

Research on Fault Diagnosis of Improved Kernel Fisher Based on Mahalanobis Distance in the Field of Chemical Industry
-
摘要: 针对化工故障诊断数据存在非线性分布、 数据类别复杂、数据量大且故障特征不易区分等问题, 本文提出一种基于马氏距离的改进核Fisher故障诊断方法(Mahalanobis distance-based kernel Fisher discrimination, MKFD). 首先, 针对数据非线性分布的特点, 本文将核Fisher判别分析算法改进, 改进后的算法可以有效解决原始样本在投影后出现的因类间距离差异过大、类内距离不够紧凑造成的样本混叠现象. 除此之外, 利用Euclidean距离对类间距做加权处理时, 用组平均距离取代质心距离, 提升了运算效率, 降低了时间复杂度; 其次, 根据高斯径向基核函数(Radial basis function, RBF)在MKFD中所呈现出的诊断精度的规律, 本文采用一种新的核参数选择方法: 区间三分法, 用以取代在实际应用中依靠经验的交叉验证法; 最后, 本文采用马氏距离对故障进行分类, 基于田纳西伊—斯特曼过程(Tennessee-Eastman, TE)数据将本方法与其他改进核Fisher算法进行仿真验证对比. 结果表明新提出MKFD算法不仅可以提高故障诊断的运算效率, 也能有效提高诊断的精度.Abstract: Aiming at the problems of the non-linear distribution, complex category, large amount of fault diagnosis data in chemical industry and the difficulty of distinguishing fault features, a improved kernel Fisher fault diagnosis method based on Mahalanobis distance is proposed in this paper. Firstly, due to the data with non-linear property, a new improved kernel Fisher discriminant analysis method is proposed, which can effectively solve the sample aliasing phenomenon caused by large difference between classes and insufficient compact distance between classes after projection of original samples. In addition, using the Euclidean distance in class spacing, the group average distance is used to replace the center of mass distance, which improves the efficiency of operation and reduces the time complexity. Secondly, according to the rule of diagnostic accuracy presented by the (RBF) in Fisher discriminant analysis (MKFD), a new method, interval “three-point method”, of selecting nuclear parameters is proposed in this paper, which is used to replace the cross-validation method relying on experience in practical application. Finally, faults are classified based on Mahalanobis distance using Tennessee-Sterman process. The proposed method is compared with other improved kernel Fisher algorithm. The results show that (MKFD) can not only improve the calculation efficiency of fault diagnosis, but also improve the accuracy of diagnosis.
-
Key words:
- Kernel Fisher /
- fault diagnosis /
- interval three-point method /
- Tennessee-Sterman process /
- optimization
-
近年来, 随着计算机技术、网络通信、控制工程等新兴产业的相互融合与促进, 信息物理系统(Cyber-physical system, CPS)随之出现, 并朝着大规模、复杂化、智能化的方向发展.多智能体系统分布式协调控制问题作为CPS系统的典型问题, 引起了众多研究者的广泛关注.分布式协同控制因效率高、鲁棒性强等优点, 被广泛应用于无人机编队控制[1]、多机器人协同控制[2]、多飞行器系统群集控制[3-4]等领域.
一致性问题是多智能体协同控制领域的基本问题, 也是协调控制中的研究热点之一[5-13].多智能体系统通过各智能体之间互相协调合作进行信息传递, 按照控制协议改变自身的状态, 从而使各个智能体达到状态一致.近年来诸多学者已经分别针对一阶、二阶、混合阶以及高阶多智能体系统展开了深入的研究[5-7].考虑到许多自然现象的动力学特性不能用整数阶方程描述, 分数阶(非整数阶)动力学的智能个体合作行为也引起了许多研究者的关注[8-9].此外, 在解决多智能体系统一致性问题时, 常常会遇到存在领导者的情况, 这被称为Leader-follower (领导跟随型)问题[10].在多个领导者情况下, 多智能体系统的跟踪问题就变成包容控制问题[11-14].这是领导跟随型一致性问题在多个领导者情况下的扩展, 跟随者在通信协议的作用下最终收敛到由多个领导者围成的某一目标区域内.文献[13]分别研究了通信拓扑为动态联合联通且存在通信时延情况下二阶网络化系统的包容控制问题.文献[14]研究了具有时延的分数阶多智能体系统的包容控制问题, 利用Laplace变换和频域定理, 提出了无向网络分数阶多智能体系统包容控制协议.
上述研究成果均是假设多智能体系统中各个智能体的状态渐近达到稳定, 即当时间趋于无穷大时, 各个智能体的状态可以达到某一共同值.然而在实际应用中, 特别是某些控制精度比较高的系统, 往往要求系统在很短的时间内能够达成一致.与渐近收敛相比, 有限时间一致性控制法不仅可以保证系统的收敛速度更快, 在系统存在外部干扰时也表现出更好的鲁棒性[15].因此研究多智能体系统的有限时间一致性是很有实际意义的.目前关于多智能体系统的有限时间一致性问题已取得比较丰富的研究成果[16-18], 文献[16]研究了二阶多智能体系统有限时间快速收敛问题.文献[17]研究了带有外部干扰的二阶多智能体系统分布式有限时间包容控制, 提出了分布式有限时间包容控制算法使得跟随者的状态在有限时间内收敛到由领导者组成的动态区域内.文献[18]针对联合连通拓扑下具有多领导者的二阶多智能体系统群集运动问题, 提出了一种有限时间收敛的包容控制算法.
由于复杂多变的工作环境, 多智能体系统通常会受到各种干扰的影响.为了处理系统干扰, 研究者提出了许多先进的控制方法, 包括自适应控制[19]、鲁棒控制[20], 滑模控制[21-22]等.然而大多数方法仅考虑匹配干扰, 即干扰与控制输入在同一通道中.在多智能体系统中, 常常存在异于控制输入通道进入系统的干扰, 即不匹配干扰.不匹配干扰广泛存在于实际工程系统中, 例如多导弹系统[23]和工业磁悬浮列车控制系统[24].由于不匹配干扰无法直接利用反馈控制器消除, 因此对带有不匹配干扰系统的协同控制的研究意义重大.文献[24]以工业磁悬浮列车控制系统为例, 详细介绍了不匹配干扰的成因和影响, 基于干扰观测器方法, 介绍了状态通道和输出通道不匹配不确定系统干扰主动控制方法.文献[25]提出基于控制的干扰观测器(Disturbance observer based control, DOBC)方法, 利用干扰前馈补偿和输出反馈复合控制来消除干扰.文献[26]研究了带有不匹配干扰的高阶多智能体系统分布式主动抗干扰控制方法, 结合滑模控制理论和DOBC方法, 实现系统的输出一致性.但文中各智能体的状态最终渐近收敛, 没有考虑有限时间收敛的情况.文献[27]研究了不匹配二阶多智能体受扰系统的输出一致性问题, 文献[28]研究了带有不匹配干扰的多智能体系统有限时间包容控制问题.这两篇文献对系统模型作了处理, 将不匹配干扰转变成匹配干扰, 从而可以利用常规的处理方式消除干扰.然而在实际应用中存在很多情况不能如此处理, 因此该方法有一定的局限性.文献[29]研究了基于扰动观测器的复合积分滑模制导律设计, 给出一种基于积分滑模控制理论和非线性扰动观测理论的复合制导律方法, 但是该方法没有考虑到系统中存在不匹配干扰的情况.
本文以文献[24]介绍的不匹配干扰为研究对象, 研究带有不匹配干扰的二阶多智能体系统的有限时间包容控制问题.相对于文献[27-28], 本文的创新点在于设计了主动有限时间干扰观测器直接估算智能体的不匹配干扰, 并在控制协议中做出干扰补偿, 提出了较为新颖的复合分布式积分滑模控制律.应用滑模控制和现代控制等相关理论, 研究了具有不匹配干扰二阶多智能体系统的有限时间包容控制问题.
1. 预备知识
1.1 代数图论
假设$n$个节点的权重连接图用$G=(V, E, A)$来表示, 其中为$n$个节点的集合, 节点的下标集合$N=\{1, 2, \cdots , n\}$, $E\subseteq V\times V$为边的集合, 为图$G$的权重邻接矩阵, 其中矩阵元素${{a}_{ij}}$表示节点${{v}_{i}}$与节点${{v}_{j}}$的连接权重.定义为节点${{v}_{i}}$的邻居集合.当${{v}_{j}}\in {{N}_{i}}$时, ${{a}_{ij}}>0$, 否则${{a}_{ij}}=0$.若对$\forall i \in N$, ${{a}_{ij}}={{a}_{ji}}$, , 则图$G$为无向拓扑图, 且邻接矩阵$A$为对称矩阵.若对, ${{a}_{ij}}\ne$ ${{a}_{ji}}$, , 则图$G$为有向拓扑图, 且邻接矩阵$A$为非对称矩阵.假设图$G$中任一节点无自环, 即对于$\forall i\in N$, ${{a}_{ii}}=0$.定义$D$为图$G$的度对角矩阵$D$ , 其中节点${{v}_{i}}$的度${{d}_{i}}=$ $\sum\nolimits_{j=1}^{n}{{{a}_{ij}}}$.图$G$的Laplacian矩阵定义为$L=D$ $-$ $A$.无向联通拓扑图的Laplacian矩阵为对称矩阵.
1.2 相关引理和定义
引理1 (Input-to-state stability theorem, ISS)[30].考虑非线性系统$\dot{x}=f(x, u, t)$, 如果系统$\dot{x}=f(x, 0, t)$是全局均一化指数型稳定, 当 $=$ $0$时, 系统的$\dot{x}=f(x, u, t)$状态渐近收敛到0, 即${\lim_{t\to \infty } }x(t)=0$.
引理2[15].考虑系统$\dot{x}=f(x)$, $f(0)=0$, $x$ $\in$ ${{\bf R}^{n}}$, 假设存在一个正定连续函数$V(x):U\to {\bf R}$, 且实数$c>0$, $\alpha \in (0, 1)$, 在${{U}_{0}}\subset U$的邻域上满足, , 则$V(x)$在有限时间内收敛到0.此外有限时间$T$满足$T$ $\le$ $\frac{{{V}^{1-\alpha }}(x(0))}{c(1-\alpha )}$.
定义1[12-13].假设集合$X$是向量空间的子集, 集合$X$的凸包定义为 ${{a}_{i}}$ $\ge 0$, $\sum\nolimits_{i=1}^{k}{{{a}_{i}}=1} \}$.
定义2[15, 18].考虑连续非线性系统: $\dot{\pmb x}=f({\pmb x})$, , 其中连续向量流$f({\pmb x})=[ {{f}_{1}}({\pmb x})$, 与带有扩张, ${ {r}_{i}}>0$的度$\kappa \in \bf R$是齐次的, 如果对于任意的$\varepsilon$ $>$ $0$, ${\pmb x}\in {{\bf R}^{n}}$都有 , $i=1, 2, \cdots , n$.
引理3[15, 18].若系统与带有扩张, ${{ r}_{i}}>0$的度$\kappa$ $\in$ $\bf R$是齐次的, 函数$f({\pmb x})$是连续的, 且${\pmb x}=0$是其一个渐近稳定平衡点.如果齐次度$\kappa <0$, 则该系统是有限时间稳定的.
定义3.如果网络化系统中的一个自主体至少存在一个邻接成员, 则称之为跟随者, 否则称为领导者.
2. 二阶多智能体系统的有限时间包容控制
假设一个具有$n$个跟随者和$m$个领导者的多智能体系统, 其中每个智能体可理解为加权无向图$G$中的一个顶点, 各智能体之间的信息传递可理解为图$G$的边.考虑二阶多智能体系统未受到干扰时的动力学模型为
$ \begin{align}\label{1} \begin{cases} {{{\dot{x}}}_{i}}(t)={{v}_{i}}(t) \\ {{{\dot{v}}}_{i}}(t)={{u}_{i}}(t) \end{cases} \end{align} $
(1) 其中, $i= \{ 1, 2, \cdots , n, n+1, \cdots , n+m \}$, $n$表示跟随者的个数, $m$表示领导者的个数, 跟随者和领导者集合分别表示为$F= \{ 1, 2, \cdots , n \}$和$L=\{ n+1$, $n+2$, $\cdots , n+m \}$. ${{x}_{i}}(t)$和${{v}_{i}}(t)$分别表示系统第$i$个智能体在$t$时刻的位置和速度, ${{u}_{i}}(t)$是控制输入.假设领导者为作匀速运动的动态领导者, 对于$\forall i$ $\in$ $L$, 其动力学模型为
$ \begin{align}\label{2} \begin{cases} {{{\dot{x}}}_{i}}(t)={{v}_{i}}(t) \\ {{{\dot{v}}}_{i}}(t)=0 \end{cases} \end{align} $
(2) 多Leader-follower型多智能体系统(1)和(2)的通信拓扑图可描述成${{G}_{n+m}}=( {{V}_{n+m}}, {{E}_{n+m}}$, , 其中$m$表示领导者的个数, $n$表示跟随者的个数.图${{G}_{n+m}}$的邻接矩阵为 $\in$ ${{\bf R}^{ ( n+m )\times ( n+m )}}$, Laplacian矩阵为${{L}_{n+m}}=[ {{l}_{ij}} ]\in$ , 可描述成, ${{L}_{f}}$ $\in {{\bf R}^{n\times n}}$, ${{L}_{d}}\in {{\bf R}^{n\times m}}$.
假设1.领导者相互间不通信, 领导者与跟随者之间单向通信, 跟随者之间为双向通信, 且每个智能体都可接收到它邻居发送的状态信息和干扰估计信息.
假设2.多Leader-follower型多智能体系统的通信拓扑${{G}_{n+m}}$包含至少一条有向生成树.
引理4[12].如果假设2成立, 多Leader-follower型多智能体系统的${{L}_{f}}$是正定的, 此外$-L_{f}^{-1}{{L}_{d}}$为非负的且行和为1.
引理5[12].令, ${{\pmb x}_{L}}=$ , 若有, 则网络化系统可以实现包容控制.
为了简化, 令, ${{\pmb v}_{F}}=[{{v}_{1}}$, , , ${{\pmb v}_{L}}=$ , . , , ${{v}_{c2}}$, .由定义1、引理3和引理5可知, ${{\pmb x}_{F}}\to {{\pmb x}_{c}}$ $({{x}_{i}}\to {{x}_{ci}}$, $i\in F)$意味着${{x}_{i}}$, 收敛到凸包$Co \{ {{x}_{j}}, j\in L \}$内, 即实现包容控制.
基于上述描述, 本节首先考虑不存在干扰的情况, 设计分布式控制协议, 使得各个跟随者的状态在有限时间内实现包容控制, 即.
首先令跟踪误差为
$ \begin{align}\label{3} \begin{cases} \omega _{i}^{x}= & \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)}} \\[2mm] \omega _{i}^{v}= & \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( {{v}_{i}}-{{v}_{j}} \right)+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{v}_{i}}-{{v}_{j}} \right)}} \end{cases} \end{align} $
(3) 基于跟踪误差(3), 设计控制器如下:
$ \begin{align}\label{4} {{u}_{i}}= -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( \omega _{i}^{x} \right)- {{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\left( \omega _{i}^{v} \right) \end{align} $
(4) 其中, 控制增益${{k}_{1}}$, ${{k}_{2}}>0$, $0<{{\alpha }_{1}} <1$, ${{\alpha }_{2}}=$ ${2{{\alpha }_{1}}}/({{\alpha }_{1}}+1)$. , 表示符号函数.假设 , .
定理1. 考虑由$n$个跟随者和$m$个领导者组成的二阶动态多智能体系统(1)和(2), 其通信拓扑图可描述成, 如果假设1和假设2成立, 则多智能体系统基于分布式控制协议(4)可实现全局有限时间包容控制.
证明.由引理4可知, 多智能体系统(1)和(2)的${{L}_{f}}$是正定的.令, ${{\bar{\pmb v}}_{F}}={{\pmb v}_{F}}$ $+$ $L_{f}^{-1}{{L}_{d}}{{\pmb v}_{L}}$, 则跟踪误差(3)转变成矩阵形式为
$ \begin{align}\label{5} \begin{cases} {{\pmb {\omega }}_{x}}={{L}_{f}}{{\pmb x}_{F}}+{{L}_{d}}{{\pmb x}_{L}}={{L}_{f}}{{{\bar{\pmb x}}}_{F}} \\ {{\pmb {\omega }}_{v}}={{L}_{f}}{{\pmb v}_{F}}+{{L}_{d}}{{\pmb v}_{L}}={{L}_{f}}{{{\bar{\pmb v}}}_{F}} \end{cases} \end{align} $
(5) 其中, , $\omega _{n}^{v}]^{\rm T}$, 且${{\dot{\pmb \omega }}_{x}}={{\pmb \omega }_{v}}$.因此速度跟踪误差${{\bar{\pmb v}}_{F}}$的微分方程为
$ \begin{align}\label{6} {{\dot{\bar{\pmb v}}}_{F}}=-{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( {{\pmb \omega }_{x}} \right)-{{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\left( {{\pmb \omega }_{v}} \right) \end{align} $
(6) 构造Lyapunov函数
$ \begin{align}\label{7} {{V}_{1}}=\frac{1}{2}\bar{\pmb v}_{F}^{\texttt{T}}{{L}_{f}}{{\bar{\pmb v}}_{F}}+\frac{{{k}_{1}}{{\left| {{\pmb \omega }_{x}} \right|}^{{{\alpha }_{1}}+1}}}{{{\alpha }_{1}}+1} \end{align} $
(7) 对${{V}_{1}}$函数沿着式(6)求一次导, 得
$ \begin{align} {{{\dot{V}}}_{1}}= &\ \bar{\pmb v}_{F}^{\rm{T}}{{L}_{f}}{{{\dot{\bar{\pmb v}}}}_{F}} +{{k}_{1}}{{\left| {{\pmb \omega }_{x}} \right|}^{{{\alpha }_{1}}}} {\pmb \omega _{v}}^{\rm{T}}{\rm sgn}\left( {{\pmb \omega }_{x}} \right) = \nonumber\\ &\ {\pmb \omega _{v}}^{\rm{T}}\left( -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( {{\pmb \omega }_{x}} \right)-{{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\left( {{\pmb \omega }_{v}} \right) \right)+ \nonumber\\ &\ {{k}_{1}}{\pmb \omega _{v}}^{\rm{T}}{{\rm sig} ^{{{\alpha }_{1}}}}\left( {{\pmb \omega }_{x}} \right) = -{{k}_{2}}{{\left| {{\pmb \omega }_{v}} \right|}^{{{\alpha }_{2}}+1}} \le 0 \nonumber \end{align} $
注意到, 当${{\dot{V}}_{1}}=0$时, ${{\pmb \omega }_{v}}=0$, 由于${{\pmb \omega }_{v}}={{L}_{f}}{{\bar{\pmb v}}_{F}}$, 且${{L}_{f}}$是正定的, 所以${{\bar{\pmb v}}_{F}}=0$.由式(6)可知 $0$.因此只有在平衡点${{\pmb \omega }_{x}}=0$, 处才有${{\dot{V}}_{1}}$ $=$ $0$.根据Lyapunov第二稳定性定理可知, 该系统在平衡点处渐近稳定.进一步由式(5)可得${{\pmb x}_{F}}$ $\to$ , ${{\pmb v}_{F}}\to -L_{f}^{-1}{{L}_{d}}{{\pmb v}_{L}}$, 由引理5可知系统可以实现渐近包容控制.
下面分析系统的齐次性.假设原动力学系统为
$ \begin{align}\label{8} \begin{cases} {{f}_{1}}\left( {{x}_{i}}, {{v}_{i}} \right)= & {{v}_{i}}\left( t \right) \\ {{f}_{2}}\left( {{x}_{i}}, {{v}_{i}} \right)= & {{u}_{i}}\left( t \right) \end{cases} \end{align} $
(8) 取${{r}_{1}}=2$, ${{r}_{2}}=1+{{\alpha }_{1}}$, , 则有
$ \begin{align} &{{f}_{1}}\left( {{\varepsilon }^{{{r}_{1}}}}{{x}_{i}}, {{\varepsilon }^{{{r}_{2}}}}{{v}_{i}} \right)={{\varepsilon }^{{{r}_{2}}}} {{v}_{i}}\left( t \right)={{\varepsilon }^{{{r}_{1}}+\kappa }} {{f}_{1}}\left( {{x}_{i}}, {{v}_{i}} \right)\notag\\ &{{f}_{2}}\left( {{\varepsilon }^{{{r}_{1}}}}{{x}_{i}}, {{\varepsilon }^{{{r}_{2}}}}{{v}_{i}} \right) =\notag\\ &\qquad -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\bigg( \sum\limits_{j=1}^{n+m}{{{a}_{ij}}\left( {{\varepsilon }^{{{r}_{1}}}}{{x}_{i}}-{{\varepsilon }^{{{r}_{1}}}}{{x}_{j}} \right)} \bigg)- \notag\\ &\qquad {{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\bigg( \sum\limits_{j=1}^{n+m}{{{a}_{ij}}\left( {{\varepsilon }^{{{r}_{2}}}}{{v}_{i}}-{{\varepsilon }^{{{r}_{2}}}}{{v}_{j}} \right)} \bigg) = \notag\\ &\qquad -{{k}_{1}}{{\varepsilon }^{{{r}_{1}}{{\alpha }_{1}}}}{{\rm sig}^{{{\alpha }_{1}}}}\bigg( \sum\limits_{j=1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)} \bigg)- \notag\\ &\qquad {{k}_{2}}{{\varepsilon }^{{{r}_{2}}{{\alpha }_{2}}}}{{\rm sig}^{{{\alpha }_{2}}}}\bigg( \sum\limits_{j=1}^{n+m}{{{a}_{ij}}\left( {{v}_{i}}-{{v}_{j}} \right)} \bigg) = \notag\\ &\qquad {{\varepsilon }^{2{{\alpha }_{1}}}}\bigg( -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\bigg( \sum\limits_{j=1}^{n+m} {{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)} \bigg)- \notag\\ &\qquad {{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\bigg( \sum\limits_{j=1}^{n+m} {{{a}_{ij}}\left( {{v}_{i}}-{{v}_{j}} \right)} \bigg) \bigg) =\notag \\ &\qquad {{\varepsilon }^{{{r}_{2}}+\kappa }}{{f}_{2}}\left( {{x}_{i}}, {{v}_{i}} \right) \nonumber \end{align} $
由定义2可知, 多智能体系统(1)和(2)与带有扩张的度是齐次的, 且由引理3可知, 系统(8)可在有限时间内收敛.
综上可知, 多智能体系统(1)和(2)可实现有限时间包容控制.
3. 带有不匹配干扰的多智能体系统的有限时间包容控制
本节考虑二阶多智能体系统中存在的不匹配干扰和匹配干扰等多源干扰的情况, 假设二阶受扰多智能体系统的动力学模型为
$ \begin{align}\label{9} \begin{cases} {{{\dot{x}}}_{i}}(t)= {{v}_{i}}(t)+{{d}_{i1}}(t) \\ {{{\dot{v}}}_{i}}(t)= {{u}_{i}}(t)+{{d}_{i2}}(t) \end{cases} \end{align} $
(9) 其中, $i\in F= \{ 1, 2, \cdots , n \}$, $n$表示跟随者的个数, ${{x}_{i}}(t)$和${{v}_{i}}(t)$分别是智能体的位置和速度, ${{u}_{i}}(t)$是控制输入, ${{d}_{i1}}(t)$和${{d}_{i2}}(t)$分别表示不匹配干扰和匹配干扰.
领导者的动力学模型为
$ \begin{align}\label{10} \begin{cases} {{{\dot{x}}}_{j}}(t)={{v}_{j}}(t) \\ {{{\dot{v}}}_{j}}(t)=0 \end{cases} \end{align} $
(10) 其中, $j\in L= \{ n+1, n+2, \cdots , n+m \}$, $m$表示领导者的个数, ${{x}_{j}}(t)$和${{v}_{j}}(t)$分别是领导者位置和速度.
为了解决系统(9)中的不匹配干扰并保持系统的标称性能, 本节将结合积分滑模控制和非线性干扰观测器给出复合分布式控制协议.首先, 通过设计非线性干扰观测器, 在有限时间内估算出系统的状态和干扰信息.然后, 基于干扰估计值, 设计出带有前馈补偿项的复合分布式积分滑模控制协议.
3.1 非线性干扰观测器设计
假设3.干扰${{d}_{ik}}(t)$和, $k$ $= 1, 2$, 都是有界的.
注1. 假设3在DOBC领域是很常见的假设.一方面, 如果干扰具有很快时变, 那么干扰观测器很难进行估算; 另一方面, 在实际应用上, 有很多种干扰满足这种假设, 例如:常值干扰, 谐波干扰等[27-29].
引理6[31].对于一般系统
$ \begin{align}\label{11} \dot{x}=f+gu+d \end{align} $
(11) 其中, $x$为状态量, $u$为控制量, $d$为系统干扰, $f, g$已知.设计的非线性干扰观测器如下:
$ \begin{align}\label{12} \begin{cases} \dot{\hat{x}}= f+gu+z \\ z= -{{\lambda }_{1}}{{\rm sig}^{\frac{2}{3}}}(\hat{x}-x)+\hat{d} \\ \dot{\hat{d}}= -{{\lambda }_{2}}{{\rm sig}^{\frac{1}{2}}}(\hat{d}-z) \end{cases} \end{align} $
(12) 其中, 增益${{\lambda }_{1}}$, ${{\lambda }_{2}}>0$, $\hat{x}$和$\hat{d}$分别是状态$x$和干扰$d$的估计值, 则该观测器是有限时间收敛的.
根据引理6, 设计干扰观测器如下:
$ \begin{align}\label{13} \begin{cases} {{{\dot{\hat{x}}}}_{i}}= {{v}_{i}}+{{z}_{i1}} \\ {{z}_{i1}}= -{{\lambda }_{i1}}{{\rm sig}^{\frac{2}{3}}}({{{\hat{x}}}_{i}}-{{x}_{i}})+{{{\hat{d}}}_{i1}} \\ {{{\dot{\hat{d}}}}_{i1}}= -{{\lambda }_{i2}}{{\rm sig}^{\frac{1}{2}}}({{{\hat{d}}}_{i1}}-{{z}_{i1}}) \\ {{{\dot{\hat{v}}}}_{i}}= {{u}_{i}}+{{z}_{i2}} \\ {{z}_{i2}}= -{{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}}({{{\hat{v}}}_{i}}-{{v}_{i}})+{{{\hat{d}}}_{i2}} \\ {{{\dot{\hat{d}}}}_{i2}}= -{{\lambda }_{i4}}{{\rm sig}^{\frac{1}{2}}}({{{\hat{d}}}_{i2}}-{{z}_{i2}}) \end{cases} \end{align} $
(13) 其中, $i\in F$, ${{\hat{x}}_{i}}$和${{\hat{v}}_{i}}$分别是系统中跟随者的位置状态和速度的估计值, ${{\hat{d}}_{i1}}$和${{\hat{d}}_{i2}}$分别是干扰的估计量, ${{z}_{i1}}$和${{z}_{i2}}$为中间量, 为观测增益.
设${{e}_{{{x}_{i}}}}={{x}_{i}}-{{\hat{x}}_{i}}$, ${{e}_{{{d}_{i1}}}}={{d}_{i1}}-{{\hat{d}}_{i1}}$, ${{e}_{{{v}_{i}}}}={{v}_{i}}-{{\hat{v}}_{i}}$, ${{e}_{{{d}_{i2}}}}$ $={{d}_{i2}}-{{\hat{d}}_{i2}}$, 则
$ \begin{align}\label{14} \begin{cases} {{{\dot{e}}}_{{{x}_{i}}}}= -{{\lambda }_{i1}}{{\rm sig}^{\frac{2}{3}}}({{e}_{{{x}_{i}}}})+{{e}_{{{d}_{i1}}}} \\ {{{\dot{e}}}_{{{d}_{i1}}}}= -{{\lambda }_{i2}}{{\rm sig}^{\frac{1}{2}}}({{e}_{{{d}_{i1}}}}-{{{\dot{e}}}_{{{x}_{i}}}})+{{{\dot{d}}}_{i1}} \\ {{{\dot{e}}}_{{{v}_{i}}}}= -{{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}}({{e}_{{{v}_{i}}}})+{{e}_{{{d}_{i2}}}} \\ {{{\dot{e}}}_{{{d}_{i2}}}}= -{{\lambda }_{i4}}{{\rm sig}^{\frac{1}{2}}}({{e}_{{{d}_{i2}}}}-{{{\dot{e}}}_{{{v}_{i}}}})+{{{\dot{d}}}_{i2}} \end{cases} \end{align} $
(14) 其中, .由引理6可知, 存在大于零的增益, 使得观测器是有限时间收敛, 即存在一个时刻${{ T}^{*}}$, 当$t\in [0, {{ T}^{*}}]$时, ${{e}_{{{x}_{i}}}}$, ${{e}_{{{d}_{i1}}}}$, ${{e}_{{{v}_{i}}}}$, ${{e}_{{{d}_{i2}}}}$均有界; 当$t>{{ T}^{*}}$时, ${{e}_{{{x}_{i}}}}=0$, ${{e}_{{{d}_{i1}}}}$ $=$ $0$, ${{e}_{{{v}_{i}}}}=0$, ${{e}_{{{d}_{i2}}}}=0$.
3.2 复合式分布式控制律设计
下面基于上述设计的有限时间干扰观测器, 结合滑模控制理论, 设计复合分布式控制协议消除干扰, 并使得系统(9)和系统(10)实现有限时间包容控制.
首先令跟踪误差为
$ \begin{align}\label{15} \begin{cases} \omega _{i}^{x}= \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)}} \\[2mm] \omega _{i}^{v}= \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( ( {{{\hat{v}}}_{i}}+{{{\hat{d}}}_{i1}} )-( {{{\hat{v}}}_{j}}+{{{\hat{d}}}_{j1}} ) \right)}\, +\\ \qquad \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( ( {{{\hat{v}}}_{i}}+{{{\hat{d}}}_{i1}} )-{{v}_{j}} \right)} \end{cases} \end{align} $
(15) 基于跟踪误差(15), 设计复合分布式控制协议如下:
$ \begin{align}\label{16} {{u}_{i}}= & -{{k}_{0}}{\rm sgn}\left( \sum\limits_{j=1}^{n}{{{a}_{ij}} \left( {{s}_{i}}-{{s}_{j}} \right)}+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}} {{s}_{i}}} \right)- \nonumber\\ &\ {{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( \omega _{i}^{x} \right)- {{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\left( \omega _{i}^{v} \right)-{{{\hat{d}}}_{i2}} \end{align} $
(16) 其中, ${{k}_{0}}, {{k}_{1}}, {{k}_{2}}>0$, 分别是干扰观测器(13)对系统速度和干扰的估计值, $i\in F$, 非线性动态积分滑模面为
$ \begin{align}\label{17} {{s}_{i}}= &\ {{{\hat{v}}}_{i}}+{{{\hat{d}}}_{i1}}-\left( {{{\hat{v}}}_{i}} (0)+{{{\hat{d}}}_{i1}}(0) \right)+ \nonumber\\ &\ \int_{0}^{t}\left({ {{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}( \omega _{i}^{x} ) +{{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}( \omega _{i}^{v} ) }\right){\rm d}\tau \end{align} $
(17) 其中, $0<{{\alpha }_{1}}<1$, .当$t=0$时, ${{s}_{i}}(0)$ $=0$, 表示各智能体的状态从初始时刻就位于非线性滑模面(17)上.
定理2.考虑由$n$个跟随者和$m$个领导者组成的二阶受扰多智能体系统(9)和(10), 其通信拓扑图可描述成, 如果假设1~3成立, 当切换增益满足${{k}_{0}}>\delta $时, 基于有限时间干扰观测器(13)和非线性积分滑模面(17)的复合分布式非线性积分滑模控制协议(16)可使得系统实现全局有限时间包容控制.其中, , $e_{{{v}_{i}}}^{*}$ $=$ , , $k=1, 2, 3$, .
证明.首先对滑模面(17)求一次导, 得
$ \begin{align*} {{{\dot{s}}}_{i}} =&\ {{{\dot{\hat{v}}}}_{i}}+{{{\dot{\hat{d}}}}_{i1}}+{{k}_{1}} {{\rm sig}^{{{\alpha }_{1}}}}\left( \omega _{i}^{x} \right)+{{k}_{2}}{{\rm sig}^ {{{\alpha }_{2}}}}\left( \omega _{i}^{v} \right)= \\ & \ {{u}_{i}}-{{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}}({{{\hat{v}}}_{i}}-{{v}_{i}})+ {{{\hat{d}}}_{i2}}+{{{\dot{\hat{d}}}}_{i1}}\, + \\ & \ {{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( \omega _{i}^{x} \right)+{{k}_{2}}{{\rm sig}^ {{{\alpha }_{2}}}}\left( \omega _{i}^{v} \right)=\\ & -{{k}_{0}}{\rm sgn}\left( \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( {{s}_{i}}-{{s}_{j}} \right)}+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}{{s}_{i}}} \right)- \\ &\ {{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}}\left( {{{\hat{v}}}_{i}}-{{v}_{i}} \right)+{{{\dot{\hat{d}}}}_{i1}}= \\ & -{{k}_{0}}{\rm sgn}\left( \sum\limits_{j=1}^{n}{{{a}_{ij}}\left( {{s}_{i}}-{{s}_{j}} \right)}+\sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}{{s}_{i}}} \right)+ \\ &\ {{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}}\left( {{e}_{{{v}_{i}}}} \right)+{{\lambda }_{i2}}{{\rm sig}^{\frac{1}{2}}}\left( {{\lambda }_{i1}}{{\rm sig}^{\frac{2}{3}}}\left( {{e}_{{{x}_{i}}}} \right) \right) \nonumber \end{align*} $
令${\pmb S}={[{{s}_{1}}, {{s}_{2}}, \cdots , {{s}_{n}}]}^{{\rm T}}$, 将上式转换成矩阵形式
$ \begin{align}\label{18} \dot{\pmb S}= & -{{k}_{0}}{\rm sgn}\left( {{L}_{f}}{\pmb S} \right)+{{\lambda }_{3}} {{\rm sig}^{\frac{2}{3}}}\left( {{\pmb e}_{v}} \right)+ \notag\\ &\ {{\lambda }_{2}} {{\rm sig}^{\frac{1}{2}}}\left( {{\lambda }_{1}}{{\rm sig}^{\frac{2}{3}}}\left( {{\pmb e}_{x}} \right) \right) \end{align} $
(18) 其中, ${{L}_{f}}$为系统的Laplacian矩阵, , ${{\lambda }_{21}}$, , , ${\rm diag} \{ {{\lambda }_{13}}$, , , , ${{\pmb e}_{v}}$ .
构造函数, 对$V_2$求一次导, 得
$ \begin{align*} {{{\dot{V}}}_{2}} =&\ {{\pmb S}^{\rm{T}}}{{L}_{f}}\dot{\pmb S} = {{\pmb S}^{\rm{T}}}{{L}_{f}}\left( -{{k}_{0}}{\rm sgn}\left( {{L}_{f}}{\pmb S} \right) \right)+ \\ &\ {{\pmb S}^{\rm{T}}}{{L}_{f}}\left( {{\lambda }_{3}}{{\rm sig}^{\frac{2}{3}}} \left( {{\pmb e}_{v}} \right)+{{\lambda }_{2}}{{\rm sig}^{\frac{1}{2}}}\left( {{\lambda }_{1}}{{\rm sig}^{\frac{2}{3}}} \left( {{\pmb e}_{x}} \right) \right) \right) = \\ & -{{k}_{0}}\sum\limits_{i=1}^{n}{\left| {{\left[ {{L}_{f}}{\pmb S} \right]}_{i}} \right|}+ \sum\limits_{i=1}^{n}\bigg( {{\lambda }_{i3}}{{\rm sig}^{\frac{2}{3}}} \left( {{e}_{{{v}_{i}}}} \right)+\\ &\ {{\lambda }_{i2}}{{\rm sig}^{\frac{1}{2}}}\left( {{\lambda }_{i1}} {{\rm sig}^{\frac{2}{3}}} \left( {{e}_{{{x}_{i}}}} \right) \right) \bigg)\left| {{\left[ {{L}_{f}}{\pmb S} \right]}_{i}} \right| \le \\ & -\left( {{k}_{0}}-\delta \right){{\left\| {{L}_{f}}{\pmb S} \right\|}_{1}} \le -\left( {{k}_{0}}-\delta \right){{\left\| {{L}_{f}}{\pmb S} \right\|}_{2}} \nonumber \end{align*} $
其中, , , , , $k=1, 2, 3$, .由有限时间观测器(13)可知, 在$[0, {{ T}^{*}}]$内, ${{e}_{{{x}_{i}}}}$, ${{e}_{{{v}_{i}}}}$是有界的, 因此$\delta $一定存在.由于${{L}_{f}}$是正定的, .因此
$ \begin{align}\label{19} \dot{V}\le -\sqrt{2}\left( {{k}_{0}}-\delta \right)\lambda _{\min }^{\frac{1}{2}}\left( {{L}_{f}} \right)V_{2}^{\frac{1}{2}} \end{align} $
(19) 因此, 当${{k}_{0}}>\delta $时, 由引理2可知各智能体状态可在有限时间内到达非线性滑模面(17)上.假设各智能体状态可在${{t}_{1}}$时刻到达滑模面上, 由引理2可得
$ \begin{align}\label{20} {{t}_{1}}\le &\ \frac{\sqrt{2}V_{2}^{\frac{1}{2}}(0)}{\left( {{k}_{0}} -\delta \right)\lambda _{\min }^{\frac{1}{2}}\left( {{L}_{f}} \right)} \le\notag\\[2mm] &\ \frac{{{\left( {{\pmb S}^{\rm{T}}}(0)L_{f}^{2}{\pmb S}(0) \right)}^{\frac{1}{2}}}} {\left( {{k}_{0}}-\delta \right){{\lambda }_{\min }}\left( {{L}_{f}} \right)}=0 \end{align} $
(20) 式(20)表明各智能体状态从初始时刻开始就一直发生在非线性滑模面上.
下面证明系统有限时间包容控制.首先假设跟随者的状态跟踪误差为, , , ${{\bar{v}}_{n}}]^{\rm{T}}$.
由有限时间观测器(13)可知, 存在一个时刻${{T}^{*}}$, 当$t>{{ T}^{*}}$时, ${{e}_{{{x}_{i}}}}={{e}_{{{d}_{i1}}}}={{e}_{{{v}_{i}}}}={{e}_{{{d}_{i2}}}}=0$.因此, 闭合系统(9), (10), (16)的有限时间稳定性可分两步证明, 即上状态跟踪误差${{\bar{x}}_{i}}$, ${{\bar{v}}_{i}}$有界, 及$t$ $>$ ${{T}^{*}}$时, 全局有限时间收敛.
1) 注意到系统的状态一直发生在非线性积分滑模面上, 因此
$ \begin{align}\label{21} {{\dot{s}}_{i}}=\, &{\dot{\hat{v}}_{i}}+{\dot{\hat{d}}}_{i1}+ {{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}}\left( \omega _{i}^{x} \right)+ {{k}_{2}}{{\rm sig}^{{{\alpha }_{2}}}}\left( \omega _{i}^{v} \right)=0 \end{align} $
(21) 令${{\tilde{v}}_{i}}={{\hat{v}}_{i}}+{{\hat{d}}_{i1}}$, 则, 因此
$ \begin{align}\label{22} \begin{cases} {{{\dot{x}}}_{i}}= {{{\tilde{v}}}_{i}}+{{e}_{{{v}_{i}}}}+{{e}_{{{d}_{i1}}}} \\ {{{\dot{\tilde{v}}}}_{i}}= -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}} \Big( \sum\limits_{j=1}^{n}{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)+\\ \qquad\, \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)} \Big)- {{k}_{2}}\, \times\\ \qquad\, {{\rm sig}^{{{\alpha }_{2}}}}\Big( \sum\limits_{j=1}^{n}{{{a}_{ij}} \left( {{{\tilde{v}}}_{i}}-{{{\tilde{v}}}_{j}} \right)+ \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{{\tilde{v}}}_{i}}-{{v}_{j}} \right)}} \Big) \end{cases} \end{align} $
(22) 应用ISS稳定性引理, 假设${{e}_{{{v}_{i}}}}$, ${{e}_{{{d}_{i1}}}}=0$, 则系统(22)转变为
$ \begin{align}\label{23} \begin{cases} {{{\dot{x}}}_{i}}= {{{\tilde{v}}}_{i}} \\ {{{\dot{\tilde{v}}}}_{i}}= -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}} \Big( \sum\limits_{j=1}^{n}{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)+\\ \qquad\, \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)} \Big)-{{k}_{2}}\, \times \\ \qquad\, {{\rm sig}^{{{\alpha }_{2}}}}\Big( \sum\limits_{j=1}^{n}{{{a}_{ij}} \left( {{{\tilde{v}}}_{i}}-{{{\tilde{v}}}_{j}} \right)+ \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{{\tilde{v}}}_{i}}-{{v}_{j}} \right)}} \Big) \end{cases} \end{align} $
(23) 由定理1可知, 系统(23)是有限时间包容控制的, 结合引理1, 系统(22)是ISS稳定的.由观测器可知, 在$[0, {{ T}^{*}}]$内${{e}_{{{v}_{i}}}}$和${{e}_{{{d}_{i1}}}}$有界, 因此系统(22)状态跟踪误差${{\bar{x}}_{i}}$和${{\bar{\tilde{v}}}_{i}}$有界.而假设1中说明${{d}_{i1}}$是有界的, 因此${{\hat{d}}_{i1}}$也是有界的, 所以速度跟踪误差${{\bar{v}}_{i}}$是有界的.
2) (全局有限时间包容控制)当$t>{{ T}^{*}}$时, ${{e}_{{{x}_{i}}}}$ $=$ ${{e}_{{{d}_{i1}}}}={{e}_{{{v}_{i}}}}= {{e}_{{{d}_{i2}}}}=0$.令${{\tilde{v}}_{i}}={{\hat{v}}_{i}}+{{\hat{d}}_{i1}}= {{v}_{i}}+$ ${{d}_{i1}}$, 则
$ \begin{align}\label{24} \begin{cases} {{{\dot{x}}}_{i}}= {{{\tilde{v}}}_{i}} \\ {{{\dot{\tilde{v}}}}_{i}}= -{{k}_{1}}{{\rm sig}^{{{\alpha }_{1}}}} \Big( \sum\limits_{j=1}^{n}{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)+\\ \qquad\, \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{x}_{i}}-{{x}_{j}} \right)} \Big)- {{k}_{2}}\, \times\\ \qquad\, {{\rm sig}^{{{\alpha }_{2}}}}\Big( \sum\limits_{j=1}^{n}{{{a}_{ij}} \left( {{{\tilde{v}}}_{i}}-{{{\tilde{v}}}_{j}} \right)+ \sum\limits_{j=n+1}^{n+m}{{{a}_{ij}}\left( {{{\tilde{v}}}_{i}}-{{v}_{j}} \right)}} \Big) \end{cases} \end{align} $
(24) 由定理1可知, 系统可实现全局有限时间包容控制, 即在有限时间内, $\to$ $-L_{f}^{-1}{{L}_{d}}{{\pmb v}_{L}}$.
注2.文献[26]研究了带有不匹配干扰的高阶多智能体系统分布式主动抗干扰控制方法, 同时采用了滑模控制理论和DOBC方法, 然而文献[26]设计的是常规的线性滑模面, 会出现抖振现象, 而本文设计的非线性积分滑模面不仅能有效消除抖振, 而且能增强系统的鲁棒性能.文献[27-28]在研究带有不匹配干扰的多智能体系统时对系统模型进行了处理, 假设不匹配干扰二阶可微, 则可将不匹配干扰转变成匹配干扰, 然后利用常规的处理方式消除干扰.但在实际应用中存在很多情况不能如此处理, 因此这种方法有一定的局限性.本文则直接对干扰进行观测, 并在控制器中添加干扰补偿项, 可有效抵消干扰的影响, 而不影响系统的性能.
4. 数值仿真
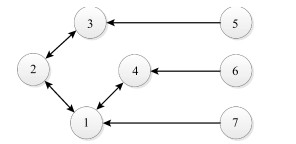
考虑4个跟随者和3个领导者组成的网络, 如图 1所示.
图 1中节点1~ 4是无向连通的跟随者, 节点5~7是单向发送信息的领导者.假设拓扑图所有边的权重都是1, 则系统的Laplacian矩阵为
$ \begin{align*}L=\begin{bmatrix} 3 & -1 & 0 & -1 & 0 & 0 & -1 \\ -1 & 2 & -1 & 0 & 0 & 0 & 0 \\ 0 & -1 & 2 & 0 & -1 & 0 & 0 \\ -1 & 0 & 0 & 2 & 0 & -1 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ \end{bmatrix}\end{align*} $
其中,
$ $${{L}_{f}}=\!\begin{bmatrix} 3 & -1 & 0 & -1 \\ -1 & 2 & -1 & 0 \\ 0 & -1 & 2 & 0 \\ -1 & 0 & 0 & 2 \\ \end{bmatrix}, ~~ {{L}_{d}}=\!\begin{bmatrix} 0 & 0 & -1 \\ 0 & 0 & 0 \\ -1 & 0 & 0 \\ 0 & -1 & 0 \\ \end{bmatrix}$$ $
假设4个智能体都受到干扰影响:智能体1: ${{d}_{1, 1}}$ $=2\tanh (2t)$, ${{d}_{1, 2}}=2$; 智能体2: ${{d}_{2, 1}}=4\tanh (t)$, ${{d}_{2, 2}}=1$; 智能体3: ${{d}_{3, 1}}={\rm sigmoid}(t)$, ${{d}_{3, 2}}$ ; 智能体4: ${{d}_{4, 1}}=3{\rm sigmoid}(t)$, ${{d}_{4, 2}}$ $=-\tanh (t)$, $t>0$.其中${{d}_{i1}}$, ${{d}_{i2}}$ ($i=1, 2, 3, 4$)分别表示不匹配干扰和匹配干扰.
控制器的参数设置为${{k}_{0}}=10$, ${{k}_{1}}=20$, ${{k}_{2}}=$ $30$, ${{\alpha }_{1}}=0.8$.干扰观测器的参数设置为${{\lambda }_{i, 1}}=10$, ${{\lambda}_{i, 2}}$ $=20$, ${{\lambda}_{i, 3}}=15$, ${{\lambda}_{i, 4}}=32$, $i=1, 2, 3, 4$; 假设4个跟随者的初始位置分别为${{x}_{1}}=(2, 0)$, ${{x}_{2}}=$ $(4, 0)$, ${{x}_{3}}=(0, 2)$, ${{x}_{4}}=(0, 4)$, 领导者的初始坐标分别为${{x}_{5}}=(6, 8)$, ${{x}_{6}}=(8, 8)$, ${{x}_{7}}= (8, 6)$.领导者为动态领导者, 其初始速度为${{v}_{5}}=(1, 1)$, ${{v}_{6}}=(1.2, 1.2)$, ${{v}_{7}}$ $=(1, 1)$.仿真结果如图 2~4所示.
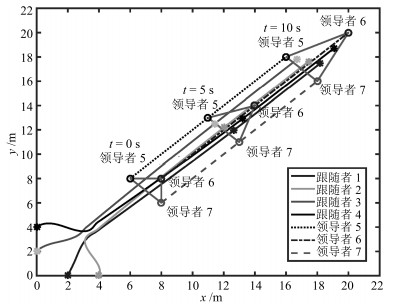 图 4 跟随者与动态领导者的位置关系Fig. 4 The trajectories of position for the followers and dynamic leaders
图 4 跟随者与动态领导者的位置关系Fig. 4 The trajectories of position for the followers and dynamic leaders图 2是干扰观测器(13)对受扰系统(9)中各智能体的不匹配干扰和匹配干扰的观测量和估计误差, 从图 2(a) 和图 2(c)可以看出观测器可以快速估计出智能体所受的干扰, 在图 2(b)和图 2(d)中各智能体所受干扰的观测误差很快的趋于0, 说明观测器可准确地估算出系统中的干扰, 表现出较好的观测性能.图 3是智能体的位置和速度状态观测误差.从图 3可知, 在不到1 s的时间误差曲线趋于0, 直观地说明观测器可快速准确地估算出跟随者的状态信息, 从而确保控制器的有效作用.
图 4是多智能体系统的位置状态轨迹图, 其中星号表示跟随者, 圆圈表示动态领导者, 可以看出3个动态领导者以一定的速度沿着某一方向移动, 而4个跟随者通过相互作用最终收敛到有领导者组成的几何体中.特别地, 当时, 跟随者还没有完全进入凸包内, 而当$t=10 \, \rm s$时, 各跟随者均进入凸包内, 且跟随着领导者同步运动.因此, 在控制律(16)下各智能体能够快速地跟踪到领导者, 并进入由领导者组成的几何体中, 实现了包容控制.
文献[26]研究的是带有不匹配干扰的多智能体系统滑模控制.为了进一步说明本文方法的优越性, 本文将文献[26]所提方法拓展到多领导者情况.利用上述数值参数, 得到图 5所示的仿真图.由图 5可知, 当$t=10\, \rm s$时跟随者没有完全进入凸包内, 当$t$ $=$ $20\, \rm s$时, 系统才实现包容控制.与文献[26]的实验结果比较, 说明本文方法可以更加快速地达到一致, 取得较好的结果.
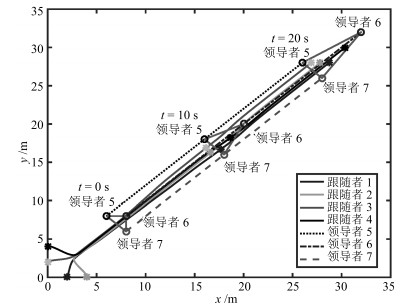
综上, 带干扰的多智能体系统(9)和(10)通过有限时间干扰观测器(13)快速地估算干扰, 在复合分布式控制协议(16)下快速消除干扰, 使得各跟随者的状态收敛到由动态领导者组成的动态凸包内, 即, 实现了包容控制.
5. 结论
本文研究带有不匹配干扰的二阶多智能体系统协同控制问题.设计了非线性有限时间干扰观测器, 使得智能体的干扰可被观测和补偿.利用滑模控制理论和基于控制的干扰观测器方法, 提出了复合分布式非线性积分滑模控制协议.通过使用Lyapunov稳定性理论、代数图论、齐次性理论等方法, 研究了带有不匹配干扰的多智能体系统有限时间包容控制.最后数值仿真表明了所提控制算法的有效性.
由于复杂多变的工作环境, 多智能体系统通常会受到各种干扰的影响.在实际工程应用中, 不匹配干扰是十分常见的干扰, 因此本文所提方法具有一定的发展前景, 而且更具有普适性.未来的研究方向将针对更为复杂的环境, 设计新型的干扰观测器, 研究多智能体系统的协同控制问题.
-
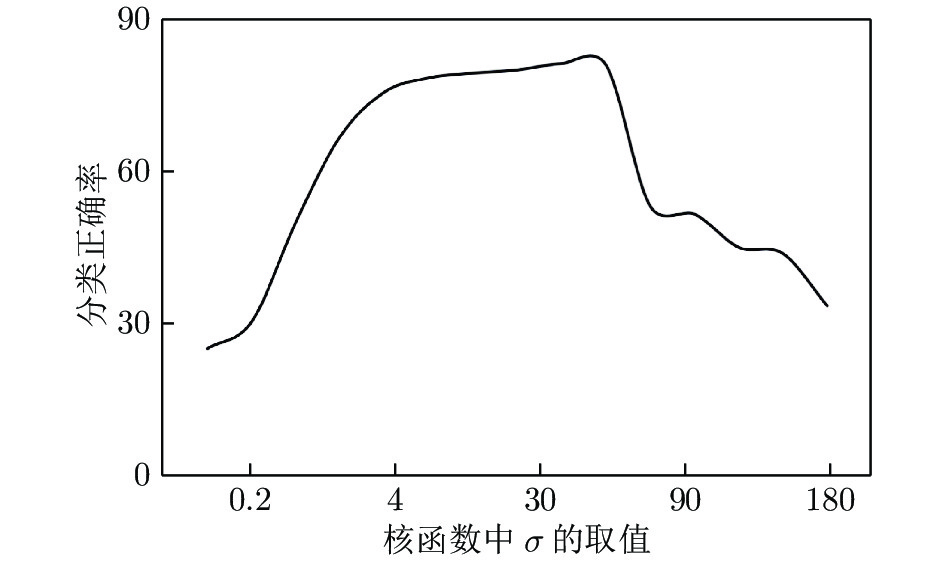
图 3 故障诊断准确率与核参数取值折线图
Fig. 3 Line diagram of the fault diagnosis accuracy and kernel parameter
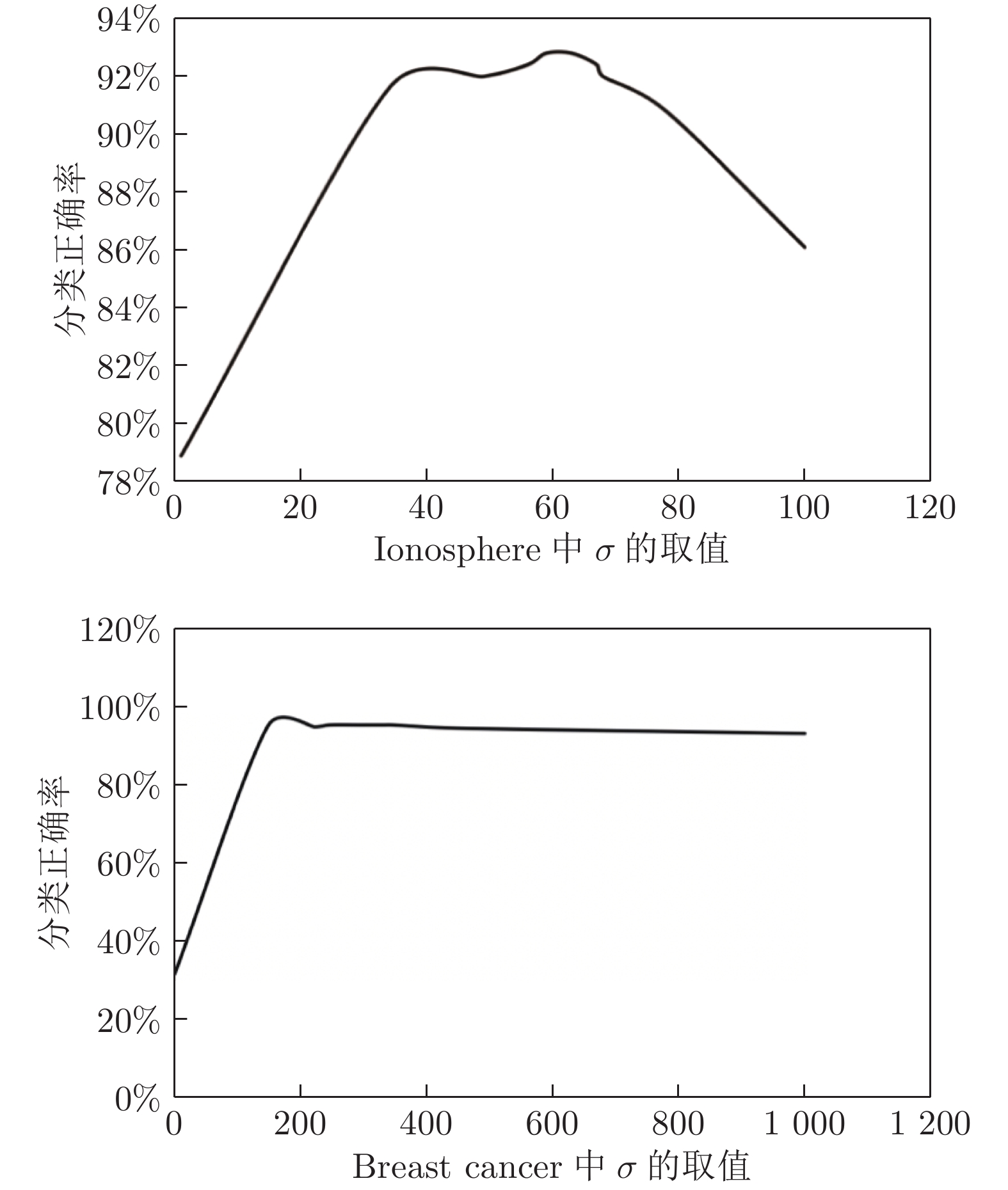
图 4 故障诊断准确率与核参数取值折线图
Fig. 4 Line diagram of the fault diagnosis accuracy and kernel parameter
表 1 故障类型描述
Table 1 Description of the selected fault sample sets
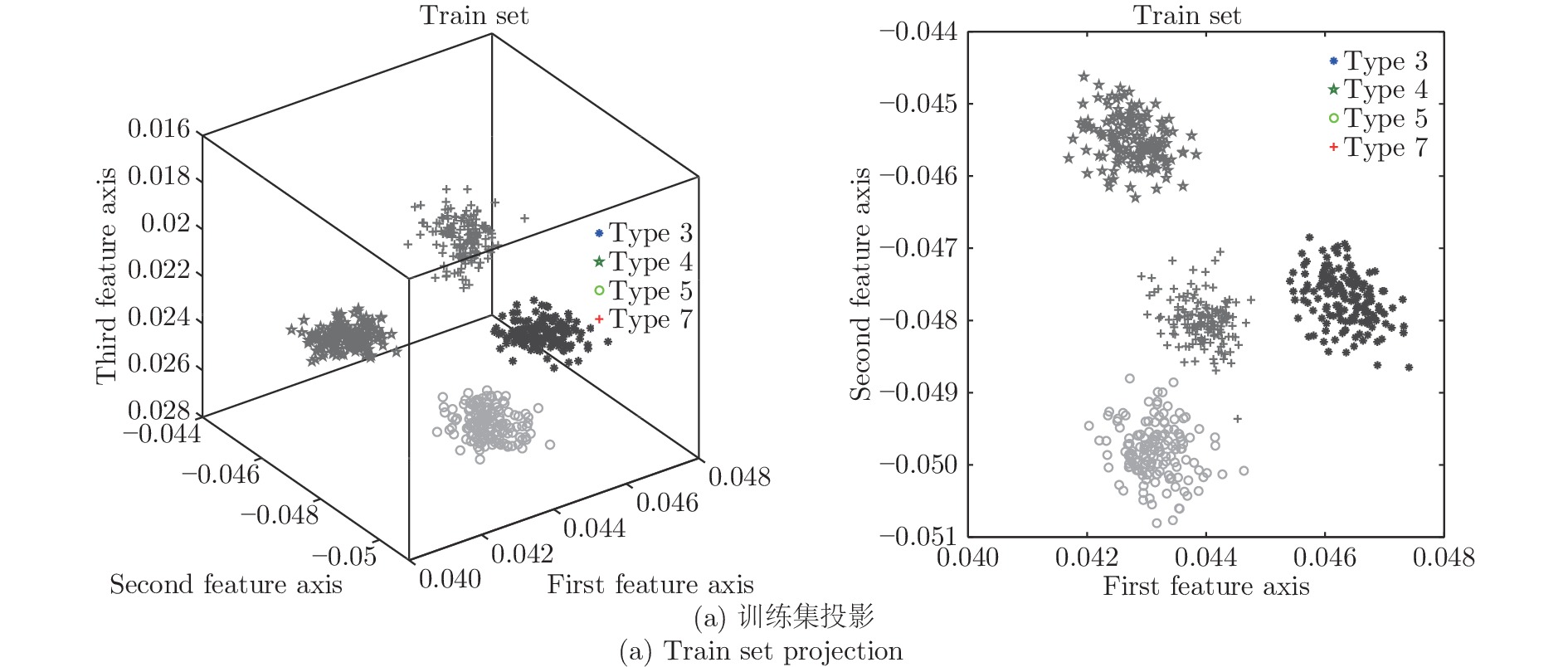
Fault Number Fault description Fault type 3 物料 D 的温度的异变 阶跃 4 反应器冷却水入口温度的异变 阶跃 5 泠凝器冷却水入口温度的异变 阶跃 7 物料 C 压力下降 阶跃  下载: 导出CSV
下载: 导出CSV
表 2 选取不同核参数σ下故障诊断的准确率 (KFD)
Table 2 The fault diagnosis accuracy based on different kernel parameter σ(KFD)
The value of the parameter σ Test accuracy (%) The value of the parameter σ Test accuracy (%) 0.1 25 30 81.25 0.2 30.31 40 80.94 0.8 50 70 53.13 2 66.88 90 51.56 4 75.63 100 45 8 78.44 160 43.75 10 79.38 180 33.44
下载: 导出CSV
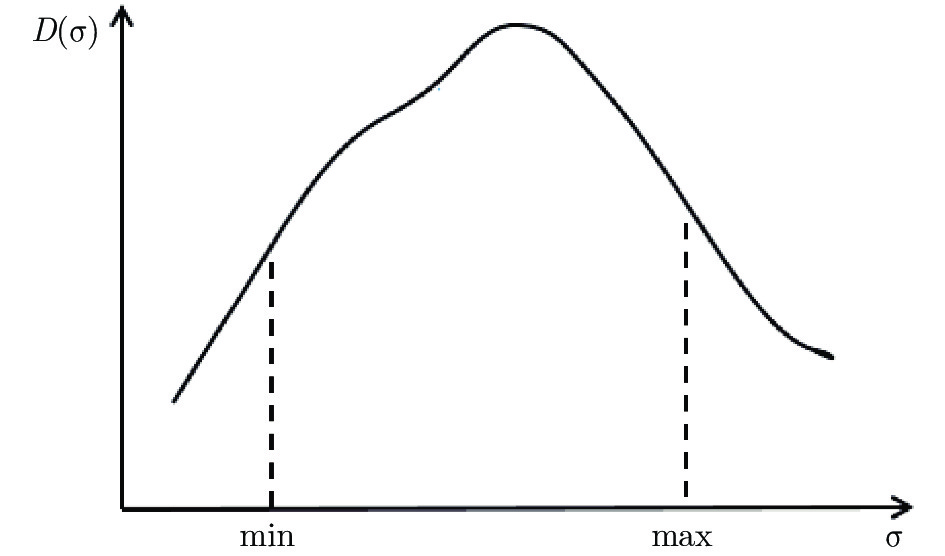
表 3 利用区间三分法求解最优核参数σ对应的故障诊断的准确率 (KFD)
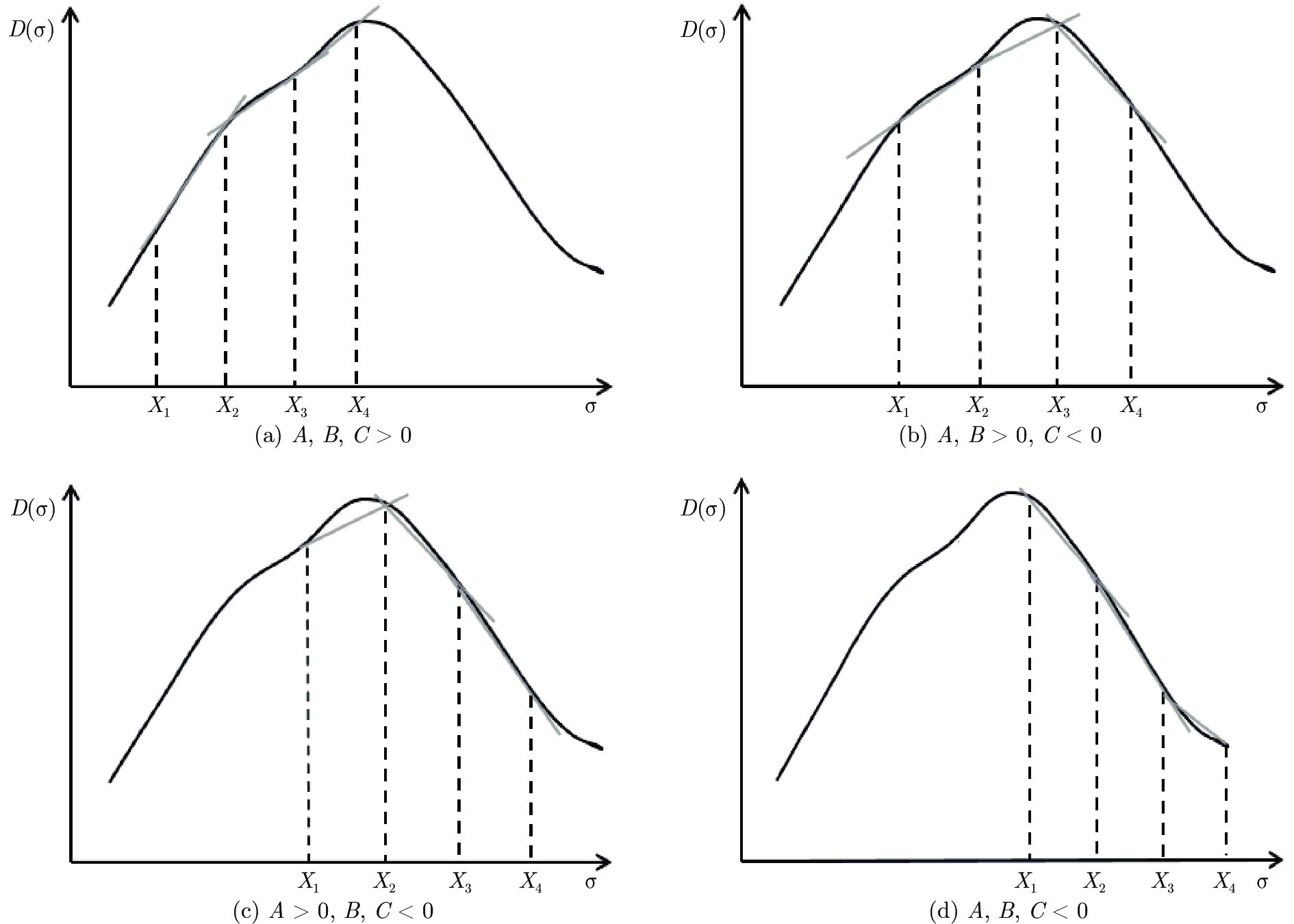
Table 3 The accuracy of fault diagnosis of optimal kernel parameter by using the interval three-part method (KFD)
迭代次数 对应区间 三分点 1 三分点 2 三分点 3 三分点 4 ${X_1}$ $D({X_1})$ ${X_2}$ $D({X_2})$ ${X_3}$ $D({X_3})$ ${X_3}$ $D({X_4})$ 1 [1, 100] 1 50 % 34 79 % 67 51 % 100 45 % 2 [1, 67] 1 50 % 23 80 % 45 73.8 % 67 51 % 3 [1, 45] 1 50 % 15.7 79.4 % 30.3 81.25 % 45 73.8 % 4 [15.7, 45] 15.7 79.4 % 25.5 80 % 35.2 78.8 % 45 73.8 % 5 [15.7, 35.2] 15.7 79.4 % 22.2 80.3 % 28.7 80.4 % 35.2 78.8 % 6 [22.2, 35.2] 22.2 80.3 % 26.5 80 % 30.9 81.25 % 35.2 78.8 %
下载: 导出CSV
表 4 KFD算法和MKFD算法中不同核参数的故障诊断结果
Table 4 The fault diagnosis with different kernel parameters in KFD algorithm and MKFD algorithm
The value of the
parameter σ in KFDTrain
accuracy (%)Test
accuracy (%)The value of the
parameter σ in MKFDTrain
accuracy (%)Test
accuracy (%)0.1 100 25 0.1 100 25 1 100 50 1 100 50 10 99.8 79.4 4 100 76.9 30 99.8 81.3 8 100 99.69 60 70.5 44.7 12 99.9 92.5 90 27.7 25.3 16 99.9 80.6
下载: 导出CSV
表 5 选取不同核参数σ下故障诊断的准确率(按照区间三分法做纵向表)
Table 5 The fault diagnosis accuracy based on different kernel parameters σ (Make the longitudinal table according to the interval three-part method)
Ionosphere Breast cancer The value of the parameter σ Test accuracy (%) The value of the parameter σ Test accuracy (%) 1 78.9 1 31.7 34 91.6 149 95.1 49 92 223 94.9 56 92.4 248 95.4 59 92.8 297 95.4 63 92.8 334 95.4 67 92.4 346 95.4 68 92 445 94.6 78 90.8 667 94 100 86.1 1000 93.2
下载: 导出CSV
表 6 区间三分法迭代求解最优核参数σ (MKFD)
Table 6 The iterative solution of the optimal kernel parameters σ using interval partition method
迭代次数 对应区间 三分点 1 三分点 2 三分点 3 三分点 4 ${X_1}$ $D({X_1})$ ${X_2}$ $D({X_2})$ ${X_3}$ $D({X_3})$ ${X_3}$ $D({X_4})$ 1 [1, 100] 1 50.9 % 34 60.6 % 67 57.5 % 100 58.1 % 2 [1, 67] 1 50.9 % 23 76.6 % 45 58.1 % 67 57.5 % 3 [1, 45] 1 50 % 15.7 96.3 % 30.3 63.8 % 45 58.1 % 4 [1, 30.3] 1 50 % 10.8 99.69 % 20.5 84.69 % 30.3 63.8 % 5 [1, 20.5] 1 50 % 7.5 99.38 % 14 97.81 % 20.5 84.69 % 6 [1, 14] 1 50 % 5.3 81.56 % 9.7 99.69 % 14 97.81 %
下载: 导出CSV
表 7 交叉验证法选取不同核参数σ下故障诊断的准确率(FDGLPP)
Table 7 The fault diagnosis accuracy based on different kernel parameters σ by cross validation method
The value of the
parameter σTest
accuracy (%)The value of the
parameter σTest
accuracy (%)The value of the
parameter σTest
accuracy (%)0.1 25 0.5 68.13 3 55.31 1 52.19 5 75.31 6 79.38 50 28.44 25 25.0 9 99.69 100 41.25 50 28.44 12 25.0 500 39.06 75 34.69 15 55.94 1000 38.75 95 40.0 18 25.0
下载: 导出CSV
表 8 四种模型的故障诊断结果与运行时间
Table 8 Fault diagnosis results and running time of the four models
Model Optimal value of parameter σ Test accuracy (%) Test time (s) KFD 30 81.25 3.90072 CKFD 8 97.81 4.14769 FDGLPP 10 99.69 9.30612 MKFD 9 99.69 3.86806
下载: 导出CSV
-
[1] 张妮, 车立志, 吴小进. 基于数据驱动的故障诊断技术研究现状及展望. 计算机科学, 2017, 44(S1): 47−52Zhang Ni, Che Li-Zhi, Wu Xiao-Jin. Present situation and prospect of data-driven based fault diagnosis technique. Computer Science, 2017, 44(S1): 47−52 [2] 郭一帆, 唐家银. 基于机器学习算法的寿命预测与故障诊断技术的发展综述. 计算机测量与控制, 2019, 27(3): 13−19Guo Yi-Fan, Tang Jia-Yin. A review of the development of life prediction and fault diagnosis technology based on machine learning algorithm. Computer Measurement & Control, 2019, 27(3): 13−19 [3] Zhang Y, Zhang Y, Zhang J, et al. Collaborative representation cascade for single-image super-resolution. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2017: 1−16 [4] Kock N, Hadaya P. Minimum sample size estimation in PLS‐SEM: The inverse square root and gamma‐exponential methods. Information Systems Journal, 2018, 28(1): 227−261 doi: 10.1111/isj.12131 [5] Maisinger K, Hobson M P, Lasenby A N. A maximum entropy method for reconstructing interferometer maps of fluctuations in the cosmic microwave background radiation. Monthly Notices of the Royal Astronomical Society, 2018, 290(2): 313−326 [6] Hwang J S, Noh J T, Lee S H, et al. Experimental verification of modal identification of a high-rise building using independent component analysis. International Journal of Concrete Structures and Materials, 2019, 13(1): 4 doi: 10.1186/s40069-018-0319-7 [7] 胡志新. 基于深度学习的化工故障诊断方法研究. 杭州电子科技大学, 中国, 2018Hu Zhi-Xin. Research on Chemical Fault Diagnosis Methods Based on Deep Learning [Master thesis], Hangzhou Dianzi University, China 2018 [8] Mika S, Ratsch G, Weston J, et al. Fisher discriminant analysis with kernel. In: Proceedings of the Neural Networks for Signal Processing IX, the 1999 IEEE Signal Processing Society Workshop. Madison, WI, USA: IEEE, 1999: 41−48 [9] 张曦, 赵旭, 刘振亚, 等. 基于核Fisher子空间特征提取的汽轮发电机组过程监控与故障诊断. 中国电机工程学报, 2007, (20): 1−6 doi: 10.3321/j.issn:0258-8013.2007.20.001Zhang Xi, Zhao Xu, Liu Zhen-Ya, et al. Process monitoring and fault diagnosis of turbine generator unit based on feature extraction in kernel Fisher subspace. Proceedings of the CSEE, 2007, (20): 1−6 doi: 10.3321/j.issn:0258-8013.2007.20.001 [10] 马立玲, 徐发富, 王军政. 一种基于改进核Fisher的故障诊断方法. 化工学报, 2017, 68(3): 1041−1048Ma Li-Ling, Xu Fa-Fu, Wang Jun-Zheng. A fault diagnosis method based on improved kernel Fisher. CIESC Journal, 2017, 68(3): 1041−1048 [11] Chikr-Elmezouar Z, Almanjahie I M, Laksaci A, et al. FDA: strong consistency of the kNN local linear estimation of the functional conditional density and mode. Journal of Nonparametric Statistics, 2019, 31(1): 175−195 doi: 10.1080/10485252.2018.1538450 [12] 李普煌, 李敏, 范新南, 等. 迭代分析相对密度的高光谱异常检测. 中国图象图形学报, 2018, 23(2): 219−228 doi: 10.11834/jig.170243Li Pu-Huang, Li Min, Fan Xin-Nan, et al. Hyperspectral anomaly detection algorithm based on iterative analysis with relative density. Journal of Image and Graphics, 2018, 23(2): 219−228 doi: 10.11834/jig.170243 [13] 赵忠盖, 刘飞. 基于马氏距离统计监控指标的应用研究. 自动化学报, 2008, 34(4): 493−495Zhao Zhong-Gai, Liu Fei. Application research of statistical monitoring index based on Mahalanobis distance. Acta Automatica Sinica, 2008, 34(4): 493−495 [14] 卫芬. 旋转机械多传感器信息融合智能故障诊断关键技术研究. 哈尔滨工业大学, 中国, 2018Wei Fen. Research on Key Technologies of Intelligent Fault Diagnosis Based on Multi-sensor Information Fusion for Rotating machinery [Ph. D. dissertation]. Harbin Institute of Technology, China, 2018 [15] 杜伟, 房立清, 齐子元. 一种邻域自适应半监督局部Fisher判别分析算法. 计算机应用研究, 2019, 36(1): 105−108Du Wei, Fang Li-Qing, Qi Zi-Yuan. Neighborhood adaptive semi-supervised local Fisher discriminant analysis algorithm. Application Research of Computers, 2019, 36(1): 105−108 [16] 杨武夷, 梁伟, 辛乐, 等. 子空间半监督Fisher判别分析. 自动化学报, 2009, 35(12): 1513−1519 doi: 10.1016/S1874-1029(08)60120-2Yang Wu-Yi, Liang Wei, Xin Le, et al. Subspace semi-supervised Fisher discriminant analysis. Acta Automatica Sinica, 2009, 35(12): 1513−1519 doi: 10.1016/S1874-1029(08)60120-2 [17] 郑建炜, 王万良, 姚晓敏, 等. 张量局部Fisher判别分析的人脸识别. 自动化学报, 2012, 38(9): 1485−1495 doi: 10.3724/SP.J.1004.2012.01485Zheng Jian-Wei, Wang Wan-Liang, Yao Xiao-Min, et al. Face recognition using tensor local Fisher discriminant analysis. Acta Automatica Sinica, 2012, 38(9): 1485−1495 doi: 10.3724/SP.J.1004.2012.01485 [18] 温廷新, 于凤俄. 基于KPCA-Fisher判别分析的煤炭自燃预测研究. 矿业安全与环保, 2018, 45(2): 49−53 doi: 10.3969/j.issn.1008-4495.2018.02.011Wen Ting-Xin, Yu Feng-E. Research on prediction of coal spontaneous combustion based on KPCA-Fisher discriminant analysis. Mining Safety & Environmental Protection, 2018, 45(2): 49−53 doi: 10.3969/j.issn.1008-4495.2018.02.011 [19] Wen T, Jia Y, Huang D, et al. Feature extraction of electronic nose signals using QPSO-based multiple KFDA signal processing. Sensors, 2018, 18(2): 388 doi: 10.3390/s18020388 [20] 刘廷瑞, 常林. 弯扭耦合风力机叶片的准稳态响应及LLTR控制. 振动与冲击, 2018, 37(13): 123−129Liu Ting-Rui, Chang Lin. Quasi-steady response and LLTR control of a wind turbine blade with bending-torsion coupled. Journal of Vibration and Shock, 2018, 37(13): 123−129 [21] Shi H, Liu J, Wu Y, et al. Fault diagnosis of nonlinear and large-scale processes using novel modified kernel Fisher discriminant analysis approach. International Journal of Systems Science, 2016, 47(5): 1−15 [22] 郭金玉, 韩建斌, 李元, 等. 基于局部Fisher判别分析的复杂化工过程故障诊断. 计算机应用研究, 2018, 35(4): 1122−1125 doi: 10.3969/j.issn.1001-3695.2018.04.035Guo Jin-Yu, Han Jian-Bin, Li Yuan, et al. Fault diagnosis of complex chemical process based on local Fisher discriminant analysis. Application Research of Computers, 2018, 35(4): 1122−1125 doi: 10.3969/j.issn.1001-3695.2018.04.035 [23] 林信川, 游贵荣. 基于iBeacon的室内定位算法优化研究. 陕西理工大学学报(自然科学版), 2017, 33(3): 67−73Lin Xin-Chuan, You Gui-Rong. Study on optimization of indoor location algorithm based on iBeacon. Journal of Shanxi University of Technology (Natural Science Edition), 2017, 33(3): 67−73 [24] Liu C, Sun Y. The research and application of learning program in adaptive learning system. Applied Mechanics & Materials, 2014, 347-350: 3109−3113 [25] 孟亚辉. 基于最优特征集和马氏距离KNN分类的机械故障分类方法研究. 机械设计与制造, 2017, (7): 104−108Meng Ya-Hui. A method of mechanical fault classification based on optimal feature subset and K-nearest neighbor using mahalanobis distance. Machinery Design & Manufacture, 2017, (7): 104−108 [26] 林升梁, 刘志. 基于RBF核函数的支持向量机参数选择. 浙江工业大学学报, 2007, 35(2): 163−167 doi: 10.3969/j.issn.1006-4303.2007.02.010Lin Sheng-Liang, Liu Zhi. Parameter selection in SVM with RBF kernel function. Journal of Zhejiang University of Technology, 2007, 35(2): 163−167 doi: 10.3969/j.issn.1006-4303.2007.02.010 [27] 魏国, 刘剑, 孙金玮, 等. 基于LS-SVM的非线性多功能传感器信号重构方法研究. 自动化学报, 2008, 34(8): 869−875Wei Guo, Liu Jian, Sun Jin-Wei, et al. Study on nonlinear multifunctional sensor signal reconstruction method based on LS-SVM. Acta Automatica Sinica, 2008, 34(8): 869−875 [28] 黄心汉, 杜克林, 王敏, 等. 基于阻抗控制的动态装配过程仿真研究. 自动化学报, 2000, 26(2): 169−175Huang Xin-Han, Du Ke-Lin, Wang Min, et al. A simulation investigation on dynamic assembly process based on impedance control. Acta Automatica Sinica, 2000, 26(2): 169−175 [29] 张小云, 刘允才. 高斯核支撑向量机的性能分析. 计算机工程, 2003, 29(8): 22−25 doi: 10.3969/j.issn.1000-3428.2003.08.009Zhang Xiao-Yun, Liu Yun-Cai. Performance analysis of support vector machines with Gauss kernel. Computer Engineering, 2003, 29(8): 22−25 doi: 10.3969/j.issn.1000-3428.2003.08.009 [30] Lawn S D, Kerkhoff A D, Burton R, et al. Diagnostic accuracy, incremental yield and prognostic value of determine TB-LAM for routine diagnostic testing for tuberculosis in HIV-infected patients requiring acute hospital admission in South Africa: A prospective cohort. Bmc Medicine, 2017, 15(1): 67 doi: 10.1186/s12916-017-0822-8 [31] 彭泽栋, 冯毅萍, 杨胜蓝, 等. 基于多智能体的TE过程扩展仿真系统设计与实现. 高校化学工程学报, 2019, 33(5): 1195−1205 doi: 10.3969/j.issn.1003-9015.2019.05.022Peng Ze-Dong, Feng Yi-Ping, Yang Sheng-Lan, et al. Design and implementation of extended TE process simulation system based on multi-agent. Journal of Chemical Engineering of Chinese Universities, 2019, 33(5): 1195−1205 doi: 10.3969/j.issn.1003-9015.2019.05.022 [32] Tang Q, Chai Y, Xu J, Fang X. Tang Q, Chai Y, Qu J, et al. Industrial process monitoring based on Fisher discriminant global-local preserving projection. Journal of Process Control, 2019, 81: 76−86 doi: 10.1016/j.jprocont.2019.05.010 -

 下载:
下载:





















计量
- 文章访问数: 1163
- HTML全文浏览量: 216
- PDF下载量: 233
- 被引次数: 0
