

-
摘要: 通过对目前现有的肺癌检测技术研究, 发现大部分研究人员主要针对肺癌(Computed tomography, CT)影像进行研究, 忽略了电子病历所隐藏的肺癌信息, 本文提出一种基于图像与文本相结合的肺癌分类方法, 从现有的基于深度学习的肺癌图像分类出发, 引入了电子病历信息, 使用Multi-head attention以及(Bi-directional long short-term memory, Bi-LSTM)对文本建模. 实验结果证明, 将电子病历信息引入到图像分类模型之后, 对模型的性能有进一步的提升. 相对仅使用电子病历进行预测, 准确率提升了大约14 %, 精确率大约提升了15 %, 召回率提升了14 %. 相对仅使用肺癌CT影像来进行预测, 准确率提升了3.2 %, 精确率提升了4 %, 召回率提升了4 %.Abstract: Through the study of the existing lung cancer detection technology, we found that most researchers mainly focus on the lung cancer (CT) images, ignoring the information of lung cancer hidden in the electronic medical records, this paper presents a lung cancer classification method based on the combination of image and text. Starting from the existing lung cancer image classification based on depth learning, the electronic medical record information is introduced, modeling text using Multi-head attention and (Bi-directional long short-term memory, BI-LSTM). The experimental results show that the performance of the image classification model is improved by introducing electronic medical record information. Predictions using only electronic medical records improved by about 14%, precision by about 15%, and recall by 14%. Compared to using only lung cancer CT images for prediction, the accuracy increased 3.2% , the precision increased 4% , and the recall increased 4%.
-
Key words:
- Deep learning /
- neural network /
- multi-head attention /
- bi-LSTM /
- lung cancer
-
表 1 检验项目
Table 1 Examine items
参考范围 检验名称 状态 结果值 血常规检查 0 ~ 0.1 嗜碱性粒细胞 正常 0.01 0.05 ~ 0.5 嗜酸性粒细胞 正常 0.07 0 ~ 1 嗜碱性粒细胞比率 正常 0.20 % 110 ~ 160 血红蛋白 正常 128 g/L 100 ~ 300 血小板 正常 $13510{\hat 9}/{\rm{L}}$ 3.5 ~ 5.5 红细胞 正常 4.25 37 ~ 50 红细胞分布宽度 正常 43.90 % 4 ~ 10 白细胞 正常 $6.1810{\hat 9}/{\rm{L}}$ 86 ~ 100 红细胞平均体积 正常 88.2 fL 痰液检查 无肿瘤细胞 痰液细胞 正常 无肿瘤细胞 肿瘤标记物 5 μg/ml CEA (Carcinoembryonic antigen) 正常 2.31 30 U/ml CA125 (Cancer antigen 125) 正常 13.70 U/ml 8.20 U/ml CA72-4 (Cancer antigen 72-4) 正常 1.34 U/ml 16.3 ng/ml NSE (Neuron-specific enolase) 正常 15.18 ng/ml 1.5 ng/ml SCC (Squamous cell carcinoma) 正常 0.8 ng/ml 2.0 ng/ml CYFRA21-1 (Cytokeratin fragment 19) 高 7.31 ng/ml 胸水检验 0.38 ~ 2.1 甘油三脂 正常 0.74 mmol/L 0.8 ~ 1.95 高密度脂蛋白 正常 1.31 mmol/L 3.8 ~ 6.1 葡萄糖 高 10.11 mmol/L 2 ~ 4 低密度脂蛋白 正常 2.02 mmol/L 109 ~ 271 乳酸脱氢酶 正常 205.2 U/L 0 ~ 6.8 直接胆红素 正常 3.49 μmol/L 3.6 ~ 5.9 总胆固醇 低 3.54 mmol/L 20 ~ 45 球蛋白 正常 31.7 g/L  下载: 导出CSV
下载: 导出CSV
表 2 MLP参数设置
Table 2 The parameter of MLP
Name 节点个数 激活函数 Hidden1 65 Sigmoid Hidden2 131 Sigmoid Hidden3 263 Sigmoid
下载: 导出CSV
表 4 实验1的结果
Table 4 The result of experiment 1
Model name Train (%) Test (%) Accuracy Precision Recall Accuracy Precision Recall Text-net 83.12 ± 0.02 80.10 ± 0.05 81.12 ± 0.02 81.21 ± 0.01 79.82 ± 0.03 80.15 ± 0.01 Text-net1 76.87 ± 0.02 75.29 ± 0.01 75.11 ± 0.03 74.91 ± 0.02 73.41 ± 0.02 74.07 ± 0.03 Text-net2 80.49 ± 0.03 78.16 ± 0.04 78.82 ± 0.03 78.43 ± 0.02 77.15 ± 0.01 78.59 ± 0.02 Text-net3 79.73 ± 0.02 77.19 ± 0.02 76.92 ± 0.01 78.19 ± 0.02 76.79 ± 0.03 75.57 ± 0.02
下载: 导出CSV
表 5 实验2的结果
Table 5 The result of experiment 2
Model Name Train (%) Test (%) Accuracy Precision Recall Accuracy Precision Recall TI-Net 97.08 ± 0.03 95.69 ± 0.01 94.37 ± 0.02 96.90 ± 0.04 95.17 ± 0.03 93.71 ± 0.01 Img+MLP 95.15 ± 0.03 93.90 ± 0.02 93.17 ± 0.03 94.76 ± 0.02 92.89 ± 0.03 91.78 ± 0.01 Img+Text 94.71 ± 0.02 92.13 ± 0.03 91.26 ± 0.04 93.17 ± 0.04 90.88 ± 0.03 89.99 ± 0.03 MLP+Text 89.88 ± 0.04 87.67 ± 0.01 86.92 ± 0.02 87.78 ± 0.03 84.23 ± 0.03 84.57 ± 0.04 Img-Net 93.85 ± 0.03 91.84 ± 0.02 90.83 ± 0.03 92.67 ± 0.02 89.77 ± 0.03 88.93 ± 0.01 VGG-19 92.53 ± 0.02 89.16 ± 0.03 88.57 ± 0.01 90.94 ± 0.02 87.10 ± 0.03 87.04 ± 0.02 MLP 86.75 ± 0.03 85.21 ± 0.02 85.12 ± 0.03 84.86 ± 0.02 82.37 ± 0.03 81.59 ± 0.01 Text-Net 83.12 ± 0.04 80.10 ± 0.05 81.12 ± 0.02 81.21 ± 0.03 79.82 ± 0.03 80.15 ± 0.02
下载: 导出CSV
-
[1] 韩坤, 潘海为, 张伟, 边晓菲, 陈春伶, 何舒宁. 基于多模态医学图像的Alzheimer病分类方法. 清华大学学报(自然科学版), 2020. 1-9Han Kun, Pan Hai-Wei, Zhang Wei, Bian Xiao-Fei, Chen Chun-Ling, He Shu-Ning. Alzheimer's disease classification method based on multimodal medical images. Journal of Tsinghua University (Natural Science), 2020. 1-9 [2] 张淑丽, 李靖宇, 穆传斌, 刘雅楠, 孟欣, 杨滇. 多模态医学图像的自由变形法融合策略. 电脑编程技巧与维护, 2019, 8: 139-140+155 doi: 10.3969/j.issn.1006-4052.2019.08.050Zhang Shu-Li, Li Jing-Yu, Mu Chuan-Bin, Liu Yanan, Meng Xin, Yang Dian. Free-form fusion method for multi-modal medical images. Computer programming skills and maintenance, 2019, 8: 139-140+155 doi: 10.3969/j.issn.1006-4052.2019.08.050 [3] 田娟秀, 刘国才, 谷珊珊, 鞠忠建, 刘劲光, 顾冬冬. 医学图像分析深度学习方法研究与挑战. 自动化学报, 2018, 44(3): 401-424Tian Juan-Xiu, Liu Guo-Cai, Gu Shan-Shan, Ju Zhong-Jian, Liu Jin-Guang, Gu Dong-Dong. Deep learning in medical image analysis and its challenges. ACTA AUTOMATICA SINICA, 2018, 44(3): 401-424. [4] Pennington J, Socher R, Manning C. Glove: Global vectors for word representation. In: Proceedings of the 2014 conference on Empirical Methods in Natural Language Processing (EMNLP). 2014. 1532−1543 [5] McCann B, Bradbury J, Xiong C, et al. Learned in translation: Contextualized word vectors. Advances in Neural Information Processing Systems. 2017. 6294-6305 [6] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in neural information processing systems. 2017. 5998-6008 [7] Sun Y, Wang S, Li Y, et al. ERNIE: Enhanced representation through knowledge integration. arXiv preprint arXiv: 1904.09223, 2019 [8] Sun W, Zheng B, Qian W. Computer aided lung cancer diagnosis with deep learning algorithms. SPIE Medical Imaging, 2016 [9] Xiao Huan-Hui, Yuan Cheng-Lang, Feng Shi-Ting. Research progress of computer aided diagnosis in cancer based on deep learning. International Journal of Medical Radiology, 2019, 42(1), 22-25 [10] Cheng JZ, Ni D, Chou YH, et al. Computer -aided diagnosis with deep learning architecture: applications to breast lesions in US images and pulmonary nodules in CT scans. Scientific Reports, 2016, 6: 24454 doi: 10.1038/srep24454 [11] Nibali A, He Z, Wollersheim D. Pulmonary nodule classification with deep residual networks. Int J Comput Assist Radiol Surg, 2017, 12: 1799-1808 doi: 10.1007/s11548-017-1605-6 [12] Shen W, Zhou M, Yang F, et al. Multi-crop convolutional neural networks for lung nodule malignancy suspiciousness classification. Pattern Recognition, 2017, 61: 663-673 doi: 10.1016/j.patcog.2016.05.029 [13] HOCHREITER S, SCHMIDHUBER J. Long Short-Term Memory. Neural Computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [14] 陈斌, 周勇, 刘兵. 基于卷积长短期记忆网络的事件触发词抽取方法. 计算机工程, 2019, 45(01): 153-158Chen Bin, Zhou Yong, Liu Bing. Event-triggered word extraction method based on convolutional long-term and short-term memory networks. Computer Engineering, 2019, 45(01): 153-158 [15] Litjens G., Sánchez C., Timofeeva, et al. Deep learning as a tool for increased accuracy and efficiency of histopathological diagnosis. Sci Rep, 2016, 6: 2628. -

 下载:
下载:
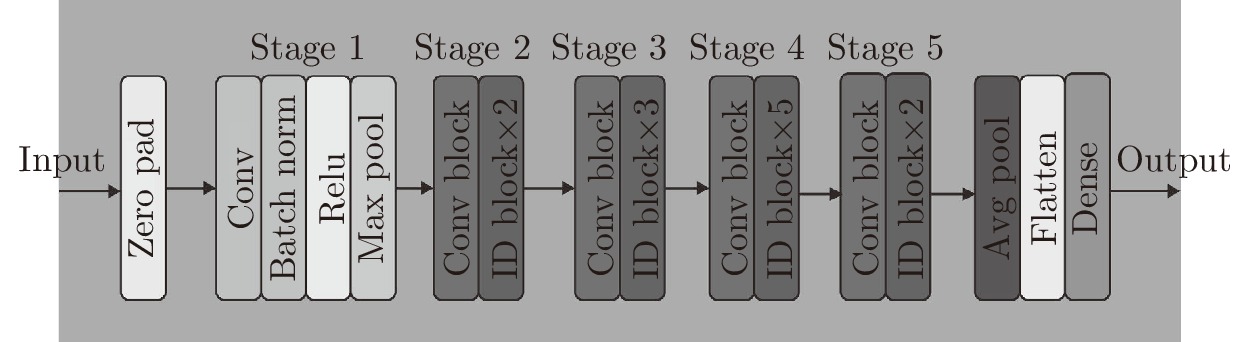


图(2) / 表(5)
计量
- 文章访问数: 1194
- HTML全文浏览量: 515
- PDF下载量: 289
- 被引次数: 0
