

-
摘要: 为解决缓冲区设置不合理带来的项目间工序松弛、工期延误等问题, 基于信息熵理论提出了一种关键链缓冲区设置方法. 首先, 提出了复杂熵、资源熵和人因熵的概念及其度量方法, 运用熵的概念量化诸多不确定因素对工序造成的影响; 其次, 提出了基于区间直觉梯形模糊数的人因熵度量步骤与方法; 最后, 给出了工序工期、项目缓冲和汇入缓冲的熵模型与修正模型, 充分考虑了人的行为因素对项目进度的影响, 并通过算例验证了模型的实用性.Abstract: In order to solve the problems caused by unreasonable buffer setting, such as process slacking and project delaying, this paper proposes a buffer setting method of critical chain based on information entropy. Firstly, it presents concepts and measurement method of complex entropy, resource entropy and human factor entropy, which are used to quantify the influence of uncertain factors on the process. Secondly, the steps and methods of human factor entropy based on interval-valued intuitionistic trapezoidal fuzzy numbers are proposed. Finally, fully considering the influence to project schedule of human behavior, it presents entropy models and modification models of procedure duration, project buffer and feeding buffer. The examples given in the end vividly convey the practicability.
-
软件演化一直是软件工程领域的挑战性问题.由于客户需求、环境变化、技术进步等原因, 软件有着更新演化的现实需要, 由此带来的开发及管理问题可能非常复杂.针对软件演化的定量分析已经被公认是横亘软件生命周期的最复杂问题之一, 而软件架构(Software architecture, SA)的提出为问题的表述与解决提供了方向.近年来, 通过使用SA相关方法和工具已较好解决了软件演化所带来的障碍、成本等问题, 并且涌现出一些新的观点如演化风格、演化路径等[1-3].但在对软件演化过程的精确描述和完整建模上, 并没有出现公认的一般性方法.需要说明的是, 目前针对演化的研究都是过程性研究, 它基于架构工程师对软件更迭过程的完整监控, 若此工作仅依赖编码人员, 会不可避免地出现架构侵蚀或架构偏移问题[4].一个可行思路是对现有的SA工具进行推广和扩充, 使之能够适用于面向软件演化的过程性分析需要. SA发展至今, 其工具和方法的易用性一直是尚待解决的难题, 如何准确、高效地描述演化需求和过程, 进而使得架构设计者和开发者都可以快速掌握和应用, 有很实际的意义.
另一方面, 脱离架构指导的代码演变极易导致软件设计与实现的错位, 而要修正此类问题往往代价巨大.以目前用户最多的学习管理软件Moodle为例, 它在演化过程中曾经历过重大变化以及大量问题的修复[5].虽然拥有庞大的开发者社群和完整的开发过程记录, 但是此开源项目尚没有清晰的架构设计和演化方案描述.每当新版本发布, 仅用文字记录下哪些新开发的组件被加入, 哪些组件被更改, 工程方法的缺失使得版本更迭脱离了SA设计指导, 很可能最终导致代码实现架构与设计架构的差异.研究已经证实这些差异或称错位情形, 对软件系统的质量指标如可用性、可维护性、可靠性等将产生非常负面的影响[6].
最近的软件演化研究多集中于实证分析, 通过软件度量和失效数据等在演化过程中的变化揭示一般规律.如文献[7]提出通过分析驱动演化的错误报告及变更请求等以评估演化过程质量, 其方法完全基于对过程度量数据的标准化衡量, 利于工具实现.文献[8]利用复杂网络对Linux操作系统演化过程进行实证研究, 通过对前后近1 300个发布版本中所有C函数及其相互调用关系构建有向网络, 展现了网络在规模、入/出度、聚类系数等不同拓扑性质下的演化过程.利用复杂网络拓扑属性分析, 作者揭示了函数模块的各类演化形式, 并指出主要组件函数模块演化的统计学规律.而文献[9]在对2002年$ \sim $ 2016年Linux各版本的Bug报告进行分类整合基础上, 重点关注了故障触发在版本演化过程中的规律性特征, 指明Linux组件模块在测试时的重要性排列以及聚类系数对衡量错误类型比例的作用.上述研究使用的模型或方法具有新颖性与可操作性, 但其关注的重点在对既有演化过程的数据分析, 对演化过程及演化行为本身的描述并没有论及.此外, 文献[10]通过构造Markov过程用以表示运行在多重环境下的系统演化, 用于系统可靠性及环境可靠性的数值分析.文献[11]关注了使用演化博弈论解决复杂网络环境下个体间间接互惠及合作演化的问题, 对演化行为研究提供了新的思路.在文献[3]中, 作者提出了一种基于QVT语言的方法, 将源码层面的演化行为转换到SA层面以缓解架构与代码的失配问题.上述方法并不面向演化过程建模, 且方法的易用性对开发者而言也并非友好.本文旨在使用轻量且抽象程度更高的代数方法建立软件演化过程的序列化描述, 侧重于分析序列中演化行为对软件系统整体的影响, 并结合代数描述的可计算性实时得出量化结果.
软件工程活动的主要目的在于开发和维护高质量的软件系统, 对软件演化的定量分析应以提高软件产品质量为出发点.评价软件质量的指标与方法众多, 本文选取可靠性指标进行研究, 这是因为: 1)结构化软件可靠性模型(区别于传统增长类模型)与SA有直接相关性, 它可伴随结构的演变工作, 适用于架构工程师预先评估整个演化过程的质量发展趋势; 2)可靠性的计算基于对软件结构的精确分析, 这与其他软件质量指标相同或相近(如可维护性), 使得研究不失一般性特点.特别地, 当对象为一类安全关键软件系统时, 因其对版本更迭前后的质量抖动更加敏感, 相应的演化需求及演化进程需要更严格的评估及监控, 而可靠性作为最关键的非功能性指标具有重要价值.基于此, 本文站在可靠性的角度分析软件演化过程及其对软件质量的影响, 主要解决以下三方面的问题:
1) 建立模型以准确描述软件结构的演化;
2) 演化过程中对软件可靠性的实时计算;
3) 对演化关键步骤及趋势的分析.
结构化软件可靠性建模研究始于Littlewood[12]的SMP (Semi-Markov process)模型, 他首先提出单个组件成功执行概率(或称组件可靠性)和在工作流上的组件间控制转移概率是决定系统整体可靠性的两个关键因素. Cheung[13]在此基础上给出DTMC (Discrete time Markov chain)模型, 它明确了二者与系统可靠性之间的函数关系. DTMC模型相较SMP具有强Markov性质, 但它仅将组件执行时间看作单位时间并忽略其在建模中的作用.随后Laprie[14]使用CTMC (Continuous time Markov chain)将组件执行时间均值作为建模参数引入, 用于刻画系统执行稳态.需要指出的是, 在CTMC模型中执行时间必须服从指数分布以满足Markov性质, 而近来有研究认为, 这一限定在更复杂的应用场景中已不合时宜.如Zheng等[15]在分析Web服务的性能与可靠性时回归了SMP方法, 其强调在单个服务上的逗留时间满足一般分布, 并通过在转移时间点(或称更新点)上建立DTMC, 以计算多种结构类型的组合服务可靠性和单个/组合服务的响应时间均值、方差, 结果可用于可靠性及性能瓶颈分析.进一步地, 通过将一维SMP泛化至二维MRGP (Markov regenerative process), 可描述服务端、用户端在不同场景、策略、行为下的组合状态迁移, 其在用户感知的服务性能评估上优于传统CTMC模型[16].
上述模型和方法的差异在对组件执行时间的处理上, 而本文主要讨论软件演化可靠性分析一般性方法, 倾向使用相对简便的DTMC模型, 以突出需要解决的核心问题是对软件演化的描述与可靠性实时分析.而解决问题的关键在于引入代数方法.通过代数方法将软件演化过程序列化, 并跟踪分析序列中每一步操作, 使得整个演化过程受到完整监控; 同时代数方法本身的精确、轻量、易用等特征也确保了架构设计者的意图能够被开发人员准确理解, 且不会造成他们太多额外的负担.本文余下的内容组织如下:第1节将介绍相关知识背景, 包括软件结构化可靠性分析的主流方法以及简单增量式演化的计算; 第2节给出了结构演化的实例, 说明对其描述的困难程度; 第3节讨论如何使用代数方法构建面向演化过程的序列化模型; 两个算例在第4节中被深入讨论, 以验证代数方法的有效性和易用性.
1. DTMC模型与增量式演化
软件可靠性分析的关键在于模型的选择.传统的软件可靠性增长类模型基于测试期失效数据, 并不适用于软件结构演化时的可靠性分析.这里只介绍主流的结构化模型分析方法, 其基本模型为Cheung的DTMC模型[13].下文以欧洲航天局ESA的小型控制系统软件[17]为例进行说明.
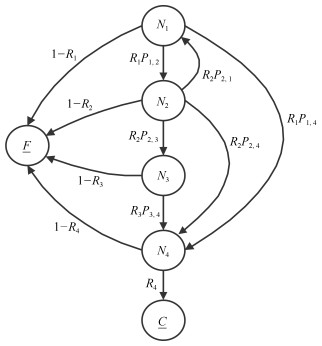
由图 1示,该软件系统含有4个主要组件$ N_1\sim N_4 $, 图中组件节点反映了系统执行的4个稳态, 节点间的控制转移以有向弧表示, 弧上标注转移概率.注意到图 1中包含两个吸收态F与C,分别表示组件失效后到达以及成功执行到达的状态节点.去除节点F与C后, 可建立DTMC一步随机转移矩阵$ Q $如下:
$$ Q = \begin{array}{*{20}{c}} {\;\;\;\;{N_1}\;\;\;\;\;\;\;{N_2}\;\;\;\;\;\;\;\;{N_3}\;\;\;\;\;\;\;{N_4}}\\ {\begin{array}{*{20}{c}} {{N_1}}\\ {{N_2}}\\ {{N_3}}\\ {{N_4}} \end{array}\left( {\begin{array}{*{20}{c}} 0&{{R_1}{P_{1,2}}}&0&{{R_1}{P_{1,4}}}\\ {{R_2}{P_{2,1}}}&0&{{R_2}{P_{2,3}}}&{{R_2}{P_{2,4}}}\\ 0&0&0&{{R_3}{P_{3,4}}}\\ 0&0&0&0 \end{array}} \right)} \end{array} $$ 其元素$ Q_{i, j} $表示了在Markov过程中从状态节点$ i $转移至节点$ j $的转移概率.如$ Q_{1, 2} = R_1P_{1, 2} $, 它反映由节点$ N_1 $经一步转移至节点$ N_2 $的概率等于成功执行$ N_1 $组件的概率$ R_1 $与转移分支概率$ P_{1, 2} $的乘积.矩阵$ Q $的$ n $次幂$ \mathrm{Q}^{n} $为$ n $步随机转移矩阵, 其元素$ Q^n_{i, j} $反映了由节点$ i $经$ n $步转移至节点$ j $的概率.而$ Q $的Neumann级数$ S $表达了由$ N_1 $经所有可能步数成功到达$ N_4 $的概率和, 即
$$ \begin{equation} {S} = {I} + {Q}+ {Q}^2+ \cdots = \sum\limits_{k = 0}^\infty {{Q}^k} = ({I}-{Q})^{-1} \end{equation} $$ (1) 其中, $ I $为单位矩阵, 并且易知级数收敛.对ESA软件系统, 其整体可靠性计算为
$$ \begin{equation} R_{sys} = S_{1, 4} \cdot R_4 \end{equation} $$ (2) 即由节点$ N_1 $出发成功到达$ N_4 $, 并正确执行$ N_4 $的概率.
由式(2), 可认为$ R_{sys} $为单个组件可靠度$ R_i $的函数.称$ B_i $为系统整体可靠性对组件$ N_i $的敏感度, 有
$$ \begin{equation} B_i = \frac{\partial R_{sys}}{\partial R_i} = \frac{\partial}{\partial R_i} (S_{1, 4} R_4), \, \, \, \, i = 1, 2, 3, 4 \end{equation} $$ (3) 一个明显的结论是$ B_4 = S_{1, 4} $, 但其余并不容易得出.
DTMC模型可以直接计算一类简单的增量式演化, 增量指的是单个组件因为改动而导致的可靠度增加或降低[18].令$ A = I-Q $, $ B = {M}_{4, 1} $, 其中, $ {M}_{4, 1} $为元素$ A_{4, 1} $的余子式.考查组件$ N_3 $获得增量$ \delta $后的情形, 演化后$ S_{1, 4} $可计算为
$$ \begin{equation} S_{1, 4} = (-1)^{4+1}\frac{|{B}|(1+\delta \cdot B^{-1}_{3, 3})}{|{A}|(1+\delta \cdot A^{-1}_{4, 3})} \end{equation} $$ (4) 式(4)即为$ N_3 $增量演化后的整体可靠性计算方法.对单个组件的简单增量式演化行为, 可靠性分析的重点在于由增量幅度与整体可靠性变化幅度的关系, 这显然与式(3)的$ B_i $有关.
考虑余子式一般情形, 令$ {U} = {M}_{n, 1} $, 可展开整理为
$$ \begin{equation} |{U}| = -\sum\limits_{j = 1}^{n-1} {(R_i P_{i, j+1}{C}_{i, j}+{C}_{i, i-1})}: = f_1(R_i) \end{equation} $$ (5) 其中, $ {C}_{i, j} $为元素$ U_{i, j} $的代数余子式, 规模为$ (n-2)\times(n-2) $.
对矩阵$ A = I-Q $, 可整理为
$$ \begin{equation} |{A}| = -\sum\limits_{j = 1}^{n} {(R_i P_{i, j}{D}_{i, j}+{D}_{i, i})}, : = f_2(R_i) \end{equation} $$ (6) 其中, $ {D}_{i, j} $为元素$ A_{i, j} $的代数余子式, 规模为$ (n-1)\times(n-1) $.综合式(5)和式(6), 对式(3)加以改进, 得到
$$ \begin{equation} B_i = \frac{\partial R_{sys}}{\partial R_i} = \frac{\partial}{\partial R_i} \left( (-1)^{n+1}\frac{f_1(R_i)}{f_2(R_i)}R_n \right) \end{equation} $$ (7) 此为单组件增量式演化后的敏感度, 推导过程这里不再展开.可知计算过程非常复杂, 并且时间复杂度在O$ (n^3) $量级, 这意味着随着转移矩阵$ Q $规模的增长, 计算负荷问题将凸显.
2. 软件结构的演化
区别于简单增量式演化, 本节讨论更一般的情形.软件系统在发布后会不断调整其体系结构以适应需求或者运行环境的变化.这些调整即演化行为可能来自软件的自适应机制(例如服务组件的动态匹配), 也可能来自软件版本的更新(出于功能修补、性能优化等目的).站在结构度量的角度, 我们希望可以完整跟踪软件的演化行为, 以确定软件某些关键性能指标(可靠性、可用性、可维护性等)的变化趋势, 并定位那些导致整体性能抖动剧烈的单个组件或局部结构模块.
以上一节ESA系统为例.图 2标注了各组件可靠度及组件间转移概率, 数据来自文献[17].假设该软件在运行期间发生了演化, 其主要模块Parsing、Computing及Formatting得到了更新, 同时系统结构也因为组件接口更迭和局部性能优化发生改变.图 3表示其在演化发生后的情形.阴影表示组件$ N_1\sim N_3 $已被更新, 可靠度也相应发生变化:解析模块因算法改进可靠度得以提升(增加0.04);格式模块因接口增加导致可靠度下降(减少0.02);组件$ N_5 $作为$ N_2 $的复制被加入到结构中, 用来分担系统实时计算的压力, 并且为了进一步优化性能, $ N_2 $与$ N_5 $耦合为并行结构, 同时$ N_2 $ (及$ N_5 $)因为并行功能扩展导致其可靠度降低(均减少0.01).
 图 2 ESA软件组件迁移图(标注可靠性信息)Fig. 2 The component transition diagram of ESA software (labeled with reliability information)
图 2 ESA软件组件迁移图(标注可靠性信息)Fig. 2 The component transition diagram of ESA software (labeled with reliability information) 图 3 ESA软件组件迁移图(演化后)Fig. 3 The component transition diagram of ESA software (after evolution)
图 3 ESA软件组件迁移图(演化后)Fig. 3 The component transition diagram of ESA software (after evolution)图 3较图 2有多处更改, 这些更改并非同时发生, 而是遵循一个演化过程来进行.过程中的每一步都由一个或多个操作组成, 而这些操作(下文称演化原子操作)都会成为影响系统整体可靠性的小的变量.如果忽略过程直接使用DTMC模型, 对软件开发并没有实际的指导意义.我们认为针对软件演化的可靠性分析应兼具宏观与微观的视角:微观上, 定位演化过程中这些小粒度原子操作以及它们所对应的组件模块和局部结构, 可暴露软件系统演化时的潜在风险, 将有利于分析影响整体可靠性的关键因素; 宏观上, 将过程看作操作序列的累积, 可用于分析完整演化进程的可靠性趋势.
满足上述需求的前提是对演化过程的理解与表达.事实上, 追踪和描述软件系统中模块及模块间关系的变化过程一直是软件可视化技术的研究热点, 可视化技术可以帮助开发者兼具静态、动态及演化的视角以分析结构和代码[19].但当前可视化技术仅聚焦于多视角分析, 因计算和描述能力的限制尚无法揭示演化过程中的潜在效用变化, 故仍然不适用于完整分析软件演化过程[20].图 4给出了一个针对图 3演化版本的系列图, 使用了可视化技术中常见的小格图[21] (Small multiples)表达.
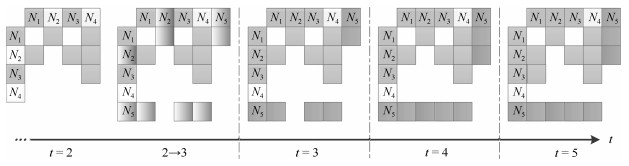 图 4 ESA软件演化过程的小格图表示Fig. 4 Evolution process of ESA software represented by the small multiples
图 4 ESA软件演化过程的小格图表示Fig. 4 Evolution process of ESA software represented by the small multiples小格图显示了软件结构沿时间$ t $连续变化的过程:在$ t = 2 $时刻, 模块$ N_1 $、$ N_3 $已经完成了更新; 在$ t = 3 $时刻加入了$ N_2 $的复制$ N_5 $, 同时也相应增加了模块间关系(边).有时为了清晰反映单步变化过程, 也可以在两个时刻间插入中间态(可使用动画), 例如这里的$ t = 2\rightarrow 3 $.需要说明的是, 即使插入中间态的动画过渡, 也无法准确描述出潜在关键信息.如这里$ t = 4 $, 相较于前一时刻新增了模块$ N_2 $与$ N_5 $之间的并行关系, 但是这种特殊的耦合结构在图中没有明确表达, 而这又是影响系统整体可靠性的关键信息.诸如小格图(包括其改进)、Difference maps[22]以及Glyphs[23]等可视化方法, 在描述演化进程时都存有类似问题, 并且它们都无法回避占用计算空间大、仍需手动对图识别比较等缺点.
下节将引入一种代数方法, 它更轻量化易于描述和计算, 能准确表达演化步骤和过程.
3. 代数方法
将图 2所示的软件结构定义为三元组$ \langle C, O, \it\Omega\rangle $, 其中, $ C $为组件模块集, $ O $为使用连接子集, $ \it\Omega $为模块关系集.它的完整含义如下:
$ \langle C, O, \it\Omega \rangle $
$ {C} = \{N_1, N_2, N_3, N_4\} $
$ {O} = \{\oplus\} $
$ {\it\Omega } = \{ Role_1 = N_1\oplus N_2, \, Role_2 = N_1\oplus N_4, \, \\ Role_3 = N_2\oplus N_1, \, Role_4 = N_2\oplus N_3, \, Role_5 = N_2\oplus \\ N_4, \, Role_6 = N_3\oplus N_4\} $
称上述三元组$ \langle C, O, \it\Omega \rangle $为ESA软件结构代数模型, 其中关系集$ \it\Omega $含6个代数表达式.这里沿用文献[24]的定义, 将连接子定义为代数算子形式, 关系集即为由组件模块和代数算子连接而成的表达式集合.此例中仅含激发算子$ \oplus $, 它被用来表述组件模块间最基本的交互方式.如$ \it\Omega $中的第1个表达式$ Role_1 = N_1\oplus N_2 $, 其涵义为$ N_1 $对$ N_2 $进行了一次激发, 激发动作完成后, 系统执行稳态将由$ N_1 $迁移至$ N_2 $.更多的算子可参考笔者前期所做的工作[25].
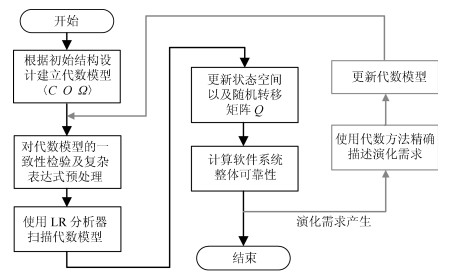
作为对软件体系结构的高度抽象, 代数模型优势在于轻量化和可计算性方面.当相关参数信息完整时, 使用现有形式语言分析技术对关系集(即表达式集)进行一趟扫描, 即可完整计算系统整体可靠性数值.笔者于文献[25]中验证了一个语法分析器, 其算法基于使用广泛的LR(1)分析, 并针对代数模型进行优化以保证可扫描并识别出$ \it\Omega $中所有表达式.在此基础上, 图 5给出了本文的可靠性自动分析流程.在建立代数模型之后, 流程可对模型进行预处理和扫描解析.扫描过程中每当匹配成功一个基本结构范式, 在状态空间对应更新系统状态节点; 当扫描结束, 一个状态空间上的DTMC全部节点信息获取完成, 参照式(2)即可完成一次整体可靠性计算.需要说明的是, 一次可靠性计算并不意味着流程终止, 每当新的演化需求产生, 其代数形式表达将用以更新现有代数模型, 流程将自动重走一趟以完成针对此次演化的可靠性实时计算.
限于篇幅, 对代数模型的预处理及扫描解析算法不再重述.下文详细解释框架中对演化处理的部分.对应图 3, 首先将ESA软件系统演化后代数模型表示如下:
$ \langle {C'}, {O'}, {\it\Omega'}\rangle $
$ {{C'}} = \{N_1, N_2, N_3, N_4, N_5\} $
$ {{O'}} = \{\oplus\} $
$ {{\it\Omega'}} = \{ \, Role_1 = N_1\oplus (N_2\parallel N_5), \, Role_2 = N_1\oplus N_4, \, \\ Role_3 = (N_2\parallel N_5)\oplus N_1, \, Role_4 = (N_2\parallel N_5)\oplus N_3, \, \\ Role_5 = (N_2\parallel N_5)\oplus N_4, \, Role_6 = N_3\oplus N_4, \, \\ Role_7 = N_3\oplus N_1\, \} $
这里算子$ \parallel $表示并行耦合关系.
如前所述, 认为从图 2至图 3必然经历一个演化过程.站在结构分析的角度, 演化过程可看成由若干原子操作组成的行为序列.为了方便讨论, 首先给出如下记号:
1) $ A_i $, 结构中间版本, 对应第$ i $步演化步骤相对前一版本$ A_{i-1} $的更改, 其中, $ A_0 $为初始版本, $ A_n $为演化完成版本;
2) $ Q_i $, 对应版本$ A_i $的整体软件质量度量(这里只讨论可靠性, 以$ R_i $代替);
3) $ D_i = |Q_i-Q_{i-1}| $, 用来表示相邻版本质量之差, 这里总是取正值以描述演化过程中的可靠性抖动程度. 图 6反映了上述记号之间的关系.
在具体演化操作方面, 文献[26]在软件质量相关度量基础上给出了演化原子操作分类, 但其并不适用于基于结构分析的可靠性建模.文献[7]从故障数、变动率以及人工成本等角度对演化操作进行数据分析与度量, 但其仍非面向过程的方法, 无法精确描述演化行为.因此本文给出如表 1所示演化原子操作分类及定义, 用以面向建模的精确性及可计算性.
表 1 演化原子操作分类Table 1 Classification of evolutionary atomic operations名称 定义描述 AM 增加组件模块 RM 移除组件模块 AMD 增加模块间依赖关系 RMD 移除模块间依赖关系 UM 更新组件模块(算法、功能) UMD 更新模块间依赖关系(接口) SM (单个)模块分割 UM (多个)模块耦合 表 1强调了演化操作定义的原子性, 即操作不可再分.每种操作都将对应更新代数模型的三个集合$ C $、$ O $及$ \it\Omega $.如增加组件AM, 其对应了组件集$ C $中元素的增加, 而移除组件间依赖RMD会使得关系集$ \it\Omega $中的表达式被移除.
注意到原子操作间具有较强关联性, 一种操作往往会关联另一种操作, 如结构中增加了新的组件模块, 因其必然参与系统执行稳态的控制转移, 故会导致模块间依赖关系的更新.单个演化步骤中不应只对应单个原子操作, 有时也须考虑若干原子操作相关联的情况.
结合上文演化前代数模型$ \langle C, O, \it\Omega \rangle $和演化后模型$ \langle {C'}, {O'}, {\it\Omega'}\rangle $, 可对演化过程作如下描述:
$ A_0 $–$ \langle C, O, \it\Omega \rangle $
$ A_1 $–UM $ {C}\{ N_1 \} $, $ A_2 $–UM $ {C}\{ N_3 \} $
$ A_3 $–AM $ {C}\{ N_5 \} $ and AMD $ {\it\Omega }\{ N_1\oplus N_5, N_5\oplus N_1, $
$ N_5\oplus N_3, N_5\oplus N_4 \} $ and UMD $ {\it\Omega }\{N_1\oplus N_2\} $
$ A_4 $–UM $ {C}\{ N_2 \, N_5\} $, $ A_5 $–CM $ {O} \{\parallel \}{\it\Omega }\{ N_2\parallel N_5\} $
$ A_6 $–AMD $ {\it\Omega }\{ N_3\oplus N_1\} $ and UMD $ {\it\Omega }\{ N_3\oplus N_4\} $
$ A_6 $–$ \langle {C'}, {O'}, {\it\Omega'}\rangle $#
其中, $ A_6 $为演化完成版本.注意这里$ A_4 $步完成后, 应将$ \it\Omega $集中所有$ N_2 $及$ N_5 $处替换为$ N_2\parallel N_5 $并删除冗余项.
中间版本$ A_1 $、$ A_2 $及$ A_4 $关联原子操作UM, 对应简单的增量式演化.注意除了$ A_1 $外, 其余不能直接套用式(4)计算可靠性, 因为版本$ A_2 $、$ A_4 $已经``身处''演化进程之中, 它们均是对前一版本更改而非对初始版本更改.相对地, 包括处理$ A_5 $中更复杂的结构演化情形, 本文提出流程框架展现了良好的适用性:通过对表达式集合$ \it\Omega $的一趟扫描, 各中间版本的计算可实时自动完成.就演化过程建模而言, 代数方法相对小格图等其它方法强调了过程描述的精确性与完整性.
根据上述演化模型并结合由图 2演化至图 3的具体数据变动, 流程自动计算从$ A_0 $至$ A_6 $各版本系统整体可靠性.图 7反映了可靠性数值在演化进程中的趋势, 可以看到:在$ A_4 $版本之前, 系统整体可靠性维持在一个较稳定水平; 当到达$ A_5 $版本后, 可靠性数值显著下降, 这是由于并行结构的引入使得组件间耦合度增加, 从而对可靠性造成负面影响.图 8显示演化时的版本抖动程度, 其数值意义为相邻版本的可靠性差值: $ D_5 $明显区别于其余值, 反映了由版本$ A_4 $演变至版本$ A_5 $的原子操作是影响整个演化过程的关键; $ D_1 $、$ D_2 $与$ D_4 $对应了简单增量式演化(对应UM操作), 其值一定程度上可揭示组件的重要度, 与式(7)所计算的敏感度值相似, 但计算难度大幅降低.
 图 7 ESA软件演化过程可靠性变化趋势Fig. 7 The reliability trends in evolution process of ESA software
图 7 ESA软件演化过程可靠性变化趋势Fig. 7 The reliability trends in evolution process of ESA software4. 算例研究
本节使用两个算例以验证本文提出代数方法的有效性与实用性.
4.1 算例1
4.1.1 数据介绍及参数设置
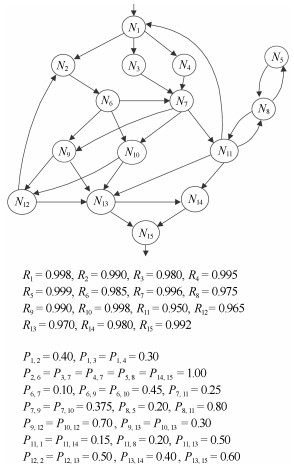
算例1数据来自文献[27], 该算例因具有典型性故被广泛应用于可靠性模型验证.最近对该算例的研究仍在持续, 如在文献[28]中被用以比较一类DTMC模型的性能.图 9中标明了算例1的可靠性相关参数设置, 包括单组件$ N_i $的可靠性数值$ R_i $, 以及组件间控制转移概率$ P_{i, j} $.图 9含该系统的初始结构设计:系统含15个组件模块, 初始设计时并不含特殊结构, 即组件间仅以最基本的激发方式进行交互.为进行算例的演化验证, 这里设定系统最终发布时, 含有并行、容错及调用返回三种特殊结构类型, 它们分别是:模块$ N_3 $、$ N_4 $构成并行结构、模块$ N_{10} $对$ N_9 $构成容错结构、模块$ N_{11} $、$ N_8 $以及$ N_8 $、$ N_5 $构成调用返回结构.
4.1.2 方法运行及阶段性结果
根据系统初始结构设计, 建立代数模型如下:
$ \langle C, O, \Omega \rangle $
$ {C} = \{N_1, N_2, N_3, N_4, N_5, N_6, N_7, N_8, N_9, N_{10}, N_{11}, \\{\qquad N_{12}}, N_{13}, N_{14}, N_{15}\} $
$ {O} = \{\oplus\} $
$ {\it\Omega } = \{ Role_1 = N_1\oplus N_2, \, Role_2 = N_1\oplus N_3, \\ Role_3 = N_1\oplus N_4, \, Role_4 = N_2\oplus N_6, \, Role_5 = \\ N_3\oplus N_7, Role_6 = N_4\oplus N_7, \, Role_7 = N_5\oplus N_8, \, \\Role_8 = N_6\oplus N_7, Role_9 = N_6\oplus N_6, \, Role_{10} = \\ N_6\oplus N_{10}, \, Role_{11} = N_7\oplus N_9, \, Role_{12} = N_7 \oplus\\ N_{10}, \, Role_{13} = N_7\oplus N_{11}, \, Role_{14} = N_8\oplus N_5, \\ Role_{15} = N_8\oplus N_{11}, \, \, Role_{16} = N_9\oplus N_{12}, \\ Role_{17} = N_9\oplus N_{13}, \, \, Role_{18} = N_{10}\oplus N_{12}, \\ Role_{19} = N_{10}\oplus N_{13}, \, Role_{20} = N_{11}\oplus N_1, \\ Role_{21} = N_{11}\oplus N_{13}, \, Role_{22} = N_{11}\oplus N_{14}, \\ Role_{23} = N_{12}\oplus N_2, \, \, Role_{24} = N_{12}\oplus N_{13}, \\ Role_{25} = N_{13}\oplus N_{14}, \, Role_{26} = N_{13}\oplus N_{15}, \\ Role_{27} = N_{14}\oplus N_{15}\} $
经流程框架自动扫描并计算, 初始结构整体可靠性数值为0.8762.令初始结构版本$ A_0 $为演化起点, 以最终发布版本$ A_{17} $为演化终点, 将演化过程作如下描述:
$ A_0 $–$ \langle C, O, \it\Omega \rangle $
$ A_1 $–UM $ {C}\{N_1\} $, $ A_2 $–UM $ {C}\{N_2\} $, $ A_3 $–UM $ {C}\{N_3\} $
$ A_4 $–UM $ {C}\{N_4\} $, $ A_5 $–UM $ {C}\{N_5\} $, $ A_6 $–UM $ {C}\{N_6\} $
$ A_7 $–UM $ {C}\{N_7\} $, $ A_8 $–UM $ {C}\{N_8\} $, $ A_9 $–UM $ {C}\{N_9\} $
$ A_{10} $–UM $ {C}\{N_{10}\} $, $ A_{11} $–UM $ {C}\{N_{11}\} $
$ A_{12} $–UM $ {C}\{N_{12}\} $, $ A_{13} $–UM $ {C}\{N_{13}\} $
$ A_{14} $–UM $ {C}\{N_{14}\} $, $ A_{15} $–UM $ {C}\{N_{15}\} $
$ A_{16} $–CM $ {O} \{\parallel \}{\it\Omega }\{ N_3\parallel N_4\} $
$ A_{17} $–CM $ {O} \{\Psi\}{\it\Omega }\{ N_9\Psi N_{10}\} $
$ A_{17} $–$ \langle {C'}, {O'}, {\it\Omega'}\rangle $#
这里$ \parallel $为并行算子, $ \Psi $为容错算子.
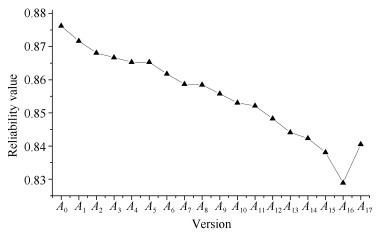
中间版本$ A_1\sim A_{15} $对应单个组件的简单增量式演化.设定因平台迁移使用了新的事件系统, 所有组件实现发生变化, 导致可靠度平均下降了0.005.版本$ A_{16} $、$ A_{17} $中使用了CM操作, 分别对应$ N_3 $、$ N_4 $以及$ N_9 $、$ N_{10} $进行结构耦合后的情形.表 2中列出演化过程的中间计算结果.其中各演化版本可靠性$ R_i $的计算由流程框架自动完成, 图 10表达演化过程的可靠性趋势.因为组件平均可靠度的降低, 系统整体可靠性呈下行趋势, 当到达最低点$ A_{16} $版本后, 因为$ A_{17} $中引入容错机制的原因使得可靠性最终有所回升.
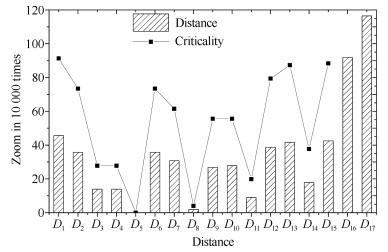
表 2 算例1演化过程计算结果Table 2 Evolution process calculation results of Case 1版本可靠性 相邻版本之差 组件关键程度 版本可靠性 相邻版本之差 组件关键程度 $R_0$ 0.87623 $R_9$ 0.85580 $D_9$ 0.00268 $C_9$ 0.55552 $R_1$ 0.87167 $D_1$ 0.00456 $C_1$ 0.91264 $R_{10}$ 0.85302 $D_{10}$ 0.00278 $C_{10}$ 0.55552 $R_2$ 0.86810 $D_2$ 0.00357 $C_2$ 0.73408 $R_{11}$ 0.85213 $D_{11}$ 0.00089 $C_{11}$ 0.19840 $R_3$ 0.86671 $D_3$ 0.00139 $C_3$ 0.27776 $R_{12}$ 0.84826 $D_{12}$ 0.00387 $C_{12}$ 0.79360 $R_4$ 0.86532 $D_4$ 0.00139 $C_4$ 0.27776 $R_{13}$ 0.84409 $D_{13}$ 0.00417 $C_{13}$ 0.87296 $R_5$ 0.86532 $D_5$ 0.00000 $C_5$ 0.00000 $R_{14}$ 0.84231 $D_{14}$ 0.00179 $C_{14}$ 0.37960 $R_6$ 0.86175 $D_6$ 0.00357 $C_6$ 0.73408 $R_{15}$ 0.83806 $D_{15}$ 0.00425 $C_{15}$ 0.88330 $R_7$ 0.85868 $D_7$ 0.00308 $C_7$ 0.61504 $R_{16}$ 0.82888 $D_{16}$ 0.00918 $R_8$ 0.85848 $D_8$ 0.00020 $C_8$ 0.03968 $R_{17}$ 0.84053 $D_{17}$ 0.01165 4.1.3 最终结果及分析
就面向过程的可靠性评价而言, 本文倾向于使用类似图 10的可靠性趋势序列表达结果, 以代替对最终版本的单次可靠性计算.除趋势外, 将演化过程序列化的另一优势在于敏感度分析, 即指出在演化过程中造成整体可靠性抖动明显的关键步骤及其背后关联的原子操作.如代数方法描述, 中间版本$ A_1\sim A_{15} $对应UM原子操作, 即单个组件更新的情形.因为组件可靠度平均下降幅度相同, 故相邻版本质量差值$ D_1\sim D_{15} $很大程度上可反映被更新组件$ N_1\sim N_{15} $的重要程度.为说明其有效性, 表 2中也给出了可靠性关键程度(Criticality)的计算结果, 它由下式定义:
$$ \begin{equation} C_i = \frac{\Delta R_{sys}}{\Delta R_i} \end{equation} $$ (8) 其中, $ \Delta R_i $为单个组件$ N_i $的可靠性变化增量, $ \Delta R_{sys} $对应因此引起的系统整体可靠性增量.当组件的平均可靠度增量幅度非常小时($ \leq 0.005 $), $ C_i $能够近似代替敏感度$ B_i $, 而相较于$ C_i $, 计算$ B_i $的代价通常要大的多.
图 11中为了与前15个$ D_1\sim D_{15} $作对比, 一组Criticality值$ C_1\sim C_{15} $以曲线形式呈现(经过适当放大).观察Criticality曲线变化与下方的Distance图形基本一致.除去起始节点组件$ N_1 $与终止节点组件$ N_{15} $外, 组件$ N_{13} $的Criticality值($ C_{13} = 0.87296 $)最大而组件$ N_{12} $其次($ C_{12} = 0.79360 $), 这与$ D_{13} $ (0.00417)及$ D_{12} $ (0.00387)是吻合的.这表明演化过程含多个简单增量式演化步骤时, 通过计算Distance值(增量幅度不同时考虑$ D_i $/$ \Delta R_i $比值)评估不同组件的可靠性关键程度是有效的.而计算Criticality值几乎没有代价, 它仅是为分析演化过程保留的中间结果.
图 11体现了演化过程的可靠性抖动情况.可看到处于最后的$ D_{16} $、$ D_{17} $明显高出其余Distance值一个量级, 这说明涉及结构的演化原子操作(SM、CM)对系统整体可靠性的影响往往最为关键.其中又以$ D_{17} $的值最为突出, 这是因为容错结构本身即具有高可靠特征, 如果对结构中关键节点(可靠性敏感的)组件进行容错结构的演化设计, 可对系统整体可靠性提升起显著作用.从架构设计者立场, 需要与编码人员一起严格监控以使演化过程中的质量抖动幅度被限制在合理的区间内.序列化的代数建模方法针对了上述需求, 并且方法本身是简洁、易用的.
4.2 算例2
4.2.1 数据介绍及参数设置
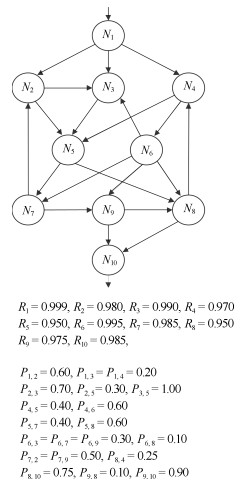
算例2来自一个大型交换机系统的软件结构设计, 它最早被文献[13]所引用, 并同样因其结构具有代表性多被用来比较和验证结构化软件可靠性模型.在文献[29]中, 作者对该算例从相关性、敏感度等角度进行了深入分析与讨论, 并与一类基于路径可靠性模型作出比较. 图 12中标明了算例2的可靠性相关参数设置, 同时也给出了系统的初始结构设计.该系统含有10个组件模块, 初始设计不含有特殊结构.在算例2的演化验证中, 将重点关注组件间的控制转移变化对可靠性影响.这里设定系统结构关键组件$ N_1 $、$ N_2 $及$ N_5 $在最终发布前控制转移分支概率发生变化, 在演化过程中将对这一行为建模并分析分支的可靠性敏感度.
4.2.2 方法运行及阶段性结果
根据系统初始结构设计, 可建立代数模型如下:
$ \langle C, O, \Omega \rangle $
$ {C} = \{N_1, N_2, N_3, N_4, N_5, N_6, N_7, N_8, N_9, N_{10}\} $
$ {O} = \{\oplus\} $
$ {\Omega } = \{ \, Role_1 = N_1\oplus N_2, \, Role_2 = N_1\oplus N_3, \\ Role_3 = N_1\oplus N_4, \, Role_4 = N_2\oplus N_3, \, Role_5 = \\ N_2\oplus N_5, Role_6 = N_3\oplus N_5, \, Role_7 = N_4\oplus N_5, \\Role_8 = N_4\oplus N_6, Role_9 = N_5\oplus N_7, \, Role_{10} = \\ N_5\oplus N_8, \, Role_{11} = N_6\oplus N_3, Role_{12} = N_6\oplus N_7, \\ Role_{13} = N_6\oplus N_8, \, Role_{14} = N_6\oplus N_9, \, Role_{15} = \\ N_7\oplus N_2, \, Role_{16} = N_7\oplus N_9, \, Role_{17} = N_8\oplus N_4, \\ Role_{18} = N_8\oplus N_{10}, \, Role_{19} = N_9\oplus N_8, \, Role_{20} = N_9\oplus N_{10}\, \} $
对此算例设定二阶段演化过程:首先在版本$ A_1\sim A_{10} $中使组件$ N_1\sim N_{10} $可靠度依次下降0.01 (对应UM原子操作), 通过实时计算版本可靠性及相邻版本Distance值, 识别出结构中的关键组件节点; 其次对关键组件, 调整与之相关的控制转移概率(对应UMD原子操作), 以分析节点转移分支的偏重对整体可靠性影响的程度.演化过程如下:
$ A_0 $–$ \langle C, O, \Omega \rangle $
Stage 1:
$ A_1 $–UM $ {C}\{N_1\} $, $ A_2 $–UM $ {C}\{N_2\} $, $ A_3 $–UM $ {C}\{N_3\} $
$ A_4 $–UM $ {C}\{N_4\} $, $ A_5 $–UM $ {C}\{N_5\} $, $ A_6 $–UM $ {C}\{N_6\} $
$ A_7 $–UM $ {C}\{N_7\} $, $ A_8 $–UM $ {C}\{N_8\} $, $ A_9 $–UM $ {C}\{N_9\} $
$ A_{10} $–UM $ {C}\{N_{10}\} $
Stage 2:
$ A_{11} $–UMD\, $ {\Omega }\{ N_1\oplus N_2, \, N_1\oplus N_4\} $
$ A_{12} $–UMD\, $ {\Omega }\{ N_1\oplus N_2, \, N_1\oplus N_3\} $
$ A_{13} $–UMD\, $ {\Omega }\{ N_2\oplus N_3, \, N_2\oplus N_5\} $
$ A_{14} $–UMD\, $ {\Omega }\{ N_5\oplus N_7, \, N_5\oplus N_8\} $
$ A_{14} $–$ \langle {C'}, {O'}, {\it\Omega'}\rangle $#
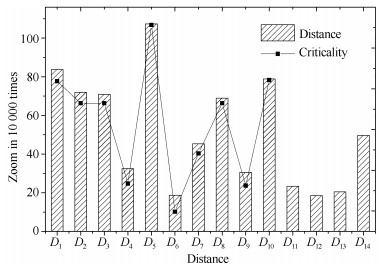
根据设定, 前10个中间版本$ A_1\sim A_{10} $被看作第一阶段, 后4个版本$ A_{11}\sim A_{14} $看作第二阶段.参照表 3中各版本可靠性数值, 图 13给出了演化过程的整体趋势.可看到系统可靠性在第一部分呈逐步快速下降趋势, 符合预期.图 14中给出了相应Distance值$ D_1\sim D_{10} $, 经比较易知软件结构中$ N_1 $、$ N_2 $、$ N_3 $、$ N_5 $及$ N_{10} $属于相对可靠性敏感的重要节点组件.其中, $ D_5 $ (0.01074)甚至超过了起始节点$ D_1 $ (0.00837)及终止节点$ D_{10} $ (0.00789), 说明其在结构中的关键程度.同样地, 为了说明$ D_1\sim D_{10} $值的有效性, 在图 14中也附以Criticality值$ C_1\sim C_{10} $ (经放大处理), 观察易知其曲线与Distance图形基本保持一致, 说明使用Distance值分析组件节点的可靠性敏感度是有效的.
表 3 算例2演化过程计算结果Table 3 Evolution process calculation results of Case 2版本可靠性 相邻版本之差 组件关键程度 版本可靠性 相邻版本之差 组件关键程度 $R_0$ 0.82996 $R_8$ 0.78002 $D_8$ 0.00690 $C_8$ 0.72890 $R_1$ 0.82159 $D_1$ 0.00837 $C_1$ 0.83725 $R_9$ 0.77697 $D_9$ 0.00305 $C_9$ 0.32505 $R_2$ 0.81440 $D_2$ 0.00719 $C_2$ 0.72890 $R_{10}$ 0.76908 $D_{10}$ 0.00789 $C_{10}$ 0.82996 $R_3$ 0.80731 $D_3$ 0.00709 $C_3$ 0.72890 $R_{11}$ 0.77142 $D_{11}$ 0.00234 $R_4$ 0.80406 $D_4$ 0.00325 $C_4$ 0.33490 $R_{12}$ 0.77327 $D_{12}$ 0.00185 $R_5$ 0.79332 $D_5$ 0.01074 $C_5$ 1.11305 $R_{13}$ 0.77532 $D_{13}$ 0.00205 $R_6$ 0.79145 $D_6$ 0.00187 $C_6$ 0.19700 $R_{14}$ 0.77035 $D_{14}$ 0.00497 $R_7$ 0.78692 $D_7$ 0.00453 $C_7$ 0.48265 4.2.3 最终结果及分析
在第一阶段演化过程计算结果基础上, 从中筛选出可靠性敏感程度最高的组件$ N_1 $、$ N_2 $及$ N_5 $.因在这些组件上的变动更易于引发明显的可靠性抖动, 利于于后续演化分析.
第二阶段中有4个中间版本$ A_{11}\sim A_{14} $, 分别对应以$ N_1 $、$ N_2 $及$ N_5 $为分支节点的UMD原子操作. 3个节点都具有代表性: $ N_1 $处于特殊的起始位置, $ N_5 $具有最大Distance值, 而$ N_2 $是结构内部仅次于N5的可靠性关键节点.
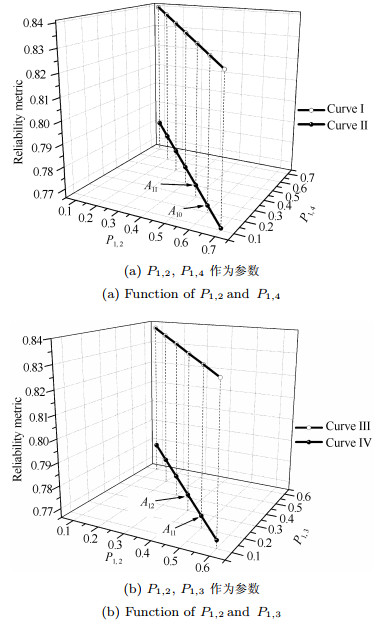
对UMD操作分析的困难在于多参数情形.从版本$ A_{11} $开始, 设定$ N_1 $的实现发生更改, 将直接影响其与后续组件$ N_1\sim N_4 $之间的控制转移关系, 表现为相关分支概率的变化.在$ A_{11} $步, 两组激发表达式被关联UMD操作, 使得分支转移概率比值$ P_{1, 2} $:$ P_{1, 3} $:$ P_{1, 4} $由0.6:0.2:0.2更新为0.5:0.2:0.3, 注意只有$ P_{1, 2} $与$ P_{1, 4} $作为参数, 而$ P_{1, 3} $保持不变.图 15(a)中曲线II表达了版本可靠性$ R_{11} $在$ P_{1, 2} $与$ P_{1, 4} $作为参数情况下所有可能的取值.当$ P_{1, 4} $所占比越大时, $ R_{11} $值越高, 实际$ A_{11} $版本较$ A_{10} $版本提升了可靠性.不考虑演化, 曲线I给出$ R_{sys} $值与参数$ P_{1, 2} $、$ P_{1, 4} $之间的关系, 它与曲线II一致, 说明了在演化过程中按曲线II分析转移概率影响是有效的.
在$ A_{12} $步, 比值$ P_{1, 2} $:$ P_{1, 3} $:$ P_{1, 4} $经演化更新为0.4:0.3:0.3.这一步中$ P_{1, 2} $与$ P_{1, 3} $作为参数, $ P_{1, 4} $保持不变.图 15(b)中曲线IV对应$ R_{12} $所有可能取值, 易知$ R_{12} $随着$ P_{1, 3} $占比增大而提升.同样地, 曲线III表达了$ R_{sys} $与参数$ P_{1, 2} $、$ P_{1, 3} $之间的关系, 作为参照它与曲线IV一致.版本$ A_{11} $、$ A_{12} $的两步演化在现实情况下可能只对应一步(由0.6:0.2:0.2至0.4:0.3:0.3), 增加1个可变参数无疑加大了分析难度, 亦不能给出两两比较的直观结果.故这里设定演化操作可进一步细分(如此处$ A_{11} $、$ A_{12} $), 将更改限制在仅2个参数可变的情况.组件节点拥有超过3个及以上的控制转移分支都可按此分析.
根据表 3, $ R_{13} $值较前一版本增加, 说明对节点$ N_2 $而言, 后续控制转移偏重$ N_5 $分支则有利于可靠性提升.而$ R_{14} $值较前减少, 说明对节点$ N_5 $, 控制转移偏重$ N_7 $将导致可靠性下降.通过观察图 14中$ D_{11}\sim D_{14} $部分, 第二阶段整体可靠性抖动程度相对平缓, 但其中, $ D_{14} $ (0.00497)明显大于$ D_{11} $ (0.00234)、$ D_{12} $ (0.00185)及$ D_{13} $ (0.00205).版本$ A_{14} $对转移概率的更改幅度与之前版本相近, 其影响程度却明显放大, 从另一角度验证了节点$ N_5 $在整体结构中是最关键的, 这与文献[29]中敏感度分析结论一致.
目前可靠性模型对控制转移分支敏感度的分析仍然缺乏有效的方法, 涉及对多参数的分析往往较为困难.一类基于路径的可靠性模型[24, 26, 29]中使用了多个执行路径来对应节点存有多个控制转移的情形, 但是这种方法计算流程繁琐, 不能简明分析关键节点组件的分支敏感度.本文在序列化的演化过程中使用原子操作细化描述控制转移概率的变化, 每一步操作均通过实时扫描代数模型计算出可靠性变化, 可监测出影响整体可靠性的关键步骤, 具有可操作性与现实意义.
5. 结论
面向演化过程建模与分析一直是软件工程领域的难点问题.使用代数方法描述软件结构是精确无二义的, 且相较于图形工具在可计算性上具有优势, 适用于可靠性实时分析、计算.将演化过程序列化是本文的创新点.演化各中间版本(步骤)可独立建模, 中间版本前后衔接为完整的演化过程, 从而建立起过程化分析模型.本文方法的有效性与易用性得到了算例验证, 下一步, 将在开源软件项目上开展实证研究, 通过对软件更迭版本依序构建演化代数模型, 并基于设计文档、源代码及代码度量数据获取可靠性建模参数, 用以计算和分析可靠性变化趋势, 以及揭示软件版本演化中的规律性特征和一些重要、易被忽视的中间环节.
-
表 1 项目中各工序基本信息
Table 1 Information of process in the program
工序编号 紧前工序 紧后工序 最乐观时间 (d) 最可能时间 (d) 最悲观时间 (d) 所需资源数量 p1 p2 p3 A − C, D 6 8 12 4 5 2 B − C, D 3 6 8 3 2 1 C A, B E, F 7 10 12 4 4 1 D A, B E, F 5 6 9 4 3 2 E G G 8 10 11 3 2 1 F H H 4 6 7 5 3 1 G E I, J 8 9 12 4 3 2 H F I, J 4 6 9 5 2 1 I G, H K 2 4 5 5 3 0 J G, H L 10 12 16 3 2 1 K I L 9 11 13 3 4 3 L J, K M, N, O 8 9 12 4 2 2 M L P, Q, R 15 20 22 6 1 1 N L P, Q, R 7 10 12 4 3 0 O L P, Q, R 4 5 6 4 3 2 P M, N, O S 8 9 12 4 4 2 Q M, N, O S 6 8 9 7 5 1 R M, N, O S 3 5 6 4 3 1 S P, Q, R − 4 5 8 7 3 1 资源限量 8 7 3  下载: 导出CSV
下载: 导出CSV
表 2 缓冲区参数计算
Table 2 Value of buffer parameters
类型 编号 三角分布 $T_{50 {\text{%} } }$ $T_{95 {\text{%} } }$ $\sigma_{i}$ $H_{f}$ $H_{z_{i}}$ $H_{r_{i}}$ $d_{i}^{X}$ ${ FB}$ $PB$ ${ FB}^{X}$ ${ PB}^{X}$ 关键链工序 A (6, 8, 12) 8.35 11.19 2.84 0.13 0.13 0.15 7.10 − 7.50 − 8.02 C (7, 10, 12) 10.38 11.42 1.04 0.12 0.18 8.51 − − E (8, 10, 11) 10.22 10.64 0.42 0.08 0.20 8.18 − − G (8, 9, 12) 9.48 11.04 1.56 0.13 0.21 7.49 − − H (4, 6, 9) 6.25 8.45 2.20 0.10 0.10 5.63 − − I (2, 4, 5) 4.54 4.83 0.29 0.08 0.13 3.85 − − K (9, 11, 13) 11.00 12.28 1.28 0.22 0.05 10.15 − − L (8, 9, 12) 9.16 11.25 2.09 0.13 0.14 7.88 − − N (6, 10, 12) 10.42 11.72 1.30 0.10 0.08 9.59 − − M (15, 20, 22) 20.08 21.16 1.08 0.22 0.27 14.66 − − Q (6, 8, 9) 8.35 8.78 0.43 0.16 0.08 7.68 − − P (8, 9, 12) 9.38 11.12 1.74 0.13 0.15 7.97 − − S (4, 5, 8) 4.92 7.34 2.42 0.11 0.23 3.79 − − 非关键链工序 B (3, 6, 8) 6.26 7.68 1.42 0 0.11 0.14 5.38 4.17 − 4.17 − D (5, 6, 9) 5.86 8.26 2.40 0.35 0.19 0.09 5.33 − − F (4, 6,7) 6.15 6.71 0.56 0 0.18 0.28 4.43 0.66 − 0.66 − J (10, 12, 16) 12.12 14.98 2.86 0 0.14 0.13 10.54 3.98 − 3.46 − O (4, 5, 6) 5.08 6.62 1.54 0 0.17 0.11 4.52 1.80 − 1.80 − R (3, 5, 6) 5.14 6.68 1.54 0 0.13 0.08 4.73 1.74 − 1.74 −
下载: 导出CSV
表 3 不同方法缓冲区消耗对比
Table 3 Comparison of buffer consumption by different methods
方法名称 汇入缓冲 (d)/汇入缓冲平均消耗率 (%) 项目缓冲 (d) 项目缓冲平均消耗率 (%) ${ FB}_{BD}$ ${ FB}_{F}$ ${ FB}_{J}$ ${ FB}_{O}$ ${ FB}_{R}$ 1) 关键路线法 − − − − − − − 2) 根方差法 2.79/8.73 0.56/10.82 2.86/2.93 1.54/8.24 1.54/9.55 5.84 91.62 3) APRT法 6.64/2.24 1.31/3.18 5.78/0.10 3.91/1.35 3.74/1.02 12.96 26.98 4) 胡晨 3.06/8.14 0.58/10.62 2.98/2.13 1.58/6.98 1.59/7.54 6.75 88.54 5) 蒋红妍 3.78/5.08 0.60/7.95 3.24/1.09 1.75/2.68 1.62/3.40 7.58 75.76 6) 张俊光 4.04/4.86 0.64/6.76 3.31/0.72 1.72/3.35 1.66/2.08 7.89 69.20 7) 本文方法 4.17/4.68 0.66/6.79 3.46/0.36 1.80/1.95 1.74/1.26 8.02 57.03
下载: 导出CSV
表 4 不同方法完工情况对比
Table 4 Completion comparison of different methods
方法名称 缓冲区主要考虑因素 计划总工期 (d) 项目平均完工率 (%) 1) 关键路线法 − 90.50 15.14 2) 根方差法 工序方差 112.76 89.62 3) APRT法 资源紧张度 124.58 98.98 4) 胡晨 活动工期分布、资源紧张度 115.82 93.56 5) 蒋红妍 工期分布、信息综合约束、资源受限程度等 118.35 96.45 6) 张俊光 资源紧张度、工序复杂度、位置系数、技术与需求不确定性等 120.30 97.68 7) 本文方法 网络复杂度、资源约束、人的行为因素 110.50 95.20
下载: 导出CSV
-
[1] 李俊亭. 关键链多项目管理理论与方法. 北京: 中国社会科学出版社, 2016. 77−99Li Jun-Ting. Critical Chain Multi-project Management Theory and Methods. Beijing: China Social Science Press, 2016. 77−99 [2] Tukel O I, Rom W O, Eksioglu S D. An investigation of buffer sizing techniques in critical chain scheduling. European Journal of Operational Research, 2006, 172 (2): 401-416 doi: 10.1016/j.ejor.2004.10.019 [3] 徐小峰,郝俊,邓忆瑞.考虑多因素扰动的项目关键链缓冲区间设置及控制模型.系统工程理论与实践, 2017, 37 (6): 1593-1601 doi: 10.12011/1000-6788(2017)06-1593-09Xu Xiao-Feng, Hao Jun, Deng Yi-Rui. Project critical chain buffer setting and control model considered multiple factors disturbance. Systems Engineering-Theory & Practice, 2017, 37 (6): 1593-1601 doi: 10.12011/1000-6788(2017)06-1593-09 [4] 刘书庆,罗丹,刘佳,陈丹丹. EPC项目关键链缓冲区设置模型研究.运筹与管理, 2015, 24 (5): 270-280 doi: 10.12005/orms.2015.0187Lie Shu-Qing, Luo Dan, Liu Jia, Chen Dan-Dan. Research on the critical chain buffer setting model of EPC project. Operations Research and Management Science, 2015, 24(5): 270-280 doi: 10.12005/orms.2015.0187 [5] 胡晨,徐哲,于静.基于工期分布和多资源约束的关键链缓冲区大小计算方法.系统管理学报, 2015, 24 (2): 237-242Hu Chen, Xu Zhe, Yu Jing. Calculation method of buffer size on critical chain with duration distribution and multiresource constraints. Journal of Civil Engineering and Management, 2019, 36 (1): 34-41 [6] 蒋红妍,彭颖,谢雪海.基于信息和多资源约束的关键链缓冲区大小计算方法.土木工程与管理学报, 2019, 36 (1): 34-41 doi: 10.3969/j.issn.2095-0985.2019.01.006Jiang Hong-Yan, Peng Yin, Xie X ue-Hai. Calculation method of buffer size on critical chain with information and multi-resource constraints. Journal of Civil Engineering and Management, 2019, 36 (1): 34-41 doi: 10.3969/j.issn.2095-0985.2019.01.006 [7] 张俊光,宋喜伟,杨双.基于熵权法的关键链项目缓冲确定方法.管理评论, 2017, 29 (1): 211-219Zhang Jun-Guang, Song Xi-Wei, Yang Shuang. Buffer sizing of a critical chain project based on the entropy method. Management Review, 2017, 29 (1): 211-219 [8] Zhang J, Song X, D´ıaz E. Project buffer sizing of a critical chain based on comprehensive resource tightness. European Journal of Operational Research, 2016, 248: 174-182 doi: 10.1016/j.ejor.2015.07.009 [9] 谢志强,张晓欢,辛宇,杨静.考虑后续工序的择时综合调度算法.自动化学报, 2018, 44 (2): 344-362XIE Zhi-Qiang, ZHANG Xiao-Huan, XIN Yu, YANG Jing. Time-selective integrated scheduling algorithm considering posterior processes. Acta Automatica Sinica, 2018, 44 (2): 344-362 [10] 邱菀华. 管理决策熵学及其应用. 北京: 中国电力出版社, 2011. 160−163Qiu Wan-Hua. Management Decesion Entropy and Application. Beijing: China Power Press, 2011. 160−163 [11] 白思俊.活动网络计划约束的复杂性度量及其应用.宇航学报, 1994, 15 (7): 891-894Bai Si-Jun. Choice model for large scale organization of project management based on information entropy. Journal of systems science, 1994, 15 (7): 891-894 [12] Atanassov K. Intuitionistic fuzzy sets. Fuzzy Sets and Systems, 1986, 20:87-96 doi: 10.1016/S0165-0114(86)80034-3 [13] 万树平.基于分式规划的区间梯形直觉模糊数多属性决策方法.控制与决策, 2012, 27 (3): 455-458Wan Shu-Ping. Multi-attribute decision making method based on inter-valued trapezoidal intuitionistic fuzzy number. Control and Decision, 2012, 27 (3): 455-458 [14] 万树平.基于区间直觉梯形模糊数的多属性决策方法.控制与决策, 2011, 26 (6): 857-860, 866Wan Shu-Ping. Multi-attribute decision making method based on trapezoidal intuitionistic fuzzy number. Control and Decision, 2011, 26 (6): 857-860, 866 [15] 汪新凡,杨小娟.基于区间直觉梯形模糊数的群决策方法.湖南工业大学学报, 2012, 26 (3): 2-8, 51Wang Xin-Fan, Yang Xiao-Juan. Approach to group decision making based on interval-valued intuitionistic trapezoidal fuzzy number. Journal of Hunan University of Technology, 2012, 26 (3): 2-8, 51 [16] 汪新凡. 直觉语言多准则决策方法研究. 北京: 知识产权出版社, 2017. 20−35Wang Xin-Fan. Study on Multi-criteria Decision Making Method Based on Trapezoidal Intuitionistic Fuzzy Number. Beijing: Intellectual Property Press, 2017. 20−35 [17] 徐泽水. 基于语言信息的决策理论与方法. 北京: 科学出版社, 2016. 118−140Xu Ze-Shui. Decesion Theories and Methods Based on Linguistic Information. Beijing: Science Press, 2016. 118−140 [18] 李喜华,王傅强,陈晓红.基于证据理论的直觉梯形模糊IOWA算子及其应用.系统工程理论与实践, 2016, 36 (11): 2915-2923 doi: 10.12011/1000-6788(2016)11-2915-09Li Xi-Hua, Wang Fu-Qiang, Chen Xiao-Hong. Intuitionistic trapezoidal fuzzy IOWA operator based on dempster-shafer theory and its application. Systems Engineering-Theory & Practice, 2016, 36 (11): 2915-2923 doi: 10.12011/1000-6788(2016)11-2915-09 [19] 付亚男,毛军军,徐丹青.基于区间直觉梯形模糊数的改进TOPSIS多属性决策方法.数学的实践与认识, 2014, 44(17):134-140Fu Ya-Nan, Mao Jun-Jun, Xu Dan-Qing. Improced topsis of multiple attribute decision making method based on interval-valued ITFN. Mathematics in Practice and Theory, 2014, 44(17): 134-140 -

 下载:
下载:




计量
- 文章访问数: 2706
- HTML全文浏览量: 1213
- PDF下载量: 151
- 被引次数: 0
