

-
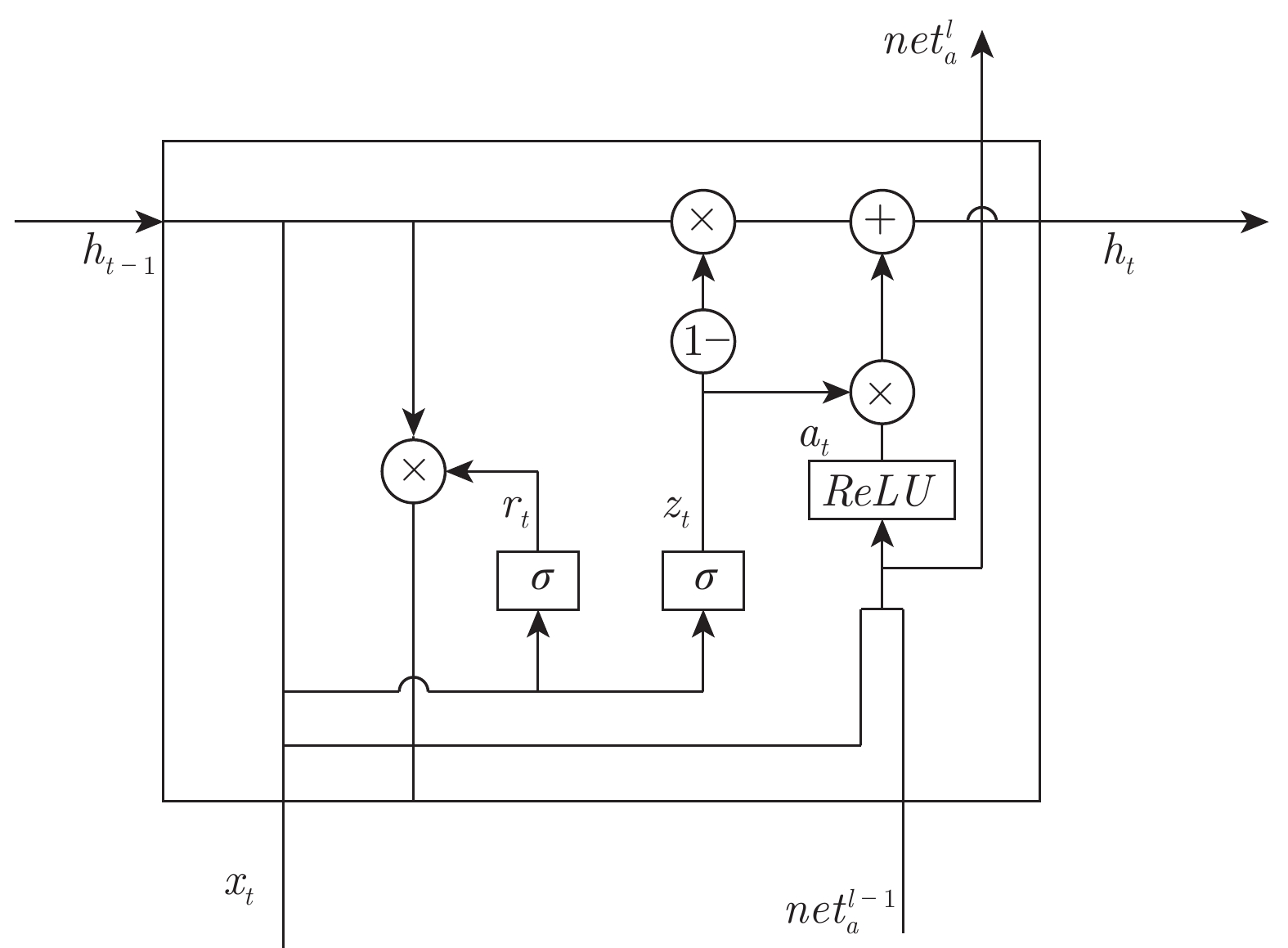
摘要: 传统循环神经网络易发生梯度消失和网络退化问题. 利用非饱和激活函数可以有效克服梯度消失的性质, 同时借鉴卷积神经网络中的残差结构能够有效缓解网络退化的特性, 在门控循环神经网络(Gated recurrent unit, GRU)的基础上提出了基于残差的门控循环单元(Residual-GRU, Re-GRU)来缓解梯度消失和网络退化问题. Re-GRU的改进主要包括两个方面: 1)将原有GRU的候选隐状态的激活函数改为非饱和激活函数; 2)在GRU的候选隐状态表示中引入残差信息. 对候选隐状态激活函数的改动不仅可以有效避免由饱和激活函数带来的梯度消失问题, 同时也能够更好地引入残差信息, 使网络对梯度变化更敏感,从而达到缓解网络退化的目的. 进行了图像识别、构建语言模型和语音识别3类不同的测试实验, 实验结果均表明, Re-GRU拥有比对比方法更高的检测性能, 同时在运行速度方面优于Highway-GRU和长短期记忆单元. 其中, 在语言模型预测任务中的Penn Treebank数据集上取得了23.88的困惑度, 相比有记录的最低困惑度, 该方法的困惑度降低了一半.Abstract: Traditional recurrent neural networks are prone to the problems of vanishing gradient and degradation. Relying on the facts that non-saturated activation functions can effectively overcome the vanishing gradient problem, and the residual structure in convolution neural network can effectively alleviate the degradation problem, we propose a residual−gated recurrent unit (Re-GRU) which leverages gated recurrent unit (GRU) to alleviate the problems of vanishing gradient and degradation. There are two main improvements in Re-GRU. One is to replace the activation function of the candidate hidden state in GRU with the non-saturated activation function. The other is to introduce the residual information into the candidate hidden state representation of the GRU. The modification of candidate hidden state activation function can not only effectively avoid vanishing gradient caused by non-saturated activation function, but also introduce residual information to make the network more sensitive to gradient change, so as to alleviate the degradation problem. We conducted three kinds of test experiments, including image recognition, building language model, and speech recognition. The results indicate that our proposed Re-GRU has higher detection performance than other 6 methods. Specifically, we achieved a test-set perplexity of 23.88 on the Penn Treebank data set in language model prediction task, which is one half of the lowest value ever recorded.
-
Key words:
- Deep learning /
- recurrent neural networks /
- gated recurrent unit /
- skip connect
-
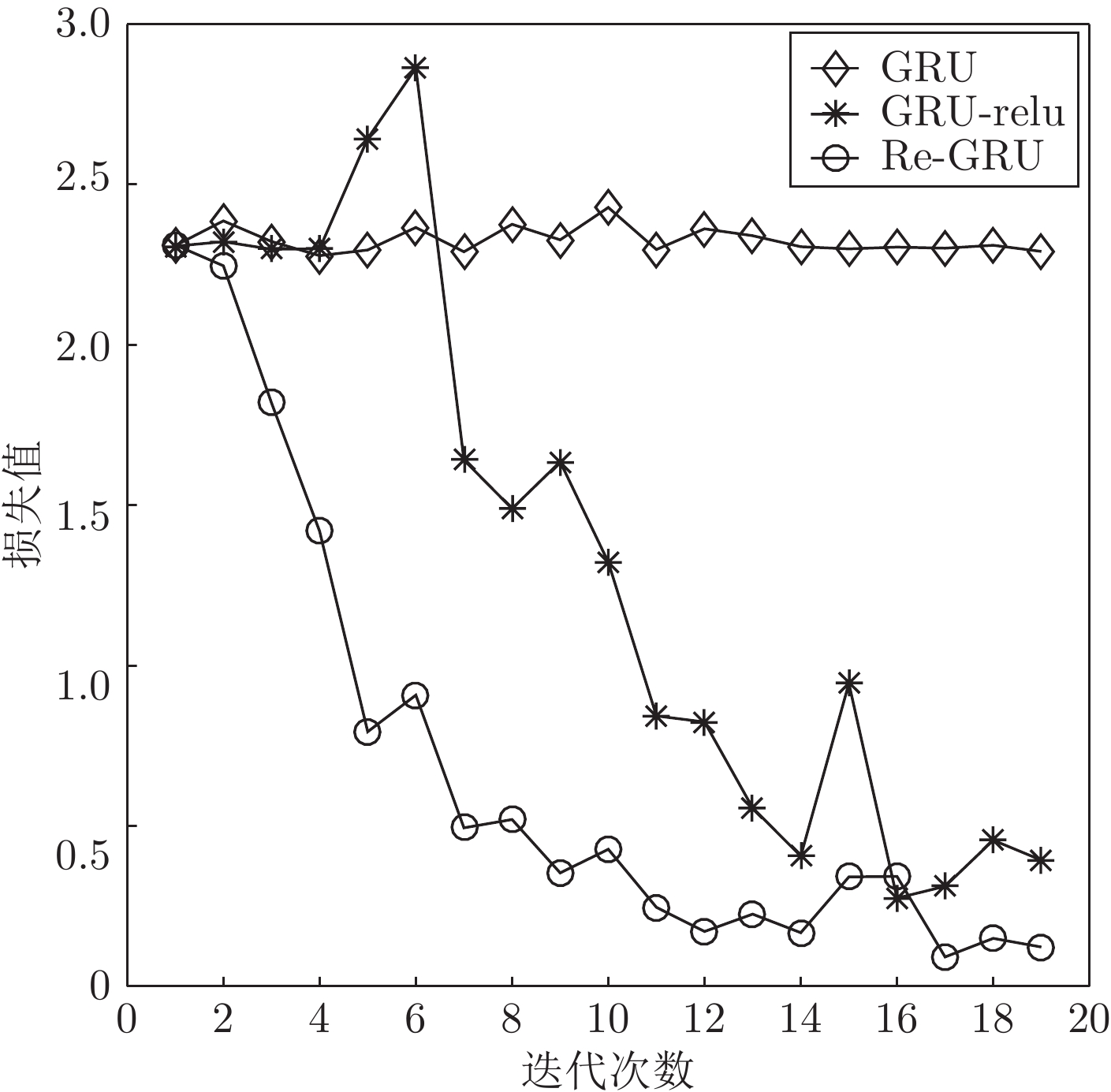
图 5 7层网络的GRU、GRU-relu、Re-GRU在MNIST数据集上的损失变化曲线
Fig. 5 Loss curve of GRU, GRU-relu and Re-GRU on the MNIST data set of a seven-layer network
表 1 MNIST数据集测试结果 (%)
Table 1 MNIST dataset test results (%)
模型 1 层网络 3 层网络 5 层网络 7 层网络 9 层网络 RNN 52 12 9 10 10 GRU 92 92 11 11 10 LSTM 94 91 10 9 10 RNN-relu 67 72 63 56 9 GRU-relu 93 93 80 76 11 SRU 86 94 93 93 93 Highway-GRU 89 95 94 92 33 Re-GRU 97 96 94 95 94  下载: 导出CSV
下载: 导出CSV
表 2 PTB的测试结果 (PPL, s)
Table 2 PTB dataset test results (PPL, s)
模型 3 层网络 5 层网络 7 层网络 RNN 142.37, 149 135.56, 188 143.68, 214 GRU 59.73, 467 50.03, 584 50.25, 750 LSTM 56.42, 409 41.03, 542 84.27, 915 RNN-relu 125.83, 81 115.79, 164 117.32, 257 GRU-relu 96.71, 453 57.03, 602 90.14, 763 SRU 104.93, 206 124.18, 334 143.77, 432 Highway-GRU 99.77, 523 108.13, 834 88, 1176 Re-GRU 24.32, 378 23.88, 682 25.14, 866
下载: 导出CSV
表 3 WikiText-2的测试结果(PPL, s)
Table 3 WikiText-2 dataset test results (PPL, s)
模型 7 层网络 RNN 155.43, 235 GRU 43.87, 618 LSTM 29.00, 733 SRU 159.39, 514 Re-GRU 23.88, 644
下载: 导出CSV
表 4 TIMIT的测试结果(%, s)
Table 4 TIMIT dataset test results (%, s)
模型 3 层网络 5 层网络 7 层网络 RNN 22.5, 151 23.7, 225 23.9, 295 GRU 18.3, 389 18.2, 620 18.5, 854 LSTM 17.4, 478 17.2, 777 17.9, 1080 RNN-relu 18.3, 154 18.4, 239 18.6, 302 GRU-relu 17.3, 385 17.9, 616 17.8, 853 SRU 17.4, 404 18.3, 656 18.4, 924 Highway-GRU 18.0, 549 18.1, 908 17.5, 1294 Li-GRU 17.6, 287 17.9, 478 18.1, 630 Re-GRU 17.8, 427 17.5, 703 17.1, 984
下载: 导出CSV
-
[1] Graves A, Jaitly N, Mohamed A. Hybrid speech recognition with deep bidirectional LSTM. In: Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding. Olomouc, Czech Republic: 2013. 273−278 [2] Mikolov T, Zweig G. Context dependent recurrent neural network language model. In: Proceedings of the 2012 IEEE Spoken Language Technology Workshop. Miami, USA: 2012. 234−239 [3] Zhao B, Tam Y C. Bilingual recurrent neural networks for improved statistical machine translation. In: Proceedings of the 2014 IEEE Spoken Language Technology Workshop. South Lake Tahoe, USA: 2014. 66−70 [4] 奚雪峰, 周国栋. 面向自然语言处理的深度学习研究. 自动化学报, 2016, 42(10): 1445-1465Xi Xue-Feng, Zhou Guo-Dong. A survey on deep learning for natural language processing. Acta Automatica Sinica, 2016, 42(10): 1445-1465 [5] Hochreiter S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 1998, 6(02): 107-116 doi: 10.1142/S0218488598000094 [6] Hochreiter S, Schmidhuber J. Long short-term memory. Neural computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [7] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks. In: Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2. Kuching, Malaysia, 2014: 3104−3112 [8] Morgan N. Deep and wide: Multiple layers in automatic speech recognition. IEEE. Transactions on Audio, Speech, and Language Processing, 2011, 20(1): 7−13 [9] Srivastava R K, Greff K, Schmidhuber J. Training very deep networks. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: 2015. 2377−2385 [10] Orhan E, Pitkow X. Skip Connections eliminate singularities. In: Proceedings of the International Conference on Learning Representations. Vancouver, Canada: 2018. 1−22 [11] He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: 2016. 770−778 [12] Lei T, Zhang Y, Wang S I, Dai H, Artzi Y. Simple recurrent units for highly parallelizable recurrence. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: 2018. 4470−4481 [13] 张文, 冯洋, 刘群. 基于简单循环单元的深层神经网络机器翻译模型. 中文信息学报, 2018, 32(10): 36-44 doi: 10.3969/j.issn.1003-0077.2018.10.006Zhang Wen, Feng Yang, Liu Qun. Deep Neural Machine Translation Model Based on Simple Recurrent Units. Journal of Chinese Information Processing, 2018, 32(10): 36-44 doi: 10.3969/j.issn.1003-0077.2018.10.006 [14] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: 2015. 448−456 [15] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Sardinia, Italy: 2010: 249−256 [16] Ravanelli M, Brakel P, Omologo M, et al. Light gated recurrent units for speech recognition. IEEE Transactions on Emerging Topics in Computational Intelligence, 2018, 2(2): 92-102 doi: 10.1109/TETCI.2017.2762739 [17] Vydana H K, Vuppala A K. Investigative study of various activation functions for speech recognition. In: Proceedings of the 23th National Conference on Communications. Chennai, India: 2017. 1−5 [18] Deng L. The MNIST database of handwritten digit images for machine learning research[best of the web]. IEEE Signal Processing Magazine, 2012, 29(6): 141-142 doi: 10.1109/MSP.2012.2211477 [19] Marcus M P, Marcinkiewicz M A, Santorini B. Building a Large Annotated Corpus of English: The Penn Treebank. Computational Linguistics, 2002, 19(2): 313-330 [20] Melis G, Dyer C, Blunsom P. On the state of the art of evaluation in neural language models. In: Proceedings of the 2018 International Conference on Learning Representations. Vancouver, Canada: 2018. 1−10 [21] Ravanelli M, Parcollet T, Bengio Y. The Pytorch-Kaldi speech recognition toolkit. In: Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Brighton, UK: 2019. 6465−6469 [22] Oualil Y, Klakow D. A Neural Network approach for mixing language models. In: Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. New Orleans, USA: IEEE, 2017. 5710−5714 [23] Zue V, Seneff S, Glass J. Speech database development at MIT: TIMIT and beyond. Speech communication, 1990, 9(4): 351-356 doi: 10.1016/0167-6393(90)90010-7 [24] Arnab G, Gilles B, Luk'as B, Ondrej G, Nagendra G, Mirko H, et al. The Kaldi speech recognition toolkit. In: Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition and Understanding. Hawaii, USA: 2011. 59−64 [25] Le Q V, Jaitly N, Hinton G E. A simple way to initialize recurrent networks of rectified linear units. arXiv preprint, 2015, arXiv: 1504.00941 -

 下载:
下载:




计量
- 文章访问数: 942
- HTML全文浏览量: 562
- PDF下载量: 201
- 被引次数: 0
