imaging, 2016, 25(5): 053033.1-053033.19 [6] Shen Z Y, Xu T F, Pan J S. Non-uniform Motion Deblurring with Kernel Grid Regularization. Signal Processing Image Communication, 2018, 62(0): 1-15 [7] Chakrabarti A. A neural approach to blind motion deblurring. In: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam, Netherlands: Springer, 2016. 221−235 [8] Xu X Y, Pan J S, Zhang Y J, Yang M H. Motion Blur Kernel Estimation via Deep Learning. IEEE Transactions on Image Processing, 2018, 27(1): 194-205 doi: 10.1109/TIP.2017.2753658 [9] Xu L, Ren J S, Liu C, Jia J Y. Deep convolutional neural network for image deconvolution. In: Proceedings of the 2014 International Conference on Neural Information Processing Systems. Montreal, Canada: Springer, 2014. 1790−1798 [10] Tao X, Gao H Y, Shen X Y, Wang J, Jia J Y. Scale-Recurrent network for deep image deblurring. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 8174−8182 [11] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D. Generative Adversarial Networks. Advances in Neural Information Processing Systems, 2014, (3): 2672-2680 [12] 吴梦婷, 李伟红, 龚卫国. 双框架卷积神经网络用于运动模糊图像盲复原. 计算机辅助设计与图形学学报, 2018, 30(12): 2327-2334Wu M T, Li W H, Gong W G. Two-frame Convolutional Neural Network for Blind Motion Image Deblurring. Journal of Computer-Aided Design & Computer Graphics, 2018, 30(12): 2327-2334 [13] Kupyn O, Budzan V, Mykhailych M, Mishkin D. DeblurGAN: Blind motion deblurring using conditional adversarial networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 1−9 [14] Tomasi C, Manduchi R. Bilateral filtering for gray and color images. In: Proceedings of the 1998 International Conference on Computer Vision. Bombay, India: IEEE, 1998. 839−846 [15] Xu L, Lu C W, Xu Y, Jia J Y. Image Smoothing via L0 Gradient Minimization. ACM Transactions on Graphics, 2011, 30(6): 174.1-174.11 [16] Wan R J, Shi B X, Duan L Y, Tan A H. CRRN: Multi-Scale guided concurrent reflection removal network. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 4777−4785 [17] 林景栋, 吴欣怡, 柴毅, 尹宏鹏. 卷积神经网络结构优化综述. 自动化学报, 2020, 46(1): 24-37Lin J D, Wu X Y, Chai Y, Yin H P. Structure Optimization of Convolutional Neural Networks: A Survey. Acta Automatica Sinica, 2020, 46(1): 24-37 [18] Deng J, Dong W, Socher R, Li L J, Li K, Li F F. ImageNet: A large-scale hierarchical image database. In: Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recogniltion. Florida, USA: IEEE, 2009: 1−8 [19] Mao X D, Li Q, Xie H, Raymond Y K L, Wang Z, Stephen P S. Least squares generative adversarial networks. In: Proceedings of the 2017 International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 2813−2821 [20] PyTorch. PyTorch Documentation [Online], available: https://pytorch.org/docs/stable/index.html, September 1, 2019 [21] Schuler C J, Hirsch M, Harmeling S, Scholkopf B. Learning to Deblur. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 38(7): 1439-1451 [22] 孙季丰, 朱雅婷, 王恺. 基于DeblurGAN和低秩分解的去运动模糊. 华南理工大学学报(自然科学版), 2020, 48(1): 32-41Sun J F, Zhu Y T, Wang K. Motion Deblurring Based on DeblurGAN and Low Rank Decomposition. Journal of South China University of Technology (Natural Science Edition), 2020, 48(1): 32-41 [23] Kupyn O, Martyniuk T, Wu J R, Wang Z Y. DeblurGAN-v2: Deblurring (orders-of-magnitude) faster and better. In: Proceedings of the 2019 International Conference on Computer Vision. Seoul, Korea: IEEE, 2019. 8878−8887 期刊类型引用(3)
1. 于勇政,王伟,蒲治伟. 基于信息关联加权的多目标跟踪算法. 现代防御技术. 2025(01): 23-36 .  百度学术
百度学术2. 许华杰,郑力文. 基于自适应卡尔曼滤波的视觉多目标跟踪. 计算机工程与应用. 2025(05): 200-210 . 百度学术3. 郑尚坡,陈德富,李坚利,林国贤,王星平. 基于改进YOLOv5s和DeepSORT的行人跟踪算法. 计算机与现代化. 2024(08): 54-58 . 百度学术其他类型引用(2)
-


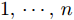
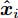
 下载:
下载:
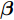
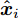
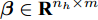
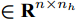
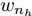
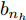
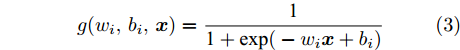
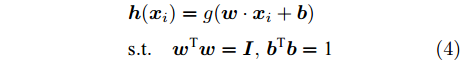
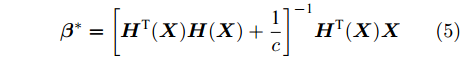
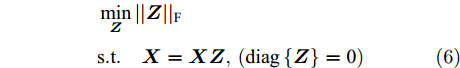
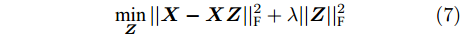
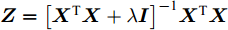
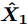
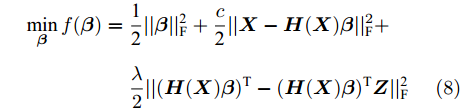
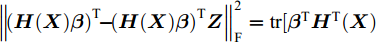
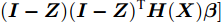
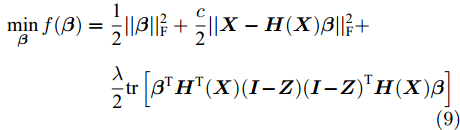
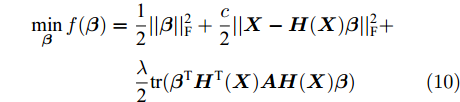
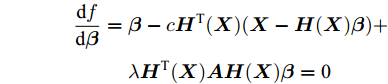
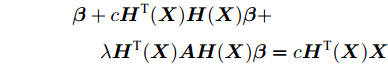
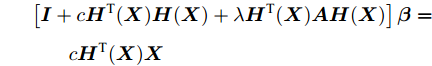
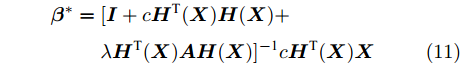
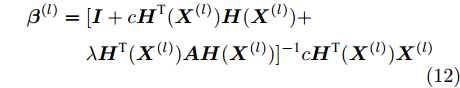
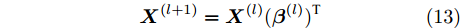
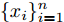
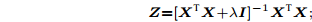







计量
- 文章访问数: 984
- HTML全文浏览量: 346
- PDF下载量: 206
- 被引次数: 5
